Portál AbcLinuxu, 2. července 2026 00:25
Ještě bych prosím potřeboval poradit s tímhle:
1) Mám starý 3,5' plotnový disk, který jsem dnes vyhrabal po několika letech z krabice a dal jej do case. Aplikace Disks mi ukazuje, že má 8 vadných sektorů, ale že je funkční. Chtěl bych jej, než úplně odejde, využít na pokusy - instalace nových verzí Mintu atd. Rád bych jej ale nějak zkontroloval a bylo by dobré, kdyby na něm byly ještě nějaké vadné sektory, aby si je disk nějak označil a aby byly při instalaci vyloučeny. Lze toho nějak docílit? Jak?
2) Dnes jsem vytáhnul z pc napájecí kabel ve chvíli, kdy byl systém spuštěn. Takže vypnutí natvrdo. Rád bych spustil kontrolu /rootfs, ale nevím jak. Problém je v tom, že systémový oddíl je šifrován (včetně /boot). Musí se tedy odemykat nadvakrát. Ikdyž díky LVM zadávám heslo jen jednou. Poradíte někdo prosím?
2) Záleží na tom, jaký FS používáš.
ext4
Ak tam má systemd. Musí pri boote pridať fsck.mode=force
Jak to prosím tě mám zjistit?
V Grubu zmáčkni 'e' a připiš to tam na řádek s ostatními parametry (ten dlouhý).
Ty dlouhé řádky tam byly dva a vůbec jsem se v tom nevyznal, tak jsem z tama raději vyjel a přepl se do Recovery. Tam byla položka fsck, vybral jsem jí a skončilo to chybou. rootfs připojit šel, ale něco jiného (přesně si to nepamatuji) nešlo a tak fsck napsal "končím".
Už to tak nechám. V /etc/fstab mám nastavenou kontrolu, takže po pár startech se to spustí automaticky. Ale je to škoda, chtěl jsem se to naučit.
Zřejmě ano. Ale upřímě řečeno, vlastně vůbec nevím, co to je a na co to je. Jen vím, že na to všichni nadávají. I když teď si uvědomuji, že na fǒru Mintu vlastně řešili, že Mint obsahuje systemd. Takže asi mám.
Btw: Koukal jsem na MHDD, ale chce to trochu nastudovat. Je toho všeho tolik, že fakt nevím, co dřiv. Zrovna zkoumám ssh klíče. Takže jsem spustil badblocks -wsv /dev/sdX, ale trochu mě zaráží, že to jede pořád dokola. Už to jede potřetí. Kolikrát to pojede?

sudo badblocks -wsv test.img Hledají se špatné bloky v režimu čtení i zápis Od bloku 0 do 102399 Zkouším se vzorkem 0xaa: hotovo Čtení a porovnání: hotovo Zkouším se vzorkem 0x55: hotovo Čtení a porovnání: hotovo Zkouším se vzorkem 0xff: hotovo Čtení a porovnání: hotovo Zkouším se vzorkem 0x00: hotovo Čtení a porovnání: hotovo Průchod dokončen, nalezeno 0 špatných bloků (0/0/0 chyb).btw: mas to napsane i v manualu - z "man badblock":
-w Use write-mode test. With this option, badblocks scans for bad blocks by writing some patterns (0xaa, 0x55, 0xff, 0x00) on every block of the
device, reading every block and comparing the contents. This option may not be combined with the -n option, as they are mutually exclusive.
POZOR "-w" je destruktivni write test, tzn. ze smaze aktualni data, pokud bys chtel write NEdestruktivni test tak misto "-w" pouzij "-n", to dela zapis jednim pruchodem ale nez zapise (nahodnej) vzorek, tak precte co tam aktualne je, zapise testovaci vzorek, zkontroluje zda se zapsalo co melo, zapise zpatky puvodni...
No přesně takový výpis jsem měl, ale už mi docházela trpělivost a (asi) při posledním průchodu jsem to stornoval.
Jinak man page jsem si přečetl, takže o tom destruktivním testu atd jsem věděl. Vybral jsem si jej záměrně, protože disk byl prázdný. Ale dík.
No dívej, já jsem včera spustil badblocks (bez uložení výpisu do souboru) a celé se to opakovalo 4x. Když to najíždělo na 5 cyklus, tak jsem to přerušil. Nicméně, (0,0,0 chyb). Pamatuji si, že jsem před 6 lety po zjištění problému spoustil na Windows XP program HD Tune, který disk sektor po sektoru zkontroloval.
badblocks nenachází?~$ sudo smartctl -a /dev/sdc
smartctl 6.6 2016-05-31 r4324 [x86_64-linux-4.15.0-46-generic] (local build)
Copyright (C) 2002-16, Bruce Allen, Christian Franke, www.smartmontools.org
=== START OF INFORMATION SECTION ===
Model Family: Western Digital Caviar SE Serial ATA
Device Model: WDC WD2000JS-55NCB1
Serial Number: WD-WMANR1083272
Firmware Version: 10.02E01
User Capacity: 200 048 565 760 bytes [200 GB]
Sector Size: 512 bytes logical/physical
Device is: In smartctl database [for details use: -P show]
ATA Version is: ATA/ATAPI-7 (minor revision not indicated)
Local Time is: Sat Mar 9 10:04:09 2019 CET
SMART support is: Available - device has SMART capability.
SMART support is: Enabled
=== START OF READ SMART DATA SECTION ===
SMART overall-health self-assessment test result: PASSED
See vendor-specific Attribute list for marginal Attributes.
General SMART Values:
Offline data collection status: (0x84) Offline data collection activity
was suspended by an interrupting command from host.
Auto Offline Data Collection: Enabled.
Self-test execution status: ( 0) The previous self-test routine completed
without error or no self-test has ever
been run.
Total time to complete Offline
data collection: ( 6300) seconds.
Offline data collection
capabilities: (0x7b) SMART execute Offline immediate.
Auto Offline data collection on/off support.
Suspend Offline collection upon new
command.
Offline surface scan supported.
Self-test supported.
