Portál AbcLinuxu, 13. července 2026 04:54
Ve hře byly storage od HP, EMC i ZFS.
HP nevyhrálo, protože bylo dražší jak NetApp, to samé platí o EMC.
Pokud jde o ZFS, tak tam jsem poptával NexentaStor u Thomas-Krenn. Jen samotná cena licence bez hw mi byla řečena 1 mil (ano, 1Milion pro 60TiB výsledné RAID-Zx konfigurace s HA). Fakt se zbláznili. Když mi toto řekli, už jsem se dál nesnažil vyjednávat a doteď nechápu, kam se svojí cenovou politikou mířili. Dokonce i pani na telefonu věděla, že jsou úplně mimo. Z telefonátu jsem měl pocit : "Já vím, že je to šílená suma, asi je to úplně mimo váš rozpočet".
Důvodů bylo hned několik.
NFS server 4.1 není na FreeBSD ani Solaris like systémech podporováno, a to dokonce ani nyní, natož před dvěma roky (a výkon NFS 4.1 je oproti verzi 3 zase někde jinde). Každá firma, co staví na Solaris like, si řeší svojí implementaci NFS, Nexenta snad měla první implementaci NFS 4.1.
Další důvod byla kompatibilita, protože máme ESXi a šéf by maximálně povolil ještě XEN a třeba Veeam je slušný zálohovací nástroj a umí pracovat přímo se storage, řídit jejich replikace, snapshoty a vše 100% konzistentně vůči běžícím VM (samozřejmě jen v té nejvyšší edici Veeamu - Enterprise Plus).
Další důvod byla nulová zkušenost s nějakým OSS řešením. ZFS teď zvládám na velmi dobré úrovni (mám postavený 60TiB backup storage na ZFS), už vím, co mohu, jak se k němu chovat, mám rozhled, vím, jaký hw použít, za jakých podmínek používat deduplikaci, jak diagnostikovat problémy atd. Toto osahání mi trvalo celkem dlouho, byly problémy, které se objevily jednou za x měsíců a byl problém je diagnostikovat atd. Nakonec to byl problém na všech frontách, za něco mohla hw vada, špatný návrh hw, špatný update OS, nepromyšlené použití deduplikace atd. Dalo by se říci, že jsem první střelou posral, co se dalo :D.
Samotné ZFS neumí jakékoli HA, to jen komerční implementace (na druhou stranu, s async by si člověk vystačil). Pokud bych chtěl storage na CEPH, tak jednak nemám zkušenosti, dále by to vyšlo dráž (minimálně 3 servery v jedné lokalitě, spíše 4), jak ten NetApp a funkcionalita by byla menší. Resp. nejsme tak velký, abychom potřebovali storage cluster s hafec nody, což by fakt vyšlo dráž, jak ten NetApp.
Poslední argument byl v tom, že i kdyby něco jiného šéf povolil, tak bych do toho nešel, protože už teď mám hafec práce a nechtěl bych nést přímou odpovědnost za další věci. Kdybych to postavil na nějakém vlastním/oss řešení, tak v případě problémů bych si mohl hodit provaz. V případě třetí strany je zde support a celkově se na takové řešení dívá vedení jinak. Prostě ani z mé strany nebyla vůle něco rozjíždět. Líbila se mi Nexenta, tak jsem chtěl aspoň to, ale jak už jsem řekl, oni evidentně nechtěli nás.
Jinak tu jsou ještě možnosti, postavit si OSS pole třetí stranou. V době, kdy se toto řešilo, jsem o tom nevěděl, ale např. firma Linuxbox, od které máme centrální mail/proxy gw, nabízí i privátní cloud včetně virtualizačního řešení s vlastním web ksichtem. Zřejmě to bude CEPH + KVM, ale asi by se dal domluvit čistě storage.
NetApp vyvíjí souborový systém WAFL (Write Anywhere File Layout), oficiální uvedení bylo ještě před dobou, kdy byl uveden ZFS.
Lze narazit na toto porovnání se ZFS : ONTAP vs ZFS, kde ZFS vede v kontrole dat (má checksummy/kontroly na všechno). Nicméně je to starší zápisek z roku 2011, takže těžko říci, jaký je aktuální stav.
Dřív i proběhla žaloba NetAppu na SUN za ZFS, kterou SUN vyhrál. Nicméně i toto je dnes argument firem, které se snaží vnutit NetApp.
Ohledně NetAppu jsme jednali s jednou firmou a pak jsem si všiml, že se na ní odkazuje i oficiální web Nexenty. Pozvali jsme si je tedy ještě jednou na jednání s tím, že nás zajímá i ZFS a oni mají zkušenosti s oběma řešeními. Chtěli jsme vědět porovnání atd. Sdělili nám, že přizvou ještě jednoho odborníka, který nám řekl :
Můj šéf viděl můj nesouhlas, ale i neochotu se hádat (koneckonců od toho to jednání nebylo, chtěli jsme jen znát zkušenosti, reálné porovnání). Po jednání jsme to probrali a usoudili jsme, že blbce ať si dělají z někoho jiného. Ta firma u nás klesla na nulu a už jsme od nich nikdy nic v budoucnu nepoptávali. Když neumí jednat narovinu a vymýšlí si bludy a umýslně dělají z klientů blbce, tak ať si to zkouší na někoho jiného.
Netapp ale od nich máme, protože v tom je ten fór. První firma, která se dozví o potencionálním zákazníkovi, hodí lock u NetAppu a nikdo jiný ani nesmí nabídnout cenu (prostě žádnou od NetAppu pro nás nedostane, konec), žádná soutěž neexistuje a není tak možnost se dostat níže u konkurence, prostě nulová konkurence. (update : Lze vyřadit konkrétního dodavatele, viz komentář #4)
Tato sviňárna se děje na celém poli. My jsme vyhráli částečně, protože jsme jednali přímo s HP i Veeam a chtěli jsme po nich, aby firmám, které budou pro nás chtít cenové nabídky, nabídnuli férové/stejné ceny. Veeam to přijal, HP nás částečně poslalo do zádele (mají své bronzové, platinium aj. dodavatele a cena musí být jiná). Ale aspoň jsme měli ceny od různých firem, u NetAppu dostane člověk cenu jen od jedné firmy. Ještě jsem slyšel, že to jde obejít tak, že lze poptat zahraniční firmu, která působí v jiném státě, tím se dá ten lock na firmu obejít. Ale potvrdit to nemohu.
Částečně jsem byl zklamán, částečně nadšen.
