 | poslední úprava: 24.10.2017 00:17
| poslední úprava: 24.10.2017 00:17
Portál AbcLinuxu, 22. června 2026 09:06
27.9.2017 21:20
| Přečteno: 3801×
| Linuxové drobty
|
| poslední úprava: 24.10.2017 00:17
Nějakou dobu jsem se věnoval naladění ntp na co nejpřesnější doregulaci času. A někdy to tedy moc nejde. Takže bych si sem zanesl pár poznámek. A možná budou i někomu k užitku.
NTP protokol je jeden z nejstarších protokolů na internetu. Funkční je od roku 1985 a ne některých postupech je to znát. Funguje tak, že system pošle UDP paket na synchronizační server, dostane odpověď, kde je napsán čas příjmu výzvy a čas odeslání odpovědi z toho serveru, má zaznamenaný čas vyslání a čas příjmu a z těchto časů spočte jednak zpoždění signálu a jednak svůj posun času.
Tohle provádí na několik nastavených serverů. Z nich pomocí "intersection algorithm" volí ty, které jsou mimo přesný čas a s ostatními pracuje. Zatím algoritmus dobrý.
Ted pár negativních postřehů. Algoritmus finálně vždy zvolí server, ke kterému se blíží (sys_peer). Pokud v nějaké situaci je několik kandidátních serverů a časově od sebe poněkud vzdálených, třeba díky zatížení linky, tak ntp může přepínat mezi servery a čas plave. Není zde žádný algoritmus, kdy klient by se blížil k nejakému váženému průměru času serverů, které byly kvalifikovány jako s OK časem.
Vztah k jednomu serveru: Klient posílá měřící pakety za interval, který považuje na základě vyhodnoceného posunu času za optimální, což je nejdříve 64 vteřin, později se interval prodlužuje až na 1024 vteřin a tam zůstane pokud není nějaká katastrofa. Z každého měření si zaznamenává zpoždění k serveru a vypočítaný offset. Pamatuje si posledních 8 měření a opět (podobně jako v případě serveru) se váže k jedinému z nich a od něj odvozuje posun častu vůči serveru. Preferuje samozřejmě měření, které má menší delay a je novější. A když je nejnovější s větším delay tak samozřejmě záleží o jak moc větší delat. Nicméně to co mne nedávno překvapilo na lokální siti, bylo jak algoritmus nebere v potaz offset. Ze stavu plně časově synchronizovaných strojů se mi při přenosu cca 100G rsyncem po lokální síti rozhodily stroje asi o 20ms. NTP mezitím začal pracovat na synchronizaci. To co bylo ale zajímavé, že v několika případech volil jako hlavní měřící paket ten, co tomu neodpovídal. Na vnitřní sítí mám delay mezi systémy pod 1ms konkrétně první starší měření 0.28 a novější 0.41ms přičemž u prvního měření bylo offset 24,49 a u druhého (pozdějšího) 16,6 (už doladění času probíhalo), přesto perzistentně klient trval na tom, že rozdíl času k tomuto serveru je podle toho prvního (rychlejšího ale s větším offsetem) měření do té doby než proběhlo ještě následující měření. Přičemž je zřejmé, že s jakýmkoliv delay pod 1ms to druhé pozdější měření je přesnější.
Tolik jen pár pozorování. Určitě s NTP nebudu nic dělat, ale když by vám trochu čas plaval, tak to může být i tímto.
Ještě přidám pár grafů:
Situace je taková. Domácí server je i zálohovací server a jednou za 2 dny prochází připojené notebooky a desktopy a provádí úplné a inkrementální zálohy podle zadanách časů. To co probíhalo a je zachyceno na grafech byla.
Zátěž které měl server je následující.
