Portál AbcLinuxu, 13. června 2026 07:09
 .
.

 13.12.2016 10:01
pavlix | skóre: 54
| blog: pavlix
13.12.2016 10:04
pavlix | skóre: 54
| blog: pavlix
13.12.2016 10:03
pavlix | skóre: 54
| blog: pavlix
13.12.2016 22:50
pavlix | skóre: 54
| blog: pavlix
13.12.2016 10:01
pavlix | skóre: 54
| blog: pavlix
13.12.2016 10:04
pavlix | skóre: 54
| blog: pavlix
13.12.2016 10:03
pavlix | skóre: 54
| blog: pavlix
13.12.2016 22:50
pavlix | skóre: 54
| blog: pavlix
Pokud se netrápíte přemýšlením, co se při tom "načítání" děje, proč ne.
Jinak… kdybyste napsal, že vám to připadá nepraktické, chápal bych to. Ale napsat "když to porovnám s tím, co všechno umí načítat"? Co konkrétně umí zpracovat "jednořádkovej regexp v perlu" a nelze to implementovat ve flexu?
Nemluvě o tom, že (f)lex umí pracovat i s kontextem.Ano, ale krkolomně. Já bych tady souhlasil s pánama, flex není moc neflexibilní. Jeho integrace do projektu a build systému není úplně snadná, na to, kolik toho (neumí). Přesně z toho důvodu jsem nahradil posledně flex výše zmíněným Ragelem, který toho umí mnohem víc, přitom se ale integruje do projektu/zdrojáku výrazně snáz.
Ragel is released under the GNU General Public License, Version 2.nesvobodne software odmitam pouzivat
 15.12.2016 00:05
xkucf03 | skóre: 50
| blog: xkucf03
15.12.2016 00:05
xkucf03 | skóre: 50
| blog: xkucf03
Co konkrétně umí zpracovat "jednořádkovej regexp v perlu" a nelze to implementovat ve flexu?Ve flexu nelze implementovat některé věci stejně rychle jako jednořádkovej regexp v perlu. Flex není součástí syntaxe C. Při vývoji parsování stringu v perlu nemusím kontrolovat segfaulty. Samozřejmě je to vykoupeno větším overheadem interpretovaného jazyka, ale v mých úlohách nebyly regexpy nikdy největší brzda.
Co konkrétně umí zpracovat "jednořádkovej regexp v perlu" a nelze to implementovat ve flexu?Ve flexu nelze implementovat některé věci stejně rychle jako jednořádkovej regexp v perlu.
Ale no tak… To je dost průhledný úhybný manévr. Přečtěte si, co píšu v komentářích 21 a 25.
} elsif ($line=~m/^[ \t]*\(tile_summary ([^ ]+) ([^ ]+) (\d+) (\d+) (\d+)\)(?: (.*))*$/) {
Návratové hodnoty v $1-$5, nerelevantní zbytek v $6 a v $7 je relevantní substring v nerelevantní zbytku (velmi zajímavá funkce ).
BTW měl jsem dojem, že flex je hlavně parser a na skládání symbolů do smysluplných kombinací se používá gramatika v yaccu/bisonu.
U složitějších jazyků ano, ale v jednodušších případech bývá často jednodušší použít samotný flex.
P.S. Jde ve flexu napsat tohle na jeden řádek? Ale to už je spíš gramatika no :-/.
} elsif ($line=~m/^[ \t]*\(tile_summary ([^ ]+) ([^ ]+) (\d+) (\d+) (\d+)\)(?: (.*))*$/) {
Na jeden určitě ne. :-) Jinak to samozřejmě půjde, ale musím přiznat, že perl mi k srdci nepřirostl (no, to byl hodně silný eufemismus), takže syntaxi PCRE bych musel pracně dohledávat.
#include <stdio.h>
#include <math.h>
int main(void)
{
float x,y;
char z;
for (printf("Kalkulačka\n");3==scanf("%f%1[+-*/]%f",&x,&z,&y);printf("%.3f %c %.3f = %.3f\n",x,z,y,'+'==z?x+y:'-'==z?x-y:'*'==z?x*y:y&&'/'==z?x/y:NAN)) while ('\n'!=getchar());
return 0;
}

while psát z pravé strany lze, ale taky můžete použít přepínače -p, -n;
V Perlu by šla jednoduchá kalkulačka rychle napsat, třeba takhle
perl -MRegexp::Common -pE 's{^ ( $RE{num}{real} \s* [\+\-\*\/] \s* $RE{num}{real} ) $}{$1 . "=" . eval $1}xmse'
 17.12.2016 16:16
Agent
| blog: Life_in_Pieces
| HC city
17.12.2016 16:16
Agent
| blog: Life_in_Pieces
| HC city
char je v C číselný typ...
19.12.2016 17:37
Agent
| blog: Life_in_Pieces
| HC city
int znak;
tak
char znak; ? A do něj pak zadám patřičný znak. Takže něco jako:char znak; nebo int znak;
printf("Zadej znak");
scanf("%c",&znak);
printf("\nZadal si znak %c, jehoz ASCII kod %d");
int c = 0x1234;
scanf("%c",&c);
Tak paměť bude vypadat 0x??34, kde ?? je zadaný znak.
Pokud uděláš naopak:
char c = 0x12; char d = 0x34;
scanf("%d",&c);
Tak se načtené číslo zapíše částečně do c a částečně do sousedního bytu, což v závislosti na implementaci může být d a nebo taky cokoliv jiného (a nebo taky nic, neboť tam může být mezera kvůli zarovnání na šířku datové sběrnice).
 19.12.2016 20:51
Jendа | skóre: 78
| blog: Jenda
| JO70FB
19.12.2016 20:51
Jendа | skóre: 78
| blog: Jenda
| JO70FB
> cat scanf.c
#include <stdlib.h>
#include <stdio.h>
int main(int argc, char **argv) {
int c = 0x1234;
scanf("%c",&c);
printf("got: %x\n", c);
}
> gcc -o scanf scanf.c
> ./scanf
a
got: 61001234
;)
Typy int a char se liší délkou. Char je na 1 byte, int bývá na dva nebo čtyři byty (záleží na procesoru).
Šestnáctibitový int už jsem neviděl zatraceně dlouho…
Pokud uděláš:
int c = 0x1234; scanf("%c",&c);Tak paměť bude vypadat 0x??34, kde ?? je zadaný znak.
Zdaleka nejpravděpodobnější je, že v c bude 0x12??. A pokud ne, tak bych vsadil spíš na 0x??001234.
#include <stdio.h>
int main()
{
int c = 0;
while (c < 128) {
printf("%d\t%x\t%o\t%c\n", c, c, c, c);
c++;
}
return 0;
}
Funkci na převod do binární soustavy si musíš napsat sám.
void printb(unsigned int n)
{
if (n) printb(n>>1), putchar((n&1)?'1':'0');
}
(n&1)?'1':'0' nahradit '0'+(n&1) a místo unsigned int stačí unsigned ...
Ale číst je to hrůza. Hlavně kvůli těm odsazeným závorkám
18.12.2016 15:28
Jendа | skóre: 78
| blog: Jenda
| JO70FB
nahradit '0'+(n&1)Norma určitě nespecifikuje, že za nulou musí následovat jednička. Určitě bude nějakou továrnu řídit mainframe, který má znaky uspořádané 1234567890
18.12.2016 16:16
xkucf03 | skóre: 50
| blog: xkucf03
18.12.2016 16:28
Jendа | skóre: 78
| blog: Jenda
| JO70FB
18.12.2016 19:18
pavlix | skóre: 54
| blog: pavlix
Stačí použít nějaké ASCII-nekompatibilní kódování…1) To je docela velký objev, že to nebude ASCII, když má ASCII sekvenci 0123456789. To je skoro na cenu kapitána obvijouse. 2) Zjevně nestačí.
