Portál AbcLinuxu, 5. května 2025 19:19
Aktuální jádro: 2.6.28-rc7. Citáty týdne: Linus Torvalds, Andrew Morton, Ingo Molnár. Sam Leffler uvolňuje zdrojové kódy HAL. Tux3: další souborový systém nové generace. Debugfs a vznik stabilního ABI. Variace férových I/O plánovačů: Řadící plánovač s férovým rozpočtem; Algoritmus; Výsledky testů; Rozšířené CFQ; Použití; Implementace.
Současné vývojové jádro je 2.6.28-rc7 vydané Linusem 1. prosince. Linus říká: Byl jsem týden pryč a nebyl tu takový klid, v jaký jsem doufal, ale tady je nový -rc se začleněným spadem. Kromě obvyklých oprav 2.6.28-rc7 obsahuje novou sadu limitů zdrojů, které mají zabránit nadměrné spotřebě paměti systémovým voláním epoll_wait().
Detaily lze jako obvykle nalézt v kompletním changelogu.
V uplynulém týdnu nebyly vydány žádné aktualizace stabilního jádra. Aktualizace 2.6.27.8 je revidována v době psaní tohoto článku; toto 104patchové monstrum lze očekávat někdy okolo 5. prosince.
unsigned i;
-- Ingo Molnár
Sam Leffler, správce vrstvy abstrakce hardwaru [hardware abstraction layer, HAL] Atherosu uvolnil zdrojový kód pod licencí ISC. Dříve byla tato část ovladače MadWifi pro bezdrátové čipové sady Atheros k dispozici pouze v binární formě. Ve svém oznámení Sam píše: Současně s uvolněním tohoto kódu jsem ukončil svou dohodu s Atherosem, díky které jsem měl přístup k informacím o jejich zařízeních. To znamená, že v budoucnosti budou všechny opravy, aktualizace pro nové čipy apod. muset být komunitním dílem. Atheros tvrdí, že platforma Linuxu bude referenční základnou zdrojového kódu, takže lidé, kteří budou chtít přidat podporu do jiných platforem, budou muset informace vyškrábat odtud.
V oblasti souborových systémů pro Linux se toho v současnosti děje hodně. Ze mnoha probíhajících projektů se nejvíce pozornosti dostává těmto dvěma: ext4, rozšíření ext3, od kterého se očekává, že tento souborový systém udrží v chodu pár dalších let, a btrfs, které je mnohými považováno za souborový systém pro budoucí dlouhodobé používání. Je zde ale další projekt, který rychle postupuje a stojí za to se na něj podívat: souborový systém Tux3 Daniela Phillipse.
Daniel není ve vývoji souborových systémů nováček. Jeho souborový systém Tux2 byl oznámen roku 2000; přitahoval slušné množství pozornosti, dokud se neukázalo, že Network Appliance, Inc. drží patenty na mnoho technik, které se v Tux2 používají. Mluvilo se o registraci obranných patentů a Jeff Merkey se dlouho objevoval s tvrzením, že najal patentového právníka, aby se situací pomohl. Ve skutečnosti došlo k tomu, že Tux2 jednoduše zmizel. Tux3 je postaven na některých stejných nápadech jako Tux2, ale mnoho z těchto nápadů se během uplynulých osmi let vyvinulo. Doufejme, že se nový souborový systém změnil natolik, aby se vyhnul pozornosti NetApp, která ukázala, že má vůli pomocí softwarových patentů bránit svůj rajón souborových systémů.
Jako každý současný souborový systém se sebeúctou je i Tux3 založen na B-stromech. Tabulka inodů je uložena v takovém stromě; každý uložený soubor je taktéž B-strom bloků. Bloky jsou samozřejmě mapovány pomocí rozsahů - další povinná vlastnost nových souborových systémů. Většina z očekávaných vlastností je přítomna, v mnoha ohledech Tux3 vypadá jako zase další souborový systém POSIXového stylu, ale jsou zde některé zajímavé odlišnosti.
Tux3 implementuje transakce pomocí mechanismu dopředného logování. Sada změn souborového systému se shromáždí do "fáze", která je poté zapsána do žurnálu. Jakmile je fáze v žurnálu, transakce se považuje za bezpečně dokončenou. Někdy v budoucnu kód souborového systému "shrne" změny žurnálu a zpětně je zapíše do statické verze souborového systému.
