Portál AbcLinuxu, 29. června 2026 13:22
 13.7.2017 15:09
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
13.7.2017 15:09
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
 13.7.2017 15:35
Marián Kyral | skóre: 29
| blog: Sem_Tam
| Frýdek-Místek
13.7.2017 15:35
Marián Kyral | skóre: 29
| blog: Sem_Tam
| Frýdek-Místek
 14.7.2017 08:12
Marián Kyral | skóre: 29
| blog: Sem_Tam
| Frýdek-Místek
14.7.2017 08:12
Marián Kyral | skóre: 29
| blog: Sem_Tam
| Frýdek-Místek
Ano, překvapivě ani jiné části systemd nejsou plnohodnotná náhrada NetworkManageru :)Všetky časti sú plnohodnotou náhradou NM?No myslel jsme to trochu jinak.
 14.7.2017 08:33
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
14.7.2017 09:33
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
14.7.2017 08:33
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
14.7.2017 09:33
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
Ano? A kde najdu repozitář obsahující jen samotný init systém, bez těch věcí (údajně modulů) kolem, který si budu moci samostatně zkompilovat, aniž by mi do procesu sestavení vstupovalo nějakých 400 000 řádků kódu, který nepotřebuji?
13.7.2017 15:11
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
if (!strcmp(user, "0day"))
die();
# userctl remove 0day Error: Invalid username. Removing user 'root' instead.
14.7.2017 07:53
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
13.7.2017 14:39
Marián Kyral | skóre: 29
| blog: Sem_Tam
| Frýdek-Místek
# eix meson
* dev-util/meson
Available versions: 0.40.1^t ~0.41.0^t ~0.41.1^t **9999^t {PYTHON_TARGETS="python3_4 python3_5 python3_6"}
Homepage: http://mesonbuild.com/
Description: Open source build system
13.7.2017 20:36
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
15.7.2017 18:21
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
15.7.2017 19:09
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
Proč se pak obtěžovat s nějakým céčkem při psaní samotného initu? Proč to pak neudělat celé v Pythonu a jen malé části (na co Python nestačí, asi nějaké věci kolem souborových deskriptorů, control groups atd.) napsat v C?Jedna vec je init a druha vec je build system. To ze Python je vhodna volba pro build system, neznamena ze je dobrou volbou pro init a plati to i naopak.
Když si budu chtít postavit vlastní systém na zelené louce, zkompiluji si zavaděč, jádro, init systém, Coreutils a pár dalších programů, tak proč bych k tomu měl potřebovat nějaký Python?A co jako? Ke kompilaci potrebuje funkci buildovaci prostredi a stalice jako Python, ktera je k dispozici vsude, tomu neprekazi.
tak proč bych k tomu měl potřebovat nějaký Python?To je volba vyvojaru, nikoliv vase, jak jsem psal vyse hrajou tam roli i jine aspekty.
Nebo je dneska potřeba Python i pro kompilaci Grubu, Kernelu a GNU Coreutils?Neni. Nicmene autotools + jeho zavyslosti bych vymenil za meson + python kdykoliv.
Jedna vec je init a druha vec je build system.
IMHO jde o celkový „code footprint“ resp. celkovou komplexitu, která se za tím skrývá, která je potřebná k dosažení určitého cíle – tím cílem je třeba to, aby mi nabootoval počítač a já v něm mohl psát texty, nebo třeba aby se připojil k ethernetu a IP síti a poskytoval soubory nějakým protokolem.
A co jako? Ke kompilaci potrebuje funkci buildovaci prostredi a stalice jako Python, ktera je k dispozici vsude, tomu neprekazi.
Když mi půjde o bezpečnost a spolehlivost, tak se mj. budu snažit minimalizovat množství potřebného kódu a to včetně toho, který byl použit pro kompilaci.
To ze Python je vhodna volba pro build system, neznamena ze je dobrou volbou pro init a plati to i naopak.
Čemu by vadilo, že by Python běžel pod rootem a spouštěl jiné procesy? Nebo spíš nějaký jiný jazyk vyšší než C? Bude v něm víc chyb než ve standardní C knihovně? Bude jich víc, že chyb, které mohl udělat programátor initu psaného v C?
16.7.2017 13:08
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
MHO jde o celkový „code footprint“ resp. celkovou komplexitu, která se za tím skrývá, která je potřebná k dosažení určitého cíle – tím cílem je třeba to, aby mi nabootoval počítač a já v něm mohl psát texty, nebo třeba aby se připojil k ethernetu a IP síti a poskytoval soubory nějakým protokolem.Jak nahrazeni autotools mesonem udela udela tyto veci horsi? Prijde mi, ze nerozlisujete tri rozdilne veci - (a) process [cross]compilace, (b) QA vysledneho buildu a (c) nasazeni na produkcnim zarizeni.
Když mi půjde o bezpečnost a spolehlivost, tak se mj. budu snažit minimalizovat množství potřebného kódu a to včetně toho, který byl použit pro kompilaci.Bezpecnost a spolehlivost buildu? Pak jdu pro meson, protoze je mene obskurni nez autotools a m4, lepe debugovatelny, s dobrou podporou pro crosscompilaci na vice platformach, s jednodussi integraci do CI, a navic s podporou pro unit testing, reproducible builds, statickou analyzu, code coverage ci PGO a vice backendu jako treba ninja.
Čemu by vadilo, že by Python běžel pod rootem a spouštěl jiné procesy? Nebo spíš nějaký jiný jazyk vyšší než C? Bude v něm víc chyb než ve standardní C knihovně? Bude jich víc, že chyb, které mohl udělat programátor initu psaného v C?Od initu a service manageru ocekavam urcite RT vlastnosti a dobrou integraci s kernel C API bez nejakych shimu, a pak je C lepsi volba nez garbage collected jazyky, zejmena pokud je navic poskytovano API pro bezici sluzby, kde je opet C opet jasna volba.
Jak nahrazeni autotools mesonem udela udela tyto veci horsi? Prijde mi, ze nerozlisujete tri rozdilne veci - (a) process [cross]compilace, (b) QA vysledneho buildu a (c) nasazeni na produkcnim zarizeni.
Představ si, že bys chtěl udělat audit veškerého kódu, aby tě nemohl někdo napadnout. V tu chvíli tě nezajímají jen závislosti v době běhu na produkci, ale i závislosti, které byly nutné pro sestavení/kompilaci – protože pokud útočník napadne (má možnost do něj zasahovat) kompilátor nebo build systém, tak může ovlivnit i výsledné binárky a dostat do nich svůj škodlivý kód.
Toto je sice trochu extrémní paranoidní přístup a většinou to v praxi tak daleko nedotáhneš (a prostě věříš rozšířeným nástrojům, které používají ostatní), ale přesto považuji za nežádoucí zbytečně množství závislostí zvyšovat.
Od initu a service manageru ocekavam urcite RT vlastnosti
Realtime? To jako opravdu? Chceš pomocí systemd řídit robota nebo nějaké CNC?
Ano, mělo by to být rychlé a nemělo by se to zadrhávat, ale opravdu to nemusí být RT – služby se klidně mohou spouštět v náhodném pořadí při splnění deklarovaných závislostí a posloupností. Např. je jedno, jestli se jednou spustí nejdřív SSH server a až po něm SMTP a jindy naopak – a pokud na pořadí záleží, tak se mezi nimi nadefinuje závislost a init systém ji vyhodnotí a splní.
C lepsi volba nez garbage collected jazyky
Tohle není typ softwaru, ve kterém by vznikalo a zanikalo tolik objektů, aby úklid GC představoval nějakou (postřehnutelnou) režii. Třídy (tedy pokud ten jazyk pracuje s konceptem tříd) budou představovat model služeb (jejich vlastnosti a závislosti) a objekty budou reprezentovat konkrétní nakonfigurované služby. Pokud smažeš konfigurák služby na disku, tak se následně odstraní i ten objekt v paměti a GC ho pak uklidí, ale to není žádná tragédie (to už má větší režii to mazání souboru a sledování přes inotify).
dobrou integraci s kernel C API bez nejakych shimu, …, zejmena pokud je navic poskytovano API pro bezici sluzby, kde je opet C opet jasna volba.
To je právě otázka – kromě té integrace s C API tam je totiž hromada kódu jako parsování konfiguráků, formátování výstupů, vyhodnocování závislostí/pořadí, které by se daleko lépe psaly v něčem vyšším, než je C.
Např. GNU Sheperd (dříve DMD) používaný v Guixu je napsaný v Guile (Scheme). Nevím, jestli je funkcionální paradigma ideální volba (možná ano, to je asi otázka osobních preferencí), ale rozhodně jde psát init systém i v něčem jiném, než nízkoúrovňovém céčku a myslím, že to je správná cesta.
