Portál AbcLinuxu, 7. května 2025 01:25
Aktuální jádro: 2.6.28-rc8. Citáty týdne: Andrew Morton, Dave Jones. Systémová volání a 64bitové architektury. Sledujeme: čítače výkonnosti, ksplice a fsnotify. Čítače výkonnosti. Ksplice. fsnotify. SLQB - a už jsou čtyři.
Současné vývojové jádro je stále 2.6.28-rc8; během minulého týdne nebyly vydány žádné předverze. Do gitového repozitáře hlavní řady pomalu přitékají další změny, v době psaní tohoto článku jich bylo od -rc8 začleněno 46.
Otázka, kdy bude vydána konečná verze 2.6.28, zůstává otevřená. Zdá se, že Linus je nakloněn vydání před svátky, hlavně protože chce před začátkem linux.conf.au v lednu odstranit z cesty začleňovací okno. Seznam regresí je v tuto chvíli docela krátký, takže vydání v této době by bylo ospravedlnitelné.
Současné stabilní jádro 2.6 je 2.6.27.9 vydané 13. prosince s dlouhým seznamem oprav. Stabilní vydání 2.6.27.10 obsahující dalších 22 patchů je revidováno v době psaní tohoto článku; pravděpodobně bude vydáno 18. prosince.
-- Dave Jones
Nové systémové volání se do jádra nepřidává s lehkostí. Je důležité ho před začleněním udělat správně, protože jakmile je přidáno, musí být navždy udržováno jako součást jaderného binárního rozhraní. Návrh přidat systémová volání preadv() a pwritev() poskytuje skvělý příklad záležitostí, kterými je potřeba se zabývat, když se něco přidává k jadernému ABI.
Tato dvě systémová volání jsou sama o sobě poměrně přímočará. V podstatě kombinují existující volání pread() a readv() (totéž pro zapisující variantu) do způsobu, jakým provádět rozsyp/sesbírej I/O operace na konkrétním posunutí [offset] souboru. Jako u pread() je současná pozice v souboru nezměněna. Volání, která jsou dostupná na různých BSD systémech, lze použít k vyhýbání se souběhům mezi voláním lseek() a čtením nebo zápisem. V současnosti se musí aplikace starat o nějaký druh zamykání, aby se jednotlivým vláknům zabránilo se při tomto druhu I/O ovlivnit.
Prototypy funkcí vypadají podobně jako readv/writev, jednoduše přidávají offset jako poslední parametr:
ssize_t preadv(int d, const struct iovec *iov, int iovcnt, off_t offset); ssize_t pwritev(int d, const struct iovec *iov, int iovcnt, off_t offset);
Ale protože je off_t 64bitová hodnota, na některých architekturách to činí problémy kvůli způsobu, jakým se předávají argumenty systémových volání. Poté, co Gerd Hoffman zaslal druhou verzi sady patchů, Matthew Wilcox rychle poukázal na problém:
Některé další architektury (ARM, PowerPC, s390, ...) mají podobná omezení. Protože je offset čtvrtý parametr, umisťuje se do 32bitových registrů r3 a r4, ale některé architektury ho potřebují buď v r2/r3 nebo r4/r5. To vedlo některé lidi k doporučení změny pořadí parametrů a přesunutí offsetu před iovcnt, aby se problém obešel. A to dřív, než tato změna probublá do uživatelského prostoru. Gerd se změnou příliš nesouhlasí: Nicméně bych byl opravdu nerad, kdyby stejné systémové volání mělo na různých systémech různé pořadí argumentů.
Zdálo se, že většina souhlasí s tím, že rozhraní do uživatelského prostoru tak, jak je prezentováno glibc, by se mělo shodovat s tím, co poskytuje BSD. Jinak to lidem, kteří se snaží psát standardy pro přenositelný kód, působí příliš mnoho bolestí hlavy. Aby se vyřešil problém s uspořádáním, systémové volání samo o sobě má změněné pořadí argumentů. To vedlo ke Gregově třetí verzi sady patchů, která stále nevyřešila celý problém.
Je několik architektur, které mají 32 a 64bitové verze a 64bitové jádro musí podporovat systémová volání z 32bitových programů v uživatelském prostoru. Tyto programy vloží 64bitové argumenty do dvou registrů, ale 64bitové jádro je bude očekávat v jediném registru. Kvůli tomu Arnd Bergmann doporučil rozdělení offsetu na dva argumenty, jeden pro horních 32bitů a druhý pro spodní bity: Vidím to jako jediný způsob, který nám umožní sdílet compat_sys_preadv/pwritev na všech 64bitových architekturách.
