 | poslední úprava: 19.2.2020 17:41
| poslední úprava: 19.2.2020 17:41
Portál AbcLinuxu, 23. července 2026 01:31
19.2.2020 16:52
| Přečteno: 5204×
| Linux
|
| poslední úprava: 19.2.2020 17:41
Linux ani Windows nepřidělují fyzickou paměť ihned při alokaci. Jinými slovy – alokace vrátí virtuální adresu, která se nemapuje na žádnou fyzickou paměť (ve skutečnosti se mapuje na nulovou stránku a při zápisu se uplatní COW, ale to je implementační detail). Při prvním zápisu do některé ze stránek alokované paměti nastane fault, který odchytí jádro a namapuje na příslušnou stránku virtuální paměti stránku fyzické paměti. Důvodů pro takové chování je několik. Aplikace může alokovat paměť rozmařile, pokud ji celou nebude potřebovat, tak to moc nevadí, protože virtuálního prostoru je na 64bit procesorech dostatek. Některé algoritmy pracují dobře s datovými strukturami, které jsou plánovitě „děravé“. Rozmělňuje se časově náročná část alokace (fyzické mapování) v čase.
Bankéři už dávno přišli na fintu, že mohou rozpůjčovat více peněz, než kolik jich mají – dokud si příliš hodně lidí současně nepřijde pro své peníze nenastane problém. Princip overcommitu je stejný. Proč nedovolit aplikacím alokovat co jim hrdlo ráčí i nad limit velikosti fyzické paměti + stránkovacího souboru. Beztak z té alokované paměti použijí jen část, takže se nic nemůže stát.
Windows overcommit nedělá. Linux se řídí proměnnou vm.overcommit_memory. Defaultně je zapnutý heuristický overcommit, který v praxi znamená, že pokud si aplikace nevyžádá absurdně velikou alokaci, tak neselže a paměť dostane. Troufám si říct, že v takto to je v praxi na 99,99 % nasazených systémech jak na serverech, tak desktopech. Existuje možnost overcommit vypnout nebo naopak vždy povolit (právě pro případ aplikací pracujících na „řídkých“ datech).
Oba přístupy mají své výhody a nevýhody. Na Windows se může stát, že alokace selže i když je k dispozici hromada volné paměti ale je překročen „commit charge“, tady alokovaná anonymní paměť překročila množství, které je systém schopen pokrýt fyzickou paměti a stránkovacím souborem. Pokud se nějaká aplikace neutrhne z řetězu, tak se to ovšem moc často nestává. V praxi je totiž velká část fyzické paměti obsazená soubory mapovanými do paměti, načtenými částmi proveditelných souborů/knihoven, diskovou cache – jinými slovy neanonymní pamětí. Tu lze kdykoliv z paměti odstranit, neboť je pokryta souborem na disku. Neanonymní paměť se nepočítá do „commit charge“. Windows se takové situaci také snaží bránit tím, že pagefile se umí za chodu zvětšovat (a zmenšovat) a defaultně to je zapnuté. Je to také jeden z argumentů proč ve Windows pagefile nevypínat. Přístup k alokované paměti nemůže selhat. Systém garantuje, že pro ni má pokrytí fyzickou stránkou.
Nevýhodou overcommitu je, že zatímco alokace (tedy místo, které se dá dobře ohlídat z hlediska návratové hodnoty případně vyhozené výjimky v hipsterských programovacích jazycích) projde skoro vždy, tak věc, která se ohlídat prakticky nedá, tedy prosté přistoupení k paměti, selhat teoretický může. Linux se tomu snaží zabránit, jak to jen jde. V nouzi nejvyšší povolá OOM killera, který vybere nějakou aplikaci a zabije ji. OOM killer v Linuxu je jako typický nácek– brutální a hloupý. Když nadejde krize, tak má ze záhadného důvodu ve velké oblibě mordování židů, eee… co to plácám, mordování Xorg samozřejmě, jehož smrt vám sestřelí všechny aplikace. To nepotěší. Jinými slovy – neví nic o userspace a jeho heuristika nebere ani nejmenší ohledy na to, co je pro uživatele podstatné. Jsou nějaké snahy to zlepšit. Už 20 let+. A furt nic.
