Portál AbcLinuxu, 21. června 2026 05:52
TeX – 3 (příklady autorského značkování)
Články
-
TeX – 3 (příklady autorského značkování)
Předvedeme jednoduchý a typický dokument s odkazy, poznámkami, generovaným
obsahem, obrázkem, tabulkou a vzorcem vytvořený třemi způsoby: pomocí
CSplainu+OPmac, pomocí XeLaTeXu a pomocí ConTeXtu. Kromě toho si mohou čtenáři
tohoto dílu trochu zasoutěžit, ovšem ceny nejsou vypsány žádné.
Obsah
Jak bylo řečeno v prvním díle seriálu, autor připraví smluveným způsobem
označkovaný zdrojový dokument ke zpracování TeXem. Příklady, jak může zdrojový
dokument vypadat a jak následně vypadá výstup po zpracování, jsou shrnuty
zde:
O značkování v jednotlivých příkladech si nyní řekneme více. Ve všech
ukázkách je deklarační část. Obsah této části ovlivní globálně celý dokument.
V této části jsem za procenta umístil komentáře vysvětlující, k čemu
konkrétní řádek deklarační části slouží. Poznámka pro čtenáře, kteří vidí TeX
poprvé: znak procento uvozuje komentář, který TeX při zpracování ignoruje (od
procenta do konce řádku). Chce-li autor procento do textu napsat, musí použít
\% nebo něco podobného. Implicitně jsou nastaveny jako „TeXovsky
specifické“ ještě tyto znaky: \, {, },
$, &, #, ^, _
a ~. To se uživatel dozví v úvodu každé příručky o TeXu.
Ve všech ukázkách se vyskytuje:
Elementární makro – lorem ipsum
link
Pokud chce typograf pouze vyzkoušet, jak vypadá font, návrh stránky atd.
a nemá po ruce konkrétní text (resp. nechce, aby byl čtenář textem
rozptylován), použije text „Lorem ipsum ... est laborum“. Je to vykousaný
text z Cicera. V ukázkách je vytvořena
zkratka \lorem expandující na tento text například takto:
\def\lorem{Lorem ipsum ... est laborum}
A nyní můžeme text použít: \lorem.
A třeba ještě dvakrát: \lorem. \lorem.
Podíváte-li se do jednotlivých ukázek, zjistíte, že primitivní příkaz
\def je použit jen v ukázce s OPmac. Na druhé straně například
uživatel LaTeXu použije \newcommand (toto makro pochopitelně interně
provede \def). Proč LaTeXista nepoužije \def rovnou? Je
to jednak proto, že v LaTeXových příručkách je zmíněno makro LaTeXu
\newcomand a zatajen primitivní příkaz \def, dále proto,
že \newcommand pohlídá, zda uživatel něco omylem nepředefinuje,
a konečně proto, že se sluší v LaTeXovém dokumentu použít lexikální prvky
z LaTeXu, třebaže by primitivní příkazy fungovaly také. Je to podobné, jako
když programátor, který užívá vyšší programovací jazyk, přejde z ničeho nic do
assembleru: může to udělat, ale nesluší se to.
Ukázka první – CSplain + OPmac
link
CSplain
i OPmac jsou má práce, jsou tedy mému srdci
nejbližší, takže popis značkování začnu u tohoto příkladu.
CSplain je základní rozšíření Knuthova plainTeXu. Samotné použití tohoto formátu
znamená, že všechny vlastnosti dokumentu (nadpisy, odkazy, generování obsahu) si
musí uživatel naprogramovat sám. Každý uživatel si tak vytvoří svou sadu maker, do
kterých vidí, kterým rozumí a která odpovídají jeho stupni pochopení, jak
funguje TeX. Pro začátečníka, který se nechce spoléhat na rozsáhlejší hotová řešení
v balíčcích maker typu LaTeX nebo ConTeXt, je zde ale velká vstupní překážka.
Naprogramovat třeba jen automatické generování obsahu není úplně jednoduché. Proto
jsem loni zveřejnil svá makra, která jsem nazval OPmac, podrobně je dokumentoval
(pro autory i pro experty) a nabídl je uživatelům, kteří chtějí zůstat
u jednoduchosti plainTeXu, ale rádi využijí Olšákova hotová řešení. Po zavedení
makra pomocí \input opmac je tedy k dispozici zhruba to, co nabízí
LaTeX+hyperref+graphicx+amsmath+color, ale vše je výrazně jednodušší.
Příkazem \input cs-schola v záhlaví dokumentu se zavádí fontová
rodina Schola projektu TeXGyre.
