Portál AbcLinuxu, 23. července 2026 15:52
 8.4.2016 23:32
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
8.4.2016 23:32
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Optar nedoporučuji nepoužívat, rozhodně ne bez ...V těch záporech jsem se trochu ztratil :)
9.4.2016 00:50
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
9.4.2016 00:53
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Osobně jsem se setkal s reálným použitím, když jsem v práci nasadil na šifrování záloh GPG a potřeboval jsem rozdistribuovat klíče mezi další dva kolegy z geograficky oddělené lokality tak, aby se k nim pokud možno nemohl dostat útočník, který má kontrolu nad počítačem. Tím pádem odpadlo poslání emailem i přenos na flashdiskuA nebylo by lepsi poslat kolegum ten klic zasifrovany symetricky a klic/heslo jim poslat postou nebo zatelefonovat?
Přišlo mi proto ideální klíč vyexportovat do nějakého grafického formátu a spolu s ASCII podobou ho doručit v obálce.Opravdu? Ne, ze bych se chtel vytahovat, ale moje reseni si vystaci jen s prikazem "gpg" nebo "openssl", coz asi dotycni budou mit nainstalovane a neni potreba nic dalsiho instalovat, skenovat nebo dlouze prepisovat.
9.4.2016 19:39
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
A nebylo by lepsi poslat kolegum ten klic zasifrovany symetricky a klic/heslo jim poslat postou nebo zatelefonovat? Opravdu? Ne, ze bych se chtel vytahovat, ale moje reseni si vystaci jen s prikazem "gpg" nebo "openssl", coz asi dotycni budou mit nainstalovane a neni potreba nic dalsiho instalovat, skenovat nebo dlouze prepisovat.Nad tím jsem taky uvažoval. Nakonec jsem to nevybral z následujících důvodů:
PS: GPG umí použít samostatně symetrické šifry?
gpg -c
9.4.2016 20:44
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Optar je program, či snad kodekJe to věc na přenos digitálních dat analogovou cestou, takže je to ve skutečnosti modem!

Důvody mohou být různé. Možná je pro vás nějaký soubor velmi důležitý (třeba bitcoin či ethereum peněženka)Tam už se asi dneska používá to generování z 12 slov.
tak i s tím, že se rozpadlo na dvě polovinyTo dělá DVD, ta jsou ze dvou kotoučků, CD je jedna placka a na ní je to natřené.
Tyto jsem vytiskl na relativně kvalitní laserové tiskárně.Prý se osamocené tečky mají tendenci odlupovat. Dlouhodobé archivaci by mohlo pomoct nechat to chvíli v parách acetonu. Že to nedokázalo obnovit, i když to tvrdí, že je to v pořádku, je škoda.
9.4.2016 19:41
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Je to věc na přenos digitálních dat analogovou cestou, takže je to ve skutečnosti modem!Modem by mělo být až konkrétní zařízení, ne? Takže model to vlastně dělá z tiskárny.
Tam už se asi dneska používá to generování z 12 slov.Pravda vlastně. Sám to tak používám.
9.4.2016 20:03
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
 10.4.2016 13:53
Grunt | skóre: 23
| blog: Expresivní zabručení
| Lanžhot
10.4.2016 13:53
Grunt | skóre: 23
| blog: Expresivní zabručení
| Lanžhot
ZIP disk (22 let od uvedení)ZIPky (včetně externích mechanik) byly perfektní. Nějaký ekvivalent pro dnešní dobu mi hodně chybí.
10.4.2016 21:55
Grunt | skóre: 23
| blog: Expresivní zabručení
| Lanžhot
Za cenu tehdejšího ZIP média dnes pořídím 32GB flashdisk, ke kterému nepotřebuju mechaniku žádnou (nebo SD kartu, ke které čtečku koupím podstatně levněji než tehdy ZIP mechaniku).Ono velikosti od dob flopyn rostou a rostou a prostě jedno médium má někdy tolik místa že už ho ani nevyužiju. Řekněme disketa o velikosti 1 či 2GB by z 90% naprosto stačila. Mně. Jinak ZIP média měla prostě ideální velikost. USB klíče furt někde ztrácím, SD karty pokud nejsou ve slotu tak jsou na 100% ztracené. Ty ZIP diskety se prostě dobře držely, měly ideální váhu, velikost tak akorát, dobrou odolnost proti pádu a co jsem si vědom já tak jsem nikdy u nich neřešil že by se disketa nějak opotřebovávala a že bych se u ní musel obávat o data. Jo a ty krabičky…mlask.
Jinak ZIP média měla prostě ideální velikost.
Tak s sebou noste CF/SD kartu ve čtečce, to bude tak přibližně odpovídat. :-)
10.4.2016 22:05
Grunt | skóre: 23
| blog: Expresivní zabručení
| Lanžhot
Tu máš, tohle snad neztratíš
BTW: v té Base64 na papíře pod tím je dětská pornografie a plán příštího teroristického útoku v západní Evropě. Oboje zašifrované Vernamovou šifrou.
10.4.2016 22:39
Grunt | skóre: 23
| blog: Expresivní zabručení
| Lanžhot
A pokud nepočítám že bych si to mohl našroubovat tak maximálně do řiti, protože PP už na ničem funkčním nemám a pokud to nějak nezarezlo či nezoxidovaloKoupit USB to LPT? (popřípadně si můžeš udělat z nějakýho PICu
 )
)
Spíš do PCI. Co si tak pamatuji, tak ty USB převodníky byly dost na nic (leda na tiskárnu, ale třeba na HW klíče byly nepoužitelné, stejně tak pro CNC).
10.4.2016 23:02
Grunt | skóre: 23
| blog: Expresivní zabručení
| Lanžhot
A pokud nepočítám že bych si to mohl našroubovat tak maximálně do řiti, protože PP už na ničem funkčním nemám
Tak to tě dost lituji, já tu mám na dohled dva počítače s paralelním portem a ve vedlejší místnosti další + Covox, kdybych si chtěl pustit nějakou muziku
Měl by ses nad sebou zamyslet a něco s tím udělat Buď PCI kartu nebo se pořád dělají základní desky s LPT.
BTW: co se týče předávání dat na CD – jak jsi psal, že je tam jen malý proužek dat – to bys mohl těm lidem napípat do telefonu, stejně jako to bylo na těch kazetách – oni by si to přes mikrofon nahráli a dekódovali.
Covox jsem si kdysi udelal taky - ale napajel jsem odpory primo na piny konektoru, takze to bylo schovane v jeho krytu. Na prehravani MODu to bylo uplne skvele
11.4.2016 00:20
Grunt | skóre: 23
| blog: Expresivní zabručení
| Lanžhot
10.4.2016 23:01
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
10.4.2016 23:04
Grunt | skóre: 23
| blog: Expresivní zabručení
| Lanžhot
USB klíče furt někde ztrácím, SD karty pokud nejsou ve slotu tak jsou na 100% ztracené.Nebo si kup tuhle hydru
.
10.4.2016 23:13
Grunt | skóre: 23
| blog: Expresivní zabručení
| Lanžhot
, ale tak do nějaké kastle si to můžeš hodit vždycky.
. V případě toho řadiče bych tipoval, že bude mít všechny neduhy první generace technologie (nejspíš to má nějakej kontroler a firmware, na PCB je "demo", takže určitě bugy, nezotavení se ze selhání jedné z karet, neefektivní vnitřní formát pole, ten slot taky zrovna k spolehlivosti nepřispěje apod.). Na webu výrobce toho čipu je rychlost max 260/225 MBps (read/write). Sem jsem to posílal hlavně ze srandy .