Mimochodem, co se týče množství kódu Sheperd:
$ cloc-sql.sh shepherd/ ╭──────────────┬─────────┬───────────┬───────────┬──────┬────────┬──────────────────────────────────────────────────────────────────────────────────╮ │ jazyk │ souborů │ prázdných │ komentářů │ kódu │ celkem │ celkem_graf │ ├──────────────┼─────────┼───────────┼───────────┼──────┼────────┼──────────────────────────────────────────────────────────────────────────────────┤ │ Lisp │ 12 │ 352 │ 688 │ 2310 │ 3350 │ ████████████████████████████████████████████████████████████████████████████████ │ │ Bourne Shell │ 8 │ 158 │ 244 │ 432 │ 834 │ ████████████████████░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░ │ │ make │ 1 │ 40 │ 45 │ 146 │ 231 │ ██████░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░ │ │ m4 │ 1 │ 17 │ 11 │ 55 │ 83 │ ██░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░ │ │ celkem │ 22 │ 567 │ 988 │ 2943 │ 4498 │ │ ╰──────────────┴─────────┴───────────┴───────────┴──────┴────────┴──────────────────────────────────────────────────────────────────────────────────╯ Record count: 5
Systemd:
$ cloc-sql.sh systemd/ ╭────────────────────┬─────────┬───────────┬───────────┬────────┬────────┬──────────────────────────────────────────────────────────────────────────────────╮ │ jazyk │ souborů │ prázdných │ komentářů │ kódu │ celkem │ celkem_graf │ ├────────────────────┼─────────┼───────────┼───────────┼────────┼────────┼──────────────────────────────────────────────────────────────────────────────────┤ │ C │ 732 │ 86189 │ 26785 │ 283105 │ 396079 │ ████████████████████████████████████████████████████████████████████████████████ │ │ XML │ 249 │ 10445 │ 3441 │ 50901 │ 64787 │ █████████████░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░ │ │ C/C++ Header │ 450 │ 8435 │ 8841 │ 20588 │ 37864 │ ████████░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░ │ │ Python │ 20 │ 619 │ 582 │ 18927 │ 20128 │ ████░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░ │ │ make │ 6 │ 1849 │ 199 │ 7847 │ 9895 │ ██░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░ │ │ NAnt scripts │ 45 │ 751 │ 0 │ 6773 │ 7524 │ ██░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░ │ │ m4 │ 16 │ 307 │ 49 │ 2746 │ 3102 │ █░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░ │ │ Bourne Shell │ 41 │ 400 │ 185 │ 1749 │ 2334 │ ░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░ │ │ Perl │ 3 │ 117 │ 41 │ 1921 │ 2079 │ ░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░ │ │ Bourne Again Shell │ 6 │ 224 │ 229 │ 1324 │ 1777 │ ░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░ │ │ HTML │ 1 │ 88 │ 3 │ 453 │ 544 │ ░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░ │ │ XSLT │ 2 │ 44 │ 78 │ 241 │ 363 │ ░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░ │ │ awk │ 8 │ 0 │ 0 │ 81 │ 81 │ ░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░ │ │ Lisp │ 1 │ 3 │ 8 │ 16 │ 27 │ ░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░ │ │ YAML │ 1 │ 0 │ 0 │ 14 │ 14 │ ░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░ │ │ sed │ 1 │ 0 │ 0 │ 1 │ 1 │ ░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░ │ │ celkem │ 1582 │ 109471 │ 40441 │ 396687 │ 546599 │ │ ╰────────────────────┴─────────┴───────────┴───────────┴────────┴────────┴──────────────────────────────────────────────────────────────────────────────────╯ Record count: 17
Upstart:
$ cloc-sql.sh upstart/ ╭──────────────┬─────────┬───────────┬───────────┬────────┬────────┬──────────────────────────────────────────────────────────────────────────────────╮ │ jazyk │ souborů │ prázdných │ komentářů │ kódu │ celkem │ celkem_graf │ ├──────────────┼─────────┼───────────┼───────────┼────────┼────────┼──────────────────────────────────────────────────────────────────────────────────┤ │ C │ 63 │ 26065 │ 17879 │ 70965 │ 114909 │ ████████████████████████████████████████████████████████████████████████████████ │ │ Bourne Shell │ 11 │ 3863 │ 4214 │ 26460 │ 34537 │ ████████████████████████░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░ │ │ m4 │ 18 │ 1161 │ 298 │ 11222 │ 12681 │ █████████░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░ │ │ C/C++ Header │ 33 │ 896 │ 2789 │ 2630 │ 6315 │ ████░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░ │ │ Python │ 5 │ 731 │ 865 │ 1608 │ 3204 │ ██░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░ │ │ make │ 12 │ 221 │ 35 │ 1149 │ 1405 │ █░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░ │ │ XML │ 3 │ 43 │ 51 │ 174 │ 268 │ ░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░ │ │ vim script │ 2 │ 25 │ 31 │ 63 │ 119 │ ░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░ │ │ sed │ 2 │ 0 │ 0 │ 16 │ 16 │ ░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░ │ │ celkem │ 149 │ 33005 │ 26162 │ 114287 │ 173454 │ │ ╰──────────────┴─────────┴───────────┴───────────┴────────┴────────┴──────────────────────────────────────────────────────────────────────────────────╯ Record count: 10
OpenRC má nějakých 14 000 řádků kódu.
Ano, každý z těch systémů má jinou funkcionalitu, nicméně těch 400 000 řádků kódu v případě systemd je naprosto monstrózní. Vždyť je to jen init systém, který má vyhodnotit závislosti a spustit procesy + na ně dohlížet. Buď je to napsané šíleně neefektivně (ve smyslu poměru řádků kódu k funkcionalitě) nebo je k tomu přibalena spousta věcí, které s init systémem nesouvisí.
I když je tedy pravda, že v souvislosti s těmito čísly, zavlečení závislosti na Mesonu/Pythonu není zase taková tragédie a hlavní problém s komplexitou je uvnitř samotného systemd.
Moc nemusím extrémisty typu Suckless, protože jejich přístup dává dost nepraktické výsledky, ale stejně jako oni si myslím, že je dobré se nad těmi závislostmi a množstvím kódu zamýšlet a netvořit úplný bloatware.
Vždyť je to jen init systémNení.
Což bude asi ten problém. Stará dobrá zásada říká, že jeden program by měl dělat jednu věc a měl by ji dělat pořádně.
Pokud systemd dělá i něco jiného (a to dělá), tak by ty funkce měly být oddělené a měly by jít používat nezávisle na sobě (což znamená i kompilovat nezávisle).
Tady by asi bylo na místě, aby si Lennart založil Systemd foundation a v rámci ní vyvíjel řadu samostatných programů. Protože jinak to je, jako kdybys potřeboval (zkompilovat a dost možná i nainstalovat) Apache Ant, Apache OpenOffice a Apache Camel, abys mohl používat Apache HTTPD, nebo třeba jako kdybys potřeboval GNU Cash, GNU MidnightCommander a GNU GIMP, abys mohl používat GNU GRUB.
třeba jako kdybys potřeboval GNU Cash, GNU MidnightCommander a GNU GIMP, abys mohl používat GNU GRUB.
Zní to sice absurdně, ale celkem to odpovídá situaci v systemd – Gimp by se při kompilaci GRUBu mohl používat např. ke konverzi obrázků, které budou ve startovací nabídce na pozadí. Co na tom, že někdo tam ty obrázky nechce nebo si dodá vlastní, které není potřeba konvertovat, nebo to udělá pomocí vlastního nástroje? A protože by API Gimpu bylo nestabilní, tak by radši celý Gimp vrazili do stejného repozitáře jako GRUB, aby se při kompilaci vždy použila kompatibilní verze.
Naštěstí jsou v GNU (nebo třeba u Apachů) dostatečně příčetní, aby tohle nedělali a vyvíjejí samostatné programy, které lze kompilovat, distribuovat a používat nezávisle na sobě.
16.7.2017 23:25
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
Stará dobrá zásada říká, že jeden program by měl dělat jednu věc a měl by ji dělat pořádně.Aaaa, Unixovske dogma. Skoda, ze to zapomneli aplikovat na kernel ci X11. Nicmene, systemd jde vlastne dobrym smerem, kolekce nastroju z jedne repository kompilovana jednim "buildworld" prikazem, tedy presne v duchu puvodniho Unixu.
Skoda, ze to zapomneli aplikovat na kernelJako na Hurd? :-P
18.7.2017 00:20
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
P.S. nerad bych, aby to vyznělo tak, že nesnáším systemd – tak to není, v mnohém se mi líbí (stejně jako třeba PulseAudio), ale vadí mi ta monolitická architektura a způsob vydávání a verzování. Chtěl bych, aby to byly samostatné repozitáře, ve kterých by byly izolované jednotlivé funkce – samotný init by byl v jiném repozitáři než imlementace různých démonů a šel by zkompilovat a používat nezávisle na nich.
 16.7.2017 18:37
xkucf03 | skóre: 50
| blog: xkucf03
16.7.2017 18:37
xkucf03 | skóre: 50
| blog: xkucf03
Debian systemd zahodí a přejde na něco rozumnějšího (čti: OpenRC)
Nebo by to mohl někdo reimplementovat. Vzít ze systemd to dobré (socket activation, práci s cgroups…), podporovat konfiguráky systemd a celé by to mělo tak 40× méně řádků kódu.
16.7.2017 19:31
xkucf03 | skóre: 50
| blog: xkucf03
Souhlas. Tak asi by stačil nástroj, který by jednorázově načetl systemd unit soubor a zkonvertoval do nějakého lepšího formátu.
16.7.2017 20:01
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
16.7.2017 20:37
xkucf03 | skóre: 50
| blog: xkucf03
Na ini like souborech nevidím nic špatného.
Tak se podívej třeba do ~/.config/plasmashellrc, jak to pak dopadá. Mám tam konfiguraci schránky.
Protože tam potřebovali nacpat stromovou strukturu s větší hloubkou než 1, tak to tam museli nějak dobastlit a kdesi na konci souboru je sekce:
[General] Number of Actions=6
Která říká, kolik je tam položek, které se následně v souboru hledají (ty jsou nad tím):
[Action_2] Automatic=true Description=Poznámky pod čarou Number of commands=2 Regexp=\[[^]]+\] [Action_2/Command_0] Commandline[$e]=echo %s | ~/bin/podČarou.pl Description=Přidat poznámky Enabled=true Icon= Output=1 [Action_2/Command_1] Commandline[$e]=echo %s | ~/bin/vlnka.sed | ~/bin/podČarou.pl | ~/bin/markdown Description=Ábíčko Enabled=true Icon= Output=1
a v každé je zase Number of commands, podle čehož se hledají další podsekce.
To by teoreticky nebylo nutné, mohly by projíždět všechny sekce a ten strom z toho nějak poskládat, takže to není až tak vada INI formátu, jako spíš implementace. Ale hezky se to nečte ani nepíše. Nemluvě o tom, že např. v XML bys mohl mít XSD nebo třeba Relax NG schéma. Pro INI soubory nějaký jazyk pro popis schématu existuje? Schéma jednak pomáhá při editaci a jednak z něj v rámci kompilace můžeš vygenerovat třídy nebo nějaké datové struktury, se kterými pak pracuješ v programu – konfigurační soubor se pak namapuje na objekty v tvém programovacím jazyce a je zaručené, že to na sebe bude pasovat – obě strany (jak ten, kdo soubor vytváří/edituje, tak ten, kdo ho čte) vycházejí ze stejné strojově čitelné specifikace.
XML se blbě čte a blbě píše. Myslím pro člověka. To by k tomu byl potřeba ještě spešl editor.
XML se dá v pohodě editovat v Emacsu, VIMu, MC atd. Nevím, jak VIM, ale Emacs automaticky načte Relax NG schéma (když je ve stejné složce stejně pojmenované jako soubor – může to být symlink) a během editace validuje.
BTW: spousta editorů podporuje XML schémata, umí napovídat, uzavírat elementy, validovat… ale neznám jediný editor, který by automaticky inkrementoval Number of Actions a Number of commands při přidání nové sekce nebo napovídal názvy sekcí a klíčů v INI souboru (tím myslím na základě specifikace, nikoli hloupé doplňování textu, který se už někde v dokumentu vyskytuje).
