Portál AbcLinuxu, 21. července 2026 06:20
 3.5.2018 12:20
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
3.5.2018 12:20
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Chci vzít objekt a mít ho uložený na disku takový, jaký je, v celé jeho nahotě a bez nutnosti ho někam serializovat a deserializovat.Objekt je v podstatě místo v paměti, má nějakou adresu na které začíná a nějakou velikost. Pak taky obvykle obsahuje ukazatele na jiné objekty (tj. jejich adresy). Pokud chci něco takového uložit na disk nebo poslat po síti, musím tyhle vazby reprezentované adresama zaznamenat nějakým jiným způsobem, protože nemůžu čekat, že příjemce (co objekt čte z disku nebo dostane přes síť) uloží na zcela stejné adresy. Což mě přivádí k dotazu: jak je tohle řešené v tom selfu? Z toho co tu píšeš hádám, že se prostě uloží celá pamět toho stroje do image, který se při příštím spuštění prostě načte do paměti, podobně jako kdybych dělal snapshot běžícího virtuálního stroje. Ale jak se řeší sdílení těch objektů mezi několika stroji (které mají ruzný stav, běží na různém hardware, ...), pokud nechci ty data serializovat?
3.5.2018 14:11
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Ale jak se řeší sdílení těch objektů mezi několika stroji (které mají ruzný stav, běží na různém hardware, ...), pokud nechci ty data serializovat?Transporter je převede na textovou reprezentaci tvořící zdroják Selfu. Ten zdroják vytvoří to, co jsi měl v paměti. Pokud mi paměť slouží, tak je to popsané tady: http://bibliography.selflanguage.org/_static/gold.pdf
Transporter je převede na textovou reprezentaci tvořící zdroják Selfu. Ten zdroják vytvoří to, co jsi měl v paměti.Což je konkrétní případ serializace, ne? Ptám se na to, protože nevím, co si mám představit pod tím "objektem uloženém na disku takový, jaký je, bez serializace". Pokud jde o to mít pouze jeden univerzální způsob, jak serializovat cokoli do zdrojáku, tak je na tom imho nejlíp lisp, kteréhož zdroják v podstatě kopíruje strukturu syntaktického stromu.
3.5.2018 16:27
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Což je konkrétní případ serializace, ne? Ptám se na to, protože nevím, co si mám představit pod tím "objektem uloženém na disku takový, jaký je, bez serializace".Ptal ses mezi počítači, ne na disku.
Pokud jde o to mít pouze jeden univerzální způsob, jak serializovat cokoli do zdrojáku, tak je na tom imho nejlíp lisp, kteréhož zdroják v podstatě kopíruje strukturu syntaktického stromu.Self je na tom v tomhle stejně, protože má v syntaxi object literals, tedy přímý způsob zapsání objektu tak jak je.
 4.5.2018 21:38
xkucf03 | skóre: 50
| blog: xkucf03
4.5.2018 21:38
xkucf03 | skóre: 50
| blog: xkucf03
A nedegraduje to trochu objekty na pouhé datové struktury? Ví objekt, že je serializován? Může to nějak ovlivnit? Nebo tam vůbec nefunguje zapouzdření?
5.5.2018 11:16
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
 7.5.2018 00:10
Bedňa | skóre: 34
| blog: Žumpa
| Horňany
3.5.2018 14:13
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
7.5.2018 00:10
Bedňa | skóre: 34
| blog: Žumpa
| Horňany
3.5.2018 14:13
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Z toho co tu píšeš hádám, že se prostě uloží celá pamět toho stroje do image, který se při příštím spuštění prostě načte do paměti, podobně jako kdybych dělal snapshot běžícího virtuálního stroje.Jop. Osobně to ale nepovažuji za úplně šťastné řešní a šel bych spíš cestou objektové databáze.
Ale jak se řeší sdílení těch objektů mezi několika stroji (které mají ruzný stav, běží na různém hardware, ...), pokud nechci ty data serializovat?Sdílení se afaik řeší tak, že je v jednom image, do kterého se připojí víc strojů, jenž objekt reprezentují přes proxy objekty.
šel bych spíš cestou objektové databázeJo, to zní rozumněji než prostý image snapshot. Jinak myslíš to tak, že ta objektová databáze by byla integrovaná přímo v jazyce, něco jako má Picolisp? Viz:
A special feature is the intrinsic CRUD functionality. Persistent symbols are first-class objects, they are loaded from database files automatically when accessed, and written back when modified.Narazil jsem teď na to, když jsem se díval, co je vlastně objektová databáze. A přijde mi, že kromě hlavního důrazu na "information is represented in the form of objects as used in object-oriented programming" vlastně neexistuje nějaká obecná formálnější definice, a tak každá taková databáze je více měně jedinečná. Což by ale asi nemuselo vadit, pokud by nějaká konkrétní implementace byla součástí jazyka.
3.5.2018 16:58
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Jo, to zní rozumněji než prostý image snapshot. Jinak myslíš to tak, že ta objektová databáze by byla integrovaná přímo v jazyce, něco jako má Picolisp? Viz:Něco podobného. Podobně jako funguje sqlite (= nad souborem snapshotu), až na to že jednotkou uchování dat není řádek v tabulce, ale objekt (v kolekci, či v rootu). Objekty jsou defacto slovníky, takže je to v podstatě grafová / stromová databáze, která má jako uzly objekty. S podporou víceuživatelského přístupu, transakcí, atomocity, indexů nad kolekcemi a automatického ukládání dat. Mou částečnou inspirací pro formát, pokud někdy budu mít dost času, je DyBASE, kde jsem trochu nastudoval vnitřnosti. Ono celkově, nejde mi jen o VM, to prostředí nad tím by mělo být samo o sobě objektová databáze.
Narazil jsem teď na to, když jsem se díval, co je vlastně objektová databáze. A přijde mi, že kromě hlavního důrazu na "information is represented in the form of objects as used in object-oriented programming" vlastně neexistuje nějaká obecná formálnější definice, a tak každá taková databáze je více měně jedinečná. Což by ale asi nemuselo vadit, pokud by nějaká konkrétní implementace byla součástí jazyka.Jo. Součástí virtuálního stroje.
Akin's rules for spacecraft design [0] include: "Any exploration program which "just happens" to include a new launch vehicle is, de facto, a launch vehicle program." By analogy, any software project that includes writing a database is, de facto, a database project. [0] http://spacecraft.ssl.umd.edu/akins_laws.htmlJinak proč by ses chtěl inspirovat zrovna tou DyBASE? Vypadá to jako mrtvý projekt a ani to není zalinkované na wikipedii. Ptám se protože jako hlavní problém databází, které jsou postavené nad nějakým obecným vysokoúrovňovým modelem (např. xml dabatáze a ty objektové tam - aspoň na první pohled - spadají taky), je to že nemají jasný datový model (respektive žádný se přímo nenabýzí) a tím pádem je velká volnost v tom, jak ten obecný model napasovat na low level model, který ta databáze bude vnitřně používat. Viz moje předchozí poznámka o tom, že každá ta databáze vypadá zcela jedinečně.
7.5.2018 10:01
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Jinak proč by ses chtěl inspirovat zrovna tou DyBASE? Vypadá to jako mrtvý projekt a ani to není zalinkované na wikipedii.Protože je jednoduchá a řeší v podstatě úplně vše, co od toho potřebuji.
3.5.2018 14:18
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Nesnažilo se o něco podobného Étoilé?To neznám, díky za odkaz.
IMHO by bylo skvělé kdyby těch rozhraní ubylo a vše komunikovalo více přímo, v reálném čase a s menším počtem serializací - ale problém je, jak zvládnout tu diverzitu. Pokud bys měl všechno objektové, mohl bys sice kdykoli posílat jakémukoli objektu zprávy, ale ty objekty by komunikovaly přes různá rozhraní, takže bys tam musel mít zase tunu adaptérů, aby to mohlo všechno vzájemně komunikovat. Ve výsledku bys mohl skončit u stejně komplexního a nepružného systému jako je tradiční souborově orientovaný desktop. Nebo by šlo nastavit nějaká pravidla, která by tomu předešla?Je to podobný problém jako s API. Nějaký adaptér si sice napsat musíš, ale může být v podstatě transparentní.
Další problém vidím v synchronizaci a řešení kolizí, pokud by jeden objekt používalo více aplikací, musely by se vzájemně notifikovat například o změnách, což by s rostoucím počtem aplikací sežralo hodně výkonu.To je otázka. Pokud by ten objekt běžel jako samostatný „„proces““ reagující na zprávy s podporou transakcí a zamykání, tak imho ne.
Jinak - už se to tady tuším probíralo - Alan Kay, 2015: Power of Simplicity.Jo, Alan Kay patří mezi moje inspirace. Viděl jsem toho od něj spoustu, ale moje snažení je dané spíš reálnou potřebou a jak moc mě sere celý IT svět. Nejde mi ani tak o nějaké revoluce, jako spíš o čistě sobeckou snahu. Ten systém prostě potřebuji. Mám o tom rozepsáno víc, jeden komplexnější blog bude v dohledné době, až zapracuji poznámky z předčasné recenze a přidám pár ilustrací.
Před pár dny jsem se bavil s Marcusem Denkerem o Selfu a řekl, že není moc chytré vylepšovat Smalltalk tím, že z něj odeberu všechno, co v něm dělá programátory produktivními. Asi je na tom kus pravdy, ale na druhou stranu, než samotný Smalltalk, pořád bych měl raději v rukou Self, který se na venek tváří jako Smalltalk s třídami, a kdykoliv bych potřeboval, mohl použít výhody jeho objektového modelu. Velice často jsem si říkal, jak by mi zrovna teď usnadnilo práci, kdybych mohl použít Selfovské objekty.
Selfovská komunita na tom je podobně jako ta Squeaku - což je ostatně důvod, proč vzniklo Pharo. Zahleděná do toho svého odkazu a naprosto nechápající základní mechanismy kontinuálního vývoje. Dnes mi na obědě třeba Marcus vyprávěl, že někdo pro starý Squeakovský parser napsal visitor a byl odmítnut s tím, že to není OOP! Podobných hororových příběhů z vývoje Squeaku jsem slyšel snad stovky. Spousta užitečných malých změn byla odmítnuta jen proto, že si někdo myslel, že nejsou dost důležité nebo dost dobré. Oni neviděli Squeak jako platformu, na které můžou postavit svou budoucnost a kterou je potřeba postupně rozvíjet, ale jako experiment, který jednou přepíší pořádně. Alan Kay takhle začal od píky několikrát (viz Marcusův poslední příspěvek do squeak-dev). Shodou okolností jsem se před pár dny znovu díval na závěrečnou zprávu projektu STEPS a byl to hodně trpký pohled.
Pharo není dokonalé. Nemá úžasný objektový model Selfu, ale je to platforma, která moc dobře chápe, že je jen základ pro něco lepšího. Nemusí vidět za horizont, ale nebojí se tam jít. Pharo 7 používá bootstrapping a změnilo implemetaci traits tak, že nyní je to volitelná knihovna a navíc vylepšená na stateful traits, takže je Selfu zase o něco blíž.
Začínat s vlastní implementací nebo forkem Selfu je skvělá příležitost, jak se naučit něco nového, což říkám jako člověk, co něco takového udělal. Ale škrtnutých čtverečků přibývá a možná existuje lepší cesta, jak naplnit svoje vize...
3.5.2018 16:03
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Před pár dny jsem se bavil s Marcusem Denkerem o Selfu a řekl, že není moc chytré vylepšovat Smalltalk tím, že z něj odeberu všechno, co v něm dělá programátory produktivními.A to maj být třídy, jo? Já moc nevidím, jak to souvisí s produktivitou. Ta je imho mnohem víc závislá na dalších nástrojích, jako jsou debuggery, dokumentace, introspekce a tak podobně.
Selfovská komunita na tom je podobně jako ta Squeaku - což je ostatně důvod, proč vzniklo Pharo. Zahleděná do toho svého odkazu a naprosto nechápající základní mechanismy kontinuálního vývoje.Řekl bych že nejenom kontinuálního, ale i opensource. A ohromný problém je totální absence dokumentace. Časem jsem dospěl k názoru, že je jenoduší se inspirovat a začít na zelené louce, než jít proti tlaku komunity.
Alan Kay takhle začal od píky několikrát (viz Marcusův poslední příspěvek do squeak-dev). Shodou okolností jsem se před pár dny znovu díval na závěrečnou zprávu projektu STEPS a byl to hodně trpký pohled.Jo, ty závěry STEPS jsem četl. Imho je tam stejný problém jako u Selfu, tedy že to všichni berou jako akademický experiment, než něco co by sami chtěli prakticky používat. Osobně už na tenhle přístup nemám trpělivost.
Pharo není dokonalé. Nemá úžasný objektový model Selfu, ale je to platforma, která moc dobře chápe, že je jen základ pro něco lepšího. Nemusí vidět za horizont, ale nebojí se tam jít. Pharo 7 používá bootstrapping a změnilo implemetaci traits tak, že nyní je to volitelná knihovna a navíc vylepšená na stateful traits, takže je Selfu zase o něco blíž.Zkoušel jsem používat tu šestku (blogpost je 7+ měsíců starý), ale tvrdě jsem narazil pokaždé, když jsem se snažil udělat něco praktického. Asi by se to dalo překonat, ale meh.
Začínat s vlastní implementací nebo forkem Selfu je skvělá příležitost, jak se naučit něco nového, což říkám jako člověk, co něco takového udělal. Ale škrtnutých čtverečků přibývá a možná existuje lepší cesta, jak naplnit svoje vize...Jo. Mě se do toho vážně nechce. Kdybych našel něco lepšího, tak to použiju.
A to maj být třídy, jo? Já moc nevidím, jak to souvisí s produktivitou. Ta je imho mnohem víc závislá na dalších nástrojích, jako jsou debuggery, dokumentace, introspekce a tak podobně.Spíš než o třídy samotné jde o uniformní způsob organizace kódu a objektů, který si vynucují. Ten pak umožňuje snazší tvorbu zmíněných nástrojů. Ale jak jsem psal, raději bych měl systém svázaný konvencemi než možnostmi.
3.5.2018 17:00
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
3.5.2018 19:03
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Článek na Rootu: GraalVM.
Problémy se ještě znásobí, povšimneme-li si obtížnosti a složitosti komunikace mezi programy napsanými v různých jazycích. To obvykle vyžaduje nákladnou serializaci a opětnou deserializaci datových struktur při volání z jednoho systému do jiného
Zvláštní pozornost byla věnována vytvoření efektivního mechanismu pro zpřístupnění dat těchto systémů pro jazyky běžících uvnitř GraalVM a to bez zbytečných konverzí či alokací proxy objektů. Jazyky mohou tudíž operovat nad daty ve formátech, které se již používají a při tom neztratit nic ze své rychlosti.
Před časem jsem si to zkoušel, zkompiloval jsem si s tím javovský program do nativní binárky (cca 7 MB), start byl srovnatelný s nativními aplikacemi, samotný běh mi pak přišel dost podobný jako JVM/OpenJDK (ale nedělal jsem moc důkladný test).
1.6.2018 12:02
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
 3.5.2018 20:33
Grunt | skóre: 23
| blog: Expresivní zabručení
| Lanžhot
3.5.2018 20:42
Bedňa | skóre: 34
| blog: Žumpa
| Horňany
3.5.2018 20:33
Grunt | skóre: 23
| blog: Expresivní zabručení
| Lanžhot
3.5.2018 20:42
Bedňa | skóre: 34
| blog: Žumpa
| Horňany
 .
4.5.2018 21:53
Bedňa | skóre: 34
| blog: Žumpa
| Horňany
.
4.5.2018 21:53
Bedňa | skóre: 34
| blog: Žumpa
| Horňany
 4.5.2018 22:18
xkucf03 | skóre: 50
| blog: xkucf03
4.5.2018 22:18
xkucf03 | skóre: 50
| blog: xkucf03
Jen by to chtělo aktualizovat teď už máme USB C.
Self je programovací jazyk, prostředí a virtuální stroj. Je to něco naprosto jiného, unikátního a jedinéA toto je cela podstata tveho rantu. Tim, ze je vse uzce provazano se vsim, je problem cokoliv dal rozvijet, nahrazovat jednotlive casti, prebirat funkcionalitu odjinud. Proto se tento koncept ukazal jako nezivotaschopny. Srovnej s unixovou filozofii, kde za bez mala padaset let bylo vsechno prepsano (nekdy i nekolikrat), jen diky tomu, ze Unix byl navrzen jako modularni, s moduly, ktere maji relativne jasne urcene hranice.
Proč by měl běžet každý proces samotný a nemít žádnou možnost interagovat s daty okolních procesů?Nekdo uz ti to tu rikal, ... ale doporucuji cestovat zpatky o tricet let a zkusit treba nejaky ten osmibit nebo MacOS Classic. Prvotni problem je stabilita (druhotny problem je bezpecnost), pokud nemas procesy oddelene (i v pripade slusne chovajicich se procesu), muze jeden ohrozit druhy, coz typicky vede k padu aplikace. Treti problem je, ze pokud bys mel primy pristup ke vsemu, co nejaky proces ma v pameti a zacal to pouzivat, muzes zapomenout na nejaka jasne definovana rozhrani a dohnat softwarovou cast systemu k dokonalemu a neuchopitelnemu chaosu.
Proč tam musím mít soubor s retardovanou textovou či bajtovou reprezentací? Nechci řešit žádné reprezentace dat, žádný JSON, XML a normálové rozložení SQL. Chci objekty až úplně dolu. Chci vzít objekt a mít ho uložený na disku takový, jaký je, v celé jeho nahotě a bez nutnosti ho někam explicitně serializovat a deserializovat.Reprezentaci dat musis nevyhnutelne resit. Hodnoty jsou ciste abstraktni entity (cislo 42 nikde fyzicky neexistuje, stejne jako nejaky popis knihy, to je cista informace) a jen jejich reprezentace s nimi umoznuje manipulovat. To, co chces ty, je vybrat si jednu reprezentaci (objektovou, protoze se ti zrovna libi). Nevim, jestli pro neco takoveho existuje i jine oduvodneni nez to, ze ty to proste chces.
4.5.2018 12:24
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
A toto je cela podstata tveho rantu. Tim, ze je vse uzce provazano se vsim, je problem cokoliv dal rozvijet, nahrazovat jednotlive casti, prebirat funkcionalitu odjinud. Proto se tento koncept ukazal jako nezivotaschopny.Já neřeším co je obecně životaschopné. Řeším to primárně čistě sobecky. Spoustu věcí si píšu jako python scripty, což je taky obecně neživotaschopné, přestože pro mě funkční. Jinak nevím, proč předpokládáš, že to musí být provázáno všechno se vším jinak než na úrovni API / interface objektů.
Srovnej s unixovou filozofii, kde za bez mala padaset let bylo vsechno prepsano (nekdy i nekolikrat), jen diky tomu, ze Unix byl navrzen jako modularni, s moduly, ktere maji relativne jasne urcene hranice.Na tom je zábavné, že sami autoři unixu se ho pokusili přepsat (viz plan9) a žalostně selhali. Zrovna unix má spoustu problémů na spoustě míst. Například tty subsystém je něco příšerného.
Nekdo uz ti to tu rikal, ... ale doporucuji cestovat zpatky o tricet let a zkusit treba nejaky ten osmibit nebo MacOS Classic.Osmibity jsem používal.
Reprezentaci dat musis nevyhnutelne resit. Hodnoty jsou ciste abstraktni entity (cislo 42 nikde fyzicky neexistuje, stejne jako nejaky popis knihy, to je cista informace) a jen jejich reprezentace s nimi umoznuje manipulovat. To, co chces ty, je vybrat si jednu reprezentaci (objektovou, protoze se ti zrovna libi). Nevim, jestli pro neco takoveho existuje i jine oduvodneni nez to, ze ty to proste chces.Viz FlatBuffers.
4.5.2018 12:25
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Osmibity jsem používal.Což mimochodem tenhle blog a celá moje snaha je jen pokračování toho o čem jsem psal v roce 2011. O sehnání lepšího systému poskytující lepší uživatelské API.
Já neřeším co je obecně životaschopné. Řeším to primárně čistě sobeckyV tom pripade nedava smysl vzlykat nad tim, kolik veci je na selfu spatne.
Jinak nevím, proč předpokládáš, že to musí být provázáno všechno se vším jinak než na úrovni API / interface objektů.Protoze ze zkusenosti vim, ze navrhnout dobre rozhrani musi bolet. Je strasne jednoduche udelat metodu jako public (bez rozmyslu, protoze ji zrovna potrebujes) a pak ji dalsich 10 let musis podporovat, protoze na tom zavisi dalsi kod/lidi. Postupem casu ti z toho vznikne neudrzovatelny moloch. Pokud nad rozhranim musis alespon chvili premyslet, je sance, ze to udelas dobre. Je to taky jeden z duvodu, proc se v poslednich cca 10 letech rozjely microservices. Umoznuji totiz implementovat modularni architekturu, pricemz jednotlive moduly jsou nezavisle a mezi moduly se komunikuje dobre definovanymi a uchopitelnymi rozhranimi. Vec, o ktere pred tim ba(snili) softwarovi inzenyri cela desetileti.
Zrovna unix má spoustu problémů na spoustě míst. Například tty subsystém je něco příšerného.Bavime se tu o navrhu architektury a koncepci. Tvuj argument je silne zavadejici, protoze kazdy dostatecne velky a leta existujici software ma podobna zakouti.
Osmibity jsem používal.Budiz. Zkus ho pouzivat par mesicu, jako hlavni nastroj na programovani. Mozna zmenis nazor na oddelene pametove prostory. Treba takova hezka chyba je, kdyz ti ujede konec smycky, zacne prepisovat pamet interpretru/prekladace, ten spadne a muzes zacit programovat od zacatku, protoze zdrojaky jsou jen v pameti.
Viz FlatBuffers.Tak sis zvolil n+1 reprezentaci dat. Co to resi?
4.5.2018 16:01
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
V tom pripade nedava smysl vzlykat nad tim, kolik veci je na selfu spatne.Proč? Je to nazvané „selfové povzdechnutí“. Proč nedává smysl si povzdechnout?
Protoze ze zkusenosti vim, ze navrhnout dobre rozhrani musi bolet. Je strasne jednoduche udelat metodu jako public (bez rozmyslu, protoze ji zrovna potrebujes) a pak ji dalsich 10 let musis podporovat, protoze na tom zavisi dalsi kod/lidi. Postupem casu ti z toho vznikne neudrzovatelny moloch. Pokud nad rozhranim musis alespon chvili premyslet, je sance, ze to udelas dobre. Je to taky jeden z duvodu, proc se v poslednich cca 10 letech rozjely microservices. Umoznuji totiz implementovat modularni architekturu, pricemz jednotlive moduly jsou nezavisle a mezi moduly se komunikuje dobre definovanymi a uchopitelnymi rozhranimi. Vec, o ktere pred tim ba(snili) softwarovi inzenyri cela desetileti.Jo, a Self jsou nanoservices, kde je microservice každý objekt.
Bavime se tu o navrhu architektury a koncepci. Tvuj argument je silne zavadejici, protoze kazdy dostatecne velky a leta existujici software ma podobna zakouti.Unix má podobná zákoutí už 30 let, jsou zcela otevřeně kritizována, ale nejde s tím vůbec nic udělat. A linux s Linusovou politikou "nikdy nerozbíjet userspace" je na tom úplně stejně.
Budiz. Zkus ho pouzivat par mesicu, jako hlavni nastroj na programovani. Mozna zmenis nazor na oddelene pametove prostory. Treba takova hezka chyba je, kdyz ti ujede konec smycky, zacne prepisovat pamet interpretru/prekladace, ten spadne a muzes zacit programovat od zacatku, protoze zdrojaky jsou jen v pameti.Já ale nemluvím o sdíleném adresním prostoru. To je naprosto nevhodná vrstva abstrakce. Mluvím tu o tom, že můžeš učinit veřejně přístupné vybrané metody objektů a posílat jim zprávy.
Tak sis zvolil n+1 reprezentaci dat. Co to resi?Nemusíš parsovat.
Jo, a Self jsou nanoservices, kde je microservice každý objekt.Dnes by stálo za to se posunout o abstrakci výš a uvažovat nad skupinami objektů - přímo nad konceptem image. Málokterý objekt žije samostatně. Tvoří rozlehlé grafy a než být nucen komunikovat s jediným objektem tvořícím rozhraní toho grafu, je mnohem výhodnější mít možnost komunikovat s vybranými objekty uvnitř. Samozřejmě ten graf, image jako celek, musí o té komunikaci vědět a mít možnost ji moderovat. To samozřejmě Self zvládá, jen chci říct, že obrovskou důležitost v tom musí hrát různé proxy objekty a pokud dnes chce člověk začít od píky, měl by to mít na zřeteli, aby si nehodil zbytečně nějaké klacky pod nohy.
4.5.2018 17:09
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
4.5.2018 22:42
xkucf03 | skóre: 50
| blog: xkucf03
Mluvím tu o tom, že můžeš učinit veřejně přístupné vybrané metody objektů a posílat jim zprávy.
D-Bus, JMX, SOAP, RMI, CORBA… a to v naprosto běžných a v praxi používaných jazycích.
5.5.2018 11:20
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Pokud to má fungovat i bez vědomí autora programu a bez jeho aktivity, tak by šel použít debugger – můžeš si naskriptovat GDB a zasahovat přes něj do programu, číst jeho vnitřní stavy, můžeš to dělat i pro Javu, Python a asi většinu jazyků. Např. v Netbeans si můžeš hezky rozklikávat strom objektů a můžeš je dokonce (do určité míry) patchovat za chodu – přepisovat kód tříd (propisuje se do již existujících instancí).
Otázka je, jak resp. kdy/kudy do programu vstoupit – protože pro program není primární koncept objektů, ale spíš koncept vláken – objekt sám o sobě nic nedělá a vlastně jen čeká, až přijde vlákno a zavolá nějaké jeho metody, vykoná jejich kód. Objekt se nemůže utrhnout ze řetězu a říct si: teď budu něco dělat a pošlu jinému objektu zprávu. Takže i když do toho budeš vstupovat zvenku, potřebuješ nějaké vlákno – to ti může připravit buď autor programu či běhového prostředí nebo si zastavíš nějaké existující a vykonáš v něm svoje vlastní instrukce.
A např. ve VisualVM můžeš psát dotazy v OQL a prohledávat objekty v paměti.
5.5.2018 14:42
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Pokud to má fungovat i bez vědomí autora programu a bez jeho aktivity, tak by šel použít debugger – můžeš si naskriptovat GDB a zasahovat přes něj do programu, číst jeho vnitřní stavy, můžeš to dělat i pro Javu, Python a asi většinu jazyků. Např. v Netbeans si můžeš hezky rozklikávat strom objektů a můžeš je dokonce (do určité míry) patchovat za chodu – přepisovat kód tříd (propisuje se do již existujících instancí).Jo, já vím. To mi ale nepřijde jako udržitelný přístup.
Treti problem je, ze pokud bys mel primy pristup ke vsemu, co nejaky proces ma v pameti a zacal to pouzivat, muzes zapomenout na nejaka jasne definovana rozhrani a dohnat softwarovou cast systemu k dokonalemu a neuchopitelnemu chaosu.
+1 O tom jsme tu už jednou mluvili – taková otevřenost a zpřístupnění implementačních detailů programu všem ostatním představuje zásadní problém do budoucna, protože a) autoři programu budou muset držet zpětnou kompatibilitu a budou mít svázané ruce, nebudou moci program vylepšovat, optimalizovat… nebo b) na zpětnou kompatibilitu se vykašlou, ale pak budou nešťastní zase ti, kteří ty objekty používají a něco na ně napojili – v příští verzi se jim to rozsype a budou muset přepisovat.
5.5.2018 11:21
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
+1 O tom jsme tu už jednou mluvili – taková otevřenost a zpřístupnění implementačních detailů programu všem ostatním představuje zásadní problém do budoucna, protože a) autoři programu budou muset držet zpětnou kompatibilitu a budou mít svázané ruce, nebudou moci program vylepšovat, optimalizovat… nebo b) na zpětnou kompatibilitu se vykašlou, ale pak budou nešťastní zase ti, kteří ty objekty používají a něco na ně napojili – v příští verzi se jim to rozsype a budou muset přepisovat.Já tu nemluvím o přímém přístupu do paměti, ale k objektům. Pak se ti ten problém smrskne na udržování API. To o čem mluvím je trochu podobné sdíleným knihovnám, které jasně definují API a způsoby volání.
5.5.2018 12:32
xkucf03 | skóre: 50
| blog: xkucf03
Já tu nemluvím o přímém přístupu do paměti, ale k objektům. Pak se ti ten problém smrskne na udržování API.
Vždyť i ty objekty/třídy se v čase mění, refaktoruješ kód, něco přejmenuješ, něco smažeš, můžeš úplně překopat vnitřní uspořádání objektů v programu a přitom zachovat rozhraní programu. A tady jde právě o to, co se prohlásí za veřejné API (tzn. zavážeš se u toho dodržovat zpětnou kompatibilitu) a co jsou vnitřní implementační detaily (na které by se nikdo cizí spoléhat neměl a které se mohou kdykoli bez varování změnit). Pokud máš v téhle otázce jasno, tak už nebývá problém to veřejné API zpřístupnit nějakým standardním protokolem – to je to nejmenší.
5.5.2018 14:47
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Vždyť i ty objekty/třídy se v čase mění, refaktoruješ kód, něco přejmenuješ, něco smažeš, můžeš úplně překopat vnitřní uspořádání objektů v programu a přitom zachovat rozhraní programu. A tady jde právě o to, co se prohlásí za veřejné API (tzn. zavážeš se u toho dodržovat zpětnou kompatibilitu) a co jsou vnitřní implementační detaily (na které by se nikdo cizí spoléhat neměl a které se mohou kdykoli bez varování změnit). Pokud máš v téhle otázce jasno, tak už nebývá problém to veřejné API zpřístupnit nějakým standardním protokolem – to je to nejmenší.Tak zrovna v programovacích jazycích je to běžně řešeno tím, že něco uděláš public a něco protected / private. V Selfu se to typicky řeší anotací. Ve skutečnosti je to klasický javařův problém. Python je dynamický jazyk, který nepodporuje výše uvedené modifikátory. Všechno se v něm dá zpřístupnit, ke všemu přistoupit a upravit to, monkeypatchnout a znásilnit jak se ti chce. Lidi z javy, když tohle vidí, tak jim vstávaj vlasy na hlavě. Přesto je python široce používaný a tyhle problémy s nekompatibilitou v něm vznikají jen úplně minimálně. Proč?
