 | poslední úprava: 24.4.2023 06:13
| poslední úprava: 24.4.2023 06:13
Portál AbcLinuxu, 29. května 2024 22:12
23.4.2023 18:50
| Přečteno: 5408×
| Programovanie
|
| poslední úprava: 24.4.2023 06:13
Tento článok sa bude o možnostiach využitia databáz PostgreSQL a MySQL (MariaDB) pri fulltextovom vyhľadávaní. Článok je rozdelený na 2 časti - výkon a kvalita. Obe časti sú na sebe nezávislé a kvalita vyhľadávania prakticky nespomaľuje vyhľadávanie. Oproti iným tutoriálom sa nevenujem len základnej funkcionalite použiteľnej maximálne tak v anglicky hovoriacich krajinách.
Nepatrím k ľuďom, ktorí za každú cenu musia používať svoju obľúbenú technológiu na všetko. Prístup typu „mám v ruke kladivo a všetko je teraz pre mňa kliniec“ považujem za vysoko kontraproduktívny. Moja snaha použiť databázu na fulltextové vyhľadávanie by mohla pôsobiť práve takým dojmom. Aby som rozptýlil pochybnosti, na začiatok hneď napíšem, že zvyčajne pracujem s pomerne malými databázami rôznych elektronických obchodov, kde je dokopy niekoľko tisíc až po stovky tisíc produktov. Keby som chcel skutočne kvalitné fulltextové vyhľadávanie nad veľkou databázou, rozhodne by som vyberal špecializované fulltextové riešenie, akým je napríklad Elasticsearch.
Keď však potrebujem niekoľko menších projektov, nechcem udržiavať špeciálny server na Elasticsearch, ktorý musí mať viacej RAM než vyžadujú všetky ostatné webové aplikácie dokopy.
V prvej časti sa budem zaoberať rýchlosťou odozvy pri vyhľadávaní. Nebude ma zaujímať kvalita a relevancia výsledkov, pretože v ďalšej časti si ukážeme, že je možné zvýšiť kvalitu bez zmeny rýchlosti.
Taktiež nebudem rozoberať rýchlosť aktualizácie indexov keďže väčšinou sa fulltextová databáza omnoho častejšie prehľadáva než zapisuje. V prípade, že by išlo skutočne o databázu, ktorá potrebuje časté zápisy, odporúčal by som neaktualizovať index automaticky, ale spúšťať aktualizáciu až po určitom počte zmien / čase.
Ako databázový server budem používať MariaDB 10.6 a PostgreSQL 15.2.
Aby boli testy ako-tak realistické, exportoval som reálne dáta z LinuxOS.sk. Súbor linuxos_texty.csv.xz obsahuje 81 MB textu vo forme CSV tabuľky s číslom dokumentu v prvom stĺpci a textom v druhom.
Databáza MariaDB sa vytvorí nasledujúcou sériou príkazov:
SET NAMES utf8mb4; CREATE DATABASE fulltext_test; ALTER DATABASE fulltext_test CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci; USE fulltext_test; CREATE TABLE ft( id INT NULL AUTO_INCREMENT PRIMARY KEY, document LONGTEXT );
Skúšobné údaje sa nahrajú príkazom:
LOAD DATA INFILE "linuxos_texty.csv" INTO TABLE ft COLUMNS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '"' ESCAPED BY '"' LINES TERMINATED BY '\n';
PostgreSQL databáza sa vytvorí príkazmi:
CREATE DATABASE fulltext_test; \c fulltext_test; CREATE TABLE ft ( id SERIAL, document TEXT, PRIMARY KEY(id) ); -- Query OK, 34760 rows affected (0,889 sec) -- Records: 34760 Deleted: 0 Skipped: 0 Warnings: 0
Pre načítanie dát pomocou psql potom slúži príkaz:
\copy ft FROM linuxos_texty.csv DELIMITER ',' CSV; -- COPY 34760 -- Time: 1725,099 ms (00:01,725)
Fulltextové vyhľadávanie bez vytvoreného indexu môže slúžiť ako celkom zaujímavá referenčná hodnota. Ak sa rýchlosť vyhľadávania bude blížiť rýchlosti bez indexu, bude to pravdepodobne znamenať, že inde sa nepoužil.
Vyhľadávam jedno z najčastejších slov na linuxovom portále. Vyberám frekventované slovo, aby sa neskôr prejavila optimalizácia pri použití klauzuly LIMIT.
Pre MySQL použijem nasledujúci select:
SELECT
COUNT(*)
FROM ft
WHERE match(document) AGAINST ('+linux' IN BOOLEAN MODE);
-- ERROR 1191 (HY000): Can't find FULLTEXT index matching the column list
MySQL (MariaDB) nepodporuje vyhľadávanie bez indexu. Ako jednoduchú alternatívu k fulltextu je možné použiť LIKE:
SELECT COUNT(*) FROM ft WHERE document LIKE "%linux%"; +----------+ | COUNT(*) | +----------+ | 17932 | +----------+ 1 row in set (0,276 sec)
PostgreSQL podporuje fulltextové vyhľadávanie aj bez indexu. Je však extrémne pomalé a v praxi nepoužiteľné.
SELECT
COUNT(*)
FROM ft
WHERE to_tsvector('simple', document) @@ to_tsquery('simple', 'linux');
-- count
-- -----
-- 10531
-- (1 row)
--
-- Time: 3810,541 ms (00:03,811)
Na porovnanie ešte pridávam výsledky LIKE s PostgreSQL:
SELECT COUNT(*) FROM ft WHERE document LIKE '%linux%'; -- count -- ----- -- 14147 -- (1 row) -- -- Time: 162,113 ms
Aby bol počet riadkov rovnaký, je potrebné použiť klauzulu ILIKE, ktorá nerozlišuje veľkosť písmen.
SELECT COUNT(*) FROM ft WHERE document ILIKE '%linux%'; -- count -- ----- -- 17932 -- (1 row) -- -- Time: 646,595 ms
Vyhľadávanie v MySQL má viac-menej rozumné štandardné nastavenie, nemá žiadnu možnosť zmeniť parametre. Preto je vytvorenie indexu veľmi jednoduché.
CREATE FULLTEXT INDEX document_idx ON ft(document); Query OK, 0 rows affected (4,699 sec) Records: 0 Duplicates: 0 Warnings: 0
Vytvorenie indexu v PostgreSQL sa zásadne líši. Hlavné rozdiely sú:
Fulltextové vyhľadávanie v PostgreSQL používa špeciálny typ stĺpca tsvector. Prvé vyhľadávanie bolo pomalé, pretože každý dokument musel byť konvertovaný funkciou to_tsvector. Výsledok sa napokon porovnáva s dotazom typu tsquery.
Indexy v PostgreSQL nevyžadujú existenciu stĺpca a dajú sa vytvoriť napríklad na volanie funkcie. Nasledujúce volanie vytvorí index typu GIN nad funkciou to_tsvector s konfiguráciou simple.
CREATE INDEX document_idx
ON ft
USING GIN (to_tsvector('simple', document));
-- Time: 11936,167 ms (00:11,936)
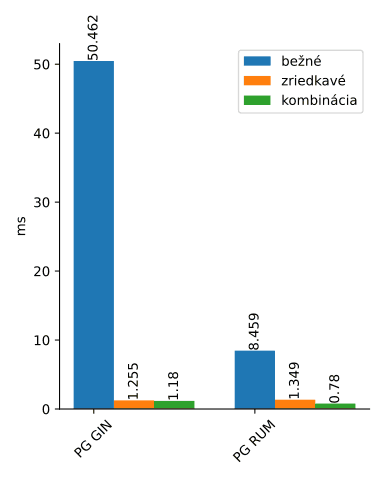
V nasledujúcich testoch bude použité bežné slovo na Linuxovom portáli - linux, zriedkavé slovo závislosť a ich kombinácia s operátorom AND, teda v dokumente sa musia vyskytovať oba slova. Testy sa robia 3x za sebou. Do grafu sa zakreslí najlepší výsledok.
