Canonical vydal (email, blog, YouTube) Ubuntu 24.04 LTS Noble Numbat. Přehled novinek v poznámkách k vydání a také příspěvcích na blogu: novinky v desktopu a novinky v bezpečnosti. Vydány byly také oficiální deriváty Edubuntu, Kubuntu, Lubuntu, Ubuntu Budgie, Ubuntu Cinnamon, Ubuntu Kylin, Ubuntu MATE, Ubuntu Studio, Ubuntu Unity a Xubuntu. Jedná se o 10. LTS verzi.
Na YouTube je k dispozici videozáznam z včerejšího Czech Open Source Policy Forum 2024.
Fossil (Wikipedie) byl vydán ve verzi 2.24. Jedná se o distribuovaný systém správy verzí propojený se správou chyb, wiki stránek a blogů s integrovaným webovým rozhraním. Vše běží z jednoho jediného spustitelného souboru a uloženo je v SQLite databázi.
Byla vydána nová stabilní verze 6.7 webového prohlížeče Vivaldi (Wikipedie). Postavena je na Chromiu 124. Přehled novinek i s náhledy v příspěvku na blogu. Vypíchnout lze Spořič paměti (Memory Saver) automaticky hibernující karty, které nebyly nějakou dobu používány nebo vylepšené Odběry (Feed Reader).
OpenJS Foundation, oficiální projekt konsorcia Linux Foundation, oznámila vydání verze 22 otevřeného multiplatformního prostředí pro vývoj a běh síťových aplikací napsaných v JavaScriptu Node.js (Wikipedie). V říjnu se verze 22 stane novou aktivní LTS verzí. Podpora je plánována do dubna 2027.
Byla vydána verze 8.2 open source virtualizační platformy Proxmox VE (Proxmox Virtual Environment, Wikipedie) založené na Debianu. Přehled novinek v poznámkách k vydání a v informačním videu. Zdůrazněn je průvodce migrací hostů z VMware ESXi do Proxmoxu.
R (Wikipedie), programovací jazyk a prostředí určené pro statistickou analýzu dat a jejich grafické zobrazení, bylo vydáno ve verzi 4.4.0. Její kódové jméno je Puppy Cup.
IBM kupuje společnost HashiCorp (Terraform, Packer, Vault, Boundary, Consul, Nomad, Waypoint, Vagrant, …) za 6,4 miliardy dolarů, tj. 35 dolarů za akcii.
Byl vydán TrueNAS SCALE 24.04 “Dragonfish”. Přehled novinek této open source storage platformy postavené na Debianu v poznámkách k vydání.
Oznámeny byly nové Raspberry Pi Compute Module 4S. Vedle původní 1 GB varianty jsou nově k dispozici také varianty s 2 GB, 4 GB a 8 GB paměti. Compute Modules 4S mají na rozdíl od Compute Module 4 tvar a velikost Compute Module 3+ a předchozích. Lze tak provést snadný upgrade.
Obrázky skenované z knížky trpí mnoha neduhy, jejichž hlavním viníkem je skutečnost, že snímaná předloha není zcela rovná – text tak bývá naskenován zešikma, okraje i hřbetní předěl mezi listy je zvýrazněn černými šmouhami, o drobném šumu napříč celou stranou nemluvě. Se všemi těmito „neřády“ se snaží vypořádat program unpaper, který představuje vlajkovou loď mého pracovního postupu. Kromě „čistění“ stránek navíc umí rozdělit nasnímané dvoustrany na jednotlivé stránky, jejich otáčení, zmenšování a zvětšování, přidávání okrajů či hromadné zpracování více souborů najednou. Abych však nepřechválil, ani unpaper není všemocný a – jak ukázaly pokusy – na některé očistné procedury se lépe uplatní i jiné prográmky.
Zpět na začátek – ke skenování. V našich poloamatérských podmínkách se jako jednoznačně nejvýhodnější ukázalo snímání na „velké“ černobílé kopírce – oproti klasickému stolnímu skeneru je výrazně rychlejší a má větší snímací plochu (tj. A3). Snímáme černobíle v rozlišení 200 dpi; vyšší rozlišení pro naše potřeby nemá valného smyslu a odstíny šedé jsou spíše ku zlosti než k užitku – skeny nemají dostatečný kontrast, okolo písmen je patrný šum, občas je patrný text z druhé strany listu a velikost skenovaného souboru roste u průměrné 400stránkové knížky do stovek megabajtů. I s těmito vadami na kráse se samozřejmě dá něco dělat (viz dále), ale osobně preferuji se jim vyhnout.
