Portál AbcLinuxu, 27. června 2026 05:48
Předchozí dva díly tohoto seriálu byly věnované teorii distribuovaných verzovacích systémů. Dnes se konečně podíváme prakticky na jeden z nich – Mercurial (zkráceně Hg). Kromě úplných základů (přidávání souborů pod správu verzí, mazání, přejmenovávání…) si také ukážeme, jak se vracet ke starším verzím a jak si verze pro větší přehlednost označovat pomocí štítků.
Instalace programu je v linuxových distribucích jednoduchá, použijeme balíčkovací systém a Mercurial si nainstalujeme např. jedním z těchto příkazů:
aptitude install mercurial # Debian/Ubuntu yum install mercurial # Fedora/RedHat
Příkaz pro práci s Mercurialem se jmenuje hg
a mělo
by nám fungovat doplňování a napovídání tabulátorem.
Např. napíšeme hg com a stiskneme tabulátor a doplní se na hg commit.
Globální nastavení Mercurialu se nachází v souboru /etc/mercurial/hgrc.
Zde nic měnit nemusíme.
Jediné, co bychom si měli nastavit, je jméno v našem uživatelském konfiguračním souboru v ~/.hgrc
– sem zadáme něco jako:
[ui] username = Jméno Příjmení <jmeno@example.com>
Při commitování změn se pak toto použije jako jméno autora.
Kromě globálního a uživatelského konfiguračního souboru existuje i nastavení pro jednotlivá úložiště
– nachází se uvnitř nich v souboru .hg/hgrc.
Dejme tomu, že píšeme článek, diplomku, nějaký svůj program/skript… přestože to nepotřebujeme nikde vystavovat nebo s někým sdílet, může se nám hodit verzovací systém. Možná se vám už taky někdy stalo, že jste něco přepsali a pak jste si vzpomněli, že formulace, kterou jste tam měli ještě před pár dny byla lepší. Nebo třeba jen chcete sledovat, jak vám jde práce hezky od ruky – vidět kolik textu kdy přibylo. Místo toho, abychom si každý týden/den kopírovali vytvořené soubory do nějak pojmenovaného adresáře je začneme verzovat – je to snadné, takže se nemusíme bát použít verzování i v banálních případech – není to pověstný kanón na vrabce – je to naopak jednodušší a můžeme u toho udělat méně chyb, než kdybychom soubory zálohovali/verzovali ručně kopírováním.
Otevřeme si terminál a vstoupíme do složky se soubory, které chceme verzovat, a zadáme příkaz:
$ hg init
Příkaz nic nevypíše (to je v pořádku) a vytvoří nové mercurialové úložiště
– vznikne adresář .hg.
Úložiště je zatím prázdné.
Následujícím příkazem zjistíme aktuální stav:
$ hg status ? index.xhtml ? soubor.txt ? video.ogv
Otazník před názvem souborů znamená, že tyto soubory nejsou zatím verzované. Soubory si tedy přidáme pod správu mercurialu:
$ hg addremove adding index.xhtml adding soubor.txt adding video.ogv $ hg status A index.xhtml A soubor.txt A video.ogv
U souborů je teď příznak A a to znamená, že jsou čerstvě přidané
a když zadáme hg commit, uložíme je trvale do mercurialu jako novou verzi.
Jenže teď si uvědomíme, že video verzovat nechceme – naštěstí se nic nestalo a můžeme se vrátit zpět:
$ hg revert --all forgetting index.xhtml forgetting soubor.txt forgetting video.ogv $ hg status ? index.xhtml ? soubor.txt ? video.ogv
A přidáme soubory raději jednotlivě – jen ty, které skutečně chceme verzovat:
$ hg add soubor.txt index.xhtml $ hg status A index.xhtml A soubor.txt ? video.ogv
Abychom na to nemuseli pokaždé myslet, vytvoříme si seznam souborů, které se nemají verzovat:
$ echo "video.ogv" >> .hgignore $ hg add .hgignore $ hg status A .hgignore A index.xhtml A soubor.txt
Nežádoucí soubory nám už nepřekáží ve výpisu hg status
a nestane se nám, že bychom je omylem postoupili do úložiště
(to bychom museli udělat záměrně: hg add video.ogv, ale hromadné přidání/odebrání pomocí hg addremove je bude ignorovat).
Samotný soubor .hgignore je rovněž verzovaný – to je dobré jednak proto, že seznam se může v čase měnit
(např. soubory, které jsme chtěli ignorovat v prvních verzích teď chceme verzovat a naopak),
a jednak proto, že tento seznam se bude šířit společně s ostatními soubory – když uděláme push nebo pull, seznam ignorovaných souborů bude všude stejný.
Soubor .hgignore
může obsahovat jak regulární výrazy, tak obyčejné vzory jako v shellu – např. *~.