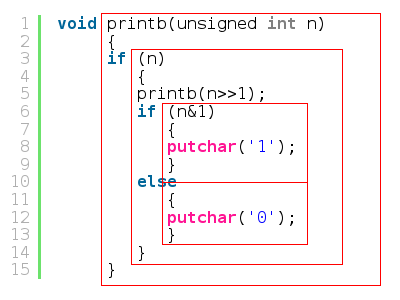
void printb(unsigned int n)
{
if (n)
{
printb(n>>1);
if (n&1)
{
putchar('1');
}
else
{
putchar('0');
}
}
}
Vytiskni si to a udělej v tom prázdném sloupci čáry podle pravítka
Našel jsem to kdysi v jedné staré učebnici Algolu (zkus si tam místo {} napsat begin a end), podobně to měl například Whitesmiths. A když ty závorky vyházím tak je z toho Python
18.12.2016 18:23
xkucf03 | skóre: 50
| blog: xkucf03
blok {
vnitřek bloku;
}
a ještě dokážu pochopit:
blok
{
vnitřek bloku;
}
Ale závorky na stejné úrovni s vnitřkem bloku mi přijdou rušivé.
P.S. a šířku tabulátoru mám 4 znaky, takže to nevypadá tak hrozně jako tady (kde se ti asi tabulátor zobrazí široký 8 znaků)
Já tabulátor nepoužívám, odskáču to mezerami podle délky příkazu, aby to bylo zároveň s mezerou. Pak mi vyjde to na obrázku příloze.
18.12.2016 19:22
pavlix | skóre: 54
| blog: pavlix
Jezis, jeste promenliva velikost odsazeni. Ja myslel ze je to chyba, ze v ty ukazce je to nejdriv 5 a pak 3 mezery, ale ono je to schvalne! :)Já bych toto a k tomu veškeré zarovnávání (kromě klasického odsazení o přesně daný násobek odsazovacích sekvencí) tvrdě odmítal. Přijde mi to jako hrozné zvěrstvo. A závorky zarovnané na vnitřek bloku nemají podle mě žádné opodstatnění. Ale se mnou tohle neřešte, já jsem trochu moc na rozum a logiku. :)
18.12.2016 19:35
xkucf03 | skóre: 50
| blog: xkucf03
18.12.2016 23:31
pavlix | skóre: 54
| blog: pavlix
Např. se změní typ návratové hodnoty a je potřeba změnit odsazení/zarovnání celého blokuGNU coding style doporucuje mit navratovou hodnotu na separatnim radku.
22.12.2016 15:45
pavlix | skóre: 54
| blog: pavlix
18.12.2016 23:24
pavlix | skóre: 54
| blog: pavlix
 18.12.2016 20:49
Bedňa | skóre: 34
| blog: Žumpa
| Horňany
18.12.2016 21:48
Bedňa | skóre: 34
| blog: Žumpa
| Horňany
18.12.2016 20:49
Bedňa | skóre: 34
| blog: Žumpa
| Horňany
18.12.2016 21:48
Bedňa | skóre: 34
| blog: Žumpa
| Horňany
foo (bar) {
a = b
if (a > 1) {
print "a > 1"
}
}
Proste jasne vidíš zarovnanie začiatku a konca. Je viacero zápisov ktoré akceptujem a sú čitateľné, ale ten tvoj medzi ne nepatrí, sorry :)
void printb(unsigned int n)
begin
if (n)
begin
printb(n>>1);
if (n&1)
begin
putchar('1');
end
else
begin
putchar('0');
end
end
end
Takhle v tom ty obdélníky prostě vidím, na obrazovce, na výtisku, i když to napíšu rukou.
18.12.2016 22:12
xkucf03 | skóre: 50
| blog: xkucf03
if (n)
begin
end
A blok kódu uvnitř je zarovnaný podle begin-end.
Ale neřeš to, mě to prostě vyhovuje a kdysi bylo něco podobného v módě, dneska to už skoro nikdo nepoužívá. Holt musím mít vždycky něco extra
18.12.2016 22:56
Bedňa | skóre: 34
| blog: Žumpa
| Horňany
18.12.2016 22:19
Bedňa | skóre: 34
| blog: Žumpa
| Horňany
void printb(unsigned int n) begin
if (n) begin
printb(n>>1);
if (n&1) begin
putchar('1');
end
else begin
putchar('0');
end
end
end
Teraz vidím kde končí. Toto je nekonečné flame, buď uznáš že je to čitatelnejšie, alebo to nikam nepovedie :)
if ( True, False, ).pick {
say 'a';
} else {
say 'b';
}
oproti doporučovanému
if ( True, False, ).pick {
say 'a';
}
else {
say 'b';
}
18.12.2016 22:47
Bedňa | skóre: 34
| blog: Žumpa
| Horňany
if ( True, False, ).pick
{
say 'a';
}
else
{
say 'b';
}
Stále tam vidím na prvý pohľad začiatok a koniec a môžem rýchlo hľadať v kóde.
perltidy pomocí --cuddled-else lze na takové chování přepnout. Děkuji za upozornění.
18.12.2016 23:26
pavlix | skóre: 54
| blog: pavlix
if, else a end na stejné úrovni. Jenže ve skutečnosti end patří k begin a tudíž by mezi nimi na stejné úrovni nic být nemělo. Ten systém je nelogický a neodpovídá skutečné struktuře kódu.
18.12.2016 23:28
pavlix | skóre: 54
| blog: pavlix
void printb(unsigned int n)
if (n)
printb(n>>1);
if (n&1)
putchar('1');
else
putchar('0');
19.12.2016 12:08
pavlix | skóre: 54
| blog: pavlix
char *decbin(int value)
{
static char digits[] = "0123456789";
static char buf[128];
char *ptr;
ptr = buf + sizeof(buf) - 1;
*ptr = '\0';
do {
*--ptr = digits[value % 2];
value /= 2;
} while (ptr > buf && value);
return ptr;
}
Originál funkce je zde, hledejte funkci _php_math_longtobase.
To je ale kod jak z roku 1980, thread safety, nic?Stačilo by umazat ten druhý
static, ten první se tam klidně může nechat (i když by bylo dobré tam dát navíc const), a na konci přidát jeden strdup() a je to. Vysledek by se ovšem musel uvolnit přes free().
Nicméně žádný opravdový Cčkař se zkušeností s hardwarem by nikdy nenapsal do vnitřní smyčky dělení a modulo, pokud se jedná o dvojku, ale použil by bitový posun doprava o jeden bit a vymaskování s nejnižším bitem. A těch 128 znaků velký buffet je zbytečně moc, pokud se to nebude pouštět na nějaké obludnosti, kde je int stodvacetiomsibitový, tak by stačilo 32+1 nebo 64+1 znaků v bufferu (případně místo +1 dát +4, kvůli zarovnání), dá se to zjistit podle INT_MAX. No a nakonec, nepoužil by konverzní tabulku (ze které se stejně používají jen dva znaky z deseti), ale přičetl by výsledek maskování ke znaku '0', protože číslice jsou za sebou jak v ASCII, tak dokonce i v EBCDIC
Nicméně žádný opravdový Cčkař se zkušeností s hardwarem by nikdy nenapsal do vnitřní smyčky dělení a modulo, pokud se jedná o dvojku, ale použil by bitový posun doprava o jeden bit a vymaskování s nejnižším bitem.Ano, to je oblibena zabava pravych ceckaru, misto toho, aby v programu vyjadrili, co ma dany program delat, tak pisou, co ma delat dany procesor. A pak, aby se v tom prase vyznalo, kdyz se clovek snazi desifrovat, jak dany program funguje. Znam lidi, kteri misto x = 0, pisou x ^= x, protoze si mysli, ze to je rychlejsi, protoze tomu tak kdysi davno bylo. Deleni i nasobeni dvojkou prekladace prevadi na shift automaticky, podobne optimalizuji i obecne nasobeni a deleni konstantou.
float wtf(float x)
{
float x2 = x * 0.5f;
long i = *(long *)&x;
i = 0x5f3759df - (i >> 1);
x = *(float *)&i;
return x * (1.5f - (x2 * x * x));
}
x = (x & 0x55555555) + ((x >> 1) & 0x55555555); x = (x & 0x33333333) + ((x >> 2) & 0x33333333); x = (x & 0x0F0F0F0F) + ((x >> 4) & 0x0F0F0F0F); x = (x & 0x00FF00FF) + ((x >> 8) & 0x00FF00FF); x = (x & 0x0000FFFF) + ((x >>16) & 0x0000FFFF);Ale nastesti buh stvoril komentare, takze vim, co to dela. ;-]
19.12.2016 12:11
Jendа | skóre: 78
| blog: Jenda
| JO70FB
Normální člověk použije builtin překladače a ten pak z toho vyrobí to, co je na daném procesoru nejrychlejšíPokud potrebujes cilit na ruzne platformy, kde se pouzivaji ruzne prekladace, prestavas byt normalnim clovekem.
