Portál AbcLinuxu, 25. dubna 2024 13:18
Vlákno bylo přesunuto do samostatné diskuse.
 5.11.2019 21:57
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
5.11.2019 22:43
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
5.11.2019 21:57
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
5.11.2019 22:43
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Obecné developerské nástroje nenabízejí možnost přímo přemýšlet v termínech doménové abstrakce. To umožňují různé na míru dělané nástroje přímo pro konkrétní doménu.S tim bych nesouhlasil. Nastroje to bez problemu zvladnou, hlavni potiz je v tom, ze programatori nejsou schopni vytvaret spravne a oddelene abstrakce.
Pro trénování systému vytvořil senior developer nástroj doménové abstrakce pro případ, kdy bylo nutné systém přetrénovat, protože něco vyhodnotil špatně.Moudry to clovek ktery vedel, ze lze mit i nekolik urovni abstrakce nad sebou. A ted, co tim chci rict. Vytvorit abstrakci pro konkretni domenu nevyzaduje nejake specialni jazykove konstrukce (makra, transformace AST), ale bohate staci bezne prostredky jazyka (procedury, funkce, objekty) a k tomu pak jen nadhled nad problemem a disciplina. Typicky nesvar i "zkusenych" programatoru je v tom, ze nevytvari jasne oddelene urovne abstrakce a bezne dochazi k prosakovani nizkourovnovych konstrukci do vysokourovnovych. Pujcim si priklad z prednasky, protoze se mi ted nechce vymyslet vlastni.
if (portfolioIdsByTraderId.get(trader.getId()).containsKey(portfolio.getId()) { ... }
Pricemz by to pri spravne navrzenych abstrakcich slo prepsat:
if (trader.canView(portfolio)) { ... }
Takto navrzeny kod je jednak snazsi pro porozumeni a zaroven to resi tvuj problem s debuggovanim. Vezmes si proceduru/metodu, kde je problem a jdes radek po radku (step-over, nemusis jit hloubeji, nechces-li), kdyz se dostanes nekam, kde uz je to moc low-level, vyskocis o level vys.
Programatori ale velice casto zabrednou do toho, ze vsechno je seznam/slovnik/tuple neceho (nektere jazyky k tomu vylozene svadi), coz pak vede k tomu, ze se michaji low-level reprezentace s kodem na vyssi urovni abstrakce a cteni a ladeni kodu zacina byt peklo.
Na druhou stranu psat kod, kde jsou vyrazne oddelene urovne abstrakce, je pro programatory nekomfortni hned z nekolika duvodu. Je to kod navic, proc si vytvaret vlastni tridu, kdyz mohu pouzit rovnou seznam/slovnik? Prinasi to urcitou rezii pri provadeni kodu. (Pro spoustu lidi mentalni blok.) Kdyz ma clovek dane hranice mezi abstrakcemi, kod neni tak tvarny, jak by mohl byt, coz nekteri povazuji za komplikaci (obvykle pri praseni).
Psát metody/funkce na jedné úrovni abstrakce je samozřejmě základ, ale samo o sobě to nezaručuje dobrou debugovatelnost. Můžete mít třeba cizí kód, který používá různé buildery, dekorátory a adaptory a získat přehled, co se v něm děje (pokud není velmi dobře zdokumentovaný) bude velmi obtížné. Viděl jsem takový případ, kdy si programátor prostě upravil debugger takovým způsobem, aby se mu během krokování zobrazoval průběžně se měnící graf objektů a referencí mezi nimi, který mu jej konečně pomohl pochopit.
Jinak většina současných debuggerů bývá navíc silně omezená. Málokterý umí třeba to si označit v příkladu výše kód trader.canView(portfolio) a spustit nad další instanci debuggeru s tím, že v té původní může kdykoliv pokračovat. Nebo, když už se člověk prostepuje do nějakého pro něj zajímavého stavu, tak by si jej mohl chít uložit, aby se do něj mohl vrátit až zjistí, že chyba, kterou hledá, vznikla na jiné úrovni abstrakce než předpokládal, a on ten bod při krokování překročil.
Viděl jsem takový případ, kdy si programátor prostě upravil debugger takovým způsobem, aby se mu během krokování zobrazoval průběžně se měnící graf objektů a referencí mezi nimi, který mu jej konečně pomohl pochopit.To by měla být celkem běžná věc. Potíž je, že to je obvykle docela obtížné udělat. Dobrá vizualizace dokáže několikanásobně zkrátit čas strávený laděním i vývojem. Kdyby debuggery umožňovaly snadno přidávat rozšíření na vykreslování různých datových struktur, tak by takový přístup byl docela běžný. Já to teď řeším tak, že aplikace má ladicí a vizualizační nástroje integrované v sobě (v run-time i v testech), takže obrázky dostanu z ní namísto z debuggeru. Je to jednodušší na implementaci, ale má to celkem zjevné nedostatky.
Jinak většina současných debuggerů bývá navíc silně omezená. [...] a spustit nad další instanci debuggeru s tím, že v té původní může kdykoliv pokračovat.To je dáno tím, že debugger se připojuje na běžící proces a ten není možné uložit a později restartovat. Ani není možné proces jen tak naklonovat. Volání
fork() sice udělá kopii, ale nenaklonuje otevřené soubory a další externí věci.
Trochu praktičtější přístup jsou time-traveling debuggery, které si prostě ukládají průběžný stav aplikace a pak si můžeš krokovat obousměrně. Některé jazyky/frameworky takový debugger mají – je to o ukládání stavu aplikace mezi událostmi, který ten stav mění.
Já to teď řeším tak, že aplikace má ladicí a vizualizační nástroje integrované v sobě (v run-time i v testech), takže obrázky dostanu z ní namísto z debuggeru. Je to jednodušší na implementaci, ale má to celkem zjevné nedostatky.
Z tohoto důvodu některé jazyky nedělají rozdíly mezi vývojovým prostředím a vytvářenou aplikací, čímž takové bariéry eliminují.
To je dáno tím, že debugger se připojuje na běžící proces a ten není možné uložit a později restartovat. Ani není možné proces jen tak naklonovat. Volání fork() sice udělá kopii, ale nenaklonuje otevřené soubory a další externí věci.
Jenže ony to neumí ani debuggery v interpretovaných jazycích, které by s tím problém mít neměly...
Kdyby debuggery umožňovaly snadno přidávat rozšíření na vykreslování různých datových struktur, tak by takový přístup byl docela běžný.Mrkni na bpftrace a flame graphs.
Volání fork() sice udělá kopii, ale nenaklonuje otevřené soubory a další externí věci.CRIU mozna?
