Společnost Espressif (ESP8266, ESP32, …) získala většinový podíl ve společnosti M5Stack, čímž posiluje ekosystém AIoT.
Byla vydána nová stabilní verze 3.5 svobodného multiplatformního softwaru pro editování a nahrávání zvukových souborů Audacity (Wikipedie). Přehled novinek také na YouTube. Nově lze využívat cloud (audio.com). Ke stažení je oficiální AppImage. Zatím starší verze Audacity lze instalovat také z Flathubu a Snapcraftu.
50 let operačního systému CP/M, článek na webu Computer History Museum věnovaný operačnímu systému CP/M. Gary Kildall z Digital Research jej vytvořil v roce 1974.
Byl zveřejněn program a spuštěna registrace na letošní konferenci Prague PostgreSQL Developer Day, která se koná 4. a 5. června. Na programu jsou 4 workshopy a 8 přednášek na různá témata o PostgreSQL, od konfigurace a zálohování po využití pro AI a vector search. Stejně jako v předchozích letech se konference koná v prostorách FIT ČVUT v Praze.
Po 48 letech Zilog končí s výrobou 8bitového mikroprocesoru Zilog Z80 (Z84C00 Z80). Mikroprocesor byl uveden na trh v červenci 1976. Poslední objednávky jsou přijímány do 14. června [pdf].
Ještě letos vyjde Kingdom Come: Deliverance II (YouTube), pokračování počítačové hry Kingdom Come: Deliverance (Wikipedie, ProtonDB Gold).
Thunderbird 128, příští major verze naplánovaná na červenec, přijde s nativní podporou Exchange napsanou v Rustu.
Byly vyhlášeny výsledky letošní volby vedoucího projektu Debian (DPL, Wikipedie). Novým vedoucím je Andreas Tille.
Po osmi měsících vývoje byla vydána nová verze 0.12.0 programovacího jazyka Zig (GitHub, Wikipedie). Přispělo 268 vývojářů. Přehled novinek v poznámkách k vydání.
Poslední měsíc byl plný zajímavých akcí, o kterých Vám bastlíři z projektu MacGyver mohou povědět, protože se na ně sami vydali. Kde všude byli, ptáte se? Objevili se na Installfestu, Arduino Day, Hackaday Europe a tajném srazu bastlířů z Twitteru. A z každé akce pro vás mají zajímavé poznatky.
… více »Řešení dotazu:
Selecty su velmi rychle koli btree primarnemu klucu. Cele to bezi na PC s 16GB RAM a platnovym diskom. Bottleck su samozrejme IOPS a klasicky disk. INSERT "on duplicate do nothing" 1e6 novych zaznamov trva aj viac ako 12 hodin.
No takhle to dopadne, když databaze admin, nemá ani šajnu, co matematika za relační databází dělá a jaké operace jsou potřeba k jeho cíli. Jednak varchar jako key je dost příšerné, klíče mají být fixní délky, jinak indexy trpí. Za druhé pokud to není nějak sofistikovaněji vypnuté, tak popsaný postup má vlastnost. insert dělá pro každý záznam z nových záznamů "search index" tedy alespoň 1e6 iops, a pro vkládané záznamy (n < 1e6) jeden záznam do souboru a jeden do indexu tedy 2n (v nejhorším případě 3e6 IOPS). Za 12 hodin je 45 600 sekund tedy pro 3e6 je to 75 IOPS za sekundu a těch operací je pravděpodobně výrazně více, protože vyhledání v indexu pro 4e9 nebude na jednu IOPS. spíše na cca 5 při cca 100 větvích pro b-tree uzel
Pravděpodobně by pomohl následující postup. Vkládané záznamy vzít jako temporální tabulku ins1 Provést ins1 LEFT JOIN main-table do tabulky ins2. Vypnout index na main-table. Na ins2 provést select na záznamy které mají v části main-table hodnutu NULL (to jsou ty neduplicitní) a insertnout je do main-table. Zapnout index.