Zmíněná kopírka umí nasnímané stránky uložit jako PDF či vícestránkový TIFF. Z hlediska obsahu je to celkem jedno, z praktického hlediska je však vhodnější PDF, neboť z něj lze získat strany v jednotlivých souborech v požadovaném formátu pro další zpracování a s potřebným číslováním přímo, zatímco s TIFFem je to poněkud krkolomnější:
# tiffsplit sken.tiff dvoustrana
→ vytvoří sadu souborů s jednotlivými nasnímanými dvoustranami pojmenovanými jako dvoustranaaaa.tif, dvoustranaaab.tif atd. až dvoustranazzz.tif
# for I in dvoustrana*.tif; do tifftopnm $I > ${I%%.tif}.pbm; done
→ převede jednotlivé dvoustrany do formátu PBM
# C=1; for I in dvoustrana*.pbm; do rename $I dvoustrana$(printf %03d $C).pbm $I; C=$((C+1)); done
→ přejmenuje do číselné posloupnosti, se kterou umí pracovat unpaper, tj. dvoustrana001.pbm atd.
Pro převod z PDF slouží program pdftoppm:
# pdftoppm -r 200 -mono sken.pdf dvoustrana
→ vytvoří sadu souborů dvoustrana001.pbm atd. ve formátu PBM
Parametr -r udává výstupní rozlišení – pokud není uveden, tak se předpokládá 150 dpi. Tímto programem tak zároveň lze měnit i velikost obrázků – za použití vhodného výstupního dpi a parametru -gray namísto -mono lze získat text obstojně vyhlazený do odstínů šedé. K tomuto účelu se mi nicméně nakonec více osvědčil jiný program, o kterém se zmíním později.
Začínám zmiňovat nějaké formáty a programy a možná by nebylo od věci zmínit, co to je za formáty a kde ty programy vzít. PDF a TIFF předpokládám není třeba představovat. PBM je zkratka z Portable BitMap a jedná se nekomprimovaný formát pro uložení černobílé rastrové grafiky. Analogicky existují též PGM (aka Portable GrayMap) a PPM (Portable PixMap) pro uložení šedoškálových a barevných nekomprimovaných obrázků. Obecně se tato rodinka tří formátů označuje zkratkou PNM.
K těmto velice primitivním formátům postupem času přibyl ještě jeden – PAM. Slouží k uchovávání obecných dat v matici, lze v něm uložit nejenom to stejné, co v PBM, PGM a PPM, ale i některé věci navíc, třeba průhlednost. Drobnou vadou na kráse je skutečnost, že jiné programy (například Gimp, Okular, Gwenview) formátu PAM (zatím?) nerozumějí.
Vzhledem ke své jednoduchosti jsou tyto formáty snadno programátorsky uchopitelné i bez použití cizích knihoven (proto s těmito formáty také pracuje unpaper), na druhou stranu zabírají nemálo diskového prostoru, takže je záhodno obrázky po zpracování převést do něčeho úspornějšího.
Celé stovky programů pro práci s obrázky PNM – převodníky, editory, generátory, analyzátory a další – jsou obsaženy v nástrojové sadě netpbm, patří k nim již zmíněný tifftopnm, některé další zmíním později – většinou obsahují jeden z formátů v názvu. Základní manipulaci s obrázky TIFF obstará knihovna libtiff, její součástí je zmíněný tiffsplit i tiffcp, který naopak seskládává samostatné obrázky do vícestránkového TIFFu. Pro úplnost dodám, že pdftoppm je součástí balíčku poppler.
Kopírka, na které skenujeme většinu knih, je vybavena funkcí automatické detekce velikosti snímané předlohy. Vinou této funkce jsme museli některé knihy skenovat znovu, neboť autodetekce samozřejmě nefunguje dobře – chybějící čísla stránek by ještě šla jakž takž překousnout, ale přepůlený poslední řádek textu na stránce už je příliš. Proto jsme kopírku fixně přenastavili na maximální možný formát A3, abychom měli jistotu, že skutečně o nic nepřicházíme. To nicméně u snímání knih menšího formátu znamená, že ve výsledku máme velké černé okraje (viz obrázek), se kterými si unpaper tak úplně neví rady.

Přesněji řečeno bylo by zapotřebí si spočítat zvětšení a posun stránky, následně trochu experimentovat a výsledek by se určitě dostavil i s unpaperem. Mnohem jednodušší však je nepotřebné okraje hromadně oříznout programem pamcut:
# for I in dvoustrana*.pbm; do pamcut 350 0 2510 1850 $I > ${I%%.pbm}orez.pbm; done
Parametry programu definují obdélník, který má po ořezu z obrázku zůstat – první dvě číselné hodnoty jsou xová a yová souřadnice levého horního rohu, druhé dvě pak šířka a výška obdélníku. Přesná čísla lze nejlépe odečíst z nějakého grafického editoru (sám používám Gimp) a jedné vybrané naskenované dvoustrany. Při počítání je jistě vhodné vymezit obdélník raději trošku větší než o něco přijít, tentokráte vlastní vinou.
Existuje též program pnmcrop, který odstraňuje okraje definované barvy, tj. nabízí se jakási automatika bez nutnosti počítání velikosti obdélníku, takto ořezané obrázky však mohou být různě velké, což pro další zpracování není zrovna žádoucí.