10.4.2016 21:58
Grunt | skóre: 23
| blog: Expresivní zabručení
| Lanžhot
11.4.2016 00:14
Grunt | skóre: 23
| blog: Expresivní zabručení
| Lanžhot
když se to vyndalo z obalu tak se to permanentně někde kutálelo
Kutálelo? CD ve tvaru obdélníku?
a dnešní Fedoru nevysmahnu ani na obyčejné CD ne na nějakou mini variantu
Začínám mít neodbytný pocit, že si stěžujete jen proto, abyste si mohl stěžovat. Před chvílí jste si stěžoval, že normální média jsou zbytečně velká a že na některé aplikace by stačilo 100 MB. No a když někdo zmíní příklad, prohlásíte: "No jo, ale ona se na to nevejde Fedora." [smajlík obracející oči v sloup]
11.4.2016 19:28
Grunt | skóre: 23
| blog: Expresivní zabručení
| Lanžhot
Kutálelo? CD ve tvaru obdélníku?Počkat, o čem je řeč?
smajlík obracející oči v sloupKurňa, chlapi! Člověk si sem nostalgicky přijde zavzpomínat na staré dobré časy a média a Kubeček s Hrachem tady naplivou jedy, obrátí oči v sloup a jdou dom. A já teď jako co?
O vizitkovém CD(-R). Ale jak vidím, tu kapacitu jsem si pamatoval špatně, je jen 50 MB.
10.4.2016 23:46
Grunt | skóre: 23
| blog: Expresivní zabručení
| Lanžhot
.
11.4.2016 19:32
Grunt | skóre: 23
| blog: Expresivní zabručení
| Lanžhot
18.4.2016 11:21
Grunt | skóre: 23
| blog: Expresivní zabručení
| Lanžhot
 25.4.2016 20:48
kyknos | skóre: 18
| blog: Quid novi?
| Ranša Rosa
25.4.2016 20:48
kyknos | skóre: 18
| blog: Quid novi?
| Ranša Rosa
 9.4.2016 20:39
Dreit | skóre: 15
| blog: Dreit a jeho dračí postřehy
| Královehradecký kraj
9.4.2016 20:39
Dreit | skóre: 15
| blog: Dreit a jeho dračí postřehy
| Královehradecký kraj
base64?
9.4.2016 20:45
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
10.4.2016 16:55
Dreit | skóre: 15
| blog: Dreit a jeho dračí postřehy
| Královehradecký kraj
K ručnímu přepisu můžu akorát odkázat na tuhle část:
Přišlo mi proto ideální klíč vyexportovat do nějakého grafického formátu a spolu s ASCII podobou ho doručit v obálce. Kolegové ho potom můžou v případě potřeby buďto ručně přepsat, nebo využít nástroje jako je optar.
Samozřejmě defaultně jsem předpokládal použití OCR, které je určitě o něco spolehlivější než před lety. Na texty v ASCII by to snad neměl být problém a v nejhorším případě program ukáže znak a bude chtít aby ho uživatel rozpoznal sám.
10.4.2016 13:49
Grunt | skóre: 23
| blog: Expresivní zabručení
| Lanžhot
10.4.2016 13:54
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
10.4.2016 14:10
Grunt | skóre: 23
| blog: Expresivní zabručení
| Lanžhot
10.4.2016 14:18
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
10.4.2016 14:22
Grunt | skóre: 23
| blog: Expresivní zabručení
| Lanžhot
10.4.2016 14:33
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
10.4.2016 14:52
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Ale už scannuju první stránku.Tady: http://kitakitsune.org/storage/optar/. Jsou to různé verze stejné stránky v závislosti na nastavení prahové hodnoty černé. Rád bych dodal, že kvalita obrázku nehraje roli na závěr, který jsem v článku učinil, protože optar vše bez problémů přečetl a neměl žádné irreparable bity.
10.4.2016 18:36
Grunt | skóre: 23
| blog: Expresivní zabručení
| Lanžhot
10.4.2016 18:55
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Nieje viac QR kodov na A4ke efektivnejsich ?Podla http://blog.liw.fi/posts/qr-backup/ citujem:
I did a quick experiment. I put 2000 bytes per barcode and printed it out in various sizes: 10, 20, 30, and 70 mm squares. Then I scanned them in. The 70 mm one was the only one that could be decoded, the others were too small and smudged. It should be possible to fit 12 squares of just under 70 mm on an A4 sized page. That's 24000 bytes of raw data.
10.4.2016 14:20
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Tu vytištěnou Base64 (viz níže) běžným mobilem vyfotím1 a dobře čitelné to je – zbytek je už jen otázka schopností OCR, (ale fyzikální limity a kvalita HW nejsou problém – ten snímač to zvládá).
[1] ne celou stránku najednou samozřejmě
~30kB na stránku
To tedy není žádná sláva, měl jsem o Optaru lepší mínění.
Zkusil jsem si stejný objem dat převést do obyčejné Base64 a vytisknout písmem velikosti 3 na A4. Přečíst to jde v pohodě, sneslo by se i menší písmo a ještě je tam spousta volného místa.
Výhoda navíc je, že nepotřebuješ žádný speciální program – přinejhorším bys to opsal ručně a Base64 dekódoval.
Hodilo by se ještě upravit Base64 – některé zaměnitelné znaky vypustit a jiné naopak přidat + tam doplnit samoopravné kódy (což by se vešlo i do toho volného místa na stránce – takže máš stejnou hustotu dat, při použití celkem primitivní technologie).
2400DPI v černobílém režimu
A nezmršil to ten scanner resp. program při konverzi do černobíla? Nebylo by to lepší ve stupních šedi? (ta fotka z mobilu vypadá o dost líp)
10.4.2016 19:05
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
To tedy není žádná sláva, měl jsem o Optaru lepší mínění.To je v mých podmínkách. Na lepší tiskárně / scanneru by to asi fungovalo lépe.
Zkusil jsem si stejný objem dat převést do obyčejné Base64 a vytisknout písmem velikosti 3 na A4. Přečíst to jde v pohodě, sneslo by se i menší písmo a ještě je tam spousta volného místa.Tak já tam ten privátní klíč taky dal v base64 podobě.
Hodilo by se ještě upravit Base64 – některé zaměnitelné znaky vypustit a jiné naopak přidat + tam doplnit samoopravné kódy (což by se vešlo i do toho volného místa na stránce – takže máš stejnou hustotu dat, při použití celkem primitivní technologie).Jo, to by nemuselo být marné. Ono kdybych já vymýšlel nějaký formát na serializaci dat do obrazu, tak si asi zaexperimentuji s glyfy nezávislými na rotaci (kolečka, čtverečky, obdélníčky, trojuhelníky a různé kombinace). Pokud by měly víc barev a různé uhly otočení, tak by to mohlo líp využívat možnosti papíru, než černé tečky. Třeba takový Microsoft tag je docela hodně efektivní, ale tam nevyužívají různé rotace.
A nezmršil to ten scanner resp. program při konverzi do černobíla? Nebylo by to lepší ve stupních šedi? (ta fotka z mobilu vypadá o dost líp)To bych zas čekal, že bude optar hlásit irreparable chyby.
10.4.2016 19:06
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
To je v mých podmínkách. Na lepší tiskárně / scanneru by to asi fungovalo lépe.
I ta fotka z mobilu mi přijde dostatečná – kdybys to ručně obkreslil v Gimpu, tak dostaneš stejnou bitmapu, jako šla do tiskárny
Ono kdybych já vymýšlel nějaký formát na serializaci dat do obrazu, tak si asi zaexperimentuji s glyfy nezávislými na rotaci (kolečka, čtverečky, obdélníčky, trojuhelníky a různé kombinace). Pokud by měly víc barev a různé uhly otočení, tak by to mohlo líp využívat možnosti papíru, než černé tečky.
Ta barva je dobrý nápad.
Na nezávislost na rotaci bych se vykašlal – to má smysl u QR kódů, u kterých často nevíš, z které strany je lidi budou skenovat. Pro archivaci dat to nepotřebuješ – buď víš, kde je vršek, nebo si tam uděláš značku jednu na stránku1 nebo to to prostě budeš otáčet tak dlouho, dokud ti nesednou kontrolní součty.
To bych zas čekal, že bude optar hlásit irreparable chyby.
