
Portál AbcLinuxu, 30. července 2026 20:47
29.1.2011 23:20
| Přečteno: 3717×
|
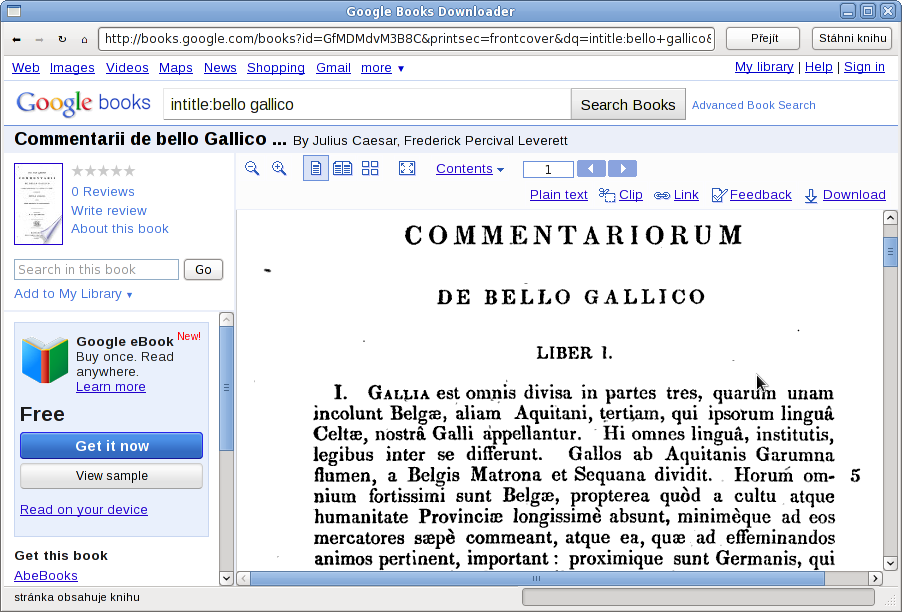
Funguje jednoduše, v okamžiku, kdy zjistí stránku s knihou, nabídne její stažení, při kterém je automaticky posouvána posuvná lišta s obsahem a nově nahrané stránky se uloží jako PNG obrázky do zvoleného adresáře. Díky tomuto primitivnímu principu fungování by měl být snad poměrně odolný vůči změnám, kterými se Google proti stahování může bránit.
K fungování vyžaduje XULRunner, ten dost možná již máte nainstalován v rámci základní instalace vaší distribuce, případně jej lze stáhnout zde. Tomu se předhodí soubor examples/googleBooksDownloader/application.ini z aktuální verze projektu XULJet.
Tento prográmek je napsán v JavaScriptu. Základ tohoto příkladu také může posloužit jako alternativa ke Greasemonkey v případech, kdy toto rozšíření nemusí dostačovat.
Tiskni
Sdílej:
![]()
![]()
![]()
![]()
![]()
![]()
Přidal jsem tam ještě lištu, pomocí které se dá (i během stahování) měnit rychlost posouvání, což se může hodit, pokud u některé knihy Google omezuje počet zobrazených stránek za určitý čas.
Také doplním, že před stahováním je lepší si přepnout zobrazení na maximální zvětšení a že se během stahování dá v knize pohybovat, takže lze přeskočit třeba na stahování až od druhé poloviny.
Na spojení PNG do jednoho PDF lze použít třeba imagemagic (příkaz convert)
 31.1.2011 18:54
otasomil | skóre: 39
| blog: puppylinux
31.1.2011 18:54
otasomil | skóre: 39
| blog: puppylinux
>>>Funguje jednoduše, v okamžiku, kdy zjistí stránku s knihou, nabídne její stažení, při kterém je automaticky posouvána posuvná lišta s obsahem a nově nahrané stránky se uloží jako PNG obrázky do zvoleného adresáře. Díky tomuto primitivnímu principu fungování by měl být snad poměrně odolný vůči změnám, kterými se Google proti stahování může bránit.
Kdy uz autori konecne pochopi, ze nemaji sanci.
jakmile se najde nadsenec tak neexistuje zpusob jak zamezit kopirovani.
Proc teda zbytecne bojovat ?
 23.3.2011 12:09
Jiří Poláček | skóre: 47
| blog: naopak
| Sivice
23.3.2011 12:09
Jiří Poláček | skóre: 47
| blog: naopak
| Sivice
ISSN 1214-1267, (c) 1999-2007 Stickfish s.r.o.
{kind=link}