Conveyance Self-test supported.
Selective Self-test supported.
SMART capabilities: (0x0003) Saves SMART data before entering
power-saving mode.
Supports SMART auto save timer.
Error logging capability: (0x01) Error logging supported.
General Purpose Logging supported.
Short self-test routine
recommended polling time: ( 2) minutes.
Extended self-test routine
recommended polling time: ( 74) minutes.
Conveyance self-test routine
recommended polling time: ( 6) minutes.
SCT capabilities: (0x103f) SCT Status supported.
SCT Error Recovery Control supported.
SCT Feature Control supported.
SCT Data Table supported.
SMART Attributes Data Structure revision number: 16
Vendor Specific SMART Attributes with Thresholds:
ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE
1 Raw_Read_Error_Rate 0x000f 200 200 051 Pre-fail Always - 0
3 Spin_Up_Time 0x0003 216 185 021 Pre-fail Always - 4200
4 Start_Stop_Count 0x0032 094 094 000 Old_age Always - 6553
5 Reallocated_Sector_Ct 0x0033 200 200 140 Pre-fail Always - 0
7 Seek_Error_Rate 0x000f 200 200 051 Pre-fail Always - 0
9 Power_On_Hours 0x0032 071 071 000 Old_age Always - 21201
10 Spin_Retry_Count 0x0013 100 100 051 Pre-fail Always - 0
11 Calibration_Retry_Count 0x0012 100 100 051 Old_age Always - 0
12 Power_Cycle_Count 0x0032 098 098 000 Old_age Always - 2549
190 Airflow_Temperature_Cel 0x0022 064 034 045 Old_age Always In_the_past 36
194 Temperature_Celsius 0x0022 114 084 000 Old_age Always - 36
196 Reallocated_Event_Count 0x0032 200 200 000 Old_age Always - 0
197 Current_Pending_Sector 0x0012 200 200 000 Old_age Always - 0
198 Offline_Uncorrectable 0x0010 200 200 000 Old_age Offline - 8
199 UDMA_CRC_Error_Count 0x003e 200 200 000 Old_age Always - 11
200 Multi_Zone_Error_Rate 0x0009 200 200 051 Pre-fail Offline - 0
SMART Error Log Version: 1
ATA Error Count: 2540 (device log contains only the most recent five errors)
CR = Command Register [HEX]
FR = Features Register [HEX]
SC = Sector Count Register [HEX]
SN = Sector Number Register [HEX]
CL = Cylinder Low Register [HEX]
CH = Cylinder High Register [HEX]
DH = Device/Head Register [HEX]
DC = Device Command Register [HEX]
ER = Error register [HEX]
ST = Status register [HEX]
Powered_Up_Time is measured from power on, and printed as
DDd+hh:mm:SS.sss where DD=days, hh=hours, mm=minutes,
SS=sec, and sss=millisec. It "wraps" after 49.710 days.
Error 2540 occurred at disk power-on lifetime: 21181 hours (882 days + 13 hours)
When the command that caused the error occurred, the device was active or idle.
After command completion occurred, registers were:
ER ST SC SN CL CH DH
-- -- -- -- -- -- --
01 51 01 c0 e1 6f e0 Error: AMNF at LBA = 0x006fe1c0 = 7332288
Commands leading to the command that caused the error were:
CR FR SC SN CL CH DH DC Powered_Up_Time Command/Feature_Name
-- -- -- -- -- -- -- -- ---------------- --------------------
42 00 01 c0 e1 6f 02 00 00:13:29.025 READ VERIFY SECTOR(S) EXT
42 00 01 bf e1 6f 02 00 00:13:27.164 READ VERIFY SECTOR(S) EXT
25 00 01 80 cf a4 0b 00 00:13:27.153 READ DMA EXT
42 00 02 c5 e1 6f 02 00 00:13:25.294 READ VERIFY SECTOR(S) EXT
25 00 01 00 00 00 00 00 00:13:25.294 READ DMA EXT
Error 2539 occurred at disk power-on lifetime: 21181 hours (882 days + 13 hours)
When the command that caused the error occurred, the device was active or idle.
After command completion occurred, registers were:
ER ST SC SN CL CH DH
-- -- -- -- -- -- --
01 51 02 c5 e1 6f e0 Error: AMNF at LBA = 0x006fe1c5 = 7332293
Commands leading to the command that caused the error were:
CR FR SC SN CL CH DH DC Powered_Up_Time Command/Feature_Name
-- -- -- -- -- -- -- -- ---------------- --------------------
42 00 02 c5 e1 6f 02 00 00:13:25.294 READ VERIFY SECTOR(S) EXT
25 00 01 00 00 00 00 00 00:13:25.294 READ DMA EXT
42 00 02 c3 e1 6f 02 00 00:13:23.309 READ VERIFY SECTOR(S) EXT
42 00 02 c1 e1 6f 02 00 00:13:21.437 READ VERIFY SECTOR(S) EXT
25 00 01 00 00 00 00 00 00:13:21.437 READ DMA EXT
Error 2538 occurred at disk power-on lifetime: 21181 hours (882 days + 13 hours)
When the command that caused the error occurred, the device was active or idle.
After command completion occurred, registers were:
ER ST SC SN CL CH DH
-- -- -- -- -- -- --
40 51 02 c3 e1 6f e0 Error: UNC at LBA = 0x006fe1c3 = 7332291
Commands leading to the command that caused the error were:
CR FR SC SN CL CH DH DC Powered_Up_Time Command/Feature_Name
-- -- -- -- -- -- -- -- ---------------- --------------------
42 00 02 c3 e1 6f 02 00 00:13:23.309 READ VERIFY SECTOR(S) EXT
42 00 02 c1 e1 6f 02 00 00:13:21.437 READ VERIFY SECTOR(S) EXT
25 00 01 00 00 00 00 00 00:13:21.437 READ DMA EXT
42 00 02 bf e1 6f 02 00 00:13:19.580 READ VERIFY SECTOR(S) EXT
25 00 01 00 00 00 00 00 00:13:19.580 READ DMA EXT
Error 2537 occurred at disk power-on lifetime: 21181 hours (882 days + 13 hours)
When the command that caused the error occurred, the device was active or idle.