V tomto projektu se autoři rozhodli přepsat obvyklé fonty Times, Helvetica,
Courier, Bookman, Palatino, Avantgarde, New Century do moderního formátu (OTF),
přidat jim další vlastnosti, opravit drobné chyby a nazvat je mírně jinak:
Termes, Heros, Cursor, Bonum, Pagella, Adventor, Schola. CSplain nabízí sadu
„fontových souborů“, kterými se zvolená rodina fontů zavede. V tomto příkladě
tedy \input cs-schola.
Dokument psaný v OPmac se člení například na sekce označené příkazem
\sec a podsekce označené příkazem \secc. Za tímto příkazem
následuje název sekce/podsekce a ten je ukončen prázdným řádkem. Analogicky
pomocí \tit vytvoříme titul.
Obsah vytvoříme příkazem \maketoc. Pro výčty je použita dvojice
\begitems a \enditems s tím, že mezi touto dvojicí je
hvězdička aktivní a zahájí další položku výčtu. Pro výpisy kódů slouží dvojice
\begtt a \endtt, kterou jsem popsal už před mnoha lety
v knize TeXbook naruby.
Odkazy (dopředné i zpětné) se řeší pomocí \label, \ref
a \pgref. Lejblík, který se používá pro propojení odkazů ve zdrojovém
dokumentu, ale ve výstupu není vidět, je třeba zapouzdřit do hranatých závorek.
Obrázky se zařadí příkazem \inspic a tabulky lze vytvořit příkazem
\table. Přímé použití primitivních příkazů TeXu nebo maker plainTeXu se
nepovažuje za projev neslušného vychování, ale je to běžný vyjadřovací prostředek.
Uživatel tím dosáhne na páky přímo spojené s TeXem bez toho, aby byl od nich
oddělen dodatečným makro-polštářem.
Vzhled ukázkového dokumentu je „implicitní pro OPmac“. Při použití OPmac se
předpokládá, že typograf přetáhne některá makra z OPmac do svého souboru
a tam je předefinuje k obrazu svému a k obrazu cíleného dokumentu.
Ve zdrojovém textu pak bude napsáno \input opmac následované například
\input styl, kde proběhne předefinování. Proto jsou makra OPmac napsána
srozumitelně a bez zbytečných parametrů.
Ukázka druhá – XeLaTeX
link
LaTeX v záhlaví dokumentu zavádí tzv.
balíčky pomocí \usepackage. Přesněji: makro \usepackage
použije primitivní příkaz \input k načtení specifikovaného souboru
maker. Uživatel LaTeXu teoreticky nemusí nic nestandardního řešit: jakýkoli
požadavek, na který si vzpomene, je pravděpodobně už vyřešen v nějakém
balíčku. Takže uživateli stačí přijít na to, který to je balíček
(CTAN je poměrně rozsáhlý), nastudovat dokumentaci
k vybranému balíčku a balíček použít. Nicméně velká většina balíčků řeší
úkol, který je na úrovni TeXu samotného řešitelný jen pár řádky maker (je jen
potřeba vědět, jakými). OPmac proto místo takových krátkých balíčků používá www
stránku OPmac triků.
Čtenáři, kteří znají LaTeX, si ve zdrojovém dokumentu v ukázce povšimnou
několika podstatných změn, které jsou typické pro XeLaTeX: místo balíčku
babel pro vícejazyčnou sazbu je použit balíček polyglossia,
dále se nepoužívá balíček fontenc ani inputenc, protože XeTeX
nekompromisně předpokládá vstup v UTF-8 a textové fonty v UNICODE.
K zavedení rodin fontů je třeba použít balíček fontspec, který je
nově vytvořen pro UNICODE fonty.
Prvním povelem LaTeXu \documentclass se specifikuje základní typ
dokumentu (tzv. třída dokumentu). Obvykle se používá jedna z možností
article, report, book, letter nebo
slides. Povel \documentclass přečte soubor odpovídajícího názvu
s příponou cls (například article.cls), kde jsou makra
nastavující výchozí stav dokumentu podle požadované třídy a dodatečných
parametrů specifikovaných v hranaté závorce.
LaTeX nutí uživatele dodržovat strukturu do sebe vnořených tzv. prostředí
obklopených příkazy \begin{něco} a \end{něco}. Pro
zahájení sekce se používá příkaz \section a pro podsekci
\subsection. Nadpis následuje uzavřený ve svorkách. Obrázek načteme
pomocí \includegraphics (toto makro je definováno v balíčku
graphicx). Tabulku tvoříme v prostředí tabular. Zájemcům
o LaTeX doporučuji Satrapovu knížku LaTeX
pro pragmatiky.
Svůj soukromý vztah LaTeXu jsem shrnul v článku
Proč nerad používám LaTeX. Ačkoli jsem
článek napsal před 16 lety, nic bych v něm neměnil ani dnes.