19.12.2016 12:03
Jendа | skóre: 78
| blog: Jenda
| JO70FB
float x2 = x * 0.5f;Určitě by bylo lepší od mantisy odečíst integerově jedničku, ne?
Sice to na současných procesorech bude pomalejší (místo jedné FPU instrukce, která může klidně trvat jenom jeden takt, že musí extrahovat bajt), ale to přece nevadí…
Znam lidi, kteri misto x = 0, pisou x ^= x, protoze si mysli, ze to je rychlejsi
BTW Na které architektuře to je rychlejší, vím jen že na x86 to je kratší o bajt (xor ax,ax), MIPS to má snad podobný - já teda dělal jen na derivátu microblaze.
xor eax, eax 33C0 xor rax, rax (zbytecne) 4833C0 mov eax, 0 (zbytecne) B800000000
Kratsi to samozrejme je, ale takovou trivialitu resi prekladac. Napsat x^=x je negramotnost.
Ano, to je oblibena zabava pravych ceckaru, misto toho, aby v programu vyjadrili, co ma dany program delat, tak pisou, co ma delat dany procesor. A pak, aby se v tom prase vyznalo, kdyz se clovek snazi desifrovat, jak dany program funguje.
Naprosto souhlasím s myšlenkou (že nemá smysl napovídat optimalizátoru), ale v tomhle konkrétním případě bych řekl, že shift a bitový and s jedničkou jsou přinejmenším stejně názorné jako dělení a zbytek (ty mají výhodu spíš v tom, že stačí drobná změna, pokud by základ soustavy nebyla mocnina dvojky).
Tak ono hlavne bit-and a modulo delaji neco jineho, takze zalezi na situaci:
#include <stdio.h>
int a(int x) { return x & 1; }
int b(int x) { return x % 2; }
int main(int argc, char* argv[]) {
printf("a(-11) -> %d\n", a(-11));
printf("b(-11) -> %d\n", b(-11));
return 0;
}
Vysledek:
a(-11) -> 1 b(-11) -> -1
Není:
When integers are divided, the result of the/operator is the algebraic quotient with any fractional part discarded.⁸⁸⁾ If the quotienta/bis representable, the expression(a/b)*b + a%bshall equala.…
⁸⁸⁾ This is often called “truncation toward zero“.
in C99 or later, division of integers involving negative operands always truncate towards zero. Note that, in C89, whether the result round upward or downward is implementation-defined. Because (a/b) * b + a%b equals a in all standards, the result of % involving negative operands is also implementation-defined in C89.
Člověka, který chování modulo vymyslel, a hlavně toho, kdo ho pak kodifikoval, bych někdy rád dostal do ruky, abych to s ním mohl proinzultovat…Proč ti to vadí?
Protože nemá některé elementární vlastnosti, které je logické očekávat, např.
(a + k * d) % d == a % d (a + k * d) / d == (a / d) + k
Nevzpomínám si, že bych někdy narazil na situaci, kde by se při záporné hodnotě prvního operandu hodila definice z C99. Naopak, už mockrát jsem to musel obcházet buď větvením nebo rovnou dodefinováním real_mod() a real_div().
Bohužel už tahle definice "vyhrála" a je pozdě s tím něco dělat, stejně jako s kalendářem bez roku 0. Tvůrce kalendáře aspoň omlouvá doba, kdy se tak stalo.
.
20.12.2016 21:46
xkucf03 | skóre: 50
| blog: xkucf03
stejně jako s kalendářem bez roku 0. Tvůrce kalendáře aspoň omlouvá doba, kdy se tak stalo.Na pravítku je taky nula jen ten bod, ale první centimetr (úsek) je první (č. 1, ne 0). Kalendář funguje stejně, ne?
Jestli je nula jen ten bod, pak jednička taky. A stejně tak -1 atd. V tom problém není, je jedno, jestli chci číslovat body nebo intervaly. Problém je v tom, že tady někdo vzal dvě kopie přirozených čísel (bez nuly), jednu otočil a nalepil je k sobě bez potřebné nuly, čímž rozbil aritmetiku. Ta nula tam prostě chybí. Takže když se budeme např. ptát, kolik let uplynulo od 1.6.5 př.n.l. do 1.6.5 n.l., oproti očekávání to nebude deset, ale jen devět.
Lidi si na to samozřejmě zvyknou a naučí se s takovým systémem s nelogickými a zbytečnými výjimkami pracovat (nebo taky ne). (Koneckonců by to šlo i s kalendářem, který by na obě strany začínal třeba desítkou.) Někteří na to jsou dokonce hrdí a ten systém zuby nehty obhajují. Já jsem holt na takové zbytečné a nelogické komplikace citlivější.
20.12.2016 23:19
pavlix | skóre: 54
| blog: pavlix
21.12.2016 00:17
pavlix | skóre: 54
| blog: pavlix
Pokud jsi citivlivější na drobné nelogičnosti, pak bys s datem a časem raději vůbec neměl pracovat. Absence roku 0 je asi tak ten nejmenší problém.+1 :D
21.12.2016 00:22
xkucf03 | skóre: 50
| blog: xkucf03
astronomický rok, který rok nula má, ie. 0 = 1BC, -1 = 2BC, atd.To mi přijde ještě pošahanější, než zapisovat nedokončené roky, měsíce a dny a vedle toho vesele zapisovat jen dokončené hodiny, minuty a vteřiny.
21.12.2016 12:33
xkucf03 | skóre: 50
| blog: xkucf03
To je prirozeny zpusob, vychazi z toho, ze se 'bod 0' proste posune o rok drive.Bod nula se ale nikam neposouvá – nachází se na hranici prvního úseku (roku) vpravo a prvního roku vlevo.
Rozdil mezi cislovanim roku a cislovanim 'nizsich' udaju (mesicu az sekund) je v tom, ze zatimco 'nizsi' udaje jsou na omezenem intervalu, tak roky jsou neohranicene.To bohužel nefunguje. Měsíce a dny totiž zapisujeme stejným způsobem jako roky – dne 10. 2. uběhl 1 celý měsíc a 9 celých dní (+ nějaké menší jednotky, které zápis nevyjadřuje) od začátku roku a jsme v 2. měsíčním úseku a v rámci něj v 10. denním úseku. Zatímco v 12:30 uběhlo od začátku dne 12 celých hodin a 30 celých minut (+ nějaké menší jednotky, které zápis nevyjadřuje) a jsme tedy ve 13. hodinovém úseku dne a v rámci něj v 31. minutovém úseku.
nachází se na hranici prvního úseku (roku) vpravo a prvního roku vlevo.Tak tomu je v 'klasickem' cislovani roku. V astronomickem cislovani roku (ktere pouziva ISO 8601) je na hranici mezi rokem 0 a rokem -1. Tedy o rok driv nez v 'klasickem' cislovani roku.
