Představena byla nová linuxová distribuce Shadowfetch Linux. Na rozdíl od mnoha nováčků, které nabízejí převážně jiné téma a výběr softwaru, tato distribuce založená na Debianu Testing s desktopovým prostředím KDE Plasma 6.6, klade lokálně běžící umělou inteligenci do centra svého desktopového zážitku.
Max Leiter v roce 2019 zkusil zprovoznit X server na iPadu (iOS). Nyní se k tématu vrátil a s pomocí LLM a balíčkovacích nástrojů Procursus rozběhl desktop s X11 i Waylandem. Jeho balíčky jsou dostupné v repozitáři xiOS.
Společnost Google Cloud dnes oznámila, že její infrastruktura a služby byly oficiálně zařazeny do Katalogu cloud computingu vedeného Digitální a informační agenturou (DIA). Tato certifikace potvrzuje, že infrastruktura a služby Google Cloud splňují přísné bezpečnostní a regulační požadavky České republiky pro provoz cloudových služeb ve veřejném sektoru.
Vůbec poprvé v historii se stát při testování digitálních služeb obrací na širokou veřejnost. Digitální a informační agentura (DIA) a Ministerstvo vnitra zvou občany k zapojení do zátěžového testu eDokladů, které od loňského podzimu prošly optimalizací aplikace a posílením infrastruktury. Test proběhne 13. srpna ve 13:00 a pro jeho úspěch bude potřeba zapojení několika desítek tisíc občanů. Zapojení do testu je zcela dobrovolné a úkol
… více »FireDragon je webový prohlížeč, doposud založený na Floorpu, jednom z forků Firefoxu s větším důrazem na ochranu soukromí a přizpůsobení uživatelského rozhraní. Spravuje ho člen komunity distribuce Garuda Linux. Nové vydání verze 13 opouští Floorp a přechází přímo na Firefox s patchi z LibreWolfu a vlastními úpravami. Dostupný je také na Flathubu.
picogame (GitHub) je malý 2D herní engine pro mikrokontroléry jako RP2040, čip uvnitř kapesní konzole Picopad. Hru napíšeš v Pythonu a vyzkoušíš ji v prohlížeči nebo desktopovém simulátoru. Až bude hotová, zkopíruješ ji na podporovanou desku. Na začátku nepotřebuješ C, sestavení firmwaru ani hardware.
Multiplatformní prohlížeč elektronických knih KOReader byl vydán ve verzi 2026.07 "Sailing Walrus". U PDF souborů s SMask lze vyčistit pozadí. Přibyla podpora Kobo v5 nebo základní podpora OPDS 2.0.
Společnost Valve sponzoruje a společnost Collabora portuje RADV (open source Vulkan ovladač pro AMD GPU z projektu Mesa) na Windows.
Starling (GitHub) je desktopové prostředí vytvořeno umělou inteligencí (s dohledem jednoho vývojáře během šesti měsíců).
Dne 30. června 2026 byla završena fyzická realizace projektu Czech National Quantum Communication Infrastructure (CZQCI), tedy České národní kvantové komunikační infrastruktury. Projekt byl realizován od 1. března 2023 a financován z Národního plánu obnovy částkou 121,6 milionu Kč. Cílem podpořeného projektu bylo vybudovat základy národní kvantové komunikační infrastruktury a ověřit možnosti jejího praktického využití. Mezi
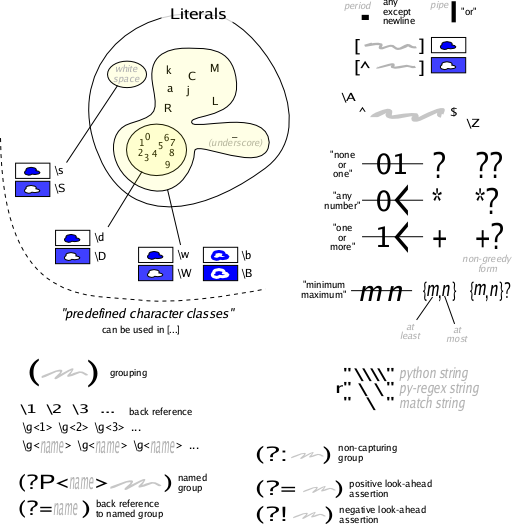
… více »Mezi obecné regexpy, které podporují všechny možné implementace (Bash, Perl, grep, GNU sed, GNU awk, glibc /regex.h/, atd.), patří množiny znaků. Ty reprezentují jeden znak a používají se pro označení části řetězce, která může mít různé podoby (různé znaky v určité části). Zapisují se mezi hranaté závorky.
b[au]f # Odpovídá řetězci baf nebo buf.
