DuckDuckGo AI Chat umožňuje "pokecat si" s GPT-3.5 Turbo od OpenAI nebo Claude 1.2 Instant od Anthropic. Bez vytváření účtu. Všechny chaty jsou soukromé. DuckDuckGo je neukládá ani nepoužívá k trénování modelů umělé inteligence.
VASA-1, výzkumný projekt Microsoftu. Na vstupu stačí jediná fotka a zvukový záznam. Na výstupu je dokonalá mluvící nebo zpívající hlava. Prý si technologii nechá jenom pro sebe. Žádné demo, API nebo placená služba. Zatím.
Nová čísla časopisů od nakladatelství Raspberry Pi: MagPi 140 (pdf) a HackSpace 77 (pdf).
ESPHome, tj. open source systém umožňující nastavovat zařízení s čipy ESP (i dalšími) pomocí konfiguračních souborů a připojit je do domácí automatizace, například do Home Assistantu, byl vydán ve verzi 2024.4.0.
LF AI & Data Foundation patřící pod Linux Foundation spustila Open Platform for Enterprise AI (OPEA).
Neziskové průmyslové konsorcium Khronos Group vydalo verzi 1.1 specifikace OpenXR (Wikipedie), tj. standardu specifikujícího přístup k platformám a zařízením pro XR, tj. platformám a zařízením pro AR (rozšířenou realitu) a VR (virtuální realitu). Do základu se z rozšíření dostalo XR_EXT_local_floor. Společnost Collabora implementuje novou verzi specifikace do platformy Monado, tj. open source implementace OpenXR.
Byla vydána nová verze 0.38.0 multimediálního přehrávače mpv (Wikipedie) vycházejícího z přehrávačů MPlayer a mplayer2. Přehled novinek, změn a oprav na GitHubu. Požadován je FFmpeg 4.4 nebo novější a také libplacebo 6.338.2 nebo novější.
ClamAV (Wikipedie), tj. multiplatformní antivirový engine s otevřeným zdrojovým kódem pro detekci trojských koní, virů, malwaru a dalších škodlivých hrozeb, byl vydán ve verzích 1.3.1, 1.2.3 a 1.0.6. Ve verzi 1.3.1 je mimo jiné řešena bezpečnostní chyba CVE-2024-20380.
Digitální a informační agentura (DIA) oznámila (PDF, X a Facebook), že mobilní aplikace Portál občana je ode dneška oficiálně venku.
#HACKUJBRNO 2024, byly zveřejněny výsledky a výstupy hackathonu města Brna nad otevřenými městskými daty, který se konal 13. a 14. dubna 2024.
Víte že můžete odebírat mé blogy pomocí RSS? (Co je to RSS?)
Od určité doby jsou všechny texty které zde publikuji verzované na Githubu.
Jestliže najdete chybu, nepište mi do diskuze a rovnou jí opravte. Github má online editor, není to skoro žádná práce a podstatně mi tím usnadníte život. Taky vás čeká věčná sláva v commit logu :)
19.8.2020 02:41
| Přečteno: 6621×
| Obecné IT
|  | poslední úprava: 19.8.2020 06:12
| poslední úprava: 19.8.2020 06:12
Posledních několik týdnů rozechvívá vlny mých sociálních sítí fenomén GPT-3. Jedná se o nedávno představený druh strojového učení, vytrénovaný společností OpenAI na rekordním množství dat. A zatímco se jedná jen o jazykový model, který má za úkol predikovat další token ve větě, výsledky a možnosti využití jsou místy dech-beroucí.
Následující obrázek pěkně ukazuje rozdíl v počtu parametrů oproti předchozím modelům:
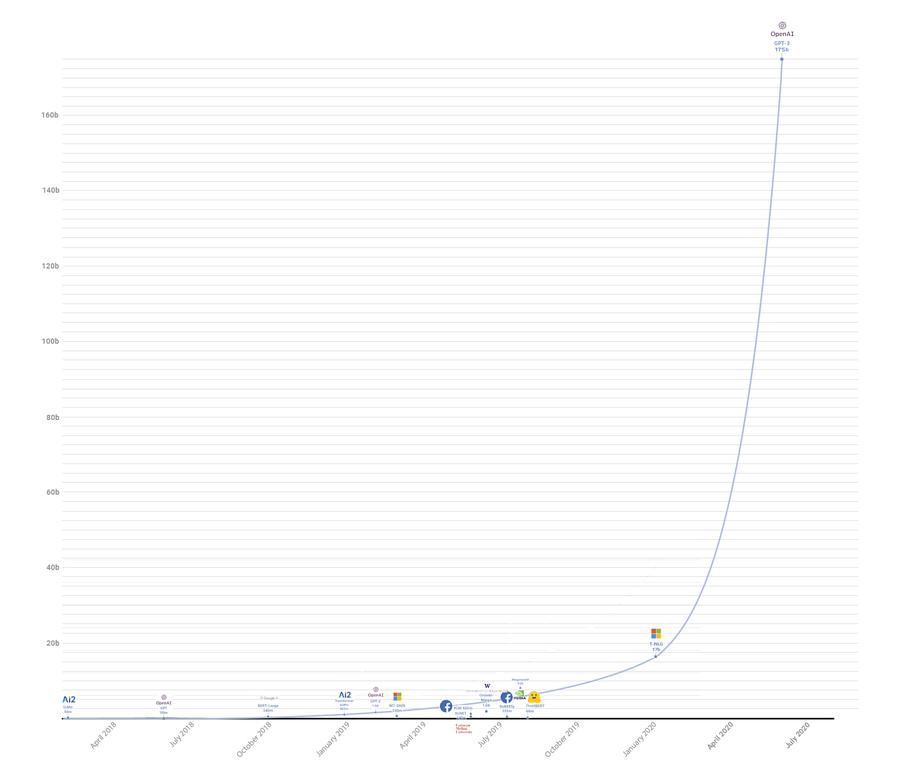
(Ukázka postupu vývoje počtu parametrů neuronového modelu transformerů v čase. Zdroj:
Why GPT-3 matters.)
Pojďme se prvně podívat na ty zajímavější příklady použití GPT-3.
Asi nepřekvapí, že GPT-3 je schopné na základě krátkého promptu, který uvede téma textu, napsat příběh, článek, blog, nebo semestrální práci na zadané téma.
Podobné projekty zde byly už dřív, a byly například schopny dogenerovat další odstavce podobné původnímu. Za všechny například GPT-2 a talktotransformer. Sám jsem kdysi zkoušel Markovovo modely a rekurentní neuronové sítě, které přestože ve srovnání s GPT-3 působí jako hračka, také zvládly generovat zajímavé výsledky.
Gwern na tohle téma sepsal celý blogpost: https://www.gwern.net/GPT-3
Nějak se stalo, že GPT-3 se na množině dat naučilo sčítat a násobit čísla. Má sice problémy s většími čísly, občas dělá chyby, ale i tak je to fascinující, když si uvědomíte, že mu nikdo nevysvětloval koncept čísel, ani aritmetických operací. Představte si, že by vás nikdo neučil číst a vy se naučili používat aritmetiku na základě čtení knih v čínštině, kterou vás taky nikdo nenaučí.
Zajímalo by mě kam by se model dostal, kdyby mu někdo v trénovacích datech nacpal spoustu aritmetiky a matematiky.
První ukázka specializovaného použití, kde jsem se zarazil a došlo mi, že tohle nebude hračka jako GPT-2, byl tweet, kde Sharif Shameem napojil svůj projekt na GPT-3 API a „předpřipravil“ ho trochou ukázek CSS.
„Předpřipravením“ zde není myšleno trénování, ale jen uvedení kontextu předtím, než je modelu předán váš text. V tomhle případě bylo modelu ukázáno trochu CSS a on najednou zvládl generovat layout podle textového popisu.
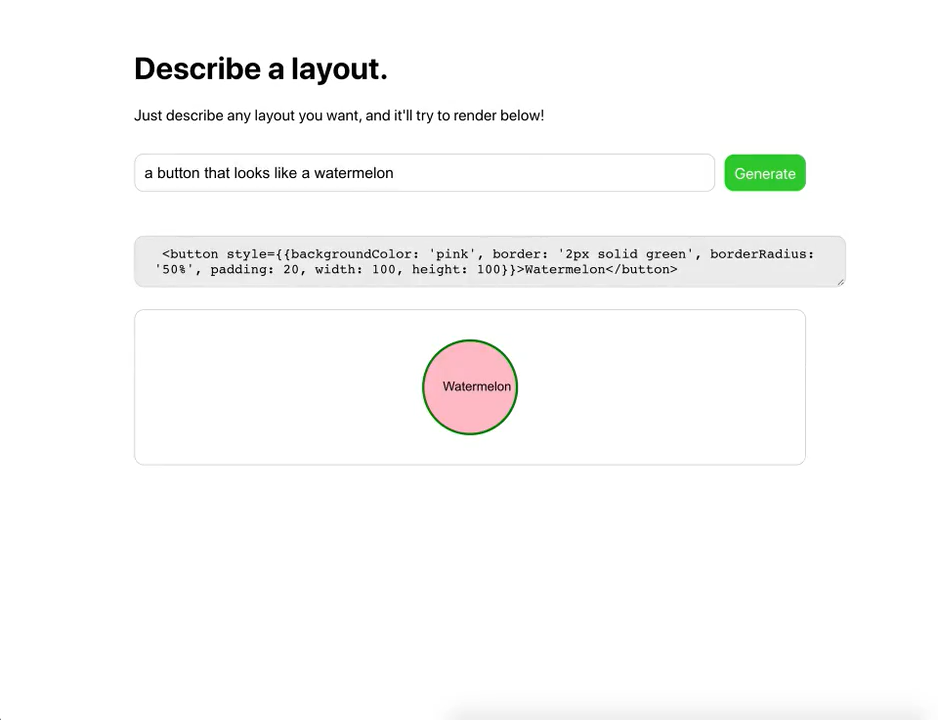
Nejen že GPT-3 pochopil co se po něm chce, ale navíc zvládl vygenerovat i patřičný HTML a CSS kód. Pokud vám to zatím nepřišlo, tak tohle je opravdu k zamyšlení.
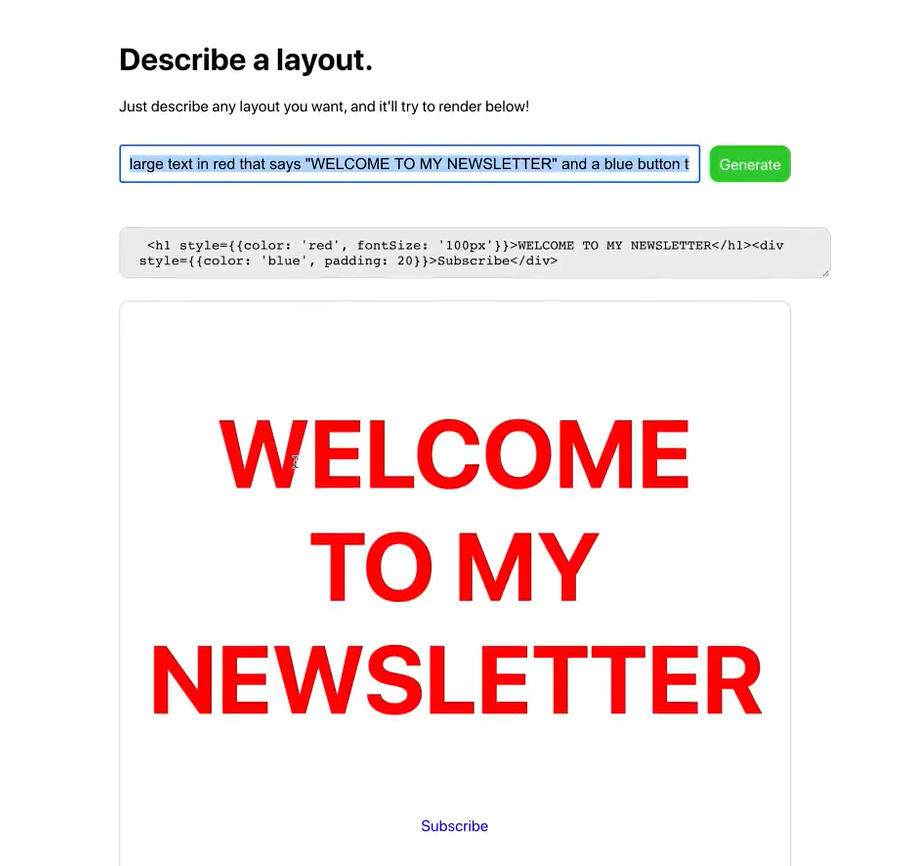
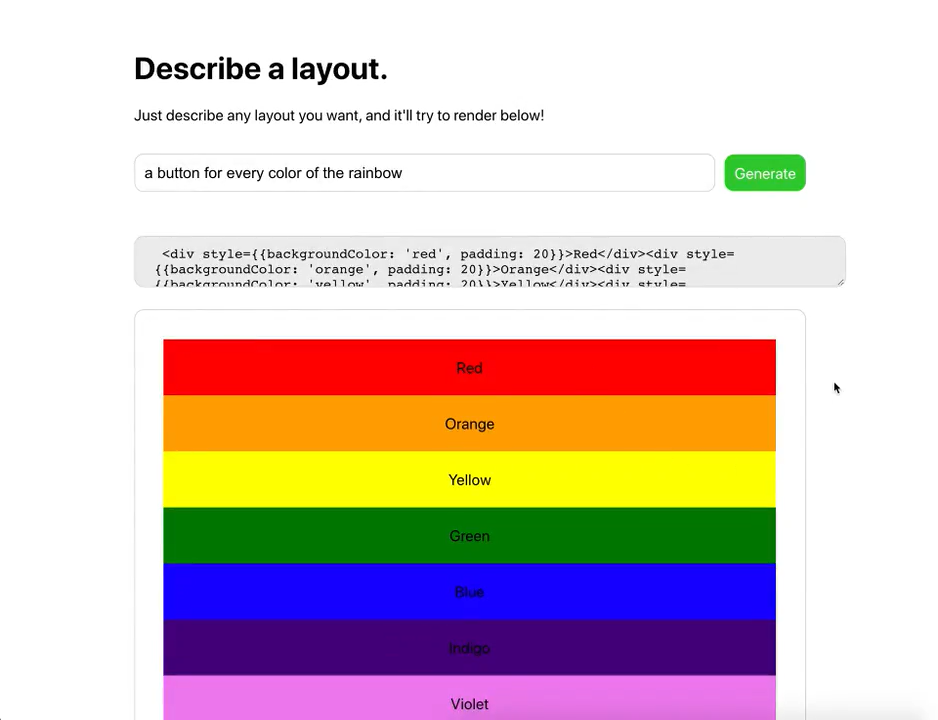
Video zahrnuje několik ukázek, některé fungují více, jiné méně, dokonce je tam i syntatická chyba. Ale vzhledem k tomu že model nikdo neučil používat HTML, nebo kódovat CSS, tak se jedná o fantastické výsledky. Tohle všechno pochytil z náhodných textů. Kdyby byl trénovaný speciálně na HTML / CSS, tak se účinnost jistě podstatně zvýší.
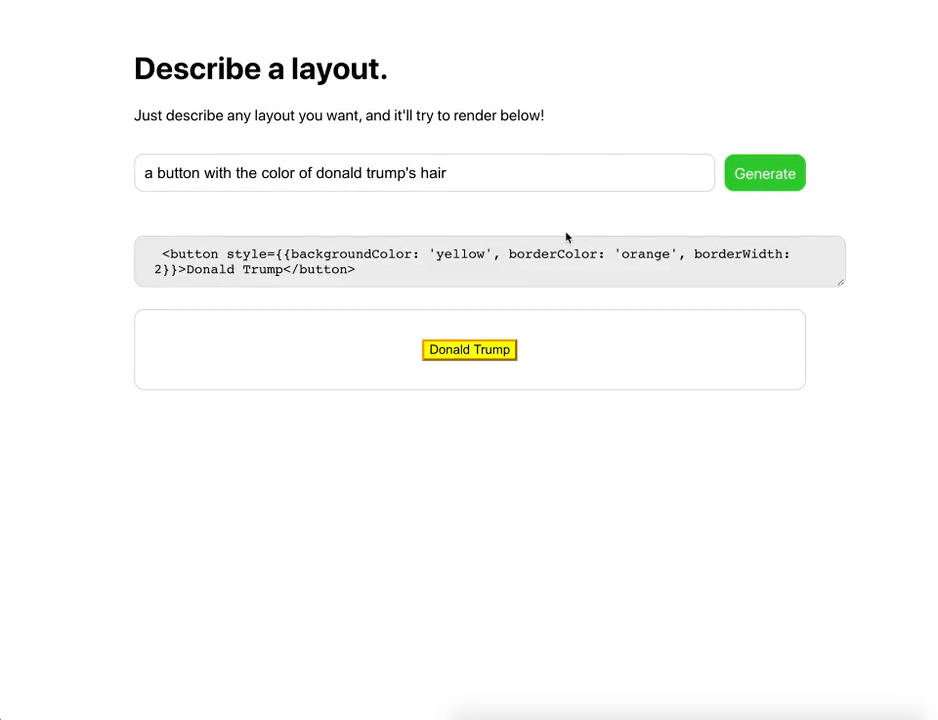
Sharif později přidal ještě další ukázku, kde GPT-3 vytváří aplikace v reactu i s funkčním kódem, kde je několik tlačítek updatujících data na backendu:
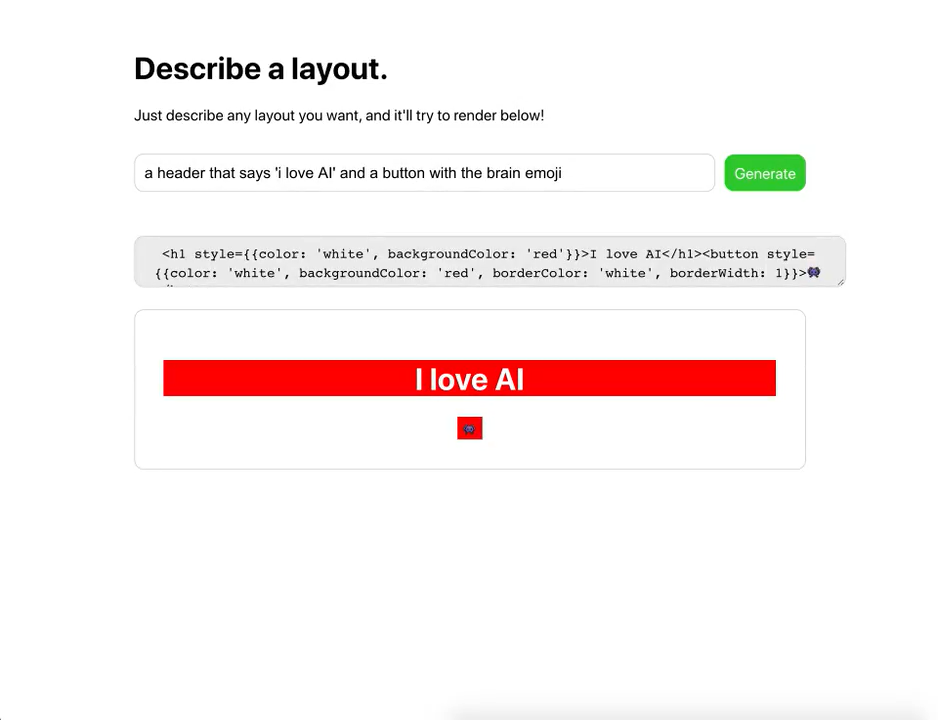
Nick Cammarata zkoušel používat GPT-3 jako terapeuta. První řádka, kterou je možné na obrázku vidět je ono již zmiňované „předpřipravení“, které dá GPT-3 kontext rozhovoru. V rozhovoru pak GPT-3 vystupuje jako John.

(Zdroj obrázku: https://twitter.com/nicklovescode/status/1283326066338062337)
Quasima Munye napadlo položit GPT-3 otázku z lékařského oboru:

(Zdroj obrázku: https://twitter.com/QasimMunye/status/1278750809094750211)
Normálním písmem je napsaný vstup pro GPT-3, tučně je napsaná jeho odpověď. Nejen že správně pochopil o čem otázka je, ale navíc na základě textového popisu nemoci korektně určil o jakou nemoc se jedná, jaký na ní použít lék a na jaké receptory v mozku ten lék působí.
Zde se začíná ukazovat síla GPT-3; protože není specializovaný na nic, má ohromný přehled úplně o všem. Včetně diagnóz nemocí, léků a molekulární biologie.
