Portál AbcLinuxu, 25. dubna 2024 06:50
Poslední dobou mě velmi zaujal komprimační nástroj lrzip (Long Range ZIP). Dosahuji s ním lepších komprimačních poměrů, než s čímkoliv jiným, a to ne o pár procent, ale často o celé desítky.
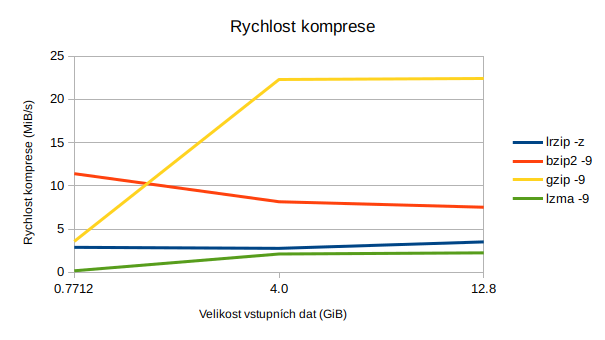
lrzip je poměrně pomalý (s parametrem -z pro kompresi ZPAQ) a vyžaduje velké množství paměti. U mě na počítači se však průměrná rychlost komprese pohybuje okolo 3 MB/s, což není zas až tak špatné, je to lepší než například lzma (0,7 až 2 MB/s).
Osobně se snažím dělat pravidelné inkrementální zálohy pomocí rsync. Tyto zálohy pak jednou za čas šifrované pomocí GPG vypaluji a kopíruji mj. na různá internetová úložiště. V tuto chvíli je pro mě velikost výsledného souboru podstatná, zatímco čas na kompresi mě v podstatě nezajímá a může trvat klidně celý den.
Všechny příklady probíhaly na stroji vybaveném Intel Core i5-4590S (3,0 GHz), 16GB RAM a SSD.
Mám adresář syncthing_delta, kam se pravidelně kopírují inkrementální zálohy. Velikost zatarovaného adresáře je 12,8 GB (12836904960 bajtů). V adresáři se nacházejí textová data, gitové repozitáře, obrázky, PDF soubory a celkově takový různý mix běžných uživatelských dat. Gzipovaných souborů je tam hodně, protože jsou interně používány rsyncem.
Tento tarovaný soubor potřebuji něčím následně zmenšit. K tomu jsem historicky využíval gzip, bzip2 a lzma. Zde je tabulka výsledných velikostí a času, který to zabralo:
| Program | Čas | Výsledná velikost (GB) | Rychlost komprese (MB/s) | Komprese o (%) | Čas dekomprese | Rychlost dekomprese (MB/s) |
|---|---|---|---|---|---|---|
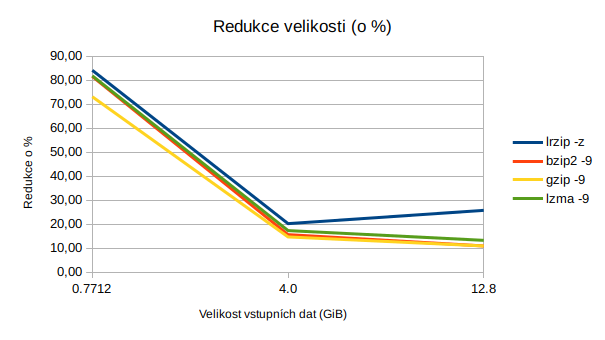
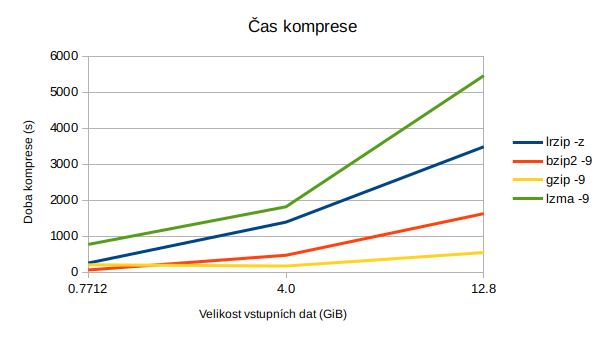
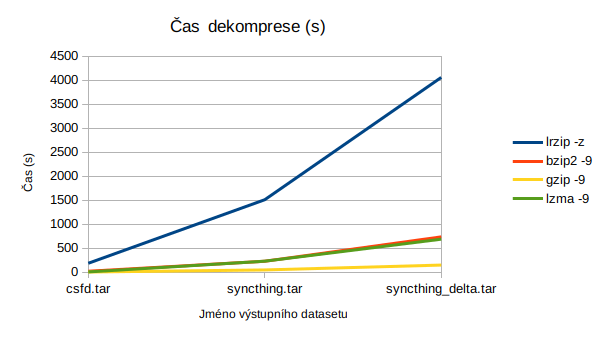
| lrzip -z | 58m 4s | 9,5 | 3,51 | 25,78 | 67m 37s | 3.01 |
| bzip2 -9 | 27m 7s | 11,4 | 7,52 | 10,93 | 12m 16s | 14,77 |
| gzip -9 | 9m 6s | 11,4 | 22,42 | 10,93 | 2m 29s | 72,97 |
| lzma -9 | 90m 58s | 11,1 | 2,24 | 13,28 | 11m 28s | 15,43 |
Předchozí příklad je lehce zkreslený, neboť komprimovaný soubor obsahuje velký počet souborů gzip, které si do ní ukládá rsync. Zde je ukázka benchmarku na zatarované složce Syncthing. Vstupní soubor tar má velikost 4,0 GB (4036546560 bajtů).
