Portál AbcLinuxu, 16. dubna 2024 09:19
Jazyky a překladače - 1 (úvod)
Články
-
Jazyky a překladače - 1 (úvod)
Zdrojový kód je ve světě Open Source (respektive Free Software) velice častým a důležitým pojmem. Tento server se problematikou F/OSS zabývá, a proto není od věci si vysvětlit, co to vlastně zdrojový kód je, co je to programovací jazyk, a jakým způsobem se zpracovává. Upozorňuji, že dnešní díl si užijí především ti, kteří se nebojí matematiky.
Poznámka: Máte-li problém se zobrazováním znaku ∪ (∪), vyzkoušejte fonty DeJavu, které jej obsahují.
Obsah
Co je to jazyk
Jazyk, co to vlastně je jazyk? Základem takového jazyka je abeceda, což je jistá množina znaků specifická pro daný jazyk. Ze znaků abecedy jsou tvořena slova (pochopitelně neuvažujeme pro nás exotické jazyky typu japonštiny). Ty dále spojujeme do vět a to za pomoci gramatických pravidel. A právě gramatika je problémem. Jazyky, které se nazývají přirozené, mají gramatiky velmi složité, plné vyjímek a pro zpracování na počítačích se nehodí. Pokud mi nevěříte, tak se podívejte na diplomovou práci Johanky (ps, 1.0MB) a pokud budete rozumět alespoň slovům v obsahu, můžete se pustit do čtení (já, nemaje humanitní vzdělání, jsem skončil právě na něm). Nebo můžete navštívit přímo stránky Ústavu formální a aplikované lingvistiky na Matematicko fyzikální fakultě Univerzity Karlovy.
Druhou skupinou jazyků jsou formální jazyky. To jsou ty, jejichž pravidla pro generování a pohlcování jsou víceméně jednoduchá a deterministická (jednoznačná). Takové se potom hodí pro zpracování na počítačích. A o nich bude tento článek.
Teorie kolem formálních jazyků je rozsáhlá, ale pro potřeby článku se musí poněkud zkrátit. Jak jsem již napsal výše, základem jazyka je abeceda, kterou označujeme jako Σ (velké sigma) a Σ* (iterace), respektive Σ+ (pozitivní iterace) je množina konečných posloupností znaků z abecedy. Ty nazýváme slova na abecedou Σ a označujeme znakem w. Slovo, jehož délka je nulová, značíme e a pozitivní iterace tento znak neobsahuje. Jazyk L je potom podmnožinou množiny Σ*, respektive Σ+.
Ovšem jazyk je nutné nějakým způsobem popsat a právě zde nastupuje další pojem - gramatika. To je to, co známe i z přirozené řeči, a zde nám slouží ke konečnému popisu nekonečného jazyka. Každý formální jazyk tudíž musí mít specifikovanou nějakou gramatiku a při zpracování se mimo jiné ověřuje, zda jí zadaný vstup odpovídá.
Formálně je potom gramatika G čtveřice G=(N, Σ, P, S), kde
- N je konečná množina nonterminálních symbolů
- Σ je konečná množina terminálních symbolů
- P je konečná množina přepisovací pravidel
- S∈N je výchozí startovací symbol gramatiky
Důležitým pojmem je potom množina přepisovacích pravidel. Jedná se o podmnožinu kartézského součinu (N∪Σ)* N (N∪Σ)* × (N∪Σ)*. Přepisovací pravidlo je potom prvek (α,β)∈P a zapisuje se ve tvaru α→β.
