
Portál AbcLinuxu, 4. června 2026 21:11
27.11.2014 09:55
| Přečteno: 2484×
|
Pro několik málo zájemců přichází pokračování seriálu o programovatelné logice. Tentokrát se pokusím popsat základní principy a doporučení, které je dobré dodržovat při vývoji logických obvodů implementovaných v FPGA. Linky na předchozí díly seriálu najdete v záhlaví minulé části.
Tato kapitola představuje souhrn základních principů vývoje aplikací pro programovatelná hradlová pole. Vše je podáno v obecné rovině, aby pro pochopení nebyla nutná znalost konkrétních technologií nebo HDL jazyků. Pokud bude v textu použit úryvek z HDL, bude se vždy jednat o jednoduchý výraz pochopitelný každým, kdo se někdy setkal s libovolným počítačovým jazykem. Samozřejmě pro vlastní implementaci popsaných základů bude nutné nastudovat další literaturu a dokumentaci, která bude souhrnně uvedena v závěru seriálu.
Vývoj pro FPGA je v mnoha ohledech podobný vývoji zákaznických číslicových integrovaných obvodů, ale umožňuje ve vývojovém cyklu využít mnoha zjednodušení. Pro úspěšný vývoj aplikací pro FPGA je dobré dodržovat několik zásad:
HDL není programovací jazyk
Využívat možností cílového obvodu
Globální a lokální prostředky
Synchronní návrh a RTL
Funkční simulace
Timing constraints a STA
Jednotlivé body jsou vysvětleny dále. Jejich dodržování sice nezaručí stoprocentně úspěšný návrh, ale pomůže vyhnout se mnoha typickým problémům a vývojářským chybám.
Přestože strukturou a syntaxí se HDL jazyky jako je třeba Verilog nebo VHDL podobají programovacím jazykům, je třeba mít neustále na paměti, že se jedná o popis číslicových obvodů. Na rozdíl od běžných programovacích jazyků, které – zjednodušeně řečeno – popisují sekvenci postupně vykonávaných příkazů, HDL definují strukturu logického obvodu. Takto definovaný obvod nevykonává žádnou posloupnost činností, ale pracuje neustále paralelně. Každá jeho součást popsaná jednotlivou konstrukcí v HDL vykonává svou funkci po celou dobu, kdy je obvod napájen.
Přestože se tento bod zdá být samozřejmý, mnoho vývojářů, kteří znají běžné programovací jazyky, v něm při přechodu na FPGA chybuje. Zlom nastane ve chvíli, kdy si uvědomí rozdíl mezi programovacím jazykem a HDL.
Jak bylo popsáno dříve, dnešní FPGA obsahují kromě bloků obecné logiky i mnoho specializovaných funkčních bloků. Pro efektivní implementaci výsledné aplikace je důležité znát strukturu cílového obvodu včetně speciálních bloků. Vlastní návrh je vhodné uzpůsobit tak, aby využíval maximum prostředků poskytovaných programovatelným obvodem.
Jako typický příklad je možné uvést například aritmetiku v pevné řádové čárce. Snad všechny dnešní FPGA obsahují bloky DSP, které se skládají z rychlé násobičky, akumulátoru, několika multiplexerů a logiky rychlého přenosu. Pokud uživatelský návrh aritmetické funkce využije blok DSP, bude výsledná implementace velmi rychlá a nebude zbytečně obsazovat bloky obecné logiky, které mohou být využity pro další funkce. Pokud bude široká násobička v uživatelské aplikaci vytvořena z bloků obecné logiky, bude pomalejší a zabere velké množství logických bloků. Pro ilustraci je na obrázku 3.1 zjednodušené schéma bloku DSP48E1 převzaté ze „7 Series DSP48E1 Slice User Guide “ firmy Xilinx.