Neumím si to tak úplně vysvětlit, ale nemálo skenovaných knih obsahovalo texty v rámečku se šedým pozadím, které naskenováno černobíle nevypadá zrovna nejlépe – viz obrázky (1:1 a 8:1).

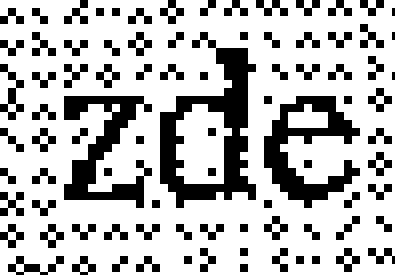
Unpaper sice obsahuje filtr na odstraňování šumu s volitelně nastavitelnou intenzitou, na takovéto šedé pozadí nicméně nezabírá – s malou intenzitou pročistí jen částečně a s velkou už se začnou ztrácet například také tečky nad „i“. Naštěstí existuje program pbmclean. Ten pro každý bod obrázku spočítá, kolik z osmi okolních bodů má stejnou barvu, a pokud jich je méně, než předepsané minimum, kontrolovaný bod invertuje. Výchozí minimum sousedů je jeden bod, takže se zahlazují pouze izolované body; s pomocí parametru -minneighbors lze toto minimum upravit. Podívejme se, co dokáže pbmclean s parametry -minneighbors=2 a -minneighbors=3:

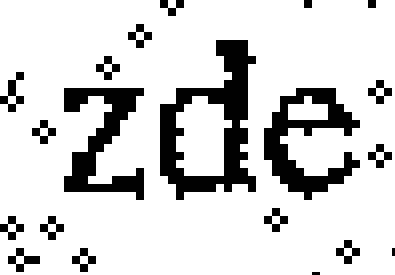

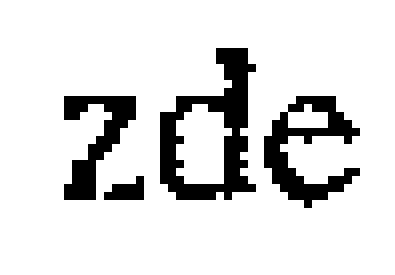
Na čtveřici dokolečka spojených bodů je podmínka minimálně dvou sousedů nedostatečná, s minimálně třemi už není po původně šedém pozadí ani památky, avšak to negativně zasáhlo i písmena, jak je vidět například na přepůleném „z“.
Jelikož jsou nechtěné černé body pospojovány především diagonálně, zatímco pro chtěné body tvořící znaky to neplatí, nebylo by od věci čistící algoritmus aplikovat tak, aby za sousední body byly považovány jenom ty se společnou hranou. To originální pbmclean bohužel neumí – naštěstí se ale jedná o open source a úprava zdrojového kódu je opravdu jednoduchá. Zkompiloval jsem si tedy vlastní pbmclean (diff) a čištění nyní provádím ve dvou krocích následovně (pominu-li konstrukci cyklu):
# ~/netpbm-10.26.62/editor/pbmclean -black zdroj.pbm > TMP && pbmclean -minneighbors=2 TMP > vysledek.pbm
Přepínač -black zajistí, že předmětem zkoumání jsou pouze černé body, aby nedocházelo k invertování izolovaných bílých bodů uprostřed „koleček“. Neskromně si troufám tvrdit, že výsledek už nemůže být lepší:

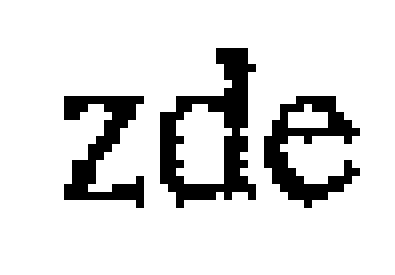
Doposud nepředstavovalo omezení na jednobitovou barevnou hloubku žádný závažnější problém, spíše naopak se dala ocenit menší velikost souborů. S korekcí sklonu naskenovaného textu a tedy otáčením obrazu programem unpaper už to však problém je. Prostě a jednoduše řečeno, otočený černobílý obrázek nevypadá dobře – rozhodně ne tak dobře, jak originál, ostatně porovnejte sami (první obrázek je originál, druhý pootočený):


Některá písmena vizuálně ztloustla, jiná nikoliv – záleží na úhlu otáčení, někdy je to patrné více, jinde méně, v každém případě je však lepší se tomu vyhnout. Možnosti jsou zhruba následující:
--no-deskew-t pgm sdělit unpaperu, aby výsledek vracel v odstínech šedéPokud šla skenovaná kniha dobře rozevírat a nasnímané texty tak jsou vesměs neskloněné, je první možnost ideální. U většiny materiálu, který se mi ale dostane na obrazovku, však touha po korekci sklonu přímo bije do očí. Druhá možnost také není vyloženě k zahození, ale výsledek trpí podobným neduhem jako černobílý výsledek:

Osobně se tedy přikláním ke třetí možnosti, protože když se povede dobrý převod do odstínů šedé, povede se i pootočení textu. A není následně problém výsledek relativně kvalitně převést zpět na černobílou, jak ukážu v příštím díle.
