 | poslední úprava: 3.7.2017 15:42
| poslední úprava: 3.7.2017 15:42
Portál AbcLinuxu, 27. června 2026 07:07
16.2.2013 16:05
| Přečteno: 4149×
| Názory
|
| poslední úprava: 3.7.2017 15:42
Po letech marného hledání jsem konečně nalezl editor, který mi stoprocentně vyhovuje. Jedná se o komerční editor Sublime text 2.
Ohledně Sublime toho bylo na webu napsáno již docela dost, přesto si nemohu odpustit tento blogpost, jelikož se skutečně jedná o to nejlepší řešení editace, na které jsem za dlouhá léta narazil.
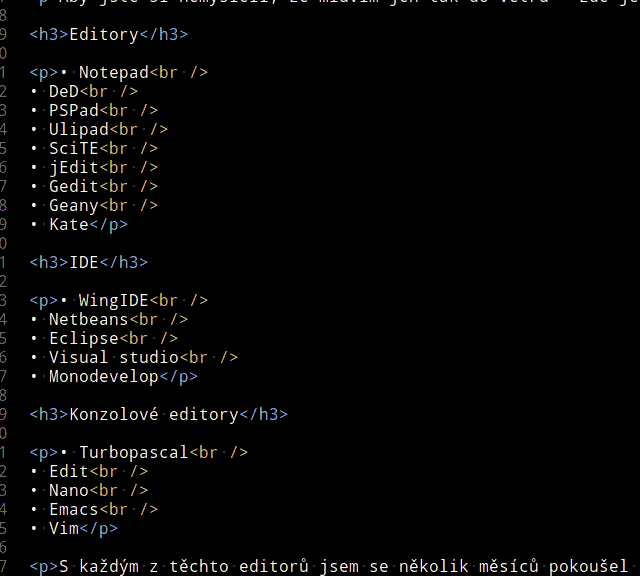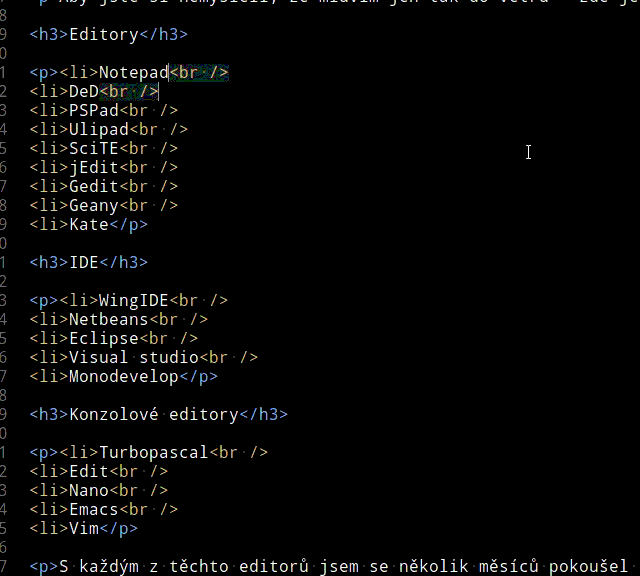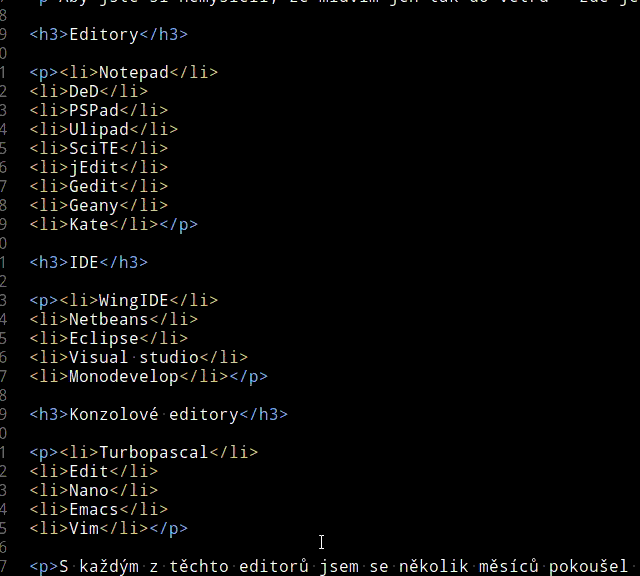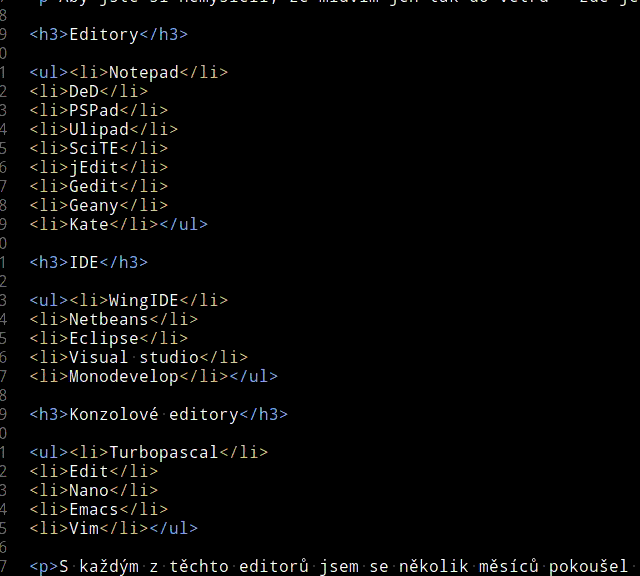
Aby jste si nemysleli, že mluvím jen tak do větru - zde je seznam editačních programů, které jsem během osmi let používal déle než měsíc:
S každým z těchto editorů jsem se několik měsíců pokoušel sžít, abych ho poté s radostí vyměnil za další z nich. Jak jste si možná všimli, vyzkoušel jsem i různá IDE, jenž mi ovšem také nikdy plně nevyhovovala, hlavně co se pomalosti reakcí týče.
Na rozdíl od ostatních editorů jsem na Sublime nenarazil náhodně na internetu, ale bylo mi doporučeno na IRC, i když jsem se neptal. Někdo prostě přišel a řekl: "Sublime je fakt nejlepší editor, který jsem kdy používal, zkus ho". Tak jsem ho zkusil a musel jsem mu dát za pravdu. U žádného jiného editoru jsem nikdy neměl ten pocit "tak jsem to našel, konečně jsem dorazil domu a nic jiného nehledám".
Jedna z věcí, které si na Sublime nejvíce vážím je intuitivnost editace. Vás se to možná týkat nemusí, ale co se mě týče, je vše přesně tam, kde bych to hledal, klávesové zkratky fungují téměř přesně tak jak bych čekal a v menu se položky nacházejí tam, kam bych je zařadil i já. To je velmi důležitý prvek, který jistě pochopí všichni, kdo se kdy zkoušeli skamarádit s VIMem*.
Vedle pravého posuvníku se ukazuje náhledovátko, které vám zobrazuje strukturu dokumentu a umožňuje se intuitivně pohybovat skrze dokument. Je to nejenom pěkná věcička, kterou vám budou ostatní závidět, ale i užitečný nástroj, protože skutečně usnadňuje pohyb v dokumentu - buď můžete kliknout, což způsobí skok na zadaný kus textu, nebo kliknout a táhnout, čímž plynule scrollujete skrz dokument.
Interní příkazový řádek je další věc, kterou můžou ostatní editory Sublime závidět. Díky němu můžete editor po stisknutí CTRL+SHIFT+P ovládat a konfigurovat ve stylu VIMu, až na to, že nepoužíváte kryptické klávesové zkratky ala :wq, ale místo toho se fuzzy vyhledáváním pohybujete v relativně přehledných seznamech položek.