A zjistil jsi, kde byla chyba? Porovnával jsi to binárně? Změnily se nějaké bajty nebo došlo k posunu (pár bajtů přibylo/ubylo)? To mi přijde jako chyba Optaru – buď by měl říct, že to nešlo načíst, nebo to vrátit na bit stejná data. Nebo to byla taková náhoda, že se to zrovna trefilo do kontrolních součtů / opravných kódů?
[1] nebo třeba dvacet na stránku, ale nemusí tuhle informaci v sobě mít každý znak
10.4.2016 20:02
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Na nezávislost na rotaci bych se vykašlal – to má smysl u QR kódů, u kterých často nevíš, z které strany je lidi budou skenovat. Pro archivaci dat to nepotřebuješ – buď víš, kde je vršek, nebo si tam uděláš značku jednu na stránku1 nebo to to prostě budeš otáčet tak dlouho, dokud ti nesednou kontrolní součty.Ne, to jsi nepochopil. Myslel jsem nezávislost na rotaci u těch glyphů (=rotací se nesmí měnit význam, což u písmen nefunguje). Například trojuhelník můžeš různě rotovat a enkódovat tak další bity informace. Napadlo mě ještě enkódovat další bity do uhlu mezi jednotlivými elementy. Představ si třeba, že se používají trojuhelníkové šipky, kterých jsou 4 typy (=2bity), mají 4 barvy (=2 bity) a můžou ukazovat do 64 různých uhlů (=6 bitů), kde je v určité vzdálenosti další trojuhelník (=x bitů za vzdálenost). Samozřejmě, že otázka je, jak by to bylo použitelné prakticky a jak často by tam docházelo ke kolizím v těch vzdálenostech, protože už v tomhle uhlu něco je. Ale to by se asi dalo do určité míry řešit, kdyby každý trojuhelník měl například tečtu značící uhel, ze kterého do něj ty data mají přijít.
A zjistil jsi, kde byla chyba? Porovnával jsi to binárně? Změnily se nějaké bajty nebo došlo k posunu (pár bajtů přibylo/ubylo)? To mi přijde jako chyba Optaru – buď by měl říct, že to nešlo načíst, nebo to vrátit na bit stejná data. Nebo to byla taková náhoda, že se to zrovna trefilo do kontrolních součtů / opravných kódů?Viz ten blog. Prostě z toho vyleze porouchaný soubor.
 10.4.2016 21:10
xkucf03 | skóre: 50
| blog: xkucf03
10.4.2016 21:10
xkucf03 | skóre: 50
| blog: xkucf03
Ne, to jsi nepochopil. Myslel jsem nezávislost na rotaci u těch glyphů (=rotací se nesmí měnit význam, což u písmen nefunguje). Například trojuhelník můžeš různě rotovat a enkódovat tak další bity informace.
OK, pochopil jsem to obráceně.
Napadlo mě ještě enkódovat další bity do uhlu mezi jednotlivými elementy. Představ si třeba, že se používají trojuhelníkové šipky, kterých jsou 4 typy (=2bity), mají 4 barvy (=2 bity) a můžou ukazovat do 64 různých uhlů (=6 bitů), kde je v určité vzdálenosti další trojuhelník (=x bitů za vzdálenost). Samozřejmě, že otázka je, jak by to bylo použitelné prakticky a jak často by tam docházelo ke kolizím v těch vzdálenostech, protože už v tomhle uhlu něco je. Ale to by se asi dalo do určité míry řešit, kdyby každý trojuhelník měl například tečtu značící uhel, ze kterého do něj ty data mají přijít.
Nebo se inspirovat tím, jak se data ukládají na HDD, CD, jak se posílají po sériové lince… nevymýšlet opičárny a na papíře mít prostě jen přiměřeně malé tečky (bity), volitelně v několika málo barvách.
Když budeš mít čtyři barvy (CMYK), tak čtyři tečky jsou jeden bajt. Máme ale ještě bílou barvu, takže už do těch čtyř teček jde zabudovat nějakou redundanci nebo řešit slívání souvislých ploch.
A další redundanci a opravy řešit až o úroveň výš – což už bude nezávislé na médiu – když se ti třeba rozmáčí nebo utrhne kus stránky, je to stejné jako když nepřečteš pár bajtů z disku nebo máš nějaký šum na telefonní lince k modemu (i když tam je rozdíl, že při chybě si lze vyžádat opakovaný přenos). Tzn. rozdělit si problém na malé části, které samostatně někdo vyřešil.
Bylo by fajn, kdyby šlo třeba zničit kus stránky (jak velký, to by bylo parametrem při kódování) nebo třeba udělat přes celou stránku čáru černou fixou a pořád by se to dalo přečíst.
Viz ten blog. Prostě z toho vyleze porouchaný soubor.
Zrovna od tebe bych čekal sofistikovanější popis chyby Máš ten původní zašifrovaný soubor? Když ho porovnáš s tím, co vylezlo z Optaru, jak a kde se liší? Začátek je asi dobrý, pak tam může něco chybět, nebo přebývat nebo být jinak… a pak zase může pokračovat správná posloupnost bajtů…
10.4.2016 21:20
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Nebo se inspirovat tím, jak se data ukládají na HDD, CD, jak se posílají po sériové lince… nevymýšlet opičárny a na papíře mít prostě jen přiměřeně malé tečky (bity), volitelně v několika málo barvách.Jenže tím zahazuješ možnosti, které papír má a binární média ne. Papír je 2D, všechny ostatní paměti, které počítač používá jsou buďto sekvenční, nebo adresované buňky. Přijde mi škoda zahodit možnost využít vlastnosti, že do samotného 2D jde v podobě různých uhlů taky kódovat informace.
Zrovna od tebe bych čekal sofistikovanější popis chybyJá vím. Problém je, že jsem to zkoušel v lednu (datum vytvoření těch ilustračních souborů je So 9. leden 2016, 10:08:17 CET), napsal jsem si k tomu poznámek a pak na to zapomněl až do doby, než mi to někdo připomněl v tom threadu. Mezitím jsem celý experiment smazal, takže teď jsem to lovil z paměti a z těch poznámek.
10.4.2016 22:05
xkucf03 | skóre: 50
| blog: xkucf03
Jenže tím zahazuješ možnosti, které papír má a binární média ne. Papír je 2D, všechny ostatní paměti, které počítač používá jsou buďto sekvenční, nebo adresované buňky. Přijde mi škoda zahodit možnost využít vlastnosti, že do samotného 2D jde v podobě různých uhlů taky kódovat informace.
Přemýšlím nad tím… ale nevím, jestli ten papír má něco navíc (kromě barev, což je vlastně MLC u SSD). Disk je taky 2D a i kdyby ne (např. děrná páska), tak si tu posloupnost bajtů můžeš (virtuálně) zalomit do řádků a tím získat 2D matici, ve které si už můžeš představovat nějak vzájemně umístěné a pootočené objekty.
Že je to fyzicky u sebe je na jednu stranu výhoda (když se jeden bod resp. jeho část ztratí nebo tam naopak přibude nějaké smetí, tak celkový tvar objektu zůstane zachován…), ale zase se ti může slít víc stejnobarevných bodů dohromady, a pak ztrácíš představu o mřížce – při nepřesnostech (nerovnoměrný posun papíru v tiskárně, dodatečně zmuchlaný papír, křivá čočka, špatný snímač…) můžeš nějakou barvu přiřadit jinému bodu v matici, než kterému patří (protože se nemáš čeho chytit, když kolem je souvislá jednobarevná plocha). Což se ti u 1D posloupnosti bajtů nestává (resp. sousední body, se kterými můžou být problémy, jsou jen vpravo a vlevo, ne ještě nahoře a dole).
BTW: teď jsem narazil na PAPERBACK.
10.4.2016 23:09
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Disk je taky 2D a i kdyby ne (např. děrná páska)Není. Na libovolné vrstvě, se kterou můžeš jako programátor pracovat je to pro tebe binární médium, navíc organizované do sekvenčních stop (to by se asi dalo změnit). Papír binární médium není.
tak si tu posloupnost bajtů můžeš (virtuálně) zalomit do řádků a tím získat 2D matici, ve které si už můžeš představovat nějak vzájemně umístěné a pootočené objekty.Jenže tady jsi omezený binární realitou úložiště, kde prostě bez kompresních algoritmů nikdy nezískáš lepší možnosti zápisu dalších informací.