16.7.2017 21:35
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
Tak se podívej třeba do ~/.config/plasmashellrc, jak to pak dopadá.Nepodívám
 . Navíc diskuse je o systemd a nikoliv o PlasmaHellRC
To, že si nějaký program vybral pro popis své konfigurace nevhodný formát ještě neznamená, že ten formát nemá použití jinde. Ostatně většina programů (se kterými pracuji) má jednoduchý konfigurák stylem klíč=hodnota. V tomhle systemd (naštěstí) není výjimkou.
. Navíc diskuse je o systemd a nikoliv o PlasmaHellRC
To, že si nějaký program vybral pro popis své konfigurace nevhodný formát ještě neznamená, že ten formát nemá použití jinde. Ostatně většina programů (se kterými pracuji) má jednoduchý konfigurák stylem klíč=hodnota. V tomhle systemd (naštěstí) není výjimkou.
BTW: spousta editorů podporuje XML schémata, umí napovídat, uzavírat elementy, validovat… ale neznám jediný editor,Asi se každý bavíme o zcela jiné úrovni. Já jako admin se občas potýkám se situacemi, kdy je na stroji jen holý vim, sotva v něm fungují kurzorové šipky. V případě nouze se konfiguráky dají nastavit i pomocí
echo "něco" > soubor.
To, že existují editory, které napovídají, doplňují, kontrolují pochopitelně vím, ale základní konfiguráky systému by měly být tak jednoduché, že k tomu žádný nástroj nemá být potřeba. Tedy kromě toho, pro co je ten konf určen.
16.7.2017 22:28
xkucf03 | skóre: 50
| blog: xkucf03
<actions>
<action
Automatic="true"
Description="Poznámky pod čarou"
Regexp="\[[^]]+\]"
>
<command
Commandline="echo %s | ~/bin/podČarou.pl"
Description="Přidat poznámky"
Enabled="true"
Icon=""
Output="1"
/>
<command
Commandline="echo %s | ~/bin/vlnka.sed | ~/bin/podČarou.pl | ~/bin/markdown"
Description="Ábíčko"
Enabled="true"
Icon=""
Output="1"
/>
</action>
</actions>
Původní INI:
[Action_2] Automatic=true Description=Poznámky pod čarou Number of commands=2 Regexp=\[[^]]+\] [Action_2/Command_0] Commandline[$e]=echo %s | ~/bin/podČarou.pl Description=Přidat poznámky Enabled=true Icon= Output=1 [Action_2/Command_1] Commandline[$e]=echo %s | ~/bin/vlnka.sed | ~/bin/podČarou.pl | ~/bin/markdown Description=Ábíčko Enabled=true Icon= Output=1 [General] Number of Actions=6Mj. v tom XML nemusíš ručně číslovat sekce (v INI musí být název sekce globálně unikátní, jinak se ti to buď spojí do jedné nebo to spadne nebo nějaký nečekaný výsledek, takže musíš vždy projít celý soubor a ověřit, že se stejné číslo nevyskytuje jinde).
echo "něco" > soubor, co zmiňoval Heron výše, obecně nefunguje ani u toho INI.)
U konfigurace záleží na tom, aby to bylo přiměřeně složité a průhledné, chovalo se to korektně a mělo to rozumnou dokumentaci.
Jak příjemné XML soubory budou na omak je víc dané jmennými konvencemi, zvolenou hierarchií, a v neposlední řadě výchozím formátováním (které si uživatel může změnit klidně automatizovaným nástrojem, ale negativní emoce už v něm zůstane, protože „zasrané XML“).
Tady jde v první řadě o to, že pokud chci programovat init systém, je naprostý nesmysl specifikovat si vlastní formát, vyvíjet parser apod. Udělat to dobře není tak jednoduché a zkušený programátor to ví. Proto bych čekal, že použijí něco existujícího a ušetří si práci, a to i v případě, že jejich osobní preference jsou jiné. Tomu se říká profesionalita. Pokud nic použitelného opravdu neexistuje, mají to vyvinout jako samostatnou knihovnu, ne to vestavět do projektu, který má řešit úplně něco jiného.
No a druhá věc je, že při použití standardního formátu okamžitě můžeš užívat již existující nástroje. V případě XML to znamená zvýrazňování syntaxe, automatické formátování a případně i ten autocomplete, pokud je k dispozici schéma (jak jsi zmiňoval výše). Ale především už jsou k dispozici hotové parsery, takže pokud budu chtít ty konfiguráky nějak strojově zpracovávat v jiném nástroji než je systemd, jsou k dispozici dobré a otestované knihovny pro téměř každý jazyk. Na INI něco bude existovat taky, ale bude to plně kompatibilní s tím, co používá systemd? Nejsem si tak jistý. INI není – narozdíl od XML – standardizované.
Pozn.: To, že o tom mluvím, neznamená, že to na systemd považuji za nejzásadnější problém. Spíš je to jedna z mnoha věcí, která ukazuje, co je ve smýšlení tvůrců systemd špatně, a proč to není dobrý projekt. Kdyby tohle byla výjimka a všechno ostatní bylo v pořádku, tak je to asi zanedbatelné. Ale tak to není.
17.7.2017 09:33
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
Mimochodem, to echo "něco" > soubor, co zmiňoval Heron výše, obecně nefunguje ani u toho INI.Zajímavé.
Tohle se používá roky v různých návodech, nastavování souborů pomocí ansible lineinfile v podstatě taky nedělá nic jiného a funguje to. Funguje to díky tomu, že většina programů (se kterými jsem se setkal), bere jako validní až poslední nastavení daného klíče.
U složitějších případů, kdy záleží na sekci a na pořadí se echo používat praktiky nedá, ale to zase není případ základních systémových nastavení. (I když v systemd... škoda mluvit. Ale tam se zase dá použít override soubor.)
Funguje to díky tomu, že většina programů (se kterými jsem se setkal), bere jako validní až poslední nastavení daného klíče.
U složitějších případů, kdy záleží na sekci
Mimochodem, to echo "něco" > soubor, co zmiňoval Heron výše, obecně nefunguje ani u toho INI.
Ale tak důležité je, že je to:
Zajímavé.
Zajímavé.
Zajímavé.
Zajímavé.
17.7.2017 23:30
xkucf03 | skóre: 50
| blog: xkucf03
Funguje to díky tomu, že většina programů (se kterými jsem se setkal), bere jako validní až poslední nastavení daného klíče.
Nikdy by mě nenapadlo se na to spoléhat, přijde mi to fakt jako prasárna. To už je lepší ten konfigurák prohnat přes perl/sed a řádek s danou volbou nahradit (případně přidat).
Je celkem pochopitelné, proč to funguje – program v cyklu parsuje řádky a při tom plní nějakou hashmapu, nastavuje atributy objektu nebo volá metody… přičemž nevadí, když se něco zavolá dvakrát a platí poslední hodnota. Nicméně i kdyby toto chování bylo zaručené specifikací daného formátu, tak není dobré to využívat kvůli čitelnosti. Dodnes si pamatuji, jak mě kdysi potrápil Python, když v programu nějaký „copy&paste“ kolega deklaroval funkci se stejným názvem víckrát a použila se bez jediného varování ta pozdější.
18.7.2017 08:10
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
18.7.2017 09:45
xkucf03 | skóre: 50
| blog: xkucf03
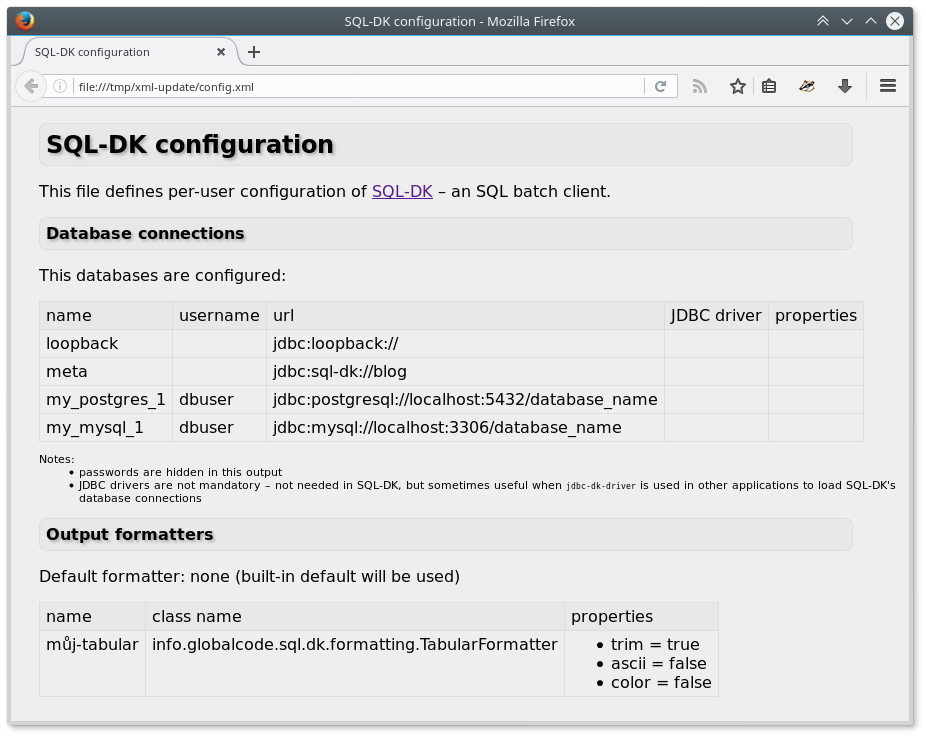
XML konfigurák:
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<?xml-stylesheet type="text/xsl" href="config.xsl"?>
<configuration xmlns="https://sql-dk.globalcode.info/xmlns/configuration">
<!-- Database Connections: -->
<database>
<name>loopback</name>
<url>jdbc:loopback://</url>
</database>
<database>
<name>meta</name>
<url>jdbc:sql-dk://blog</url>
</database>
<database>
<name>my_postgres_1</name>
<url>jdbc:postgresql://localhost:5432/database_name</url>
<userName>dbuser</userName>
<password>dbpass</password>
</database>
<database>
<name>my_mysql_1</name>
<url>jdbc:mysql://localhost:3306/database_name</url>
<userName>dbuser</userName>
<password>dbpass</password>
</database>
<formatter>
<name>můj-tabular</name>
<class>info.globalcode.sql.dk.formatting.TabularFormatter</class>
<property name="trim">true</property>
<property name="ascii">false</property>
<property name="color">false</property>
</formatter>
</configuration>
Vypsání hodnoty:
xmlstarlet select -N c=https://sql-dk.globalcode.info/xmlns/configuration -t -c "/c:configuration/c:database[c:name='my_postgres_1']/c:userName/text()" < config.xml dbuser
Aktualizace hodnoty:
$ xmlstarlet edit -P -N c=https://sql-dk.globalcode.info/xmlns/configuration --update "/c:configuration/c:database[c:name='my_postgres_1']/c:password/text()" --value jméno < config.xml > config2.xml && diff config.xml config2.xml 24c24 < <password>dbpass</password> --- > <password>jméno</password>Aktualizace hodnoty – zvláštní znaky:
$ xmlstarlet edit -P -N c=https://sql-dk.globalcode.info/xmlns/configuration --update "/c:configuration/c:database[c:name='my_postgres_1']/c:password/text()" --value 'nbusr123<xxx>omg&imho' < config.xml > config2.xml && diff config.xml config2.xml 24c24 < <password>dbpass</password> --- > <password>nbusr123&lt;xxx&gt;omg&amp;imho</password>
Co víc pro automatizaci potřebuješ?