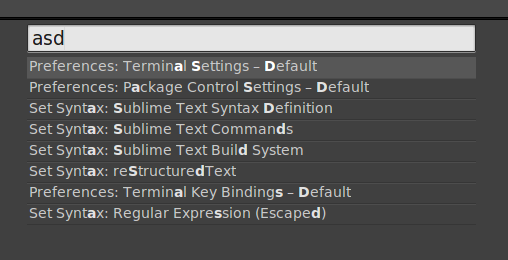
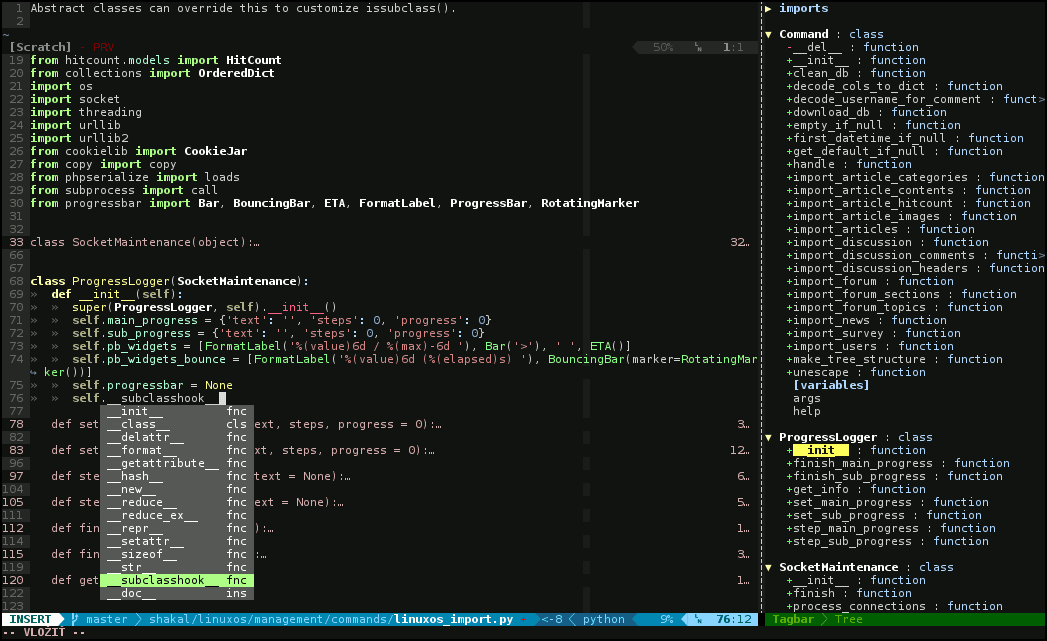
Výše zmíněné fuzzy vyhledávání je skvělá věc, pod kterou si můžete představit nerozlišování velikosti písmen a ignoraci znaků, které se nacházejí mezi těmi které chcete hledat. Jak to funguje v praxi myslím dobře dokumentuje následující obrázek:
Poprvé v životě jsem také v Sublime použil makra a musím uznat, že nyní nechápu, proč jsem se jim tak dlouho vyhýbal.
Jejich použití je (nejen v Sublime!) triviální; Stisknete klávesovou zkratku pro začátek nahrávání, provedete několik editačních kroků a poté můžete zaznamenané makro stiskem další klávesové zkratky přehrávat. To je velmi vhodné na nudnou práci, kde potřebujete stereotypně upravit větší počet záznamů, případně pokud potřebujete definovat složitější chování editoru, na které se vám ale nechce psát plugin.
Samozřejmostí je ukládání maker a případné mapování na vlastní klávesové zkratky.
Sublime vám pomocí klávesových zkratek, či kliknutím s CTRL umožňuje vložit kurzor na vícero míst najednou, takže pak píšete do několika míst v dokumentu zároveň.
Na první pohled možná blbost, pro mě je to však velmi pěkná vlastnost, na které mě nejvíc ze všeho těší, že jí díky její jednoduchosti implementace skutečně používám.
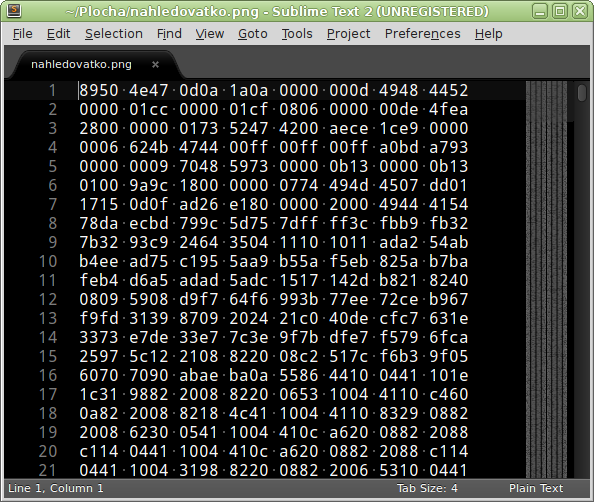
Pokud v Sublime otevřete binární soubor, umožní vám ho editovat v jednoduchém hexeditoru. Není to nic převratného, ale patří to k věcem, které potěší.
A slovem plná myslím skutečně plná - zatím jsem nenarazil na věc, která by se v Sublime nedala konfigurovat. Toto se skutečně nedá srovnávat s menu konfigurací u ostatních editorů, kde si můžete nastavit pár základních věcí. V souboru s default konfigurací se nachází 326 řádek, ve kterých je obsažena naprostá většina toho, co kdo může chtít nastavit.
Před nějakou dobou jsem nezávazně uvažoval o napsání editoru, který by toho sám o sobě moc neumožňoval, jen poskytoval API a možnost na něj věšet vlastní callbacky a tím si ho plně přizpůsobit.
Sublime k této myšlence nemá moc daleko, protože umožňuje používat spousty pluginů. K dokonalosti to dotáhl plugin Package controll, který vám umožňuje spravovat nainstalované pluginy ve stylu package manageru z linux distribucí - na speciální příkazové řádce si ze seznamu vybíráte co chcete nainstalovat, či odinstalovat.
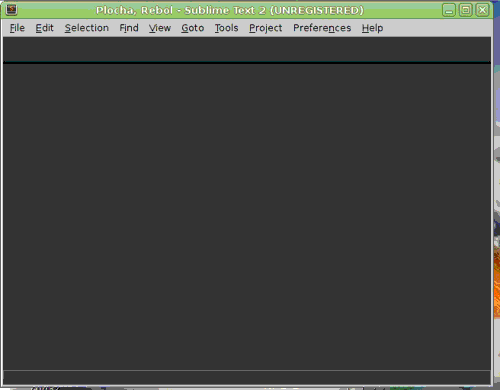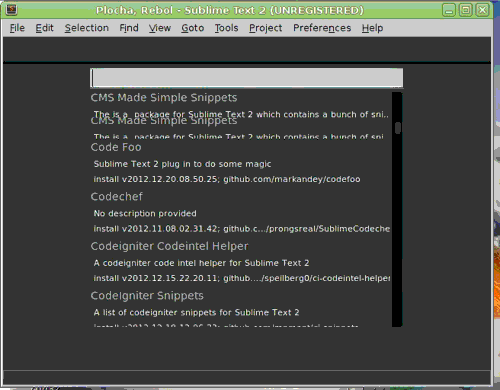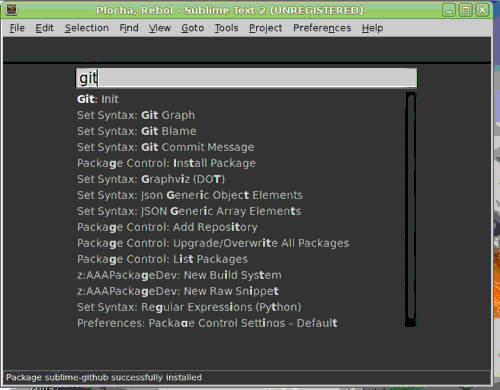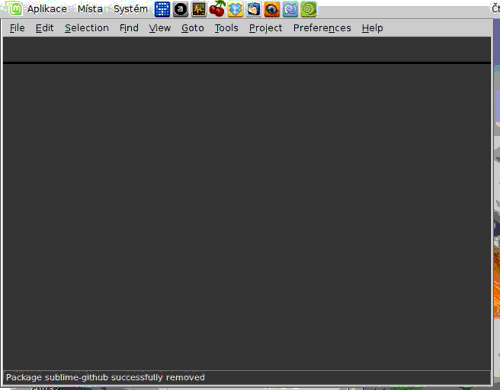
Pluginů existují desítky, ne-li stovky a každou chvíli vznikají nové, což je další rozdíl oproti většině ostatních editorů, kde pluginů najdete pár desítek a jejich instalace bývá často pěkně otravná. V Sublime se jedná o záležitost stisknutí CTRL+SHIFT+P, napsání "inst", který díky fuzzy vyhledávání označí package manager a pak si již šipkami vybíráte ze seznamu pluginů dostupných v repozitáři, které budou po stisknutí ENTERu nainstalovány.
Jediná "slabina" Sublime je jeho licence - jedná se o komerční produkt, který je ovšem možné v rámci časově neomezeného testování používat jak dlouho chcete**:
Sublime Text may be downloaded and evaluated for free, however a license must be purchased for continued use.
Editor vás během evaluace při každém ~20 uložení souboru upozorňuje, že máte zvážit zakoupení licence.
Cena lincence je $59 a rozhodně mám v plánu si jí koupit****, jakmile dokončím proces evaluace ;)
Sublime text 2 je super, doporučuji.
* Ne že bych měl něco proti VIMu, je to jediný konzolový editor, který po všech těch letech stále používám.
** Tohle je dle mého názoru přístup jak má být - tvůrce umožní používat SW prakticky bezplatně***, a pokud vám vyhovuje a cítíte se na to, zaplatíte za licenci.
*** Ano, uvědomuji si, že za něj máte platit jakmile si ho vyzkoušíte, ale prakticky vám nic nebrání v tom ho používat jak dlouho chcete.
