Portál AbcLinuxu, 31. července 2026 18:42
Regulární výrazy
Články
-
Regulární výrazy
Regulární výraz (regular expression, dále jen regexp) slouží k vyhledání části řetězce, kterou předem (úplně) neznáme nebo která může mít více podob. Používá se v programovacích a skriptovacích jazycích.
Obecné regulární výrazy
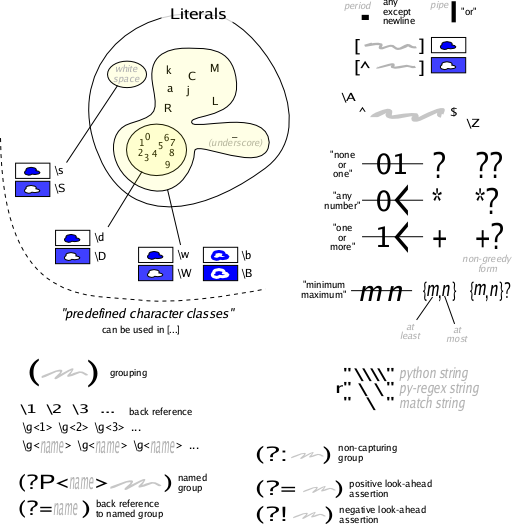
Mezi obecné regexpy, které podporují všechny možné implementace (Bash, Perl, grep, GNU sed, GNU awk, glibc /regex.h/, atd.), patří množiny znaků. Ty reprezentují jeden znak a používají se pro označení části řetězce, která může mít různé podoby (různé znaky v určité části). Zapisují se mezi hranaté závorky.
b[au]f # Odpovídá řetězci baf nebo buf.
[a-zA-Z] # Množina rozsahu znaků. Odpovídá jednomu výskytu písmene
# A až Z (malá i velká písmena,
# pouze bez diakritiky).
[[:alpha:]] # Totéž, ale zahrnuje i písmena s háčky a čárkami
# (pokud jsou nastavené české locales).
[[:alnum:]] # Jako předchozí, ale navíc zahrnuje číslice.
[aeiouy] # Množina malých písmen (a, e, i, o, u, y).
[0-9] # Množina všech číslic.
[[:digit:]] # Jiný zápis téhož.
[123] # Množina číslic 1, 2 a 3.
[[:space:]] # Množina "whitespace" znaků
. # Množina všech znaků. Odpovídá jednomu znaku.
\. # Odpovídá tečce.
\\ # Odpovídá zpětnému lomítku.
\* # Odpovídá hvězdičce.
Přidáte-li za výraz (např. množinu či znak) hvězdičku, změní se jeho význam. Místo jednoho výskytu se bude hledat libovolný počet výskytů; žádný až nekonečno. Například a* odpovídá libovolnému počtu písmen a za sebou. Výraz .* odpovídá úplně všem řetězcům.
Množiny znaků lze přidáním ^ na začátek negovat tak, že znaky v nich obsažené se v daném řetězci nesmějí vyskytovat. Přidáte-li znak ^ jinam, než na začátek, stane se prostým znakem z množiny.
Regexp vždy odpovídá své nejdelší možné variantě v řetězci (v Perlu toto chování lze ovlivnit, vizte níže), takže použijete-li například o odstavec výše zmíněný výraz .* a ihned za něj dáte například [0-9]* (libovolný počet číslic), tak si všimněte, že výraz .* využil své moci a označil vše, co jen mohl a na množinu [0-9]* nezbylo nic, místo toho aby se .* při prvním výskytu číslice zastavil, jak by se někdo mohl mylně domnívat. Zmiňuji se o tom zde proto, že tyto znegované množiny znaků jsou univerzálním řešením tohoto problému. Použijete-li místo původního výrazu .*[0-9]* výraz [^0-9]*[0-9]*, tak výraz [0-9]* označí celé první číslo, na které narazí, jelikož [^0-9]* se před číslicí zastaví. Pro lepší pochopení jsem níže (do části článku o GNU sedu) přidal dva ilustrující příkazy, ale nepředbíhejme. Následuje ukázka znegovaných množin znaků:
[^0-9] # Odpovídá jednomu znaku, který není číslice.
[^[:digit:]] # Jiný zápis téhož.
Dále mezi obecné regexpy patří symboly začátku a konce řádku, které mají ovšem tento význam jen tehdy, jsou-li správně umístěny (začátek na začátku a konec na konci výrazu).
^ # Začátek řetězce.
$ # Konec řetězce.
Několik ukázek obecných regexpů:
^$ # Odpovídá prázdnému řetězci (začátek a hned konec).
^a. # Odpovídá řetězci, který začíná písmenem 'a'
# a je následován jedním libovolným znakem.
^[^0-9]* # Odpovídá libovolnému počtu nečíselných znaků
# od začátku řetězce
b$ # Odpovídá řetězci, který končí písmenem 'b'.