Swapování se používalo zejména na mainframech. Fungovalo to tak, že CELÁ paměť procesu se vyhodila z fyzické paměti, nahrála se tam celá paměť jiného procesu, proces dostal přidělený procesorový čas, pak se opět celý z paměti odsunul, a tak pořád dokola. Linux neumí swapovat a nikdy to neuměl. Umí „pouze“ stránkovat, což je mnohem pokročilejší metoda pracující s granularitou stránek nikoliv celých procesů. Název swap partition/file, swapping je tak zapečený v systému i hlavách, že de facto zastínil původní název a je zbytečné s tím bojovat. Asi tak, jak je zbytečné obhajovat původní význam slova hacker. V tomto blogu však budu důsledně používat pojem stránkování, aby bylo zřejmé, oč jde. Windows umí stránkovat, a swapovat paradoxně nedávno naučil. Umí „modern apps“ kompletně odstranit z fyzické paměti. Je to ale okrajová záležitost. Ve Windows je terminologie správná (paging, page file).
Tohle je asi největší principiální rozdíl. Linux má seznam stránek „active“. Je v ní guláš stránek ze všech procesů. Pak má seznam „inactive“ kam přehazuje stránky z „active“ LRU algoritmem, který nijak nezohledňuje přináležitost k procesu, tedy padni, komu padni.
Oproti tomu Widnows má pro každý proces separátní seznam aktivních stránek, kterému se říká „working set“. Taktéž „inactive“ seznam není jeden, ale je jich 8 dle priority. Nevýhodou je větší komplikovanost a větší režie spojená s obsluhou těch seznamů. Výhodou je větší flexibilita – aplikace si může nastavit prioritu jak důležité jsou její stránky, může si nastavit minimální working set, může si sama na sebe zavolat EmptyWorkingSet před dlouhotrvajícím spánkem.
Windows má také heuristiku, která nedovolí narůst WS procesu nad mez, kdy příliš omezuje ostatní procesy. Jinými slovy od určité hranice proces dostane do WS stránku pouze na úkor vyhození odtamtud jiné stránky. Nemělo by tedy dojít k trashování a hladovění ostatních procesů, kterého lze v Linuxu dosáhnout snadno. Historku typu „přihlášení přes SSH mi trvalo půl hodiny“ prožil každý správný linuxák  Přes cgroups se to dá omezit, ale vyžaduje to ruční fidlání a zkušeného sysopa.
Přes cgroups se to dá omezit, ale vyžaduje to ruční fidlání a zkušeného sysopa.
Jaký je tedy koloběh stránek ve Windows? Aplikace se rodí s minimálním worksetem (není to jako v linuxu, že po forku je proces COW klonem rodiče). WS se postupně zvětšuje, jak aplikace bere stránky ze „zero page list“ a načítá exec, knihovy a další soubory, alokuje, memmapuje, … V určité chvíli windows určí, že proces má dost a začne mu stránky z WS vyhazovat. Ty se můžou vrátit zpět do WS, když k nim proces přistoupí. A to softfaultem pokud je stránka ještě v paměti nebo hardfaultem pokud není. Stránka vyhozená z WS může skončit buďto v „modified page list“ nebo ve standby. Modifid je paměť, kterou nelze ihned z paměti zahodit a musí se předtím zapsat na disk. Zejména je to anonymní paměť ale i modifikované stránky neanonymní paměti (dokud se neprovede sync). Jednou za čas se probudí thread „modified page writer“ zhodnotí situaci (množství volné paměti, zatížení IO a CPU) a případně začne stránky zapisovat na disk (anonymní do pagefile, neanonymní do příslušných souborů) a tím se dostanou z „modified“ do „standby“. Ve standby jsou stránky paměti, které je možné okamžitě uvolit – neanonymní paměť (protože ji lze vždy načíst zpět z příslušného souboru) i anonymní (protože musela být předtím zapsána do pagefile a lze je tedy získat zpět odtamtud). Standby je tedy taková cache stránek. Paměť odtamtud lze v případě potřeby kdykoliv uvolnit a současně je pravděpodobnost, že si některý proces přes softfault přitáhne zpět do svého WS. Když je paměť vyhozená ze standby nebo proces vrátí paměť systému, dostane se do seznamu free. Tam ale douho nepobude, vyzvedne si ji ihned thread, který ji vynuluje a přehodí ji do „zeroed page list“. Tím se koloběh uzavírá.