6.11.2019 13:43
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Já to teď řeším tak, že aplikace má ladicí a vizualizační nástroje integrované v sobě (v run-time i v testech), takže obrázky dostanu z ní namísto z debuggeru. Je to jednodušší na implementaci, ale má to celkem zjevné nedostatky.Jo, tak jsem to nakonec vyřešil taky (dump do plantuml), to je právě ta tvorba doménových nástrojů.
6.11.2019 13:58
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Psát metody/funkce na jedné úrovni abstrakce je samozřejmě základ,Ano je, ale obrovska cast programatoru toho neni schopna a kod je pak prolezly ruznymi ArrayList-y, HashMap-ami, tupli a vlastne si ani neuvedomuje, ze je na tom potencialne neco spatneho. Jazyky, ktere maji pohodlnou praci s temito datavymi typy, jsou na tom nejhur, protoze takove programovani z principu podporuji.
Můžete mít třeba cizí kód, který používá různé buildery, dekorátory a adaptory a získat přehled, co se v něm děje (pokud není velmi dobře zdokumentovaný)To se domnivam, ze to je presne ten problem michani (prosakovani) urovni abstrakce.
Viděl jsem takový případ, kdy si programátor prostě upravil debugger takovým způsobem, aby se mu během krokování zobrazoval průběžně se měnící graf objektů a referencí mezi nimi, který mu jej konečně pomohl pochopit.Toto "neni" problem ani treba v Eclipse (a patrne ani v zadnem jinem modernim IDE). To "neni" jsem dal do uvozovek, protoze toho kodu, jak se pripojit k existujicimu debuggeru a pracovat s nim, neni pro tento ucel zase tolik potreba, ale je hodne komplikovane zjistit, jak to udelat, protoze nikdo si s tim moc nelamal hlavu a dokumentace kulha. Ale to je spis nez koncepcni zalezitost zalezitost kvality. Verim, ze takove problemy budou v temer kazdem IDE bez ohledu na to, v cem je naprogramovane.
Nebo, když už se člověk prostepuje do nějakého pro něj zajímavého stavu, tak by si jej mohl chít uložit, aby se do něj mohl vrátitTo bohuzel zustane domenou jazyku (resp. runtimu), ktere umi ulozit kompletni stav a vratit se k nemu.
To se domnivam, ze to je presne ten problem michani (prosakovani) urovni abstrakce.
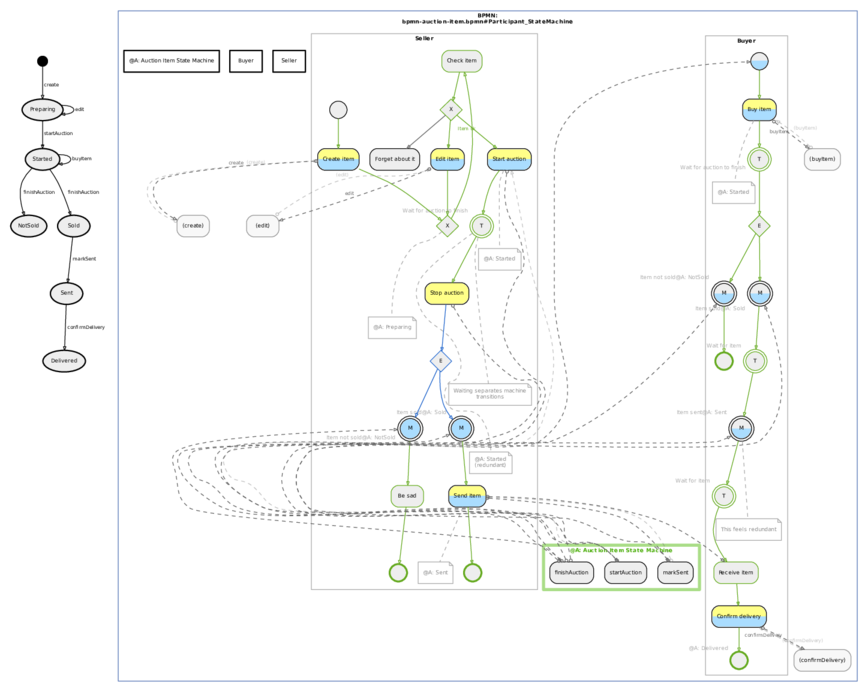
Když pomineme to, že s takovým kódem se ve výsledku člověk bohužel setká nejčastěji, pak je ještě třeba říct, že i ve správně strukturovaném programu nemusí být krokování přímočaré. Jako třeba v klasickém případě rozesílání oznámení těm, kdo jsou pro jejich odběr přihlášení (viz obrázek). V jednom bodě se rozešle oznámení, které projde nějakým nízkoúrovňovým procesem, ve kterém se určuje, komu vlastně patří, a pak vybublá zpět na původní úroveň abstrakce někde úplně jinde. A odlišit to, které úrovně vlastně patří k sobě, musí buď pracně programátor sám. Nebo ten rozesílací framework umí rozšířit debugger takovým způsobem, že tyto informace poskytne programátorovi automaticky.
Když pomineme to, že s takovým kódem se ve výsledku člověk bohužel setká nejčastěji, pak je ještě třeba říct, že i ve správně strukturovaném programu nemusí být krokování přímočaré.Vzdyt to rikam, ze chyba neni v nastrojich, ale v tom, jak se pouzivaji.
odlišit to, které úrovně vlastně patří k sobě, musí buď pracně programátor sám. Nebo ten rozesílací framework umí rozšířit debugger takovým způsobem, že tyto informace poskytne programátorovi automaticky.Ale jdete... pokud je kod naprogramovany alespon minimalne civilizovane, jsou jednotlive vrstvy rozdeleny do balicku. Neni pak problem v debuggeru oznacit, ktere low-level balicky se maji preskocit. Kdyz delam v Jave EE (tj. mam pod sebou brutalni moloch low-level veci), tak neco takoveho proste beru za uplnou samozrejmost a doted me nenapadlo, ze by s tim mohl byt problem nebo ze bych kvuli tomu musel hackovat debugger.
 6.11.2019 15:01
Gréta | skóre: 36
| blog: Grétin blogísek
| 🇮🇱==❤️ , 🇵🇸==💩 , 🇪🇺==☭
7.11.2019 14:45
Gréta | skóre: 36
| blog: Grétin blogísek
| 🇮🇱==❤️ , 🇵🇸==💩 , 🇪🇺==☭
6.11.2019 15:01
Gréta | skóre: 36
| blog: Grétin blogísek
| 🇮🇱==❤️ , 🇵🇸==💩 , 🇪🇺==☭
7.11.2019 14:45
Gréta | skóre: 36
| blog: Grétin blogísek
| 🇮🇱==❤️ , 🇵🇸==💩 , 🇪🇺==☭
<pre class="brush: zkratka jazyku">
sem se strčí zdroják
</pre>
jo a zkratky těch jazyků jsou tady hele
sem na to přišla i bez tebe a moc dobře vim že si tady včera byl ;D 13.11.2019 18:26
xkucf03 | skóre: 49
| blog: xkucf03
13.11.2019 18:26
xkucf03 | skóre: 49
| blog: xkucf03
Vtipné je, že to máš napsáno hned pod formulářem, kterým vkládáš komentáře: Nápověda k formátování (včetně těch zkratek jazyků).