Když 32bitový program v uživatelském prostoru provede systémové volání na 64bitovém systému, rozdíly ve velikosti dat řeší verze funkce compat_sys_*. Jestliže je systémovému volání předán ukazatel na strukturu a tato struktura má na 32 bitech jinou reprezentaci než na 64 bitech, vrstva kompatibility provede překlad. Protože různé 64bitové architektury dělají, co se konvencí volání a požadavků na zarovnání týče, různé věci různě, jediný způsob, jakým sdílet compat kód, je zcela odstranit 64bitovou hodnotu z rozhraní systémového volání.
Tím zbývá jenom jediný problém, který je potřeba překonat: endianitu. Jak poznamenává Ralf Baechle, MIPS může být jak little- tak big-endian, takže compat_sys_preadv/pwritev() musí obě 32bitové hodnoty offsetu složit ve správném pořadí. Doporučil přesunutí pro MIPS specifického makra merge_64() do společného include souboru compat.h, který by poté bylo možné použít ve společných compat funkcích. Zatím se čtvrtá verze sady patchů neobjevila, ale dá se předpokládat, že rozdělení argumentu offset a použití merge_64() bude její součástí.
Implementace operace preadv() a pwritev() je velmi průzračná, rozhodně při porovnání se složitostmi předávání jejich argumentů. VFS implementace readv()/writev() již přebírají parametr posunutí, takže jde o jednoduchou záležitost volání těchto funkcí. Je zajímavé, že během revidování si Christoph Hellwig všiml chyby v existujících implementacích compat_sys_readv/writev(), které by vedly k neaktualizování účetních informací [accounting information] těchto volání.
Není to poprvé, co jsou navržena tato systémová volání; už v roce 2005 jsme se dívali na nějaké patche, které zaslal Badari Pulavarty a které je přidávaly. Kromě krátkého výskytu v -mm stromě se zdá, že se ztratily. I kdyby se toto vydání preadv() a pwritev() do hlavní řady nedostalo - a zatím není žádný náznak, že jim v tom bude bráněno - revize kódu okolo něj byly rozhodně užitečné. Náznak toho, jaké složitosti představují 64bitové hodnoty předávané systémovým volání, byl také poučný.
V několika oblastech, kterým se Jaderné noviny věnovaly v minulosti, nastal pokrok. Zde je rychlé pokračování o tom, jak věci stojí nyní.
V epizodě z minulého týdne rozhýbal diskuzi a určité množství opozice patch pro sledování výkonnosti, který se objevil z ničeho nic. Jednoduchost nového přístupu Inga Molnára a Thomase Gleixnera byla do určité míry přitažlivá, ale rozhodně není jisté, jestli je tento přístup dostatečně mocný, aby splnil potřeby komunity, která používá komplexnější sledování výkonnosti.
Od té doby byly zaslány třetí a čtvrtá verze patche. Pohled na changelogy ukazuje, že práce na tomto kódu pokračuje rychle. Bylo provedeno mnoho změn včetně:
Přirozeně jsou z tohoto nového přístupu ke sledování stále obavy. Vývojáři se bojí, že uživatelé nemusí být schopni získat informace, které potřebují, a stále se zdá, že bude potřeba vložit do jádra velké množství pro hardware specifických informací o programování čítačů. Nicméně v očích autora článku tato sada patchů nabývá známek nevyhnutelnosti, které se obvykle objevují u patchů od Inga a spol. Bude nicméně ještě nějaký čas trvat, než dojde k rozhodnutí.
V listopadu jsme se dívali na novou verzi kódu Ksplice, který umožňuje vložit patche do běžícího jádra. Vývojáři Ksplice by rádi viděli svůj kód začleněný do hlavní řady, takže nedávno rýpli do Andrewa Mortona, aby se zeptali, jaký je stav. Jeho odpověď zněla:
Reakce v konferenci, jak už tak bývá, naznačovaly, že distributory ve skutečnosti tato vlastnost příliš nezajímá. Dave Jones komentoval:
Vývojáři Ksplice souhlasí, že psát vlastní kód, který zajistí, aby se patche daly začlenit do běžícího jádra, je děsivý nápad; to je důvod, říkají, proč ušli svou cestu, aby takový kód většinou nebyl potřeba.