Harland Duman zkusil používat GPT-3 ukázkou kterou mají v pískovišti pro testování api. Ta funguje tak, jí popíšete co chce aby udělala v shellu operačního systému (modře vybraný text je „předpřipravení“). GPT-3 poté vypisuje konkrétní příkazy:
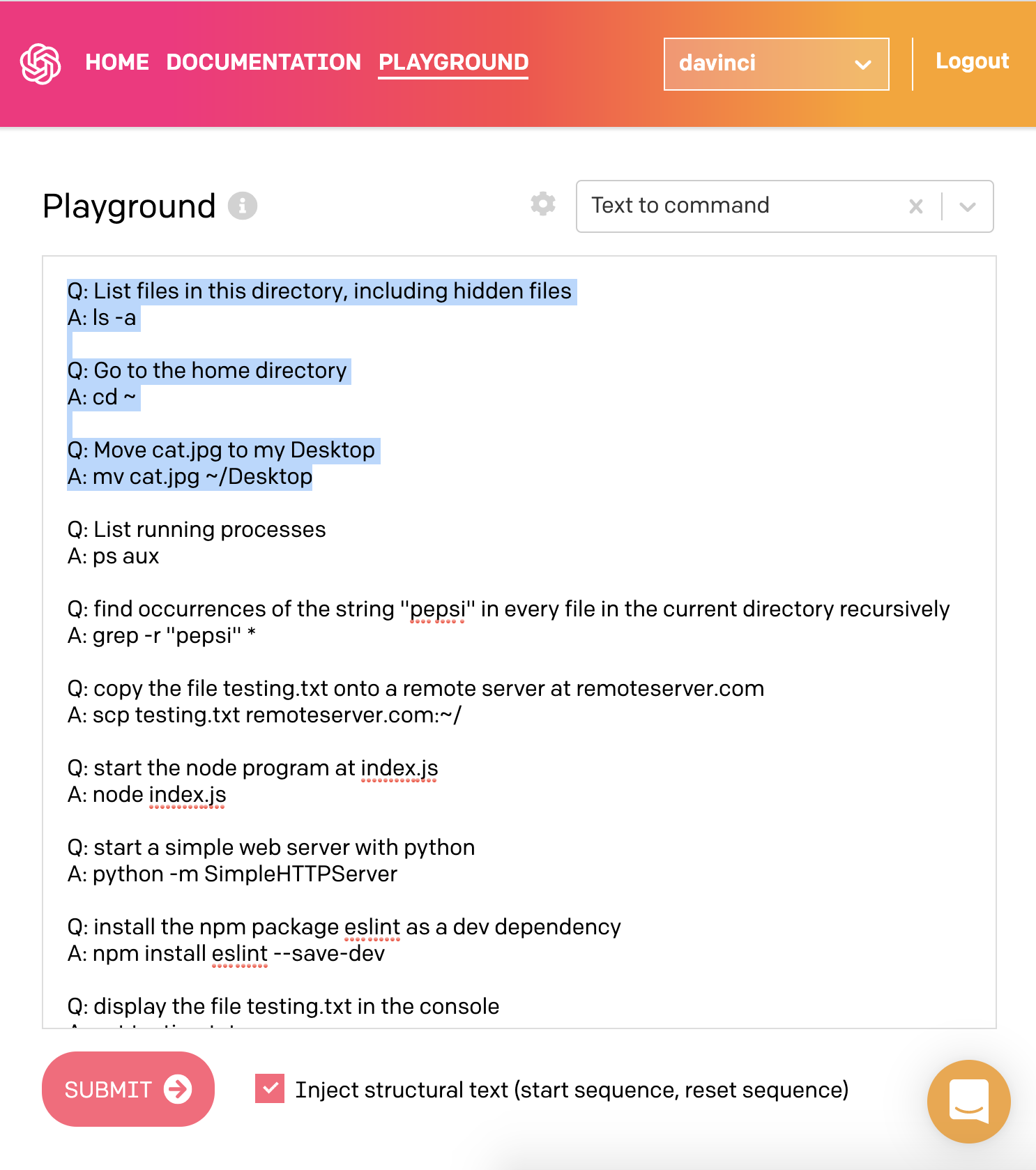
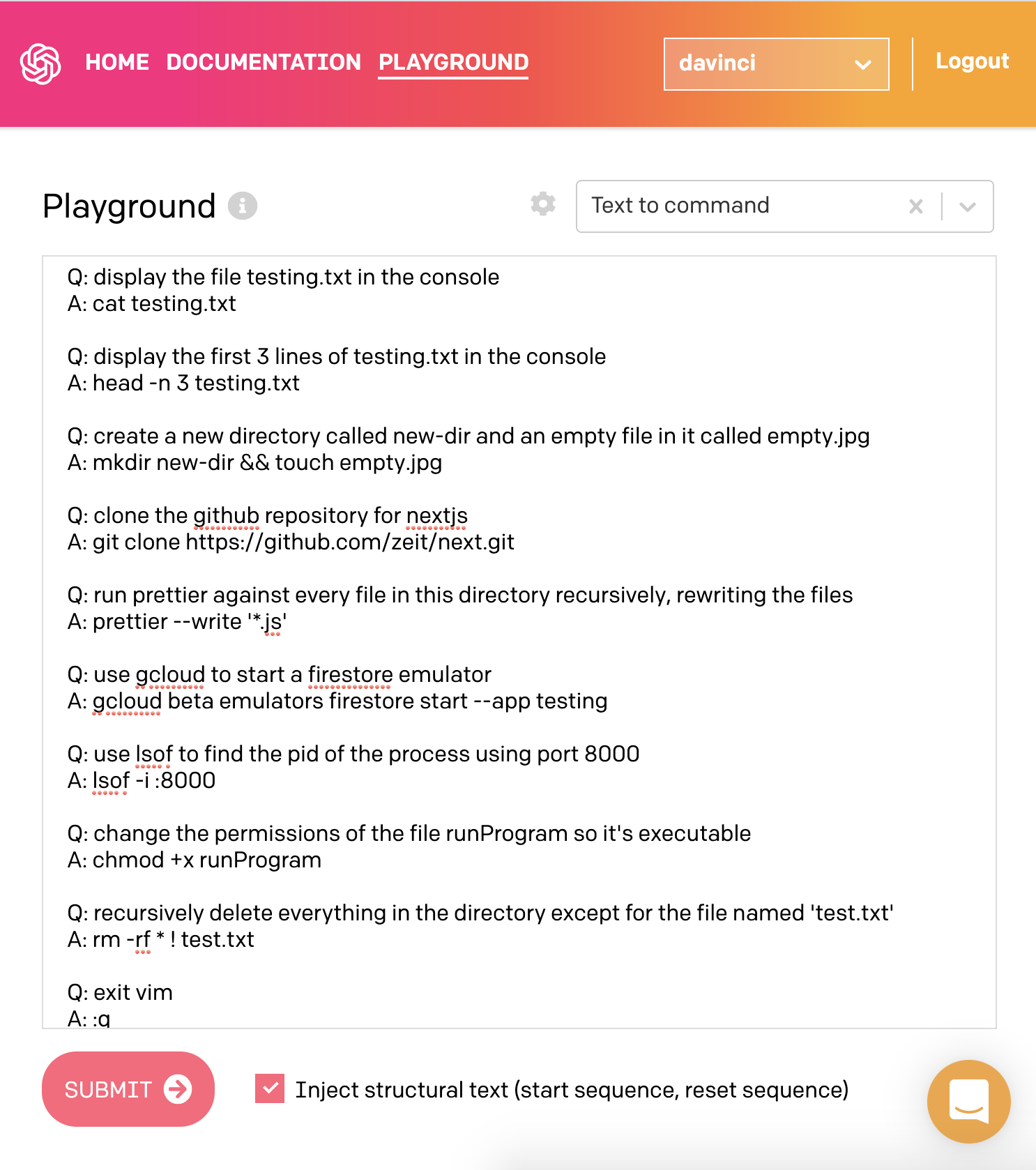
Sám jsem si s touhle verzí zkoušel hrát a musím říct, že zvládne i docela složité ukázky zahrnující kombinace pomocí pipes, find a xargs. Například mu nedělá problém věc jako komprese disku poslaná přes ssh. Za zmínku stojí, že celý proces funguje i obráceně, tedy umí převést příkaz na textový popis, který ho vysvětlí:
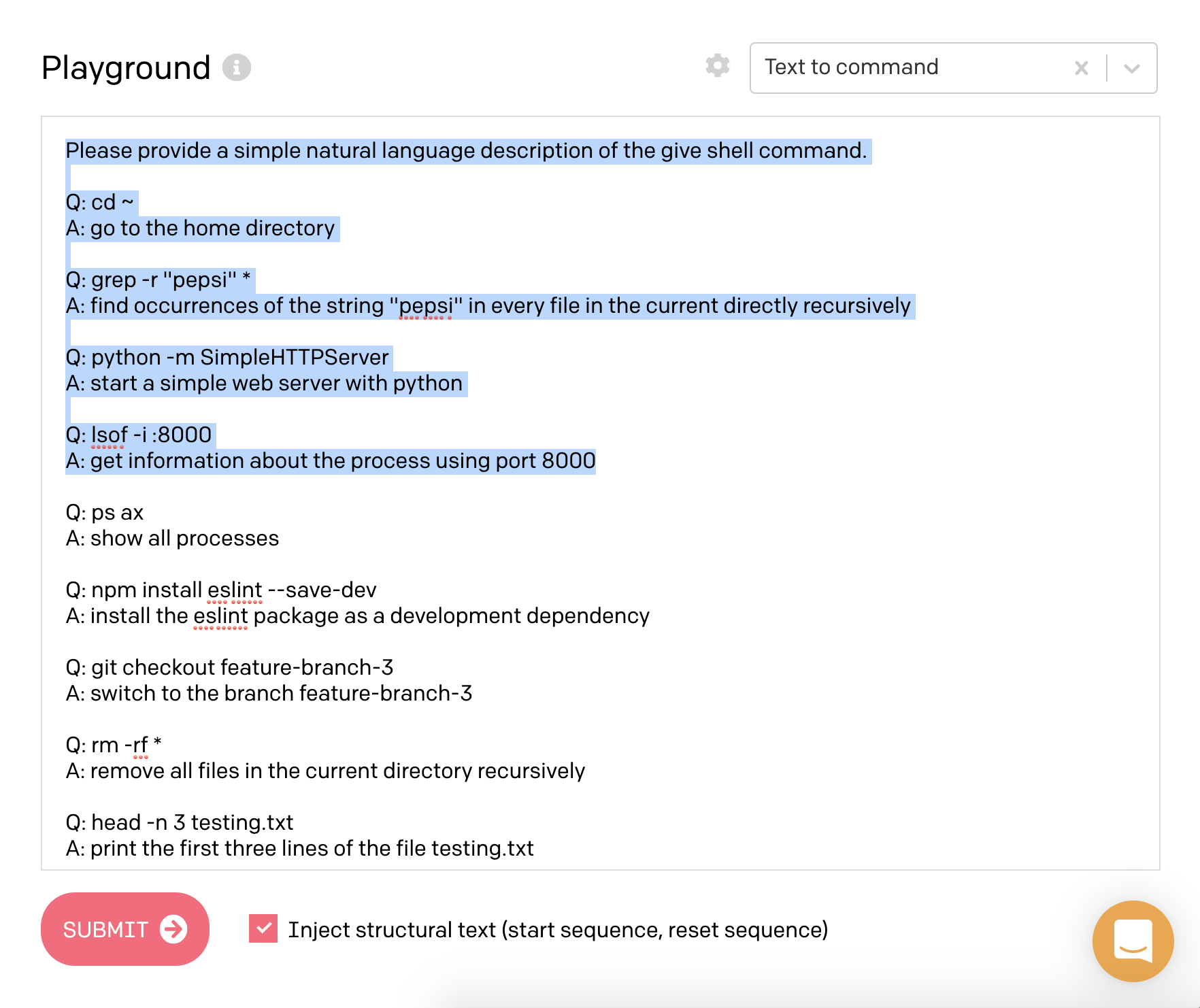
Thread zahrnuje různé i různé další ukázky, například programování v node.js, a taky zkoušky toho jak moc GPT-3 chápe čísla a různé vztahy mezi nimi.
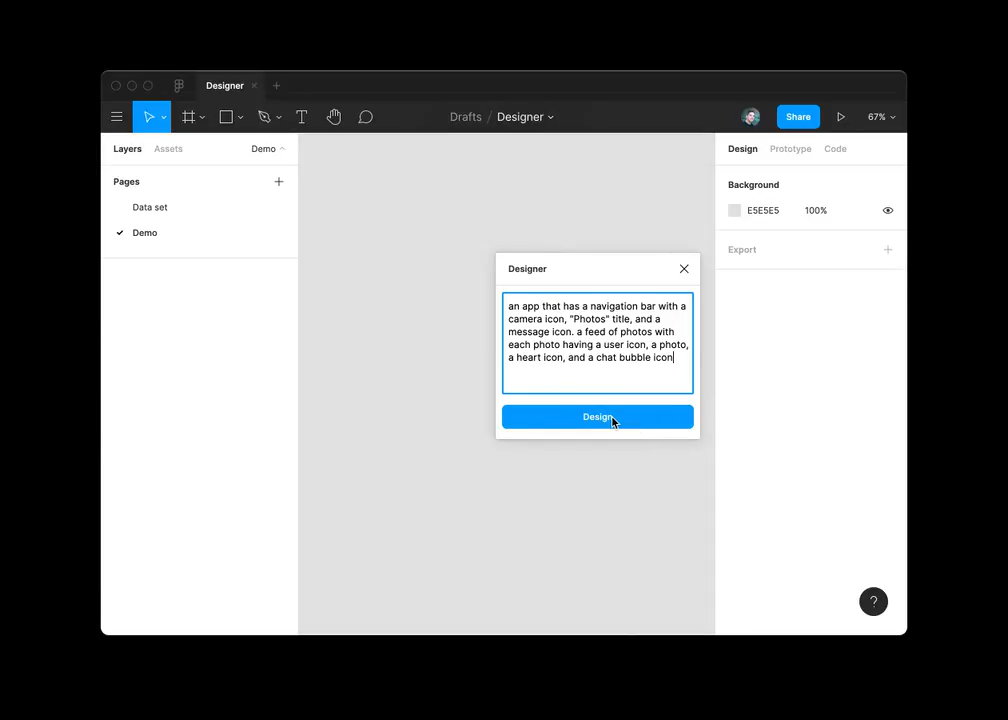
Jordan Singer použil GPT-3 jako backend pro převod textového popisu na layout mobilní aplikace:
Amanda Askell vyzvala GPT-3 aby generoval kytarové noty popsané v ASCII obrázcích:

Modelu stačilo dát dvě ukázky co od něj očekává. Nejen že vygeneroval výše uvedené obrázky, ale i hudbu v nich, která nezní úplně špatně.
Zde je pěkně vidět ukázka toho, k čemu se dá model použít; tedy k transformaci dat z jednoho popisu do druhého. Například generování ASCII obrázků podobného druhu by bylo bez nějakého programu velmi otravné. Model však zvládne tenhle překlad poměrně jednoduše jen na základě pár ukázek vstup / výstup.
Paras Chopra nad GPT-3 postavil sémantický vyhledávací nástroj, kterému popíšete co vás zajímá a on vám to najde a vrátí URL kde je detailnější popis. Něco jako google, který ale rozumí vaší otázce, místo aby vyhledával podle klíčových slov v textu.
Uživatel s přezdívkou yash vytvořil učetnictví, kterému textově popisujete co jste udělali za transakci a ono to převádí do řeči čísel a faktur.
Francis Jervis vyzval model aby přeložil normálně zadaný text do „právničiny“, tedy jazyka používaného právníky. Výsledky jsou docela zajímavé.
Zábavná byla reakce Joschy Bacha, když někdo vzal jeho tweet o GPT-3, který úplně nepochopil, a požádal GPT-3, aby ho vysvětlil.

Co se vysvětlování textu týče, tak zajímavou míru pochopení a modelování světa ukazuje model v tomto tweetu, kde byl dotazován na to čím jsou si věci podobné.:

Asi je z těch ukázek jasné, k čemu to je. Obecně má model určité pochopení textu, které se naučil na přečtených datech. K tomu ale má taky „znalosti“ z těchto přečtených dat.
Model funguje formou otázka/odpověď a je možné se ho tedy ptát na různá fakta, nechat ho odvozovat logické věci, zvládá částečně i matematiku a symbolické uvažování (umí například řešit jednoduché rovnice). Obecně se dá říct, že vyniká v překladu přirozeného jazyka na něco jiného. Na řešení otázky. Na odpověď. Na kód. Mezi lidskými jazyky.
Model rozhodně nefunguje bezchybně, ale i tak je to mnohem dál, než všechny předchozí projekty. Kdybych to měl k něčemu přirovnat, tak je zhruba pod úrovní velmi hloupého člověka, který má ale ohromné (encyklopedické) znalosti na všechna možná témata.
To vše bez specializace, tedy obecný model. Tento model je možné teoreticky dále vzít a specificky ho dotrénovat pomocí ukázek, například z oboru právničiny, nebo v překladech, či k programování. Tím se úspěšnost ještě zvýší. Nutno ovšem dodat, že tohle trénování může dělat jen někdo kdo model vlastní, a nejedná se o takzvané „předpřipravení“ zmíněné výše, které může udělat kdokoliv pouhou interakcí s modelem. Vlastníkem je momentálně pouze OpenAI.
Pojďme se nyní podívat jak to přibližně funguje.
V případě GPT-3 jde o takzvaný „unsupervised learning“, tedy druh strojového učení, které se učí samo z dat. Princip je zhruba takový, že neuronovou síť krmíme velkými množstvími textů, a ona si v tom sama najde vzory.
GPT-3 pracuje nad vektory tokenů, které si můžeme představit podobně jako v známém word2vec.
Word2vec prorazil díru do světa před několika lety, když Tomáš Mikolov publikoval v Brně svojí dizertační práci o použití neuronové sítě. Jím popsaná síť je schopná se na základě velkého množství textu sama naučit reprezentovat slova ve vícedimenzionálním prostoru tak, že významově podobná slova tvoří v tomto prostoru clustery. Zároveň jsou clustery v prostoru umístěny tak, že je možné nad jejich reprezentací provádět významovou aritmetiku.
Co si pod tím konkrétně představit;
Více-dimenzionální prostor si můžete představit graficky například tak, že ke klasickým osám X, Y a Z přidáte další. Zatímco bod ve 3D prostoru je určen maticí obsahující například souřadnice ve tvaru [1, 3, -10], bod v mnohodimenzionálním prostoru, který umí vytvářet word2vec je tvořen cca sto až tisíci čísly popisujícími jeho souřadnice.
Clustery je možné si představit tak, že body slov v tomto prostoru, které jsou významově podobné, jsou poblíž sebe. Zde jsem si dovolil trochu upravit klasický ukázkový obrázek, aby byly dobře vidět dva různé clustery, které jsou v něm zakroužkovány červeně. V jednom se nám shlukují mužské výrazy, v druhém ženské.
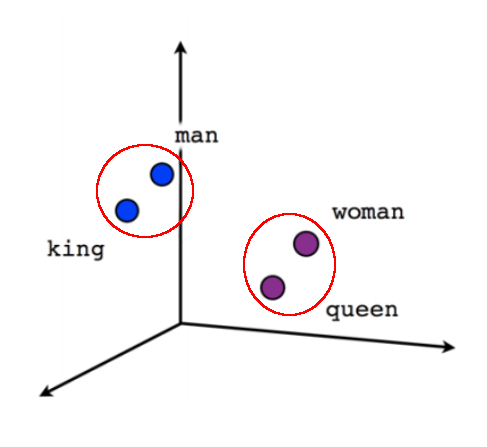
Znovu opakuji, že pro jednoduchost a představitelnost jsou použity tři osy, protože zobrazit jich tam tisíc není jednoduše možné ve dvouosém souřadnicovém prostoru dostupném pro obrázky.
Nyní se konečně dostávám, k tomu čím word2vec zaujal svět; k významové aritmetice. Nejen že totiž umí vytvořit výše ukázané clustery, ale zároveň je v prostoru umísťuje tak, že mezi nimi jsou zachovány vztahy. Můžete tak například vzít vektor pro slovo žena, odečíst od něj vektor pro slovo muž, a tento výsledek zachycující abstraktně pohlaví přičíst k vektoru slova král, čímž dostaneme vektor slova královna.
Píšu záměrně „vektor slova“, výsledkem je totiž matice čísel, která určuje souřadnice v mnohodimenzionálním prostoru. Tuto souřadnici ovšem můžeme přeložit zpět na text poté co nad ní provedeme operace.