**** Stalo se v březnu 2014
Tiskni
Sdílej:
![]()
![]()
![]()
![]()
![]()
![]()
 16.2.2013 21:22
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
16.2.2013 22:16
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
16.2.2013 21:22
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
16.2.2013 22:16
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
 16.2.2013 16:17
Člověk z Horní Dolní
| blog: blbeczhornidolni
16.2.2013 17:59
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
16.2.2013 16:17
Člověk z Horní Dolní
| blog: blbeczhornidolni
16.2.2013 17:59
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
 16.2.2013 20:13
kozzi | skóre: 55
| blog: vse_o_vsem
| Pacman (Bratrušov)
16.2.2013 20:13
kozzi | skóre: 55
| blog: vse_o_vsem
| Pacman (Bratrušov)
Tak Java oriented sice je ale to se tyka hlavne te verze zadarmo, ta placena ti umoznuje perfektni praci v ruby, PHP, python a mnohem vice. Popravde ja jsme na tom byl podobne jako ty, a taky si po zkonceni zkusebni licence Intellij IDEA koupim jeji plnou verzi :).
Dokonce premyslim ze napisi podobnou odu na Intellij IDEA
17.2.2013 11:53
kozzi | skóre: 55
| blog: vse_o_vsem
| Pacman (Bratrušov)
Jo, to ja si te akce vsiml den pote, taky jsem myslel ze me trefi slak :D
 16.2.2013 21:21
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
16.2.2013 18:42
Člověk z Horní Dolní
| blog: blbeczhornidolni
16.2.2013 21:19
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
16.2.2013 21:18
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
16.2.2013 21:21
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
16.2.2013 18:42
Člověk z Horní Dolní
| blog: blbeczhornidolni
16.2.2013 21:19
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
16.2.2013 21:18
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
 16.2.2013 21:14
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
16.2.2013 21:39
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
16.2.2013 21:14
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
16.2.2013 21:39
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Pokiaľ však autora živí nejaká americká trojpísmenková organizácia...Aha. Co ti přesně zajistí, že podobná organizace neživí někoho z těch, kteří ti poskytují ostatní software? Ty si skutečně čteš veškeré zdrojáky toho co používáš? Pokud ano, umíš v nich najít všechny 0day chyby, které by třípísmenková organizace viděla imho mnohem radši než nesmyslné trojany, které je dnes triviální detekovat?
16.2.2013 22:55
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
A doufam ze chapes ze uvaha: "na 100% nejde nic zabezpecit => nema cenu se snazit o bezpecnost" je chybna...Já se o security zajímám už docela dost dlouho, takže tohle mi nemusíš vysvětlovat :)
Jsou k tomu zdrojaky? Jestli ne tak se nabizi spojitost s jednim slavnym vojenskym manevremJasně, každej ví, že alkajdovci používají na nejcitlivjší dokumnety programátorské editory. Proto si člověk musí dávat majzla, jinak mu američani budou číst jeho seznam pornofilmů, že. ;P
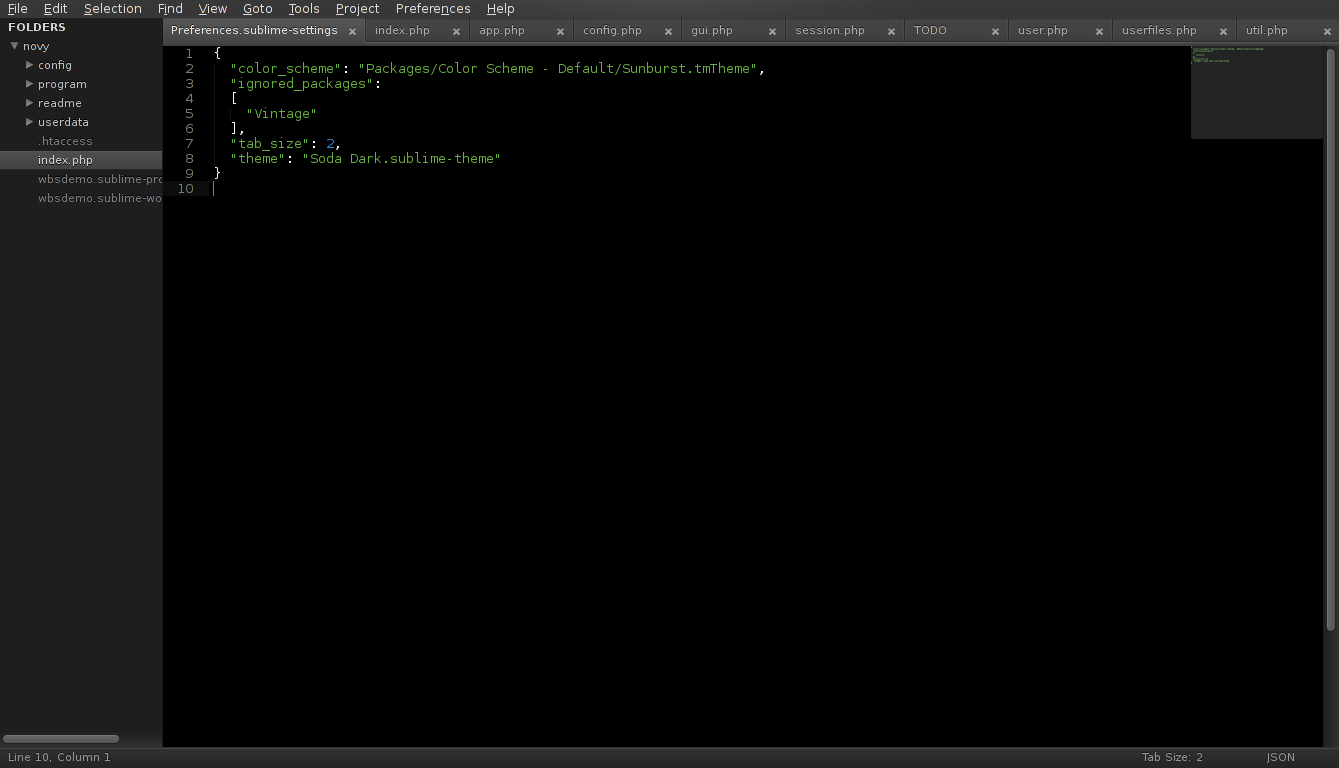
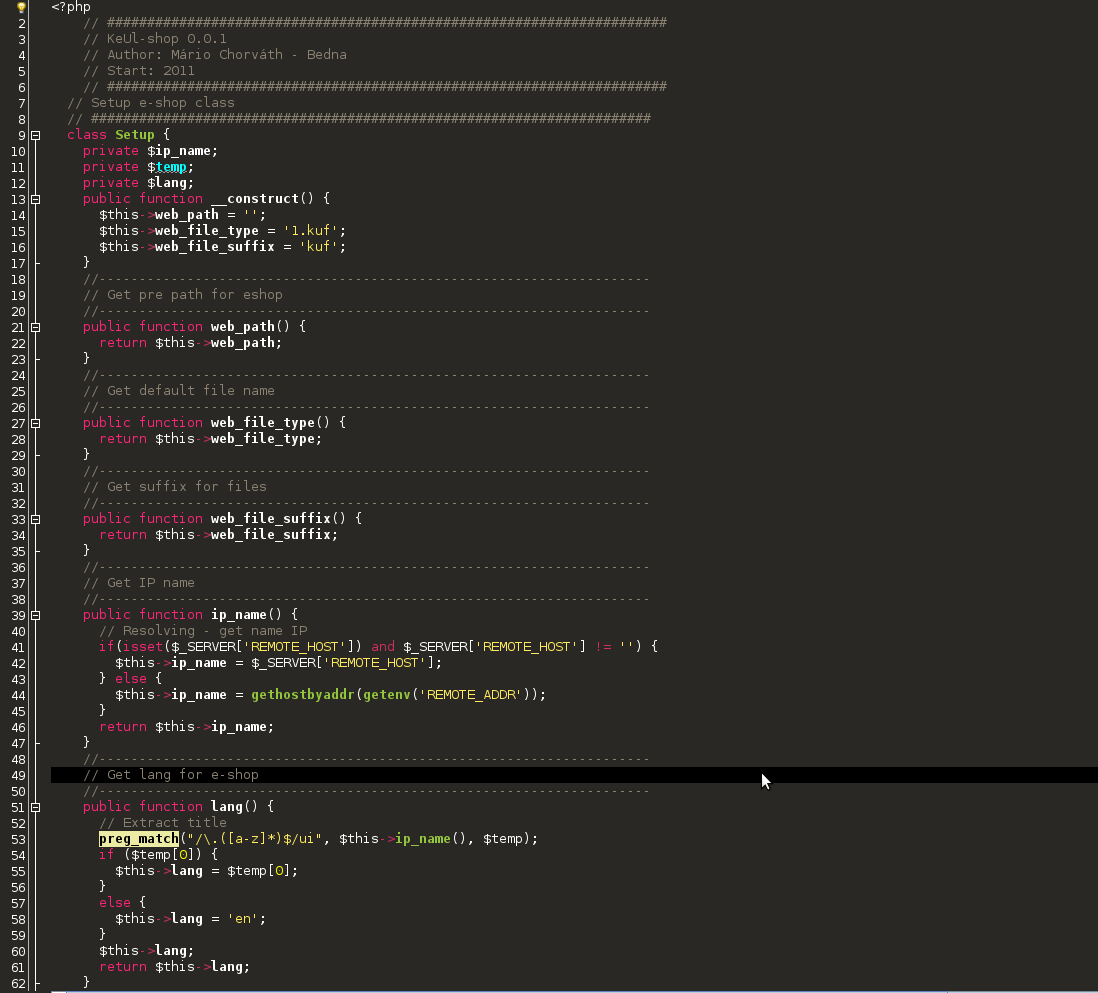
Přišel jsem na něj úplnou náhodou z fotky na wikipedii v článku Software bug  Pro milovníky tmavých témat & vzhledů a světlého textu na tmavém pozadí doporučuju dev verzi Sublime spolu s tématem "Soda Dark", v něm je pořešen levý sloupec s prohlížečem složek, který jinak nejde nastylovat na tmavo. Viz screenshot.