After command completion occurred, registers were:
ER ST SC SN CL CH DH
-- -- -- -- -- -- --
01 51 02 c1 e1 6f e0 Error: AMNF at LBA = 0x006fe1c1 = 7332289
Commands leading to the command that caused the error were:
CR FR SC SN CL CH DH DC Powered_Up_Time Command/Feature_Name
-- -- -- -- -- -- -- -- ---------------- --------------------
42 00 02 c1 e1 6f 02 00 00:13:21.437 READ VERIFY SECTOR(S) EXT
25 00 01 00 00 00 00 00 00:13:21.437 READ DMA EXT
42 00 02 bf e1 6f 02 00 00:13:19.580 READ VERIFY SECTOR(S) EXT
25 00 01 00 00 00 00 00 00:13:19.580 READ DMA EXT
42 00 04 c3 e1 6f 02 00 00:13:17.643 READ VERIFY SECTOR(S) EXT
Error 2536 occurred at disk power-on lifetime: 21181 hours (882 days + 13 hours)
When the command that caused the error occurred, the device was active or idle.
After command completion occurred, registers were:
ER ST SC SN CL CH DH
-- -- -- -- -- -- --
01 51 04 c3 e1 6f e0 Error: AMNF at LBA = 0x006fe1c3 = 7332291
Commands leading to the command that caused the error were:
CR FR SC SN CL CH DH DC Powered_Up_Time Command/Feature_Name
-- -- -- -- -- -- -- -- ---------------- --------------------
42 00 04 c3 e1 6f 02 00 00:13:17.643 READ VERIFY SECTOR(S) EXT
42 00 04 bf e1 6f 02 00 00:13:15.783 READ VERIFY SECTOR(S) EXT
42 00 08 c7 e1 6f 02 00 00:13:15.763 READ VERIFY SECTOR(S) EXT
25 00 01 80 cf a4 0b 00 00:13:15.762 READ DMA EXT
42 00 08 bf e1 6f 02 00 00:13:13.873 READ VERIFY SECTOR(S) EXT
SMART Self-test log structure revision number 1
No self-tests have been logged. [To run self-tests, use: smartctl -t]
SMART Selective self-test log data structure revision number 1
SPAN MIN_LBA MAX_LBA CURRENT_TEST_STATUS
1 0 0 Not_testing
2 0 0 Not_testing
3 0 0 Not_testing
4 0 0 Not_testing
5 0 0 Not_testing
Selective self-test flags (0x0):
After scanning selected spans, do NOT read-scan remainder of disk.
If Selective self-test is pending on power-up, resume after 0 minute delay.
Tak jsem to Pavle zkusil, ale pohořel jsem. Vypálil jsem CD obraz na DVD RW, pro jistotu jsem v BIOSu vypnul ostatní disky a nechal zapnutý jen ten k oskenování. Ještě k tomu disku. Datový kabel je SATA a napájecí je MOLEX, protože jsem už neměl SATA. Ale to by asi vadit nemělo. Takže jsem nabootoval to DVD a na výběr byly 2 možnosti:
Možnost 2:
Microsoft RAMDrive version 3.06 virtual disk C: Disk size: 2,048k Sector size: 512 bytes Allocation unit: 2 sectors Directory entries: 64 Warning: the high memory area (HMA) is not available. Additional low memory (below 640K) will be used instead. HDD startup disk could not create a temporary drive for itself. This happen because this computer has less than 4 Mbytes of memory. Path not found - :\COMMAND.COM Bad command or file name Directory already exists File cannot be copied onto itself General failure writing drove A Abort, Retry, Fail?
Když jsem zvolil možnost 1, tak to taky končilo "Abort, Retry, Fail?", jen ten výpis byl trochu delší. A něco to dělalo, ale nevím co.
F5 - příkazový řádek, Shift+F5 - příkazový řádek, Shift+F8 - nic, F4 - nic (nikde).
Četl jsem dokumentaci, ale neobjevil jsem v ní nic, co by mi mohlo pomoci. Snad jen to, že autor tam zmiňuje, že pro člověka jako jsem já je nezbytné strávit pár hodin přípravou, aby do toho člověk trochu pronikl. A na to teď nemám čas, jinak bych to klidně studoval a zkoušel. Takže pokud víš kde je zádrhel, tak super. Pokud ne, tak to teď studovat nebudu a ten pokusný Linux na ten disk nainstaluji i bez MHDD skenu.
Máš pravdu, rozhraní je jednoduché a přehledné. Škoda, že se mi do něj nepodařilo dostat. Jestli to nebylo tím, že jsem to vypálil na DVD místo na CD. Až bude čas, tak nějaké CD pohledám a ze studijních důvodů si to zkusím. Jinsk jsem v BIOSu změnil AHCI na Intel Premium a zkusil to ještě jednou. Položilo mi to asi tak 40 otázek, kterým jsem vůbec nerozuměl. Tak jsem dával Y, nebo N podle toho, jak se mi to líbilo a skončil jsem stejně v příkazovém řádku. Takže MHDD už ten disk kontrolovat nebudu a jdu instalovat. Věřím, že to bude funkční.
198 Offline_Uncorrectable 0x0010 200 200 000 Old_age Offline - 8Jo 8 už přealokovanych sektorů. Místo nich se používá spare.
The total count of uncorrectable errors when reading/writing a sector. A rise in the value of this attribute indicates defects of the disk surface and/or problems in the mechanical subsystem.Jménem "Uncorrectable Sector" bych myslel že už nepomůže ani přepis teda :-/.
