Portál AbcLinuxu, 27. července 2026 19:08
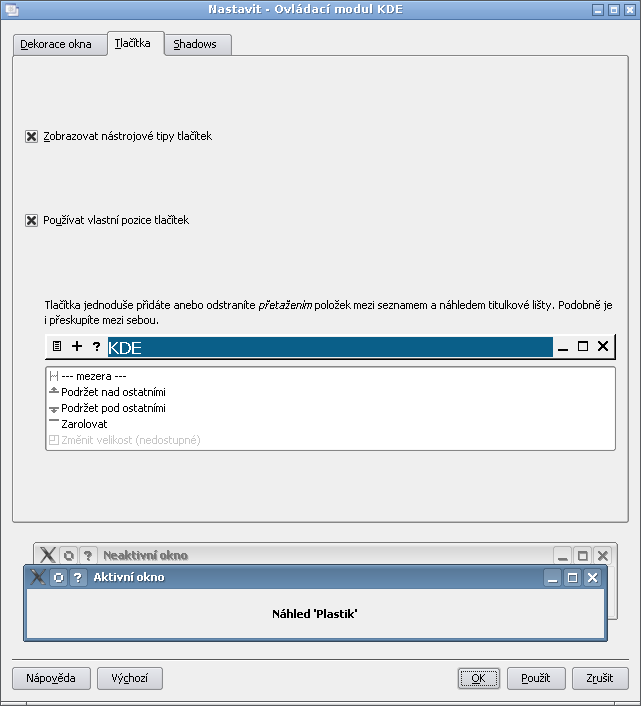
WebUpd8.org informuje, že Mark Shuttleworth oznámil konečné rozhodnutí ohledně tlačítek pro ovládání oken v Ubuntu Lucid Lynx. Tlačítka zůstanou na levé straně, změní se však jejich pořadí na „zavřít“, „minimalizovat“ a „maximalizovat“.
Tiskni
Sdílej:
![]()
![]()
![]()
![]()
![]()
![]()
nejsou komunisticke, protoze ac kazdy muze dany kod "vlastnit", ve smyslu "mit u sebe a jen pro sebe", tak s nim nemuze nakladat libovolne (treba zmenit jeho licenci, protoze autorske pravo).Já bych právě řekl, že z tohoto důvodu komunistické jsou -- i komunismus musí mít svá pravidla nakládání s (výrobními) prostředky.
Projekty a komunity jsou spise hierarchicke meritokracie s prvky formalni demokracie.S tím se dá vesměs souhlasit.
 2.4.2010 11:58
corwin78 | skóre: 10
| Ostrava
2.4.2010 11:58
corwin78 | skóre: 10
| Ostrava
Já myslel, že všichni používáme GNU/Linux.Řekl jsem snad že ne? (pominu-li uživatelé co tady chodí a používají třeba BSD apod..). Možná by neškodilo si přečíst vlákno znovu a přeformulovat otázku, respektive ten dovětek.
2.4.2010 12:17
corwin78 | skóre: 10
| Ostrava
2.4.2010 12:45
corwin78 | skóre: 10
| Ostrava
 Peace...
Vždyť aj v naší politické situaci existují pravicové strany. Jen je stále více slyšet o převaze těch levicových (a přechodu středových k levici)
Ha, politika!
Peace...
Vždyť aj v naší politické situaci existují pravicové strany. Jen je stále více slyšet o převaze těch levicových (a přechodu středových k levici)
Ha, politika!
Ha, politika!Jen tu tady prosím netahej =)
 4.4.2010 19:02
default | skóre: 22
| Madrid
4.4.2010 19:02
default | skóre: 22
| Madrid
 2.4.2010 11:52
Dent | skóre: 21
| blog: Standovo
2.4.2010 11:52
Dent | skóre: 21
| blog: Standovo
 2.4.2010 11:54
Jakub Lucký | skóre: 40
| Praha
2.4.2010 11:54
Jakub Lucký | skóre: 40
| Praha
 2.4.2010 11:57
tmr | skóre: 17
| blog: Offtopic
| Praha 5
2.4.2010 12:20
tmr | skóre: 17
| blog: Offtopic
| Praha 5
2.4.2010 22:55
tmr | skóre: 17
| blog: Offtopic
| Praha 5
3.4.2010 11:31
tmr | skóre: 17
| blog: Offtopic
| Praha 5
2.4.2010 11:57
tmr | skóre: 17
| blog: Offtopic
| Praha 5
2.4.2010 12:20
tmr | skóre: 17
| blog: Offtopic
| Praha 5
2.4.2010 22:55
tmr | skóre: 17
| blog: Offtopic
| Praha 5
3.4.2010 11:31
tmr | skóre: 17
| blog: Offtopic
| Praha 5
(Win7 ma napr. tak o rad min bugu nez jakakoliv Linuxova distribuce)Vista 7 je sama jeden velký bug. Mimochodem, skoro jakákoli distribuce toho umí o řád víc než Windows, takže srovnání absolutního počtu bugů vůbec nic neříká, a to i kdyby ty Windowsácké byly sledovány veřejně.
 3.4.2010 08:50
otula | skóre: 45
| blog: otakar
| Adamov
3.4.2010 08:50
otula | skóre: 45
| blog: otakar
| Adamov
(Win7 ma napr. tak o rad min bugu nez jakakoliv Linuxova distribuceLež. http://secunia.com/advisories/product/27467/?task=statistics_2010 http://secunia.com/advisories/product/339/?task=statistics_2010
3.4.2010 11:36
tmr | skóre: 17
| blog: Offtopic
| Praha 5
 3.4.2010 11:54
Sešívaný | skóre: 23
| Brno
3.4.2010 12:01
tmr | skóre: 17
| blog: Offtopic
| Praha 5
3.4.2010 12:14
Sešívaný | skóre: 23
| Brno
3.4.2010 11:54
Sešívaný | skóre: 23
| Brno
3.4.2010 12:01
tmr | skóre: 17
| blog: Offtopic
| Praha 5
3.4.2010 12:14
Sešívaný | skóre: 23
| Brno
Microsoft a Apple si mohou dovolit tymy, ktere testuji a vylepsuji pouzitelnost, grafikuOtázka je, zda to není kontraproduktivní. V poslední době mám pocit, že jakmile je někde napsáno „vylepšená použitelnost“, „navrženo odborníky na ergonomii“ nebo něco podobného, znamená to, že to skoro nepůjde používat (např. souborové dialogy GTK, MS Office 2007…)
opravuji bugy„O problému víme, záplata zatím není k dispozici.“
Win7 ma napr. tak o rad min bugu nez jakakoliv Linuxova distribuceTaké mají o několik řádů méně programů.