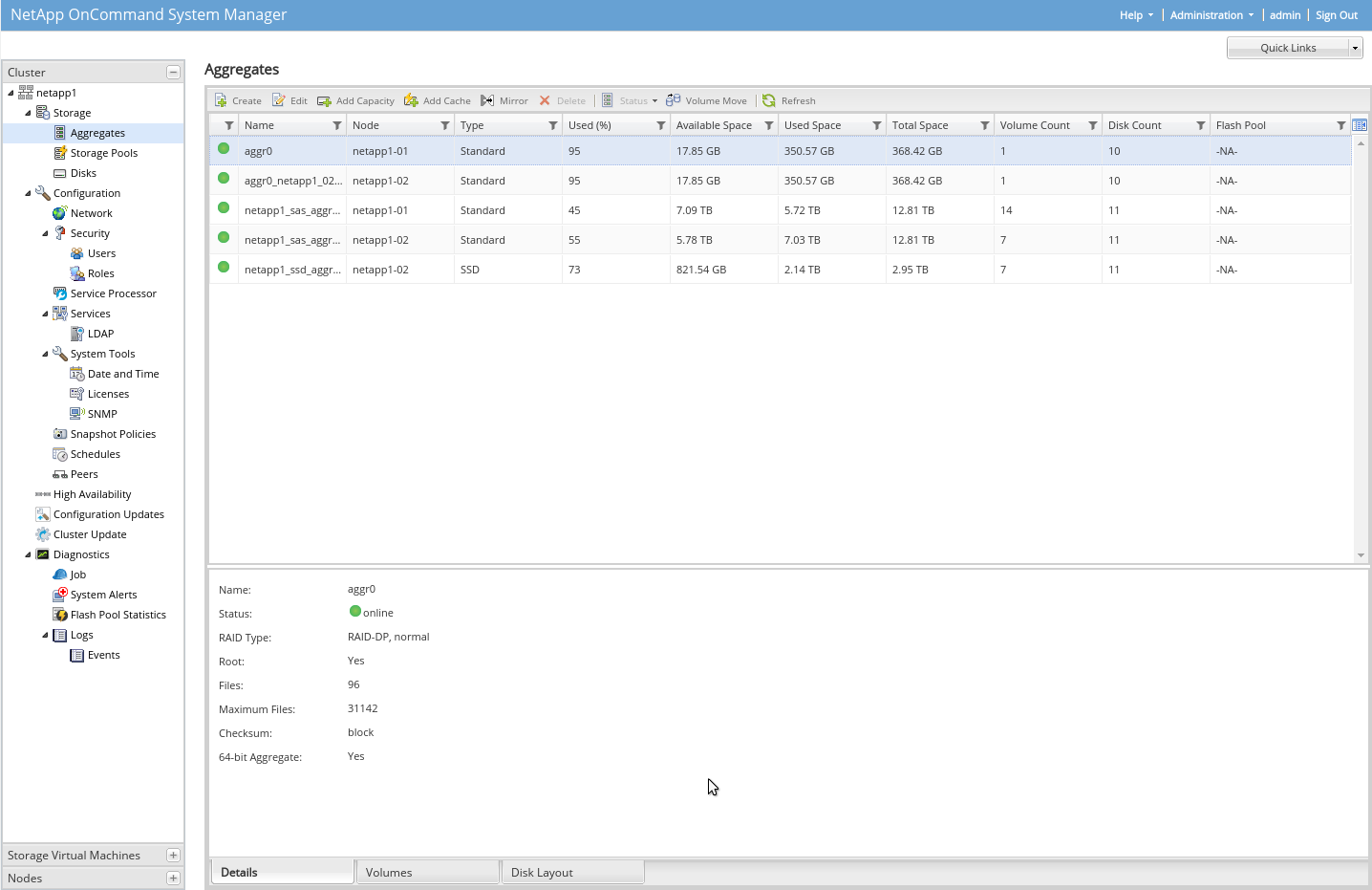
Samotný storage je řešen tak, že je třeba vytvořit agregátor, který obsahuje disky s určitým typem pole. Vesměs lze u NetAppu mluvit o RAID-DP (dva disky mohou vypadnout, takže něco jako RAID6 bez penality), spare disk je vyžadován, bez aspoň jednoho spare nejde agregátor vytvořit. Takový agregátor lze zrychlit pomocí SSD, což se dělá tak, že se vytvoří ssd pool a z něj se pak může ukrojit část s SSD pro ten SAS agregátor. Problém je, že toto je nevratná operace, která trvá celkem dlouho (nevím, co vše se na ty SSD přesune, nezkoumal jsem to). Není to tedy jako u ZFS, kdy se pro SLOG vyhradí SSD, pro LARC se vyhradí SSD a lze to vždy bez problémů vrátit zpět. To byla věc, která mně zklamala a i důvod, proč toto nemám nasazeno (původně bylo SSD vyhrazeno jen pro OracleDB a kdybych ukrojil moc, měl bych v budoucnu problém s tím hýbat).
Pole má dva řadiče (=prostě servery, hafec jader, hafec ram, každý 2x 10Gbit pro připojení ke storage atd.), kde se definuje, jaký řadič má vlastnit jaký disk. Proto je dobré pole rozdělit do dvou agregátorů, aby disky v jednom agregátoru vlastnil jeden řadič a v druhém agregátoru další řadič a byla tak rozdělena zátěž. Když padne jeden řadič, druhý převezme jeho fci (vlastnictví disků u služeb), to je cajk.
Dále každý řadič má jedno napájení, padne jedna UPS, padne jeden řadič, takže fci převezme druhý řadič a místo 2x 2x10Gbit se jeden 2x 10Gbit. Nicméně to mají i další výrobci u menších polí.
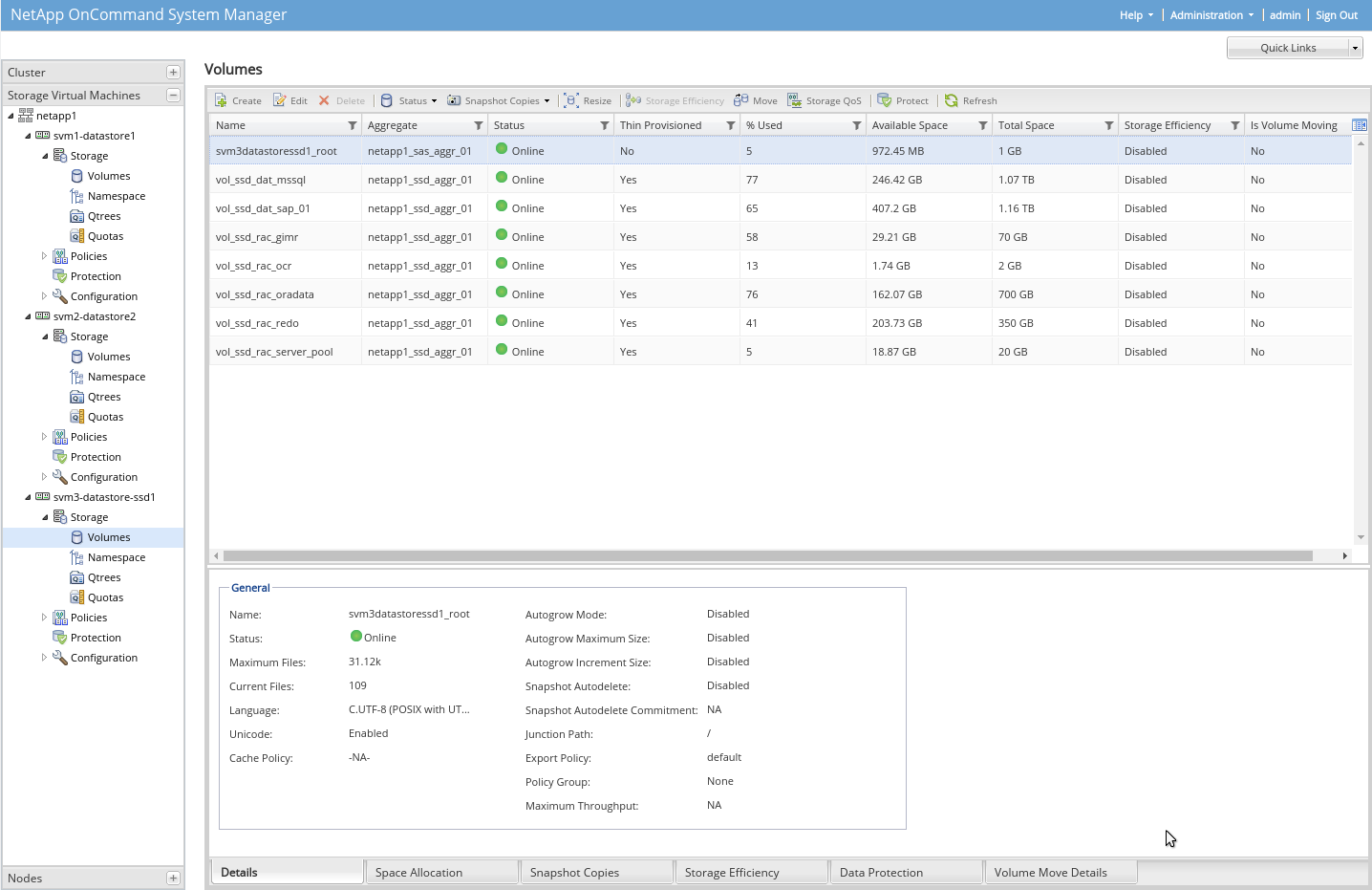
Poté, co máme vytvořený agregátor, je třeba vytvořit SVM (Virtual Server). Je to tak, že pod NetAppem běží SVM, má svojí IP a poskytuje různé služby, které povolíme (NFS/SMB). V rámci SVM pak vytvoříme volume na těch agregátorech, definujeme si jména volume, mountpointy (namespace), povolené verze protokolů, povolené rozsahy IP apod.