16.2.2013 21:16
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Jinak teď jsem zjistil, že podpora pro TODO/FIXME/BUG/... ve zdrojácích není nic moc :-/
16.2.2013 20:17
kozzi | skóre: 55
| blog: vse_o_vsem
| Pacman (Bratrušov)
Pro milovníky tmavých témat & vzhledů a světlého textu na tmavém pozadí doporučuju dev verzi Sublime spolu s tématem "Soda Dark", v něm je pořešen levý sloupec s prohlížečem složek, který jinak nejde nastylovat na tmavo. Viz screenshot.
16.2.2013 21:16
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Jinak teď jsem zjistil, že podpora pro TODO/FIXME/BUG/... ve zdrojácích není nic moc :-/
16.2.2013 20:17
kozzi | skóre: 55
| blog: vse_o_vsem
| Pacman (Bratrušov)
Zkousel jsem a byl jsem ohromen. Je to opravdu perfektni nastroj. Bohuzel jsem nenasel pro nej vyuziti. Pro obycejnou obcasnou editaci nejakeho souboru staci pouzit cokoliv (vim, geany) a co se tyka nejakeho programovani tak tam mi prijde vhodnejsi pouzit IDE
16.2.2013 21:15
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
16.2.2013 21:58
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
16.2.2013 21:24
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
btw kdyz uz jsme u toho, pochopil jsem spravne, ze clovek nemuze mit ve splitu otevrenej ten samej soubor?To je momentální chyba dvojkové verze, ve trojce to bylo upraveno. Jinak na to samozřejmě jsou doplňky, jejichž instalace je záležitostí 20 vteřin :)
17.2.2013 01:33
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
A co ti, kteří se zkusili skamarádit s Vimem a uspěli?Jak jsem poznamenal v samotném blogpostu, mezi tyto lidi se řadím i já. Problém je, že VIM nikdy nebyl úplně přirozený způsob editace, což doufám všichni uznávají. Neříkám tu nic o efektivitě, ta je pokud se ho člověk naučí nejspíš jedna z největších, ale osobně mě nebaví se celý život učit pracovat s editačním nástrojem. Přesto po něm sáhnu, pokud potřebuji něco nastavit přes SSH a celkově k němu mám pozitivní postoj, ale sublime je pro mě prostě lepší.
25.2.2013 13:28
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Jediný vyhovující editor nad vimem je pro mě editor, který si sám naprogramuji podle svých potřeb. Po 25 letech hledání editorů jsem zjistil tuto pravdu.Nad tím jsem uvažoval, ale co se tohoto týče, jsem zbabělec, vždy když mi dojde, kolik práce by to chtělo, tak mě chuť přejde.
 17.2.2013 08:52
mirec | skóre: 32
| blog: mirecove_dristy
| Poprad
17.2.2013 08:52
mirec | skóre: 32
| blog: mirecove_dristy
| Poprad
Co je na šipkách neintuitivního?Třeba to, že na některých systémech ve VI(Mu) nepohybují kurzorem, ale vypisují nesmyslné paznaky. Totéž platí o několik dalších obvyklých kláves používaných při editaci textu. Muset se přepínat mezi dvěma režimy podle toho, jestli chceš písmena psát nebo je mazat, taky není zrovna intuitivní.
Třeba to, že na některých systémech ve VI(Mu) nepohybují kurzorem, ale vypisují nesmyslné paznaky.
Obávám se, že to jsou především systémy prehistorické nebo blbě nastavené.
Muset se přepínat mezi dvěma režimy podle toho, jestli chceš písmena psát nebo je mazat, taky není zrovna intuitivní.
Kde je řeč o intuitivitě? Neintuitivní je prakticky všechno nad rámec běžného klikacího UI a zkratek Ctrl+něco, ale i to je intuitivní jen proto, že si na to lidi zvykli, jelikož je to všude. Jenže to klikací UI a Ctrl+něco jsou pro změnu hraniční, co se nějaké ergonomie/efektivity týče (stačí se zeptat Google na "RSI Emacs" ohledně zkratek a zkusit si celoživotně furt sahat na myš (to zní jako perverzní prasárna) ohledně GUI).
Obávám se, že to jsou především systémy prehistorické nebo blbě nastavené.Ano, třeba jeden taková jedna archiválie: UNIX, který má podporu až do roku 2014 a zatím poslední aktualizace na něm byla instalována vloni. Tak primitivní editor jako je Joe na něm funguje bezchybně. Zatímco ve vi/vim nefunguje ani taková základní věc, jako kurzorové šipky. Případně si stěžuje:
Terminal too widekdyž to člověk má v okně na celou obrazovku při (dnes) obvyklém rozlišení. V GNU/Linuxu jsem jsem s VIMem na tyto problémy nenarazil, nicméně ani tak to není žádné velké potěšení s tím editorem pracovat. To už mě víc baví ten Emacs.
U obyčejných editorů umíš základ hned, ale pak nemáš kam růst.Ale máš. Např. takový jEdit zvládne obsluhovat i BFU, může s ním klidně pracovat stejně jako s „notepadem“. Časem se naučí klávesové zkratky, nastaví si vlastní, doinstaluje pluginy, začne si psát makra, začne si psát vlastní pluginy…
kdyby tam byl místo toho třeba Python, to by mě asi jeblo
Nejaký rozumný dôvod, alebo len kopnutie si do jazyka, ktorý nepoznám? Už nie je stredovek a nástroje, ktoré vedia pri písaní zobrazovať nápovedu (dokonca vrátane typov argumentov a návratových hodnôt v prípade, že sa to niekomu chcelo dokumentovať) dávno existujú.
Jenže -1 se zde vyhodnotí jako true a test projde. V jiném jazyku by tě kompilátor seřval a chybu bys opravil.Tím "jiným jazykem" nejspíš myslíš Javu
V C a odvozených jazycích (C++, D, Obj-C) je tohle úplně stejné. Tohle je kontroverzní otázka, každý na to má svůj názor... Já osobně tohle chování považuju za feature, ne bug. Naopak mě štve nutnost explicitně přetypovávat čísla na bool (nebo používat != 0 apod.) v jazycích jako Java, C# a dalších...
Špatně:
$ cat Test.java; javac Test.java && echo kompilace ok
public class Test {
public static void main(String[] args) {
String s = "ahoj";
if (s.indexOf("xxx")) {
System.out.println("obsahuje");
} else {
System.out.println("neobsahuje");
}
}
}
Test.java:4: incompatible types
found : int
required: boolean
if (s.indexOf("xxx")) {
^
1 error
(Python je ještě zákeřňější v tom, že find() si člověk spíš může splést nalezeno/nenalezeno a nacpat do IFu, zatímco u indexOf() tě to spíš ťukne, že to bude číslo a tudíž že do IFu musíš dát ještě rovnost/nerovnost s jiným číslem)
Správně:
$ cat Test.java; javac Test.java && echo kompilace ok
public class Test {
public static void main(String[] args) {
String s = "ahoj";
if (s.indexOf("xxx") > -1) {
System.out.println("obsahuje");
} else {
System.out.println("neobsahuje");
}
}
}
kompilace ok
Podle mých zkušeností se na odhalování podobných chyb vyplýtvá mnohem víc času než se ušetřilo tím, že někdo nemusel napsat > -1.
Zneužívat číselné typy pro booleovské hodnoty je prasárna. Dnes se často doporučuje jít ještě dál: používat ve svých rozhraních co nejméně map, polí, seznamů, čísel, booleanů a dalších obecných typů a používat místno nich vlastní typy a enumy. Např. pro pohlaví osoby je lepší použít enum MUŽ/ŽENA místo nicneříkajícího booleanu, u kterého si někde bokem poznamenáme, že true je muž a false žena, nebo naopak.