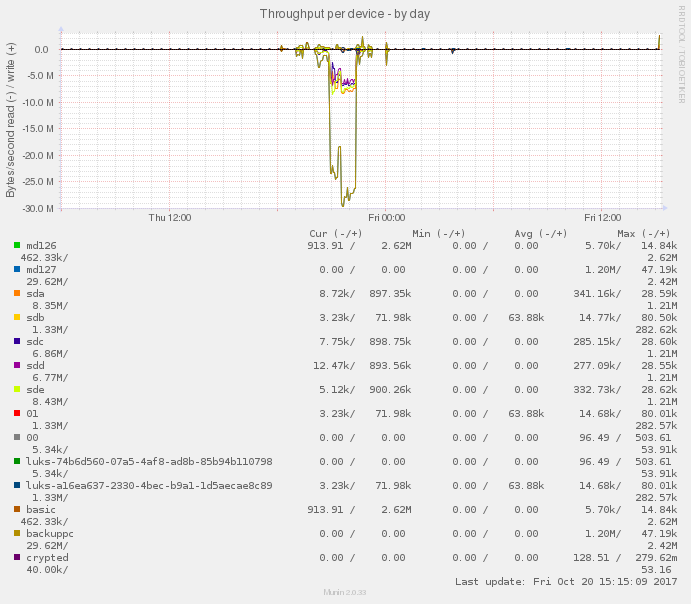
Průtok dat disky
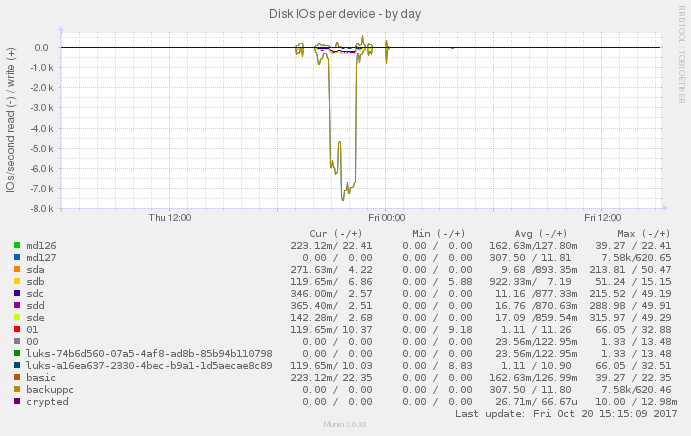
IOPS
Zatížení disků
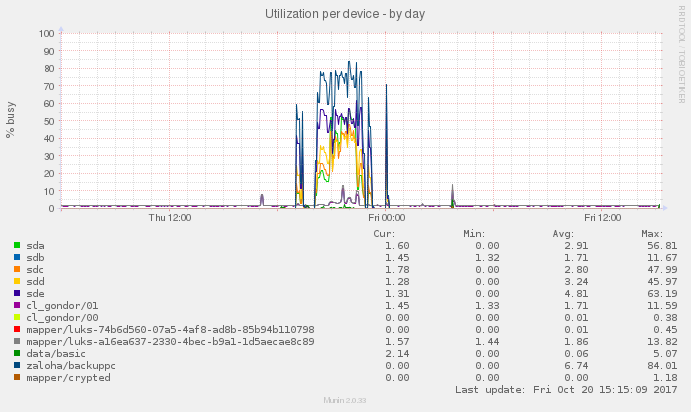
Zatížení je primárně na zařízení backuppc, což je RAID 10 nad disky a,c,,d,e.
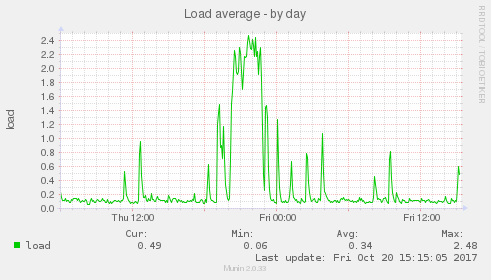
Toto zatížení se projeví jako load:
interupty
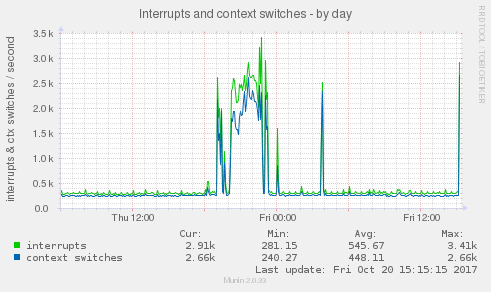
a v zatížení paměti
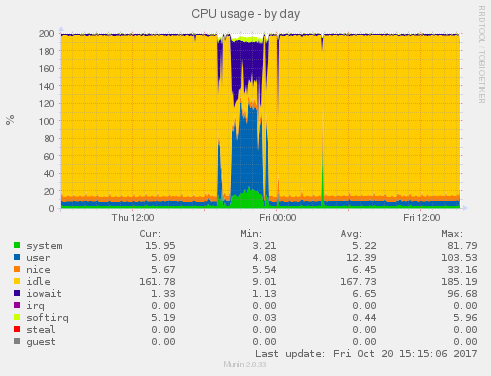
díky této zátěži se začnou i posouvat presnosti hodin procesoru systému. Celkový obrázek je:
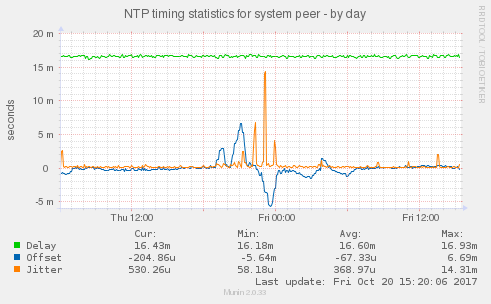
Jak máme porozumět tomu kmitání ofsetu nahoru a dolů.
