Portál AbcLinuxu, 12. června 2026 16:22
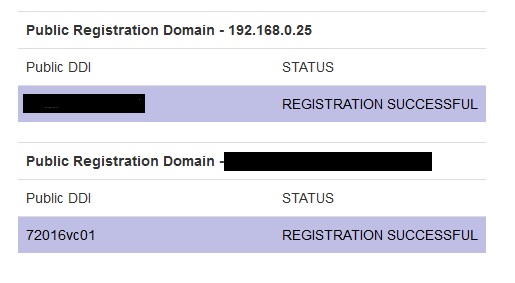
PRD, PDDI, STATUS
192.168.0.25, somestring, REGISTRATION SUCCESSFUL
our.domain.de, somestring, REGISTRATION FAILED
https://192.168.3.200/services/webapp/monitor/sip_i.php?sip_i=regstatussip_i.js
jquery.js
bootstrap.min.js
sorttable.js
jquery.quicksearch.js
var dataTable;
function init()
{
dataTable = document.getElementById("datatable");
var aCheckBoxes = document.getElementsByName("checkboxes");
dataTable.CheckBoxes = aCheckBoxes;
}
function selectAllRows(x)
{
var aCheckBoxes = dataTable.CheckBoxes;
var bChecked = false;
if(x.id == 'clearall' || x.id == 'checkall')
{
bChecked = (x.id == 'clearall') ? false : true;
}
var aRows = dataTable.tBodies[0].rows;
// nRows is the index of the last checkbox
// warning : remove the title line
var nRows = aRows.length-2;
for(var i=nRows;i>=0;i--)
{
aCheckBoxes[i].checked = bChecked;
}
}
function deleteSelected()
{
var aRows = dataTable.tBodies[0].rows;
var nRows = aRows.length-2;
var parm="";
var aCheckBoxes = dataTable.CheckBoxes;
for(var i=nRows;i>=0;i--)
{
if (aCheckBoxes[i].checked)
{
if (parm != "")
parm+=" "
parm+=aCheckBoxes[i].value;
}
}
document.getElementById("theParam").value = parm ;
document.getElementById("theForm").submit();
}
dataTable = document.getElementById("datatable");var dataTable;
function init()
{
dataTable = document.getElementById("datatable");
} 18.3.2020 11:33
MakeIranBombedAgain❗ | skóre: 42
| blog: Grétin blogísek
| 🇮🇱==❤️ , 🇵🇸==💩 , 🇪🇺==☭
18.3.2020 11:33
MakeIranBombedAgain❗ | skóre: 42
| blog: Grétin blogísek
| 🇮🇱==❤️ , 🇵🇸==💩 , 🇪🇺==☭
nóóóóóó vygenerovaná ne :O :O ;D ten řádeček kódu dělá že se v html dokumentu najde element co má parametr id nastavenej na 'datatable' a tan se uloží do proměný dataTable ;D
zisti z kterýho html souboru seto volá a tam si najdi tu tabluku a tu asi jako možná pude parsovat pythonem :O ;D
Díky, svatá Gréto! :) Jediný element s nějakým parametrem id je tento:
ífrejm width="100%" frameborder="0" src="./blank.html" name="content" id="content" onload="javascript:resizeIframe(this);"> ífrejm
A to bohužel není to co bysme potřebovali. Pak už jsem tam našel jen dvě tabulky s class="dataTable, ale to mi taky nepomůže. Kód stránky po načtení vypadá takto:
https://pastebin.com/X89nPLzyVidím tam, že se načte skript:
SRC="./js/sip_i.js"A o kus níže se zavolá funkce init() z tohohle skriptu:
init();hhhmmmmm celý je to takový divný :O :'( to je celej ten sip_i.js co sems dával?? tam seasi jako jenom nějak čaruje s checkboxama :'( fakt ty data nenačítá nějakej php skript strčenej v místě tý tabulky v tom html dokumentu?? jestli mužeš tak sem hoď jak ten dokument z pastebin vypadá bez zapnutýho js třeba staženej wgetem
ještě sem dej možná tamto sorttable.js třeba to nedělá jenom řazení nevim
podezírám podobně pomenovanej skript sip_i.php že se někde asi bude volat ale jako hádám :'(
https://192.168.2.100/services/webapp/monitor/sip_i.php?sip_i=regstatus/fakt si to jako dobře nakopíroval ten html kód?? tam tabulka neni uzavřená :O :O