Vždy jeden vzor na jednom řádku.
Obvykle budeme ignorovat celé adresáře jako dist/*, build/* a záložní soubory.
Ještě jednou si pro jistotu vypíšeme hg status a když jsme s výsledkem spokojeni, můžeme vytvořit svoji první verzi:
$ hg commit
Otevře se nám textový editor, do něj napíšeme popis změn, které daná verze přináší – první řádka by měla být výstižná a stručná (zobrazuje se v krátkých výpisech historie) a na dalších řádcích se můžeme rozepsat klidně trochu víc. Hodně záleží co a pro koho verzujeme – když si verzujeme jen tak pro sebe, asi tam nebudeme psát moc dlouhé romány, ale když pracujeme v týmu, je dobré napsat srozumitelný popis změn (ne každý chce číst zdrojový kód a dělat si diff), nějaké vzkazy pro člověka, který bude dělat revizi naší práce, a pokud používáme systém na správu požadavků/chyb, měli bychom zadat i čísla úkolů, které jsme zde řešili (obvykle se před číslo dává # a systémy jako Trac z toho pak umí udělat odkaz na daný úkol). Platí zde podobné zásady jako pro komentáře v kódu: neměli bychom psát až tak, co jsme udělali (např. „do metody xyz() jsem přidal a = b + 10;“ – to je vidět z diffu, tudíž zbytečná informace), ale proč jsme to udělali a jaký to má smysl (např. „oprava chyby: zdvojování teček v protokolu SMTP“ a ideálně i její #číslo).
Zprávu nemusíme psát do editoru a můžeme ji uvést na příkazové řádce:
$ hg commit -m „Popis změn…“
Také můžeme postoupit jen konkrétní soubory, přestože jich bylo přidáno či změněno více:
hg commit index.xhtml soubor.txt
A když si to úplně na poslední chvíli rozmyslíme, stačí ukončit editor a žádnou zprávu nepsat – Mercurial to pochopí:
abort: empty commit message
a žádnou verzi nevytvoří.
Kromě zdrojových kódů nebo různých vlastních souborů můžeme tímto způsobem verzovat i konfiguraci našeho počítače v /etc:
# cd /etc # hg init # chown root:root .hg/ # chmod 700 .hg/ # hg addremove # hg commit -m „prvotní verze konfigurace“
Na chmod a chown nesmíme zapomenout
– jinak by se mohlo stát, že se k souborům,
které může normálně číst jen superuživatel, dostane přes verzovací systém i někdo jiný.
Verze pak můžeme vytvářet při každé ruční změně konfiguračních souborů,
případně si tento proces automatizujeme programem etckeeper
(verzuje /etc v pravidelných intervalech a při aktualizacích balíčků).
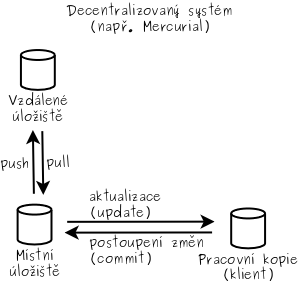
Zatím jsme se pohybovali pouze mezi pracovní kopií (normální soubory v adresáři, které upravujeme)
a místním úložištěm (uvnitř adresáře .hg, spravované Mercurialem, zde nic ručně neupravujeme, maximálně konfigurační soubor .hg/hgrc)
Pro připomenutí jeden obrázek z minula:
Jelikož se obvykle verzují důležité a pracně vytvořené věci, bylo by škoda o ně přijít třeba při havárii pevného disku. Proto je potřeba zálohovat – s verzovacím systémem to jde velice snadno.
Přepneme se do adresáře na externím nebo třeba síťovém disku a naklonujeme sem svoje dosavadní úložiště:
$ cd /mnt/externí-disk/ $ hg clone ~/diplomka/ destination directory: diplomka updating to branch default 3 files updated, 0 files merged, 0 files removed, 0 files unresolved $ cd diplomka
Máme teď kompletní kopii náší práce včetně všech předchozích verzí. Vazba na původní úložiště (odkud jsme klonovali) zůstává zachována – najdeme ji v konfiguračním souboru:
$ cat .hg/hgrc [paths] default = /home/franta/diplomka
Díky tomu nám budou fungovat příkazy hg push a hg pull,
pomocí kterých můžeme „synchronizovat“ obě úložiště.
Můžeme tedy pracovat střídavě v obou úložištích a třeba i na více počítačích současně (nosit si externí disk s sebou).
A zároveň máme ve věcech pořádek – vždy víme, která verze je aktuální, a nestane se nám, že bychom si omylem soubory přepsali nějakou špatnou verzí
– i kdyby se nám to stalo, vždy se můžeme vrátit zpět a chybu napravit.
