Portál AbcLinuxu, 17. července 2026 21:09
The H představuje údajně první volně prodejné PC s UEFI Secure Boot připravené pro Windows 8. S počítačem "Medion Akoya P4210 D" dodávané UEFI 2.3.1 dovoluje uživateli spravovat vlastní databáze klíčů a podpisů: Platform Key (PK), Key Exchange Key Database (KEK), Authorized Signature Database (DB) a Forbidden Signature Database (DBX). Neměl by tedy být problém s generováním klíčů pro libovolnou linuxovou distribuci. Článek obsahuje náhledy nastavení UEFI.
Tiskni
Sdílej:
![]()
![]()
![]()
![]()
![]()
![]()
 11.7.2012 14:28
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
11.7.2012 14:28
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
On an ARM system, it is forbidden to enable Custom Mode. … Disabling Secure MUST NOT be possible on ARM systems,
11.7.2012 22:29
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
 11.7.2012 20:58
the.max | skóre: 46
| blog: Smetiště
11.7.2012 22:21
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
11.7.2012 20:58
the.max | skóre: 46
| blog: Smetiště
11.7.2012 22:21
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
 11.7.2012 22:02
Člověk z Horní Dolní
| blog: blbeczhornidolni
11.7.2012 22:24
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
11.7.2012 22:02
Člověk z Horní Dolní
| blog: blbeczhornidolni
11.7.2012 22:24
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
má pár zbytečných funkcí navícMozna par zbytecnych, ale plno uzitecnych.
za cenu hrozného zesložitění.Je to spise naopak, zbavime se konecne prehistorickeho balastu vlaceneho od dob AT a MSDOSu.
11.7.2012 22:31
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
pribudnu tony novych polofunkcnych sraciek...Vyborne, silne tvrzeni. Muzete byt konkretni? UEFI specifikaci lze nalezt zde, snad vam to pomuze.
 A jaký přínos pro uživatele tedy má, že se PC bude chovat po zapnutí jinak? Grafické blbosti na mě neplatí - to se dá koneckonců realizovat i v BIOS. Zamyslete se nad tím a pochopíte, že jediný přínos je v GPT, kterou se pochopitelně také může naučit i BIOS.
12.7.2012 18:54
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
A jaký přínos pro uživatele tedy má, že se PC bude chovat po zapnutí jinak? Grafické blbosti na mě neplatí - to se dá koneckonců realizovat i v BIOS. Zamyslete se nad tím a pochopíte, že jediný přínos je v GPT, kterou se pochopitelně také může naučit i BIOS.
12.7.2012 18:54
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
Adminům na PC přibyde další pakárna navíc - před instalací OS vypnout secure boot.....A nenabootovat Windows?
13.7.2012 11:09
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
BFU, který si koupí PC s předinstalovanými Windows 8 není admin. Za toho se dá považovat až člověk, který aspoň trochu ví co dělá a bude ten "zázrak" nahrazovat něčím normálním.Hloupa arogance.
11.7.2012 22:40
Člověk z Horní Dolní
| blog: blbeczhornidolni
11.7.2012 23:11
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
 12.7.2012 00:27
Grunt | skóre: 23
| blog: Expresivní zabručení
| Lanžhot
12.7.2012 00:27
Grunt | skóre: 23
| blog: Expresivní zabručení
| Lanžhot
Proc je to blbost?Já osobně tohle netvrdím. Jenže kteří lidi vymýšleli BIOS? A ti stejní lidi (ba co víc, se do toho montujou ještě horší lidi) vymysleli UEFI. Co z toho asi tak může vzejít?
12.7.2012 01:36
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
12.7.2012 21:30
Grunt | skóre: 23
| blog: Expresivní zabručení
| Lanžhot
12.7.2012 00:21
Grunt | skóre: 23
| blog: Expresivní zabručení
| Lanžhot
12.7.2012 01:14
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
12.7.2012 00:45
Člověk z Horní Dolní
| blog: blbeczhornidolni
12.7.2012 01:13
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
Nevim k cemu mi bude GPT,GPT je to nejlepsi, co UEFI prinesl!
nazor Linuse Torvaldse na UEFI.Linus argumentuje X let starou implementaci na Mac-u, uzivaje silna slova, aby to za nejakou dobu vzal na "milost". To uz jsem zazil mnohokrat. Pokud beru nekoho argumenty, tak je to Matthew Garrett, treba zde, ten alespon vi o cem mluvi.