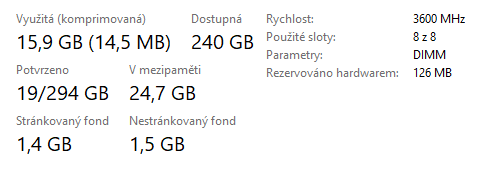
Když s kompresí paměti přišel Apple v roce 2013, byl jsem k tomu dost skeptický. Na vlastní kůži jsem se ale přesvědčil, že jsem se pletl. Pomohlo to, a to i na počítačích s SSD. A viděl jsem to i na modelech s nvme takže snad to mají vyzkoušené, že se to vyplatí i tam. Nebo tím jen šetří disky s ohledem na objem zapsaných dat, kdo ví. Funguje to (v MacOS) tak, že systém při nedostatku paměti začne procházet inactive frontu stránek a komprimovat je místo toho, aby je hned vyhazoval do stránkovacího souboru. Pokud ani to nestačí, tak začne i tak stránky odkládat ale už v komprimované podobě, což dále snižuje IO jak při zápisu, tak při čtení. V Linuxu je několik různých soupeřících řešení, zejména zram a zswap. Mají jedno společné – nikdo to nepoužívá. No možná až na Android (zram).
Ve Windows komprese paměti implementována je a využívá se vždy, i na počítačích s nvme a hromadou paměti. Vypnout se dá ( Disable-MMAgent -mc ) ale nikdo to nedělá. Implementace je taková… řekl bych lajdácká. Existuje userspace proces (s dost mimořádnými právy, až v tom někdo najde díru…) „memory compression“, který prochází standby seznamy, nasává z nich stránky, komprimuje je a ty pak žijí v jeho working setu. Nebo z něho vypadnou zase do standby seznamu a odstamtud se dostanou do page file.
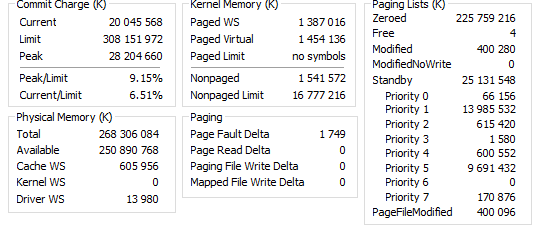
Memory management v Linuxu je líný. Pokud není nedostatek, tak skoro nic nedělá. K troše akce se dá vyprovokovat experimentováním se swapiness nebo jinými parametry. Oproti tomu Windows je _akční_. Dovolím si zde přiložit obrázek, který myslím tu akčnost dobře ilustruje. Mám 240 GiB „dostupné paměti“, z toho je 224 GiB ve frontě „zeroed“ takže tam není disková cache ani nic. Systém od bootu neměl využito nikdy více než 40 GiB. Ale Windows si i tak mírnix týrnix zkomprimoval něco přes 14 MiB… Asi aby nevyšel ze cviku. Můžete hádat, kolik místa je obsazeno ve stránkovacím souboru, když je systém v takto komfortním stavu z hlediska paměti. Nula to opravdu není…
Každé pravidlo musí mít výjimku, takže i tady je. Windows provádí stárnutí stránek (Dělá se to tak, že se shodí accessed bit všem stránkám a za nějaký čas se je opět projdou a ty, které ho nemají nastaveny „zestárnou“) až v případě, že začne paměť docházet. Linux to dělá pořád. Má tak lepší vstupy pro LRU algoritmus za cenu mírně větší režie.