5.5.2018 20:05
xkucf03 | skóre: 50
| blog: xkucf03
Zrovna tohle jsem nemyslel jako narážku na Java vs. Python. Na téhle úrovni je celkem jedno, jestli pro to jazyk poskytuje nějakou podporu formou anotací nebo public/private. Tady mi šlo primárně o to, že je to hlavně organizační problém, otázka komunikace a nastavení pravidel mezi programátory. Klidně to může být napsané někde v textu stylem: tyhle konkrétní třídy nebo třídy v tomhle balíčku/modulu jsou veřejné API a u nich budeme držet zpětnou kompatibilitu, zatímco jiné třídy/funkce/struktury/… jsou náš interní implementační detail a můžeme si ho měnit kdykoli a bez varování. Samozřejmě, že je lepší, když k tomu jazyk poskytne podporu a lze tuto informaci sdělit strojově čitelnou formou, ale není to nezbytně nutné.
A když už máš jasně vymezené, co je to veřejné API, tak opravdu není tak těžké tyto objekty zpřístupnit nějakým protokolem/rozhraním, aby se na něj mohli ostatní napojovat – a není k tomu potřeba žádný revoluční jazyk nebo platforma, opravdu to jde i v těch běžně používaných nebo i celkem obstarožních technologiích.
Přesto je python široce používaný a tyhle problémy s nekompatibilitou v něm vznikají jen úplně minimálně. Proč?
Tak to opravdu netuším. Dejme tomu, že si v debuggeru prostuduji nějaký cizí program a napojím svůj kód na jeho datové struktury a vnitřní metody. V další verzi se autor programu rozhodne, že tyto vnitřní implementační detaily zrefaktoruje. Jak Python přispěje k tomu, aby se ten můj kód nerozsypal? IMHO to nebude fungovat o nic líp než, kdyby to bylo v Javě. Kompatibilní to bude leda za předpokladu, že se věci moc nemění, nesaháš na starý kód, nerefaktoruješ… (nicméně opravdu se tu nechci hádat na téma Java vs. Python, tak tohle klidně ignoruj, šlo mi spíš o to, co píšu v tom prvním odstavci)
5.5.2018 20:14
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Zrovna tohle jsem nemyslel jako narážku na Java vs. Python.Já vím, že ne. Jenže python umožňuje v tomhle ohledu to samé co Self a přesto v něm problémy nevznikají, nebo jen tak zřídka, že se ke mě prostě nedostanou, přestože python dělám každý den od rána do večera a vystřídal jsem už několik fakt velkých projektů.
Tak to opravdu netuším. Dejme tomu, že si v debuggeru prostuduji nějaký cizí program a napojím svůj kód na jeho datové struktury a vnitřní metody. V další verzi se autor programu rozhodne, že tyto vnitřní implementační detaily zrefaktoruje. Jak Python přispěje k tomu, aby se ten můj kód nerozsypal? IMHO to nebude fungovat o nic líp než, kdyby to bylo v Javě. Kompatibilní to bude leda za předpokladu, že se věci moc nemění, nesaháš na starý kód, nerefaktoruješ… (nicméně opravdu se tu nechci hádat na téma Java vs. Python, tak tohle klidně ignoruj, šlo mi spíš o to, co píšu v tom prvním odstavci)Chápu. Osobně jsem proto, aby to bylo možné, s tím že když se chceš střelit do nohy, tak můžeš. Když to autor změní, tak to prostě budeš muset změnit. Ničím se to neliší od toho, kdyby změnil třeba API. Teoreticky se to může měnit častěji, ale znova .. tohle je podle mých zkušeností v praxi docela lichá obava. Určitě bych na tom nestavěl elektrárnu, ale vlastní script? Proč ne?
5.5.2018 21:23
xkucf03 | skóre: 50
| blog: xkucf03
To mi připomíná systémy, které se pokoušejí parsovat HTML stránky a získávat z nich nějaké strukturované informace.1 Přijde mi smutné, že se tohle musí dělat, je to obrovské plýtvání potenciálem, hloupé2 využívání technologií, které máme. Asi jako kdybys měl dopravní prostředek, který tě dostane na Mars a ty jsi s ním jen jezdil kolem baráku. Tohle je součást toho špatného stavu, ve kterém se IT nachází.
Jak z toho ven? Napadají mě dvě řešení. Buď nějaká umělá inteligence, která porozumí mj. přirozenému jazyku a která se bude umět adaptovat. Nebo se lidi naučí používat formáty pro strukturovaná data, použijí nějaký strojově čitelný formát, poskytnou API.
Ta první varianta zní lákavě, v některých případech by mohla přinést nevídané a jinak nedosažitelné výsledky, ale ve většině případů se obávám, že povede ke stagnaci a zafixování současného stavu – lidi se budou chovat hloupě a nebudou se rozvíjet, nebudou se snažit, protože umělá inteligence to vyřeší za ně. Výsledky budou stejné, jako kdyby se člověk snažil a zlepšoval (např. poskytl data ve strojově čitelném formátu), ale obrovsky naroste komplexita a spolehlivost spíš klesne.
Ten nárůst komplexity souvisí s tím, co vnímám jako ztrátu determinističnosti a exaktnosti. IT býval exaktní obor, počítače se chovaly předvídatelně a dělaly jen to, co jim člověk nařídil. Ale s tím, jak rostoucí komplexita přesahuje lidské schopnosti věci porozumět, se posouváme spíš k nějakému šamanismu a mytologii. Už teď se na sebe nekontrolovatelně vrší knihovny, frameworky a další vrstvy softwaru, které mají údajně usnadňovat a šetřit práci, ale výsledek je často opačný. Věci budou nějak fungovat, ale nikdo nebude vědět proč. Ztratíme schopnost spolehlivě zasahovat do systémů a jednoznačně ovlivňovat jejich chování. Budeme kolem počítačů zapalovat svíčky, stavět oltáře a doufat, že se to nerozbije. Občas zkusíme něco poštelovat a požadované výsledky se někdy dostaví, jindy ne a nebo se to taky rozbije na úplně nečekaném místě. Nějací šamani a mudrcové budou říkat, jestli to je či není dobrý nápad, asi nějak na základě intuice a zkušeností, ale občas se netrefí a předpověď selže – to se pak prohlásí za trest bohů a osud, který je třeba přijmout.
[1] Slyšel jsem např. o systému, který poskytuje seznam obecních úřadů a data získává tak, že na zoznam.sk vyhledá frázi „obecní úřad“ (slovensky) a pak parsuje HTML výstup. Občas se to samozřejmě rozsype.
[2] Je to jako kdyby jeden vyplňoval hodnoty do papírového formuláře, posílal faxem nebo poštou a druhý to pak skenoval a pomocí OCR převáděl do počítače. Technologie sice zajistila, že to nějak funguje, ale celé jsme si to mohli odpustit a ten první to mohl vyplňovat do webového formuláře třeba na tabletu – místo toho na něm zabíjí čas sledováním zbytečných lidí, kteří se předvádí před kamerou, nebo konzumací infotainmentových imaginárních zpráv, které mají spíš pobavit než přinést užitečné a pravdivé informace.
5.5.2018 21:51
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
To mi připomíná systémy, které se pokoušejí parsovat HTML stránky a získávat z nich nějaké strukturované informace.1 Přijde mi smutné, že se tohle musí dělat, je to obrovské plýtvání potenciálem, hloupé2 využívání technologií, které máme. Asi jako kdybys měl dopravní prostředek, který tě dostane na Mars a ty jsi s ním jen jezdil kolem baráku. Tohle je součást toho špatného stavu, ve kterém se IT nachází.Souhlasím. Těch systémů jsem napsal spoustu, ke konci jsem si udělal zobecnění v podobě autoparseru, kterému předhodíš vzory dat a on už si najde způsob parsování sám. Ale i tak je to bolest.
Jak z toho ven? Napadají mě dvě řešení. Buď nějaká umělá inteligence, která porozumí mj. přirozenému jazyku a která se bude umět adaptovat. Nebo se lidi naučí používat formáty pro strukturovaná data, použijí nějaký strojově čitelný formát, poskytnou API.To se v posledních letech hodně zlepšilo, ale pořád je co dohánět. Hlavně po uživatelské stránce, protože například poskytování toho API a dat přes něj je pro normálního smrtelníka něco naprosto nemožného. Mám v hlavě určité řešení, ale nechci to teď rozebírat a bude to trvat dlouho.
Ten nárůst komplexity souvisí s tím, co vnímám jako ztrátu determinističnosti a exaktnosti. IT býval exaktní obor, počítače se chovaly předvídatelně a dělaly jen to, co jim člověk nařídil. Ale s tím, jak rostoucí komplexita přesahuje lidské schopnosti věci porozumět, se posouváme spíš k nějakému šamanismu a mytologii. Už teď se na sebe nekontrolovatelně vrší knihovny, frameworky a další vrstvy softwaru, které mají údajně usnadňovat a šetřit práci, ale výsledek je často opačný. Věci budou nějak fungovat, ale nikdo nebude vědět proč. Ztratíme schopnost spolehlivě zasahovat do systémů a jednoznačně ovlivňovat jejich chování. Budeme kolem počítačů zapalovat svíčky, stavět oltáře a doufat, že se to nerozbije. Občas zkusíme něco poštelovat a požadované výsledky se někdy dostaví, jindy ne a nebo se to taky rozbije na úplně nečekaném místě. Nějací šamani a mudrcové budou říkat, jestli to je či není dobrý nápad, asi nějak na základě intuice a zkušeností, ale občas se netrefí a předpověď selže – to se pak prohlásí za trest bohů a osud, který je třeba přijmout.Každá akce probouzí protiakci a protiakce k nárůstu nesmyslné komplexity, které nikdo nerozumí už je možné pomalu, ale polehoučku vidět.
5.5.2018 22:27
xkucf03 | skóre: 50
| blog: xkucf03
Hlavně po uživatelské stránce, protože například poskytování toho API a dat přes něj je pro normálního smrtelníka něco naprosto nemožného.
Tím normálním smrtelníkem myslíš programátora nebo uživatele?
a) programátor: nástroje a technologie jsou, ve většině jazyků stačí1 přidat nějakou tu anotaci, zavolat metodu, přidat nějaký řádek to kompilačního skriptu… Proč se to nedělá je většinou dané tím, že programátor strukturovaná data nemá nebo je nechce poskytnout nebo je to dané organizací práce – programátor nedostal za úkol to udělat a ten, kdo práci řídí, to nepovažuje za důležité, nevidí v tom smysl nebo svůj zájem (je hodnocen a odměňován za něco jiného). Další věc je, že zveřejnit API je závazek, svazuje ti to ruce, nemůžeš ho jen tak měnit. Už před mnoha lety jsi mohl vystavit strukturovaná data ve formátu XML a k tomu připojit XSLT šablonu, která data převede na lidsky čitelný tvar. To je podle mého ideální, jsou to strojově čitelná data a zároveň jim rozumí běžný uživatel. Zároveň ten závazek se týká jen toho XML – díky oddělení dat od jejich prezentace si tu prezentaci (XSLT) můžeš překopat libovolně kdykoli se ti zachce. Že se to moc nepoužívá považuji za selhání člověka, nikoli technologie. Kdo nemá rád XML, mohl si vymyslet jiný formát s jiným druhem závorek, ale pravděpodobně by to dopadlo stejně.
b) uživatel: tady by se hodilo mít wiki-systém, ve kterém by se neupravovaly textové dokumenty, ale strukturovaná data. Něco jako OpenStreetMap, ale pro libovolný typ dat. Nejobecnější by byla nějaká grafová/objektová databáze, ale přijde mi, že pro uživatele je mentálně uchopitelnější koncept tabulek – tedy relační databáze. Bez ohledu na zvolený model by to mělo uchovávat historii, umožnit porovnávat verze nebo vracet změny.
protiakce k nárůstu nesmyslné komplexity, které nikdo nerozumí už je možné pomalu, ale polehoučku vidět.
Můžeš být konkrétnější?
Doufám, že nemyslíš Suckless.org – protože s tímhle přístupem to nikam nedotáhnou, nemá šanci se to rozšířit mezi běžné uživatele, a i z pohledu pokročilého uživatele/programátora mi tam některé koncepty přijdou vyloženě vadné (např. konfigurace spočívající v editaci zdrojáku a následném překompilování).
Sám píšu něco trochu podobného – Manifest příčetného softwaru – kde jedním z hlavních motivů je právě zvládnutí komplexity resp. její předcházení. Ale jdu trochu jinou cestou než Suckless.
[1] ovšem úplně jiná věc je promyšlený návrh takového API – to je netriviální mentální činnost a nelze ji nahradit žádnou technologií – to si bohužel spousta lidí neuvědomuje a pod pojmem „udělat API“ vidí jen tu technologii, frameworky, generátory… přitom největší úkol je právě to přemýšlení o návrhu, datových strukturách a službách
5.5.2018 22:42
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Tím normálním smrtelníkem myslíš programátora nebo uživatele?Myslel jsem uživatele.
programátor: nástroje a technologie jsou, ve většině jazyků stačí1 přidat nějakou tu anotaci, zavolat metodu, přidat nějaký řádek to kompilačního skriptu…Jo, a server (stroj), doménu, způsob správy obsahu a deployment a ..
b) uživatel: tady by se hodilo mít wiki-systém, ve kterém by se neupravovaly textové dokumenty, ale strukturovaná data. Něco jako OpenStreetMap, ale pro libovolný typ dat. Nejobecnější by byla nějaká grafová/objektová databáze, ale přijde mi, že pro uživatele je mentálně uchopitelnější koncept tabulek – tedy relační databáze. Bez ohledu na zvolený model by to mělo uchovávat historii, umožnit porovnávat verze nebo vracet změny.Tak nějak. Až na to, že nemusíš pracovat s textovými formáty, ale můžeš přímo upravovat objekty.
Doufám, že nemyslíš Suckless.org – protože s tímhle přístupem to nikam nedotáhnou, nemá šanci se to rozšířit mezi běžné uživatele, a i z pohledu pokročilého uživatele/programátora mi tam některé koncepty přijdou vyloženě vadné (např. konfigurace spočívající v editaci zdrojáku a následném překompilování).Ne jen suckless, ale i nástup jazyků jako Rust, které se snaží některé věci podstatně usnadnit. Pak taky ty projekty Alana Kaye, které na to jdou přes generování kódu meta-jazyky, které umí parsovat textové a lidmi čitelné specifikace (tuším že v případě TCP/IP stacku šlo o lehce upravené RFC).
 5.5.2018 22:10
|🇵🇸 | skóre: 94
| blog:
5.5.2018 22:10
|🇵🇸 | skóre: 94
| blog:
 6.5.2018 01:29
Jendа | skóre: 78
| blog: Jenda
| JO70FB
6.5.2018 01:29
Jendа | skóre: 78
| blog: Jenda
| JO70FB
[1] Slyšel jsem např. o systému, který poskytuje seznam obecních úřadů a data získává tak, že na zoznam.sk vyhledá frázi „obecní úřad“ (slovensky) a pak parsuje HTML výstup. Občas se to samozřejmě rozsype.Tak to jsi ještě neslyšel o tomhle. TL;DR lidstvo (jenom v ČR) tráví stovky člověkolet přepisováním dat z faktur a tento startup desítky člověkolet vývojem rozpoznávače údajů (co, kdo, částka, bankovní spojení), protože jsme se nedokázali dohodnout na tom, že v rohu bude QR kód, kde budou tyto informace napsány.
Nebo se lidi naučí používat formáty pro strukturovaná data, použijí nějaký strojově čitelný formát, poskytnou API.Myslíš, že tohle lidé dokážou pojmout (i za předpokladu např. ideálního školství)?
6.5.2018 12:08
xkucf03 | skóre: 50
| blog: xkucf03
Tak to jsi ještě neslyšel o tomhle. TL;DR lidstvo (jenom v ČR) tráví stovky člověkolet přepisováním dat z faktur a tento startup desítky člověkolet vývojem rozpoznávače údajů (co, kdo, částka, bankovní spojení)
Tohle je šílené, smutné a absurdní plýtvání potenciálem technologií, zbytečná práce, která se nemusela vůbec dělat a ještě se to tváří jako nějaká inovace a pokrok. Technologie vede akorát k fixaci špatného stavu a hloupých řešení. Kdyby se to jen opisovalo ručně, tak třeba někoho napadle, že by by bylo fajn, kdyby se faktury rovnou generovaly ve strojově čitelném formátu a svoje dodavatele by k tomu dotlačil. Ale jak se to jednou automatizuje, tak se akorát zafixuje ten současný stav a výsledkem bude nárůst komplexity a zbytečná závislost na složité technologii – což má dopad na všechny kolem, protože když se tohle rozšíří, tak už jen tak někoho k použití strojově čitelného formátu nedotlačíš a budeš si muset pořídit složitou technologii nebo to opisovat ručně.
protože jsme se nedokázali dohodnout na tom, že v rohu bude QR kód, kde budou tyto informace napsány
Ten standard existuje (QR Faktura) a na některých fakturách to i vídám. Což mi připomíná, že bych si měl zamést před vlastním prahem a QR kód na svoje faktury přidat – zatím mám jen ISDOC (ze kterého generuji LaTex a z něho PDF), ale přijde mi, že to nikdo nepoužívá.
Myslíš, že tohle lidé dokážou pojmout (i za předpokladu např. ideálního školství)?
Tady mi šlo hlavně o autory informačních systémů a o manažery, kteří rozhodují, co se bude dělat, které funkce se implementují.
Ale i u obecné veřejnosti si myslím, že data, která se dají reprezentovat formou tabulky, mají celkem šanci na úspěch, na pochopení. Jde jen o praxi, o zkušenost, aby lidi viděli (třeba v těch školách), že něco takového vůbec existuje, že to lze a že to není nějaké sci-fi, ale běžná věc, kterou můžou používat i oni. Pak je potřeba přijmou myšlenku normalizace dat – třeba si párkrát nabít hubu při práci s nenormalizovanými daty a pochopit, proč je to špatně a proč to přidělává práci při dalším zpracování. Tzn. uvědomit si, že tabulka v databázi se navrhuje podle trochu jiných principů než tabulka na papíře, která se pověsí třeba někam na nástěnku (to je až koncový výstup).
A zrovna SQL je podle mého stravitelné i pro ne-IT lidi, uživatele. Vytvořil jsem program SQL Výuka, kde jsou lekce se základy SQL – na tom by se to měl naučit každý, kdo o to má zájem. Znám i dost neprogramátorů (a neprogramátorek), kteří SQL zvládají.
Co se týče nástrojů, pro začátek stačí udělat apt install sqlitebrowser a už si člověk může vytvářet databáze. Pak bych doporučoval přejít na PostgreSQL.
Pro načtení dat z externího zdroje se zase hodí umět ty regulární výrazy nebo umět použít funkci xmltable.
Na straně publikace dat by to chtělo zase nějaký ten wiki-systém, kde by uživatelé mohli vystavovat svoje data. Existuje dbhub.io, ale nevím, jestli tam jde data i upravovat online nebo jen publikovat hotové databáze.
Rezervy tu samozřejmě jsou, sám se to snažím trochu zlepšit… ale i s dnešními nástroji se dají dělat hezké věci a ušetřit si spoustu práce – ale běžní uživatelé ani neví, že něco takového existuje, nebo si myslí, že je to něco šíleně složitého, čemu by nerozuměli – přitom to ale nikdy nezkoušeli. Školství tomu může dost pomoci, ukázat lidem, že ty věci existují a není tak těžké je používat. Jenže dnešní školství dokáže lidem znechutit i dějepis nebo matematiku, tak to je potom těžké. Záleží v první řadě na učitelích – ale pokud naše společnost nebude do vzdělávání investovat, tak těch dobrých učitelů bude málo.
6.5.2018 12:50
|🇵🇸 | skóre: 94
| blog:
Pak je potřeba přijmou myšlenku normalizace dat – třeba si párkrát nabít hubu při práci s nenormalizovanými daty a pochopit, proč je to špatně a proč to přidělává práci při dalším zpracování.
Jenže to je ta inženýrská snaha nějak to svázat, omezit, naplánovat atd. Proto dneska každý druhý používá tabulkový procesor a nikoliv rigidní databázový software, přestože těch před ~30 lety bylo pro koncové uživatele fpysk.
Přesně proto, že strukturu dat chci měnit ad-hoc za chodu (takže obecná matice nebo multigraf mě neomezuje) a dosud jsem neviděl žádný software, ve kterém by šlo pohodlně dělat páratributové relace (aby byla splněna X. normální forma), ale pracovat s nimi, jakoby to byla třeba jedna velká „tabulka“.
O hubu to začíná být ve chvíli, kdy se někdo snaží v tom „excelu“ trochu moc programovat, to už by bylo lepší si ta data nechat načíst do (např.) Matlabu/Octave, R nebo Pythonu a zpracovat je tam (Jupyter je super na to, co vůbec máme).
6.5.2018 13:39
xkucf03 | skóre: 50
| blog: xkucf03
Jenže to je ta inženýrská snaha nějak to svázat, omezit, naplánovat atd.
Ale relační databáze tě k ničemu nenutí, klidně to tam můžeš zmastit stejně blbě jako v tom tabulkovém kalkulátoru. Sloupečky si můžeš přidávat za chodu, v tom není problém. Sám pak přijdeš na to, že ty normální formy dávají smysl (i když třeba ani nebudeš vědět, že se to takhle jmenuje).
Problém je spíš v tom, že lidi nemají ta data kde hostovat, jak je sdílet. Často to jsou serverové aplikace, které se musí nainstalovat, nakonfigurovat v nich uživatelské účty, založit databáze… není to těžké, ale pro BFU to prostě určitá překážka je. To má bohužel za následek, že většina uživatelů otevře ten tabulkový kalkulátor, začne to mastit v něm a výsledek pak pošle e-mailem kolegovi.
To už je lepší použít LibreOffice Base než ten tabulkový kalkulátor.
takže obecná matice nebo multigraf mě neomezuje
Ty myslíš, že BFU zvládne pracovat s grafovými daty? Vyvářet je dovede (dost lidí používá třeba myšlenkové mapy), ale pak už na to může leda tak koukat nebo maximálně posouvat jednotlivé uzly myší. Ale že by nad tím dovedl psát dotazy nebo transformovat data do jiného tvaru, to jsem ještě neviděl. Data v takovém tvaru jsou pro většinu lidí konečná. Naopak dělat nějakou tu projekci a restrikci nad relacemi lidé celkem zvládají.
6.5.2018 14:49
|🇵🇸 | skóre: 94
| blog:
Ale relační databáze tě k ničemu nenutí, klidně to tam můžeš zmastit stejně blbě jako v tom tabulkovém kalkulátoru. Sloupečky si můžeš přidávat za chodu, v tom není problém. Sám pak přijdeš na to, že ty normální formy dávají smysl (i když třeba ani nebudeš vědět, že se to takhle jmenuje).
Taky je možné, že jsem ještě neviděl databázový software s rozumným UX.
Problém je spíš v tom, že lidi nemají ta data kde hostovat, jak je sdílet. Často to jsou serverové aplikace, které se musí nainstalovat, nakonfigurovat v nich uživatelské účty, založit databáze… není to těžké, ale pro BFU to prostě určitá překážka je. To má bohužel za následek, že většina uživatelů otevře ten tabulkový kalkulátor, začne to mastit v něm a výsledek pak pošle e-mailem kolegovi.
Google Docs. Ano, figuruje tam Google. LibreOffice prý umí něco podobného a integruje s (Own|Next)Cloudem.
Ty myslíš, že BFU zvládne pracovat s grafovými daty?
Ano, „tabulka“ v „excelu“ je typicky graf, kde buňky jsou uzly. ~_^
Asi by mi nevadilo, kdyby za podobným UX backend data nějak chytře ukládal jako relace, ale asi by tam byla dost velká režie, když nic jiného.
Ale relační databáze tě k ničemu nenutí, klidně to tam můžeš zmastit stejně blbě jako v tom tabulkovém kalkulátoru. Sloupečky si můžeš přidávat za chodu, v tom není problém. Sám pak přijdeš na to, že ty normální formy dávají smysl (i když třeba ani nebudeš vědět, že se to takhle jmenuje).Hezka predstava. Vrele doporucuji nahlednout do par instituci, kde se sikovnejsi zamestnanec (prip. z sefova napadu) rozhodl, ze si udelaji ,,evidenci na XY'' v Accessu. Zacne to jako jedna, dve, tri jednoduche tabulky a po peti letech inkrementalniho vyvoje z toho vznikne predobraz databazoveho pekla, ve kterem se uz nikdo nevyzna, natoz aby tam sly hledat normalni formy. Par takovych ,,systemu'' jsem jiz videl a opravdu tem lidem nedochazelo, ze by se data mohla nejak normalizovat, byli proste radi, ze jim to nejak funguje.
6.5.2018 14:30
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Na straně publikace dat by to chtělo zase nějaký ten wiki-systém, kde by uživatelé mohli vystavovat svoje data. Existuje dbhub.io, ale nevím, jestli tam jde data i upravovat online nebo jen publikovat hotové databáze.Je to v todo.
6.5.2018 14:35
xkucf03 | skóre: 50
| blog: xkucf03
To mi připomíná systémy, které se pokoušejí parsovat HTML stránky a získávat z nich nějaké strukturované informace.1 Přijde mi smutné, že se tohle musí dělat, je to obrovské plýtvání potenciálem, hloupé2 využívání technologií, které máme. Asi jako kdybys měl dopravní prostředek, který tě dostane na Mars a ty jsi s ním jen jezdil kolem baráku. Tohle je součást toho špatného stavu, ve kterém se IT nachází.IMHO to není až tak hloupé a není to až tak špatný stav, spíš je to tradeoff. Je dobrý si uvědomit, co by se muselo stát, aby měl být web XY dobře strojově zpracovatelný a/nebo mít API. Musel by se držet nějakého standardu k tomu určeného, s tím, že ten standard není a nebude jen jeden. Dále by to musel někdo (správně) nasadit a udržovat ve funkčnosti. V případě API ho musí někdo udržovat, zajišťovat kompatibilitu, mít k němu nějakou dokumentaci, atd... Nehledě k tomu, že některé weby nemají API a parsovatelná data zcela záměrně - např. YouTube... Samozřejmě, že se to všechno dá udělat, v dnešní době to ani není těžký. Ale stojí to nezanedbatelné úsilí a nikdo to dělat nebude, pokud pro to nemá dostatečný důvod. Ono není až tak divné, že lidi s tím dopravním prostředkem jezdí jen kolem baráku, i když by uměl letět na Mars, vzhledem k tomu, kolik by je stálo prachů na ten Mars letět, navíc tam třeba ani nechtějí. Myslim si, že reálná šance, jak dosáhnout něčeho bližšího tomu, co si ty (a asi Bystroušák) představujte pod lepším stavem, by bylo jít na to přes accesibility (tj. myšleno přístupnost pro postižené uživatele). Tam by asi byla větší ochota lidí něco implementovat.
21.5.2018 14:01
|🇵🇸 | skóre: 94
| blog:
Samozřejmě, že se to všechno dá udělat, v dnešní době to ani není těžký. Ale stojí to nezanedbatelné úsilí a nikdo to dělat nebude, pokud pro to nemá dostatečný důvod.
To mi něco (přepis) připomíná.
We hear that not only is change accelerating but that the pace of change is accelerating as well. While this is true of computational carrying-capacity at a planetary level, at the same time – and in fact the two are connected – we are also in a moment of cultural de-acceleration.
We invest our energy in futuristic information technologies, including our cars, but drive them home to kitsch architecture copied from the 18th century. The future on offer is one in which everything changes, so long as everything stays the same. We'll have Google Glass, but still also business casual.
This timidity is our path to the future? No, this is incredibly conservative, and there is no reason to think that more gigaflops will inoculate us.
Because, if a problem is in fact endemic to a system, then the exponential effects of Moore's law also serve to amplify what's broken. It is more computation along the wrong curve, and I doubt this is necessarily a triumph of reason.
21.5.2018 14:16
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Nehledě k tomu, že některé weby nemají API a parsovatelná data zcela záměrně - např. YouTube...YouTube má API a parsovatelná data úplně od začátku: https://developers.google.com/youtube/v3/. Naopak, moderní javascriptový web a trend mobilních aplikací způsobil takový gigantický boom v růstu API na internetu, jako nikdy nic jiného. Dneska s tebou celý všechno mluví a nabízí možnost interagovat. Co chybí je prostředí, které by ti to umožnilo stejně nativně, jako ti například operační systém umožňuje pracovat se soubory.
Myslim si, že reálná šance, jak dosáhnout něčeho bližšího tomu, co si ty (a asi Bystroušák) představujte pod lepším stavem, by bylo jít na to přes accesibility (tj. myšleno přístupnost pro postižené uživatele). Tam by asi byla větší ochota lidí něco implementovat.Já nemám problém si to implementovat sám. Pro abclinuxu jsem si taky API napsal během asi dvou dní. Kdysi jsem ještě v Národní knihovně začal psát autoparser, který byl po pár dnech vývoje schopný generovat velké části podobných API čistě jen na základě několika příkladů toho co chceš parsovat na základě hledání invariantních cest a vztahů ve stromových strukturách. Přes ten tebou zmiňovaný machine learning by se asi dalo dostat i dál, tahle otázka mi tedy přijde více/méně vyřešená.
21.5.2018 20:46
|🇵🇸 | skóre: 94
| blog:
There are two ways of constructing a software design: One way is to make it so simple that there are obviously no deficiencies and the other way is to make it so complicated that there are no obvious deficiencies.C.A.R. Hoare, The 1980 ACM Turing Award Lecture
21.5.2018 21:38
xkucf03 | skóre: 50
| blog: xkucf03
není to až tak špatný stav, spíš je to tradeoff
V případě webu možná. Tam bylo zřejmě cílem umožnit lidem co nejsnazší publikování, protože ti lidé měli cenné informace a kdyby jim někdo „házel klacky pod nohy“ tím, že by vyžadoval formálně správný a přesný výstup (syntaxi), tak by si ty informace nechali pro sebe a web by se tolik nerozšířil.