21.12.2016 13:31
xkucf03 | skóre: 50
| blog: xkucf03
Ale tvrdit, že existuje rok nula a zároveň, že letos máme 2016, je naprosto zcestné.Šmarja. Nic nesmyslného na tom není. Prostě akorát udávají tu nulu v jiný moment, než kde na ní z nepochopitelného důvodu trváš ty. Má to tu výhodu, že astronomický letopočet je v rovině s gregoriánský anno dominy, což je mnohem užitečnější než být kompatibilní s BC částí, pokud bys nulu umístil o rok později, jak navrhuješ...
21.12.2016 14:56
xkucf03 | skóre: 50
| blog: xkucf03
yyyy-MM-dd HH:mm:ss, kde
yyyy – máme nulu MM – nemáme nulu dd – nemáme nulu HH – máme nulu mm – máme nulu ss – máme nulu?
21.12.2016 15:14
pavlix | skóre: 54
| blog: pavlix
A k čemu je rok 0K tomu aby se dalo s letopočty dobře počítat.
21.12.2016 15:34
xkucf03 | skóre: 50
| blog: xkucf03
21.12.2016 15:35
pavlix | skóre: 54
| blog: pavlix
21.12.2016 15:40
xkucf03 | skóre: 50
| blog: xkucf03
21.12.2016 15:32
pavlix | skóre: 54
| blog: pavlix
21.12.2016 15:39
xkucf03 | skóre: 50
| blog: xkucf03
pondělí = -2 úterý = -1 středa = 1 čtvrtek = 2 pátek = 3 sobota = 4 neděle = 5Tzn. kolikátý den od bodu nula to je. Zcela logické.
21.12.2016 15:45
xkucf03 | skóre: 50
| blog: xkucf03
21.12.2016 15:49
xkucf03 | skóre: 50
| blog: xkucf03
21.12.2016 15:56
xkucf03 | skóre: 50
| blog: xkucf03
for (int i = x; i < y; i++) {
// dělej něco s rokem i
}
tak si to pořadí (např. 2016) musíš převést na počet celých let od počátku a na výstupu si to zase naformátovat zpět (převést dokončené roky na pořadí).
Ale posunout kvůli pouhému formátování bod nula o rok je nehorázná prasárna.
21.12.2016 19:14
xkucf03 | skóre: 50
| blog: xkucf03
Ocislovani objektu (napr. roku, dni) neni nic jineho nez vzajemne jednoznacne zobrazeni mezi temi objekty a intervalem celych cisel, ktere zachovava usporadani a operace predchudce/naslednika.Pokud to bereš čistě jako mapování nějakých seřazených entit na celá čísla, tak to nějaký smysl dává. To uznávám. Co mi na tom moc nesedí, je, že běžně a primárně nečíslujeme úseky – prakticky vždy číslujeme body – např. délka, teplota, hmotnost. A číslování úseků je až odvozené od číslování těch bodů (např. úsek x-tý kilometr).
Cislovani, ktere mapuje utery i stredu na 0 je jeste pitomejsi, nebot ani neni proste (dva objekty se mapuji na stejne cislo).Tam se totiž nejedná o mapování, ale o měření, jako kdybys měřil třeba teplotu nebo délku. Tam máš 0,5 a -0,5 centimetrů nebo stupňů, tzn. oboje je 0 celých jednotek, akorát jednou je ta nula kladná a jednou záporná (resp. kladné nebo záporné jsou ty menší jednotky/desetiny). BTW: číslují se ještě někde jinde úseky místo bodů? Napadají mne třeba stránky v knize, ale to není zrovna fyzikální veličina.
BTW: číslují se ještě někde jinde úseky místo bodů? Napadají mne třeba stránky v knize, ale to není zrovna fyzikální veličina.To je dobrá poznámka, letopočty se blíží právě spíše něčemu takovému jako je číslování knih. Jsou podobně vágní. Číslo stránky nedopovídá číslu v jiném vydání téže knihy. Ani nemusíme chodit moc daleko do nějakého starověku. Například mezi lety 1155 až 1752 začínal v Británii oficiálně rok 25. března. V důsledku toho například poprava Karla I. Stuarta je v historických záznamech datována na 30. ledna 1648, z pohledu standardního gregoriánského kalendáře to ale bylo 30. ledna 1649. Letopočty a kalendáře mají do fyzikálních veličin dost daleko. Je to v podstatě záležitost kulturních zvyklostí.
21.12.2016 22:42
xkucf03 | skóre: 50
| blog: xkucf03
Například mezi lety 1155 až 1752 začínal v Británii oficiálně rok 25. března. V důsledku toho například poprava Karla I. Stuarta je v historických záznamech datována na 30. ledna 1648, z pohledu standardního gregoriánského kalendáře to ale bylo 30. ledna 1649.A jak se s tím vyrovnává astronomický rok? (oproti tomu je „absence roku nula“ úplná prkotina, která se kompenzuje jednoduchou konverzí: „do určitého okamžiku posouvám o konstantu, pak už neposouvám“)
21.12.2016 22:45
pavlix | skóre: 54
| blog: pavlix
A jak se s tím vyrovnává astronomický rok?Také nerozumim souvislosti. Astronomický rok je určený pro - ehm - astronomii, ne úplně pro historii středověké Evropy...
 22.12.2016 15:12
kyknos | skóre: 18
| blog: Quid novi?
| Ranša Rosa
22.12.2016 15:12
kyknos | skóre: 18
| blog: Quid novi?
| Ranša Rosa
Co mi na tom moc nesedí, je, že běžně a primárně nečíslujeme úseky – prakticky vždy číslujeme body – např. délka, teplota, hmotnost. A číslování úseků je až odvozené od číslování těch bodůPokud mam spojitou velicinu (napr. delka, teplota, cas). tak v ni body odpovidaji hodnotam realnych cisel. Pokud mam diskretni objekty, tak ty cisluji celymi cisly. Cas je sice spojita velicina, ale v okamziku, kdy ji rozdelim na pevne intervaly, tak ty intervaly jsou jiz diskretni objekty, ktere normalne cisluji celymi cisly. Neni pravda, ze by primarni byl u roku/mesicu/dnu pevny bodovy pocatek a z nej se teprve odvozovaly intervaly. Historicky je to naopak. Intervaly byly prirozene vymezene prirodnimi cykly (dny, lunarni mesice, solarni roky) ci jejich vice ci mene arbitrarni aproximaci podle stylu konkretniho kalendare. Ale v oznacovani konkretnich intervalu byl dost zmatek. Napriklad za doby stareho Rima se roky oznacovaly jmeny podle jmen konzulu, kteri ten rok nastoupili do uradu. Model 'AD' cislovani roku julianskeho kalendare od 'bodoveho pocatku' odvozeneho od mytickych krestanskych udalosti vznikl az teprve cca 500 let po vzniku julianskeho kalendare, tedy hranice tech intervalu byly jiz davno vymezene, nez je nekdo zpetne ocisloval a zpetne stanovil 'bodovy pocatek'.
20.12.2016 23:53
xkucf03 | skóre: 50
| blog: xkucf03
2015'11'19 23:53 (místo apostrofu by byl asi vhodnější nějaký jiný symbol).
Tam jde jen o to, že datum zapsané jako 1. 6. 0005 není 5,5, ale 4,5 (od bodu nula).V gregoriánském kalendáři žádný bod 0 není, v tom je ten fór.
Rok nula: Neexistuje v našem (křesťanském) letopočtu, který se používá souběžně s gregoriánským kalendářem (dříve s juliánským kalendářem). V tomto systému je rok 1 př. n. l. přímo následován rokem 1.To chápu tak, že rok (úsek) nula sice nemáme, ale jako bod nula můžeme označit okamžik (půlnoc) mezi lety 1 př.n.l a 1 n.l. Jako kdybys dal dvě pravítka proti sobě a to levé prohlásil za záporné – pak nemáš nultý úsek, ale máš první a mínus první centimetr a mezi nimi je bod nula.
ale jako bod nula můžeme označit okamžik (půlnoc) mezi lety 1 př.n.l a 1 n.l.A k čemu to je dobré?