Přijde mi lepší používat nástroj, který danému formátu rozumní, než s tím pracovat jen jako s textem a snažit se na správné místo nastřelit nějaký řádek a při tom doufat, že to nebude třeba uvnitř blokového komentáře nebo že nebude potřeba escapovat nějaké znaky atd.
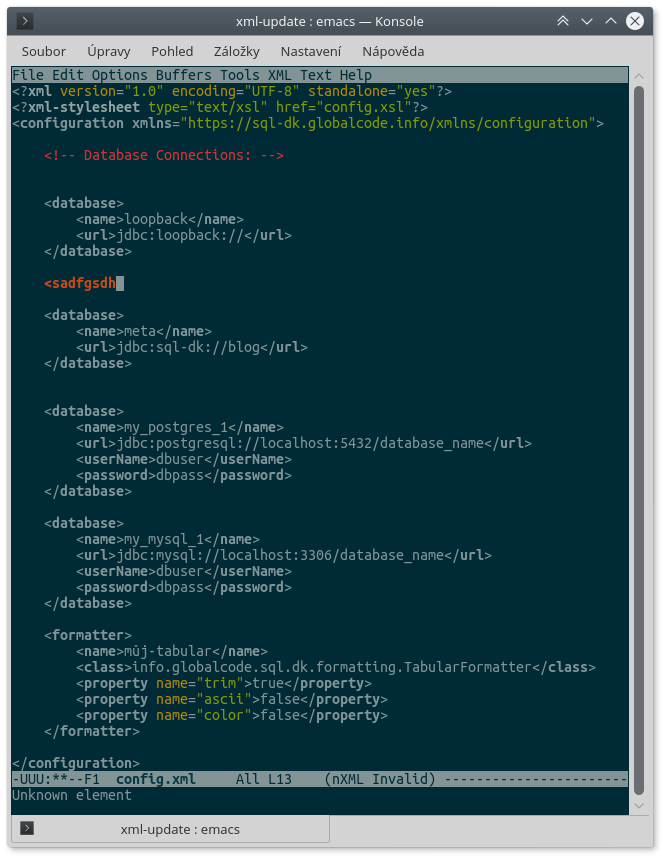
P.S. v příloze je pak ukázka Emacsu, který při editaci validuje, a Firefoxu, ve kterém je náhled konfiguráku naformátovaný připojenou XSLT šablonou.
18.7.2017 10:50
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
Přijde mi lepší používat nástroj, který danému formátu rozumníNejen formátu. Proto jsem pro příklad uváděl ten postconf, ten rozumí nejen formátu, ale taky hodnotám a jejich významu a může je validovat. Pokud by všechny služby měly něco podobného, byla by automatizace radost.
P.S. v příloze je pak ukázka Emacsu, který při editaci validuje, a Firefoxu, ve kterém je náhled konfiguráku naformátovaný připojenou XSLT šablonou.Super, děkuju za to ... Ted prosím to samé na 80x24 konsoli zdechlého serveru. Kvalita systému se nepozná podle toho, jak skvěle to běží, když to zrovna skvěle běží, ale pozná se podle toho, když totálně všechno selže. Takže je fakt zbytečné neustále posílat ukázky z případu, kdy všechno skvěle běží a admin má pohodlí a všechny luxusní nástroje.
Ted prosím to samé na 80x24 konsoli zdechlého serveru.To vám ten server zdechnul tak moc, že nefunguje ani vga=0x314 (nebo 317, 31a)?
18.7.2017 13:18
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
18.7.2017 16:12
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
), je tady navrhován způsob, který sice nepřináší nic moc nového, ale za to potřebuje grafické rozhranní a funkční sít. Aneb není nad další zbytečné závislosti.
18.7.2017 17:08
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
Jednou z podstatných věcí na unixu je to, že se zpracovávají obecné textové soubory, a k tomu je spousta nástrojů. Jenže se ukázalo, že čistě textové soubory strukturované maximálně na řádky často nestačí. Takže by bylo docela logické zopakovat znovu to samé (tj. sadu nástrojů pro práci s univerzálním formátem), akorát ne nad čistě textovými soubory, ale nad něčím strukturovanějším – a XML je v tomto směru zdaleka nejdál.Logické je využít prostředků, které jsou. Nikoliv vše zahodit, překopat a postavit to znovu. Pokud nějaká aplikace (a v této diskusi padla zatím jediná, uživatelská) vyžaduje hierarchickou konfiguraci, tak může využít stávajících prostředků (přirozeně se nabízí fs), nebo sama svou konfiguraci uložit svým způsobem.
Já nevidím žádnou výhodu v tom, že když mám připravenou nějakou šablonu konfigurace (ať jedné aplikace nebo celé stanice), musím pak řešit u každé aplikace zvlášť, že má jiný formát konfiguračního souboru a příslušné hodnoty do šablony musím dosazovat jiným způsobem. Kdyby všechny aplikace pro konfiguraci používaly stejný formát, to nahrazení provedu jednotným způsobem pro vše.To už jsem popisoval jinde. Nepokládám za správné automatizaci konfigurace dělat přímým zásahem do konfiguračních souborů, ideální by bylo, kdyby se každá služba uměla nastavit sama pomocí příkazů. Pokud je konfigurace služby v šabloně, tak to znamená, že je potřeba tu šablonu updatovat s každou další verzí programu. Nehledě na to, že pokud už teda ty šablonu mám, tak mě konkrétní formát nezajímá, protože automatizační nástroj tam stejně jen nastrká příslušné hodnoty a vygeneruje soubor.
Logické je využít prostředků, které jsou. Nikoliv vše zahodit, překopat a postavit to znovu.
Vždyť nástroje pro práci s XML tu jsou už spoustu let. A řada programů vznikla už v době existence těchto nástrojů a stejně znovu-vynalézají kolo, definují si vlastní formáty konfiguračních souborů a snaží se to dělat „jednoduše“, ale ve výsledku je to složitější a méně spolehlivé. Nesnažím se kritizovat několik desetiletí staré programy, které drží zpětně kompatibilní formáty, ale u nových programů mi přijde celkem škoda, že opakují staré chyby.
Pokud nějaká aplikace (a v této diskusi padla zatím jediná, uživatelská) vyžaduje hierarchickou konfiguraci, tak může využít stávajících prostředků (přirozeně se nabízí fs), nebo sama svou konfiguraci uložit svým způsobem.
Další příklad je třeba konfigurace sítě. Máš více rozhraní, ty mají více IP adres, pak máš množinu DNS serverů (případně nějaká VPN spojení, tam bude ta konfigurace ještě košatější) atd. Myslím, že to byl NetworkManager, kde se používá INI a kde jsem viděl, jak seznam více položek zapisují několika různými způsoby, takže bez dokumentace ani ránu, intuitivní to rozhodně není. A ani jeden z těch způsobů zřejmě není podpořen tím formátem (na úrovni něj je to jen textová hodnota nebo klíče s podobným názvem, nikoli pole/strom).
A zrovna více IP adres téhož rozhraní asi není věc, u které bys chtěl zapisovat hierarchickou strukturu formou FS (co IP adresa, to soubor).
Prostě potřeba vytvářet stromové struktury je ve většině aplikací a přijde mi lepší si vzít rovnou nějaký dostatečně robustní nástroj než to na začátku podcenit – dobastlených formátů jsem už viděl hodně – je na nich přímo vidět, jak si původně autor představoval, jak to bude jednoduché a pak se postupně objevovala potřeba přidat toto a tamto, povolit víc hodnot, přidat vnořenou strukturu nebo třeba „nečekané“ zjištění, že by uživatel mohl chtít používat něco jiného než ASCII, nebo mezery nebo znaky, které autor formátu používá jako oddělovače, nebo třeba delší texty na více řádek….
18.7.2017 18:06
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
.
Eric Steven Raymond se na XML dívá celkem pozitivně a za největší problém považuje:
The most serious problem with XML is that it doesn't play well with traditional Unix tools.
Což řeší třeba ten xmlstarlet.
Nebo Keith Packard:
Among the hardest things to get right in designing any text file format are issues of quoting, whitespace and other low-level syntax details. Custom file formats often suffer from slightly broken syntax that doesn't quite match other similar formats. Using a standard format such as XML, which is verifiable and parsed by a standard library, eliminates most of these issues.
18.7.2017 19:37
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
18.7.2017 21:31
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
18.7.2017 18:09
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
A zrovna více IP adres téhož rozhraní asi není věc, u které bys chtěl zapisovat hierarchickou strukturu formou FS (co IP adresa, to soubor).Na konfiguraci sítě používám
systemd-networkd a ta konfigurace je fakt jednoduchá. Ukázka jednoho rozhranní s hafo adresami:
[Match] Name=eth0 [Network] Address=91.214.x.y1/24 Gateway=91.214.x.1 Address=91.214.x.y2/24 Address=91.214.x.y3/24 Address=2a01:X::152:0000/64 Gateway=2a01:X::1 DNS=...Na tohle fakt není potřeba vymýšlet nic složitého. Pokud jsou potřeba routy, dodá se několik sekcí route. K NM bych se raději nevyjadřoval. Když jsem to používal naposledy, tak to po páté statické routě přestalo fungovat a když jsem se podíval, jak si to ukládá konfiguraci, tak se to snaží generovat network-scripts like konfiguráky a na první pohled každý vypadal jinak a byl jinak pojmenovaný. Nevím, co bylo za problém, čistá instalace CentOSu. Tohle v networkd udělali dobře. netdev je device, network je nastavení sítě. Konfiguráky pro brigde a bond vypadají vlastně stejně a konfigurace více adres nebo více rout je jednochuchá a přehledná.
