Příspěvek na blogu Google Security popisuje, jak tým Chrome Security využívá umělou inteligenci k zásadnímu zrychlení a zlepšení procesu odhalování, třídění a opravování bezpečnostních chyb v prohlížeči Chrome. Díky AI byla nalezena kritická chyba, která byla v kódu přes 13 let. Ve verzích Chrome 149 a 150 bylo opraveno více chyb než v předchozích 23 verzích dohromady.
Firmy v EU musí počínaje dnešním dnem označovat obsah vytvořený umělou inteligencí. Znamená to povinnost informovat uživatele, že člověk komunikuje s chatbotem či jiným systémem AI. Rovněž obrázky, audia či videa, které jsou vytvořené nebo zmanipulované pomocí umělé inteligence a které mohou působit jako autentické, musejí být jasně označeny jako uměle vytvořené.
Byla vydána nová major verze 11.0 open source unixového operačního systému NetBSD (Wikipedie). Přehled novinek v poznámkách k vydání.
Národní úřad pro kybernetickou a informační bezpečnost (NÚKIB) se zapojil do mezinárodní iniciativy vedené americkou agenturou CISA (Cybersecurity and Infrastructure Security Agency) a dalšími partnery, jejímž cílem je stanovit minimální náležitosti pro tzv. Software Bill of Materials (SBOM). Nový dokument přináší praktická doporučení, jak by měl vypadat přehled komponent softwaru a jak s ním v praxi pracovat. SBOM lze
… více »V aktuálním přehledu vývoje renderovacího jádra webového prohlížeče Servo (Wikipedie) bylo oznámeno vydání nové verze 0.4.0. Výrazně se zlepšilo vykreslování stránek jako lichess.org, Zulip nebo Speedtest.
Vládní CERT upozorňuje (𝕏) na kritické zranitelnosti v produktech VMware: CVE-2026-59309, CVE-2026-59310 a CVE-2026-47876. Zranitelnosti v VMware vCenter umožňují vzdálenému útočníkovi se síťovým přístupem obejít autentizaci a získat neoprávněný přístup k vCenter, případně zneužít directory traversal ke spuštění libovolného kódu na vCenter.
Společnost Coinkite upozorňuje na bezpečnostní chybu svých hardwarových kryptopeněženek Coldcard. Jedná se o kritickou chybu v generování náhodných čísel (RNG). Místo hardwarového generátoru náhodných čísel (TRNG) byl omylem používán softwarový fallback (PRNG).
Představena byla nová linuxová distribuce Shadowfetch Linux. Na rozdíl od mnoha nováčků, které nabízejí převážně jiné téma a výběr softwaru, tato distribuce založená na Debianu Testing s desktopovým prostředím KDE Plasma 6.6, klade lokálně běžící umělou inteligenci do centra svého desktopového zážitku.
Max Leiter v roce 2019 zkusil zprovoznit X server na iPadu (iOS). Nyní se k tématu vrátil a s pomocí LLM a balíčkovacích nástrojů Procursus rozběhl desktop s X11 i Waylandem. Jeho balíčky jsou dostupné v repozitáři xiOS.
Společnost Google Cloud dnes oznámila, že její infrastruktura a služby byly oficiálně zařazeny do Katalogu cloud computingu vedeného Digitální a informační agenturou (DIA). Tato certifikace potvrzuje, že infrastruktura a služby Google Cloud splňují přísné bezpečnostní a regulační požadavky České republiky pro provoz cloudových služeb ve veřejném sektoru.