Dotazy pre MySQL a PostgreSQL vyzerajú nasledovne:
-- MySQL
SELECT COUNT(*) FROM ft WHERE match(document) AGAINST ('+linux' IN BOOLEAN MODE);
+----------+
| COUNT(*) |
+----------+
| 11457 |
+----------+
-- PostgreSQL
SELECT COUNT(*) FROM ft WHERE to_tsvector('simple', document) @@ to_tsquery('simple', 'linux');
count
-----
10531
Kombinovaný výraz má tvar +linux +závislosť v MySQL a linux & závislosť v PostgreSQL. Do výsledkov som zahrnul aj RUM index, ku ktorému sa vrátim neskôr.

Obrázok 1: Porovnanie rýchlosti
Aby bolo v grafe vôbec niečo vidieť, musím trocha zrezať stĺpec MySQL.
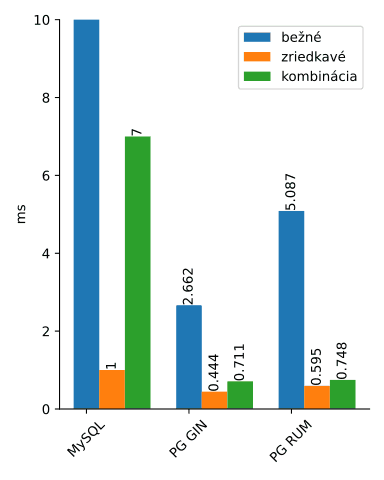
Obrázok 2: Porovnanie rýchlosti s orezaným MySQL
Vrátenie všetkých výsledkov nie je typické pre fulltextové vyhľadávanie. Omnoho častejšie chce používateľ vidieť niekoľko prvých výsledkov zoradených podľa relevancie.
Než sa pustím do samotného testu vytvorím v PostgreSQL reálny tsvector stĺpec, ktorý sa bude automaticky aktualizovať pri zmene dokumentu. Syntax selectov bude po tomto kroku mierne jednoduchšia, pretože už nebude potrebné volanie to_tsvector.
DROP INDEX document_idx;
ALTER TABLE ft
ADD COLUMN document_tsvector tsvector
GENERATED ALWAYS AS (to_tsvector('simple', document)) STORED;
CREATE INDEX document_idx
ON ft
USING GIN (document_tsvector);
Výpis 10 výsledkov zoradených poľa relevancie vyzerá v MySQL nasledovne:
SELECT
id,
match(document) AGAINST ('+linux' IN BOOLEAN MODE) AS score
FROM ft
WHERE match(document) AGAINST ('+linux' IN BOOLEAN MODE)
ORDER BY score DESC
LIMIT 10;
+-------+--------------------+
| id | score |
+-------+--------------------+
| 1165 | 113.36463165283203 |
| 24467 | 112.66340637207031 |
| 6899 | 84.8481674194336 |
| 5973 | 78.53714752197266 |
| 24940 | 64.04517364501953 |
| 14574 | 61.94150161743164 |
| 482 | 55.162994384765625 |
| 15541 | 52.12435531616211 |
| 11346 | 50.72190856933594 |
| 14764 | 48.384490966796875 |
+-------+--------------------+
10 rows in set (0,372 sec)
EXPLAIN SELECT id, MATCH(document) AGAINST ('+linux' IN BOOLEAN MODE) AS score FROM ft WHERE match(document) AGAINST ('+linux' IN BOOLEAN MODE) ORDER BY score DESC, id ASC LIMIT 10;
+------+-------------+-------+----------+---------------+--------------+---------+------+------+----------------------------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+------+-------------+-------+----------+---------------+--------------+---------+------+------+----------------------------------------------+
| 1 | SIMPLE | ft | fulltext | document_idx | document_idx | 0 | | 1 | Using where; Using temporary; Using filesort |
+------+-------------+-------+----------+---------------+--------------+---------+------+------+----------------------------------------------+
Ten istý dotaz v PostgreSQL vyzerá takto:
SELECT
id,
ts_rank(document_tsvector, to_tsquery('simple', 'linux')) AS rank
FROM ft
WHERE document_tsvector @@ to_tsquery('simple', 'linux')
ORDER BY rank
DESC LIMIT 10;
id rank
----- -----------
24940 0.09976207
1165 0.09976207
14574 0.09976207
5973 0.09976207
24467 0.09976207
15541 0.09972675
11346 0.09972046
6899 0.09967747
482 0.099663176
23873 0.09965749
(10 rows)
Time: 66,747 ms
EXPLAIN (COSTS FALSE, ANALYZE TRUE, TIMING FALSE) SELECT id, ts_rank(document_tsvector, to_tsquery('simple', 'linux')) AS rank FROM ft WHERE document_tsvector @@ to_tsquery('simple', 'linux') ORDER BY rank DESC LIMIT 10;
QUERY PLAN
-------------------------------------------------------------------------------
Limit (actual rows=10 loops=1)
-> Sort (actual rows=10 loops=1)
Sort Key: (ts_rank(document_tsvector, '''linux'''::tsquery)) DESC
Sort Method: top-N heapsort Memory: 25kB
-> Bitmap Heap Scan on ft (actual rows=10531 loops=1)
Recheck Cond: (document_tsvector @@ '''linux'''::tsquery)
Heap Blocks: exact=4021
-> Bitmap Index Scan on document_idx (actual rows=10531 loops=1)
Index Cond: (document_tsvector @@ '''linux'''::tsquery)
Planning Time: 0.115 ms
Execution Time: 60.946 ms
Z výpisu MySQL sa nedozvieme nič zaujímavé okrem toho, že dotaz sa vykonáva niekoľkonásobne pomalšie. Výpis PostgreSQL je však omnoho zaujímavejší.
Z výpisu vyplýva, že index vrátil 10 531 výsledkov. Z nich sa pomocou dátovej štruktúry heap vybralo 10 najrelevantnejších výsledkov postupným skenovaním cez všetkých relevantných 10 531 riadkov. Ak by nebol použitý LIMIT, alebo by bol príliš vysoký, PostgreSQL by zvolil priamo stratégiu zoradenia výsledkov bez výberu najčastejších cez heap.
Kým v prvom teste bol rádový rozdiel medzi MySQL a PostgreSQL, v tomto teste to už na takú dominanciu nevyzerá.
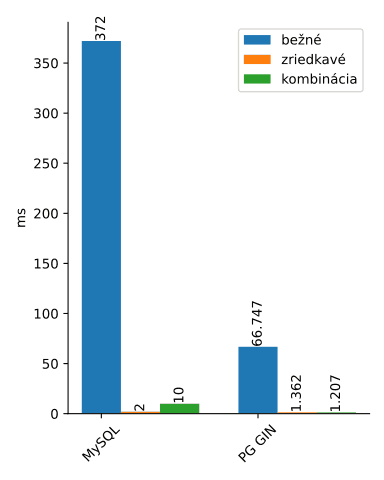
Obrázok 3: Zoradenie výsledkov
Vrátenie výsledkov v PostgreSQL je rýchle, ale zoradenie výsledkov podľa relevancie je pomalé. Problém zoradenia rieši RUM prístupová metóda.
