 | poslední úprava: 3.3.2021 01:15
| poslední úprava: 3.3.2021 01:15
Portál AbcLinuxu, 28. července 2026 11:44
18.5.2020 12:56
| Přečteno: 9512×
| linux
|
| poslední úprava: 3.3.2021 01:15
ZFS (Zettabyte File System) je souborový systém vyvinutý firmou Sun Microsystems. Ze začátku probíhal vývoj uzavřeně v rámci Solarisu. ZFS byl vypuštěn na světlo v rámci projektu OpenSolaris v roce 2005 pod licencí CDDL, která není kompatibilní s GPL licencí. V roce 2007 zažaloval NetApp firmu Sun, protože údajně došlo k porušení patentů NetAppu, který vyvíjel WAFL filesystém (Write Anywhere File Layout). V této souvislosti na oplátku zažaloval Sun firmu NetApp. Soud byl ukončen v roce 2010 vyrovnáním, ohledně kterého nejsou známy žádné další podrobnosti.
V roce 2010 koupil Oracle firmu Sun. Mj. projekty Solaris a ZFS tedy přešly pod křídla Oracle. Oracle zrušil OpenSolaris a vývoj začal pomalu uzavírat.
V roce 2013 proto vznikl projekt OpenZFS, který si kladl a klade za cíl spojit vývoj ZFS pro Illumos(vychází z projektu OpenSolaris), FreeBSD, Linux, MAC OS a Windows. Nad tímto projektem je postaveno spousta komerčních řešení a sponzoruje jej nemálo firem. V současné době tedy nejsou na místě obavy z toho, že by podpora ZFS zanikla.
Výhody a vlastnosti ZFS jsou :
Pokud bych já osobně měl srovnávat btrfs se zfs, tak řeknu, že to je zatím nesrovnávatelné. Nepřijde mi, že by si tyto dva FS nějak konkurovaly, tedy zatím. ZFS je dělaný pro big storage, což btrfs nedává a dávat zfs na něco malýho také není nejrozumnější. Každopádně nechám zde prostor pro diskusi. Budu jen rád, když někdo v diskusi ukáže, jak podobný storage tomu, co popíšu, postavit na btrfs. Osobně si myslím, že to nejde udělat nějak rozumně.
Máme samotné disky, ze kterých uděláme vdev. Vdev je něco jako RAID pole. Tzn., že můžeme použít mirror, raidz, raidz2, raidz3. A tyto vdevy se vkládají to poolu. Když máme vytvořen pool, tak v rámci něj vytváříme datasety. A do těchto datasetů pak už zapisujeme data (adresáře, soubory atd.). Dataset je tedy něco jako hlavní adresář, nad kterým si můžeme zapínat online kompresi, dělat snapshoty atd. Pokud jednou vytvoříme vdev z 5 disků a dáme do poolu, tak už ten vdev neodebereme. Stejně tak nelze ten vdev ponížit např. o jeden disk a nechat v něm jen 4 disky. Jak to ze začátku nastavíme, tak už s tím nehneme a musíme pokračovat v tom, co jsme započali.
ZFS si pak spoustu věcí cachuje do ram do ARC (Adaptive Replacement Cache).
Tady se můžete podívat na velmi základní schema, jak je ZFS koncipováno :
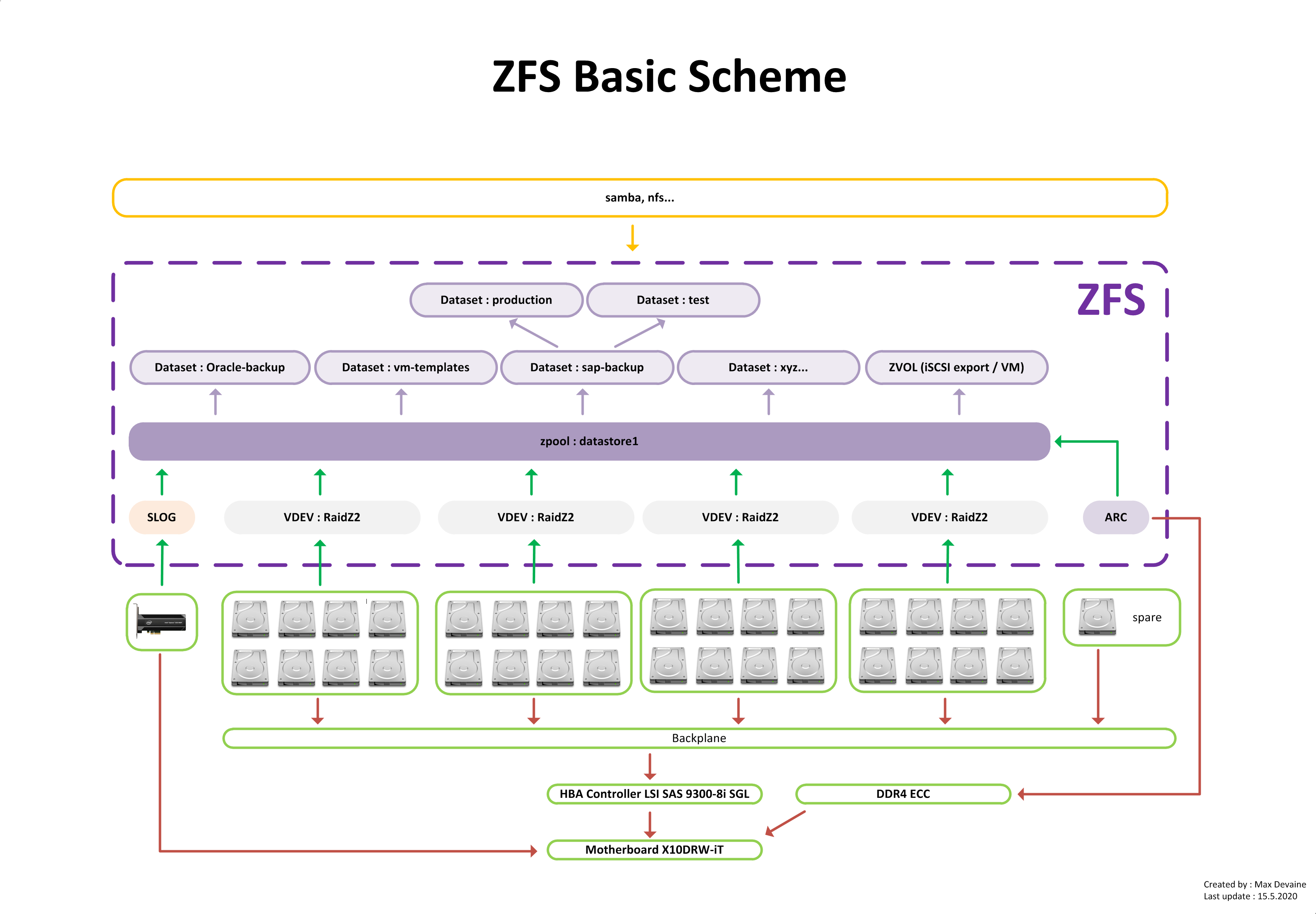
Když se bavíme o storage na zálohy, tak chceme hlavně velkou kapacitu, ale i nějaký rozumný výkon v IOPS kvůli paralelním operacím. Nechceme třeba vypínat zálohování, když potřebujeme něco rychle obnovit. Nebo když chceme udělat instant recovery nějaké VM (= spustit VM ze zálohy a pak live migrací přelít zpět na produkční storage).
Pro tento účel jsem vybral zlatou střední cestu. Tzn. storage založený na enterprise SATA diskách. Konkrétně jsem šel cestou 4TB WD RE4(později WD Gold, WD Ultrastar DC HC310, Toshiba MG04). Je to sice dražší, než desktop disky, ale lépe se chovají při chybách, mají 5 let záruku a jsou levnější jak SAS disky a výkon je přitom rozumný. Kdybych stavěl produkční storage pro ostré app, tak bych šel rozhodně do SAS disků, resp. dnes už čistě do SSD pole.

ZFS pool je poskládaný takto :
4x RAIDZ2, každý z 8xSATA 4TB + společný 1x spare
Víc, jak 8 SATA disků v jednom RAIDZ2 bych nepoužíval. Je to kombinace kapacity a rozumné redundance disků. Dále nechci dělat žádné divočiny, takže jakékoli rozšiřování pole chci dělat ve stejném duchu. Pokud tedy teď jedu RAIDZ2 z 8x SATA, tak při rozšiřování pole skákat opět po 8x SATA je celkem rozumné.