todleto by ti mohlo fungovat i tak ;D
from bs4 import BeautifulSoup
import urllib3
http = urllib3.PoolManager()
url = 'https://192.168.2.100/services/webapp/monitor/sip_i.php?sip_i=regstatus'
response = http.request('GET', url)
soup = BeautifulSoup(response.data,"html.parser")
counter=0
#maj tam chybu tag table neni uzavřenej a nemužeme rozumě skákat po tabulkách fakt si to dobře nakopíroval?? :O :O
#proto sem šáhla po těch 'td'
counter=0
PRD="" # :D :D :D :D
PDDI=""
STATUS=""
rows=[]
#pro všechny td tagy v html až jako na ten poslední
#poslední je nějaká kravinka
for td in soup.find_all("td")[:-1]:
if counter==0:
PRD=td.find('b').text.split('-')[1].strip()
counter+=1
elif counter==1:
if not "Public DDI" in td.text:
raise IndexError('sem jako cekala na indexu 1 hodnotu Public DDI a mam tam '+td.text+'!!!! :O :O')
counter+=1
elif counter==2:
if not "STATUS" in td.text:
raise IndexError('sem jako cekala na indexu 2 hodnotu STATUS a mam tam '+td.text+'!!!! :O :O')
counter+=1
elif counter==3:
PDDI=td.text
counter+=1
elif counter==4:
STATUS=td.text.strip()
#udělali jsme kolečko jedný tabulky uložíme řádek napotom
counter=0
rows.append({'PRD': PRD,'PDDI': PDDI,'STATUS': STATUS})
else:
raise IndexError('jako neco je hoooooooooooooooodne spatne protoze index neni v intervalu 0-4!!!! :O :O')
for row in rows:
print("PRD: {PRD} PDDI: {PDDI} STATUS: {STATUS}".format(**row))
Tak po pár menší úpravách mi to funguje. Bylo potřeba přidat autentizaci a ignorovat chybu certifikátu. A split v prvním td bylo potřeba udělat pomocí mezery, protože string za pomlčkou může pomlčku obsahovat:
#!/usr/bin/env python3
# importing the libraries
import requests
from urllib3.exceptions import InsecureRequestWarning
from bs4 import BeautifulSoup
# Suppress only the single warning from urllib3 needed.
requests.packages.urllib3.disable_warnings(category=InsecureRequestWarning)
# Define variables
url = "https://192.168.2.100/services/webapp/monitor/sip_i.php?sip_i=regstatus"
user = 'user'
passwd = 'secret'
# Make a GET request to fetch the raw HTML content
response = requests.get(url, auth=(user, passwd), verify=False)
# Parse the html content
soup = BeautifulSoup(response.text, "html.parser")
counter=0
counter=0
PRD=""
PDDI=""
STATUS=""
rows=[]
for td in soup.find_all("td")[:-1]:
if counter==0:
PRD=td.find('b').text.split(' ')[4].strip()
counter+=1
elif counter==1:
if not "Public DDI" in td.text:
raise IndexError('Expected value "Public DDI" but got '+td.text+'')
counter+=1
elif counter==2:
if not "STATUS" in td.text:
raise IndexError('Expected value "STATUS" but got '+td.text+'')
counter+=1
elif counter==3:
PDDI=td.text
counter+=1
elif counter==4:
STATUS=td.text.strip()
# First table is ready. We save the row for next time.
counter=0
rows.append({'PRD': PRD,'PDDI': PDDI,'STATUS': STATUS})
else:
raise IndexError('Critical Error. Index is not within interval 0-4')
for row in rows:
print("PRD: {PRD} PDDI: {PDDI} STATUS: {STATUS}".format(**row))
Teď z toho ještě zbastlit check pro check_mk, ale s tim už si nějak poradim.
Díky všem.