Nejsou to universální rady, najdou se výjimky, kdy je potřeba optimalizovat – dost záleží na tom, jestli je pro tebe dražší výpočetní výkon nebo lidská práce. Většinou je dražší práce a navíc vyžaduješ bezchybnost/spolehlivost – pak použiješ spíš enum nebo vlastní typ místo primitiv. A pokud někdo píše v Pythonu, tak nepředpokládám, že ho nějak trápí výkon HW a má ho dostatek.
Podle mých zkušeností se na odhalování podobných chyb vyplýtvá mnohem víc času než se ušetřilo tím, že někdo nemusel napsat > -1.Moje zkušenost je, že tahle chyba nastala tím, že si někdo nepřečetl dokumentaci. Já nevim, proč bych já měl doplácet na to, že někteří lidé jsou líní dokumentaci číst. Krom toho, ono to je celkom jasné už z toho názvu "find" i bez dokumentace - to asi nebude funkce, která ověřuje eixstenci substringu, ale zjevně funkce, která ten substring hledá a vrací pozici. To úplně vybízí k tomu, že se člověk zamyslí a řekne si něco jako "Aha, jakpak se asi tahle funkce chová, když string není nalezen? Vratí nějakou specielní hodnotu? Vyhodí výjimku? Lepší kouknout do dokumentace." Sorry, ale pokud někdo tuhle úvahu neprovede, míst toho napíše
if(find(string, substring)) {...} a očekává, že to bude ověřovat existenci substringu, je prostě vůl.
Zneužívat číselné typy pro booleovské hodnoty je prasárna.A to je dogma kteréže církve?
Ať už kterékoli, já členem nebudu...
Dnes se často doporučuje jít ještě dál: používat ve svých rozhraních co nejméně map, polí, seznamů, čísel, booleanů a dalších obecných typů a používat místno nich vlastní typy a enumy. Např. pro pohlaví osoby je lepší použít enum MUŽ/ŽENA místo nicneříkajícího booleanu, u kterého si někde bokem poznamenáme, že true je muž a false žena, nebo naopak.S tím souhlasim. To je ovšem úplně jiný problém. Všimni si, že i takové C++ ve verzi C++11 už obsahuje strongly typed enums. Zároveň ovšem měli autoři dost rozumu na to, aby nevyřadili slabě typované (ie. integerové) enumy, protože někdy se to prostě hodí; typicky pro bit flags. Zatímco v jiných jazycích (*ehm*, Java, *zkřípění zubů*) enumy pro bit flags použít nemůžeš a musíš jako magor definovat konstanty.
Moje zkušenost je, že tahle chyba nastala tím, že si někdo nepřečetl dokumentaci. Já nevim, proč bych já měl doplácet na to, že někteří lidé jsou líní dokumentaci číst.No, pokud budeš číst dokumentaci a budeš dostatečně pečlivý, můžeš klidně programovat komplexní informační systémy v BrainFucku nebo podobném jazyce.
je prostě vůl.Já mu to vyřídím
Nicméně nemusí to být nutně vůl – stačí chvilka nepozornosti, běžná lidská chyba, omyl – a pokud jde takovým omylům bezpracně předejít, tím, že je kontroluje technika, jsem pro. Lidská práce je drahá – mu můžeš věnovat odhalování chyb v byznys logice.
To je ovšem úplně jiný problém.To je úplně stejný problém – používáš obecný primitivní typ (číslo, boolean) a někde bokem si poznamenáš významy jednotlivých hodnot.
No, pokud budeš číst dokumentaci a budeš dostatečně pečlivý, můžeš klidně programovat komplexní informační systémy v BrainFucku nebo podobném jazyce.Vzhledem k tomu, že se mi nechce psát
!= 0, tak BrainFuck by se mi nechtěl psát už vůbec...
To je úplně stejný problém – používáš obecný primitivní typ (číslo, boolean) a někde bokem si poznamenáš významy jednotlivých hodnot.No... nevim, jestli ti rozumim, jak by sis to teda u té funkce
find() představoval? V C++ je tohle na některých místech řešeno konstantou npos, s kterou se porovnává...
jak by sis to teda u té funkce find() představoval?-1 je v pořádku. Ještě lepší je null, ale někdy ho nemůžeme nebo nechceme použít (chceme vracet primitivní datový typ a nevyhazovat výjimku). V tom problém není. Problém je v tom, že si jazyk chybně vyloží -1 jako true – přitom tady -1 znamená, když už, tak false. Komické na tom je, že rozhodnutí vracet -1 pro nenalezeno (false) pochází zřejmě od stejných lidí, kteří zde rozhodli, že cokoli různé od 0 se vyhodnotí jako true.
Problém je v tom, že si jazyk chybně vyloží -1 jako true – přitom tady -1 znamená, když už, tak false.V těchto jazycích to chybné není,
-1 = 0xffff...ff = true. Ten problém je spíš v tom, že se snažíš použít jednu funkci pro dva různé účely. Přitom by bylo naprosto triviální napsat wrapper funkci třeba nazvanou 'contains()', která by vracela bool - to by bylo imho správné řešení, a bylo by to i čitelnější.
Dělat ústupky lidem, kteří nečtou dokumentaci nebo používají funkce jinak, než jak byly navrženy, vede jen k dalším ústupkům a problémům.
1.3.2013 20:54
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
-1 = 0xffff...ff = true.To je pouze technická implementace a určité konkrétní kódování čísla. Mně šlo o sémantiku, o logický význam: 0,1,2,3… = nalezeno =
true + číslo udává pozici výskytu; -1 = nenalezeno = false (případně jiné záporné číslo může udávat důvod, proč nebylo nalezeno – pokud tedy nechceme použít výjimky).
Dělat ústupky lidem, kteří nečtou dokumentaci nebo používají funkce jinak, než jak byly navrženy, vede jen k dalším ústupkům a problémům.A skutečně je to ústupek? Podle mého ne – IMHO by počítač měl být exaktní stroj, měl by být dostatečně „přísný“ a na neplatný vstup reagovat chybovou hláškou – ne se snažit uhodnout, co by to asi tak mohlo být a pokračovat. Za ústupek považuji naopak to magické přetypovávání. Tady se právě hezky ukazuje, jak automatické přetypování vede k nesmyslným výsledkům – případy, kdy je řetězec nenalezen i případy kdy je nalezen na vyšších pozicích spadnou do jednoho pytle – pouze případ, kdy je řetězec nalezen na první (nulté) pozici je vyhodnocen jinak. Logická hodnota je jeden bit, proč pro ni používat bajtové nebo několikabajtové číslo? Proč by mi odněkud mělo přijít číslo s významem logické hodnoty a navíc tak, že bude pasovat na to automatické přetypování? Vždyť to často právě nesedí – viz to hledání řetězce nebo třeba věk osoby – nikdo nemůže mít záporný věk, přirozené číslo znamená, že známe věk a nese jeho hodnotu, -1 může znamenat, že osoba nechtěla věk prozradit, -2 třeba že věk osoby nikdo nezná atd. (když nepoužíváme null/výjimky, tak si můžeme dohodnout zjevně nesmyslnou hodnotu pro předání informace o chybě/výjimce). Explicitní přetypování může znamenat zavolání jednopísmenkové funkce/makra, nikoho to nezabije – a naopak to v ostatních případech povede ke spolehlivějším programům s méně chybami.
1.3.2013 22:21
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Logická hodnota je jeden bit, proč pro ni používat bajtové nebo několikabajtové číslo?Protože na většině "moderních" architektur to tak není a používá se přinejmenším byte. Dejme tomu, že 0 = false, 1 = true. Co je pak celý zbytek do 255?
2.3.2013 18:04
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Můžeš si taky uložit víc booleanů do jednoho bajtu a pak si je z něj zase vytáhnout.Jo, to sice jo, ale adresace (chce si to pamatovat kam jsi který bit uložil, tedy nestačí ti jen adresa paměťové buňky, ale taky pozice v té buňce) a serializace/deserializace do byte ti sežere víc prostředků, než tím ušetříš.
Mně šlo o sémantiku, o logický význam: 0,1,2,3… = nalezeno = true + číslo udává pozici výskytu; -1 = nenalezeno = false (případně jiné záporné číslo může udávat důvod, proč nebylo nalezeno – pokud tedy nechceme použít výjimky).
BTW: když už mít nějaký výchozí způsob konverze čísla na boolean, tak by bylo dobré podporovat více variant od true i false – např.:
Jinak ti to umožňuje popsat 255 chybových variant, ale jen jednu nechybovou (nebo naopak).