Ukázka jednoho rozhranní s hafo adresami
Aha, takže tady pro změnu neplatí, že když se nějaký klíč objeví víckrát, použije se jen jeho poslední hodnota.
18.7.2017 18:35
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
Tj totéž jako u ip a. Pokud budeš opakovat ip a add ... pro různé adresy, na konci ti tam nestůstane jen jedna adresa (ta poslední), ale všechny. Pokud budeš opakovat postconf -e pro stejné klíče a různé hodnoty, zůstane ti jen ta poslední (která taky jiná, že).
18.7.2017 19:01
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
ip naházené do jednoho souboru, takže:
addr add ip1 addr add ip2 addr add ip3 route add default via ... route add dest via gwSnad to bylo soubor per iface (takže se všude nemuselo psát
dev).
Podobně jak se ukládá iptables-save, což jsou taky jen argumenty pro příkaz iptables.
Za networkd jsem rád, protože ta hrůza co byla v centos (network skripty, nebo interfaces v debu) se pro 30 ip na iface nedalo používat.
18.7.2017 19:18
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
Nikoliv vše zahodit, překopat a postavit to znovu.Asi nerozumím. Ta diskuze vyplynula ze systemd, který vznikl na zelené louce. Může si tedy zvolit cokoliv. Autoři se rozhodli zvolit vlastní nestandardizovaný INI-like formát a napsat si pro něj parser. Místo toho mohli použít to XML.
18.7.2017 23:54
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
 .
.
.gitignore. Taky je to vlastní formát, ale rozdíl je v tom, že s výjimkou ignorování prázdných řádků a komentářů se tam veškerá další komplexita odehrává až na jednotlivých hodnotách (řádcích) jako takových. Tam už fakt nevidím takový rozdíl, protože jestli se pak v kódu rozhodovat podle toho, co je tam za XML elementy/atributy, nebo podle speciálních tokenů (lomítka, hvěždičky) v té hodnotě, to už mi přijde prakticky totéž. Přínos XML tam moc nevidím, protože to vesměs nic moc neusnadní. Ty konfiguráky v systemd už mají sekce, klíče, zalamování hodnot do více řádků apod., což už je o dost komplexnější.
Pro pořádek – nevadilo by mi standardizované INI. XML osobně rád nemám, přijde mi příliš složité; ale opět, i jako v jiných případech – neznám lepší alternativu. (Mohl by být celkem fajn nějaký subset XML, který je plně kompatibilní s běžným XML a parsovatelný i normálním těžkotonážním parserem. Ale opět by bylo vhodné to udělat samostatně a ne jako součást jiného projektu, kterému se to zrovna hodilo.)
Logické je využít prostředků, které jsou. Nikoliv vše zahodit, překopat a postavit to znovu.Jak už jsem psal, to, že něco funguje, neznamená, že to nemůže fungovat lépe. S tím vaším přístupem bychom dosud žili v jeskyních.
Pokud nějaká aplikace (a v této diskusi padla zatím jediná, uživatelská) vyžaduje hierarchickou konfiguraci, tak může využít stávajících prostředků (přirozeně se nabízí fs), nebo sama svou konfiguraci uložit svým způsobem.Řeč není o hierarchické konfiguraci, ale o strukturované. A abych pravdu řekl, nemůžu si momentálně nějak vzpomenout na žádnou aplikaci, která by používala nestrukturovanou konfiguraci, měla jenom řádkový soubor. Napadají mne jenom samé strukturované konfigurace – Apache2, PostgreSQL, mySQL, DNS zónový soubor, KnotDNS, KnotDNS Resolver, nginx, ISC DHCP, OpenSSH, systemd, OpenRC konfigurace sítě… Vlastně jedna aplikace, která používá i řádkový konfigurační soubor, mne napadla – main.cf Postfixu.
Nepokládám za správné automatizaci konfigurace dělat přímým zásahem do konfiguračních souborů, ideální by bylo, kdyby se každá služba uměla nastavit sama pomocí příkazů.Já to vidím přesně opačně, co je možné definovat deklarativně, definovat deklarativně. Pak to můžu snadno validovat, verzovat, transformovat. Konfigurace pomocí příkazů přidává příliš mnoho stupňů volnosti, najednou závisí na pořadí, na prodlevách, nikdy se to nedá zopakovat za přesně stejných podmínek.
Pokud je konfigurace služby v šabloně, tak to znamená, že je potřeba tu šablonu updatovat s každou další verzí programu.Ta potřeba je úplně stejná, jako u konfigurace pomocí příkazů. Buď se použije pro novou vlastnost default, a není potřeba měnit nic, nebo to nějak nakonfigurovat musím, a pak musím změnit šablonu i posloupnost příkazů.
Nehledě na to, že pokud už teda ty šablonu mám, tak mě konkrétní formát nezajímá, protože automatizační nástroj tam stejně jen nastrká příslušné hodnoty a vygeneruje soubor.Jenže ten automatizační nástroj to neudělá sám od sebe, ten automatizační nástroj musí někdo naučit ten tří stý sedmdesátý sedmý formát „inspirovaný INI“, „inspirovaný XML“, „založený na JSON“ nebo „odvozený z YAML“.
18.7.2017 19:46
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
S tím vaším přístupem bychom dosud žili v jeskyních.Nikoliv. Jen nemám rád přepisování pro přepisování a nemám rád vymýšlení věcí, které už jsou dávno vyřešené. Tzn mě nechává chladným hromada hype za poslední roky, spokojím se programem, který je sice starší jak já, ale na rozdíl od těch hyper startup pokusů funguje. Pokud někdo přijde s něčím novým (resp. "novým" protože většina těch nových nápadů je taky starší jak já, ale konečně je na to hw to implementovat), tak to rád přijmu.
Řeč není o hierarchické konfiguraci, ale o strukturované.Ok, hierarchickou konfiguraci sem zatáhl Franta.
Já to vidím přesně opačně, co je možné definovat deklarativně, definovat deklarativně. Pak to můžu snadno validovat, verzovat, transformovat. Konfigurace pomocí příkazů přidává příliš mnoho stupňů volnosti, najednou závisí na pořadí, na prodlevách, nikdy se to nedá zopakovat za přesně stejných podmínek.V tom případě by asi chtělo opravit ten program, který se takto chová.
Buď se použije pro novou vlastnost default, a není potřeba měnit nic, nebo to nějak nakonfigurovat musím, a pak musím změnit šablonu i posloupnost příkazů.Jistě, ale nestarám se o ten konf. O to se postará ten program. Pro mě se rozhraní nezměnilo, jen tak přidám pár nových položek navíc.
Jenže ten automatizační nástroj to neudělá sám od sebe, ten automatizační nástroj musí někdo naučit ten tří stý sedmdesátý sedmý formát „inspirovaný INI“, „inspirovaný XML“, „založený na JSON“ nebo „odvozený z YAML“.Tak psal jsi o šablonách. Pokud už tu šablonu mám, tak je mi celkem jedno, v jakém je to formátu. Jinak právě proto jsem psal o konfiguračních programem dodávaných s těmi službami. Protože potom vůbec nemusím řešit ten formát a jen volám program s argumenty.
18.7.2017 20:38
xkucf03 | skóre: 50
| blog: xkucf03
Jistě, ale nestarám se o ten konf. O to se postará ten program. Pro mě se rozhraní nezměnilo, jen tak přidám pár nových položek navíc.
A tomu programu budeš předávat jen dvojice klíč=hodnota? Jak třeba změníš nějakou položku kdesi uvnitř konfiguračního stromu? Např. chci přidat IP adresu k pátému síťovému rozhraní nebo k rozhraní s MAC adresou 00:16:3e:2d:49:ba. Použije se tečková notace? Jak tam dostanu tu MAC adresu? Vymyslí se nějaká proprietární obdoba jazyka XPath? Nebo to bude vyžadovat vícenásobnou interakci a příkazy/jazyk specifické pro daný program (nejdřív si vypíšu seznam síťových rozhraní a nějaká jejich ID a pak zavolám příkaz na přidání IP adresy k danému ID)? A jak tomu příkazu předám strukturovaná data? Opět vícenásobná interakce? Přidám síťovku, pak dalším voláním přidám IP adresu. Něco půjde udělat pomocí více parametrů na příkazové řádce, ale pořád je to jen plochá struktura (pole textových řetězců).
18.7.2017 20:56
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
A tomu programu budeš předávat jen dvojice klíč=hodnota?Ne, proč? Tomu programu budeš předávat to, co ten program očekává. Například u balíčku
iproute2 by mohl být program něco jako iptables-save a iptables-restore, který by si mohl uložit resp načíst vlastní konfiguraci. Takže po sérii příkazů ip něco by mohlo následovat ip-save a bylo by uloženo. Při bootu by se to načetlo. Nebo by program mohl mít třeba --permanent a rovnou by si to ukládal do konfigu.
ip --permanent addr add ...
Pravidla netfilteru taky nastavuješ pomocí několika volání příkazu iptables s různými parametry.
Např. chci přidat IP adresu k pátému síťovému rozhraní nebo k rozhraní s MAC adresou 00:16:3e:2d:49:baNic blbějšího mě nenapadlo, tak co třeba fiktivní program:
network-set --match-mac '00:16:3e:2d:49:ba' --set-ip 1.2.3.4/5Pravda, příkaz ip je dost nízkoúrovnový, takže by se celkem hodilo nad ním napsat nějaký funkční sítový manager
, který by se dal snadno konfigurovat pomocí naznačených příkazů.
Nebo by program mohl mít třeba --permanent a rovnou by si to ukládal do konfigu.A ten konfig zase musí mít nějaký formát. A samozřejmě, ž eje lepší, když je to univerzální formát, než když si programátor vymyslí svou vlastní tisící variaci na konfigurační soubor.