Tato diskuze ponechává Ksplice v poněkud obtížné situaci; pokud nebude jasná poptávka, jaderní vývojáři pravděpodobně nebudou chtít začlenit patch tohoto druhu. Jestli jde o vlastnost, o kterou uživatelé opravdu stojí, měli by pravděpodobně tento fakt sdělit svým distributorům, kteří by poté mohli zvážit jeho podporu a zapracovat na protlačení projektu do hlavní řady.
Mechanismus prohledávání souborů známý jako TALPA měl poněkud drsný start, co se interakce s jadernou komunitou týče. Mnoho vývojářů nemá rádo průmysl vyhledávající malware obecně a zaslaná implementace se jim nelíbila. Je nicméně jasné, že touha po této funkci nezmizí, takže vývojář Eric Paris pracoval na implementaci, která by prošla revizí.
Jeho nejnovější pokus lze vidět v podobě sady patchů fsnotify. Tento kód sám o sobě nepodporuje funkci vyhledávání malwaru, ale, jak říká Eric: Lepší bude, když budete vědět, že se chystá. Místo toho vytváří nové, nízkoúrovňové upozorňovací mechanismy pro události v souborovém systému.
Na první pohled se může zdát, že se používá ještě problematičtější přístup než předtím. Linux již má dva různé oznamovače událostí v souborech: dnotify a inotify. Jaderní vývojáři často vyjadřují svou nespokojenost s těmito rozhraními, ale nebylo příliš křiku, který by požadoval, aby někdo přidal třetí alternativu. Jaký smysl tedy má fsnotify?
Ericův nápad zjevně spočívá v tom, aby vytvořil něco, co vylepšuje jádro, aby lidé neměli snahu stěžovat si na funkci vyhledávání malwaru. Proto bylo napsáno fsnotify - obsahuje mnoho podnětů od vývojářů souborových systémů - aby z něj byl lépe promyšlený a podporovatelný upozorňovací subsystém. Existující kód dnotify a inotify je poté vytržen a znovu implementován nad fsnotify. Konečným výsledkem je, že dopad na zbytek VFS kódu je ve skutečnosti snížen; nyní je jenom jedna sada volání oznamovačů tam, kde předtím byly dvě. A přesto byl upozorňovací mechanismus zobecněn, takže podporuje funkce, které v něm v minulosti nebyly.
Krom toho se Ericovi podařilo zmenšit vnitřní strukturu inode. Vzhledem k tomu, že těchto struktur mohou být na běžícím systému tisíce, i malé omezení velikosti může znamenat velký rozdíl. Takže, jak tvrdí Eric: Přesně tak, můj kód je menší a rychlejší. Tumáte.
Co kód nyní potřebuje, je detailní revize ze strany hlavních vývojářů VFS. Tito vývojáři bývají zdrojem, o který se hodně soupeří, takže není jisté, kdy budou schopni se na fsnotify pořádně podívat. Nicméně se zdá, že dřív či později si tato vlastnost najde cestu do hlavní řady.
Linux nemá nouzi o nízkoúrovňové správce paměti. Stařičký slab alokátor byl motorem funkcí jako kmalloc() a kmem_cache_alloc() po mnoho let. Nedávno byl přidán SLOB, ořezaný alokátor vhodný pro systémy, které nemají tolik paměti ke spravování. Ještě v bližší době byl jako navrhovaný náhradník slab začleněn SLUB, který, i když byl navržen pro systémy s velkou pamětí, byl míněn tak, aby byl použitelný i na menších systémech. Konsenzem z posledních let je, že alespoň jeden z těchto alokátorů znamená přebytek nad potřebami a musí odejít. Typicky byl za alokátor, který je navíc, považován slab, ale nepříjemné pochyby o SLUBu (a některé regrese výkonnosti ve specifických situacích) držely slab ve hře.
Vzhledem k situaci by si jeden nemyslel, že jádro potřebuje ještě další alokátor. Nick Piggin si ale myslí, že navzdory přebytku nízkoúrovňových správců paměti je vždycky místo ještě pro jeden. Za tímto účelem vyvinul SLQB alokátor, o kterém doufá, že bude nakonec začleněn do hlavní řady. Podle Nicka:
Jako jiné jako-slab alokátory, SLQB sedí na alokátoru stránek a stará se o alokaci objektů pevné velikosti. Byl navržen s ohledem na škálovatelnost na high-end systémech; také se skutečně snaží se vyhnout alokaci oblasti stránek, kdykoliv je to možné. Vyhnutí se alokacím vyšších řádů může významně zvýšit spolehlivost, když je paměti nedostatek.