Výsledkem je tedy 128TB RAW pole, použitelných je 96TB, resp. je třeba i myslet na to, že by se nemělo jít nad 80% zaplnění, takže reálně máme k využití 77-80TB a větší zaplnění raději nepřekračovat.
Nejnativnější je ZFS na Solaris like systémech. Problém těchto OS je ale v přecijen o něco menší podpoře HW. ZFSonLinux má stále několik nedostatků a pak je tu ten licenční problém. Jako operační systém jsem tedy zvolil FreeNAS (tzn. FreeBSD). Důvodů bylo několik. Jednak pomohl ze začátku web ksicht pochopit celou filozofii ZFS a další věci, dále možnost správy mých neunixových kolegů (jako vždy se ukázalo, že to je zbytečné, protože nikdo jiný nemá potřebu ani vůli na to sahat), poté kvůli dobrému přehledu a statistikám a nakonec a hlavně kvůli tomu, že lidi od projektu FreeNAS mají ZFS vytuněné lépe, než to, co je v core FreeBSD. Když bych měl stavět další storage, nešel bych do čistého FreeBSD, ale opět do FreeNAS.
FreeNAS si každý disk rozdělí a na začátek si dá malý oddíl, který používá jako swap. Ve finále tedy máme třeba 30 disků a u každého první 2GB jsou použity jako swap. Osobně tuto filozofii nechápu, protože jakmile disk odejde do věčných lovišť, tak storage jde 100% do kolen (dokonce mám i osobní zkušenost). Doporučuji si dělat dobrý sizing, mít dost ram, neprovozovat na FreeNAS různé pluginy, co žerou ram atd. a hned po instalaci FreeNAS si v jeho nastavení vypnout vytváření swap oddílů a jet čistě bez swapu. Pokud už je pozdě a swap máte vytvořen, není nic jednoduššího, než příslušné partition ze swapu odebrat a tím i swap zrušit.
Pokud chcete šifrovat data, tak s tím musíte začít od začátku, tj. zvolit tuto možnost při vytváření poolu. Šifrování se totiž dělá nad blokovým zařízením (geli), protože FreeBSD nemá v ZFS podporu šifrování (zdroj). Zajímavé je, že ZFSonLinux tuto podporu již má. Pokud máte vytvořený pool a už máte produkční provoz, tak přejít na šifrování není jednoduché. Jeden z postupů je si vždy zašifrovat nový disk a pak ho prohodit za jiný v poolu. Ten, co byl prohozen pak zašifrovat a opět prohodit s jiným diskem v poolu a tak stále dokola, dokud nebudou všechny disky zašifrovány (jde to, ale dře to).
ZFS má ZIL (ZFS Intent Log). Ten se používá v případě sync zápisů. To jsou ty, u kterých se musí čekat, až pool odpoví, že je vše zapsáno na disky. To bývá někdy pomalé, obzvláště pokud máme pomalý pool. Proto se nejdříve zápis provede do ZIL, potvrdí se zápis a pak na pozadí se to zapíše do poolu. Dalo by se tedy říci, že to je něco jako journal u journalovacích FS (ext3/ext4/reiserfs/ntfs apod.)
ZFS ale umožňuje tento ZIL umístit bokem na jiné zařízení. Tomu se pak říká SLOG (Separate Intent Log). Je tedy vhodné pro SLOG mít vyčleněný nějaký rychlý SSD disk. A protože se jedná o data, která jsou již potvrzena a brána tak, že jsou zapsána, tak je nutné si SLOG dostatečně chránit. Není tedy moc vhodné jej mít jen na jednom SSD, ale vytvořit si vdev (mirror) dvou SSD. Toto opatření ale nestačí. Je také třeba volit vhodné SSD. Pokud pole stavíme pro kritické aplikace, tak je dobré zainvestovat do SSD, které mají Power Loss Protection (zaručují, že výpadkem proudu nepřijdete o jediný bit dat).
Do tohoto SSD jsem šel z několika důvodů. První je to, že současný řadič nepodporuje připojení SSD přes U.2 / NVMe. Druhým důvodem byla relativně hodně slušná životnost na přepisy i latence a parádní cena. Pokud bych chtěl něco takového ze světa MLC, musel bych si také nemálo zaplatit. Nicméně tento SSD používám v menším risku. První risk je v tom, že tento Optane nemá power loss protection. Druhý malý risk je v tom, že mám jen jeden Optane jako SLOG. Každopádně jedná se o backup storage pověšený na 2x 10kVA UPS, takže si to lajznu. U produkčního storage, kde by měly běžet ostré služby, bych to řešil určitě dvěma SSD pro SLOG (pokud bych pole neskládal z SSD, ale rotačních disků).

Celkem hodně. A kdo nemá SSD na otestování, může si trochu zariskovat a v rámci testování si může vytvořit SLOG z ramdisku a porovnat výkon BEZ a S. Jak na to viz :
# vytvořit ramdisk : mdconfig -a -t swap -s 32g -u 1 # přidat do zpoolu jako SLOG : zpool add datastore1 log md1 ------- # odebrání ze zpoolu : zpool remove datastore1 md1 # zrušení ramdisku : mdconfig -d -u 1
Je třeba si uvědomit, že vdev (ať mirror, nebo RAIDZ) má výkon IOPS v zápisu na úrovni 1xHDD. Je to dáno tím, že při zápisu se čeká vždy na všechny disky ve vdevu, až dokončí operaci. Výše mám tedy poskládaný pool z 4x RAIDZ2, takže v IOPS mám výkon 4x 80-150IOPS. Reálně díky cache a pár věcem kolem není problém dlouhodobě vykrývat přes 5k IOPS. Storage mám stále pod zátěží, aktuálně na něm nouzově běží jedna celkem diskově náročná VM (šmejďárna, co se snaží permanentně žrát 300-500IOPS), takže tento test je třeba brát jen jako malou indicii :
root@storage:# fio --randrepeat=1 --direct=1 --gtod_reduce=1 --name=test --filename=random_read_write.fio --bs=4k --iodepth=64 --size=40G --readwrite=randrw --rwmixread=75
test: (g=0): rw=randrw, bs=(R) 4096B-4096B, (W) 4096B-4096B, (T) 4096B-4096B, ioengine=psync, iodepth=64
fio-3.5
Starting 1 process
test: Laying out IO file (1 file / 40960MiB)
Jobs: 1 (f=1): [m(1)][99.4%][r=149MiB/s,w=50.6MiB/s][r=38.2k,w=12.9k IOPS][eta 00m:03s]
test: (groupid=0, jobs=1): err= 0: pid=25346: Fri Apr 24 21:22:45 2020
read: IOPS=16.6k, BW=64.7MiB/s (67.9MB/s)(29.0GiB/474686msec)
bw ( KiB/s): min=29780, max=329121, per=99.49%, avg=65927.84, stdev=23640.12, samples=949
iops : min= 7445, max=82280, avg=16481.60, stdev=5910.01, samples=949
write: IOPS=5522, BW=21.6MiB/s (22.6MB/s)(10.0GiB/474686msec)
bw ( KiB/s): min=10451, max=109844, per=99.49%, avg=21977.88, stdev=7939.04, samples=949
iops : min= 2612, max=27461, avg=5494.12, stdev=1984.76, samples=949
cpu : usr=2.80%, sys=88.62%, ctx=655585, majf=0, minf=0
IO depths : 1=100.0%, 2=0.0%, 4=0.0%, 8=0.0%, 16=0.0%, 32=0.0%, >=64=0.0%
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
issued rwts: total=7864104,2621656,0,0 short=0,0,0,0 dropped=0,0,0,0
latency : target=0, window=0, percentile=100.00%, depth=64
Run status group 0 (all jobs):
READ: bw=64.7MiB/s (67.9MB/s), 64.7MiB/s-64.7MiB/s (67.9MB/s-67.9MB/s), io=29.0GiB (32.2GB), run=474686-474686msec
WRITE: bw=21.6MiB/s (22.6MB/s), 21.6MiB/s-21.6MiB/s (22.6MB/s-22.6MB/s), io=10.0GiB (10.7GB), run=474686-474686msec
ZFS si fragmentaci dat řeší samo online. Stav fragmentace lze zjistit takto :
root@storage~ # zpool list datastore1 NAME SIZE ALLOC FREE CKPOINT EXPANDSZ FRAG CAP DEDUP HEALTH ALTROOT datastore1 116T 91.7T 24.3T - - 27% 79% 1.00x ONLINE /mnt # nebo root@storage:~ # zpool get capacity,size,health,fragmentation datastore1 NAME PROPERTY VALUE SOURCE datastore1 capacity 79% - datastore1 size 116T - datastore1 health ONLINE - datastore1 fragmentation 27% -
Pokud jde o zaplnění diskového prostoru, udává se, že se nesmí přešvihnout 80% zaplnění. Poté jde výkon dolu a začne stoupat fragmentace. Nicméně pozor, těch 80% se netýká všech možných nasazení. Lze se třeba dočíst, že v případě provozu VM, kde bude jako storage backend ZFS, je nejlepší používat vdev mirror a nepřesáhnout zaplnění 50%. Důvod je ten, že takové nasazení je náchylnější na fragmentace a degradaci výkonu. Toto samozřejmě platí, pokud budeme mít pole poskládané z magnetických disků, u kterých je fragmentace problém. Osobně jsem ale toto nikdy neřešil, takže nemohu potvrdit, jak moc reálný dopad to má.