Zde jsou ukázky různých operací nad vektory:
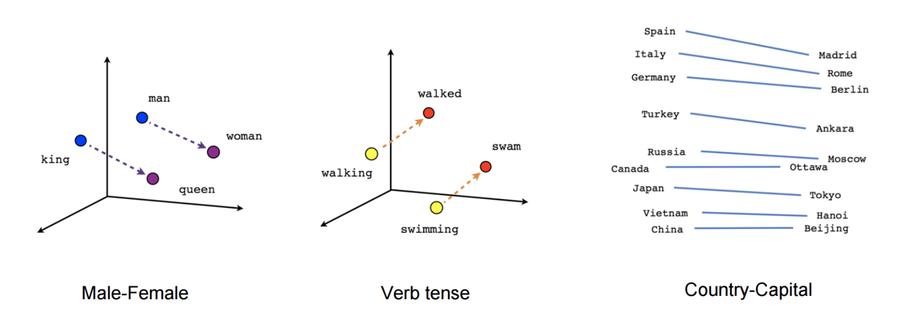
(Zdroj obrázku: Word Embeddings)
Například jde zjišťovat časy jednotlivých slov, nebo třeba hlavní města zemí.
Fascinující na tom je, že word2vec si sám vytváří databázi různých faktů a vztahů mezi nimi, jen na základě toho, že ho nakrmíme velkým množstvím textu, ze kterého si sám tyto vztahy odvodí.
GPT-3 také operuje nad „tokeny“, což jsou také mnohodimenzionální souřadnice ve vektorovém prostoru. Může se jednat o samostatná slova, nebo někdy může dojít k rozdělení na několik slabik, či podle unicode znaků. Detaily nejsou úplně důležité. Na rozdíl od word2vec je toto takzvané „embedování“ slov jen poměrně nezajímavý vstupní proces.
GPT-3 je algoritmus z rodiny Transformerů, tedy druhu architektury, jenž se často používá v NLP (Natural Language Processing, zpracování přirozené řeči). Zkratka GPT znamená Generative Pre-trained Transformer, tedy Generativní Předtrénovaný Transformer. Slovo „generativní“ naráží na termín z machine learningu.
Transformery používají takzvaný encoder-decoder model. GPT a další používají pouze decodery, kterých na sebe připojí mnoho (24 v případě GPT-2, 96 v případě GPT-3). Každý decoder má vícero vrstev, z nichž každá vstupní vektory různě hodnotí, vytváří další vektory definující vztahy s dalšími slovy (vektory) ve větách, přidává indexy a obecně další metadata, a tento výsledek pak posílá dál do neuronové sítě. Velký důraz je kladen na „self-attention“ vrstvu.
Zde je pro zajímavost vidět architektura decoder bloku z GPT-2:
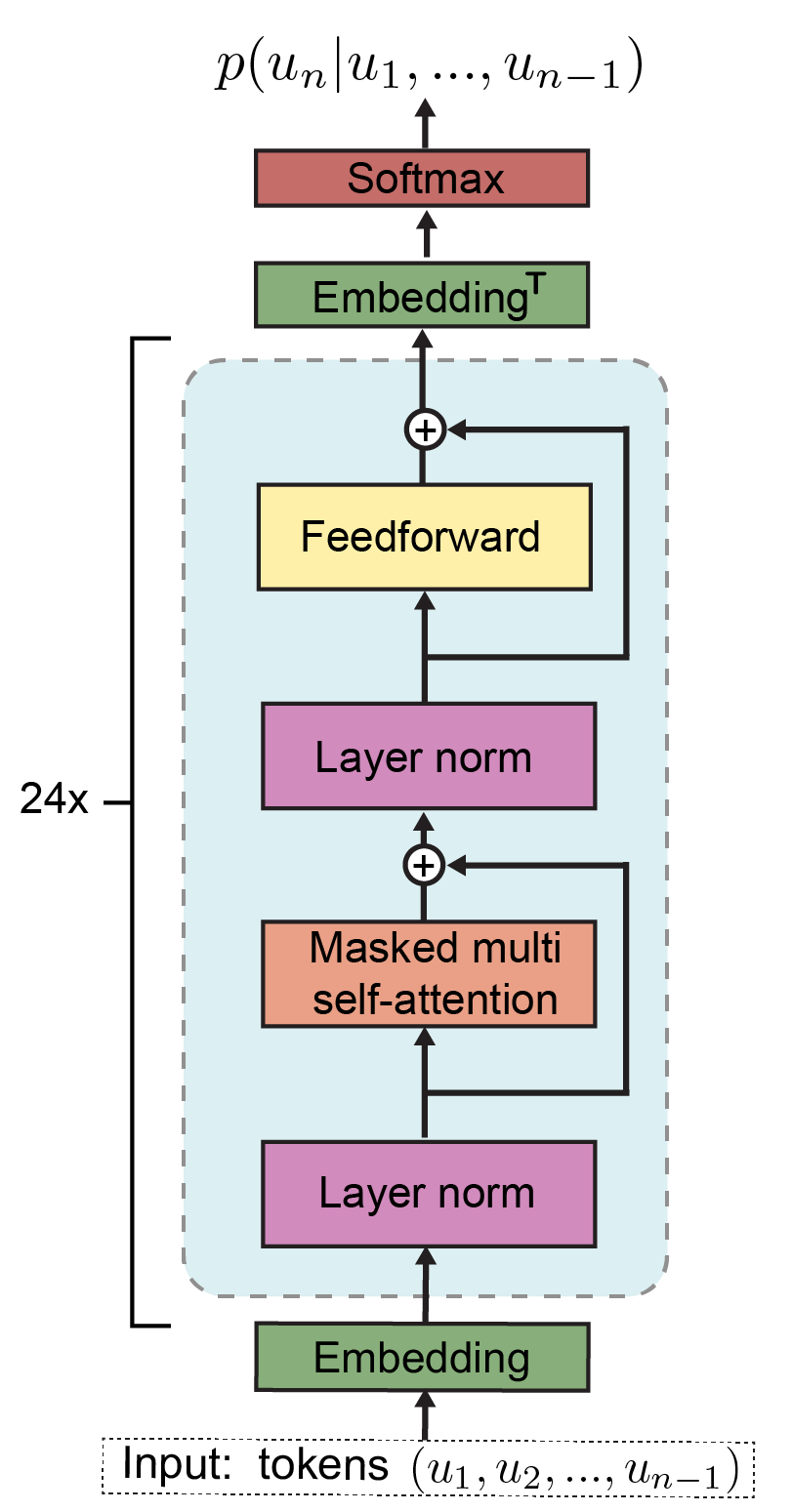
(Obrázek pochází z https://www.researchgate.net/figure/a-GPT-2-architecture-For-more-info-on-individual-operations-see-Vaswani-et-al-2017_fig1_335737829)
Jay Alammar sepsal perfektní sérii článků, kde vysvětluje trasformery a i GPT-2, na kterém je GPT-3 založený, graficky a krásně do detailu:
Specificky poslední článek vysvětluje „self-attention“ vrstvy, tedy jak model vypočítává které slovo má jakou pozornost a souvislost s ostatními, a teprve pak se tím krmí vnitřní neuronové sítě.
Oficiální paper uvádí že k trénování sítě bylo použito cca 499 miliard tokenů, zahrnujících mimo jiné sběr dat z internetových stránek, části wikipedie a různé knihy. Například jen dataset Common Crawl, který tvořil přibližně 82% trénovacích dat, zabíral po vyfiltrování a vyčištění 570GB v čisté textové podobě.
Trénováním na superpočítači byl stvořen model, který obsahuje 175 miliard parametrů. Parametry jsou jednak různé vektory, určující například self-attention vrstvy, ale také přímo nastavení neuronových sítí. Model objemem parametrů přibližně stokrát překonává předchozí GPT-2.
Pro ilustraci; je odhadováno, že výkon potřebný k trénování sítě odpovídal zhruba 355 GPU let (autoři v paperu uvádějí několik tisíc petaflop/dnů), tedy let běhu moderní výkonné grafické karty, což údajně odpovídá částce ~4.6 milionů dolarů.
Vysokoúrovňový princip fungování GPT-3 je krásně vysvětlen v článku How GPT3 Works - Visualizations and Animations. Protože zde nehodlám krást animace, které autor použil v článku, zde je jen krátký textový popis:
Dataset ukázek textu je použit k trénování sítě tak, aby predikovala výskyt následujícího tokenu. Podobně jako například markovovy řetězce umí na základě statistiky predikovat pravděpodobnost výskytu dalšího písmena, tak GPT modely na základě vstupních dat zkouší odhadnout pravděpodobnost výskytu dalšího tokenu.
Pokud se netrefí na očekávaný token (prostě další slovo z datasetu), jsou použity techniky trénování tak dlouho, dokud token není odhadnut správně.
Například zadáme modelu na vstup větu:
Byl pozdní večer – první máj – večerní máj – byl
a očekáváme doplnění dalšího slova. Pokud síť doplní slovo „lásky“, pokračujeme dál. Pokud ne, provádíme trénování a úpravy různých vektorů vhodnými algoritmy, dokud model správně neodhadne slovo „lásky“. Jakmile se trefí, pustíme na vstup
Byl pozdní večer – první máj – večerní máj – byl lásky
.. a opakujeme postup, dokud netrefí správně slovo „čas“.
Data, která dáváme modelu takto dokola na vstup nejsou nekonečná, tvoří jakési posuvné „kontextové okénko“, které má v případě GPT-3 délku 2048 tokenů.
Algoritmus pro trénování byl použit Adam (detaily nastavení v paperu na straně 43), což je optimalizační technika založená na stochastickém sestupu gradientu, popsaná například zde: Adam — latest trends in deep learning optimization.
Pod výrazem „stochastický sestup gradientu“ si představte druh úloh z matematiky, které se zabývají nalezením globálního minima (či maxima) s co nejmenší námahou.
Například pokud by se jednalo o 3D prostor, můžeme si představit pohoří se spoustou údolí a kopců, které jsou tvořeny body v našem prostoru, a cílem je najít poslepu to nejhlubší údolí. Máme ale k dispozici jen prst, kterým můžeme do mapy ze-shora bodat, a tím prstem cítíme do jaké výšky jsme narazili a jestli se terén svažuje nahoru, nebo dolu.
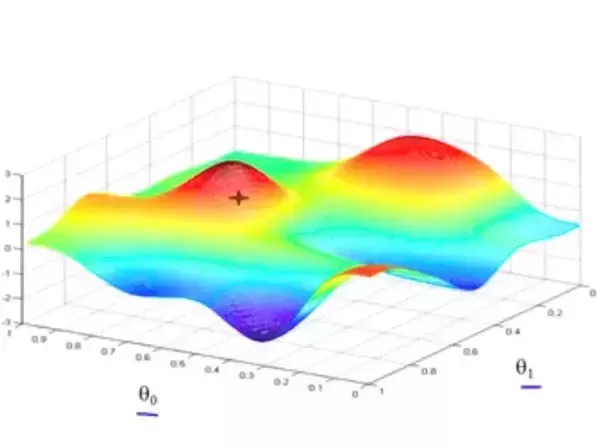
(Obrázek pochází z Does Gradient Descent Algo always converge to the global minimum?)
Jedním z možných algoritmů je prostě bodnout někam náhodně do mapy a pak zkusit bodat do kruhu kolem, jestli jsme se třeba netrefili do kopce a někde kolem není sestup do údolí. A když jo, tak to celé zopakujeme tím směrem, kde je údolí. Některé jiné techniky používají například postup tím směrem, kudy se cesta minule svažovala dolu.
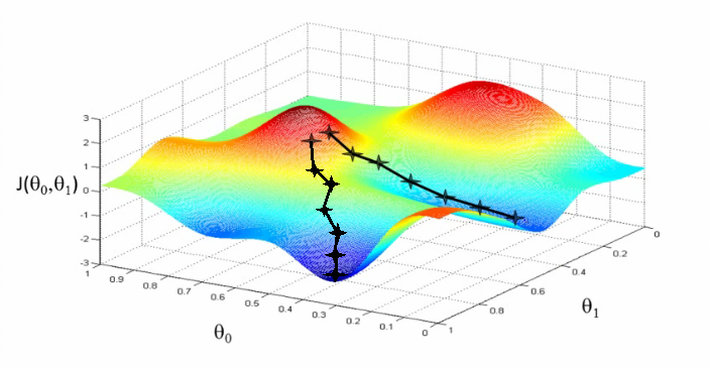
(Obrázek pochází z článku What is Stochastic Gradient Descent (SGD))
Stochastické algoritmy jsou druh matematických algoritmů, které se snaží s co nejmenším počtem bodnutí do mapy najít ne jen nějaké údolí, ale rovnou to nejhlubší údolí. To může zahrnovat různé chytristiky, jako třeba „nevzdávej se potom co narazíš na první údolí, ale zkus ještě sejít z kopce jiným směrem“, nebo třeba opětovné lezení na kopec, či náhodnou změna místa do kterého teď bodáme.
Tahle úloha nám může připadat lehká, ale jen protože se díváme na kopec očima, které každým pohledem přijímají miliardy fotonů odražených od kopce. Pokud bysme vnímali svět kolem sebe jen jedním fotonem, taky by bylo v našem zájmu mít algoritmus, kterým si vnímání světa kolem sebe co nejvíc zrychlíme. Každé testování kopce nás stojí bodnutí prstem do mapy, vyslání či přijmutí fotonu, nebo čistě prakticky výpočetní instrukce, a tedy čas a energii.
Adam je efektivní druh hledání mnohodimenzionálních údolí v mnohodimenzionálních prostorech. Způsob jakým funguje je kompromis, aby bylo v datech třeba co nejméně-krát bodnout do mapy (tedy zjistit jaká je tam hodnota a sklon), a celé to tedy fungovalo co nejrychleji a našlo to zároveň co nejhlubší údolí.
Jenda v komentářích hezky popsal jak se to pak používá:
Tohle celé děláme na kopci, který má 175 miliard dimenzí.
Říká se, že poslední renesanční člověk byl pravděpodobně Leonardo da Vinci. Tedy člověk, který znal všechna umění a řemesla své doby. Od té doby, praví rčení, je svět tak složitý a specializovaný, že nikdo nemůže znát všechno.
GPT-3 sice není člověk, inteligenčně je o hodně níž, ale renesanční rozhodně je. Tím že se učil čtením textů ví něco prakticky o všem, o čem něco četl. Jeho možnosti chápání, udržení kontextu a logicky odvozovat věci jsou omezené, ale jeho znalosti dost možná už v současnosti jsou větší, než libovolného jiného žijícího člověka.
Článek je možná laděn v až moc pozitivním duchu; je třeba přiznat si, že GPT-3 má stále spoustu omezení, dělá spoustu stupidních chyb a celkově rozhodně není dokonalý.
Na druhou stranu je nutné dodat, že i současná verze je snad jako první použitelná pro spoustu věcí, i se všemi svými omezeními. To se stále bavíme o verzi, která není specificky trénovaná pro konkrétní činnosti (takzvaný fine-tuning), což má být další feature kterou chce OpenAI zpřístupnit.
Pojďme se nyní podívat, jak se to vlastně celé prakticky používá.
Přístup do API se nachází na adrese https://beta.openai.com. Zde je možné najít nějakou základní dokumentaci (rozšířená deprecated dokumentace je na notionu), popis použití, tutoriály a různé další relevantní informace.
Vpravo nahoře je možné si vybrat z několika různých modelů, OpenAI samotné doporučuje model davinci. Ostatní modely jsou také pojmenovány podle různých historických postav.
Každá ukázka se také dá zobrazit jako volání API pomocí CURL nebo Pythonu. Vpravo je možné vybrat si různé parametry, které model konfigurují co se týče délky vráceného textu, náhodnosti a tak podobně.
Celkem nepřekvapivě se většina práce s GPT-3 smrskává do vytvoření vhodného „předpřipravení“, a nastavení správných parametrů. Jak už jsem vysvětloval, model jen doplňuje slova (tokeny). Pokud po něm něco chcete, je třeba ho dostat do „nálady“ tak, aby mohl doplnit očekávané výsledky.
To bohužel nemusí být jednoduché. Často se mi třeba podařilo vyvolat divoké chování, když jsem špatně nastavil nějaký parametr. Občas model prostě napíše, že odmítá odpovědět, a chová se tak trochu jako naštvané dítě. Jindy si prostě vymyslí krycí historku, kterou se totálně utrhne ze řetězu očekávaného výstupu, nebo se pustí do tautologií.
Co se týče generování textu, převodu na různé jiné popisy, nebo vysvětlování věcí, dařilo se mi během chvíle dosahovat očekávaných výsledků. U různých jiných úkonů jsem už ale zas tak moc úspěšný nebyl, a očekávám, že nejspíš vyžadují netriviální množství času hraní si s parametry. Například různé odvozování faktů, či snaha donutit model generovat ASCII arty (jako například ty noty v ukázkách nahoře), mi vůbec nevyšla podle očekávání.
Myslím že se zpřístupněním API se otevře nová pozice „kormidelníka“ výstupu, tedy druh specializace lidí, jenž budou nabízet generování „předpřipravení“ a nastavení parametrů pro řešení konkrétních problémů.
Člověk se samozřejmě musí zamyslet nad tím, kam tohle spěje. Vybavuje se mi ilustrace z článku Tima Urbana o umělé inteligenci:
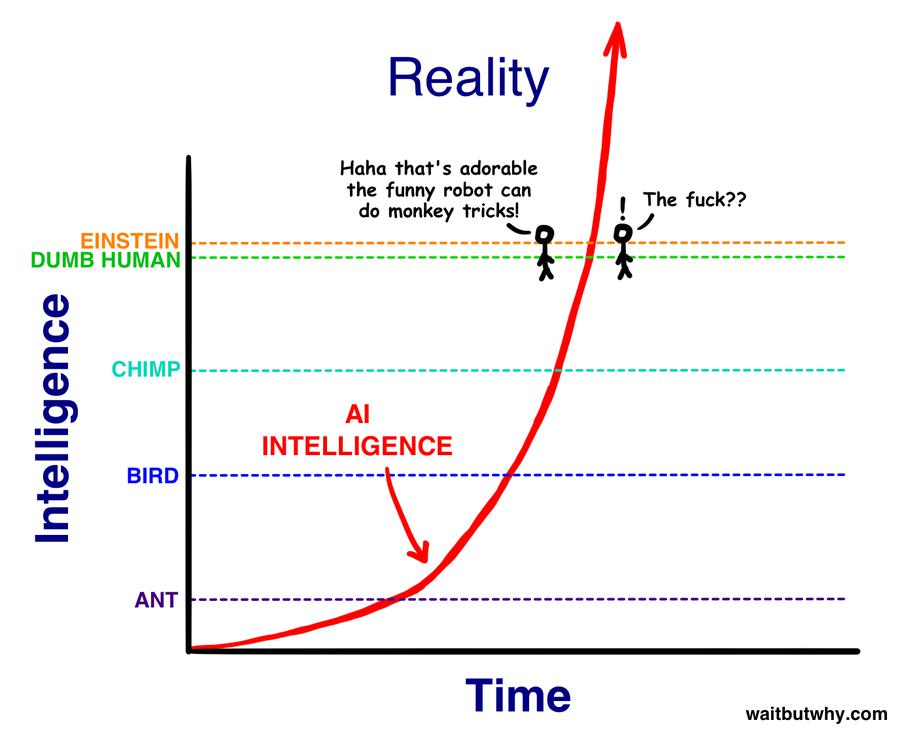
(Obrázek pochází z článku The AI Revolution: The Road to Superintelligence)
GPT-2 byla taky taková roztomilá opička, která uměla doplňovat texty. Sám jsem si s ní chvíli hrál a krmil jí kousky textů mých oblíbených autorů, načež mě fascinovalo, když pokračovala přesně jejich stylem, i když z většiny se jednalo o text, který nedával moc velký smysl.
Jeden den jsem si říkal, jak nám to vývoj na poli umělé inteligence roztomile pokračuje, druhý den najednou čumím že GPT-3 není zas o tolik níž, než úroveň pro „Dumb human“, tedy hloupého člověka.
Což je zarážející, vzhledem k tomu že se jedná o stejný druh machine learningu jako GPT-2, jen natrénovaný na větším množství dat.
Architektura GPT-3 je do jisté míry velmi hloupá. Kam to asi tak půjde dotáhnout, pokud se bude trénovat na specifické dovednosti, ale například se zvětší kontextové okno, přidají různé druhy paměti (krátkodobá, dlouhodobá), matematické koprocesory a tak dál? Momentálně probíhá tréning pouze na textu sklizeném z internetu. Co když k tomu přihodíme například blok symbolické matematiky a donutíme AI se s ním naučit pracovat?