Rozšírenie nie je súčasťou štandardnej inštalácie PostgreSQL, ale väčšinou je dostupné v distribučných balíkoch. Licencia je rovnaká, ako v PostgreSQL. Po inštalácii je výmena GIN indexu veľmi jednoduchá:
DROP INDEX document_idx; CREATE EXTENSION rum; CREATE INDEX document_idx ON ft USING RUM(document_tsvector rum_tsvector_ops);
Dotaz pre zoradenie používa trochu iný spôsob výpočtu relevancie. Upravený dotaz vyzerá takto:
SELECT
id,
document_tsvector <=> to_tsquery('simple', 'linux') AS "rank"
FROM ft
WHERE document_tsvector @@ to_tsquery('simple', 'linux')
ORDER BYrank
LIMIT 10;
id rank
----- ---------
24467 10.02385
14574 10.02385
24940 10.02385
5973 10.02385
1165 10.02385
15541 10.027397
11346 10.028029
6899 10.032354
482 10.033794
23873 10.034368
(10 rows)
Time: 5,757 ms
EXPLAIN (COSTS FALSE, ANALYZE TRUE, TIMING FALSE) SELECT id, document_tsvector <=> to_tsquery('simple', 'linux') AS "rank" FROM ft WHERE document_tsvector @@ to_tsquery('simple', 'linux') ORDER BY rank LIMIT 10;
QUERY PLAN
------------------------------------------------------------------
Limit (actual rows=10 loops=1)
-> Index Scan using document_idx on ft (actual rows=10 loops=1)
Index Cond: (document_tsvector @@ '''linux'''::tsquery)
Order By: (document_tsvector <=> '''linux'''::tsquery)
Planning Time: 0.155 ms
Execution Time: 7.598 ms
Podľa výpisu explain sa využilo presne 10 riadkov získaných rýchlym index skenom.
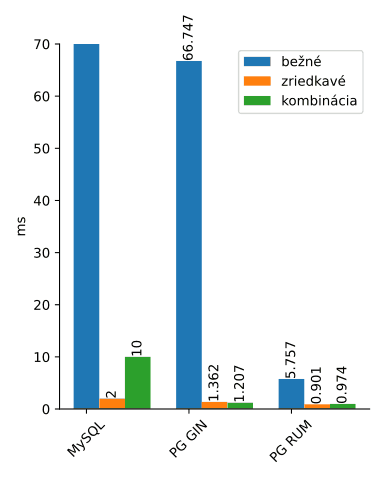
Obrázok 4: Zoradenie výsledkov s RUM indexom
To je 64-násobne rýchlejšie oproti MySQL a skoro 12-násobne rýchlejšie oproti GIN indexu pri častých slovách.
Databázový systém PostgreSQL môže podľa potreby meniť a spravidla aj mení pri rôznych hodnotách LIMIT a OFFSET stratégiu prístupu k riadkom. Ak sú riadky zoradené iba podľa ranku, môže sa poradie riadkov s rovnakým rankom zmeniť. Zamedziť sa tomu dá napríklad pridaním id do zoradenia - ORDER BY rank, id.
SELECT
id,
document_tsvector <=> to_tsquery('simple', 'linux') AS "rank"
FROM ft
WHERE document_tsvector @@ to_tsquery('simple', 'linux')
ORDER BY rank, id
LIMIT 10;
…
Time: 64,808 ms
Zrazu sa výhoda RUM prístupovej metódy niekde stratila.
Myslím, že problém zoradenia je dosť zaujímavý na to, aby som mu venoval jednu malú kapitolu. Tá sa nebude týkať priamo fulltextového vyhľadávania, ale bude o zoradení všeobecne.
Testy budú prebiehať ne jednoduchej tabuľke so stĺpcami ID, číslo s plávajúcou desatinnou čiarkou a bod na ploche. V tabuľke bude 10 000 000 náhodných záznamov. Každý stĺpec bude mať index. Najskôr začnem MySQL:
CREATE TABLE s(id INT NULL AUTO_INCREMENT PRIMARY KEY, d DOUBLE, p POINT); DELIMITER $$ CREATE PROCEDURE create_sample_data() BEGIN DECLARE i INT DEFAULT 0; WHILE i < 10000 DO INSERT INTO `s` (`d`, `p`) VALUES (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())), (RAND(), POINT(RAND(), RAND())); SET i = i + 1; END WHILE; END$$ DELIMITER ; CALL create_sample_data(); DROP PROCEDURE create_sample_data; CREATE INDEX d_idx ON s(d); CREATE INDEX p_idx ON s(p); -- Query OK, 10000000 rows affected (47,067 sec) -- Query OK, 0 rows affected (15,734 sec) -- Query OK, 0 rows affected (26,970 sec)
Tabuľka je vytvorená za 47 sekúnd a indexy za ďalších 43 sekúnd. Vytvorenie náhodných dát si môžme skontrolovať:
SELECT COUNT(*) FROM s;
+----------+
| COUNT(*) |
+----------+
| 10000000 |
+----------+
1 row in set (1,293 sec)
SELECT * FROM s LIMIT 10;
+----+---------------------+---------------------------+
| id | d | p |
+----+---------------------+---------------------------+
| 1 | 0.9137433598877335 | â¶]w¸mç?ɱu@rlí? |
| 2 | 0.40100952368323645 | /@~º
Ï?zlzp? |
| 3 | 0.4096927758396536 | å¹úTy®î?
OȦÂâ? |
| 4 | 0.948166525874442 | ¯g^Ø뙧?®Ïbë³Ø? |
| 5 | 0.791618720434251 | JkfҚé?+PÊJä? |
| 6 | 0.7290030342796846 | Z8âè?Ù)SMvÊä? |
| 7 | 0.9465388887995285 | cKäÆØé?PlÁ ´? |
| 8 | 0.04003077656033521 | {¥`çî?^´Zmæ? |
| 9 | 0.6459137253890873 | C+j´Њº?#SʸȔâ? |
| 10 | 0.5922686621474742 | OpÈãÌ?%êQ!zÔ? |
+----+---------------------+---------------------------+
MySQL nevie vypísať typ point, preto sa namiesto hodnôt zobrazujú binárne dáta.
