Portál AbcLinuxu, 9. června 2026 18:48
�kol 2..pdfKdyž ho rozbalím, nejde spustit, smazat prostě nic (hlásí: "Soubor nebo složka /home/daniel/Plocha/�kol 2..pdf neexistuje.").
Řešení dotazu:
rm, pro přejmenování mv a pro spuštění třeba okular soubor.pdf. V konzoli můžete i detailně zanalyzovat jak se ten soubor vlastně přesně jmenuje. Jinak chyba bude asi v tom zip archivu, který neobsahuje správný typ kódování jména souboru, pokud vůbec.

\332kol\ 2..pdfKdyž se ale snažím se souborem pracovat pod tímto názvem tak to nefunguje (píše - soubor neexistuje).
rm \332kol\ 2..pdf ho nesmaze?
rm -b, což nemáte, i když by se asi hodilo.
rm $'\332kol\ 2..pdf'
rm $'\332kol 2..pdf' nebo rm $'\332'kol\ 2..pdf s ohledem na apostrofy není potřeba escapovat mezeru, stačí vypsat C notací to nepovedené Ú.
ls *"kol 2..pdf" |od -t x1
?
P.S.: to sú tam fakt dve bodky?
0000000 da 6b 6f 6c 20 32 2e 2e 70 64 66 0a 0000014Co to značí?
 Mno, skrátka by som tipol, že pri správnom fonte a nastavení locale by to mohlo zafungovať.
Mno, skrátka by som tipol, že pri správnom fonte a nastavení locale by to mohlo zafungovať.
ls -i 130997 �kol 2..pdf find . -inum 130997 -delete
unzip -U files. )., takže si vytvořím nějaký adresář a tam si jej případně zkopíruji a hlavně rozbalím, takže tam nejsou jiné soubory než z toho archivu.
)., takže si vytvořím nějaký adresář a tam si jej případně zkopíruji a hlavně rozbalím, takže tam nejsou jiné soubory než z toho archivu.mv to přejmenuji.touch si ten soubor vytvářím):
Stupid Windows-1250 > mkdir kuk Stupid Windows-1250 > cd kuk Stupid Windows-1250 > touch $'\332kol 2..pdf' Stupid Windows-1250 > ls ?kol 2..pdf Stupid Windows-1250 > ls -b \332kol\ 2..pdf Stupid Windows-1250 > mv *kol\ 2..pdf úkol\ 2..pdf Stupid Windows-1250 > ls úkol 2..pdf Stupid Windows-1250 >nebo (důležitá část):
Stupid Windows-1250 > mv *'kol 2..pdf' 'úkol 2..pdf' Stupid Windows-1250 > ls úkol 2..pdf Stupid Windows-1250 >Samozřejmně lze použít ? místo *, ale ono kolikrát těch klikiháků je tam více, takže je to tak snazší.
mv *.pdf Ukol_2.pdfAle pozor ať jste v tom speciálně vytvořeném adresáři, nicméně v případě
mv se při nejednoznačnosti obvykle zas tam moc nestane (pokud tedy neexistuje cílový název souboru jako adresář).
 21.3.2013 10:46
masomlejn | skóre: 16
21.3.2013 10:46
masomlejn | skóre: 16
detox?
mv je „čistější-jasnější“ (detox je pro mě osobně buď složitá nebo nedostatečná utilita, které se vyhýbám).
mv.
\332 nebo případně 5 dalších diakritických znaků v souboru, nemluvě o tom, když jméno souboru v tom zipu pro dost lidí může mít 5-6 oddělených českých slov, je 30 i více znaků dlouhé a čistě pracnost napsání přesného mv se správně umístěnými otazníky je větší, než zkopírovat soubor na flash, rozbalit tam a kopírovat zpět.
.modprobe brd rd_size=300000 fdisk /dev/ram1 c, n, p, 1, <enter>, <enter>, w mkntfs /dev/ram10 mount -t ntfs-3g /dev/ram10 /mnt/smaz… a
/mnt/smaz jsem použil k nakopírovaní a rozbalování (a pak jsem to zkusil i s fat-kou).unzip (UnZip 6.00) 21.3.2013 12:53
Michy | skóre: 11
| Praha
21.3.2013 12:53
Michy | skóre: 11
| Praha
 23.3.2013 22:42
Matelko | skóre: 2
23.3.2013 22:42
Matelko | skóre: 2
A navíc vývojáři KDE se vyjádřili, že to je problém Qt, a ti řekli, že to nikdy neopraví:
@TheBlackCat: no, no one has the intention of ever fixing that in Qt. Broken filename encodings will be forever considered filesystem corruption.
-U jsem již uváděl, ale ani -U ani -UU zabere jen na omezené skupině znaků a naopak to spíše uškodí než pomůže.