18.11.2019 16:05
Gréta | skóre: 36
| blog: Grétin blogísek
| 🇮🇱==❤️ , 🇵🇸==💩 , 🇪🇺==☭
sem tady chtěla jakože vybuchnout že to maj blbě udělaný když si to rychlejc najdu ve zdrojáku ale ty máš fakt pravdu a je to hnedka pod tim editorem :D to tam museli ale přidělat snad až těďka jinak to snad ani neni možný :D
Typicky nesvar i "zkusenych" programatoru je v tom, ze nevytvari jasne oddelene urovne abstrakce a bezne dochazi k prosakovani nizkourovnovych konstrukci do vysokourovnovych.IMO ten problém je ještě hlubší, zobecnil bych to na dvě asumpce:
Tyhle dvě asumpce IMO nikdo neukázal jako platné, nicméně autoři mnoha úvah s nimi taknějak implicitně počítají jako s platnými...Chapu tvou pripominku, ale v podstate je to nirvana fallacy.
Existuje sada abstrakcí (a jejich rozdělení do úrovní), které je pro daný software (dostatečně) jednoznačně "správné", tj. vhodné pro všechny/mnoho usecases a z pohledu všech/mnoha lidí.Abstrakce by nemely byt neco statickeho, ale neco se vytvari a rusi podle toho, jak je to potreba. Mimochodem na nizsich urovnich rozdeleni do vrstev (CPU, OS, std. knihovna, runtime, aplikacni server) funguje rozdeleni dobre, je nejaky duvod, proc by to nemelo fungovat v dalsich vrstvach?
Je možné mít non-leaky abstrakce.Leaky abstrakce jsou problematicke, ale je to malinko neco jineho nez to, s cim asi bystroushaak zapasi a na co poukazuju ja. To jest, ze mezi programatory je zvykem michat ruzne vrstvy abstrakce jen z toho duvodu, ze je to pohodlne a pak se z ladeni stava peklo.
8.11.2019 15:28
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Leaky abstrakce jsou problematicke, ale je to malinko neco jineho nez to, s cim asi bystroushaak zapasi a na co poukazuju ja. To jest, ze mezi programatory je zvykem michat ruzne vrstvy abstrakce jen z toho duvodu, ze je to pohodlne a pak se z ladeni stava peklo.To si zrovna vůbec nemyslím, že je můj problém. Můj problém je, že v debuggeru debuguji virtuální stroj, který očividně musí provést spoustu instrukcí jazyka ve kterém je napsán, aby mohl provést jednu interpretovanou instrukci. S mně dostupnými nástroji není nic, co by mi umožnilo posunout se ve "věži abstrakce" výš a debugovat v debuggeru pythonu přímo tinySelf. Například ani neexistuje možnost, jak v něm přeskakovat ten správný kus kódu v závislosti na kontextu (tj prováděná instrukce), nebo vizualizovat objekty. To o čem mluvíš ty je, že programátoři občas používají blbé způsoby abstrakce, ze kterých není vidět co vlastně modeluješ. To o čem mluvím já je že i když použiješ dobré způsoby abstrakce (všechno vymodeluješ ve smysluplných objektech a bude to mít smysluplné kontejnery, zapouzdření a pojmenování), tak stále může ta implementace být příliš nízkoúrovňová a budeš ztrácet moc času procházením té nízkoúrovňovosti. Analogie je, jako kdybys debuggoval interpret Pythonu v (dis)assemblerovském debuggeru, kde ani nevidíš C kód, ve kterém je ten interpret psaný. Moldable tools debugger ti umožňuje posunout abstrakci tak, abys (dis)assemblerovací debugger rozšířil tak, že bude ukazovat nejenom C, ale rovnou Python objekty a kód. Samozřejmě, že já bych mohl a časem asi budu muset napsat custom debugger přímo pro tinySelf, ale to je klasický yak shaving ve chvíli kdy jen potřebuju odladit nějakou úplně nesouvisející chybu.
Abstrakce by nemely byt neco statickeho, ale neco se vytvari a rusi podle toho, jak je to potreba. Mimochodem na nizsich urovnich rozdeleni do vrstev (CPU, OS, std. knihovna, runtime, aplikacni server) funguje rozdeleni dobre, je nejaky duvod, proc by to nemelo fungovat v dalsich vrstvach?Pokud vím, SmallTalkisti si stěžují i na ten OS...
Leaky abstrakce jsou problematicke, ale je to malinko neco jineho nez to, s cim asi bystroushaak zapasi a na co poukazuju ja. To jest, ze mezi programatory je zvykem michat ruzne vrstvy abstrakce jen z toho duvodu, ze je to pohodlne a pak se z ladeni stava peklo.S tím souhlasim, ale IMO problém bývá, i když programátoři neprasí. Mnohokrát jsem viděl případ, kdy snaha vytvořit nějaké rozšíření na vyšší úrovni vede k tomu, že člověk zjistí, že vrstva/vrstvy níž něco takového nepodporuje/í (nebo blbě), takže se může stát, že musí projít napříč několika vrstavam až někam kdovíkam do střev, abys dosáhl cíle... Případně zjistí, že tohle dělat by bylo složité / nepraktické / apod., a vykašle se na to... Snažim se vymyslet nějakej příklad. Napadá mě např. že u nějakého kompilátoru nebo něčeho, co netriviálně zpracovává nějaký vstupní formát, chceš mít typicky hezké chybové hlášky. Na to typicky potřebuješ, aby skrz celou tu věc (a její mnohé vrstvy) procházely informace o pozicích ve vstupních datech (tj. nějaké spany apod.). Pokud ta nižší vrstva (lexer) tohle nepodporuje, ostrouháš. Jiný příklad je třeba jazyk Go, který pro dobré fungování gorutin potřebuje, aby OS poskytoval epoll/kqueue/iocp nebo ekvivalent. Dnes takovéhle věci (jakože ti parser poskytuje spany a že ti OS poskytuje epoll apod.) považujeme za samozřejmé, ale to je IMO hlavně protože jsou dobře známé vlastnosti a use-cases těchto mechanismů. Oproti tomu psát do rozšiřitelných programů abstrakce pro nějaké úplně nové use-cases, které třeba vůbec neznáme, mi přijde na hranici možností. Určitě se dá už dnes udělat spousta věcí pro to, aby software byl rozšiřitelnější a souhlasim, že lidi na to často kašlou. Nicméně bych to neházel jenom na blub programmers, jak je dobrým zvykem, započítal bych, že psát vysoce rozšiřitelný / vysoce flexibilní software je těžký.