Na tom něco je. Ovšem byla by chyba tohle považovat za univerzálně správný přístup, který by se měl uplatňovat všude – protože dokáže být hodně škodlivý a zásadně zkomplikovat věci v budoucnu (i v hodně blízké budoucnosti). Proti tomu jde myšlenka, že většinou píšeš jen jednou zatímco čteš mnohokrát (resp. mnoho lidí nebo strojů čte), tudíž je lepší optimalizovat jinde – dát si trochu víc práce při psaní a ušetřit si spoustu práce a starostí při čtení. On ten přístup „buď striktní v tom, jaká data produkuješ, ale tolerantní v tom, jaká přijímáš“ je sice teoreticky správný a měl by přispívat k vyšší kompatibilitě, ale problém je, že to začne brzo hnít, vyvolá to reakci, která změní původní situaci – lidi si zvyknou, že někam můžou poslat nepřesný vstup (což ale ve specifikaci popsáno není) a bude to fungovat – a pak se budou divit, že jinam stejně nepřesný vstup poslat nemohou. A tím se bude prohlubovat nejistota, co je správně a co ne, a pak se různé systémy budou v různé míře přizpůsobovat a tolerovat horší vstup a bude se akorát roztáčet spirála nejednoznačnosti. Až v určitém ne příliš vzdáleném bodě narazíš na kolize, kdy si jednu nepřesnost jeden vyloží nějak a druhý jinak a celé se to začne hroutit.
Já jsem teď v trochu podobné situaci jako ten web tehdy, protože něco tvořím a je v mém zájmu, aby se co nejvíc lidí (autorů) připojilo a přidalo do svého programu podporu výstupu v novém formátu. Ale nemyslím si, že by byla správná cesta tolerovat chyby oproti formátu (jako třeba v HTML). Cestou podle mého je poskytnout dostatečně srozumitelnou specifikaci + příčetné referenční implementace v různých jazycích (což je taky důvod, proč se teď zabývám i C a C++, protože v nich je stále většina relevantního softwaru). S dobrou knihovnou může kdokoli generovat formálně přesný výstup, aniž by ho to nějak bolelo.
Musel by se držet nějakého standardu k tomu určeného, s tím, že ten standard není a nebude jen jeden. Dále by to musel někdo (správně) nasadit a udržovat ve funkčnosti.
Obávám se, že v rámci té kultury, která vznikla kolem webu je to už nereálné, že není cesty zpět. Ti lidé si zvykli mlít hovna a přijde jim to normální. Kdyby se šlo vrátit zpět, tak by podle mého pomohlo, kdyby od začátku existovaly nástroje na kontrolu správnosti – HTML bys sice asi pořád psal ručně, ale hned by sis zkontroloval, jestli v něm nejsou chyby. Ba co víc, měl existovat nástroj, který by z HTML-hnoje vygeneroval formálně správné HTML, které bys teprve nahrál na webový server. Make tehdy samozřejmě existoval a různé generátory parserů/gramatik taky. Stačil by na to jediný skript/program, který by to přesypal z /var/hovna do /var/www. Ostatně dneska lidi kompilují i JavaScripty nebo PHPko a zjevně jim to nijak nevadí. Prohlížeče pak mohly být jednodušší, nemusely by řešit chyby (ty by se vyřešily před nahráním na WWW server) a mohly být kompatibilnější. Jmenné prostory by zase umožnili, aby se specifická dodatečná funkcionalita a rozšíření nemísila se standardem a nedocházelo ani ke kolizím mezi rozšířeními různých autorů.
Ale stojí to nezanedbatelné úsilí
Úsilí to stojí jen jednou a na začátku. Jenže pokud ho nejsi ochotný vynaložit, tak uvázneš v lokálním maximu. Je to asi jako „napsat si jednou skript“ vs. „tisíckrát opakovat ruční operaci“. Jasně, spousta lidí zvolí to druhé, protože toho prvního není schopna, ale nevidím důvod, proč se tomu přizpůsobovat a uhýbat tímhle směrem – nebo k tomu dokonce někoho nabádat a vést (to směřuje k Idiokracii).
nikdo to dělat nebude, pokud pro to nemá dostatečný důvod
On ten důvod může časem „zmizet“ – jak jsem tu psal v tom vlákně o rozpoznávání faktur. Najednou už nebude potřeba tolik ručních opisovačů, takže pro mnoho lidí ten problém zmizí – a tím zmizí i motivace dělat věci lépe a vyspělá technologie zafixuje současný špatný stav. Komplexita ale naroste a už bude pro lidstvo obtížnější ovládat ten nástroj, protože nástroj je najednou řádově složitější – přitom ale dělá stejný užitek, jako původní primitivní nástroj + rozumnější návrh. Tohle lze omluvit leda tím, že se ta technologie pak použije k něčemu jinému, kde bude nenahraditelně užitečná, protože tu jinou věc by nešlo opravit stejným způsobem jako lidský produkt (faktury). Např. rozpoznávání nějakých věcí v přírodě nebo ve vesmíru, které nejsou produktem člověka.
Myslim si, že reálná šance, jak dosáhnout něčeho bližšího tomu, co si ty (a asi Bystroušák) představujte pod lepším stavem, by bylo jít na to přes accesibility (tj. myšleno přístupnost pro postižené uživatele). Tam by asi byla větší ochota lidí něco implementovat.
Ono hodně záleží, co je za tou neochotou dělat věci líp. Jestli je to lenost, neschopnost, absence vhodných nástrojů nebo úmysl. Zrovna u postižených bude mít spousta lidí pocit, že by jim měla pomoci a naopak nebudou mít strach, že jim třeba slepec „ukradne jejich data“. Navíc to může být podpořené nějakým „módním“ trendem nebo legislativou. Ale otevírat svoje data pro obecné strojové zpracování, to bude spoustě lidí proti srsti. A vlastně se jim ani moc nedivím. Protože na druhém konci drátu nemusí být nějaký zvídavý Bystroušák, který to použije pro sebe, ale třeba nějaká korporace, která si chce přivlastnit výsledky cizí práce a přeprodávat je dál, aniž by se podělila o zisk. Tohle je ještě dost neznámá – jak zajistit motivaci, zachovat autorství a zásluhy a nějak transparentně a spravedlivě směrovat případný zisk k tomu, kdo se podělil o svoje data a služby.
Pokud někdo začne ve velkém vytěžovat rozhraní pro postižené, tak se dočkáme leda nějaké CAPTCHy, kde budeš muset prokázat, že jsi skutečně slepý, nebo v horším případě budou mít čtecí zařízení DRM a klíče, aby se zajistilo, že poskytovatel komunikuje s autorizovaným zařízením a ne někým, kdo jen vytěžuje jeho API.
21.5.2018 22:19
xkucf03 | skóre: 50
| blog: xkucf03
Ale stojí to nezanedbatelné úsilíZrovna tady je trefný obrázek: Workaround :-)
Obávám se, že v rámci té kultury, která vznikla kolem webu je to už nereálné, že není cesty zpět. Ti lidé si zvykli mlít hovna a přijde jim to normální. Kdyby se šlo vrátit zpět, tak by podle mého pomohlo, kdyby od začátku existovaly nástroje na kontrolu správnosti – HTML bys sice asi pořád psal ručně, ale hned by sis zkontroloval, jestli v něm nejsou chyby. Ba co víc, měl existovat nástroj, který by z HTML-hnoje vygeneroval formálně správné HTML, které bys teprve nahrál na webový server.Jenže když by ses vrátil zpět, tak bys zjistil, že na začátku žádné "validní HTML" neexistovalo, to přišlo až později, až dodatečně. Navíc mi přijde, že "validní HTML" taky nemá úplně smysluplné požadavky, nehledě k tomu, že strojovému zpracování až tak nepomáhá. Abychom si rozuměli, mně se kultura okolo webdevolopementu taky kdovíjak nelíbí. (Zejména hipstři poslední doby.) Ale přijde mi jako dost iluzorní si myslet, že dřív to bylo "lepší" a web to "zkazil". Třeba kultura okolo Javy mi nepřijde o nic lepší - v je to akorát podstatě hromada fetiše okolo OOP, "zapouzdření", "extenzibility" a poodobných volovinek, které jsou sice někdy užitečné, ale v té míře a v tom způsobu, jakým k nim javisti přistupují, jsou spíš samoúčelné. Lidi okolo Javy mají zlozvyky zakořeněné úplně stejně jako webdevisti a úplně stejně to považují za normální. A to samé platí i o C/C++. Stačí se podívat do historie jakým způsobem tyhle jazyky vznikly (například na redditu jsem onehdá narazil na tohle - je to validní C kód, btw.) Dále fetiš okolo výkonu a "chytré" implementace. Případně můžeme jít do dalších oblastí - vem si, co za humus jsou z technického hlediska široce používané platformy (x86, Arm, ...). Nebo jakej hnus je rodina DEC VT protokolů, to je kupa hnoje, která si s HTML v ničem nezadá, a přesto na tu funkcionalitu spoléhají shelly, curses-based aplikace, Vim, Emacs a mnoho další. Takhle to prostě funguje. "Hezký" návrh existuje a funguje pouze v omezených virtuálních světech oddělených od toho reálného a udržovaných za cenu velkého úslií a energie. Všechno ostatní podléhá entropii.
Úsilí to stojí jen jednou a na začátku.No tak to ani blbou náhodou. Metainformace je potřeba udržovat. Formáty a jejich interoperabilitu je potřeba udržovat a rozvíjet. API je potřeba udržovat a rozvíjet. Je potřeba řešit měnící se požadavky. Systém, do kterého naleješ úsilí jen na začátku funguje jen na začátku, pak postupně buď přestává fungovat a obsahuje staré informace nebo v lepším případě stále funguje, ale svět se mezitím přesune k něčemu jinému, protože starý systém neposkytuje nové fíčury. Trochu mi to připomíná dobu když mi bylo něco jako ~15 let a měl jsem pečlivě spravovanou sbírku hudby. Písničky byly přehledně rozdělený do složek podle autorů, alb, atd., měly správná metadata bylo to všechno krásné a konzistentní. Co si budem povídat, nechal jsem toho velmi rychle. Dnes mám složku
hudba, ve které jsou věci sice do jisté míry organizované, ale ve velmi volném stylu. Něco je v podsložkách, něco ne. Hudba je v různých formátech, něco má i video, něco je jen audio, a metadata neřešim vůbec kromě jména souboru. A jsem šťastný člověk, nebo minimálně šťastnější než předtím. Pro nějakého audio nadšence by pravděpodobně dávalo smysl to dělat tím prvním způsobem, i za cenu času a energie, který to vyžaduje. Ale to já nejsem a 99% ostatních lidí taky ne.
Je to asi jako „napsat si jednou skript“ vs. „tisíckrát opakovat ruční operaci“.Skripty na různé věci si píšu a vím jedno: mám-li je reálně využívat a mají-li být užitečné po delší dobu, potřebují stálou údržbu. Množství té údržby víceméně koreluje s komplexitou toho skriptu, která zase víceméně koreluje s jeho užitečností. Např. mám skripty na zálohy počítačů a telefonu. Nejsou nijak dramaticky složité, ale úplně jednoduché taky nejsou, ale mají-li mi dobře fungovat a dělat, co potřebuju, potřebují pravidelnou údržbu. Koneckonců, pro stárnutí skriptů a software existuje i pojem: Bit rot.
On ten důvod může časem „zmizet“ – jak jsem tu psal v tom vlákně o rozpoznávání faktur. Najednou už nebude potřeba tolik ručních opisovačů, takže pro mnoho lidí ten problém zmizí – a tím zmizí i motivace dělat věci lépe a vyspělá technologie zafixuje současný špatný stav.NOTABUG. Nebo minimálně ne bug, který by bylo reálné fixovat - to by bylo jako snažit se spasit svět.
Takhle to prostě funguje. "Hezký" návrh existuje a funguje pouze v omezených virtuálních světech oddělených od toho reálného a udržovaných za cenu velkého úslií a energie. Všechno ostatní podléhá entropii.Takže zakonzervujeme současný stav a nikdy nebudeme nic měnit? Nedává právě naopak smysl ve chvíli, kdy se něco ukáže jako špatné a nevyhovující, přijít se změnou i s vědomím, že někdy v budoucnu se to bude znovu muset změnit? Proč mi přijde, že v praxi se mění hlavně kraviny? V paralelním threadu se vede diskuze o KDE. Tam ty změny byly moc v pořádku, ale stavět dnes na naprosto prohnilých technologiích si změnu nezasluhuje? S xkucf03 se někdy budu muset spojit soukromě, protože jeho myšlenky v téhle diskuzi naprosto přesně vystihují i moje vlastní myšlenky a dlouhodobě plánuji nějaké související projekty. BTW: Nenašel ty sis v poslední době holku?
Takže zakonzervujeme současný stav a nikdy nebudeme nic měnit?Určitě bych nechtěl, abychom šli do opačného extrému a aktivně se snažili zakonzervovat aktuální neideální stav. Když něco nového vytvářím, taky se snažím o pokudmožno dobrý návrh. Ono to spíš bude tak, že špatný stav je a bude zakonzervován navzdory aktivitě lidí ho zlepšit. Tak to typicky chodí. Nechci podporovat opačný extrém. Samozřejmě má smysl snažit se přijít s lépe a čistěji navrženými technologiemi atd. Ale nevěřim, že to bude někdy reálně fungovat tak utopicky, jak si někteří představují, že by to být mělo. Taky si myslim, že není úplně možné udělat revoluci - to je to, s čím se potýká třeba ta zmiňovaná architektura x86. Něco, co je tak široce používaného (x86, web psaný v HTML, ...), prostě jen tak snadno nenahradíš lepším návrhem, i kdyby ten lepší návrh byl sebelepší.
BTW: Nenašel ty sis v poslední době holku?To by mi žena dala
Jak tě ta otázka napadla?
22.5.2018 17:24
|🇵🇸 | skóre: 94
| blog:
Něco, co je tak široce používaného (x86, web psaný v HTML, ...), prostě jen tak snadno nenahradíš lepším návrhem, i kdyby ten lepší návrh byl sebelepší.paradigm shift
22.5.2018 17:42
|🇵🇸 | skóre: 94
| blog:
Vyvracím, že se nejde zbavit rozšířené technologie – paradigm shift je vcelku zavedený termín:
Since the 1960s, the concept of a paradigm shift has also been used in numerous non-scientific contexts to describe a profound change in a fundamental model or perception of events, even though Kuhn himself restricted the use of the term to the physical sciences.
(A tady jde jít k vědě samotné, netřeba věc chápat přeneseně.)
Teď jde o to, jak velký je/bude odpor vůči změně.
22.5.2018 18:53
|🇵🇸 | skóre: 94
| blog:
22.5.2018 21:18
|🇵🇸 | skóre: 94
| blog:
Tohle je nesrovnatelné – mobily/tablety se používají převážně ke konzumaci obsahu a k nakupování. Ale někdo musí ten obsah a produkty vytvářet, aby bylo co konzumovat. A tvořit na mobilu moc nejde. Distribuovanost s tím nemá moc co dělat – resp. mobily jsou spíš mnohem centralizovanější, protože tam většina lidí má data v „cloudu“ zatímco na desktopu ti samí lidé měli data často primárně na lokálním disku.
Co se týče x86 – ta může klidně zmizet a většina lidí si ničeho nevšimne – operační systémy poskytují dostatečnou abstrakci, aby ti mohlo být jedno, co máš v počítači za procesor. Časem budou levnější OpenPOWER procesory a výkonnější RISC-V než dnes a půjde je běžně používat místo Intelu/AMD.
Tohle je nesrovnatelné – mobily/tablety se používají převážně ke konzumaci obsahu a k nakupování. Ale někdo musí ten obsah a produkty vytvářet, aby bylo co konzumovat. A tvořit na mobilu moc nejde. Distribuovanost s tím nemá moc co dělat – resp. mobily jsou spíš mnohem centralizovanější, protože tam většina lidí má data v „cloudu“ zatímco na desktopu ti samí lidé měli data často primárně na lokálním disku.+1. Tablety a telefony jsou v tomhle ohledu skoro spíš krokem zpět.
Co se týče x86 – ta může klidně zmizet a většina lidí si ničeho nevšimne – operační systémy poskytují dostatečnou abstrakci, aby ti mohlo být jedno, co máš v počítači za procesor.To samozřejmě ano, x86 byl jen příklad široce používaného návrhu.
Časem budou levnější OpenPOWER procesory a výkonnější RISC-V než dnes a půjde je běžně používat místo Intelu/AMD.No to jsem opravdu zvědav. Jako líbilo by se mi to, ale aktuálně to imho vypadá spíše na prosazování Armu...
Tohle je nesrovnatelné – mobily/tablety se používají převážně ke konzumaci obsahu a k nakupování. Ale někdo musí ten obsah a produkty vytvářet, aby bylo co konzumovat. A tvořit na mobilu moc nejde.
Koukám, že jsi tu změnu paradigmatu nějak nezaznamenal.
Šmatlaplacky se nasazují ve zdravotnictví, výrobě a leckde jinde, chromebooky jdou masově do škol…
Zrovna Office 365 nebo Google Docs – na chromebooku – je typický příklad poměrně radikální změny hned na více úrovních.
Současně šmatlaplacka (připojená k internetu) je typickým příkladem aplikace rozšířené reality. Už rozšíření mobilního telefonu bylo bezprecedentní změnou (možnost komunikace více méně odkudkoliv, dostupnost více méně neustále), šmatlaplacky vedle toho mají bezpočet různých senzorů – nebo třeba jenom foťák (kameru, mikrofon), což má další zásadní implikace (zřejmé je to u dostupnosti kompaktního foťáku kdekoliv a možnosti sdílet téměř okamžitě).
Ke změně architektury už v podstatě došlo: jednak když se kvůli fyzikálním limitům začalo intenzivněji paralelizovat, jednak rozšířením ARM v jiném způsobu užití.
Že někdo (výrazná menšina) stále závisí na něčem jiném… psaní rukou také nezmizelo, ale není příliš relevantním způsobem zaznamenávání informací v kontextu civilizace.
Šmatlaplacky se nasazují ve zdravotnictví, výrobě a leckde jindeAno, ale to je v zásadě minoritní použití, navíc v minulosti v těhle usecasech byl typicky specializovaný hardware. Jinak celkově mi přijde, že mluvíš o jiném druhu změny než zbytek vlákna.
Today we hear ebook publishers tell each other and anyone who'll listen that the barrier to ebooks is screen resolution. It's bollocks, and so is the whole sermonette about how nice a book looks on your bookcase and how nice it smells and how easy it is to slip into the tub. These are obvious and untrue things, like the idea that radio will catch on once they figure out how to sell you hotdogs during the intermission, or that movies will really hit their stride when we can figure out how to bring the actors out for an encore when the film's run out. Or that what the Protestant Reformation really needs is Luther Bibles with facsimile illumination in the margin and a rent-a-priest to read aloud from your personal Word of God. New media don't succeed because they're like the old media, only better: they succeed because they're worse than the old media at the stuff the old media is good at, and better at the stuff the old media are bad at. Books are good at being paperwhite, high-resolution, low-infrastructure, cheap and disposable. Ebooks are good at being everywhere in the world at the same time for free in a form that is so malleable that you can just pastebomb it into your IM session or turn it into a page-a-day mailing list.Tohle je z Microsoft Research DRM Talk, kterou mám zrovna při ruce – mimochodem tenhle komentář je krásnou ukázkou té poslední věty v praxi. Pokud chceš jiný izolovaný příklad, tak mobilní telefon v každé kapse učinil technické problémy telefonních budek irelevantními. Rozšíření šmatlaplacek a vysokorychlostního připojení k Internetu můžeš rozřezat po mnoha osách a dostaneš takové dílčí drastické změny, nebo také představu, že se vlastně nic nezměnilo (to je pro změnu to, o čem hovoří Bratton). Dohromady to dává nějaký obraz společnosti.
Ke změně architektury už v podstatě došlo: jednak když se kvůli fyzikálním limitům začalo intenzivněji paralelizovat, jednak rozšířením ARM v jiném způsobu užití.Jakou změnu přineslo přeorientování na multi-core pro architekturu x86? Z hlediska celkového návrhu v zásadě vůbec žádnou, přibyly sice nějaké nové fíčury pro paralelizaci, ale to proběhlo úplně stejným způsobem jako všechny předchozí nové fíčury a x86 je stále to stejné klubko šíleností jako dřív. Vzestup ARMu v tomhle taky nepřinesl žádnou změnu, je to viceméně úplně stejný clusterfuck jako x86. To samé programovací jazyky: Které jazyky nabízí nějaký pokrok v oblasti paralelismu? S výhradami Erlang, Rust, Haskell... tím to asi tak končí a z nich pouze Rust je nedávno vzniklý jazyk. Ostatní mainstream jazyky jsou stále víceméně ten samý suchý záchod, kde si musíš všecko řešit ručně stejně jak roce 80. Prostě si zamkni mutex a čus, víc nás nezajímá. Občas se najde něco pěkného (třeba nějaké paralelní streamy apod.), ale to je typicky jen na úrovni knihoven. Třeba takový JavaScript vlákna skoro ani nepodporuje. A Go-čko se sice chlubí děsně suprovou concurrency podporou, ale ten přínos je víceméně jen v implementačních detailech, spuštění gorutiny je z hlediska sémantiky programu víceméně stejné jako vlákno v céčku a synchronizace je v Go v zásadě stejný středověk. V C++ se afaik chystá transactional memory, ale to je furt experimentální a nejspíš to stejně bude plné gotchas, jak znám C++.
Nechci podporovat opačný extrém. Samozřejmě má smysl snažit se přijít s lépe a čistěji navrženými technologiemi atd. Ale nevěřim, že to bude někdy reálně fungovat tak utopicky, jak si někteří představují, že by to být mělo. Taky si myslim, že není úplně možné udělat revoluci - to je to, s čím se potýká třeba ta zmiňovaná architektura x86. Něco, co je tak široce používaného (x86, web psaný v HTML, ...), prostě jen tak snadno nenahradíš lepším návrhem, i kdyby ten lepší návrh byl sebelepší.tak to je pravda v rámci stejného paradigmatu, ale toliko v rámci stejného paradigmatu.
Frantovy komentáře se, myslím, dotýkají toho článku, který jsem odkazoval mezi příklady paradigm shift, tj. racionálního versus empirického přístupu k návrhu systémů. Toho se ostatně týká i ten Hoarův citát (ačkoliv jemu AFAIK šlo v principu o dokazatelnosti správnosti, zatímco Franta řeší rigidní API apod.).Ok, nicméně nemam dojem, že by v tomhle ohledu došlo k nějakému významnému paradigm shiftu někdy v posledních X desítkách let... Taky mi nepřijde, že by ty dva přístupy byly v až tak striktní opozici, typicky, přijde mi, že používá kombinace obojího... Vyjímky samozřejmě existují, ale typicky jsou na okraji...
Toho se ostatně týká i ten Hoarův citát (ačkoliv jemu AFAIK šlo v principu o dokazatelnosti správnosti, zatímco Franta řeší rigidní API apod.).
Nevím, jestli to souvisí s tím, co jsem psal… Protože já se poslední dobou dost zamýšlím nad tím, jak se zbavit komplexity1 a zároveň zachovat maximálně funkčnost/užitečnost systémů a nemuset sklouznout do režimu nějakých digitálních Amišů.
Může to znamenat vrátit se v čase zpět, ale to samo o sobě nic neřeší – jde v první řadě o objevení nějakých principů, které umožní pokračovat v evoluci lepším a udržitelnějším způsobem. A jedním z těch principů jsou podle mého dobře popsaná rozhraní. Ovšem to neznamená rigidní – právě naopak. Rozhraní nepopisuješ proto, aby zůstalo navždy stejné, ale proto, abys ho mohl změnit a věděl, co se změnilo a čemu se má přizpůsobit systém nebo člověk na druhém konci.
[1] kterou vnímám nejen jako zbytečnou, ale i nebezpečnou
mobilní telefon v každé kapse učinil technické problémy telefonních budek irelevantními.
Většina problémů vychází z toho, že ostatní lidé jsou neschopní, zlí nebo líní. A to, že na ně můžeš křičet po telefonu, ti nijak nepomůže. Dokonce ani v případě, že ten telefon bude mobilní.
Šmatlaplacky se nasazují ve zdravotnictví, výrobě a leckde jinde, chromebooky jdou masově do škol…
O nasazení ve zdravotnictví se mluvilo už v souvislosti s TabletPC před bezmála dvaceti lety (děsně ten čas letí). Už tehdy nás krmili fotkami doktorů, kteří na vizitě obcházejí pacienty s nějakým počítačem v ruce. Myšlenka to tedy nijak nová není.
…na chromebooku
Chromebook není tablet/mobil. Sice je to primárně (určením, nikoli možnostmi) jen hloupý terminál, ale způsobem ovládání a velikostí displeje má mnohem blíž ke klasickému počítači/notebooku.
Co se týče přesunu dat do „cloudu“ – svět IT se vyvíjí po spirále a tohle je akorát reinkarnace velkých sálových počítačů a výpočetních středisek, která prodávala výkon chudákům, kteří vlastní počítače neměli. Navíc se objevují hlasy, že to zase tak dobrý nápad není a že je neefektivní všechna data centralizovat nebo že to ani moc nejde (šířky pásma a doby odezvy přestávají stačit), takže se to pravděpodobně zase začne přelévat směrem k decentralizovanějším distribuovaným systémům. Ale nedělám si iluze, že by to bylo nějak idylické – velké korporace se nebudou chtít vzdát kontroly, kterou s nástupem „cloudu“ získaly nad uživateli a jejich daty, takže data budou sice uložená všude možně, ale bude to nějaká zaDRMovaná sračka, kterou bude ovládat někdo jiný. Skutečně distribuované a decentralizované systémy (kde ta decentralizace není jen technologická, ale i mocenská), se samy neudělají – to musíme udělat my.
Současně šmatlaplacka (připojená k internetu) je typickým příkladem aplikace rozšířené reality. Už rozšíření mobilního telefonu bylo bezprecedentní změnou (možnost komunikace více méně odkudkoliv, dostupnost více méně neustále), šmatlaplacky vedle toho mají bezpočet různých senzorů – nebo třeba jenom foťák (kameru, mikrofon), což má další zásadní implikace (zřejmé je to u dostupnosti kompaktního foťáku kdekoliv a možnosti sdílet téměř okamžitě).
Mluvil jsem o tvorbě obsahu a opravdu jsem tím nemyslel to, že si puberťák vyfotí nějakou část těla a nahraje to na internet. Měl jsem na mysli tvůrčí proces při kterém vznikají nějaké užitečné hodnoty. Jasně s mobilem/tabletem můžeš fotit třeba QR kódy ve skladu, nebo reálné objekty, nebo vyplňovat dotazníky či sbírat jiná data v terénu… ale těžko na tom vytvoříš nové hodnoty typu kniha, software, návrh v CADu, podle kterého se dá vyrobit součástka, nebo plán, podle kterého se dá postavit dům.
Pokud k tomu připojíš klávesnici, polohovací zařízení a pořádnou obrazovku, aby se to dalo používat, tak z toho děláš zase ten desktop nebo pracovní stanici.
Že někdo (výrazná menšina) stále závisí na něčem jiném… psaní rukou také nezmizelo, ale není příliš relevantním způsobem zaznamenávání informací v kontextu civilizace.
Třeba kreslení na rýsovacím prkně už prakticky vymizelo, je to víceméně jen pro milovníky retra a jinak všichni už používají CADy. Ale to je dané tím, že nová technologie přináší kvalitativně lepší způsob práce. Ovšem mobil/tablet oproti pracovní stanici kromě té mobility nepřináší nic – naopak je to v podstatě ve všem krok zpátky a méněcenný nástroj. Takže pokud potřebuješ běhat v terénu a pořizovat tam nějaká data, je to OK. Pokud ale potřebuješ v klidu něco tvořit, bude daleko vhodnější nástroj desktop/notebook resp. pracovní stanice.
Ke změně architektury už v podstatě došlo: jednak když se kvůli fyzikálním limitům začalo intenzivněji paralelizovat, jednak rozšířením ARM v jiném způsobu užití.
Vlastně přesně nevím, v čem spočívá spor v tomto vlákně. Ano, technologie se v čase vyvíjí, pro náročné výpočty se snažíme používat GPU, FPGA, ASICy… nebo se paralelizuje – nicméně to není moc nová věc, protože dřív jsi musel velký výpočet paralelizovat mezi větší množství počítačů, zatímco dneska ho paralelizuješ mezi více jader v rámci jednoho počítače.
Ten mobilní trend má obrovský význam z pohledu trhu a podnikatelů, kteří dodávají masám. Je to příležitost, jak něco prodat lidem, kteří se válí na gauči a matlají při tom po placce, nebo lidem, kteří se nudí v tramvaji, škole, práci… s tím souvisí i popularita YouTubu. Taky můžeš lidem prodat třeba virtuální sekyrky nebo virtuální čarovné lektvary, které použijí v nějaké hře (kde klidně i můžou běhat venku, zaznamenávat svoji pozici pomocí GPS a něco snímat kamerou nebo data ze senzorů odesílat na server…). Příležitost pro byznys to je, o tom nepochybuji. Ale že by to byl nějaký fundamentální posun, něco, co by učinilo lidstvo šťastnějším nebo zásadně zvedlo jeho produktivitu… to mi nepřijde. Spíš na tom lidi promrhají čas a nechají se zahltit zbytečně moc aktuálními a lokálními informacemi. Např. víš, co se stalo před dvěma minutami, protože ti to okamžitě naskakuje na mobilu nebo to dokonce někdo streamuje online, ale už je mnohem těžší najít, co důležitého se stalo před dvěma lety.
Spíš než od mobilů se dá čekat posun paradigmatu od umělé inteligence, ale zatím je to spíš na úrovni nějakého hloupějšího Inda – chytá se klíčových slov a odpovídá rychle, ale úplně blbě.1 Např. až se software začne psát sám, tak to může být podobný skok, jako když upadl význam těžkého průmyslu a spousta lidí přišla o práci. Nicméně u toho těžkého průmyslu byl ten původní stav dost nepřirozený a uměle držený tehdejšími režimy.
Jinde je ta AI úspěšnější, ale hodně těch nových věcí je morálně přinejmenším problematických. Např. klasický totalitní stát ti mohl před dům postavit maringotku s policajtem, který zapisoval, co děláš – to samozřejmě nechci zlehčovat – ale bylo to přirozeně regulované počtem lidí ochotných dělat toho policajta a jejich možnostmi a možnostmi následného zpracování dat. Dneska to díky automatizaci a vyloučení lidského faktoru nabývá úplně jiných rozměrů – viz rozpoznávání lidí podle obličejů nebo chůze, centralizace informací o platebních transakcích, big data obecně, všudypřítomná proprietární elektronika, nekontrolovaný nárůst komplexity…
Na druhou stranu se objevují i potěšující tendence – zrovna dneska mi např. Pošta doručila pár RISC-V čipů a desek. Nebo existuje OpenPOWER – sice nekřesťansky drahý, ale reálně na trhu.