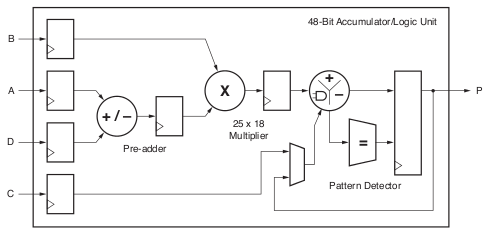
Obr. 3.1: Blok DSP48E1 v obvodech řady 7 firmy Xilinx
Využití speciálních bloků v návrhu je možné dvěma způsoby. Buď vložením instance daného bloku do návrhu z knihovny dodané výrobcem obvodu, nebo správným vysokoúrovňovým popisem funkce daného bloku. Pro výše uvedený příklad násobičky pak může její vysokoúrovňový popis vypadat takto jednoduše:
result <= a * b;
Pokud budou vstupní signály a a b a výstup result definovány shodně jako znaménkové nebo bezznaménkové vektory, šířka vektoru result bude rovna součtu šířek vektorů a a b, využije implementační nástroj pro implementaci násobičky blok DSP.
Další důležitou vlastností programovatelných logických obvodů, kterou je třeba během návrhu vzít v úvahu je určení jednotlivých pinů. Přestože je struktura většiny vstupně-výstupních buněk FPGA shodná, nebo velmi podobná, ne všechny piny jsou navzájem záměnné. Některé vstupně-výstupní piny podporují pouze některé vstupní nebo výstupní standardy a napěťové úrovně, některé piny jsou vhodné pro vstup hodinových signálů, některé dvojice pinů tvoří diferenciální páry, některé piny mohou být použity pro vstup nebo výstup rychlých sériových dat nebo třeba připojení pamětí DDR. Vstupně-výstupní piny jsou obvykle rozděleny do takzvaných bank, které například sdílejí napájecí a referenční napětí. Před návrhem schématu zapojení desky s FPGA je vždy vhodné zkontrolovat zapojení pinů podle dokumentace k programovatelnému obvodu a nejlépe i připravit základní návrh pro FPGA s přiřazenými piny. Implementace takového návrhu pak odhalí případné problémy a je možné schéma zapojení změnit.
Jednotlivé prostředky dostupné v obvodech FPGA je možné rozdělit na lokální a globální. V tomto kontextu se jedná především o dostupné propojovací prostředky. Programovatelná hradlová pole obsahují obvykle tři rozdílné typy propojovacích prostředků:
krátké rychlé spoje s omezeným dosahem
globální rychlé spoje vyhrazené pro speciální signály
běžné spoje schopné propojit libovolné body na čipu
Krátké rychlé spoje s omezeným dosahem mohou propojit například pouze sousední funkční bloky. Příkladem takových spojů je například vertikální propojení logických buněk sloužící k rychlému šíření přenosu.
Globální rychlé spoje se používají pro společné signály, které jsou potřebné téměř po celé ploše čipu s co nejmenším zpožděním a především s co nejnižším rozptylem hodnot zpoždění. Tyto spoje se používají hlavně pro globální hodinové signály nebo třeba globální set/reset. Množství těchto spojů na čipu je omezené. Některé „globální“ spoje jsou ve skutečnosti omezeny do takzvaných regionů, například pouze na polovinu nebo čtvrtinou plochy FPGA.
Běžných spojů je na ploše čipu nejvíce. Slouží pro propojení jednotlivých funkčních bloků. Rychlost šíření signálu těmito spoji je obvykle nižší než u předchozích dvou skupin a koherence jednotlivých zpoždění ve skupině podobných signálů je nižší.
Pro efektivní návrh je důležité správně využívat vhodné propojovací prostředky. Globální hodinové signály a další důležité globální signály by měly vždy využívat odpovídající globální spoje. Lokální hodiny a jiné rychlé signály s lokální působností by měly využívat různé specializované lokální propoje. Pouze obecná logika by měla být propojena pomocí běžných spojů. Důležité je dobře si rozmyslet například nutnost použití globálních resetů. Na rozdíl od ASIC je možné ve většině FPGA definovat počáteční stavy registrů a globální reset pak často není nutný. V některých částech obvodu pak jeho funkci zastane lokálně generovaný reset pro tuto konkrétní část obvodu, zatímco většina obvodu může v FPGA často správně fungovat kompletně bez resetu.
Až na některé výjimky jsou FPGA navržena pro efektivní implementaci plně synchronního návrhu. To znamená, že samotný návrh aplikace by měl dodržovat pravidla synchronního návrhu. Popis synchronního obvodu ve formě signálových toků pomocí střídajících se úrovní kombinační logiky a registrů se nazývá „register-transfer level“ – RTL. Tento princip je zjednodušeně znázorněn na obrázku 3.2.