Přesnější pohled na odchylku dává:
Tedy v 19:00 hodiny začaly odjíždět do 19:20 a pak se srovnávaly do 20:00. ve 20:00 začaly odjíždět znovu až do 21:00 kde se začaly rovnat, přibližně od 21:40 do 22:40 se držely jakž takž a pak ujely do záporné odchylky s maximem 23:30. Současně pokud se podíváme na chybu, tedy hodnotu kolik si ntpd myslí, že jsou správné hodiny daleko.
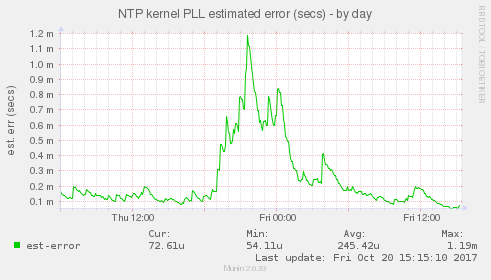
je vidět jak chyba stoupá od 19:00 do maxima v 21:30 a pak s prestávkami padá. v nezatíženém systému je odhadovaná chyba hluboce pod milisekundu.
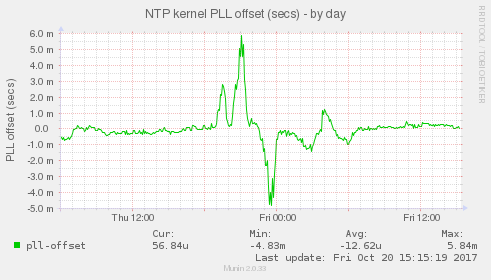
Jak si tohle vysvětlovat? Každé hodiny jsou špatné a ntpd je kompenzuje. Standardně na mém nezatíženém systému je to kolem 20 ppm. Při zatíženém systému (mém systému) se hodiny zpomalí a ntpd to musí vykompenzovat. Kompenzuje to upravami jaderného parametru ppm, tedy kolik jednotek za milion tiků musí přidat nebo ubrat. viz následující graf.
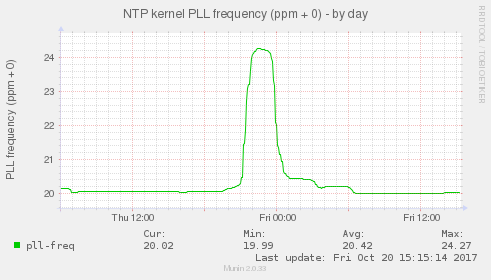
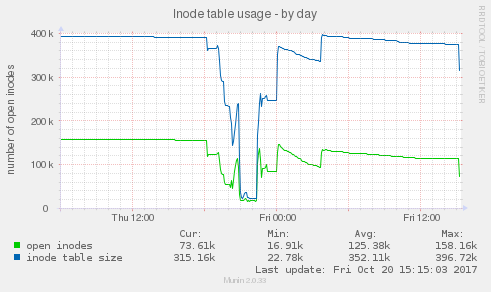
A teď trochu vysvětlování a souvislostí. První záloha trochu pohnula časem ale nic moc. chyba vybehla a ntpd na to zareagoval mírnou vlnkou ppm v čase cca 19:30 která dokázala odchylku trochu stáhnout i když chyba se zatím moc nesnížila. Velká zátěž pohnula s hodinami více a ntpd reagoval celkem pomalu. až v 21 začal masívně navyšovat ppm, aby chybu stáhnul. Nicméně, jak vidět se mu to podařilo brzy cca 21:30 už byly hodiny celkem přesné Hodnota ppm 24 a něco se asi dá chápat jako správná kompenzace pro můj zatížený systém, nicméně zátěž skončí v 22:40 s malou ještě zátěží po 23. A vysoká hodnota ppm zůstává a hodiny zbytečně zrychlí, odchylka letí do záporna (čas serveru proti kterému se synchronizujeme je pomalejší) a ntpd trvá až do 0:30 než výrazně ppm vrátí nebo přesněji až do 6 a něco než najde znovu správnou hodnotu ppm pro nezatížený systém. což je důvod kmitání odchylky kolem přesného času. Jen poznámka - zajímavost - nesouvisející s časem. když jedou mi ty zálohy, tak rapidně se změní práce s inody.