Realokace z rezervy probiha za behu, zcela mimo kontrolu jakyhokoli SW, a realokuji se nikoli vadny sektory, ale sektory u kterych dochazi k prilis velkemu poctu !OPRAVITELNYCH! chyb.Moc silné tvrzení. Nemyslím si, že to píšeš správně:
SMARTMonUX allows you to clear the grown defect list at the time you format the disk, or more correctly, allows you to turn on this feature that is inherent in the disk drive, when the SCSI command to reformat is sent to the disk.
realokuji se nikoli vadny sektory, ale sektory u kterych dochazi k prilis velkemu poctu !OPRAVITELNYCH! chyb.Tohle je příliš specifické. Implementace realokace vadného sektoru (=sektoru kde dojde k neopravitelné chybě) je jen otázka jednoho podmíněného skoku (v ideálním případě).
Pokud disk vykazuje BB, tak se uz zadna realokace konat NEBUDE.Do stejného stavu dojdeme i v případě, kdy už je rezervovaná oblast pro realokaci zaplněná.
Děkuju
Už na tom disku mám nainstalovaný systém, takže nic do /dev/null posílat nebudu, ale poznamenám si to pro příště. Můžeš mi sem prosím tě uvést ten příkaz pro přečtení disku do /dev/null?
sudo dd if=/dev/sdX of=/dev/null status=progress
Takže to můžu použít i teď a tomu nainstalovanému systému se nic nestane, jo?
smartctl -t long /dev/sdX
Děkuju
# zobrazeni kolik casu long a smart by priblizne zabral(je to vazane na konkretni disk) sudo smartctl -a /dev/sdX | grep "recommended polling time" -B1 # zobrazeni stavu testu (kdyz bezi zobrazi kolik % zbevja, kdyz dojel zobrazi vysledek) sudo smartctl -a /dev/sdX | grep "Self-test execution status" -A2 # pokud bys spustenej test chtel zrusit (jinak kdyz bezi, tak disk samozrejme muzes normalne pouzivat cist/zapisovat) sudo smartctl -X /dev/sdXpripadne muzes pouzit GUI nadstavbu: gsmartcontrol, tam kdyz pustis test vidis primo v nem prubeh...
Díky Keďo,
uložím si to. Píšu si na všechno návody. Co mi tu poradíte, ukládám.
Když jsem to pustil, tak na začátku ti to napíše, jak dlouho to bude trvat. Ale cos napsal se určitě bude hodit. Koukal jsem i do man page. Ta je v tomto případě dost obsáhlá.
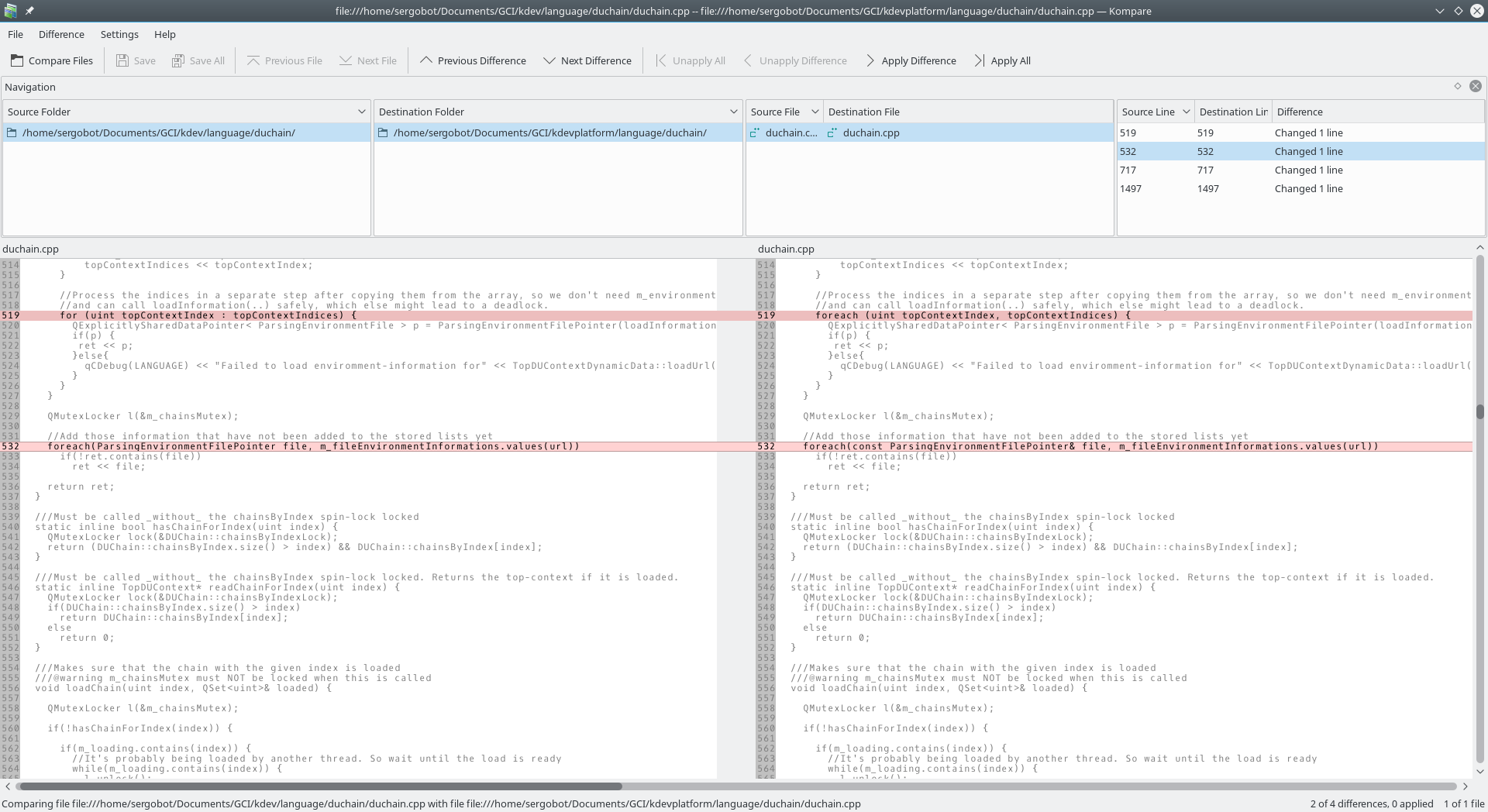
Prosím tě, mohl bys mi ještě poradit, jak mám spustit kontrolu rootfs (LUKS > LVM)? Včera mi tu něco radili, ale nebyl jsem schopen to provést. Měl jsem při bootu zmáčknout "e" a v GRUBu přidat na nějaký dlouhý řádek nějaký příkaz, ale absolutně jsem se tam v tom nevyznal. Tak jsem to raději nedělal. Povedlo se mi totiž vytáhnout napájecí kabel z pc v době, kdy systém běžel a rád bych jej raději zkontroloval a opravil, ale nevím jak?