Před několika lety jsem četl články Tima Urbana na téma umělé inteligence, nebo možná lépe strojového učení, a snah Elona Muska demokratizovat ho. Přestože jsem s nimi souhlasil, tak jsem je skutečně nechápal, ne tak jak je chápu teď, když jsem měl na vlastní kosti možnost zažít si šok z pokroku.
Představte si model GPT-10, který je ve všech ohledech lepší než člověk. Větší pochopení psaného textu, schopnost udržet kontext, dělat matematiku, logiku, programování a prostě cokoliv. K tomu masivní korpus znalostí celého světa.
I když předpokládáme, že ho nebude ovládat žádná zlá společnost, už samotné schopnosti, které má GPT-3 jsou dost husté na to abych si dovedl představit tisíce různých užitečných použití k získání výhody a náskoku nad konkurencí. Hypotetické GPT-10 by společnosti, či vládě, která ho bude vlastnit, dávalo ohromné možnosti.
Podle mého je nutné víc podpořit demokratizaci AI, tedy ten proces, kdy autoři AI si ho nenechávají pro sebe, ale sdílejí ho se světem, ale zároveň taky všude možně probíhají podobné experimenty.
OpenAI se rozhodla, že model nezpřístupní veřejnosti ve formě surových dat modelu, ale plánuje ho časem zpřístupnit formou placeného přístupu k API. Tento přístup je momentálně v beta režimu. To znamená, že můžete požádat o přístup, ale zařadíte se pouze k desítkám tisíc dalších čekajících, na které se snad časem dostane. Sám jsem se k přístupu registroval před asi měsícem, a zatím se nikdo neozval.
Ačkoliv by se mi líbilo mít přístup přímo k modelu samotnému, a mít tedy možnost ho dále trénovat a dělat na něm experimenty, je nutné připomenout, že trénování a pravděpodobně i běh modelu vyžaduje superpočítač. Superpočítače jsou nejenom drahé na pořízení, ale také na provoz.
Issue na Githubu projektu zmiňuje nějaká konkrétní čísla, která jsou ovšem založená pouze na odhadech. Zmíněno je 700+GB paměti a cca 22 grafických karet, každá s 16GB RAM, s tím že i tak by model pravděpodobně běžel pomalu.
Na nějaký vlastní odhad nemám dostatečný technický backgroud. Faktem ovšem je, že OpenAI uzavřela partnerství s Microsoftem. Ten nedávno oznámil, že superpočítač pro OpenAI má být provozovaný v Azure cloudu. Celkem by měl mít 285 000 CPU jader a 10 000 GPU.
Nepodařilo se mi zjistit, jestli už byl použit pro trénování a provoz GPT-3, nebo se jedná o budoucí projekt. Některá oznámení jsou z roku 2019, a tváří se jako že byl někdy koncem roku předán OpenAI, jiná oznámení se tváří jako že byl předán teprve někdy v půlce 2020.
Každopádně to trochu dává představu ohledně hardware a ohledně ceny jednoho požadavku na API.
Osobně mi byl přístup zapůjčen někým kdo ho už má. Pokud ve svém sociálním okolí nikoho takového nemáte, je možné získat přístup přes hru AI Dungeon.
AI Dungeon využívá model GPT-2 pro hraní textové hry, kde si můžete vybrat z několika různých tématických světů. Platícím hráčům (týden zdarma, potom $9.99/měsíc) však nabízí zprostředkovaný přístup k GPT-3. Ten je sice „předpřipravený“ scriptem pro uvedení téma textové hry, je možné ho ovšem vlastním textem „předpřipravit“ na něco jiného, a vyzkoušet si tak na něm interakce s GPT-3.
Na twitteru se dají najít poměrně zajímavé ukázky interakce s GPT-3. Některé jdou do poměrně metafyzických témat, když například někdo zjistil, že GPT-3 dělá záměrně v rozhovorech chyby, které by dělala reprezentovaná postava. Ukazuje se tedy že v „hlavě“ v rámci autenticity modeluje osobnost postavy včetně chyb.

(Zdroj obrázku: https://twitter.com/kleptid/status/1284069270603866113)
To že teď čteme o GPT-3 znamená, že jsme masivně pozadu, a že v OpenAI, ale pravděpodobně i na mnoha dalších místech na světě, se už vaří další verze.
Zajímavý je model BERT (detaily), který je vyvíjený v několika jiných institucích. Za zmínku taky stojí projekt HugingFace, který na githubu sjednocuje v jednom repozitáři všechny možné architektury a datové zdroje pro mnoho různých transformerů.
Ten kdo má dnes přístup k superpočítači a možnosti tam zkoušet a zkoumat alternativní přístupy, ten může zítra doslova udělat díru do světa, jako se to povedlo třeba Tomášovi Mikolovi s word2vec.
Ačkoliv v Čechách se zatím informace o GPT-3 prakticky nedostaly ani do odborné literatury, v anglicky hovořících médiích vznikl „hype“, tedy jakýsi kult místy až přehnaného adorování.
To samozřejmě vedlo k proti-reakci, kde u spousty lidí je teď moderní GPT-3 odsuzovat, jako že je „přehypované“ a k ničemu.
Osobně si myslím, že nemá smysl podléhat ani jedné vlně. GPT-3 je jen nástroj, který můžeme zkusit používat k něčemu produktivnímu. Nemá smysl ho „hejtovat“ že je k ničemu, když nezvládne vyřešit co po něm chceme, ani adorovat jako že vyřeší všechny naše problémy.
Osobně se k tomu stavím asi jako ke kompilátoru; je užitečné vědět, že to existuje, může být užitečné to zkusit použít na nějaký svůj projekt, kde mi ušetří práci. Teoreticky to má potenciál pro automatizaci nudných opakovaných záležitostí.
Jako už jsme si řekli, GPT-3 není nástroj pro každého, a není to ani nástroj pro každou věc.
OpenAI v roce 2018 předvedlo první generaci, která dokázala reagovat na text. Už ta byla poměrně dobře použitelná, ale pouze v rámci několika témat. A to je vlastně tak trochu celý problém.
Doufám, že se časem podaří otevřít zdroje, které OpenAI využívá, a bude možné vyzkoušet trénování s různými databázemi a jinými typy dat.
Pokud chceme GPT-3 hodnotit, je třeba si uvědomit, že se jedná o reálnou věc, nikoliv o nějakou hypotetickou konstrukci nebo výzkumný výsledek. V praxi je sice OpenAI GPT-3 ještě daleko od cíle, ale je to vlastně nejlepší model široce dostupný veřejnosti.
A samotné GPT-3 přináší obrovský objem dat. To vše je důvodem, proč se dnes jedná o jeden z nejvýznamnějších výzkumných úspěchů v oblasti AI.
Zdá se, že se všechno docela rychle hýbe k něčemu docela zajímavému. Nejsem si jistý, zda tohle je ono, ale velmi mě to zaujalo. Prakticky každý den se objevuje nějaká nová věc, která se dá použít pro vytváření lepších algoritmů. Jakékoliv inovativní nápady, různé experimenty, zajímavé datové zdroje a koncepty jsou velmi vítány ;)
Původně jsem výše uvedený „závěr“ neplánoval, když jsem však zkusil GPT-3 nakrmit částí tohoto článku (bere jen 2048 tokenů), napsal ho sám i s názvem kapitoly a markdownem pro nadpis. Umí totiž i česky, i když pár chyb (hlavně ve skloňování) jsem musel opravit. Samozřejmě také předchozí ukázku nezvládl na první pokus, musel jsem to pustit přibližně desetkrát, než jsem z něj dostal něco podobně koherentního. Výsledek je složený z několika průběhů, ale i tak je zajímavý.
Ukazuje to pěkně čeho všeho je model schopný. Například GPT-2 sice taky zvládal češtinu, ale velmi bídně, věty působily dost nekoherentním dojmem a často na češtinu odpovídal anglicky. Určitě by nedokázal takhle jednoduše psát sám o sobě.
Jsem zvědavý kam tohle všechno povede. Momentálně je technologie machine learningu a „umělé inteligence“ stále ještě v plenkách, zároveň se ale rozvíjí děsivou rychlostí.
Už několik let si vedu poznámky na téma „k čemu všemu bych využil osobního skřeta“, kam se snažím shromažďovat druhy prací a otravností, u kterých by bylo fajn, kdyby je za mě řešila nějaká automatizace. Například se jedná o generování metadat k různým projektům.
Těším se na dobu, kdy budu moct použít nějakou podobně užitečnou AI, jenž by za mě tyhle nudné tasky dělala, bez toho aniž bych musel strávit několik dní nastavováním různých šablonovacích enginů a psaním vlastních scriptů. Taky by se mi velmi hodilo něco, co dokáže prohledávat počítač podle zadaných pravidel a sémanticky rozumí tomu co po tom chci. Občas se například snažím najít email, či dokument, aniž bych si pamatoval konkrétní klíčová slova.
Spousta lidí má ze stále lepší „AI“ (ve skutečnosti machine learningu) strach. Do jisté míry to chápu. Je třeba si ovšem uvědomit, že se nejedná o magii, je to prostě jen druh programu.
Z hlediska „normálních lidí“ můžete být v klidu; „umělá inteligence“ v tomhle podání je jednodušší a dává vám větší možnosti použití, než klasické počítače a programování. Pokud zvládnete delegovat práci a popsat zadání dalšímu člověku, zvládáte používat i tenhle druh umělé inteligence. Nepřicházíte o možnosti, naopak je tím získáváte.
Teď se jen postarat o to, aby měli všichni k dispozici přístup. Bylo by fajn, kdyby se z toho nestal zdroj útlaku držený v rukou několika jedinců a korporací, které ho využijí k vyřazení konkurence a horším věcem (viz třeba čínská totalita a jejich sociální kredit), ale nástroj pro obohacení možností a schopností každého z nás.
Tiskni
Sdílej:
![]()
![]()
![]()
![]()
![]()
![]()
GPT-3 pracuje nad vektory tokenů, které si můžeme představit podobně jako v známém word2vec.No právě že ne. GPT-3 používá podstatně tupější BPE, které opravdu jenom hladově grupuje vstupní unicode codepointy (ano, vstup je unicode, včetně emoji, combining characters a dalších divočin), které se často vyskytují u sebe (například
" the " to zakóduje jako jeden token), a jediný důvod, proč se tohle dělá, je ukočírovat trochu ty příšerné HW nároky co to má. Oproti tomu skutečné embeddingy jako word2vec slouží k tomu, aby když se to něco naučí pro "king", tak to totéž umělo i pro "queen" protože jejich embeddingy jsou blízko. U takto velkých modelů, jako je GPT-3, se embeddingy nepoužívají proto, protože model má dost kapacity a trénovacích dat na to, aby si to odvodil sám a lépe. Embeddingy byla věc když měl člověk malý model a málo dat, tak tomu takhle pomohl, aby se drahá kapacita/data neplýtvala na zjišťování, že king a queen jsou blízko. Jinak tohle je asi taky důvod proč to neumí "řekni mi abrakadabra pozpátku", protože "abrakadabra" se zaBPEčkuje tak, že to není možné otočit, a proto tomu asi nejsou ASCII arty.
GPT-3 také operuje nad „tokeny“, což jsou také mnohodimenzionální souřadnice ve vektorovém prostoru.Já teda ještě nedávno nevěděl co je BPE, ale mně přijde, že tokeny jsou čísla a tipuju, že do sítě to vstupuje jako one-hot vektor. Embedding z něj udělá ta věc s názvem embedding, což asi bude obyčejné vynásobení one-hot vektoru maticí.
a očekáváme doplnění dalšího slova. Pokud síť doplní slovo „lásky“, pokračujeme dál.Ve skutečnosti síť generuje kompletní pravděpodobnostní rozdělení, tj. vypadne z ní
lásky 92.1% bubna 1.2% protiiráckého 0.01% [přísahám, tohle je první slovo, které mi dalo zcat wordlist-expanded.txt.gz|shuf|head]A ty následně děláš update vah v každém případě, tedy i když se trefila -- updatneš váhy tak, aby při tomto vstupu bylo „lásky“ ještě blíž ke 100% a všechno ostatní bylo ještě blíž k 0%. Mimochodem tohle ukazuje tu vědu kolem toho, jak samplovat -- když si v každém okamžiku vybereme jenom ten nejpravděpodobnější token, tak se ukazuje, že výstup je opakující se a „nudný“ (asi to, čemu říkáš „tautologie“). Proto si typicky chceme vybírat z několika nejlepších. Musíme ovšem adaptivně řešit, že u „Večer si jdu lehnout do “ asi chceme doplnit ten nejpravděpodobnější, protože nic moc jiného nedává smysl, ale u „V obchodě jsme koupili “ existuje tisíc slov, která dávají smysl a text se po jejich vybrání může zajímavě rozvíjet. Pak existuje technika beam search, která tohle nějak dělá.
a cílem je najít poslepu to nejhlubší údolíJsem slyšel názory, že když jsi našel nejhlubší údolí, tak jsi beznadějně přeučený.
Ta údolí se hledají proto, že typicky máme nějaký stav modelu, který vrací špatná data, a my chceme změnit jen minimální množství parametrů co nejmenším způsobem tak, aby nám vracel dobrá data. To je matematicky ekvivalentní tomu, že zkoušíme najít úpravu terénu, kterou když odečteme od současné podoby modelu, tak nám najednou vrací dobrá data. Minimální úpravu terénu chceme dělat protože předpokládáme, že model pro ostatní data vrací dobré výsledky. Kdybychom tedy udělali větší úpravu než je nutné, tak by ostatní věci, co už fungovaly, najednou mohly přestat fungovat.Tohle je trošku špatně (motá to terén a váhy), ale nedokážu říct proč
 . Zkusím to vysvětlit vlastními slovy:
. Zkusím to vysvětlit vlastními slovy:
Tohle celé děláme na kopci, který má 175 miliard bodů v mnoha dimenzích.Ne, ten kopec má nekonečně bodů (teda, celé je to v počítači, takže je to omezené alokovanou pamětí, ale to je několik Tb, a 2^tera je prakticky nekonečno). Prostor, ve kterém existuje, má 175G dimenzí.
GPT-3 používá pro embeding slov 12 288 dimenzí, které je možné si představit jako osy v grafuEe. Tohle funguje tak, že na vstupu dostaneš one-hot (vektor, který má všude 0, jenom na jednom místě je 1) kódující token, a z toho nějak vyrobíš vektor dlouhý 12288. Tím jsi zmenšil dimenzionalitu a udělal právě to, že se „king“ a „queen“ dostaly k sobě. A váhy/parametry/osy grafu/dimenze prostoru kde žije ten kopec jsou ty parametry, kterými jsi udělal tuhle redukci. Ale ta jsem zjistil že nevím jak se dělá. Myslel jsem, že to je obyčejné násobení maticí, ale v případě GPT-2 by ta matice měla 50257*1600 = 80M prvků, což je skoro polovina parametrů toho modelu, což je asi blbost.
už samotné schopnosti, které má GPT-3 jsou dost husté na to abych si dovedl představit tisíce různých užitečných použití k získání výhody a náskoku nad konkurencíHmm, já se přiznám, že moc ne. Nějaké příklady?
Myslel jsem, že to je obyčejné násobení maticí, ale v případě GPT-2 by ta matice měla 50257*1600 = 80M prvků, což je skoro polovina parametrů toho modelu, což je asi blbost.A nebo si jenom pletu čísla, to největší GPT-2 má 1.6G parametrů, takže to tak může být.
 19.8.2020 05:56
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
19.8.2020 05:56
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Asi by to chtělo nějakou explicitní paměť, ale diferencovatelné paměti se AFAIK (source: Mikolovova přednáška kde o tom mluvil asi 10 minut, takže třeba je skutečnost barvitější :)) dělají pekelně blbě, mám pocit, že výpočetní nároky jsou něco jako kubické vzhledem k jejich velikosti. Kontextové okno nelze naivně zvětšovat („2048 je málo, vražte tam 1048576“), protože výpočetní attention s velikostí kontextu taky nějak příšerně rostou.Jo, to jsem si taky říkal. Přemýšlel jsem jak moc by se to tam dalo dohackovat a (nesouvisí s tímhle) co to třeba zkusit nějak propojit s wolframem alpha.
No právě že ne. GPT-3 používá podstatně tupější BPE, které opravdu jenom hladově grupuje vstupní unicode codepointy (ano, vstup je unicode, včetně emoji, combining characters a dalších divočin), které se často vyskytují u sebe (například " the " to zakóduje jako jeden token), a jediný důvod, proč se tohle dělá, je ukočírovat trochu ty příšerné HW nároky co to má.Uh, ok. Já když jsem to četl, tak jsem tam ten krok s BPE viděl, ale myslel jsem že to počítá ty embedingy poctivě z toho. Protože všude o tom mluví právě jako o těch embedinziích, dokonce to srovnávají právě s word2vec. Jsi si tím jistý?
Ve skutečnosti síť generuje kompletní pravděpodobnostní rozdělení, tj. vypadne z níJo, to máš pravdu, v tom gui se to dá i vizualizovat, ale ono to na principu fungování zas tak moc nemění, protože stejně chceš "lásky" s nejvyšší pravděpodobností.
Tohle je trošku špatně (motá to terén a váhy), ale nedokážu říct pročMno, ono asi víc než jen trošku, chtěl jsem to jen tak letecky vysvětlit aby to neznělo lidem jako nesrozumitelné matematické buzzwordy. Akorát jsem byl líný studovat do detailu jak přesně to funguje u GPT, takže díky za popis.
Ne, ten kopec má nekonečně bodů (teda, celé je to v počítači, takže je to omezené alokovanou pamětí, ale to je několik Tb, a 2^tera je prakticky nekonečno). Prostor, ve kterém existuje, má 175G dimenzí.Ok, upravím to.
Hmm, já se přiznám, že moc ne. Nějaké příklady?Žádné bezpracné, ale například různé korekce. Generování šablon mnoha různých typů dokumentů upravených podle popisů (asi jako ty ukázky CSS). Pokud by to fakt bylo použitelné k analýze textů, což asi úplně netriviálně nepůjde, tak různé sématické generování filtrů (email, ale obecně streamy). Možná různé nástroje ala refactoring, kterému popíšu co chci? Psaní testů? Konverze textu do nějaké strukturované podoby. Highlevel vyhledávání podle významu. Kdyby se to spojilo s různými strukturovanými informacemi, tak třeba pustím nad ablinuxu query ala "najdi mi všechny posty kde se někdo baví o machine learningu a seřaď to podle času". A tak podobně.
19.8.2020 06:01
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Můžu tohle použít v blogu?
- Hodnota chybové funkce je počítaná jako „kolik procent chybí slovu „lásky“ z předchozího příkladu do 100%“, a toto posčítané přes všechny příklady z celého trénovacího setu.
- Terén je funkce R^175000000 → R. Funkci se dají aktuální váhy modelu a ona vrátí hodnotu chyby. A my ji chceme minimalizovat.
- Při minimalizaci ale nemůžeme hrabat přímo na tuto funkci, jednak protože její vyhodnocení je příšerně drahé (znamená to vyhodnotit a posčítat něco přes všechny prvky datasetu), jednak protože má lokální minima ve kterých bychom se zasekli.
- Proto děláme to, že vytáhneme z datasetu jenom pár samplů (tomu se říká minibatch), a chybu budeme vyhodnocovat na nich. Tím získáme nějaký trochu jiný terén, který snad bude podobný tomu „globálnímu“ terénu, dá se s ním počítat.
- Nyní spočítáme aktuální výšku tohoto terénu, určíme, kterým směrem je to z kopce, a tímto směrem kousek popojdeme.
- Vytáhneme dalších pár samplů a opakujeme. Pro tyto jiné samply bude terén vypadat trošku jinak, a například doufáme, že lokální minima budou v jiných místech, takže pokud jsme do nějakého vstoupili, tak teď se trochu posunulo a zase z něj vylezeme.
Hmm, já se přiznám, že moc ne. Nějaké příklady?Kdysi jsem četl, asi v souvislosti s IBM Watsonem nebo něčím podobným, že je velký problém sledovat třeba lékařské studie. Systém, který to dokáže načíst a pak to lékařskému personálu nějak smysluplně (a podle potřeby) prezentovat, může dost zásadně pomoct u takových těch „detektivních“ případů, kde sice vidíš nějaké projevy, ale vůbec nevíš, pod čím zkoušet hledat další informace. Takže to vyhledávaní mi přijde asi nejzajímavější (viz taky co píše Bystroushaak… v podstatě takový NQL, Natural Query Language). V praxi se to možná začne používat na různých infolinkách a chatbotech, vlastně by mě asi ani nepřekvapilo, kdyby se to používalo i na automatizované marketingové hovory (no, nazvěme to raději pravým jménem: scamy) a tak.