Podobná tabuľka sa v PostgreSQL vytvorí nasledujúcou sériou príkazov:
CREATE TABLE s (id SERIAL, d DOUBLE PRECISION, p POINT, PRIMARY KEY(id)); INSERT INTO s (SELECT generate_series(1, 10000000), random(), point(random(), random())); -- Time: 12890,828 ms (00:12,891) CREATE INDEX d_idx ON s USING btree(d); -- Time: 3037,142 ms (00:03,037) CREATE INDEX p_idx ON s USING gist(p); -- Time: 13632,420 ms (00:13,632)
Opäť nasleduje kontrola údajov:
SELECT COUNT(*) FROM s; count -------- 10000000 (1 row) Time: 145,828 ms SELECT * FROM s LIMIT 10; id d p -- ------------------- ------------------------------------------ 1 0.44124624029167525 (0.5581773825358121,0.308156906191311) 2 0.09759067947576683 (0.07393451293407116,0.027710011644558552) 3 0.18220250470085753 (0.2150454304704421,0.0663700457660914) 4 0.14895286756377923 (0.8180180986740628,0.9082178023263434) 5 0.969328504585125 (0.8755523928021021,0.3570828194116715) 6 0.930351821656485 (0.22167092351788575,0.3140584019365069) 7 0.12802135544719762 (0.21196181026395955,0.8765903299419724) 8 0.9919567843128472 (0.5165731957649631,0.38102477994165995) 9 0.3887398838466707 (0.8947758235085952,0.16025279565670614) 10 0.5337890264197422 (0.36275067768781977,0.8799555047323149) (10 rows) Time: 0,448 ms
Najjednoduchšie, čo môžme spraviť je vypísať si údaje zoradené podľa stĺpca so zoradeným indexom. V MySQL je to veľmi rýchla operácia, ktorá využíva index:
SELECT d, id FROM s ORDER BY d DESC LIMIT 10; +-------------------+---------+ | d | id | +-------------------+---------+ | 0.999999949708581 | 8815993 | | 0.999999949708581 | 8716153 | | 0.999999949708581 | 7083193 | | 0.999999949708581 | 5502393 | | 0.999999949708581 | 5068153 | | 0.999999949708581 | 1854393 | | 0.999999376945197 | 4773466 | | 0.999999376945197 | 4578586 | | 0.999999376945197 | 4244186 | | 0.999999376945197 | 2979866 | +-------------------+---------+ 10 rows in set (0,000 sec) EXPLAIN SELECT d, id FROM s ORDER BY d DESC LIMIT 10; +------+-------------+-------+-------+---------------+-------+---------+------+------+-------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +------+-------------+-------+-------+---------------+-------+---------+------+------+-------------+ | 1 | SIMPLE | s | index | NULL | d_idx | 9 | NULL | 10 | Using index | +------+-------------+-------+-------+---------------+-------+---------+------+------+-------------+ 1 row in set (0,000 sec)
PostgreSQL robí v zásade to isté:
SELECT d, id FROM s ORDER BY d DESC LIMIT 10;
d id
------------------ -------
0.9999999729912039 7971458
0.9999996724381648 5372047
0.999999547273573 3593807
0.9999995099932779 2321234
0.9999994120221605 5259286
0.9999993095493327 3329543
0.999999264140115 2294627
0.9999991310452243 2958705
0.9999990016531421 7973130
0.9999989705945129 5978095
(10 rows)
Time: 0,443 ms
EXPLAIN (COSTS FALSE, ANALYZE TRUE, TIMING FALSE) SELECT d, id FROM s ORDER BY d DESC LIMIT 10;
QUERY PLAN
-------------------------------------------------------------------
Limit (actual rows=10 loops=1)
-> Index Scan Backward using d_idx on s (actual rows=10 loops=1)
Planning Time: 0.098 ms
Execution Time: 0.087 ms
Obe databázy si so selectom poradili bez problémov.
Pri fulltextovom vyhľadávaní sa problém prejavil až pri pokuse o zoradenie podľa 2 stĺpcov. Poďme si vyskúšať zoradenie podľa 2 obyčajných stĺpcov bez fulltextu. Najskôr MySQL:
SELECT d, id FROM s ORDER BY d DESC, id LIMIT 10; +-------------------+---------+ | d | id | +-------------------+---------+ | 0.999999949708581 | 1854393 | | 0.999999949708581 | 5068153 | | 0.999999949708581 | 5502393 | | 0.999999949708581 | 7083193 | | 0.999999949708581 | 8716153 | | 0.999999949708581 | 8815993 | | 0.999999376945197 | 79386 | | 0.999999376945197 | 91866 | | 0.999999376945197 | 2979866 | | 0.999999376945197 | 4244186 | +-------------------+---------+ 10 rows in set (2,467 sec) EXPLAIN SELECT d, id FROM s ORDER BY d DESC, id LIMIT 10; +------+-------------+-------+-------+---------------+-------+---------+------+---------+-----------------------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +------+-------------+-------+-------+---------------+-------+---------+------+---------+-----------------------------+ | 1 | SIMPLE | s | index | NULL | d_idx | 9 | NULL | 9712432 | Using index; Using filesort | +------+-------------+-------+-------+---------------+-------+---------+------+---------+-----------------------------+ 1 row in set (0,000 sec)
Zrazu pri takmer identických výsledkoch trvá dotaz 2,467 s a potrebuje skenovať 9712432 riadkov. Zaujímavé je, že ak otočím zoradenie pri ID, rýchlosť sa zásadne zmení, pričom oba stĺpce majú na sebe nezávislé indexy.
SELECT d, id FROM s ORDER BY d DESC, id DESC LIMIT 10; … 10 rows in set (0,000 sec) EXPLAIN SELECT d, id FROM s ORDER BY d DESC, id DESC LIMIT 10; +------+-------------+-------+-------+---------------+-------+---------+------+------+-------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +------+-------------+-------+-------+---------------+-------+---------+------+------+-------------+ | 1 | SIMPLE | s | index | NULL | d_idx | 9 | NULL | 10 | Using index | +------+-------------+-------+-------+---------------+-------+---------+------+------+-------------+ 1 row in set (0,000 sec)
Pri rovnakom zadaní PostgreSQL dokáže využívať indexy aj keď majú opačné zoradenie:
SELECT
d,
id
FROM s
ORDER BY d DESC, id
LIMIT 10;
d id
------------------ -------
0.9999999729912039 7971458
0.9999996724381648 5372047
0.999999547273573 3593807
0.9999995099932779 2321234
0.9999994120221605 5259286
0.9999993095493327 3329543
0.999999264140115 2294627
0.9999991310452243 2958705
0.9999990016531421 7973130
0.9999989705945129 5978095
(10 rows)
Time: 0,547 ms
EXPLAIN (COSTS FALSE, ANALYZE TRUE, TIMING FALSE) SELECT d, id FROM s ORDER BY d DESC, id LIMIT 10;
QUERY PLAN
--------------------------------------------------------------------------------------------
Limit (actual rows=10 loops=1)
-> Incremental Sort (actual rows=10 loops=1)
Sort Key: d DESC, id
Presorted Key: d
Full-sort Groups: 1 Sort Method: quicksort Average Memory: 25kB Peak Memory: 25kB
-> Index Scan Backward using d_idx on s (actual rows=11 loops=1)
Planning Time: 0.109 ms
Execution Time: 0.080 ms
Z výpisu vyplýva, že index scan v spätom smere vrátil len 11 záznamov. Tie boli následne zoradené metódou inkrementálneho zoradenia, čiže zoradia sa len tie, ktoré rovnakú hodnotu v stĺpci d.
Bežnou požiadavkou je zobrazenie najbližších bodov v okolí. Pri testoch sa generovali náhodne body v rozsahu 0-1 na x-ovej aj y-ovej osi. Údaje sa budú zoraďovať podľa vzdialenosti od stredu. Najskôr dotaz v MySQL, ktorý ani nebudem rozoberať, lebo ani tie jednoduché dotazy nefungovali dobre.
SELECT ST_DISTANCE(p, POINT(0.5, 0.5)) dist, id FROM s ORDER BY dist LIMIT 10; … 10 rows in set (5,301 sec)
Rovnaký dotaz v PostgreSQL prebehne podľa očakávania celkom rýchlo:
SELECT
p <-> point(0.5, 0.5) dist,
id
FROM s
ORDER BY dist
LIMIT 10;
…
Time: 0,650 ms
EXPLAIN (COSTS FALSE, ANALYZE TRUE, TIMING FALSE) SELECT p <-> point(0.5, 0.5) dist, id FROM s ORDER BY dist LIMIT 10;
QUERY PLAN
----------------------------------------------------------
Limit (actual rows=10 loops=1)
-> Index Scan using p_idx on s (actual rows=10 loops=1)
Order By: (p <-> '(0.5,0.5)'::point)
Planning Time: 0.112 ms
Execution Time: 0.354 ms
GIST Index v PostgreSQL vie ukladať body do R-tree, čo umožňuje efektívne prehľadávať body podľa vzdialenosti. Index tak skutočne vráti najbližšie body bez nutnosti dodatočného zoradenia. Čo sa však stane keď je požadované zaradenie bodov s rovnakou vzdialenosťou podľa druhého stĺpca?
