ESPHome, tj. open source systém umožňující nastavovat zařízení s čipy ESP (i dalšími) pomocí konfiguračních souborů a připojit je do domácí automatizace, například do Home Assistantu, byl vydán ve verzi 2024.4.0.
LF AI & Data Foundation patřící pod Linux Foundation spustila Open Platform for Enterprise AI (OPEA).
Neziskové průmyslové konsorcium Khronos Group vydalo verzi 1.1 specifikace OpenXR (Wikipedie), tj. standardu specifikujícího přístup k platformám a zařízením pro XR, tj. platformám a zařízením pro AR (rozšířenou realitu) a VR (virtuální realitu). Do základu se z rozšíření dostalo XR_EXT_local_floor. Společnost Collabora implementuje novou verzi specifikace do platformy Monado, tj. open source implementace OpenXR.
Byla vydána nová verze 0.38.0 multimediálního přehrávače mpv (Wikipedie) vycházejícího z přehrávačů MPlayer a mplayer2. Přehled novinek, změn a oprav na GitHubu. Požadován je FFmpeg 4.4 nebo novější a také libplacebo 6.338.2 nebo novější.
ClamAV (Wikipedie), tj. multiplatformní antivirový engine s otevřeným zdrojovým kódem pro detekci trojských koní, virů, malwaru a dalších škodlivých hrozeb, byl vydán ve verzích 1.3.1, 1.2.3 a 1.0.6. Ve verzi 1.3.1 je mimo jiné řešena bezpečnostní chyba CVE-2024-20380.
Digitální a informační agentura (DIA) oznámila (PDF, X a Facebook), že mobilní aplikace Portál občana je ode dneška oficiálně venku.
#HACKUJBRNO 2024, byly zveřejněny výsledky a výstupy hackathonu města Brna nad otevřenými městskými daty, který se konal 13. a 14. dubna 2024.
Společnost Volla Systeme stojící za telefony Volla spustila na Kickstarteru kampaň na podporu tabletu Volla Tablet s Volla OS nebo Ubuntu Touch.
Společnost Boston Dynamics oznámila, že humanoidní hydraulický robot HD Atlas šel do důchodu (YouTube). Nastupuje nová vylepšená elektrická varianta (YouTube).
Desktopové prostředí LXQt (Lightweight Qt Desktop Environment, Wikipedie) vzniklé sloučením projektů Razor-qt a LXDE bylo vydáno ve verzi 2.0.0. Přehled novinek v poznámkách k vydání.
Některé programy, které vyvíjíme (Fotomon, Měření) , používají množství různé statistiky. Moje chápání statistiky je spíše klasické, ale existuje ještě jiný pohled na statistiku - Bayesiánská statistika. Rozhodl jsem se jí porozumět a naučit se ji prakticky používat.
Moje první kroky vedly na Wikipedii:
http://cs.wikipedia.org/wiki/Bayesova_věta
Našel jsem tam přesně to, co jsem čekal: matematický formalismus, pod kterým si nedovedu nic představit (pravděpodobnost, že na Wikipedii najdu to, co hledám, ve formě stravitelné pro průměrného inženýra, už dnes dovedu pomocí bayesiánské statistiky docela dobře odhadnout). Ale je tam odkaz:
http://cs.wikipedia.org/wiki/Bayesovská_statistika
Je tam příklad. Skvělé! Ale kdo tohle psal!? Velmi volně cituji:
Test na nemoc dá kladnou odpověď u 99% nemocných pacientů a u 5% zdravých pacientů. Nemocí trpí jen 0.1% populace. Jaká je pravděpodobnost?
He? WTF? Jaká pravděpodobnost? Co se po mě chce? Pravděpodobnost čeho? No nic, třeba to vyplyne z textu dále:
"Pravděpodobnost choroby je o 19% větší, než u těch, kdo se testu nepodrobili."
No nazdar, máme zde další skupinu: přibyli nám ještě netestovaní. Kam si je mám zařadit? Navíc to je formulováno tak nešťastně, že kdybych nevěděl, jak veliký je to nesmysl, mohl bych usuzovat, že provedení testu nějak ovliní, jestli člověk onemocní, nebo zůstane zdravý.
Jsem ztracen.
Několikrát jsem narazil na příklad s dvěma pytlíky s bílými a černými kuličkami, což mi celou problematiku ještě více zatemnilo. Tuhle míchanici současné a předchozí pravděpodobnosti, střídaní minulosti, přítomnosti a budoucno také nedokázal nikdo dostatečně jasně vysvětlit. Popis primitivní úlohy na tři listy formátu A4 zvyšuje WTF faktor nade všechny meze.
