Portál AbcLinuxu, 19. července 2026 01:03
Aneb malé povídání o n-gramech a Rku. Honzíkovi slibuji, že to bude mít větší hodnotu a lepší formátovaní než minule!
O co nám dnes půjde? Na vstupu máme titulky (anglické) z kompletní první série seriálu Southpark a budeme zjišťovat, jestli se v textu neobjevují nějaké opakující se patterny. K analýze nám poslouží tradičně jazyk R a jeho knihovny textcat, tau a k zobrazení výsledků pak wordcloud.
Jako první si někde obstaráme textové soubory s titulky, které budeme analyzovat. Ty umístíme do jednoho adresáře, v našem případě nazvaném "southpark", a s tím již pracujeme v R. Dále načteme potřebné knihovny a vytvoříme korpus, který bude obsahovat náš adresář.
library(textcat)
library(tau)
library(wordcloud)
korpus <- Corpus(DirSource("southpark", encoding="UTF-8"), readerControl = list(language = "en"))
Dále si do proměnné ngramy uložíme výsledek funkce textcnt, které předáváme v parametru n řád n-gramu. Postupně jsem to provedl pro n=1, 2, 3 a 4.
ngramy <- textcnt(korpus, method = "string",n=3)
Abychom mohli výsledek zobrazit jako wordcloud, musíme jej převézt z formátu textcnt na dataframe. To řeší následující příkaz:
df <- data.frame(word = names(ngramy), freq=unclass(ngramy))
Zbytek již je opakování z minula:
pal2 <- brewer.pal(8,"Dark2")
png("wordcloud_ngram.png", width=1024,height=768)
wordcloud(df$word,df$freq, scale=c(10,.2),min.freq=3,
max.words=150, random.order=FALSE, rot.per=.15, colors=pal2)
dev.off()
V prvním kroku nám vyjde úplně normální wordcloud, který je dosti nevypovídající - nebyla použita žádná stopwords, a tak převládají členy "a" a "the".

V dalším kroku pro n=2 je výsledek již zajímavější. Mezi nejčastějšími spojeními dvou slov se nám již objeví "south park", ale pořád to hyzdí nicneříkající "have to", "are you" a podobné.

U n=3 začíná být výsledek již opravdu zajímavý. Mezi nejčastějšími tříslovnými výrazy se objevují věci jako "oh my god", což je klasická Cartmanovská hláška, popřípadě "Terrance and Phillip" podle které Southpark zcela jistě identifikujeme a "Kathie Lee Gifford", která prostě musí zemřít!

A máme tady zlatý hřeb večera - n=4! Zde dominuje především asi nejvíce WTF věta "hut hut hut hut", u které doteď nevím co znamená. Southpark se dá rozeznat podle "my god they killed" a "a big fat ass". Pro n-gram pro čtyři slova je problematická především malá délka vstupního textu, kvůli čemuž máme velmi málo výsledků a nejsou příliš reprezentativní.

