 | poslední úprava: 10.2.2015 18:59
| poslední úprava: 10.2.2015 18:59
Portál AbcLinuxu, 21. června 2026 22:38
10.2.2015 18:01
| Přečteno: 26361×
| Obecné IT
|
| poslední úprava: 10.2.2015 18:59
Občas se stane, že potřebujete přistupovat k nějakému zdroji na internetu nepřímo. Pokud se jedná o desítky až stovky requestů, a neplánujete dělat nic ošklivého, dá se použít třeba VPS, nebo VPN. Pokud však potřebujete například postahovat nějakou větší databázi, která vám zabere tisíce a statisíce requestů, je většinou dobré, či přímo nutné, použít proxy.
Obecně platí, že proxy server(y) je vhodné použít pouze tehdy, pokud chcete zmást cílový systém, aby si myslel, že jste někdo jiný.
To může vypadat jako zcela samozřejmá informace, důležitý je ale důraz na slovo zmást, neboť cílem je zmatení, nikoliv neprůstřelná bezpečnost.
Nad použitými proxy většinou nemáme žádnou kontrolu a přestože se dají řetězit, čímž se bezpečnostní hledisko zvětšuje, nikdy nevíte, jestli proxy neloguje všechny přístupy do souboru, který její provozovatelé s radostí vydají každému, kdo si o něj řekne. Dnes je také běžné, že povinnost logovat přístupy na úrovni "kdy-kdo-kam" mají všichni poskytovatelé.
Pokud nad proxy serverem nemáte kontrolu, nespoléhejte na něj jako na anonymizační prvek!
Kdy je tedy vhodné použít proxy? Všude tam, kde není předpoklad, že se někdo bude vaší identitou zabývat. Z hlavy mě napadá například vytěžování databází, trolling, obcházení limitů na jeden účet či jednu IP adresu. Obecně tehdy, když chcete zabránit podezření, že mnoho přístupů ve skutečnosti pochází z jednoho zdroje.
Výjimky z tohoto principu můžete udělat pouze tehdy, pokud vám nezáleží na zjistitelnosti stroje, ze kterého požadavky přichází, či pokud máte v cestě zapojeny další anonymizační prvky (TOR třeba).
Při použití proxy je také nutno brát v úvahu, že provozovatel může číst veškerá přenášená data, pokud přes to netaháte ještě nějaký vlastní šifrovaný tunel. Nevyplatí se tedy přenášet loginy k systémům, na kterých vám záleží.
Pro ty kdo se s proxy servery nikdy nesetkali zde v krátkosti uvedu jednotlivé parametry, které běžně proxy listy zobrazují:
HTTP - proxy přes kterou je možné směřovat HTTP požadavky. Vhodné k procházení webu. Port většinou 80 či 8080, ale může být i jiný.
HTTPS - to samé jako předchozí, jen fungující skrz šifrovaný tunel na portu 443.
SOCKS - Pokud někde uvidíte jen SOCKS, může se jednat o SOCKS4 či SOCKS5 proxy. SOCKS4 umožňuje přenos libovolného protokolu, neboť pracuje přímo se socketem a spojeními, nikoliv s HTTP requesty.
SOCKS5 - Vůbec nejlepší, neboť umožňuje jak IPv4, tak i IPv6 requesty, libovolné protokoly, autentizaci a tak dále. Navíc je docela vysokoúrovňová co se protokolu týče.
Většinu času vám nejspíš vystačí HTTP proxy, neboť je nejjednodušší na použití a zcela dostatečná pro spoustu případů. V pythonu jsem napsal klienta httpkie, který umožňuje pro každou instanci použít jinou proxy. Tohle může být trochu problém u SOCKS, kde je v pythonu většinou nahrazován celý socket, což může znesnadňovat paraelizaci.
Transparent - pro běžné účely k ničemu, neboť tato proxy vyzrazuje vaší IP adresu přes hlavičku HTTP_X_FORWARDED_FOR. Občas se dá použít k obejití hloupějších firewallů.
Anonymous - proxy která vaší IP adresu maskuje tou svojí. Z hlaviček se dá zjistit samotný fakt, že používáte proxy.
Elite - proxy která skrývá vaší IP adresu a nedá se jednoduše zjistit, že se jedná o proxy server.
Pro většinu potřeb postačuje Anonymous proxy, neboť jsou dostatečně rychlé a když se nikdo nedívá, tak ani nezjistí, že se jedná o proxy.
Port, na kterém proxy naslouchá. Najít se dají v podstatě všechny možné, imho je nejžádoucnější chtít co nejvyšší, od deseti tisíc začínaje, protože ten většinou nenajdou ti, kdo se dívají zda se jedná o proxy zpětným scannem. Pro většinu použití však stačí ty běžné - 80, 443, 8000, 8080 atd..