Že je to fyzicky u sebe je na jednu stranu výhoda (když se jeden bod resp. jeho část ztratí nebo tam naopak přibude nějaké smetí, tak celkový tvar objektu zůstane zachován…), ale zase se ti může slít víc stejnobarevných bodů dohromady, a pak ztrácíš představu o mřížce – při nepřesnostech (nerovnoměrný posun papíru v tiskárně, dodatečně zmuchlaný papír, křivá čočka, špatný snímač…) můžeš nějakou barvu přiřadit jinému bodu v matici, než kterému patří (protože se nemáš čeho chytit, když kolem je souvislá jednobarevná plocha). Což se ti u 1D posloupnosti bajtů nestává (resp. sousední body, se kterými můžou být problémy, jsou jen vpravo a vlevo, ne ještě nahoře a dole).To je pravda. Stejně si to asi někdy zkusím implementovat jen tak pro zábavu, abych viděl, jestli to k něčemu je, nebo ne.
některé zaměnitelné znaky vypustit a jiné naopak přidat
Některé znaky z azbuky nebo z nějakého asijského písma, případně si vymyslet písmo vlastní. Takže by se asi dalo dostat zpátky na úroveň 1 znak = 1 bajt.
10.4.2016 19:15
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
10.4.2016 19:24
Grunt | skóre: 23
| blog: Expresivní zabručení
| Lanžhot
asijského písmaJestli myslíš kanji (Japonská varianta čínského písma) tak těch je pro standardní výuku přes 2000, JIS jich má 6879 a nedokuemntovaných čínských znaků v Číně se odhaduje až přes 10k a většina jich hraničí s naprostým šílenstvím. Proto taky v Japosnku vymysleli QR kódy. Ty jsou při stejné datové hustotě čitelnější a na procesorový čas méně náročné.
10.4.2016 20:00
Dreit | skóre: 15
| blog: Dreit a jeho dračí postřehy
| Královehradecký kraj
Hodilo by se ještě upravit Base64 – některé zaměnitelné znaky vypustit a jiné naopak přidat
Jinak řečeno, prostě vytvořit vlastní font, co bude líp spolupracovat s OCR 
10.4.2016 20:05
Grunt | skóre: 23
| blog: Expresivní zabručení
| Lanžhot
10.4.2016 20:25
Dreit | skóre: 15
| blog: Dreit a jeho dračí postřehy
| Královehradecký kraj
Jistá je jen smrt a daně. Když převedu text na trojúhelníčky, čtverečky, křížky a kolečka v několika barvách (viz výše to o náhradě písmen), získám barevný a unikátnější výstup (snad lepší detekce?), ale pořád je to jen base64 bez samoopravných kódů a všeho co umí optar. Je to jen návrh jak to udělat jinak, ne jak shodit optar a nahradit ho něčím vlastním
10.4.2016 22:27
Dreit | skóre: 15
| blog: Dreit a jeho dračí postřehy
| Královehradecký kraj
Čísla teda nicmoc
10.4.2016 23:10
Grunt | skóre: 23
| blog: Expresivní zabručení
| Lanžhot
Já si jen tak cvičně zkusil vytisknout dvě stránky na inkoustovce co se mi válí pod nohama ale soudě dle dvou různých výsledků v závislosti na odškrtnutí jakési propietární zaostřovací technologie si myslím že to nebude vůbec tak jednoduché.
10.4.2016 23:11
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
.
 ).
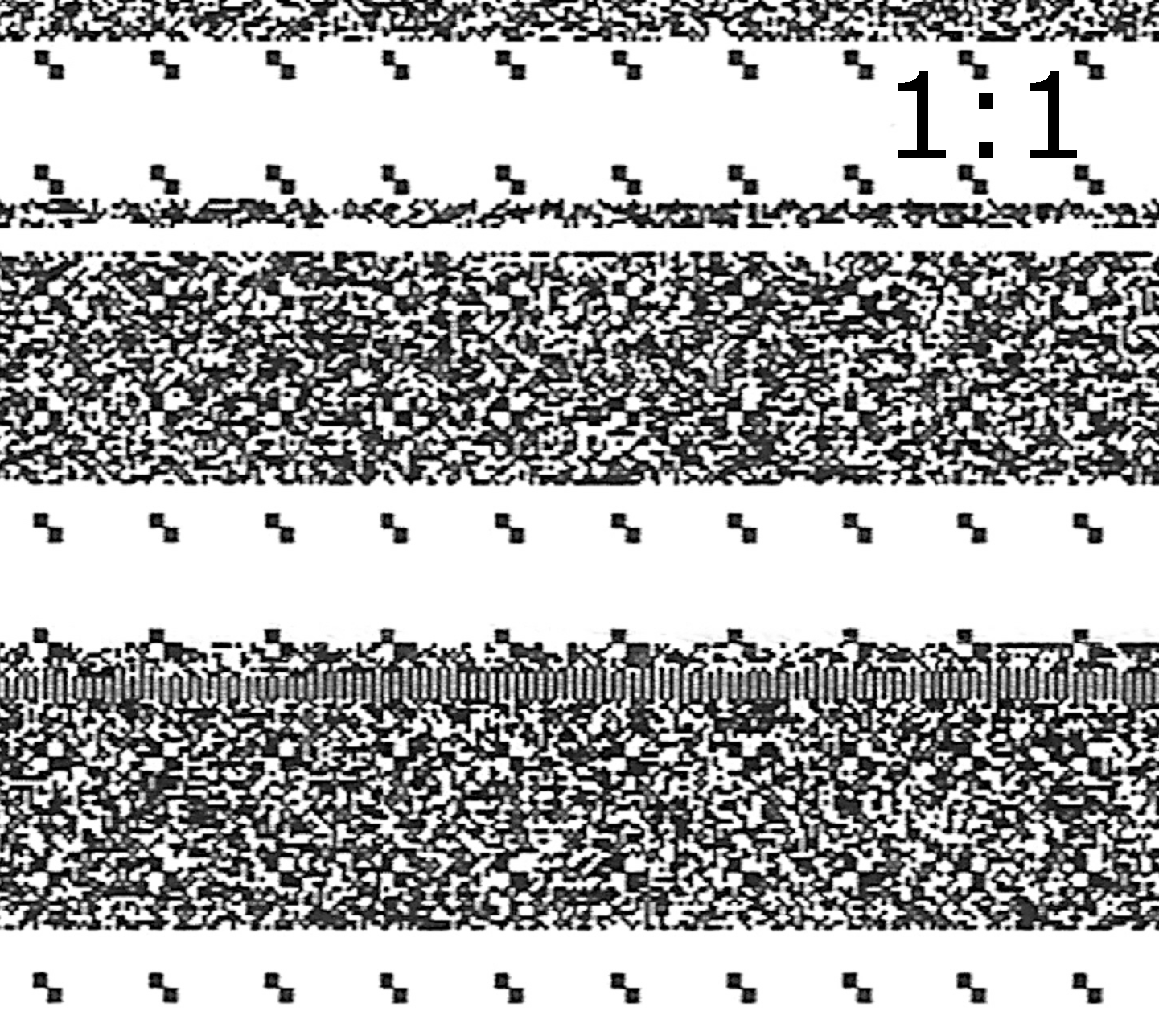
Papír jsem pak asi rok nosil v batohu, takže je mírně ohnutý ke kraji, ale žádná perforace. Nicméně tiskárna (LaserJet III nalezená u popelnic - nejprve z ní bylo třeba vymést mokré listí) mírně špinila papír tonerem, takže jsou na papíru horizontální čáry a fuser (zažehlovač) byl poškrábaný, takže jsou i vertikální bílé výpadky. Tiskárna umí 150 DPI s něčím jako dithering až 300 DPI (což jde ale proti efektu optaru).
Sken byl proveden:
).