3.4.2010 11:52
tmr | skóre: 17
| blog: Offtopic
| Praha 5
Otázka je, zda to není kontraproduktivní. V poslední době mám pocit, že jakmile je někde napsáno „vylepšená použitelnost“, „navrženo odborníky na ergonomii“ nebo něco podobného, znamená to, že to skoro nepůjde používat (např. souborové dialogy GTK, MS Office 2007…)Urcite to neni kontraproduktivni, celkove jsou na tom Win7 co se tyce pouzitelnosti mnohem lepe, napr. hlavni lista/start menu. Konec koncu i ty Office 2007 jsou pouzitelnejsi nez OpenOffice (ktere se inspirovali u starsich Officu). Problem s Office 2007 je, ze je rozhrani uplne predelane, takze si uzivatel musi nejakou dobu zvykat.
„O problému víme, záplata zatím není k dispozici.“Mam na mysli spis takove bugy, jako ze mi nefunguje uspavani, v Eclipse nereaguji tlacitka na stisk, nefunguje flash atd. Win7 mi proste prijdou odladenejsi.
Také mají o několik řádů méně programů.Viz komentare vyse.
Problem s Office 2007 je, ze je rozhrani uplne predelane, takze si uzivatel musi nejakou dobu zvykat.Rozhraní, na které si člověk nezvykne ani po dvou letech, je podle mne k ničemu.
Mam na mysli spis takove bugy, jako ze mi nefunguje uspavani, v Eclipse nereaguji tlacitka na stisk, nefunguje flash atd. Win7 mi proste prijdou odladenejsi.jestli to nebude tím, že ve Windows 7 Eclipse ani Flash nejsou…
3.4.2010 12:38
tmr | skóre: 17
| blog: Offtopic
| Praha 5
Rozhraní, na které si člověk nezvykne ani po dvou letech, je podle mne k ničemu.Spousta lidí si zvykla...
jestli to nebude tím, že ve Windows 7 Eclipse ani Flash nejsou…To s tim Eclipse byl bug v GTK, coz povazuju za soucast OS. Flash - ok souhlasim...
 4.4.2010 20:50
Marián Kyral | skóre: 29
| blog: Sem_Tam
| Frýdek-Místek
4.4.2010 20:50
Marián Kyral | skóre: 29
| blog: Sem_Tam
| Frýdek-Místek
Jo jo, proto to MS v nové verzi zase změníRozhraní, na které si člověk nezvykne ani po dvou letech, je podle mne k ničemu.Spousta lidí si zvykla...
 3.4.2010 12:21
xkucf03 | skóre: 50
| blog: xkucf03
3.4.2010 12:47
tmr | skóre: 17
| blog: Offtopic
| Praha 5
3.4.2010 12:21
xkucf03 | skóre: 50
| blog: xkucf03
3.4.2010 12:47
tmr | skóre: 17
| blog: Offtopic
| Praha 5
Win7 ma napr. tak o rad min bugu nez jakakoliv Linuxova distribuceNějaký odkaz na statistiky? Počet bugů u Windows 7 atd..? Nebo jen "fakta" vycucána z prstu? Tvůj komentář by měl obsahovat tak minimálně pět odkazů podporující tvá tvrzení, jinak se jedná o totální hovadinu, za kterou tvůj komentář momentálně považuju.
3.4.2010 11:40
tmr | skóre: 17
| blog: Offtopic
| Praha 5
3.4.2010 15:15
tmr | skóre: 17
| blog: Offtopic
| Praha 5
- Dovolte, abych vám představil svoje spolupracovníky: Kojot Kid, Pancho Kid.
- Nestojím o vaše kydy.

"zlepsovatele", kteri nemaji tuseni o tom, co uzivatel potrebujeZatímco u jiných systémů jsou si výrobci proklatě jistí tím, co uživatel potřebuje. Jen ani jedni, ani druzí se nejspíš nikdy žádného uživatele nezeptali ;)
5.4.2010 11:51
Sešívaný | skóre: 23
| Brno
pokud Canonical vnese do te veci trochu radu i za cenu urcitych konfliktu a kontroverznich rozhodnuti, bude to zasluzny cinCanonical nesmyslným šachováním s ovládacími tlačítky akorát vytváří další bordel a že takový přístup lidi odmítají (je "kontroverzní") je zcela na místě.
2.4.2010 11:59
otula | skóre: 45
| blog: otakar
| Adamov
2.4.2010 12:01
otula | skóre: 45
| blog: otakar
| Adamov
 2.4.2010 12:16
Jardík | skóre: 40
| blog: jarda_bloguje
2.4.2010 12:16
Jardík | skóre: 40
| blog: jarda_bloguje
/apps/metacity/general/button_layout
Arrangement of buttons on the titlebar. The value should be a string, such as "menu:minimize,maximize,spacer,close"; the colon separates the left corner of the window from the right corner, and the button names are comma-separated. Duplicate buttons are not allowed. Unknown button names are silently ignored so that buttons can be added in future metacity versions without breaking older versions. A special spacer tag can be used to insert some space between two adjacent buttons.
2.4.2010 23:04
Jardík | skóre: 40
| blog: jarda_bloguje
 po katastrofe zvane KDE4 dochazi ke zprzneni dalsiho desktopoveho prostredi. fakt diky osvicenemu Markovi, ze nam vnucuje svoji zajiste skvelou predstavu o linuxovem desktopu. doufam, ze to neprosakne i do dalsich distribuci, alespon v tom rozsahu, ze to nebude default a zmena nebude vyzadovat boj s odpornym gconf-editorem.
po katastrofe zvane KDE4 dochazi ke zprzneni dalsiho desktopoveho prostredi. fakt diky osvicenemu Markovi, ze nam vnucuje svoji zajiste skvelou predstavu o linuxovem desktopu. doufam, ze to neprosakne i do dalsich distribuci, alespon v tom rozsahu, ze to nebude default a zmena nebude vyzadovat boj s odpornym gconf-editorem.
bohuzel me tohle hrani s gconf-editorem az prilis pripomina jiz temer zapomenutou onanii s windows registryTohle narikani me vzdycky dostane. Pamatuju dobu, kdy se autori jakekoliv klikaci utility setkali s odporem, protoze "klikani je pro lamy, tohle preci jde tak snadno nastavit v konfiguraku". Naopak KDE oproti GNOME boduje, protoze umoznuje spoustu veci nastavit (rozumnej naklikat) a "neomezuje" uzivatele (rozumnej uprava gconf je si nad sily prumerneho linux hackera). Tuhle schizofrenii jsem nikdy nepochopil. Nerad bych se dotkl uzivatelu KDE, at si kazdy pouziva to, co mu vyhovuje. Osobne ale veci nastavuji jednou, typicky po instalaci (a je mi temer jedno jestli to naklikam, prepisu konfigurak ci spustim nejaky prikaz). Muj bezny pracovni den ma jinou napln, nez neustale meneni nastaveni v KDE/GNOME. Proto je mi prakticky jedno, co za prostredi pouzivam. Btw, ten tvuj boj predstavuje spusteni jednoho prikazu z terminalu. To by uzivatel Slackware zvladnout mohl.