SELECT
p <-> point(0.5, 0.5) dist,
id
FROM s
ORDER BY dist, id
LIMIT 10;
Time: 420,092 ms
EXPLAIN (COSTS FALSE, ANALYZE TRUE, TIMING FALSE) SELECT p <-> point(0.5, 0.5) dist, id FROM s ORDER BY dist, id LIMIT 10;
QUERY PLAN
--------------------------------------------------------
Limit (actual rows=10 loops=1)
-> Sort (actual rows=10 loops=1)
Sort Key: ((p <-> '(0.5,0.5)'::point)), id
Sort Method: top-N heapsort Memory: 25kB
-> Seq Scan on s (actual rows=10000000 loops=1)
Planning Time: 0.080 ms
Execution Time: 1151.684 ms
Neexistuje objektívny dôvod, prečo by PostgreSQL nemala používať rovnakú metódu zoradenia Incremental Sort, ako v predchádzajúcom prípade. Napriek tomu ho nepoužíva.
Strávil som niekoľko hodín hrabaním sa v zdrojových kódoch PostgreSQL, aby som objavil dôvod. V prvom rade by som rád pochválil vývojárov za veľmi prehľadný kód, v ktorom som nemal ani zďaleka tak veľký problém zorientovať sa než som pôvodne čakal.
Nakoniec príčinou problému je to, že PostgreSQL vie použiť Incremental Sort len v prípade keď používa zoradený index. Lenže index bodov nie je zoradený, pretože tu zoradenie ani nedáva zmysel. Čo však dáva zmysel je zoradenie podľa vzdialenosti voči referenčnému bodu. Index, alebo prístupová metóda (access method) na to implementuje order operator.
Jedinou chybou je, že kým pri zoradenom indexe sa kontroluje, či index má spoločný prefix s ORDER klauzulou, pri nezoradenom indexe s order operátorom sa kontroluje exaktná zhoda ORDER klauzuly. Problém sa dá vyriešiť malým patchom, ktorý som zaslal vývojárom. Po jeho aplikácii vyzerajú výsledky takto:
SELECT
p <-> point(0.5, 0.5) dist,
id
FROM s
ORDER BY dist, id
LIMIT 10;
…
Time: 0,707 ms
EXPLAIN (COSTS FALSE, ANALYZE TRUE, TIMING FALSE) SELECT p <-> point(0.5, 0.5) dist, id FROM s ORDER BY dist, id LIMIT 10;
QUERY PLAN
--------------------------------------------------------------------------------------------
Limit (actual rows=10 loops=1)
-> Incremental Sort (actual rows=10 loops=1)
Sort Key: ((p <-> '(0.5,0.5)'::point)), id
Presorted Key: ((p <-> '(0.5,0.5)'::point))
Full-sort Groups: 1 Sort Method: quicksort Average Memory: 25kB Peak Memory: 25kB
-> Index Scan using p_idx on s (actual rows=11 loops=1)
Order By: (p <-> '(0.5,0.5)'::point)
Planning Time: 0.121 ms
Execution Time: 0.356 ms
Po aplikovaní záplaty funguje už aj zoradenie podľa viacerých stĺpcov pomerne rýchlo.
SELECT
id,
document_tsvector <=> to_tsquery('simple', 'linux') AS "rank"
FROM ft
WHERE document_tsvector @@ to_tsquery('simple', 'linux')
ORDER BY rank, id
LIMIT 10;
…
Time: 5,658 ms
EXPLAIN (COSTS FALSE, ANALYZE TRUE, TIMING FALSE) SELECT id, document_tsvector <=> to_tsquery('simple', 'linux') AS "rank" FROM ft WHERE document_tsvector @@ to_tsquery('simple', 'linux') ORDER BY rank, id LIMIT 10;
QUERY PLAN
--------------------------------------------------------------------------------------------
Limit (actual rows=10 loops=1)
-> Incremental Sort (actual rows=10 loops=1)
Sort Key: ((document_tsvector <=> '''linux'''::tsquery)), id
Presorted Key: ((document_tsvector <=> '''linux'''::tsquery))
Full-sort Groups: 1 Sort Method: quicksort Average Memory: 25kB Peak Memory: 25kB
-> Index Scan using document_idx on ft (actual rows=11 loops=1)
Index Cond: (document_tsvector @@ '''linux'''::tsquery)
Order By: (document_tsvector <=> '''linux'''::tsquery)
Planning Time: 0.221 ms
Execution Time: 8.861 ms
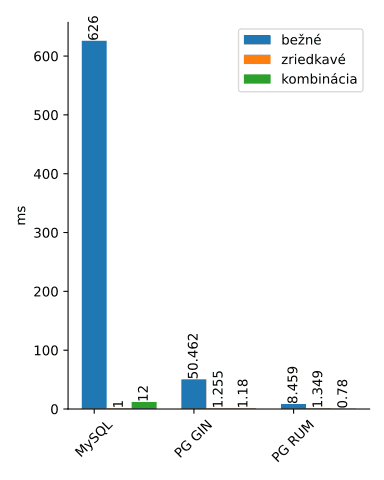
Obrázok 5: Zoradenie podľa 2 stĺpcov
Obrázok 6: Zoradenie podľa 2 stĺpcov bez MySQL
Väčšina blogov o fulltextovom vyhľadávaní sa zaoberá iba vyhľadávaním zriedkavých slov, alebo sa vôbec nezaoberá poradím výsledkov. Práve kombinácia veľkého množstva a zoradenia je problematická. Dovolím si tvrdiť, že v tomto blogu som zašiel ďalej než ktokoľvek iný, čo skončilo malou, ale nevyhnutnou úpravou zdrojových kódov postgresu.
Výsledky ukazujú, že PostgreSQL je dostatočne výkonnou pre fulltextové vyhľadávanie na malých až stredne veľkých databázach.
MySQL je kapitola sama o sebe. Sťažnosti na mizerný optimalizátor počúvam už najmenej 15 rokov a teraz som sa mohol presvedčiť, že je to pravda dokonca aj pri veľmi jednoduchých dotazoch.
Prvá časť článku bola zameraná len na maximalizáciu výkonu. Pravdou je, že takto navrhnuté vyhľadávanie nenájde ani len výraz závislosť ak ho zadám bez diakritiky. V tejto časti ukážem ako pri vyhľadávaní ignorovať diakritiku, či vyhľadávať slová so skloňovaním.
Vyhľadávanie v PostgreSQL prebieha nad špeciálnym dátovým typom tsvector. Ako konkrétne vyzerá si môžme vyskúšať použitím funkcie to_tsvector. Ako pokusnú vetu budem používať tretí termodynamický zákon:
Zmena entropie sústavy sa pri ľubovoľnom izotermickom deji prebiehajúcom pri teplote absolútnej nuly rovná nule.
Dotaz SELECT to_tsvector('simple', 'Zmena entropie sústavy sa pri ľubovoľnom izotermickom deji prebiehajúcom pri teplote absolútnej nuly rovná nule.') vypíše nasledujúcu štruktúru (dovolil som si ju pre lepší prehľad preformátovať).
'absolútnej': 12 'deji': 8 'entropie': 2 'izotermickom': 7 'nule': 15 'nuly': 13 'prebiehajúcom': 9 'pri': 5, 10 'rovná': 14 'sa': 4 'sústavy': 3 'teplote': 11 'zmena': 1 'ľubovoľnom': 6
Text bol nahradený zoznamom slov a ich pozíciou v dokumente. Ak sa jedno slovo vyskytuje v niekoľkých exemplároch, má v štruktúre viacej pozícií.
Druhá štruktúra, ktorá sa používa pri vyhľadávaní je tsquery, čo je štruktúrovaný dotaz. Pri vytvorení dotazu je k dispozícii hneď niekoľko rôznych funkcií pre zostrojenie dotazu.
Funkcia to_tsquery bola použitá už v časti o výkone. Funkcia používa špeciálnu syntax pre zadávané výrazy a pozor, pri chybe syntaxe vyhodí výnimku. Keď chcem vyhľadať výrazy obsahujúce napríklad slová "zmena" a "entropie" zostrojím dotaz ako to_tsquery('simple', 'zmena & entropie').