Implementace logování je zajímavá. Tux3 používá variantu mechanismu kopírování při zápisu, který používá Btrfs; tato varianta neumožňuje žádnému bloku souborového systému přepis na místě. Zápis do bloku v souboru tedy vyvolá alokaci nového bloku, do kterého se zapíší nová data. To následně vyžaduje, aby datová struktura souborového systému, která mapuje logické bloky souboru na fyzické bloky (rozsah), byla změněna a obsahovala nové umístění bloku. Tux3 toto řeší zápisem nových bloků přímo na jejich konečnou pozici, poté vkládá do logu "slib", že aktualizuje blok metadat. V době shrnutí je tento slib splněn alokací nového bloku a, pokud je to potřeba, zalogováním slibu změnit nejbližší vyšší blok ve stromě. Tímto způsobem změny v souborech postupují souborovým systémem krok po kroku bez potřeby provést rekurzivní změnu všeho naráz.
Konečným důsledkem je, že výsledek specifické změny může v logu nějaký čas zůstat. V Tux3 lze log považovat za nedílnou součást metadat souborového systému. To je pravda do té míry, že Tux3 se ani neobtěžuje shrnout log, když je souborový systém odpojen; svůj stav prostě inicializuje z logu při příštím připojení. Daniel říká, že mezi jiným tento přístup zajišťuje, že bude kód pro obnovení ze žurnálu dobře otestovaný a robustní, protože se bude provádět při každém připojení souborového systému.
Na většině souborových systémů jsou inody na disku objekty pevné velikosti. V Tux3 je jejich velikost proměnná. Inody jsou v podstatě kontejnery pro atributy; s běžnými daty souborového systému i rozšířenými atributy se zachází téměř stejně. Inode s více atributy tedy bude větší. Rozšířené atributy se komprimují pomocí "tabulky atomů", která mapuje jména atributů na malá celá čísla. Souborové systémy s rozšířenými atributy mívají velké množství souborů, které používají jen několik jmen atributů, ušetřené místo na souborovém systému jako celku tedy může být významné.
Mezi atributy souboru se počítá i to, kde jsou uložena data. Návrh Tux3 počítá s mnoha odlišnými způsoby, jak lze sledovat bloky souborů. B-strom rozsahů je běžné řešení tohoto problému, ale jeho výhody jsou obecně k vidění jen u větších souborů. U menších souborů - což je stále většina souborů na typickém linuxovém systému - lze data uložit buď přímo v inodu, nebo na druhém konci obyčejného ukazatele na blok. Tyto reprezentace jsou pro malé soubory kompaktnější a také poskytují rychlejší přístup k datům. V současnosti jsou nicméně implementovány pouze rozsahy.
Dalším zajímavým - ale neimplementovaným - nápadem Tux3 je koncept verzovaných ukazatelů. Souborový systém btrfs implementuje snapshoty uchováváním kopie celého stromu souborového systému; pro každý snapshot existuje jedna kopie. Mechanismus kopírování při zápisu v btrfs zajišťuje, že tyto snapshoty sdílí data, které se nezměnila, takže to není tak hrozné, jak to zní. Tux3 plánuje použít jiný přístup k problému; bude udržovat jednu kopii stromu souborového systému, ale udržovat různé verze bloků (či ve skutečnosti rozsahů) v tomto stromě. Verzovací informace tak budou uloženy v listech stromu místo v jeho vrcholu. Myšlenka verzovaných rozsahů byla nicméně prozatím odložena ve prospěch snahy dát dohromady funkční souborový systém.
Z původního seznamu vlastností byla také odstraněna podpora podsvazků. Původně se tato vlastnost zdála být jednoduchá, ale interakce s fsync() se projevila jako obtížná. Daniel se tedy nakonec rozhodl, že správu svazků je nejlépe ponechat správcům svazků a vlastnost podsvazků z Tux3 vypustil.
Jednou z vlastností, která nikdy na seznamu nebyla, jsou kontrolní součty dat. Daniel kdysi psal v jednom komentáři:
Vývoj Tux3 má daleko do bodu, kdy se budou vývojáři moci zabývat "dekoracemi"; v tomto okamžiku jde stále o projekt v embryonickém stádiu vývoje, který je tlačen vývojářem s reputací někoho, kdo má skvělé nápady, které nikdy nejsou dokončeny. Kód je zatím vyvíjen v uživatelském prostoru pomocí FUSE. Existuje nicméně i jaderná verze, která je připravena na další vývoj. Podle Daniela:
Potenciální komunita uživatelů oříznutého zachybovaného ext2 bude pravděpodobně relativně malá, nicméně návrh Tux3 může nabízet dost na to, aby se z něj nakonec stala zvažovaná možnost.