3.4.2010 20:08
default | skóre: 22
| Madrid
4.4.2010 19:12
default | skóre: 22
| Madrid
 Bohužel hodně lidí si pořád myslí, že XML jsou jen špičaté závorky a ukecaná syntaxe, ale často nevědí o těch technologiích nad tím.
4.4.2010 19:33
xkucf03 | skóre: 50
| blog: xkucf03
4.4.2010 22:16
default | skóre: 22
| Madrid
Current track: Chris Standring — All In Good Time
4.4.2010 22:17
default | skóre: 22
| Madrid
Bohužel hodně lidí si pořád myslí, že XML jsou jen špičaté závorky a ukecaná syntaxe, ale často nevědí o těch technologiích nad tím.
4.4.2010 19:33
xkucf03 | skóre: 50
| blog: xkucf03
4.4.2010 22:16
default | skóre: 22
| Madrid
Current track: Chris Standring — All In Good Time
4.4.2010 22:17
default | skóre: 22
| Madrid
Current track: Chris Standring — All In Good TimeNakoupíte v nejbližším iTunes Store.
(Abych si rejpnul )
4.4.2010 22:20
default | skóre: 22
| Madrid
Linux je nejlepší, protože na něm běží Oracle Database 11gR1 a Oracle Database 11gR2.
4.4.2010 22:25
default | skóre: 22
| Madrid
 5.4.2010 09:21
Algi | skóre: 1
| blog: Sinner
5.4.2010 10:49
default | skóre: 22
| Madrid
5.4.2010 09:21
Algi | skóre: 1
| blog: Sinner
5.4.2010 10:49
default | skóre: 22
| Madrid
S tím Oracle je to dost trefná poznámka. Ale je fakt, že ono nainstalovat 10g na Mac byl takový humus, že jsem to v půlce vzdal. V tomhle směru zlaté PostgreSQL. Jednoduchá instalace a pro mé potřeby identická funkcionalita. V tomhle směru obrovské mínus pro Oracle.Já to ani neměl chuť zkoušet. Dovedu si představit, že by to skončilo reinstalací OS X.
Oni jsou hoši od Oracle tak trošku prasata, když se člověk podívá dovnitř. Třeba takový Enterprise Manager, to je síla! Jestli budou v tomhle stylu dělat Javu, tak nevím, nevím.
Jo a sorry, že ti tu kazím tvůj MONOlogNic se neděje. Zase za rok.
4.4.2010 22:27
xkucf03 | skóre: 50
| blog: xkucf03
Co je na XML konfigurácích špatně?Čitelnost a editovatelnost pro člověka je mizerná. A ukaž mi nějaký pěkně okomentovaný XML konfigurák s poznámkami, který zároveň funguje jako svoje dokumentace.
Podle mne jakýkoli takový formát nakonec bude jenom XML s jinými závorkami. Jenže pro XML už je tady spousta nástrojů a standardů, které se dají využít.Ve skutečnosti je to naopak. Cokoli lze samozejmě zapsat do XML, když to kreativně olepím špičatými závorkami. Ale XML není syntaxe toho konfiguráku, to je až příslušné schéma, XML je zde pouze serializační formát (IMO dost nepraktický). Ovšem potom padá tvé tvrzení o nástrojích, protože na editaci obecných textových souborů mám taky nástroje. Jak textové nástroje, tak XML nástroje pracují pouze na úrovni serializačního formátu, nikoli na úrovni konfiguráku. Uznávám, že pro XML existují validační nástroje, jenže abychom je mohli použít, je třeba mít schéma, které za něco stojí... A konečně, representace v XML je iluze. Chci representovat např. tento jednoduchý segment ssh_configu:
Host *.muni.cz SendEnv LANG LC_CTYPE LC_NUMERIC LC_TIME LC_COLLATE LC_MONETARY LC_MESSAGES ...Pak mohu udělat, jak se typicky dělá:
<Host pattern="*.muni.cz"> <SendEnv>LANG LC_CTYPE LC_NUMERIC LC_TIME LC_COLLATE LC_MONETARY LC_MESSAGES</SendEnv> ... </Host>Ale co nám tam dělá to *.muni.cz a ten seznam v SendEnv? To je pořád ne-XML syntaxe, akorát zabalená do XML, takže teď tam mám pořád ad-hoc syntaxi, a navíc se to celé zamatlalo špičatými závorkami. Jak to přečtu? Nalepím na XML parser parsery různých ad-hoc syntaxí. Jak to zvaliduji? Nijak. Mohu jít zpět ke kreslicímu prknu a navrhnout XML representaci vzorů, seznam udělat pěkně po prvcích, etc. Výsledek bude přesvědčivě XMLodiní, ale dlouhý a zpracovatelný pouze pro stroj (což ovšem nikdo nepřizná a bude stále tvrdit, že když je to XML, je to přece upravovatelné pro člověka). A náš konfigurák přitom stále vůbec nejsou ty špičaté závorky, je to to, co dostaneme, když všechny ty špičaté závorky smažeme (nebo abstrahujeme pryč). A to byl velmi jednoduchý příklad z konnfiguráku, který má hierarchickou strukturu, na kterou XML napasuješ snadno. Pokud bude konfigurace vypadat více jako deklarativní jazyk (sada pravidel s různými výrazy), tak zabalením do XML dosáhneš jediného, a to řádového prodloužení a znečitelnění celé věci. Na úrovni konfiguráku budeš mít přesně tutéž syntaxi, cos měl, jen to na serializační úrovni bude zabaleno do mraků špičatých závorek.
Okomentovaný konfigurák třeba zdeA teď to zkus srovnat s takovým konfigurákem Apache...
5.4.2010 10:54
default | skóre: 22
| Madrid
domain.xml GlassFishe.
Hele, co dělat všechny konfiguráky v Perlu! A ještě zazipovaný.
Ale XML není syntaxe toho konfiguráku, to je až příslušné schémaA co je lepší? Mít konfigurák s XML schématem, na jehož zpracování existuje spousta nástrojů, nebo konfigurák se schématem, které je zadrátované v kódu programu, který konfigurák načítá?
Výsledek bude přesvědčivě XMLodiní, ale dlouhý a zpracovatelný pouze pro strojPro mne je naopak čitelný seznam v XML a nečitelný ten v
ssh_config. V XML snadno přidám další položku, i když tam budu mít na počátku jen jednu, nebo jich budu chtít přidat dalších deset. V konfiguráku ssh_config v případě jedné položky na začátku musím začít zjišťovat, jak se víc položek vlastně zapisuje – zopakuju řádek SendEnv? Nebo uvedu víc hodnot na jeden řádek? A oddělují se mezerou, bílím místem, čárkou? A když budu potřebovat přidat víc položek a zalomit řádek, můžu zase znova zkoumat, jak se zalamují řádky…
A teď to zkus srovnat s takovým konfigurákem Apache...Tam ty špičaté závorky máte také, takže tam máte všechny vaše „nevýhody“ XML, jenom to XML není, takže vám žádné existující nástroje pro XML nepomohou.