SELECT to_tsquery('simple', 'zmena & entropie');
to_tsquery
--------------------
'zmena' & 'entropie'
Jednoduchšie dotazy sa dajú dosiahnuť volaním plainto_tsquery. Táto funkcia nevyhadzuje výnimku a zvolený výraz sa zloží ako keby bol medzi každým slovom operátor AND.
SELECT plainto_tsquery('simple', 'zmena entropie');
plainto_tsquery
--------------------
'zmena' & 'entropie'
Najnovšou funkciou je websearch_to_tsquery, ktorá umožňuje vytvoriť aj zložitejšie dotazy, ale zároveň nikdy nevyhadzuje výnimku. Vhodná je práve na užívateľom zadaný vstup.
SELECT websearch_to_tsquery('simple', 'zmena entropie');
websearch_to_tsquery
--------------------
'zmena' & 'entropie'
Funkcia websearch_to_tsquery umožňuje kombinovať výrazy napríklad s operátorom OR, alebo vynútiť poradie slov, či zakázať určitý výraz vo vyhľadávaní.
-- alebo
SELECT websearch_to_tsquery('simple', 'zmena or entropie');
websearch_to_tsquery
--------------------
'zmena' | 'entropie'
-- presné poradie slov
SELECT websearch_to_tsquery('simple', '"zmena entropie"');
websearch_to_tsquery
----------------------
'zmena' <-> 'entropie'
-- len dokumenty s výrazom zmena neobsahujúce slovo entropie
websearch_to_tsquery
---------------------
'zmena' & !'entropie'
Zhoda dokumentu s hľadaným výrazom sa kontroluje operátorom dokument @@ query
SELECT
to_tsvector('simple', 'Zmena entropie sústavy sa pri ľubovoľnom izotermickom deji prebiehajúcom pri teplote absolútnej nuly rovná nule.')
@@
websearch_to_tsquery('simple', 'Zmena entropie');
?column?
--------
t
(1 row)
Ako implementovať ignorovanie diakritiky? Veľmi jednoducho, stačila by funkcia, ktorá upraví texty pri konverzii do tsvector a tsquery. Potom by sa automaticky vyhľadával výraz s odstránenou diakritikou v dokumente s odstránenou diakritikou.
Úprava výrazov je implementovaná ako súčasť konfigurácie fulltextového vyhľadávania. Doteraz bola vo všetkých výrazoch použitá konfigurácia 'simple'. Vstavaných je niekoľko ďalších konfigurácií a ich zoznam sa dá zobraziť príkazom \dFd+.
Obrázok 7: Zoznam konfigurácií
Nasledujúci kód vytvorí konfiguráciu 'unaccent' fulltextu pre vyhľadávanie bez diakritiky. Zvláštne výrazy ako asciihword sú popísané v dokumentácii. Rozšírenie unaccent je aplikované iba na slová, ktoré môžu obsahovať diakritiku. Tie, ktoré sú bez diakritiky sú ponechané bez zmeny.
CREATE EXTENSION unaccent; CREATE TEXT SEARCH CONFIGURATION unaccent (COPY = simple); ALTER TEXT SEARCH CONFIGURATION unaccent ALTER MAPPING FOR asciiword, asciihword, hword_asciipart WITH simple; ALTER TEXT SEARCH CONFIGURATION unaccent ALTER MAPPING FOR hword, hword_part, word WITH unaccent, simple;
Teraz je potrebné nahradiť index, ktorý využíval konfiguráciu 'simple' indexom s konfiguráciou 'unaccent'.
DROP INDEX document_idx;
ALTER TABLE ft DROP COLUMN document_tsvector;
ALTER TABLE ft
ADD COLUMN document_tsvector tsvector
GENERATED ALWAYS AS (to_tsvector('unaccent', document)) STORED;
CREATE INDEX document_idx ON ft USING GIN (document_tsvector);
Počet výsledkov výrazu "závislosť" sa zvýšil z 45 na 108.
SELECT COUNT(*) FROM ft WHERE document_tsvector @@ to_tsquery('unaccent', 'závislosť');
count
-----
108
Okrem odstránenia diakritiky je možné počas konverzie zmeniť tvar slov na základný, vďaka čomu bude možné vyhľadávať v ľubovoľnom tvare.
Konfigurácie pre niektoré jazyky sú už vstavané, ale slovenčina medzi ne nepatrí. Okrem toho vstavaná podpora používa snowball stemmer (program pre prevod slov na základný tvar). Nevýhodou snowballu je, že nepoužíva slovník. Namiesto neho sa snaží odstrániť predpony / prípony algoritmom, čo nie je vždy správne. Či už je nejaká konfigurácia vstavaná v postgrese, alebo nie, stále má zmysel vytvoriť si vlastnú s použitím slovníka.
Nová konfigurácia bude mať názov 'sk'.
CREATE TEXT SEARCH CONFIGURATION sk (COPY = simple); CREATE TEXT SEARCH DICTIONARY slovak_ispell ( TEMPLATE = ispell, DictFile = sk, AffFile = sk, Stopwords = sk );
Príkaz pravdepodobne skončí chybou ERROR: F0000: could not open dictionary file "/usr/share/postgresql-15/tsearch_data/sk.dict". Znamená to, že súbory sk.dict, sk.affix a sk.stop z balíka ispell majú byť skopírované do /usr/share/postgresql-15/tsearch_data/.
Súbory s príponou .affix a .dict sú dostupné ako súčasť ispell slovníka. Súbor častých slov, ktoré sa nemajú indexovať je potrebné doplniť ručne, alebo nájsť niektorý s vhodnou licenciou. Jeden s MIT licenciou je dostupný na githube.
Po skopírovaní súborov do tsearch_data už bude možné vytvoriť slovník.
CREATE TEXT SEARCH DICTIONARY slovak_ispell ( TEMPLATE = ispell, DictFile = sk, AffFile = sk, Stopwords = sk ); ALTER TEXT SEARCH CONFIGURATION sk ALTER MAPPING FOR asciiword, asciihword, hword_asciipart WITH slovak_ispell, simple; ALTER TEXT SEARCH CONFIGURATION sk ALTER MAPPING FOR hword, hword_part, word WITH slovak_ispell, unaccent, simple;
Opäť je potrebné upraviť document_tsvector a vygenerovať index.
DROP INDEX document_idx;
ALTER TABLE ft DROP COLUMN document_tsvector;
ALTER TABLE ft
ADD COLUMN document_tsvector tsvector
GENERATED ALWAYS AS (to_tsvector('sk', document)) STORED;
CREATE INDEX document_idx ON ft USING GIN (document_tsvector);
Najskôr pre ukážku, že konfigurácia pracuje správne nakŕmim funkciu to_tsvector rôznymi tvarmi slova. Výsledkom by malo byť zlúčené to isté slovo v základnom tvare.
SELECT to_tsvector('sk', 'závislosť závislosti závislostí');
to_tsvector
-----------------
'závislosť':1,2,3
Fulltextové vyhľadávanie podľa očakávania vráti aj riadky s ostatnými tvarmi slova, čo zvýši počet výsledkov zo 108 na 527.
SELECT COUNT(*) FROM ft WHERE document_tsvector @@ to_tsquery('sk', 'závislosť');
count
-----
527
Skloňovanie však nefunguje pre dotazy zadané bez diakritiky.
SELECT to_tsvector('sk', 'závislosť závislost');
to_tsvector
---------------------------
'zavislost':2 'závislosť':1
Výraz bez diakritiky sa nenachádza v slovníku, preto sa jeho tvar nezmení na základný. Či už je použitý skôr slovník a potom unaccent, alebo opačne, stále bude problém s vyhľadávaním bez diakritiky.
