 | poslední úprava: 24.4.2007 22:03
| poslední úprava: 24.4.2007 22:03
Portál AbcLinuxu, 30. července 2026 19:39
12.3.2007 18:55
| Přečteno: 2929×
|
| poslední úprava: 24.4.2007 22:03
S vynálezem Unicodu jsme dostali do rukou silný nástroj pro zpracovaní přirozeného jazyka. Bohužel bez správných kreseb všech písem nám zbudou oči pro ordinární čísla.
Abychom si mohli říci A je to!
, musíme určit množinu
písem, která chceme být schopni zobrazit.
Nebuďme troškaři, spokojme se jen s celým Unicodem. Ne, takový sebevrah nejsem. Mnoho jazyků sice používá stejné písmo, ale i tak je to příliš velké sousto. Nehledě na neexistenci volných fontů pro všechna písma. A to především těch mrtvých, archaických nebo těch, kam počítače ještě nedorazily.
Proto jsem se rozhodl do nutného minima zařadit všechny v Internetu aktivně užívané jazyky. A kde vzít lepší vzorek než na Wikipedii? Jazyk, pro který existuje lokalizovaná mutace Wikipedie, si to jistě zaslouží.
Ve světě linuxového GUI existuje asi několik způsobů, jak nahrazovat chybějící glyphy z jiných fontů. Já znám pango, které je oblíbené u GTK aplikací (rád se nechám poučit o Qt). Tento balík obsahuje nástroj pango-view, který umí zobrazit požadovaný text požadovaným fontem s požadovaným hintingem požadovaným renderovacím backendem atd. Nám bude stačit tato formulka:
pango-view --text='Ahoj světe!'
Samozřejmě po nainstalování fontu bude třeba říci systému, kde jej hledat.
Toho, kdo používá fontconfig, bude zajímat příkaz fc-cache,
připadne adresář /etc/fonts/.
Dále bude třeba ověřit, že daný font obsahuje všechny symboly daného písma. K tomu se výborně hodí rozcestník s testovacími stránkami pro unicodové rozsahy jednotlivých písem, kde ihned uvidíte, zda je dané písmo plně podporováno.
Také se může stát, že font s požadovaným písmem najdete, ale v podivné místní nikde nespecifikované znakové sadě (nejlépe nahrazující místo určené pro latinku). Pak, dovoluje-li to licence [1], použijeme fontforge a příslušné stránky z Unicodu a symboly zpřeházíme.
Toto je práce v pravdě detektivní a často končí neúspěšně. Je třeba najít font, který je úplný, rozumně vypadá, rozumí si s hintingem, má správně definovanou velikost, kerningové páry také nejsou k zahození a samozřejmě je licenčně v pořádku.
Tady bych rád viděl nějakou iniciativu (asi kolem FSF), která by shromažďovala takové fonty. Člověk neznající cizí písma a cizí poměry dokáže dosti obtížně posoudit, zda font vše toto splňuje.
A jaké fonty tedy budou třeba? V Gentoo mám nainstalované následující, v závorce je jazyk či písmo:
Ne všechny jsou však třeba a ne všechny naleznete v oficiálním portage. Chybějící ebuildy jsou připraveny na mém webu. Pokud nepoužíváte Gentoo zkuste prohledat repozitář vaší distribuce na podobná slova, případně se podívejte do ebuildů na definici proměnné SRC_URI, nebo navštivte domovskou stránku daného fontu (HOMEPAGE). Pokud nerozumíte ebuildům, doporučuji seriál Davida Watzke.