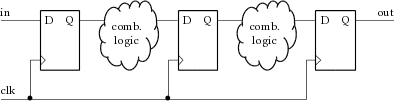
Obr. 3.2: Synchronní popis obvodu
Kombinační logické funkce na obrázku 3.2 jsou proloženy registry, které pracují na společném hodinovém signálu. Takováto struktura odpovídá struktuře logických elementů FPGA, kde je vždy LUT následována registrem. Implementace takto strukturovaného obvodu v FPGA vede k nejlepším výsledkům.
Pro správný synchronní návrh je velmi důležité dodržet několik bodů:
co nejnižší počet hodinových domén, v ideálním případě realizovat celý obvod s jediným hodinovým signálem
zajistit správný přechod signálů mezi jednotlivými hodinovými doménami, aby nevznikly problémy způsobené metastabilitou nebo nekoherencí
synchronizovat všechny vnější vstupy do hodinové domény a v rámci domény používat pouze tuto synchronizovanou verzi
Redukce počtu hodinových domén může být někdy dosaženo například použitím jednoho společného hodinového signálu s nejvyšší společnou frekvencí a vygenerováním povolovacích signálů (clock enable) pro jednotlivé domény obvodu.
Problematika hodinových domén a použití asynchronních signálů je natolik široká, že jí bude věnována samostatná kapitola.
Před vlastní implementací popisu obvodu je důležité ověřit jeho funkci. V případě synchronního návrhu pro FPGA stačí pro ověření správné funkce návrhu jeho verifikace pomocí funkční simulace. Simulace by měla ideálně pokrýt veškeré možné stavy celého obvodu a veškeré možné kombinace vstupů a vnitřních stavů včetně chybných a nepředpokládaných možností.
Oblast číslicových simulací a verifikace obecně je velice rozsáhlá a přesahuje rámec tohoto seriálu. Touto problematikou se detailně zabývá velké množství literatury, která bude uvedena v závěru seriálu.
Funkční simulace sama o sobě nezaručuje správnou funkčnost výsledného obvodu po implementaci. Na rozdíl od plně zakázkového návrhu ASIC je však situace ve světě FPGA mnohem jednodušší. Celý návrh je implementován pomocí pevně daných obvodových struktur, které byly plně charakterizovány. Pro ověření správnosti implementace a správné funkce výsledného obvodu proto stačí kromě funkční simulace pouze nadefinovat všechny časové vlastnosti obvodu, tzv. „timing constraints“ a provést statickou časovou analýzu (STA). Kroky jako extrakce parametrů z implementace a post-implementační simulace známé z ASIC nejsou v případě návrhů pro FPGA nutné.
Před spuštěním syntézy a implementace návrhu je nutné mít nadefinovány všechny časové poměry v obvodu – timing constraints. Současné implementační nástroje tyto parametry nepoužívají pouze pro statickou časovou analýzu, ale i pro vlastní syntézu a implementaci. Timing constraints musí být úplné a musí být definovat:
Frekvence nebo periody všech vnějších hodinových signálů a případné fázové posuny mezi nimi.
Vztahy mezi jednotlivými hodinovými doménami.
Setup a hold časy pro vnější vstupní signály.
Clock to output pro výstupní signály.
Splněním všech těchto bodů jsou veškeré časové poměry v návrhu známy a STA může provést kompletní kontrolu všech hodinových a signálových cest v implementovaném obvodu a nahlásit případné problémy jako je překročení maximální možné frekvence, porušení setup a hold časů synchronních prvků a podobně. Časové parametry jednotlivých prvků FPGA i spojů mezi nimi jsou známy z tovární charakterizace obvodu a výsledku implementace. Dalším výsledkem STA bývá často odhad maximální možné frekvence jednotlivých hodinových signálů.
