Portál AbcLinuxu, 22. června 2026 10:09
 ). ) je mezi uzavíračem textu " nebo ne.
). ) je mezi uzavíračem textu " nebo ne.
Pred lety jsem delal v Bash prototyp streamoveho filtru.
Pak jsem to prepsal s jinou filosofii v C.
Nicmene vyvoj sel velmi rychle (stale jsem odchytaval dalsi a dalsi zverstva v tom streamu).
Myslim ze by to slo snadno priohnout.
Je to ale dost pomale....
Marek
#!/bin/bash
export IFS=""
ramecky=0
while read -rsn1 char
do
if [ $ramecky -eq 1 ]
then
case "$char" in
$'\033')
read -rsn1 char1
if [ "$char1" = '[' ]
then
read -rsn1 char2
if [ "$char2" = '1' ]
then
read -rsn1 char3
if [ "$char3" = '0' ]
then
read -rsn1 char4
if [ "$char4" = 'm' ]
then
#rozpoznana escape sequence na zapnuti ramecku
ramecky=0
echo -en "\\033[0;39m"
else
echo -n "$char$char1$char2$char3$char4"
fi
else
echo -n "$char$char1$char2$char3"
fi
else
echo -n "$char$char1$char2"
fi
else
echo -n "$char$char1"
fi
;;
D)
echo -n '-'
;;
Z)
echo -n ','
;;
'?')
echo -n '.'
;;
'@')
echo -n '`'
;;
'Y')
echo -n "'"
;;
'3')
echo -n '|'
;;
'')
echo
;;
*)
echo -n "$char"
esac
else
case "$char" in
$'\033')
read -rsn1 char1
case "$char1" in
"d")
read -rsn1 char2
if [ "$char2" = '#' ]
then
#tady probiha tisk
read -rsn1 char3
( while [ ! "$char3" = $'\024' ]
do
[ "$char" ] || echo
echo -n "$char3"
read -rsn1 char3
done ) | /usr/local/sbin/print1
else
echo -n "$char$char1$char2"
fi
;;
'[')
read -rsn1 char2
case "$char2" in
1)
read -rsn1 char3
if [ "$char3" = '2' ]
then
read -rsn1 char4
if [ "$char4" = 'm' ]
then
#rozpoznana escape sequence na zapnuti ramecku
ramecky=1
echo -en "\\033[1;43m"
else
echo -n "$char$char1$char2$char3$char4"
fi
else
echo -n "$char$char1$char2$char3"
fi
;;
5)
read -rsn1 char3
if [ "$char3" = ';' ]
then
read -rsn1 char4
if [ "$char4" = '1' ]
then
read -rsn1 char5
if [ "$char5" = 'i' ]
then
#rozpoznany zacatek tisku
konec=0
( while [ "$konec" -eq 0 ]
do
read -rsn1 char6
if [ "$char6" = $'\033' ]
then
read -rsn1 char7
if [ "$char7" = '[' ]
then
read -rsn1 char8
if [ "$char8" = '4' ]
then
read -rsn1 char9
if [ "$char9" = 'i' ]
then
konec=1
else
echo -n "$char6$char7$char8$char9"
fi
else
echo -n "$char6$char7$char8"
fi
else
echo -n "$char6$char7"
fi
else
[ "$char6" ] || echo
echo -n "$char6"
fi
done ) | /usr/local/sbin/print1
else
echo -n "$char$char1$char2$char3$char4$char5"
fi
else
echo -n "$char$char1$char2$char3$char4"
fi
else
echo -n "$char$char1$char2$char3"
fi
;;
*)
echo -n "$char$char1$char2"
esac
;;
*)
echo -n "$char$char1"
esac
;;
$'\221')
echo -en "\\033[1;43m \\033[0;39m"
;;
$'\237')
echo -en "\\033[1;42m \\033[0;39m"
;;
$'\233')
echo -n "-"
;;
$'\232')
echo -n "|"
;;
'')
echo
;;
*)
echo -n "$char"
esac
fi
done
No ono to s tou pomalosti zas tak strasne neni.
Fungovalo to jako obalka pro telnet+xterm a nez ten telnet to i na starodavnych pleckach, na ktere to bylo urceno, bylo rychlejsi.
Pomalost se projevovala pouze pri tisku velkych souboru.
MarekJo a nesmelo to bufferovat, takze se muselo parsovat opravdu znakove.
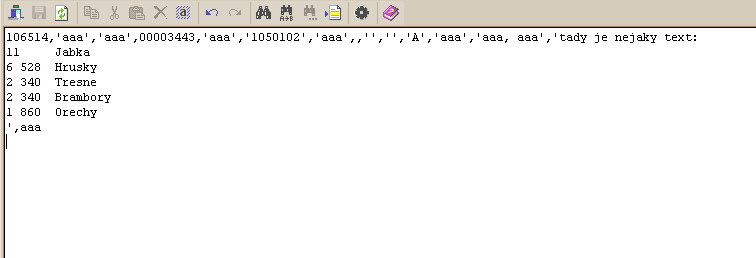
sed ':a;N;$!ba;s/\("[^"]*\)\n\([^"]*"\)/\1Shit_new_line\2/g' kuk.csv
funguje to na , a " a LF na ' jsem neměl nervy to zapisovat do $quot; a escapovat, sed ':a;N;$!ba;s/\("[^"]*\)\r\n\([^"]*"\)/\1Shit_new_line\2/g' kuk.csv
Což by mohl být základ „workaround-u“ co chcete…Shit_new_line musí být unikátní v souboru se nevyskytující řetězec.
s/$quot;/\" , nebo-li $quot; mělo být " 
load data local infile 'pokus.csv' into table adresa fields terminated by ',' enclosed by '"' lines terminated by '\n' (jmeno,cislo,ulice);Vyzkoušel jsem s podobnými vstupy, funguje to. Včetně diakritiky. OpenOffice Calc to načte také.
 22.7.2011 00:33
xkucf03 | skóre: 50
| blog: xkucf03
22.7.2011 00:33
xkucf03 | skóre: 50
| blog: xkucf03
A jinak bych to asi předělal do XMLA v čem to bude lepší?
22.7.2011 10:23
xkucf03 | skóre: 50
| blog: xkucf03
xsltproc – to mi přijde rozumnější, než psát několikastránkové skripty v bashi. Nebo ty data naládovat do relační databáze a pak s tím pracovat už hezky v SQL
CSV lze specifikovat velmi jednoduše (RFC je výjimka, jenž potvrzuje pravidlo), což se o XML říct nedá.
<rejp>Napsat CSV parser dá zhruba stejně práce jako napsat hlavičku a patičku XSLT skriptu.</rejp>
CSV lze specifikovat velmi jednodušeCož bohužel znamená, že si CSV naspecifikuje každý znova a trochu jinak. Takže napsat obecný automatický parser CSV nakonec nejde, vždycky musí uživatel ze vzorku okem odhadnout, co asi budou jaké oddělovače atd.
Tiskni
Sdílej:
![]()
![]()
![]()
![]()
![]()
![]()
ISSN 1214-1267, (c) 1999-2007 Stickfish s.r.o.
{kind=link}