Nejprve je tu ale několik problémů, které je potřeba vyřešit. Na prvním místě seznamu je pravděpodobně kompletní absence zamykání - přičemž zamykání je jako kamení, na kterém jiné souborové systémy ošklivě zakoply. Kód potřebuje nějaké pročištění - malé problémy jako téměř kompletní nedostatek komentářů a použití maker jako formálních parametrů funkcí pravděpodobně při širším revidování vyvolají negativní ohlasy. Práce na utilitě fsck, zdá se, ještě nezačala. Zatím nebylo provedeno žádné benchmarkování; bude zajímavé podívat se, jak bude Daniel schopen zvládnout politiku "nikdy nepřepisovat blok" takovým způsobem, který časem nebude fragmentovat soubory (a tudíž snižovat výkon). A tak dál.
Mnoho z těchto problémů může skončit tak, že budou poměrně rychle vyřešeny. Daniel zveřejnil kód a zdá se, že přitáhl energickou (i když malou) komunitu přispěvatelů. Tux3 představuje jádro nového souborového systému s nějakými zajímavými nápady. Komentáře u kódu jsou možná vzácné, ale Daniel - který nikdy nebyl znám jako nemluvný vývojář - zaslal spoustu informací, které lze najít v archivech mailové konference Tux3. Potenciální přispěvatelé by si měli být vědomi Danielova licenčního schématu - GPLv3 s rezervovaným unilaterálním právem přelicencovat kód na cokoliv jiného - nicméně vývojáři, kterým to nevadí, zde pravděpodobně najdou zajímavý a rychle se pohybující projekt, kterého se mohou účastnit.
Remi Colinet nedávno navrhl přidání nového virtuálního souboru /proc/mempool, který by ukazoval použití fondů paměti [memory pools] v jádře. Proti návrhu zpřístupnit tuto informaci v podstatě nikdo neprotestoval, ale objevily se protesty proti jejímu vložení do /proc. Kdysi dávno do tohoto adresáře mohlo přijít v podstatě cokoli, ale v posledních letech je zde silná snaha omezit /proc do jeho původního účelu: poskytování informací o procesech. /proc/mempool se procesů netýká, takže je považován za proc-soubor-non-grata. Bylo navrženo, aby byl tomuto souboru nalezen jiný domov.
Kde by tento jiný domov měl být, však není zjevné. Místo v /sys/kernel by mohlo dávat smysl, ale sysfs má svá vlastní pravidla; konkrétně pravidlo "v každém souboru jedna hodnota" ztěžuje vytvoření souboru, kde by se vývojáři mohli ptát na stav jaderného subsystému, takže sysfs pro tento soubor také není vhodný domov.
Další volbou je debugs, který byl vytvořen v prosinci 2004. Debugfs je míněn jako podpora pro jaderné vývojáře; výslovně zavrhuje jakákoliv pravidla o typech souborů, které tam lze vložit. Všechna pravidla kromě jednoho: debugfs není povinnou součástí jakékoliv instalace jádra a nic, co tam lze nalézt, by nemělo být považováno za součást stabilního ABI do uživatelského prostoru. Místo toho jde o smetiště, kam jaderní vývojáři mohou rychle exportovat informace, které jsou pro ně užitečné.
Protože debugfs není součástí ABI do uživatelského prostoru, zdá se to být jako ubohé místo, do kterého vložit věci, na kterých by uživatelé mohli záviset. Když na to bylo upozorněno, ukázalo se, že náhled, že debugfs není ABI, není tak přesvědčivý, jak by si jeden mohl myslet. Citujeme Matta Mackalla:
Jako příklad Matt poukázal na obsáhle dokumentované rozhraní usbmon, které poskytuje mnoho informací o tom, co se děje na USB sběrnici. Jestliže to není ABI, říká, nikdo by neměl být naštvaný, když pošle patch, který ho rozbije.
Je to stálý problém s rozhraními mezi jádrem a uživatelským prostorem; jejich změna způsobí uživatelům problémy. To je důvod, proč nejsou nekompatibilní změny v těchto rozhraních téměř nikdy dovoleny; důležitým cílem vývojového procesu jádra je vyhnout se rozbití programů v uživatelském prostoru. Dalo by se předpokládat, že tomuto problému se lze u specifického rozhraní vyhnout tak, že se zdokumentuje jako nestabilní. Soubory v Documentation/ABI/testing mají mít tuto roli - cokoliv, co je v nich k nalezení, by mělo být považováno za nestabilní. Nicméně jakmile lidé začnou používat programy, které na specifickém rozhraní závisí, z praktického hlediska to znamená stabilizaci dané části jaderného ABI.