<circle> <coord x="1" y="2" /> <radius value="3" /> </circle>je ok, tak
<circle> <radius value="3" /> <coord x="1" y="2" /> </circle>už je chyba. I s XML se dají některé věci těžce "zprasit" takže uživatel pak místo "circle X=1 Y=2 R=3" může být nucen psát zhůvěřilosti typu:
<circle>
<parameters>
<radius>3</radius>
<coordinates>
<x>1</x>
<y>2</y>
</coordinates>
</parameters>
</circle>
Případně se čas od času objeví i šílenosti typu
... <config key="bla" encoding="base64" value="BORw0KGgoAAAA........" /> ...Pokud je autor programu "prase" tak XML to nezachrání, naopak to může i dost zhoršit.
5.4.2010 16:49
xkucf03 | skóre: 50
| blog: xkucf03
Zadat klíč/certifikát jako odkaz na externí soubor umí každý (v XML to samozřejmě jde taky), ale v XML snadno můžu vložit ten soubor i dovnitř konfiguráku (pokud chci) a mít tak vše v jednom.
když to kreativně olepím špičatými závorkami. Ale XML není syntaxe toho konfiguráku, to je až příslušné schéma, XML je zde pouze serializační formát
Svým způsobem máš pravdu – XML umožňuje jednoznačný zápis (serializaci) něčeho někam. Máme tu* elementy, atributy, textový obsah a samozřejmě další vnořené elementy (a tak dále až to libovolné úrovně složitosti). Samotné XML mi pomůže s tím, že nemusím váhat, jak zapsat více položek (prostě vložím víc elementů) nebo jak zapsat hodnotu s mezerami (nemusím řešit, zda bude v uvozovkách, apostrofech, zapsaná jen tak, escapovaná – prostě ji napíši dovnitř elementu nebo atributu). A není to zrovna málo – už jen kvůli tomuto pořádku a jednoznačnosti má smysl XML používat.
Samotné XML mi se syntaxí (nebo spíš sémantikou) konfiguráku nepomůže – to máš pravdu – ale s tím mi nepomůže ani textový konfigurák: v něm taky musím vědět, jak se která položka jmenuje (v XML by tomu odpovídal název elementu/atributu) a jaké může nabývat hodnoty – ale v textovém konfiguráku musím navíc řešit ty nízkoúrovňové věci (jak serializovat seznamy, mezery, escapovat atd.).
Se sémantikou konfiguráku mi pomůže XML schéma nebo DTD – na základě něj přesně vím, jak se ty elementy/atributy mají jmenovat, znám jejich textový popis, přípustný počet opakování (jestli tam mají být jen jednou, nebo jich můžu zapsat seznam…), přípustné hodnoty (číslo, datum, text, regulární výraz…). V textovém konfiguráku tohle samozřejmě jde taky, ale má to dvě nevýhody: jednak k tomu potřebuji obrovské množství komentářů, kde vyjmenuji všechny možné příklady (a to nejen z hlediska sémantiky, ale i syntaxe-serializace) a jednak to není deklarativní, komentáře nejsou strojově zpracovatelné, takže není možná automatická podpora ze strany softwaru (na základě komentářů mi např. editor nebude napovídat přípustné konfigurační volby).
<Host pattern="*.muni.cz">
<SendEnv>LANG LC_CTYPE LC_NUMERIC LC_TIME LC_COLLATE LC_MONETARY LC_MESSAGES</SendEnv>
...
</Host>
Tohle je špatně navrženého XML konfiguráku – který vznikl jen obalením původního textového těmi <závorkami>, což je celkem na nic. Lépe by bylo:
<Host pattern="*.muni.cz">
<SendEnv>LANG</SendEnv>
<SendEnv>LC_CTYPE</SendEnv>
<SendEnv>LC_NUMERIC</SendEnv>
...
</Host>
Dovnitř elementů by se neměla zanášet další syntaxe (v tomto případě oddělení položek mezerami) – zejména v takových případech, jako je výčet položek. V XML schématu budu mít uveden minimální a maximální počet výskytů <SendEnv/> a z toho snadno poznám, že jich můžu zadat víc (a taky nemusím zadávat žádný).
A teď to zkus srovnat s takovým konfigurákem Apache...
Konfiguráky Apache jsou jedny z nejhorších, které jsem kdy viděl. Velmi vzdáleně se tváří jako XML, ale z XML si berou jen ty ostré závorky a to ještě jen někdy. Člověk tam pak nachází takové obludnosti jako <Directory /> což připomíná element bez vnitřku, ale omyl: je to otevírací značka. Uvnitř je jakýsi text s jakousi vlastní specifickou syntaxí, kterou se člověk musí naučit. Dokonce ani není vnitřně jednotná – jednou se položky seznamu oddělují mezerami (Options Indexes FollowSymLinks MultiViews) a jindy zase čárkami (Order allow,deny). A podobných prásáren by se tam našlo víc. Raději nekomentovat
*) jmenné prostory, komentáře, CDATA atd. nechme teď stranou
XML umožňuje jednoznačný zápis (serializaci) něčeho někamAle kdež... jak uhodnu, jestli mám při té serializaci použít vnořený element nebo atribut? (Pokud tedy neusoudím, že používat atributy je vlastně vždycky špatně, protože taková schémata jsou nerozšiřitelná – nemohu se dodatečně rozhodnout, že hodnota může být strukturovaná.) Nemohu se ubránit dojmu, že pro serializaci stromových struktur (a nic obecnějšího v XML nenareprezentujete) existují mnohem jednodušší a praktičtější prostředky. Za všechny zmiňme třeba S-expressions.
Jak se popisuje schéma S-expressions?Je něco takového doopravdy potřeba? Dává smysl zavádět schémata, kterými se dá vyjádřit pouze minimální podmnožina syntaktických omezení? Mnohdy by se daleko víc hodilo, aby to nebylo nějaké formální schéma, nýbrž program, který syntaxi zkontroluje kompletně.
Jak se tam vkládají komentáře?Od středníku do konce řádku.
Kolik existuje nástrojů a knihoven pro práci s nimi?V každém LISPu aspoň jedna
Tohle nemá smysl porovnávat. Když vám v nějakém jazyce chybí knihovny pro práci s XML, tak je to příležitost k bezmocnému úpění. Pokud chybí parser S-expressions, tak si těch 100 řádků kódu prostě napíšete. On je to opravdu formát, který má jednoduchost i jinde než v reklamních letácích
Indexes, MultiViews nebo FollowSymLinks, a nemusí hledat, jestli se to píše Indexes nebo index, MultiViews nebo Multiviews… Pokud tam má být kladné číslo, rovnou to vidím atd.