Papír jsem pak asi rok nosil v batohu, takže je mírně ohnutý ke kraji, ale žádná perforace. Nicméně tiskárna (LaserJet III nalezená u popelnic - nejprve z ní bylo třeba vymést mokré listí) mírně špinila papír tonerem, takže jsou na papíru horizontální čáry a fuser (zažehlovač) byl poškrábaný, takže jsou i vertikální bílé výpadky. Tiskárna umí 150 DPI s něčím jako dithering až 300 DPI (což jde ale proti efektu optaru).
Sken byl proveden:
Ultima Electronics Corp. Artec Ultima 2000 (GT6801 based)/Lifetec LT9385/ScanMagic 1200 UB Plus Scannerna 600 DPI v odstínech šedi (resp zeleně). Skener umí i 1200 DPI, ale IMO overkill a vím, že to jde i s míň (v té době jsem měl málo paměti v kompu a 1200 DPI by se dost možná nevešlo - OT: mám ještě lineární CCD "čip" na 2400, ale nepovedlo se mě od GT6801 firmy vydyndat datasheet, abych mohl napsat vlastní firmware, ale alespoň mě odepsali, sposta jich neodpoví). Po skenu jsem zjistil, že na sklu byl nějakej bordel, kterej překryl spojitou oblast asi 20 "pixelů". První unoptar se nepovedl kvůli černým okrajům bez papíru. Po upravení úrovní barev v GIMPu (autodetekce) a manuálnímu odříznutí okrajů se sken povedlo dekódovat. Na výsledek jsem se docela těšil, protože jsem už zapomněl, co jsem to tam ukládal. Výsledný soubor je doplněn nulama na nějakou hodnotu (asi plná kapacita papíru - BTW bylo by zajímavý přidávat samoopravné kódy podle volného místa). Po odříznutí přebytečného paddingu má soubor stejnej hash jako originál, co mám ještě na disku. Celková kapacita 13824 bajtů (s lepším nastavením DPI by mělo jít 4x víc, s moderní laserovkou možná ještě víc). Modifikace starší verze optaru (minimální změny) je v příloze. Pamatuju si, že jsem snad ten výstup před tiskem musel ještě ručně editovat. P.S. Kruci jsem mohl na uloztu nastavit, že to je 18+
.
Optar nedoporučuji používat, rozhodně ne bez další masivní redundance (program par2)Čistě teoreticky, co je efektivnější, zvýšení redundance v samopravném algoritmu optaru (golay), snížení hustoty záznamu, nebo zvýšení redundance v samoopravném algoritmu na datové úrovni?
jinak se vůbec nechytá, i přestože má správné parametry na příkazové řádceV mé verzi:
sscanf(format,"%u-%u-%u-%u-%u-%u-%u-%u",
&dummy,
&dummy,
&dummy,
&dummy,
&dummy,
&dummy,
&dummy,
&text_height);
13.4.2016 10:54
Grunt | skóre: 23
| blog: Expresivní zabručení
| Lanžhot
.
BTW Pokud bys hackoval ten optar (já nemám čas ), tak ještě trochu rozmixuj ty pixely, teďka jsou po řádcích (viz ty tvé skeny). Ideálně, aby bylo umístění pixelů po sobě jdoucích dat rezistentní vůči protnutí libovolnou přímkou (= libovolné přehnutí papíru).
Blbý je že se musí ořezávat ty černé okraje. Asi by to chtělo udělat okraj v nějaké specifické synchronizační frekvenci. Koneckonců ta sync šachovnice funguje podobně.
13.4.2016 09:41
Grunt | skóre: 23
| blog: Expresivní zabručení
| Lanžhot
Input 4644 x 6748 pixels, taking 62.6754 megabytes for 2 framebuffers. Average pixel value 159 Black 19.1073, white 252.759, cutlevel 42 (0x2a), fill cutlevel 136 (0x88) Black 5.65176, white 239.744, cutlevel 29 (0x1d), fill cutlevel 123 (0x7b) Black 4.19368, white 236.423, cutlevel 27 (0x1b), fill cutlevel 120 (0x78) Black 3.94404, white 235.763, cutlevel 27 (0x1b), fill cutlevel 120 (0x78) Removing dirt from the white border: white border identified, data area identified, erased 6 pixels of dirt. Searching for the corners. One bit is 2.98254 horizontal pixels and 2.99755 vertical pixels. Input horizontal pixel vector 1,0.000108272, vertical -0.00208317,0.999998. skew -0.0627803 deg, perpendicularity 90.1132 deg. Allocating search area of 8 x 8 (64) pixels. Upper corners at 19, 8 and 4637, 11, lower corners at 5, 6731 and 4623, 6729. Cross half for searching is 4 x 4 input pixels. 33702 bits bad from 3196368, bit error rate 1.05438%. 10.3644% black dirt, 83.5826% white dirt and 2040 (6.05305%) irreparable. Golay stats =========== 0 bad bits 108334 1 bad bit 18528 2 bad bits 4296 3 bad bits 1514 4 bad bits 510 total codewords 133182Výsledek není bůh ví co, ale věřím že kdybych vyčistil sklo alkoholem, nepřekládal papír a v první řadě to naskenoval na něčem normálním, neměl bych mít problém ani u originálního rozlišení.
Za zmínku určitě stojí že čím víc se snažím v GIMPu přiblížit pomocí úrovní a křivek černé a bílé o to míň to hlasí neopravitelných bitů ale o to větší nesmysl z toho taky leze (čtverečky se mi opticky začínají slévat). Nakonec dodám že výsledné čtverečky jsou tak malé a tak škaredé že kdybych to měl dékodovat očima bez nějakého mikroskopu, asi bych radši spáchal sebevraždu.
13.4.2016 10:27
Grunt | skóre: 23
| blog: Expresivní zabručení
| Lanžhot
.
14.4.2016 09:31
Grunt | skóre: 23
| blog: Expresivní zabručení
| Lanžhot
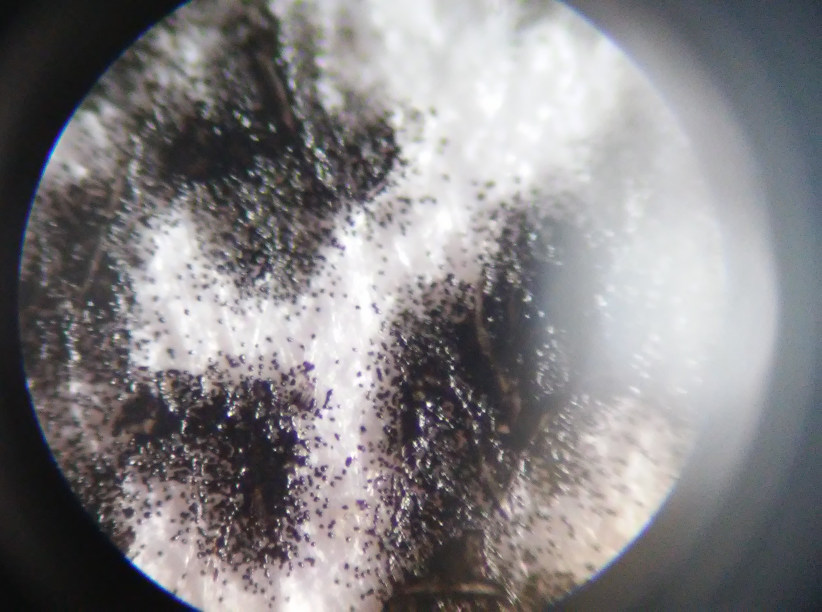
Jinak pod mikroskopem jde vidět proč ty tečky mají jasně černý okraj ale uprostřed jsou světlejší. Na okrajích je toner vpitý do papíru, takže pohlcuje světlo a je jasně černý, ale uprostřed (nebo v místě kde se ho nakupí víc) se zapeče do vrstvy a je na povrchu lesklý. Proti slunci to ještě není tak vidět, ale když na to posvítím zářivkou jsou na toneru jasně viditelné modré čepičky. Jak ten skener odhaduje bílé místo uprostřed černých teček je mi záhadou, protože tam nic není, ale asi nějak jo když to funguje. Ideální by bylo prohnat to ještě XORem se vzorcem 10101010… aby se někde kde je moc nul nekupil černý toner.