12.7.2012 01:17
Grunt | skóre: 23
| blog: Expresivní zabručení
| Lanžhot
BTW, nazor Linuse Torvaldse na UEFI.Nechápu na co tolik slov. Přitom stačilo jen říct „UEFI, Fuck you!“
je pro me krok kupreduDětské krůčky
 , co nahradit procesor?
, co nahradit procesor?
Uz jen to, ze se zbavim MSDOS partition table a nahradi se to GPT je pro me krok kupreduJe dobre si uvedomit, ze GPT na UEFI neni zavisla - stavajici BIOS je schopen nabootovat disk s vicemene libovolnym formatem partitions. Tedy je v podstate mozne pouzivat GPT i s BIOSem.
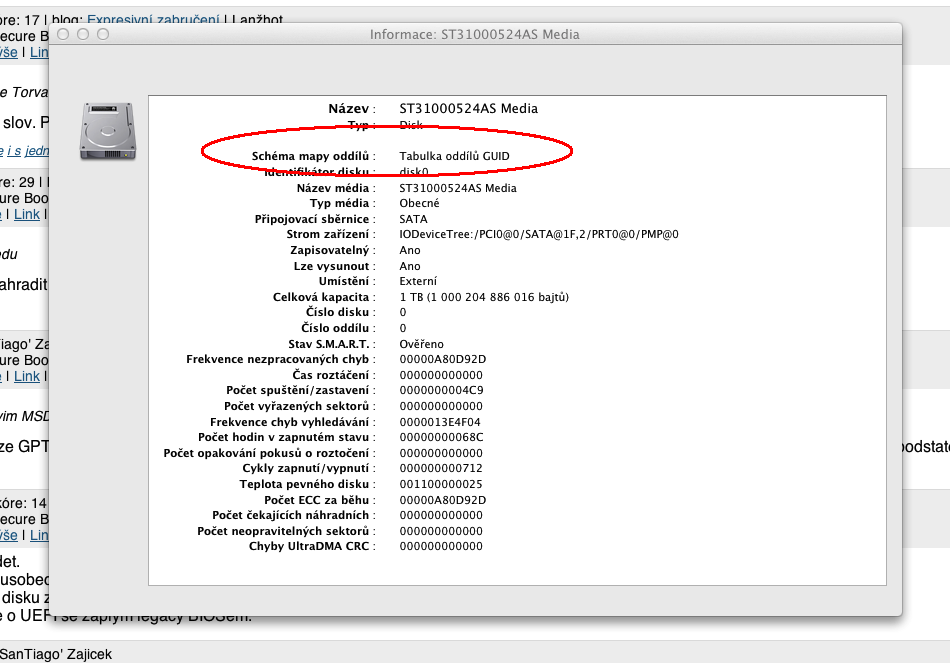
Tak to bych chtel videt.Jak je libo, viz příloha.
12.7.2012 18:52
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
12.7.2012 18:59
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
stavajici BIOS je schopen nabootovat disk s vicemene libovolnym formatem partitionsS libovolnym formatem, pokud ma MBR.
12.7.2012 19:27
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
12.7.2012 22:55
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
Sovičko, proč jste prve hlásal jednoduchost UEFI a nyní připouštíte jeho komplikovanost díky modularitě?Psal jsem:
UEFI je modularni a v minimalni konfiguraci neni o moc slozitejsi nez BIOS, spise naopak.Z ceho dovozujete, ze pripoustim komplikovanost diky modularite?
Já, ač pro Arch mám UEFI v repu, ani mne nenapadne ji použít, neb odnáší více než přináší.Coze ma konkretne Arch v repu?
Coze ma konkretne Arch v repu?Řekl bych, že toto, nicméně bez UEFI hardware to bude k ničemu.
13.7.2012 11:15
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
nicméně bez UEFI hardware to bude k ničemu.Cely jeho prispevek nedava smysl. Bud mate UEFI HW a pak nemate na vyber - i kdyz lze bootovat UEFI kernel primo bez EFI bootloaderu a nebo ho nemate a pak by si EFI bootloader instaloval jen uplny imbecil.
.
12.7.2012 23:03
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
V Brightonu to neví pouze noční ptactvoCoze ptactvo nevi? Ze to interne pouziva UTF16? A jak jste k tomu dosel?
12.7.2012 23:17
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
 ).
).
Zobrazuje/používá se to pole někde?Tak třeba ve
fstab má člověk pole LABEL, nebo to bude v /dev/disk/by-label/. Otázka je, jak se s tím popasují udev, systemd a podobné věci, ale glibc je unicodované už dlouho, takže by to nemusel být problém.