SVM můžeme mít více. Já jich mám na jednom NetAppu 4.
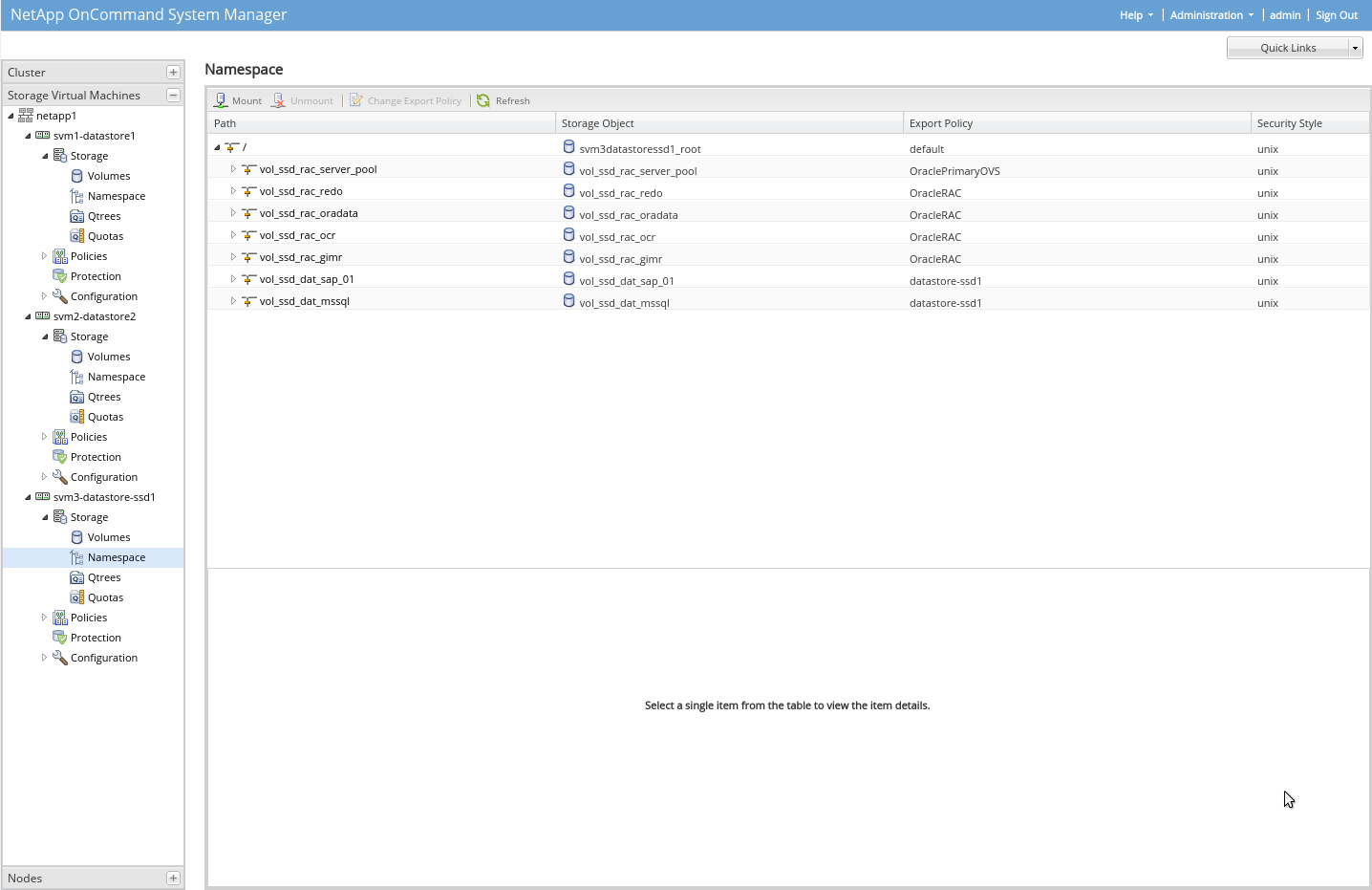
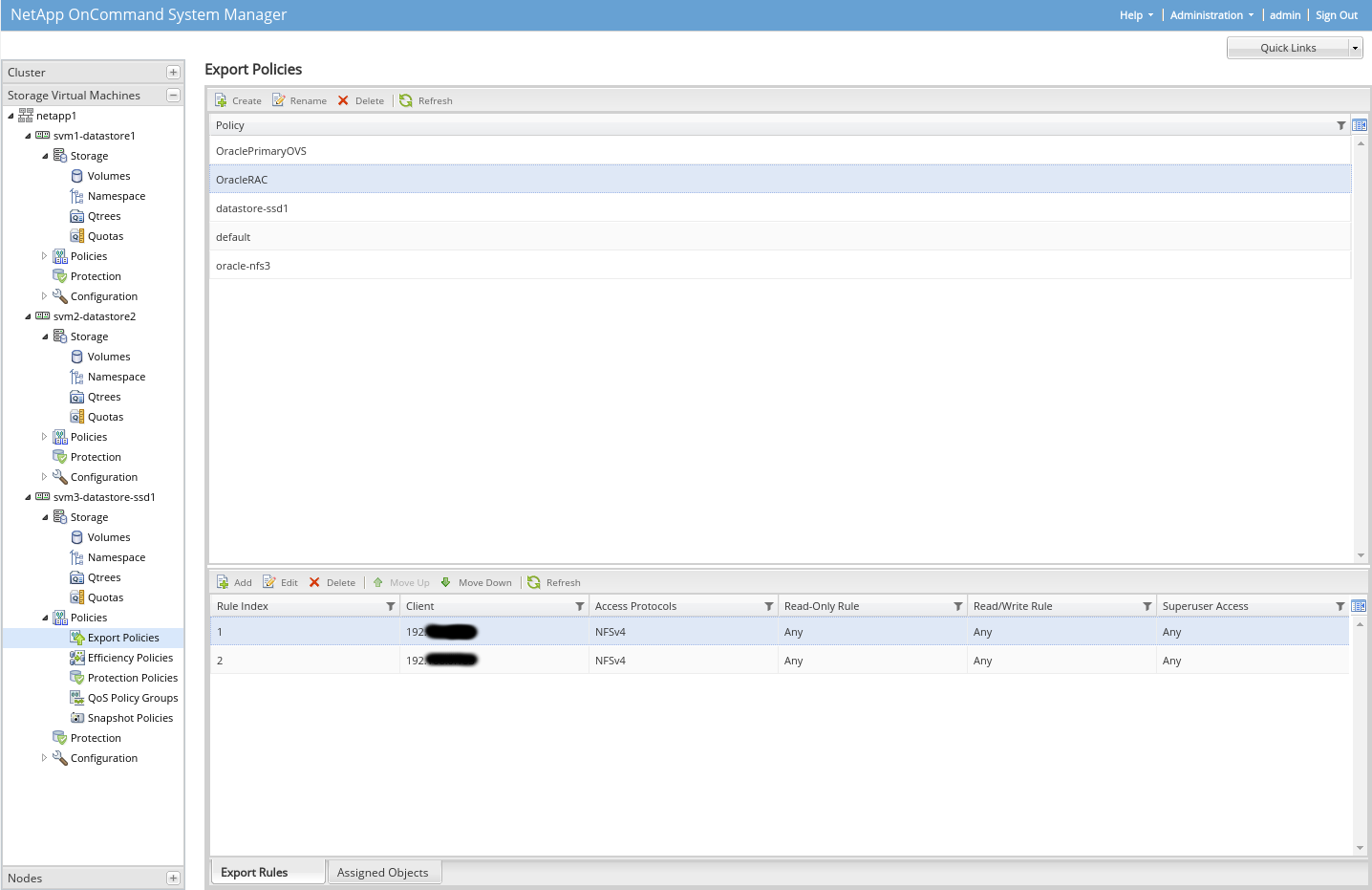
U SVM lze nastavit DR (Disaster Recovery), lze definovat replikaci konkrétního SVM na vzdálený NetApp, lze nastavit intervaly apod. Na vzdáleném NetAppu pak běží SVM ve standby modu (není spuštěn). Když primární NetApp padne, lze aktivovat v záložní lokalitě SVM a je tam hned stejná konfigurace, stejné volume a data z určité doby.