Ideální by bylo prohnat to ještě XORem se vzorcem 10101010… aby se někde kde je moc nul nekupil černý toner.Podívej se, jak se kóduje signál např. pro bezdrátový přenos. Tam je s mnoha nulama nebo mnoha jedničkama docela problém a je na to pár hezkých triků.
17.4.2016 14:48
Grunt | skóre: 23
| blog: Expresivní zabručení
| Lanžhot
.
BTW můžeš použít LFSR, ten (pokud je normální) nemá nikdy výplň 00000000. Ale podle mě to bude fungovat na poloprázdnou buňku i jen synchronizací v rozích té buňky.
18.4.2016 19:16
Grunt | skóre: 23
| blog: Expresivní zabručení
| Lanžhot
18.4.2016 19:07
Grunt | skóre: 23
| blog: Expresivní zabručení
| Lanžhot
) zhruba 20-30 teček, což odpovídá délce slova v golayově kódu. A z toho "BMW loga" si to nejspíš extrapoluje synchronizaci i na místa mimo (zas tolik se ten papír snad nezmuchlá ).
OT: Škoda, že Bystroušák neměl k dispozici celej řetězec a nedodal víc informací. Před chvílí mě napadlo, že vlastně to prázdný místo na optaru se může kódovat do znaku 0x00 (data 000 000 000 000 v golay kódu zakódovano do 24x "0"). Takže vlastně pokud se nepoužije na každý jeden papír speciální archív (s headerem kolik dat je validních - heh by šlo udělat "skrytý" volume), tak to doplní na konec dummy nuly. Nebo má optar vlastní formát kontejneru? :-/
13.4.2016 10:31
Grunt | skóre: 23
| blog: Expresivní zabručení
| Lanžhot
One bit is 2.98254 horizontal pixels and 2.99755 vertical pixels.Jako že by to klidně zvládlo ještě 3× menší bity?
14.4.2016 09:36
Grunt | skóre: 23
| blog: Expresivní zabručení
| Lanžhot
bych to ještě mohl zmenšovat až na jeden bit = 1 pixel.Jestli mluvíš o pixelech skeneru, tak nemohl, vzorkovací teorém IMO.
13.4.2016 11:05
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Hele bobku a nemůže být problém v tom, že to tam fakt cpeš v B&W?Já to dělal v lednu, takže už fakt nevím, jestli jsem to tam cpal v B&W nebo v greyscales. Jinak si zkus tohle na nějakém 300kB dokumentu. Jinak btw: u mě to nehlásilo žádné irreparable bity, když se koukneš do toho výstupu, co jsem posílal do prvního komentáře. U tebe to hlásí and 2040 (6.05305%) irreparable.
13.4.2016 11:07
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
73 bits bad from 492576, bit error rate 0.01482%. 0% black dirt, 100% white dirt and 0 (0%) irreparable. 133 bits bad from 492576, bit error rate 0.0270009%. 0% black dirt, 100% white dirt and 0 (0%) irreparable. 114 bits bad from 492576, bit error rate 0.0231436%. 0% black dirt, 100% white dirt and 0 (0%) irreparable. 116 bits bad from 492576, bit error rate 0.0235497%. 0% black dirt, 100% white dirt and 0 (0%) irreparable. 168 bits bad from 492576, bit error rate 0.0341064%. 0% black dirt, 100% white dirt and 0 (0%) irreparable. 143 bits bad from 492576, bit error rate 0.0290311%. 0% black dirt, 100% white dirt and 0 (0%) irreparable. 131 bits bad from 492576, bit error rate 0.0265949%. 0% black dirt, 100% white dirt and 0 (0%) irreparable. 118 bits bad from 492576, bit error rate 0.0239557%. 0% black dirt, 100% white dirt and 0 (0%) irreparable. 296 bits bad from 492576, bit error rate 0.0600922%. 0% black dirt, 100% white dirt and 0 (0%) irreparable. 505 bits bad from 492576, bit error rate 0.102522%. 0% black dirt, 100% white dirt and 0 (0%) irreparable.
13.4.2016 11:51
Grunt | skóre: 23
| blog: Expresivní zabručení
| Lanžhot
23058 bits bad from 3196368, bit error rate 0.721381%. 90.4068% black dirt, 9.21155% white dirt and 88 (0.381646%) irreparable. Golay stats =========== 0 bad bits 112893 1 bad bit 17775 2 bad bits 2281 3 bad bits 211 4 bad bits 22 total codewords 133182Naskenuj to v odstínech šedi, nic s tím nedělej maximálně ořež trochu okraje (neuřež regulérní okraj optaru), optar ti to musí slupnout jako malinu.
13.4.2016 14:27
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
13.4.2016 14:32
Grunt | skóre: 23
| blog: Expresivní zabručení
| Lanžhot
Protokol, který nedokáže rozpoznat konzistenci přenosové vrstvy je mi docela k ničemuNo můžeš ho klidně do optaru dopsat. I clock to tam píše:
Each 24 bit code word however carries only 12 bits of payload, the remaining 12 bits are guard against these three errors. If 4 bits get flipped, this situation is detected and reported, but cannot be corrected. If more, the outcome is uncertain.Žádnou takovou vrstvu to nemá. A jestli chceš poradit, tak to můžeš implementovat po paketech ať de zpracování serializovat
13.4.2016 16:31
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Each 24 bit code word however carries only 12 bits of payload, the remaining 12 bits are guard against these three errors. If 4 bits get flipped, this situation is detected and reported, but cannot be corrected. If more, the outcome is uncertain.Aha no. Já to chápal tak, jako že oprava je nejistá, ne že i detekce je nejistá.
Žádnou takovou vrstvu to nemá. A jestli chceš poradit, tak to můžeš implementovat po paketech ať de zpracování serializovatTak určitě. Stane se to jednou za temné noci, když půjdu pozdě domu z práce. Zaslechnu zašustění odpadků, po zádech mi přeběhne mráz. Ohlédnu se, ale za mnou nikdo není. Přesto mám pocit, jako kdyby mě někdo sledoval. Radši přidám do kroku, přeci jen, poslední dobou se Prahou nesou divné zvěsti o mizejících lidech a nerad bych byl jeden z nich. Jsem už skoro doma, když v tu chvíli to zaslechnu znovu. Divný šoupavý zvuk, závan chladu, trnutí v kostech. Ohlédnu se a překvapením vyjeknu, když za sebou spatřím krásnou ženu s krvavě rudými rty, jak se ke mě naklání a z úst jí trčí tesáky. Zbytek je zmatený. Probudím se v rakvi s notebookem na klíně a neodolatelnou chutí na krev. Vím, že je právě den a že nesmím vyjít z rakve ven, ale naštěstí mám ten notebook a bezdrátový internet, takže se nenudím. Prvních pár let nočního života si čtu knihy, které jsem si naházel do todo stacku, a sleduji, jak všichni, na kom mi záleželo stárnou a umřou. Když knihy dočtu, začnu se učit hrát na housle, klavír a programovat v haskellu. Skládat origami a haiku. Střílet z luku, létat na rogalu. Všechny ty věci, na které jsem jako smrtelník neměl čas. Naprogramuji si vlastní operační systém, vymyslím programovací jazyk. Vyšlechtím novou rasu psa. Po mnoha letech, když už mi na todo listu nezbyde nic, ani užít si sex ve stavu beztíže za šňupání koksu z prdele tří rotujících děvek, kdy si splním všechny své tajné přání, zjistím, že se konečně začínám nudit. Pak si snad jednoho večera sednu a možná mi zbude čas a nálada na doprogramování optaru.