Tady se právě hezky ukazuje, jak automatické přetypování vede k nesmyslným výsledkůmAle vždyť to není pravda, ten nesmyslný výsledek je daný tím, že ta funkce byla prostě špatně použita. Úplně stejně můžeš k nesmyslnému výsledku dojít jakýmkoli jiným špatným použitím funkce/API. Opravdu nevim, jak z tohoto jednoho případu chceš vyvodit to zobecnění, že "automatické přetypování vede k nesmyslným výsledkům".
případy, kdy je řetězec nenalezen i případy kdy je nalezen na vyšších pozicích spadnou do jednoho pytle – pouze případ, kdy je řetězec nalezen na první (nulté) pozici je vyhodnocen jinakO tom vůbec nemá smysl se bavit, protože ta funkce nikdy nebyla určena k použití stylem
if(find(...)) {...}.
Logická hodnota je jeden bit, proč pro ni používat bajtové nebo několikabajtové číslo?Protože CPU typicky neumí s jedním bitem efektivně pracovat, resp. pracuje se slovem (word), proto dává smysl ukládat bool do slova. Nicméně v některých jazycích můžeš optimalizovat a ukládat bool do jednoho bitu v případech, kdy to dává smysl. Např. v Qt tohle dělají interně v QStringu, afaik.
Vždyť to často právě nesedí – viz to hledání řetězce nebo třeba věk osoby – nikdo nemůže mít záporný věk, přirozené číslo znamená, že známe věk a nese jeho hodnotu, -1 může znamenat, že osoba nechtěla věk prozradit, -2 třeba že věk osoby nikdo nezná atd. (když nepoužíváme null/výjimky, tak si můžeme dohodnout zjevně nesmyslnou hodnotu pro předání informace o chybě/výjimce).To jde úplně proti tomu, cos psal předtím, že není dobré zneužívat primitivní typy pro tyhle informace, poznamenávat si někde stranou, že -1 je to a ono, -2 je něco jinýho atd...
O tom vůbec nemá smysl se bavit, protože ta funkce nikdy nebyla určena k použití stylem if(find(...)) {...}.Já ale v zásadě nerozporuji, zda se dané prostředí/jazyk chová deterministicky – věžím, že někde to popsané je a chová se to podle svých pravidel. Spor je o tom, zda se v daném prostředí/jazyce programuje příjemně, pohodlně, efektivně, bezpečně, spolehlivě… jak složitá je týmová spolupráce, jak snadné je udělat chybu…
Protože CPU typicky neumí s jedním bitem efektivně pracovat…To by tě ale jako programátora aplikace nemělo zajímat. Ty bys měl deklarovat, že potřebuješ prostor pro uložení true/false – a je pak na interpretu, kompilátoru či virtuálním stroji, aby program na daném hardwaru vykonal co nejefektivněji. U takového programu je tu prostor pro optimalizace, třeba v dalších verzích kompilátorů (a spol.) nebo v dalších generacích hardwaru. Programy se pak mohou zrychlit, aniž by se změnil jejich kód. Pokud ale datové typy definuješ mlhavě, tohle možné není. Když potřebuješ místo dvou hodnot třeba 256 hodnot nebo víc, použij číselný typ (nebo enum, objekty atd.) a kompilátor bude vědět, že tady už optimalizovat nemůže a že potřebuješ celý ten deklarovaný prostor. BTW: nejde jen o CPU – data se ukládají do paměti, posílají po síti, ukládají do souborů… Např. objekt, který obsahuje různé atributy a z nich několik logických hodnot, se dá z optimalizovat docela hezky. Ovšem tyto atributy musí být deklarované jako boolean, ne jako číslo.
To jde úplně proti tomu, cos psal předtím, že není dobré zneužívat primitivní typy pro tyhle informace, poznamenávat si někde stranou, že -1 je to a ono, -2 je něco jinýho atd...Proto tam píšu:
když nepoužíváme null/výjimky
To by tě ale jako programátora aplikace nemělo zajímat.Imho mělo. Programátor by se vždycky měl zajímat o to, jakým způsobem bude jeho kód na daném železe fungovat. Alespoň rámcově. Důsledkem tohohle přesvědčení jsou pak programátoři, kteří úplně kašlou na nějaké optimalizace a spoléhají, že za ně všechno vyřeší kompilátor, VM nebo interpreter.
Ty bys měl deklarovat, že potřebuješ prostor pro uložení true/false – a je pak na interpretu, kompilátoru či virtuálním stroji, aby program na daném hardwaru vykonal co nejefektivněji.Souhlas, s tím, že člověk by měl mít možnost to ručně ovlivnit, pokud to potřebuje...
Pokud ale datové typy definuješ mlhavě, tohle možné není.Na booleanu v pythonu/C/C++/... nevidim nic mlhavého a už vůbec nevidim, jak to souvisí s compile-time optimalizacemi...
Na booleanu v pythonu/C/C++/... nevidim nic mlhavého…Používat číselný typ pro uložení booleanu je „mlhavé“. Stejně jako používání řetězcových typů pro uložení určitého čísla – sice to tam uložit/serializovat můžeš, ale ztrácí se informace o původním konkrétním typu – místo toho se na všechno používá jeden obecnější typ.
Používat číselný typ pro uložení booleanu je „mlhavé“.Afaik tohle dělá pouze C. Jinak tohle je obecně otázka type safety, imho. Zřejmě máš výhrady proti type unsafe jazykům. Nejsem si vědom toho, že by programy napsané v těchto jazycích byly zamořeny nějakým výrazně větším počtem chyb než programy napsané v typ safe jazycích. Ty jo?
Já mam špatné zkušenosti s programy napsanými v lecčems, včetně i té Javy. Např. kdybych podle KDE4 posuzoval Qt nebo C++, dopadly by opravdu špatně, přitom ale oboje znám a vím, že v tom to nevězí.
když se pak podívám do konsole, tak to jsou často chyby typu volání neexistující metody, špatný počet parametrů atd. – tzn. věci, které by jinde odhalil už kompilátor. Případně „záhadné chování“ a „náhodná“ nefunkčnost – což tipuji na podobné chyby jako ta s tím findem v ifu.Tohle ale zdaleka neplatí pouze pro Python, v podstatě jsi tím odsoudil celé rodiny jazyků (dynamic, type unsafe). V podstatě z toho vychází, že správně to dělá pouze Java nebo jazyky Javě dost podobně, což už píše David Jaša...
Tohle ale zdaleka neplatí pouze pro Python, v podstatě jsi tím odsoudil celé rodiny jazyků (dynamic, type unsafe).
IMO jedinou výhodou dynamicky typovaných jazyků (tj. staticky typovaných jazyků s jedním typem) může být jednoduchost. Ostatní výhody jsou na straně jazyků s bohatšími typovými systémy.
dynamicky typovaných jazyků (tj. staticky typovaných jazyků s jedním typem)
>>> 'abc' + 2 Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: cannot concatenate 'str' and 'int' objectWTF? Ne, že bych byl v tom odborník, ale síla typové kontroly a statické/dynamické typování mi přijdu jako víceméně nezávislé vlastnosti.
'abc' + 2 … TypeError: cannot concatenate 'str' and 'int' objectA přitom sčítání řetězců a čísel při ukládání do řetězcového typu je bezpečné a přirozené. Kompilátor ví, že výsledkem má být řetězec, tudíž není pochyb o tom, že + zde znamená spojit text a číslo, nikoli nějaké sčítání (součet řetězce a čísla nedává smysl). V Javě můžu napsat:
String a = "cena je " + 100 + " Kč"; System.out.println(a);a vypíše se
Cena je 100 Kč.
(jasně, jsou i efektivnější a elegantnější způsoby jak pospojovat text nebo vyplnit nějakou šablonu – ale tohle je diskuse o poměrně nízkoúrovňových věcech)
String a = 100;ti neprojde:
$ javac Test.java
Test.java:3: incompatible types
found : int
required: java.lang.String
String a = 100;
^
1 error
(což je dobře)
BTW: ani explicitní přetypování
int i = 100; String a = (String)i;neprojde:
$ javac Test.java
Test.java:5: inconvertible types
found : int
required: java.lang.String
String a = (String)i;
^
1 error
stream << "Cena je: " << 100 << " Kc\n";
Javě můžeš vyčítat snad leda to, že si v ní nemůžeš definovat vlastní operátory (ale to je zase na jinou diskus – spíš mi přijde, že je to dobře, protože ten jazyk je díky takovým omezením jednoduchý a snadno srozumitelný)Pythonu můžeš vyčítat leda to, že operátor
+ sežere různé typy jen pokud se jedná o "mixed-mode arithmetics" (ale to je zase na jinou diskus – spíš mi přijde, že je to dobře, protože ten jazyk je díky takovým omezením jednoduchý a snadno srozumitelný)
Obecně mi spíš vadí ta přílišná benevolence a tolerantnost, kdy Python schroustá ledasco, v tichosti pokračuje a „něco“ dělá.Pokud je tvoje výchozí stanice Java, tak "přílíš benevolentní" bude prakticky jakýkoli jazyk. Ze známějších jazyků bude imho v tomhle podobný jen C#, a i ten je afaik benevolentnější než Java (operator overloading). "Schroustá ledasco a něco dělá" se dá říct o celé paletě jazyků, od C a jeho odvozenin až po takové jako Perl, PHP nebo JS... No prakticky jaýkoli
String cena = ... // Načítanie políčka užívateľa ... String query = "INSERT INTO objednavky ... " + (cena + poplatky) + "...