Zajímavá diskuse na toto téma je zde :
Some differences between RAIDZ and mirrors, and why we use mirrors for block storage
Zde odkážu jen na tento zajímavý thread :
ZFS read performance of mirrored VDEVs
Životnost kontroluji přes SMART. Dělám jednou týdně long SMART testy, ale přemýšlím o jejich zbytečnosti (jak z podstaty, tak z hlediska zbytečného performance impactu). Ten storage je celkem vytížený (denně se zapíše cca 2TiB dat a jednou týdně backup menší 7TiB databáze navrch), takže se kontroluje neustále to, co se stejně už děje věčným čtením a zápisy. Přemýšlím, že ty long testy stopnu a nebudu je už dělat a nechal bych jen shorty. Uvidíme, zatím je to jen ve stádiu úvah.
Pokud jde o scrub (kontrolu konzistence dat celého poolu), tak tu dělám jednou měsíčně. Pokud vypnu SMART long testy, tak to zkrátím na 14 dní.
Poslední scrub praví toto (trval jeden den, takže kromě toho, že na tom běží jedna VM, se tam zapsal ještě i denní backup) :
root@storage:~ # zpool status datastore1
pool: datastore1
state: ONLINE
scan: scrub repaired 2.45M in 1 days 08:08:57 with 0 errors on Mon Apr 20 08:09:06 2020
config:
NAME STATE READ WRITE CKSUM
datastore1 ONLINE 0 0 0
raidz2-0 ONLINE 0 0 0
gptid/2a663563-3a91-11e9-b585-0cc47a34a53a ONLINE 0 0 0
gptid/2e3c3fd6-3a91-11e9-b585-0cc47a34a53a ONLINE 0 0 0
gptid/313dc33b-3a91-11e9-b585-0cc47a34a53a ONLINE 0 0 0
gptid/33f0312b-3a91-11e9-b585-0cc47a34a53a ONLINE 0 0 0
gptid/3595c593-3a91-11e9-b585-0cc47a34a53a ONLINE 0 0 0
gptid/36530c30-3a91-11e9-b585-0cc47a34a53a ONLINE 0 0 0
gptid/b3cfb3ce-4997-11e9-9147-0cc47a34a53a ONLINE 0 0 0
gptid/3bd6c7cc-3a91-11e9-b585-0cc47a34a53a ONLINE 0 0 0
raidz2-1 ONLINE 0 0 0
gptid/72a6e04c-3a91-11e9-b585-0cc47a34a53a ONLINE 0 0 0
gptid/75edbf3c-3a91-11e9-b585-0cc47a34a53a ONLINE 0 0 0
gptid/77f2aba2-3a91-11e9-b585-0cc47a34a53a ONLINE 0 0 0
gptid/7a9a7a58-3a91-11e9-b585-0cc47a34a53a ONLINE 0 0 0
gptid/7e27cce7-3a91-11e9-b585-0cc47a34a53a ONLINE 0 0 0
gptid/7ff754a7-3a91-11e9-b585-0cc47a34a53a ONLINE 0 0 0
gptid/80a703cb-3a91-11e9-b585-0cc47a34a53a ONLINE 0 0 0
gptid/8153ec3f-3a91-11e9-b585-0cc47a34a53a ONLINE 0 0 0
raidz2-2 ONLINE 0 0 0
gptid/aa1f9e5a-5aa1-11e9-81fa-0cc47a34a53a ONLINE 0 0 0
gptid/b19b82c6-5aa1-11e9-81fa-0cc47a34a53a ONLINE 0 0 0
gptid/b6cf9f02-5aa1-11e9-81fa-0cc47a34a53a ONLINE 0 0 0
gptid/be2876dc-5aa1-11e9-81fa-0cc47a34a53a ONLINE 0 0 0
gptid/c3568f08-5aa1-11e9-81fa-0cc47a34a53a ONLINE 0 0 0
gptid/c92abbc7-5aa1-11e9-81fa-0cc47a34a53a ONLINE 0 0 0
gptid/d0774cf2-5aa1-11e9-81fa-0cc47a34a53a ONLINE 0 0 0
gptid/d630b1bb-5aa1-11e9-81fa-0cc47a34a53a ONLINE 0 0 0
raidz2-3 ONLINE 0 0 0
gptid/baed7380-497b-11e9-b585-0cc47a34a53a ONLINE 0 0 0
gptid/bbadca4c-497b-11e9-b585-0cc47a34a53a ONLINE 0 0 0
gptid/bc618666-497b-11e9-b585-0cc47a34a53a ONLINE 0 0 0
gptid/bd17e6d3-497b-11e9-b585-0cc47a34a53a ONLINE 0 0 0
gptid/bdd28194-497b-11e9-b585-0cc47a34a53a ONLINE 0 0 0
gptid/be8e40c6-497b-11e9-b585-0cc47a34a53a ONLINE 0 0 0
gptid/bf443662-497b-11e9-b585-0cc47a34a53a ONLINE 0 0 0
gptid/917fe6ed-d60b-11e9-9c34-0cc47a34a53a ONLINE 0 0 0
logs
gptid/94428971-570e-11ea-af91-0cc47a34a53a ONLINE 0 0 0
errors: No known data errors
Je tedy vidět, že našel a opravil 2,45MiB nekonzistencí. Smysl to tedy má značný. Konzistenci databázových dumpů (600GiB) ověřuji většinou 1x za 14 dní, kdy dělám full db restore do testovacích databází a nikdy žádný problém. Restore záloh VM taktéž dělám (jakékoli větší updaty nebo změny si nejdříve otestuji v testovacím prostředí)
Pokud jde o replace vadného disku za nějaký jiný, tak u poslední výměny mám poznamenáno (storage byl vytíženější a snad jsem ani v té době neměl SLOG) :
resilvered 2.62T in 0 days 15:03:27 with 0 errors
Disky většinou nechávám skoro dožít, nějaký občasný realokace mně nechávají klidným. Aktuálně mám špatný toto a zatím mně to nijak extrémně netrápí :
1) Tři disky občas mají tento problém (příklad z da9):
(da9:mpr0:0:17:0): CAM status: CCB request completed with an error
(da9:mpr0:0:17:0): Retrying command
(da9:mpr0:0:17:0): READ(16). CDB: 88 00 00 00 00 01 cc 6c 7c a8 00 00 01 00 00 00
(da9:mpr0:0:17:0): READ(16). CDB: 88 00 00 00 00 01 28 ed 2c 90 00 00 00 20 00 00 length 16384 SMID 213 terminated ioc 804b l(da9:mpr0:0:17:0): CAM status: CCB request completed with an error
oginfo 31080000 scsi 0 state 0 xfer 0
(da9:mpr0:0:17:0): WRITE(16). CDB: 8a 00 00 00 00 01 d1 c0 ba 90 00 00 00 10 00 00 length 8192 SMID 722 terminated ioc 804b l(da9:oginfo 31080000 scsi 0 state 0 xfer 0
mpr0:0:17:0): Retrying command
(da9:mpr0:0:17:0): READ(16). CDB: 88 00 00 00 00 01 cc 6c 7d a8 00 00 01 00 00 00
(da9:mpr0:0:17:0): CAM status: CCB request completed with an error
(da9:mpr0:0:17:0): Retrying command
(da9:mpr0:0:17:0): READ(16). CDB: 88 00 00 00 00 01 cc 6c 7e a8 00 00 00 e8 00 00
(da9:mpr0:0:17:0): CAM status: CCB request completed with an error
(da9:mpr0:0:17:0): Retrying command
(da9:mpr0:0:17:0): WRITE(6). CDB: 0a 00 02 90 10 00
(da9:mpr0:0:17:0): CAM status: CCB request completed with an error
(da9:mpr0:0:17:0): Retrying command
(da9:mpr0:0:17:0): READ(16). CDB: 88 00 00 00 00 01 cc 6c 80 90 00 00 00 80 00 00
(da9:mpr0:0:17:0): CAM status: CCB request completed with an error
(da9:mpr0:0:17:0): Retrying command
(da9:mpr0:0:17:0): READ(10). CDB: 28 00 be 3d 0b 58 00 01 00 00
(da9:mpr0:0:17:0): CAM status: CCB request completed with an error
(da9:mpr0:0:17:0): Retrying command
(da9:mpr0:0:17:0): READ(10). CDB: 28 00 be 3d 0c 58 00 00 c0 00
(da9:mpr0:0:17:0): CAM status: CCB request completed with an error
(da9:mpr0:0:17:0): Retrying command
(da9:mpr0:0:17:0): READ(16). CDB: 88 00 00 00 00 01 28 ed 2c 90 00 00 00 20 00 00
(da9:mpr0:0:17:0): CAM status: CCB request completed with an error
(da9:mpr0:0:17:0): Retrying command
(da9:mpr0:0:17:0): WRITE(16). CDB: 8a 00 00 00 00 01 d1 c0 ba 90 00 00 00 10 00 00
(da9:mpr0:0:17:0): CAM status: CCB request completed with an error
(da9:mpr0:0:17:0): Retrying command
2) U dvou paměťových modulů se občas objeví chybka (až bude time odstávky, zkusím je prohodit, pokud nepomůže, půjdou na reklamaci):
MCA: Bank 7, Status 0x8c00004000010090 MCA: Global Cap 0x0000000007000c16, Status 0x0000000000000000 MCA: Vendor "GenuineIntel", ID 0x306f2, APIC ID 16 MCA: CPU 12 COR (1) RD channel 0 memory error MCA: Address 0x2bf837e100
3) SMART pár disků ukazuje, že je možná čas řešit reklamaci (zbytek je ok, tzn. 0 realokací a žádné chyby ve SMART error logu) :
da13 Reallocated_Sector_Ct : 107 Reallocated_Event_Count : 4 da14 Reallocated_Sector_Ct : 41 Reallocated_Event_Count : 1 da20 Reallocated_Sector_Ct : 64 Reallocated_Event_Count : 45
Zatím pošlu da20, protože začíná dost často vyhazovat v logu "CCB request completed with an error" a těch realokovaných eventů už má fakt dost. První dva jsou zatím ok, resp. nejsou, ale je to zatím v klidu (= neohrožují provoz). Nicméně vzhledem k tomu, že se blíží konec záruky, je otočím také.