[a-zA-Z] # Množina rozsahu znaků. Odpovídá jednomu výskytu písmene
# A až Z (malá i velká písmena,
# pouze bez diakritiky).
[[:alpha:]] # Totéž, ale zahrnuje i písmena s háčky a čárkami
# (pokud jsou nastavené české locales).
[[:alnum:]] # Jako předchozí, ale navíc zahrnuje číslice.
[aeiouy] # Množina malých písmen (a, e, i, o, u, y).
[0-9] # Množina všech číslic.
[[:digit:]] # Jiný zápis téhož.
[123] # Množina číslic 1, 2 a 3.
[[:space:]] # Množina "whitespace" znaků
. # Množina všech znaků. Odpovídá jednomu znaku.
\. # Odpovídá tečce.
\\ # Odpovídá zpětnému lomítku.
\* # Odpovídá hvězdičce.
Přidáte-li za výraz (např. množinu či znak) hvězdičku, změní se jeho význam. Místo jednoho výskytu se bude hledat libovolný počet výskytů; žádný až nekonečno. Například a* odpovídá libovolnému počtu písmen a za sebou. Výraz .* odpovídá úplně všem řetězcům.
Množiny znaků lze přidáním ^ na začátek negovat tak, že znaky v nich obsažené se v daném řetězci nesmějí vyskytovat. Přidáte-li znak ^ jinam, než na začátek, stane se prostým znakem z množiny.
Regexp vždy odpovídá své nejdelší možné variantě v řetězci (v Perlu toto chování lze ovlivnit, vizte níže), takže použijete-li například o odstavec výše zmíněný výraz .* a ihned za něj dáte například [0-9]* (libovolný počet číslic), tak si všimněte, že výraz .* využil své moci a označil vše, co jen mohl a na množinu [0-9]* nezbylo nic, místo toho aby se .* při prvním výskytu číslice zastavil, jak by se někdo mohl mylně domnívat. Zmiňuji se o tom zde proto, že tyto znegované množiny znaků jsou univerzálním řešením tohoto problému. Použijete-li místo původního výrazu .*[0-9]* výraz [^0-9]*[0-9]*, tak výraz [0-9]* označí celé první číslo, na které narazí, jelikož [^0-9]* se před číslicí zastaví. Pro lepší pochopení jsem níže (do části článku o GNU sedu) přidal dva ilustrující příkazy, ale nepředbíhejme. Následuje ukázka znegovaných množin znaků:
[^0-9] # Odpovídá jednomu znaku, který není číslice. [^[:digit:]] # Jiný zápis téhož.
Dále mezi obecné regexpy patří symboly začátku a konce řádku, které mají ovšem tento význam jen tehdy, jsou-li správně umístěny (začátek na začátku a konec na konci výrazu).
^ # Začátek řetězce. $ # Konec řetězce.
Několik ukázek obecných regexpů:
^$ # Odpovídá prázdnému řetězci (začátek a hned konec).
^a. # Odpovídá řetězci, který začíná písmenem 'a'
# a je následován jedním libovolným znakem.
^[^0-9]* # Odpovídá libovolnému počtu nečíselných znaků
# od začátku řetězce
b$ # Odpovídá řetězci, který končí písmenem 'b'.
[0-9].[[:alpha:]] # Odpovídá řetězci, který obsahuje číslici,
# poté libovolný znak a za ním písmeno.
Rozšířené (extended) regexpy značně rozšiřují možnosti těch obecných. Často je třeba je explicitně povolit. Bash je nepodporuje, Perl a GNU awk je používají běžně, grep potřebuje přepínač -E (příp. -P pro použití perlových regexpů; tento přepínač je dostupný, jen pokud byl grep zkompilován s podporou libpcre), GNU sed přepínač -r a při použití regex.h v C/C++ musíte předat funkci regcomp() flag REG_EXTENDED.