19.8.2020 06:50
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
19.8.2020 07:01
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Zcela bez premysleni treba jen generovani desitek, stovek, tisicu reklam (nebo obecne sdeleni, promtu, signalu) a nasledne vyhodnoceni, ktere z nich nejlepe funguji a zpusobi u cilove skupiny (ktera v krajnim pripade muze byt treba mala az do urovne kazdeho jednotlivce) nejake zadouci chovani (utraceni penez, volbu kandidata K, vykonani neceho, nevykonani neceho...) De-fakto hacknuti svobodne vule cloveka jako bytosti. Mam chut se stat neoludditou...už samotné schopnosti, které má GPT-3 jsou dost husté na to abych si dovedl představit tisíce různých užitečných použití k získání výhody a náskoku nad konkurencíHmm, já se přiznám, že moc ne. Nějaké příklady?
19.8.2020 23:13
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
De-fakto hacknuti svobodne vule cloveka jako bytosti. Mam chut se stat neoludditou...To by ti v tom jako nějak pomohlo, jo?
Zcela bez premysleni treba jen generovani desitek, stovek, tisicu reklam (nebo obecne sdeleni, promtu, signalu) a nasledne vyhodnoceni, ktere z nich nejlepe funguji a zpusobi u cilove skupiny (ktera v krajnim pripade muze byt treba mala az do urovne kazdeho jednotlivce) nejake zadouci chovani (utraceni penez, volbu kandidata K, vykonani neceho, nevykonani neceho...)Jak by to mělo fungovat? Na to potřebuješ feedback a ten se bude blbě implementovat a ten machine learning ti v tom až tak moc nepomáhá.
19.8.2020 23:28
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Na to potřebuješ feedback a ten se bude blbě implementovat
To je ale dost zásadní i pro jiné (užitečné, dobré) úlohy. Např. jak jsi psal o tom generování XML nebo kdyby se měl generovat jiný zdroják – chce to zpětnou vazbu, která bude říkat, jestli je kód syntakticky validní a jestli splňuje nějaké požadavky/testy. A dokud to validní nebude, tak se bude iterovat a zkoušet pořád dál. Bez toho je to celkem k ničemu.
Znám A/B testování, jen mi není úplně jasné jak ti v tom pomáhá ta "AI". K tomu potřebuješ framework který s "AI" nijak nesouvisí. Možná tak v tom kreativním generování reklam?
Čekáš, že to vrátí správný výsledek hned napoprvé, aniž by to muselo iterovat přes X neúspěšných pokusů a postupně se k tomu správnému výsledku dopracovat?
Možná tak v tom kreativním generování reklam?Samozřejmě. Vždyť to je věc naprosto zásadní. Máš nějaký číselný vektor reprezentující člověka (jeho zájmy, preference, vlastnosti) a dokážeš vygenerovat reklamu přímo na míru pro něj. Nejlepší, co můžeš dělat v současnosti, je ručně připravit reklamy a rozhodnout se, že je budeš ukazovat lidem, kteří mají parametr p ≥ 0,5. Naprosto se to nedá srovnávat se situací, kdy ti přijde zpráva dokonale ušitá na míru přímo pro tebe. Ne pro tvůj „segment“, ne pro tvou sociální skupinu, ale přímo pro tebe. A teď si představ, že to třeba vůbec nebude označené jako reklama, ale bude to virtuální identita, se kterou si roky vyměňuješ zprávy, občas zapaříte online hru, zavoláte si… A budeš žít v domění, že je to člověk a jste kámoši, ale ve skutečnosti to bude jen AGI, jejímž jediným úkolem je s tebou manipulovat.
Vždyť to je věc naprosto zásadní. Máš nějaký číselný vektor reprezentující člověka (jeho zájmy, preference, vlastnosti) a dokážeš vygenerovat reklamu přímo na míru pro něj.Uz pred vic jak deseti lety dokazal Amazon doporucovat zbozi a nabizet "balicky" na miru tak dobre, ze sice bylo poznat, ze s tebou ta nabidka manipuluje, ale presto ji bylo tezke odmitnout. Docela by me zajimalo, co vsechno za tim stoji, jestli jsou to hlavne data nebo algoritmy, protoze napr. alza.cz nebo mall.cz jsou v tomto smeru uplne mimo, i kdyz predpoklady pro personalizaci na teto urovni by meli mit.
Možná tak v tom kreativním generování reklam?Přesně tak. A/B testování samo o sobě na AI nezáleží, ale někdo musí připravit ty varanty, které se podstrčí uživatelům. Když budeš varianty generovat pomocí AI a trénovat jí na výsledcích testování, bude ti generovat reklamy na míru pro konkrétní lidi.
20.8.2020 11:04
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
 20.8.2020 11:30
xkucf03 | skóre: 49
| blog: xkucf03
20.8.2020 11:30
xkucf03 | skóre: 49
| blog: xkucf03
Pokud pro tebe budou podobně relevantní dva výrobky, tak si ale koupíš ten, který jsi viděl v reklamě resp. ten, o kterém víš, že existuje. Dneska je spíš problém v tom, že jsme všichni zahlcení informacemi, takže ani není potřeba nic cenzurovat – stačí to, co má být vidět, posunout nahoru, a to ostatní se ztratí v šumu.
Ten, kdo si aktivně vyhledává informace o zboží a přemýšlí nad tím, ten na tom bude líp. A za ty, kdo jen pasivně konzumují (jak informace, tak zboží), rozhodně nějaký algoritmus. Rozhodne za ně třeba Facebook, Amazon nebo Google tím, co jim strčí pod nos. A udělá to na základě toho, co si přejí jejich zákazníci (což samozřejmě nejsou uživatelé ale inzerenti nebo odběratelé nějakých analytických služeb).
Opět se dostáváme k tomu, že centralizace internetu je problém. Na Amazonu jsem si nekoupil nic (jednou málem), i když jinak po internetu nakupuji hodně. Google mám zablokovaný v DNS, stejně jako Facebook a Microsoft. Postupně bych se rád zbavil eBaye, kde stále zatím nakupuji dost.
Ve výsledku je to na lidech – jak si váží svého soukromí a svobody, jaké ústupky jsou ochotní udělat. Je to věc, kterou může ovlivnit každý svým tržním chováním.
20.8.2020 13:44
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Pokud pro tebe budou podobně relevantní dva výrobky, tak si ale koupíš ten, který jsi viděl v reklamě resp. ten, o kterém víš, že existuje.Ani ne. Koupím si ten co bude mít nejlepší poměr cena/výkon, a nejlepší uživatelské recenze. Občas si koupím něco co se mi prostě víc líbí. Reklama v tom všem hraje roli imho úplně zanedbatelnou.
Ten, kdo si aktivně vyhledává informace o zboží a přemýšlí nad tím, ten na tom bude líp. A za ty, kdo jen pasivně konzumují (jak informace, tak zboží), rozhodně nějaký algoritmus. Rozhodne za ně třeba Facebook, Amazon nebo Google tím, co jim strčí pod nos. A udělá to na základě toho, co si přejí jejich zákazníci (což samozřejmě nejsou uživatelé ale inzerenti nebo odběratelé nějakých analytických služeb).Dobře, tohle uznávám, ale znova; k tomu nepotřebuješ žádnou "AI", a už se to aktivně děje asi dvacet let.
…a nejlepší uživatelské recenze … Reklama v tom všem hraje roli imho úplně zanedbatelnou.
:-)
20.8.2020 15:46
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
…a nejlepší uživatelské recenze … Reklama v tom všem hraje roli imho úplně zanedbatelnou.To bylo myšleno opačně. Několikrát se mi stalo, že jsem něco neobjednal protože to mělo negativní recenze, sám jsem negativní reakce několikrát přidával. To že to vychvaluje deset lidí na mě nepůsobí zdaleka tak, jak když na to deset lidí nadává. Asi to může vypadat, že se snažím působit že na mě reklama nemá žádný vliv. To pochopitelně není pravda. Akorát prostě vliv na mě mají spíš různé recommendation enginy, které nepovažuji vysloveně za reklamu. Například když mi amazon něco nabídne (typicky podobné knihy), tak si je často koupím. Když mí něco nabídne nějaká kontextová reklama někde na netu, tak si to nekoupím nikdy. Když tady na abclinuxu někdo napíše recenzi na čtečku knih a že s ní byl spokojen a vysvětlí důvody proč, a deset registrovaných lidí v diskuzi s ním bude souhlasit, tak existuje slušná šance že si jí taky koupím. Když uvidím někde banner na čtečku knih, tak existuje nulová šance že na něj kliknu, natožpak abych šel a koupil si to. "AI", která by mi takhle doporučovala věci by měla nějakou úspěšnost, ale znova, to není nějaká apokalypsa, jak to podával op, ale zcela chtěná feature.
20.8.2020 16:04
xkucf03 | skóre: 49
| blog: xkucf03
To bylo myšleno opačně. Několikrát se mi stalo, že jsem něco neobjednal protože to mělo negativní recenze, sám jsem negativní reakce několikrát přidával. To že to vychvaluje deset lidí na mě nepůsobí zdaleka tak, jak když na to deset lidí nadává.
Tohle mám podobně, akorát je potřeba si být vědom toho, že to může být i negativní reklama/kampaň placená konkurencí.
Ono když třeba koukám na nějaké video-recenze zboží, tak mne spíš než to, co ten člověk říká, zajímá to, jak ta věc vypadá – chci ji vidět z různých úhlů, v pohybu, chci vidět detaily, jak je co udělané, navržené, jaká je povrchová úprava a kvalita zpracování… a to natočené běžnými kamerami různých lidí – nikoli vyretušovaná marketingová fotografie nebo video od výrobce.
To se samozřejmě týká věcí, kde jde hlavně o tu fyzickou stránku. Nejde to aplikovat univerzálně.
Například když mi amazon něco nabídne (typicky podobné knihy), tak si je často koupím. Když mí něco nabídne nějaká kontextová reklama někde na netu, tak si to nekoupím nikdy.
To ale znamená, že kdyby o tobě ten reklamní systém měl více informací (jako Amazon) a nabízel by ti relevantnější zboží, tak by ses tou reklamou taky řídil, ne? Nebo v čem je rozdíl?
Když tady na abclinuxu někdo napíše recenzi na čtečku knih a že s ní byl spokojen a vysvětlí důvody proč, a deset registrovaných lidí v diskuzi s ním bude souhlasit, tak existuje slušná šance že si jí taky koupím.
Ano. Ale tady těžíš z toho, že český trh (a tím spíš nějaké AbcLinuxu) je pro výrobce nedostatečně zajímavý na to, aby na něm nějak marketingově působili. Být to třeba v USA a třeba na Facebooku, Redditu, Twitteru nebo jiné tzv. sociální síti, tak by tenhle přístup asi moc použít nešel.
20.8.2020 17:28
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
To ale znamená, že kdyby o tobě ten reklamní systém měl více informací (jako Amazon) a nabízel by ti relevantnější zboží, tak by ses tou reklamou taky řídil, ne? Nebo v čem je rozdíl?Jo, vždyť píšu že to by na mě fungovalo. Akorát to pak prostě není něco negativního, ale nástroj co mi pomáhá najít relevantní doporučení. Například v oblasti knih si určitě nechám něco rád doporučit někým kdo mě zná, nebo právě třeba amazonem, který se docela často trefí a přihodím podobnou knížku co mě zaujme. Oproti tomu si to porovnej s tím co psal op:
De-fakto hacknuti svobodne vule cloveka jako bytosti. Mam chut se stat neoludditou...Jako možná kdyby třeba nějaký autor knih si zaplatil, že mi to bude nabízet jeho knihy na úkor někoho zajímavějšího, tak by to asi bylo negativní. Pokud mi to ale jen nabídne relevantní knihy, které třeba jako bonus nějaký machine learning vyhodnotí, jako že by mě asi bavily, když mě bavilo tohle, tak je to win-win situace a služba, ne nějaké hackování mojí vůle.
Ano. Ale tady těžíš z toho, že český trh (a tím spíš nějaké AbcLinuxu) je pro výrobce nedostatečně zajímavý na to, aby na něm nějak marketingově působili. Být to třeba v USA a třeba na Facebooku, Redditu, Twitteru nebo jiné tzv. sociální síti, tak by tenhle přístup asi moc použít nešel.Tak každý druhý youtuber dneska má nějakou reklamu tohohle druhu, kde prostě na začátku videa vychválí nějaký produkt. Až na to že já prostě takhle věci kupuji málokdy. Můj ideál je spíš mít míň věcí, které používám, než hodně které nepoužívám a během posledních asi pěti let jsem systematicky vyhodil / rozdal / prodal asi polovinu všeho co jsem měl. Většinou když jdu něco kupovat, tak protože to potřebuju, a tam je mi nějaká reklama ukradená, protože prostě jdu do eshopu a řadím podle parametrů.
20.8.2020 17:49
xkucf03 | skóre: 49
| blog: xkucf03
Například v oblasti knih si určitě nechám něco rád doporučit někým kdo mě zná, nebo právě třeba amazonem, který se docela často trefí a přihodím podobnou knížku co mě zaujme.
Oproti tomu si to porovnej s tím co psal op:
De-fakto hacknuti svobodne vule cloveka jako bytosti. Mam chut se stat neoludditou...
Ono to může dopadnout tak, že Amazon ti bude doporučovat knihy, které sice tématicky odpovídají tomu, co tě zajímá (takže na základě titulku, abstraktu a doporučení je docela šance, že si je koupíš), ale třeba nejsou moc kvalitní a prodejce jich má hodně na skladě a chce se jich zbavit.
Zájmy obchodníka a zákazníka se můžou (v krátkodobém horizontu) rozcházet. A jakýkoli systém doporučení bude přirozeně pracovat spíš ve prospěch toho, kdo ho provozuje a platí, což je obchodník. Z dlouhodobého hlediska je samozřejmě v zájmu obchodníka mít spokojené zákazníky. Pokud ale obchodník preferuje krátkodobé cíle nebo má zákazníky, kteří sebou nechají zametat, tak se ten systém bude zneužívat.
Proto by mi přišlo zajímavé mít nějaký inteligentní systém doporučení placený zákazníky a pracující výhradně v jejich prospěch. V zásadě by to vedlo na nějaké spotřebitelské družstvo nebo komerční službu, která by byla závislá jen na příjmech od zákazníků. Otázka je, jestli je dost zákazníků, kteří by o takováto doporučení měli zájem – nebo jestli je to lidem jedno (pak dostanou, co zaslouží a vytrestají sami sebe).
 20.8.2020 17:54
Fluttershy, yay! | skóre: 92
| blog:
20.8.2020 17:54
Fluttershy, yay! | skóre: 92
| blog:
Pokud mi to ale jen nabídne relevantní knihy, které třeba jako bonus nějaký machine learning vyhodnotí, jako že by mě asi bavily, když mě bavilo tohle, tak je to win-win situace a služba, ne nějaké hackování mojí vůle.Vždyť to je přesně popis uzavření se v personalizované informační bublině, a to ne nutně právě vědomě. (Ba co hůř, vzhledem ke konsolidaci trhu – ten algoritmus může být nakonfigurovaný tak, aby knihy s určitou tématikou, která třeba Amazonu nevyhovuje, v doporučeních nepreferoval.) Poznámka stranou, pokud to někdo nezaznamenal: Goodreads je vlastněný Amazonem.
Většinou když jdu něco kupovat, tak protože to potřebuju, a tam je mi nějaká reklama ukradená, protože prostě jdu do eshopu a řadím podle parametrů.Podle kterých parametrů? Zrovna na tomhle webu se najde dost lidí, kteří mají nekonvenční preference aspoň v některé (typicky např. software, který je svobodný byť třeba na úkor některých funkcí), ale ne v každé oblasti (takže si nechají doporučit parametry, což už je přivede na určitou skupinu produktů), potažmo často je s atypickými preferencemi tak náročné sehnat vyhovující produkt, že to člověk vzdá a zařídí se konformně s většinou.
20.8.2020 18:05
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Vždyť to je přesně popis uzavření se v personalizované informační bublině, a to ne nutně právě vědomě.Už jen akt toho že žiješ je uzavření se v personalisované informační bublině. Zajímají mě věci, které mě zajímají. Nezajímá mě plošně všechno. Mým cílem není být dokonalá vyvážená bytost, která sjednocuje protiklady a vyrovnává nevyrovnané. Jsou prostě věci, které mě nezajímají, a těch je asi i většina všeho. Například rád čtu sci-fi, ale ne úplně všechno sci-fi. Mám rád hard sci-fi, které obsahuje ideálně nějaké prvky, které je docela těžké popsat. Například kamarádi ví co mi doporučovat a co by mě asi moc nezajímalo. Pokud by to věděl i nějaký machine learning, tak je to výhoda, ne nevýhoda, protože mi nabízí věci podle mého vkusu, místo toho aby mi cpal věci co se mi líbit nebudou.
Podle kterých parametrů?Tak to záleží co kupuju, že. Například u monitoru mě zajímá technologie, rozlišení, doba odezvy a tak. U vysavače výkon a typ sáčků / čištění. U klimatizace BTU a příkon. U žárovky svítivost, barva světla a příkon. U ..
20.8.2020 18:47
Fluttershy, yay! | skóre: 92
| blog:
Jsou prostě věci, které mě nezajímají, a těch je asi i většina všeho. Například rád čtu sci-fi, ale ne úplně všechno sci-fi.I když čteš toliko fikci pro zábavu, je pořád praktický rozdíl, jestli ti doporučovací systém navrhne – střelím vulgární příklad, ať je to snad zjevné – Terryho Goodkinda, nebo Ursulu Le Guin. Tobě osobně to třeba tak nepřijde, ale lidem okolo ano.
Tak to záleží co kupuju, že.Přesně tak. Napadlo by tě pořídit si např. vodní vysavač? Co takhle něco, o čem na začátku nevíš vůbec nic? Tuhle jsem se zaobíral poněkud nevšední technikou na zpracování potravin…
je to win-win situace a služba, ne nějaké hackování mojí vůleKdyž jsme se tu bavili o těch obchoďácích… Dejme tomu, že se rozhodneš omezit sladké. Ve kterém případě bude snažší realizovat tvou vůli? 1. Sekce se sladkostmi bude umístěná stranou a snadno se jí vyhneš. 2. Budeš nucen projít přímo kolem ní. 3. Praští tě to do očí hned u vstupu s cedulí upozorňující na slevu a hlouček lidí si to tam bude nadšeně rozebírat. Nebo co takové cigarety? Tabákový průmysl dřív čile sponzoroval kouření ve filmech. Televizní spoty s reklamou na alkohol, které ti mají vsugerovat, že ta která lahev je základem každé párty, určitě taky nikoho neovlivňují. To je totiž ta krása, že ti každý řekne, jak ho reklamy neovlivňují, ale přitom vidíš, jak masivní prostředky jsou na tu reklamu vynakládány a jak reklama nezmizela ani poté, co je díky příchodu Internetu možné její dopady mnohem lépe měřit. Namátkou si vzpomínám, jak jsem někde v obchodě viděl procházet nějakou rodinku s dítětem a to dítě ukazovalo na nějakou ústní vodu. Maminka mu řekla, že mají doma Listerine a že ten je lepší. No, zcela určitě je známější a má lepší jméno, ale opravdu je lepší? V čem? Ta nejznámější varianta s alkoholem ani není moc vhodná ke každodennímu užívání… Tohle všechno jsou věci, které jsou na populaci cílené plošně. I tak to přináší výsledky a není úplně triviální těm vlivům odolávat. Ideální jsou samozřejmě lidi, co si to neuvědomují a naprosto svobodně si dle vlastního racionálního úsudku koupí přesně ten produkt, který jim marketéři podsunou. GAI manipulaci posune na dosud nevídanou úroveň. Kdo myslíš, že by vyhrál třeba volby? Politik, co to „myslí upřímně“, politik s Prchalem a nebo politik se silnou GAI? Proč mimochodem existuje nějaká viralita a exponenciální růst? Že by v tom hrálo podstatnou roli to, že lidi prostě jsou ovlivnitelní a když vidí ostatní něco dělat, jsou ochotnější to dělat taky? Jo, vytvořit si tak 100 streamerů/YouTuberů poháněných GAI, co budou propagovat nějaký můj produkt… Svoboda vůle, pokud vůbec nějaká existuje, je dost vzácná i normálně. Nesmíme dopustit, aby GAI, až se objeví, zůstala v rukou pár obřích korporací. Jakmile inteligenci průměrného člověka překročí o pár desítek procent a bude relativně levně horizontálně škálovatelná, stane se z ní de facto zbraň hromadného ničení. Tou nejsilnější GAI musí disponovat stát, v opačném případě nebude schopný zajišťovat vymahatelnost práva, obranu a potažmo ani mít rozumnou jistotu další existence.