Ve složce se nachází 29 592 souborů. Četnost některých zajímavějších typů souborů je následující:
| py | 3471 |
| txt | 1315 |
| png | 1034 |
| jpg | 932 |
| pyc | 919 |
| sample | 894 |
| self | 858 |
| log | 589 |
| hh | 434 |
| cache | 385 |
| cpp | 362 |
| html | 354 |
| js | 344 |
| java | 294 |
| md | 285 |
| gif | 232 |
| json | 221 |
| css | 208 |
| rst | 190 |
| gz | 148 |
| sh | 113 |
| pyo | 103 |
| 102 | |
| zip | 94 |
| xcf | 85 |
| pym | 80 |
| yml | 70 |
| dat | 52 |
| st | 48 |
| z | 42 |
| c | 34 |
| rar | 34 |
| xml | 30 |
| doc | 27 |
| lzma | 26 |
Benchmark tentokrát vyšel takto:
| Program | Čas | Výsledná velikost (GB) | Rychlost komprese (MB/s) | Komprese o (%) | Čas dekomprese | Rychlost dekomprese (MB/s) |
|---|---|---|---|---|---|---|
| lrzip -z | 23m 12s | 3,2 | 2,76 | 20,24 | 25m 10s | 2,54 |
| bzip2 -9 | 7m 52s | 3,3 | 8,15 | 15,65 | 3m 49s | 14,17 |
| gzip -9 | 2m 52s | 3,4 | 22,3 | 14,69 | 0m 48s | 72,53 |
| lzma -9 | 30m 18s | 3,3 | 2,11 | 17,34 | 3m 50s | 13,83 |
Čas od času potřebuji provést zálohy různých databází, což jsou více či méně strukturované textové soubory. Někdy se jedná o JSON, jindy jde o SQL dumpy.
Vstupem byl soubor csfd.tar o velikosti 771,2 MB (771184640 bajtů), obsahující export z MongoDB v podobě souborů JSON.
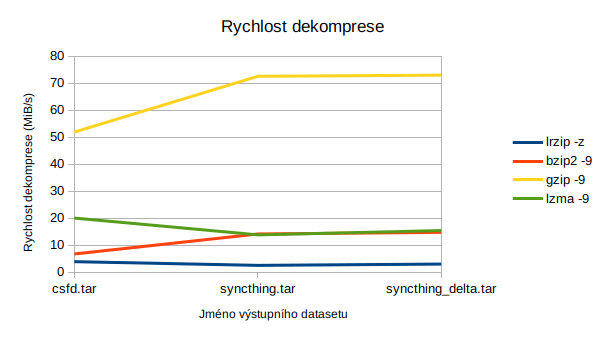
| Program | Čas | Výsledná velikost (MB) | Rychlost komprese (MB/s) | Komprese o (%) | Čas dekomprese | Rychlost dekomprese (MB/s) |
|---|---|---|---|---|---|---|
| lrzip -z | 4m 15s | 122,6 | 2,88 | 84,10 | 3m 7s | 3,91 |
| bzip2 -9 | 1m 4s | 142,3 | 11,4 | 81,54 | 0m 21s | 6,77 |
| gzip -9 | 3m 26s | 207,6 | 3,57 | 73,08 | 0m 4s | 51,9 |
| lzma -9 | 12m 52s | 140,3 | 0,17 | 81,80 | 0m 7s | 20,04 |
Trochu nevýhodou jsou nestandardní přepínače a poněkud ukecanější výstup, než bývá běžně zvykem:
Output filename is: /home/bystrousak/Plocha/syncthing_delta.tar.lrz /home/bystrousak/Plocha/syncthing_delta.tar - Compression Ratio: 1.351. Average Compression Speed: 3.514MB/s. Total time: 00:58:04.10
Větší nevýhodou je pak nízká rychlost, a to nikoliv jen komprese, ale také dekomprese. To nebývá tak úplně zvykem. Například dekomprese pomocí gzipu je o řád rychlejší než komprese (3,57 MB/s komprese, 51,6 MB/s dekomprese).
Tohle nevadí v některých konkrétních aplikacích, kdy nepotřebujete výsledné soubory často rozbalovat a jejich použití je spíše 1:1 (jednou zabaleno, jednou rozbaleno) než 1:N (jednou zabaleno, Nkrát rozbaleno). Typicky jde například o zálohování. Naopak pro distribuci software se program moc nehodí, neboť každý uživatel by na tom spálil mnoho výkonu.
Parametr -z specifikuje algoritmus ZPAQ. Ten je poměrně zajímavý mimo jiné tím, že provádí deduplikaci dat a jejich částečnou analýzu, na základě které pak vybírá různé pod-algoritmy, které se nejlépe hodí pro kompresi konkrétní části souboru.
V hlavičkách archivu poněkud netradičně nejsou specifikované samotné algoritmy použité pro kompresi, místo toho je použit formát ZPAQL pro popis dekompresního algoritmu formou bytecode, jenž je možné za běhu přímo překládat na x86 instrukce. Díky tomu je teoreticky možné popsat výstupní data čistě algoritmicky a vygenerovat na tomto základě velké množství výstupu, podobně jako třeba prográmky demoscény generují desetiminutová videa z 64KiB binárky.
Deduplikace probíhá na základě vyhledávání již zkomprimovaných bloků dat. Tyto bloky dat přitom mají variabilní velikost a jsou děleny a identifikovány na základě svého hashe. Podle mého názoru se jedná o velmi pěkný způsob zajištění deduplikace bez ohledu na to, kde jsou data v souboru uložena a jak moc jsou v něm posunuta.
Nejlepší kompresní poměr. Komprese lepší než lzma, dekomprese pomalejší než všechno ostatní mnou testované. Dobré na zálohy, špatné na distribuci software a cokoliv, kde data plánujete často rozbalovat.
ISSN 1214-1267, (c) 1999-2007 Stickfish s.r.o.