Rozšířené jsou možnosti pro zachycení řetězce, ve kterém se určité části několikrát za sebou opakují. Tyto znaky se zapíší za určitou část regexpu.
? # Volitelný výskyt (jeden nebo žádný).
+ # Jeden a více výskytů.
{n} # Za n se dosadí požadovaný počet výskytů.
# Toto nepodporuje GNU awk.
{n,} # Odpovídá n a více výskytům.
{n,m} # Odpovídá n až m výskytům.
Například:
a? # Jedno nebo žádné písmeno a.
[ao]+ # Jeden nebo více výskytů písmen z množiny.
[^ ]{3,5} # Tři až pět znaků různých od mezery.
[0-9]* # Libovolný počet číslic.
Kromě množin znaků jsou dostupné i množiny řetězců resp. výrazů, které se zapisují do kulatých závorek a oddělují pomocí znaku | (pipe).
(str|pwd) # Odpovídá řetězci str nebo pwd.
(foo)+ # Jeden a více výskytů řetězce foo.
(foo|bar)* # Libovolný počet řetězců foo nebo bar.
(gentoo){3,} # Odpovídá třem a více výskytům řetězce gentoo.
((li){2}e)? # Volitelný výskyt řetězce lilie.
Jak jsem naznačil, množina řetězců není úplně správný název, protože zrovna tak může jít o regexpy. Následující množina je složená ze dvou výrazů. Hned za množinou následuje otazník, který znamená, že výskyt všech výrazů z množiny je volitelný. První výraz značí jeden nebo více výskytů znaků a a b za sebou a druhý výraz odpovídá pěti libovolným číslicím.
([ab]+|[0-9]{5})?
Pokud chcete regexp odpovídající například sudému počtu řetězců, lze použít toto:
^((linux){2})*$
Vysvětlení: Máme regexp na označení dvou výskytů řetězce linux za sebou. Když se celý výraz obalí dalšími závorkami, hvězdička za ním zajistí označení též čtyř, šesti, osmi, deseti (atd.) výskytů. Pokud chcete minimálně dva výskyty, použijte místo hvězdičky plus.
Kromě toho, že sed podporuje nahrazování řetězců odpovídajících regexpům, má zajímavou vlastnost, a tou je podpora referencí. Když si regexpem vyberete určitou část řetězce a chcete ji použít i v nové (nahrazující) části, máte možnost použít příkazy podobné následujícím. Předávám sedu řetězec přes echo, abyste si to pro lepší představu mohli rovnou vyzkoušet.
# Ukázka výše (u znegovaných množin) zmiňovaného problému. # Na výraz [0-9]+ zbude jen poslední číslo, tedy 1. echo retezec4241 | sed -r 's/.*([0-9]+)/\1/' # ... a ukázka řešení pomocí znegované množiny. # Výraz [^0-9]* se před první číslicí zastaví; vypíše se 4241. echo retezec4241 | sed -r 's/[^0-9]*([0-9]+)/\1/' # Výraz začínající číslicí bude vložen mezi hvězdičky. echo "nahodne cislo: 11.256" | sed -r 's/([0-9][^ ]+)/*\1*/' # Je možné použít i více referencí. Zkusme třeba označit # řetězec "lol" s libovolným počtem 'o' a za ním nějaké číslo. echo "nejdriv looool a pak cislo 123 ..." | \ sed -r 's:.*(lo+l)[^0-9]+([0-9]+).*:\\1 je \1\n\\2 je \2:'
Za reference jsou považovány pouze regexpy v kulatých závorkách, tedy množiny výrazů.
Perlové regexpy obsahují několik vlastních rozšíření. Jedním z nich jsou množiny.
| Perl | standardní |
| \d | [[:digit:]] |
| \D | [^[:digit:]] |
| \w | [[:alnum:]] |
| \W | [^[:alnum:]] |
| \s | [[:space:]] |
| \S | [^[:space:]] |
Tyto zkrácené zápisy množin se používají úplně stejně jako ty běžné; \d+ – ekvivalent [0-9]+ či [[:digit:]]+, \s{3,} – tři a více whitespace nebo třeba \W* – libovolný počet znaků, které se nevyskytují v množině [[:alnum:]]. Pokud chcete, aby Perl do množin, jako je \w, zahrnoval i písmena s diakritikou, kromě českých locales je třeba v programu nastavit jejich použití:
use locale;
Perl poskytuje možnost kontroly nad tím, zda se bude označovat nejkratší nebo nejdelší možná varianta výrazu. Pokud chceme tu nejkratší, za daný výraz přidáme otazník; nejdelší je výchozí chování regexpů (nejen perlových).