6.11.2019 14:13
Gréta | skóre: 36
| blog: Grétin blogísek
| 🇮🇱==❤️ , 🇵🇸==💩 , 🇪🇺==☭
 10.11.2019 18:07
Agent
| blog: Life_in_Pieces
| HC city
13.11.2019 17:55
xkucf03 | skóre: 49
| blog: xkucf03
10.11.2019 18:07
Agent
| blog: Life_in_Pieces
| HC city
13.11.2019 17:55
xkucf03 | skóre: 49
| blog: xkucf03
Z programátorského hlediska prakticky vždy dává smysl vytvořit si nástroj pro práci s doménovou abstrakcí. V téměř každém eshopu se s modelem doménové abstrakce nepracuje pomocí shellu programovacího jazyka, ale pomocí nějakého grafického rozhraní. V něm je možné například zrušit objednávku kliknutím na tlačítko, či sledovat její stav.
Přitom relační databáze jsou na to jako dělané. Je to sice extrémně neobjektový přístup (data jsou striktně oddělená od chování), ale to uživatelům nemusí až tolik vadit. Mají totiž dobrý vhled přímo do dat, mají silný jazyk pro jejich procházení (SQL), funguje tam reflexe… a když chceš s daty něco udělat, tak použiješ buď standardní jazyk (DML) nebo zavoláš uloženou proceduru, která může (měla by) obsahovat dostatečnou dokumentaci toho, co dělá, a díky vhodné jmenné konvenci a strukturování (schémata) zajistíš, aby uživatel věděl, co volat.
Napsat nad tím obecné GUI není až tak těžké – máš tam information_schema, kde se dočteš vše potřebné k tomu, abys GUI pro danou doménu vygeneroval.
Někdo se možná zděsí nad tím, že by se měl uživatel hrabat přímo v databázi, ale podobně by se asi zděsil i nad tím, že by se uživatel měl hrabat v nějakých objektech a používat reflexi k tomu, aby věděl, co na nich volat za metody. Mimochodem v té databázi jsou navíc práva, takže lze pro každého uživatele/roli definovat, co může číst, měnit nebo jaké procedury/funkce může volat + se dá auditovat, kdo co dělal.
Debugger je typickou ukázkou programu, který pracuje jen na úrovni debugovaného jazyka, což může být ve spoustě případů špatná úroveň abstrakce.
Nebo řešíš úlohu pomocí nevhodného nástroje. Podle mého debugger slouží právě k hrabání se v kódu a zkoumání, jak to nízkoúrovňově funguje. Nikoli k ladění obchodní logiky. Sám debugger používám poměrně svátečně a jsou programátoři, kteří ho nepoužívají vůbec.
Obchodní logika (tzn. ty doménově specifické věci) se řeší třeba v procesním modelování a existují nástroje, které umožňují ty procesy (které sis nakreslil jako diagramy) spouštět – a kromě toho, že ten proces pak „ožije“ a stane se z něj program, tak se dá různě měřit a sledovat. To už se pak dá nazvat tím debuggerem pro obchodní logiku.
Nicméně na objekty rozpoznané v kamerových záznamech by se to nehodilo – tam se asi bez ručně napsaného nástroje neobejdeš. A dost možná bude jednodušší napsat takový jednoúčelový nástroj, než natolik obecný debugger + jeho parametrizaci pro danou doménu. Osobně taky preferuji abstraktní a obecné nástroje, ale tady mi přijde, že by náklady na vývoj obecného řešení byly asi až příliš vysoké.
Další věc je, že na produkci se moc nechceš připojovat debuggerem nebo spíš ti to ani není dovoleno, a je potřeba se spolehnout na logy.
Pak tu jsou mikroslužby, kde je aplikace rozdělená na více samostatných procesů (služeb), které spolu komunikují po síti, a na jejich propojení dohlíží nějaké běhové prostředí nebo framework. Tam pak často bývají různé nástroje na monitorování jednotlivých interakcí a trasování jednotlivých volání napříč jednotlivými službami. Ale to je všechno dost v počátcích a co jsem viděl, tak tam moc podpora pro obchodní logiku a doménově specifické věci není a jde spíš o ten technický pohled na věc. Je otázka, jestli se to k tomu časem dopracuje, nebo jestli móda mikroslužeb dřív vyprchá…
tinySelf, můj interpreter programovacího jazyka, je napsaný v restriktivní kompilované verzi pythonu. Teoreticky tedy mám možnost používat k debugování nástroje pythonu, jmenovitě například debugger pdb, či debugger zabudovaný v PyCharmu. Když ve svém jazyce objevím chybu narážím na problém, že použitý debugger pracuje na moc nízké úrovni modelovaného problému. Modeluji lexer, parser, kompilátor a interpreter bytecode. Debuger mi však nabízí pouze debugování „hmoty“, ze které je modelováno. … Když jsem se snažil tuto chybu debugovat, neustále jsem narážel na to že ve chvíli, kdy používám nástroje pythonu narážím na to že ve skutečnosti debuguji moc nízkou úroveň modelu. Aby se vykonala jedna instrukce bytecode v mém interpretru, bylo nutné projít stovky řádků kódu v pythonu jazyce. Typicky bylo třeba projít desítky instrukcí, než jsem porozuměl povaze problému. Než jsem došel do správného bodu, strávil jsem krokováním klidně půl hodiny.
Kdybys to postavil nad GraalVM, tak bys v debuggeru (ať už Netbeans nebo třeba Chromium) pracoval s konstrukty toho svého tinySelfu a ne s nějakým nízkoúrovňovým bajtkódem, do kterého se tvůj jazyk přeložil. Nízkoúrovňové optimalizace bys mohl případně řešit v IGV.
Oproti tomu existují jazyky, které umožňují definovat různé DSL a dynamicky je střídat. Například Helvetia, či REBOL, jenž umožňuje přímo přistupovat k BNF parseru a definovat do něj nové gramatiky.
Tohle je věc vkusu a osobních preferencí, ale podle mého už to příliš zvyšuje složitost jazyka/syntaxe a nároky na toho, kdo má kód číst a porozumět mu. Kromě standardních jazykových konstrukcí se musíš naučit i ty doménově specifické – a dostat se z kódu k jejich definicím bývá těžší, než se v IDE prokliknout třeba na definici metody nebo anotace a přečíst si tam jejich dokumentaci. Opačný extrém je Go, které podle mého trpí zase přehnanou snahou o zjednodušení jazyka.