[1] moje zkušenost s podporou eBaye – nakonec jsem usoudil, že takhle hloupý nikdo být nemůže a že jsem si musel dopisovat s robotem…
Ale to jsi nemusel znovu explicitně psát, že tvoje představa o Tvorbě Obsahu™ spočívá v tom, že si mnich s brkem u svíčky sedne a půl roku iluminuje Užitečné Hodnoty™, zatímco plebs někde mrhá časem na blbosti.
24.5.2018 00:18
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Ale to jsi nemusel znovu explicitně psát, že tvoje představa o Tvorbě Obsahu™ spočívá v tom, že si mnich s brkem u svíčky sedne a půl roku iluminuje Užitečné Hodnoty™, zatímco plebs někde mrhá časem na blbostiObsah může být různý, nicméně to co píše má něco do sebe. Přijde mi smysluplnější to definovat skrz fraktální složitost (to video patří k jedněm z nejlepších co jsem kdy viděl na youtube btw). Věci, které mají vysoku fraktální složitost je těžké na tabletech a mobilech vytvářet*, pokud se nejedná o video něčeho už předem připraveného, či o kreslený obraz. *Je to těžké i normálně, proto chceš co největší šířku pásma pro editace.
Pod tu poznámku s plebsem se podepsat nemůžu, zas takový elitář asi nejsemAle to jsi nemusel znovu explicitně psát, že tvoje představa o Tvorbě Obsahu™ spočívá v tom, že si mnich s brkem u svíčky sedne a půl roku iluminuje Užitečné Hodnoty™, zatímco plebs někde mrhá časem na blbosti.
Ale to s tím mnichem co půl roku někde nad něčím laboruje, to je naprosto přesné, tak to přece funguje, ne?
Už asi rozumím. Problém je, že není možné si všechno dělat sám, ale současně je žádoucí na jiné lidi spoléhat co nejmíň to jen jde. Snažit se lidi přimět k tomu, aby třeba začali používat nějaký tvůj projekt, i když by to třeba bylo zdarma a lepší než konkurence, bude těžké a většinou to nepůjde bez agresivního marketingu nebo prvku náhody.Přesně tak... Bystroušák zmiňoval, že by rád přístup k webovým API na úrovni souborů. Soubor je dobrej příklad takovýhohle kompromisu. Je to v podstatě hrozně hloupá abstrakce - má jméno a nějaký data a to je všechno. Je poučný uvědomit si, jak i u takhle primitivního datově-výměnného prostředku je problém s interoperabilitou (povolené znaky v názvu, case-sensitivity v názvu, ACLs, délka názvu, povolené velikosti obsahu, atd...). Jinak že Fakezoob má příšerný UI, to zcela souhlasim. Jednu dobu jsem si na to psal nějaký CSS, ale vykašlal jsem se na to. Naštěstí ho nemusim mít v telefonu, tak tohle tolik neřešim... Naštěstí Fakezoob je jedna singulární služba. Už jsem v té minulé diskusi věštil, že Facebook je za svým zenitem, odhaduju, že je teď kratce za poločasem rozpadu. Samozřejmě můžu se zcela mýlit, je to jen z prstu vycucaný odhad. A taky ten poločas je docela dlouhá doba, vzhledem k tomu, jak dlouho tu Facebook už působí. Ale přesto mám naději, že to v dohledný době opadne...
22.5.2018 21:09
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Bystroušák zmiňoval, že by rád přístup k webovým API na úrovni souborů. Soubor je dobrej příklad takovýhohle kompromisu.Čistě jen pro pořádek: Ne na úrovni souborů, ale stejně přirozeně, jako přistupuješ k souborům. Něco nad čím nepřemýšlíš, co má discoverabilitu (můžeš si to prohlédnout v souborovém manažeru) a pracovat s tím úplně nativně. Rozhodně zcela a vůbec mi nešlo o mapování API na soubory.
Jak tě ta otázka napadla?Smíření se se status quo.
5.5.2018 21:33
Grunt | skóre: 23
| blog: Expresivní zabručení
| Lanžhot
Nekdo uz ti to tu rikal, ... ale doporucuji cestovat zpatky o tricet let a zkusit treba nejaky ten osmibitJe to tak. Velmi mě zaujala ta teze co má zrzek v patičce The operating system: should there be one?. Je to tak trošku návrat k dobám minulým. Bedňa na BASIC sice nadává, ale byl pečlivě navržen jako jednoduše naučitelný komunikační prostředek s počítačem, který se dal implementovat do ROM o velikosti 4 či 8kB. V podstatě šlo o prostředek, který dovolil používat širokým masám počítač k tomu co popisuje Liška v druhém odstavci (resp. docela skok od ručního markování strojového kódu přes switche u Altairu) a dostal tak mikropočítače ze sálového prostředí do domácností. Bohužel expandovat svoji mysl a používat počítače chtějí všichni i když na to nemají a neumí nic naprogramovat. Proto ty operační systémy, programy a aplikace. Jakékoliv programování (či jen používání příkazového řádku) by představovalo nepřekonatelnou bariéru pro široké masy. Je to velmi podobné neustále se snižujícím standardům v počítačových hrách, které jsou produkovány pro masy a ne hráče. Takže manifest pěkný, ale pokud to nezvládne i retardovaný Franta (bez urážky), hodně stěstí při expanzi přeju…wink wink nudge nudge
4.5.2018 01:20
xkucf03 | skóre: 50
| blog: xkucf03
Díky za zápisek (pro případ, že bych byl moc kritický, tak předesílám, že si moc vážím toho, že takové věci píšeš a za každý tvůj text jsem rád).
Self nemá skoro žádnou dokumentaci. … a důvod proč nemít docstringy?
Ty argumenty mi přijdou liché a lze to jednoduše dokázat: Pokud jde rozhraní popsat stručněji a lze ho používat na základě dokumentace, kterou lze pochopit rychleji než přečíst kompletní zdrojový kód, pak má dokumentace smysl. To se ještě násobí faktem, že kód (a jeho dokumentace) se píše jen jednou, ale je čten a používán mnohokrát.
Grafika vypadá fakt špatně a není ani možné jednoduše zvětšit font, který je na 2k monitoru hodně blbě čitelný. Což mi připomíná, že celý font subsystém je 20 let stará věc, která ani neumí načítat normální fonty a celé je to jeden hack.
Možná je nešťastná ta myšlenka spojení samotného jazyka a nějakého GUI. Proč nemít raději čistý a geniální jazyk, jakési jádro. A až kolem něj hromadu knihoven, které se starají o všechno možné včetně GUI. Tyhle knihovny může psát kdokoli a může mezi sebou soutěžit více konkurenčních implementací téhož.
Naposledy když se někdo v konferenci zeptal jak se v Selfu ukládají data a co používá do databáze, tak dostal jako odpověď výsměch, že samotný Self je databáze, protože je založený na konceptu image.
To mi přijde zvrácené. Ne kvůli nějakému paměťovému limitu, ale kvůli tomu, že považuji za užitečné mít možnost oddělit data od programu. Pak můžu provozovat různé verze programu nad stejnými daty nebo naopak jednu verzi programu nasadit na jinou databázi – např. na produkční poté, co jsem verzi programu otestoval na testovacích datech. Data taky můžou patřit někomu jinému, než kdo píše kód…
Co mě nejvíc zdeptalo je, že moje schopnost v Selfu programovat je pořád na stejně špatné úrovni. Chtěl jsem si naprogramovat jednoduchou aplikaci na evidenci knih, jenže jsem selhal. To navíc vynechávám, že dokud nedodělám tu podporu unicode, tak to ani nemá smysl, protože do toho nemůžu psát česky. Self je pro mě stále příšerně těžký. A není to mnou, je to Selfem, respektive absencí dokumentace, moderních nástrojů (hodil by se třeba lepší editor, než ekvivalent notepadu) a jakékoliv smysluplnné komunity.
Pak je otázka, proč je to i po třiceti lety pořád v takovém stavu? Je ten jazyk skutečně tak úžasný? Proč tě dosud ještě nikdo nepředběhl a neudělal to za tebe? Vždyť na univerzitách a ve firmách na celém světě jsou spousty lidí, kteří to mohli udělat? Jaký je důvod si myslet, že tenhle úkol čeká právě na tebe?1
absencí … jakékoliv smysluplnné komunity. Ten poslední bod je asi největší zabiják.
Asi je to demotivující, ale kdyby to jinak bylo schůdné, tak bys přece mohl udělat fork, implementovat věci po svém a lépe a vytvořil by sis vlastní komunitu, protože by to bylo tak super, že by to chtěl používat každý.
jak fungují běžné opensource projekty o víc jak třech lidech
Jak? Podle mého dost různě a ta vstupní bariéra resp. ochota přijímat změny z vnější a od nových vývojářů se dost liší. Někdy jsou to hodně uzavřené komunity a jindy opačný extrém, kdy nechají do kódu se vyblít každého, kdo šel kolem – a to zase považuji za nezodpovědnost vůči uživatelům a vůči dřívějším vývojářům, díky kterým ten projekt třeba má dnešní jméno a důvěru uživatelů. Ideál bude někde mezi tím. Ale dost možná ani žádný obecně platný ideál neexistuje, protože s různými druhy softwaru by se mělo zacházet různě. (když ti někdo rozbije např. hudební přehrávač, tak to nebude tak fatální, jako kdyby rozbil šifrovací knihovnu, operační systém nebo obecně kritickou komponentu používanou na mnoha místech).
Chci být jen uživatel, dělat v něm aplikace, ne se stát core vývojářem a hackovat standardní knihovnu a C++ kód a Xlib a věnovat tomu roky času, abych nebyl schopný napsat jednu debilní grafickou aplikaci.
Otázka je, proč to děláš. Může to být založené na principu: teď si něco nastuduji nebo vyrobím nástroj a pak se mi tahle investice vrátí, protože mi ta práce půjde mnohem rychleji než bez toho. Jenže pokud by měl člověk celý život vyrábět nástroj a rozšiřoval si schopnosti, ale k normální práci by se nestihl dostat, tak by to nemělo smysl.
S tímhle vlastně taky bojuji. Pořád mám pocit, že pořádně nic neumím, nerozumím spoustě věcí, že bych si měl dostudovat ještě tohle a támhleto… ještě si trochu vylepšit svoje nástroje, aby se mi pak (kdy?) pracovalo lépe a efektivněji. Dost je to dané povahou, částečně je to dobrá vlastnost, ale zároveň i špatná. Rozumná cesta asi je vyjít s tím, co mám, co už umím a pracovat – a k tomu si stanovit nějaký paušální „rozpočet“ (měřeno časem, mentální energií), kolik toho investuji do rozvoje. Ale chce to dost disciplíny…
Mimochodem, takový Bitcoin – o kterém asi v klidu můžeme říct, že změnil svět – je napsaný v C++. Tzn. ani tak „nemoderní“ a „nebezpečný“ jazyk, „špatný“ nástroj nebyl překážkou k vytvoření něčeho tak velkého a revolučního.
Nechci používat operační systém, ani programy v něm. Chci expandovat svojí mysl skrz hardware a počítačové sítě. Chci pracovat přímo s informacemi, dotýkat se svojí myslí nehmotného rozhraní stroje.
Můj sen je o software, který by mi dovolil přestat pracovat s věcmi navrženými pro masy podprůměrných uživatelů a začít si psát vlastní rozhraní do infosféry. Což dělám už teď, jen interakce se zbytkem systému je tak bolestně neohrabaná, že skoro fyzicky bolí.
Mluvíš pořád o softwaru a uživatelském rozhraní? V jednu chvíli mě připadalo, že by to mělo být nějaké bezešvé propojení mozku/člověka a sítě, tzn. koukáš očima, cítíš hmatem atd. a na stejné úrovni by bylo získávání informací ze sítě a poslat zprávu/informaci do sítě by bylo na stejné úrovni jako když mozek posílá signál ruce, že se má pohnout.
Proč by měl běžet každý proces samotný a nemít žádnou možnost interagovat s daty okolních procesů? Proč když pustím python script, tak z dalšího terminálu nemám přístup k jeho datům?
Procesy můžou sdílet paměť a pokud by navzájem svým datovým strukturám rozuměly, není moc těžké to zařídit.
Někdy jsem přemýšlel, jestli by mohla existovat společná reprezentace objektových dat v paměti… pak by jeden proces programu mohl být psaný v jednom jazyce a druhý proces v jiném a oba by mohly přistupovat k těm samým datům v paměti. Mohl bys pro každou činnost použít optimální jazyk, ale pracoval bys pořád s jedněmi daty, nic by se nemuselo serializovat, deserializovat ani kopírovat. Ale je to těžko proveditelné, jednak by se musely přepsat implementace všech těch jazyků, protože každý ukládá v paměti objekty trochu jinak, a jednak bys pak narazil na sémantické problémy, různá pojetí objektů by na sebe nepasovala na 100 %. A praktické přínosy jsou sporné…
Proč po jeho běhu data zanikají?
Co třeba proto, aby to bylo deterministické a opakovatelné? Abys mohl jednou ověřit funkčnost a pak ten program (který už se sám nemění a chová se pořád stejně) mohl použít na víc místech? Proto, aby si software nežil svým vlastním životem a sloužil uživateli?
Proč když vezmu dataset všech mnou přečtených knih, rozparsuju ho na objekty, se kterými můžu manipulovat jak chci, které mají strukturu a nesou implicitní sémantickou informaci o obsažených datech, proč je nemůžu mít jen tak na ploše?
A co kdybys ta data rozsekal na adresáře a soubory? Pak je na ploše klidně mít můžeš.
To máš univerzální formát objektových dat se kterým můžeš pracovat z libovolného jazyka. Co se týče implementace, začít se dá se současnými souborovými systémy a časem bys třeba napsal vlastní FS, který si poradí s obrovskými počty malých souborů a který má nějaké lepší indexování případně dynamické pohledy a vyhledávání. Ale základní rozhraní mezi úložištěm a programem je už hotové. Program si nemusí data kopírovat k sobě do RAM a může je číst vždy rovnou z disku – souborový/operační systém je uloží do mezipaměti, takže v RAM už budou. Průběžně se to dá všelijak optimalizovat, ale na hodně případů užití by bohatě stačila už současná implementace a současný HW.
Proč tam musím mít soubor s retardovanou textovou či bajtovou reprezentací? Nechci řešit žádné reprezentace dat, žádný JSON, XML a normálové rozložení SQL. Chci objekty až úplně dolu. Chci vzít objekt a mít ho uložený na disku takový, jaký je, v celé jeho nahotě a bez nutnosti ho někam explicitně serializovat a deserializovat.
Vždyť takhle se to dřív dělalo, že se jen obsah paměti vyblil na disk a bylo uloženo. Akorát to má „drobný“ problém s přenositelností a kompatibilitou. Takové programy nebyly někdy kompatibilní ani samy se sebou. Postupně se od toho upustilo a používají se různé formáty pro serializaci dat.
Když napíšu článek… Když si na webu prohlížím galerii… Když si čtu fórum, chci vzít všechny příspěvky, udělat z nich stromovou strukturu, hodit si jí před sebe na plochu…
Přijde mi, že to, co chceš, jde realizovat i s běžnými programovacími jazyky a formáty (ať už XML nebo třeba nějaký binární formát) a nepotřebuješ k tomu speciální jazyk, který nikdo nepoužívá a který neumí Unicode. A že se to bude někde uvnitř serializovat a deserializovat? To ti přece nemusí vadit – jde to napsat dostatečně transparentně a efektivně, aby ti to jako uživateli mohlo být jedno.
I kdybys vzal třeba Javu (nebo jiný jazyk s reflexí) a napsal si nad tím jen nějaký framework a GUI, tak by to fungovalo a už jsi to mohl mít hotové.
Je mi jasné, že je to katastrofa z hlediska bezpečnosti, nepoužitelné pro běžného uživatele a blah blah. Nic takového. Já nejsem běžný uživatel.
Jenže aby to k něčemu bylo, tak s tím musíš být schopný komunikovat i s lidmi, kteří nejsou tak schopní, nebo třeba schopní jsou, ale mají zlé nebo škodolibé úmysly.
Protože předtím, než ztratil cestu v něm byla tahle myšlenka, jejíž ozvěny se dají stále cítit v celém systému a ze všeho, co jsem kdy viděl, má k tomu co chci naprosto nejblíž.
A kde jsou jeho původní autoři? Co říkají o současném stavu Selfu? Na čem sami teď dělají?
[1] Na druhou stranu, tahle otázka nedává úplně smysl, protože to bych si při každé své činnosti mohl říct, že to nemá cenu, protože kdyby mělo, už by to někdo udělal → takže bych pak nemohl dělat nic
4.5.2018 12:16
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Možná je nešťastná ta myšlenka spojení samotného jazyka a nějakého GUI. Proč nemít raději čistý a geniální jazyk, jakési jádro. A až kolem něj hromadu knihoven, které se starají o všechno možné včetně GUI. Tyhle knihovny může psát kdokoli a může mezi sebou soutěžit více konkurenčních implementací téhož.GUI je záležitost image. Historicky bylo několik GUI a není problém udělat nové. Jazyk s tím není propojený nijak. To GUI je tam asi jako .. standardní knihovny v pythonu.
Pointa je, že předpokládat, že Self je databáze jen proto, že umí uložit svůj paměťový obraz jasně ukazuje na zásadní nepochopení konceptu databáze. Ta dělá stokrát víc, než že jen umí uložit svojí paměťovou image. Osobně úplně nevidím, proč by nemělo jít oddělit data od programu v konceptu image.Naposledy když se někdo v konferenci zeptal jak se v Selfu ukládají data a co používá do databáze, tak dostal jako odpověď výsměch, že samotný Self je databáze, protože je založený na konceptu image.To mi přijde zvrácené. Ne kvůli nějakému paměťovému limitu, ale kvůli tomu, že považuji za užitečné mít možnost oddělit data od programu. Pak můžu provozovat různé verze programu nad stejnými daty nebo naopak jednu verzi programu nasadit na jinou databázi – např. na produkční poté, co jsem verzi programu otestoval na testovacích datech. Data taky můžou patřit někomu jinému, než kdo píše kód…
Pak je otázka, proč je to i po třiceti lety pořád v takovém stavu? Je ten jazyk skutečně tak úžasný? Proč tě dosud ještě nikdo nepředběhl a neudělal to za tebe? Vždyť na univerzitách a ve firmách na celém světě jsou spousty lidí, kteří to mohli udělat?Jeden čas (~1995) měl Self docela drive a probíhalo v něm hodně vývoje. Pak se Sun rozhodl podporovat Javu a od té doby po něm skoro neštěkl pes, až na pár nadšenců. Osobně si myslím, že za současným stavem Selfo stojí komplexita C++ kódu (100k+ řádek) a zároveň komunita, která ho má jako svou posvátnou krávu, než jako něco co by fakt lidi používali. Zrovna lidi z univerzit jsou spíš na škodu než co jiného. Vezmou nějaký pro ně úžasný koncept inspirovaný Selfem, implementují ho, napíšou o něm práci a tím to hasne. Nic nejde do praxe, není z toho nic užitečného běžným smrtelníkům.
Jaký je důvod si myslet, že tenhle úkol čeká právě na tebe?Uf. To není žádný spasitelský komplex. Jsem jen otrávený a zhnusený tím co je k dispozici, že prostě chci něco lepšího. Už jen proto, že jsem to několikrát začal stavět na různých existujících technologiích a pozoroval, jak se mi to zhroutilo jako domeček z karet, protože to nestálo na správných základech. Já to nechci dělat. Vážně, hrozně moc se mi do toho nechce. Ale prostě nemám alternativu.
Asi je to demotivující, ale kdyby to jinak bylo schůdné, tak bys přece mohl udělat fork, implementovat věci po svém a lépe a vytvořil by sis vlastní komunitu, protože by to bylo tak super, že by to chtěl používat každý.Můj přístup jde jinudy. Časem se tomu budu věnovat. Ve zkratce nevidím pointu v onanii nad technologiemi, chci prakticky fungující věc, i za cenu ztráty části výkonu a přenesení těžké práce na framworky pro psaní jazyků (see rpython for details). Dělám to primárně pro sebe. Počítám, že nějaká komunita se k tomu připojí později až kolem aplikací, které v tom chci napsat.
Jak? Podle mého dost různě a ta vstupní bariéra resp. ochota přijímat změny z vnější a od nových vývojářů se dost liší. Někdy jsou to hodně uzavřené komunity a jindy opačný extrém, kdy nechají do kódu se vyblít každého, kdo šel kolem – a to zase považuji za nezodpovědnost vůči uživatelům a vůči dřívějším vývojářům, díky kterým ten projekt třeba má dnešní jméno a důvěru uživatelů. Ideál bude někde mezi tím. Ale dost možná ani žádný obecně platný ideál neexistuje, protože s různými druhy softwaru by se mělo zacházet různě. (když ti někdo rozbije např. hudební přehrávač, tak to nebude tak fatální, jako kdyby rozbil šifrovací knihovnu, operační systém nebo obecně kritickou komponentu používanou na mnoha místech).Tak třeba dobrý začátek je mít veřejnou wiki, diskuzní fórum. Package manager. Verzovací systém. Aby issue četlo víc lidí, než tři a aby je někdo adresoval. Četl jsem "Tvorba open source softwaru" z edice CZ NIC od Karla Fogela, tam má docela hodně poznatků na tohle téma.
S tímhle vlastně taky bojuji. Pořád mám pocit, že pořádně nic neumím, nerozumím spoustě věcí, že bych si měl dostudovat ještě tohle a támhleto… ještě si trochu vylepšit svoje nástroje, aby se mi pak (kdy?) pracovalo lépe a efektivněji. Dost je to dané povahou, částečně je to dobrá vlastnost, ale zároveň i špatná. Rozumná cesta asi je vyjít s tím, co mám, co už umím a pracovat – a k tomu si stanovit nějaký paušální „rozpočet“ (měřeno časem, mentální energií), kolik toho investuji do rozvoje. Ale chce to dost disciplíny…Jo, to je odvěký problém. Tohle ale konkrétně je zrovna nástroj na stavění nástrojů. Není to jen další nástroj stejného typu, je to fundamentálně odlišná filosofie k přístupu k problému. A uznávám, že se může klidně stát, že se ukáže jako nevhodná.
Mimochodem, takový Bitcoin – o kterém asi v klidu můžeme říct, že změnil svět – je napsaný v C++. Tzn. ani tak „nemoderní“ a „nebezpečný“ jazyk, „špatný“ nástroj nebyl překážkou k vytvoření něčeho tak velkého a revolučního.Určitě, pointou není hejtovat C++. Zcela nepopírám, že jsou lidi, co si C++ užívají a dělají v něm rádi. Já ne. Navíc mi přijde jako z podstaty nevlídný a nesouhlasím s jeho filosofickým přístupem k věci.
Znáš: http://abstrusegoose.com/171? Použiji kousek mé rozepsané knihy:Nechci používat operační systém, ani programy v něm. Chci expandovat svojí mysl skrz hardware a počítačové sítě. Chci pracovat přímo s informacemi, dotýkat se svojí myslí nehmotného rozhraní stroje. Můj sen je o software, který by mi dovolil přestat pracovat s věcmi navrženými pro masy podprůměrných uživatelů a začít si psát vlastní rozhraní do infosféry. Což dělám už teď, jen interakce se zbytkem systému je tak bolestně neohrabaná, že skoro fyzicky bolí.Mluvíš pořád o softwaru a uživatelském rozhraní? V jednu chvíli mě připadalo, že by to mělo být nějaké bezešvé propojení mozku/člověka a sítě, tzn. koukáš očima, cítíš hmatem atd. a na stejné úrovni by bylo získávání informací ze sítě a poslat zprávu/informaci do sítě by bylo na stejné úrovni jako když mozek posílá signál ruce, že se má pohnout.
Člověk řídící auto přestává být člověkem a stává se autem samotným. Nevnímá každý pohyb, který dělá rukama, každé šlápnutí na pedál. Místo toho vnímá sebe jako auto. Když mu někdo jiný řekne „zatoč doprava“, nemyslí tím, aby otočil volantem doprava, ale aby sofistikovaným a koordinovaným systémem pohybů, které zahrnují otáčení volantem, řazení, šlapání na pedály a sledování celého širokého okolí, ostatních účastníků provozu, silnice, značek, tachometru a zrcátek navedl plechovou bednu na kolech udaným směrem.Hofstadter se tomu v knize I Am Strange Loop věnuje víc a jde i po důvodech. Pointa je, že lidé jsou vážně dobří v přechodu abstrakce, kde svoje tělo používají jen jako interaface k něčemu většímu (což můžou být jiní lidé). Stejně jako při řízení auta nevnímáš všechny detaily a máš pocit, že sám jsi auto, tak pokud se přes tight coupled feedback loop (těsně spojená zpětnovazební smyčka?) spojíš s nějakým systémem, přestanež ho vnímat jako oddělenou věc a vnímáš ho jako část sebe. Takový systém musí splňovat některé požadavky, ale o tom někdy jindy (pokud tě to zajímá, viz Programming as an Experience, Directness and Liveness in the Morphic User Interface Construction Environment a Experiencing Self Objects: An Object-Based Artificial Reality). Další hezký příklad jsou počítačové hry, kdy lidé je hrající zapomínají, že koukají na pixelový grid a složitými pohyby rukou ovládají klávesnice a myši ovládají program. Místo toho se ‚stávají‘ postavou v té hře. Tahle myšlenka není nic nového, přišel s tím už Engelbart. Jedna její část jsou interaktivní systémy, což více méně máme. Co chybí jsou interaktivní programovací systémy, převážně proto, že programovat zvládne relativně málokdo. Jde však navázat tight coupled feedback loop přímo s takovým systémem a výsledkem je synergie na úplně jiné úrovni, než když je to jen s interaktivním uživatelským ovládáním počítače. Meh. Mám o tom rozepsanou celou knihu, což je taky jeden z důvodů, proč chci tenhle systém prakticky naprogramovat - abych neměl jen teoretické řeči a mohl to podložit reálnými daty.
Někdy jsem přemýšlel, jestli by mohla existovat společná reprezentace objektových dat v paměti… pak by jeden proces programu mohl být psaný v jednom jazyce a druhý proces v jiném a oba by mohly přistupovat k těm samým datům v paměti. Mohl bys pro každou činnost použít optimální jazyk, ale pracoval bys pořád s jedněmi daty, nic by se nemuselo serializovat, deserializovat ani kopírovat. Ale je to těžko proveditelné, jednak by se musely přepsat implementace všech těch jazyků, protože každý ukládá v paměti objekty trochu jinak, a jednak bys pak narazil na sémantické problémy, různá pojetí objektů by na sebe nepasovala na 100 %. A praktické přínosy jsou sporné…V brzké době sem na tohle téma vložím rozsáhlejší text. Je to v pořadí.
Co třeba proto, aby to bylo deterministické a opakovatelné? Abys mohl jednou ověřit funkčnost a pak ten program (který už se sám nemění a chová se pořád stejně) mohl použít na víc místech? Proto, aby si software nežil svým vlastním životem a sloužil uživateli?To není důvod k neustálému zahazování struktury a jejímu kolapsování na surové bajty.
A co kdybys ta data rozsekal na adresáře a soubory? Pak je na ploše klidně mít můžeš. objekt/struktura = adresář atribut = soubor hodnota atributu = obsah souboru To máš univerzální formát objektových dat se kterým můžeš pracovat z libovolného jazyka. Co se týče implementace, začít se dá se současnými souborovými systémy a časem bys třeba napsal vlastní FS, který si poradí s obrovskými počty malých souborů a který má nějaké lepší indexování případně dynamické pohledy a vyhledávání. Ale základní rozhraní mezi úložištěm a programem je už hotové. Program si nemusí data kopírovat k sobě do RAM a může je číst vždy rovnou z disku – souborový/operační systém je uloží do mezipaměti, takže v RAM už budou. Průběžně se to dá všelijak optimalizovat, ale na hodně případů užití by bohatě stačila už současná implementace a současný HW.Jo, tohle bude taky v tom slibovaném textu. Teď se tomu nebudu věnovat.
I kdybys vzal třeba Javu (nebo jiný jazyk s reflexí) a napsal si nad tím jen nějaký framework a GUI, tak by to fungovalo a už jsi to mohl mít hotové.Vzal jsem python, napsal to, pak to přepsal, pak to znovu přepsal a pak to zahodil. Jeden čas jsem šel cestou Rebolu, pak lispu, ale ani to úplně nepomohlo. Časem tu o tom bude víc (mám o tom rozepsaný seriál článků, kde jsou hotové tři díly z asi deseti a tohle je vysvětlené v prvním z nich).
Jenže aby to k něčemu bylo, tak s tím musíš být schopný komunikovat i s lidmi, kteří nejsou tak schopní, nebo třeba schopní jsou, ale mají zlé nebo škodolibé úmysly.To je pravda. Proto to musí umět sandboxování na úrovni jazyka a reflexe. Což v Selfu jde docela dobře. Na tohle téma viz Constructing a Metacircular Virtual Machine in an Exploratory Programming Environment, který prezentuje jazyk Klein. Zatímco jazyky jako lisp jsou jedno-dimenzionální, ve smyslu že jedna
(funkce přijímá_data), jazyky jako Self jsou dvou-dimenzionální, protože obsahují (objekt mající_metody: přijímající_data), kde máš na jedné ose objekt a na druhé metody objektu. Klein byl experimentální třídimenzionální jazyk, kde jsi měl ještě třetí osu zahrnující celé .. plochy objektů. Bylo možné vzít přijatý objekt a pustit ho v prázdné ploše, jakémsi sandboxu, ze kterého se nemohl jednoduše sám dostat.
A kde jsou jeho původní autoři? Co říkají o současném stavu Selfu? Na čem sami teď dělají?Jeden z nich se zapojuje do konference, ale spíš míň, než víc. Pro ně to více/méně vždy byl výzkumný projekt, za který sklidili granty a ceny. Odvedli úžasné množství práce, o tom žádná. Spousta jejich myšlenek byla geniálních. Nechci zas vypadat, že to jen kritizuji.