Začal jsem hledat v angličtině. Odfiltroval jsem všechny kuličky v pytlíku a nakonec jsem skvělý příklad objevil zde:
http://people.hofstra.edu/Stefan_Waner/RealWorld/tutorialsf3/frames6_6.html
Konečně mi docvaklo. Celý ten Bayesův vzorec je obyčejná trojčlenka. To mi mohli vysvětlit už v prváku na střední a nemusí se z toho dělat zbytečná věda. Jakmile jsem si to namaloval a pochopil, vypadá základ bayesovské statistiky prostince:
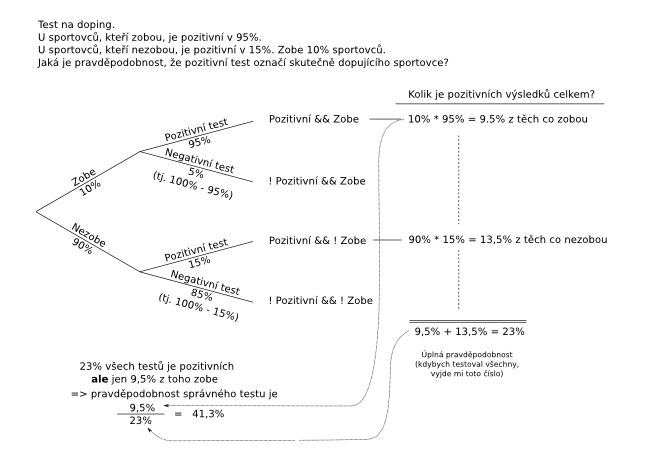
Pro praktické použití je třeba ještě pochopit jednu věc: bayesiánský vzorec je často uváděn ve zjednodušené formě a není jasné, jak z něj spočítat například toto:
Ve jmenovateli (část zlomku pod čarou) Bayesova vzorce figuruje takzvaná "úplná pravděpodobnost". V příkladu dopujících a nedopujících sportovců je to součet všech pozitivních výsledků, tj. 9,5% + 13,5%. V případě tří fabrik je to:
Sečteme jednotlivá procenta: celkem 2,9% ze všech výrobků na trhu jsou zmetky. Z fabriky A jich pochází: 50% * 2% / 2,9% = 34,4%
(Příklad jsem nalezl v dokumentu, který nyní není dostupný, googlujte "Bayes Krčková").
Možnost použít libovolný počet různých vstupních parametrů (zde fabriky A, B a C) je dobrá zpráva pro praktické použití v programech - dovoluje to snadno dekomponovat problém na několik samostatných částí.
Jakmile jsem pochopil princip, došlo mi, že bayesiánská statistika není nic složitého či nepochopitelného. Zkuste si to. Namalujte si třeba dva pytlíky s kuličkami - uvidíte sami.
Tiskni
Sdílej:
![]()
![]()
![]()
![]()
![]()
![]()
Moje chápání statistiky je spíše klasické, ale existuje ještě jiný pohled na statistiku - Bayesiánská statistika.
WtF?
Nicméně, je jasné, že různé pohledy na statistiku nemohou nic změnit na platnosti Bayosova vzorce. Tj. i "frekventisté" platnost Bayosova vzorce samozřejmě uznávají.Presne tak, pokud tomu rozumim, tak rozdil mezi 'frekventistickou' a 'bayesovskou' interpretaci pravdepodobnosti je ciste zalezitost interpretacni, na vzorce a vysledky to nema vliv (podobne jako ruzne interpretace kvantove mechaniky). Proto je treba nemichat 'bayesovskou interpretaci' na jedne strane a bayesuv vzorec ci bayesovskouu inferenci, coz jsou elementarni veci z pravdepodobnosti a statistiky platne a pouzivane nezavisle na interpretaci.
 14.4.2014 13:04
Fluttershy, yay! | skóre: 92
| blog:
14.4.2014 13:04
Fluttershy, yay! | skóre: 92
| blog:
 16.4.2014 21:59
=^..^= AmigaPower® | skóre: 30
| blog: BLB
| Praha
16.4.2014 21:59
=^..^= AmigaPower® | skóre: 30
| blog: BLB
| Praha
 14.4.2014 09:09
Petr Bravenec | skóre: 43
| blog: Bravenec
14.4.2014 13:01
Petr Bravenec | skóre: 43
| blog: Bravenec
14.4.2014 09:09
Petr Bravenec | skóre: 43
| blog: Bravenec
14.4.2014 13:01
Petr Bravenec | skóre: 43
| blog: Bravenec
 14.4.2014 13:52
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
14.4.2014 21:50
Petr Bravenec | skóre: 43
| blog: Bravenec
15.4.2014 13:35
Petr Bravenec | skóre: 43
| blog: Bravenec
15.4.2014 06:21
Petr Bravenec | skóre: 43
| blog: Bravenec
17.4.2014 09:49
Petr Bravenec | skóre: 43
| blog: Bravenec
14.4.2014 13:52
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
14.4.2014 21:50
Petr Bravenec | skóre: 43
| blog: Bravenec
15.4.2014 13:35
Petr Bravenec | skóre: 43
| blog: Bravenec
15.4.2014 06:21
Petr Bravenec | skóre: 43
| blog: Bravenec
17.4.2014 09:49
Petr Bravenec | skóre: 43
| blog: Bravenec
 AbcLinuxu.cz
AbcLinuxu.cz ITBiz.cz
ITBiz.cz HDmag.cz
HDmag.cz AbcPráce.cz
AbcPráce.cz Ale jiz jsem o tom zde psal, kdo hleda, najde.
Ale jiz jsem o tom zde psal, kdo hleda, najde.
{kind=link}