Linus to říká takto:
Zajistit, aby se dané jaderné rozhraní nestalo ABI, je možné tak, že je obtížné se k němu dostat a je tak nestabilní, že na něm nic nezačne záviset. Rozhraní jaderných modulů tomu rozhodně vyhovuje. Moduly musí být obecně přeloženy přesně proti jádru, se kterým mají fungovat, a často musí být přeloženy se stejnými konfiguračními volbami stejným překladačem. Každý, kdo se dal na temné povolání distributora pouze binárních modulů, zjistil, jak velká to může být výzva.
Debugfs je ale jiný. Je povolen v mnoha distribučních jádrech, i když ve výchozím nastavení není připojen. Jakmile je do něj vložena sada souborů, jejich formát se většinou nemění. Lidé tedy mohou napsat programy, které závisí na souborech v debugfs. A konečným výsledkem se tedy může stát, že soubory v debugfs se mohou stát částí stabilního jaderného ABI. To obecně není výsledek, který by někdo zamýšlel, ale i tak se to stává. Jediným způsobem, jak tomu zabránit, by bylo úmyslně debugfs protřepat v každém vývojovém cyklu - a jen málo vývojářů má dostatek touhy to dělat.
Tato diskuze nemá příliš mnoho užitečných závěrů; /proc/mempool ponechává bez domova. Navrhování ABI, jak se ukazuje, je stále obtížné. V dlouhodobějším měřítku je zacházení s ABI, které nikdy nebylo navrženo, ale prostě nějak vzniklo, dokonce ještě těžší. Zdá se, že není žádná náhrada za vážné zamyšlení nad každým rozhraním mezi jádrem a uživatelským prostorem, i když jde pouze o ladící nástroj pro vývojáře.
Originál tohoto článku napsal Goldwyn Rodrigues
I/O plánovač je subsystém jádra, který plánuje I/O operace různých úložných zařízení tak, aby z nich dostal co největší propustnost. Algoritmus těchto plánovačů často připomíná algoritmus, který používají výtahy, když řeší požadavky pro jízdu nahoru a dolů pocházející z různých podlaží. To je důvod, proč jsou I/O plánovací algoritmy často nazývány "výtahy". I/O požadavky jsou zasílány tak, aby se minimalizoval pohyb hlaviček disku (a tím čas vyhledávání) a přitom byly garantovány dobré rychlosti I/O. Další vybraný požadavek je závislý na současné pozici hlav disku ve snaze obsloužit požadavky rychle a strávit méně času vyhledáváním nebo přesouváním hlaviček. Algoritmy nicméně mohou také uvažovat další aspekty, jako je férovost či garance doby zpracování.
Zcela férový řadící I/O plánovač [Completely Fair Queuing scheduler, CFQ] je jeden z nejpopulárnějších I/O plánovacích algoritmů; ve většině distribucí je použit jako výchozí plánovač. Jak jméno naznačuje, CFQ plánovač se pokouší udržovat férovost distribuce šířky pásma procesům a přitom neztratit příliš mnoho propustnosti. Férovost výtahu je zajištěna obsluhou všech procesů a nepenalizováním těch, které mají požadavky daleko od současné pozice diskových hlav. Každému procesu garantuje časový díl [time slice]; jakmile úloha svůj díl spotřebuje, je díl přepočítán a úloha je přidána na konec fronty. Pro výpočet přiděleného časového dílu a posunu ve frontě požadavků se používá I/O priorita.
Na čase založené přidělování služby disků v CFQ, i když má požadovaný efekt jasného účtování doby vyhledávání [seek time], kterou aplikace způsobí, má stále problémy s férovostí obzvláště u procesů, které nejlepším možným způsobem využívají šířku pásma disku. Když je stejný časový díl přiřazen dvěma procesům, každý může získat jinou propustnost v závislosti na pozici jejich požadavků na disku. Navíc kvůli své politice round-robin je CFQ charakterizováno zpožděním dokončení požadavku v nejhorším případě O(N), kde N je počet úloh, které o disk soupeří.