Autor v knize zkoumá různé možnosti, jak je typicky dosahováno rozšiřitelnosti. Například se věnuje různým architekturám aplikací, a jak jsou v nich vytvářeny pluginy. Mimo jiné probírá a analyzuje integrace pluginů vůči standardnímu API, použití konektorů, či message busu. Zkoumá také skládatelnost aplikací ve stylu unixu. Na různých studiích s reálnými uživateli ukazuje, jak moc je náročné vytvoření pluginu a rozšíření funkcionality komponenty.
Tohle jsem teď shodou okolností řešil v relpipe-in-filesystem. Přemýšlel jsem, jaká všechna data by to mělo mělo být schopné ze souborů vytěžit (umělo to takový ten základ jako velikost soubru, vlastníka, symlinky, rozšířené atributy atd.) a nakonec jsem se rozhodl místo rozšiřování funkcionality (což zvyšuje komplexitu a obvykle přidává závislosti na nějakých knihovnách) tam dát jen obecné rozhraní pro spouštění vlastních skriptů a přidat jen pár příkladů (PDF metadata, MIME typy, XPath…). Takže si napíšeš skript/program na pár řádků v libovolném jazyce a ten ze souborů vytahá atributy, které potřebuješ (klidně i doménově specifické). Ale ještě to budu trochu předělávat – jednak aby to využilo vícejádrové procesory (tzn. forknout víc procesů) a jednak opakovaně používat jeden proces skriptu pro více atributů a záznamů (tzn. jinde naopak ten fork()/exec() nedělat tak často).
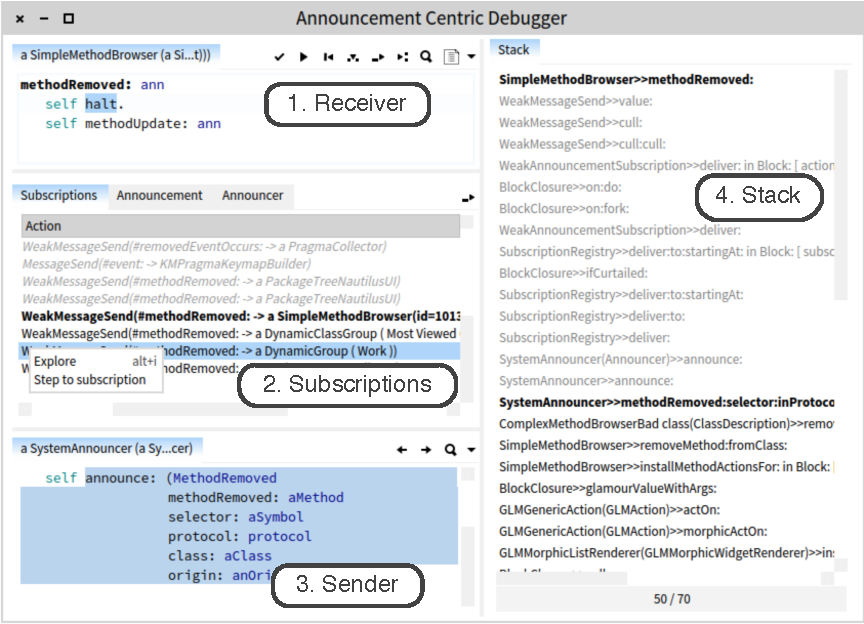
Inspector umožňuje objektům definovat jak se mají zobrazit přidáním speciálních metod do objektu. Cosi jako .__repr__() či .__str__() (nebo .toString()), ale pro user interface inspectoru, či debuggeru, nebo spotteru.
Tady je otázka, jestli tento ladící kód má být součástí zdrojáků nebo zda má být dodaný zvenku. Na jednu stranu to takhle funguje automaticky a nemusíš nic konfigurovat, ale na druhou stranu to znečišťuje produkční kód a taky to závisí na autorovi – když to bude cizí knihovna, tak si budeš muset její třídy podědit nebo nějak upravit za běhu, abys to tam doplnil. Případně může mít jeden objekt resp. třída více možných využití a každý bude chtít jinou reprezentaci v debuggeru.
Pro textový výstup tohle běžně jde – viz příloha. Zajímavý je ten grafický výstup. Případně volání metod (i když na to stačí běžná reflexe třeba v Javě).
Spotter nabízí cosi jako search engine pro jednotlivé objekty
Tohle zase připomíná OQL (náhodný článek z roku 2005, nebo Eclipse, IBM).
Zde je například možné vidět debugger pro parser … Typické rozšíření se skládá z doménově-specifikých debugovacích operací a doménově-specifického pohledu, přičemž oboje je založeno na debugovací session. … Developeři můžou vytvářet doménové abstrakce pomocí:
Tohle už je zajímavější.
Pokud vás zajímá, jak budou vypadat vývojářské nástroje za dvacet let, a případně se chcete podílet na této snaze už nyní, rozhodně doporučuji knihu k přečtení.
Co mi tam chybí (nicméně četl jsem jen tvůj článek, ne tu knihu), je jakákoli podpora asynchronního programování a systémů založených na poslínální zpráv. Ono ladit synchronní kód je ještě relativně jednoduché a většinou ani není potřeba ho ladit – stačí si ho přečíst. Ale daleko obtížnější bývá pracovat s asynchronním kódem, kde se např. na jedné straně programu zadá nějaký vstup nebo pošle nějaká zpráva do fronty a na druhé straně programu se (kdykoli v blíže neupřesněné budoucnosti) něco stane, aniž by tam byla nějaká na první pohled zřejmá vazba (jako např. že jedna metoda volá druhou).
Je otázka, jestli budou dřív běžně dostupné nástroje pro ladění asynchronního kódu, nebo spíš jazykové prostředky, které umožní psát (ve výsledku) asynchronní a neblokující kód přímočarým až naivním synchronním způsobem. Viz Fibers v Javě.
Je otázka, jestli budou dřív běžně dostupné nástroje pro ladění asynchronního kódu, nebo spíš jazykové prostředky, které umožní psát (ve výsledku) asynchronní a neblokující kód přímočarým až naivním synchronním způsobem. Viz Fibers v Javě.Hm, takže v podstatě chtějí v Javě to samé, co dělá Go. Je zajímavé, že na konci si všimli tohohle:
Continuations and fibers dominate async/await in the sense that async/await is easily implemented with continuations (in fact, it can be implemented with a weak form of delimited continuations known as stackless continuations, that don't capture an entire call-stack but only the local context of a single subroutine), but not vice-versa.... přesně takhe totiž funguje asynchronní programování v Rustu, kde vzhledem k zaměření jazyka na výkon chtěli právě ty stackless continuations (a na nich je postaveno async/await tak, jak popisují). V každém případě explicitní podpora ze strany debuggeru je stále potřeba, i když máš podporu asynchronního programování v jazyce.