Jazyk generovaný gramatikou je potom definován takto:
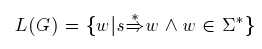
Je to množina slov w, které získáme derivacemi ze startovacího symbolu gramatiky. Symbol 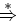 označuje reflexivní a tranzitivní uzávěr derivace. Pro nematematiky se jedná o postupné textové náhrady symbolů podle přepisovacích pravidel gramatiky. Zároveň musí být splněna podmínka, že slovo patří do množiny Σ*, tedy, že je tvořeno pouze symboly abecedy Σ.
označuje reflexivní a tranzitivní uzávěr derivace. Pro nematematiky se jedná o postupné textové náhrady symbolů podle přepisovacích pravidel gramatiky. Zároveň musí být splněna podmínka, že slovo patří do množiny Σ*, tedy, že je tvořeno pouze symboly abecedy Σ.
Chomského klasifikace gramatik
Důvody, proč jsem se tolik zabýval gramatikami a jejich formálním vyjádřením, jsou dva. Jednak je gramatika možnost, jak popsat potenciálně nekonečný jazyk konečným způsobem. A navíc tvar přepisovacích pravidel z množiny P umožňuje zařazení jazyka do některé z následujících čtyř tříd.
- Typ 0 obecné gramatiky
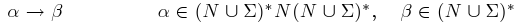
- Typ 1 kontextové gramatiky
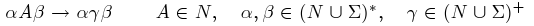
- Typ 2 bezkontextové gramatiky
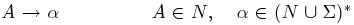
- Typ 3 pravé regulární gramatiky
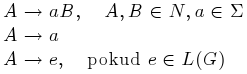
Přičemž jazyk generovaný gramatikou typu X se nazývá jazyk typu X a množina takových jazyků se značí LX. Platí 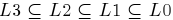 , což znamená, že množina regulárních jazyků je podmnožinou bezkontextových, ta zase podmnožinou kontextových a to celé je podmnožinou obecných jazyků. Podstatné na této klasifikaci je, že každá z výše uvedených tříd jazyků má jistou výpočetní sílu, přičemž čím vyšší třída, tím nižší síla.
, což znamená, že množina regulárních jazyků je podmnožinou bezkontextových, ta zase podmnožinou kontextových a to celé je podmnožinou obecných jazyků. Podstatné na této klasifikaci je, že každá z výše uvedených tříd jazyků má jistou výpočetní sílu, přičemž čím vyšší třída, tím nižší síla.
| Typ |
Gramatika |
Jazyk |
Stroj |
| 0 |
obecná |
rekurzivně vyčíslitelný |
Turingův stroj |
| 1 |
kontextová |
kontextový |
Lineárně ohraničený TS |
| 2 |
bezkontextová |
bezkontextový |
Zásobníkový automat |
| 3 |
regulární |
regulární |
Konečný automat |
Tabulka udává jednotlivé typy gramatik, jazyky, které generuje a také minimální stroj, který dokáže načíst jejich věty. Rozdíl mezi pravou a levou regulární gramatikou je pouze v pozici nonterminálního symbolu B, obecně takové gramatiky nazýváme regulární.
Praktický příklad
Dost již bylo teorie. Představíme si gramatiky v praxi
. Mějme gramatiku G:
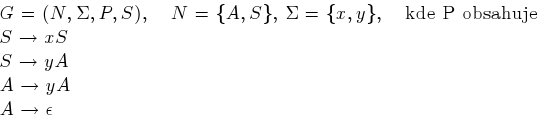
Příklad tvorby
věty jazyka generovaného touto gramatikou:
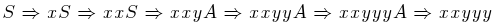
Na počátku byl startovací symbol gramatiky S. S využitím prvního pravidla jsme získali řetězec xS, další aplikací prvního pravidla jsme dostali xxS. Poté jsme aplikovali pravidlo číslo dvě a získali xxyS a s využitím dalších pravidel jsme nakonec vytvořili výsledné slovo xxyyy. Naše primitivní a jednoduchá gramatika ovšem umí
generovat i jiná slova, například y, xy, xyy, xxyy, xxxx...xxxy a tak dále. Pokud se podíváte pozorněji, tak mají daná slova něco společného. Dají se zapsat do regulárního výrazu x*y+, což značí, že na začátku může být žádné až nekonečně mnoho znaků x, které jsou následované alespoň jedním (ale i více) znaky y.