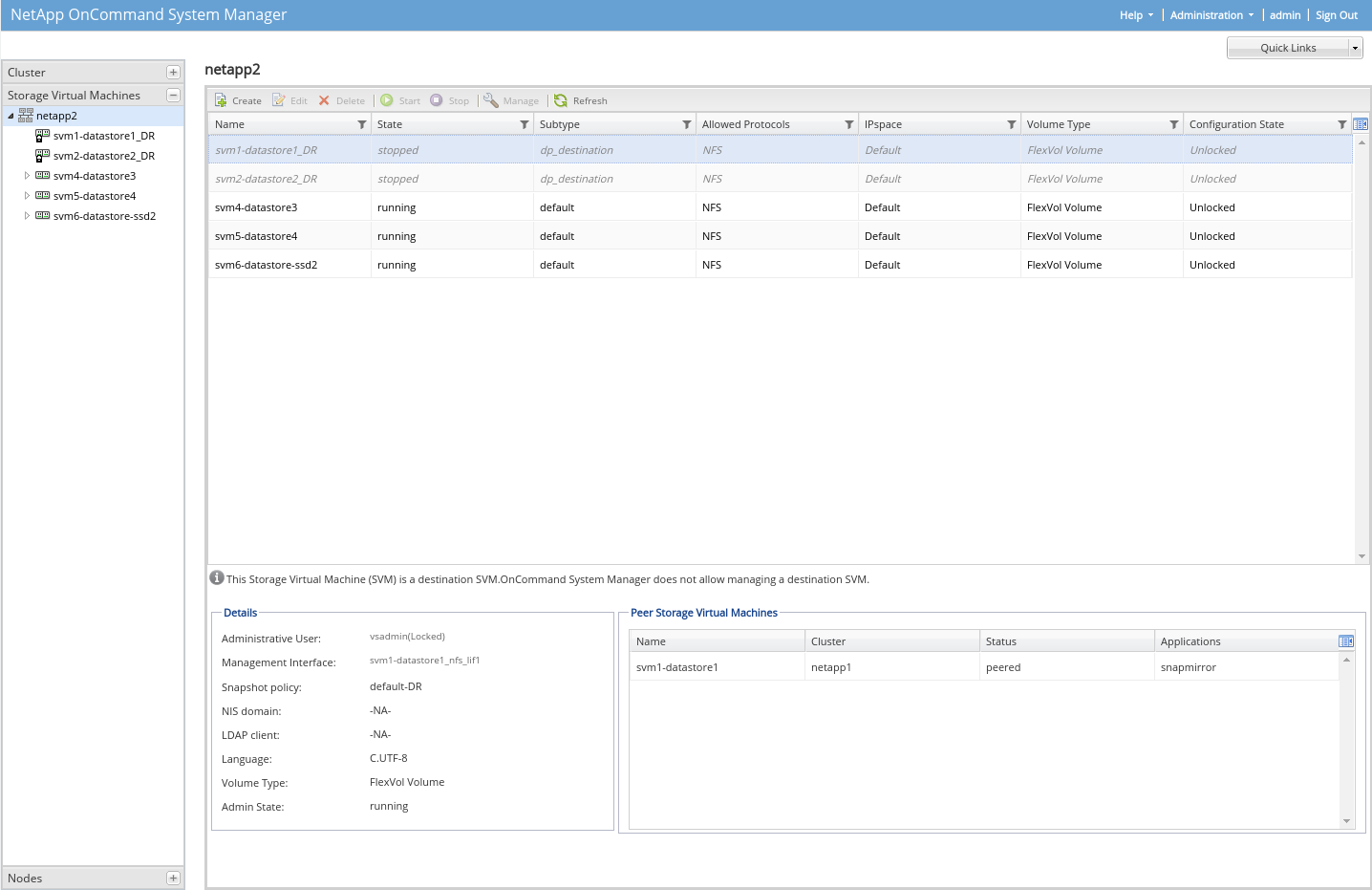
Výhodou tohoto SVM DR je rychlost překlopení služeb, kdy v záložní lokalitě jedeme hnedle jedle. Nevýhodou je, že tento DR nelze řídit z Veeamu, nejsou pro to web služby a další věci, takže se jedná o data ve stavu crash-consistency (tj. jako když vypadne u serveru proud, což by dnes mělo přežít všechno včetně db).
Dále NetApp nepodporuje async NFS, takže sice se můžeme bavit o nějaké výkonnostní nevýhodě, ale zase máme jistotu konzistence. Nicméně pro někoho to může být nedostatečné.
FAS2552 má 2x10Gbe/controller a podporuje LACP. Šířku pásma si řídí sám, lze jí nastavit a řídit si priority podle sebe, ale týpek, co to u nás nasazoval říkal, že to v žádné firmě neřešil a nikdy nebyl problém. Také jsme asi byli první, co jsme chtěli NFS 4.1 :).
V případě výpadku proudu má NetApp ještě k udržení cache baterii. Životnost je prý 5 let a jde vyměnit jen v offline tak, že se odpojí řadič, odmontuje z pole, vymění se v něm baterie a zase se zapojí zpět. Je to částečně bez výpadku, protože roli offline řadiče převezme ten druhý.
Jinak NetApp je asi BSD like. Lze se dostat do různých úrovní systému. První je cluster (je myšlen cluster v rámci jednoho pole = propojení dvou řadičů), pak se lze dostat na konkrétní řadič a přímo do systému, což je ta nejnižší úroveň přístupu. Svému systému říká ONTAP.
Relativně nedávno přišel NetApp se sw řešením, kdy poskytuje jen SW a člověk si to může rozjet na svém HW. Tomuto řešení Netapp říká ONTAP Select (SDS - software defined storage). Je dodáván formou Virtual Appliance a může běžet jak pod ESXi, tak pod KVM.
Člověk se jako nováček začne v těch licencích pěkně ztrácet. Jednak se licencuje na kapacitu, dále se licencují fce.
Chcete smb, potřebujete licenci, chcete nfs, potřebujete licenci, chcete FC potřebujete licenci, chcete iSCSI, potřebujete licenci atd.
Dále existují např. fce
Poté existují licenční balíčky, které obsahují některé výše zmíněné licence a vycházejí levněji. Takže bacha na to, co chcete a co vám kde řeknou. Oni vám třeba řeknou, že NetApp umí snapshoty, ale pak když je chcete z Veeamu/nástroje třetí strany použít, tak zjistíte, že nemůžete atd. Už přesně ty ceny nevím, ale myslím, že se v našem konkrétním případě bavíme o 200kkč / snapmirror apod. to je asi s jinými feature.
Když tedy dostane nabídku na NetApp za nějakou cenu, tak vězte, že to může být holá verze třeba jen s podporou FC a konec. Je třeba od začátku vědět, co chci, což je v případě nového, neznámého řešení většinou problém. My jsme věděli, co chceme, i jsme to řekli, ale nakonec nám byl prodán málem NetApp bez snapmirroru a snaprestore nemáme, což jsem právě zjistit v době, kdy jsem v rámci testování chtěl obnovit/spustit VM ze snapshotu ve Veeamu. Prostě v době, kdy všechny nabídky byly odsouhlaseny vedením a nákup byl vlastně už uskutečněn. Tj. v době, kdy už bych si dalších x tisíc neobhájil (předpokládám, že dalších 200kkč).