 jakmile to upravis, tak musis nastartovat tlacitkem F10 (kdyz bys dal ESC a enter, tak se zmeny ignorujou), jinak takto se to pri pristim startu ztrati, pokud bys (nekdy) chtel pridat nejakej kernel parametr trvale, tak to se dela upravou "/etc/default/grub" na radku GRUB_CMDLINE_LINUX_DEFAULT (opet pro jednoduchost, mezi quiet a splash a nasledne pregenerovanim grub.cfg pomoci "sudo update-grub"
jakmile to upravis, tak musis nastartovat tlacitkem F10 (kdyz bys dal ESC a enter, tak se zmeny ignorujou), jinak takto se to pri pristim startu ztrati, pokud bys (nekdy) chtel pridat nejakej kernel parametr trvale, tak to se dela upravou "/etc/default/grub" na radku GRUB_CMDLINE_LINUX_DEFAULT (opet pro jednoduchost, mezi quiet a splash a nasledne pregenerovanim grub.cfg pomoci "sudo update-grub"
Jen se chci ujistit. Takže při bootu zmáčknu "e" a mezi quiet a splash vložím fsck.mode=force, ano?
Mě to právě před tím přišlo divné zadávat tam tohle, protože všechny parametry tam začínaly dvojitou pomlčkou --parametr.
Jasně. Jen jsem popisoval, co mi nesedělo poprvé. Dnes jsem to tedy udělal, ale pochybuji, že nějaká kontrola proběhla. V naběhlém systému jsem v terminálu dal touch /forcefsck a pak jsem rebootoval. Po rebootu jsem zmáčknul "e" a na ten správný řádek jsem mezi quiet a splash vložil fsck.mode=force a pak jsem zmáčknul F10. Počítač ani nečekal, jaký systém vyberu a vybral první položku z GRUB menu, což byla ta co jsem potřeboval a zavedl systém tak do 10 vteřin. Takže mám pochybnosti o tom, jestli vůbec nějaká kontrola proběhla. Dá se to nějak ověřit?
# pokud by byl filesystem primo na oddilu sudo tune2fs -l /dev/sdXY | grep 'Last checked' # pokud by byl filesystem na LV (pri LVM) sudo tune2fs -l /dev/mapper/vgjmeno-lvjmeno | grep 'Last checked'pokud si nejses jistej svojim vg a lv jmenem, po napsani /dev/mapper/ zmackni 2x tab(ulator) a zobrazi dostupne, kde to uz poznas
Díky díky
Měl jsem pravdu:
~$ sudo tune2fs -l /dev/sdc1 | grep 'Last checked' Last checked: Sat Mar 9 19:55:08 2019
Co kdybych tu kontrolu přidal natvrdo do /etc/default/grub a po jejím provedení to zase smazal? To by mělo zabrat. Raději mi prosím ale napiš, co tam tedy mezi quiet a splash mám vložit.
cat /proc/cmdlinejinak krome fsck.mode=force musis stale (pokud se nepletu, nezkousel sem) pouzit i "sudo touch /forcefsck" (resp. do korene toho filesystemu co chces kontrolovat)...
# nejdriv zjistis aktualni hodnotu kterou pak vratis, predpokladam: -1 sudo tune2fs -l /dev/sdXY | grep 'Maximum mount count' # nastavis 'Maximum mount count' na hodnotu 1, tzn. jakmile dojde k 1 primontovani provede se kontrola, tzn. po kazdem reboot/zapnuti sudo tune2fs -c 1 /dev/sdXY
pro jistotu, ses si jistej ze sdc1 je oddil s rootfs??
Ne. sdc1 je sice oddíl s rootfs, ale u toho starého disku, u kterého jsem spouštěl ten dlouhý test. Takže tohle byla ta chyba.
... ze zkontrolujes pritomnost v pouzitejch kernel parametrech:cat /proc/cmdline
Užitečný příkaz. Po korekci disku a oddílu ve výpisu dnešní kontrola byla. Btw: moc času ta kontrola nezabere. Prakticky ani nepoznáš, že se něco kontroluje. Na ploše jsi za pár vteřin od stisknutí F10.
jinak krome fsck.mode=force musis stale (pokud se nepletu, nezkousel sem) pouzit i "sudo touch /forcefsck" (resp. do korene toho filesystemu co chces kontrolovat)...
To jsem zadal.
pak si jeste nejsem jist, zda probehne tahle kontrola pri startu i kdyz bys ji nemel povolenou v /etc/fstab, je to tam posledni cislo na radku daneho filesystemu, kdyz je 0 tak kontrola se nedala, 1 kontrola se dela prvni(pouziva se pro rootfs), 2 kontrola se udela az po zkontrolovani tech s 1)
Mám tam 1. Tohle už znám. Jen se zeptám. Když bych měl v pc např. 1 systémový disk a 5 datových a do /etc/fstab bych uvedl do posledního sloupce čísla pro systémový disk 1 a pro datové 2-6, budou se ty disky kontrolovat v tom pořadí, jaké zadám?
pak mas jeste jednu moznost, nastavit primo filesystem aby se kontroloval pri kazdem mountu:# nejdriv zjistis aktualni hodnotu kterou pak vratis, predpokladam: -1 sudo tune2fs -l /dev/sdXY | grep 'Maximum mount count'
V mém případě se jedná o -1 (Takto to nastavil ten skript).