Připojím rychlý postřeh k tomuhle: u vývoje her se hodně řeší to, že množství informací co se dají takhle interaktivně (tight coupled feedback loop) přenášet od uživatele do té hry je hodně omezené. To dnes hlavně tvoří hlavní rozdíl mezi mobilními, konzolovými a počítačovými hrami - přes dotykové ovládání se toho nedá takhle imersivně přenést tolik jako přes gamepad a přes ten se zase nedá přenést tolik jako pomocí myši a klávesnice (u určitých žánrů to je u gamepadu a myši/klávesnice naopak, protože myš/klávesnice mají jen jeden dvouosý analogový vstup kdežto gamepad má dva). Zajímavé je, že zpátky (ze hry ke hráči přes display) se těch informací přenese výrazně víc, ale také je to značné omezené. Jaké si z toho vzít ponaučení pro vývoj interaktivního programovacího prostředí? Nesmí být člověk naivní a myslet si, že hned naprogramuje prostředí do kterého půjde interaktivně přenášet neomezenou rychlostí. Začal bych nejdříve u rychlosti přenosu informací podobného (nebo klidně i nižšího) jako u her, z toho se pak poučil a postupně v několika krocích bych to množství informací zvyšoval. Takže pak přes to půjde skutčně pohodlně programovat. Myšlenky selfu a smalltalku s tím nemusí být v rozporu, jen by si tohohle limitu interaktivity člověk měl být vědom.Znáš: http://abstrusegoose.com/171? Použiji kousek mé rozepsané knihy:Nechci používat operační systém, ani programy v něm. Chci expandovat svojí mysl skrz hardware a počítačové sítě. Chci pracovat přímo s informacemi, dotýkat se svojí myslí nehmotného rozhraní stroje. Můj sen je o software, který by mi dovolil přestat pracovat s věcmi navrženými pro masy podprůměrných uživatelů a začít si psát vlastní rozhraní do infosféry. Což dělám už teď, jen interakce se zbytkem systému je tak bolestně neohrabaná, že skoro fyzicky bolí.Mluvíš pořád o softwaru a uživatelském rozhraní? V jednu chvíli mě připadalo, že by to mělo být nějaké bezešvé propojení mozku/člověka a sítě, tzn. koukáš očima, cítíš hmatem atd. a na stejné úrovni by bylo získávání informací ze sítě a poslat zprávu/informaci do sítě by bylo na stejné úrovni jako když mozek posílá signál ruce, že se má pohnout.Člověk řídící auto přestává být člověkem a stává se autem samotným. Nevnímá každý pohyb, který dělá rukama, každé šlápnutí na pedál. Místo toho vnímá sebe jako auto. Když mu někdo jiný řekne „zatoč doprava“, nemyslí tím, aby otočil volantem doprava, ale aby sofistikovaným a koordinovaným systémem pohybů, které zahrnují otáčení volantem, řazení, šlapání na pedály a sledování celého širokého okolí, ostatních účastníků provozu, silnice, značek, tachometru a zrcátek navedl plechovou bednu na kolech udaným směrem.Hofstadter se tomu v knize I Am Strange Loop věnuje víc a jde i po důvodech. Pointa je, že lidé jsou vážně dobří v přechodu abstrakce, kde svoje tělo používají jen jako interaface k něčemu většímu (což můžou být jiní lidé). Stejně jako při řízení auta nevnímáš všechny detaily a máš pocit, že sám jsi auto, tak pokud se přes tight coupled feedback loop (těsně spojená zpětnovazební smyčka?) spojíš s nějakým systémem, přestanež ho vnímat jako oddělenou věc a vnímáš ho jako část sebe. Takový systém musí splňovat některé požadavky, ale o tom někdy jindy (pokud tě to zajímá, viz Programming as an Experience, Directness and Liveness in the Morphic User Interface Construction Environment a Experiencing Self Objects: An Object-Based Artificial Reality). Další hezký příklad jsou počítačové hry, kdy lidé je hrající zapomínají, že koukají na pixelový grid a složitými pohyby rukou ovládají klávesnice a myši ovládají program. Místo toho se ‚stávají‘ postavou v té hře. Tahle myšlenka není nic nového, přišel s tím už Engelbart. Jedna její část jsou interaktivní systémy, což více méně máme. Co chybí jsou interaktivní programovací systémy, převážně proto, že programovat zvládne relativně málokdo. Jde však navázat tight coupled feedback loop přímo s takovým systémem a výsledkem je synergie na úplně jiné úrovni, než když je to jen s interaktivním uživatelským ovládáním počítače. Meh. Mám o tom rozepsanou celou knihu, což je taky jeden z důvodů, proč chci tenhle systém prakticky naprogramovat - abych neměl jen teoretické řeči a mohl to podložit reálnými daty.
4.5.2018 14:04
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Přestože se na první pohled může zdát editace vícero kurzory složitá a cizí, jedná se o věc, na kterou si člověk zvykne rychle a jakmile se s ní jednou naučí operovat, začne jí používat všude. Po několika měsících používání této vlastnosti jsem kdysi ukazoval něco kolegovi, a několikrát za sebou jsem přitom použil tuhle funkci. Když mi neodpovídal, tak jsem se na něj podíval a zjistil jsem, že jen fascinovaně kouká a kroutí hlavou, protože naprosto nepochopil, co se to právě stalo. Je mi jasné, že celá tato podkapitola může znít jako reklama na Sublime text, pointa je však jinde. Po třech letech každodenní práce s tímto editorem jsem dosáhl takové schopnosti a familiarity s toutou funkcí, že nadále text needituji. Místo toho ho transformujísvojí myslí, s naprosto brutální efektivitou. Věci, na které bych kdysi musel psát program nyní interaktivně upravím během několika vteřin, i když se jedná o změny v souborech čítajících desítky tisíc řádků. Moje mysl se s editorem spjala natolik, že vůbec nevnímám svoje ruce, nevnímám klávesnici a pohyby, které musím udělat abych provedl editaci v editačním programu. Nevnímám ani editační program. Když pracuji s textem, mám pocit jako kdybych měl několik chapadel, kterými se ho přímo dotýkám a formuji ho na mnoha místech zároveň.A pokud to jde s editací textu, tak proč by to nemělo jít při práci s objekty a vlastně čímkoliv v počítači a obecně v infosféře?
4.5.2018 19:25
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Nejde mi o to, že by to nešlo. Ale že to je jedna z těch složitějších částí. Když má člověk vymyslet něco nového, něco na čem už před ním řada lidí ztroskotala, není od věci si uvědomit, co byly ty náročné věci, na kterých ztroskotali. A nemyslet si, že když si ten problém uvědomím, tak se mě najednou netýká, ale přistupovat k tomu problému s respektem, zdolávat ho postupně a ne najednou a brát to tak, že postupným zdoláváním tohohle problému odvádím tu práci (=vytvářím inovaci). Opakováním toho, co dělali ti přede mnou a fungovalo jim to si vytvářím prostor pro tu inovaci, ale není to to, v čem ta inovave spočívá.Určitě. Myslím, že tady nejsme v rozporu.
Takže neříkám, že by nešlo mít dobrý nápad, který umožní přenášet imersivně do programu široký proud informací. Jenom říkám, že by k tomu měl člověk přistupovat s respektem a nechtít po tom programu, aby v tomhle ohledu byl hned dokonalý. Místo toho by po tom programu měl chtít, aby se v tomhle ohledu spolehlivě postupně zlepšoval.Já bych ještě jednou rád zdůraznil, že mým cílem není to mít jako obecně použitelný systém, ale jako platformu, která stavění takového systému umožňuje. Jedno z přesvědčení, ke kterým jsem dospěl je, že aby to fakt fungovalo, tak si to musí každý postavit sám, plně to pochopit a projít si iterativním vývojem. Je to něco jako sešit s poznámkami - nemá smysl ho zkopírovat od někoho jiného, aby dával smysl, tak si ty poznámky musíš napsat sám. Počítá se i cesta, ne jen výsledek.
A pokud to jde s editací textu, tak proč by to nemělo jít při práci s objekty a vlastně čímkoliv v počítači a obecně v infosféře?
Já tohle nedělám s objekty, ale se záznamy1 – odešlu jeden UPDATE a upravím spoustu záznamů najednou, dokonce jsou ty úpravy kontextové (každý záznam mohou měnit jinak na základě jeho vlastností) a množinu záznamů si vyberu mnohem mocnější podmínkou, než že bych musel jednotlivé záznamy určené k úpravě ručně vybrat. Jasně, je to jen trapná relační/SQL databáze, historická technologie, ale stejně…
Jinak co se týče hromadné práce s daty a proudového zpracování: mám rozpracovaný koncept relačních rour… snad se mi podaří bojovat s leností a dotáhnout to letos do nějakého publikovatelného stavu.
[1] což je svým způsobem jen pohled na objekty, zjednodušený model
5.5.2018 11:28
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
SQL databáze se OOP naopak podobá více než je zdrávo:Sice se to podoba, ale to same to neni.
3) Řádek v tabulce = instance třídy objektu.Toto je velice popularni nepochopeni, coz ale nabrani nikomu v tom, aby vznikl N+1 ORM framework. V OOP je identita objektu urcena odkazem na misto v pameti, kde je objekt umisten. Muzu 2x udelat
new Car("1XY 2345") a vzniknou mi dva odlisne objekty, ale v principu je to v poradku.
V relacnim modelu je identita urcena hodnotou atributu. To znamena, udelam-li 2x INSERT INTO cars VALUES("1XY 2345"), "vznikne" mi jeden objekt.
Muzu do tabulky pridat nejaky atribut "id", ktery bude suplovat "identitu", jak ji maji objekty. V tom pripade ale relacni databazi degraduji na grafovou databazi se vsemi dusledky, hlavne co se tyka efektivity zpracovani dotazu a pohodlnosti dotazovani.
Ukládání grafů a stromů není v relační databázi žádný problém.S cimz ale nekteri nemaji problem.
CREATE TABLE cars (značka_auta varchar(20));
INSERT INTO cars VALUES("1XY 2345");
INSERT INTO cars VALUES("1XY 2345");
A máte 2 objekty, 2 řádky.
je dáno technickým řešením současných počítačů. Je to ale jen podstatná technikálie.Jak je realizovana, je jen technikalie, to je pravda, ale ma to fundamentalni dusledek. Jsem schopen odlisit identitu objektu, tj.
a = new Car("1XY 2345")
b = new Car("1XY 2345")
plati a == a a a != b. Jsem schopen odlisit, se kterym objektem pracuji.
A máte 2 objekty, 2 řádky.A jak se od sebe tyto radky v relacnim modelu daji odlisit? Jak se daji od sebe odlisit treba s pomoci SQL?
Nedělejte ze sebe chytrého, když tomu ani za mák nerozumíte!!!Tak se uklidnime a zopakujeme si, na cem je postaven relacni model. Je to relace, coz je mnozina n-tic. Tato mnozina n-tic je nejcasteji zobrazovana jako dvourozmerna tabulka, avsak ne kazda dvou rozmerna tabulka je mnozina n-tic. A to proc? Protoze, jak jsem se ucili v prvni tride, kazda hodnota muze v mnozine nanejvys jednou! Abych to zduraznil dostatecne, pokud mam v tabulce vice nez jednou radek se stejnymi hodnotami, neni model databaze navrzen dobre (v souladu s relacnim modelem), coz samozrejme povede k dalsim problemum.
To hlavní, co vás degraduje, jsou neznalosti relačních databází.Silna a vsak chybna tvrzeni.
A) Protože klidně můžete 10 x vytvořit objekt, a všech 10 bude mít stejnou adresu, protože programovací jazyk zjistí, že vytváříte 10 x stejný konstantní objekt, tak ho prostě dostane 10 x a vytvoří se jen jednou. Například v C# takto pracujete se Stringy.V tomto pripade jde o nepochopeni pojmu identita. Diky ni jsem schopen odlisit, jakemu objektu zasilam zpravu. Je pravda, ze to nemusi byt konkretni misto v pameti, muze to byt treba adresa v nejakem distribuovanem systemu, ale to je jedno. V teto souvislosti priklad se Stringy ukazuje na toto nepochopeni. Budu to demonstrovat na Jave (protoze v C# si nejsem 100% jisty detaily.)
String a = "AAA"; String b = "AAA";V tomto pripade, prekladac vytvori jenom jeden objekt volanim
new String a do promennych a a b jako optimalizaci, ulozi odkaz na identicky objekt (ale nemusel by, na chovani vetsiny programu by to nemelo vliv.) Pokud ale udelam nasledujici
String a = new String("AAA");
String b = new String("AAA");
Promenne a a b nebudou odkazovat na identicke objekty!
Relační databáze vnitřně hledá ("identitu") pomocí adresy, kde jsou data uložena na disku/paměti.Je sice fajn, ze relační databáze vnitřně hledá ("identitu") pomocí adresy, ale to je otazka fyzicke implementace. V relacnim modelu, ani v SQL, neni (a to zamerne) zadny prostredek, jak tyto adresy zpristupnit. Coz otevirat moznost deklarativne pokladat dotazy a efektivni je prekladat na konkretni implementaci pracujici s fyzickymi daty. Coz je jeden z duvodu, proc databaze postavene na SQL vytlacily sve predchudce jako jsou sitove (a ruzne ,,souborove'') databaze.
Vaše ptákoviny, že je "identita" určená hodnotou atributu si zařaďte do mýtů.Obavam se, ze tohle si do mytu rozhodne zarazovat nebudu. Ale kdyz uz to bylo nakousnute, tak by me zajimalo, proc se podle vas u databazovych tabulek definuje primarni klic.
Ten String v Javě je hlavně dost speciální případ, optimalizace, a s objekty to nemá moc společného (taky u těch literálů není žádné new a naopak když uděláš new String(), tak to má vlastní identitu, jak píšeš a „nededuplikuje“ se to).
Je sice fajn, ze relační databáze vnitřně hledá ("identitu") pomocí adresy, ale to je otazka fyzicke implementace. V relacnim modelu, ani v SQL, neni (a to zamerne) zadny prostredek, jak tyto adresy zpristupnit.
SQL jako takové to sice nemá, ale k té fyzické adrese se v mnoha SŔBD dostaneš přes nějaký virtuální sloupec viz např. PostgreSQL. A někdy se to používá i v aplikacích, ale není to moc čisté, spíš je to taková nouzová optimalizace, když ti nestačí ani indexy a chceš jít k datům víc na-přímo.
Jinak v zásadě souhlasím spíš s tebou.
Ten String v Javě je hlavně dost speciální případ, optimalizace, a s objekty to nemá moc společnéhoNo, prave, proto mi to jako argument do diskuze, prijde pochybne.
SQL jako takové to sice nemáSQL nic takoveho samozrejme nema, stejne tak jako to nema relacni model, ze ktereho SQL vychazi. Tam se pracuje s mnozinami, u kterych se o zadnych adresach samozrejme neda mluvit.
ale k té fyzické adrese se v mnoha SŔBD dostaneš přes nějaký virtuální sloupec viz např. PostgreSQLTo uz je ovsem vedome poruseni abstrakcni bariery. Muj argument se tykal prislusneho modelu a rozlisitelnosti objektu v danem modelu jeho vlastnimi prostredky. Dalsi problem s timto pristupem je, ze pokud si zpristupnis prislusne interni atributy, stavaji se ti z nich bezne atributy, tj. pokud zacnes pouzivat treba v tom Postgresu atribut
oid, je to v podstate to same, jako by sis zavedl dalsi sloupec id, jen jsou v tomto pripade jednotlive hodnoty generovany jinak. V dusledku cehoz ti zacne z relacni databaze opet vznikat nejaka sitova/grafova databaze.
Takže String je objekt, ale String nemá s objekty nic společného.String je objekt, ale povazovat optimalizaci, kterou dela prekladac/behove prostredi, za priklad jednoho z principu OOP je chybne. Obzvlast, kdyz to nema prakticky vliv na to, jak je zaveden pojem identita (rozlisitelnost) objektu.
Takže SQL ani relační databáze to nemají. Ale NĚKTERÉ implementace databázových strojů jako extenze umožňují i to co popisujete.V reakci na me jsi suverene psal:
A ted se z toho stalo: NĚKTERÉ implementace databázových strojů jako extenze umožňují Skvele!V relacnim modelu je identita urcena hodnotou atributu. To znamena, udelam-li 2x INSERT INTO cars VALUES("1XY 2345"), "vznikne" mi jeden objekt.Odkdy? Dělal jste vůbec kdy s databází? Nedělejte ze sebe chytrého, když tomu ani za mák nerozumíte!!!
Upřímně, pokud souhlasíte s děda.jablko stylem argumentace, že logiku musíte překroutit do vrtuleZamet si pred vlastnim prahem, nez zacnes nekoho povysene poucovat.
Protože váš vysněný vlhký sen o "identitě" objektů je jen vaše fantazie.Ale tato optimalizace s identitou objektu neni nijak v rozporu. Mam-li opakovane pouzity literal reprezentujici nejakou nemennou hodnotu, muzu jej nahradit identickym objektem. Jestli se jedna o identiticky objekt, jde rozlisit (pomoci operatoru ==), v relacnim modelu (resp. v SQL) to nejde a je nutne porovnat hodnoty. A to je to, na co jsem tu narazal. Zbytek je z tve strany omylani toho sameho bez prinosu k diskuzi.
Java vám nezaručuje, že vždy bude vyrábět různé objekty na různých adresách. Takovou záruku jste si vymyslel, ale standard Javy vám ji nedává. A že momentálně kompilátor a JVM to dělá tak jak popisujete neznamená, že příští verzi to nebude jinak.Specifikace hovoří celkem jasně. Osobně bych nechtěl programovat v jazyce, kde se může stát, že:
List a = new ArrayList(); List b = new ArrayList(); a.add(1); // b obsahuje prvek '1', protože kompilátor do proměnné b přiřadil již existující instanci místo nové
Vlákno je o tom, že u konstantních objektů může dojít k optimalizaci jazykem, a vytvořit se méně instancí objektů, než je zapsáno v kóduJe tu diskuze o objektovem programovani a rozlisitelnosti objektu a ty tu zacnes resit konkretni optimalizaci pro immutable objekty, pricemz to na rozlisitelnost objektu nema vliv, viz. Chapu, ze se v tom ehm mohl ztratit, kdyz specialni pripad stavis na roven beznemu chovani.
Tak já bych se i nerad dočkal toho, že v kódu zavolám new NějakýTyp() a kompilátor nebo běhové prostředí se rozhodne tentokrát neprovádět konstruktor a nevytvářet novou instanci (byť neměnného typu) a místo toho vrátit nějakou starou instanci. Přijde mi to velice nekonzistentní a matoucí.
U těch literálů je to ještě přijatelné. Stejně tak by to mohlo být přijatelné u jiného způsobu zápisu hodnot. Ale mít new, které vlastně není new, to mi přijde dost pochybné…
Vy v programovacím jazyce zasíláte zprávu objektu, který zpřístupňujete skrze identifikátor, nikoli skrze adresu.Identifikator je ten nejjednodussi pripad, jak drzet odkaz na objekt, ale budiz.
Vy nepotřebujete v 99,999 % záruku, zda dva různé identifikátory objektů ukazují na jeden stejný objekt či na dva různé.Ano, porovnavat dva identifikatory, zda obsahuji odkaz na stejny, objekt je spis ucebnicovy priklad. V praxi ale shodnost objektu resim naprosto bezne. Napr. mam kolekci a potrebuji najit pozici, kde se dany objekt nachazi; mam obecny graf, potrebuji jej projit urcitym zpusobem a chci si hlidat, ze jsem kazdy uzel zpracoval prave jednou.
Java vám nezaručuje, že vždy bude vyrábět různé objekty na různých adresách. Takovou záruku jste si vymyslel, ale standard Javy vám ji nedává.JLS 15.9.4 (SE 10) rika neco jineho.
Zajimave...Ale kdyz uz to bylo nakousnute, tak by me zajimalo, proc se podle vas u databazovych tabulek definuje primarni klic.1) Protože se chcete dostat ke každému řádku snadno a jednoznačně. Ve valné většině případů dává smysl mít jendoznačně identifikovaný řádek.
4.5.2018 14:00
|🇵🇸 | skóre: 94
| blog:
Člověk řídící auto přestává být člověkem a stává se autem samotným. Nevnímá každý pohyb, který dělá rukama, každé šlápnutí na pedál. Místo toho vnímá sebe jako auto. Když mu někdo jiný řekne „zatoč doprava“, nemyslí tím, aby otočil volantem doprava, ale aby sofistikovaným a koordinovaným systémem pohybů, které zahrnují otáčení volantem, řazení, šlapání na pedály a sledování celého širokého okolí, ostatních účastníků provozu, silnice, značek, tachometru a zrcátek navedl plechovou bednu na kolech udaným směrem.
Tady pro úplnost doplním důležitou studii: Cardinali, Lucilla et al. Tool-use induces morphological updating of the body schema. Current Biology, Volume 19, Issue 12, R478 – R479.
Ta hypotéza přitom byla mnohem starší, z dřevních dob neurologie (začátek 20. století).
4.5.2018 17:11
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
To je pravda. Proto to musí umět sandboxování na úrovni jazyka a reflexe. Což v Selfu jde docela dobře. Na tohle téma viz Constructing a Metacircular Virtual Machine in an Exploratory Programming Environment, který prezentuje jazyk Klein. Zatímco jazyky jako lisp jsou jedno-dimenzionální, ve smyslu že jedna (funkce přijímá_data), jazyky jako Self jsou dvou-dimenzionální, protože obsahují (objekt mající_metody: přijímající_data), kde máš na jedné ose objekt a na druhé metody objektu. Klein byl experimentální třídimenzionální jazyk, kde jsi měl ještě třetí osu zahrnující celé .. plochy objektů. Bylo možné vzít přijatý objekt a pustit ho v prázdné ploše, jakémsi sandboxu, ze kterého se nemohl jednoduše sám dostat.Ach jo, ta paměť děravá. Klein je sice zajímavý, ale šlo o něco jiného. Měl jsem na mysli Korz, který je popsán v tomto paperu: A Simple, Symmetric, Subjective Foundation for Object-, Aspect- and Context-Oriented Programming.
Přijde mi, že to, co chceš, jde realizovat i s běžnými programovacími jazyky a formáty (ať už XML nebo třeba nějaký binární formát) a nepotřebuješ k tomu speciální jazyk, který nikdo nepoužívá a který neumí Unicode. A že se to bude někde uvnitř serializovat a deserializovat? To ti přece nemusí vadit – jde to napsat dostatečně transparentně a efektivně, aby ti to jako uživateli mohlo být jedno.Stejně to jsou ve finále jen zápisy do flipflopů :-P.
5.5.2018 11:38
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
A jsi si jistý že má smysl dělat takový systém dnes? Trošku (hodně) jsi předběhl dobu. I když se mne tvoje vize opravdu líbí a měl jsem období kdy jsem se o něco podobného pokoušel v LISPu a Javascriptu, rozhodně bych do toho dnes neinvestoval ani minutu svého života. Moc velký a bombastický plán a moc málo lidí kteří by chtěli jít touto cestou. Takové spojení člověka a stroje skrz programovatelnou interface je třeba EMACs.Self inspiroval vznik Javascriptu, btw. Akorát JS ze Selfího objektového modelu přejal jen polovinu (chybí efektivní delegace) a celé to úplně zbytečně narouboval na C-like syntaxi, čímž tomu akorát uškodil a úplně zabil myšlenku posílání zpráv. Emacs znám, jeden čas jsem ho zkoušel používat a znám pár lidí, co ho používají na velmi pokročilé úrovni (například orgmode jako osobní DB a wiki). Je to inspirativní, ale není to ono. Uvažoval jsem nad lisp os, jako byla třeba genera, ale osobně jsem dospěl k názoru, že objektové jazyky jsou pro reprezentaci informací lepší, než lisp.
Je mi jasný že zrovna odrazování jsi asi nechtěl slyšet, koneckonců, píšeš o tom knihu a nacpal jsi do toho plno let života. Nemohl jsem si ale pomoct.V pohodě. Dělám to, protože mám potřebu podobného systému. To že jsem o tom před půl rokem napsal tenhle blog ve chvíli, kdy jsem byl fakt otrávený ze Selfu na tom nic nemění. Od té doby jsem změnil svůj přístup a hodně si promyslel cestu, kterou se musím vydat. Ta se dá částečně pochopit z diskuze, ale v blogu jí nenajdeš. Časem o tom budou články.
Člověk zvládne za svůj život napsat extrémně malé množství kódu, je proto strašně důležité rozmyslet se co psát...Jo, to mi taky došlo. Akorát to nemá jen jedno řešení, další je například lidi na to najmout, nebo dostatečně nadchnout, aby to dělali za tebe.
Vydej knihu a na exampl se vybodni, to už udělá hejno které třeba tvoje kniha přitáhne. Bojuješ s vlastním perfekcionismem bitvu kterou nejde vyhrát už z principu.Ah. Jenže já nepotřebuji vydat knihu. Potřebuji ten systém a jeho širší filosofické souvislosti řeším v té knize. Časem jí chci použít i k tomu, abych přitáhl další lidi (ve smyslu opensource vývoje), prvně ale chci mít myšlenku dostečně jasně konkrétní, aby mohla být inkrementálně vylepšována, místo aby se zvrhla úplně jiným směrem.
Jenže já nepotřebuji vydat knihu. Potřebuji ten systém…
K čemu? Jaký je tvůj cíl? (pokud to není tajné) Chceš vytvořit nástroj, který budou používat příští generace, který pomůže lidstvu? Nebo pomocí toho nástroje dosáhnout nějakého svého cíle? Nedá se toho cíle efektivněji dosáhnout pomocí stávajících nástrojů a technologií? Nebo to plánuješ tak, že teď budeš pár let pilovat nástroj a pak pomocí něj dosáhneš něčeho velkolepého?
Kdybych to přirovnal k podnikání, tak můžeš investovat, vytvářet postupy, nástroje a zlepšovat technologii, být roky v účetní ztrátě a pak jednoho dne uspět a začít z toho těžit. A nebo můžeš dělat něco přízemního, brát nějaké trapné zakázky, dělat relativně nudnou práci a investovat do rozvoje jen menší část kapacit. V tom prvním případě by měl úspěch přijít dřív, protože se svému cíli budeš věnovat na 100 %, ale zároveň riskuješ, že ti dojdou peníze a dílo zůstane nedokončené. Na druhou stranu ten druhý způsob ti třeba mohl vydělat dost peněz, abys najal další lidi, což by ti urychlilo práci.
5.5.2018 15:08
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
K čemu? Jaký je tvůj cíl? (pokud to není tajné)Myslím, že už jsem to tu psal a že je to napsáno i v tom blogu. Jednak mě sere současný stav IT. Obecně, ale i čistě osobně. Jsou prostě věci, které mi přijdou dementní a se kterými bojuji na každodenní bázi. Ale chci prostě jít obecně o úroveň jinam.
Chceš vytvořit nástroj, který budou používat příští generace, který pomůže lidstvu?To je mi relativně jedno. Mohl by to být fajn bonus se trefit do toho, co popisoval Alan Kay v těch zde linkovaných talcích, kde popisuje, že po vynálezu knihtisku trvalo stovky let, než lidé přestali tisknout bible a začali tisknout cokoliv, co je zrovna napadlo, včetně učebnic, časopisů a letáků a teprve pak proběhla revoluce ve vědě a poznání. Stejně jako on si myslím, že dnešní koncept operačního systému, ale i vývoje, kam se celé IT ubírá k čím dál většímu konzumerství, je špatný a bude muset být nahrazen něčím jiným. Nemám ale ambice ho nahrazovat. To co chci vytvořit já necílí na masy uživatelů, ale na relativně malou frakci lidí jenž umějí programovat a zároveň chtějí osobní programovací prostředí, do kterého přesunou veškeré svoje interakce.
Nebo pomocí toho nástroje dosáhnout nějakého svého cíle? Nedá se toho cíle efektivněji dosáhnout pomocí stávajících nástrojů a technologií? Nebo to plánuješ tak, že teď budeš pár let pilovat nástroj a pak pomocí něj dosáhneš něčeho velkolepého?Hm, tady asi dochází k nepochopení. Já schopnost programování často přirovnávám k novým smyslům a novým končetinám - chapadlům, kterými se dotýkáš infosféry. Nejde mi o konkrétní produkt, ale o nástroj / framework, kterým maximalizuji a usnadňuji tvorbu svých chapadel. Tak jako chodím posilovat, abych zlepšil a zpevnil svoje svaly, tak tvořím systémem, který zlepšuje a zesiluje dosah mého mozku. Vážně, tohle není nic nového. Naopak je to původní Engelbartova myšlenka (citace v odpovědi). V současnosti to primárně dělám pythonem a scriptama a linuxem a databázema a osobníma wiki, ale v každém kroku bojuju s tím, že nic z toho na to není navrženo a často to má za sebou úplně jiná designová rozhodnutí a historicky je to omezeno. Primárně se tedy nesnažím vytvořit produkt, ale zvětšit možnosti sebe sama. Jestli to teda dává nějaký smysl. Moje kniha se tomu věnuje víc, ale je masivně rozdělaná a bude trvat dlouho, než vyjde.
Na druhou stranu ten druhý způsob ti třeba mohl vydělat dost peněz, abys najal další lidi, což by ti urychlilo práci.Nad tím momentálně uvažuji. Tenhle měsíc mi začaly chodit faktury přesahující mez kterou jsem schopný rozumně utratit a pohrávám si s myšlenkou, že bych kdyžtak někomu zaplatil za konkrétní implementace některých částí VM. Kdyby to náhodou četl někdo kdo dělá v pythonu, zajímá ho návrh virtuálních strojů a měl by chuť se na tom podílet, tak se ozvěte.