Linux má paměť jádra a ovladačů zamknutou, nikdy se neodstránkuje pryč. Ve Windows je část zamknutá (nonpaged) ale část odstránkovat lze. Je to výhoda, protože v případě potřeby bude nějaká fyzická paměť navíc (ovšem kernel ani ovladače by příliš paměti spotřebovat neměly…). Je to také potenciální bezpečnostní riziko. Pagefile není chráněn před zvídavým útočníkem tak dobře jako stránky jádra. Zejména pokud natvrdo vypnete počítač a analyzujete pagefile v jiném počítači. Klade to větší nároky na vývojáře jádra a ovladačů aby touto cestou neleakovaly citlivá data.
Windows zarovnává virtuální adresy na 64 kB Linux na stránky. Linux má slab alokátor a windows má asi něco jako buddy alokátor (to muže být důvod, proč je latence vytváření některých objektu ve windows o dost větší a s rostoucím počtem jader v CPU se to zhoršuje). Je to ale asi přísně tajné, jak to uvnitř funguje, protože se k tomu nedá nic dohledat.
Vynechávám rozdíly, které už nejsou aktuální, tedy zejména řešení omezení 32bit systémů, kuriozity jako AWE. Také věci jako SuperFetch, které MS vyvinul… ovšem těsně před tím, než nastoupily SSD, takže se staly brzy obsoletní. Nebo ReadyBoost, který nefungoval nikdy.
Politici mají zvláštní cit, jak odhalit kdy se mají otázce vyhnout, protože nezávisle na odpovědi někoho naštvou. Tohle zcela jistě do této kategorie patří. Já nejsem politik, tak si můžu dovolit naštvat dokonce obě strany „sporu“ :-p Windows má v defaultním nastavení memory management, který se v krizových situacích chová lépe. Poskytuje také detailnější informace uživateli (když, jaký nástroj použít). Linux má mnohem přizpůsobivější memory management a dá se ohnout pro potřeby aplikace.
Zmiňoval jsem v úvodníku nějaké rozhovory. Je zajímavé, že windowsáci mají tendenci linuxovou stranu trochu idealizovat a linuxáci naopak Windows trochu démonizovat (zajímavé, že ve věcech, které se neliší a nejsou tedy v tomto článku zmíněné, třeba podpora huge tables nebo podpora NUMA, ASLR/KASLR). Jsou oblasti, kde to je oprávněné ale MM k nim nepatří.


Tiskni
Sdílej:
![]()
![]()
![]()
![]()
![]()
![]()
 19.2.2020 18:57
MakeIranBombedAgain❗ | skóre: 42
| blog: Grétin blogísek
| 🇮🇱==❤️ , 🇵🇸==💩 , 🇪🇺==☭
19.2.2020 18:57
MakeIranBombedAgain❗ | skóre: 42
| blog: Grétin blogísek
| 🇮🇱==❤️ , 🇵🇸==💩 , 🇪🇺==☭
že ty jako budeš mit dualboot?? ;D
Na domácím serveru mám Linux, na NASce mám linux, v routeru mám linux, v asi 20 virtuálech je linux, na produkčních serverech až na jednu výjimku linux. I na desktopu jsem měl linux od cca 1998. Ale posledních 10 let pokud správně počítám mám na desktopu windows. Periodicky to zkouším, snažím se, vydržím to tak týden. Nejde to, dře to, sorry jako
 19.2.2020 20:15
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
19.2.2020 20:15
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
V poslední době jsem se bavil s několika linuxáky i windowsáky o memory managementu a zjistil jsem, že obě strany se docela dobře vyznají, jak to funguje v „jejich“ systémuNa něco podobného jsem narazil taky. Známej, co tvoří programy snad ve Visual Basicu (jsem ani nevěděl, že to dneska ještě existuje), takže dalo by se říct takovej power user, a pokecali jsme a téma padlo i na memory management a celkem mě překvapil. Diskuse kolem overcommit a ballooning ve vm (v jeho podání hyper-v) apod. Chytal se. Jinak je nějaký důvod, proč je to ve widlích navrženo takto složitě? Tohle je poněkolikáté, co se setkávám s tím, že ve widlích je něco takto komplexního (příkladem budiž třeba NTFS, které už v době NT 4.0 umělo hardlinky i linky na adresář, ale začalo se používat snad až ve W7). Nevím, jestli Windows pořád návrhově míří na nějaké ultrasuperpočítače, ale pořád jsou zaseklí na desktopech, kde je to vlastně kontraproduktivní.