Problém sa dá veľmi jednoducho vyriešiť odstránením diakritiky zo slovníka napríklad pomocou nástroja Unidecode.
unidecode < sk.dict > sk_unaccent.dict unidecode < sk.affix > sk_unaccent.affix unidecode < sk.stop > sk_unaccent.stop
Definícia novej konfigurácie vyhľadávania vyzerá takto:
CREATE TEXT SEARCH CONFIGURATION sk_unaccent (COPY = simple); CREATE TEXT SEARCH DICTIONARY slovak_unaccent_ispell ( TEMPLATE = ispell, DictFile = sk_unaccent, AffFile = sk_unaccent, Stopwords = sk_unaccent ); ALTER TEXT SEARCH CONFIGURATION sk_unaccent ALTER MAPPING FOR asciiword, asciihword, hword_asciipart WITH slovak_unaccent_ispell, simple; ALTER TEXT SEARCH CONFIGURATION sk_unaccent ALTER MAPPING FOR hword, hword_part, word WITH unaccent, slovak_unaccent_ispell, simple;
Opäť nasleduje vygenerovanie nového indexu:
DROP INDEX document_idx;
ALTER TABLE ft DROP COLUMN document_tsvector;
ALTER TABLE ft
ADD COLUMN document_tsvector tsvector
GENERATED ALWAYS AS (to_tsvector('sk_unaccent', document)) STORED;
CREATE INDEX document_idx ON ft USING GIN (document_tsvector);
Teraz už konverzia rôznych tvarov a spôsobu zadávania skončí rovnakým slovom. Dokonca z indexu sú zároveň vylúčené časté slová ako "a", "alebo", "ani" …
SELECT to_tsvector('sk_unaccent', 'závislosť závislosti zavislost zavislosti alebo a ani');
to_tsvector
-------------------
'zavislost':1,2,3,4
Vyhľadávanie zriedkavého slova teraz vráti 25x viac výsledkov než pôvodne v PostgreSQL a 10x viac než v MySQL, pretože vo vyhľadávaní sú zahrnuté rôzne tvary slov.
SELECT
COUNT(*)
FROM ft
WHERE document_tsvector @@ to_tsquery('sk_unaccent', 'zavislost');
count
-----
1107
Týchto niekoľko trikov výrazne zlepšilo kvalitu vyhľadávania. Spolu s trikmi v prvej časti článku máme k dispozícii slušné vyhľadávanie s akceptovateľnou rýchlosťou pre menšie a stredné aplikácie.
Neznamená to, že by boli všetky problémy vyhľadávania vyriešené. Stále je čo vylepšovať a preto dopĺňam niektoré zaujímavé možnosti.
Nie každá časť článku má rovnakú váhu. V PostgreSQL sú k dispozícii 4 úrovne - A - D. Štandardná váha je tá najnižšia - D.
Ak máme napríklad tabuľku s titulkom a dokumentom a chceme vytvoriť kombinovaný vektor, je dobré zvýšiť prioritu titulku funkciou setweight.
setweight(to_tsvector('sk_unaccent', title), 'A') || setweight(to_tsvector('sk_unaccent', content), 'C')
Ako vyzerá vytvorený vektor si môžme vyskúšať nasledujúcim selectom:
SELECT
setweight(to_tsvector('sk_unaccent', 'obsah titulku'), 'A') ||
setweight(to_tsvector('sk_unaccent', 'obsah stránky'), 'C');
-- 'obsah': 1A, 3C
-- 'stranka': 4C
-- 'titulok': 2A
Často sa stáva, že užívateľ zadá slovo s preklepom. PostgreSQL neobsahuje žiadnu funkciu pre automatické rozpoznanie a opravu chýb. Nie je problém si navrhnúť vlastný jednoduchý systém.
Ako detekcia môže poslúžiť napríklad to, že vyhľadávanie nevráti žiadne výsledky, alebo vráti málo výsledkov. V takom prípade zistíme podobné slová v databáze slov.
Nasledujúca séria príkazov vytvorí databázu slov.
CREATE EXTENSION IF NOT EXISTS pg_trgm;
CREATE TABLE words (
id SERIAL,
word VARCHAR(100),
ndoc int,
PRIMARY KEY(id)
);
-- Naplnenie tabuľky
INSERT INTO words(word, ndoc)
SELECT word, ndoc
FROM ts_stat('SELECT to_tsvector(''simple'', document) FROM ft');
CREATE INDEX word_idx
ON words USING GIST (word gist_trgm_ops);
Tabuľka so slovami je naplnená všetkými slovami z dokumentov. Ako jednoduchý tokenizér je použitý to_tsvector. V novej tabuľke sa nachádza stĺpec so slovom (word) a počet výskytov (ndoc). Nová tabuľka zahŕňa 552 314 slov.
Výber slov zoradený podľa podobnosti vyzerá nasledovne:
SELECT word, ndoc, word <-> 'zévislosť' AS sml FROM words WHERE word % 'zévislosť' ORDER BY sml LIMIT 4; -- word ndoc sml -- ----------- ---- ---------- -- závislosť 45 0.46153843 -- ávislosť 1 0.53846157 -- súvislosť 23 0.57142854 -- nezávislosť 5 0.625
Pri použití skloňovanie nie je jednoduché zistiť slová, ktoré boli vyhľadané v dokumente, keďže môžu mať iný tvar než zadaná fráza. Z toho dôvodu je v PostgreSQL implementovaná funkcia ts_headline.
SELECT
ts_headline(
'sk_unaccent',
document,
to_tsquery('sk_unaccent', 'závislosť'),
'MaxFragments=10, MaxWords=7, MinWords=3, StartSel=«, StopSel=», FragmentDelimiter= … '
)
FROM ft
WHERE document_tsvector @@ to_tsquery('sk_unaccent', 'závislosť')
ORDER BY document_tsvector <=> to_tsquery('sk_unaccent', 'závislosť')
LIMIT 1;
-- ts_headline
-- ------------------------------------------------------------------------------------------------------------
-- Anketa -> Vaše «závislosti» okrem Linuxu +
-- Aké…Vaše "«závislosti»"? Zámerne som zvolil túto anketu…Anketa -> Vaše «závislosti» okrem Linuxu +
-- Odkazy…anketa pokračuje -> Vaše «závislosti» okrem Linuxu…Anketa -> Vaše «závislosti» okrem Linuxu +
-- Hmm, «zavislosti»…mojou asi najvacsou «zavislostou» su ZENY!! Takze…Anketa -> Vaše «závislosti» okrem Linuxu+
-- Heeh, dobra…Anketa -> Vaše «závislosti» okrem Linuxu…Anketa -> Vaše «závislosti» okrem Linuxu +
-- strašne veľa…Anketa -> Vaše «závislosti» okrem Linuxu +
-- A zabudol
Článok bol pôvodne vydaný na wisdomtech.sk.
Tiskni
Sdílej:
![]()
![]()
![]()
![]()
![]()
![]()
 24.4.2023 09:05
mirec | skóre: 32
| blog: mirecove_dristy
| Poprad
24.4.2023 09:05
mirec | skóre: 32
| blog: mirecove_dristy
| Poprad
Skúšal som sa hrať so všeličím, okrem vyše uvedených aj napríklad Xapian, typesense ...
Momentálne pre ne však nemám veľké využitie. Absolútna väčšina klientov potrebuje tak do 200MB RAM, nasadenie niečoho komplexného by brutálne zdvihlo náklady na servery.
Okrem toho som nespomenul ešte jednu veľkú výhodu vyhľadávania v databáze - môžem kombinovať fulltextové vyhľadávanie s rôznymi filtrami podľa atribútov, kategórií, dostupnosti, ceny atď (nie, že by sa to nedalo v elasticsearchi ale ... veľká časť výpisu produktov by musela byť duplikovaná s dotazmi cez elasticserch).