my($string) = "popokatepetl"; # označí (a přiřadí do $1) celý řetězec $string =~ m/(p.*[oel])/; # označí řetězec "po" $string =~ m/(p.*?[oel])/; # totéž, tentokrát obecně $string =~ m/(p[^oel]*[oel])/;
Toto zdaleka není vše, co Perl s regulárními výrazy umí – popsat vše by vydalo na dost dlouhý seriál. Jako zdroj dalších informací můžete použít například manuálovou stránku perlre(1).
Asi neuškodí, když si ukážeme nějaké to využití regulárních výrazů v praxi.
# Vypíše ze souboru (/etc/fstab) unixové cesty bez mezer. egrep -o '(/[^/ ]*)*' /etc/fstab # Vypíše názvy skupin v systému. egrep -o '^[^:]+' /etc/group sed 's/:.*//' /etc/group # Rozparsuje z unixové cesty adresář a soubor. echo /etc/fstab | sed -r 's:(.*)/(.*):adresář "\1", soubor "\2":' # Získá tagy z Ogg a přiřadí je do proměnných ($ALBUM, $ARTIST, $TITLE). eval $(ogginfo Floor-Fee-La.ogg | sed -r -e \ '/^[[:space:]]+(TITLE|ARTIST|ALBUM)=/!d' -e 's:=:=":' -e 's:$:":')
Šikovnou pomůckou je i stránka s ukázkami Užitečné jednořádkové skripty pro sed.
Regexpy se jeví složitější, než ve skutečnosti jsou. Ovšem až na ty perlové, ty složité opravdu jsou :-). Po nějakém čase už píšete rozšířené regexpy bez velkého přemýšlení. Svoje zkušenosti můžete prověřit třeba interaktivními testy na lexmasterclass.com.
Nástroje: Tisk bez diskuse
Tiskni
Sdílej:
![]()
![]()
![]()
![]()
![]()
![]()
 23.1.2008 14:06
David Watzke | skóre: 74
| blog: Blog...
| Praha
23.1.2008 14:06
David Watzke | skóre: 74
| blog: Blog...
| Praha
my $mode_map = {
'show' => \ &do_show,
'submit' => \ &do_submit,
};
$mode_map->{$mode}->(@param);
uznávam, na given/when to nemá, obyčajný switch/case to zvládne v pohode.
pre parsovanie textu si pozri \G a modifikátory cg
 23.1.2008 00:29
Honza Balák | skóre: 23
| blog: Jaxův linuxový zápisník
| Předklášteří
23.1.2008 00:29
Honza Balák | skóre: 23
| blog: Jaxův linuxový zápisník
| Předklášteří
takže použijete-li například o odstavec výše zmíněný výraz .* a ihned za něj dáte například [0-9]* (libovolný počet číslic), tak si všimněte, že výraz .* využil své moci a označil vše, co jen mohl a na množinu [0-9]* zbyla už jen poslední číslice v řetězciNa [0-9]* nezbyde nic.
23.1.2008 00:39
Honza Balák | skóre: 23
| blog: Jaxův linuxový zápisník
| Předklášteří
23.1.2008 07:29
David Watzke | skóre: 74
| blog: Blog...
| Praha
[0-9]+.

z nie je posledné písmeno abecedy [a-ž]  23.1.2008 11:33
David Watzke | skóre: 74
| blog: Blog...
| Praha
23.1.2008 11:33
David Watzke | skóre: 74
| blog: Blog...
| Praha
Len taka drobnost: [a-zA-Z] != [:alpha:]Já jsem někde napsal, že je to totéž?
[a-zA-Z] # Množina rozsahu znaků. Odpovídá jednomu a více
# výskytům písmen A až Z (malá i velká písmena,
# pouze bez diakritiky).
Jenom drobnost - tenhle zapis odpovida prave jednomu znaku z mnoziny A-Z nebo a-z. Kdyby to bylo jeden a vic, tak za tim musi byt "+".