I když je v SLQB poměrně hodně ošidného kódu, základním algoritmům není těžké porozumět. Jako jiné jako-slab alokátory implementuje abstrakci slab cache - odkládací cache, ze které lze alokovat paměťové objekty pevné velikosti. Slab cache se používají přímo, když je paměť alokována funkcí kmem_cache_alloc(), či nepřímo pomocí funkcí jako kmalloc(). V SLQB je slab cache reprezentována datovou strukturou, která vypadá přibližně jako ta následující:
(Vezměte na vědomí, že kvůli zjednodušení diagramu bylo mnoho věcí zanedbáno.)
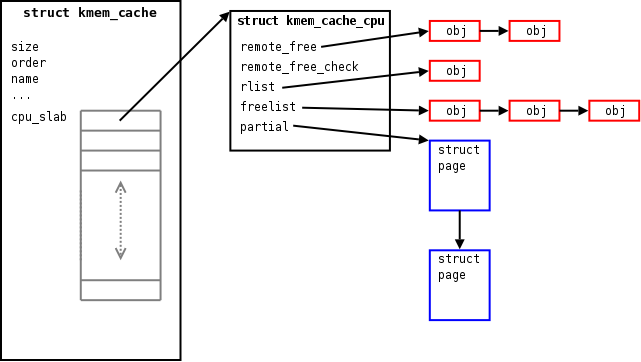
Hlavní struktura kmem_cache obsahuje očekávané globální parametry - velikost objektů, které se alokují, řád alokací stránek, jméno cache atd. Škálovatelnost nicméně diktuje oddělit procesory od sebe, takže většina datové struktury kmem_cache je uložena v podobě "pro jednotlivá CPU jednotlivě". Konkrétně je pro každý procesor v systému jedna struktura mem_cache_cpu.
V této struktuře pro konkrétní CPU lze najít mnoho seznamů objektů. Jeden z nich (freelist, seznam volných) obsahuje seznam dostupných objektů; když je zadán požadavek na alokaci objektu, na seznam volných se alokátor obrací nejdříve. Když jsou objekty uvolněny, vrací se na seznam. Vzhledem k tomu, že je seznam součástí struktury pro dané CPU, objekty běžně zůstávají na stejném CPU, takže se minimalizuje poskakování mezi cachemi. A ještě důležitější je, že rozhodnutí o alokaci jsou specifická pro CPU, takže zde není žádné špatné chování cache a kromě zakázání přerušení není potřeba žádné zamykání. Seznam volných je spravován jako zásobník, takže požadavky na alokaci vrátí nejnověji uvolněný objekt; tento přístup je opět použit jako pokus o optimalizaci chování cache paměti.
SLQB bere svou paměť ve formě celých stránek od alokátoru stránek. Když je přijat požadavek na alokaci a seznam volných je prázdný, SLQB alokuje novou stránku a vrátí objekt z této stránky. Zbývající prostor ve stránce je zorganizován do seznamu volných pro konkrétní stránku (samozřejmě za předpokladu, že jsou objekty dostatečně malé na to, aby se do stránky vešel víc než jeden) a stránka je přidána do seznamu partial (částečné). Při požadavku na alokaci jsou vraceny ostatní objekty v této stránce, ale jenom v případě, že je seznam volných prázdný. Když je alokován poslední objekt ve stránce, SLQB na ni zapomene - alespoň dočasně.
Objekty jsou po uvolnění přidány do seznamu volných. Je snadné předpovědět, že tento seznam může poměrně narůst po vyšší aktivitě systému. Umožnit seznamu volných neomezeně růst by znamenalo bezúčelné riskování obsazení velké části systémové paměti, která nebude nic dělat a možná bude potřeba jinde. Jakmile tedy velikost seznamu volných překročí limit (nebo když alokátor stránek začne žádat o pomoc s uvolňováním paměti), jsou objekty v seznamu volných vyprázdněny zpět do svých stránek. Jakákoliv částečná stránka, která je zcela zaplněna uvolněnými objekty, je poté vrácena alokátoru stránek k použití jinde.