# nastavis 'Maximum mount count' na hodnotu 1, tzn. jakmile dojde k 1 primontovani provede se kontrola, tzn. po kazdem reboot/zapnuti sudo tune2fs -c 1 /dev/sdXY
A neškodí to nějak SSDčku? Nastavovat to zatím nebudu, ale třeba 5 bych dal.
Jinak tahle reakce je dobrý zdroj informací, takže opět DÍKY
sudo tunefs -m 0.5 /dev/sdXY(pro LVM samozrejme opet zarizeni /dev/vgname/lvname)
sudo tune2fs -l /dev/sdXY | grep -e 'Block count:' -e 'Reserved block count:' -e 'Block size:'zobrazi ti ti pocet bloku celkem, pocet reservovanejch a velikost bloku (ta bude 512 nebo 4096), z toho si pripadne muzes dopocitat kolik MB/GB mas nastavenejch pro reservaci... nebo nerucne takto(vysledek v MB):
disk="/dev/sdXY; echo $(( $(sudo tune2fs -l ${disk} | grep 'Reserved block count:' | sed 's/.*: \+//') * $(sudo tune2fs -l ${disk} | grep 'Block size:' | sed 's/.*: \+//') / 1024 / 1024 ))
Vypadá to dobře:
~$ sudo smartctl -a /dev/sdc | grep "Self-test execution status" -A2 Self-test execution status: ( 0) The previous self-test routine completed without error or no self-test has ever been run.
Jen by mě ještě zajímalo, jestli je pravda tohle, nebo ta reakce hned pod tím. Výpis smartctl -a je nad tím.
Rozhodne takhle ale neumi nahradit sektor necitelnej, proste proto, ze bys tak pekne potichu prisel o data.Tak tady se zase pleteš ty. Já nikde nepsal, že se budou automaticky nahrazovat nečitelný sektory, ale že se nahradí teprve tím, že do nich uživatel zapíše (=nechce stará data, ať jsou tam jakákoliv).
Bude to posílat mejly? Tak to je svělé :)
Dík
Já jsem pustil long test. Ten příkaz:
~$ sudo smartctl -a /dev/sdc | grep "Self-test execution status" -A2
si mi tady radil mj. pro výpis dojetého testu. Takže ten výsledek je z dojetého long testu :)
Nedorozumění.
Tys myslel long test ve vztahu k tomu "tohle" (druhá polovina mojí reakce. A já myslel, že je to ve vztahu k tomu výpisu (první polovina mojí reakce) 
pv -L 10M /dev/sdX > /dev/null
pv -L /dev/zero > /dev/sdX
fdisk -l
Taky zdravím, díky za pomoc.
Řekl bych, že je to v pořádku:
~$ sudo dd if=/dev/sdc of=/dev/null status=progress 200035779072 bajtů (200 GB, 186 GiB) zkopírováno, 3711 s, 53,9 MB/s 390719855+0 záznamů přečteno 390719855+0 záznamů zapsáno 200048565760 bajtů (200 GB, 186 GiB) zkopírováno, 3713,19 s, 53,9 MB/s ~$
Zajímavé je, že aplikace Disky už nezobrazuje těch 8 vadných sektorů, ale místo toho tam teď je:
"Disk je funkční, jeden z příznaků vykazuje selhání z dřívějška"
Ale ty vadné sektory jsou pryč
GSmartControl jsem neinstaloval, protože se chci učit ovládat systém z terminálu.
Tady je ten výpis:
~$ sudo smartctl -a /dev/sdc
smartctl 6.6 2016-05-31 r4324 [x86_64-linux-4.15.0-46-generic] (local build)
Copyright (C) 2002-16, Bruce Allen, Christian Franke, www.smartmontools.org
=== START OF INFORMATION SECTION ===
Model Family: Western Digital Caviar SE Serial ATA
Device Model: WDC WD2000JS-55NCB1
Serial Number: WD-WMANR1083272
Firmware Version: 10.02E01
User Capacity: 200 048 565 760 bytes [200 GB]
Sector Size: 512 bytes logical/physical
Device is: In smartctl database [for details use: -P show]
ATA Version is: ATA/ATAPI-7 (minor revision not indicated)
Local Time is: Tue Mar 12 19:29:42 2019 CET
SMART support is: Available - device has SMART capability.
SMART support is: Enabled
=== START OF READ SMART DATA SECTION ===
SMART overall-health self-assessment test result: PASSED
See vendor-specific Attribute list for marginal Attributes.
General SMART Values:
Offline data collection status: (0x82) Offline data collection activity
was completed without error.
Auto Offline Data Collection: Enabled.
Self-test execution status: ( 0) The previous self-test routine completed
without error or no self-test has ever
been run.
Total time to complete Offline
data collection: ( 6300) seconds.
Offline data collection
capabilities: (0x7b) SMART execute Offline immediate.
Auto Offline data collection on/off support.
Suspend Offline collection upon new
command.
Offline surface scan supported.
Self-test supported.
Conveyance Self-test supported.
Selective Self-test supported.
SMART capabilities: (0x0003) Saves SMART data before entering
power-saving mode.
Supports SMART auto save timer.
Error logging capability: (0x01) Error logging supported.
General Purpose Logging supported.
Short self-test routine
recommended polling time: ( 2) minutes.
Extended self-test routine
recommended polling time: ( 74) minutes.
Conveyance self-test routine
recommended polling time: ( 6) minutes.
SCT capabilities: (0x103f) SCT Status supported.
SCT Error Recovery Control supported.
SCT Feature Control supported.
SCT Data Table supported.