[0-9].[[:alpha:]] # Odpovídá řetězci, který obsahuje číslici,
# poté libovolný znak a za ním písmeno.
Rozšířené regulární výrazy
Rozšířené (extended) regexpy značně rozšiřují možnosti těch obecných. Často je třeba je explicitně povolit. Bash je nepodporuje, Perl a GNU awk je používají běžně, grep potřebuje přepínač -E (příp. -P pro použití perlových regexpů; tento přepínač je dostupný, jen pokud byl grep zkompilován s podporou libpcre), GNU sed přepínač -r a při použití regex.h v C/C++ musíte předat funkci regcomp() flag REG_EXTENDED.
Rozšířené jsou možnosti pro zachycení řetězce, ve kterém se určité části několikrát za sebou opakují. Tyto znaky se zapíší za určitou část regexpu.
? # Volitelný výskyt (jeden nebo žádný).
+ # Jeden a více výskytů.
{n} # Za n se dosadí požadovaný počet výskytů.
# Toto nepodporuje GNU awk.
{n,} # Odpovídá n a více výskytům.
{n,m} # Odpovídá n až m výskytům.
Například:
a? # Jedno nebo žádné písmeno a.
[ao]+ # Jeden nebo více výskytů písmen z množiny.
[^ ]{3,5} # Tři až pět znaků různých od mezery.
[0-9]* # Libovolný počet číslic.
Kromě množin znaků jsou dostupné i množiny řetězců resp. výrazů, které se zapisují do kulatých závorek a oddělují pomocí znaku | (pipe).
(str|pwd) # Odpovídá řetězci str nebo pwd.
(foo)+ # Jeden a více výskytů řetězce foo.
(foo|bar)* # Libovolný počet řetězců foo nebo bar.
(gentoo){3,} # Odpovídá třem a více výskytům řetězce gentoo.
((li){2}e)? # Volitelný výskyt řetězce lilie.
Jak jsem naznačil, množina řetězců není úplně správný název, protože zrovna tak může jít o regexpy. Následující množina je složená ze dvou výrazů. Hned za množinou následuje otazník, který znamená, že výskyt všech výrazů z množiny je volitelný. První výraz značí jeden nebo více výskytů znaků a a b za sebou a druhý výraz odpovídá pěti libovolným číslicím.
([ab]+|[0-9]{5})?
Pokud chcete regexp odpovídající například sudému počtu řetězců, lze použít toto:
^((linux){2})*$
Vysvětlení: Máme regexp na označení dvou výskytů řetězce linux za sebou. Když se celý výraz obalí dalšími závorkami, hvězdička za ním zajistí označení též čtyř, šesti, osmi, deseti (atd.) výskytů. Pokud chcete minimálně dva výskyty, použijte místo hvězdičky plus.
GNU sed
Kromě toho, že sed podporuje nahrazování řetězců odpovídajících regexpům, má zajímavou vlastnost, a tou je podpora referencí. Když si regexpem vyberete určitou část řetězce a chcete ji použít i v nové (nahrazující) části, máte možnost použít příkazy podobné následujícím. Předávám sedu řetězec přes echo, abyste si to pro lepší představu mohli rovnou vyzkoušet.
# Ukázka výše (u znegovaných množin) zmiňovaného problému.
# Na výraz [0-9]+ zbude jen poslední číslo, tedy 1.
echo retezec4241 | sed -r 's/.*([0-9]+)/\1/'
# ... a ukázka řešení pomocí znegované množiny.
# Výraz [^0-9]* se před první číslicí zastaví; vypíše se 4241.
echo retezec4241 | sed -r 's/[^0-9]*([0-9]+)/\1/'
# Výraz začínající číslicí bude vložen mezi hvězdičky.
echo "nahodne cislo: 11.256  " | sed -r 's/([0-9][^ ]+)/*\1*/'
# Je možné použít i více referencí. Zkusme třeba označit
# řetězec "lol" s libovolným počtem 'o' a za ním nějaké číslo.
echo "nejdriv looool a pak cislo 123 ..." | \
sed -r 's:.*(lo+l)[^0-9]+([0-9]+).*:\\1 je \1\n\\2 je \2:'
" | sed -r 's/([0-9][^ ]+)/*\1*/'
# Je možné použít i více referencí. Zkusme třeba označit
# řetězec "lol" s libovolným počtem 'o' a za ním nějaké číslo.
echo "nejdriv looool a pak cislo 123 ..." | \
sed -r 's:.*(lo+l)[^0-9]+([0-9]+).*:\\1 je \1\n\\2 je \2:'
Za reference jsou považovány pouze regexpy v kulatých závorkách, tedy množiny výrazů.