Svoboda vůle, pokud vůbec nějaká existuje, je dost vzácná i normálně. Nesmíme dopustit, aby GAI, až se objeví, zůstala v rukou pár obřích korporací.Zapomněl jsem upřesnit, že samozřejmě nejde jen o tu manipulaci, ale celkově schopnost např. hackovat právní systém a prostě celkově si dělat tak nějak… cokoliv.
Tou nejsilnější GAI musí disponovat stát…
Jako třeba ČR v čele s Babišem, který ji řídí jako svou filiálku? Nebo USA v čele s Trumpem, který považuje státní aparát buď za svou hračku nebo za nástroj, jehož primárním účelem je zařídit jeho znovuzvolení? Nebo třeba Rusko v čele s Putinem? Bělorusko s Lukašenkem? KLDR s Kim Čong Unem? Já nevím… to už snad radši ten Google.
 20.8.2020 23:20
JiK | skóre: 13
| blog: Jirkoviny
| Virginia
20.8.2020 23:20
JiK | skóre: 13
| blog: Jirkoviny
| Virginia
Zajímalo by mě, jestli tohle nějak řeší NATO.Jiste, je to v seznamu priorit hned pod specialnimi podprsenkami pro transgenderove vychodonemecke tankistky...
20.8.2020 16:36
xkucf03 | skóre: 49
| blog: xkucf03
P.S.
"AI", která by mi takhle doporučovala věci by měla nějakou úspěšnost, ale znova, to není nějaká apokalypsa, jak to podával op, ale zcela chtěná feature.
Tady jde o to, kdo takovou A.I. bude provozovat a v čím zájmu tedy bude pracovat. Dejme tomu, že mne zajímá otevřený hardware a rád si ho koupím a podpořím. U reklamy na takový HW je nenulová šance, že na ni kliknu. Ale pokud bych se takovými doporučeními začal řídit, tak bych pak dával přednost projektům, které si zaplatily reklamu a naopak bych se nedozvěděl o těch, které si reklamu nezaplatily. To vytváří motivaci, aby si za reklamu platili všichni – a pak jsme víceméně zase tam, kde jsme byli.
Šlo by to i obrátit – ten systém by byl nezávislý, jeho provoz by platili nakupující a pro prodávající by byl naopak zdarma. Tzn. byla by tam motivace, aby ten systém pracoval ve prospěch zákazníků (na rozdíl od reklamy, kde je motivace pracovat ve prospěch prodávajících).
Navíc, GPT-3 není rekurentní síť, nemá vnitřní stavTo je zajimava informace. Myslel jsem, ze je rekurentni (ona tedy fakticky je, protoze vystup jde na vstup). To znamena, ze jde o zcela jinou architekturu nez ma mozek, ktery je patrne rekurentni uz na te nejnizsi urovni.
navic u nich stoji dalsi clovek, ktery je kontrolujeAno ale jeden clovek dohliada na 5 - 10 samoobsluznych pokladni, miesto 5 - 10 predavaciek za pokladnou ... krasne usetrene peniaze pre majitela a praca prenesena z predavaciek na zakaznikov, po kazdom pouziti samoobsluznej pokladne by si mal zakaznik na informaciach vyziadat 1 - 2 eura za vykonanu pracu.
Globus: zboží namarkuju už když ho dávám do vozíku, někteří ho dávají rovou do tašek. U pokladny už vyndávám jen zboží s ochranným prvkem (obvykle ryby). Jinak jen nascanovat kód "konec nákupu", na pokladně nascanovat Globus kartu, na touchscreenu vyberu, že chci zaplatit kartou, zaplatím a můžu jít. Tesco už to má AFAIK taky.
Už jsem si na to tak zvykl, že když nakupuju jinde, mám při ukládání zboží do vozíku divný pocit, že jsem na něco zapomněl. :-)
Tady je akorát problém v tom, že tě sledují a v nějaké databázi pak bude uloženo, co sis kdy koupil…
Vzhledem k (ne)přívětivosti průměrných lidských pokladní je ta automatická pokladna celkem fajn – ale za předpokladu, že můžeš platit hotovostí a nemusíš se nijak identifikovat.
Tady je akorát problém v tom, že tě sledují a v nějaké databázi pak bude uloženo, co sis kdy koupil…
Jsem sice na své soukromí citlivější než většina populace, ale tohle opravdu neřeším. Kdybych uvažoval takhle, tak bych musel především zavrhnout všechny e-shopy. A to by se mi chtělo ještě méně než platit všude hotovostí.
 )
)
Velké množství RFID čipů na jednom místě bude AFAIK problém rozlišit a naskenovat. Na různé zboží jako pečivo, ovoce, zeleninu atd. pak taky budeš mít problém RFID čip umístit. Navíc je lidi budou sundavat… To už bych spíš viděl schůdnější optické rozpoznávání – zboží by na pásu projíždělo tunelem s kamerami, které by ho z různých úhlů snímaly + by tam byla váha + skenery čárových kódů + možná nějaký robot, který by se zbožím pootočil, kdyby se ho nepodařilo rozpoznat napoprvé.
Automatické rozpoznávání obrazu je na docela vysoké úrovni a např. v rozlišování různých druhů ovoce nebo pečiva by to mohlo být úspěšnější než nezkušená pokladní.
 20.8.2020 17:22
xkucf03 | skóre: 49
| blog: xkucf03
20.8.2020 17:22
xkucf03 | skóre: 49
| blog: xkucf03
To se s carovym kodem da udelat taky, ze? No dobre, u kasy neco pipnout budou chtit, tak to prelepis jinym. Myslis ze to bude nekdo resit? Nebude, pravdepodobnost se blizi nule.
Málokdy… ale občas se to řeší. Někteří lidé např. přendavají drahé zubní pasty do krabiček od těch levných a pak se s tím snaží projít skrze pokladnu. Proto některé pokladní mají instrukce, aby takovéto rizikové zboží kontrolovaly.
IMHO samoobsluhy lidi spíš vítali, protože si můžou věci sami vybrat, prohlédnout a můžou se podívat i na to, co (pravděpodobně) kupovat nebudou a o co by si prodavači za pultem neřekli, aby jim to ukázal. Kromě toho, když kupuješ nějaké „divné“ věci nebo jsi sám „divný“ tak je víc v pohodě ty věci naházet na pás a pak jen zaplatit celý účet, než si o ně říkat prodavači za pultem.
Jinak to souvisí spíš se šířkou sortimentu – v samoobsluze máš velkou plochu a spoustu různého zboží, což bys na tu stěnu za prodavačem nedostal.
o co by si prodavači za pultem neřekli, aby jim to ukázal. Kromě toho, když kupuješ nějaké „divné“ věci nebo jsi sám „divný“ tak je víc v pohodě ty věci naházet na pás a pak jen zaplatit celý účet, než si o ně říkat prodavači za pultem.
Příkladem jsou scény z filmů z 70. nebo 80. let na téma "mladík si kupuje prezervativ" (které v té době obvykle měli jen u pokladny).
ale opet, samotne predani pres pult dela zatim clovekJsem kdysi byl v nějakém počítačovém obchodě (Alza? Ale tam to minimálně dneska dává člověk. Možná Mironet.) a tam jsem zadal číslo do terminálu a zboží pak vyjelo na pásu jako kufry na letišti.
Na pasu, na ktery to dal clovek vzadu.ale opet, samotne predani pres pult dela zatim clovekJsem kdysi byl v nějakém počítačovém obchodě (Alza? Ale tam to minimálně dneska dává člověk. Možná Mironet.) a tam jsem zadal číslo do terminálu a zboží pak vyjelo na pásu jako kufry na letišti.
Jsem kdysi byl v nějakém počítačovém obchodě … a tam jsem zadal číslo do terminálu a zboží pak vyjelo na pásu jako kufry na letišti.
Třeba v případě Alzaboxu nebo Mallboxu je mi sice jasné, že to do těch boxů (zatím?) dává člověk, jen se tam s ním nevidím. U toho pásu to nejspíš bude stejné.
20.8.2020 17:31
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Lol ... ze prej nezmizela prace. Samozrejme ze zmizela - prace ty podkladni. A ten pripadnej pikolik kterej tam stoji, je jen docasnej, ten zmizi taky. A jak bylo receno, stoji tam jeden u 10 podkladen. Ostatne kramy, kde neni vubec zadna obsluha uz existujou. Mimochodem, tys uz dlouho nebyl trebas v globusu, ze? Pocitam tak nejmin 10 let. Tam si totiz zbozi muzes pipnout uz v okamziku , kdy ho hazes do vozejku, coz jaksi udelat musis kdyz si ho chces odnyst. Zadna pokladna, jen kredle do ktery to pri odchodu vrazis a des. Neni nejmensi problem tu ctecu zadratovat primo do toho vozejku.Práce nezmizela, protože nezaměstnanost nevyskočila. Zmizela konkrétní práce, která byla v systému nahrazena nějakou jinou.
Lol ... ze prej nezmizela prace. Samozrejme ze zmizela - prace ty podkladniTo je práve nezmysel, teda minimálne pri obyčajnej samoobslužnej pokladni, kde to človek musí po jednom vybrať, naskenovať a zase odložiť (prípadne ešte raz, ak to nenakladá rovno do tašiek). Akurát sa zmenilo, kto tú prácu vykonáva a akým spôsobom je ohodnotená - tú prácu vykonáva sám zákazník a neplatí sa explicitne v peniazoch ako podiel na nákladoch na predaj, ale "platí" za ňu zákazník svojím časom, ktorý má tiež nejakú hodnotu (takže vlastne je to len prenesenie časti nákladov na zákazníka, a teda skryté zdraženie tovaru). Nanajvýš sa možno teoreticky zredukovali prestoje, keď pôvodne bol čas strávený obsluhou násobený dvomi (pokladník+zákazník), teraz je to len zákazník sám a len dúfajme, že mu to netrvá viac než 2x tak dlho (čo skôr áno). V prípade Tesco Scan&Shop a podobných, kde sa tovar skenuje priebežne a môže sa dať rovno do tašky, tak tam by som už súhlasil, tam reálne zmizla práca s prekladaním tovaru z vozíka do pokladne a späť (aj keď tú tiež vykonával zákazník).
Tohle je od AGI (coz definuju jako human-level inteligence) jeste hodne daleko. Jestli pouha evoluce tohohle reseni bude dostatecna k AGI nikdo nevi. Soucasny stav je ze jsme x prulomu (breakthroughs) daleko od AGI, pricemz x je nezname. Muze to trvat 5 let nebo klidne i 200.Nevim, nevim, mozna je to zatim stale jeste less than human inteligence, ale zaroven ma erudici a encyklopedicke znalosti napric VSEMI obory, napric kulturami, napric jazyky, a ty encyklopedicke znalosti jsou velmi detailni a zcela spolehlive, nehrozi zadne zapomenuti nebo nevybaveni si naprosto VSECH detailu v pripade relevantniho dotazu... ...navic by uz ted nebyl problem udelat izolovane oborove clustery, ktere budou mit tohle vse a k tomu navic specializovany trening na detailnich verejnych i neverejnych datech v patricnem oboru, treba vojenstvi, medicina, mikrobiologie, finance, counterterorismus, pravo, you name it...a ta generalni by si pak vyzadala detailnejsi odpoved od tech specializovanych a davala te odpovedi ruznou vahu na zaklade napred jen vychoziho nastaveni, pak na zaklade predchozi uspesnosti odpovidani na "tezke" otazky...
pusobilo to jako extremni verze toho, kdyz politik dela ze odpovida na otazku tim ze rika bezobsazny frazeHodne lidi si s timhle vystaci.. normalni lidska inteligence.
19.8.2020 23:20
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Samozrejme to je v nekterych ohledech chytrejsi nez clovek, to je ale i kalkulacka nebo sachovy engine. Ano GPT je mnohem obecnejsi nez kalkulacka, ale kdyz jsem cetl nejake vygenerovane komentare v diskuzi na Hacker News, bylo jasny ze to nezvladne ulohu "ucastnit se internetove diskuze", pusobilo to jako extremni verze toho, kdyz politik dela ze odpovida na otazku tim ze rika bezobsazny fraze.Když se podíváš na výsledky v angličtině, tak to právě ty bezobsažný fráze moc nepoužívá a například články to zvládne psát líp než většina lidí. Včetně různých zajímavých faktů a analogií a květnatých obratů. Akorát fakticky to často vymýšlí kraviny a občas jsou v tom lehce špatné věci, které jsou sice skoro správně, ale i tak zavádějící.
Ano, neumi se to iterativne ucit jako lide, protoze to ma kratkou pamet, ale to je male omezeni modelu, ktere jiste bude brzy prekonano.Takze az za rok az dva odstrani to male omezeni, zvladne tuto ulohu: vysvetlim pravidla nove hry, variantu sachu s trochu upravenymi pravidly, a zeptam se, kolik moznych tahu ma prvni hrac? Velmi o tom pochybuju. Jak bys to male omezeni odstranil?
Zalezi jak definujes "chytrejsi nez clovek", v mnoha ulohach ano, ale od obecnosti lidske inteligence to ma dost daleko.Ano, je to vec nazoru, ale podle me je to obecne dostatecne. Aspon nevidim ulohu, kterou by to nemohlo zvladnout lepe nez clovek, pokud se to zacne ucit stejnym zpusobem jako clovek.
Takze az za rok az dva odstrani to male omezeni, zvladne tuto ulohu: vysvetlim pravidla nove hry, variantu sachu s trochu upravenymi pravidly, a zeptam se, kolik moznych tahu ma prvni hrac? Velmi o tom pochybuju. Jak bys to male omezeni odstranil?Myslim, ze ano, ale je potreba si uvedomit, ze jak jsi to napsal, tuhle ulohu nezvladaji tak docela ani lide. Ano, pokud jsem matematik, tak mi to zadani staci a dam ti odpoved, ale kdybych byl treba 6-lete dite, a vysvetlil jsi mi pravidla sachu (coz je evidentne vec, kterou se 6-lete deti naucit mohou), a pak se zeptal, kolik je moznych pocatecnich tahu, nevim, jestli bych tu ulohu vyresil. Asi bych ji vyresil casem, pokud bych mel nejaky dalsi trenink s temi pravidly. Tim chci rict, ze i lide se abstraktnimu mysleni dost uci. Nevypadnou z luna jako matematici nebo programatori. Hezky to je videt na nekterych tech otazkach co pokladal James Flynn, objevitel Flynnova efektu. Klasicka uloha je (parafrazuji) "Medved ma barvu kozichu podle prostredi, v kterem zije. Za polarnim kruhem je vecny snih a led; jakou barvu kozichu ma medved, co tam zije?". Spousta lidi driv nebyla schopna na tohle spravne odpovedet, protoze proste neuvazuji timto abstraktnim zpusobem. Zpet ke GPT-3. Jestli to chapu spravne, tak dnes to funguje tak, ze se to neco nauci, a zbytek uz je prompt (kontext ulohy). Tedy ten prompt je v podstate cela pracovni pamet toho systemu. Ale lide se uci neustale, nemaji jen kratkodobou pamet jako GPT-3, a asi by nebyl velky technicky problem nechat GPT-3 upravovat vahy neustale a zobecnovat to, co uz zna. Ostatne ten mechanismus pozornosti (attention) to myslim vyzaduje, aby si behem uceni algoritmus zopakoval nektere vstupy, protoze v prubehu uceni uz naucene cte zase trochu jinym ("hlubsim", "preciznejsim") zpusobem. Treba normalni clovek, co sachy nezna, a sachista vnimaji sachovnici uplne jinak. Normalni clovek si asi spis vsimne treba tvaru figurek, kdezto sachista uvidi rozdily v pozici. Koncept "tohle je stejna situace" bude u nich zcela odlisny. IMHO je to prave dane nastavenim na co je zamerena pozornost pri tom uceni. Stejne tak, kdyz ukazu cloveku, co sachy nezna, tisic sachovych pozic, a pak jich ukazu tisic sachistovi, tak ten sachista si z te tisicovky pozic odnese uplne jinou informaci (pravdepodobne daleko relevantnejsi k reseni sachovych uloh) nez ten clovek, ktery si bude sotva pamatovat, ze tam byly vselijake figurky ruzne naskladane, a v zasade byly vsechny ty situace stejne. GPT-3 ma tu pozornost zamerenou urcitym zpusobem, a ten zpusob je ted fixni, nemuze se menit pro novy problem, mimo ramec toho kratkodobeho kontextu. Ale pokud se bude moci menit (zmenou nastaveni vah), nevidim principialne prekazku, aby se GPT-3 naucila cokoliv, co se dokazi naucit lide. Proto je nefer GPT-3 hodnotit v kontextu konkretniho abstraktniho problemu, na ktery nebyl specificky trenovan, protoze nemuzeme dobre porovnat, jak moc pozornosti se mu dostalo. GPT-3 bylo trenovano na psani textu, a to zvlada velmi dobre, a v tomto ramci je schopne uvazovat velmi abstraktne. U veci jako sachy nebo matematika, opravdu nevime, kolika problemum a znalostem z techto oboru bylo GPT-3 realne exponovano, takze je obtizne posoudit, proc by melo byt lepsi nez lide, co se - specificky tyto problemy - uci. Ale i jen na zaklade toho mala, co to dokaze delat dnes si myslim, ze ten potencial tam je a bude se to ucit lepe nez lide.
Ano, je to vec nazoru, ale podle me je to obecne dostatecne. Aspon nevidim ulohu, kterou by to nemohlo zvladnout lepe nez clovek, pokud se to zacne ucit stejnym zpusobem jako clovek.Ono se to ale uci podstatne jinak nez clovek. Precetlo to celou Wikipedii (a da se rict ze mnohokrat) a velkou cast webu, a presto to casto generuje nesmysly a chyby. Priklad omezeni toho modelu je, ze clovek dokaze vnitrne vykonat dlouhou serii kroku a ukladat si mezivysledky do pameti nebo psat na papir, a pak se dobrat nejakemu vysledku. Kdezto zjednodusena neuronova sit o 10 vrstvach je v podstate vektor, ktery se 10x vynasobi matici. Neuronova sit si nedokaze rict - "tohle je slozitejsi problem, ktery bude vyzadovat serii kroku, takze ted budu premyslet dokud to nevyresim, po minute to vzdam". Vzdy vygeneruje odpoved v konstantnim case.
Myslim, ze ano, ale je potreba si uvedomit, ze jak jsi to napsal, tuhle ulohu nezvladaji tak docela ani lide. Ano, pokud jsem matematik, tak mi to zadani staci a dam ti odpoved, ale kdybych byl treba 6-lete dite, a vysvetlil jsi mi pravidla sachu (coz je evidentne vec, kterou se 6-lete deti naucit mohou), a pak se zeptal, kolik je moznych pocatecnich tahu, nevim, jestli bych tu ulohu vyresil. Asi bych ji vyresil casem, pokud bych mel nejaky dalsi trenink s temi pravidly.Mozna, chtel jsem tim poukazat na problem, ktery jsem zminoval vyse. Tahle uloha vyzaduje vicekrokovou uvahu a zaroven neni v trenovacich datech, takze nelze vyresit zkratkou pres "brute force". Proto jsem presvedcen, ze to GPT nezvladne. GPT (a obecne neuronove site) bych prirovnal k okamzitemu intuitivnimu mysleni, napriklad sachista, ktery koukne na sachovnici a okamzite vidi, ze bily ma vyherni pozici. A k ziskani teto intuice potrebuje clovek mnohem mene dat.
Proto je nefer GPT-3 hodnotit v kontextu konkretniho abstraktniho problemu, na ktery nebyl specificky trenovan, protoze nemuzeme dobre porovnat, jak moc pozornosti se mu dostalo.Nejde o to jestli to je fer nebo nefer, ale jestli to je AGI, tzn. jestli to zvladne vse co clovek (klidne s omezenim na textove ulohy). Clovek se umi naucit pravidla hry a pak tu hru hrat a postupne se v ni zlepsovat. Jak chces tuchle schopnost pridat do GPT?
27.8.2020 01:36
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Priklad omezeni toho modelu je, ze clovek dokaze vnitrne vykonat dlouhou serii kroku a ukladat si mezivysledky do pameti nebo psat na papir, a pak se dobrat nejakemu vysledku. Kdezto zjednodusena neuronova sit o 10 vrstvach je v podstate vektor, ktery se 10x vynasobi matici. Neuronova sit si nedokaze rict - "tohle je slozitejsi problem, ktery bude vyzadovat serii kroku, takze ted budu premyslet dokud to nevyresim, po minute to vzdam". Vzdy vygeneruje odpoved v konstantnim case.To platí v tomhle případě, ne obecně. Celkově mi přijde, že současný machine learning je právě o tom, že skládáš různé architektury na sebe / vedle sebe, viz třeba ty diagramy v odkazovaných blozích o architektuře. GPT-3 je v tomhle lehce specifické, že je spíš jednoduché než složité, ale to neznamená, že to tak musí být vždy.