Jedinou nevýhodu oproti S-expressions vidím v tom, že se v XML nedají psát zkrácené koncové tagy </>. Druhá je pak ještě v parsování entit, ale to můžu vždy obejít tak, že řeknu, že v mém konfiguráku nejsou entity kromě systémových povolené…
Navíc XML je také modulární – plugin může být jednoduše nakonfigurován uvnitř hlavního konfiguračního souboru, jenom použije vlastní jmenný prostor.
Schémata se nepoužívají jenom ke kontrole, ale také třeba k dokumentaci nebo nápovědě.Vůbec mi nepřijde zřejmé, že je správně pokoušet se o strojově čitelnou dokumentaci za cenu toho, že bude neúplná. Neplnil by účel daleko lépe nějaký prostý formát dokumentace navázaný na strukturu stromu? To jde vcelku snadno navrhnout nezávisle na tom, jak stromy reprezentujete.
Jedinou nevýhodu oproti S-expressions vidím v tom, žeJá vidím zásadní nevýhodu zejména v tom, že je to celé úplně zbytečně překomplikované. XML neumí víc než ty S-expressions, a přitom má o několik řádů složitější specifikaci.
Já mluvím o případu, kdy člověk potřebuje jednou za půl roku změnit jednu hodnotu v konfiguraci SSH [...]U slušně napsaných konfiguráků úplně stačí podívat se na komentář, který u dotyčné položky autor zanechal.
Jediné, co je na specifikaci XML složité, jsou entity.Eh... namátkově: processing instructions, volba znakové sady, CDATA, atributy.
U slušně napsaných konfiguráků úplně stačí podívat se na komentář, který u dotyčné položky autor zanechal.To by u toho bloku
directory v konfiguráku Apache byl ten komentář hodně dlouhý. Navíc mi většinou úplně stačí seznam názvů položek, který přečtu výrazně rychleji, než celý komentář.
Eh... namátkově: processing instructions, volba znakové sady, CDATA, atributy.PI začíná
<? a končí prvním ?>, CDATA začínají <![CDATA[ a končí prvním ]]>, hodnota atributu začíná dvojitou uvozovkou a končí první další uvozovkou. Co je na tom složitého? Volbu znakové sady musíte řešit u každého formátu do té doby, než se budou standardně i na souborových systémech ukládat do rozšířených atributů. A u toho konfiguráku klidně můžete říct, že musí být v UTF-8 (pokud na to teda budete psát ten vlastní parser).
Navíc mi většinou úplně stačí seznam názvů položek,Právě u toho Directory je seznam položek, které mohou být uvnitř, proklatě dlouhý (skoro všechny existující direktivy).
Co je na tom složitého?Především to, že věcí (byť jednoduchých), o které se korektní parser XML musí postarat, jsou mrtě. Vybrat si nějakou podmnožinu a napsat parser pouze na ni, je cesta do pekel, protože Vám rázem přestane fungovat polovina nástrojů, neboť budou generovat věci, které Váš parser neumí. Ale pokud chcete, klidně můžeme uspořádat souboj
Vy napíšete korektní XML parser, já korektní parser S-expů a schválně, který bude jednodušší.
(Jinak volbu znakové sady je u formátu dat v dnešní době sotva potřeba řešit. UTF-8 je dostatečně obecné.)
Především to, že věcí (byť jednoduchých), o které se korektní parser XML musí postarat, jsou mrtě. Vybrat si nějakou podmnožinu a napsat parser pouze na ni, je cesta do pekel, protože Vám rázem přestane fungovat polovina nástrojů, neboť budou generovat věci, které Váš parser neumí.Neznám žádný nástroj, který by svévolně generoval do výstupního souboru entity. Naopak bych myslím měl dost problémů k vygenerování nesystémových entit spoustu nástrojů donutit.
Ale pokud chcete, klidně můžeme uspořádat soubojParser XML (bez entit) bude trochu delší, protože je v XML víc kontextů. Ale složitost bude myslím stejná. Otázka taky je, proč psát nový parser, když si mohou vybrat ze spousty existujících. On se ten souboj totiž taky dá uspořádat opačně – sestavit celou infrastrukturu (parser, validátor, editor, transformační nástroj, dotazovací nástroj) třeba v pěti jazycích. Pro XML to bude znamenat vybrat si vhodné knihovny, pro S-expressions budete muset většinu toho napsat. Pro jednoúčelovou utilitu, která bude samotná desetkrát menší, než XML parser, je XML samozřejmě kanón na vrabce – ale to bude jakákoli konfigurace uložená jako stromová struktura, takové nástroje si zpravidla vystačí s mapou klíč=hodnota (škoda, že pro serializaci takového formátu také neexistuje nějaký jeden široce používaný formát). Ale když je potřeba něco složitějšího, vyplatí se podle mne rovnou použít XML, protože tak zadarmo získáte spoustu funkcionality, kterou můžete hned využít – schémata, validaci a dokumentaci, jmenné prostory, vkládání externích souborů (Xinclude, ne entity), spoustu nástrojů…
Neznám žádný nástroj, který by svévolně generoval do výstupního souboru entity.A co třeba CDATA?
On se ten souboj totiž taky dá uspořádat opačně – sestavit celou infrastrukturu (parser, validátor, editor, transformační nástroj, dotazovací nástroj) třeba v pěti jazycích.Problém ovšem je v tom, že o tuto infrastrukturu spousta lidí nestojí, alespoň v podobě, kterou nabízí XML. Jak už bylo v této diskusi zmíněno, validita XML neslibuje vůbec nic stran syntaktické korektnosti (říká pouze to, že korektnost nebyla porušena jistým zjevným způsobem). Transformační a dotazovací nástroje nad XML jsou neuvěřitelně těžkopádné a jsou snůškou ad-hoc technik, nikoliv něčím, co by mělo jasně definovanou výpočetní sílu. Mohl by to být věru zajímavý souboj, kdybyste chtěl, aby ta infrastruktura opravdu fungovala
Celkově mi přijde, že ekosystém okolo XML by měl posloužit zejména k tomu, aby se lidé poučili z jeho chyb a nahradili ho něčím solidním, co nebude zbytečně komplikované.
A co třeba CDATA?Ani takový. Navíc parsování CDATA je triviální záležitost, těžko může být něco jednoduššího.
Jak už bylo v této diskusi zmíněno, validita XML neslibuje vůbec nic stran syntaktické korektnosti (říká pouze to, že korektnost nebyla porušena jistým zjevným způsobem).Nejsem si jist, zda se bavíme o stejné validitě. Já mluvím o tom, že dokument odpovídá nějakému schématu. Tím můžete kontrolovat i povinnost či nepovinnost elementů, pořadí, přípustné hodnoty… RelaxNG myslím umí kontrolovat i kontextové závislosti.