Tiskni
Sdílej:
![]()
![]()
![]()
![]()
![]()
![]()
Nejdříve bych rád dokončil obecný úvod a seznámení. Nějaké příklady pak můžu vymyslet. Určitě by ale nebyly pro Parallelu. Platforma by mohla být buď nějaká standardní vývojová deska Xilinx nebo Altera, případně PicoZed od Avnetu. Mimochodem, tohle je náš produkt, který bude u Avnetu ke koupi od začátku příštího roku.
 ) + FPGA. Akorát budeš mít asi problém s GPIO, protože Parallella má nějaký superhustý konektory (žádnej 2.54mm header
) + FPGA. Akorát budeš mít asi problém s GPIO, protože Parallella má nějaký superhustý konektory (žádnej 2.54mm header  ).
P.S. Jinak ty ani grafiku nepotřebuješ. V SoC je od výroby řadič 1G ethernetu (tedy žádnej pomalej USB převodník), takže to můžeš ovládat klidně přes vnc/ssh.
P.P.S. Akorát je blbý, že ta deska vyžaduje externí větráček .
P.P.P.S. Mírně OT: Maník, co se původně snažil financovat otevření 3D enginu jedné staré grafiky na kickstarteru, to nakonec otevřel pod GPL.
P.P.P.P.S. Jsem chtěl původně taky napsat blog, ale teďka nemám absolutně čas.
).
P.S. Jinak ty ani grafiku nepotřebuješ. V SoC je od výroby řadič 1G ethernetu (tedy žádnej pomalej USB převodník), takže to můžeš ovládat klidně přes vnc/ssh.
P.P.S. Akorát je blbý, že ta deska vyžaduje externí větráček .
P.P.P.S. Mírně OT: Maník, co se původně snažil financovat otevření 3D enginu jedné staré grafiky na kickstarteru, to nakonec otevřel pod GPL.
P.P.P.P.S. Jsem chtěl původně taky napsat blog, ale teďka nemám absolutně čas.
Díky za link na gplgpu. Nějak jsem to přestal sledovat a tohle mi uniklo. Musím, ale říct, že mě docela zarazila tahle část v README:
The IP is licensed under the GPL v3 license. As this applies to hardware, if you develop any hardware system utilizing this code the entire ASIC or FPGA containing the Ip must be licensed under the GPL v3 and source made available.
Nejsem si úplně jistý, jestli to skutečně z GPL v3 vyplývá. Pokud ve svém projektu použiji instanci gplgpu jako black-box bez sebemenšího zásahu do zdrojáku, skutečně musím zveřejnit zdrojáky celého systému? Tuhle situaci bych přirovnal k přilinkování statické knihovny pod GPL v3 k mému vlastnímu programu. Znamenalo by to v tom případě, že skutečně musím zveřejnit zdrojový kód celého programu?
. Jinak jsem ale měl za to, že linkování knihovny staticky do programu GPL vyžaduje i když tuším existují vyjímky.
Osobně bych to teda radši licencoval pod LGPL. Ale nejradši fakt pod nějakou HW licencí, takhle není ani pořádně jasný rozdíl mezi tím, co je vlastně to IP, protože HDL může popisovat hardware buď abstraktně, ale klidně na úrovni LUTů a FF (tak to maj snad některý verze PicoBlazu). A pak do toho vleze rekonfigurace, kde může být funkce v LUTu nebo FF změněná na základě obsahu jiných LUTů a FF . V extrémním případě by to znamenalo zveřejnění masek celýho FPGA pod GPL (ekvivalent toho ASICu).
Jinak pokud by to s tím linkovaním platilo, tak to ani nelze zapojit na třeba Microblaze (ten až na jeden incident s uniklejma zdrojákama je closed source).
P.S. Když se to tak vezme, tak optimalizace při implementaci bude do toho blackboxu zasahovat (mazat "open" dráty, slučovat LUT kaskádu apod.).
... přilinkování statické knihovny pod GPL v3 k mému vlastnímu programu. Znamenalo by to v tom případě, že skutečně musím zveřejnit zdrojový kód celého programu?Podle výkladu autorů licence (RMS) ano. A i jen design tak, aby bylo možno přilinkovat GPL dynamickou knihovnu (ani ne přímo její přilinkování), aspoň podle GPL2 (a nemyslím si že by se to s GPL3 uvolnilo). Viz např. readline (GPL) a clisp.