Perl
Perlové regexpy obsahují několik vlastních rozšíření. Jedním z nich jsou množiny.
| Perl |
standardní |
| \d |
[[:digit:]] |
| \D |
[^[:digit:]] |
| \w |
[[:alnum:]] |
| \W |
[^[:alnum:]] |
| \s |
[[:space:]] |
| \S |
[^[:space:]] |
Tyto zkrácené zápisy množin se používají úplně stejně jako ty běžné; \d+ – ekvivalent [0-9]+ či [[:digit:]]+, \s{3,} – tři a více whitespace nebo třeba \W* – libovolný počet znaků, které se nevyskytují v množině [[:alnum:]]. Pokud chcete, aby Perl do množin, jako je \w, zahrnoval i písmena s diakritikou, kromě českých locales je třeba v programu nastavit jejich použití:
use locale;
Perl poskytuje možnost kontroly nad tím, zda se bude označovat nejkratší nebo nejdelší možná varianta výrazu. Pokud chceme tu nejkratší, za daný výraz přidáme otazník; nejdelší je výchozí chování regexpů (nejen perlových).
my($string) = "popokatepetl";
# označí (a přiřadí do $1) celý řetězec
$string =~ m/(p.*[oel])/;
# označí řetězec "po"
$string =~ m/(p.*?[oel])/;
# totéž, tentokrát obecně
$string =~ m/(p[^oel]*[oel])/;
Toto zdaleka není vše, co Perl s regulárními výrazy umí – popsat vše by vydalo na dost dlouhý seriál. Jako zdroj dalších informací můžete použít například manuálovou stránku perlre(1).
Regulární výrazy v praxi
Asi neuškodí, když si ukážeme nějaké to využití regulárních výrazů v praxi.
# Vypíše ze souboru (/etc/fstab) unixové cesty bez mezer.
egrep -o '(/[^/ ]*)*' /etc/fstab
# Vypíše názvy skupin v systému.
egrep -o '^[^:]+' /etc/group
sed 's/:.*//' /etc/group
# Rozparsuje z unixové cesty adresář a soubor.
echo /etc/fstab | sed -r 's:(.*)/(.*):adresář "\1", soubor "\2":'
# Získá tagy z Ogg a přiřadí je do proměnných ($ALBUM, $ARTIST, $TITLE).
eval $(ogginfo Floor-Fee-La.ogg | sed -r -e \
'/^[[:space:]]+(TITLE|ARTIST|ALBUM)=/!d' -e 's:=:=":' -e 's:$:":')
Šikovnou pomůckou je i stránka s ukázkami Užitečné jednořádkové skripty pro sed.
Závěr
Regexpy se jeví složitější, než ve skutečnosti jsou. Ovšem až na ty perlové, ty složité opravdu jsou :-). Po nějakém čase už píšete rozšířené regexpy bez velkého přemýšlení. Svoje zkušenosti můžete prověřit třeba interaktivními testy na lexmasterclass.com.
Související články
Odkazy a zdroje
Další články z této rubriky
Diskuse k tomuto článku
23.1.2008 00:06
I
Re: Regulární výrazy
23.1.2008 00:29
petris
Re: Regulární výrazy
23.1.2008 00:44
|🇵🇸 | skóre: 94
| blog:
Re: Regulární výrazy
23.1.2008 00:48
petris
Re: Regulární výrazy
23.1.2008 08:38
DarkCraft | skóre: 3
| Praha
Re: Regulární výrazy
23.1.2008 09:41
CET
Re: Regulární výrazy
23.1.2008 10:18
geon | skóre: 18
| blog:
bavaria
Re: Regulární výrazy
23.1.2008 11:13
mj41 | skóre: 17
| blog:
mj41
| Brno
Perlové jsou především nejmocnější
23.1.2008 11:22
depka
Re: Regulární výrazy
23.1.2008 13:30
b*d
| blog:
b_d
Re: Regulární výrazy
23.1.2008 21:41
spenat28
| Loc: 53.422224, -1.967178
doplnil bych do článku
24.1.2008 01:04
Semo | skóre: 45
| blog:
Semo
Re: Regulární výrazy
25.1.2008 12:24
Daniel Novotny | skóre: 3
Re: Regulární výrazy - echo /etc/fstab
25.1.2008 18:56
Ash | skóre: 53
Re: Regulární výrazy
25.1.2008 20:12
jakub
Re: Regulární výrazy
ISSN 1214-1267, (c) 1999-2007 Stickfish s.r.o.
 23.1.2008 14:06
23.1.2008 14:06
 23.1.2008 14:33
23.1.2008 14:33
 23.1.2008 00:29
23.1.2008 00:29
 23.1.2008 00:44
23.1.2008 00:44


 23.1.2008 10:18
23.1.2008 10:18
 23.1.2008 11:13
23.1.2008 11:13
 23.1.2008 16:36
23.1.2008 16:36
 23.1.2008 21:41
23.1.2008 21:41
{kind=link}