SMART Attributes Data Structure revision number: 16
Vendor Specific SMART Attributes with Thresholds:
ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE
1 Raw_Read_Error_Rate 0x000f 200 200 051 Pre-fail Always - 0
3 Spin_Up_Time 0x0003 234 185 021 Pre-fail Always - 3266
4 Start_Stop_Count 0x0032 094 094 000 Old_age Always - 6578
5 Reallocated_Sector_Ct 0x0033 200 200 140 Pre-fail Always - 0
7 Seek_Error_Rate 0x000f 200 200 051 Pre-fail Always - 0
9 Power_On_Hours 0x0032 071 071 000 Old_age Always - 21286
10 Spin_Retry_Count 0x0013 100 100 051 Pre-fail Always - 0
11 Calibration_Retry_Count 0x0012 100 100 051 Old_age Always - 0
12 Power_Cycle_Count 0x0032 098 098 000 Old_age Always - 2560
190 Airflow_Temperature_Cel 0x0022 054 034 045 Old_age Always In_the_past 46
194 Temperature_Celsius 0x0022 104 084 000 Old_age Always - 46
196 Reallocated_Event_Count 0x0032 200 200 000 Old_age Always - 0
197 Current_Pending_Sector 0x0012 200 200 000 Old_age Always - 0
198 Offline_Uncorrectable 0x0010 200 200 000 Old_age Offline - 0
199 UDMA_CRC_Error_Count 0x003e 200 200 000 Old_age Always - 11
200 Multi_Zone_Error_Rate 0x0009 200 200 051 Pre-fail Offline - 0
SMART Error Log Version: 1
ATA Error Count: 2540 (device log contains only the most recent five errors)
CR = Command Register [HEX]
FR = Features Register [HEX]
SC = Sector Count Register [HEX]
SN = Sector Number Register [HEX]
CL = Cylinder Low Register [HEX]
CH = Cylinder High Register [HEX]
DH = Device/Head Register [HEX]
DC = Device Command Register [HEX]
ER = Error register [HEX]
ST = Status register [HEX]
Powered_Up_Time is measured from power on, and printed as
DDd+hh:mm:SS.sss where DD=days, hh=hours, mm=minutes,
SS=sec, and sss=millisec. It "wraps" after 49.710 days.
Error 2540 occurred at disk power-on lifetime: 21181 hours (882 days + 13 hours)
When the command that caused the error occurred, the device was active or idle.
After command completion occurred, registers were:
ER ST SC SN CL CH DH
-- -- -- -- -- -- --
01 51 01 c0 e1 6f e0 Error: AMNF at LBA = 0x006fe1c0 = 7332288
Commands leading to the command that caused the error were:
CR FR SC SN CL CH DH DC Powered_Up_Time Command/Feature_Name
-- -- -- -- -- -- -- -- ---------------- --------------------
42 00 01 c0 e1 6f 02 00 00:13:29.025 READ VERIFY SECTOR(S) EXT
42 00 01 bf e1 6f 02 00 00:13:27.164 READ VERIFY SECTOR(S) EXT
25 00 01 80 cf a4 0b 00 00:13:27.153 READ DMA EXT
42 00 02 c5 e1 6f 02 00 00:13:25.294 READ VERIFY SECTOR(S) EXT
25 00 01 00 00 00 00 00 00:13:25.294 READ DMA EXT
Error 2539 occurred at disk power-on lifetime: 21181 hours (882 days + 13 hours)
When the command that caused the error occurred, the device was active or idle.
After command completion occurred, registers were:
ER ST SC SN CL CH DH
-- -- -- -- -- -- --
01 51 02 c5 e1 6f e0 Error: AMNF at LBA = 0x006fe1c5 = 7332293
Commands leading to the command that caused the error were:
CR FR SC SN CL CH DH DC Powered_Up_Time Command/Feature_Name
-- -- -- -- -- -- -- -- ---------------- --------------------
42 00 02 c5 e1 6f 02 00 00:13:25.294 READ VERIFY SECTOR(S) EXT
25 00 01 00 00 00 00 00 00:13:25.294 READ DMA EXT
42 00 02 c3 e1 6f 02 00 00:13:23.309 READ VERIFY SECTOR(S) EXT
42 00 02 c1 e1 6f 02 00 00:13:21.437 READ VERIFY SECTOR(S) EXT
25 00 01 00 00 00 00 00 00:13:21.437 READ DMA EXT
Error 2538 occurred at disk power-on lifetime: 21181 hours (882 days + 13 hours)
When the command that caused the error occurred, the device was active or idle.
After command completion occurred, registers were:
ER ST SC SN CL CH DH
-- -- -- -- -- -- --
40 51 02 c3 e1 6f e0 Error: UNC at LBA = 0x006fe1c3 = 7332291
Commands leading to the command that caused the error were:
CR FR SC SN CL CH DH DC Powered_Up_Time Command/Feature_Name
-- -- -- -- -- -- -- -- ---------------- --------------------
42 00 02 c3 e1 6f 02 00 00:13:23.309 READ VERIFY SECTOR(S) EXT
42 00 02 c1 e1 6f 02 00 00:13:21.437 READ VERIFY SECTOR(S) EXT
25 00 01 00 00 00 00 00 00:13:21.437 READ DMA EXT
42 00 02 bf e1 6f 02 00 00:13:19.580 READ VERIFY SECTOR(S) EXT
25 00 01 00 00 00 00 00 00:13:19.580 READ DMA EXT
Error 2537 occurred at disk power-on lifetime: 21181 hours (882 days + 13 hours)
When the command that caused the error occurred, the device was active or idle.
After command completion occurred, registers were:
ER ST SC SN CL CH DH
-- -- -- -- -- -- --
01 51 02 c1 e1 6f e0 Error: AMNF at LBA = 0x006fe1c1 = 7332289
Commands leading to the command that caused the error were:
CR FR SC SN CL CH DH DC Powered_Up_Time Command/Feature_Name
-- -- -- -- -- -- -- -- ---------------- --------------------
42 00 02 c1 e1 6f 02 00 00:13:21.437 READ VERIFY SECTOR(S) EXT
25 00 01 00 00 00 00 00 00:13:21.437 READ DMA EXT
42 00 02 bf e1 6f 02 00 00:13:19.580 READ VERIFY SECTOR(S) EXT
25 00 01 00 00 00 00 00 00:13:19.580 READ DMA EXT
42 00 04 c3 e1 6f 02 00 00:13:17.643 READ VERIFY SECTOR(S) EXT
Error 2536 occurred at disk power-on lifetime: 21181 hours (882 days + 13 hours)
When the command that caused the error occurred, the device was active or idle.