Takový způsob označování by měl smysl, kdyby ten "bod 0" byl nějaký naprosto zásadní přelom, kde bychom měli dvě zcela oddělené epochy, mezi nimiž by nebyla žádná kontinuita. Pak by mělo smysl mít nezávislé a oddělené datování "před" a "po" a vůbec by nevadilo, že se na obě strany čísluje od jedničky. Tak tomu ale není, zvolený "bod 0" je naprosto náhodně zvolený okamžik, který není významný vůbec ničím (kromě toho, že byl kdysi za ten počátek zvolen). Takže neexistuje žádný praktický důvod, proč uměle vymýšlet dva nezávislé letopočty a komplikovat si život při práci s jakýmkoli intervalem, který prochází přes počátek.
Mimo jiné bych doporučil zamyslet se nad tím, že jen proto, abychom se za na levé straně osy vyhnuli použití záporných čísel, číslujeme tam roky v opačném směru, než plyne čas - ale kupodivu jen roky, u všech menších komponent používáme stejný směr jako vpravo.
zapisovat nedokončené roky, měsíce a dny a vedle toho vesele zapisovat jen dokončené hodiny, minuty a vteřiny.
…což je ale vlastně opět jen důsledek uměle vynechané nuly. :-)
A tím bych radši skončil, diskusí na toto téma už jsem absolvoval spoustu a všechny (včetně této) probíhaly tak, že se mi lidé snažili trpělivě stále dokola vysvětlovat, jak byl ten kalendář navržen, a ignorovali, že chápu, jak byl navržen, ale považuji za nešťastný, nelogický a nepraktický a snažím se jen vysvětlit proč. Pro mne je to prostě jen názorný příklad, jak to dopadne, když se matematický model pokouší udělat někdo bez matematického myšlení.
A tím bych radši skončil, diskusí na toto téma už jsem absolvoval spoustu a všechny (včetně této) probíhaly tak, že se mi lidé snažili trpělivě stále dokola vysvětlovat, jak byl ten kalendář navržen, a ignorovali, že chápu, jak byl navržen, ale považuji za nešťastný, nelogický a nepraktický a snažím se jen vysvětlit proč. Pro mne je to prostě jen názorný příklad, jak to dopadne, když se matematický model pokouší udělat někdo bez matematického myšlení.+1 Můžeme k tomu zkusit přidat římský kalendář, který je přirozeným rozšířením debility římského systému zápisu čísel.
Takový způsob označování by měl smysl, kdyby ten "bod 0" byl nějaký naprosto zásadní přelom, kde bychom měli dvě zcela oddělené epochy, mezi nimiž by nebyla žádná kontinuita. Pak by mělo smysl mít nezávislé a oddělené datování "před" a "po" a vůbec by nevadilo, že se na obě strany čísluje od jedničky. Tak tomu ale není, zvolený "bod 0" je naprosto náhodně zvolený okamžik, který není významný vůbec ničím (kromě toho, že byl kdysi za ten počátek zvolen).O významnosti dané události nemá smysl se hádat. Klidně nad tím můžeme uvažovat v teoretické rovině a zvolit si libovolnou jinou událost. Např. si zvolíme 1. 1. 1970 jako bod nula a od něj počítáme vteřiny:
$ date --date="1970-01-01 00:00:00" --utc +%s 0 $ date --date="1970-01-01 00:00:01" --utc +%s 1 $ date --date="1970-01-01 00:01:00" --utc +%s 60 $ date --date="1970-01-01 01:00:00" --utc +%s 3600 $ date --date="1970-01-02 00:00:00" --utc +%s 86400Co se týče zápisu, jde o to, zda si dohodneme, že budeme zapisovat dokončené úseky nebo nedokončené, právě probíhající. Ale to nic nemění na tom, že nultý úsek neexistuje, existuje jen bod nula. Všude jinde např. při měření vzdáleností nebo peněžních částek se zapisují jen dokončené úseky a zbytek se vyjádří menší jednotkou nebo se zaokrouhlí nebo zahodí a nezapisuje vůbec. Dokonce i věk člověka se uvádí v dokončených letech a ten zbytek se zahodí resp. neuvádí. Tzn. novorozeně je staré nula let, prožívá svůj první rok, ale žádný nultý rok/úsek tu není.
Mimo jiné bych doporučil zamyslet se nad tím, že jen proto, abychom se za na levé straně osy vyhnuli použití záporných čísel, číslujeme tam roky v opačném směru, než plyne čas - ale kupodivu jen roky, u všech menších komponent používáme stejný směr jako vpravo.Ano, tohle je skutečný problém tohoto systému – na rozdíl od absence „roku nula“, která je zcela logická, protože nula je bod, nikoli úsek a neexistuje nultý rok, existují jen první (a další) roky na obě strany od tohoto bodu. Na druhou stranu chápu, že je to dané snahou mít vztah mezi datem a ročním obdobím, dnem a nocí.
…což je ale vlastně opět jen důsledek uměle vynechané nuly. :-)Nezaměňuj příčinu a následek.
chápu, jak byl navržen, ale považuji za nešťastný, nelogický a nepraktický a snažím se jen vysvětlit pročSouhlasím, že ten systém je v mnoha ohledech špatný a nelogický. Ovšem zavedením „roku nula“ ničemu neprospěješ a naopak situaci ještě zhoršíš.
21.12.2016 00:34
xkucf03 | skóre: 50
| blog: xkucf03
Léta Páně se počítají od kdysi předpokládaného dne Ježíšova obřezání, ke kterému mělo dojít 1. 1. roku 1. Za tohoto předpokladu k narození Krista došlo osm dní před začátkem letopočtu, tedy v roce označovaném 1 ante Christum natum, doslova v roce 1 před narozením Krista. Půlnoc na počátku dne, kdy měl být Kristus obřezán, tedy představuje bod na časové ose. Od tohoto bodu jsou oběma směry v čase roky (jednoroční časové úseky) číslovány počínaje číslem jedna. Není tedy rok 0, protože nulu představuje právě onen časový bod.což potvrzuje moji představu.
21.12.2016 00:07
xkucf03 | skóre: 50
| blog: xkucf03
2016 × počet_vteřin_v_roce + 12 × počet_vteřin_v_měsíci* + 20 × počet_vteřin_ve_dni + 23 × počet_vteřin_v_hodině + 53 × počet_vteřin_v_minutě
ale musíme počítat:
2015 × počet_vteřin_v_roce + 11 × počet_vteřin_v_měsíci* + 19 × počet_vteřin_ve_dni + 23 × počet_vteřin_v_hodině + 53 × počet_vteřin_v_minutě
Tam je ta nelogičnost v zápisu data oproti zápisu času (kde jedničku neodečítáme a rovnou násobíme). Chyba je v tom, že zapisujeme rok, který ještě nedoběhl – zatímco u hodin, minut, vteřin, centimetrů atd. zapisujeme jen celé části a ten zbytek (po dělení) vyjadřujeme menší jednotkou, kterou logicky přičítáme.
BTW: v některých programovacích jazycích resp. knihovnách je leden = 0 a první den v měsíci/týdnu je taky 0.