Vyhlazení textu do šedých odstínů jde vynutit změnou velikosti obrázku, jak již jsem zmínil u programu pdftoppm, z balíčku netpbm by na to šel použít například pamscale. Lepší způsob je ale použití programu příznačně pojmenovaného jako pbmtopgm. Jeho aplikací jsou všechny body v obrázku přepočítány jakou průměr hodnot z definovaného okolí; pár pokusů ukázalo, že nejmenší možné okolí 2 × 2 dává nejlepší výsledky. Poslední přípravnou operací před použitím unpaperu je tedy následující:
# for I in dvoustrana*.pbm; do pbmtopgm 2 2 $I > ${I%%.pbm}.pgm; done

Ale ouha. Výsledek sice vypadá dobře, ale je uložen s deklarací, že body nabývají pěti různých barevných hodnot, zatímco unpaper očekává plný rozsah 256 hodnot a není tak schopen zdrojový soubor zpracovat správně. I zde tedy přichází ke slovu úprava zdrojového textu programu pbmtopgm (diff) a kompilace vlastní verze, která uloží výsledek v odstínech šedé v kódování, kterému unpaper rozumí (chybu jsem nahlásil, ale těžko říci, zda bude někdy unpaper v tomto ohledu opraven).
Na závěr prvního dílu návodu tu mám ještě jeden tip, který představuje další dva programy z balíku netpbm. Na začátku návodu jsem tvrdil, že je lepší se vyhnout skenování dokumentů v odstínech šedé – pokud však přeci jenom takový materiál dostaneme ke zpracování, zachrání nás následující magická formule:
# pgmdeshadow strana001.pgm | pnmnorm -maxexpand=50 > vylepsena_strana001.pgm
 →
→

Program pgmdeshadow – jak již název napovídá – odstraňuje stíny v šedých obrázcích, pnmnorm pak normalizuje kontrast.
Druhý (a zároveň poslední) díl návodu k retušování digitalizovaného textu popíše program unpaper a potřebné kroky ke zkompletování výsledku.
Nástroje: Tisk bez diskuse
Tiskni
Sdílej:
![]()
![]()
![]()
![]()
![]()
![]()
 13.7.2009 00:11
Fluttershy, yay! | skóre: 92
| blog:
13.7.2009 00:11
Fluttershy, yay! | skóre: 92
| blog:
 13.7.2009 00:22
Petr Tomášek | skóre: 39
| blog: Vejšplechty
13.7.2009 00:22
Petr Tomášek | skóre: 39
| blog: Vejšplechty
Bohužel tyto postupy nelze doporučit u rozličných orientálních písem (arabské, hebrejské, syrské...), kde občas dost záleží na detailech (tečky, tj. tzv. punktace, případně i tvary písmen). Nakonec jsem osobně unpaper úplně vyloučil ze svého repertoáru a při převodu na formát DJVU vyloučil „optimalizaci“.
Raději jsem se naučil, jak kopírovat a skenovat texty tak, aby se co nejméně musely posléze zpracovávat v počítači...
 13.7.2009 01:40
Jardík | skóre: 40
| blog: jarda_bloguje
13.7.2009 01:40
Jardík | skóre: 40
| blog: jarda_bloguje
13.7.2009 01:40
Jardík | skóre: 40
| blog: jarda_bloguje
13.7.2009 01:40
Jardík | skóre: 40
| blog: jarda_bloguje
 13.7.2009 13:11
Fluttershy, yay! | skóre: 92
| blog:
13.7.2009 17:16
Jardík | skóre: 40
| blog: jarda_bloguje
13.7.2009 17:24
Fluttershy, yay! | skóre: 92
| blog:
13.7.2009 13:11
Fluttershy, yay! | skóre: 92
| blog:
13.7.2009 17:16
Jardík | skóre: 40
| blog: jarda_bloguje
13.7.2009 17:24
Fluttershy, yay! | skóre: 92
| blog:
Kdyz uz jsme u toho OCR - jake mate zkusenosti a co pouzivate sa programy?