Co jsme to vlastně definovali za gramatiku? Pohledem na výše uvedenou klasifikaci gramatik zjišťujeme následující. První tři pravidla odpovídají prvnímu vzoru pro regulární gramatiky, protože S a A patří do množiny nonterminálních symbolů a x a y do množiny terminálních symbolů. A poslední pravidlo odpovídá třetímu vzoru pro regulární gramatiky. To znamená, že je naše gramatika regulární. Vyjadřovací síla regulárních gramatik, konečných automatů a regulárních výrazů naprosto stejná, proto je možné je navzájem zaměňovat. Nicméně regulární výrazy mají daleko kompaktnější zápis než gramatiky.
Na tomto místě si dovolím poznamenat, že spousta nástrojů svoje regulární výrazy vylepšovala do té míry, že přeskočili až do vyšších jazyků.
Meze regulárních jazyků
Regulární jazyky mají nejmenší vyjadřovací sílu. Ale pro spoustu problémů naprosto stačí a unixové regulární výrazy jsou toho jenom dokladem. Na druhou stranu by bylo vhodné mít něco
, co nám pomůže zjistit hranice regulárních gramatik. To něco se nazývá Pumping teorém (česky lemma o vkládání):
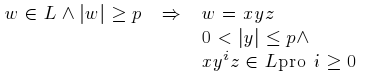
Daný vztah říká, že v dostatečně dlouhém slově w, které patří do jistého jazyka, můžeme nalézt tři části — x, y a z, přičemž nejdůležitější část y může zahrnovat i celé slovo. Poslední vztah potom značí, že část y můžeme z jazyka vyjmout, nebo jí libovolně zopakovat, a přitom stále zůstáváme v rámci stejného jazyka.
Díky této větě potom můžeme dokázat, že daný jazyk není regulární. Klasickým učebnicovým příkladem je například jazyk 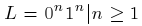 . Definice jazyka hovoří, že generuje stejný počet znaků a i b. Při hledání podřetězce y potom můžeme narazit na následující případy.
. Definice jazyka hovoří, že generuje stejný počet znaků a i b. Při hledání podřetězce y potom můžeme narazit na následující případy.
- {a}+ (samá a) — není hledaný podřetězec, protože jej nemůžeme vynechat, ani ziterovat, protože by se nerovnaly počty znaků
- {b}+ (samá b) — stejný případ
- {a}+.{b}+ (alespoň jedno a následované alespoň jedním b) — iterace takového podřetězce potom poruší podmínku, že všechny znaky b následují až za znaky a
Protože nedokážeme najít žádný podřetězec y, dokázali jsme, že daný jazyk není regulární. To má i praktický význam, jelikož nemusíme hledat složité regulární výrazy na detekci takových řetězců, protože to prostě nejde. Na druhou stranu dokáží regulární jazyky vyřešit i některé problémy (bez důkazu)
Závěr
Tento díl představoval lehký (velice lehký, zájemce odkazuji na přístupné materiály některých vysokých škol k této problematice) úvod do problematiky formálních jazyků. Tématem příštího dílu by měly být především regulární výrazy (ano i to je formálně podchyceno) a konečné automaty, protože k sobě spolu neodmyslitelně patří. Myslím, že na unixově založeném serveru se bude jednat o vděčné téma.
Toto je tak trochu experiment, protože se vymyká běžným tématům na ábíčku. Navíc obsahuje dost formálních náležitostí, a proto potřebuji vědět, jak se na to díváte po přečtení. Mám přidat, nebo raději ubrat? Těším se na vaše názory a na případné opravy chyb, které jsem napáchal.
Související články
Odkazy a zdroje
Další články z této rubriky
ISSN 1214-1267, (c) 1999-2007 Stickfish s.r.o.