13.4.2016 16:53
Grunt | skóre: 23
| blog: Expresivní zabručení
| Lanžhot
Tak určitě. Stane se to jednou za temné noci, když půjdu pozdě domu z práce. Zaslechnu zašustění odpadků, po zádech mi přeběhne mráz. Ohlédnu se, ale za mnou nikdo není. Přesto mám pocit, jako kdyby mě někdo sledoval. Radši přidám do kroku, přeci jen, poslední dobou se Prahou nesou divné zvěsti o mizejících lidech a nerad bych byl jeden z nich. Jsem už skoro doma, když v tu chvíli to zaslechnu znovu. Divný šoupavý zvuk, závan chladu, trnutí v kostech. Ohlédnu se a překvapením vyjeknu, když za sebou spatřím krásnou ženu s krvavě rudými rty, jak se ke mě naklání a z úst jí trčí tesáky.
Zbytek je zmatený. Probudím se v rakvi s notebookem na klíně a neodolatelnou chutí na krev. Vím, že je právě den a že nesmím vyjít z rakve ven, ale naštěstí mám ten notebook a bezdrátový internet, takže se nenudím. Prvních pár let nočního života si čtu knihy, které jsem si naházel do todo stacku, a sleduji, jak všichni, na kom mi záleželo stárnou a umřou. Když knihy dočtu, začnu se učit hrát na housle, klavír a programovat v haskellu. Skládat origami a haiku. Střílet z luku, létat na rogalu. Všechny ty věci, na které jsem jako smrtelník neměl čas. Naprogramuji si vlastní operační systém, vymyslím programovací jazyk. Vyšlechtím novou rasu psa.
Po mnoha letech, když už mi na todo listu nezbyde nic, ani užít si sex ve stavu beztíže za šňupání koksu z prdele tří rotujících děvek, kdy si splním všechny své tajné přání, zjistím, že se konečně začínám nudit. Pak si snad jednoho večera sednu a možná mi zbude čas a nálada na doprogramování optaru.
Ty se na doprogramování optaru vyser zcela určitě. Ty máš střevo ty vole. Ty zační psát, ale úplně něco jiného než kód v optaru.
 13.4.2016 18:17
mirec | skóre: 32
| blog: mirecove_dristy
| Poprad
13.4.2016 18:17
mirec | skóre: 32
| blog: mirecove_dristy
| Poprad
+ 1, ten komentár nemá chybu.
13.4.2016 20:59
Grunt | skóre: 23
| blog: Expresivní zabručení
| Lanžhot
Aha no. Já to chápal tak, jako že oprava je nejistá, ne že i detekce je nejistá.Ono to není vůbec složitý. Prostě se to musí rozdělit na nějaké tratě nebo sektory (podobně jako u disket, disků nebo optických disků) a každá musí mít na konci svůj hash. Ono se zdá že to už tak rozdělené je. A když to některý sektor přečte špatně, prostě se to musí zkoušet znova a znova do doby než ho to přečte korektně. Ideálně kdyby to ještě bylo projený skrze SANE nebo TWAIN a v průběhu skenování by si hlava přejela zpátky a pokoušela se sektor přečíst vždycky s násobně vyšším rozlišení až nativního rozlišení skeneru a nebo prohlášení že papír prostě bez chyb přečíst nejde. To by bylo naprosto ideální.
13.4.2016 21:46
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Aha no. Já to chápal tak, jako že oprava je nejistá, ne že i detekce je nejistá.Minimální Hammingova vzdálenost golayova kódu je 8 (= libovolné dvě slova se liší minimálně v 8 bitech). Pokud změníš 4 bity, tak se může vyskytnout situace, že nevíš, ke kterému z těch validních (kódových) slov to patří. Například jediné dvě validní slova 00000000 a 11111111 a po skenu dostaneš 00001111. A teď babo raď zda se změnily ty 4 na začátku a bylo to původně 11111111 nebo se změnily ty 4 na konci a bylo to původně 00000000. P.S. Golay má kódové slovo 24 bitů, ale 12 z toho je datových a tam je minimální vzdálenost 1 (000, 001, 010, 011, atd.), takže ty zbylý se musej o ten rozdíl správně postarat (+ Golay to má tak, že se dá lehko generovat).
13.4.2016 11:57
Grunt | skóre: 23
| blog: Expresivní zabručení
| Lanžhot
Jinak si zkus tohle na nějakém 300kB dokumentu.No v mém případě to na žádném dokumentu zkoušet nemůžu. Sám vidíš ten obrázek. Ty tři blbě non-aligned lajny v JPEGu přesně korespondujou s tím jak ten můj krám skenuje. Naskenuje třetinu, pak se zasekne, pak naskenuje další třetinu, zas počká a popřemýšlí si a pak to doskenuje. Jak se zasekne tak poskočí asi o pár řádků nahoru či dolů a opakuje nebo přeskočí bajty. Musel bych mít něco co lineárně naskenuje obrázek odshora dolů bez přerušení abych do toho mohl cpát dokumenty.
13.4.2016 12:27
Grunt | skóre: 23
| blog: Expresivní zabručení
| Lanžhot
.
13.4.2016 16:11
Grunt | skóre: 23
| blog: Expresivní zabručení
| Lanžhot
Nedalo mi to, stáhnul jsem si nějakých 250MB Centrum řešení HP pro moji DeskJet F2180 a je to přesně jak jsem si myslel. Ono to při libovolném formátu importu komunikuje přes USB pomocí JPEGu. Je tam na to tlačítko a dá se to vypnout společně s všelijakými zaostřováky a zlepšováky všeho možného.
600dpi:Decoding PNG file /media/sf_sdileni/optar_scan_0001.png... Input 4652 x 6740 pixels, taking 62.709 megabytes for 2 framebuffers. Average pixel value 147 Black 19.0456, white 245.613, cutlevel 42 (0x2a), fill cutlevel 132 (0x84) Black 6.1389, white 230.297, cutlevel 29 (0x1d), fill cutlevel 118 (0x76) Black 4.59569, white 226.256, cutlevel 27 (0x1b), fill cutlevel 115 (0x73) Black 4.35399, white 225.504, cutlevel 26 (0x1a), fill cutlevel 115 (0x73) Black 4.21027, white 225.228, cutlevel 26 (0x1a), fill cutlevel 115 (0x73) Removing dirt from the white border: white border identified, data area identified, erased 0 pixels of dirt. Searching for the corners. One bit is 2.98124 horizontal pixels and 2.99599 vertical pixels. Input horizontal pixel vector 1,-0.000216685, vertical -0.00178651,0.999998. skew -0.0449722 deg, perpendicularity 90.1148 deg. Allocating search area of 8 x 8 (64) pixels. Upper corners at 21, 15 and 4636, 17, lower corners at 9, 6735 and 4624, 6731. Cross half for searching is 4 x 4 input pixels. Finding crosses (93 lines), numbers indicate individual cutlevels: 14518 bits bad from 3196368, bit error rate 0.454203%. 39.0274% black dirt, 60.5869% white dirt and 56 (0.385728%) irreparable. Golay stats =========== 0 bad bits 120249 1 bad bit 11523 2 bad bits 1249 3 bad bits 147 4 bad bits 14 total codewords 1331821200dpi:
Decoding PNG file /media/sf_sdileni/optar_scan_0001.png... Input 9277 x 13463 pixels, taking 249.792 megabytes for 2 framebuffers. Average pixel value 150 Black 20.5287, white 248.202, cutlevel 43 (0x2b), fill cutlevel 134 (0x86) Black 5.77002, white 232.286, cutlevel 28 (0x1c), fill cutlevel 119 (0x77) Black 4.02953, white 227.892, cutlevel 26 (0x1a), fill cutlevel 116 (0x74) Black 3.79116, white 227.147, cutlevel 26 (0x1a), fill cutlevel 115 (0x73) Removing dirt from the white border: white border identified, data area identified, erased 0 pixels of dirt. Searching for the corners. One bit is 5.96281 horizontal pixels and 5.99219 vertical pixels. Input horizontal pixel vector 1,-0.000162505, vertical -0.00174923,0.999998. skew -0.0454562 deg, perpendicularity 90.1095 deg. Allocating search area of 16 x 16 (256) pixels. Upper corners at 35, 11 and 9265, 16, lower corners at 11, 13452 and 9242, 13444. Cross half for searching is 8 x 8 input pixels. 28620 bits bad from 3196368, bit error rate 0.895391%. 14.7345% black dirt, 83.1971% white dirt and 592 (2.06848%) irreparable. Golay stats =========== 0 bad bits 110126 1 bad bit 18551 2 bad bits 3594 3 bad bits 763 4 bad bits 148 total codewords 133182K výsledku nemám co dodat. Nejen že po vypnutí zlepšováků to funguje ale výsledkem je dokonce opticky nepoškozená Lena Söderbergová. Na debilní domácí rozvrzané DeskJetce. Takže milé děti, nevěřte všemu co Lišák napíše a zkoumejte sami.