Tiskni
Sdílej:
![]()
![]()
![]()
![]()
![]()
![]()
 29.9.2017 00:00
Bedňa | skóre: 34
| blog: Žumpa
| Horňany
29.9.2017 00:00
Bedňa | skóre: 34
| blog: Žumpa
| Horňany
 29.9.2017 08:17
Marián Kyral | skóre: 29
| blog: Sem_Tam
| Frýdek-Místek
29.9.2017 08:17
Marián Kyral | skóre: 29
| blog: Sem_Tam
| Frýdek-Místek

…oédeslání… …nění… …měžení… …perzisteně… …že z jakýmkoliv delay…Jinak já jsem rád, že ntp alespoň nějak funguje. Bohužel v některých případech ani ntp nepomůže. Třeba když zapnu počítač po delší době a mezitím došlo k posunu času na letní/zimní. Ntp v tomto případě nezafunguje - že prý to je moc velký posun - a musím to řešit ručně. Je to sice jen dvakrát ročně, ale uvítal bych, pokud bych ani tohle řešit nemusel.
30.9.2017 18:50
Marián Kyral | skóre: 29
| blog: Sem_Tam
| Frýdek-Místek
 25.10.2017 09:36
Dalibor Smolík | skóre: 54
| blog: Postrehy_ze_zivota
| 50°5'31.93"N,14°19'35.51"E
25.10.2017 09:36
Dalibor Smolík | skóre: 54
| blog: Postrehy_ze_zivota
| 50°5'31.93"N,14°19'35.51"E
hwclock -systohc, které zapíše systémový čas do hw hodin a pak při dalším startu to není nijak moc daleko.
V mnoha současných distribucích je jako základ pro NTP použitá varianta daemona chrony. Ten používá následující konfigurační soubor /etc/chrony/chrony.conf. V něm je možné povolit, že je na začátku přípustné provést korekci mimo běžné limity.
makestep 1 -1
První hodnota říká, při jak velkém rozdílu již nedojíždět k správnému času plynule, u nás, jakmile je rozdíl větší než 1 sekunda. Druhý parametr pak omezuje do kolika výměn po startu je ještě přechod na srovnání času skokem přípustný. U studentských stanic v lokální síti to moc neřešíme a záporná hodnota (-1) pak specifikuje, že kdykoliv dojde k velkému odstupu od serveru, tak se natvrdo stanice sesynchronizují. Pro server nebo prostředí s certifikáty a bezpečností to asi není ideální, ale i když bootujeme naše prostředí v laboratořích, kde jiné katedry používají Windows, tak je od problémů s časem pokoj.
Volby rtconutc a rtcsync máme zakomentované, aby nebyly při nutnosti soužití s jinými systémy potíže a GNU/Linux pak na stanicích RTC ignoruje.
Více ke zkušenostem může říct správce naší infrastruktury - Aleš Kapica.
Není zde žádný algoritmus, kdy klient by se blížil k nejakému váženému průměru času serverů, které byly kvalifikovány jako s OK časem.Takový algoritmus v
ntpd je, dokonce je i ve specifikaci NTP jako "combining algorithm". Offsety serverů, které ve výpisu ntpq -pn mají značku + jsou zkombinovány s tím co má *. Jako váha se bere "root distance".
Appendix F describes an optional algorithm to improve accuracy by combining the time offsets of a number of clocks.Takže díky "optional" netuším, jak to je u konkrétních daemonů. U standardního
ntpd jsem nenašel žádnou volbu, kterou bych tento volitelný algoritmus zapnul nebo vypnul. A osobní pocit z pozorování chování hodin bylo: "Přibližuji se k sys-peer serveru (s hvězdičkou v ntpq -p)." Ne že se přibližuje k nějakému váženému průměru.
tos minclock a tos maxclock.
Když si vypíšete asociace přes ntpq -c as a pak proměnné všech serverů přes ntpq -c 'rv $ID', jakou root dispersion a delay má ten server s hvězdičkou oproti těm s pluskem? Možná je mnohem blíž a tak má jeho offset mnohem větší váhu.
ISSN 1214-1267, (c) 1999-2007 Stickfish s.r.o.