4) Takto to vypadá, když už i ZFS si všimne vadného disku :
root@storage:~ # zpool status datastore1
pool: datastore1
state: ONLINE
status: One or more devices has experienced an unrecoverable error. An
attempt was made to correct the error. Applications are unaffected.
action: Determine if the device needs to be replaced, and clear the errors
using 'zpool clear' or replace the device with 'zpool replace'.
see: http://illumos.org/msg/ZFS-8000-9P
scan: resilvered 10.3M in 0 days 00:00:25 with 0 errors on Sun May 2 04:47:59 2019
config:
NAME STATE READ WRITE CKSUM
datastore1 ONLINE 0 0 0
raidz2-0 ONLINE 0 0 0
gptid/2a663563-3a91-11e9-b585-0cc47a34a53a ONLINE 0 0 0
gptid/2e3c3fd6-3a91-11e9-b585-0cc47a34a53a ONLINE 0 0 0
gptid/313dc33b-3a91-11e9-b585-0cc47a34a53a ONLINE 0 0 0
gptid/33f0312b-3a91-11e9-b585-0cc47a34a53a ONLINE 0 0 0
gptid/3595c593-3a91-11e9-b585-0cc47a34a53a ONLINE 0 0 0
gptid/36530c30-3a91-11e9-b585-0cc47a34a53a ONLINE 0 0 0
gptid/b3cfb3ce-4997-11e9-9147-0cc47a34a53a ONLINE 0 0 0
gptid/3bd6c7cc-3a91-11e9-b585-0cc47a34a53a ONLINE 0 0 0
raidz2-1 ONLINE 0 0 0
gptid/72a6e04c-3a91-11e9-b585-0cc47a34a53a ONLINE 0 0 0
gptid/75edbf3c-3a91-11e9-b585-0cc47a34a53a ONLINE 0 0 0
gptid/77f2aba2-3a91-11e9-b585-0cc47a34a53a ONLINE 0 0 0
gptid/7a9a7a58-3a91-11e9-b585-0cc47a34a53a ONLINE 0 0 0
gptid/7e27cce7-3a91-11e9-b585-0cc47a34a53a ONLINE 0 0 0
gptid/7ff754a7-3a91-11e9-b585-0cc47a34a53a ONLINE 0 0 0
gptid/80a703cb-3a91-11e9-b585-0cc47a34a53a ONLINE 0 0 0
gptid/8153ec3f-3a91-11e9-b585-0cc47a34a53a ONLINE 0 0 0
raidz2-2 ONLINE 0 0 0
gptid/aa1f9e5a-5aa1-11e9-81fa-0cc47a34a53a ONLINE 0 0 0
gptid/b19b82c6-5aa1-11e9-81fa-0cc47a34a53a ONLINE 0 0 0
gptid/b6cf9f02-5aa1-11e9-81fa-0cc47a34a53a ONLINE 0 0 0
gptid/be2876dc-5aa1-11e9-81fa-0cc47a34a53a ONLINE 0 0 0
gptid/c3568f08-5aa1-11e9-81fa-0cc47a34a53a ONLINE 0 0 0
gptid/c92abbc7-5aa1-11e9-81fa-0cc47a34a53a ONLINE 0 0 0
gptid/d0774cf2-5aa1-11e9-81fa-0cc47a34a53a ONLINE 0 0 0
gptid/d630b1bb-5aa1-11e9-81fa-0cc47a34a53a ONLINE 0 0 0
raidz2-3 ONLINE 0 0 0
gptid/baed7380-497b-11e9-b585-0cc47a34a53a ONLINE 0 0 0
gptid/bbadca4c-497b-11e9-b585-0cc47a34a53a ONLINE 0 0 0
gptid/bc618666-497b-11e9-b585-0cc47a34a53a ONLINE 0 0 0
gptid/bd17e6d3-497b-11e9-b585-0cc47a34a53a ONLINE 0 0 0
gptid/bdd28194-497b-11e9-b585-0cc47a34a53a ONLINE 0 41 0
gptid/be8e40c6-497b-11e9-b585-0cc47a34a53a ONLINE 0 0 0
gptid/bf443662-497b-11e9-b585-0cc47a34a53a ONLINE 0 0 0
gptid/917fe6ed-d60b-11e9-9c34-0cc47a34a53a ONLINE 0 0 0
logs
gptid/94428971-570e-11ea-af91-0cc47a34a53a ONLINE 0 0 0
errors: No known data errors
SMART pak u takového disku vypadá takto :
1 Raw_Read_Error_Rate 0x002f 199 162 051 Pre-fail Always - 8 3 Spin_Up_Time 0x0027 151 151 021 Pre-fail Always - 11441 4 Start_Stop_Count 0x0032 100 100 000 Old_age Always - 25 5 Reallocated_Sector_Ct 0x0033 195 195 140 Pre-fail Always - 180 7 Seek_Error_Rate 0x002e 200 200 000 Old_age Always - 0 9 Power_On_Hours 0x0032 053 053 000 Old_age Always - 34549 10 Spin_Retry_Count 0x0032 100 253 000 Old_age Always - 0 11 Calibration_Retry_Count 0x0032 100 253 000 Old_age Always - 0 12 Power_Cycle_Count 0x0032 100 100 000 Old_age Always - 25 16 Total_LBAs_Read 0x0022 011 189 000 Old_age Always - 635193355198 183 Runtime_Bad_Block 0x0032 100 100 000 Old_age Always - 0 192 Power-Off_Retract_Count 0x0032 200 200 000 Old_age Always - 23 193 Load_Cycle_Count 0x0032 200 200 000 Old_age Always - 1 194 Temperature_Celsius 0x0022 109 103 000 Old_age Always - 43 196 Reallocated_Event_Count 0x0032 190 190 000 Old_age Always - 10 197 Current_Pending_Sector 0x0032 200 200 000 Old_age Always - 20
Jak vidíte výše, zas tak moc si z malého zaškobrtnutí nelámu hlavu (hlavně proto, že používám ZFS, jinak bych si to nelajz). Dřív stačilo 50 realokovaných sektorů a už disk šel. Jo, kdyby to nebyl backup storage, tak bych tam ani jeden z těch tří disků už neměl. Za 4 roky provozu jsem reklamoval celkem 6 disků a ty tři výše půjdou teď. Zde je ale třeba si uvědomit jednu věc. Nemám od začátku takové rozložení disků ani to SSD jako SLOG. Ty disky jsem někdy dost silně zatěžoval a měl pod 100% zatížením celkem dlouho. Kdybych měl od začátku rozložení jako teď + ten Optane, tak si myslím, že by jich doteď odešly(=vykazovaly chyby) třeba jen dva a né 9.