 13.7.2009 08:25
Jiří Poláček | skóre: 47
| blog: naopak
| Sivice
13.7.2009 09:44
Jiří Poláček | skóre: 47
| blog: naopak
| Sivice
13.7.2009 11:50
Jiří Poláček | skóre: 47
| blog: naopak
| Sivice
13.7.2009 13:09
Jiří Poláček | skóre: 47
| blog: naopak
| Sivice
13.7.2009 08:25
Jiří Poláček | skóre: 47
| blog: naopak
| Sivice
13.7.2009 09:44
Jiří Poláček | skóre: 47
| blog: naopak
| Sivice
13.7.2009 11:50
Jiří Poláček | skóre: 47
| blog: naopak
| Sivice
13.7.2009 13:09
Jiří Poláček | skóre: 47
| blog: naopak
| Sivice
 13.7.2009 16:12
Bilbo | skóre: 29
13.7.2009 16:12
Bilbo | skóre: 29
Chtel jsem podotknout k tomu cernobilemu skenovani. Ja jsem si knizky vzdycky skenoval ve skale sedi ve 150 nebo 300 dpi (pokud byla vedecka a byly tam male symboly), a prislo mi to (uz tech 150) citelnejsi nez cernobila v rozliseni 600 dpi. Nedelal jsem to ale kvuli OCR, ktere miva se skalou sedi problemy (stejne jako ostatni nastroje). I kdyz je pak pomerne snadne to prevest - muzete to nejak interpolovat treba na tech 600 dpi a pak provest prahovani.
Ale moje hlavni zduvodneni bylo, ze pokud mam ja jako clovek mensi problem se ctenim knihy (na obrazovce) ve 150 dpi / 16 odstinu nez 600 dpi / 2 odstiny, pak by tato schopnost mela byt definovatelna nejakym algoritmem. Komprese je samozrejme jina otazka, ale dnes uz snad velikost knih nikdo neresi (ovsem dokud jsem neznal DJVU, tak i ten 600 dpi TIFF zabira vice nez 150 dpi PNG).
Jeste zajimava vec, kterou jsem delal k odstraneni cernych okraju byla, ze jsem vsechny stranky logicky secetl. Vysledny obrazek ukazoval, kde mam odstrihnout cerne pozadi (abych neporusil pismenka).
Vícestupňový scan je něco jako antialiasing. Na výstupním zařízení s podobným rozlišením (obrazovky mají kolem 100 dpi) vypadá moc dobře. Ale zkuste si pak takový dokument zpětně vytisknout. Vzhledem k tomu, že většina tiskových technik (inkoustové taky?) mouhou odstíny pouze simulovat ditheringem, tak pak tisk vícestupňového 150dpi obrázku na řekněme černobílé 600dpi tiskárně dopadne hrůzostrašně. Proto si považuji za rozumnější scanovat ve vyšším rozlišení bitonálně. Na obrazovce se díky vyššímu rozlišení zubatost (téměř) ztratí, při tisku naopak získám přesně to, co jsem naskenoval, protože nedám šanci přepočítavacím algoritmům tiskárny.
Ohledně účinnosti DjVu: Nedávno jsem dělal pokus. 600dpi bitonální scan A4 čistého textu s větším písmem jsem bezztrátově zkomprimoval pomocí cjb2 -dpi 600 -clean. Výsledek 40 KB. To považuji za více než uspokojivý výsledek.
DjVu definuje několik kompresních formátů. Každý je vhodný na jiný typ „obrázku“. Třeba beletrie, kde jsou celostránkové ilustrace se dělají tak, že na běžné textové stránky a na stránky s obrázky se používají jiné algoritmy.
Silná zbraň DjVu je vlnková komprese. Jenže ta má smysl jen u čistých scanů ve vysokém rozlišení, protože je postavená na vyhledávání hran. U obrázků spíše připomínajících kostičky (což třeba 9pt písmo na 150 dpi je) je kontraproduktivní.
Další silná zbraň je oddělení pozadí od popředí. Tyto dvě vrstvy mají obvykle odlišný charakter, a tak se každá komprimuje jiným algoritmem.
Tohle všechno ale jsou věci, které se automatikou neudělají, protože ta těžko změří subjektivní dojem.
Je pravda, že DjVu nemá žádný überalgortimus, který by zázračně smrsknul soubor. Nicméně mám zkušenosti, že u hloupě zvolené komprese nebo nevhodného vstupu je výstup porovnatelný (mnohdy o deset dvacet třicet procent menší) s třeba PDF/JPEG. U kvalitních scanů s dobře vybraným algoritmem DjVu válcuje ostatní formáty velmi výrazně (50 a více procent). U opravdu mrňavých dokumentů s mizerným rozlišením a pár barev je ale PNG často lepší. To ale není cílová skupina DjVu.
Prostě moje zkušenosti jsou opačné. Jestli se ale chceme bavit seriózně, musíme se uchýlit k experimentu. Zkusím najít ten mnou vzpomínaný scan.