Zcela kontra-intuitivně vyšší rozlišení (dpi) scanu automaticky neznamená lepší výsledek ale 100% větší velikost scanu (na 1200dpi mělo PNG co z toho vypadlo při Grayscale téměř 100MB a optar se mi mohl zalknout). No na druhou stranu při takovém rozlišení jsou jasně viditelné a identifikovatelné jednotlivé bity jak je patrné z výřezu. Jsem si téměř jistý že i taková rozvrzaná mrcha zvládne ještě mnohem větší datovou hustotu, při troše toho tweakování. Mám doma nějakej xeroxovej papír tak až se zas dostanu k laseru, hned poběžím vyzkoušet jak si poradí i s vyšší hustotou. Zkusím zaútočit tak na 1MB na jedné A4 straně. Večer pokud mi zbude nějakej čas se pokusím vypočítat velikost jednoho toho bitu nebo baudu nebo čtverečku v Golay poli nebo co to je. Dost mě to samotného zajímá.
13.4.2016 16:37
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
K výsledku nemám co dodat. Nejen že po vypnutí zlepšováků to funguje ale výsledkem je dokonce opticky nepoškozená Lena Söderbergová. Na debilní domácí rozvrzané DeskJetce. Takže milé děti, nevěřte všemu co Lišák napíše a zkoumejte sami.Já jsem náhodou velmi potěšený, když někdo nevěří tomu co napíšu a zkoumá sám. Dialog/debata mi přijde podstatně lepší, než schvalující, či žádné komentáře. Jinak proto jsem taky nenapsal "optar je nahovno", ale popsal jsem osobní zkušenost, ze které plyne závěr, že optar nemůžu doporučit na zálohování bez toho, aniž by to člověk otestoval na vlastním hardware. Doslova:
Optar nedoporučuji používat, rozhodně ne bez další masivní redundance (program par2), a důkladného otestování celého kroku s vaším vlastním hardwarem.Za tím si pořád stojím.
29.4.2016 23:24
Grunt | skóre: 23
| blog: Expresivní zabručení
| Lanžhot
#define XCROSSES 97 /* Number of crosses horizontally */ #define YCROSSES 139 /* Number of crosses vertically */ Mříž: 2310x3319pix Datový bitů: 7 181 502 bitů Teoretická velikost jednoho bitu:85µm Což odpovídá cca. 300dpi, tisk na xeroxový papír o 160g/m2 Scan: 600dpiVýsledek nic moc, scan v B&W napovídá že jsem zcela mimo schopnosti/rozlišení skeneru, ale na to jak to vypadá je 10% BER celkem úspěch:
One bit is 2.00389 horizontal pixels and 2.00194 vertical pixels. Input horizontal pixel vector 1,0.000753417, vertical -0.00231394,0.999997. skew -0.0878735 deg, perpendicularity 90.0894 deg. Allocating search area of 6 x 6 (36) pixels. Upper corners at 22, 18 and 4666, 25, lower corners at 5, 6720 and 4652, 6720. Cross half for searching is 3 x 3 input pixels.
670608 bits bad from 7179192, bit error rate 9.341%. 52.4569% black dirt, 19.9568% white dirt and 184996 (27.5863%) irreparable. Golay stats =========== 0 bad bits 23025 1 bad bit 61528 2 bad bits 80909 3 bad bits 87422 4 bad bits 46249 total codewords 299133 Writing debug image into scan_0001_debug.pgm.A znovu s podivem, ale různé vylepšovací softwarové algoritmy nemají na BER vůbec pozitivní vliv. Spíš naopak.
802354 bits bad from 7179192, bit error rate 11.1761%. 48.3253% black dirt, 14.4886% white dirt and 298364 (37.1861%) irreparable. Golay stats =========== 0 bad bits 10675 1 bad bit 36403 2 bad bits 64805 3 bad bits 112659 4 bad bits 74591 total codewords 299133 Writing debug image into scan_0001_debug.pgm.3× softwarově zaostřeno:
751309 bits bad from 7179192, bit error rate 10.4651%. 45.4097% black dirt, 21.4828% white dirt and 248740 (33.1075%) irreparable. Golay stats =========== 0 bad bits 14258 1 bad bit 46191 2 bad bits 73119 3 bad bits 103380 4 bad bits 62185 total codewords 299133S barvou (zanese barevným šumem všech možných barev)
706523 bits bad from 7179192, bit error rate 9.84126%. 51.4416% black dirt, 18.3366% white dirt and 213524 (30.2218%) irreparable. Golay stats =========== 0 bad bits 19252 1 bad bit 54546 2 bad bits 77409 3 bad bits 94545 4 bad bits 53381 total codewords 299133Takže čím víc RAW, tím lepší výsledek i když to tak opticky nemusí vůbec vypadat.
Dále mě ještě zajímalo jak by vypadal tisk na nativní rozlišení což jsem napočítal na cca. 195x297 zaměřovacích křížů.
#define XCROSSES 195 /* Number of crosses horizontally */ #define YCROSSES 279 /* Number of crosses vertically */ Mříž: 4662x6679pix Datový bitů: 29 178 918 bitů Teoretická velikost jednoho bitu:42µm Což odpovídá cca. 600dpi, tisk na obyčejnou kancelářskou A4 o 80g/m2Tím už jsem optar netrápil, protože u tak šíleného rozlišení mám problém přes lupu sledovat ty crashtestové zaměřovací kříže 6x6pix i já. Pouze jsem to vyfotil a prozkoumal (viz příloha). Nenechte se mýlit dobrým vzhledem z optiky foťáku, oči takový výstavní kousek i pod přímým sluncem vnímají jako slitek s nějakým bílím prachem na povrchu. Zaměřovací kříže vnímám pouze jako nahnuté tečky pokud jsou v poli nul a v datech nejdou vnímat vůbec. Formát dat pro unoptar se musí číst pod lupou s osvětlením protože i moje velmi dobré oči to bez pomoci nahé nepřečtou. Velmi zajímavých výsledků jsem dosáhl pod UV světlem. Pod mikroskopem jde sice sledovat jednotlivé smítka prachu z toneru, ale z dat je jen jakési statistické puzzle u kterého těžko hádat jestli se zrovna špatně vyprskl toner nebo jde o datovou nulu.V každém případě u toho spodního ráměčku jde moc dobře pozorovat že půlka těch smítek stejně opadá než to vůbec vyjede z tiskárny a prosvítá z toho bílý papír i když má jít o čisté černé pole. Velmi by mě zajímalo jestli je vůbec v takovém rozlišení na papír (na ten kancelářský určitě ne) nějakým způsobem možné ty data dostat. Muselo by se to prozkoumat nějakým mikroskopickým skenerem který dovede načíst celou A4ku v gigantickém rozlišení. Jinak doporučte nějaký levný ale dobrý USB mikroskop a můžu se vrhnout do výzkumu a zásobovat obrázkama a videama tonerového prachu na papíře který by měl odpovídat digitálním datům.
Tiskni
Sdílej:
![]()
![]()
![]()
![]()
![]()
![]()
ISSN 1214-1267, (c) 1999-2007 Stickfish s.r.o.
 9.4.2016 18:45
9.4.2016 18:45
 9.4.2016 19:29
9.4.2016 19:29
 12.4.2016 21:09
12.4.2016 21:09
 11.4.2016 11:35
11.4.2016 11:35
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}