*) teď ignorujme, že měsíce jsou navíc různě dlouhé
21.12.2016 00:19
pavlix | skóre: 54
| blog: pavlix
21.12.2016 00:24
xkucf03 | skóre: 50
| blog: xkucf03
21.12.2016 08:40
pavlix | skóre: 54
| blog: pavlix
21.12.2016 12:09
xkucf03 | skóre: 50
| blog: xkucf03
21.12.2016 15:17
pavlix | skóre: 54
| blog: pavlix
21.12.2016 12:08
xkucf03 | skóre: 50
| blog: xkucf03
21.12.2016 00:45
xkucf03 | skóre: 50
| blog: xkucf03
21.12.2016 01:19
xkucf03 | skóre: 50
| blog: xkucf03
Ano, mohli bychom počátek označit jako 0000'00'00 anebo taky třeba jako 123'04'00 a pak by dnes byl 2138'15'00 - v čem je pointa? Ten "bod 0" mi nepřijde v ničem relevantní.Ano a pravítko by taky mohlo začínat bodem 123 a pokračovat 124, 125… ale začíná bodem nula, což dává mnohem větší smysl – stejně jako bod nula v čase, po kterém následuje rok 1, což je vlastně první rok resp. úsek mezi bodem nula a bodem „1 R“ (analogicky: první centimetr je úsek mezi body 0 cm a 1 cm). *) akorát když to nebude 1. ledna, tak to nebude sedět přírodní roky a měsíce – ale na ty bychom se mohli vykašlat a používat jiné úseky a nelpět na souvislosti s oběhem slunce a měsíce.
21.12.2016 01:35
xkucf03 | skóre: 50
| blog: xkucf03
Půlnoc na začátku toho dne prohlásíme za bod nula. Den té události je první den.Nebo za bod nula označíme přesně okamžik té události, pokud je nám jedno, kdy je světlo a kdy tma a stačí nám počítat úseky a označovat okamžiky nějakou jednotkou, aniž by v ní celé hodnoty měly souvislost s něčím dalším (oběh slunce, měsíce…). Nic to nemění na tom, že počátkem je bod nula. A pak jde jen o to, dohodnout si způsob zápisu dalších bodů, pokud budeme mít nějaké větší jednotky než základní. Např. bychom mohli počítat v kilosekundách, megasekundách… pak by počátek byl 0'0'0, o tisíc sekund později bychom měli 0'1'0 a o milion sekund později 1'0'0 (nebo jinak zapsáno 1 Ms + 0 ks + 0 s). To je ta logičtější varianta zápisu. Nebo bychom to mohli zapisovat méně logicky (jako dnes píšeme datum a čas): např. 1. 1. 1, což by znamenalo bod vzdálený od počátku 0 000 001 vteřin tzn. jednu vteřinu a ne, jak by jeden čekal, 1 001 001 vteřin. Protože by autor normy rozhodl, že jedny jednotky (zde megasekundy a kilosekundy) budeme zapisovat ty nedokončené, právě probíhající, zatímco jiné budeme zapisovat ty dokončené (sekundy).
Protože by autor normy rozhodl, že jedny jednotky (zde megasekundy a kilosekundy) budeme zapisovat ty nedokončené, právě probíhající, zatímco jiné budeme zapisovat ty dokončené (sekundy).To, že rok ti připadá "nedokončený" je dáno pouze tím, že sis bod nula zvolil jako první sekundu roku 1, což je ale v podstatě pouze tvoje osobní arbitrátní/náhodná volba a nevím, proč to děláš. Objektivně není definováno, jestli je rok dokončený nebo ne. Můžeš zkusit vymyslet nějaký praktický use case, pro který je ten tvůj návrh užitečný. Osobně moc žádný nevidim...
21.12.2016 08:43
pavlix | skóre: 54
| blog: pavlix
To, že rok ti připadá "nedokončený" je dáno pouze tím, že sis bod nula zvolil jako první sekundu roku 1, což je ale v podstatě pouze tvoje osobní arbitrátní/náhodná volba a nevím, proč to děláš. Objektivně není definováno, jestli je rok dokončený nebo ne.Asi tak. Ta dokončenost a nedokončenosti mi taky připadá jako bullshit vycucaný z prstu, jenom jsem to nechtěl hned napsat takhle naplno, kdyby za tím byla třeba nějaká myšlenka. Už jsem se nedávno spálil s Andrejem...
21.12.2016 17:50
Agent
| blog: Life_in_Pieces
| HC city
Když teda pravítkem naměřim 0.5 mm od nuly tak je teda jedno jestli napíšu 0cm a 5mm nebo 1cm 5mm?No jestli se snažíš změřit vzdálenost od místa, kde byl podle legendy Ježíš narozen/obřezán/etc., pak nejspíše ano...
21.12.2016 18:47
pavlix | skóre: 54
| blog: pavlix
Kam jinam dát nulu, doprostřed pravítka?I takové někde doma mám, ale to není předmětem diskuze. I když potom, co jsem viděl tu fotku pravítek, co Franta posílal, už si vůbec nejsem jistý, zda vůbec existuje nějaký předmět diskuze společný všem účastníkům, spíše asi ne.
21.12.2016 14:09
xkucf03 | skóre: 50
| blog: xkucf03
V kalendáři ale žádnou takovou potřebu nemam. K čemu je mi dobré zjišťovat, kolik času uběhlo od okamžiku, který nějaký mizerný historik i matematik v 6. století z nábožensko-politických důvodů víceméně náhodně určil za počátek? To je přece naprosto k prdu.Jak už jsem tu psal, v diskusi se klidně můžeme oprostit od jakýchkoli náboženských a historických souvislostí a jako bod nula si zvolit třeba začátek dne 1. 1. 1970 UTC nebo jakýkoli jiný okamžik, který dokážeme identifikovat a shodnout se na něm tak, abychom všichni mluvili o tom samém okamžiku. Následně si zvolíme základní jednotku (např. sekundu) a pak i nějaké větší jednotky (např. kilosekundy, megasekundy) a pak už jednoduše počítáme. Nultá sekunda neexistuje, resp. není to úsek, ale bod nula. Existuje první sekunda, první kilosekunda, první megasekunda… a taky mínus první s, ks, Ms.
To, že rok ti připadá "nedokončený" je dáno pouze tím, že sis bod nula zvolil jako první sekundu roku 1, což je ale v podstatě pouze tvoje osobní arbitrátní/náhodná volba a nevím, proč to děláš. Objektivně není definováno, jestli je rok dokončený nebo ne.Je to zcela objektivní. Pokud ujdeš 1 100 metrů, ušel jsi jeden celý (dokončený) kilometr + 100 metrů. Novorozeně žije svůj první rok, ale je staré nula let (nula celých let), staré jeden rok bude až po prvních narozeninách. Když vlezeš do prázdné místnosti, jsi tam první, nikoli nultý. Když tam vleze další člověk, tak je druhý a jsou tam dva celí lidé (dokončení – proces vlezení do místnosti byl dokončen u dvou lidí). Když si další stoupne do dveří, můžeme říct, že v místnosti je 2,5 člověka, ale jsou tam jen dva celí lidé a on je třetí. Pokud hledáš anologii s indexováním polí např. v C, tak index je něco jiného než pořadí a navíc index pole může být jen kladný, takže by nešlo vyjádřit roky před Kristem. A index vyjadřuje vzdálenost adresy počátku prvku od adresy počátku pole, kde měrnou jednotkou je délka datového typu. První rok bychom tedy mohli označit indexem 0, ovšem pak bychom letos měli rok označený jako 2015, nikoli 2016. Nemůžeš smíchat tyto dva koncepty dohromady a tvrdit, že byl rok 0 a zároveň, že letos máme 2016 – to nedává smysl.
Kalendář není jako pravítko, resp. je jako pravítko, které je nekonečné na obě strany a nemá stejně dlouhé dílky. Ty dílky jsou nestejně dlouhé jednak z historických důvodů (na některých částech pravítka jsou definované jinak), ale také z fyzikálních důvodů (viz), ie. nikdy ani při sebelepší přesnosti měření stejně dlouhé nebudou.Taky už jsem to tu psal – ten systém je v mnoha ohledech nedokonalý a nelogický, ale zavedením „roku nula“ tomu nijak nepomůžeš – naopak situaci ještě zhoršíš.