Zde je ukázka, toto:
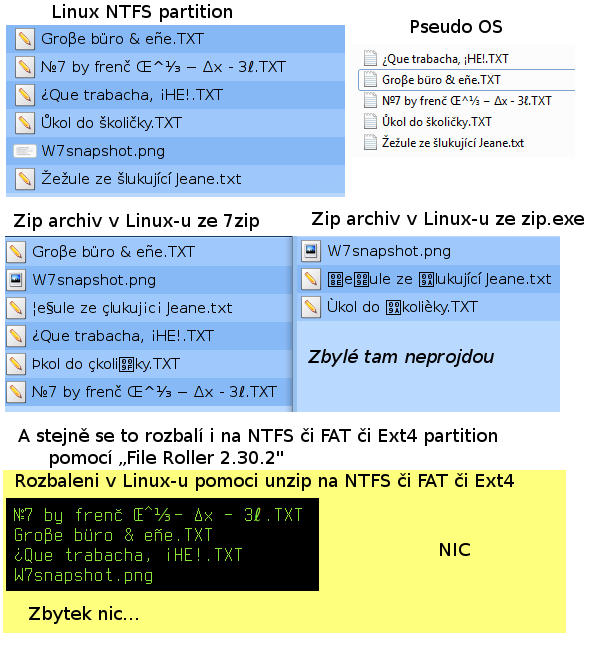
№7 by frenč Œ^⅓ − ∆x - 3ℓ.TXT Groβe büro & eñe.TXT ¿Que trabacha, ¡HE!.TXT Ůkol do školičky.TXT W7snapshot.png Žežule ze šlukující Jeane.txtZabalaené do zipu a následně rozbalené
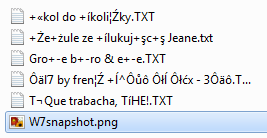
Unzip > unzip diakritika.zip 2>/dev/null >/dev/null Unzip > ls -1 diakritika №7 by frenč Œ^⅓ − ∆x - 3ℓ.TXT ?e?ule ze ?lukuj?c? Jeane.txt Groβe büro & eñe.TXT ?kol do ?koli?ky.TXT ¿Que trabacha, ¡HE!.TXT W7snapshot.png Unzip > rm -rf ./diakritika --------- Unzip > unzip -U diakritika.zip 2>/dev/null >/dev/null Unzip > ls -1 diakritika ?e?ule ze ?lukuj?c? Jeane.txt Gro#U03b2e b#U00fcro & e#U00f1e.TXT ?kol do ?koli?ky.TXT #U00bfQue trabacha, #U00a1HE!.TXT #U21167 by fren#U010d #U0152^#U2153 #U2212 #U2206x - 3#U2113.TXT W7snapshot.png Unzip > rm -rf ./diakritika --------- Unzip > unzip -UU diakritika.zip 2>/dev/null >/dev/null Unzip > ls -1 diakritika ???7 by fren-? +?^??? ??? ???x - 3???.TXT ?e?ule ze ?lukuj?c? Jeane.txt Gro+?e b++ro & e+?e.TXT ?kol do ?koli?ky.TXT -+Que trabacha, -?HE!.TXT W7snapshot.png Unzip > rm -rf ./diakritikaA jak je vidět problémy to nevyřeší, jen přidá
Je možné, že se přepínač -U použije jen na názvy uložené v unicodu. Můj distribuční unzip-6.0 obsahuje patch, který archiv vytvořený zipem 3.0 správně escapuje:
$ find . ./test ./test/#U00bfQue trabacha, #U00a1HE!.TXT ./test/#U21167 by fren#U010d #U0152^#U2153 #U2212 #U2206x - 3#U2113.TXT ./test/#U016ekol do #U0161koli#U010dky.TXT ./test/Gro#U03b2e b#U00fcro & e#U00f1e.TXT ./test/#U017de#U017eule ze #U0161lukuj#U00edc#U00ed Jeane.txt ./test/W7snapshot.png
Tak jsem si nastudoval problematiku. Není to o „linuxový“ nebo „windowsí“. PKWARE v září 2012 vydal novou specifikaci, která zavádí další pole, kam se název ukládá v UTF-8, a příslušný bit, který říká, že pole je použito. Celý problém tedy je, že integrovaný zip ve Windows (nevěděl jsem, že tam je něco takové je) tuto změnu ještě neimplementuje a do původního pole cpe, co mu zrovna přijde pod ruku (to znamená, že to není přenositelné ani mezi dvěma jazykovými mutacemi Windows :)
libzip přidal do vývojové verze příznak ZIP_FL_NAME_GUESS pro získání názvu, který později udělali výchozí. Nicméně, co jsem zkoušel, tak nefunguje. A je to proto, že nejprve zkusí ASCII, pak UTF-8 a nakonec CP437.
Bude třeba jim říct, ať to udělají z venku konfigurovatelné nebo ať použijí knihovnu libnatspec, která rozumně předpokládá, že protože archiv není přenositelný, tak se bude šířit jen v jednom jazykovém prostředí, tedy prostě z locale zjistí jazyk a znakovou sadu vybere tu, která se v daném jazyce používá ve Windows.
24.3.2013 12:24
Matelko | skóre: 2
Tiskni
Sdílej:
![]()
![]()
![]()
![]()
![]()
![]()
ISSN 1214-1267, (c) 1999-2007 Stickfish s.r.o.
{kind=link}
{kind=link}
{kind=link}