14.11.2019 23:44
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
*Vyprskne* Tady jde taky o to, že je to pořád lowlevel přístup, kde se něco děje v textu a ty to modelování musíš ve skutečnosti pořád dělat ve své vlastní hlavě. Což většina lidí zvládne cca s 7+-2 proměnnými (viz Millerovo magické číslo) na jedné úrovni abstrakce. Pak musíš buďto tvořit vnořené hierarchie (kterých si ale lidi zase zvládnou zapamatovat cca 7+-2), nebo přejít na jiné části mozku než symbolické, tedy typicky grafické reprezentace, kde mozek nemá problém sledovat stovky proměnných a jejich stavů.Z programátorského hlediska prakticky vždy dává smysl vytvořit si nástroj pro práci s doménovou abstrakcí. V téměř každém eshopu se s modelem doménové abstrakce nepracuje pomocí shellu programovacího jazyka, ale pomocí nějakého grafického rozhraní. V něm je možné například zrušit objednávku kliknutím na tlačítko, či sledovat její stav.Přitom relační databáze jsou na to jako dělané.
Nebo řešíš úlohu pomocí nevhodného nástroje. Podle mého debugger slouží právě k hrabání se v kódu a zkoumání, jak to nízkoúrovňově funguje. Nikoli k ladění obchodní logiky. Sám debugger používám poměrně svátečně a jsou programátoři, kteří ho nepoužívají vůbec.Slouží k tomu, protože k tomu slouží, ne protože by nějaké omezení v realitě diktovalo, že to tak má být. Představ si třeba jak by mohlo být užitečné moct krokovat skrz abstraktní doménový model a například sledovat co konkrétně zákazník v eshopu dělal jako kdybys mu koukal přes rameno.
Obchodní logika (tzn. ty doménově specifické věci) se řeší třeba v procesním modelování a existují nástroje, které umožňují ty procesy (které sis nakreslil jako diagramy) spouštět – a kromě toho, že ten proces pak „ožije“ a stane se z něj program, tak se dá různě měřit a sledovat. To už se pak dá nazvat tím debuggerem pro obchodní logiku.Zaměřuješ se na moc velké implementační detaily. To byla jen analogie schválně vybraná tak, aby jí pochopil každý kdo to bude číst, protože každý má zkušenost s eschopem a dokáže si ty vztahy tam představit. V praxi samozřejmě jde o naprosto libovolný příklad, kde můžeš uvažovat třeba objekty v mém tinySelfu, kde se do toho navíc zapojují různé procesy a stacky a kde co.
A dost možná bude jednodušší napsat takový jednoúčelový nástroj, než natolik obecný debugger + jeho parametrizaci pro danou doménu. Osobně taky preferuji abstraktní a obecné nástroje, ale tady mi přijde, že by náklady na vývoj obecného řešení byly asi až příliš vysoké.Tak třeba v pythonu ti nic jiného ani nezbyde. Ale kdyby to bylo psané ve smalltalku, hodně by mě zajímalo kam by se dalo zajít s moldable debuggerem a jaké by měl limitace.
Tohle je věc vkusu a osobních preferencí, ale podle mého už to příliš zvyšuje složitost jazyka/syntaxe a nároky na toho, kdo má kód číst a porozumět mu. Kromě standardních jazykových konstrukcí se musíš naučit i ty doménově specifické – a dostat se z kódu k jejich definicím bývá těžší, než se v IDE prokliknout třeba na definici metody nebo anotace a přečíst si tam jejich dokumentaci. Opačný extrém je Go, které podle mého trpí zase přehnanou snahou o zjednodušení jazyka.Souhlasím, osobně se mi to moc nelíbilo.
Kdybys to postavil nad GraalVM, tak bys v debuggeru (ať už Netbeans nebo třeba Chromium) pracoval s konstrukty toho svého tinySelfu a ne s nějakým nízkoúrovňovým bajtkódem, do kterého se tvůj jazyk přeložil. Nízkoúrovňové optimalizace bys mohl případně řešit v IGV.Jo, vím o tom, i když zrovna IGV jsem úplně nepobral, přišlo mi to jako solidní bordel, který jsem si ale už několikrát u rpythonu přál. Tam se sice dá použít na JIT divná vizualizace skrz pygame, ale prase aby se v tom vyznalo.
ale na druhou stranu to znečišťuje produkční kód a taky to závisí na autoroviOsobně si nemyslím že zrovna definice __repr__ či __str__ nějak znešišťuje produkční kód. Naopak to umožňuje mnohem jednodušeji pochopit co se tam vlastně děje. Jinak ve Smalltalku je možné injectovat metody do objektů i po jejich vytvoření a použití, takže je možné třeba distribuovat zvlášť balíček, který by mé objekty rozšířil o tyhle metody. To se mi zdá jako docela dobré řešení.
Tohle zase připomíná OQL (náhodný článek z roku 2005, nebo Eclipse, IBM).Je dost možné že autor to tam referencuje. Na Eclipse se konkrétně odkazuje několikrát, tedy na studie které vedly ke konkrétním featurám Eclipse.
Tohle jsem teď shodou okolností řešil v relpipe-in-filesystem. Přemýšlel jsem, jaká všechna data by to mělo mělo být schopné ze souborů vytěžit (umělo to takový ten základ jako velikost soubru, vlastníka, symlinky, rozšířené atributy atd.) a nakonec jsem se rozhodl místo rozšiřování funkcionality (což zvyšuje komplexitu a obvykle přidává závislosti na nějakých knihovnách) tam dát jen obecné rozhraní pro spouštění vlastních skriptů a přidat jen pár příkladů (PDF metadata, MIME typy, XPath…). Takže si napíšeš skript/program na pár řádků v libovolném jazyce a ten ze souborů vytahá atributy, které potřebuješ (klidně i doménově specifické). Ale ještě to budu trochu předělávat – jednak aby to využilo vícejádrové procesory (tzn. forknout víc procesů) a jednak opakovaně používat jeden proces skriptu pro více atributů a záznamů (tzn. jinde naopak ten fork()/exec() nedělat tak často).Cool.
Představ si třeba jak by mohlo být užitečné moct krokovat skrz abstraktní doménový model a například sledovat co konkrétně zákazník v eshopu dělal jako kdybys mu koukal přes rameno.Viz Time travelling debugger ... což stále ještě není úplně to co chceš - je to stále víceméně jedna úroveň abstrakce, ale je to IMO krok tím směrem...