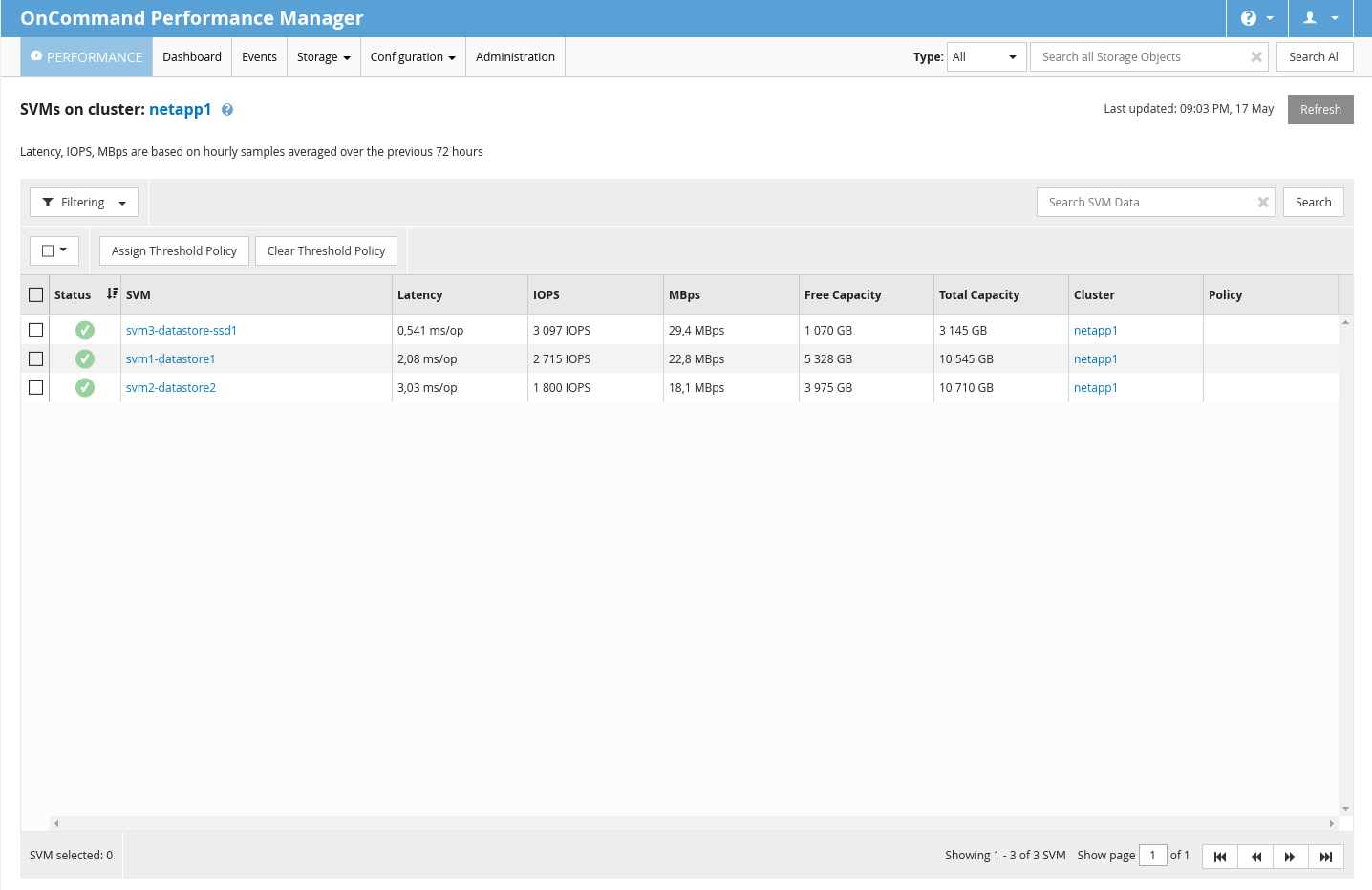
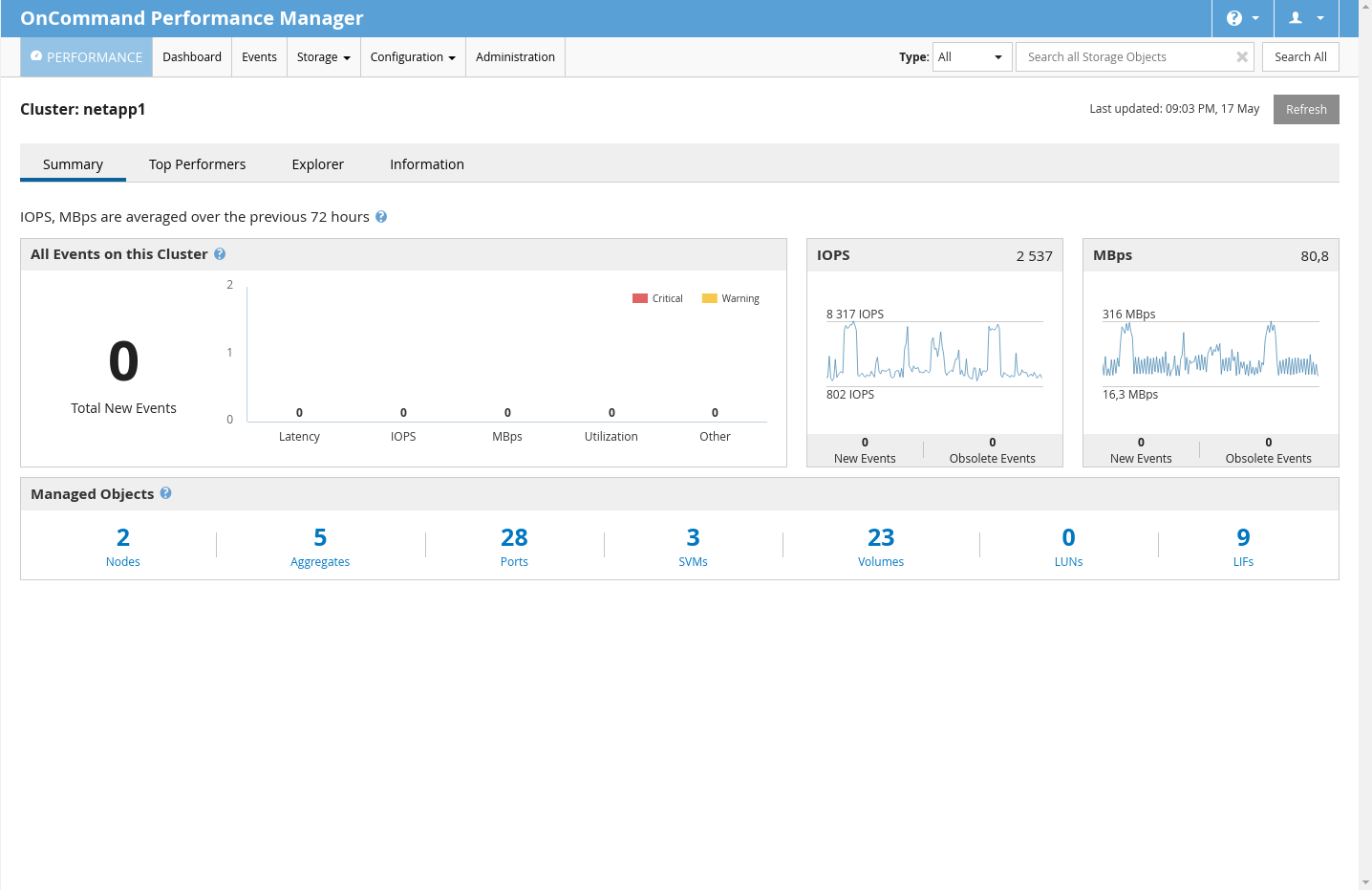
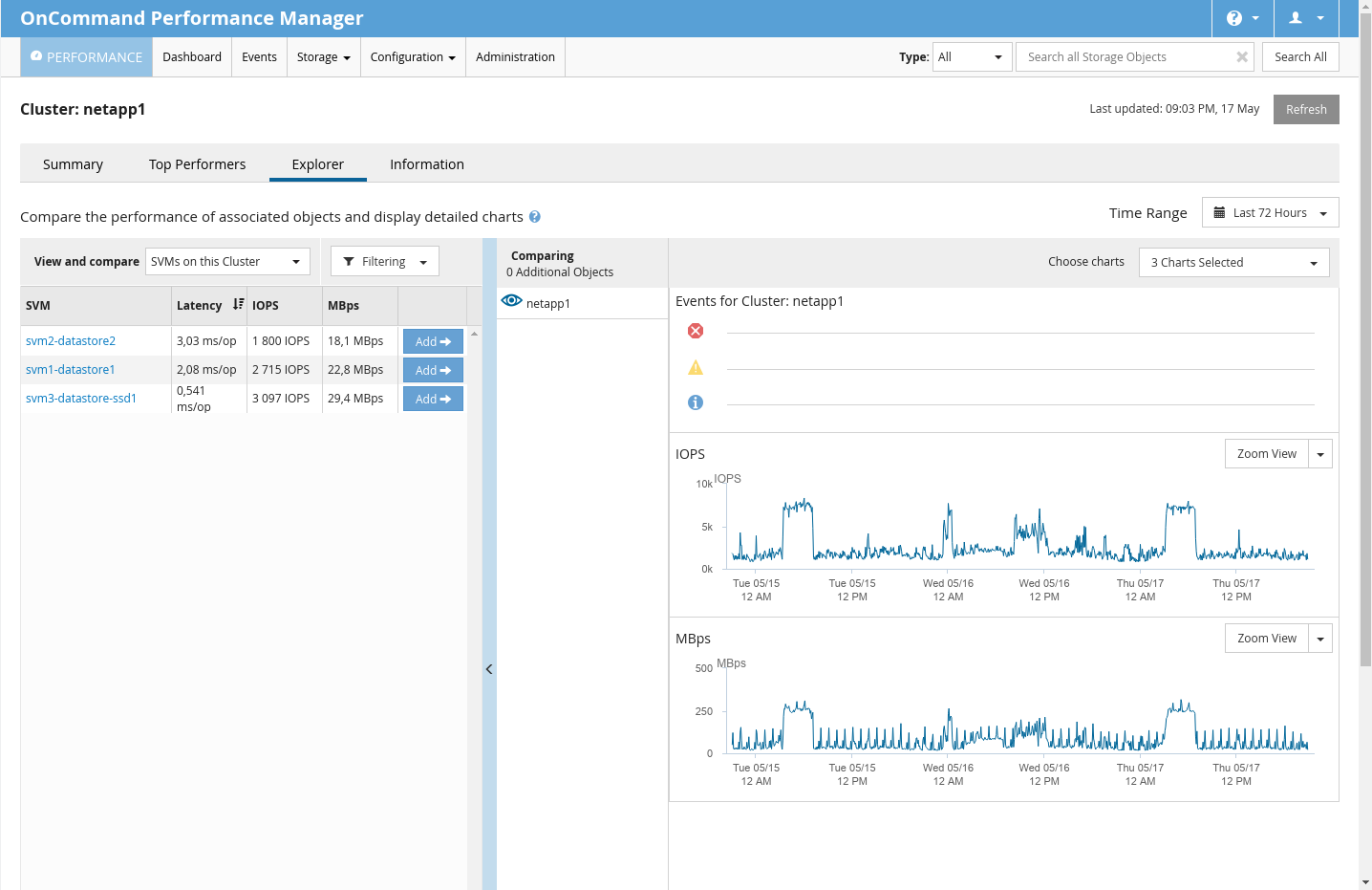
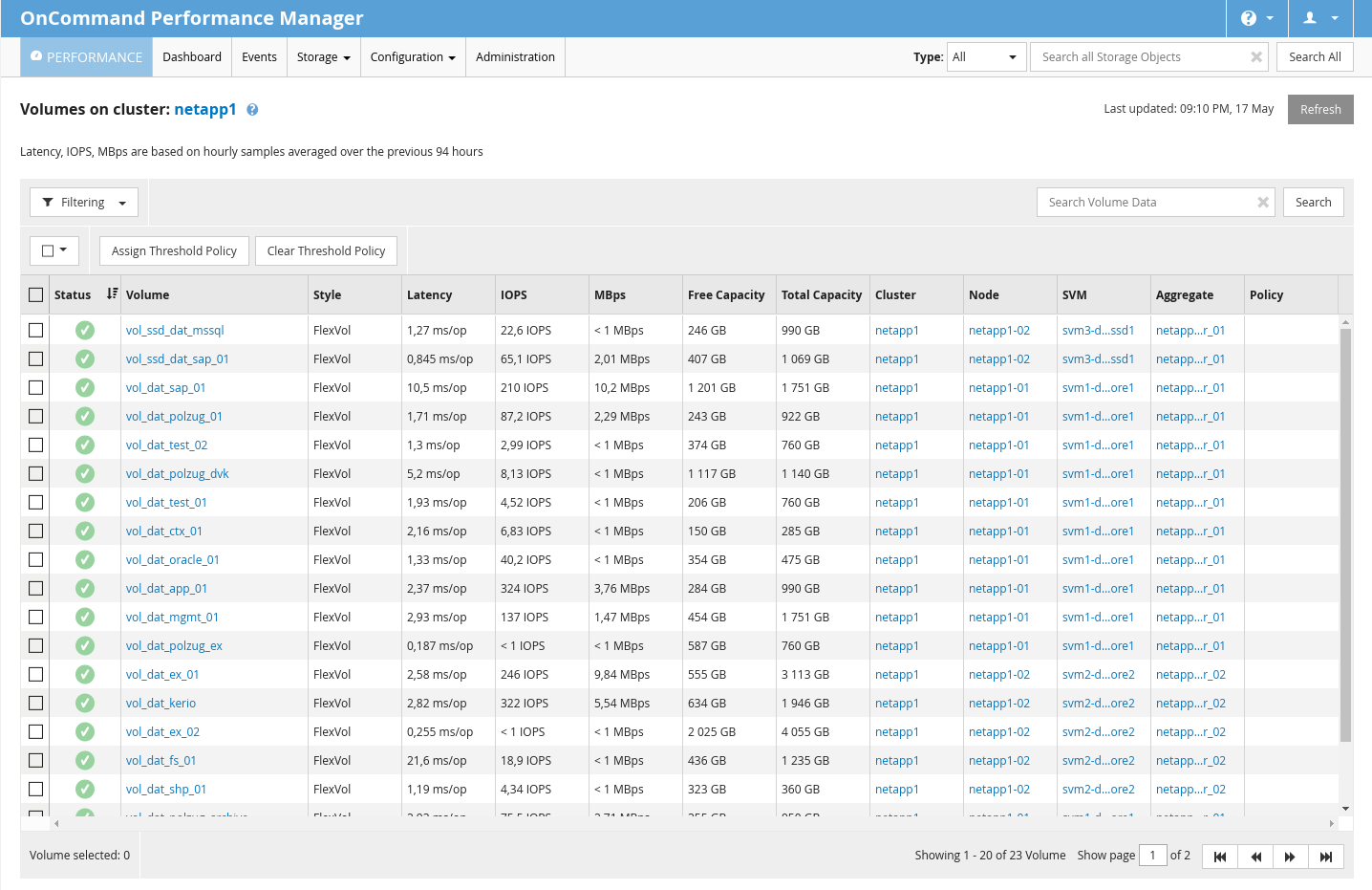
NetApp má k dispozici monitorovací nástroj jménem OnCommand Performance Manager. Tento nástroj dodává jak v podobě VM Appliance, tak formou app pro RHEL like systémy. Ze začátku jsem používal VM Appliance, ale byla pomalá, tuhla a byl s ní problém (mám snad pocit, že to bylo na RHEL 4 like systému, už nevím). Tak jsem naladil CentOS 7, nainstaloval OnCommand ručně a od té doby to běží svižně a stabilně.
Toto rozhraní disponuje přehlednými statistikami o datovém toku, iOPS apod. Zároveň dokáže notifikovat, zobrazovat grafy s historií apod. Je to velmi užitečný nástroj.