Abych nebyl nařčen, že jsem si vše vycucal z prstu, přikládám
zastřelenou obrazovku mírně upravené stránky Wikipedie:
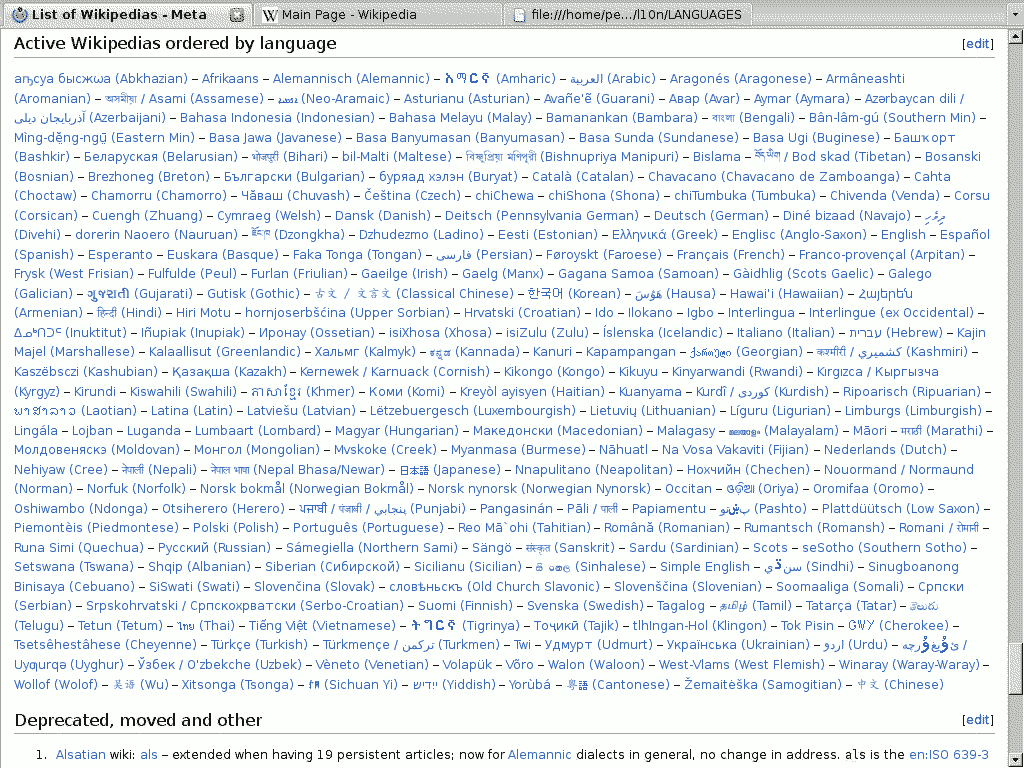
Jediný nesplněný úkol zůstává Old Church Slavonic, v Česku známá jako staroslověnská cyrilice. Na Wikipedii jí je věnovaná doména cu.wikipedia.org, leč vyskytuje se jen na hlavní stránce. Dále se už slabošsky používá současná azbuka. Našel jsem pro ni několik fontů, ale žádný nebyl alespoň freeware.
Otázka je, zda lze font považovat za software nebo za databázi nebo za umělecké dílo. V prvním případě nám autorský zákon dovoluje opravit chybný font tak, aby fungoval v našem systému. V druhém případě obvykle máme smůlu, protože na fonty se často vztahují drakonické licence nebo licenci nelze vůbec nalézt, a ve třetím jej můžeme alespoň pro osobní potěchu kopírovat, což by řešilo dilema chybějící licence.
Existuje ebuild media-fonts/fonts-indic, ktery obsahuje fonty pro jazyky: Assamese, Bengali, Gujarati, Hindi, Kannada, Malayalam, Marathi, Oriya, Punjabi, Tamil, Telugu.
Fonty pro staroslověnštinu (neznám kvalitu)

Tiskni
Sdílej:
![]()
![]()
![]()
![]()
![]()
![]()
 12.3.2007 19:26
JiK | skóre: 13
| blog: Jirkoviny
| Virginia
12.3.2007 19:26
JiK | skóre: 13
| blog: Jirkoviny
| Virginia
 12.3.2007 19:25
stativ | skóre: 54
| blog: SlaNé roury
12.3.2007 19:25
stativ | skóre: 54
| blog: SlaNé roury
ISSN 1214-1267, (c) 1999-2007 Stickfish s.r.o.