Transformační a dotazovací nástroje nad XML jsou neuvěřitelně těžkopádné a jsou snůškou ad-hoc technik, nikoliv něčím, co by mělo jasně definovanou výpočetní sílu.Jenže jsou a fungují. Navíc na transformaci konfiguráku nepotřebuju nástroj, který místo 0,1 sekundy poběží jen 0,03 sekundy.
Celkově mi přijde, že ekosystém okolo XML by měl posloužit zejména k tomu, aby se lidé poučili z jeho chyb a nahradili ho něčím solidním, co nebude zbytečně komplikované.Klidně. Ale kdo to vymyslí, jak dlouho bude trvat, než se to prosadí? A bude to skutečně tak odlišné od XML?
Navíc parsování CDATA je triviální záležitost, těžko může být něco jednoduššího.Jak už jsem psal, všechno to jsou triviality, jen jich je moc. Svým způsobem celé XML je jedna trivialita, kterou bohužel někdo nakrmil kyblíkem steroidů
Nejsem si jist, zda se bavíme o stejné validitě. Já mluvím o tom, že dokument odpovídá nějakému schématu.Já mluvím o tom, že dokument je korektní, čili že splňuje nějakou množinu omezení. To zahrnuje jak podmínky, které se dají vyjádřit v XML schématech, tak i podmínky složitější (ale stále často potřebné), jako třeba že hodnota nějakého elementu je prvočíslo, syntakticky správné URL nebo třeba syntakticky správný Céčkový program.
jak dlouho bude trvat, než se to prosadí?Na tom moc nezáleží. Na dobrých myšlenkách je důležitá jejich existence, masovost málokdy. Linux také nepoužívám proto, že by se nějakým způsobem prosadil.
A bude to skutečně tak odlišné od XML?Na jisté úrovni nebude. Zase to budou jenom stromy (z tohoto pohledu XML neumí nic, co by lidstvo neznalo už před 50 lety). Ale třeba se s nimi bude pracovat o něco příjemněji.
Na jisté úrovni nebude. Zase to budou jenom stromy (z tohoto pohledu XML neumí nic, co by lidstvo neznalo už před 50 lety). Ale třeba se s nimi bude pracovat o něco příjemněji.V čem by se tedy ten formát lišil? Že by se místo špičatých závorek použily složené? To mi jako zásadní změna nepřipadá…
V čem by se tedy ten formát lišil?Zejména v tom, že by zmizela spousta balastu: rozlišení vnořené elementy vs. atributy, opakování jmen elementů, entity, znakové sady, CDATA a tak dále. Zbylo by jen přímočaré kódování stromů pomocí závorek.
Rozlišení vnořených elementů vs. atributů by zhoršilo čitelnostKonstrukce
(element (xyz 1) (abc 2)) mi tedy nepřijde o nic méně čitelná než <element xyz="1" abc="2">.
ponechal bych uvádění jména koncového elementu jako volitelnéDalší komplikace.
UTF-8 není formát vhodný pro všechny jazykyProč vlastně?
CDATA mi připadá jako mnohem lepší způsob vkládání binárních datZpůsob vkládání binárních dat, kterým nejdou vložit binární data, která obsahují určité podřetězce, je dost nanic.
Konstrukce (element (xyz 1) (abc 2)) mi tedy nepřijde o nic méně čitelná než <element xyz="1" abc="2">.Pokud se na XML díváte jenom jako na formát pro uložení obecného stromu, pak možná ne. Když se na něj podíváte zároveň jako na značkovací jazyk, pak už je v tom výrazný rozdíl.
Proč vlastně?Některé asijské jazyky mají v UTF-8 průměrně 3 bajty na písmeno, v jiném kódování (UCS-2?) jsou to 2 bajty na písmeno.
Způsob vkládání binárních dat, kterým nejdou vložit binární data, která obsahují určité podřetězce, je dost nanic.Pro počítač je samozřejmě lepší uložit jako prefix délku dat a pak samotná data bez escapování, pro člověka je to ale nečitelné, ten dá naopak přednost rozumnému escapování. CDATA volí druhou variantu, takže tam nějaké escapování být musí – a escapovat jediný triplet
]]> (při serializaci to musíte nahradit za ]]>]]><![CDATA[) je podle mne rozumná volba
Když se na něj podíváte zároveň jako na značkovací jazyk, pak už je v tom výrazný rozdíl.Možná je na čase opustit představu, že jeden jazyk může být vhodný současně pro značkování textu a pro ukládání obecných stromových dat. Pro značkování textu psaného člověkem je mnohem příjemnější než XML obecné SGML (konstrukce typu
&left;b/tučně/ se píší velmi snadno). Byť samozřejmě může existovat přímočará projekce syntaktického stromu SGML do nějakého jazyka pro popis stromů.
Některé asijské jazyky mají v UTF-8 průměrně 3 bajty na písmeno, v jiném kódování (UCS-2?) jsou to 2 bajty na písmeno.Záleží na tom doopravdy? Stojí za to zkrátit texty v některých jazycích o 50% (ze 3 bajtů na 2) za cenu toho, že v jiných jazycích je prodloužíte o 100% (z 1 bajtu na 2)? Navíc UCS-2 evidentně nestačí, takže je potřeba uchýlit se buďto k UTF-16 (což je obludnost, která kombinuje prostorovou nenažranost UCS-2 s proměnlivou délkou UTF-8) nebo rovnou k UCS-4, čímž ovšem prodloužíte texty v prakticky všěch jazycích světa. Navíc si troufám tvrdit, že většina textů na světě je a bude v čistém ASCII (mimo jiné proto, že dost pravděpodobně je většina existujících textů textovým zápis nějakých automaticky generovaných dat), takže prodloužení ASCII na dvojnásobek je mnohem větší zlo než 3-bajtové čínské znaky. Z toho mi vychází, že UTF-8 je velmi rozumný kompromis. (A komu na velikosti textů opravdu záleží, ten stejně nejspíš použije nějakou dodatečnou kompresi, jež nevýhody UTF-8 odstíní.)
pro člověka je to ale nečitelné, ten dá naopak přednost rozumnému escapování.Pro člověka jsou binární data nečitelná tak jako tak, takže na čitelnosti escapování sotva záleží. (Nemluvě o tom, že téměř každý textový editor binární data nevratně zmrší, což činí ruční editování souborů s binárními částmi tak jako tak značně problematickým.)
člověk potřebuje jen najít konec těch datCož se očima v hromadě rozsypaného čaje hledá opravdu dobře
Jinými slovy člověku to nepomuže, stroji práci zkomplikuje.