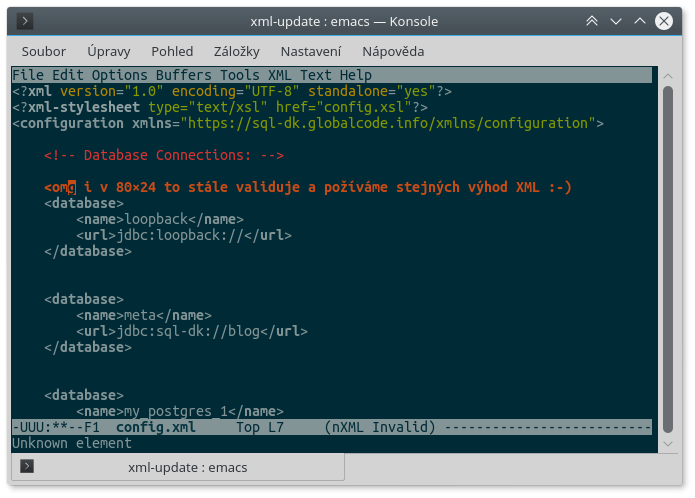
Jaké grafické rozhraní? Jaká síť? Emacs je editor pro textový režim (existuje i GUI verze, ale tu nepoužívám). Tady máš to okno zmenšené na 80×24:
File Edit Options Buffers Tools XML Text Help
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<?xml-stylesheet type="text/xsl" href="config.xsl"?>
<configuration xmlns="https://sql-dk.globalcode.info/xmlns/configuration">
<!-- Database Connections: -->
<omg i v 80×24 to stále validuje a požíváme stejných výhod XML :-)
<database>
<name>loopback</name>
<url>jdbc:loopback://</url>
</database>
<database>
<name>meta</name>
<url>jdbc:sql-dk://blog</url>
</database>
<database>
<name>my_postgres_1</name>
-UUU:**--F1 config.xml Top L7 (nXML Invalid) --------------------------
Unknown element
Oproti INI tam máš sice většinou odsazení, ale na 80 znaků se toho i s odsazením vejde celkem dost (dřív se na tom běžně programovalo, vejde se tam několik úrovní zanoření IFů, FORů…). BTW: když použiješ tabulátory, tak si můžeš nastavit jejich zobrazovanou šířku třeba jen na dva znaky a vejde se ti tam toho víc (jedna z výhod tabulátorů).
A xmlstarlet je příkaz pro příkazovou řádku (překvapivě), opět nepotřebuješ žádné GUI ani síť.
Občas se něco rozbije tak, že máš jen sériový port (nebo to zařízení prostě nemá obrazovku), ale i po něm se dají přenášet soubory (viz XMODEM – už před 40 lety…), takže i s rozbitou sítí a bez obrazovky můžeš aplikovat ten Filipův přístup, kdy si soubory přeneseš na nějaký nerozbitý počítač, tam je upravíš a pak přeneseš zpátky.
Nicméně většinou to nebude tak rozbité, abys nemohl upravit nějaké to XML lokálně.
P.S. ten nástroj typu postconf, po kterém voláš, může být v případě XML formátu jen jednoduchý skript třeba nad xmlstarlet, který může udělat nějaké předběžné validace hodnot a/nebo následně prohnat upravené XML validátorem (a pokud prošlo, tak se jím nahradí původní soubor). Opravdu není potřeba znovu-vynalézat kolo při psaní každého programu.
P.P.S. vi, ve kterém nefungují kurzorové klávesy, Backspace atd., je k vzteku bez ohledu na to, jaký formát pomocí toho edituješ. Což je asi důvod, proč se ty konsole (obrazovka+klávesnice) do racku dělají tak masivní :-)
18.7.2017 17:39
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
Jsou tam vidět celé tři klíče a dvě hodnoty. Skvělé.
Jo a asi to není well-formed, tak omg není uzavřený
Nic, asi toho necháme. Jestli tohle někdo chce editovat, nechť je ctěná libost.
Ta chyba je tam schválně – zobrazuje se to červeně a dole ti to píše „Unknown element“ podle toho, kam najedeš kurzorem.
Prázdné řádky a komentáře zabírají stejně místa bez ohledu na formát (v INI by zabíraly stejný počet řádků).
A není to prosté přiřazení klíč=hodnota, ale struktura, ve které je více atributů (což akorát na tomto příkladu není vidět, jinde jsou i vnořené strukury – konfigurace proxy pro dané DB spojení).
Pokud bys chtěl zapisovat jen klíč=hodnota, tak to ti i v XML zabere přesně jeden řádek:
<klíč1>hodnota1</klíč1> <klíč3>hodnota1</klíč2> <klíč3>hodnota1</klíč3>
Případně můžeš na jeden řádek psát i jednoduché struktury:
<struktura id="s1" atribut1="1" atribut2="2" atribut3="3"/> <struktura id="s2" atribut1="1" atribut2="2" atribut3="3"/> <struktura id="s3" atribut1="1" atribut2="2" atribut3="3"/>
echo, ale nebude ti tam fungovat ten xmlstarlet nebo v nejhorším scp, to se snažíš říct?
17.7.2017 00:50
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
17.7.2017 23:50
xkucf03 | skóre: 50
| blog: xkucf03
Zatim jste neilustroval nic jineho nez vase osobni preference pro XML.
Nejde o preferenci XML ale o preferenci nějakého (meta)formátu, pro který jde vytvářet strojově čitelnou specifikaci a existují pro něj dostupné nástroje.
Nemůžu za to, že XML je často nejvhodnější nebo jediná volba. (taky z toho nejsem úplně nadšený a dovedu si představit pro některé úlohy i vhodnější formáty)
kdyz prave XML(-like) komponenty jsou pomerne castym zdrojem zdrojem cele rady CVE v aplikacich.
XML je tady už dost dlouho a XML parsery (a obecně nástroje) jsou po těch letech už odladěné. Což se ale často nedá říct o nástrojích pro více či méně proprietární formáty, které si napsal někdo na koleně v rámci jiného projektu.
Viz třeba tahle chyba, což je souhra nebezpečného nízkoúrovňového jazyka a rádoby jednoduchého (bohužel jen na první pohled) formátu (v tomto případě CSV), pro který se někdo rozhodl napsat generátor, místo aby použil nějaký hotový a ve svém programu se soustředil jen na jeho byznys logiku.
Nemůžu za to, že XML je často nejvhodnější nebo jediná volba.+1
18.7.2017 00:19
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
18.7.2017 01:02
xkucf03 | skóre: 50
| blog: xkucf03
Zlo je v podstatě všechno, ideální by bylo, kdyby stačilo, že si konfiguraci jen pomyslíš a počítač to vycítí a sám si to zapamatuje. :-) Ale zpět na zem – jaké máme tedy další reálné možnosti?
JSON si můžeme rovnou škrtnout, protože neumí komentáře. YAML je v mnohém snad ještě složitější než XML, i když na psaní je celkem fajn (chvíli trvá, než se do toho člověk dostane, a většina lidí ho nezná, ale pokud to překonáš, tak se to asi dá). INI je poměrně dobrý, ale velice brzy narazíš na jeho limity (jen jedna úroveň sekcí – hierarchii je potřeba tam nějak dobastlit) a navíc není standardizovaný resp. každý používá trochu jiný formát. To trochu vylepšili v KDE a GNOME, kde jsem viděl nějakou trochu použitelnou specifikaci a implementaci. Jenže když to pak ostatní (např. systemd) nepoužívají a radši si vytvoří vlastní „INI formát“, tak to je potom těžké.
18.7.2017 03:05
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
0day je pro User neplatná hodnota – a to zcela libovolný editor, který umí validovat XML podle XSD, nemusel by nic vědět o jednotkových souborech.
18.7.2017 08:18
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
18.7.2017 10:27
xkucf03 | skóre: 50
| blog: xkucf03
Proč by měl existovat jeden formát na vše?
Nemusí být striktně jen jeden, ale stačí několik málo (třeba 2-3) (meta)formátů, které by pokryly potřeby aplikací napříč GNU/Linuxovým desktopem, serverem i malými zařízeními typu modemy. Opravdu těch formátů nemusí být desítky nebo stovky.
A důvod? Můžeš používat jednotné nástroje, neplýtvá se energií na psaní specifických programů a specifických parserů/generátorů. Lidé se to lépe naučí a budou dělat méně chyb – protože budeš používat všude stejný formát (resp. třeba tři formáty pořád dokola), budeš s jistotou vědět, kde psát jaké uvozovky, závorky, jak se escapují znaky, jak se píše pole více hodnot, komentáře, jak se dělá stromová struktura…
Mohli bychom mít třeba tři formáty:
A k tomu tři sady nástrojů a lidi s dobrou znalostí.
Nehledě teda na to, že hierarchii tady máme už od počátku věků a říká se tomu fs.
To je pravda. Režie souborového systému je dostatečně malá na to, aby to šlo používat. Taky se to dá dobře verzovat a už ve verzovacím systému vidíš, kde v hierarchii došlo ke změně a taky se tím vyřeší část konfliktů, když to spravuje víc lidí. Ale bohužel se to moc často nepoužívá. Nebo pak lidi nadávají, že je konfigurace GRUBU rozpadlá do několika souborů a výsledný konfigurák se z nich generuje.
Mimochodem, napsal jsem nástroj, který čte různé alternativní formáty (INI, JSON, souborový systém…) a navenek se chová jako SAX parser a umožňuje s těmito formáty pracovat jako s XML (vypsat jako XML, dělat XPath dotazy…). Viz Alt2xml + prezentace v příloze.
Není to hotové a pro produkční nasazení zralé, ale přijde mi to jako zajímavá myšlenka: vložit mezi program a jeho konfigurák abstrakci, která to odstíní → program pak pracuje s nějakými logickými strukturami, ale uživatel si může psát konfiguraci v různých formátech (resp. nejen konfiguraci ale jakákoli vstupní data).
18.7.2017 11:04
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
Nemusí být striktně jen jeden, ale stačí několik málo (třeba 2-3) (meta)formátů, které by pokryly potřeby aplikací napříč GNU/Linuxovým desktopem, serverem i malými zařízeními typu modemy. Opravdu těch formátů nemusí být desítky nebo stovky.Tak abych řekl pravdu, ve své praxi se zcela vyjímečně potkávám s něčím jiným, než jsou ini like konfigurační soubory. Asi by se něco našlo, ale teď si fakt nevybavuju nic, co bych ručně editoval a bylo to něco jiného než klíč=hodnota. Ostatně to nemusí být zrovna ini, může se jednat třeba o BASH snippet, který se potom (source) includuje do nějakého skriptu. Nebo python. Vypadá to všechno stejně (klíč=hodnota) a admin to nemusí příliš řešit. Dá se to dobře zpracovat strojově pomocí základních příkazů (grep, sed, awk). Spíš mě trochu připadá, že se řeší problém, který reálně neexistuje. Tohle se používá mnoho let a příliš problémů s tím není.
18.7.2017 11:13
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
Viz Alt2xml + prezentace v příloze.OT: Nešlo by tam místo nedůvěryhodného StartSSL/WoSign certifikátu dát Let's Encrypt?
18.7.2017 13:25
xkucf03 | skóre: 50
| blog: xkucf03
Mám to na seznamu úkolů a celkem vysoko, tak snad už brzy…
Na ini like souborech nevidím nic špatného.Řeč byla o tom, že init systém si nemá co navrhovat a psát parser pro vlastní formát. Ale hezký pokus.