A máme tu SQL injection. Toľko k "zbytočnému" pretypovaniu pri skladaní reťazcov, ale "dobrému" explicitnému pretypovaniu na boolean. Inými slovami všetko, čo je inak než v Jave je zle a všetci sme hlupáci a blablabla, týmto môžme diskusiu uzavrieť a venovať sa písaniu našich zabugovaných programov.
Používá, ale
A máme tu SQL injection.
Lepení SQL (či podobných výrazů) z kousků textu je blbost – o tom jsem sám psal mnohokrát a hodně lidí jsem od toho (nejen tady) odrazoval.
Pokud jde ale o výstup třeba na konsoli, nebo do textového souboru nebo prostě někam, kde není co rozbít, můžeme to tak udělat.
Toľko k "zbytočnému" pretypovaniu pri skladaní reťazcov,
vložení čísla do řetězce je bezpečné, protože jestliže máš tu proměnnou deklarovanou jako int (nebo jiný číselný typ případně boolean nebo někdy enum), tak se ti tu* nikdy nestane, že by obsahovala nějaký závadný obsah.
String cena = ... // Načítanie políčka užívateľa
...
String query = "INSERT INTO objednavky ... " + (cena + poplatky) + "...
Tvůj příklad je chybný. Nemůžeš sčítat dva textové řetězce a čekat, že dostaneš číselný součet. Taky v tom, že nepoužíváš správný datový typ – cena má být v nějakém číselném typu – to v Javě můžeš udělat a pokud uživatel pošle nějakou podvrženou nečíselnou hodnotu, vyletí výjimka – k tvému kódu se tedy dostane buď (bezpečné) číslo nebo se ten kód (díky vyhozené výjimce) vůbec nespustí.
Nicméně ani tady bych nedoporučoval lepit SQL z kousků textů a čísel (byť je to celkem bezpečné).
*) při výstupu do některých jazyků/formátů bys mohl narazit na problém s tím, že číslo bude obsahovat desetinnou čárku (nicméně to u intu nehrozí) – a ta by v daném formátu znamenala třeba oddělovač
Lepení SQL (či podobných výrazů) z kousků textu je blbost
Použitie find namiesto operátora in je blbosť. Rovnaký argument ako proti pythonu.
Tvůj příklad je chybný. bla bla
Poplatky sú vypočítané v aplikácii (tj. typ int). Cena je načítavaná od užívateľa a nedopatrením nie je parsovaná na int.
Cieľom môjho komentára bolo poukázať na prípad kedy je implicitná konverzia na reťazec nebezpečná.
int cena = …) vstup od uživatele.
Kdybys zakázal operátoru „+“ připojit k řetězci číslo ale jen další řetězec, co bys tím vyřešil? Nic – operace by se zdařila a chyba by tam zůstala. Nebo chceš zakázat i spojování dvou řetězců pomocí „+“ operátoru?
cannot concatenate 'str' and 'int'? Pokud by ta proměnná byla řetězec, tak by „součet“ prošel a navíc by to bylo řádově nebezpečnější (do řetězce může útočník procpat jakékoli znaky, zatímco z číselného typu vzejde jen omezená a v zásadě bezpečná množina znaků – resp. je to bezpečnější než, co může být v řetězci).
Typové systémy jsou vždy statické. Cituji z Practical Foundations for Programming Languages od R. Harpera (kapitola 4, první odstavec):
Most programming languages exhibit a phase distinction between the static and dynamic phases of processing. The static phase consists of parsing and type checking to ensure that the program is well-formed; the dynamic phase consists of execution of well-formed programs. A language is said to be safe exactly when well-formed programs are well-behaved when executed.
Podobně v Types and Programming Languages od B. Pierce se píše:
A type system can be regarded as calculating a kind of static approximation to the run-time behaviors of the terms in a program.
Tzv. dynamicky typované jazyky se považují za staticky typované jazyky, které mají pouze jeden typ. Výpočetní modely některých jazyků pak hodnoty jednoho typu dále rozdělují (klasifikují) do menších skupin (tomu se Harper v PFPL věnuje v kapitole 18), jedné takové skupině pak Harper říká class (od slova klasifikovat). Jádro pudla je tedy v tom, že lidé nerozlišují pojem type a pojem class (to asi není úplně nejlepší název). Klíčový rozdíl obou pojmů je v tom, že typy se kontrolují před spuštěním programu a špatně typovaný program se nespouští a ani se mu nepřiřazuje sémantika.
Např. kompilátor OCamlu po provedení typové kontroly typy zahodí – pro běh programu nejsou potřeba. Naproti tomu například interpretr Pythonu nemůže zahodit informace o class – on je nutně potřebuje při interpretaci.
Poznámka na okraj: Nevím jak v Pythonu, ale v C/C++ toto není otázka konkrétní implementace, konverze signed → unsigned je definována standardem, aby se vždy chovala právě takhle.-1 = 0xffff...ff = true.To je pouze technická implementace a určité konkrétní kódování čísla.
1.3.2013 11:18
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
konkrétní příklad: v ifu kontrola pomocí find() zda jeden řetězec obsahuje jiný řetězec. Jenže -1 se zde vyhodnotí jako true a test projde.K tomuhle by se měl používat operátor
in.
1.3.2013 15:36
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Jasně, nebo si můžu udělat pomocnou metodu/funkci, která dostane dva řetězce a vrací boolean a tím tento problém řeší – obejít se to dá, ale příčina zůstává.Ani ne. Tohle je prostě featura, ne chyba. Python není java, takže nemá smysl očekávat, že se bude stejně chovat.
Zase hovoríme o niečo o čom netušíme?
In [1]: "abcd".index("bc")
Out[1]: 1
In [2]: "abcd".index("x")
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-2-257d22bc2d8f> in <module>()
----> 1 "abcd".index("x")
ValueError: substring not found
V prípade, že neexistuje podreťazec vyhodí sa výnimka. Stačí volanie find nahradiť volaním index.
Stačí volanie find nahradiť volaním index.Ano, jakoukoli chybu stačí opravit a pak už program funguje. A obvykle oprava spočívá v nahrazení pár znaků, v horším případě řádků. Jenže nejdřív tu chybu musíš najít. Jde o to, jak drahé je to hledání. A nejlevnější je chyba, která vůbec nevznikne (např. díky tomu, že ti ji ohlásí kompilátor).
Lepší by bylo vracet null, což lépe vystihuje „pozice nenalezena“ (to ale vyžaduje objektový typ)
Co je na nil v Lispu objektového? Teda krom toho, že třeba v Common Lispu jsou všechno objekty, akorát v té jejich terminologii se to nemyslí ve smyslu OOP.
nicméně i ta -1 je v tomto případě dobré řešení.
Což je zhruba na stejné úrovni jako vracení maximální možné délky (která je zaručeně o jedna větší než max. index) v C++. Intuitivní to možná není, ale programátor by o tom měl vědět, pokud není úplný začátečník (nebo vůl ~.^).
Objektový ve smyslu primitivní tyoy (např. int) vs. objektové typy (Integer).
Což je anomálie Javy.
použiješ -1 nebo jinou zápornou hodnotu, protože je na první pohled zřejmé, že pozice nemůže být záporná (pozice sice nemůže být větší než horní hranice ale k tomu už potřebuješ dodatečné informace → zbytečné zesložitění – zatímco dolní hranice je daná).No jo, jenže ono je lepší v tomto případě použít unsigned typ, protože index pak může být dvakrát větší než se signed. A pak dává smysl použít maximální hodnotu spíš než -1. Naštěstí v jazycích jako C/C++/... se počítá s two's complement, a tudíž -1 přetypováno na unsigned dá právě tu maximální hodnotu...
in, a používat místo něj přímo návratovou hodnotu funkce find není dobrý nápad, protože:
>>> a = 'abc'
>>> a[a.find('bž')]
'c'
Závěr: kdyby Franta věnoval učení se a používání pythonu zhruba tak setinu té energie, co věnoval Javě, předtím, než se na jeho adresu začne vyjadřovat, celé tohle vlákno by vůbec nemuselo vzniknout.
Výjimky se jak z designových tak z výkonových důvodů vyhazují skutečně pouze tehdy, když nastane něco výjimečného. Rozhodně by neměly být použity pro "good path".A to je dogma kteréže církve?
Ať už kterékoli, já členem nebudu.
Mj., jak jste k tomu dospěl?
ale co se týče standardního předpokládaného běhu – tam bys snad někdy vyhazoval výjimku?
Klidně. Třeba ve zmiňovaném Pythonu se to normálně dělá – například výjimky GeneratorExit a StopIteration. Nebo třeba v OCamlu je to také běžné – například funkce ze standardní knihovny, jenž něco hledají, vyhazují výjimku Not_found, když to nenajdou.