LRUJsem to jen já, nebo i ostatním tyhle simple přístupy vyhovují nejvíc? Ve widlích io cache (pro můj workflow) nefunguje. Nebo nefunguje vůbec. I před chvílí čtený soubor se čte opět. Všímám si toho i ve hrách, kdy i přes dostatek volné ram, kam by se vešly všechny datové soubory hry, se neustále čte z disku. V linuxu, i přes jednoduchost lru, se na disk po určitém čase chodí jen pro zápisy. (Tentýž problém v bledě modrém i ARC na ZFS na FreeBSD. Je to tak adaptive, že to vyhodí stránky zrovna těsně před tím, než je opět potřebuju.)
Je to tak adaptive, že to vyhodí stránky zrovna těsně před tím, než je opět potřebuju.
Tomu říkám "problém screensaveru". Ideální screensaver by neměl o zhasínání obrazovky rozhodovat podle doby od posledního stisku klávesy nebo pohybu myši, ale podle doby do příštího. :-)
20.2.2020 08:08
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
Mě spíše fascinuje, že už jsou tu 2 příspěvky, které hodnotí algoritmy Windows podle her.To má poměrně jednoduché vysvětlení, dual boot mám už jen pro hry. Posledního pracovního programu na win jsem se zbavil před několika měsíci. Navíc je jedno, jaký typ appky si daný soubor otevře. IO cache by měla zafungoval stejně.
Co jsem se kdy setkal, tak každá počítačová hra je napsaná jako největší prasárna.I kdyby to snad byla pravda, tak to nic nemění na stavu io cache. Pokud si 32b hra vezme svých max 3GB, její datové soubory mají 16GB a stroj má volné paměti několikrát tolik, tak je podivné, že se datové soubory pokaždé čtou z disku a nikoliv už z OS io cache. (A ano, existují flagy, aby se daný soubor necachoval, ale nevěřím tomu, že se toto používá tak často. U těch, podle vás "prasáren", bych spíše očekával, že vývojáři takové detaily nebudou řešit vůbec.)
20.2.2020 15:23
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
20.2.2020 17:05
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
cat soubor > /dev/null ten soubor bude v io cache. Občas toho využívám jako "prefetch". Bohužel tuhle jistotu už vůbec nemám třeba na FreeBSD s ZFS ARC, kde ani opakované (klidně i 15x) čtení nepřinutí ARC si to zapamatovat. A na widlích si už ani netipuju (ale tam nemám potřebu dělat systémové prográmky nebo skripty, takže mě to až tak netankuje).
 20.2.2020 17:10
Josef Kufner | skóre: 70
20.2.2020 17:17
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
20.2.2020 17:10
Josef Kufner | skóre: 70
20.2.2020 17:17
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
Na linuxu mám, na systému s dostatkem volné paměti, jistotu, že po cat soubor > /dev/null ten soubor bude v io cache.
To není s dostatečně novými jádry tak úplně pravda. Před časem jsem to tu psal; pokud už je page cache "plná", typicky až třetí čtení souboru jde z cache, druhé je ještě pomalé.