Uděláme replace (nedělá se fullscrub, překopírují se jen data toho disku na nový / náš spare disk). Následně si rozsvítím červenou diodu na šasi u disku, který chci vyměnit pomocí příkazu :
# zapnout led na kleci sas3ircu 0 locate 2:8 ONAž disk vyměním za nový (do budoucna bude dělat spare, jelikož jsme replace udělali s náhradním diskem), tak červenou led vypnu :
# vypnout led na kleci (když dáme nový disk) sas3ircu 0 locate 2:8 OFF
Existují případy, kdy disk vykazuje drobné chyby a nebo úplně vypadne a odmlčí se. To jsou ty lepší případy. Pak je zde případ, kdy disk je silně poškozen, ale ještě se drží a funguje s velkou chybovostí. Poté si toho všimne ZFS :
root@storage:~ # zpool status datastore1
pool: datastore1
state: ONLINE
status: One or more devices is currently being resilvered. The pool will
continue to function, possibly in a degraded state.
action: Wait for the resilver to complete.
scan: resilver in progress since Thu May 7 10:17:45 2019
26.6T scanned at 3.63G/s, 19.6T issued at 1.56G/s, 102T total
0 resilvered, 19.29% done, 0 days 15:00:13 to go
config:
NAME STATE READ WRITE CKSUM
datastore1 ONLINE 0 0 0
raidz2-0 ONLINE 0 0 0
gptid/2a663563-3a91-11e9-b585-0cc47a34a53a ONLINE 0 0 0
gptid/2e3c3fd6-3a91-11e9-b585-0cc47a34a53a ONLINE 0 0 0
gptid/313dc33b-3a91-11e9-b585-0cc47a34a53a ONLINE 0 0 0
gptid/33f0312b-3a91-11e9-b585-0cc47a34a53a ONLINE 0 0 0
gptid/3595c593-3a91-11e9-b585-0cc47a34a53a ONLINE 0 0 0
gptid/36530c30-3a91-11e9-b585-0cc47a34a53a ONLINE 0 0 0
gptid/b3cfb3ce-4997-11e9-9147-0cc47a34a53a ONLINE 0 0 0
gptid/3bd6c7cc-3a91-11e9-b585-0cc47a34a53a ONLINE 0 0 0
raidz2-1 ONLINE 0 0 0
gptid/72a6e04c-3a91-11e9-b585-0cc47a34a53a ONLINE 0 0 0
gptid/75edbf3c-3a91-11e9-b585-0cc47a34a53a ONLINE 0 0 0
gptid/77f2aba2-3a91-11e9-b585-0cc47a34a53a ONLINE 0 0 0
gptid/7a9a7a58-3a91-11e9-b585-0cc47a34a53a ONLINE 0 0 0
gptid/7e27cce7-3a91-11e9-b585-0cc47a34a53a ONLINE 0 0 0
gptid/7ff754a7-3a91-11e9-b585-0cc47a34a53a ONLINE 0 0 0
gptid/80a703cb-3a91-11e9-b585-0cc47a34a53a ONLINE 0 0 0
gptid/8153ec3f-3a91-11e9-b585-0cc47a34a53a ONLINE 0 0 0
raidz2-2 ONLINE 0 0 0
gptid/aa1f9e5a-5aa1-11e9-81fa-0cc47a34a53a ONLINE 0 0 0
gptid/b19b82c6-5aa1-11e9-81fa-0cc47a34a53a ONLINE 0 0 0
gptid/b6cf9f02-5aa1-11e9-81fa-0cc47a34a53a ONLINE 0 0 0
gptid/be2876dc-5aa1-11e9-81fa-0cc47a34a53a ONLINE 0 0 0
gptid/c3568f08-5aa1-11e9-81fa-0cc47a34a53a ONLINE 0 0 0
gptid/c92abbc7-5aa1-11e9-81fa-0cc47a34a53a ONLINE 0 0 0
gptid/d0774cf2-5aa1-11e9-81fa-0cc47a34a53a ONLINE 0 0 0
gptid/d630b1bb-5aa1-11e9-81fa-0cc47a34a53a ONLINE 0 0 0
raidz2-3 ONLINE 0 0 0
gptid/baed7380-497b-11e9-b585-0cc47a34a53a ONLINE 0 0 0
gptid/bbadca4c-497b-11e9-b585-0cc47a34a53a ONLINE 0 0 0
gptid/bc618666-497b-11e9-b585-0cc47a34a53a ONLINE 0 0 0
gptid/bd17e6d3-497b-11e9-b585-0cc47a34a53a ONLINE 0 0 0
replacing-4 ONLINE 0 0 6.08K
gptid/bdd28194-497b-11e9-b585-0cc47a34a53a ONLINE 259 711 0
gptid/8bb2c39b-95ad-11ea-af91-0cc47a34a53a ONLINE 0 0 0
gptid/be8e40c6-497b-11e9-b585-0cc47a34a53a ONLINE 0 0 0
gptid/bf443662-497b-11e9-b585-0cc47a34a53a ONLINE 0 0 0
gptid/917fe6ed-d60b-11e9-9c34-0cc47a34a53a ONLINE 0 0 0
logs
gptid/94428971-570e-11ea-af91-0cc47a34a53a ONLINE 0 0 0
Ve výpisu vidíte pokus udělat replace. Ten ale nikdy nedojde a zpomalý pool. Je tam vidět, že chybovost při čtení i zápisu je opravdu velká. Řešením v takovém případě je vykašlat se na probíhající replace, vyndat vadný disk, detachnout nový
zpool detach datastore1 /dev/gptid/8bb2c39b-95ad-11ea-af91-0cc47a34a53akterý jsme pro replace použili a provést replace s tímto diskem znovu s tím, že už tam nebude původní vadný disk a replace tak bude za chybějící disk. Výsledný replace pak bude o dost rychlejší :
root@storage:~ # zpool status datastore1
pool: datastore1
state: ONLINE
status: One or more devices is currently being resilvered. The pool will
continue to function, possibly in a degraded state.
action: Wait for the resilver to complete.
scan: resilver in progress since Mon May 10 09:50:11 2019
57.9T scanned at 2.91G/s, 48.3T issued at 1.75G/s, 104T total
425G resilvered, 46.30% done, 0 days 09:04:23 to go
config:
NAME STATE READ WRITE CKSUM
datastore1 ONLINE 0 0 0
raidz2-0 ONLINE 0 0 0
gptid/2a663563-3a91-11e9-b585-0cc47a34a53a ONLINE 0 0 0
gptid/2e3c3fd6-3a91-11e9-b585-0cc47a34a53a ONLINE 0 0 0
gptid/313dc33b-3a91-11e9-b585-0cc47a34a53a ONLINE 0 0 0
gptid/33f0312b-3a91-11e9-b585-0cc47a34a53a ONLINE 0 0 0
gptid/3595c593-3a91-11e9-b585-0cc47a34a53a ONLINE 0 0 0
gptid/36530c30-3a91-11e9-b585-0cc47a34a53a ONLINE 0 0 0
gptid/b3cfb3ce-4997-11e9-9147-0cc47a34a53a ONLINE 0 0 0
gptid/3bd6c7cc-3a91-11e9-b585-0cc47a34a53a ONLINE 0 0 0
raidz2-1 ONLINE 0 0 0
gptid/72a6e04c-3a91-11e9-b585-0cc47a34a53a ONLINE 0 0 0
gptid/75edbf3c-3a91-11e9-b585-0cc47a34a53a ONLINE 0 0 0
gptid/77f2aba2-3a91-11e9-b585-0cc47a34a53a ONLINE 0 0 0
gptid/7a9a7a58-3a91-11e9-b585-0cc47a34a53a ONLINE 0 0 0
gptid/7e27cce7-3a91-11e9-b585-0cc47a34a53a ONLINE 0 0 0
gptid/7ff754a7-3a91-11e9-b585-0cc47a34a53a ONLINE 0 0 0
gptid/80a703cb-3a91-11e9-b585-0cc47a34a53a ONLINE 0 0 0
gptid/8153ec3f-3a91-11e9-b585-0cc47a34a53a ONLINE 0 0 0
raidz2-2 ONLINE 0 0 0
gptid/aa1f9e5a-5aa1-11e9-81fa-0cc47a34a53a ONLINE 0 0 0
gptid/b19b82c6-5aa1-11e9-81fa-0cc47a34a53a ONLINE 0 0 0
gptid/b6cf9f02-5aa1-11e9-81fa-0cc47a34a53a ONLINE 0 0 0
gptid/be2876dc-5aa1-11e9-81fa-0cc47a34a53a ONLINE 0 0 0
gptid/c3568f08-5aa1-11e9-81fa-0cc47a34a53a ONLINE 0 0 0
gptid/c92abbc7-5aa1-11e9-81fa-0cc47a34a53a ONLINE 0 0 0
gptid/d0774cf2-5aa1-11e9-81fa-0cc47a34a53a ONLINE 0 0 0
gptid/d630b1bb-5aa1-11e9-81fa-0cc47a34a53a ONLINE 0 0 0
raidz2-3 ONLINE 0 0 0
gptid/baed7380-497b-11e9-b585-0cc47a34a53a ONLINE 0 0 0
gptid/bbadca4c-497b-11e9-b585-0cc47a34a53a ONLINE 0 0 0
gptid/bc618666-497b-11e9-b585-0cc47a34a53a ONLINE 0 0 0
gptid/bd17e6d3-497b-11e9-b585-0cc47a34a53a ONLINE 0 0 0
gptid/e93ab71e-98db-11ea-af91-0cc47a34a53a ONLINE 0 0 0
gptid/be8e40c6-497b-11e9-b585-0cc47a34a53a ONLINE 0 0 0
gptid/bf443662-497b-11e9-b585-0cc47a34a53a ONLINE 0 0 0
gptid/917fe6ed-d60b-11e9-9c34-0cc47a34a53a ONLINE 0 0 0
logs
gptid/94428971-570e-11ea-af91-0cc47a34a53a ONLINE 0 0 0
errors: No known data errors
Dobré je tedy to, že pole i takto ošklivý disk ustojí. Pokud bychom na něco podobného narazili u jiného řešení (třeba mdadm), tak se bude čekat na hodně velké timeouty, které budou mít za následek znefunkčnění pole a služeb nad tím běžících. V našem případě všechny služby fungovaly, VM nad storage běžela, ale některé backup úlohy se hodně protáhly.