Pokud je jeden klíč použitý pro x různých věci, mají to být reálně x klíčů.To jsem psal ve vedlejší diskuzi o tom bugu. Ano, mají to být dva klíče.
XML se blbě čte a blbě píše. Myslím pro člověka. To by k tomu byl potřeba ještě spešl editor.Stačí obyčejný textový editor. Čitelnost bude záležet na struktuře toho XML (počet odsazení, používání/nepoužívání atributů apod.). Nicméně – pokud chybí rozumný standardizovaný formát pro zápis konfiguračních souborů, možná je na čase jej vytvořit. Ale rozhodně ne v rámci init systému. Můj názor je ovšem takový, že textové soubory jsou zastaralé a bylo by lepší se jich úplně zbavit (jak pro zápis konfiguráků, tak zdrojových kódů).
17.7.2017 02:23
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
[...] ale to je podle vas spatne, nebot init nema co navrhovat a psat parser pro vlastni format. Ale zaroven na strane druhe tady navrhujete OpenRC, kde runscript pouzivaji naprosto nestandardni format, nedeklarativni, jakousi smes shell skriptu a deklarovanych promenych, kterou je vpodstate nemozne rozumne parsovat externimi nastroji.Viz poznámka výše:
Pozn.: To, že o tom mluvím, neznamená, že to na systemd považuji za nejzásadnější problém. Spíš je to jedna z mnoha věcí, která ukazuje, co je ve smýšlení tvůrců systemd špatně, a proč to není dobrý projekt. Kdyby tohle byla výjimka a všechno ostatní bylo v pořádku, tak je to asi zanedbatelné. Ale tak to není.OpenRC navrhuji proto, že v současnosti neznám lepší alternativu. Upstart už je nevyvíjený. Než se objeví něco nového, co by bylo otestované a produkčně použitelné, bude trvat roky. A v mezičase bych raději používal to OpenRC než systemd.
17.7.2017 03:25
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
OpenRC navrhuji proto, že v současnosti neznám lepší alternativu.To je spise vas problem. Systemd ma obcas bugy, ale alespon je pomerne promptne opravuji a pres vsechny reci se ukazuje, ze Lennart si nemuze delat v systemd co chce. OpenRC ma roky nevyresene fundamentalni bugy, jako treba nespolehlivy parallelni start, viz treba zde, kdy detektor loopu od Dmitry Yu Okunev problem nevyresil. Pokud by to nebyl okrajovy init mimo mainstreamove nasazeni ve vsech noznych situacich, tak by se velmi rychle ukazaly jeho limity.
17.7.2017 08:47
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
Možná to bude tím, že paralelní boot je experimentální fíčura, která je stále ve vývoji.Tak co dela rozbita featura v produkcnim kodu, bez jakehokoliv varovani mimo rc.conf, kde dlouhe roky zadne varovani nebylo? Parallelni start je jedna z hlavnich vlastnosti systemd a to ze OpenRC to ani po deseti letech neni schopno vubec vyresit o necem svedci. Manualove stranky OpenRC a a cela dokumentace ve srovnani se systemd neexistuji. Pokud se zacnem bavit o parseru runscript, tak tam se v podstate mimo primitivni osetreni rc_conf zadna validace neceho nekona a zpusti se cokoliv, takze riziko neocekavaneho chovani je oproti systemd vyssi.
strstrip, co volají v tom parseru, neořízne a po spuštění systemctl daemon-reload se podívej do logu. Píše to: „Assignment outside of section. Ignoring.“. Ale samozřejmě se to spustí. Dokumentace (man systemd.unit) o kódování i o bílých znacích mlčí.
Je to korektní chování? Prostě narazím na nějaký token, který neznám, tak to asi bude přiřazení. Ani tam nemusí být rovnítko. Sorryjako.
Takhle se parsery fakt nepíšou.
17.7.2017 08:45
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
Prostě narazím na nějaký token, který neznám, tak to asi bude přiřazení.Zajimave. Muzete sem dat priklad unity, ktera se takto chova? Ja to nejsem schopen reprodukovat a pokud pouziji \u2003 a zklohnim kodovani v radce, dostanu vedle rady "Assignment outside of section. Ignoring." jeste kupu
Jul 17 07:44:18 builder systemd: test-abc.service lacks both ExecStart= and ExecStop= setting. Refusing. Jul 17 07:44:18 builder systemd: [/etc/systemd/system/test-abc.service:1] Missing '='.Kodovani unit by melo byt v dokumentaci specifikovano, ale ocekaval bych podporu pouze pro UTF8.
# less nasrat.service NASRAT [Service] ExecStart=/bin/echo ExecStop=/bin/echo # systemctl daemon-reload # systemctl status nasrat ● nasrat.service Loaded: loaded (/usr/lib/systemd/system/nasrat.service; bad; vendor preset: enabled) Active: inactive (dead) Jul 17 18:04:50 desktop systemd[1]: /usr/lib/systemd/system/nasrat.service:1: Assignment outside of section. Ignoring.
18.7.2017 00:16
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
18.7.2017 00:36
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
18.7.2017 03:02
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
18.7.2017 02:59
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
17.7.2017 08:38
xkucf03 | skóre: 50
| blog: xkucf03
Mluvime o jednoduchych INI souborech, kde napsani bezpecneho parseru je zalezitost jednoho dne - viz conf-parser.h a conf-parser.c. Kvuli temto dvema souborum nema smyslu pridavat run time zavislosti na dalsich projektech.
Nechci hodnotit kvalitu kódu, nicméně tohle je přesně případ, kdy to mělo být modulární a funkce oddělená do samostatné knihovny a repozitáře. (když už tedy nemohl/nechtěl použít existující knihovnu) Tyhle funkce by se pak mohly klidně staticky zakompilovat jak do systemd, tak by je šlo použít v jiných programech, které např. generují konfiguráky, nebo je někde zobrazují nebo v nich umí vyhledávat atd. O tom, že by měla existovat specifikace toho formátu (a ne jen implementace) ani nemluvě.
17.7.2017 11:49
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
18.7.2017 00:17
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
18.7.2017 00:39
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
18.7.2017 01:05
xkucf03 | skóre: 50
| blog: xkucf03
Bohužel je to problém mnoha distribucí, do kterých se systemd rozšířil.
16.7.2017 23:30
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
16.7.2017 23:20
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
Představ si, že bys chtěl udělat audit veškerého kódu, aby tě nemohl někdo napadnout.Pracuji na projektech podle ISO 26262, v tride ASIL B/C/D, a ted zaciname i delat nove penetracni testy, takze o tom neco malo vim. U certifikovanych systemu se posuzuje system jako celek, vcetne kodu, pouzitych nastroju, vyvojoveho procesu a SW/HW architektury. V kontextu veci si troufam tvrdit, ze vase argumentace proti zmene build systemu je absurdni a pokud byste chtel obstat v podobne tride certifikaci a auditu, pocet pouzivanych nastroju bystem musel podstatne rozsirit.
Realtime? To jako opravdu? Chceš pomocí systemd řídit robota nebo nějaké CNC?Nechci. Staci mi videt problemy ktere vedou k navrhu veci jako kdbus/bus1, a vedle toho ze programy ze systemd kolekce zpracovavaji i systemove udalosti, kde by latence mela byt pokud mozno minimalizovana.
kromě té integrace s C API tam je totiž hromada kódu jako parsování konfiguráků, formátování výstupů, vyhodnocování závislostí/pořadí, které by se daleko lépe psaly v něčem vyšším, než je C.No a co? To ze nektere casti by bylo vhodnejsi napsat v jinem jazyce, neznamena ze je to lepsi jazyk pro celek. Kdyz jsme u te bezpecnosti, ukazte mi ktery vas "vysokourovnovy" jazyk mimo C/C++ ci Ada ma dostupne kompilatory na vice platformach certifikovane pro ASIL C/D ci SIL-3/4?
Mimochodem, co se týče množství kódu ...Srovnavate projekty s rozdilnym ramcem pusobnosti, hrusky a jabka. Co se tyce mereni komplexity, LOC je velmi slaba mira, a systemy budou z podstaty veci komplexnejsi a komplexnejsi.
Pracuji na projektech podle ISO 26262, v tride ASIL B/C/D…
Automobilový průmysl neznám, ale pokud např. do bankovního softwaru zatáhnu novou knihovnu, tak tím dávám jejímu autorovi1 možnost ovládnout celý výsledek2 a i možnost spouštět libovolný kód na počítačích vývojářů 3, protože v rámci sestavení (typicky Mavenem) si můžou pustit vlastní příkazy na tvém počítači.
Takže musíš použít buď něco dostatečně malého, co si dokážeš zkontrolovat sám (pár stovek nebo pár tisíc řádků se ještě v pohodě dá) nebo dostatečně důvěryhodného a rozšířeného (GNU, Apache, Spring, Sun/Oracle, PostgreSQL…), co používají víceméně všichni kolem, takže i když tam chyba bude, tak sice máš problém, ale nejsi na tom hůř než zbytek trhu (konkurence, zákazníci, dodavatelé, stát…).
A i u těch důvěryhodných a rozšířených knihoven a frameworků je vhodná určitá střídmost – snižuješ tím možná rizika.
programy ze systemd kolekce zpracovavaji i systemove udalosti, kde by latence mela byt pokud mozno minimalizovana
Taková komunikace by měla být asynchronní a latence či výpadek konzumenta (zde systemd) nějaké fronty zpráv by neměla brzdit toho, kdo dané zprávy/události generuje.
Srovnavate projekty s rozdilnym ramcem pusobnosti, hrusky a jabka. Co se tyce mereni komplexity, LOC je velmi slaba mira
LOC je sice hodně hrubá metrika, ale pro to, aby si člověk udělal řádovou představu o komplexitě daného softwaru poslouží docela dobře. Druhá věc jsou pak nepřímé závislosti, na kterých se člověk stane závislým taky, pokud se daný software rozhodně použít. Takže si sečti řádky kódu dané knihovny + řádky jejích závislostí, vynásob to nějakými koeficienty týkajícími se použitých jazyků a vynásob to koeficienty důvěryhodnosti a rozšířenosti daných knihoven… a máš hrubou představu o rizicích, která tě čekají, když danou knihovnu použiješ
a systemy budou z podstaty veci komplexnejsi a komplexnejsi
Pokud budeme jako vývojáři jen nabalovat další a další kód a lepit na sebe další a další vrstvy, tak ano. Ale nemyslím si, že je to dobrá cesta, ani že je to nevyhnutelné.