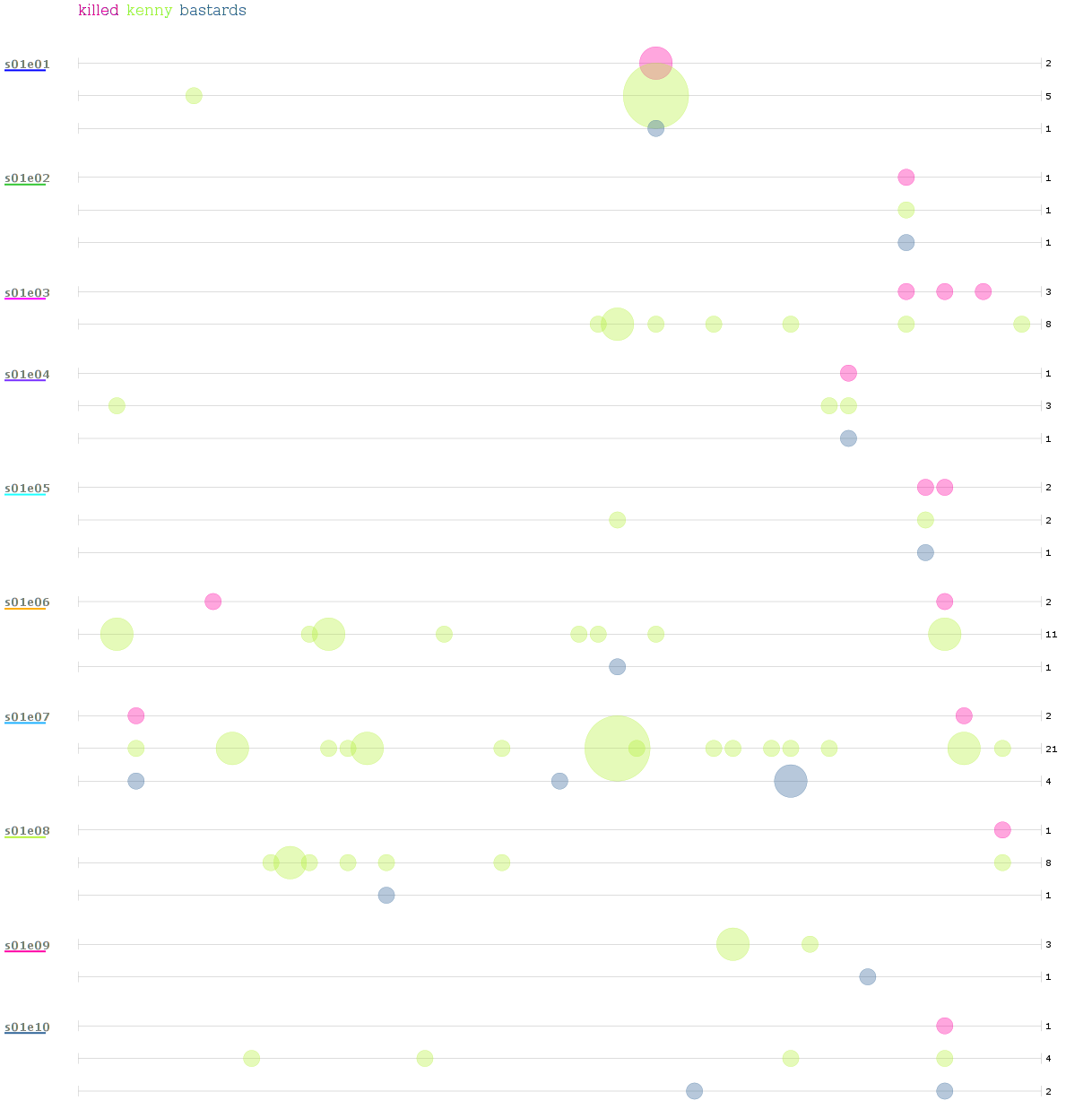
Jako bonus jsem spočítal a vykreslil do grafu vzdálenost slov "killed", "kenny" a "bastards" v jednotlivých epizodách. Výsledek zde:
Měření dopadlo úspěšně a nebyl při něm nikdo zraněn. Na pár příkladech jsme si předvedli, jak analyzovat text z pohledu výskytů sousloví. Největší smysl dávají asi 3-gramy, u kterých jde relativně dobře poznat, jaký text byl analyzován. U kratších spojení narážíme na přílišnou obecnost, zde by bylo potřeba implementovat zakázaná slova. U delších je pak problém v krátkosti textu. Pokud byste si chtěli něco podobného zkusit a nechtěli si při tom složitě instalovat R a hledat, které RStudio je nejlepší, vyzkoušejte online Voyant-tools. O kostičku se hlaste v komentářích!




Tiskni
Sdílej:
![]()
![]()
![]()
![]()
![]()
![]()
 2.2.2014 23:01
Bedňa | skóre: 34
| blog: Žumpa
| Horňany
2.2.2014 23:58
Bedňa | skóre: 34
| blog: Žumpa
| Horňany
3.2.2014 00:10
Bedňa | skóre: 34
| blog: Žumpa
| Horňany
2.2.2014 23:01
Bedňa | skóre: 34
| blog: Žumpa
| Horňany
2.2.2014 23:58
Bedňa | skóre: 34
| blog: Žumpa
| Horňany
3.2.2014 00:10
Bedňa | skóre: 34
| blog: Žumpa
| Horňany
 2.2.2014 23:50
AsciiWolf | skóre: 41
| blog: Blog
2.2.2014 23:50
AsciiWolf | skóre: 41
| blog: Blog
 3.2.2014 10:03
pools | skóre: 19
| blog: Svědek Damdogův
| Opava/Praha
3.2.2014 10:03
pools | skóre: 19
| blog: Svědek Damdogův
| Opava/Praha
 3.2.2014 21:22
Agent
| blog: Life_in_Pieces
| HC city
3.2.2014 21:22
Agent
| blog: Life_in_Pieces
| HC city
 5.2.2014 09:44
grubber | skóre: 6
| blog: grubber
| Břeclav / Brno
5.2.2014 09:44
grubber | skóre: 6
| blog: grubber
| Břeclav / Brno
Zde dominuje především asi nejvíce WTF věta "hut hut hut hut", u které doteď nevím co znamená.Že by More crap?
5.2.2014 17:04
pools | skóre: 19
| blog: Svědek Damdogův
| Opava/Praha
ISSN 1214-1267, (c) 1999-2007 Stickfish s.r.o.
 3.2.2014 11:02
3.2.2014 11:02