Papírově se udává minimálně 1GB ram na 1TB RAW. V případě zapnuté deduplikace je doporučováno 5GB ram na 1TB RAW. Toto nejsou minimální možné hodnoty, ale hodnoty doporučované, u kterých máte jistotu, že se vám to nesesype. Já mám té paměti opravdu hodně, protože jsem jednak musel přidat CPU kvůli dalším kartám, dále jsem počítal s rezervou na rozšiřování (to mně teď čeká, do začátku o 8x SATA) a jeden čas jsem na tom serveru provozoval i nějaké VM, které dělaly bridge pro jiné druhy záloh.
Reálné využití paměti se odvíjí od reálných dat. Tzn. záleží na tom, co máte na storage uloženo. Když bych měl já uvést maximální alokaci paměti u mých dat, tak je to tato :
root@storage:~ # arcstat.py -a
time hits miss read hit% miss% dhit dmis dh% dm% phit pmis ph% pm% mhit mmis mread mh% mm% arcsz c mfu mru mfug mrug eskip mtxmis dread pread
19:40:42 56G 1.9G 58G 96 3 56G 621M 98 1 279M 1.3G 17 82 53G 183M 53G 99 0 149G 149G 52G 3.8G 7.1M 12M 93K 2.1M 57G 1.6G
Jinými slovy, aktuální storage využívá v produkci 56GB RAM, což je 438MiB na 1TB RAW kapacity, nebo také 584MiB na 1TB dat. To je tedy úplně oholená kost. Pokud bychom chtěli fungovat, tak dává smysl minimálně 750MB ram na 1TB dat + režie OS / dalších služeb.
Pokud chcete vědět, zda má deduplikace na vašem poolu smysl a kolik minimálně potřebujete ram, abyste dedup uživili, tak si spusťte analýzu poolu (How to Determine Memory Requirements for ZFS Deduplication):
# u FreeNAS není zpool.cache ve standardní cestě, proto musíme jeho umístění specifikovat
root@storage:~ # time zdb -S -U /data/zfs/zpool.cache datastore1
Simulated DDT histogram:
bucket allocated referenced
______ ______________________________ ______________________________
refcnt blocks LSIZE PSIZE DSIZE blocks LSIZE PSIZE DSIZE
------ ------ ----- ----- ----- ------ ----- ----- -----
1 539M 67.3T 52.2T 52.8T 539M 67.3T 52.2T 52.8T
2 32.9M 4.11T 2.75T 2.80T 75.0M 9.37T 6.30T 6.41T
4 2.78M 355G 154G 161G 13.8M 1.72T 770G 806G
8 1.81M 232G 146G 149G 19.5M 2.44T 1.46T 1.50T
16 444K 55.4G 28.1G 28.8G 9.03M 1.13T 585G 600G
32 60.8K 7.60G 3.75G 3.87G 2.08M 266G 131G 135G
64 393 47.7M 7.43M 8.95M 33.4K 4.06G 615M 748M
128 175 21.4M 1.14M 1.89M 31.3K 3.84G 200M 337M
256 62 7.27M 336K 640K 19.6K 2.30G 103M 201M
512 15 1.63M 178K 247K 10.2K 1.12G 134M 180M
1K 4 512K 16K 34.1K 5.55K 710M 22.2M 47.3M
2K 4 512K 264K 273K 10.3K 1.29G 622M 647M
4K 12 1.50M 1.26M 1.27M 74.6K 9.33G 7.84G 7.90G
8K 2 256K 256K 256K 17.7K 2.21G 2.21G 2.21G
32K 2 256K 2K 17.1K 92.2K 11.5G 92.2M 786M
64K 1 128K 4K 8.53K 122K 15.2G 486M 1.01G
128K 1 128K 4K 8.53K 180K 22.5G 719M 1.50G
256K 1 128K 4K 8.53K 368K 46.1G 1.44G 3.07G
Total 577M 72.1T 55.3T 55.9T 659M 82.3T 61.4T 62.2T
dedup = 1.11, compress = 1.34, copies = 1.01, dedup * compress / copies = 1.47
3278.945u 5009.703s 1:20:44.54 171.0% 141+2615k 8132798+0io 7pf+0w
Jak je vidět, tak analýza poolu trvala 1h 20min. Předpokládaný dedup ratio je 1.11, takže bychom zapnutím moc místa neušetřili.
Jeden DDT (deduplikační tabulka) zápis má v průměru 320 byte. v případě mých dat by bylo tedy potřeba minimáně : 577M * 320 = 184 640MB RAM. Jinými slovy 185GB RAM jen pro DDT tabulky (a to přesně, je potřeba připočítat ještě rezervu pro další záznamy). Poté je ještě potřeba ram pro běžné režie (výše zmíněných 750MB ram na 1TB dat). Můj příklad tedy vychází, že se zapnutou deduplikací bych potřeboval minimálně 1,45GB ram na 1TB RAW, nebo 1,93GB ram na 1TB dat. Reálně však ale 1,8 + 0,75 = 2,55GB na 1TB RAW, nebo 2,3 + 0,75 = 3GB RAM na 1TB dat + režie OS / dalších služeb.
Jak je tedy vidět, tak v obou případech nejsou tabulkové doporučení od těch skutečných tak daleko, pokud tedy započítáme, že data mohou být hodně rozdílná a v určitých případech může být využití ram ještě o něco vyšší.
Několik základních tipů :
Pokud si chcete hrát a zapnete si bez uvážení deduplikaci a nebudete mít dostatek ram, tak máte velký problém. Dojde vám ram a server padne. Po restartu se vám pool, potažmo datasety, nenaimportují, protože při jejich importu opět dojde ram. Východisko z této situace může být jediné, doplnit fyzickou paměť do serveru. Tj. celkem nepříjemná věc, která většinou nejde hned vyřešit.
Zásadně nepoužívejte žádné řadiče s cache apod. Vždy jen čistě HBA řadiče, aby ZFS vidělo na fyzické disky. V opačném případě si zaděláváte na problém. Já to vyhrál úplně, protože jsem kdysi pořídil Areca řadič, který sám o sobě nebyl stable. V případě 100% vytížení disků se odmlčel. Celkem náhoda jednou za x měsíců. A to jsem měl disky v passthrough. Další problém s Arecou byl, že k omezeným SMART informacím se dalo dostat jen přes tool od Arecy. Tzn. i když byly disky v passthrough, smartmontools měl problém. Občas i Areca disky odpojovala (vnitřní timeout, když disk byl delší dobu ve 100% zatížení, jí asi donutil). Pokud tedy nepoužijete hloupý HBA řadič, tak se vystavujete potenciálním problémům i co se diagnostiky životnosti disků týče. Myslím si, že výše uvedené LSI je parádní. Dnes už bych sáhl po novějším ks v podobě Tri-Mode řady, která právě podporuje připojení kromě SATA/SAS i NVMe disků.