Spousta programů je v principu dostatečně jednoduchých na to, aby šly v pohodě napsat v jednom jazyce, jen se standardní knihovnou a trochou disciplíny a rozumného návrhu. Dodatečné knihovny a frameworky samozřejmě mají smysl, ale měly by mít dostatečně jemnou granularitu, aby každý mohl použít jen podmnožinu, kterou potřebuje, a nebyl nucen si do systému zatáhnout hromadu dalšího nesouvisejícího kódu.
Jednalo se pouziti jineho build systemu pro sestaveni systemd a mam pocit, ze vam uchazi podstata. Naprosta vetsina kompilovacnich cyklu (>99%) se dela behem vyvoje, trojice Edit->Compile->Debug a v praxi mluvime o desitkach kompilaci denne na vyvojare a pak v ramci CI pri overovani komitu.
A jsme zase u toho návrhu a modulárnosti. Pokud budu chtít dělat na nějaké malé součásti systemd např. na jednom z mnoha démonů, tak bych měl mít možnost si stáhnout jen jeho kód + nějaké hlavičkové soubory / rozhraní (přes které je to propojené se zbytkem systému) a měl bych mít možnost si samostatně kompilovat jen tuhle jednu malou část. A měl by z toho vypadnout .deb/.rpm/… balíček, obsahující tuto komponentu, který si mohu nainstalovat a otestovat ve svém systému, kde mám jinak normální distribuční verzi zbytku systemd (pokud zrovna nedošlo k nekompatibilní změně rozhraní, ale to by se nemělo stávat moc často a když už, tak by to mělo být vidět na sémantickém verzování).
P.S. „One of my most productive days was throwing away 1000 lines of code.“ – Ken Thompson
[1] resp. lidem kteří do jejího kódu můžou zasahovat, včetně těch, kdo mají přístup k distribučním serverům atd.
[2] např. internetové bankovnictví nebo nějakou vrstvu uvnitř banky
[3] např. jim ukrást soukromé klíče nebo hesla
Automobilový průmysl neznámIt boots? Ship it.
Pokud budeme jako vývojáři jen nabalovat další a další kód a lepit na sebe další a další vrstvy, tak ano.Projekt je potřeba co nejrychleji doprasit do stavu popsaném v předchozím odstavci.
18.7.2017 10:49
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
It boots? Ship it.Boot a shutdown jsou jedny z nejtezsich casti. Standartni pozadavky pro boot jsou plna funckcionalita pod 2s (casto legal requirement) v teplotnim rozsahu -40C az 125C, v situaci kdy auto startuje a napeti napajeni velmi kolisa (>7.5V), kde se ve stejnou dobu se inicializuje cela vnitrni sit (CAN/Flexray/Ethernet) a probiha handshake s dalsimi jednotkami. Predprodukcni testy mohou vyzadovat nekolik tisic uspesnych bootu s korektnim casovanim v celem operacnim rozsahu a mohou trvat nekolik dni.
18.7.2017 10:46
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
I když jsem velký příznivec Javy, tak init bych v ní mít nechtěl. Leda nějaký pro specializované/experimentální použití (napsat si vlastní Java OS).
Na jednu stranu by se v tom psalo pohodlně, ale je to přeci jen příliš mnoho kódu, který by pod tím běžel, a taky by se v tom těžko dělaly věci jako socket activation nebo práce s cgroups.
To už radši něco typu Go nebo Rust. Případně nějaký vyšší jazyk, který má minimalistické běhové prostředí a zároveň umožňuje nízkoúrovňovou práci se sokety, procesy atd. V javě sice máme JNI a JNA, ale stejně mi na to moc nesedí (i když jiné jazyky asi budou mít udělané to lepení vlastního a nízkoúrovňového/nativního kódu dost podobně). Nakonec z toho možná vychází nejlíp nějaká rozumná podmnožina C++ (jestli něco takového tedy existuje).
I když jsem velký příznivec Javy, tak init bych v ní mít nechtěl.V pořádku. Já taky ne, ale nemohl jsem si nechat ujít tak skvělou příležitost vyprovokovat flame.
Leda nějaký pro specializované/experimentální použití (napsat si vlastní Java OS).Nad tím jsem přemýšlel, ale byl by to časově moc náročný koníček. Kdysi jsem si vlastní JVM napsal, ale v high-level jazyce a spíš jako prototyp (nebyla to kompletní implementace). Tady by JVM sloužila jako kernel. Koncepčně je to zajímavé (vše by bylo objektové atp.), ale asi do toho vidím až moc na to, abych sebral nadšení a optimismus se do toho pouštět. Pokud už nad něčím takovým uvažovat, snad by bylo lepší použít linuxový kernel a OpenJDK a stavět až nad tím. Pak místo FS driveru napíšeš jen nějaký wrapper v Javě, tj. můžeš si udělat jaké API chceš (např. tě nic nenutí mít FS, který umožňuje jeden soubor mapovat na právě a pouze jednu cestu, což je největší defekt současných FS), a dosáhneš svého bez nutnosti se zaobírat nízkoúrovňovou komunikací s hardwarem apod. Kromě toho, že už to udělali jiní a líp, by to mělo alespoň nějakou šanci na reálnou použitelnost. Psát si moderní systém from-scratch je na dnešním hardwaru IMO v jednom člověku neproveditelné. Ale všestraně lepší by bylo napsat JVM s pořádnou správou paměti. Designová rozhodnutí za GC v Javě jsem dodnes nepochopil. Nechat běžet jeden a víc threadů, aby uvolňovaly paměť, je prostě absurdní a zdráhám se uznat, že to je korektní návrh.
můžeš si udělat jaké API chceš (např. tě nic nenutí mít FS, který umožňuje jeden soubor mapovat na právě a pouze jednu cestu, což je největší defekt současných FS)
Vždyť máme pevné a symbolické odkazy – nebo myslíš něco jiného? Akorát nejde standardně udělat pevný odkaz na adresář.
 15.7.2017 10:41
Grunt | skóre: 23
| blog: Expresivní zabručení
| Lanžhot
15.7.2017 14:32
Grunt | skóre: 23
| blog: Expresivní zabručení
| Lanžhot
15.7.2017 10:41
Grunt | skóre: 23
| blog: Expresivní zabručení
| Lanžhot
15.7.2017 14:32
Grunt | skóre: 23
| blog: Expresivní zabručení
| Lanžhot
A more complete example would need a more complete runtime, either by implementing the native and JVM parts of a class library or by implementing the stubs that are generated for missing dependencies.Nedalo by se to nějak slinkovat s implementací nativních metod z OpenJDK? Měly by to být normální sdílené knihovny. Asi tam tedy budou existovat nějaké výjimky a některé nativní metody budou zahrnuty přímo v JVM (např.
System.gc()).
Mimochodem, před nějakým časem jsem si dělal drobnou analýzu a počet nativních metod v celém OpenJDK mi vyšel něco kolem jednoho tisíce (teď už nevím, jestli včetně AWT/Swingu, nebo s ním).
teď už nevím, jestli bez AWT/Swingu, nebo s nímAle myslím, že to bylo s ním...
K tomu, abychom psali ve vyšším a bezpečnějším jazyce?
15.7.2017 19:36
Grunt | skóre: 23
| blog: Expresivní zabručení
| Lanžhot
15.7.2017 20:35
Grunt | skóre: 23
| blog: Expresivní zabručení
| Lanžhot
root@whatever:~# apt-get --assume-no autoremove openjdk-8-jre-headless Reading package lists... Done Building dependency tree Reading state information... Done The following packages will be REMOVED: ca-certificates-java cups-common java-common libavahi-client3 libavahi-common-data libavahi-common3 libcups2 liblcms2-2 libnspr4 libnss3 libnss3-nssdb openjdk-8-jre-headless 0 upgraded, 0 newly installed, 12 to remove and 0 not upgraded. After this operation, 107 MB disk space will be freed. Do you want to continue? [Y/n] N Abort. root@whatever:~# apt-get --assume-no autoremove python3 Reading package lists... Done Building dependency tree Reading state information... Done The following packages will be REMOVED: apparmor apport byobu command-not-found dh-python distro-info-data landscape-common language-selector-common libpython3-dev libpython3.5-dev lsb-release pastebinit plymouth-theme-ubuntu-text python-pip-whl python3 python3-apport python3-apt python3-bs4 python3-chardet python3-commandnotfound python3-dbus python3-debian python3-dev python3-distupgrade python3-gdbm python3-gi python3-html5lib python3-lxml python3-newt python3-pip python3-pkg-resources python3-problem-report python3-pycurl python3-requests python3-setuptools python3-six python3-software-properties python3-systemd python3-update-manager python3-urllib3 python3-wheel python3.5-dev software-properties-common ssh-import-id ubuntu-minimal ubuntu-release-upgrader-core ubuntu-standard ufw unattended-upgrades update-manager-core update-notifier-common 0 upgraded, 0 newly installed, 51 to remove and 0 not upgraded. After this operation, 75.8 MB disk space will be freed. Do you want to continue? [Y/n] N Abort.Stojí za zmínku, že
rt.jar má 62 MB a nic ti nebrání ho pro specializované použití ořezat, tj. vyházet z něj nepotřebné věci. Byl by na to potřeba tool, který stanoví veškeré přímé i nepřímé závislosti aplikace (ze speciálních případů je třeba dát pozor alespoň na věci jako Class.forName(), případný další dynamický loading už si musí ošetřit autor sám), ale je to proveditelné.
15.7.2017 22:21
Grunt | skóre: 23
| blog: Expresivní zabručení
| Lanžhot
15.7.2017 22:52
Grunt | skóre: 23
| blog: Expresivní zabručení
| Lanžhot
15.7.2017 23:29
Grunt | skóre: 23
| blog: Expresivní zabručení
| Lanžhot
16.7.2017 19:46
Grunt | skóre: 23
| blog: Expresivní zabručení
| Lanžhot
Tiskni
Sdílej:
![]()
![]()
![]()
![]()
![]()
![]()
ISSN 1214-1267, (c) 1999-2007 Stickfish s.r.o.
 13.7.2017 14:56
13.7.2017 14:56
 14.7.2017 17:43
14.7.2017 17:43
 13.7.2017 14:46
13.7.2017 14:46
 13.7.2017 16:11
13.7.2017 16:11
 14.7.2017 10:49
14.7.2017 10:49
 13.7.2017 15:18
13.7.2017 15:18
 15.7.2017 08:39
15.7.2017 08:39
{kind=link}
{kind=link}
{kind=link}