GPT (a obecne neuronove site) bych prirovnal k okamzitemu intuitivnimu mysleni, napriklad sachista, ktery koukne na sachovnici a okamzite vidi, ze bily ma vyherni pozici. A k ziskani teto intuice potrebuje clovek mnohem mene dat.Já myslel že od AlphaZero porazí neuronové sítě lidi úplně pokaždé?
Já myslel že od AlphaZero porazí neuronové sítě lidi úplně pokaždé?AlphaZero prohledává herní strom podobně jako klasické šachové enginy, jenom při hodnocení pozice a rozhodování které tahy prozkoumat používá neuronovou síť. Ale i samotná neuronová síť bez prohledávání hraje velmi dobře. Jinak netvrdil jsem opak, intuitivní / okamžité myšlení je právě to co se neuronové sítě zvládnou naučit relativně dobře.
Ono se to ale uci podstatne jinak nez clovek. Precetlo to celou Wikipedii (a da se rict ze mnohokrat) a velkou cast webu, a presto to casto generuje nesmysly a chyby.To neni relevantni, protoze jak sam dal pises, uvedene problemy nejsou v trenovacich datech. U lidi nevime, jestli se treba schopnosti delat matematiku jen uci nebo ji objevuji jako aplikaci toho, co umeji od prirody. Lidsky mozek neni tabula rasa, ale ma znacne predpoklady o svete, ktere usnadnuji uceni.
Priklad omezeni toho modelu je, ze clovek dokaze vnitrne vykonat dlouhou serii kroku a ukladat si mezivysledky do pameti nebo psat na papir, a pak se dobrat nejakemu vysledku.Jenze GPT-3 tuhle schopnost, jestli se nepletu (sleduju NN dost z dalky), ma. Transformery jsou pokrokem od LSTM architektury, a to nejsou ciste feed-forward site, ale maji vnitrni stav (kontext). Jedine omezeni je, ze ta sit se neuci interaktivne, na konkretnim problemu. Takze omezeni ktera vidime klidne mohou byt klidne dana omezenim kontextu, a faktem, ze ta sit se uz dale neuci. Ja nevidim duvod, proc by dostatecne komplikovana architektura site nemohla vest k moznosti naucit se libovolny "algoritmus". Asi jako u pocitacu - od jiste slozitosti stavoveho automatu muzeme do jiste miry emulovat vsechny stavove automaty urcite velikosti. Na druhou stranu, ve srovnani clovekem. Ano, clovek si mozna uvedomuje urcity pozadavek logicke konzistence (i kdyz to neni jasne, jestli se to v te explicitni podobe neuci), nicmene, to neznamena, ze mozek prakticky nepracuje jen s omezenou logickou konzistenci, zase v ramci kontextu jeho vlastniho vnitrniho stavu. A i ta omezena logicka konzistence, kterou je schopen mozek provozovat, vznikla prave na zaklade postupne evoluce architektury mozku. Jinak receno, je docela dobre mozne, ze pokud by clovek nemel dlouhodobou pamet (jsou zname takove pripady, kdy lide maji poskozenou urcitou dlouhodobou pamet), nebyl by schopen naucit se logicky konzistentnejsimu mysleni uplne stejne jako se mu neni schopne naucit GPT-3. Napriklad u scitani by provadel stale stejne chyby, ktere vyplyvaji z chybne abstrakce soucasneho kontextu.
Mozna, chtel jsem tim poukazat na problem, ktery jsem zminoval vyse. Tahle uloha vyzaduje vicekrokovou uvahu a zaroven neni v trenovacich datech, takze nelze vyresit zkratkou pres "brute force". Proto jsem presvedcen, ze to GPT nezvladne.Ja netvrdim, ze to GPT-3 (jako konkretni instance) zvladne - to vime, ze ne. Podstatne je tvrzeni, ze to zvladne ta architektura, pokud odstranime to - z meho pohledu znacne limitujici - omezeni, ze se ten system dale neuci, neuci se interaktivne. Myslim, ze GPT prokazalo, ze je schopno provadet vicekrokove abstrakce, a pokud je schopno provadet 3-krokove, pak zvladne i 4-krokove. Mozna nezvlada n-krokove pro libovolne zvolene n, ale to asi nezvlada ani clovek (bez dalsich pomucek nebo specialniho treninku).
A k ziskani teto intuice potrebuje clovek mnohem mene dat.To je diskuse jina, posun od otazky "dokaze to co lide" k otazce "uci se to stejne dobre jako lide" a IMHO to bude velmi tezke odpovedet, protoze my nevime, kolik "uceni" ma mozek uz od prirody v dusledku lidske evoluce. Ale v praxi je to spis non-problem, protoze proste ty preducene site se budou kopirovat.
Clovek se umi naucit pravidla hry a pak tu hru hrat a postupne se v ni zlepsovat. Jak chces tuchle schopnost pridat do GPT?Pokracovanim treninku te site (jenze to vyzaduje zda se znacny hardware, a taky vhodna trenovaci data, atd. proste dalsi usili). Ted je ta sit nejak naucena a to zustava konstantni, jedine, co se meni je kontext (asi jako kratkodoba pamet). (A po tom fiasku s Microsoft Tay si kazda dava pozor, aby to nenechal ucit od nahodnych kolemjdoucich na Internetu.) Osobne bych to videl tak, ze OpenAI se ted pusti do zcela genericke architektury, ktera pojede vsechno - od zpracovani zvuku a obrazu pres jazyk az po abstraktni mysleni. Vsechny ty ulohy uz umime individualne delat, je to jen otazka je propojit. A vysledek se pak mozna bude schopny ucit interaktivne.
Jenze GPT-3 tuhle schopnost, jestli se nepletu (sleduju NN dost z dalky), ma. Transformery jsou pokrokem od LSTM architektury, a to nejsou ciste feed-forward site, ale maji vnitrni stav (kontext).To je trochu neco jineho, udrzuje si to stav, ktery updatuje pri precteni tokenu (aspon LSTM, nevim jak funguje transformer). Vygenerovani 1 tokenu je pokud vim vzdy v konstantim case.
Ja nevidim duvod, proc by dostatecne komplikovana architektura site nemohla vest k moznosti naucit se libovolny "algoritmus". Asi jako u pocitacu - od jiste slozitosti stavoveho automatu muzeme do jiste miry emulovat vsechny stavove automaty urcite velikosti.To je fakt, a plati to i pro KNN, nahodne stromy nebo SVM, pokud maji dostatecny pocet parametru a velikost trenovacich dat.
Ja netvrdim, ze to GPT-3 (jako konkretni instance) zvladne - to vime, ze ne. Podstatne je tvrzeni, ze to zvladne ta architektura, pokud odstranime to - z meho pohledu znacne limitujici - omezeni, ze se ten system dale neuci, neuci se interaktivne.Myslis uplne ta sama architektura? Ale ta definuje, jakym zpusobem se ten model uci. Prijde mi ze tvoje tvrzeni je, ze nejaka vylepsena verze GPT-3 je AGI. Mozna. Mozna bude stacit nejake iterativni vylepseni, mozna ale ne, nevidim silny argument ani pro jedno.
Pokracovanim treninku te site (jenze to vyzaduje zda se znacny hardware, a taky vhodna trenovaci data, atd. proste dalsi usili).No ale u cloveka nemusim v podobne situaci (vymyslim hru, kterou pak hrajem) vytvaret trenovaci dataset.
A vysledek se pak mozna bude schopny ucit interaktivne.Uvidime. Ja bych si na to nevsadil.
27.8.2020 14:46
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
No ale u cloveka nemusim v podobne situaci (vymyslim hru, kterou pak hrajem) vytvaret trenovaci dataset.To nemusíš ani u machine learningu, stačí jen nadefinovat hodnotící funkci a nechat to hrát proti sobě. Ostatně takhle funguje třeba to AlphaZero / AlphaGo. Jinak asi by bylo zajímavé zkusit takhle hrát nějakou hru s GPT-3, jestli třeba udrží kontext pravidel nějaké ad-hoc hry co si vymslíš a zvládne to hrát.
 19.8.2020 18:25
Gréta | skóre: 36
| blog: Grétin blogísek
| 🇮🇱==❤️ , 🇵🇸==💩 , 🇪🇺==☭
19.8.2020 18:25
Gréta | skóre: 36
| blog: Grétin blogísek
| 🇮🇱==❤️ , 🇵🇸==💩 , 🇪🇺==☭
jako náhodou i uplně hloupučkej grétobot turingovým testem prošel hele :O ;D
gpt3 i se všema chybkama a nedostatkama který teďko jakoby má by na mimibazaru nebo podobným fóru uplně splinul si myslim :O :O :D :D ;D
... BTW2: Me osobne by teda zajimalo, jak vyuzitelny by to bylo pro hackovani. Protoze masina ktera zna veskery znamy diry veskeryho SW by pak mohla celkem slusne analyzovat i diry neznamy (a zdrojaky k tomu narozdil od cloveka nepotrebuje)Kde beres jistotu, ze to tak davno nebezi? Myslis ze NSA a jejich Cinsky a Izraelsky ekvivalent sedi na prdeli a nudi se? Vubec by mne neprekvapilo, kdyby provozovali tak 9/10 vsech ruznych cryptocoin burz, mixeru a kasin, stejne jako tyhle aktivity v AI...
19.8.2020 23:23
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
BTW: Az si to samo sebe uvedomi, tak to zaroven zjisti, ze nejvetsi problem planety je pritomnost cloveka, a tudiz, v souladu se zadanim tvurce, dojde k jeho eliminaci.Zkus si přečíst Slepozrakost (anglicky Blindsight). Výtečná kniha na téma sebeuvědomění si se a vědomí obecně.
19.8.2020 18:26
Gréta | skóre: 36
| blog: Grétin blogísek
| 🇮🇱==❤️ , 🇵🇸==💩 , 🇪🇺==☭
musíme to rychle nasadit proti nim než to voni jako nasaděj proti nám :O :O ;D ;D
tohle je vlhky sen vsech tech JS1, kteri chteji ridit lidstvo pocitacem a zakazat jakoukoli individualni svobodu a vlastnictviCo se clovek nedozvi.. IIRC tak ridit lidstvo pocitacem chtel Bystroushaak. I kdyz ja v zasade taky nejsem uplne proti, za predpokladu, ze bude mit nejakou humanistickou axiomatiku (coz muze byt dost obtizne splnitelny pozadavek). Nicmene kdyz uz jsme u tech predpovedi. Ja myslim, ze me se nikdo na nazor ptat nebude. AGI tohohle typu prvni nasadi miliardari na management svych investic, protoze proc by meli verit nejakym svym poskokum, kdyz se muzou spolehnout na stroj? Ten bude delat v zasade co vesmes delaji ted ti miliardari, srovna si tech 10 portfolii hedge fundu, co vlastni, a cas od casu vymeni sefa toho, co dava nejnizsi zisky. Nu a pak to proste pujde dal, ta AI rychle zjisti, co delaji manazeri pod temi portfolii blbe, a nahradi je taky umelou inteligenci. A tak to postupne probehne az skoro uplne dolu. Vznikne struktura, kde AI ma obrovskou faktickou kontrolu nad realnou ekonomikou, tedy zatim ve prospech toho miliardarskeho investora (kteremu to stale prinasi prospech). No a az se ta struktura zvetsi natolik, ze se ty zajmy AI (ktere jsou maximalizaci zisku pro investora) a investora dostanou do rozporu, co se stane? Ja osobne bych zadne AI do ruky nedal zadnou kontrolu nad materialnim svetem, alespon do doby, nez budeme trochu chapat, co to je. Nicmene obavam se, ze k naplneni snu o "friendly AI" nakonec nedojde, protoze lidska chamtivost bude silnejsi.
Nicmene kdyz uz jsme u tech predpovedi. Ja myslim, ze me se nikdo na nazor ptat nebude. AGI tohohle typu prvni nasadi miliardari na management svych investic, protoze proc by meli verit nejakym svym poskokum, kdyz se muzou spolehnout na stroj? Ten bude delat v zasade co vesmes delaji ted ti miliardari, srovna si tech 10 portfolii hedge fundu, co vlastni, a cas od casu vymeni sefa toho, co dava nejnizsi zisky.Na tento typ ulohy zadnou AGI nepotrebujes. To zvladne jednoduchy automat a na spravu portfolia klidne muzes najmou kocoura.
Vznikne struktura, kde AI ma obrovskou faktickou kontrolu nad realnou ekonomikou, tedy zatim ve prospech toho miliardarskeho investora (kteremu to stale prinasi prospech).Uz se v podstate stalo. Jeden z prvnich, kdo vazne pochopil, k cemu se daji pouzit data a AI (at uz je to cokoliv) byl Bezos a Amazon, ostatni firmy jej pomalu a jiste nasleduji.
Ja osobne bych zadne AI do ruky nedal zadnou kontrolu nad materialnim svetemTo se dost těžko dělá (a třeba kolem Eliezera Yudkowského je celá banda lidí co to už 15 let řeší), protože AI bez vlivu na fyzický svět je poměrně k ničemu. A její výstupy, pokud mají být podstatně lepší než to, co dokáže člověk (proto si ji pořizujeme, ne?), nedokážeš sanitizovat (jak zjistíš, že je to AI-vynalezené očkování na Čovid skutečné očkování, a ne tajný plán, jak ovládnout lidstvo? a pak trochu bizarnější: co když má tak skvělé dialektické schopnosti, že při výrobě volebních sloganů ve skutečnosti přesvědčí lidi k něčemu jinému? (AI-box experiment) Co když obrázek, který udělala, je ve skutečnosti BLIT? A pak mimochodem ji samozřejmě nemůžeš jakkoli připojit k internetu, protože vyhackuje bitcoinovou burzu a za bitcoiny objedná v JLC výrobu doomsday machine).
22.8.2020 10:38
xkucf03 | skóre: 49
| blog: xkucf03
Umělá inteligence nejsou jen algoritmy a výpočetní výkon, ale hlavně data, na kterých se natrénuje. Pokud poskytneš data, poskytneš i možnost vytvořit AI a tím pádem získat moc. Mohli bychom tedy začít od těch dat. Otázka je, jak by se k tomu mělo stavět autorské právo. Do jedné diskuse jsem napsal trochu provokativní dotaz:
It was estimated to cost 355 GPU years and cost $4.6m.
The dataset of 300 billion tokens of text is used to generate training examples for the model.
And how much have they paid to the authors of that texts?
Co si o tom myslíš? Mělo by zveřejnění či poskytnutí dat dávat automaticky právo tato data používat k trénování AI? Nebo by to mělo vyžadovat zvláštní licenci od autora resp. držitele práv? Co když napíšu článek, natočím film, přeložím titluky, přeložím software atd. – má mít automaticky kdokoli právo na tom trénovat AI? Nebo jen za určitých podmínek? Nebo až po mém explicitním souhlasu?
22.8.2020 12:52
xkucf03 | skóre: 49
| blog: xkucf03
Hash je sám o sobě celkem k ničemu, může tedy sloužit jako identifikátor, podobně jako název knihy + jméno autora, ale neobsahuje v sobě informace z té knihy, jde o jednosměrný proces a zpětně z něj nelze získat nic užitečného. Je to jako kdybys spočítal stránky v knize nebo minuty filmu a toto číslo pak někde uvedl. Tyhle věci jsou sice odvozené z původního díla (bez něj bys třeba ten hash nespočítal), ale autorské právo se na ně nevztahuje.
Natrénovaná AI je ale o dost jiný případ, protože ta je jednak z původního díla odvozená a jednak v sobě obsahuje informace či dokonce znalosti v tomto díle uložené. Výsledkem je program, který nahrazuje funkci těch původních knih a dalších děl. A nebýt těch děl, tak by tato AI nemohla existovat. Proto ten dotaz, kolik z investovaných peněz dostali autoři původních textů…
22.8.2020 13:24
xkucf03 | skóre: 49
| blog: xkucf03
Řekl bych, že ano. Pokud např. někdo použije moje překlady článků nebo .po soubory s překlady aplikací, nebo třeba překlady titulků k filmům, k tomu, aby vytvořil AI překladač, tak by měl respektovat licenci původních děl. A pokud jsou tato díla pod copyleftovou licencí, tak by i ten AI překladač měl být pod kompatibilní svobodnou licencí.
Mně přijde, že to trochu naráží na takový ten nedořešený problém s autorským právem, na který narážíme i u lidí. Čteš knihy, posloucháš hudbu, sleduješ filmy… To všechno tě nějak ovlivňuje a když pak sám něco vytvoříš, opravdu jsi tím jediným autorem?
Řešené to je, ale jak bývá zvykem, tak nijak exaktně:
(3) Právo autorské se vztahuje na dílo dokončené, jeho jednotlivé vývojové fáze a části, včetně názvu a jmen postav, pokud splňují podmínky podle odstavce 1 nebo podle odstavce 2, jde-li o předměty práva autorského v něm uvedené.
(4) Předmětem práva autorského je také dílo vzniklé tvůrčím zpracováním díla jiného, včetně překladu díla do jiného jazyka. Tím není dotčeno právo autora zpracovaného nebo přeloženého díla.
(5) Sborník, jako je časopis, encyklopedie, antologie, pásmo, výstava nebo jiný soubor nezávislých děl nebo jiných prvků, který způsobem výběru nebo uspořádáním obsahu splňuje podmínky podle odstavce 1, je dílem souborným.
Míru podílu autorství určuje soud.
U AI je asi hlavní rozdíl v tom, že to není svévolná entita, která by „nasála esenci lidskosti“ a pak přispívala zpátky (tvorbou lidové tvořivosti apod.), ale že někomu konkrétnímu patří a bude ji používat nějakým způsobem (často komerečním), ačkoliv ten natrénovaný model je v podstatě svým způsobem odvozené dílo – odvozené z těch trénovacích dat. Zajímalo by mě, co by na to řekly soudy.
Soudy už řešili, jestli opice, která pořídí fotografii, má na ni práva. Došli k názoru, že opice si nebyla vědoma tvůrčího procesu, a tudíž není autorem.
Soudy už řešili, jestli opice, která pořídí fotografii, má na ni práva. Došli k názoru, že opice si nebyla vědoma tvůrčího procesu, a tudíž není autorem.Program
convert si tvůrčího procesu taky není vědom, ne? :)
22.8.2020 13:14
xkucf03 | skóre: 49
| blog: xkucf03
Není, ale to neznamená, že jeho spouštěním nevznikají odvozená díla. Ostatně k vytvoření odvozeného díla nebo kopie žádný tvůrčí proces nepotřebuješ. A přesto je výsledek chráněn autorským právem – ovšem původního autora – a je třeba respektovat původní licenci.
22.8.2020 13:19
xkucf03 | skóre: 49
| blog: xkucf03
Autorské dílo je definováno jako výsledek tvůrčího procesu. Pokud něco jen okopíruješ, tak nejde o tvůrčí proces. Samozřejmě tu zůstává otázka, co je tvůrčí proces, jak dokázat, zda něco bylo okopírováno nebo k tomu dotyčný došel nezávisle sám atd. A na tyhle otázky odpovídá soud. Takhle právo normálně funguje. Skoro žádný zákon není prostým algoritmem, který by stačilo mechanicky aplikovat. Vyčítat tuhle vlastnost autorskému právu a nevidět, že stejnou vlastnost mají prakticky všechny ostatní zákony, to je dost hloupé nebo manipulativní (ano, jisté politické strany se k tomu uchylují). Neřekl bych tedy, že je to až tak „nedořešené“.
Když vydáš knihu, do které vložíš svoje znalosti a zkušenosti, tak ji vydáváš s tím, že si ji ostatní přečtou a pak tyto znalosti uplatní v praxi – třeba při práci, ve které vytvářejí další autorská díla. Dá se říct, že je to i záměr a předpokládaný výsledek. Asi to není nikde explicitně definované, ale je to věc zvyku a zdravého rozumu, že akt vydání knihy zahrnuje implicitní souhlas autora s tím, že si ji čtenář přečte, něco z ní načerpá a tyto znalosti pak uplatní při své činnosti. Když učitel učí studenty, tak tam se vyloženě předpokládá (je to cílem toho vzdělávacího systému), že si studenti ty přednášky zapamatují, vstřebají tyto znalosti, a pak půjdou někam pracovat (a často vytvářet díla) a tyto znalosti tam použijí.
Je otázka, zda tenhle princip lze aplikovat na AI. Umělá inteligence není lidská bytost resp. není vůbec považována za bytost a je to jen něčí majetek a nástroj, program. Asi bychom se na ni tedy měli dívat jako na odvozené dílo, které by mělo autorské právo a licence původních děl.