Řadící plánovač s férovým rozpočtem [Budget Fair Queuing scheduler, BFQ], který vyvinuli Fabio Checconi a Paolo Valente, mění round-robin politiku CFQ založenou na časových dílech na férovou řadící politiku založenou na rozpočtech sektorů. Každé úloze je přiřazen rozpočet počítaný v počtu sektorů místo v množství času a rozpočty jsou plánovány za použití řadícího algoritmu s férovým nejhorším zpožděním a váhováním+ [Worst-case Fair Weighted Fair Queuing+ algorithm, WF2Q+] (popsán v tomto článku [komprimovaný PS]), který garantuje složitost O(logN) v nejhorším případě a ve většině případů se dostává k O(1). Rozpočet přiřazený každé úloze se postupem času mění v závislosti na jejím chování. Lze nicméně nastavit maximální hodnotu rozpočtu, kterou může BFQ každé úloze přiřadit.
BFQ může poskytnout silné garance distribuce šířky pásma, protože přiřazené rozpočty jsou počítány v sektorech. Jsou zde nicméně omezení: procesy, kterým trvá příliš dlouho spotřebovat svůj rozpočet, jsou penalizovány a plánovač vybere další proces, jehož I/O vyšle. Další rozpočet je vypočítán podle zpětné vazby poskytnuté obsluhou požadavku.
BFQ také zavádí I/O plánování v kontrolních skupinách. Fronty jsou shromážděny ve stromu skupin a v každém uzlu, který není listem, je zvláštní B-WF2Q+ plánovač. Uzly, které jsou listy, jsou fronty požadavků stejně jako v nehierarchickém případě. BFQ podporuje třídy I/O priorit na každé úrovni hierarchie a vynucuje striktní řazení priorit mezi třídami. To znamená, že nečinné [idle] fronty nebo skupiny jsou obslouženy jenom v případě, že ve stejné kontrolní skupině nejsou fronty nebo skupiny s nejvyšší snahou [best effort]; tyto fronty nebo skupiny jsou zase obslouženy jenom v případě, že nejsou žádné realtimové fronty nebo skupiny. V porovnání s cfq-cgroups (popsán níže) postrádá priority pro jednotlivá zařízení. Vývojáři nicméně tvrdí, že tuto vlastnost lze snadno doplnit.
Požadavky přicházející I/O plánovači se dělí do dvou kategorií na synchronní a asynchronní. Synchronní požadavky jsou typicky ty, na které aplikace musí čekat předtím, než může poslat další - typicky jde o požadavky čtení. Na druhou stranu asynchronní požadavky - typicky zápisy - neblokují postup aplikace zatímco jsou vykonávány. V BFQ jsou stejně jako v CFQ synchronní požadavky shromažďovány ve frontách zvlášť pro jednotlivé úlohy, zatímco asynchronní jsou shromažďovány ve frontách pro zařízení (nebo v případě hierarchického plánování pro skupinu).
Když ovladač zařízení ležícího pod ním žádá další požadavek, který má obsloužit, a není obsluhována žádná fronta, BFQ použije B-WF2Q+, modifikovanou verzi WF2Q+, a vybere frontu. Z ní poté vybere první požadavek podle pořadí C-LOOK a vrátí ho ovladači. C-LOOK je algoritmus plánování disku, kde další vybraný požadavek je ten s nejbližším vyšším číslem sektoru vzhledem k současné pozici hlaviček disku. Jakmile disk obslouží nejvyšší číslo sektoru ve frontě požadavků, přesune hlavy na sektor požadavku s nejnižším číslem sektoru.
Když je vybrána nová fronta, je jí přiřazen rozpočet sektorů, který je snížen pokaždé, když je obsloužen požadavek z této fronty. Když ovladač zařízení žádá o nový požadavek a je obsluhována fronta, je požadavek vybrán z této fronty, dokud nenastane jeden z následujících případů: (1) fronta vyčerpá svůj rozpočet, (2) frontě trvá vyčerpání rozpočtu příliš dlouho nebo (3) fronta nemá žádné další požadavky.
Při dokončení požadavku plánovač přepočítá rozpočet přidělený každému procesu podle zpětné vazby, kterou dostane. Například chamtivým procesům, které svůj rozpočet vyčerpaly, je rozpočet zvýšen, zatímco nečinným procesům je snížen. Maximální rozpočet, který může proces získat, je konfigurovatelný parametr systému (max_budget). Další dva parametry - timeout_sync a timeout_async - řídí časový limit pro spotřebování rozpočtu synchronních a asynchronních front v uvedeném pořadí. max_budget_async_rq navíc omezuje maximální počet obsloužených požadavků v asynchronní frontě.