5.5.2018 15:18
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
The dream of using the computer as a tool to master tides of information is as old as computing itself. In a 1945 essay titled “As We May Think,” Vannevar Bush, who oversaw the U.S. government’s World War II research program, unveiled his blueprint for the Memex, a desk console with tape recorders in its guts that would give a researcher ready access to a personal trove of knowledge. Bush’s Memex provided the nascent field of computing with its very own grail. For decades it would inspire visionary inventors to devise balky new technologies in an effort to deliver an upgrade to the human brain. By far the most ambitious and influential acolyte of the Memex dream was Douglas Engelbart, best known today as the father of the computer mouse. Engelbart, a former radar technician and student of Norbert Wiener’s cybernetics, woke up one day in 1950 with an epiphany: The world had so many problems, of such accelerating complexity, that humankind’s only hope of mastering them was to find ways to get smarter faster. He vowed to devote his life to developing a “Framework for the Augmentation of Human Intellect.” Beginning in the early 1960s under the aegis of the Stanford Research Institute, he gathered a band of researchers and began breaking conceptual and technical ground. The work culminated in a legendary public demonstration in 1968 at the San Francisco Convention Center. A video of that event is still available online, which means that today anyone can, by following some Web links and clicking a mouse, watch Engelbart introduce the world to the very idea of a link, and the mouse, and many other elements of personal computing we now take for granted. If you watch those videos, you’ll learn that Engelbart’s “oNLine System,” or NLS, was, among other things, a PIM. Its goal was to allow users to “store ideas, study them, relate them structurally, and cross-reference them.” It provided what a computer user today would call an outliner—a program with expandable and collapsible nodes of hierarchically structured lines of information. But this outliner could be shared across a network—not only within a single office but remotely, between the downtown San Francisco auditorium and the SRI office in Menlo Park, thirty miles away, as Engelbart showed his suitably impressed 1968 crowd. Today the NLS’s flickery monochrome screens and blurry typography look antediluvian, but its capabilities and design remain a benchmark for collaboration that modern systems have a tough time matching. Engelbart showed the 1968 audience how easy it was to use NLS to make and store and share a grocery list. But the real purpose of NLS was to help Engelbart’s programmers program better. In the 1962 essay that laid out his plan of research into the augmentation of human intelligence, Engelbart explained why computer programmers were the most promising initial target group. He listed nine different reasons, including the programmers’ familiarity with computers and the intellectual challenge of the problems they confronted. But he also noted that “successful achievements can be utilized within the augmentation-research program itself, to improve the effectiveness of the computer programming activity involved in studying and developing augmentation systems. The capability of designing, implementing, and modifying computer programs will be very important to the rate of research progress.” In other words, if NLS could help his programmers program better, they’d be able to improve NLS faster. You’d have a positive feedback loop. You’d be, in the term Engelbart favored, bootstrapping. To Engelbart, bootstrapping meant “an improving of the improvement process.” Today the term may dimly remind us that each time we turn on our computers we’re “booting up.” The builders of early computer systems had borrowed the term from the concept of pulling one’s self up by the bootstraps to describe the paradox of getting a computer up and running. When you first turn a computer on, its memory is blank. That sets up a sort of chicken-and-egg paradox: The computer’s hardware needs operating system software of some kind in order to load any program—including the operating system itself. Computer system inventors escaped this dilemma by using a small program called a “bootstrap loader” that gave the machine just enough capabilities to load the big operating system into memory and begin normal functioning. In early generations of computing, human operators would enter the bootstrap loader manually via console switches or from punch cards; modern computers store it on fixed memory chips. For Engelbart, bootstrapping was less an engineering problem than an abstract and sometimes abstruse way of talking about the goals of his “augmentation” program. Boostrapping involved “the feeding back of positive research results to improve the means by which the researchers themselves can pursue their work.” A “third-order phenomenon,” it wasn’t about improving a process—like, say, getting people to solve problems faster. It was about improving the rate of improving a process—like figuring out how you could speed up ways of teaching people to solve problems faster. This is not a simple distinction to fathom, and that may be one reason Engelbart’s project, unlike his mouse, never caught fire. Another reason, perhaps, was his determination to stick to a pure version of his “augmentation” plan. Unlike later computer innovators who elevated the term “usability” to a mantra, Engelbart didn’t place a lot of faith in making tools simple to learn. The computer was to be a sort of prosthesis for human reason, and Engelbart wanted it to be powerful and versatile; he didn’t want to cripple it just to ease the user’s first few days or weeks in the harness. The typical office worker might be comfortable with the familiar typewriter keyboard, but Engelbart believed that the “chord keyset” he had built, which looked like five piano keys and allowed a skilled user to input text with one hand, gave users so much more power that it was worth the effort required to adapt to it. His vision was of “coevolution” between man and machine: The machine would change its human user, improving his ability to work, even as the human user was constantly improving the machine. And, indeed, as the band of researchers clustered around his Stanford lab wove the NLS into their lives, something like that could be observed. According to Engelbart biographer Thierry Bardini, “Some astonished visitors reported that [Engelbart’s team had developed] strange codes or habits, such as being able to communicate in a ‘weird’ sign language. Some staff members occasionally communicated across the distance of the room by showing the fingers position of a specific chord entry on the keyset.” You can glean a little of that sense of weirdness today in the picture of Engelbart we encounter in the 1968 video: With a headset over his ear, one hand moving the mouse, and the other tickling the chord keyset, he looks like an earth-bound astronaut leading a tour of inner space, confident that he is showing us a better future. From the apogee of the 1968 demo, though, his project fell into disarray. He wanted to keep improving the existing NLS, whereas many of his young engineers wanted to throw it away and start afresh with the newer, more powerful hardware that each new year offered. Over time, his organization lost its sense of mission and, in the mid-seventies, foundered on the shoals of the human potential movement and Werner Erhard’s est. Engelbart’s demand that users adapt to the machine found few followers in subsequent decades. As computing pioneer Alan Kay later put it, “Engelbart, for better or worse, was trying to make a violin”—but “most people don’t want to learn the violin.” This tension between ease and power, convenience and subtlety, marks every stage of the subsequent history of software. Most of us are likely to start with an understandable bias toward the principle of usability: Computers are supposed to make certain kinds of work easier for us; why shouldn’t they do the heavy lifting? But it would be unfair to dismiss Engelbart’s program as “user-hostile” when its whole purpose was to figure out how technology could help make exponential improvements in how people think. Computer scientist Jaron Lanier tells a story about an encounter between the young Engelbart and MIT’s Marvin Minsky, a founding father of the field of artificial intelligence. After Minsky waxed prophetic about the prodigious powers of reason that his research project would endow computers with, Engelbart responded, “You’re gonna do all that for the computers. What are you going to do for the people?”-- ROSENBERG, Scott. Dreaming in code [online]. Three Rivers Press, 2008, CHAPTER 2: THE SOUL OF AGENDA [cit. 2014-05-18]. ISBN 978-0-307-38144-6. A pak něco z Tools for Thought:
The authors did not begin the article by talking about the capabilities of computers; instead, they examined the human function they wished to amplify, specifically the function of group decision-making and problem-solving. They urged that the tool to accomplish such amplification should be built according to the special requirements of that human function. In order to use computers as communication amplifiers for groups of people, a new communication medium was needed: "Creative, interactive communication requires a plastic or moldable medium that can be modeled, a dynamic medium in which premises will flow into consequences, and above all a common medium that can be contributed to and experimented with by all." The need for a plastic, dynamic medium, and the requirement that it be accessible to all, grew out of the authors' belief that the construction and comparison of informational models are central to human communication. "By far the most numerous, most sophisticated, and most important models," in Licklider's and Taylor's opinion, "are those that reside in men's minds." Collections of facts, memories, perceptions, images, associations, predictions, and prejudices are the ingredients in our mental models, and in that sense, mental models are as individual as the people who formulate them. The essential privacy and variability of the models we construct in our heads create the need to make external versions that can be perceived and agreed upon by others. Because society, a collective entity, distrusts the modeling done by only one mind, it insists that people agree about models before the models can be accepted as fact. The process of communication, therefore, is a process of externalizing mental models. Spoken language, the written word, numbers, and the medium of printing were all significant advances in the human ability to externalize and agree upon models. Each of those developments, in their turn, transformed human culture and increased collective control over our environment. In this century, the telephone system added a potent new modeling medium to the human communication toolkit. Licklider and Taylor declared that the combination of computer and communication technologies, if it could be made accessible to individuals, had the potential to become the most powerful modeling tool ever invented.-- strana 158r, 159
First, life will be happier for the on-line individual because the people with whom one interacts most strongly will be selected more by commonality of interests and goals than by accidents of proximity. Second, communication will be more effective, and therefore more enjoyable. Third, much communication will be with programs and programmed models, which will be (a) highly responsive, (b) supplementary to one's own capabilities, rather than competitive, and (c) capable of representing progressively more complex ideas without necessarily displaying all the levels of the structure at the same time -- and which will therefore be both challenging and rewarding. And fourth, there will be plenty of opportunity for everyone (who can afford a console) to find his calling, for the whole world of information, with all its fields and disciplines, will be open to him -- with programs ready to guide him or to help him explore. For the society, the impact will be good or bad, depending mainly on one question: Will "to be on-line" be a privilege or a right? If only a favored segment of the population gets a chance to enjoy the advantage of "intelligence amplification," the network may exaggerate the discontinuity in the spectrum of intellectual opportunity.-- strana 162r, 163
The structure of the Smalltalk language, the tools used by the first-time user to learn how to get around in the Dynabook, and the visual or auditory displays were deliberately designed to be mutable and movable in the same way: "Animation, music, and programming," wrote Kay and Goldberg, "can be thought of as different sensory views of dynamic processes. The structural similarities among them are apparent in Smalltalk, which provides a common framework for expressing those ideas.-- strana 186r, 187
One of the first things Kay pointed out was the connection between the use of interactive graphic tools and the exercise of a new cognitive skill -- a skill at selecting new ways to view the world. The metamedium which Kay still saw to be a decade in the future would only achieve its full power when people use it enough to see what it is about. The power that the 1977 prototypes granted to the human who used such devices was the power to create many new points of view.-- strana 186r - 187r, 187 - 188
The user/programmer explores a universe that reacts, in which the degree of the user's power depends upon and grows with one's understanding of the way the worlds work. The power of simulation to empower the imagination and give form to whatever can be clearly discerned in the mind's eye is what makes this kind of device a "fantasy amplifier."-- strana 188r - 189r, 189 - 190
dnešní koncept operačního systému, ale i vývoje, kam se celé IT ubírá k čím dál většímu konzumerství, je špatný
To sice je, ale je otázka, jestli tomu nějak pomůžeš, když budeš tvořit software pro jakousi „elitu“ resp. velmi úzkou skupinu lidí. Osobně věřím spíš v nějakou postupnou cestu, kdy pomůžeš lidem se rozvíjet. Můžou to být malé kroky, např. že se uživatel naučí regulární výrazy, a efektivněji pak dokáže pracovat s textem, nebo že se místo tabulkového kalkulátoru naučí používat relační databázi a SQL, nebo že bude používat svobodný GNU/Linux místo proprietárního operačního systému, který ho omezuje a kde je uživatel jen otrokem nebo produktem, který si mezi sebou navzájem prodávají nějaké korporace. A tenhle posun prospěje i tobě, protože najednou bude víc lidí jako ty (resp. alespoň s částečně podobnými zájmy a potřebami), což ovlivní trh a výrobce.
Nejde mi o konkrétní produkt, ale o nástroj / framework, kterým maximalizuji a usnadňuji tvorbu svých chapadel. Tak jako chodím posilovat, abych zlepšil a zpevnil svoje svaly, tak tvořím systémem, který zlepšuje a zesiluje dosah mého mozku.
Ano, ale k čemu to je? Legitimní odpověď je třeba i to, že tě to baví a že se chceš prostě v různých směrech zlepšovat. Tzn. máš radost z větších svalů, z lepší schopnosti zpracovávat informace atd. Ale taky to zlepšení může být za nějakým účelem – např. cvičíš, abys byl schopný se ubránit nějakému útoku nebo abys byl zdravější, žil déle, abys ušel delší vzdálenosti atd. Totéž s těmi informačními schopnostmi – např. já se učím i jiné jazyky než Javu, protože chci napsal některé nízkoúrovňovější věci nebo příkazy, které se mají spouštět rychle a těch cca 100 ms startu JVM by tam bylo na překážku. Jinak by mi Java bohatě stačila ke všemu, co chci napsat (tzn. jazyk je dobrý, byť ne dokonalý, ale běhové prostředí by mohlo být lepší). Nebo šifrování mě zajímá kvůli tomu, abych ochránil určité informace a zajistil jejich integritu – nikoli proto, abych se kochal genialitou těch algoritmů. Resp. technologiemi se někdy kochám nebo se něco učím jen tak pro zábavu, ale je to něco jako se dívat na seriály nebo si občas zahrát nějakou hru – je nesmysl, aby to byla hlavní náplň života.
5.5.2018 19:58
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Postupné cesty nefungují. Když vznikl Linux, tak první rozhodnutí bylo nechat unix v architektuře jaké byl ze 70. let 20. století i s chlupama. Žádný posun v architektuře se u Linuxu nekonal. Vytvořil se dokonalejší a lépe naprogramovaný Linux stejné koncepce jako nejstarší unixy. Se všemi věcmi, které dřou a ví se to o nich.Přesně. Linux je jen iterativní vylepšení špatné metafory používání a ovládání počítače.
5.5.2018 19:56
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
To sice je, ale je otázka, jestli tomu nějak pomůžeš, když budeš tvořit software pro jakousi „elitu“ resp. velmi úzkou skupinu lidí. Osobně věřím spíš v nějakou postupnou cestu, kdy pomůžeš lidem se rozvíjet. Můžou to být malé kroky, např. že se uživatel naučí regulární výrazy, a efektivněji pak dokáže pracovat s textem, nebo že se místo tabulkového kalkulátoru naučí používat relační databázi a SQL, nebo že bude používat svobodný GNU/Linux místo proprietárního operačního systému, který ho omezuje a kde je uživatel jen otrokem nebo produktem, který si mezi sebou navzájem prodávají nějaké korporace. A tenhle posun prospěje i tobě, protože najednou bude víc lidí jako ty (resp. alespoň s částečně podobnými zájmy a potřebami), což ovlivní trh a výrobce.Jo, dlouhodobě možná, momentálně to není v prioritách.
Tzn. máš radost z větších svalů, z lepší schopnosti zpracovávat informace atd. Ale taky to zlepšení může být za nějakým účelem – např. cvičíš, abys byl schopný se ubránit nějakému útoku nebo abys byl zdravější, žil déle, abys ušel delší vzdálenosti atd. Totéž s těmi informačními schopnostmi – např. já se učím i jiné jazyky než Javu, protože chci napsal některé nízkoúrovňovější věci nebo příkazy, které se mají spouštět rychle a těch cca 100 ms startu JVM by tam bylo na překážku.Pro mě je to i součást sebevyjádření. Ale celkově tu otázku nechápu. Kdybys měl třeba špatné oči a existoval způsob, jak si je zlepšit, tak bys to neudělal čistě jen pro tu radost, že líp vidíš?
produktivita se jednoduše o několik řádů nezvýšila neb je z větší části omezovaná jinými faktory než schopností efektivně editovat kód. Podobně to asi bude i v plně programovatelném prostředí. Interní datové kanály v lidském mozku jsou jednoduše výrazně větší brzda než kanál mezi mozkem a strojem.
Taky mám ten pocit – a v různých diskusích na to narážím opakovaně. Ono totiž při intelektuální práci nebývá úzké hrdlo v tom, jak rychle zvládneš něco nabouchat do počítače nebo jak vysoké rozlišení zobrazí monitor. A hodně lidí se snaží optimalizovat na nesprávném místě. Např. pro moji práci je úplně jedno, zda píši všemi deseti nebo jen několika prsty. Texty (jako třeba tento komentář) píši všemi deseti, ale programuji na jiné klávesnici a jen několika prsty (na ErgoDox jsem si ještě úplně nezvykl a zatím ještě ladím optimální rozložení kláves). Ale je to vlastně jedno, protože stejně delší čas přemýšlím nebo čtu než píši.
A když autoři editorů tak rádi zasírají viditelnou plochu nesmysly. Potřebuji já vidět po celou dobu práce vlevo seznam souborů a adresářů?
Asi všechny moje editory mají možnost ten panel se seznamem souborů skrýt nebo minimalizovat na jedno kliknutí myši nebo klávesovou zkratku. A třeba v takových Netbeans stačí poklepat na záložku souboru a rázem má člověk editor přes celou plochu – minimalizují se všechny panely – a při dalším poklepání se vrátí do původního stavu.
Programátorské editory často neumějí ani tak základní věci, jako je vyříznout obdélník textu a přesunout ho jinam.
Např. jEdit nebo Kate to umí.
Nebo když mám 100 MB dat ve formě CVS (comma separated value), jak dlouho ve vašem editoru trvá vyrobit z toho SQL INSERT/UPDATE příkazy a vyrobit SQL skript?
Na tohle používám proudový editor sed nebo perl, případně pro složitější úlohy nějaký programovací jazyk s patřičnou knihovnou, aby vstupní formát spolehlivě načetl. Nemyslím si, že by to byla úloha pro interaktivní textový editor – buď tu konverzi postavíš na regulárním výrazu, a pak je jedno, odkud ho spustíš (jestli z interaktivního nebo proudového editoru), nebo potřebuješ nějakou knihovnu pro zpracování vstupního formátu, a pak už to vůbec není úloha pro interaktivní textový editor.
6.5.2018 11:36
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Na tohle používám proudový editor sed nebo perl, případně pro složitější úlohy nějaký programovací jazyk s patřičnou knihovnou, aby vstupní formát spolehlivě načetl. Nemyslím si, že by to byla úloha pro interaktivní textový editor – buď tu konverzi postavíš na regulárním výrazu, a pak je jedno, odkud ho spustíš (jestli z interaktivního nebo proudového editoru), nebo potřebuješ nějakou knihovnu pro zpracování vstupního formátu, a pak už to vůbec není úloha pro interaktivní textový editor.Dá se to udělat přes vícenásobné kurzory. U 100MB se to bude v Sublime trochu sekat, ale podle mého názoru by to pořád mělo jít.
6.5.2018 12:11
xkucf03 | skóre: 50
| blog: xkucf03
A jak tomu řekneš, kam ty kurzory má umístit? Protože to nebude na pevných pozicích, ale třeba „za třetí čárkou“ nebo v horším případě „za třetí čárkou, která se nevyskytuje uvnitř uvozovek“.
6.5.2018 14:25
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Na tohle používám proudový editor sed nebo perlJá na tohle používám funkcionalitu databáze případně nástroje s ní pracující, protože lidé, kteří dělají „SQL skripty“ s inline uživatelskými daty z počátku mají příjemné pocity, ale potom onemocní, ztratí touhu žít a umřou dříve než jiní lidé.
6.5.2018 15:18
xkucf03 | skóre: 50
| blog: xkucf03
Myslíš SQL injection a náhodné chyby? To byl jeden z důvodů proč jsem si napsal SQL-DK (umí parametrizované dotazy a dávky) a proč teď dělám na relačních rourách (ve zkratce: proud tabulkových dat, spojení konceptu relačních databází a unixových rour).
Ale na druhou stranu, když mám log aplikace, ve kterém je, kolik ms. která operace trvala, tak to klidně proženu regulárním výrazem a udělám z toho SQL INSERTy, protože tam stejně budou jen čísla a [a-z] v názvu operace (jinak by to neprošlo přes ten regulární výraz)
6.5.2018 10:27
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Jaký je důvod kreslit „pseudo-uml diagramy“ v grafickém (!) editoru a ne nějakém CASE nástroji?
6.5.2018 11:39
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
5.5.2018 20:02
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
S čím nesouhlasím je ale vize, co je tím nejlepším paradigmatem. Je to v zásadě ale jedno, paradigma je jen interface, který se zvolí. Nejsem přesvědčen, že objektové paradigma je právě to nejlepší - a už vůbec není univerzální. Na něco je geniální, na jiné úkoly je špatné.Není objektové paradigma jako objektové paradigma. To o co jde mě jsou prototypy s delegací a posíláním zpráv, ne class based přístup. Netvrdím, že je to nějaká spása, ale podle mě to má největší potenciál z věcí co znám. Osobně si myslím, že objektové paradigma je nejlepší z hlediska reprezentace dat, neboť jim dává sebe-popisnou reflexivní strukturu. Všechny ostatní přístupy vesměs mají popis externě, včetně třeba takového lispu, který dodává strukturu, ale význam už v něm chybí.
5.5.2018 20:51
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Podle mého je objekt v jakémkoli pojetí vhodný jen pro některé případy toho, co jinak řeší modul s API. Lidi jsou prostě líní si rozmyslet strukturu a API, a OOP jim nabídne iluzi, že to ani nepotřebují. Všechno bude objekt, všechno budou metody/zprávy - a oni se vlastně nemusí o nic jiného zajímat. Všechno tak vyplyne nějak automaticky. Objekt není nic jiného než flák paměti (nesoucí data) a jedinou metoda zvaná "přijmi zprávu" (v tomto pojetí). S nějakou tou syntaktickou omáčkou. To není úplně univerzální koncept, který by řešil všechno.Pozor, psal jsem to v kontextu reprezentace informací. Je to (potenciálně) samopopisná stromová key-value struktura dat s reflexí a nápovědou.
5.5.2018 21:52
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
5.5.2018 22:37
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
5.5.2018 20:09
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Smalltalk má dobře udělané objektivní paradigma. Je to v zásadě velice univerzální, všechno je objektem. Nevolají se metody, ale předávají se zprávy. Dědičnost nijak nezasahuje do typového systému, je pouze a toliko implementačním detailem. Je to neefektivní z hlediska rychlosti, ale je to příjemné a jendoduché.Self je v tomhle víc Smalltalk, než kdy Smalltalk byl a bude. Existuje pořekadlo: Self is like Smalltalk, but more. Hezky je to vysvětleno tady: https://stackoverflow.com/questions/16959539/differences-between-self-and-smalltalk
Nedokáži si dost dobře představit, jak Smalltalk nějak podstatně změnit či předělat, aby to nezpůsobilo tisíce nedomyšleností a problémů jinde. Naznám Self, znám Smalltalk. O Selfu jsem slyšel kdysi dávno v souvislosti se Sunem - což pro mě byla dostatečná informace abych se Selfem dále nezabýval. Tudíž nevím, co se Smalltalkem udělal Self.Self Smalltalk zjednodušil a ořezal o vše nepodstatné, až zbylo jen pár axiomů. Na nich pak postavil konzistentní systém, který je podle mého názoru o stupeň lepší. Když jsem se nato ptal Alana Kaye, tak taky říkal, že se mu Self líbí a že OOP pořád čeká na něco lepšího, než třídy: https://news.ycombinator.com/item?id=11941330
Tenhle nesmysl dokonale zchaotičtily jazyky C/C++, které dokonce neumožnují zvolit ani toto, ale mají své short/int/long/long long kraviny - u kterých vůbec netušíte co se do nich vejde. (Nalepovák typu stdint.h je spíše z nouze ctnost než řešení.)Souhlas.
Kolik programovacích jazyků vám pomůže s multitaskingem? Tůdle! Volejte si a udržujte své mutexy, podmínkové proměnné, semafory, události, spin-locky a další pěkně růčo! Low level. Progrmaovací jazyk se tváří, že o nich nic neví.Afaik všechny nové. Go, D, Rust.
5.5.2018 20:24
xkucf03 | skóre: 50
| blog: xkucf03
OOP není univerzální koncept.
Vzhledem k tomu, že i v objektovém jazyce můžeš snadno programovat procedurálně nebo funkcionálně, tak poměrně univerzální je (opačným směrem to jde podstatně hůř).
Kolik programovacích jazyků vám pomůže s multitaskingem? Tůdle! Volejte si a udržujte své mutexy, podmínkové proměnné, semafory, události, spin-locky a další pěkně růčo! Low level. Progrmaovací jazyk se tváří, že o nich nic neví.
Zrovna na tohle se dneska klade celkem důraz a když se nějaký nový jazyk snaží prorazit, tak je to jedna z prvních věcí, kterou se chlubí – že zajistí bezbolestné vícevláknově zpracování a že to člověk nebude muset řešit ručně jako v těch „starých jazycích“. Zároveň i ty starší jazyky dostávají podporu (ať už na úrovni syntaxe nebo knihoven a frameworků), aby tyhle úkoly byly pohodlné a bezpečné.
Osobně si nemyslím, že by vše muselo být řešeno přímo v syntaxi jazyka, že by na všechno byl potřeba syntaktický cukr – dobře napsaná knihovna je často užitečnější. Narvat všechno do syntaxe vede v extrémním případě k jazyku typu C++, kde opravdu jen málokdo (nebo nikdo?) ovládá tento jazyk kompletně a je schopný spolehlivě a efektivně číst libovolný program psaný v tomto jazyce. Na opačné straně jsou jazyky typu Go, které mi přijdou nedostatečné a myslím, že tam se to se snahou o zjednodušení přehnalo.
5.5.2018 23:10
xkucf03 | skóre: 50
| blog: xkucf03
namísto polí budou mít pointerovou aritmetiku. A počet nalepováků, aby to syntakticky nějak slušně slo už přesahuje v C++ možná i počet atomů ve vesmíru.
Co je tak špatného na nalepovácích typu std::string1 nebo std::array a std::vector? Resp. tyhle konkrétní implementace můžou být špatné, ale to ještě neznamená, že by to nešlo udělat správně formou knihovny a že je nutné to narvat přímo do syntaxe jazyka, ne? Na C++ mi přijde právě zajímavé, že spoustu věcí lze implementovat formou dodatečné knihovny a není potřeba rozšiřovat jazyk samotný (přesto se dosáhne srovnatelného výsledku), což by třeba v takové Javě nešlo2. Copak by nad C++ nešla napsat dobrá pole nebo textové řetězce formou knihovny?
A jiná cesta k PHP než tupé naučení se referenční příručky nazpaměť nebo ji mít před sebou neustále otevřenou i pro primitivní a základní věci - neexistuje.
Tohle by mělo řešit IDE a jeho napovídání, okamžitá kontrola kódu a kontextové zobrazování dokumentace. Jenže u dynamických jazyků tohle funguje poněkud hůře.
Neexistuje programovací jazyk, který by se nedal zašmodrchat natolik, že bude luštit zdroják 14 dní. Touto schopností sluje každý programovací jazyk na světě.
Předpokládejme „za jinak stejných okolností“. Zatímco v jednodušším jazyce musí být ten program napsaný koncepčně špatně, s chybami, aby byl nečitelný, tak v tom C++ může být program dobře napsaný, ovšem používá jinou podmnožinu jazyka, postupů a knihoven, než jakou je zvyklý používat ten, kdo ho čte. Aspoň tohle je můj dojem – ale jsem v C++ začátečník, něco už napsal umím a i ty moje (jednoduché) programy dělají, co od nich chci, ale se čtením cizího kódu je to o dost horší – dost možná nikdy nebudu schopný přečíst libovolný kód v C++, protože tomu prostě nevěnuji toho času a budu umět jen nějakou podmnožinu, která mi přijde užitečná (nevidím moc smysl v tom, abych si dostudoval všechny styly, jakými se v C++ za jeho dlouhou historii psalo – naopak moderní C++ mi přijde celkem zajímavé).
[1] resp. std::wstring – chápu, že by měl být spíš jen jeden typ postavený na konceptu znaků a zcela odstiňující programátora od toho, že jsou pod tím nějaké bajty
[2] takže tam se to řeší jinak… ale zase Java má reflexi, takže tam jdou dělat jiné zajímavé věci, které by zase nešly v C++
19.5.2018 20:08
xkucf03 | skóre: 50
| blog: xkucf03
Osobně mi přijde horší1 špatně použitelný polymorfismus. Nebo jen něco nechápu a „snažím se z toho zase dělat Javu“?
Narážím na problémy jako object slicing a další.
Chtěl jsem např. napsat něco jako:
istream input = isatty(fileno(stdin)) ? ifstream("/etc/fstab") : cin;
// ... tady bude nějaký kód, který zpracuje vstup
Jenže to nejde a místo toho jsem musel napsat:
int processDataStream(ostream &output, istream* input) {
// ... tady bude nějaký kód, který zpracuje vstup
}
// ...
if (isatty(fileno(stdin))) {
ifstream s("/etc/fstab");
return processDataStream(output, &s);
} else {
return processDataStream(output, &cin);
}
Což sice celkem použitelné je, ale stejně mi přijde jako vada jazyka, že neumožňuje psát tím prvním způsobem.
Kdybych místo istream input použil istream* input, tak musím řešit jednak to, že v jednom případě chci dělat delete input, zatímco v druhém ne, a jednak to, že kód může vyhodit výjimku a já bych ji musel odchytit a volitelně udělat delete input. Což připomíná Javu před try-with-resources. Chytrý ukazatel by mi zase chtěl na konci smazat i ten cin, ne?
A taková nemožnost kombinovat šablony a dědičnost je taky významná vada. Chápu proč to tak je (šablona v podstatě rozkopíruje kód do více variant), ale stejně mi to přijde škoda. Vždycky jsem bral šablony v C++ jako taková mocnější generika z Javy, ale tak to není, v něčem jsou naopak omezenější a hůře použitelné.
[1] protože třeba ty stringy se aspoň nějak dají řešit pomocí těch „nalepováků“ a knihoven.
Osobně mi přijde horší1 špatně použitelný polymorfismus. Nebo jen něco nechápu a „snažím se z toho zase dělat Javu“?No, jde o to, že tam používáš něco, co Java vůbec nemá - objekty jako hodnoty. Ten "object slicing" je tam až druhotný problém, primární problém je, že se snažíš přiřadit
cin (nebo obecně istream) hodnotou, tj. ho zkopírovat, což tenhle objekt zakazuje (tím, že deletuje kopírovácí operátor), protože reprezentuje resource.
Polymorfismem máš zřejmě na mysli subtyping + dynamic dispatch a ten ti na holých hodnotách fungovat opravdu nebude (pokud chceš vědět proč, zamysli se nad implementací dynamic dispatche v Javě a C++, btw. ze stejného důvodu není v C# implementovaná dědičonst pro ty jejich struct typy, což jsou hodnotové typy).
Je potřeba mít na paměti, že kód, který v Javě vypadá stejně, je ve skutečnosti ekvivalentní spíš něčemu takovýmuhle:
GcPtr<istream> input = podmínka ? gc_ptr_1 : gc_ptr_2;
Ten dynamic dispatch tam funguje díky těm pointerům.
Kdybych místoOperátoristream inputpoužilistream* input, tak musím řešit jednak to, že v jednom případě chci dělatdelete input, zatímco v druhém ne
delete bys neměl používat víceméně vůbec. (Vyjma nějakých specielních situací, ale to pravděpodobně nebude tvůj případ...) Co se týče výjimek, neměl bys potřebovat chytat výjimku jen kvůli tomu, abys uvolnil nějaký resource (třeba paměť) - to bys měl řešit přes RAII.
Chytrý ukazatel by mi zase chtěl na konci smazat i ten cin, ne?
Ne nutně, smart pointerům můžeš nastavit 'deleter', což může být i lambda funkce, která může obsahovat nějakou logiku apod.