Najvacsi rozdiel medzi varchar a integer je v PostgreSQL v tom, ze interne sa pouziva abstraktny typ Datum, ktory ma velkost pointera. Ak potrebujes prenasat hodnotu (typicky parameter funkcie) typu integer, moze sa do Datum nastavit priamo hodnota. Naproti tomu, varchar/text (ako aj ostatne typy dlhsie nez Datum) je potrebne prenasat odkazom na strukturu varlena, ktora pozostava z dlzky a hodnoty. Typ varchar/text ma tiez mozny overhead pri de/toastovani, porovnavanie dvoch hodnot tak moze byt radovo zlozitejsie nez porovnanie dvoch integerov, z ktorych kazdy sa bezne zmesti do jedineho registra. No a btree index je vlastne zoradenim hodnot - a na zoradenie je potrebne ich porovnanie. Vid skvele zhrnutie od Pavla.
Kazdopadne to nie je příšerné - je to len menej efektivne. Ak je to potrebne, tak to je potrebne a neda sa s tym nic robit. Ale to si uz musi povedat a zdovodnit ten, kto tu DB pozna. Expertne emocionalne vylevy tu budu vzdy - treba sa ich naucit filtrovat a ignorovat ;)
Hlavne by som pockal na doplnenie informacii od Superklokana - napr. ake su typicke hodnoty key, aku formu insertov pouziva, ako benchmarkoval bottleneck pri pouziti partitioningu a bez neho - ci mu to moze vyliezat z RAM na disk (napr. ma tam sorty pri insert-selectoch?), kolko klientov sa pripaja, ci sa klienti vzajomne nelockuju, ...
Tu je definicia tabulky, particie som zrusil a vratil sa k monolitickej tabulke, pretoze inserty boli este pomalsie.
CREATE UNLOGGED TABLE public.csvaddresses(
address character varying(34) COLLATE pg_catalog."default" NOT NULL,
private_key character varying(51) COLLATE pg_catalog."default",
CONSTRAINT csvaddresses_address_pk PRIMARY KEY (address) USING INDEX TABLESPACE crypto)
WITH (OIDS = FALSE) TABLESPACE crypto;
stlpec address moze mat dlzku 33 alebo 34 znakov
btree som zvolil lebo som si nebol isty ci hash index mozem pouzit v spojitosti s primarnym klucom, kedze chcem aby key/value boli unikatne.
tu su vzorove data - su to skutocne data, nie su obfuskovane, ani nijak upravene:
'176wsMBztSjpgSUJn3XY36gRT5gMRjPTu8','5KQ97zSKN3F368Yx91MmeXUezBiCziQS4gM6EaBr6Kb68u2Hxkt'
'1MyLinoP3PxWFuZVMrV4gFZixqqqK1qppJ','5JFSptsznKycpRxMhpDjysELbNvWsUNS3DZjJnqBA7pV7S5wbxU'
'1FrrVykiPsQTUNncJtfjKDBHRaKp2Tv1Bp','5KRBPVtAEctVcffBfJKNFAv4Ak8SYxfKHqA2mCuSuVExghzsgiU'
'14GeuhxLMdnQwLHKCtmiPiYiFxRUhANV5Z','5J5QbjmQZLRy5zkaWutn68z7CBsdvf7Gt46qPCk2PzeG9SEuAyz'
'1F8Z4N17FEgaokEpNUNUZuPmMAec8wSATj','5Kb6WQ5AzV7Rsv1XGBuTuh2w4vBkjP7d3vyGvQmVtyyq8JsUhGe'