Objevuje se nicméně zajímavá situace: vzpomeňme, že SLQB je v podstatě alokátor pro jednotlivá CPU. Není zde ale nic, co by vyžadovalo, aby byly objekty uvolňovány na stejném CPU, které je alokovalo. A u dlouhožijících objektů na systému s mnoha procesory vskutku roste pravděpodobnost, že budou uvolňovány na jiném CPU. Proces neví nic o částečných stránkách, ze kterých byly tyto objekty alokovány, a tím pádem je nemůže uvolnit. Je tedy potřeba použít jiný přístup.
Tento jiný přístup vyžaduje udržování dvou dalších seznamů objektů nazvaných rlist a remote_free. Když se alokátor pokouší vyprázdnit "vzdálený" objekt (objekt alokovaný na jiném CPU) ze svého lokálního seznamu volných, jednoduše tento objekt přesune do rlist. Alokátor příležitostně sáhne mezi CPU, aby si z jejich lokálního seznamu rlist vybral objekty a vložil je do sezamu remote_free na CPU, které tyto objekty původně alokovalo. CPU se potom může rozhodnout tyto objekty znovu použít, nebo je uvolnit do jejich stránek.
Tato mezi-CPU operace zjevně vyžaduje zamykání, takže remote_free je chráněno spinlockem. Příliš častá práce se seznamy remote_free tudíž riskuje přeskakování řádku v cache a soupeření o zámek - ani jedno není vhodné, když je cílem škálovatelnost. To je důvod, proč procesory nejprve nasbírají skupinu objektů ve svých lokálních seznamech rlist předtím, než v jedné operaci přidají celý seznam do odpovídajícího seznamu remote_free. Krom toho alokátor příliš často nehledá objekty ve svém seznamu remote_list. Místo toho je objektům umožněno se hromadit do doby, než je překročen limit, v tu chvíli procesor, který přidal poslední objekt, nastaví příznak
Kód SLQB je relativně nový a pravděpodobně potřebuje významné množství práce předtím, než si bude moci hledat svou cestu do jádra. Nick tvrdí, že výsledky benchmarků jsou přibližně porovnatelné s těmi získanými při používání jiných alokátorů. "Přibližně porovnatelné" nicméně samo o sobě nebude dost na to, aby byl přidán ještě jeden alokátor paměti. Posunout SLQB od "porovnatelné" směrem k "zjevně lepší" je pravděpodobně dalším Nickovým úkolem.
V poslední době si hodně hraji s netfilterem a někdy dnes (tedy včera) po obědě jsem narazil na
printk("ipt_hook: happy cracking.\n");
při náhodném grepování "checksum". To je ale náhoda.
A hned jsem si říkal, že by to mohlo pěkně zahrtil logy 
Haha, přesně tohle jsem si u dnešních JN a zejména u téhle věty taky říkal. Méně je někdy více a v případě termínů specifických pro kernel je, myslím, překlad dost k ničemu. Kdo neví co je scatter-gather tomu překlad na rozsyp-sesbírej vůbec nic neřekne a kdo ví v čem spočívá scatter-gather ten zase překlad nepotřebuje. A takových příkladů je víc. Lepší by bylo nechat scatter-gather a uvést odkaz na vysvětlení o co se jedná než si z prstu vycucnout nic neříkající překlad.
Stejně tak offset by v tomhle kontextu měl být spíš "pozice" než "posunutí", ale od člověka čtoucího JN bych čekal že bude vědět co znamená "offset". Zas tak neobvyklý termín to není.
Myslím že by nebylo od věci nechávat odborné termíny v angličtině a přeložit jen ten obecný text kolem. To by mimochodem mělo tu výhodu že by lidem za čas nemuselo dělat problém číst si o kernelu v angličtině - anglicky se naučí ve škole, technické termíny na abíčku a dohromady budou mít dost znalostí na pochopení kernel news v originále 
BTW Ještě mě dostala věta "Tito vývojáři bývají zdrojem, o který se hodně soupeří" - ale jakmile jsem si "zdroj" přeložil do angličtiny tak jsem pochopil vo co go.
Myslím že by nebylo od věci nechávat odborné termíny v angličtině a přeložit jen ten obecný text kolem.Mnohokrát diskutováno, mnohokrát opakováno, takže to shrnu v krátkosti: ne.
Ještě mě dostala věta "Tito vývojáři bývají zdrojem, o který se hodně soupeří" - ale jakmile jsem si "zdroj" přeložil do angličtiny tak jsem pochopil vo co go.Máš lepší překlad? Sem s ním.