Nevím, jaký je kontext tvého kódu, ale nejspíše bys mohl použít prostě referenci (za předpokladu, že zajistíš dostatečnou životnost toho ifstreamu), případně si můžeš zkonstruovat nový istream podmíněně s různým bufferem:
istream my_input_stream(isatty(fileno(stdin)) ? cin.rdbuf() : nejaky_stream.rdbuf());
(Nezkoušel jsem to, snad to není moc blbě...)
A taková nemožnost kombinovat šablony a dědičnost je taky významná vada.Co tím myslíš? Šablony a dědičnost je možný kombinovat... Viz třeba CRTP.
20.5.2018 20:23
xkucf03 | skóre: 50
| blog: xkucf03
No, jde o to, že tam používáš něco, co Java vůbec nemá - objekty jako hodnoty. Ten "object slicing" je tam až druhotný problém, primární problém je, že se snažíš přiřadit cin (nebo obecně istream) hodnotou, tj. ho zkopírovat, což tenhle objekt zakazuje (tím, že deletuje kopírovácí operátor), protože reprezentuje resource. …Jasně, já to většinou buď tuším nebo na to v průběhu přijdu, že když se mi na C++ něco nelíbí, není za tím nějaká hloupost nebo zlý úmysl, ale má to svoje důvody, ať už nějaké návrhové nebo prostě historické okolnosti, se kterými už dneska nejde nic dělat. Tohle bylo spíš takové povzdechnutí nad tím, že ten jazyk je v něčem fajn a v něčem mě neskutečně … a přijde mi to škoda.
Je potřeba mít na paměti, že kód, který v Javě vypadá stejně, je ve skutečnosti ekvivalentní spíš něčemu takovýmuhle:GcPtr<istream> input = podmínka ? gc_ptr_1 : gc_ptr_2;
Jenže pak je to jednak děsně nečitelné, zahnojené obalujícími kontejnery, a jednak si musíš předem rozmyslet, jestli někdy budeš potřebovat dědičnost nebo ne a už od začátku to psát tak nebo tak. Je to dost nešikovné – opět: chápu, že za tím jsou nějaké objektivní důvody, ale přijde mi to škoda. Oproti tomu Java má mnohem příjemnější a čitelnější syntaxi a nezavíráš si tam vrátka – kdykoli v budoucnu můžeš místo nějakého typu předat jeho potomka a bude ti to fungovat.
A pak je taky problém s kombinováním generik/šablon a dědičnosti. Něco jsem o tom četl a přešla mě chuť – radši jsem změnil návrh (a nemyslím si že k lepšímu). Teď tam mám např. jednu třídu:
#pragma once
#include <string>
#include <iostream>
#include <vector>
#include "common.h"
#include "DataType.h"
#include "BooleanDataType.h"
#include "IntegerDataType.h"
#include "StringDataType.h"
using namespace std;
namespace rp_prototype {
/**
* TODO: this class should be generated.
*/
class DataTypeCatalog {
private:
BooleanDataType booleanType;
IntegerDataType integerType;
StringDataType stringType;
public:
integer_t toTypeId(const wstring typeCode) {
if (booleanType.supports(typeCode)) return booleanType.getTypeId();
if (integerType.supports(typeCode)) return integerType.getTypeId();
if (stringType.supports(typeCode)) return stringType.getTypeId();
throw RelpipeException(L"Unsupported data type: " + typeCode, EXIT_CODE_DATA_ERROR);
}
wstring toTypeCode(const integer_t typeId) {
if (booleanType.supports(typeId)) return booleanType.getTypeCode();
if (integerType.supports(typeId)) return integerType.getTypeCode();
if (stringType.supports(typeId)) return stringType.getTypeCode();
throw RelpipeException(L"Unsupported data type: " + typeId, EXIT_CODE_DATA_ERROR);
}
void writeString(ostream &output, const wstring &stringValue, const integer_t typeId) {
if (booleanType.supports(typeId)) return booleanType.writeString(output, stringValue);
if (integerType.supports(typeId)) return integerType.writeString(output, stringValue);
if (stringType.supports(typeId)) return stringType.writeString(output, stringValue);
throw RelpipeException(L"Unsupported data type: " + typeId, EXIT_CODE_DATA_ERROR);
}
wstring readString(istream &input, const integer_t typeId) {
if (booleanType.supports(typeId)) return booleanType.readString(input);
if (integerType.supports(typeId)) return integerType.readString(input);
if (stringType.supports(typeId)) return stringType.readString(input);
throw RelpipeException(L"Unsupported data type: " + typeId, EXIT_CODE_DATA_ERROR);
}
};
}
A to je fakt hnus. Je to prototyp, tak jsem to tak zatím nechal, protože cílem je ověřit proveditelnost jiných věcí a nějaké koncepty… ale v produkčním kódu tohle rozhodně mít nechci, takže se s tím budu muset nějak vypořádat.
Operátor delete bys neměl používat víceméně vůbec. (Vyjma nějakých specielních situací, ale to pravděpodobně nebude tvůj případ...)
Když udělám new, tak musím někde udělat i delete. Třeba když si v rámci své třídy vytvářím instanci něčeho jiného a při ukončení platnosti instance mojí třídy to chci uklidit. Leda balit i tohle do těch chytrých ukazatelů.
Ne nutně, smart pointerům můžeš nastavit 'deleter', což může být i lambda funkce, která může obsahovat nějakou logiku apod.
To by mi možná pomohlo, ale tak daleko jsem se zatím nedostal.
Nevím, jaký je kontext tvého kódu
Úplně primitivní věc, chci rozlišit, zda jak je program spuštěn – zda STDIN je TTY nebo je to roura/soubor při přesměrování – a podle toho nabídnout vhodné výchozí chování (půjde přebít přes CLI parametr) tzn. buď číst ze standardního vstupu, pokud do něj uživatel nasměroval nějaký svůj soubor či výstup jiného programu, nebo číst z výchozího umístění (nepředpokládá se, že by uživatel chtěl datlovat vstupní data na klávesnici). A proto jsem chtěl zvolit vhodný vstupní proud, a pak už pokračovat stejným způsobem.
istream my_input_stream(isatty(fileno(stdin)) ? cin.rdbuf() : nejaky_stream.rdbuf());
Tohle ještě prozkoumám, možná je to řešení…
Ale dost mi vadí, že tady nejde obalovat proudy podobně jako v Javě. Přitom to mohlo být úplně jednoduché – binární proud by šel obalit textovým, který má jako parametr kódování. V Javě je tohle krásně jednoduché a čisté. Tady mi to přijde takové zprasené (míchání textových a binárních přístupů… do toho se na stejné úrovni řeší i formátování čísel a lokalizace). Dokonce jsem koukal, že někdo přepsal tuhle část Javy do C++ :-)
Co tím myslíš? Šablony a dědičnost je možný kombinovat...
To je ten příklad výše, původně to měl být vector<DataType>, přes kterých bych mohl v několika metodách iterovat. V předkovi měla být generická metoda, kterou bych v potomkovi implementoval pro konkrétní typ, ale to mi nešlo… Resp. možná existuje nějaký složitý způsob, jak toho dosáhnout, ale to, co jsem si o tom tehdy přečetl, mne dostatečně odradilo.
Konkrétně mi v tom katalogu nešlo udělat:
type.writeValue(type.getValue(textValue));
Kde obě metody byly generické a pasovaly by na sebe (getValue() by např. vrátila int a writeValue() by ho přijala).
Tohle bylo spíš takové povzdechnutí nad tím, že ten jazyk je v něčem fajn a v něčem mě neskutečně … a přijde mi to škoda.C++ je v řadě věcí vopruz. (Ačkoli mě asi štve v jiných aspektech než tebe, což bude v tom, že ty jsi "zkažen" Javou, zatímco já Rustem.)
Oproti tomu Java má mnohem příjemnější a čitelnější syntaxi a nezavíráš si tam vrátka – kdykoli v budoucnu můžeš místo nějakého typu předat jeho potomka a bude ti to fungovat.Ale platíš za to vysokou cenu - nemožnost použít hodnotové typy.
Jenže pak je to jednak děsně nečitelné, zahnojené obalujícími kontejnery, a jednak si musíš předem rozmyslet, jestli někdy budeš potřebovat dědičnost nebo ne a už od začátku to psát tak nebo tak. Je to dost nešikovné – opět: chápu, že za tím jsou nějaké objektivní důvody, ale přijde mi to škoda.Ano, taková je podstata psaní v těhle jazycích - musíš si dopředu rozmyslet co kam patří, jaký to má lifetime a kde se tem lifetime řídí, jestli použiješ static nebo dynamic dispatch atd. Je to v podstatě schválně, protože díky tomu jsou pak tyhle jazyky schopny nabídnout relativně vysoké abstrakce s nízkým overheadem.
Když udělám new, tak musím někde udělat i delete. Třeba když si v rámci své třídy vytvářím instanci něčeho jiného a při ukončení platnosti instance mojí třídy to chci uklidit. Leda balit i tohle do těch chytrých ukazatelů.Ano, tak se to dělá. Na kompozici použij
unique_ptr. Samozřejmě pokud bys mohl mít ten komponovaný objekt napřío bez pointeru, tak to je vůbec nejlepší...
Ale dost mi vadí, že tady nejde obalovat proudy podobně jako v Javě. Přitom to mohlo být úplně jednoduché – binární proud by šel obalit textovým, který má jako parametr kódování. V Javě je tohle krásně jednoduché a čisté. Tady mi to přijde takové zprasené (míchání textových a binárních přístupů… do toho se na stejné úrovni řeší i formátování čísel a lokalizace).To, že máš binární i textové I/O v jedom objektu, mi jako problém opravdu nepřijde - prostě použiješ to, co potřebuješ. Jinak ano, je to sprasené, ale hlavně tím, že C++ nepodporuje (pořádně) Unicode bez 3rd party vylepšení. Celkově standardní knihovna C++ je dost chudá. A některé věci nejsou ani v boostu nebo ne tak dobře, jak bych rád...
V předkovi měla být generická metoda, kterou bych v potomkovi implementoval pro konkrétní typ, ale to mi nešlo…Já do toho moc nevidím, co se snažíš udělat, takže asi moc nepomůžu, ale zní to jakože dědičnost tady není ta správná odpověď. Možná by byla lepší template specializace třídy - tam by sis mohl dělat víceméně co bys chtěl.
BTW: nemáte někdo tip jak správně určit délku řetězce obsahujícího emoji? Některé zabírají jeden znak a některé dva. Délku textů s diakritikou mi wstring.length() určí správně, ale emoji mi rozbíjí výstup.
wstring je dost nahouby, a to zejména v unix prostředí, kde se moc nehraje na UTF-16 jako ve Windows. wstring trpí právě těmihle problémy podobně jako stringy v Javě, JavaScriptu, Qt a dalších, které byly primárně navrženy pro UCS-2 spíš než pro Unicode/UTF-16, takže jejich podpora surrogate pairs je mizerná. (Datové typy wchar_t, Javovský char a Qt QChar jsou vlastně v dnešní době dost nanic.)
Celkově podpora Unicode v C++ je blbá. Často se doporučuje používat std::string, mít v tom utf-8 a používat na to nějaký extra funkce pro práci s utf-8, což se mi ale osobně moc nelíbí, protože std::string na to není dělaný a umožǔje nevalidní sekvence, iterátor je nahouby, atd.
Vzhledem k tomu, že jsem zmlsaný Stringem z Rustu, tak bych hledal ekvivalent v C++. Chvíli jsem googloval a například tohle vypadá slibně. Možná bych si to taky vyzkoušel...
3.6.2018 22:40
xkucf03 | skóre: 50
| blog: xkucf03
Jinak celkově wstring je dost nahouby
Chápu, ale já se právě snažím o minimalizaci závislostí, takže chci, aby moje knihovna závisela jen na GCC resp. kompilátoru a standardní knihovně, aby si to každý mohl použít v libovolném programu. Zatím ten prototyp píšu v C++ a pak udělám ještě verzi v čistém C. Je to malá věc, teď to má asi 300 řádek, ve výsledku to bude tak 500 a ještě to chci rozsekat na menší části, takže když budeš chtít třeba jen zapisovat ten formát a ne ho číst, tak by ti na to měl stačit tak 200 řádkový hlavičkový soubor.
Zjišťování délky je nakonec potřeba jen v jednom výstupním modulu, který formátuje data do tabulky a potřebuje to zarovnat hezky pod sebe. Tam by možná nějaká knihovna být mohla, ale ten základ by měl fungovat jen nad standardní knihovnou (a tam na délce tisknutých znaků nezáleží).
Pro převody mezi různými kódováními používám:
wstring_convert<codecvt_utf8<wchar_t>> convertor;
což mi funguje dobře a jsem s tím celkem spokojený. To by mělo být OK, ne? Někde jsem četl, že to časem nebude podporované (deprecated), ale pak že zase neexistuje alternativa – takže dokud nebude náhrada, tak to tam prý nechají.
Pak by byla možnost použít klasický iconv, což jsem si taky zkoušel, ale to je zbytečně nízkoúrovňové a C, což se mi teď nechce používat, když je zbytek programu v C++.
Vzhledem k tomu, že jsem zmlsaný Stringem z Rustu
Část aplikací kolem toho pak asi napíšu v Rustu1 nebo v čemkoli jiném2, ale ten základ je potřeba udělat v C a C++, aby ho šlo použít ve stávajících programech.
Chvíli jsem googloval a například tohle vypadá slibně. Možná bych si to taky vyzkoušel...
Ještě na to kouknu, ale má to o řád víc LOC než můj program. Napsat vlastní funkci na počítání znaků by nemělo být těžké, ne? Takže pokud by to měl být jediný důvod pro přidání knihovny, tak bych si to radši napsal sám. Jinak samozřejmě pokud těch důvodů/funkcí je víc, tak dává smysl použít hotovou knihovnu.
Ale fakt nechci jít cestou jako to dělají lidi od webu/JavaScritu (nebo někdy i v Pythonu), kdy sice píší triviální aplikaci, ale natahají do toho milion závislostí často i dost pochybné kvality. Ono NIH je sice špatný, ale opačný extrém taky. Jde pak např. o to, že chceš použít nějakou aplikaci a chceš si před tím udělat audit – a samotná aplikace má celkem málo řádků, takže by nebyl problém ji projít, ale závisí na spoustě knihoven, které bys musel auditovat taky3.
To už bych spíš použil Boost, tam jsem myslím nějaké řešení zahlédl. Ale pokud to půjde i bez Boostu, bude to lepší.
[1] aspoň pro něj budu mít nějaké využití a bude motivace se ho učit
[2] Perl, něco asi v Javě – ostatně pointa toho, co dělám, je, že by to měl být společný jazyk/formát, který snadno umožní propojovat programy bez ohledu na jazyk, ve kterém jsou psané.
[3] většinou to právě nejsou široce používané věci, u kterých by sis mohl říct, že je to buď OK – a nebo není, ale v tom případě v tom jedeme všichni, a tak bude velký tlak na opravu, která by měla přijít rychle a měl by se jí někdo seriózně zabývat, tzn. ten problém za tebe vyřeší ostatní nebo ti aspoň pomůžou
To by mělo být OK, ne?Pokud vim, tak jo...
Zjišťování délky je nakonec potřeba jen v jednom výstupním modulu, který formátuje data do tabulky a potřebuje to zarovnat hezky pod sebe. (...) Napsat vlastní funkci na počítání znaků by nemělo být těžké, ne?Parsování utf-8 i utf-16 je obecně celkem jednoduché a pokud se můžeš navíc spolehnout, že v tom stringu je pouze validní utf-16, tak to už je vůbec jednoduché. Zarovnávání unicode textu je ale složitější, pouze počet codepointů na to nestačí, a to ani i když řešíš pouze neproporcionální text jen na úrovni znaků. Unicode codepoint ("znak") může mít šířku 0 (diakritika et al.), 1 (normální znak), nebo 2 (fullwidth CJK znak). Například tam pak vyvstane otázka, co s fullwidth znakem, který je poslední na řádku a už se tam nevejde. Příkládám skript, kterým si to můžeš vyzkoušet v terminálu. Existují na to tabulky, který řeknou, jak široký je znak xy, ale do 500 LOC se to nevejde...
Ono NIH je sice špatný, ale opačný extrém taky.Jj, s tim souhlas. Zejména jestli děláš něco takhle minimalistckýho...
20.5.2018 21:41
xkucf03 | skóre: 50
| blog: xkucf03
P.S. ještě si vzpomínám, že jsem tam narazil na to, že virtuální metoda nemůže být šablonová.
Pro doplnění – jak vypadají ty třídy:
template<typename T> class DataType { … }
class BooleanDataType : public DataType<bool> { … }
 Blíž té Javovské generické metodě by v C++ asi byla spíše metoda, která bere referenci/pointer na interface.
Je v Javě vůbec nějaký rozdíl mezi tím, když metoda má typ argumentu
Blíž té Javovské generické metodě by v C++ asi byla spíše metoda, která bere referenci/pointer na interface.
Je v Javě vůbec nějaký rozdíl mezi tím, když metoda má typ argumentu FooInterface versus T, kde T extends FooInterface? (Kromě toho, že v tom generickém případě může metoda vrátit stejný typ.)
5.5.2018 20:53
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
"Obecná cesta pro popis kontextových formátů existuje (nezkoumal jsem to do hloubky, možná tím nějaké formáty popsat nejdou), ale já jsem chtěl grafickou reprezentaci, protože tohle je sice dobrý strojový popis pro počítač, ale mentální model toho formátu si z toho člověk nesloží o moc lépe, než kdyby to bylo popsané v pár odstavcích textu. Na to jsou diagramy IMHO ideální."
Jakékoli obecné řešení bude vždy výrazně hůře srozumitelné pro člověka než když to nakreslíte ručně pro složité případy.
Každý konkrétní model jazyka/formátu není zkrátka naprosto obecný. Je vždy jednodušší než obecný model.
Váš požadavek řešitelný je. Ale není řešitelný uspokojivě. Prezentovat něco dobře člověku se v obecné formě řešit nedá.
Stejný druh požadavků je mít program, který sáhne do databáze, zjistí její strukturu a nakreslí ERA model databáze. Takové programy existují, ale člověk ty chlívečky prostě uspořádá lépe, čitelněji, srozumitelněji a mnohonásobně lépe než co se dosud podařilo vygenerovat. Přitom je to stále jednodušší úkol, než váš požadavek - tedy v zásadě zobrazit složitý graf libovolné obecné úrovně, závislostí, atd. Ona ta relační databáze má jen tabulky, sloupce a relace.
7.5.2018 16:22
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
9.5.2018 14:18
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Atd... sam se to teprv ucim, ale cekal bych, ze ty uz tam jsi.Funkcionální programování je mi relativně blízké a používám některé jeho prvky tam, kde se mi to hodí. Nevidím v tom ale samospásu a hlavně to vůbec nesouvisí s tím co dělám. To nemyslím nijak negativně, prostě teď řeším něco úplně jiného z jiných důvodů. Něco, co mě aktuálně pálí.
7.5.2018 20:40
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
7.5.2018 20:55
Grunt | skóre: 23
| blog: Expresivní zabručení
| Lanžhot
Ale filozoficky a principiálně s tou myšlenkou souhlasím.
Současné počítače člověku opravdu moc nepomáhají proti možnostem, které by mohly být.
Zejména stav programovacích jazyků je prachbídný. Což považuji za hlavní příčinu současného špatného stavu.
Pokud dodnes lidi programují operační systémy, ale i většinu služebních i jiných programů v jazyce, kde se stringy musíte pracovat pomocí strlen(), strcpy(), strcmp(), apod., pak už takové programování je nesmírně neefektivní. A taky se v takovém jazyce programátor vykašle na abstrakci, rozhraní, UI, protože je plně zaměstnán ptákovinami. Dokola a doblba řeší to, co programovací jazyk měl udělat dávno dávníčko za něho. Prostě ten jazyk nutí lidi myslet na velice low level úrovni, a jen menšina lidí/programátorů dokáže myslet na mnoha úrovních současně - tedy programujíc low level myslet na high level výsledek a úroveň.
Na druhé straně mám dojem, že jazyky typu Smalltalk a jejich odvozeny se už trochu přežily. Navíc není možné dost dobře modifikovat Smalltalk, aby to nedrhlo. Pod dojmem tohoto článku jsem se trochu začetl do Selfu, a měl jsem dojem, že je implementace grafu, která je úžasná pro data, méně už pro kód a algoritmy. Applí odvozenina Smalltalku zvaná ObjectiveC byl kočkopes. A další odvozenina Smalltalku zvaná Ruby mi také nepřijde ideální. Vždy mi přišlo, že oproti Smalltalku je to krok zpět a něco nedomyšleného.
Současný trend programovacích jazyků je mít co nejhloupější jazyk a vše dohnat knihovnami. Výsledkem je, že jazyk nemůže programátorovi pomoci, protože nemá dostatek informací ke kontrole kódu o záměru programátora. Nemůže ani dobře optimalizovat, protože má málo informací o kódu.
Navíc jazyky jsou nekonzistentní. Obvykle nejvíce je u všech programovacích jazyků nedomyšlen typový systém:
1) Např. Java/C# má něco jako objekty, něco jako primitivní typy. Proč sakra nemůže být všechno objekt? To má být to čisté OOP, kterou se Java nezaslouženě všude chlubí?
2) C/C++ má nesmyslné celočíselné typy a domrvený systém znakových typů (char jako většinou signed integer? to má být apríl?)
Podle mého to chce kvalitní dvojici programovacích jazyků. Kvalitní programovací jazyk a kvalitní skriptovací jazyk. To druhé by mělo být volitelně interaktivní - třeba ten Smalltalk, Self, cokoli. S kvalitním jazykem přijde i kvalitnější výsledek, přestanou se řešit low level ptákoviny, které má řešit jazyk sám a ne s tím zatěžovat programátora.
7.5.2018 22:16
xkucf03 | skóre: 50
| blog: xkucf03
Podle mého to chce kvalitní dvojici programovacích jazyků. Kvalitní programovací jazyk a kvalitní skriptovací jazyk. To druhé by mělo být volitelně interaktivní - třeba ten Smalltalk, Self, cokoli. S kvalitním jazykem přijde i kvalitnější výsledek, přestanou se řešit low level ptákoviny, které má řešit jazyk sám a ne s tím zatěžovat programátora.
A co operační systémy? Má nějaký jiný1 jazyk než C šanci na tom, aby se v něm dal napsat operační systém (a tím myslím opravu, ne jen jako experiment, že to jde)? Koukal jsem, že někdo píše OS v Rustu (Redox). Má to šanci být reálně použitelným jádrem systému a konkurovat současným OS?
To by pak šly psát aplikace ve stejném jazyce (a zároveň pohodlně) jako OS. A pak by už stačil jen nějaký dynamický jazyk na skriptování. (no dobře, a pak spousta DSL pro různé specifické úlohy)
[1] vyšší – ne nějaký hnusný assembler
8.5.2018 01:29
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Mimochodem, myslíte si, že třeba NASA by poslala do vesmíru cokoli, co je řízeno kódem v jazyce C? To by si pěkně zavařili.NASA je docela notoricky známá používáním C a C++. Dokonce mám pocit, že je toho většina. Podle mě to ale moc nevypovídá - s těmi pravidly co pro to mají by fakt mohli psát v čemkoliv a jazyk je jen detail.
v Pascalu, v Module-2, Module-3, Adě, PL/I, Forthu, FortranuSi teda nedokážu představit, jak by se v takových jazycích psal driver na stránkování nebo patch na Spectre o_o. A v psát cokoliv v Adě, to bych se asi zbláznil
.
8.5.2018 09:09
Grunt | skóre: 23
| blog: Expresivní zabručení
| Lanžhot
Dříve se běžně psaly operační systémy v Pascalu, v Module-2, Module-3, Adě, PL/I, Forthu, Fortranu, atd. atd. atd.Nechci do toho moc kecat, ale aspoň co já pamatuju, tohle se mohlo týkat tak akademické sféry. Většina „operačních systémů“ nebo to co za ně můžeme považovat (tedy různé interprety BASICu, první DOSy, dokonce i ten první UNIX) byly psané v assembleru. Takže Céčko bylo něco jako dar shůry (Resp. teda z Bell Labs). Třeba nějaký opraní systém v Adě bych si klidně rád zkusil nabootovat v emulátoru
Navíc v původní verzi C byste asi programovat nechtěl: žádné prototypy funkcí, pouze signed integer typy, funkce nemohly vrátit struktury. Všechny členy struktur sdílely jména. Takže třeba toto by byla chyba konfliktu jmen: struct a { int x; }; struct b { char x; };Pohoda v tomhle prostředí programuju dnes a denně
.
C/C++ má nesmyslné celočíselné typy a domrvený systém znakových typů (char jako většinou signed integer? to má být apríl?)Já měl za to že v C není téměř žádná abstrakce. Maximálně leda tak nad asemblerem.
Hmm a co Scala? By mě třeba zajímalo co si Bystroushaak myslí o Scale.Současný trend programovacích jazyků je mít co nejhloupější jazyk a vše dohnat knihovnami. Výsledkem je, že jazyk nemůže programátorovi pomoci, protože nemá dostatek informací ke kontrole kódu o záměru programátora. Nemůže ani dobře optimalizovat, protože má málo informací o kódu.
Navíc jazyky jsou nekonzistentní. Obvykle nejvíce je u všech programovacích jazyků nedomyšlen typový systém
9.5.2018 10:44
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
9.5.2018 16:29
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
In the 1960s object-orientated programming was put into practice with the Simula language, which introduced important concepts that are today an essential part of object-orientated programming, such as class and object, inheritance, and dynamic binding.(zdroj) Late binding už je zase koncept, který nesouvisí ani s jednou z těch dvou věcí, ale odvíjí se od statičnosti nebo dynamičnosti toho jazyka. Konkrétní jazyk je výsledkem mixu různých přístupů, které mu dodávají jedinečnost a od kterých se mj. odvíjí, jak v něm bude vypadat idiomatický kód. Jinak to vypadá, že ty off-topic plivnutí na Javu už lidi nechávají chladné. Budeš si muset najít nějaké jiné téma, pokud chceš zase vyrobit diskuzi o 1000+ komentářích.
9.5.2018 21:45
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Konkrétní jazyk je výsledkem mixu různých přístupů, které mu dodávají jedinečnost a od kterých se mj. odvíjí, jak v něm bude vypadat idiomatický kód.Tak samozřejmě. Psal jsem to v kontextu toho, že OOP s funkcionálním programováním původně relativně souviselo, dokud to nezazdilo právě C++ a později Java. Dneska s tím lidi přichází jako s anti-oop hnutím a zmiňované jazyky pomalu pod tlakem přijímají některé prvky a myslí si, bůh ví jak nejsou moderní, když přitom OOP v počátcích svého používání bylo částečně funkcionální a všichni to považovali za naprostou samozřejmost.
Jinak to vypadá, že ty off-topic plivnutí na Javu už lidi nechávají chladné. Budeš si muset najít nějaké jiné téma, pokud chceš zase vyrobit diskuzi o 1000+ komentářích.Javu a C++. Jinak pointou nebylo plivnutí, pointou bylo upozornit, že OOP původně znamenalo něco úplně jiného, než co se dnes učí děti ve škole.
Jo, jenže Simula nebyla nikdy široce používaná, zato Smalltalk byl jeden čas to co dnes Java a právě on stál za popularizací termínu OOP.Takže prostě za původní OOP považuješ nikoliv první jazyk, který s OOP přišel, ale až nějaký náhodný další, který se ti zrovna líbí. Pokud Smalltalk je původní OOP jazyk proto, že je/byl používanější než Simula, pak Java je původní OOP jazyk proto, že je používanější než Smalltalk. Pěkně jsme předefinovali slovo původní.
Psal jsem to v kontextu toho, že OOP s funkcionálním programováním původně relativně souviselo, dokud to nezazdilo právě C++ a později Java.Aha. Takže imperativní Simulu vynecháme, protože se nám to nehodí, a vypíchneme až další jazyk v řadě. Že dávno před Javou (1995) tu bylo nejen to C++ (1985), ale i Object Pascal (1986), Ada (OOP přidáno 1995) a ostatně i Python (1990), kde je OOP také class-based a velmi podobné tomu v Javě (drobné rozdíly vyplývají jen z toho, že Python je na rozdíl od Javy dynamický), lze přehlídnout. To slovo zazdít je taky pěkně sugestivní. Kdybych přistoupil na to, že jazyk, který udělá z tvého hlediska chybný krok, může zazdít následující vývoj, tak Java nezazdila nic, protože ta prostě převzala OOP z C++ (jen odebrala vícenásobnou dědičnost než ji v 8. edici znovu zavedla). A Bjarne Stroustrup uvadí Simulu jako hlavní inspiraci pro C++:
Then when I came to Bell Labs in 1979 and I needed to build some systems. [...] And so I tried to take the strength of Simula in terms of type system and object-oriented programming and object-oriented design and marry it with the strengths of C which was that it could interact with lots of other software, it was open, and it was good for systems level work. And it was efficient, and that was the origin of the thing.
Jinak pointou nebylo plivnutí, pointou bylo upozornit, že OOP původně znamenalo něco úplně jiného, než co se dnes učí děti ve škole.Ne, OOP původně znamenalo přesně to, co znamená dnes, a že se někdy v průběhu historie objevil alternativní směr, který ty myšlenky dál rozvedl a poupravil, na tom nic nemění.
9.5.2018 23:47
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Takže prostě za původní OOP považuješ nikoliv první jazyk, který s OOP přišel, ale až nějaký náhodný další, který se ti zrovna líbí. Pokud Smalltalk je původní OOP jazyk proto, že je/byl používanější než Simula, pak Java je původní OOP jazyk proto, že je používanější než Smalltalk. Pěkně jsme předefinovali slovo původní.Nazývám ho původním, neboť byl tím, kdo ten termín zpopularizoval. Stejně jako je možné napsat původní žárovka a myslet tím Edisonův vynález, přestože Edison žárovku nevynalezl, jen jí rozšířil mezi lidi.
Aha. Takže imperativní Simulu vynecháme, protože se nám to nehodí, a vypíchneme až další jazyk v řadě. Že dávno před Javou (1995) tu bylo nejen to C++ (1985), ale i Object Pascal (1986), Ada (OOP přidáno 1995) a ostatně i Python (1990), kde je OOP také class-based a velmi podobné tomu v Javě (drobné rozdíly vyplývají jen z toho, že Python je na rozdíl od Javy dynamický), lze přehlídnout.Ano, proto jsem tam C++ napsal, dokonce v pořadí před Javou, abych zdůraznil že tu bylo dřív.