 21.12.2016 14:13
|🇵🇸 | skóre: 94
| blog:
21.12.2016 15:08
xkucf03 | skóre: 50
| blog: xkucf03
21.12.2016 15:22
|🇵🇸 | skóre: 94
| blog:
21.12.2016 14:13
|🇵🇸 | skóre: 94
| blog:
21.12.2016 15:08
xkucf03 | skóre: 50
| blog: xkucf03
21.12.2016 15:22
|🇵🇸 | skóre: 94
| blog:
a ještě to udělá bordel v historických datech
Víš, kdy byla VŘSR? 😏
21.12.2016 15:24
pavlix | skóre: 54
| blog: pavlix
21.12.2016 16:01
xkucf03 | skóre: 50
| blog: xkucf03
21.12.2016 17:05
xkucf03 | skóre: 50
| blog: xkucf03
A nemám (na rozdíl od některých) mentální problém s tím, že letopočet (tak jak ho běžně chápeme) označuje pořadí nedokončeného roku (aktuálně probíhajícího) od bodu nula, zatímco hodiny, minuty a vteřiny vyjadřují počet dokončených úseků.Rok můžeš klidně chápat i jako dokončený, nebude v tom vůbec žádný rozdíl. U měsíců/dnů by to sice jistý rozdíl byl (mohlo by ti připadat, že máme aktuálně 13. měsíc), ale měsíce jsou stejně nepravidelné, takže se s nima beztak moc nedá pracovat běžnou aritmetikou...
Pokud si chce někdo očíslovat všechny roky souvislou řadou celých čísel, aby se mu s tím „dobře počítalo“, tak je to jeho věc.Má to svoje použití v astronomii, např. počítání, kdy dojde/došlo k všelijakým zatměním a podobně... No a krom toho se to využívá v ISO8601.
Ale aby byl kompatibilní se zbytkem světa, tak ty záporné stejně musí převádět tam a zase zpátky.Jistě, ale pánové IMHO celkem střízlivě vyhodnotili, že muset přepočítávat BC roky bude menší PITA než AD...
Je to zcela objektivní. Pokud ujdeš 1 100 metrů, ušel jsi jeden celý (dokončený) kilometr + 100 metrů. Novorozeně žije svůj první rok, ale je staré nula let (nula celých let), staré jeden rok bude až po prvních narozeninách.Ano, ale tohle nemá moc smysl aplikovat na letopočet, protože nikde žádný objektivní počátek nemá, a navíc vzdálenost od tohoto počátku nikoho nezajímá a není k ničemu dobrá. Když jdu na túru, zajímá mě, kolik jsem ušel kilometrů, proto je tam užitečný ten výchozí nultý bod. Naproti tomu nemám úplně potřebu se ptát, kolik sekund uplynulo od okamžiku, kdy se na Ježíšovy genitálie někdo vrhl s nožem nebo jakéhokoli jiného podobného náhodného bodu historie.
Pokud hledáš anologii s indexováním polí např. v C, tak index je něco jiného než pořadí a navíc index pole může být jen kladnýJe to sice mimo diskusi, ale čistě pro pořádek, index pole v C klidně může být záporný.
Nemůžeš smíchat tyto dva koncepty dohromady a tvrdit, že byl rok 0 a zároveň, že letos máme 2016 – to nedává smysl.Tak znova a postupně. Řekni, na kterým checkpointu ti selhavá logika: Položení nuly je arbitrární, můžeme si ji položit kamkoli (checkpoint). Pokud ji položíme na začátek gregoriánského roku 1600AD, bude letos rok 416 (checkpoint). Pokud ji položíme na začátek roku gregoriánského 1AD, bude letos 2015 (checkpoint). Pokud na začátek 1BC, bude letos 2016 (checkpoint). Žádná z těchto voleb není nadřazená ostatním, protože objektivní nula neexistuje (leda bychom počítali big-bang, ale to je příšerně dávno, to by bylo jako používat Kelviny pro pečení kuřete) (checkpoint). Výhoda astronomického roku je v tom, že v něm funguje běžná aritmetika i pro roky před našim letopočtem, ie. třeba výpočet vzdálenosti roku -1000 a 1000 netrpí tím off-by-one jako v gregoriánském kalendáři (checkpoint). Astronomický rok byl zarovnán tak, aby označení let odpovídalo naším aktuálním AD rokům v greogriánském kalendáři, čistě z praktických důvodů (checkpoint). To, že BC roky gregoriánského kalendáře se v absolutní hodnotě liší o 1 od astronomických nás až zas tak netrápí, ačkoli ideální to není (grand finish).
21.12.2016 16:38
|🇵🇸 | skóre: 94
| blog:
tohle nemá moc smysl aplikovat na letopočet, protože nikde žádný objektivní počátek nemá
Třeba je Franta kreacionista.
leda bychom počítali big-bang, ale to je příšerně dávno
Kdo říká, že letopočet musí růst lineárně...
21.12.2016 16:45
xkucf03 | skóre: 50
| blog: xkucf03
Třeba je Franta kreacionista.V tom případě by ale počátek byl mnohem dřív než v době narození Ježíše. Už jsem tu psal, že za počátek si klidně můžeme zvolit 1. 1. 1970 a bude to fungovat stejně.
Kdo říká, že letopočet musí růst lineárně...Pak ale nepotřebuješ ani rok nula, protože by ses stejně ničeho kloudného nedopočítal.
21.12.2016 17:21
xkucf03 | skóre: 50
| blog: xkucf03
Chápu, že je to jakási aproximace a snaha o zjednodušení. Ale jde o to, že všechny historické události před naším letopočtem, u kterých známe konkrétní rok, tudíž ty u kterých by teoreticky dávalo smysl si aritmeticky počítat jejich vzdálenosti (např. kolik let uběhlo od události A př.n.l do události B n.l.), bys musel přečíslovat, což je krajně nepraktické a přineslo by to víc zmatků než užitku.Při výpočtu kolik let uběhlo mezi událostmi A a B musíš přepočítávat v gregoriánském kalendáři úplně stejně jako v astronomickém letopočtu. Historické události před rokem 1AD (a vlastně i nějakou dobu po něm) jsou stejně tak jako tak vždy přepočítané na juliánský nebo gregoriánský kalendář. Nebo máš pocit, že to tehdy fungovalo jako v picrelated?
To asi úplně ne, že, oni používali svoje historické kalendáře (např. ten římskej byl mimořádně zmatenej) a naše datování historických událostí je uměle dopočítané (s větší či menší přesností) - říká se tomu proleptické datování.
21.12.2016 17:31
Agent
| blog: Life_in_Pieces
| HC city
Jde (asi) o to, abychom měli nějaký všeobecně uznávaný souřadný systém, ze kterého se dá odvodit, kolik let uplynulo od nějaký události.Přesně tak, z tohohle hlediska je úplně jedno, kde máš nulu. To, že kolem roku 1AD je v gregoriánském kalendáří určitá nepravidelnost je pravda, ale těch nepravidelností tam stejně bude vícero (různé přestupné roky, juliánský kalendář, etc.) - záleží, co se snažíš spočítat a s jakou přesností to potřebuješ.
*) akorát když to nebude 1. ledna, tak to nebude sedět přírodní roky a měsíce – ale na ty bychom se mohli vykašlat a používat jiné úseky a nelpět na souvislosti s oběhem slunce a měsíce.
Gratuluji, právě jsi dospěl k systému založenému na vydávání Linuxu.
21.12.2016 17:16
Agent
| blog: Life_in_Pieces
| HC city
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
char *decbin(int value);
int main()
{
int n;
char *ps_bin;
for(n = 0; n < 101; n++) {
ps_bin = decbin(n);
printf("%d\t%s\n", n, ps_bin);
free(ps_bin);
}
return 0;
}
char *decbin(int value)
{
char buf[64 + 1];
char *ptr;
ptr = buf + sizeof(buf) - 1;
*ptr = '\0';
do {
*--ptr = '0' + (value % 2);
value /= 2;
} while (ptr > buf && value);
return strdup(ptr);
}
Akorát je špatné, že ten kod funguje normálně, i když odstraníte free().