19.3.2020 22:18
MakeIranBombedAgain❗ | skóre: 42
| blog: Grétin blogísek
| 🇮🇱==❤️ , 🇵🇸==💩 , 🇪🇺==☭
mužeš udělat split jenom prvním výskytem znaku/stringu uplně jednoduše takhle text.split('-',1)
taky je dobrý nedělat takovýdle krkolomný jednořádkový šílenosti jakože td.find('b').text.split('-',1)[1].strip()protože každej z těch kroků muže selhat třeba to jako nenajde tag b a vrátí to None b nemusí mit text za pomlčkou už nic nemusí bejt a tak. lepšejší je to mit rozdělený na jednotlivý kroky a ty případný chyby hlídat jim moc nevěřim když neuměj ani uzavřit tabulku :O ;D joa že tam je proměná counter dvakrát to je samo že navíc stačí ho mit jenom jednou ;D
nóóó sem trošku čuňačila aby to jako bylo rychle hotový :O :O :D ;D
OXO Connect Rel. 3.2
cpu name: PowerCPU
Software: ONEDE032/039.001
Linux kernel: Linux version 2.6.29.6-rt23-030.001
 18.3.2020 13:44
Josef Kufner | skóre: 70
18.3.2020 13:44
Josef Kufner | skóre: 70
#!/usr/bin/env python3
# importing the libraries
import sys, getopt
import requests
import re
from urllib3.exceptions import InsecureRequestWarning
from bs4 import BeautifulSoup
# Suppress only the single warning from urllib3 needed.
requests.packages.urllib3.disable_warnings(category=InsecureRequestWarning)
#def main (argv):
url = ''
user = ''
passwd = ''
hostname = ''
prd = ''
# Get full command-line arguments
full_cmd_arguments = sys.argv
# Keep all but the first
argument_list = full_cmd_arguments[1:]
short_options = "hu:p:H:P:"
long_options = ["username=","password=","hostname=","publicregistrationdomain"]
def usage():
print('check-sip-trunk.py -u <username> -p <password> -H <hostname> -P <publicregistrationdomain>')
try:
arguments, values = getopt.getopt(argument_list, short_options, long_options)
except getopt.GetoptError as err:
print (str(err))
usage()
sys.exit(2)
if not arguments:
usage()
sys.exit(2)
for opt, arg in arguments:
if opt == '-h':
usage()
sys.exit()
elif opt in ("-u", "--username"):
user = arg
elif opt in ("-p", "--password"):
passwd = arg
elif opt in ("-H", "--hostname"):
hostname = arg
url = f"https://{hostname}/services/webapp/monitor/sip_i.php?sip_i=regstatus"
elif opt in ("-P", "--publicregistrationdomain"):
prd = arg
# Make a GET request to fetch the raw HTML content
response = requests.get(url, auth=(user, passwd), verify=False)
# Parse the html content
soup = BeautifulSoup(response.text, "lxml")
counter=0
PRD=""
PDDI=""
STATUS=""
rows=[]
for td in soup.find_all("td")[:-1]:
if counter==0:
PRD=td.find('b')
if PRD is not None:
PRD=PRD.text.split('-',1)[1].strip()
counter+=1
else:
raise IndexError('Tag containing Public Registration Domain not found')
elif counter==1:
if not "Public DDI" in td.text:
raise IndexError('Expected value "Public DDI" but got '+td.text+'')
counter+=1
elif counter==2:
if not "STATUS" in td.text:
raise IndexError('Expected value "STATUS" but got '+td.text+'')
counter+=1
elif counter==3:
PDDI=td.text
counter+=1
elif counter==4:
STATUS=td.text.strip()
counter=0
if STATUS=="REGISTRATION SUCCESSFUL":
trunkstatus = "0 SIP-TRUNK - OK: Public Registration Domain - "+PRD+", Public DDI - "+PDDI+", Status - "+STATUS
rows.append(trunkstatus)
elif STATUS=="REGISTRATION FAILED":
trunkstatus = "2 SIP-TRUNK - CRITICAL: Public Registration Domain - "+PRD+", Public DDI - "+PDDI+", Status - "+STATUS
rows.append(trunkstatus)
else:
trunkstatus = "3 SIP-TRUNK - UNKNOWN: Public Registration Domain - "+PRD+", Public DDI - "+PDDI+", Status - "+STATUS
rows.append(trunkstatus)
else:
raise IndexError('Critical Error. Index is not within interval 0-4')
for item in rows:
if re.search(rf"\b{prd}\b",item):
print(item)
sys.exit()
else:
print("Public Registration Domain \""+prd+"\" does not exist.")
sys.exit(2)
Tiskni
Sdílej:
![]()
![]()
![]()
![]()
![]()
![]()
ISSN 1214-1267, (c) 1999-2007 Stickfish s.r.o.
{kind=link}