15.11.2019 15:53
xkucf03 | skóre: 49
| blog: xkucf03
Pořád mi není moc jasné, k čemu by tam ten debugger měl být. Ten zákazník má být skutečný zákazník na produkci? Tak se přece stejně jednak nebudeš připojovat debuggerem a jednak bys to stejně asi nechtěl krokovat, protože bys to chudákovi zákazníkovi pozastavil a on by nemohl pracovat. Takže to má být jen pro vývoj?
Různé webové frameworky tohle už mají – jde zaznamenávat pohyb uživatele po webu a akce, které tam provádí, a pak si to zpětně přehrávat. To jde použít na produkci i na testech.
A ta data se stejně budou průběžně propisovat do nějaké databáze a v RAM (v objektech daného jazyka) se budou držet většinou jen krátkou dobu, v nesouvislých časových úsecích, takže to jednak je lepší sledovat v té DB (případně na jiném externím rozhraní) a jednak z těch objektů v RAM by toho člověk moc nevykoukal (není tam kompletní informace).
Souhlasím, že by bylo hezké mít na to nějaké obecné řešení a třeba ta grafická reprezentace dat se mi líbí, ale aby to k něčemu bylo, tak je potřeba brát v úvahu to, že data poměrně často opouštějí ten objektový svět a náš program, odcházejí někam ven (DB, síť atd.) a později se zase vracejí, ale v tu chvíli jsou to už jiné instance, ten původní objekt byl požrán GC a místo něj vznikl nový, který má třeba v atributu ID stejné číslo. Takže by bylo potřeba dohledat vazby i napříč objekty a nějak je korelovat, párovat.
O něčem jiném by to bylo u objektové databáze typu Caché… Nicméně dneska jsou moderní/módní mikroslužby a tam je program rozpadlý na spoustu procesů, které spolu komunikují po síti a data se pořád serializují a deserializují, takže tam by nějaké sledování/ladění na úrovni objektového systému bylo k ničemu, protože ty objekty tam mají hodně krátkou životnost a velice rychle zmizí a pak se zase vynoří v nějakém jiném procesu/kontejneru/virtuálce.
Ten zákazník má být skutečný zákazník na produkci?Ne ne, tohle je na debugování frontendu, kdy si simuluješ různé vstupy/výstupy v různém pořadí a sleduješ, jak se to chová.
Souhlasím, že by bylo hezké mít na to nějaké obecné řešení a třeba ta grafická reprezentace dat se mi líbí, ale aby to k něčemu bylo, tak je potřeba brát v úvahu to, že data poměrně často opouštějí ten objektový svět a náš program, odcházejí někam ven (DB, síť atd.) a později se zase vracejíTo právě v úvahu je bráno. To je to, o čem jsme tu vedli flamewar minule - V tom pure FP paradigmatu jaký má např. Elm je např. síťová odpověď stejný koncept jako uživatelský vstup - tj. je to pouze hodnota (kust dat), která prochází tou funkcionální pipeline té aplikace. Takže v rámci toho debuggingu simuluješ/sleduješ vstupy/výstupy a díváš se, jestli na to program správně reaguje, případně jestli vnitřní stav (což je opět zase jenom nějaký hodnota) je správný.
ale v tu chvíli jsou to už jiné instance, ten původní objekt byl požrán GCCo na to říct kromě ať žijí hodnotové typy
 Jinak nechci tu nějak extrémně protežovat Elm, mám k němu i výhrady (teřba to FFI IMO stojí za houby) a kdybych dělal frontend (což naštěstí nemusim
Jinak nechci tu nějak extrémně protežovat Elm, mám k němu i výhrady (teřba to FFI IMO stojí za houby) a kdybych dělal frontend (což naštěstí nemusim  ), tak to asi spíš nepoužiju, ale tenhle přístup se mi opravdu líbí.
15.11.2019 17:05
xkucf03 | skóre: 49
| blog: xkucf03
), tak to asi spíš nepoužiju, ale tenhle přístup se mi opravdu líbí.
15.11.2019 17:05
xkucf03 | skóre: 49
| blog: xkucf03
Přitom relační databáze jsou na to jako dělané.
*Vyprskne*
Z toho pohledu, že v nich máš obvykle kompletní obraz systému, zatímco v tom objektovém světě máš obvykle jen nějakou dočasnou podmnožinu, viz #43. A máš tam běžně dostupné nástroje na procházení těch dat a zkoumání jejich struktury – různé SQL klienty. To je pohodlím a možnostmi většinou mnohem dál než různé debuggery v objektovém světě, kterými se sice taky můžeš koukat dovnitř, ale ne tak jednoduše a pohodlně. Pokud tohle to Moldable hnutí změní, tak to bude jedině dobře, ale v současnosti je pro mne značně užitečnější se podívat do DB než se hrabat v objektech v RAM nějakého běžícího procesu.
Další užitečná funkce SŘBD jsou transakce – pro uživatele to vlastně znamená funkci „Zpět“ – může si něco vyzkoušet, a když se mu to nepovede, tak udělá ROLLBACK. Tohle v objektovém světě asi nikdo implementované nemá, ne? A pak ta práva, aby uživatel/role mohl dělat jen to, co má explicitně dovoleno – zatímco v OOP jsi prakticky vždy root a když už, tak si můžeš dělat, co chceš.
Neber to jako kritiku OOP – když programuji, tak je mi OOP (případně OOP s funkcionálními prvky) jako paradigma nejbližší – ale jen říkám, že relační databáze jsou v některých ohledech mnohem dál.
Tady jde taky o to, že je to pořád lowlevel přístup, kde se něco děje v textu a ty to modelování musíš ve skutečnosti pořád dělat ve své vlastní hlavě. Což většina lidí zvládne cca s 7+-2 proměnnými (viz Millerovo magické číslo) na jedné úrovni abstrakce. Pak musíš buďto tvořit vnořené hierarchie (kterých si ale lidi zase zvládnou zapamatovat cca 7+-2), nebo přejít na jiné části mozku než symbolické, tedy typicky grafické reprezentace, kde mozek nemá problém sledovat stovky proměnných a jejich stavů.
S tímhle souhlasím, textový pohled není ideální a grafická reprezentace je často užitečnější.