Pokud si postavíte pool z jednoho RAIDZ, tak si uvědomte, že výkon v IOPS bude tragický, obzvláště bez SLOG. Takový případ nelze pomalu použít ani na zálohy, protože stačí spustit zálohu i obnovu najednou a storage se může lehce ubít.
Sestavit si server, kde není něco úplně 100% funkční ve FreeBSD/ Solaris like OS je dost zásadní chyba. Je tedy třeba vybírat rozumné řadiče i síťové karty. Lidi ze světa Linuxu na to už moc zvyklý nejsou, ale ostatní OS nemají tak rozšířenou podporu HW jako Linux.
Se Supermicro nemám problém. Jejich skříně jsou parádní, člověk si může poskládat, co jen chce. Zálohovací storage bych dnes poskládat úplně stejně, jen s tím rozdílem, že bych jako CPU použil jeden Epyc Rome 7232P a LSI tri mode řadič (podpora ve FreeBSD už je), abych do něj mohl jako SLOG dát Optane 905p 480GB U.2. Pokud jde o disky, tak sice mně trochu nahlodává lepší cenová rentabilita 6TB SATA disků, ale asi bych přecijen zůstal u 4TB variant.
Pokud bych měl stavět storage např. pro produkční běh VM, tak bych postupoval podobně, jen bych použil dva řadiče a SAS disky (kvůli lepší životnosti a podpoře DP - DualPort). Jako SLOG bych pak použil dva SSD v mirroru.
Resp. bych asi rovnou použil SSD SAS nebo NVMe disky s podporou DP a vůbec neřešil SLOG a rotační disky.
Kromě různých možností tunění je síla ZFS i ve velmi podrobných diagnostických nástrojích. Analýzu ARC v podobě "arcstat.py" jsme si již částečně ukázali. Zobrazit stav fragmentace, deduplikace a zaplnění lze pomocí příkazu :
root@storage:~ # zpool list datastore1 NAME SIZE ALLOC FREE CKPOINT EXPANDSZ FRAG CAP DEDUP HEALTH ALTROOT datastore1 116T 102T 14.2T - - 34% 87% 1.00x ONLINE /mntZobrazit kompresní poměr lze třeba takto :
root@storage1:~ # zfs get compressratio NAME PROPERTY VALUE SOURCE datastore1 compressratio 1.32x - datastore1/ISO compressratio 1.08x - datastore1/datastore-test compressratio 1.49x - datastore1/dms-backup compressratio 1.21x - datastore1/helios-backup compressratio 1.99x - datastore1/oracle-backup compressratio 1.71x - ...Pomocí "zfs get" lze získat spoustu dalších informací, viz :
root@storage:~ # zfs get all datastore1/oracle-backup NAME PROPERTY VALUE SOURCE datastore1/oracle-backup type filesystem - datastore1/oracle-backup creation Fri Mar 15 12:50 2019 - datastore1/oracle-backup used 12.0T - datastore1/oracle-backup available 7.52T - datastore1/oracle-backup referenced 12.0T - datastore1/oracle-backup compressratio 1.71x - datastore1/oracle-backup mounted yes - datastore1/oracle-backup quota none default datastore1/oracle-backup reservation none default datastore1/oracle-backup recordsize 128K default datastore1/oracle-backup mountpoint /mnt/datastore1/oracle-backup default datastore1/oracle-backup sharenfs off default datastore1/oracle-backup checksum on default datastore1/oracle-backup compression lz4 inherited from datastore1 datastore1/oracle-backup atime on default datastore1/oracle-backup devices on default datastore1/oracle-backup exec on default datastore1/oracle-backup setuid on default datastore1/oracle-backup readonly off default datastore1/oracle-backup jailed off default datastore1/oracle-backup snapdir hidden default datastore1/oracle-backup aclmode passthrough inherited from datastore1 datastore1/oracle-backup aclinherit passthrough inherited from datastore1 datastore1/oracle-backup canmount on default datastore1/oracle-backup xattr off temporary datastore1/oracle-backup copies 1 default datastore1/oracle-backup version 5 - datastore1/oracle-backup utf8only off - datastore1/oracle-backup normalization none - datastore1/oracle-backup casesensitivity sensitive - datastore1/oracle-backup vscan off default datastore1/oracle-backup nbmand off default datastore1/oracle-backup sharesmb off default datastore1/oracle-backup refquota none default datastore1/oracle-backup refreservation none default datastore1/oracle-backup primarycache all default datastore1/oracle-backup secondarycache all default datastore1/oracle-backup usedbysnapshots 0 - datastore1/oracle-backup usedbydataset 12.0T - datastore1/oracle-backup usedbychildren 0 - datastore1/oracle-backup usedbyrefreservation 0 - datastore1/oracle-backup logbias latency default datastore1/oracle-backup dedup off default datastore1/oracle-backup mlslabel - datastore1/oracle-backup sync standard default datastore1/oracle-backup refcompressratio 1.71x - datastore1/oracle-backup written 12.0T - datastore1/oracle-backup logicalused 19.9T - datastore1/oracle-backup logicalreferenced 19.9T - datastore1/oracle-backup volmode default default datastore1/oracle-backup filesystem_limit none default datastore1/oracle-backup snapshot_limit none default datastore1/oracle-backup filesystem_count none default datastore1/oracle-backup snapshot_count none default datastore1/oracle-backup redundant_metadata all default datastore1/oracle-backup org.freenas:description local datastore1/oracle-backup org.freebsd.ioc:active yes inherited from datastore1Dalším dobrým nástrojem je gstat :
root@storage:~ # gstat
dT: 1.062s w: 1.000s
L(q) ops/s r/s kBps ms/r w/s kBps ms/w %busy Name
0 67 0 0 0.0 67 667 0.0 0.2| nvd0
0 0 0 0 0.0 0 0 0.0 0.0| da0
0 0 0 0 0.0 0 0 0.0 0.0| da1
0 7 7 139 0.2 0 0 0.0 0.1| da2
0 8 8 136 1.5 0 0 0.0 1.1| da3
0 8 8 128 1.6 0 0 0.0 1.2| da4
0 8 8 147 0.2 0 0 0.0 0.2| da5
0 9 9 151 1.5 0 0 0.0 1.4| da6
0 6 6 105 0.4 0 0 0.0 0.2| da7
0 1 1 4 0.1 0 0 0.0 0.0| da8
0 6 6 117 0.2 0 0 0.0 0.1| da9
1 8 8 147 6.3 0 0 0.0 4.7| da10
1 9 9 177 1.1 0 0 0.0 1.0| da11
1 8 8 162 0.4 0 0 0.0 0.4| da12
0 9 9 169 3.9 0 0 0.0 2.4| da13
0 10 10 185 1.7 0 0 0.0 1.7| da14
0 0 0 0 0.0 0 0 0.0 0.0| da15
0 0 0 0 0.0 0 0 0.0 0.0| da16
0 0 0 0 0.0 0 0 0.0 0.0| da17
0 0 0 0 0.0 0 0 0.0 0.0| da18
0 0 0 0 0.0 0 0 0.0 0.0| da19
0 0 0 0 0.0 0 0 0.0 0.0| da20
0 0 0 0 0.0 0 0 0.0 0.0| da21
0 0 0 0 0.0 0 0 0.0 0.0| da22
0 5 5 87 0.2 0 0 0.0 0.1| da23
0 1 1 4 14.7 0 0 0.0 1.4| da24
0 1 1 4 10.8 0 0 0.0 1.0| da25
0 1 1 4 15.4 0 0 0.0 1.5| da26
0 6 6 105 0.3 0 0 0.0 0.2| da27
1 7 7 113 0.3 0 0 0.0 0.2| da28
1 9 9 169 0.7 0 0 0.0 0.7| da29
0 0 0 0 0.0 0 0 0.0 0.0| da30
0 1 1 4 0.1 0 0 0.0 0.0| da31
0 0 0 0 0.0 0 0 0.0 0.0| da32
0 0 1 4 13.4 0 0 0.0 1.3| da33
Zobrazení iostat a průtoku dat jinak (aktuální hodnoty se po 1s vypisují pod sebou):
root@storage:~ # zpool iostat datastore1 1
capacity operations bandwidth
pool alloc free read write read write
---------- ----- ----- ----- ----- ----- -----
datastore1 102T 14.2T 494 826 48.4M 47.5M
datastore1 102T 14.2T 37 1.70K 1.11M 108M
datastore1 102T 14.2T 36 46 1.76M 663K
datastore1 102T 14.2T 38 41 1.47M 691K
datastore1 102T 14.2T 34 1.17K 2.48M 14.4M
datastore1 102T 14.2T 37 89 2.40M 1.02M
...