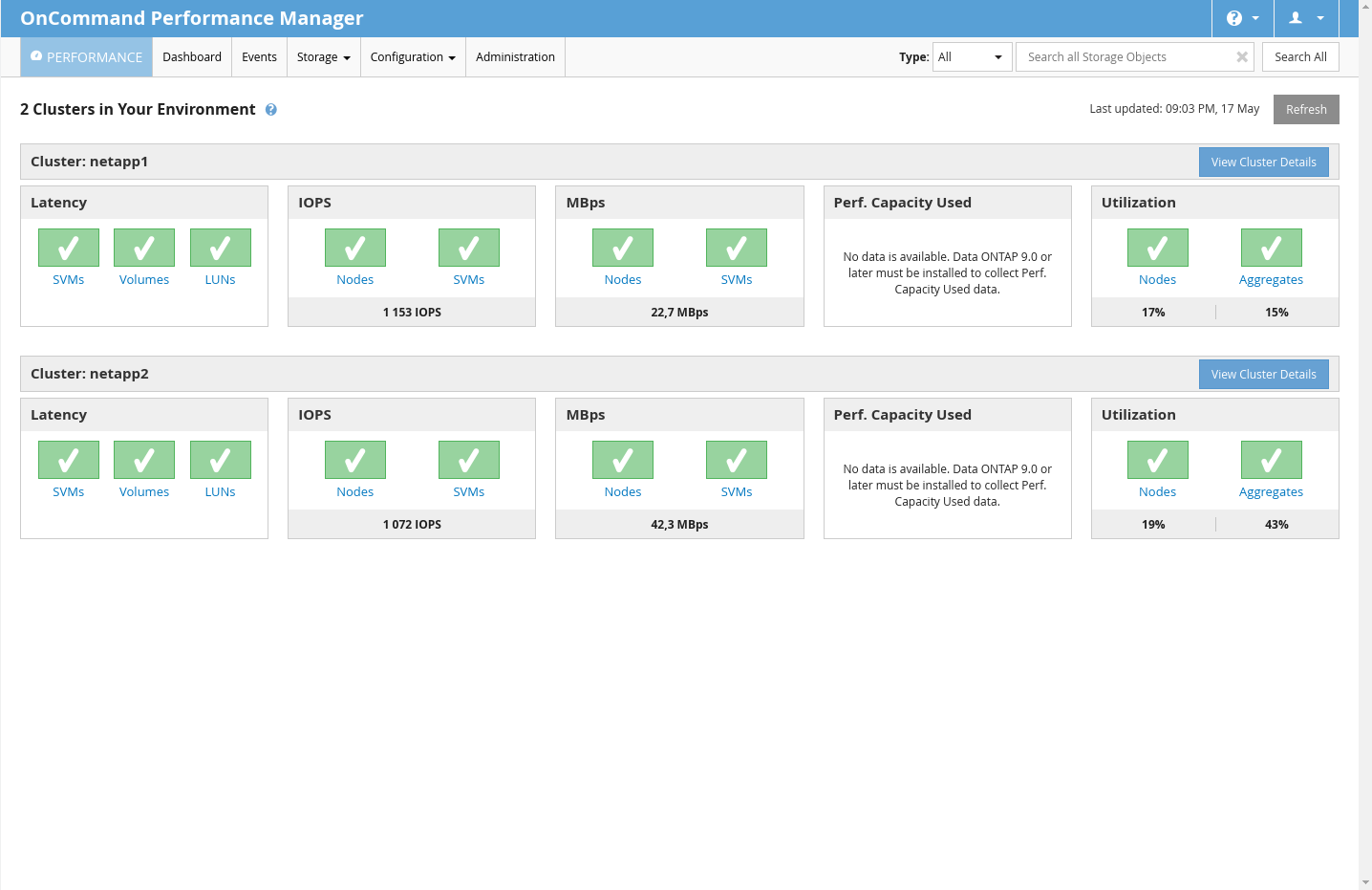
Migrace na jiný NetApp, upgrade, případně migrace na jiný NetApp a další věci by měly procházet online, bez výpadku. Zatím jsem nic z toho nezkoušel, ONTAP je stále ve verzi 8.3.2 a na devítku jsme ještě nešli. Každopádně známý dělal upgrade na svém FAS2552 a prý online a bez problémů.
NetApp umí nejen async mezi dvěma poli, ale i plný cluster (MetroCluster). Veeam v případě dobře nastaveného SnapMirroru umí udělat zálohu VM tak, že nejdříve vytvoří konzistentní Snapmirror (= snapshot + replikace do vzdálené lokality) a následně může udělat backup z onoho záložního NetAppu. Tj. lze takto silně minimalizovat režie primárního storage a zároveň mít aktuální a 100% konzistentní zálohu.
Dalo by se říci, že 90% našich serverů má jako storage backend NetApp připojený přes NFS. NetApp má jeden shelf, který je plný SAS disků (2x "11x RAID-DP + 1xspare", celkem tedy 24x SAS). Dále má druhý shelf z půlky plný SSD disky. Špičky na SAS poli jdou k 5000 iOPS a odezvy všech služeb jsou zatím plně ok.
Zatím jsem tedy s NetAppem spokojen, jak s výkonem, tak s monitoringem. Jen by to chtělo mít i možnost ovládání toho DR z nástrojů třetích stran a pak možnost lépe šachovat s SSD.
A jak jste na tom vy? Co používáte? Jak jste spokojeni? Máte někdo Nexentu?
Tiskni
Sdílej:
![]()
![]()
![]()
![]()
![]()
![]()
 21.5.2018 13:04
Max | skóre: 73
| blog: Max_Devaine
21.5.2018 16:58
Max | skóre: 73
| blog: Max_Devaine
21.5.2018 13:04
Max | skóre: 73
| blog: Max_Devaine
21.5.2018 16:58
Max | skóre: 73
| blog: Max_Devaine
Když mi toto řekli, už jsem se dál nesnažil vyjednávat a doteď nechápu, kam se svojí cenovou politikou mířili.Na rozumě velké storage systémy? :) Koupil sis ten nejnižsí model od NetApp s dumpingovým pricingem, tak se nediv, že mu nikdo jiný nedokázal konkurovat
 21.5.2018 10:44
Max | skóre: 73
| blog: Max_Devaine
21.5.2018 10:44
Max | skóre: 73
| blog: Max_Devaine
Netapp ale od nich máme, protože v tom je ten fór. První firma, která se dozví o potencionálním zákazníkovi, hodí lock u NetAppu a nikdo jiný ani nesmí nabídnout cenu (prostě žádnou od NetAppu pro nás nedostane, konec), žádná soutěž neexistuje a není tak možnost se dostat níže u konkurence, prostě nulová konkurence.To není pravda, stačí dopis s podpisem statutárního orgánu společnosti, že jste zvoleného partnera byli nuceni vyřadit z výběrového řízení; lhaní ze strany partnera na obchodní schůzce by museli uznat jako validní důvod pro takový krok a kdyby ne, tak od toho je tady Peter Kos...
21.5.2018 10:49
Max | skóre: 73
| blog: Max_Devaine
ení to tedy jako u ZFS, kdy se pro SLOG vyhradí SSD, pro LARC se vyhradí SSD a lze to vždy bez problémů vrátit zpět.NetApp používá pro transakční logy NVRAM, proto není potřeba používat SSD.
První je cluster (je myšlen cluster v rámci jednoho pole = propojení dvou řadičů), pak se lze dostat na konkrétní řadič a přímo do systému, což je ta nejnižší úroveň přístupu. Svému systému říká ONTAP.Ještě je tam Unix shell
Relativně nedávno přišel NetApp se sw řešením, kdy poskytuje jen SW a člověk si to může rozjet na svém HW. Tomuto řešení Netapp říká ONTAP Select (SDS - software defined storage). Je dodáván formou Virtual Appliance a může běžet jak pod ESXi, tak pod KVM.Pokud nedávno myslíš půlku roku 2015
SnapVault, slouží k zálohování, záložní lokalita není 1:1, ale je tam historie záloh SnapVault a lze dělat zálohy na jiné místo. Rozdíl oproti SnapMirror viz Comparison between qtree SnapMirror and SnapVaultTvůj odkazovaný článek pojednává o 7-mode; v cDOT je to už jinak.