'1BARTFB38UDZBymaKSDMftvCqMTV764nVE','5KXfrNqWm1NYGej2jDtVF73d3VWpSBuExbsrQwCS6QoGTnayzz7'
'1DMcSTmu7v6rhgVKQCuCaDTdH2vyvX5Pv1','5Jv5DLGBA3ip9XEabDxS8n6SgaZqEXQjoFvaDfDgVRjCto1RwqS'
'16yt1YqLuPqEn2vrAgwPqP5ZZhLhMdD3bC','5J8pkqkaX49cRYMM1o9Wb8fieSJgJWdbTw2jxvKYHeCGPY6L5K7'
'16om5EuYn2zbKqCznbK7g1ZZVSfEWu9ACg','5KY1bCQC1XEFW8Jus9fLnj7pvyGRm4speKDxwEEssCwjVwurVR2'
'1EYmvuVioUEV4AzaqAQRaikMnUYrCnr9yS','5JxojRJ29VXr38DFkKFLK96PdMneVjmhfm69gnMfd5w4BjZaEXt'
'18yfQtKAavtkEvrxSHZyYFgUnsZMTeufBq','5KaufvZ8uKnzancuChdLzVbGFcswJc66r7aLBxJbaNj7HDh81AE'
'15QoMdtZ73cgAkNMXCb4sk9qMrCXmaMJU3','5KKttwPpDguBo6gy6iPKDLiiwVtnTYiQv2NarxuFk5WCupVAoRi'
'1N664oBTfjCBbzPyN6r4iwndCVCvo8EkGx','5K4GjKeobmxdebY4CjcAnBHSrsox88TyGvKd5YW6Vp83avDNMUj'
'138xDo1VqcMJGJGpA5MRGBJSR8y8L66y2o','5KQKQduF8gNt9pbxxvX7bLq9AGGB9LoVGsAgJP8smtuPtEe9RU8'
'1EbpKC9uDRwaj9YEopBPSed9v8neS2thTo','5JqPNMM5XnpnFYRKis9GkpqFc9nRDSeB1HxFmAL3Kcy7wpjRUE9'
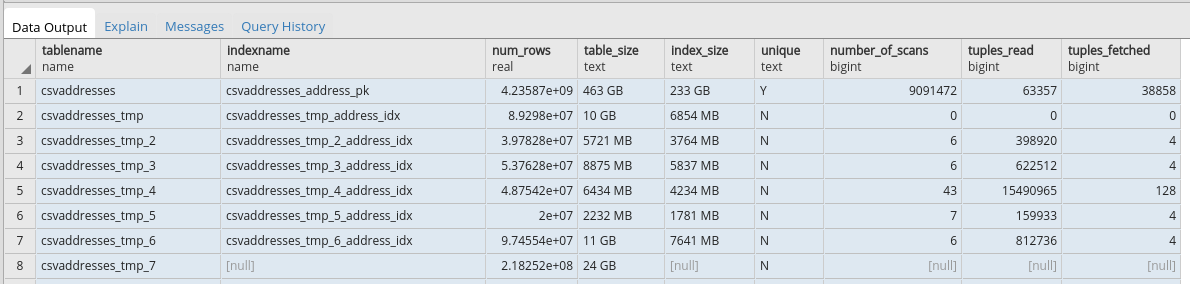
na strankach https://wiki.postgresql.org/wiki/Index_Maintenance som nasiel SQL prikaz na zobrazenie statistik "Index size/usage statistics". Screenshot prikladam do prilohy. Su tam vidiet aj docasne tabulky "*_tmp_*" do ktorych som importoval data z CSV suboru pomocou COPY, aby som sa vyhol importu dat do velkej "pomalej" tabulky.
data vkladam pomocou utility napisanej v C s vyzuitim kniznice libpq. nevyuzivam ziadne transacie iba cisto jeden prikaz - INSERT v cykle
paramValues[0] = (char *)crypto_address;
paramValues[1] = (char *)private_key;
PGresult *res = PQexecParams(
conn, /* connection string */
"INSERT INTO csvaddresses(address, private_key) VALUES($1, $2) ON CONFLICT DO NOTHING;", /* sql query */
2, /* number of parameters */
NULL, /* oid param type - default data type */
(const char * const *)paramValues, /* variable value */
NULL, /* length */
NULL, /* format */
0 /* result format - text mode */
);
ako je vidiet na prilozenom screenshote indexy sa v ziadnom pripade nevojdu do pamate, index ma 233GB co je cca 50% velkosti tabulky.
tak isto som sa pohraval aj s myslienkov na nasadenie BDB/DB4, alebo RocksDB, ale nebol som si isty ci su vhodne na tento use case.
Tak index se ti očividně nevleze do tabulky, rozhodně by to chtělo našetřit alespoň na 1TB SSD risk a dát indexy na ten; teďka má index 233GB, takže 1TB disk by ti vydržel do 2TB velikosti databáze zhruba...niekto uz robil benchmarky https://blog.2ndquadrant.com/tables-and-indexes-vs-hdd-and-ssd ked bol index na SSD pocet transakcii sa zvysil iba malo. najvaci narast vykonu (transakcii za sekundu) bolo v pripade tabulky na SSD.