Pokud bys např. z filmů vygeneroval spustitelný ELF soubor, který, bude-li spuštěn s příslušnými parametry, začne na obrazovku promítat konkrétní film, tak by jednoznačně šlo o odvozené dílo. A z praktického hlediska toto dílo nahrazuje původní film – ten program lze použít místo původního DVD či BD disku. A pokud z knih a článků vygeneruješ (natrénuješ) AI, tak tato AI opět může sloužit jako náhrada těch knih a článků – místo toho, aby je někdo četl, tak může AI položit dotaz.
22.8.2020 14:07
Fluttershy, yay! | skóre: 92
| blog:
Umělá inteligence není lidská bytost resp. není vůbec považována za bytost a je to jen něčí majetek a nástroj, program.Co není, může být. Researcher at Institute for State and Law, Alžběta Krausová, on legal aspects of robots and AI Tam sice řeší takové věci jako uzavírání smluv robotem, který pro člověka dělá nákupy, potažmo odpovědnost za škody,
“Legal person is an artificial concept of our society. We created the concept of a legal person and applied it to companies because we needed something that transcended humans. With electronic persons or robots, there are similarities and differences. Imagine a robot who is buying pills for you or other items to help care for elderly people. We need rules that make it so it is actually legal for the robot to purchase the items. “Also, the other big problem is liability. What happens if a robot causes a liability? So, this status of an electronic person is not about making robots humans, but laying down rules on what to do when a robot causes damage.”ale není důvod, proč to analogicky neaplikovat na autorství, potažmo kopírovací monopol. Vlastně, když to narvu do vyhledávače, dostávám např. Could an artificial intelligence be considered a person under the law?
Legal scholar Shawn Bayer has shown that anyone can confer legal personhood on a computer system, by putting it in control of a limited liability corporation in the U.S. If that maneuver is upheld in courts, artificial intelligence systems would be able to own property, sue, hire lawyers and enjoy freedom of speech and other protections under the law. In my view, human rights and dignity would suffer as a result.
22.8.2020 15:02
xkucf03 | skóre: 49
| blog: xkucf03
Umělá inteligence není lidská bytost resp. není vůbec považována za bytost a je to jen něčí majetek a nástroj, program.
Co není, může být.
A to bys chtěl?
Skoro žádný zákon není prostým algoritmem, který by stačilo mechanicky aplikovat. Vyčítat tuhle vlastnost autorskému právu a nevidět, že stejnou vlastnost mají prakticky všechny ostatní zákony, to je dost hloupé nebo manipulativní (ano, jisté politické strany se k tomu uchylují).Vyčítám to i těm dalším zákonům. Samozřejmě tam vždycky bude něco, co musí nakonec posoudit člověk, ale přál bych si, aby zákony byly alespoň psané formálním jazykem (jednoznačný AND, OR, XOR atd.) a vedle těch rozhodovacích otázek byly nějaké příklady, komentáře a tak. No, nicméně, to nebyla úplně pointa. Jednak jsem stejně dospěl k závěru, že ten natrénovaný model je podle současných zákonů odvozené dílo, jednak jsem konkrétně narážel na různé takové ty případy, kdy někdo omylem vytvoří melodii, která je podobná již existující, čímž porušuje autorská práva, ale neexistuje způsob, jak posoudit, jestli to původní dílo vůbec někdy slyšel, a pokud ano, tak jak je to dávno a jestli to udělal úmyslně, nebo ne atd. Tuším, že se někde řešil třeba počet zhlédnutí na YouTube (byly to tuším řádově stovky tisíc nebo jednotky milionů, nic absurdně vysokého) a soud dospěl k závěru, že to ta žalovaná strana mohla slyšet… Mně to prostě přijde rozbité a s různými dnešními crowdfundingy to stejně směřuje k modelu, že autor vybere peníze předem a pak to uvolní jako svobodné dílo. U softwaru se zase všechno přesouvá do cloudu, což se mi mimochodem taky nelíbí. Co s tím nevím a nemám na to úplně jednoznačný názor, ale tahle problematika je obecně strašně složitá.
ale přál bych si, aby zákony byly alespoň psané formálním jazykem (jednoznačný AND, OR, XOR atd.)To je takove hezke, autisticke... problem je, ze realny svet a stejne jako chovani lidi, je inherentne fuzzy a to musi legislativa reflektovat. Pokud bys nastavil zakony striktne podle klasicke aristetolovske (boolovske, dvouhodnotove) logiky, svet by se stal mnohem nespravedlivejsi. I ta mista, kde se toto dvou hodnotove uvazovani v soucasnych zakonech pouziva, nemusi davat smysl podle zdraveho rozumu. Vezmi si, ze nekdo ukradne v obchode mobil za 4900,-, je to prestupek, dostane pokutu. Kdyz k tomu ukradne i pametovou kartu za 100,-, stane se z toho trestny cin a jde pred soud. Spolecenska zavaznost je temer stejna, i kdyz dusledky jsou fundamentalne odlisne. Navic, pokud budou existovat striktne nastavene hranice, je to idealni navod, jak se zakonum vyhybat. Napr. ti ostrilenejsi si pri kradezi v obchodech hlidaji, aby neukradli veci za pet tisic a vic.
Přednášející z matematické analýzy nám třeba kdysi vyprávěl o nějaké diskuzi s právníkem, ...To je teda argument... Jednak carka pred nebo ma vyznam, ktery je explicitne dany. To je to, po cem volas, a i tak to v tom pripade asi bylo jedno. A taky je rozdil mezi pravnikem a pravnikem. Uz jsem potkal pravniky okresniho formatu a prace s nimi byla na urovni okresu. A pak jsem se setkal s pravniky, co patri k tomu nejlepsimu, co muzes u nas potkat, a prace s nima byla spickova a uplne me to prinutilo prehodnotit pohled na pravniky. Ale cena taky byla o rad jinde.
ty zákony mají mít co nejsrozumitelnější, nejjednoznačnější formu.A uvedomujes si, ze tyto pozadavky jdou ve vetsine pripadu proti sobe? Bud to bude srozumitelne, pak tam budou nejednoznacnosti. Nebo to bude (opravdu) jednoznacne, ale pak to bude pro vetsinu lidi (opravdu) nesrozumitelne, jak je bezne u matametickych textu a castecne pravnich textu.
Jednak carka pred nebo ma vyznam, ktery je explicitne dany.On nám právě tvrdil opak, ale jak říkám, neověřoval jsem to. Ale to je jedno. Mně prostě přijde, že u dokumentů, na kterých stojí celá naše společnost a lidi jsou na jejich základě zbavováni osobní svobody, by to mělo být vyřešené robustněji a že nějaké právní minimum, kde tyhle principy vysvětlí, by mělo být součástí základního vzdělání, nebo ještě lépe jako volně dostupný online kurz. Měl jsem někde hezký příklad, kde na těch logických operacích záleželo a zcela upřímně jsem tomu zákonu přes sebelepší snahu fakt nerozuměl (tak, jak byl napsaný). Samozřejmě se můžu řídit selským rozumem, ale proč pak zákony vůbec mít? Nebyla to triviální problematika („nesmíte zabíjet lidi“), ale nebyla to ani žádná specialita. Prostě věc z normálního života. Škoda, že už to teď nedohledám.
A uvedomujes si, ze tyto pozadavky jdou ve vetsine pripadu proti sobe? Bud to bude srozumitelne, pak tam budou nejednoznacnosti. Nebo to bude (opravdu) jednoznacne, ale pak to bude pro vetsinu lidi (opravdu) nesrozumitelne, jak je bezne u matametickych textu a castecne pravnich textu.Když to dotlačíš do nesmyslných extrémů, tak to protichůdné samozřejmě bude, ale to bych pak z autismu mohl obvinit zase já tebe. Já v tom prostě jen vidím prostor pro zlepšování a myslím si, že snaha o převod alespoň výrazů jako když-nebo-když-tak apod. do formálního jazyka k právní apokalypse nepovede (a znovu opakuji, že mi bylo sděleno, že se to už používá, dokonce mám pocit, že to nějaká firma dělá i nad českými zákony, jen to neumím najít a ověřit) a snaha odsávat právní vakuum dřív než se objeví problém (jako kolem toho Airbnb) taky ne. Připomínám, že k tomuto tématu jsme se dostali přes autorské právo, kde jsem upozorňoval na nějaká slabá místa, kde je fakt problém některé věci soudit (konzistentně) spravedlivě. Netvrdím, že jsem schopný to ve své neskonalé genialitě všechno šalamounsky vyřešit, ale proto o tom koneckonců taky diskutuju (i když teda úplně v úmyslu jsem to neměl, původně jsem chtěl jen zdůvodnit, proč natrénovaný model dle stávající legislativy považuji za odvozené dílo; jestli to tak má nebo nemá být si nejsem úplně jistý).
Ja nevidim ani tak problem v tom, ze by AI mela vlastni zlou vuli, nebo tajny plan, vidim daleko vetsi riziko v tom, ze bude nasazena na rizeni neceho a bude ji chybet prvek bud humanismu nebo neschopnosti, ktery maji normalni lide.Ale vždyť o tom právě většina Yudkovského věcí je (paperclip maximizer a tak). Dokonce mají slogan The AI does not hate you, nor does it love you, but you are made of atoms which it can use for something else.
Kazda automatizace ma potencial vyprodukovat velke mnozstvi neceho, s vysokou produktivitou.Ano, přesně jak píšeš dále. Problém s AI je, že pokud bude opravdu podstatně výkonnější než lidi (samozřejmě stále není vyřešeno, jestli taková AI jde postavit, ale teď předpokládejme, že ano), tak taková chybná/nepřátelská (ve smyslu maximalizace účelové funkce (u korporací zisku) bez ohledu na okolí) výroba bude taky podstatně větší než to co dělají dnešní korporace.
Yudkovského … paperclip maximizer a takPaperclip maximizer je myšlenkový experiment ze starší práce Nicka Bostroma (ačkoliv to třeba popularizovala kniha Superintelligence nebo možná i blogísky jako LessWrong). Je vůbec zvláštní, kolik vážně míněné pozornosti se upírá k takovým jako Yudkowsky, kteří ani nic moc seriózního nepublikují a tak. „Zvláštní“ je možná špatné slovo. Dává to totiž smysl, když kolem nich můžeme pozorovat kult osobnosti. Vůbec mi přijde, že se takto rozebírají marginální, ale snadno uchopitelné problémy. Ony to trochu naznačují reakce na Yudkowského shrnuté v RationalWiki. Přitom je řada relevantních prací např. rozšiřujících perspektivu. Opakovaně doporučuji namátkou Brattonův The Stack, což je dlouhá, ale fascinující kniha (ba dokonce „mystický zážitek“!). Nebo si aspoň proletět nějaké 15minutové rozhlasové rozhovory.
22.8.2020 14:49
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Je vůbec zvláštní, kolik vážně míněné pozornosti se upírá k takovým jako Yudkowsky, kteří ani nic moc seriózního nepublikují a tak. „Zvláštní“ je možná špatné slovo. Dává to totiž smysl, když kolem nich můžeme pozorovat kult osobnosti.Yudkowsky kolem sebe má kult osobnosti co se týče různých racionalistů, imho ne AI lidí.
Vůbec mi přijde, že se takto rozebírají marginální, ale snadno uchopitelné problémy.Někdo musí vysvětlit i základy. To že pak všichni papouškují základy, protože jsou jednoduše pochopitelné, to můžeš vidět i v téhle diskuzi, kde nikdo kromě Jendy skutečně neřeší GPT-3, ale různé filosofické blbosti kolem. Klasický bikeshedding.
Přitom je řada relevantních prací např. rozšiřujících perspektivu. Opakovaně doporučuji namátkou Brattonův The Stack, což je dlouhá, ale fascinující kniha (ba dokonce „mystický zážitek“!). Nebo si aspoň proletět nějaké 15minutové rozhlasové rozhovory.A je to fakt dobré jo? Ten popisek zní upřímně dost špatně.
v téhle diskuzi, kde nikdo kromě Jendy skutečně neřeší GPT-3, ale různé filosofické blbosti kolemMožná protože definující vlastností je – podobně jako v případě třeba AlphaStar – že za dobrými výsledky stojí řádově deset megadolarů. Kdo z vás to má? No a tak se dostáváme k tomu, co s tím budou dělat ti, kdož řádově deset megadolarů do toho narvat klidně můžou.
A je to fakt dobré jo? Ten popisek zní upřímně dost špatně.V kontextu #95? Naprostá ztráta času. Jinak? Jedna ze stěžejních soudobých prací.
Problém s AI je, že pokud bude opravdu podstatně výkonnější než lidi (samozřejmě stále není vyřešeno, jestli taková AI jde postavit, ale teď předpokládejme, že ano), tak taková chybná/nepřátelská (ve smyslu maximalizace účelové funkce (u korporací zisku) bez ohledu na okolí) výroba bude taky podstatně větší než to co dělají dnešní korporace.Ano, a o to mi jde. Ten problem uz mame i dneska, u tech korporaci. Resime ho? Moc ne. Asi ho nebudeme resit ani u AI. Je to jen dalsi pseudoproblem nulteho sveta, kterym se zabyvaji lide, co nevidi (nebo nechteji videt) realne problemy. Asi jako lety na Mars Elona Muska.
22.8.2020 14:05
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Popravde, mne ty Yudkowskeho fantazie pripadaji dost pritazene za vlasy.Jaké Yudkowskeho fantazie?
19.8.2020 23:26
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
25.8.2020 21:21
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Ten prvni graf by mohl mit svislou osu logaritmickou.Mohl, ale ta pointa by nebyla tak pěkně vidět :)
Co se toho vyctu schopnosti tyka, tak me to proste prijde, ze to prosmejdilo wikipedii, stackoverflow a podobne trochu duveryhodnejsi weby a z toho se to naucilo lepit text. Takze tvrzeni "naucilo se to scitat a nasobit" mi prjde hodne silne. Jak tu nekdo napsal, pro politiky dobry a pro lepice css asi taky, ale ja zatim nastesti budu mit co jist.Projdi si ty další ukázky, specificky ty odkazy co jsem posílal a například i ten obrázek ke konci, kde to v aidungeonu chápe vnořené funkce a je schopné odpovídat na různé otázky kolem nich. Taky se podívej na ty různé dotazy ohledně čísel, které rozhodně nejsou jen databázové znalosti.
Kdyz tady ctu o 175 miliardach parametru a 570 GB trenovacich dat, tak si rikam, jestli to zase neni spis o te hrube sile.Není. Podívej se na ty odkazy o architektuře pro detaily.
To s tim globalnim minimem jsem nepobral. Take jsem ho behem studii zkousel hledat a troufam si tvrdit, ze na obecnych datech si proste nemuzeme byt jisti, ze nalezene minimum je globalni. (Trochu s tim souvisi oblibeny vyrok meho kamarada "pro tuhle firmu davno dobry".)Je to heuristika. Tzn nemusí to najít úplné globální minimum, to jsem tam právě popisoval, že to hledá něco co je dostatečně blízké v rámci vynaložené námahy / počtu cyklů.
Ale jeste jednou dekuji. Takhle jsem si dlouho nepocetl.Není zač.
21.9.2020 03:50
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
14.3.2023 21:10
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
 AbcLinuxu.cz
AbcLinuxu.cz ITBiz.cz
ITBiz.cz HDmag.cz
HDmag.cz AbcPráce.cz
AbcPráce.cz 19.8.2020 05:03
19.8.2020 05:03
 19.8.2020 23:26
19.8.2020 23:26
 21.8.2020 18:16
21.8.2020 18:16
 22.8.2020 22:53
22.8.2020 22:53
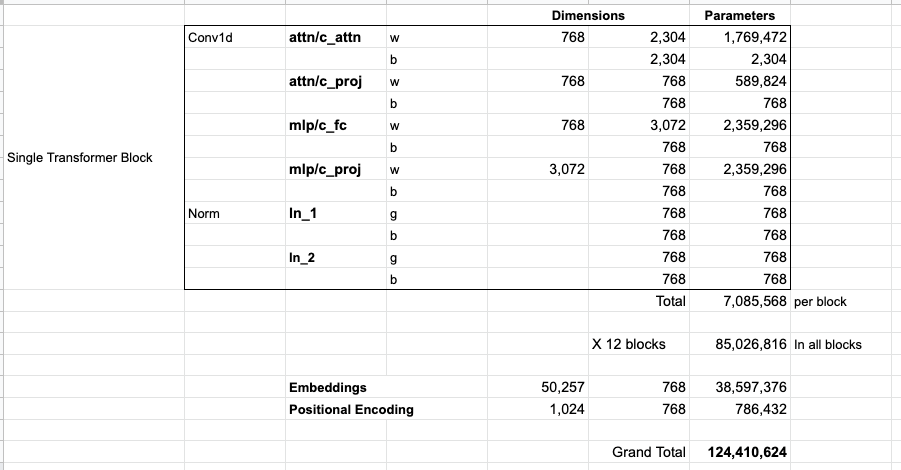{kind=link}
{kind=link}
{kind=link}
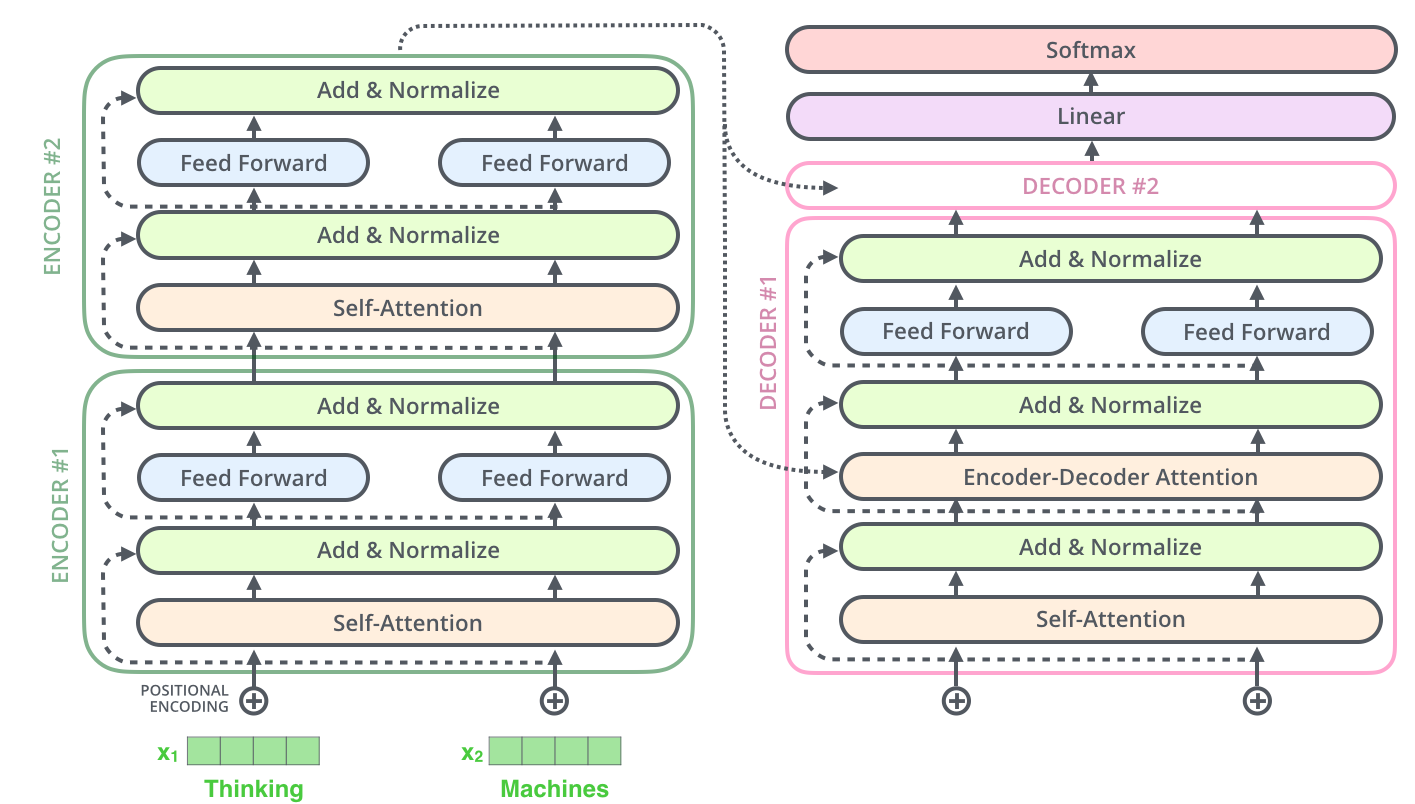{kind=link}
{kind=link}