Dalším často uváděným parametrem je ping. Někde se jedná o pouhé pingnutí proxy serveru, jinde je měřeno jak dlouho trvá jeden request.
Tahle hodnota se v čase pořád mění podle zátěže, ale vždy chcete co nejnižší.
Poslední často uváděnou hodnotou je země, kde se proxy server nachází. Většinou je dobré volit jinou zemi, než kde se zrovna nacházíte a vyhnout se zemím jako Čína, kde je vše monitorované. V některých případech také cílíte na službu, která bere pouze přístupy z čech (registrace na wz.cz například).
V praxi tohle pole moc neznamená, protože je detekováno na základě geoip a whois a vše může být úplně jinak, jen proto že poskytovatel byl moc líný měnit záznamy.
Máte tedy několik možností - proxy si zaplatit, což stojí peníze a také to klade větší nároky na zachování alespoň zdání anonymity, nebo se naučit pracovat s různými nestandardními chováními, které se dají nalézt u proxy zdarma.
Třetí možnost, která vyžaduje vytvoření vlastního botnetu zde nebudu uvažovat, protože jestli zvládnete tohle, tak tenhle problém vůbec nemusíte řešit a rovnou můžete použít cílové počítače pro běh vašeho programu.
Co se týče placených proxy serverů, nekupujete si konkrétní údaje pro proxy, ale v drtivé většině případů přístup k neustále updatovanému proxy listu, kde by se teoreticky měly nacházet jen kvalitnější servery, které alespoň pár hodin budou vykazovat konzistentní chování.
Není na tom moc co řešit - prostě převedete peníze na účet poskytovatele a zpět dostanete login na server, kde máte přístupný seznam několika stovek až tisíc proxy-serverů, většinou i s metadaty ohledně typu (Transparent/Anonymous/High anonymous, Sock/HTTP), odezvy a země původu.
Někdy se platí za čas (incloak), jindy je přístup doživotní (hidemyass).
Neplacených proxy listů není tak moc - většinou se jedná jen o živé ukázky pro placené servery. To nám ovšem nijak nebrání napsat parser a strojově je zpracovávat.
Příklady:
Psaní jednotlivých parserů nechám na vás - za sebe můžu říct, že jsem napsal parsery na všechny uvedené a většina z nich nezabrala skoro žádnou práci, stačí k tomu prostě stahovátko, HTML parser a trocha pythonu. Nejvíc ze všech mi dal zabrat server hidemyass.com, kde rychle zjistíte že vše je obfuscované a kompletní parser tedy vyžaduje částečnou implementaci Javascriptu a CSS. Jako bonus dostanete při opakovaných přístupech ban, takže potřebujete proxy, aby jste mohli stáhnout seznam proxy ;)
Jako příklad zde uvádím implementaci HTTP proxy (!) grabberu na prvně jmenovaný server:
#! /usr/bin/env python
# -*- coding: utf-8 -*-
#
# Interpreter version: python 2.7
#
# Imports =====================================================================
import httpkie
import dhtmlparser as d
# Functions & objects =========================================================
def getProxies():
"""
Return array of dicts following this structure:
{
ip: str(ip),
port: int(port),
ping: int(ms)
}
"""
down = httpkie.Downloader()
dom = d.parseString(
down.download("http://incloak.com/proxy-list/?type=h&anon=234")
)
proxies = []
for tr in dom.find("table")[6].find("tr")[1:]:
proxy = {
"ip": tr.find("td")[0].getContent(),
"port": 8080,
"ping": int(tr.find("div")[-1].getContent().split()[0])
}
proxies.append(proxy)
return proxies
if __name__ == '__main__':
import json
print json.dumps(getProxies())
print len(getProxies())
Jak vidíte, nejedná se o nic sofistikovaného a napsat celý script mi zabralo tak 30 minut.
Takže co existuje za proxy víte. Kde je vzít víte. Script, který stáhne šedesát čtyři nově publikovaných máte. Teď už vám nic nebrání v jejich použití. Celé to zakomponujete do existujícího programu a spustíte váš ďábelský plán. Teď už jen hromy, blesky a váš šílený chechot, který se line nocí..
Jenže ouha, celé to po chvíli vymrzlo. Chechot se mění do bolestného vytí a vás čekají dlouhé hodiny debugování a zjišťování, co je vlastně špatně.
Všechno to, co jste si mohli přečíst až sem jsou obecně známé informace, které jde poměrně lehce najít všude možně po internetu. To co bude následovat dál jsou zkušenosti, které většinou musíte získat tou horší, bolestivější cestou, protože o nich nikdo moc nepíše.