Tohle je 600dpi dvoutónový scan. Poněkud větší patkové písmo, řídký text, malá grafika, černobílá předloha:
-rw-r--r-- 1 petr users 41194 11. čec 20.27 nebezpecny_odpad.jb2 -rw-r--r-- 1 petr users 41966 13. čec 20.26 nebezpecny_odpad.jb2.noclean -rw-r--r-- 1 petr users 4348196 13. čec 21.02 nebezpecny_odpad.pbm -rw-r--r-- 1 petr users 108221 13. čec 20.22 nebezpecny_odpad.pbm.lzma -rw-r--r-- 1 petr users 161144 13. čec 20.22 nebezpecny_odpad.png
Verze *.noclean se liší vypnutým vyčištěním „drobků“. Podle rozdílového testu čištění příliš pixelů neodebralo.
když už se takto skenuje ve "velkém" - neexistuje na to nějaký spec. kus HW, který by to usnadnil? Někde jsem viděl celé robotizované pracoviště, ale to nemyslím. Stačilo by něco, aby i bez lámání hřbetů zůstaly řádky rovné nevznikal středový pruh.
U dokumentů se používají specializované dokumentové skenery (malý / velký). Důležitá je rychlost skenování a objem naskenovaných listů za den. U knihy je špatné, že ji nelze šoupnout do zásobníku, pokud ji neroztrháte vazbu. Samotné naskenování je k ničemu pokud se dokumenty nezařadí do nějaké úložiště (digitální archiv) a nepřiřadí indexy. K tomu se většinou používají specializované programy jako Teleform, Kofax express (určitě jsou i další, ale s těmi nemám zkušenosti). Nedokáži si představit digitalizování dokumentů v domácích podmínkách. Obětovaný čas musí být nepředstavitelný.
Autorovi přikladám pár zkušeností s libtiff knihovnou (i pro win):
Instalace pod win: http://gnuwin32.sourceforge.net/packages/tiff.htm a http://gnuwin32.sourceforge.net/packages/jpeg.htm
Instalace pod Linuxem: apt-get install libtiff (či něco podobného), doporučuji si, ale přeložit 4.0.0beta3, která bez problémů zvláda kompresi/dekompresi JPEG, Old-style JPEG
Zjištění informace o TIFFu (šikovné i na testování zda není TIF špatný, jinak pozor na Old-style JPEG kompresi)
C:\Program Files\GnuWin32\bin>tiffinfo.exe C:\tiff-test\test.tif
Dekomprese TIFFu black and white s CCIT4 kompresí
C:\Program Files\GnuWin32\bin>tiffcp.exe -c none C:\tiff-test\test.tif C:\tiff-test\none-black-and-white.tif
Dekomprese TIFFu gray s JPEG kompresí
C:\Program Files\GnuWin32\bin>tiffcp.exe -c none C:\tiff-test\test.tif C:\tiff-test\none-gray.tif
Dekomprese color bohužel u verze win nejde, na Linuxu lze přeložit verze 4.0.0beta3 libtiff knihovny, která zvládne i toto.
Komprese TIFFu black and white pomocí CCIT4 komprese
C:\Program Files\GnuWin32\bin>tiffcp.exe -c g4 C:\tiff-test\none-black-and-white.tif C:\tiff-test\g4-black-and-white.tif
Komprese TIFFu gray s JPEG kompresí
C:\Program Files\GnuWin32\bin>tiffcp.exe -r 8 -c jpeg:r:82 C:\tiff-test\none-gray.tif C:\tiff-test\jpeg-gray.tif
Příkazy jsou samozřejmě stejné i v Linuxu s úpravou cest. Nechtělo se mi to přepisovat, tak snad nebudou rýpalové, kterým by to vadilo .
Ještě na závěr zjištění dle mých zkušeností:
Pro B/W je nejlepší CCIT4 komprese a pro Color JPEG komprese (ne Old-style JPEG - to je prasárna mimo standard!).
Tak ještě malé doplnění. Pro retušování (odstranění šedého pozadí, narovnání stránky, otočení dle orientace textu, oříznutí černých okrajů, odstranění prostřihů pro vkládání do desek, ostření, atd.) se používá technologie VRS (Virtual ReScan), pěkně popsáno zde. OCR je fajn věc při rozeznávání čárových kódů (pro indexaci ideální, pokud s tím počítá výstup). Rozeznání textu už je náročnější, ale pokud je pěkný sken nebývá to problém (stačí přidat většinou DPI). Velmi pěkné je rozeznávání textů u rukou psaných formulářů, kde je s pomocí korigovacího softwaru vyšší produktivita zpracování (např. Teleform Verifier).
13.7.2009 11:37
Jiří Poláček | skóre: 47
| blog: naopak
| Sivice
jasně. Jednotlivé listy jsou triviální. Já se ptal speciálně na vázané dokumenty. Očekával bych, že bude existovat buď něco tenkého, co jde přímo vložit mezi stránky nebo že snímací plocha bude tvarově přizpůsobena částečně otevřené knize.
S tímto nemám zkušenosti, ale viděl jsem pouze něco jako foťák na stojánku, což mi nepřišlo moc praktické. Jinak na webu jsem našel super článek s video prezentací, jak takový automatický skener na digitalizaci knih vypadá a pracuje. Je to tak, jak si předpokládal.