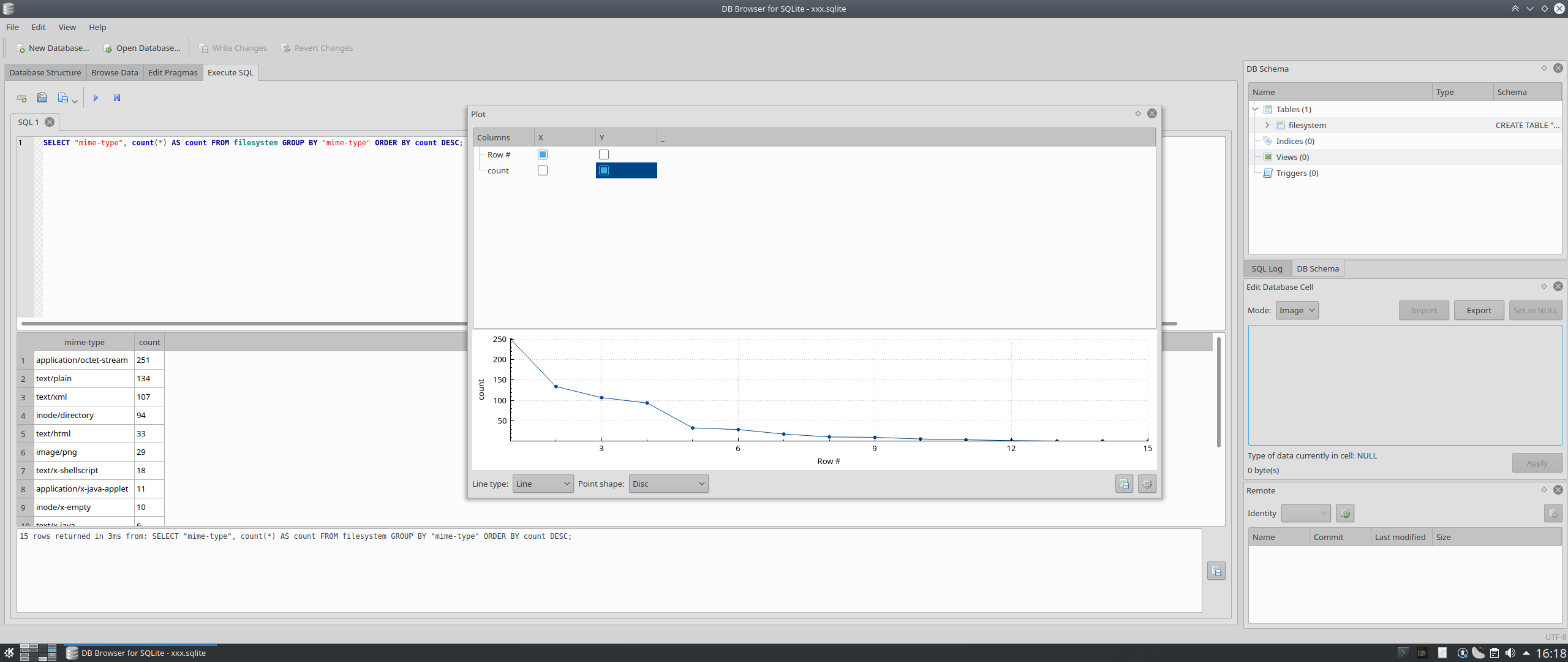
Ale to taky není nic, co by šlo v objektovém světě a nešlo v relačním. Např. i jednoduchý klient typu sqlitebrowser umí kreslit grafy nebo zobrazovat BLOBy jako obrázky (viz příloha).
V těch Relačních dýmkách (jak tomu říká Jenda :-) mám už teď sloupcové grafy. A časem budou další druhy grafů a dovedu si tam představit i třeba generování diagramů v .dot formátu, které se pak vykreslí přes GraphViz – a tím půjde vizualizovat vazby mezi daty. A je to obecný nástroj použitelný pro libovolná relační data – tzn. něco, jako když si napíšeš plugin do objektového debuggeru, který nějak graficky znázorní objektová data.
Slouží k tomu, protože k tomu slouží, ne protože by nějaké omezení v realitě diktovalo, že to tak má být. Představ si třeba jak by mohlo být užitečné moct krokovat skrz abstraktní doménový model a například sledovat co konkrétně zákazník v eshopu dělal jako kdybys mu koukal přes rameno.
Viz #43.
Chápu to v případě aplikací, kde ty objekty mají nějaký smysluplně dlouhý život a nějak zajímavě mění svoje stavy a neopouštějí moc hranice programu (neodcházejí do databáze, na síť atd.). Otázka je, jak velké části aplikací se to týká – protože dneska je tendence programovat hodně beze-stavově, životnost objektů bývá krátká a je snaha je co nejdřív vyplivnout někam mimo OOP a RAM procesu. Poskládat potom z těch útržkovitých úseků, kdy jsou data ve formě objektů, nějaký smysluplný celkový obraz může být dost těžké.
Tyhle nástroje samy o sobě nic moc nepřinesou a vyžadují buď změnu paradigmatu (aby lidi programovali víc objektově) a nebo jsou určeny pro ty, kdo už takto objektově programují. Což se ale týká dost úzké skupiny lidí – zdaleka ne všech, kteří píší v OOP jazycích, protože i v těch OOP jazycích se často programuje spíš procedurálně (to by ještě tak nevadilo) a hlavně dost beze-stavově.
Pro mne by to začalo být hodně zajímavé ve chvíli, kdy by takový debugger byl schopný sledovat stav napříč aplikací i databází a spojit si, že např. objekt Uživatel(id=123), který byl právě požrán GC, je totéž jako záznam v databázi Uživatel(id=123) a to samé, jako objekt Uživatel(id=123), který o chvíli později vznikl v jiné části aplikace voláním konstruktoru (tzn. jde o jinou instanci než byl ten původní objekt, který už teď neexistuje, ale z logického pohledu je to ten samý objekt). Nedejbože, aby tam ale byly mikroslužby, kde to bude skupina samostatných procesů, které si mezi sebou nějak posílají data. Nicméně i u běžných aplikací se může stát, že data mění/zpracovávají dva různé procesy, takže by se hodilo, aby se ten debugger byl schopný připojit na víc než jeden proces.
V praxi samozřejmě jde o naprosto libovolný příklad, kde můžeš uvažovat třeba objekty v mém tinySelfu, kde se do toho navíc zapojují různé procesy a stacky a kde co.
U těch objektů tinySelfu to chápu a rozumím, proč to potřebuješ a proč by to bylo užitečné (pro vývoj toho jazyka/kompilátoru/interpretru). Já dělám většinou ty podnikové nebo bankovní aplikace, takže na to koukám trochu z jiného úhlu.
Tiskni
Sdílej:
![]()
![]()
![]()
![]()
![]()
![]()
ISSN 1214-1267, (c) 1999-2007 Stickfish s.r.o.
 6.11.2019 11:12
6.11.2019 11:12
{kind=link}
{kind=link}
{kind=link}
{kind=link}