<< v shellu nebo boundary v MIME). Pokud na nějaká "binárnější" data, pak se především můžete rozloučit s tím, že Vám je běžný textový editor nerozsype, ať už jsou ukončena ]]> nebo třeba "amen".
Chápu, za jakým účelem CDATA vznikla, jen jsem přesvědčen, že téhož účelu jde dosáhnout daleko vhodnějšími prostředky než obskurní syntaxí s hranatými závorkami.
uvést kódování na začátku souboruTo ovšem funguje jenom tehdy, když použijete kódování, které je nadmnožinou ASCII. Třeba s UCS-2 funguje XML jen proto, že je na něj speciální hack ve specifikaci. To nezní rozumně. Nevidím jinou konsistentní možnost, než buďto kódování uvádět vně souboru, nebo umožnit uvnitř souboru kódování přepnout (takže začátek bude třeba v ASCII a bude tam řečeno, jak číst zbytek souboru). XML nedělá ani jedno z toho, takže je v praxi použitelná pouze část kódování, která jsou buď nadmnožiny ASCII nebo zadrátovaná ve specifikaci. Tomu tedy říkám rozšiřitelnost
rozlišení vnořené elementy vs. atributyTohle by možná šlo. Ale na druhou stranu si nemyslím, že by existence atributů v XML nějak překážela – spíš se může hodit.
opakování jmen elementůMožné to je, ale co z toho? Počítač by si ty koncové značky/závorky našel. Člověku by někdy mohly chybět… ale to je celkem jedno. Nějaký zásadní přínos? Pár ušetřených bajtů? Nevím.
entityEntity někdy slouží k prostému zakódování znaků (např. češtiny do kódování, které ji nepodporuje). Takové by šly oželet. Jenže entity se dají používat i jako „makro“ pro dosazování textu – a těch by, podle mého, byla škoda. Další použití entit je pro zápis speciálních znaků (např. uzavíracích závorek) – tyhle entity by musely zůstat nebo by se musel vymyslet jiný způsob escapování těchto znaků – což by zjednodušení nepřineslo – když už budeme mít escapování, můžeme rovnou nechat entity.
CDATAA co když budu chtít zapsat delší text, který obsahuje speciální znaky? Budu muset všechny escapovat. Proto mi přijde vhodnější udělat složitější parser (který se píše jen jednou nebo několikrát) než dělat složitější práci všem uživatelům a otravovat je escapováním (uživatelé totiž nepíší jeden dokument, ale miliony nebo miliardy dokumentů – tudíž práce „ušetřená“ při vývoji parseru by se lidem vrátila jako bumerang v podobě pracnějšího zápisu dokumentů – což je ve výsledku dost nevýhodné).
znakové sadyKódování? Ale jak to řešit? Donutit všechny lidi, aby používali UTF-8? To mi přijde jako krok zpět – v devadesátých letech se nás MS taky snažil donutit používat cp1250, ale selhalo to, byly z toho akorát problémy a lidi ztratily spousty hodin a nervů řešením „rozbité češtiny“. A teď je běžnou praxí, že se kódování uvádí, např. v HTML stránce nebo v e-mailu a už to funguje. Je potřeba se smířit s tím, že kódování je na světě víc a že se nepodaří lidem naordinovat jediné správné. Případně by kódování mohlo ležet „mimo formát“, ale to jde třeba u HTTP nebo u MIME, ale u souborů na disku to moc nefunguje. Dokud se tohle nevyřeší, je potřeba mít možnost deklarovat kódování uvnitř souboru. XML na to jde chytře a u UTF-8 se kódování deklarovat nemusí.
Zbylo by jen přímočaré kódování stromů pomocí závorek.A pak už jen zbývá dopsat všechny ty technologie, které nad XML existují. Aneb, kde byli ti zastánci „jednoduchých formátů“ když se XML rozjíždělo? Proč si nevytvořili ty „nadstavbové“ technologie, jako má XML, nad těmi svými formáty stejně rychle jako to stihlo XML? Nebo rychleji? Vždyť by to mělo být méně práce, když se nemusí řešit takové blbosti jako kódování, CDATA atd.
Člověku by někdy mohly chybět…Já si naopak myslím, že člověku velice překáží. Lidské chápání je často omezeno tím, kolik dat najednou lze vnímat. Pokud ta data naředíte balastem, půjdou psát i chápat efektivněji.
Jenže entity se dají používat i jako „makro“ pro dosazování textuTohle nepatří do formátu dat. Pokud chcete používat makra, pořiďte si preprocesor. Tak silný, jak potřebujete. (Mně například přijde poněkud zvrhlá idea používat v dnešní době preprocesor, který není turingovsky úplný, takže dříve či později narazím na nějaké jeho omezení.)
A co když budu chtít zapsat delší text, který obsahuje speciální znaky?Co když budu chtít udělat tak triviální věc, jako vložit do jednoho dokumentu textovou podobu jiného? CDATA uvnitř jiných CDAT snadno neudělám… Taktéž pokud si zvolíte střídmější sadu znaků se speciálním významem než má XML (třeba v S-expech to jsou uvnitř řetězců pouze uvozovky), značně tím tento problém minimalizujete.
Ale jak to řešit? Donutit všechny lidi, aby používali UTF-8?Dokud se neobjeví něco ještě obecnějšího než UTF-8, mohou všichni spokojeně používat UTF-8. Až se jednou objeví, můžete kódování ukládat externě, nebo se ještě lépe na Unixových systémech spolehnout na locale (pokud Vaše locale bude určovat charset obecnější než UTF-8, není problém, aby programy při ukládání dat na disk do tohoto charsetu překódovávaly a pak je v tomto charsetu načítaly; v zásadě podobně to teď na Unixech s textovými soubory chodí a funguje to rozumně).
XML na to jde chytře a u UTF-8 se kódování deklarovat nemusí.Jak už jsem psal o pár příspěvků vedle, nijak chytře na to nejde a mimo nadmnožin ASCII a pár hacků ve specifikaci jeho volba znakové sady nefunguje.
Aneb, kde byli ti zastánci „jednoduchých formátů“ když se XML rozjíždělo? Proč si nevytvořili ty „nadstavbové“ technologie, jako má XML, nad těmi svými formáty stejně rychle jako to stihlo XML?Myslím, že důvody jsou dva. Jednak u mnoha z těchto "technologií" nebyli přesvědčeni o tom, že jsou k něčemu dobré (já si to například o schématech nemyslím dodnes, přijde mi, že správná cesta vede jinudy). A také proto, že vymyslet něco jednoduchého a elegantního není vůbec jednoduché. Docela zajímavou paralelu můžete sledovat na poli systémů pro správu verzí. Po mnoha letech vývoje stále složitějších a složitějších systémů přišel najednou Git, jehož základy jsou téměř triviální, ale trvalo dlouho, než byl někdo schopen udělat ten správný myšlenkový skok a uvědomit si, co je doopravdy důležité. Na XML se projevuje starý dobrý Second-system effect – autoři XML si dobře uvědomovali, jakými problémy trpěly starší formáty, a usmysleli si, že každou z těchto věcí vymyslí lépe a sofistikovaněji. Jen je někdy rozumnější nezalepovat jeden problém po druhém a místo toho se zaměřit na základy. To se bohužel nestalo.
když už budeme mít escapování, můžeme rovnou nechat entity.Ještě dodávám, že mezi psaním backslashe před speciální znak, aby ztratil svůj speciální význam, a syntaxí entit vnímám dost podstatný skok ve složitosti (jak na straně parseru, tak na straně člověka editujícího text – při psaní příspěvků do této diskuse jsem už několikrát mrmlal nad tím, kolik práce dá napsat ukázku nějakého tagu, když by přitom stačil jediný backslash).