Jestliže nemá synchronní fronta žádné další požadavky k obsloužení, ale zbývá jí nějaký rozpočet, plánovač je po krátkou dobu nečinný (tj. řekne ovladači zařízení, že nemá žádné další požadavky k obsloužení, i když jsou další aktivní fronty) a očekává nový požadavek od úlohy, která frontu vlastní.
Vývojáři porovnali šest různých algoritmů plánování I/O: BFQ, YFQ, SCAN-EDF, CFQ, linuxový předvídající [anticipatory] plánovač a C-LOOK. Porovnali mnoho testovacích scénářů analogických k situacím z reálného života, včetně propustnosti, distribuce šířky pásma, latence a krátkodobých garancí časování. Co se týče distribuce šířky pásma, lze BFQ považovat za nejlepší s tím, že ve většině případů je dobrý. Také proběhly rozsáhlé testy porovnávající BFQ proti CFQ, výsledky jsou k dispozici zde. Propustnost BFQ je víceméně stejná jako CFQ, ale boduje ve férové distribuci šířky I/O pásma mezi procesy a vykazuje nižší latence u proudů dat.
Použití rozpočtu sektorů místo času jako faktoru pro určování férového podílu při distribuci šířky pásma je zajímavý koncept. Algoritmus také využívá časové limity, aby ukončil požadavky "vyhledávajících" [seeky] procesů, kterým příliš dlouho trvá spotřebovat svůj rozpočet, a penalizuje je. Zpětná vazba od současných požadavků pomáhá určit budoucí rozpočty, díky čemuž je algoritmus samoučící. Takto přesnější distribuce šířky pásma bude nutná u systémů, na kterých běží virtuální stroje nebo třídy kontejnerů. Nicméně to závisí na tom, jak BFQ časem obstojí v konkurenci proti vyzkoušenému a otestovanému stabilnímu CFQ.
(Mnohem) více informací vizte v technické zprávě BFQ [PDF].
Kontrolní skupiny poskytují mechanismus pro shromáždění skupiny úloh a všech jejich budoucích potomků do hierarchických skupin. Těmto skupinám mohou být alokovány určené části dostupných zdrojů, sdílení zdrojů může být v těchto skupinách prioritizováno. Kontrolní skupiny jsou řízeny pseudosouborovým systémem cgroups. Jakmile je připojen, adresář na nejvyšší úrovni obsahuje kompletní sadu existujících kontrolních skupin. Každý adresář vytvořený v kořenovém adresáři souborového systému vytvoří novou skupinu a zdroje mohou být alokovány úlohám vyjmenovaným v souboru tasks v jednotlivých adresářích skupin.
Kontrolní skupiny lze použít k regulaci přístupu k času CPU, paměti a dalších. Je zde také několik projektů, které pracují na vytvoření plánovače šířky I/O pásma pro kontrolní skupiny. Jedním z nich je patch rozšířeného CFQ plánovače pro cgroups Satoshiho Uchida. Tato sada patchů zavádí nový I/O plánovač nazvaný cfq-cgroups, který zavádí kontrolní skupiny do subsystému plánování I/O.
Tento plánovač, jak jméno naznačuje, je založen na CFQ plánovači. Umí využít hierarchické plánování procesů s ohledem na to, do které kontrolní skupiny patří, každá kontrolní skupina má svůj vlastní CFQ plánovač. I/O zařízení v kontrolní skupině lze priorizovat. Časový díl daný každé hierarchické skupině pro dané zařízení závisí na prioritě zařízení pro tuto skupinu. To pomáhá dělit šířku I/O pásma podle skupiny i zařízení.
cfq-cgroups je využit jako výchozí plánovač, pokud je jádru při bootu předán parametr elevator=cfq-cgroups. To lze také dynamicky změnit pro jednotlivá zařízení zápisem cfq-cgroups do /sys/block/<zařízení>/queue/scheduler. Jsou dvě úrovně řízení: přes souborový systém cgroups pro jednotlivé skupiny a přes sysfs pro jednotlivá zařízení.