20.2.2020 20:18
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
fd = open(argv[1], O_RDONLY); addr = mmap(NULL, length + offset - pa_offset, PROT_READ, MAP_PRIVATE, fd, pa_offset); s = write(STDOUT_FILENO, addr + offset - pa_offset, length); munmap(addr, length + offset - pa_offset); close(fd);Při použití
mmtest soubor 0 | pv > /dev/null to nacachovalo soubor. Důvod, proč jsem tam zařadil pv je ten, že při obyčejném přesměrování mmtest ... > /dev/null to nic neudělalo (hádám, že to poznalo, že výstup je null; což se mi opět nelíbí). Následné čtení souboru i jinými metodami potvrdilo, že soubor je skutečně v cache. (zpool iostat, rychlost překračující možnou rychlosti disku)
při obyčejném přesměrování mmtest ... > /dev/null to nic neudělalo (hádám, že to poznalo, že výstup je null; což se mi opět nelíbí)
Nechce se mi to dohledávat, abych se ujistil, ale IMHO by bylo docela logické, že se v takovém případě ze souboru nebude vůbec číst. Nammapovaný soubor je pro systém prostě jen kus (virtuální) paměti a teprve když se z příslušných stránek něco zkusí přečíst, vyvolá se pagefault, handler zjistí, že je to mmap a potřebná data načte z filesystému. V tomhle případě ale write() v důsledku povede na odpovídající metodu blokového zařízení /dev/null, která velmi pravděpodobně ten blok, který dostane, vůbec číst nebude (proč taky) a jenom vrátí příslušnou délku, čímž oznámí, že se data úspěšně zapsala. Takže se žádný pagefault nekoná a vůbec se nepozná, že to byl kus mmapovaného souboru a ne obyčejný kus paměti.
Ty linky (je jich několik typů) fungují docela obstojně pokud se použijí správně. Mimochodem NTFS svazek nemusí mít písmeno, dá se připojit jako adresář.
20.2.2020 17:31
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
 V dobách malých ssd jsem měl datový disk připojen jako iscsi ze serveru ve vedlejším pokoji (aby byl klid). To samo funguje celkem OK a překvapivě s tím nebyl roky žádném problém. Potom mě napadlo, že si udělám další iscsi disk pro hry a připojím jej ne jako písmenko, ale jako složku do steamapps. (Před tím jsem měl steam nainstalovanej na velkým iscsi D:, takže viděl místa dost.) A to byla tragédie. Disk C: jsem měl jen 60GB, volného já nevím třeba 15GB (v době WinXP) a iscsi několik TB. A přesně jak popisuješ, každej druhej instalátor měl problém s nedostatkem místa na disku. Takže jsem se pokorně vrátil zpět k písmenkům. Dneska už má steam přímo podporu pro více úložišť na více disků, takže to není takový problém.
21.2.2020 09:13
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
20.2.2020 10:15
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
V dobách malých ssd jsem měl datový disk připojen jako iscsi ze serveru ve vedlejším pokoji (aby byl klid). To samo funguje celkem OK a překvapivě s tím nebyl roky žádném problém. Potom mě napadlo, že si udělám další iscsi disk pro hry a připojím jej ne jako písmenko, ale jako složku do steamapps. (Před tím jsem měl steam nainstalovanej na velkým iscsi D:, takže viděl místa dost.) A to byla tragédie. Disk C: jsem měl jen 60GB, volného já nevím třeba 15GB (v době WinXP) a iscsi několik TB. A přesně jak popisuješ, každej druhej instalátor měl problém s nedostatkem místa na disku. Takže jsem se pokorně vrátil zpět k písmenkům. Dneska už má steam přímo podporu pro více úložišť na více disků, takže to není takový problém.