(muhehe už se těším na instalaci asijských fontů nebo na ZALGO během bootuVzhledem k tomu, že je pro mě utf-16 sekvence čitelná stejně jako asijské znaky, tak fonty netřeba. Takový LABEL bude v podstatě neunikátní UUID
13.7.2012 11:23
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
Doby kdy bylo mozne prijmout akceptovatelny mezinarodni standard reflektujici jen ASCII jsou uz pryc.tak kdyz uz ne ascii tak utf-8, nebo klidne utf-32. Na disku by tech par byte nikoho nezabilo, ale utf-16? To se fakt musel jednoho dne nekdo probudit, nasranej na celej svet, a rict si tak cim bych se tem uzivatelum/vyvojarum pomstil...
13.7.2012 14:08
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
tak kdyz uz ne ascii tak utf-8, nebo klidne utf-32.Proc? UTF8 je pro nektere asijske jazyky horsi nez UTF16, navic to neni tak spatne, viz zde.
Na disku by tech par byte nikoho nezabilo,UTF16LE je pouzito napric UEFI, tedy i mimo disk.
UTF8 je pro nektere asijske jazyky horsi nez UTF16To je ovšem dost slabý argument, protože pro většinu ostatních jazyků vychází UTF-8 lépe.
navic to neni tak spatne, viz zdeDost pochybné srovnání, v němž se tvrdí ledacos, co prostě není pravda. Například:
From a programming point of view it reduces the need for error handling that there are no invalid 16-bit words in 16-bit Unicode strings.High surrogate bez odpovídajícího low surrogate rozhodně error handling potřebuje.
13.7.2012 15:20
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
To je ovšem dost slabý argument, protože pro většinu ostatních jazyků vychází UTF-8 lépe.Silny argument je, ze jen Cina ma vice moznych uzivatelu, ze EU a USA dohromady, o Indii, Indonesii a dalsich radsi nemluve, a ze spolecnou rukou vetuji cokoliv co nebude reflektovat jejich zajmy. UTF16 je kompromis.
High surrogate bez odpovídajícího low surrogate rozhodně error handling potřebuje.Prectete si znovu onu vetu:
From a programming point of view it reduces the need for error handling that there are no invalid 16-bit words in 16-bit Unicode strings.
 14.7.2012 01:34
kyknos | skóre: 18
| blog: Quid novi?
| Ranša Rosa
14.7.2012 01:34
kyknos | skóre: 18
| blog: Quid novi?
| Ranša Rosa
Indonesiico s tím mají chudáci Indonésané píšící latinkou společného?
14.7.2012 09:40
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
14.7.2012 10:01
kyknos | skóre: 18
| blog: Quid novi?
| Ranša Rosa
14.7.2012 10:33
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
je asi tak častá jako u nás hlaholiceHlaholice je vic nez tisic let mrtve pismo, narozdil od vyse uvedenych pisem, ktere se stale uci ve skolach vedle latinky a ktere jsou pro ne dost dulezita na to aby si je protlacili do Unicode a tom se zde bavime.
Druhy je arabsky transkriptCož ovšem není písmo, pro které by UTF-16 byla výhodnější, vyjde nastejno (stejně jako cokoliv mezi U+0100 a U+07FF).
Hlaholice je vic nez tisic let mrtve pismo, narozdil od vyse uvedenych pisem, ktere se stale uci ve skolach vedle latinky a ktere jsou pro ne dost dulezita na to aby si je protlacili do Unicode a tom se zde bavime.My se zde bavíme především o statistice, takže pokud někdo používá nějaké písmo pro 1% psaných textů, lze to s klidným svědomím zanedbat.
14.7.2012 11:32
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
stejně jako cokoliv mezi U+0100 a U+07FFPro Javanese to neplati.
My se zde bavíme především o statistice, takže pokud někdo používá nějaké písmo pro 1% psaných textů, lze to s klidným svědomím zanedbat.My se bavime predevsim o tom, co je pro ne dluhodobe [politicky] akceptovatelne na urovni standardu, a i kdyby to 1% byly jen liturgicke texty a napisy na nahrobnich kamenech, uziti UTF16 je pak kompromis.
14.7.2012 13:38
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
Technicky je to prece uz jasne, nebot i podle vasich cisel je UTF16 pro vetsinu bud vyhodnejsi nebo neutralni. Technicky mluvi ve prospech i to, ze UTF16 je jiz na systemove urovni pouzivane ve Windows, NET, Jave a jinde.Pro to, že by UTF-16 byla výhodnější, zde nepadl jediný argument. Počty uživatelů jazyků jsou takřka vyrovnané a jelikož čínština spotřebuje na tentýž text výrazně méně codepointů než IE jazyky, je celková statistika výrazně ve prospěch UTF-8. Jasně, je to hrubý odhad, ale pokud umíte sehnat lepší data, sem s nimi. Co se standardů týče, mimo Windows a Javu moc příkladů použití UTF-16 nenajdete. Naopak např. všechny internetové protokoly používají UTF-8.