Ukázka třetí – ConTeXt
link
Podíváte-li se do ukázkového zdrojového souboru, shledáte, že prostředí
v ConTeXtu se vymezují příkazy \startněco a \stopněco.
Nejpodstatnějším rysem ConTeXtu je možnost nastavení parametrů sazby příkazem
\setupněco následovaným údaji ve tvaru klíč=hodnota
v hranatých závorkách. Pro sekce a podsekce se používají příkazy
\section a \subsection stejně jako v LaTeXu. Na rozdíl
od něj ale může za těmito příkazy v hranaté závorce následovat lejblík pro
odkaz bez nutnosti psát slovo \label.
Záměrem ConTeXtu je umožnit uživateli nastavovat typografické a další
parametry sazby pomocí dokumentovaných parametrů. Tím se liší od LaTeXu, kde se
předpokládá, že použitím stylového souboru jsou typografické parametry nastaveny
a uživatel se o to nestará. ConTeXt se liší pochopitelně taky od OPmac, kde
si typografické parametry uživatel nastaví přímo na úrovni primitivních registrů
TeXu a není nucen hledat v dokumentaci, jak se která vlastnost jmenuje
a jak ji nastavit v nové vrstvě, která se nad TeXem rozprostírá
a jmenuje se ConTeXt.
ConTeXt (ve verzi MKIV) je silně propojen
s Lua skriptováním a (v obou verzích MKIV i MKII)
s Metapostem, což je (zhruba řečeno) jazyk na „programování obrázků“. Grafické
prvky tak kooperují se samotnou sazbou prostřednictvím Metapostu. K této
problematice se vrátím až v díle věnovaném grafice. K verzi ConTeXtu MKII
vyšel před léty seriál na rootu.
Soutěž o LaTeXového a ConTeXtového experta
link
Osobně nejsem ani jedním z uvedených expertů. Proto jsem s ukázkami
LaTeXu a ConTeXtu měl jisté potíže. Například v LaTeXu nevím, jak
přesvědčit tabulku, aby měla kolem vodorovných čar více vertikálního prostoru
a zejména aby ty vodorovné čáry neprotínaly dvojitou svislou čáru. Kdo první
v diskusi pod tímto článkem ukáže LaTeXové řešení (tj. nikoli TeXové, na úrovni
\halign, \strut atd. to umím taky), toho budu nazývat
LaTeXovým expertem.
Dále je zde druhá XeLaTeXová úloha: matematické
fonty zůstaly v Computer Modern, což se k písmu Schola poněkud
nehodí. Chtěl bych tam mít (jako v ukázce s OPmac) TXfonty. Použití
\usepackage{txfonts} se nesnáší s balíčkem fontspec. Kdo
vyřeší tento problém, toho budu nazývat XeLaTeX-fontovým expertem. Komu se
podaří vytvořit tabulku se dvojitými čarami dle vzoru z OPmac-ukázky
v ConTeXtu, toho budu nazývat ConTeXtovým expertem.
Další články z této rubriky
Diskuse k tomuto článku
30.10.2013 07:22
beginer
Re: TeX – 3 (příklady autorského značkování)
30.10.2013 08:05
K>
Re: TeX – 3 (příklady autorského značkování)
30.10.2013 10:15
Jaroslav
Re: TeX – 3 (příklady autorského značkování)
30.10.2013 11:10
vencas | skóre: 32
Re: TeX – 3 (příklady autorského značkování)
30.10.2013 11:14
vencas | skóre: 32
tex.stackexchange.com
31.10.2013 00:00
dgvdtfdsffx
Re: TeX – 3 (příklady autorského značkování)
31.10.2013 15:17
fxf
Re: TeX – 3 (příklady autorského značkování)
2.11.2013 09:19
olsak | skóre: 29
Re: TeX – 3 (příklady autorského značkování)
4.11.2013 13:20
bhy | skóre: 36
| blog:
bhyblog
| brno
Re: TeX – 3 (příklady autorského značkování)
4.11.2013 21:08
olsak | skóre: 29
Re: TeX – 3 (příklady autorského značkování)
5.11.2013 20:18
lama
TeX – 3 (příklady autorského značkování) - Angličtina?
ISSN 1214-1267, (c) 1999-2007 Stickfish s.r.o.
 30.10.2013 10:26
olsak | skóre: 29
30.10.2013 10:26
olsak | skóre: 29
 30.10.2013 09:14
30.10.2013 09:14
 30.10.2013 10:28
30.10.2013 10:28
 30.10.2013 18:55
30.10.2013 18:55

 31.10.2013 18:05
31.10.2013 18:05
 1.11.2013 12:18
1.11.2013 12:18
 V tomto konkrétním případě můžou být důvody následující:
V tomto konkrétním případě můžou být důvody následující:
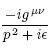 6.11.2013 09:41
6.11.2013 09:41
{kind=link}