13.7.2009 16:08
Bilbo | skóre: 29
Po tomhle řešení už jsem se také poohlížel, ale nenarazil jsem na žádný scanner s dostatečně malým okrajem. Díky za tip.
podle těch videí by se našlo víc lidí, co by ten scanner při práci dokázali celé hodiny pozorovat 
 13.7.2009 10:03
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
13.7.2009 10:03
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
Dobrý článek. Na scan používáme komerční programy (njn. dotace), ale takový návod se vždy hodí.
Snímáme černobíle v rozlišení 200 dpi; vyšší rozlišení pro naše potřeby nemá valného smyslu
Proč ne? Při vyšším DPI by písmenka vyšla mnohem silnější (a po převodu do šedé vyhlazenější) a okolní šum by naopak zůstal jedno pixelový, čímž by šel snáze odstranit. Nebo je tam jiný problém?
13.7.2009 11:45
Jiří Poláček | skóre: 47
| blog: naopak
| Sivice
13.7.2009 19:00
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
Primárním výstupním zařízením digitalizovaných knih by měla být obrazovka, proto si vystačíme s menším DPI
To jo, na výstupu. Proces zpracování by mohl probíhat třeba na 600 DPI a na konci by se to zmenšilo na 200 DPI. Dělají to tak běžně zvukovky (interně pracují v 32b rozlišení), profesionální grafika se také tvoří v mnohem větším rozlišení než je konečný výstup. Dělá se to k vůli chybám, které proces zpracování do signálu stejně vnáší.
Co to je za šílenosti? Připadám si jak v době t602. Není lepší koupit nějaký dobrý komerční OCR balík (Fine Reader) a neřešit?
Proč se radši budu šťourat levou rukou v pravém uchu na Linuxu, místo rychlého splnění úkolu na Windows? Nechápu fanatika, který týden ladí postup s nevhodnými programy a to jen proto, že to má na Linuxu...
asi Vas jako radu ostatnich zmatlo to slovo 'digitalizovanych' v nadpisu a prestal jste dal cist. Jinak byste zahledl to slovo 'retusovani' . Ale takovou vadu ma rada lidi, nekteri kdyz slysi 'uspech', tak si predstavi 'podnikatel' a jdou hodit listek ODS.
Možná jste si nevšiml titulku článku: "Automatizované retušování digitalizovaných textů." A asi se budete divit, ale jsou lidé, které zajímá jak zpracování obrazu vlastně funguje a rádi se dívají věcem "pod pokličku".
Ono je totiž celé kouzlo ukryto ve slůvku "automatizované". Fine Reader je výborný program (mám jej), ale na desítky knih o různých formátech je to jako "levou nohou za pravým uchem" - prostě nevhodné. Je mnohem časově i finančně úspornější několk hodin/dní ladit skript a pak jej mnoho měsíců používat. Na jednoúčelovky je samozřejmě FR vhodnější.
Navíc zatím moc o OCR řeč nebyla. Co když dokumenty jen potřebuji zdigitalizovat a posléze se rozhodnout zda tisk nebo OCR? V tomto směru je skriptování téměř nezastupitelné (včetně šifrování, archivace apod.)
Rucni prace s Fine Readerem neni nutna. Korporatni verze umi vybirat soubory ze zadaneho adresare a automaticky je prevadi a vyhazuje vysledky v pozadovanem formatu (trebas zde zminovane pdf). Moznych nastaveni je hafo, lze vytvaret ruzne adresare pro soubory s ruznymi parametry atd atd. Sekretarka se pak s ocr vubec nepotka, po naskenovani dokumentu se k ni dostane jen prislusny pdfko k zalozeni.
FR samozrejme umi "narovnavat" ohnutte radky od hrbetu knih, lze nastavovat vzory pro ruzne typy souboru, zminovane vzorce se prevadeji jako obrazky, uroven rozpoznani je natolik vysoka, ze tech par ojedinelych "preklepu" v x-strankovem dokumentu fakt nehraje roli. Pri slusne predloze nemivame 100% uspesnost precteni stranky v jednom pripade ze 30-40 stran. To znamena ze se na te chybove strance neprecte jeden znak spravne.
H.
Ja sam jsem naskenoval celkem dost knih. Unpaper mne prisel naprosto tragicky. Nejlepsi efektivity i vysledne kvality jsem dosahl v ruskem programu (podle vseho freewaru) ScanKromsator, originalne pro windows, bezi ale bez problemu pod wine. Pri googleni pozor, nejnovejsi (a nejlepsi) mne znama verze je 5.91. Umoznuje mj. automaticke (ale kvalitni!) rozrezani stranek na dve poloviny, kvalitni vyrovnani naklonu, sumu v obrazcich, etc. Je to dost sofistikovany program. Jedine, co mi neni jasne, je jeho status, resp. proc pri jeho kvalitach neni daleko znamejsi a nema nejakou slusnou webovou stranku.