Mj., jak jste k tomu dospěl?Tak samozřejmě záleží to na konkrétním jazyku a konkrétní implementaci, nicméně většinou se výjimky implementují tak, aby v "good path" měly minimální overhead a v "exceptional path" pak probíhá nějaký ten stack unwinding nebo něco na ten způsob, případně se někde taky uchovávají informace o výjimce k případnému pozdějšímu logování atd. atp., prostě ten overhead v "exceptional path" je většinou značný.
25.2.2013 12:47
mirec | skóre: 32
| blog: mirecove_dristy
| Poprad
17.2.2013 13:25
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
doplňování např. v pythonu tak jsem se nestačil divit;)A zkoušel jsi to s doplňkem, nebo bez něj?
17.2.2013 17:37
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Kde ho naleznu?Kdybych o tom nepsal v samotném blogpostu, tak bych se tomu dotazu nedivil, ale takhle.. Zkus doplněk sublime code intell.
Jediná "slabina" Sublime je jeho licence - jedná se o komerční produkt…Za dobrý editor bych dal klidně 100 USD, ale „dobrý“ v sobě zahrnuje fakt, že k tomu dostanu zdrojáky pod svobodnou licencí. Takže za tohle ani korunu.
Budu tuze rád, když xkucf03 nějakou konkrétní, která s licencí počítá, uvede.Např. FURPS:
…
S (supportability) – schopnost být udržována – Dalším hlediskem hodnocení je oblast údržby a podpory aplikace, její testovatelnosti. V této oblasti se taktéž hodnotí i přizpůsobitelnost a rozšiřitelnost o nové vlastnosti. Důležitá je také schopnost zapojení aplikace do existujících procesů podpory a údržby SW.
…
Obchodní a právní aspekty – licencování a případná právní omezení pro různé demografické regiony
Už jen proto, že neexistuje jediné dobré uspořádání na množině licencí.Můžete to rozvést?
Kvalita s licencí nesouvisí.Co je podle vás kvalita? Např. Wikipedie píše:
Quality in business, engineering and manufacturing has a pragmatic interpretation as the non-inferiority or superiority of something; it is also defined as fitness for purpose. Quality is a perceptual, conditional and somewhat subjective attribute and may be understood differently by different people.Proč by licence neměla souviset s kvalitou?
Je rozdíl, když mají (typicky u komplexních RTS pro více hráčů, shodou okolností skoro žádné svobodné neexistují) všichni potenciálně zhruba stejnou učící křivku a když si někdo nastuduje zdrojáky.Hele, a že to jde reverznout…? Co spíš než na utajení a obfuskaci kódu a protokolů používat protokoly, kde tohle prostě nejde, i když ho všichni znají?
Hele, a že to jde reverznout…?
Prakticky to téměř nikdo nedělá.
Nicméně v metrikách se s ní nepočítá. Kvalita s licencí nesouvisí. Už jen proto, že neexistuje jediné dobré uspořádání na množině licencí.a
Protože licence jsou obvykle pro někoho výhodnější a pro někoho méně výhodné.?
). A chování hry se taky většinou vypozoruje nebo zpětně dopočítá...
Pointa ale je, že u těch komplexních RTS máš typicky tolik proměnných, že dělat na nich nějakou analýzu (hledat nějaký extrémy, průběhy, ...) není moc možný, alespoň ne prakticky, a to dokonce ani aproximačně. V podstatě jediný účinný přístup je evoluční, ať už nějak automatizovaně nebo (to spíš) ručně.
Následuje obvyklý flejm "BSD vs GNU".Nenásleduje, protože ten se týká tří různých skupin (původní autor, redistributor, koncový uživatel), které můžou mít odlišné zájmy. Ale tady se na věc díváme z pohledu koncového uživatele. Důležité je, aby měl uživatel možnost software svobodně používat, upravovat, redistribuovat… rozdíl mezi GPL a BSD tu není až tak podstatný – zatímco rozdíl mezi proprietárním a svobodným softwarem je kruciální.
Tak znovu:
Jaká jsou kritéria pro porovnávání licencí?
Třeba: je svobodná / není svobodná.
Co když dvě licence těsně nesplňují podmínky FSF/OSI, ale jen v detailech, leč zcela odlišných?
Tak budou neporovnatelné.
Třeba: je svobodná / není svobodná.
Což vytváří aspoň dva problémy:
Definice svobodných licencí je problematická, už tak tu máme open-source software a svobodný software.Definice svobodného softwaru není problematická, je jednoduchá, stručná, jasná. Definice otevřeného softwaru je trochu delší, ale v zásadě stejná, kompatibilní.
Svobodný software je někdy z principu horší (např. hra více hráčů, a to především na soutěžní úrovni; existuje aspoň jedno MMORPG, které klienty po otevření znovu uzavřelo, aby se hra stala opět hratelnou, jméno mi zrovna vypadlo).To máš jako s DRM… obejít se dá všechno a podvádět se dá ve všech hrách, je potřeba to řešit nějak jinak. I kdyby ta hra běžela na serveru a k tobě by se jen streamoval obraz a zpátky posílaly pohyby myši a stisky kláves, stejně si můžeš napsat robota, který bude hrát za tebe.
např. hra více hráčů, a to především na soutěžní úrovni; existuje aspoň jedno MMORPG, které klienty po otevření znovu uzavřelo, aby se hra stala opět hratelnou, jméno mi zrovna vypadloKerckhoffs's principle
Jak tvá metrika počítá s tím, že software je svobodný, ale z hlediska měřitelných parametrů jako četnost chyb nebo výkon úplná sračka?Záleží, jaká je tu perspektiva zlepšení (ať už vlastními silami nebo od původních autorů nebo někoho jiného). Pokud perspektiva není a nevyplatí se ten software vyvíjet, tak prostě nevyhovuje a použiji jiný.
Jaká jsou kritéria pro porovnávání licencí? Co když dvě licence těsně nesplňují podmínky FSF/OSI, ale jen v detailech, leč zcela odlišných?Tak jsou za hranicí toho, co chci používat a nemá cenu to řešit a přemýšlet, co je horší/lepší. (trochu mi to připomíná druhé kolo prezidentské volby)
Jaká jsou kritéria pro porovnávání licencí? Co když dvě licence těsně nesplňují podmínky FSF/OSI, ale jen v detailech, leč zcela odlišných?Tak jsou za hranicí toho, co chci používat a nemá cenu to řešit a přemýšlet, co je horší/lepší. (trochu mi to připomíná druhé kolo prezidentské volby)
Jsem rád, že jsi ekonom a nikoliv vědec, protože za současné situace by s tvým přístupem byl pokrok např. v přírodních vědách podobný čekání na Godota^WSadámův svobodný CAD.
Jak tvá metrika počítá s tím, že software je svobodný, ale z hlediska měřitelných parametrů jako četnost chyb nebo výkon úplná sračka?Jak tvá metrika počítá s tím, že software nemá funkční chyby, ale z hlediska výkonu je to úplná sračka?
Jak tvá metrika počítá s tím, že software je svobodný, ale z hlediska měřitelných parametrů jako četnost chyb nebo výkon úplná sračka??
18.2.2013 23:08
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
19.2.2013 22:32
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
19.2.2013 22:50
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Ale i tak se mi líbí jeho přístup, kdy ho můžeš používat jak chceš a platba za něj je více/méně dobrovolná.Tím spíš je to pro mne podezřelé a nedůvěryhodné. Ještě dokážu pochopit, že někdo prodává třeba proprietární hry/software/filmy a chce zaplatit za každé použití – prostě jen neumí vydělat na ničem jiném, než je prodej licencí, budiž. Ale když žije z prakticky dobrovolných příspěvků – proč to neuvolní jako svobodný software? Dobrovolníků ochotných zaplatit by se našlo víc.
Dobrovolníků ochotných zaplatit by se našlo víc.
[citation needed]
20.2.2013 09:46
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Ale když žije z prakticky dobrovolných příspěvků – proč to neuvolní jako svobodný software? Dobrovolníků ochotných zaplatit by se našlo víc.Nevím, nejsem autorův mluvčí, jen používám jeho software. Zkus mu napsat, docela by mě zajímala odpověď, ale jsem moc líný smolit dotaz v angličtině.
ISSN 1214-1267, (c) 1999-2007 Stickfish s.r.o.
 16.2.2013 22:06
16.2.2013 22:06
 16.2.2013 18:12
16.2.2013 18:12
 16.2.2013 21:13
16.2.2013 21:13
 17.2.2013 01:03
17.2.2013 01:03
 25.2.2013 03:05
25.2.2013 03:05
 25.2.2013 20:01
25.2.2013 20:01
 25.2.2013 20:23
25.2.2013 20:23
 19.2.2013 13:27
19.2.2013 13:27
 20.2.2013 13:11
20.2.2013 13:11
 18.2.2013 21:45
18.2.2013 21:45
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}