Entity někdy slouží k prostému zakódování znaků (např. češtiny do kódování, které ji nepodporuje). Takové by šly oželet. Jenže entity se dají používat i jako „makro“ pro dosazování textu – a těch by, podle mého, byla škoda. Další použití entit je pro zápis speciálních znaků (např. uzavíracích závorek) – tyhle entity by musely zůstat nebo by se musel vymyslet jiný způsob escapování těchto znaků – což by zjednodušení nepřineslo – když už budeme mít escapování, můžeme rovnou nechat entity.Já to mám teda přesně opačně. Ponechal bych systémové entity (
&, <, >, " a '), ponechal bych znakové entity, a zrušil bych „makra“, která nikdo nepoužívá a málokdo jim rozumí. Pro vkládání jiných částí se dá použít XInclude.
6.4.2010 16:22
xkucf03 | skóre: 50
| blog: xkucf03
Zase to budou jenom stromyOno to nemusí být stromy – můžeme si třeba posílat vyexportované relační databáze – mnohdy by to byl vhodnější popis reality než jakýkoli strom
Ostatně některé programy to tak dělají, když si konfiguraci ukládají např. do sqlite databázových souborů.
6.4.2010 18:37
xkucf03 | skóre: 50
| blog: xkucf03
Rozdíl je spíš v logickém pohledu na věc, zapsat relace do XML samozřejmě jde. BTW: neexistuje na to nějaký standardizovaný formát? Zatím jsem viděl leda formáty pro „dump databáze do XML“ specifické pro daný SŘBD.
Parser XML (bez entit) bude trochu delší, protože je v XML víc kontextů. Ale složitost bude myslím stejná.Jednoduchý parser XML jde napsat jedním regulárním výrazem v Perlu.
Na atributy se dá rezignovat a vůbec je nepoužívat. Je fakt, že jsou trochu nesystémové, v podstatě místo nich stačí vnořený element, který by měl minimální počet výskytů 0 nebo 1 a maximální právě 1. Jenže z toho by se někteří lidé by se vztekali, že nestačí napsat id="xyz", ale musí psát <id>xyz</id>*. Tak kvůli nim asi ty atributy existují
což je o celé tři znaky delší zápis – jak skandální!No skandální na tom je především to, že naprosto zbytečně opakujete totéž jméno dvakrát. Takže pokud si atribut pojmenujete "id", jsou to jen 3 znaky navíc, pokud ovšem "satanarcheolegenialkohrozny", je to jaksi víc.
</id> má funkci uzavírací závorky, takže je nanejvýš divné ho tak nepsat.
</id> má funkci uzavírací závorky, takže je nanejvýš divné ho tak nepsat.V tomhle máš pravdu – zjistit, která uzavírací závorka patří ke které je pro stroj snadné. Zajímavé ale je, že kritici XML často argumentují tím, že XML je vhodné pro strojové zpracování a nevhodné pro člověka – přitom tady je to přesně naopak: ono redundantní opakování názvu v uzavírací „závorce“ (<id/>) je vhodné pro člověka*, který na první pohled vidí, který element je uzavírán a nemusí počítat závorky – navíc to slouží jako kontrola proti překlepům a dalším hloupým chybám – protože taková hloupá chyba s velkou pravděpodobností způsobí invaliditu dokumentu, a je tak hned odhalena.
*) programu je to jedno, ten by si závorky dopočítal
redundantní opakování názvu v uzavírací „závorce“ <id/>) je vhodné pro člověkaOpravdu? Pokud mám do sebe vnořených několik elementů stejného jména, pranic nepoznám. Zato každý rozumný textový editor umí ukazovat párování závorek a také odsazovat.
cat nebo less – tam mi spíš pomůže ukecanější XML. Navíc, aby mi editor zvýraznil párovou závorku, tak na ni většinou musím najet kurzorem – kdežto párové značky vidím všechny najednou.
*) např. jEdit, vim, emacs, Netbeans
Rozdíl spíš bude, když si vypíši soubor třeba pomocí příkazu cat nebo lessTam pomůže jednoduchý filtr, který obsah souboru správně poodsazuje, aby byla vidět jeho struktura. Opět je ho daleko jednodušší napsat pro S-expy než pro XML.
Navíc, aby mi editor zvýraznil párovou závorku, tak na ni většinou musím najet kurzorem – kdežto párové značky vidím všechny najednou.Opět jenom za předpokladu, že nevnořujete více elementů téhož jména do sebe. Některé editory navíc umí závorky barvit podle hloubky vnoření, takže vidíte párování, aniž byste rejdil kurzorem. Jinak tohle všechno potřebujete jen tehdy, když neodsazujete. Zkrátka přehlednost párování závorek by měla být záležitostí nástrojů, ne formátu.
Tam pomůže jednoduchý filtr, který obsah souboru správně poodsazuje, aby byla vidět jeho struktura.Ukázka příšerně* formátovaného XML:
curl http://nekurak.net/Uděláme ho čitelné pro člověka – odsadíme:
curl http://nekurak.net/ | xmlindentStačí jeden příkaz, roura
*) taky kdo by se s tím patlal, když je na druhé straně prohlížeč, který to zchroustá i takhle – a uživatele formátování XHTML nemusí zajímat.
2.4.2010 23:06
Jardík | skóre: 40
| blog: jarda_bloguje
 5.4.2010 12:03
OndraZX | skóre: 27
| blog: OndraZX
| Frydek-Mistek
6.4.2010 08:55
Jakub Lucký | skóre: 40
| Praha
5.4.2010 12:03
OndraZX | skóre: 27
| blog: OndraZX
| Frydek-Mistek
6.4.2010 08:55
Jakub Lucký | skóre: 40
| Praha
ISSN 1214-1267, (c) 1999-2007 Stickfish s.r.o.
 2.4.2010 11:45
2.4.2010 11:45
 2.4.2010 12:14
2.4.2010 12:14
 5.4.2010 20:48
5.4.2010 20:48
 5.4.2010 14:53
5.4.2010 14:53
{kind=link}
{kind=link}