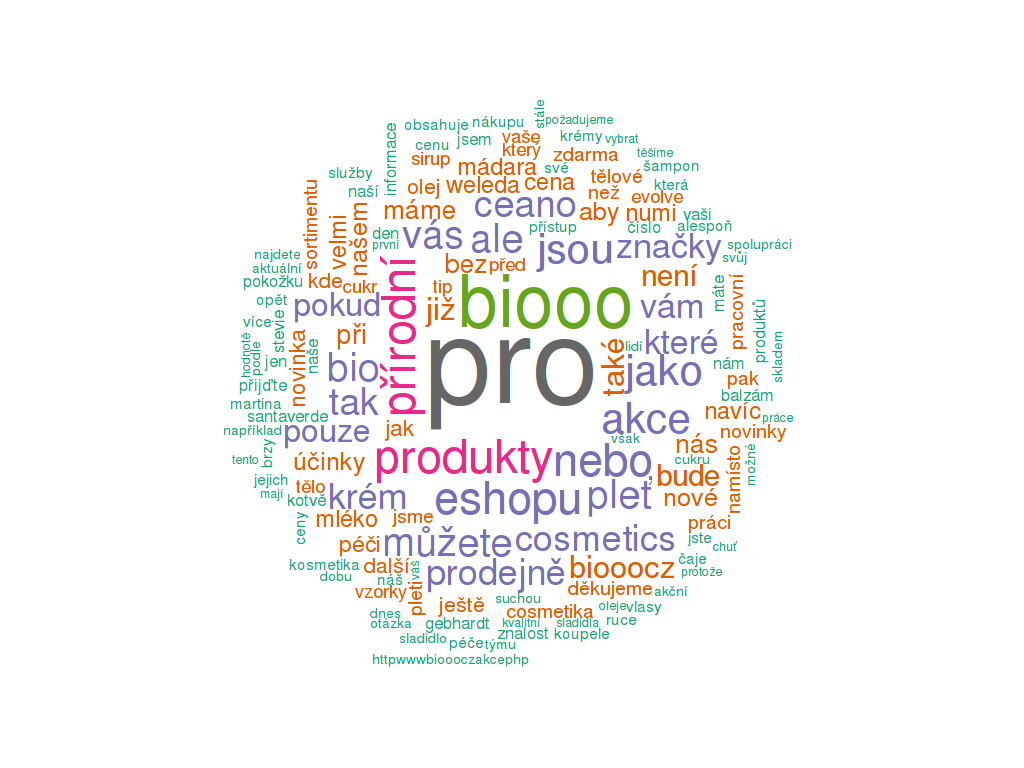
Dneska si jako správné novomediální *** ukážeme, jak jednoduše udělat naprosto zbytečný (ale vypadá to fakt pěkně) word cloud s pomocí programu R project.
Co k tomu potřebujeme:
Jako první si pustíme R konzoli a nainstalujeme potřebné balíčky.
# instalace knihoven
install.packages("Rfacebook")
install.packages("tm")
install.packages("wordcloud")
# nacteni knihoven
library(Rfacebook)
library(tm)
library(wordcloud)
Jakmile si seženeme facebook token, ze stránky https://developers.facebook.com/tools/explorer, můžeme se zvesela pustit do načítání dat z Facebooku pomocí R. Nám bude stačit načíst 300 komentářů z jakékoliv Facebook stránky. A trochu si je předpřipravíme.
# nacteni tokenu do promenne
token <- "token_pro_graph_api"
# nacteni prispevku stranky do promenne
page <- getPage("biooo.cz", token=token, n=300)
# vytvoreni korpusu, ktery bude obsahovat pouze sloupec se zpravami
corpus <- Corpus(VectorSource(page$message))
# slova z korpusu zmenšíme, odstraníme interpunkci a čísla
corpus <- tm_map(corpus, tolower)
corpus <- tm_map(corpus, removePunctuation)
corpus <- tm_map(corpus, removeNumbers)
V další fázi vytvoříme z předpřipraveného korpusu matici slov a spočteme jejich frekvenci.
ap.tdm <- TermDocumentMatrix(corpus) ap.m <- as.matrix(ap.tdm) ap.v <- sort(rowSums(ap.m), decreasing=TRUE) ap.d <- data.frame(word = names(ap.v), freq=ap.v)
Již se zdárně blížíme k cíli, teď si načteme do proměnné předpřipravenou paletu barev:
require(RColorBrewer) pal <- brewer.pal(8,"Dark2")
Nyní stačí již jen nastavit soubor výstupu a spustit samotné vytvoření word cloudu!
png("wordcloud.png",width=1024,height=1024)
wordcloud(ap.d$word,ap.d$freq, scale=c(10,.2),min.freq=3,max.words=150, random.order=FALSE, rot.per=.15, colors=pal)
dev.off()
TADÁ! Máme náš první word cloud.
Spousta věcí! Především:
Přece absolutně k ničemu!  P.S. Hlavně to neukazujte markeťákům, nebo vám utrhají ruce!
P.S. Hlavně to neukazujte markeťákům, nebo vám utrhají ruce!
Zdroj: https://gist.github.com/josefslerka/2344144
Tiskni
Sdílej:
![]()
![]()
![]()
![]()
![]()
![]()
 24.11.2013 17:54
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
24.11.2013 17:54
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
 24.11.2013 23:01
Bedňa | skóre: 34
| blog: Žumpa
| Horňany
24.11.2013 23:01
Bedňa | skóre: 34
| blog: Žumpa
| Horňany
 25.11.2013 09:12
pools | skóre: 19
| blog: Svědek Damdogův
| Opava/Praha
25.11.2013 09:12
pools | skóre: 19
| blog: Svědek Damdogův
| Opava/Praha
 AbcLinuxu.cz
AbcLinuxu.cz ITBiz.cz
ITBiz.cz HDmag.cz
HDmag.cz AbcPráce.cz
AbcPráce.cz