14.7.2012 18:18
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
Pro to, že by UTF-16 byla výhodnější, zde nepadl jediný argument. Počty uživatelů jazyků jsou takřka vyrovnanéArgumenty padly, vcetne Unicode Technical Note #12 - autor je dlouholety prispevatel ICU a v teto oblasti zastupuje Google, predtim IBM, vi o cem pise. Jestlize pocty uzivatelu jsou takrka vyrovnane, je UTF16 dobry kompromis.
14.7.2012 23:48
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
jednodušší error handling (jen o trochu jednodušší;Tenhle jeho argument bych moc nebral. Detekce chyby je sice u UTF16 jednodussi u poskozene sekvence, ale pokud vam mohou chybet byty, je pripadna recovery nasledujicich znaku slozitejsi a muze narozdil od UTF8 selhat. U seriovych protoku ma smysl pouzivat pouze UTF8.
Politika ve vecech mezinarodnich standardu hraje vzdy roli neb zastupci hajicich zajmy jednotlivych statu jsou jmenovani vladami a to se pak neprimo promita i do velmi volnych standardu jako je UEFI.To velmi záleží na tom, kdo ty standardy tvoří. Pokud ISO, tak ano. Pokud IETF, tak nikoliv. A je to konec konců na výsledcích vidět :)
.
Hlaholice je vic nez tisic let mrtve pismo, narozdil od vyse uvedenych pisem, ktere se stale uci ve skolach vedle latinky a ktere jsou pro ne dost dulezita na to aby si je protlacili do Unicode a tom se zde bavime.... nemluvě o tom, že hlaholice v Unicode také je (U+2C00 až U+2C5F).
14.7.2012 10:46
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
14.7.2012 10:55
kyknos | skóre: 18
| blog: Quid novi?
| Ranša Rosa
14.7.2012 11:17
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
14.7.2012 19:06
kyknos | skóre: 18
| blog: Quid novi?
| Ranša Rosa
).
13.7.2012 14:53
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
přiblblý anachronismus,Anchronismus? Presne naopak, dnesni UTF16 je pokracovatelem UCS2.
ani efektivitu UTF-8.UTF8 je efektivni predevsim pro evropske jazyky, nikoliv treba pro BMP Chinese.
Anchronismus? Presne naopak, dnesni UTF16 je pokracovatelem UCS2.Nikoliv, UTF-16 je zoufalý hack, který vymysleli v sitauci, kdy ledaskdo používal UCS-2 a přišlo se na to, že 2^16 znaků nestačí. Ve světě Windows je používán běžně (protože UCS-2 se už tak snadno nešlo zbavit), ledaskde jinde (například v internetových protokolech) dost zásadně odmítan. Naopak se mi zdá, že celkově vývoj směřuje k UTF-8 a UCS-4.
UTF8 je efektivni predevsim pro evropske jazyky, nikoliv treba pro BMP Chinese.BMP Chinese (nebo přesněji blok CJK) je asi tak jediný běžný případ, kdy je UTF-16 efektivnější. Pro jazyky psané latinkou (což nejsou jen evropské, ale třeba také většina afrických) je efektivnější UTF-8 a pro většinu ostatních jazyků to vyjde nastejno. Krátký průzkum v Ethlonogue Language Statistics odhalil mezi jazyky s více než 50M rodilými mluvčími 1968M mluvčích, pro které by byla výhodnější UTF-16, dále pak 1258M mluvčích, pro něž je jednoznačně výhodnější UTF-8, a 504M, kterým je to jedno. Takže to vychází přibližně nastejno. Přičteme-li k tomu, že mezi nemateřskými jazyky jasně vede francouzština (190M), angličtina (150M) a ruština (128M) [zde údaje podle Weltalmanachu 1986, protože Ethnologue je nemá] a že v počítačovém světě s velkým odstupem vede angličtina, veškeré výhody UTF-16 jsou iluzorní.
13.7.2012 17:42
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
Nikoliv, UTF-16 je zoufalý hack, který vymysleli v sitauci, kdy ledaskdo používal UCS-2 a přišlo se na to, že 2^16 znaků nestačí.Pokud byste vypustil slovo "zoufaly", klidne bych souhlasil. Ja nejsem fanda UTF16, ale ani mi tak nevadi.
mezi jazyky s více než 50M rodilými mluvčími 1968M mluvčích, pro které by byla výhodnější UTF-16, dále pak 1258M mluvčích, pro něž je jednoznačně výhodnější UTF-8, a 504M, kterým je to jedno.Tohle hovori ve prospech UTF16, zejmena pokud posunete hranici 50M treba k 20M.