Ne, OOP původně znamenalo přesně to, co znamená dnes, a že se někdy v průběhu historie objevil alternativní směr, který ty myšlenky dál rozvedl a poupravil, na tom nic nemění.Díky, že jsi mi to vysvětlil na základě pěti minut čtení wikipedie. Asi si z hlavy vymažu poslední tři roky studia tehdejší doby a situace kolem Smalltalku, který se používal desetiletí předtím, než C++ vůbec bylo prakticky využitelné kvůli posranému standardu a brutálně pomalému a neoptimálnímu kompilátoru (~90 +- 2 roky).
Nazývám ho původním, neboť byl tím, kdo ten termín zpopularizoval. Stejně jako je možné napsat původní žárovka a myslet tím Edisonův vynález, přestože Edison žárovku nevynalezl, jen jí rozšířil mezi lidi.V tom se prostě neshodneme. Uznal bych to, kdyby Simula byla historicky fakt naprosto bezvýznamná, ale jestliže to přímo inspirovalo vznik C++ (a jako inspiraci ji ostatně uvádí i sám Gospling), tak za původní OOP těžko můžu považovat až nějakého budoucího nástupce.
Ano, proto jsem tam C++ napsal, dokonce v pořadí před Javou, abych zdůraznil že tu bylo dřív.A proto jsem psal nejen to C++ a následně vyjmenoval několik dalších jazyků ještě starších než Java. Ještě dál jsem rozvíjel, proč je nesmyslné mluvit o tom, že Java něco zazdila, když ta prostě převzala OOP z C++ a C++ zase ze Simuly. Celá tahle diskuze se odvinula od toho, že jsem zmínku o Javě označil za off-topic. Off-topic to je, protože z hlediska vývoje OOP je Java dost irelevantní a prakticky žádné nové myšlenky v tomto směru nepřináší. Tím, že se rozšířila, pomohla tuhle koncepci zpropagovat, ale nijak ji neformovala.
Díky, že jsi mi to vysvětlil na základě pěti minut čtení wikipedie.Ad hominem. FYI – kupodivu jsem v době, kdy jsem nedisponoval připojením k Internetu, chodil do knihovny, kde asi kvůli nedostatečnému rozpočtu byla v regálu s počítačovou literaturou slušná sbírka muzejních knih. Jmenovitě jsem četl starou bibli o Pascalu z asi 80. let a pokud si správně vzpomínám, už se tam řešilo právě i OOP. O nějaký ten rok později jsem taky na IRC hojně diskutoval s jistým individuem, které si nejprve vychvalovalo COBOL a později přešlo na Objective-C, které bylo masivně inspirované právě Smalltalkem. Web Stroustrupa (na který odkazuju v předchozím příspěvku) jsem taky pročítal už před kolika lety, stejně jako jsem viděl různé rozhovory s ním. Např. konkrétně tenhle. Jmenovitě tam mluví o Simule. Nevím, jak by mě mělo dehonestovat to, že když se mi něco nezdá (v tomto případě tvrzení o původním OOP – protože se vynořila jakási mlhavá vzpomínka, že to asi není úplně pravda), tak si dám práci, abych si to ověřil a ještě poslal ozdrojovaný příspěvek.
10.5.2018 10:10
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
V tom se prostě neshodneme. Uznal bych to, kdyby Simula byla historicky fakt naprosto bezvýznamná, ale jestliže to přímo inspirovalo vznik C++ (a jako inspiraci ji ostatně uvádí i sám Gospling), tak za původní OOP těžko můžu považovat až nějakého budoucího nástupce.Simula ale historicky byla poměrně nevýznamná (sama o sobě, ne jako inspirace) a pokud je mi známo, tak kromě sálových počítačů se nedočkala širšího rozšíření. Asi jako jazyk B, který předcházel C.
A proto jsem psal nejen to C++ a následně vyjmenoval několik dalších jazyků ještě starších než Java. Ještě dál jsem rozvíjel, proč je nesmyslné mluvit o tom, že Java něco zazdila, když ta prostě převzala OOP z C++ a C++ zase ze Simuly.Není to jen jazyk, ale také prostředí a kultura. U nás například vyrostla už celá generace lidí učících se Javu a představujících si pod pojmem OOP právě C++, nebo Javu.
Ad hominem. FYI – kupodivu jsem v době, kdy jsem nedisponoval připojením k Internetu, chodil do knihovny, kde asi kvůli nedostatečnému rozpočtu byla v regálu s počítačovou literaturou slušná sbírka muzejních knih. Jmenovitě jsem četl starou bibli o Pascalu z asi 80. let a pokud si správně vzpomínám, už se tam řešilo právě i OOP. O nějaký ten rok později jsem taky na IRC hojně diskutoval s jistým individuem, které si nejprve vychvalovalo COBOL a později přešlo na Objective-C, které bylo masivně inspirované právě Smalltalkem. Web Stroustrupa (na který odkazuju v předchozím příspěvku) jsem taky pročítal už před kolika lety, stejně jako jsem viděl různé rozhovory s ním. Např. konkrétně tenhle. Jmenovitě tam mluví o Simule.Nevidím jak to souvisí s mým tvrzením, že Smalltalk zpopularizoval OOP.
Nevím, jak by mě mělo dehonestovat to, že když se mi něco nezdá (v tomto případě tvrzení o původním OOP – protože se vynořila jakási mlhavá vzpomínka, že to asi není úplně pravda), tak si dám práci, abych si to ověřil a ještě poslal ozdrojovaný příspěvek.Ozdrojovaný příspěvek s daty vzniku jednotlivých jazyků vypovídá jen velmi, velmi málo o tehdejší situaci v programátorském světě.
Simula ale historicky byla poměrně nevýznamná (sama o sobě, ne jako inspirace)Ona ta inspirace je ale docela významná, když se bavíme o původním OOP a Simula je považovaná za první jazyk s podporou OOP. Kdyby Simula byl jen nějaký experiment s nulovým impaktem, tak ti lze dát za pravdu, ale pakliže naprostá většina dnes užívaných programovacích jazyků má OOP model stejný jako Simula a autoři jedněch z nejpoužívanějších jazyků všech dob, Javy a C++, ji shodně označují za hlavní inspiraci, tak nechápu, jak bych za původní OOP mohl brát cokoliv jiného.
Není to jen jazyk, ale také prostředí a kultura. U nás například vyrostla už celá generace lidí učících se Javu a představujících si pod pojmem OOP právě C++, nebo Javu.A to je vina Javy, nebo čeho? Protože jsi psal, že C++ a Java něco zazdily. Ostatně, na OS X a iOS se dodnes používá Objective-C, které je je přímo inspirované právě tím Smalltalkem, jako primární jazyk. Ten směr tedy dodnes existuje a žije. Druhá věc je, že mi přijde, že většina vývojářů, která s Objective-C přijde do styku jako s dalším jazykem, je poměrně otřesená. To můžeme přičíst neochotě se učit něco nového, ale vzhledem k tomu, že např. funkcionální programování nabírá na popularitě přesto, že naučit se uvažovat funkcionálně je podle mě řádově těžší než si zvyknout na to, že místo volání metod posílám zprávy apod., si nemyslím, že by to byl ten hlavní efekt. Samozřejmě je otázka, do jaké míry by to bylo jiné u čistého Smalltalku, ne kočkopsa mezi C a Smalltalk-like OOP.
Nevidím jak to souvisí s mým tvrzením, že Smalltalk zpopularizoval OOP.Já především nerozporoval, že OOP bylo zpopularizováno Smalltalkem. Rozporuju, že Simula by byla natolik bezvýznamná, že by bylo možné Smalltalk označit za původní OOP jazyk.
Ozdrojovaný příspěvek s daty vzniku jednotlivých jazyků vypovídá jen velmi, velmi málo o tehdejší situaci v programátorském světě.Další jazyky jsem zmiňoval proto, abych ukázal, že Java je z hlediska vývoje OOP dost irelevantní. Měl na mysli třeba tu výpověď Stroustrupa.
Já především nerozporoval, že OOP bylo zpopularizováno Smalltalkem. Rozporuju, že Simula by byla natolik bezvýznamná, že by bylo možné Smalltalk označit za původní OOP jazyk.Pokud přijmete, že slovo původní lze chápat nejen jako chronologicky předchozí, ale i jinak, bude tím spor vyřešen, alespoň v tomto ohledu. Sám bych mohl například - jakožto idealisticky smýšlející člověk - nazvat původním něco, co odpovídá původní myšlence ze světa idejí a analogicky k tomu jako nepůvodní něco, kde už dochází k neorganickému smísení několika myšlenek dohromady. Pokud se na to podíváte takto, tak Smalltalk je asi dost původní, protože tu OOP myšlenku zachycuje dost slušně.
To zavání trochu definicí kruhem. Jaký je tedy nějaký pevný bod, kterého se lze chytnout? Nějaká definice nebo manifest objektového přístupu, podle kterého jde posoudit, zda daný jazyk dostatečně naplňuje tyto původní myšlenky? Pokud se formovala teorie současně s praxí a implementacemi prvních jazyků, tak to půjde těžko rozlišit.
Ne. Není to původní v žádném ohledu.Nevím proč Vám to tak leží v žaludku? Zřejmě Smalltalku nepřisuzujete žádnou OOP původnost, možná ani originalitu myšlenek či přístupu, přiznáváte mu akorát popularizační význam. Pro celou debatu je to ale detail, nic podstatného. Pokud by Bystroushaak býval místo „původní OOP“ napsal „OOP v podobě, v jaké ho propagoval Smalltalk“, bude význam debaty nezměněný a může celá diskuze pokračovat víc k tématu (tj. jak realizovat ten systém). Proto jsem taky chtěl trochu otupit hrany v chápání slova původní. Což se zřejmě nepodařilo
11.5.2018 12:41
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
9.5.2018 22:57
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Neumim si ho dost dobre predstavit jako flow dat, asi bych ho tam musel dostrcit nasilim, ale pak je tam ta obalka objektu jaksi navic, ci?A tak to zas jo. V tom by ti asi Smalltalk / Self otevřel oči.
9.5.2018 23:00
Bedňa | skóre: 34
| blog: Žumpa
| Horňany
9.5.2018 23:49
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
9.5.2018 23:59
Bedňa | skóre: 34
| blog: Žumpa
| Horňany
9.5.2018 23:07
Bedňa | skóre: 34
| blog: Žumpa
| Horňany
9.5.2018 23:50
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
AFAIK by z hlediska funkcionální čistoty jazyku nemělo ubrat to, že funkce může namísto např. čísla vracet immutable objekt, který nese nějakou informaci a současně obsahuje funkce (metody), které s ní pracují. Je to spíš forma členění kódu a imperativní přístup to neimplikuje.Tak. Ale asi by to bylo kapku neoptimální a pomalé.
10.5.2018 10:07
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
10.5.2018 19:05
xkucf03 | skóre: 50
| blog: xkucf03
Ono „vytvořit objekt“ může spočívat v tom, že dáš na začátek dat jeden ukazatel směřující na definici třídy, ne? Jasně, oproti primitivnímu typu nesoucímu čistá data to nějakou režii má, ale z dnešního pohledu bude dost zanedbatelná. A hlavně s postupem času1 čím dál víc platí, že čas programátora je drahý, zatímco výpočetní výkon levný2, takže pokud má smysl na něco optimalizovat obecný programovací jazyk, tak je to hlavně srozumitelnost pro člověka, snadný přirozený zápis a hlavně čtení – v důsledku toho můžeme očekávat rychlejší vývoj a spolehlivější software. Oproti tomu jsou nějaké ty ušetřené bajty nebo cykly procesoru irelevantní.
[1] ostatně píše to i ESR v Umění programování v Unixu – a to je kniha z roku 2003
[2] a to neříkám, abych nabádal k plýtvání výpočetním výkonem – spíš proto, abychom neplýtvali kapacitami programátorů
Tam, kde není potřeba ani jedno z toho, je režie nulová: objekt, který nese jedno číslo (a libovolné množství metod), může být při kompilaci zrovna tak nahrazen tím jedním číslem apod.Nevim, jaky je stav skutecneho prekladace, ale videl jsem papery ke Scale, kde prekladac byl schopen v rade situaci eliminovat typ objektu, protoze to bylo potreba znat jen v dobe kompilace.
Protože musíš pořád vytvářet nové objekty?Na druhou stranu, muzes data bez problemu sdilet. Nabizi se jeste otazka, zda problematika mnozstvi vytvarenych objektu neni z dnesniho pohledu uz mikrooptimalizace. Jeste pred par lety jsem narazel na individua, co byla schopna tvrdit, ze rekurze je spatna, protoze je pomala, protoze jim pred triceti lety rekli, ze volani funkce ma velkou rezii.
11.5.2018 12:39
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Ono „vytvořit objekt“ může spočívat v tom, že dáš na začátek dat jeden ukazatel směřující na definici třídy, ne?No, ale pokud jsou objekty pokaždé immutable, tak je musíš neustále transformovat na něco jiného, což sice principiálně může sdílet stejná data, ale určitě to přináší režii navíc, ne?
11.5.2018 20:07
xkucf03 | skóre: 50
| blog: xkucf03
Možná není úplně dobrý nápad mít všechny objekty „immutable“…
Necham se velmi rad opravit, ale mel jsem za to, ze OOP v podstate implikije imperativni pristup.Ne nezbytne, jak tu jiz jini naznacovali. Ta dichotomie mezi FP a OOP nelezi ani tak v tom, co dany jazyk umi, ale v pristupu k tvorbe programu a co se od urciteho pristupu ocekava jako ,,ideologicky ciste''. Zatim co ve FP jsou (typicky) primarni data, ktera jsou sama o sobe interpretovatelna. (Proto je v urcitych komunitach takovy duraz na typovy system.) V OOP je na druhou stranu (typicky) primarni kod, protoze az ten v podobe volani metod (zasilani zprav) dodava intepretaci jednotlivym objektum, protoze princip zapouzdreni. Pro jaky pristup se rozhodnes je na tobe a jazyk ti pro to dava jen vhodne prestredky. Napriklad v Jave bezne programuju tak, ze mam casti kodu pracujici ciste s immutable objekty. Degraduji tak objekty jen na pouhe hodnoty, ktere jednotlive metody transformuji na jine hodnoty, takze de facto FP pristup. Diky tomu ziskam pohodlne debugovani, testovani a casto i jednodussi kod. A kdyz potrebuji resit UI, I/O a podobne zalezitosti, prejdu ke klasickemu OOP. V podstate podobny pristup ma Scala, jen s lepsi podporou syntaxe a knihoven.
A jak bys pojmenoval styl, který je převážně objektový a na vhodných místech1 používá prvky z funkcionálního programování, např. předává do metody funkci, která upraví chování uvnitř metody, něco do něj doplní…? Je to mix OOP a FP? Je to špatně? Mělo by se to – když už – dělat všechno objektově a předat tam místo funkce objekt? Nebo je to pořád OOP?
[1] což bude asi subjektivní
Mixování OOP a FP je katastrofa. Obojí vyžaduje jiný mindset.Mozna bych ti i uveril, kdybych s tim nemel za poslednich N let velmi dobre zkusenosti. Pricemz ke kombinovani OOP a FP me dotlacily zkusenosti z pouzivani ciste OOP pristupu. Po case se nektere projekty od urcite velikosti nedaly rozumne uchopit. Pokud chces kombinovat OOP a FP bohate staci rozumne urcit hranice mezi moduly a rict si, jaky pristup se v tom modulu pouziva.
elegantní kombinace s OOP či FP není moc snadná.Jako protipriklad bych pouzil (zde jiz jednou zminene) microservices, ktere casto v mnoha ohledech odpovidaji FP, tj. posles nekam nejakou hodnotu, vrati se ti hodnota jina. Zajimave, ze vetsine lidi to problem nedala a pouzivaji to naprosto prirozene.
SIGINT* a je potřeba s tím něco dělat. Jestli chceš mít možnost dělat ty věci, které popisuješ v tom manifestu (jako třeba ten pěkný přístup k diskusím atd.), nejspíše se tam mnohem rychleji dostaneš s hloupým strojovým učením natrénovaným na hloupé formáty než se Smalltalkem apod.
*) Existuje samozřejmě mnohem víc programátorských nepříjemností než jen SIGINT, ale zvolil jsem ho jako zástupce veškerého zla, které na programátory číhá v reálném světě. Pochybuju, že by proti tomu někdo něco měl...
20.5.2018 22:34
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Blog jsem četl už týdny zpátky, ale neměl jsem sílu reagovat. S tím manifestem je toho prostě špatně příliš mnoho ... snažím se to říct bez nějaké urážky nebo podobně, přijde mi to prostě jako utopie.Naopak, negativní reakce vidím v tomhle případě radši, než ty pozitivní, neboť mi dávají šanci se nad tím zamyslet i z druhého uhlu pohledu.
Myslim, že řada těch myšlenek je společná s nápady za konceptem Sémantického webu. Důvody, proč tyhle myšlenky v praxi nefungují shrnul velmi pěkně Cory Doctorow v eseji Metacrap.Některé koncepty jsou podobné. Sémantický web je ale docela hodně nejasné klubko hadů a štírů, které za líbivou maskou skrývají propasti vedoucí směrem do matematiky, Gödelovo teorémů neurčitosti, reprezentace informací, vědomostních bází a teorie umělé inteligence. Osobně chci něco jiného, co třeba ostatním nemusí připadat tak užitečné, ale pro mě osobně je to důležité. Budu se tomu dál věnovat v navazujících blozích a knihách v následujících letech.
Obecně mám z toho zaujetí jazyky/prostředími jako Scheme, Smalltalk/Pharo, Self apod. dojem úniku z reality. Realita je na nás zlá, tak si vymyslíme svkělé prostředí s jednoduchými počátečními axiomy/invarianty, které pak platí univerzálně a všechno je hezké. Pak už je jen potřeba překecat všechny (nebo alespoň někoho), aby na tu 'správnou' platformu taky přešli. Problém typicky je, že adopce obvykle zůstane nízká a je otázka, jestli, kdyby byla vysoká, by ten jazyk/prostředí vůbec dostatečně škáloval. Můj soukromý názor je, že většinou ne nebo ne zdaleka tak dobře, jak bylo očekáváno.Ha, to právě vůbec nechci. Tohle je mi naprosto jasné - jde mi o osobní nástroj. Strávil jsem přibližně pět let diskuzí na IRC na téma stavby tohohle nástroje a mám kolegu, který k tomu spěje taky, i když z úplně jiného uhlu přes lisp. Pak je tu taky Bryce Lynch, který o určitém konkrétním odstínu myšlenky, která může být celou paletou barev, mluví poměrně hodně veřejně. Postupem času jsem dospěl k názoru, že to co chci nedává smysl sdílet jako produkt, neboť ten bude vždy z principu omezen, ale je možné to sdílet jako filosofii, nástroje a proces. Mým cílem není konkrétní produkt, jako třeba Ubuntu, ale spíš něco jako LFS.
Jestli chceš mít možnost dělat ty věci, které popisuješ v tom manifestu (jako třeba ten pěkný přístup k diskusím atd.), nejspíše se tam mnohem rychleji dostaneš s hloupým strojovým učením natrénovaným na hloupé formáty než se Smalltalkem apod.Já už to ale dělám. Chybí mi k tomu integrace.
Moje $.02: Prostě se na to vykašlat, IMHO to nemá cenu. Nejlepší je smířit se s vlastnostmi reálného světa a vyrovnat se s tím, že existuje SIGINT* a je potřeba s tím něco dělat.To bych rád, ale prostě nemůžu. Provedl jsem sérii praktických experimentů a testů, které mi ukázaly, že ten přístup v omezené, jasně specifikované míře, kterou se mi podařilo dát dohromady během posledních cca 3/4 roku je možný a technicky realizovatelný. Je mi jasné, že je to trochu zmatené, protože ten blog působí jinak, než o čem tady píšu v diskuzi. Ale napsal jsem ho v září (před víc jak půl rokem) při psaní Na čem dělám 2017/9 jako jednu z kapitol a pak se mi to nechtělo publikovat, kvůli tomu jak to vyznívá. Jediný důvod, proč jsem to teď zveřejnil byla emailová konverzace s Pavlem Křivánkem, po kterém jsem chtěl radu ohledně instrukční sady Selfu, kterou použil ve svém interpretru Marvin. Ptal se mě na některé z motivací, tak jsem si řekl, že než to rozepisovat, tak bude jednodušší publikovat tuhle nadšenou starožitnost, a třeba to i vyvolá dobrou diskuzi, což ano.
Strávil jsem přibližně pět let diskuzí na IRC na téma stavby tohohle nástroje a mám kolegu, který k tomu spěje taky, i když z úplně jiného uhlu přes lisp.To mi popravdě nepřijde jako "úplně jiný úhel"
Ale to je jedno...
Pak je tu taky Bryce Lynch, který o určitém konkrétním odstínu myšlenky, která může být celou paletou barev, mluví poměrně hodně veřejně.Asi jsem přízemní a nevidim v tom ty velké myšlenky. Přijde mi to prostě jako automatizační framework na všelijaké tasky. Což ale není kritika - vypadá to užitečně. No já si asi počkám na nějaké příští třeba konkrétnější vyjádření...
BTW: co si myslíš o D-Bus?
Viz třeba (napovídání přes bash-completion):
$ gdbus call --session --dest org.kde.kate-1337 --object-path /kate/MainWindow_1 --method org. org.freedesktop.DBus.Introspectable.Introspect org.kde.kate.KateMainWindow.slotQuickOpen org.kde.KMainWindow.actions org.qtproject.Qt.QWidget.hide org.qtproject.Qt.QWidget.setWindowTitle org.freedesktop.DBus.Peer.GetMachineId org.kde.kate.KateMainWindow.slotWindowActivated org.kde.KMainWindow.actionToolTip org.qtproject.Qt.QWidget.lower org.qtproject.Qt.QWidget.show org.freedesktop.DBus.Peer.Ping org.kde.kate.KateMDI.MainWindow.setSidebarsVisible org.kde.KMainWindow.activateAction org.qtproject.Qt.QWidget.raise org.qtproject.Qt.QWidget.showFullScreen org.freedesktop.DBus.Properties.Get org.kde.kate.KMainWindow.appHelpActivated org.kde.KMainWindow.disableAction org.qtproject.Qt.QWidget.repaint org.qtproject.Qt.QWidget.showMaximized org.freedesktop.DBus.Properties.GetAll org.kde.kate.KMainWindow.setCaption org.kde.KMainWindow.enableAction org.qtproject.Qt.QWidget.setDisabled org.qtproject.Qt.QWidget.showMinimized org.freedesktop.DBus.Properties.Set org.kde.kate.KMainWindow.setPlainCaption org.kde.KMainWindow.grabWindowToClipBoard org.qtproject.Qt.QWidget.setEnabled org.qtproject.Qt.QWidget.showNormal org.kde.kate.KateMainWindow.sizeHint org.kde.kate.KMainWindow.setSettingsDirty org.kde.KMainWindow.winId org.qtproject.Qt.QWidget.setFocus org.qtproject.Qt.QWidget.update org.kde.kate.KateMainWindow.slotFileClose org.kde.kate.KParts.MainWindow.configureToolbars org.qtproject.Qt.QMainWindow.setAnimated org.qtproject.Qt.QWidget.setHidden org.kde.kate.KateMainWindow.slotFileQuit org.kde.kate.KXmlGuiWindow.configureToolbars org.qtproject.Qt.QMainWindow.setDockNestingEnabled org.qtproject.Qt.QWidget.setStyleSheet org.kde.kate.KateMainWindow.slotFocusNextTab org.kde.kate.KXmlGuiWindow.slotStateChanged org.qtproject.Qt.QMainWindow.setUnifiedTitleAndToolBarOnMac org.qtproject.Qt.QWidget.setVisible org.kde.kate.KateMainWindow.slotFocusPrevTab org.kde.KMainWindow.actionIsEnabled org.qtproject.Qt.QWidget.close org.qtproject.Qt.QWidget.setWindowModified $ gdbus call --session --dest org.kde.kate-1337 --object-path /kate/MainWindow_1 --method org.qtproject.Qt.QWidget.setWindowTitle "ahoj :-)"
Jasně, musel to někdo připravit a říct, co bude přes tohle API přístupné, ale i tak mi to přijde dobré. A jak na to tak koukám, tak mi přijde, že (aspoň v KDE/Qt) spousta těch věcí funguje tak nějak sama od sebe (pochybuji, že by autoři editoru Kate tohle všechno explicitně nadefinovali jako přístupné API).
28.5.2018 13:07
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Chápu, pocit1 z toho mám trochu podobný, ale přesto mi to přijde asi jako to nejlepší, co je. Připomíná mi to trochu JMX, ale D-Bus navíc prokázal, že je v praxi schopný fungovat napříč různými jazyky.
Ono je totiž otázka, jestli je vůbec dosažitelné, aby podobný nástroj/protokol byl zároveň nativní, aby byl všude doma, abys nemusel pořád serializovat/deserializovat, aby ses nemusel omezovat na jeden jazyk, aby to bylo aspoň trochu (nebo aspoň volitelně) bezpečné, aby to mělo rozumnou propustnost a latenci… Dílčí řešení naplňující jednotlivé pohledy/priority samozřejmě už existují.
Před necelým rokem jsem tu měl zápisek Ideální datový formát, kde jsem došel k tomu, že těch kritérií je spousta a člověk si musí některá vybrat a některá obětovat. Přijde mi, že pokud se toho svého ideálu dobereš, tak to bude za cenu omezení se na jeden jazyk resp. běhové prostředí. Což nemusí být nutně špatně. A pro spojení se zbytkem světa bude potřeba dopsat nějaké adaptéry/proxy.
[1] nedokážu říct, jestli to má nějaký reálný základ nebo je to prostě dané tím, na co jsem zvyklý, ale třeba takové propojování programů přes roury a STDIO mi přijde mnohem přirozenější a přímější (ale tomu zase chybí společný jazyk/formát, čímž se teď trochu zabývám…)
28.5.2018 21:32
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Ono je totiž otázka, jestli je vůbec dosažitelné, aby podobný nástroj/protokol byl zároveň nativní, aby byl všude doma, abys nemusel pořád serializovat/deserializovat, aby ses nemusel omezovat na jeden jazyk, aby to bylo aspoň trochu (nebo aspoň volitelně) bezpečné, aby to mělo rozumnou propustnost a latenci… Dílčí řešení naplňující jednotlivé pohledy/priority samozřejmě už existují.Jasně no. Imho nemá smysl se to snažit vyřešit obecně. Asi by to šlo, ale stálo by to mnohokrát víc námahy, než se snažit vyřešit čistě vlastní problémy.
Před necelým rokem jsem tu měl zápisek Ideální datový formát, kde jsem došel k tomu, že těch kritérií je spousta a člověk si musí některá vybrat a některá obětovat. Přijde mi, že pokud se toho svého ideálu dobereš, tak to bude za cenu omezení se na jeden jazyk resp. běhové prostředí. Což nemusí být nutně špatně. A pro spojení se zbytkem světa bude potřeba dopsat nějaké adaptéry/proxy.Nu, ne nutně na jeden jazyk. Například úplně všechno asi umí interfacovat s C. A různé jiné jazyky se většinou dají embedovat.
Tiskni
Sdílej:
![]()
![]()
![]()
![]()
![]()
![]()
ISSN 1214-1267, (c) 1999-2007 Stickfish s.r.o.
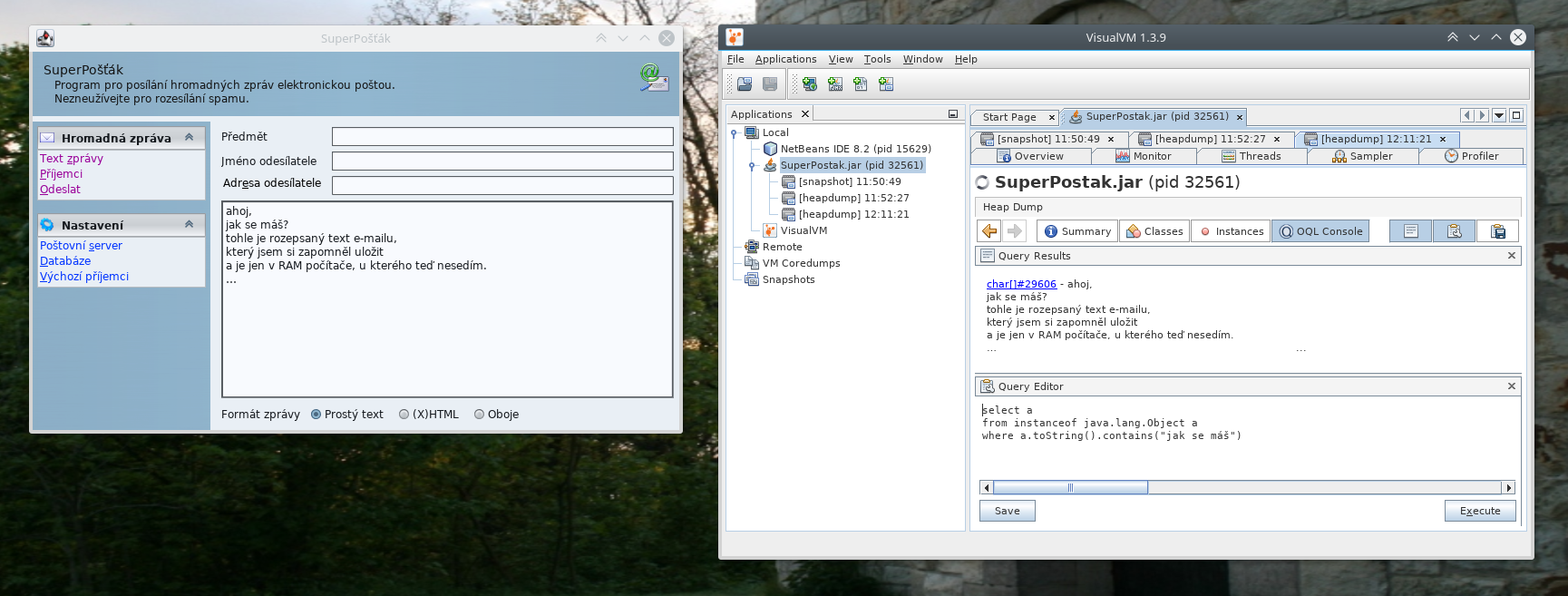{kind=link}