Již to výše zmiňoval kit, ale protože to asi zapadlo, tj bez vaší reakce tak si dovolím víceméně zopakovat: Vyzkoušejte rozdělit vkládání do transkací (např 1k/10k/50k/100k insertů ) a změřte jak dlouho to trvá. pqlib sice neznám ale očekávám že bude mít defaultně autocommit, což znamená že se vynucuje "zapsání" dat a přepočítání indexů po každém insertu což zbytečně zpomaluje. Můžete i vyzkoušet jednu jedinou transakci(jak také zmiňuje kit), ale každopádně vyzkoušejte(a změřte) i transakce po částech, většinou je to rychlejší.data vkladam pomocou utility napisanej v C s vyzuitim kniznice libpq. nevyuzivam ziadne transacie iba cisto jeden prikaz - INSERT v cykle
Vyzkoušejte rozdělit vkládání do transkací (např 1k/10k/50k/100k insertů)S tímhle mám dobrou zkušenost na MySQL i SQLite. Při seskupení několika stovek insertů do transakcí se rychlost vkládání zvýšila i o několik řádů.
 3.2.2018 01:55
Jendа | skóre: 78
| blog: Jenda
| JO70FB
3.2.2018 01:55
Jendа | skóre: 78
| blog: Jenda
| JO70FB
Pocas benchmarkov som nasiel bottleneck - dovod preco sa pomaly zapisuje do velkej tabulky. Podelim sa s vysledkami a nakoniec zhodnotim kde bol problem.
Tak ako bolo navrhnute vyssie zvolil som 4 datasety o 1k, 10k, 50k, 100k zaznamoch a budem ich vkladat do najvacsej tabulky csvaddresses, kde je momentalne 4.23587e+09 riadkov.
1. Benchmark: "INSERT ON DUPLICATE DO NOTHING" v cykle pomocou utility (je napisana v C) vyuzivajucu libpq
1k zaznamov:
16s
10k zaznamov:
164s
50k zaznamov:
817s
100k zaznamov:
1621s
2. Benchmark: z predpripravenych docasnych tabuliek s 1k, 10k, 50k, 100k riadkov.
1k zaznamov:
INSERT INTO csvaddresses SELECT * FROM csvaddresses_tmp_1k ON CONFLICT DO NOTHING;
15s
10k zaznamov:
INSERT INTO csvaddresses SELECT * FROM csvaddresses_tmp_10k ON CONFLICT DO NOTHING;
129s
50k zaznamov:
INSERT INTO csvaddresses SELECT * FROM csvaddresses_tmp_50k ON CONFLICT DO NOTHING;
758s
100k zaznamov:
INSERT INTO csvaddresses SELECT * FROM csvaddresses_tmp_100k ON CONFLICT DO NOTHING;
6149s - neviem si vysvetlit tak vysoku hodnotu oproti ostatnym.
Ako vidno z benchmarkov, lepsi vykon sa dosiahne za pouzitia docasnych tabuliek csvaddresses_tmp_#k. Sice som netestoval vlozenie 1m riadkov, ale podla dosiahnutych vysledkov to urcite nebude viac ako niekolko hodin.
Uz teraz viem kde som spravil chybu (prisiel som na to pocas robenia benchmarkov) a tym velky bottleneck. Chcel som si velmi zdednodusit pracu a pouzival som len tieto 2 prikazy, skratka pouzival som pattern matching - LIKE '111%' aby som velmi jednoducho vedel zmazat z docasnej tabulky uz vlozene zaznamy do tej velkej.
INSERT INTO csvaddresses SELECT * FROM csvaddresses_tmp_6 ON CONFLICT DO NOTHING WHERE address LIKE '111%';
DELETE FROM csvaddresses_tmp_6 WHERE address LIKE '111%';
Teraz len tak cvicne som pustil prikaz na zratanie hodnot ktore vyhovuju '111%'. No po asi 90 minutach som ho zastavil. Takze teraz s istotou mozem povedat ze bottleneck bol LIKE
SELECT count(*) FROM csvaddresses_tmp_6 WHERE address LIKE '111%';
Riesenie:
Doplnit docasnu tabulku o stlpec id, pouzivat ho ako offset na presunutie dat do velkej tabulky a nasledne ich zmazanie.