Před stažením změn z druhého úložiště (hg pull) se můžeme podívat, jaké změny čekají na druhé straně:
$ hg incoming comparing with /home/franta/diplomka searching for changes changeset: 1:87df11cb506b tag: tip user: František Kučera <franta-hg@example.com> date: Thu Nov 24 15:18:08 2011 +0100 summary: Druhá verze
Vidíme, že provedením hg pull si stáhneme jednu sadu změn, víme kdo ji vytvořil, kdy a vidíme její popis.
Pustíme tedy hg pull a následně hg update (tím aktualizujeme pracovní kopii na poslední verzi).
Obdobným způsobem fungují příkazy hg push a hg outgoing,
akorát v opačném směru.
Příkazem hg log si vypíšeme historii celého úložiště:
$ hg log changeset: 1:87df11cb506b tag: tip user: František Kučera <franta-hg@example.com> date: Thu Nov 24 15:18:08 2011 +0100 summary: Druhá verze changeset: 0:01c1e32a34f5 user: František Kučera <franta-hg@example.com> date: Thu Nov 24 14:13:04 2011 +0100 summary: Moje první verze
A příkazem hg annotate index.xhtml zjistíme, z jaké verze pocházejí jednotlivé řádky daného souboru
– každý řádek začíná krátkým číslem verze (v našem případě by to byly 0 a 1, protože máme zatím dvě verze a čísluje se od nuly).
Díky tomu víme, jak je který řádek starý a který autor ho má na svědomí.
Užitečné je to zvlášť při vývoji softwaru – když nějaké části kódu nerozumíme, můžeme jít přímo za konkrétním kolegou a zeptat se, co tím myslel.
Ostatně v Subversionu se tato funkce jmenuje svn blame (obvinit).
Pro podrobnější výpis použijeme hg annotate s volbami --changeset a --user.
Práce na příkazové řádce je sice fajn, ale některé věci jsou přeci jen lépe vidět v GUI. K pokročilejším externím nástrojům se dostaneme v příštím díle – zatím si vystačíme se samotným Mercurialem. Ten disponuje vestavěným HTTP serverem, který zpřístupní dané úložiště.
$ cat ~/bin/hg-náhled #!/bin/bash konqueror http://localhost:8000/?style=gitweb & hg serve -p 8000
Pomocí tohoto skriptu si spustíme www prohlížeč a HTTP server a podíváme se, co je v daném úložišti. Přehledně vidíme všechny verze, můžeme si rozkliknout jednotlivé změny a rozdíly v souborech. K dispozici je i vyhledávání, stromový pohled a další funkce.
Tím můžeme zkoumat změny, které byly již postoupené do úložiště. Pro porovnání pracovní kopie s úložištěm se nám bude hodit následující skript:
$ cat ~/bin/hg-porovnej #!/bin/bash hg diff | kompare -o -
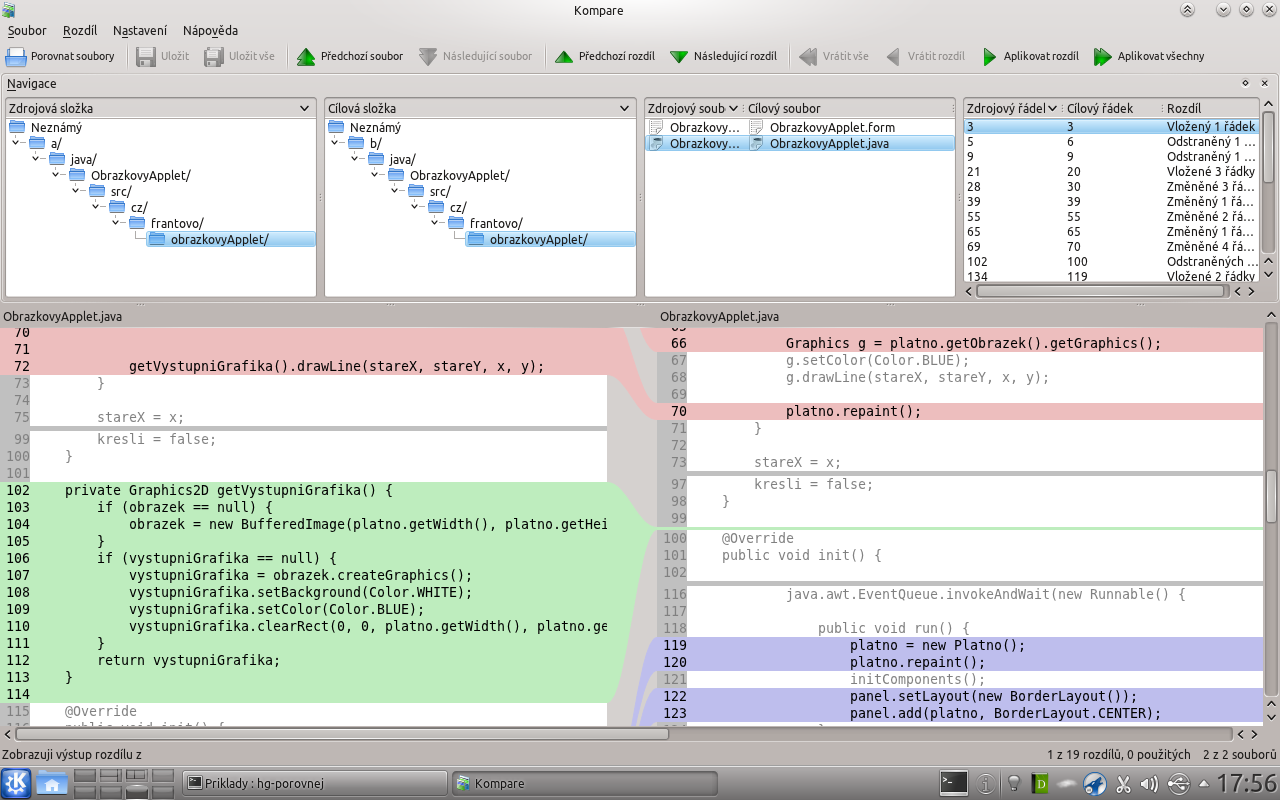
Tento příkaz je dobré spustit před hg commit
a podívat se, co přesně se chystáme odeslat – vidíme nové řádky (modře), změněné (červeně) a smazané (zeleně).