Máme tu několik asi nejvýraznějších řešení se ZFS:
V zápisku není zmíněno vše, je to jen ukázka toho, jak věci mohou fungovat / nefungovat. Dokumentační projekt k ZFS v tom tedy nehledejte. Zajímavé ale je, jakým tempem jde implementace ZFS na Linuxu kupředu (jak z hlediska funkčnosti, tak z hlediska zájmu firem).
Zdar Max
PS: Snajpo, ZFS zdar!
Tiskni
Sdílej:
![]()
![]()
![]()
![]()
![]()
![]()
i když z technického hlediska problém není, je problém z hlediska morálníhoStačí zastávat názor, že já mám nárok na všechno a respektovat přání autorů software tudíž nemusím, a morální problém je vyřešen.
asi jedinou slabinou v kontrole integrity dat je to, že na data v ram se neaplikují checksummy, proto jsou nutné ECC pamětiAha, já jsem si říkal, kde se bere to, že pro ZFS MUSÍTE mít ECC.
online kompresyKompresy jsou obvazový materiál. Vy chcete zapnout kompresi. (x2)
 18.5.2020 21:15
Max | skóre: 73
| blog: Max_Devaine
19.5.2020 12:26
Max | skóre: 73
| blog: Max_Devaine
18.5.2020 21:15
Max | skóre: 73
| blog: Max_Devaine
19.5.2020 12:26
Max | skóre: 73
| blog: Max_Devaine
Poté existují náhrady za baterie v podobě plata kondíků, které by v sobě měly udržet potřebný počet energie, aby data v cache nechcíply. Nevím ale, jak moc se to používá.Superkondenzátorů - oproti normálním kondenzátorům je to trochu rozdíl. Používá se to třeba u
To by šlo, ale nemáme nikde rozumnou kontrolu konzistence dat.dm-integrity? Teda pokud kontrolu konzistence dat nemá filesystém.
19.5.2020 13:49
Max | skóre: 73
| blog: Max_Devaine
obávám se, že by tam bylo pár zbytečných výkonnostních propadůIMO je jedno, na které vrstvě se ten checksum udělá, takže spíš záleží na konkrétní implementaci
19.5.2020 16:28
Max | skóre: 73
| blog: Max_Devaine
Dělat checksum na úrovni FS je neúplné, když pod tím bude ještě další vrstva, která to dělat nebudeNeúplné v čem? Cílem je rozpoznat/opravit poškození dat a k tomu checksum na úrovni FS přece stačí, ne?
19.5.2020 18:01
Max | skóre: 73
| blog: Max_Devaine
19.5.2020 19:09
Max | skóre: 73
| blog: Max_Devaine
19.5.2020 21:29
Max | skóre: 73
| blog: Max_Devaine
 20.5.2020 00:34
Max | skóre: 73
| blog: Max_Devaine
20.5.2020 00:34
Max | skóre: 73
| blog: Max_Devaine
S ext3/4/reiserfs/ntfs apod. nic takového ani nezjistíš.Jednoho krásného dne se podívám na to dm-integrity a uvidí se, jak to nezjistím
19.5.2020 16:26
Max | skóre: 73
| blog: Max_Devaine
 .
19.5.2020 17:57
Max | skóre: 73
| blog: Max_Devaine
.
19.5.2020 17:57
Max | skóre: 73
| blog: Max_Devaine
3GB/1TB dat je v případě duduplikace, což se moc nepoužívá (není moc nasazení, kde to dává smysl).Nič proti, ale pokiaľ sa to správa tak mizerne, ako si uviedol v článku, tak to nielen že nedáva zmysel, ale tá deduplikácia by sa ani nemala uvádzať medzi vlastnosťami toho FS, nanajvýš niekde v TODO.
21.5.2020 19:04
Max | skóre: 73
| blog: Max_Devaine
19.5.2020 13:25
Max | skóre: 73
| blog: Max_Devaine
19.5.2020 16:23
Max | skóre: 73
| blog: Max_Devaine
20.5.2020 10:44
Max | skóre: 73
| blog: Max_Devaine
21.5.2020 12:54
Max | skóre: 73
| blog: Max_Devaine
time read miss miss% dmis dm% pmis pm% mmis mm% arcsz c
13:18:57 44 4 9 4 9 0 0 4 9 179G 180G
Moje zkušenost s DEDUP - až na velmi specifické usecase nebrat. Nestojí to za hlavobol. A to mám 256GB RAM na 24TB RAW kapacity.
Můj pool přežil už vadný diskový řadič, vadný napájecí káblik, který v náhodných intervalech způsoboval reset 2 disků v poli, 2 migrace mezi počítači, při upgradech, výměnu vadného disku a celkově značně hrubé zacházení typu přehození disku za chodu do jiného šuplíku kvůli výměně ventilátoru. Nesmrtelna věc
20.5.2020 14:17
Max | skóre: 73
| blog: Max_Devaine
root@storage:~ # nvmecontrol logpage -p 2 nvme0 SMART/Health Information Log ============================ Critical Warning State: 0x00 Available spare: 0 Temperature: 0 Device reliability: 0 Read only: 0 Volatile memory backup: 0 Temperature: 318 K, 44.85 C, 112.73 F Available spare: 100 Available spare threshold: 0 Percentage used: 0 Data units (512,000 byte) read: 29 Data units written: 198421208 Host read commands: 494 Host write commands: 1095760618 Controller busy time (minutes): 878 Power cycles: 4 Power on hours: 2059 Unsafe shutdowns: 0 Media errors: 0 No. error info log entries: 0 Warning Temp Composite Time: 0 Error Temp Composite Time: 0Takže Optane by už za sebou mělo mít : 96,6TB zápisu, pěkný.
21.5.2020 11:27
Max | skóre: 73
| blog: Max_Devaine
97TB
85dní
= 1,2TB/den
DWPD: 2,5
21.5.2020 12:08
Max | skóre: 73
| blog: Max_Devaine
21.5.2020 12:57
Max | skóre: 73
| blog: Max_Devaine
24.5.2020 22:10
Max | skóre: 73
| blog: Max_Devaine
7.6.2020 15:42
Max | skóre: 73
| blog: Max_Devaine
Je to uděláno naprosto parádně. Aktualizace oznamuje web ksicht a přes něj je můžeš nainstalovat + si můžeš nastavit, zda chceš být ve stable větvi, nebo beta větvi. Taktéž není problém je stáhnout a nainstalovat ručně z cmd.
Každý update vygeneruje snapshot OS a pokud se ti něco nelíbí, není problém na pár kliků myší přejít na předchozí verzi OS (je to tedy otázka jednoho rebootu).
Pokud jde o ZFS, tak ten se neaktualizuje automaticky. Web ksicht tě jen upozorní, že nový OS podporuje nové fce ZFS a zda chceš udělat aktualizaci poolu (ZFS). Dále tě upozorňuje, že se jedná o nevratnou věc a aby jsi to pečlivě zvážil.
Reálně tedy postupuji tak, že aktualizuji OS a pokud po několika týdnech nenarazím na problém, provedu i update ZFS poolu (pokud je k dispozici).
Dále je možné udělat backup nastavení (export do jednoho file). FreeNAS pak umožňuje takový export znovu importovat. Pokud ti tedy z nějakého důvodu padne HW (všechny disky), na kterých máš OS, tak obnova je celkem easy, prostě nainstaluješ freenas a importneš nastavení a hotovo.
Zdar Max
7.6.2020 15:46
Max | skóre: 73
| blog: Max_Devaine
7.6.2020 17:05
Max | skóre: 73
| blog: Max_Devaine
7.6.2020 19:09
Max | skóre: 73
| blog: Max_Devaine
 No co, ceny komponent jsou teď takové, že asi není kam se hnát (pokud to tedy není jako ve zmíněném případě nezbytně nutné).
8.6.2020 08:15
Max | skóre: 73
| blog: Max_Devaine
No co, ceny komponent jsou teď takové, že asi není kam se hnát (pokud to tedy není jako ve zmíněném případě nezbytně nutné).
8.6.2020 08:15
Max | skóre: 73
| blog: Max_Devaine
ISSN 1214-1267, (c) 1999-2007 Stickfish s.r.o.