Programem, jenz miri ke stejnemu cili, ale zatim u nej zdaleka neni je ScanTailor, rovnez rusky program. Na rozdil od ScanKromsatora je open-source a ma peknou stranku http://scantailor.sourceforge.net/ Tesim se, ze z nej vzejde program kvality ScanKromsatora, ovsem bez te obskurity.
Na prevod pdf do obrazku pbm nebo jpeg pouzivam program pdfimages. Ten vytahne obrazky v puvodni kvalite, takze neni treba nastavovat rozliseni ani nic dalsiho.
14.7.2009 15:59
Bilbo | skóre: 29
-j
Jinak dotycny tool ma mozna malou mouchu: "nepodporuje" JPEG2000 - resp. obrazky v PDF komprimovane pomoci JPEG2000 zapise jako PBM (at zije rekomprese ...)
14.7.2009 20:21
Jiří Poláček | skóre: 47
| blog: naopak
| Sivice
pdfimages je stejně jako pdftoppm součástí poppler, takže se dá očekávat stejný výsledek při extrakci obrázků (samozřejmě při správném DPI u druhého programu). Ale jinak díky ta tip.
Pred nekolika lety jsem se timto problemem take zabyval. Snazil jsem se pripravit text, aby:
1. se dobre zpracoval OCR
2. dobre skladoval (male soubory => malo sumu)
3. dobre cetl
4. zmizely prostredni sede pruhy (polozime-li rozevrenou knihu na scanner, pismenka uprostred jsou na sedsim podklade a deformovana - tento problem autor zjevne neresi)
Dospel jsem ke zcela opacnemu postupu, nez autor: nascannovat to na 300dpi ve stupnich sedi, pote udelat vsechny transformace a nakonec to pripadne prevest do dvou stavu (cerna/bila) a nizsiho rozliseni.
Rucnim cistenim jsem dospel k zaveru, ze neni treba prevadet do dvou stavu a nizsiho rozliseni, protoze vycisteny text je velmi dobre komprimovatelny a temer nic se tim neusetri (nicmene to jde zcea snadno).
Diky menici se barve pozadi jsem zacal "derivaci" a orizl vse pod 5 (sum - puvodne bylo 255 urovni), cimz z pismen zbyly jen obrysy. Tecka nad i mela cca 10x10px (skripta z FELu). Normalni pismena mela hranu obrysu sirokou 2-4px, ale u pismen blizko hrbetu (nechtel jsem knihy nicit) to byl 1-2px a sem tam se obrys i prerusil, coz byl problem. Pak jsem vyhazel vsechny souvisle objekty mensi, nez cca 25px.
Pak melo nasledovat vybarveni obrysu, ale tim, ze se pismena u hrbetu rozpadala, zacal jsem resit, jak je opravit a nakonec jsem to vzdal z casovych duvodu. Za predpokladu spojitych obrysu je vybarveni pomerne snadne - nahodny pixel, ktery neni soucasti obrysu se vybarvi jednou barvou a od nej se barva rozlije vsude. Pak se najde rozhranni, kde je z jedne strany vybarveny a z druhe nevybarveny pixel a hned za nim se to vybarvi druhou barvou. Opakujeme, dokud neco takoveho existuje. Pak se hleda rozhranni druhe barvy a niceho a za nej se da prvni barva. a porad dokola (nektera recka pismena potrebuji 3 cykly pri optimalni volbe prvniho bodu). Barva, ktere je vice, je bila. hrany se linearne interpoluji do sede.
14.7.2009 21:14
Jiří Poláček | skóre: 47
| blog: naopak
| Sivice
4. zmizely prostredni sede pruhy (polozime-li rozevrenou knihu na scanner, pismenka uprostred jsou na sedsim podklade a deformovana - tento problem autor zjevne neresi)Při černobílém skenování samozřejmě pruh uprostřed není šedý, ale v černobílém ditheringu, který bezpečně odstraní například filtry unpaperu (o tom se zmiňuji v druhém díle návodu). V případě skenování v odstínech šedé pruh uprostřed odstraní pgmdeshadow, jak ukazuje příklad v textu. Co se týče deformace písmenek, tak to je skutečně nepříjemný problém, který nicméně opravdu neřeším, neboť si ani nedokážu představit, jak by to automatizovaně šlo udělat
 Naštěstí jsem se ještě nesetkal s takovou deformací, že by to už nešlo přečíst.
14.7.2009 21:19
Bilbo | skóre: 29
Naštěstí jsem se ještě nesetkal s takovou deformací, že by to už nešlo přečíst.
14.7.2009 21:19
Bilbo | skóre: 29
 16.7.2009 22:42
Pavel Čejka | skóre: 28
| blog: tosinezaslouzijmeno
16.7.2009 22:42
Pavel Čejka | skóre: 28
| blog: tosinezaslouzijmeno
 AbcLinuxu.cz
AbcLinuxu.cz ITBiz.cz
ITBiz.cz HDmag.cz
HDmag.cz AbcPráce.cz
AbcPráce.cz