Akorát je špatné, že ten kod funguje normálně, i když odstraníte free().Co je na tom špatného? To je leak, funkci by neměl ovlivnit...
19.12.2016 12:08
Jendа | skóre: 78
| blog: Jenda
| JO70FB
Akorát je špatné, že ten kod funguje normálně, i když odstraníte free().Pokud chceš kontrolovat konzistenci paměti a leaky, musíš si o to říct. Třeba satan (ASAN) to umí:
/tmp> jcc decbin.c
/tmp> ./decbin
0 0
...
100 1100100
=================================================================
==21025==ERROR: LeakSanitizer: detected memory leaks
Direct leak of 682 byte(s) in 101 object(s) allocated from:
#0 0x7f8336536d28 in malloc (/usr/lib/x86_64-linux-gnu/libasan.so.3+0xc1d28)
#1 0x7f8335c361d9 in __strdup (/lib/x86_64-linux-gnu/libc.so.6+0x801d9)
SUMMARY: AddressSanitizer: 682 byte(s) leaked in 101 allocation(s).
Problém je že podle úlohy se program zpomalí 0.1-3x (za což asi může hardwarově neakcelerovaná kontrola out-of-bounds přístupu (mají nejnovější Intely) a mohlo by jít nastavit že chceš kontrolovat jenom něco).
19.12.2016 12:11
pavlix | skóre: 54
| blog: pavlix
19.12.2016 12:12
Jendа | skóre: 78
| blog: Jenda
| JO70FB
19.12.2016 12:43
pavlix | skóre: 54
| blog: pavlix
-g. Mimo toho, proti pomalosti jde u některých typů úloh použít trik, že se na místa, kde se něco dělá, ale žádná paměť se nealokuje ani neuvolňuje, nandají "zapoznámkovací" #ifdefy a pro Valgrind se vytvoří speciální omezená verze binárky. Občas je to i nutné, některé knihovny po sobě moc neuklízejí ...
19.12.2016 23:59
pavlix | skóre: 54
| blog: pavlix
19.12.2016 12:00
pavlix | skóre: 54
| blog: pavlix
snprintf(). Pro lamy by se kolem toho udělal wrapper s alokací, viz asprintf(). ;)
Nicméně žádný opravdový Cčkař se zkušeností s hardwarem by nikdy nenapsal do vnitřní smyčky dělení a modulo
To platilo v minulem tisicileti, a je mi lito tech lidi, co takto pisou... priklad.
20.12.2016 12:37
pavlix | skóre: 54
| blog: pavlix
... the following are disabled: C++, MIPS16e, LTO, -Os, -O3 and -O2A nejspíš používaj nějakou vlastní uzavřenou libc (na tu by se GPL z GCC vztahovat nemělo). Asi by šlo nahradit vanilla GCC, akorát se tu bavíme o velikostech kódu okolo 100kB, takže pokud GCC/newlib nemá ty optimalizace dostatečné, tak se prostě program nevejde (rozdíl optimalizací, co jsem testoval na eval licenci XC32 byl opravdu velký).
20.12.2016 13:38
pavlix | skóre: 54
| blog: pavlix
. Kromě klasických binárek jsou v toolchainu už jen crtbegin.o, crtend.o, libgcc.a a libgcov.a (pro různé konfigurace jako mips16, size, speed apod.). Libc je taky ve formátu libc.a. Takže to není součást binárky GCC, ale nejspíš daný kompilátor ten objektovej soubor potřebuje, aby vytvořil funkční MCU kód.
Pak jsou ještě objektové soubory pro periferie v MCU.
20.12.2016 13:39
pavlix | skóre: 54
| blog: pavlix
:-P.
19.12.2016 21:27
xkucf03 | skóre: 50
| blog: xkucf03
protože číslice jsou za sebou jak v ASCII, tak dokonce i v EBCDICŽe to pro nějaká dvě kódování (nebo dokonce většinu dnes běžně používaných kódování) funguje, neznamená, že bys to měl zadrátovat do kódu. Podle mého je to předpoklad/závislost na něčem, na čem bys záviset neměl – je to podobně špatný přístup jako např. předpokládat, že klient bude používat stejné kódování jako server. A když už tam takový předpoklad zadrátuješ, tak bys to měl napsat do dokumentace.
Když už tu byla řeč o napovídání překladači a dělání práce za optimalizátor, zkusil jsem přeložit
char b1(unsigned int n)
{
unsigned int i = n % 2;
return i ? '1' : '0';
}
char b2(unsigned int n)
{
unsigned int i = n & 1;
return '0' + i;
}
pomocí gcc6 a výsledek je
0000000000000000 <b1>: 0: 83 e7 01 and $0x1,%edi 3: 8d 47 30 lea 0x30(%rdi),%eax 6: c3 retq 7: 66 0f 1f 84 00 00 00 nopw 0x0(%rax,%rax,1) e: 00 00 0000000000000010 <b2>: 10: 83 e7 01 and $0x1,%edi 13: 8d 47 30 lea 0x30(%rdi),%eax 16: c3 retq
Závěr: nekomplikujme si život a nesnažme se za překladač dělat jeho práci, pokud k tomu nemáme opravdu dobrý důvod. I když totiž občas zašmodrcháním kódu opravdu nějaký takt získáme, zdaleka ne vždy to bude mít měřitelný efekt, zato tím spolehlivě naštveme toho, kdo po nás ty mikrooptimalizace bude muset luštit (nezřídka sami sebe).
Zajímavé je, že gcc 4.8 přeloží první funkci jako
0000000000000000 <b1>: 0: 83 e7 01 and $0x1,%edi 3: 83 ff 01 cmp $0x1,%edi 6: 19 c0 sbb %eax,%eax 8: 83 c0 31 add $0x31,%eax b: c3 retq c: 0f 1f 40 00 nopl 0x0(%rax)
tj. překladač ještě není dost chytrý, aby si uvědomil, že výsledek první operace může být jen 0 nebo 1, ale je dost chytrý na to, aby využil toho, že '1' je hned za '0', a vyhnul se podmíněnému skoku.
b1(unsigned int): # @b1(unsigned int)
andb $1, %dil
orb $48, %dil
movl %edi, %eax
retq
b2(unsigned int): # @b2(unsigned int)
andl $1, %edi
leal 48(%rdi), %eax
retq
char b1(unsigned int n)
{
unsigned int i = n % 2;
return i ? unsigned('1') : unsigned('0');
}
char b2(unsigned int n)
{
unsigned int i = n & 1;
return '0' + i;
}
To je ale kod jak z roku 1980, thread safety, nic?1980? Kéžby. Spousta těhle interpreterů skritovacích jazyků jsou stále víceméně napsány s předpokladem, že kód poběží v zásadě single-threaded. PHP, JavaScript, CPython, ...
 18.12.2016 12:42
kozzi | skóre: 55
| blog: vse_o_vsem
| Pacman (Bratrušov)
18.12.2016 12:42
kozzi | skóre: 55
| blog: vse_o_vsem
| Pacman (Bratrušov)
Tak proc by neslo?
import std.stdio;
void main()
{
writefln("%b", 16);
}
18.12.2016 12:43
kozzi | skóre: 55
| blog: vse_o_vsem
| Pacman (Bratrušov)
toto je priklad v D
Tiskni
Sdílej:
![]()
![]()
![]()
![]()
![]()
![]()
ISSN 1214-1267, (c) 1999-2007 Stickfish s.r.o.
 14.12.2016 22:54
14.12.2016 22:54
 15.12.2016 18:40
15.12.2016 18:40
{kind=link}
{kind=link}
{kind=link}