23.1.2008 11:35
David Watzke | skóre: 74
| blog: Blog...
| Praha
 23.1.2008 11:13
mj41 | skóre: 17
| blog: mj41
| Brno
.
23.1.2008 14:03
David Watzke | skóre: 74
| blog: Blog...
| Praha
23.1.2008 11:13
mj41 | skóre: 17
| blog: mj41
| Brno
.
23.1.2008 14:03
David Watzke | skóre: 74
| blog: Blog...
| Praha
Složitější? Ja bych to napsal, tak že ty Perlové uměly vždycky nejvíceNo právě
Dokonce si člověk může napsat vlastní RE engine.
Ale to už jsme se dostal k té nejsložitější věci co jsem kdy viděl a samozřejmě ještě nepochopilAno, přesně o tom mluvím
 23.1.2008 17:01
zoul | skóre: 43
| blog: ☂
| Boskovice
23.1.2008 17:01
zoul | skóre: 43
| blog: ☂
| Boskovice
(.*)\1 (WikiWiki, MoinMoin apod.), což podle Wikipedie není ani bezkontextové, natož regulární. I v rámci třídy regulárních výrazů ale můžou být některé věci navíc – viz například pojmenované závorky (named captures) v novém pětkovém Perlu.
23.1.2008 17:18
zoul | skóre: 43
| blog: ☂
| Boskovice
(str|pwd) # Odpovídá řetězci str nebo pwd.
nemelo by to byt radej:
(str)|(pwd) ?
23.1.2008 11:36
David Watzke | skóre: 74
| blog: Blog...
| Praha
man perlre:
The first alternative includes everything from the last pattern delimiter (“(”, “[”, or the beginning of the pattern) up to the first “|”, and the last alternative contains everything from the last “|” to the next pattern delimiter. That’s why it’s common practice to include alternatives in parentheses: to minimize confusion about where they start and end.
Nevím, jestli je to perlre, ale můžete zkusit použít \v ve vyhledávaném řetězci. Více viz :help magic
23.1.2008 21:52
David Watzke | skóre: 74
| blog: Blog...
| Praha
vim ve formě \<slovo\>.
Rozšířené regulární výrazy ...Bash je nepodporujeman bash: An additional binary operator, =~, is available, with the same precedence as == and !=. When it is used, the string to the right of the operator is considered an extended regular expression and matched accordingly. Zatvorky {,} zvladaju aj basic regexpy, len sa musia escapovat pomocou \, inak su to obycajne znaky. V extended regexp presne naopak. Uplne rovnako je to aj s (, ), ? a +. Vsetky su zvladane aj v BRE ak su escapovane. Vsetko je popisovane spravanie grepu a sedu a grep -E a sed -r.
25.1.2008 13:58
David Watzke | skóre: 74
| blog: Blog...
| Praha
Ale někdo se toho koukám chytnul a změnil to...
bash$ sed -n -e "s/^\([A-Z]\)$/\1/p" <<<a aobzvlášť ve formě
bash$ sed -n -e "s/^.*\([A-Z]\).*$/\1/p" <<<Aa aversus
bash$ sed -r -n -e "s/^.*([[:upper:]]).*$/\1/p" <<<Aa AJinak bash umí i extended regexp.
bash$ [[ a =~ ^[A-Z]$ ]] && echo matches matches bash$ [[ a =~ ^[[:lower:]]$ ]] && echo matches matches bash$ [[ a =~ ^[[:upper:]]$ ]] && echo matches
25.1.2008 19:05
David Watzke | skóre: 74
| blog: Blog...
| Praha
25.1.2008 20:14
David Watzke | skóre: 74
| blog: Blog...
| Praha
g na konci.)
echo "retezec4214" | sed 's/e/y/g'Toto není regulární výraz, mimochodem.
 AbcLinuxu.cz
AbcLinuxu.cz ITBiz.cz
ITBiz.cz HDmag.cz
HDmag.cz AbcPráce.cz
AbcPráce.cz 23.1.2008 00:44
23.1.2008 00:44
 23.1.2008 10:18
23.1.2008 10:18
 23.1.2008 16:36
23.1.2008 16:36
 23.1.2008 21:41
23.1.2008 21:41
{kind=link}