DROP INDEX csvaddresses_tmp_6_address_idx;
ALTER TABLE csvaddresses_tmp_6 ADD COLUMN id bigserial PRIMARY KEY;
3. Benchmark: "INSERT INTO csvaddresses SELECT * FROM csvaddresses_tmp_6 WHERE id < ##### ON CONFLICT DO NOTHING;"
1k zaznamov:
INSERT INTO csvaddresses(address, private_key) SELECT address, private_key FROM csvaddresses_tmp_6 WHERE id <= 1000 ON CONFLICT DO NOTHING;
18s
10k zaznamov:
INSERT INTO csvaddresses(address, private_key) SELECT address, private_key FROM csvaddresses_tmp_6 WHERE id <= 10000 ON CONFLICT DO NOTHING;
134s
50k zaznamov:
INSERT INTO csvaddresses(address, private_key) SELECT address, private_key FROM csvaddresses_tmp_6 WHERE id <= 50000 ON CONFLICT DO NOTHING;
789s
100k zaznamov:
INSERT INTO csvaddresses(address, private_key) SELECT address, private_key FROM csvaddresses_tmp_6 WHERE id <= 100000 ON CONFLICT DO NOTHING;
1592s
A nasledne mozem pohodlne a rychlo vymazat presunute zaznamy
DELETE FROM csvaddresses_tmp_6 WHERE id <= 100000;
Vyhodnotenie:
Dakujem vsetkym za rady/otazky, pomocou benchmarkov bolo odhalene uzke hrdlo a ukazany priklad ako sa to NEMA robit :). Pre mna to boli nazaj vyzivne prispevky, mam ale dalsie otazky ked budu aktualne urcite sa ozvem. @EtDirloth si mi nasadil chrobaka do hlavy s tym base64 enkodovanim :). Pri rainbow tabulke sa hodi kazdy bit :)

povodne data som mal v CSV suboroch - niekolko 100viek GB dat s duplicitami. aj ked som urobil "sort | unique" a CSV importoval do velkej 4e9 tabulky pomocou prikazu COPY aj tak som dostaval hlasky "Error duplicate primary key". Bolo to peklo, a za kazdu cenu som chcel mat velku tabulku bez duplicit.
ano v zasade bol problem SELECTU s LIKE :), Je super ze je tu ziva IT komunita odbornikov, ktory pomohli najst riesenie a ponukli moznosti ako dalej pri vytvarani BTC rainbow tabulky :), popripade tie benchmarky co sme robili s kolegom budu niekom k niecomu :)
cat FILE | sort | uniqueVám filtruje unikátní celé řádky, zatímco jste potřeboval mít unikátní jen tu část toho řádku. Unikátní řádky jsou např.
aaa 123 aaa 456 ccc 789a stejně se tam opakuje to "aaa". Jinak problém, který jste řešil při importu, chápu. Bylo tu nebo na root.cz rozsáhlé vlákno na téma hromadného importu velkého množství dat, co si pamatuju tak nejrychlejší z toho byl ten COPY.
(vlastní zkušenost...).
Neda mi a musim zareagovat. V tomto momente sme uz davno za hranicou technickej temy o postgrese a diskusia nabrala silny OT filozoficky smer ci ma zmysel klast otazky. teraz neuvazujme nad kvalitou otazok/odpovedi, Aj ked vsetko ma svoje hranice a nato tu musi byt mechanizmus aby zabranil urazaniu/osocovaniu/spamovaniu a podla moznosti drzal diskusiu v rozumnych medziach.
Ludia stojaci za ABC robia svoju pracu a robia ju DOBRE. Mam dojem ze ABC chce by portalom ktory poskytuje rozne sluzby komunite a ludom zo sveta IT. Nie vsetci tito ludia su naskillovany geeci alebo hakery. Su to ludia ktory sa hraju, su to ludia ktory travia svoj volny cas (relaxuju) programovanim/bastlenim blbniek, su to ludia, ktory si na otazku "Preco?" odpovedali "Because I can!".