21.2.2020 09:13
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
20.2.2020 10:15
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
Windows mají i serverové variantyTo samozřejmě vím.
a tam se ten "složitý návrh" může hoditOčekával bych nějaký příklad. Neříkám, že se hodit nemůže, ale co potkávám windowsáky vývojáře, tak u nich mnohem víc platí (i když už to přestává být tak silné jako dřív) "umlátíme to větším železem". A navíc jim hw za pár mega nepřijde nic přehnaného, protože za licence zaplatí mnohem víc. A když k nim přijdu s tím, že to celé by mohlo běžet na hw o čtvrtinovém výkonu a licence 0Kč, tak se na mě dívají, jak kdybych spadl z Marsu. Standard je MSSQL, pokud ne rovnou Oracle, k tomu superrychlé pole a pár mega za licence. Nějak mi nepřijde, že by se někde používal ten sofistikovanější návrh Windows.
Pokusů udělat OOM killer (nebo page reclaim) chytřejším byla spousta a soudě podle občasného nadávání kolegy sedícího ob dva stoly se stále objevují další, které v lepším případě sice zlepší chování v tom specifickém use case, kterým jsou motivovány, ale obvykle za cenu zhoršení jinde.
Pokud se někomu overcommit nelíbí, může ho vypnout. Otázkou ale je, nakolik je to rozumné po tolika letech, kdy se userspace aplikace píší s vědomím, že overcommit tu prostě je, takže není důvod si hned po startu nenamapovat hromadu paměti, co kdyby se někdy hodila. Zkusil jsem se trochu porozhlédnout po systému, u kterého zrovna sedím (destktop, uptime 2.5 dne):
Všechny ty procesy běží celou dobu a kromě firefoxu není pravděpodobné, že by jejich skutečné nároky na fyzickou paměť nějak zásadně narostly.
Pokud je nějaký proces pro systém důležitý (podle okolností to může být třeba sshd nebo X server), lze ho před OOM celkem spolehlivě ochránit nastavením /proc/*/oom_{,score_}adj
 19.2.2020 20:49
Jendа | skóre: 78
| blog: Jenda
| JO70FB
19.2.2020 20:49
Jendа | skóre: 78
| blog: Jenda
| JO70FB
 20.2.2020 09:33
Max | skóre: 73
| blog: Max_Devaine
20.2.2020 21:51
Max | skóre: 73
| blog: Max_Devaine
21.2.2020 09:30
Max | skóre: 73
| blog: Max_Devaine
20.2.2020 09:33
Max | skóre: 73
| blog: Max_Devaine
20.2.2020 21:51
Max | skóre: 73
| blog: Max_Devaine
21.2.2020 09:30
Max | skóre: 73
| blog: Max_Devaine
Hezké srovnání.
V článku i diskuzi mě zaujaly narážky na "debilní programátory", který nedokážou využít volnou paměť. A celkem by mě zajímalo, jak si tedy představujete, že by aplikace měla postupovat, když běžná metoda vyhradit pro cache nějakou "rozumnou", fixně omezenou velikost je zcela špatně? Má se zjistit velikost fyzické paměti a podle ní nastavit ten limit? Nebo velikost aktuálně volné paměti? Stroj sice může mít 32GB, ale co když uživatel bude chtít mít s mojí aplikací spuštěné zároveň dvě další aplikace v elektronu? Nebo obráceně, co když měl tyto dvě elektronové aplikace spuštěné v době mé alokace, ale poté je zavře? Nemluvě o tom, že první "expert", co uvidí, že mu ta aplikace "žere" 30GB paměti jí udělá takovou "reklamu", že i Horst Fuchs (Ví Gréta, kdo je (byl - žije ještě vůbec?) Horst Fuchs?) bude blednout závistí?!
Tak Horst, zdá se, žije, ale "Die WS Teleshop International Handels-GmbH aus Wiener Neudorf ist pleite." (2007). Prej za to může internet.
Byl bych se ochotný hádat, že to v článku bylo (vlevo dole), ale teď to tam nemůžu najít. Takže je to asi jenom v diskuzi. Ale pointa zůstává.
 25.2.2020 15:06
pushkin | skóre: 43
| blog: FluxBlog
25.2.2020 15:06
pushkin | skóre: 43
| blog: FluxBlog
ISSN 1214-1267, (c) 1999-2007 Stickfish s.r.o.