Jako každá kontrolní skupina je cfq-cgroup spravován pomocí pseudosouborového systému cgroup. Pro přístup ke kontrolním skupinám je potřeba připojit pseudosouborový systém cgroups:
# mount -t cgroup -o cfq cfq /mnt/cgroup
Adresář cgroup bude ve výchozím stavu obsahovat soubor cfq.ioprio, který obsahuje jednotlivé priority podle zařízení. Časový díl přidělený podle zařízení a skupiny závisí na prioritě uvedené v cfq.ioprio. Soubor tasks reprezentuje seznam úloh v konkrétní skupině. Další skupiny lze vytvořit založením adresáře v připojeném adresáři cgroup:
# mkdir /mnt/cgroup/skupina1
Nové adresáře jsou automaticky osazeny soubory cfq.ioprio, tasks atd., které se používají k řízení zdrojů v této skupině. Úlohy lze do skupiny přidat zápisem ID procesu nebo úlohy do souboru tasks:
#echo <pid> > /mnt/cgroup/group1/tasks
Soubor cfq.ioprio obsahuje seznam zařízení a jejich priorit. Každé zařízení v kontrolní skupině má výchozí I/O prioritu 3, přičemž platné hodnoty jsou 0 - 7. Prioritu zařízení pro kontrolní skupinu skupina1 lze změnit spuštěním:
# echo 2 > /mnt/cgroup/skupina1/cfq.ioprio
To by změnilo prioritu pro celou skupinu. I/O priorita konkrétního zařízení se mění:
# echo 2 sda > /mnt/cgroup/skupina1/cfq.ioprio
Změna výchozí priority bez změny nastavené priority zařízení:
# echo 4 defaults > /mnt/cgroup/skupina1/cfq.ioprio
Pohled na zařízení zobrazuje seznam kontrolních skupin a jejich priorit pro jednotlivé skupiny. To lze změnit zavoláním:
# echo 2 skupina1 > /sys/block/sda/queue/iosched/ioprio
Pohled na zařízení obsahuje další parametry podobné CFQ plánovači, jako jsou back_seek_max či back_seek_penalty, které jsou specifické při řízení jednotlivých zařízení stejně jako u tradičního CFQ.
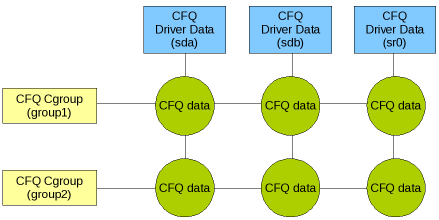
Patch zavádí pro řízení šířky I/O pásma pro kontrolní skupiny novou datovou strukturu cfq_driver_data. Do ní byla z tradiční struktury cfq_data přesunuta všechna s ovladači spojená data. Podobně je zde nová datová struktura cfq_cgroups pro řízení parametrů kontrolních skupin. Organizaci dat lze považovat za matici, kde cfq_cgroups jsou řádky a cfq_driver_data sloupce, jak je zobrazeno na obrázku níže.
V každém průsečíku je datová struktura cfqd_data, která je zodpovědná za zpracování front spojených s CFQ, takže každá cfq_data odpovídá jedné kombinaci cfq_cgroup a cfq_driver_data.
Když je vytvořena nová kontrolní skupina, cfq_data z rodičovské kontrolní skupiny se kopíruje do nové skupiny. Když se do kontrolní skupiny vkládají nové uzly cfq_data, struktura cfq_data je inicializována prioritou cfq_cgroup. Tímto způsobem jsou všechna data rodiče zděděna třídou potomka a objevují se v odpovídajících souborech v každé skupině v souborovém systému cgroup.
Plánování v cfq_data v CFQ plánovači je podobné jako v nativním CFQ plánovači. Každému uzlu je přiřazen časový díl. Tento díl je vypočítán s ohledem na I/O prioritu zařízení, kde se používá časový díl pro jednotlivá zařízení. Posun časového dílu vytváří klíč v červeno-černém uzlu, který se vkládá do stromu obsluhy. Jeden záznam cfq_data je vybrán z červeno-černého stromu a naplánován. Jakmile jeho časový díl vyprší, je po přepočítání posunu časového dílu vrácen zpět do stromu. Každá struktura cfq_data se tedy chová jako uzel fronty pro zařízení a v každé datové struktuře CFQ jsou požadavky řazeny jako v obyčejné CFQ frontě.
Jak BFQ, tak cfq-cgroups jsou pokusy přinést vyšší stupeň férovosti I/O plánování, kde "férovost" je zmírňována snahou přidat více administrativního řízení pomocí mechanismu kontrolních skupin. Oba se zdají být užitečnými řešeními, ale musí soupeřit s nepřeberným množstvím dalších implementací řízení šířky I/O pásma, které jsou k dispozici. Dospět k nějakému konsenzu o tom, který přístup je správný, by mohlo nakonec trvat déle, než tyto algoritmy vůbec implementovat.
Je otázka, kolik těch patentů společnosti NetApp zbyde po patentovém sporu se společností SUN Microsystems. SUNu se zatím docela úspěšně daří patenty NetAppu zneplatňovat (viz more_on_the_netapp_litigation a one_more_thing).