 24.4.2023 11:23
Max | skóre: 72
| blog: Max_Devaine
24.4.2023 11:50
mirec | skóre: 32
| blog: mirecove_dristy
| Poprad
24.4.2023 11:23
Max | skóre: 72
| blog: Max_Devaine
24.4.2023 11:50
mirec | skóre: 32
| blog: mirecove_dristy
| Poprad
Ako je napísané vyššie, sú to menšie prenajaté VPS-ky s menšími kontajnermi v kubernetese do 200MB RAM a cenou za prevádzku na zákazníka za smiešne sumy. Jednoducho pri tomto projekte sa orientujem na časť trhu, kde by bola cena za elasticsearch neakceptovateľná.
24.4.2023 20:34
mirec | skóre: 32
| blog: mirecove_dristy
| Poprad
Na mieru robené b2b / b2c e-commerce riešenia. O cene hovorím nerád, lebo je to vysoko individuálne. Záleží na tom koľko prostriedkov je potrebných na beh, či je to na dedikovanej VPS, alebo sú služby ako db zdieľané atď. Ale bavíme sa v zásade do 100€ mesačne.
Napríklad tu vidím samostatnú VPS s vlastným postgresom, cleery, rabbitmq, cez 30k produktov, dáta v CDN s cenou keď tak pozerám pod 10€ mesačne.
24.4.2023 09:12
mirec | skóre: 32
| blog: mirecove_dristy
| Poprad
Ešte malý tip, PostgreSQL má podporu FDW s možnosťou prepojiť napríklad elasticsearch. Nikdy som sa nedokopal k tomu, aby som to reálne vyskúšal, ale možnosť tu je.
Vyhľadávanie zriedkavého slova teraz vráti 25x viac výsledkov než pôvodne v PostgreSQL a 10x viac než v MySQL, pretože vo vyhľadávaní sú zahrnuté rôzne tvary slov ... Ako detekcia môže poslúžiť napríklad to, že vyhľadávanie nevráti žiadne výsledky, alebo vráti málo výsledkov. V takom prípade zistíme podobné slová v databáze slov.
Týchto niekoľko trikov výrazne zlepšilo kvalitu vyhľadávania.Zlepsilo?!? Vyhledavani ma vratit pokud mozno jeden spravny vysledek, pripadne nekolik nejblizsich shod. Zaplevelit vysledky dohadama, fake-opravama a nesouvisejima podobnostma je uplny antipattern. Kazdeho kdo ve vyhledavani nepodporuje rezim "pouze presna shoda" povesit za koule do pruvanu.
24.4.2023 12:35
mirec | skóre: 32
| blog: mirecove_dristy
| Poprad
Nie, presný výsledok nie je objektívne lepší. Nebavíme sa tu o vrátení nesúvisiacich výsledkov pre podobné slová. Bavíme sa len a len o skloňovaní (využíva sa reálny slovník) a ignorovaní diakritiky. Vďaka tomu nemusím skúšať zadávať slovo v 14 možných tvaroch a keďže sa vyhľadávajú všetky tvary.
24.4.2023 14:40
mirec | skóre: 32
| blog: mirecove_dristy
| Poprad
Linus, linux, linuxák nie sú v slovníku definované ako skloňovanie slova "linuxačka". V tomto fiktívnom prípade by sa so skloňovaním mali vyhľadať tvary linuxačka, linuxačky, linuxačke, linuxačku, linuxačkou + plurál. Skloňovanie nie je vyhľadávanie podobne znejúcich slov.
24.4.2023 15:01
mirec | skóre: 32
| blog: mirecove_dristy
| Poprad
Teraz ma asi napadlo, v čom je nedorozumenie. Postgres má štandardne konfiguráciu pre stemmer, čo je softvér, ktorý urobí zo slova jeho základ (koreň) pomocou algoritmu. V tom prípade je celkom pravdepodobné, že by z linuxačky zobral ako základ linux. Ak sa však bavíme o slovníku, ten má skutočne vypísané jednotlivé tvary slová, alebo pravidlá, akými sa skloňujú. Nedochádza teda ku odstráneniu prípon / predpon, ale k skutočnému nahradeniu slova jeho základným tvarom a to aj pre nepravidelné skloňovanie. Dúfam, že teraz je to už jasné.
Nechcem tým povedať, že požiadavka na exaktnú zhodu je úplne nelegitímna, ale v drvivej väčšine prípadov je nájdenie rôznych tvarov toho istého slova žiadúce.
25.4.2023 17:57
Max | skóre: 72
| blog: Max_Devaine
RAC myslím stále jiná řešení neumějí. Ale ano, má to performance impact (asi do 10%) a je to řešení kvůli blbě navrženým app a věcím okolo.Ok, beru, praktické zkušenosti nemám takže je to možné.
26.4.2023 12:20
Max | skóre: 72
| blog: Max_Devaine
26.4.2023 13:39
Max | skóre: 72
| blog: Max_Devaine
25.4.2023 17:59
Max | skóre: 72
| blog: Max_Devaine
Ještě se zeptám na tu hlášku o DB2? To je jakože co? Resp. o čem to má vypovídat? DB2 je komerční produkt stejně jako Oracle, jaký je rozdíl?No právě, když někdo chce komerční produkt od megakorporace, může si koupit DB2 a klidně i platit víc. A moje praktické zkušenosti (byť několik let staré) jsou takové, že takové ty základní věci jako optimalizace dotazů fungují v DB2 výrazně lépe.
Zdar Max
26.4.2023 12:23
Max | skóre: 72
| blog: Max_Devaine
{'en': 'Hello', 'zh': '你好', 'defaultLocale': 'en'}
Predpokladam, ze budu muset vytvorit jeden index na kazdy mozny jazyk, a pak ho vybrat pri vyhledavani?
25.4.2023 17:02
mirec | skóre: 32
| blog: mirecove_dristy
| Poprad
V tomto prípade samostatné indexy pre každý jazyk.
Mimochodom ja používam preklady v externej tabuľke, ktorá vyzerá: (id int, master_id int, language_code varchar, text ...) a tsvector je vytvorený ako to_tsvector("language_code", "text"), teda nastavenie jazyka sa načítava priamo zo stĺpca v tabuľke. Nie je to úplne ideálne riešenie, ale ide to aj s jediným indexom.
25.4.2023 17:00
mirec | skóre: 32
| blog: mirecove_dristy
| Poprad
Morfológia práve, že nie je žiaden problém. Stačí uložiť text so slovami konvertovanými na základný tvar a query tak isto konvertovať na základný tvar (presne to som popisoval v druhej časti blogu). Ku konverzii však musí byť použitý reálny slovník obsahujúci informácie o skloňovaní. Napríklad vyberám z ispellu:
// sk_SK.dict žena/zZ po:noun is:feminine // sk_SK.aff SFX z Y 7 # vzor žena jednotné číslo SFX z a y a is:genitive SFX z a e [^euo]a is:dative SFX z a i [euo]a is:dative SFX z a u a is:accusative SFX z a e [^euo]a is:locative SFX z a i [euo]a is:locative SFX z a ou a is:instrumental ...
Okrem slov sú v slovníku uložené metainformácie k skloňovaniu vďaka čomu je možné väčšinu slov jednoznačne konvertovať na základný tvar.
25.4.2023 17:04
mirec | skóre: 32
| blog: mirecove_dristy
| Poprad
Ak ľudia zadávajú s diakritikou, je blbosť ju odstraňovať. U mňa je 70-80% výrazov, ktoré majú diakritiku zadaných bez diakritiky, takže dáva zmysel skôr odstránenie..
ISSN 1214-1267, (c) 1999-2007 Stickfish s.r.o.