Mimochodem, tohle je náš produkt, který bude u Avnetu ke koupi od začátku příštího roku.Zynq 7015? WOW a má to vyvedenej PCIe na ten header?
V podstatě ano. Verze se 7015 a 7030 mají na konektoru JX3 vyvedené čtyři transceivery a referenční hodiny. Účel našeho setu SVDK je trochu jiný, takže transceivery používáme pro CoaXPress rozhraní.
Záleží na typu a technologii. Interní synchronní prvky jsou obvykle schopné pracovat na stovkách MHz, což u low-endu znamená frekvence řekněme do 200-300MHz, u high-endu třeba 800-900MHz. Na druhou stranu sériové transceivery můžou pracovat na jednotkách až desítkách GHz. To ovšem vůbec nic nevypovídá o tom jak rychle a dokonce ani na jaké frekvenci bude fungovat nějaký konkrétní návrh. U FPGA stejně jako u libovolných obecných logických obvodů jsou pracovní frekvence a "rychlost" dvě různé věci, které spolu nemusí až tak moc souviset. Vezměte si například jeden obvod, který zpracovává 64b slova a pracuje na hodinové frekvenci 100MHz. Druhý obvod zpracovává 8b slova na hodinové frekvenci 500MHz. Oba obvody implementují stejnou funkci a oba zpracují jedno slovo v každém hodinovém cyklu. Který obvod je rychlejší?
 27.11.2014 21:51
Josef Kufner | skóre: 70
27.11.2014 21:51
Josef Kufner | skóre: 70
Mě to přišlo pro ábíčko off-topic docela dost. V ČR je v podstatě jediný server kam by to tématicky patřilo, ale z něj je už řadu let reklamní kanál, kde publikovat nechci. Seriál sice vychází v jednom tištěném časopise, ale tam zase chybí zpětná vazba. Publikovat to tady na blogu mi přišlo jako docela dobrý kompromis.
 28.11.2014 22:20
Agent
| blog: Life_in_Pieces
| HC city
28.11.2014 22:20
Agent
| blog: Life_in_Pieces
| HC city
 28.11.2014 22:33
Jendа | skóre: 78
| blog: Jenda
| JO70FB
28.11.2014 22:33
Jendа | skóre: 78
| blog: Jenda
| JO70FB
Jelikož jsem totál lama, tak odpusťte možná blbé dotazy, ale teoreticky jak maximálně výkonný počítač by se dal implementovat? Řekněme něco na úrovni P2?Jo, tak něco.
Lze využít i nějaký klasický programovací jazyk?Pro všechno možné, od Microblaze přes AVR po ARM, jsou normální kompilátory Cčka. Koukni na OpenCores.
Lze využít i nějaký klasický programovací jazyk?Pro všechno možné, od Microblaze přes AVR po ARM, jsou normální kompilátory Cčka. Koukni na OpenCores.
Aha, já tu otázku pochopil jinak (viz má odpověď níže). Samozřejmě pro CPU implementované v FPGA je možné použít libovolný jazyk, pro který existuje kompilátor.
29.11.2014 01:26
Agent
| blog: Life_in_Pieces
| HC city
Tak on Cray-1A je velmi dávná historie a ta implementace je fakt maličká a i v hodně starém FPGA běží rychleji než originál.
Implementace obecného procesoru nebo počítače není úplně nejlepší nápad, protože mezi návrhem a křemíkem máte jednu mezivrstvu navíc (FPGA), která poněkud snižuje výkon oproti přímé implementaci jako ASIC. Soft-procesory se v FPGA používají spíše v kombinaci s jinou logikou, jako takzvané programovatelné systémy na čipu.
Samozřejmě dnešní FPGA jsou použitelné pro implementaci i velmi výkonných procesorů, ideálně ale spíše s architekturou RISC. P2 by implementovatelná určitě byla, ale architekturou není pro implementaci v FPGA úplně ideální. Jako příklad velmi výkonných CPU použitelných i v FPGA bych uvedl třeba Leon4, což implementace architektury SPARC V8e, nebo třeba Sun (dnes tedy Oracle) OpenSPARC T1 a T2, což jsou 64b architektury UltraSPARC T1 a T2. Můžete najít i nějaké informace o implementaci Intel Atom nebo architektury Nehalem (první Core i5/i7). Tyhle implementace jsou ale trochu starší, takže třeba to jádro Nehalem nacpali do pěti FPGA Xilinx Virtex-4. Věřím, že dnešní Xilinx Virtex UltraScale by stačil jeden.