Do kategorie "Because I can!" spadam aj ja. Precital som si nieco ohladom rainbow tabuliek, o BTC, precital som si, ze ani vo vermire nie je tolko atomov, kolko BTC adries. A napiek tomu ja ako laik som si zbastlil C program na generovanie BTC adries a ukladam si ich do databazy. Preco? "Because I can!" a pretoze ma to zaujima/bavi a popri tom som sa dozvedel milion iny zaujimavych veci.
Samozrejme pocas bastlenia som narazil na problemy ktore som sam nevedel vyriesit. Koho som sa mal opytat? frajerky, ktora si mysli ze Sun Solaris je opalovaci krem do solarka? rodicov pre ktorych cely internet je oranzova liska? spoluziakov, ktory maju PC len na fb/hry/porno? kamaratov co si myslia ze RPI je nieco ako RPMN?
Som preto rad ze mozem niekde polozit otazku, som rad ze sem chodia naskillovanejsi ludia ako ja, som rad ze ludia mi zadarmo pomohli/nasmerovali, som rad za pre mna vyzivnu diskusiu. za co som vdacny.
Bez zivej diskusie, bez zivej komunity by sa tento portal premenil iba na polomrtvy spravodajsky web typu linuxexpress.cz
Takze za mna ano, ma zmysel sa pytat, ma zmysel sa pytat aj nie celkom presne. na to je tu diskusia. aby ten co CHCE poradit si vypytal dalsie informacie, ktore pre zakladatela temy nemusia byt zrejme/klucove. Napokon aj code review alebo programovanie v paroch/teamoch je o "viac hlav viac rozumu".
První milión - 182s Druhý milión - 201s Třetí milión - 205s Čtvrtý milión - 214s Pátý milión - 220sProgram napsán v PHP, CPU Intel Celeron 2,4 GHz, 2 GB RAM. Výsledná databáze s 5M záznamy má 985 MB.
dakujem za data.
ja mam v PG tabulku (csvaddresses_tmp_5) o 1.99221e7 riadkoch. Data: 2394 MB data + Btree Index varchar(34): 1122 MB spolu 3516MB, co je o trochu menej voci DB4, asi tym ze je UNLOGGED, takze DB4 vyrazny space overhead nema.
aj ja som urobil 2 testy, vlozenim 1m a 10m riadkov do tabulky s poctom riadkov 1.99221e7.
cielova tabulka:
CREATE UNLOGGED TABLE public.csvaddresses_tmp_5
(
address character varying(34) COLLATE pg_catalog."default" NOT NULL,
private_key character varying(51) COLLATE pg_catalog."default"
)
WITH (
OIDS = FALSE
)
CREATE INDEX csvaddresses_tmp_5_idx
ON public.csvaddresses_tmp_5 USING btree
(address COLLATE pg_catalog."default")
Vysledok:
INSERT INTO csvaddresses_tmp_5(address, private_key) SELECT address, private_key FROM csvaddresses_tmp_6 LIMIT 1000000 ON CONFLICT DO NOTHING;
INSERT 0 1000000
Time: 9063.276 ms (00:09.063)
INSERT INTO csvaddresses_tmp_5(address, private_key) SELECT address, private_key FROM csvaddresses_tmp_6 LIMIT 10000000 ON CONFLICT DO NOTHING;
INSERT 0 10000000
Time: 99088.943 ms (01:39.089)
Az som neveril ked som uvidel ten cas. Zrejme velmi zalezi na velkosti cielovej tabulky. predtym benchmark ukazal cas 1592s pri vkladani 100k zaznamov do cielovej tabulky o 4e9 zaznomoch.
Tiskni
Sdílej:
![]()
![]()
![]()
![]()
![]()
![]()
 AbcLinuxu.cz
AbcLinuxu.cz ITBiz.cz
ITBiz.cz HDmag.cz
HDmag.cz AbcPráce.cz
AbcPráce.cz 31.1.2018 22:39
31.1.2018 22:39
{kind=link}