SnapRestore - přístup ke snapshotům v rámci produktů třetích stran. Kdo má licenci na SnapRestore, tak může třeba z Veeamu spustit VM přímo ze Snapshotu, kdo ne, má smůlu, nedostane se z Veeamu k datům, musí ručně vykopírovat obsah snapshotuHlavně SnapRestore umožňuje atomický roll-back k nějaké verzi snapshotu...
Migrace na jiný NetApp, upgrade, případně migrace na jiný NetApp a další věci by měly procházet online, bez výpadku. Zatím jsem nic z toho nezkoušel, ONTAP je stále ve verzi 8.3.2 a na devítku jsme ještě nešli. Každopádně známý dělal upgrade na svém FAS2552 a prý online a bez problémů.Jen pokud budeš provádět migraci připojením do existujícího clusteru; já osobně bych to v mission-critical nasazení takhle rozhodně nedělal.
21.5.2018 14:57
Max | skóre: 73
| blog: Max_Devaine
2x FAS2552 2x 24xSAS 1,8TB 10k 1x extra Shelf s 12x SSD 400GB kabely instalace / konfigurace školení licenceZdar Max
 21.5.2018 15:34
Max | skóre: 73
| blog: Max_Devaine
21.5.2018 15:43
Max | skóre: 73
| blog: Max_Devaine
22.5.2018 11:18
Max | skóre: 73
| blog: Max_Devaine
23.5.2018 12:33
Max | skóre: 73
| blog: Max_Devaine
22.5.2018 07:37
Max | skóre: 73
| blog: Max_Devaine
21.5.2018 15:34
Max | skóre: 73
| blog: Max_Devaine
21.5.2018 15:43
Max | skóre: 73
| blog: Max_Devaine
22.5.2018 11:18
Max | skóre: 73
| blog: Max_Devaine
23.5.2018 12:33
Max | skóre: 73
| blog: Max_Devaine
22.5.2018 07:37
Max | skóre: 73
| blog: Max_Devaine
Ta v ontape prebieha tak ze sa zapise do RAM, nasledne skopiruje do NVRAM a posle do NVRAM partnera. Vsetko su to zapisy do pamate.NVRAM je namapovaní jako blok pamětového prostoru s přímým přístupem, k zápisu do klasické RAM nedochází; replikace do NVRAM partnera dochází atomicky a transakce se necommitne, dokud není záznam i v transakčním logu partnera; za předpokladu, že je zapojený MPHA pár samozřejmě...
Zapisy su teda rychle a async IO by nemalo zmysel.I NVRAM se dá zaplnit :)
Zapisy su teda rychle a async IO by nemalo zmysel. Malo by to zmysel ak su kontrollery daleko(napriklad MCC alebo 7mode FMC) a s obmedzenou linkouMetroCluster "s pomalou linkou" ale není podporovaná konfigurace :)
Qtree SnapMirror - tento vie o filesysteme a je pomalsi(musi preliezat filesystem.To platilo u 7-mode.
23.5.2018 09:36
Max | skóre: 73
| blog: Max_Devaine
Ahoj,
Pouzivam 3x raidz2 po 8 diskoch. Nepouzivam SLOG, je to full-flash pole. Mame zapnutu lz4 kompresiu s pomerom 1.72x. Na netappe sme ledva mali 1.1x + nam to zabijalo CPU...
# zpool status -v
pool: data
state: ONLINE
scan: scrub repaired 0 in 4186h16m with 0 errors on Sat Feb 3 07:00:13 2018
config: NAME STATE READ WRITE CKSUM
data ONLINE 0 0 0
raidz2-0 ONLINE 0 0 0
c0t50000396DC8B773Dd0 ONLINE 0 0 0
c0t50000396DC8B6F3Dd0 ONLINE 0 0 0
c0t50000396DC8B76F9d0 ONLINE 0 0 0
c0t50000396DC8B7701d0 ONLINE 0 0 0
c0t50000396DC8B76E9d0 ONLINE 0 0 0
c0t50000396DC8B76FDd0 ONLINE 0 0 0
c0t50000396DC8B7739d0 ONLINE 0 0 0
c0t50000396DC8B7705d0 ONLINE 0 0 0
raidz2-1 ONLINE 0 0 0
c0t50000396DC8B6F4Dd0 ONLINE 0 0 0
c0t50000396DC8B6F39d0 ONLINE 0 0 0
c0t50000396DC8B76F5d0 ONLINE 0 0 0
c0t50000396DC8B7715d0 ONLINE 0 0 0
c0t50000396DC8B75BDd0 ONLINE 0 0 0
c0t50000396DC8B7721d0 ONLINE 0 0 0
c0t50000396DC8B770Dd0 ONLINE 0 0 0
c0t50000396DC8B7725d0 ONLINE 0 0 0
raidz2-2 ONLINE 0 0 0
c0t50000396DC8B6F49d0 ONLINE 0 0 0
c0t50000396DC8B6F55d0 ONLINE 0 0 0
c0t50000396DC8B7711d0 ONLINE 0 0 0
c0t50000396DC8B76EDd0 ONLINE 0 0 0
c0t50000396DC8B75C5d0 ONLINE 0 0 0
c0t50000396DC8B7719d0 ONLINE 0 0 0
c0t50000396DC8B7729d0 ONLINE 0 0 0
c0t50000396DC8B6F51d0 ONLINE 0 0 0
Config je cca:
2x Dell R730xd (controller)
- 2x Intel 10GE DP x520 - 256 GB RAM
- 2x 12 core XEON v4 high freq (neviem presny model z hlavy)
- 2x SAS3 radic v passthru mode
- 24x Toshiba SX04SR? 1,92TB SSD v JBODe (myslim, ze MD1420)
NexentaStor + HA plugin.
K tomu existuje este dalsia nexenta pre DR backupy, kde su rotacne disky a SLOG na SSD. Ta je ulozena v druhom DC a priamy L2 tunel. Tam sa primarne pole replikuje pre pripad, ze by sa nieco katastrofalne stalo. Replika bezi par krat do dna. Este zaujimavostou je, ze na primarnom poli drzime 3 dni snapshoty (okrem teda zakaznickych) a na sekundarnom 21 dni, cim sa zaujimavo setri miesto a v pripade potreby starsieho snapshotu sa proste posle snapshot spat cez zfs send/receive na primarne pole.
24.5.2018 09:31
Max | skóre: 73
| blog: Max_Devaine
Este priatelska rada:
"Pole má dva řadiče (=prostě servery, hafec jader, hafec ram, každý 2x 10Gbit pro připojení ke storage atd.), kde se definuje, jaký řadič má vlastnit jaký disk. Proto je dobré pole rozdělit do dvou agregátorů, aby disky v jednom agregátoru vlastnil jeden řadič a v druhém agregátoru další řadič a byla tak rozdělena zátěž. Když padne jeden řadič, druhý převezme jeho fci (vlastnictví disků u služeb), to je cajk."
Vyskusaj si to pri plnej produkcii. Z mojej skusenosti su casto oba agregaty az moc zatazene a v pripade padu jedneho z nich ide cele pole do ... v lepsom pripade su jeho odozvy v sekundach. Idealne by sa v peaku teda nemala CPU / Net utilizacia dostat nad 35-40%. Zataz nestupa uplne linearne, ale horsie.
Vyskusaj si to pri plnej produkcii. Z mojej skusenosti su casto oba agregaty az moc zatazene a v pripade padu jedneho z nich ide cele pole do ... v lepsom pripade su jeho odozvy v sekundach. Idealne by sa v peaku teda nemala CPU / Net utilizacia dostat nad 35-40%. Zataz nestupa uplne linearne, ale horsie.presne tak ziadne prevzatie funkcii druhym radicom, sekundove lagy az pad na drzku...
ISSN 1214-1267, (c) 1999-2007 Stickfish s.r.o.