Některé klasické programovací jazyky použít jde. Používají se ale neklasickým způsobem, což může být pro běžného programátora v těchto jazycích dost matoucí. I s využitím těchto jazyků se totiž stále popisuje zapojení logického obvodu, nikoliv sekvenční posloupnost instrukcí. O jazycích pro vývoj a verifikaci bude přespříští pokračování seriálu.
29.11.2014 01:26
Agent
| blog: Life_in_Pieces
| HC city
29.11.2014 02:05
Jendа | skóre: 78
| blog: Jenda
| JO70FB
29.11.2014 02:08
Jendа | skóre: 78
| blog: Jenda
| JO70FB
29.11.2014 18:04
Jendа | skóre: 78
| blog: Jenda
| JO70FB
Jak se píše tady, oficiálně se ISE nevyvíjí už přes rok. Fakticky se ale nevyvíjí více než dva roky. Ty poznámky o kritických opravách je třeba brát s velkou rezervou, protože u firmy Xilinx už dost dlouho nepracuje žádný z původních vývojářů ISE.
Co se týče podpory FPGA, je to skutečně tak, že ISE podporuje vše do řady 6. Podpora některých obvodů řady 7 je v ISE spíše jenom dobastlená a je v podstatě nepoužitelná. Rozhodně doporučuji se kombinaci 7-series a ISE vyhnout. Řadu 7 a výše (momentálně 7 a UltraScale) podporuje naplno až Vivado.
Ještě poznámka k potenciální možnosti podpory řady 6 ve Vivadu. Sice platí "nikdy neříkej nikdy", ale dovolím si téměř s jistotou prohlásit, že toho se nedočkáme. Jakožto oficiální Xilinx Alliance Partner máme dost informací navíc a o ničem podobném se bohužel ani neuvažuje. Přitom ze strany zákazníků by byl obrovský zájem. Velké firmy především z Asie v tomto ohledu na Xilinx tlačí, ale zatím bezvýsledně.
Jelikož jsem totál lama, tak odpusťte možná blbé dotazy, ale teoreticky jak maximálně výkonný počítač by se dal implementovat?Hehe no třeba moje patička (Opensource 32bit osmijádro). Ale to je spíš na úrovni MCU. Jinak, co se týče výpočetně výkonných CPU, tak tam máš nějvětší omezení maximální frekvenci toho FPGA (pro CPU to budou tak maximálně pár (slovy dvě
) stovek MHz). Co by neměl být takový problém je počet bitů sběrnice, třeba AXI Microblaze jima vůbec nešetří (rozhraní pro data, pro instrukce, jednosměrné kanály, zvlášť čtení a zápis, zvlášť adresa). Ale je klidně možný, že to je právě ten problém, proč je Microblaze tak pomalý. Při velkém počtu "drátů" ti postupně docházejí propoje na FPGA (jsou nedražší a je jich vždycky málo) a musí se použít neoptimální cesty, který trvají moc dlouho (a optimální cesty/hodiny zase musejí na ty neoptimální čekat než na nich dorazí data).
Co se týče výkonu, tak jsem postavit vícejádrovej Microblaze s linuxem, ale je to pomalejší než PXA272 (ne zrovna v přetaktovaném stavu). U Microblazu ale nejvíc zdržuje polosoftwarová MMU, takže má ještě velké rezervy.
Jinak to můžeš porovnat třeba i z hlediska cache, FPGA mají tak maximálně 1MB SRAM (pokud to teda nejsou supernadupaně a superpředražené Virtexy), ale pro cache se ti povede využít tak odhadem 256KB.
Pokud bys ale použil nějakou paralelní architekturu, kde nemusí být jednotlivá jádra těsně svázané (=míň propojů mezi nima), tak to IMHO pojede rychle a budeš moct použít velké procento prostředků.
ISSN 1214-1267, (c) 1999-2007 Stickfish s.r.o.