V ideálním světě by vznikla proxy, někdo by jí zaindexoval do proxy listu a vy by jste jí mohli používat. Proxy by byla neomezeně rychlá, plně anonymní a hlavně stále stejná, tedy konzistentní, až do konce světa.
Ve skutečném světě vznikne proxy, někdo jí zaindexuje a vy jí můžete používat. Na první request odpoví okamžitě, na druhý za 10 sekund a na další neodpoví nikdy. Nebo na něj bude odpovídat půl hodiny, či půl dne, písmenko za písmenkem, každou minutu jedno.
Proxy list nepoužíváte jen vy, ale zároveň pár (desítek) tisíc uživatelů, takže na každou proxy, která se tam vyskytne se automaticky vrhne i spousta dalších lidí. To že proxy server minutu funguje, další půl hodinu je zahlcen a potom znova funguje je zcela běžný stav.
Dál je také nutné poznamenat, že žádná proxy nebude fungovat do nekonečna. Život většiny z nich je docela jepičí a měří se na dny, přičemž nikdy nevíte, jak dlouho se ta vámi používaná povaluje na proxylistu.
Najdete servery, které vám na prvních 5 požadavků odpoví bleskově a potom začnou odpovídat už jen reklamní stránkou.
Taky jsem viděl servery, které modifikují přenášená data a vkládají do nich reklamy, či škodlivý kód pomocí "on the fly" modifikace binárních souborů.
Velmi zřídka narazíte i na servery, které jsou několik requestů anonymní a potom se najednou přepnou na transparent.
Už jsem psal, že život proxy je jepičí, ale nutno taky zdůraznit, že jejich umírání je skokové. Jak je jednou odhalí, tak budou vypnuty z milisekundy na milisekundu, dle zákona schválnosti nejčastěji právě uprostřed vašeho datového přenosu.
Dostali jste ze seznamu krásnou Elite proxy s malým pingem? Jak to víte?
Nemá smysl věřit údajům, které si stáhnete ze seznamu, jsou spíš jen takové orientační, sloužící k filtrování ostatních záznamů co vás nezajímají.
Pište si unittesty na vaše parsery proxy serverů. Ochrany na jednotlivých serverech se čas od času mění, stejně jako se mění design a layout stránky. To že nějaký grabber funguje teď neznamená, že bude fungovat i zítra, proto testujte, co vlastně vrací a jestli náhodou nepadl na tom, že server vás zabanoval, změnil adresu, nebo úplně přestal existovat.
Není nic víc otravného, než když se po měsíci přihlásíte na VPS, aby jste zkopírovali výsledky dlouhé sklizně a zjistíte, že celý script stál na tom, že mu vyschl proxy pool, protože nebylo odkud brát. Na tohle by vás měl program proaktivně upozornit mnohem dřív!
Řešení je na dvou úrovních - na úrovni kódu a na úrovni filtrování proxy.
Všechny proxy servery, které ze seznamu získáte si musíte prověřit na zde popsané jevy, před tím než je můžete použít. V krátkosti:
Pokud sklízíte nějaké větší objemy dat a program poběží déle, než jen pár hodin, je nutné počítat s tím, že nebudete zadávat jen jednu proxy při spuštění a musí být přítomna nějaká cesta, jak z filtru nových proxy serverů načítat další a případně dát zpět vědět, že by měl filtr přesunout nefunkční proxy na banlist.
Dál je nutné počítat s načítáním a ukládáním stavu - tohle přímo nesouvisí s proxy, ale je dobré počítat s tím, že program může zhavarovat a po startu by měl začít tam kde přestal, nikoliv dělat vše úplně odznova.
Na úrovni funkce, která stahuje data z internetu je nutné počítat s několika efekty:
Ideální architektura by vypadala nějak takhle:
Máte samostatně fungující stahovače, které pročesávají proxylisty a stahují z nich informace. Tyto informace cpou do fronty příchozích proxy.
Frontu sleduje spouštěč prověřovačů. Pokud se v ní objeví nová proxy, která není na banlistu, je spuštěn proces prověřovače s timeoutem pár minut, který proxy prověří a případně jí schválí, či umístí na banlist, aby s ní příště neztrácel čas.
Schválené proxy jsou přesunovány do fronty ověřených proxy listů, odkud si je berou aplikace. Pokud aplikace proxy použije, resetuje timeout do dalšího prověření. Jestliže se proxy během použití ukáže jako nevhodná, je přidána na banlist.