Co je spatneho na unsigned i; ??
Tipoval bych neco jako, ze i znaci integer. Cili cislo se znamenkem:
int i;
unsigned u;
Dava to smysl?
Kdyz budu pracovat s neinicializovanou promennou, tak bude kompilator pekne nahlas rvat pri `gcc -Wall -W -Werror` a pokud to projde, tak bude rvat valgrind, takze bych v tom problem nevidel. Naopak vidim problem v tom, kdyz nekdo zavadi zcela zbytecna dogmata jako tato. A co az budete mit strukturu, budete ji inicializovat uz pri deklaraci pomoci { ... }? A cim, prosim, kdyz spravny postup je init_struct_xy()? Takze nejprve dummy hodnotami jen proto, aby pak valgrind nepoznal ze je neinicializovana?
> /* Split the existing block in the middle, size-wise */
> size = 0;
> move = 0;
> for (i = count-1; i < count; i--) {
> /* is more than half of this entry in 2nd half of the block? */
> if (size + map[i].size/2 > blocksize/2)
> break;
count ostava konstantny tak i-- moze dekrementovat i do negativnych hodnot. Predpokladam ze Roel sa postaral o to aby sa to nestalo avsak uz to nadeklaroval unsigned i a pouziva i-- (bez toho aby aspon spomenul v komentari ze 'toto nebude nikdy zaporne') nie je velmi sympaticke, takze Andrewovu namietku beriemtaky dekuji za prima cteni a mel bych jeden teoreticky dotaz:
Napadlo me, jestli by byl rychlejsi filesystem, takovy ktery obsahuje jen jeden soubor (mam totiz partition, kde je jen jeden soubor (databaze)).
Dnes jsou filesystemy kde je mozne mit strasny spousty souboru a tak by zajimalo by me jestli by byl rychlejsi filesystem v tomto pripade.
Jestli to dobre chapu, vubec by nezalezelo na strukture souboru, byl by tam jeden soubor, tak by to muselo byt v urcitem smeru rychlejsi.
Jestli placam tak me zastavte:) A prominte ze sem to takhle zbesile napsal, snad to nekdo pochopi.
 16.1.2009 11:42
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
16.1.2009 11:42
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
Napadlo me, jestli by byl rychlejsi filesystem, takovy ktery obsahuje jen jeden soubor (mam totiz partition, kde je jen jeden soubor (databaze)).
Některé DB servery umožňují mít data přímo na oddílu (nebo celém disku, zkrátka blokovém zařízení) a netřeba tak používat souborový systém.
Obecně, souborové systémy musí řešit mnoho problémů. Musí vyhledat soubor podle plného jména, což je ale velice rychlé. Dále musí najít všechny datové bloky požadovaného souboru, zde už záleží na vnitřní struktuře toho systému souborů. A samozřejmně práva k danému souboru, požadavky na vícenásobné čtení atd (a to jsme jen u čtení, pro zápis se ještě řeší alokace bloků a další). Jenže toto se musí řešit i pro ten jeden soubor - zvýšení počtu souborů tuto řežii příliš nezvyšuje (resp. nemělo by), takže nejužším hrdlem je tak jako tak HW.
Některé DB servery umožňují mít data přímo na oddílu (nebo celém disku, zkrátka blokovém zařízení) a netřeba tak používat souborový systém.
Aha to jsem nevedel. Diky.
.... nejužším hrdlem je tak jako tak HW.
Je to fakt.
Škoda, že mezi filesystémy úplně upadl v zapomnění SpadFS. Rychlost stále nedostižná, filosofie neotřelá.

K tem kontrolnim souctum. Treba takovy oracle nebo informix ukladaji kontrolni soucet do kazdeho bloku. Diky tomu muzete napriklad zjistit ze jste si nechali od OS natahnout do pameti 16KB stranku, ale OS vam nacetl jen prvnich 8KB. Neni nemozne, je to jen velice nepravdepodobne.
takhle prelozene jsem to cesky jeste nikde nevidel.Tomu bych věřil v případě, že tohle je první díl Jaderných novin, který čteš za poslední rok.
Polštinou bych se neoháněl. Sice mají wideo, ale taky sukces.
Osobně nevidím na rozsahu nic špatného. Podstatu to vystihuje velmi dobře (rozsah – interval – bloků namísto seznamu bloků), je to doslovný překlad extent, co víc si přát?
ISSN 1214-1267, (c) 1999-2007 Stickfish s.r.o.