Takže to vychází přibližně nastejno.Ne, viz vase udaje a vezmete v uvahu demografickou prognozu.
Weltalmanachu 1986Za tu dobu vam pribyla miliarda lidi v Asii a severni Africe.
Tohle hovori ve prospech UTF16, zejmena pokud posunete hranici 50M treba k 20M.Pokud posunu hranici k 20M, moc se poměr nezmění, pokud ještě níže, začne to být ve prospěch UTF-8, protože spousta "malých" jazyků přijala písmo až dost pozdě a typicky to byla nějaká varianta latinky nebo azbuky.
Ne, viz vase udaje a vezmete v uvahu demografickou prognozu.Jenže mám-li brát v úvahu demografické prognózy, měl bych brát v úvahu i ty lingvistické a ty často říkají, že Čína za řádově desítky let přejde na fonetické písmo. Kdo ví, jak bude vypadat.
Za tu dobu vam pribyla miliarda lidi v Asii a severni Africe.... kteří mají jako druhý jazyk nejspíš angličtinu (rodný jazyk jsem uváděl podle novější statistiky). A obecně za těch 26 let nejspíš mezi druhými jazyky přibylo nejvíc angličtiny.
13.7.2012 18:51
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
Pokud posunu hranici k 20M, moc se poměr nezmění, pokud ještě níže, začne to být ve prospěch UTF-8, protože spousta "malých" jazyků přijala písmo až dost pozdě a typicky to byla nějaká varianta latinky nebo azbuky.Neni pravda, kouknete se treba sem
i ty lingvistické a ty často říkají, že Čína za řádově desítky let přejde na fonetické písmo.Spise ne v nasem zivote, pismo je to co je drzi staleti pohromade, foneticky se totiz mezi sebou zatim nedomluvi.
druhý jazyk nejspíš angličtinuPro vetsinu z nich sice muze byt druhy jazyk anglictina, ale asi jako pro nas: uci se to ve skole, vzdelanejsi lide se s tim nejak domluvi, ale primarni roli to zatim nehraje. Sorry, ale stale si myslim, ze cisla jsou celkem jasne na strane UTF16.
Pro vetsinu z nich sice muze byt druhy jazyk anglictina, ale asi jako pro nas: uci se to ve skole, vzdelanejsi lide se s tim nejak domluvi, ale primarni roli to zatim nehraje.No, v techto zemich (napr. Indie ci znacna cast Afriky) je to preci jen jinak nez v CR - desitky ruznych kmenovych jazyku a anglictina (ci francouzstina) jako uredni a obchodni jazyk. Takze ty jazyky tam bezne pouziva vzdelanejsi cast populace.
13.7.2012 20:36
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
Neni pravda, kouknete se treba semPozor, tam jsou mezi 20–50M i dialekty čínštiny, které jsem já už do čínštiny započítal. Ale zejména pořád zapomínáte na jinou věc, totiž že tentýž text má v čínštině daleko méně codepointů než (třeba) v indoevropských jazycích, takže pokud chcete počítat celosvětovou statistiku, musíte nutně indoevropským jazykům dávat větší váhu.
Pro vetsinu z nich sice muze byt druhy jazyk anglictina, ale asi jako pro nas: uci se to ve skole, vzdelanejsi lide se s tim nejak domluvi, ale primarni roli to zatim nehraje.Naopak – v mnoha státech je nějaký indoevropský jazyk (v Indii angličtina, v Africe francouzština, v jižní Americe španělština a portugalština) jazykem vzdělanců a úředníků a píše se v něm daleko větší objem textu než v rodných jazycích.
13.7.2012 20:58
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
Pozor, tam jsou mezi 20–50M i dialekty čínštiny, které jsem já už do čínštiny započítal.Jenze pak jste musel vynechat neco jineho, neb vam cisla nesedi. Jen Indie a Cina budou mit 2.5 miliardy lidi, a kde je Indonesie, Vietnam, Thajsko, Malajsie, Banglades, Korea, Japonsko ci Pakistan a dalsi?
14.7.2012 00:00
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
ISSN 1214-1267, (c) 1999-2007 Stickfish s.r.o.
 12.7.2012 08:24
12.7.2012 08:24
 13.7.2012 13:00
13.7.2012 13:00
{kind=link}
{kind=link}