After command completion occurred, registers were:
ER ST SC SN CL CH DH
-- -- -- -- -- -- --
01 51 04 c3 e1 6f e0 Error: AMNF at LBA = 0x006fe1c3 = 7332291
Commands leading to the command that caused the error were:
CR FR SC SN CL CH DH DC Powered_Up_Time Command/Feature_Name
-- -- -- -- -- -- -- -- ---------------- --------------------
42 00 04 c3 e1 6f 02 00 00:13:17.643 READ VERIFY SECTOR(S) EXT
42 00 04 bf e1 6f 02 00 00:13:15.783 READ VERIFY SECTOR(S) EXT
42 00 08 c7 e1 6f 02 00 00:13:15.763 READ VERIFY SECTOR(S) EXT
25 00 01 80 cf a4 0b 00 00:13:15.762 READ DMA EXT
42 00 08 bf e1 6f 02 00 00:13:13.873 READ VERIFY SECTOR(S) EXT
SMART Self-test log structure revision number 1
Num Test_Description Status Remaining LifeTime(hours) LBA_of_first_error
# 1 Extended offline Completed without error 00% 21246 -
SMART Selective self-test log data structure revision number 1
SPAN MIN_LBA MAX_LBA CURRENT_TEST_STATUS
1 0 0 Not_testing
2 0 0 Not_testing
3 0 0 Not_testing
4 0 0 Not_testing
5 0 0 Not_testing
Selective self-test flags (0x0):
After scanning selected spans, do NOT read-scan remainder of disk.
If Selective self-test is pending on power-up, resume after 0 minute delay.
~$
diff smart-pred-testem.txt smart-po-testu.txt >rozdil.diff mcedit rozdil.diffsamozrejme to nemusis presmerovat do rozdil.diff a/nebo nemusis pouzit mcedit, ale takto vidis rozdil pak pekne barevne (cervene rozdil v starem, zelene rozdil v novem)...
tak lekce jak porovnat data v terminaludiff smart-pred-testem.txt smart-po-testu.txt >rozdil.diff mcedit rozdil.diff
Takže celé by to bylo nějak takto?
sudo smartctl -a /dev/sdXY >smart-pred-testem.txt /home/user/Dokumenty sudo touch /forcefsck reboot # při bootu "e" a mezi quiet a splash vložit fsck.mode=force a pak F10 sudo smartctl -a /dev/sdXY >smart-po-testu.txt /home/user/Dokumenty cd Dokumenty diff smart-pred-testem.txt smart-po-testu.txt >rozdil.diff mcedit rozdil.diff
sudo smartctl -a /dev/sdXY >/home/user/Dokumenty/smart-pred-testem.txt sudo smartctl -t long /dev/sdXY # pockat nez dojede test sudo smartctl -a /dev/sdXY >/home/user/Dokumenty/smart-po-testu.txt diff /home/user/Dokumenty/smart-pred-testem.txt /home/user/Dokumenty/smart-po-testu.txt >/home/user/Dokumenty/rozdil.diff mcedit /home/user/Dokumenty/rozdil.diffpripominky k puvodnimu:
smart_path="/home/user/Dokumenty"
smart_pred="${smart_path}/smart-pred-testem.txt"
smart_po="${smart_path}/smart-po-testu.txt"
a pouzivat pak jen promene "${smart_pred}" a "${smart_po}"
tak lekce jak porovnat data v terminalu
Tohle je super. Použil jsem to pro porovnání hashe a je to paráda. Akorát mám otázku. Když dám:
sha512sum /cest/k/obraz.iso >sha_1.txt
Tak potom mám v souboru sha_1.txt ten hash a za ním je "/cesta/k/obraz.iso". Takže když ten soubor pak porovnávám s druhým souborem sha_2.txt, který obsahuje hash z netu, ale neobsahuje "/cesta/k/obraz.iso, tak to pak samozřejmě nesedí. Co v terminálu zadat, aby soubor sha_1.txt za vypočítaným hashem neobsahoval "/cesta/k/obraz.iso"?
sha512sum -c sha_1.txtpokud tam chces jen ten soucet, parametr na to neni, ale lze pres | (rouru) text zpracovat, moznosti je vice(a nejen co uvadim):
# pomoci nastroje cut, -d nastavi mezeru jako oddelovac, -f pise prvni sloupec
sha512sum /cest/k/obraz.iso | cut -d' ' -f1 >sha_1.txt
# v awk neni oddelovac treba nastavit, print pise prvni sloupec
sha512sum /cest/k/obraz.iso | awk '{print $1}' >sha_1.txt
# v sed, vse co je za mezerou(vcetne) nahrad za nic(tedy se odstrani)
sha512sum /cest/k/obraz.iso | sed 's/ .*//' >sha_1.txt
jinak spis bych soucet ukladal do nazvu obraz.iso.sha512, nechaval u iso a priste kdyz budes chtit zkontrolovat, tak nebudes nic tahat z netu ale pouzijes -c viz nahore
Díky za vysvětlení.
jinak spis bych soucet ukladal do nazvu obraz.iso.sha512, nechaval u iso a priste kdyz budes chtit zkontrolovat, tak nebudes nic tahat z netu ale pouzijes -c viz nahore
Vyzkoušel jsem si to a je to naprosto perfektní. Díky!
Na pokusy si jeden koupím. Na hraní to stačí a za ty peníze paráda.
Tiskni
Sdílej:
![]()
![]()
![]()
![]()
![]()
![]()
ISSN 1214-1267, (c) 1999-2007 Stickfish s.r.o.
 8.3.2019 20:33
8.3.2019 20:33
 8.3.2019 22:33
8.3.2019 22:33
 9.3.2019 00:14
9.3.2019 00:14
 10.3.2019 23:40
10.3.2019 23:40
 10.3.2019 20:55
10.3.2019 20:55
{kind=link}
{kind=link}
{kind=link}