Ale budiž, k lidem, kteří tohle čeli jako první JN v životě, bylo neuvedení původního termínu nefér.
Přece vůbec nejde o to jestli tam byl nebo nebyl anglický termín. Jde o to že když někdo neví co je scatter/gather tak je mu přelklad na rozsyp/sesbírej platný asi tolik jako překlad na bugh/dugh. Kdo neví o co jde tomu překlad nepomůže a kdo ví o co jde toho to leda zmátne. Myslím že čtenářům by víc prospělo ponechání původního termínu s odkazem na vysvětlení místo nic neříkajícího překladu.
Jde o to že když někdo neví co je scatter/gather tak je mu přelklad na rozsyp/sesbírej platný asi tolik jako překlad na bugh/dugh.Není. Pokud někdo neví, o jaká přesně operace se tím termínem v angličtině označuje, bude se řádit pouze obecným významem těch slov. A stejně se lze řídit i obecným významem těch slov v češtině (a nemusím to hledat ve slovníku). Pro toho, kdo ví, co přesně znamená ten anglický termín, pak může být originál uveden v závorce. A i z překladu rozsyp/sesbírej získám alespoň základní představu, o co se jedná -- určitě to odliším třeba od operace "vymaž" nebo "zapiš na disk".
Myslím že by nebylo od věci nechávat odborné termíny v angličtině a přeložit jen ten obecný text kolem. To by mimochodem mělo tu výhodu že by lidem za čas nemuselo dělat problém číst si o kernelu v angličtiněHlavně by to mělo tu "výhodu", že by žádná česká terminologie nevznikla, takže by za chvíli nezbývalo, než na češtinu zapomenout a přejít zcela na angličtinu (a pokud by se tím pravidlem řídily i jiné obory, pak nejen v IT, ale všude). Pokud ale někdo dává přednost angličtině, nechápu, proč si ten článek nepřečte v originále. Samozřejmě něco jiného je uvádět u nových termínů anglický originál, překladatel nemusel vymyslet ten nejlepší překlad (nebo se už používá jiný překlad) a taky si to čtenář může rovnou s originálem spojit. Mimochodem -- pokud by se termíny nepřekládaly, vznikne ještě další problém, a to se skloňováním. Buď je budete skloňovat, pak už to ale nebudou moc originální termíny, nebo je ponecháte skutečně v originále, pak zase bude problém číst "českou" větu, kde je půlka slov cizích a neskloňovaných.
Vyraz "rozsyp/pozbirej operace" mi tiez nepride dvakrat sklonovany.To bude asi tím, že nebyl v žádném pádě, ve kterém by bylo potřeba skloňovat...
Ale no tak! (sem patří smajlík obracející oči v sloup)
Někdy není od věci zapojit selský rozum. O tom že kernel = jádro se tu taky nikdo hádat nebude.
Nepřekládat tam, kde se cizí termín už stal součástí české slovní zásoby a běžně se používá. Není potřeba překládat tam, kde se stal součástí české slovní zásoby (jako třeba kernel), ale pokud existuje i česká alternativa, nevidím důvod, proč jí nedat přednost. V ostatních případech překládat, a pokud není z překladu zřejmé, o co jde, v závorkách ponechat originál.Jinak řečeno dělat to, co se dělalo doteď. Já jsem pro.
Nepřekládat tam, kde se cizí termín už stal součástí české slovní zásoby a běžně se používá. Není potřeba překládat tam, kde se stal součástí české slovní zásoby (jako třeba kernel), ale pokud existuje i česká alternativa, nevidím důvod, proč jí nedat přednost.
Přesně tak.
V ostatních případech překládat, a pokud není z překladu zřejmé, o co jde, v závorkách ponechat originál.
V ostatních případech nepřekládat, raději nechat originál a v závorce uvést vysvětlení nebo odkaz na vysvětlení. Ale na tomhle se asi neshodneme 
Neprekladat nikde, okrem pripadov, ze ceska verzia je uz tak zauzivana, ze sa masovo uprednostnuje voci anglickej.http://lwn.net
Ja viem, o S/C je tu uz zda sa dohoda, ze sa ponecha v AJ, ale nenapadol ma momentalne iny priklad.Takové dohody jsem si nevšiml. U S/C dál hodlám uvádět anglický výraz v hranatých závorkách za českým překladem

ISSN 1214-1267, (c) 1999-2007 Stickfish s.r.o.