Pokud je proxy ve frontě ověřených proxy listů déle jak N minut, je znova předána na prověření.
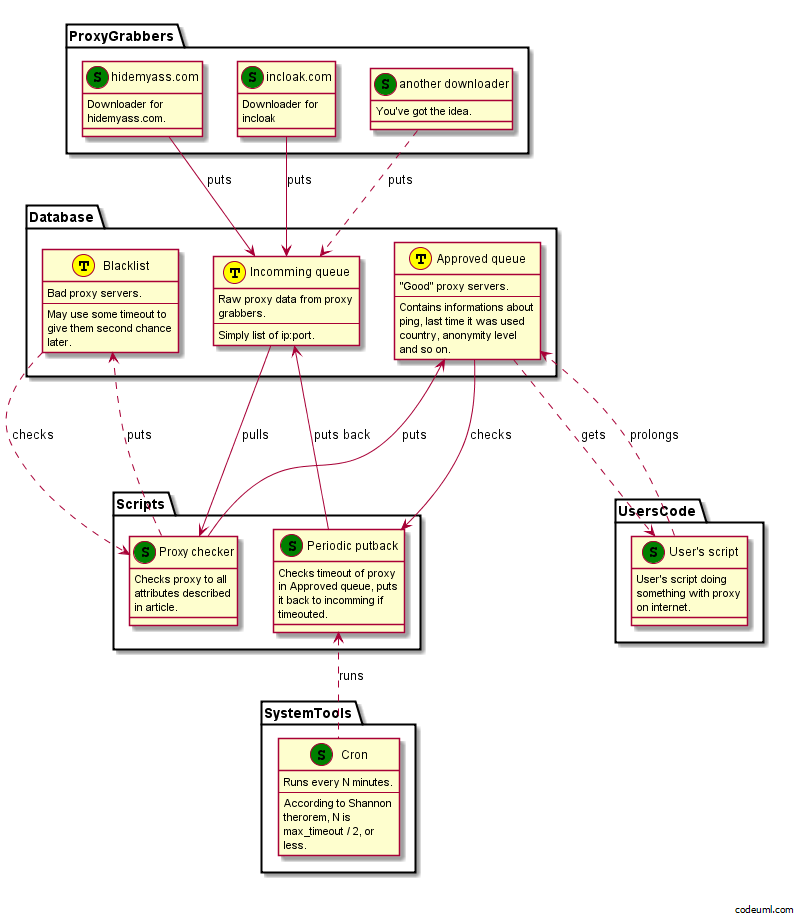
Pokud nejste zas tak moc zruční programátoři, nebo prostě a jednoduše nemáte moc času, celé se to dá udělat špinavě a ošklivě, podmínkou však je, že váš program umí pokračovat tam, kde přestal.
K tomu jsou zapotřebí dvě věci:
Již dlouhá léta používám tento maximálně triviální scriptík, který jsem nazval doitfaggot:
#!/bin/sh while ! $*; do :; sleep 2; done
Jediné co tento script dělá je, že spouští parametr do té doby, dokud se neukončí s nulovým výstupním kódem.
timeout je linuxový program, který spustí parametr a čeká na ukončení maximálně nějakou stanovenou dobu. Pokud program běží déle, je násilně ukončen.
Asi už vám došlo, jak to celé bude fungovat:
doitfaggot timeout 10m my_program.py -p `./get_proxy.py | head -n 1`
Celé to funguje tak, že doitfaggot spouští váš program dokud timeoutuje (=timeout vrací kód >0), což se děje každých 10 minut. Jakmile se váš program korektně ukončí, timeout vrátí 0, čímž se vypne i doitfaggot. Proxy server je při každém zavolání načten jako parametr vašeho programu.
Tento přístup je z programátorského hlediska neskutečná prasečina, ale dá se docela úspěšně použít na menší věci. V podstatě veškeré uvedené dobré rady a možné chybové chování ignoruje a hrubou silou to zkouší stále znova a znova a znova a zase, dokud neuspěje.
Tiskni
Sdílej:
![]()
![]()
![]()
![]()
![]()
![]()
 10.2.2015 21:19
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
10.2.2015 22:07
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
11.2.2015 00:36
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
12.2.2015 01:03
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
23.6.2015 13:51
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
12.9.2017 18:21
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
10.2.2015 21:19
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
10.2.2015 22:07
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
11.2.2015 00:36
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
12.2.2015 01:03
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
23.6.2015 13:51
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
12.9.2017 18:21
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
ISSN 1214-1267, (c) 1999-2007 Stickfish s.r.o.

 11.2.2015 16:24
11.2.2015 16:24
 11.2.2015 19:52
11.2.2015 19:52