Při přesouvání souborů je lepší použít příkazů Mercurialu – místo:
$ mv soubor.txt Soubor.TXT $ hg status ! soubor.txt ? Soubor.TXT
použijeme raději:
$ hg mv soubor.txt Soubor.TXT $ hg status A Soubor.TXT R soubor.txt
a soubor se nejen přesune/přejmenuje, ale zároveň se i správně připraví na postoupení do úložiště:
původní soubor je ve stavu R (ke smazání) a nový ve stavu A (přidání).
Mercurial si navíc pamatuje, že Soubor.TXT vznikl ze soubor.txt
(Soubor.TXT má nastaveno parent 1 soubor.txt@87df11cb506b),
takže je historie zachována a lze sledovat změny (např. pomocí hg annotate) zpětně i do dob,
kdy se soubor ještě jmenoval jinak.
Což by nemuselo fungovat, kdybychom jeden soubor jen smazali a druhý vytvořili bez vědomí Mercurialu
(pak by to byly dva úplně jiné nezávislé soubory).
Naštěstí Mercurial je celkem inteligentní, takže se dokáže vypořádat i s tím,
když soubor přejmenujeme bez něj a pak dáme hg addremove:
$ hg addremove removing soubor.txt adding Soubor.TXT recording removal of soubor.txt as rename to Soubor.TXT (100% similar)
Nicméně jistější je ten první způsob (hg mv),
protože pak můžeme soubor v jednom kroku přejmenovat i měnit jeho obsah
a přesto se neztratí informace, že jde o tentýž soubor.
Pokud soubor smažeme obyčejně pomocí rm, Mercurial si všimne, že chybí:
$ rm Soubor.TXT $ hg status ! Soubor.TXT
Ale při následujícím hg commit se toto smazání nijak neprojeví.
Je to stejné, jako když vytvoříme nový soubor a nepřidáme ho pod správu verzí pomocí hg add.
Aby se smazání uložilo v rámci dané verze, musíme dát hg remove (místo obyčejného smazání, nebo dodatečně po něm):
$ hg rm Soubor.TXT $ hg status R Soubor.TXT
Při postoupení změn se tento soubor v úložišti smaže (staré verze tam samozřejmě zůstanou a můžeme se k nim kdykoli vrátit).
Jedním z důvodů, proč verzovací systémy používáme, je cestování v čase – můžeme se vracet ke starým verzím souborů.
Pomocí hg up -r ? se vrátíme k vybrané verzi (její číslo zjistíme z hg log):
$ hg up -r 0 2 files updated, 0 files merged, 2 files removed, 0 files unresolved
A pomocí hg up bez parametru aktualizujeme pracovní kopii na poslední verzi, která je v úložišti.
Pro označení verzí můžeme samozřejmě používat i hashe:
$ hg up -r 7f906c7d62cc 1 files updated, 0 files merged, 1 files removed, 0 files unresolved
Následujícím příkazem pak zjistíme, kde v čase se právě nacházíme:
$ hg identify 7f906c7d62cc
Odkazovat se na verze pomocí podivných čísel je dost nepohodlné.
Proto existují tzv. štítky, kterými si můžeme jednotlivé verze označit.
Dejme tomu, že verze 4:7f906c7d62cc je nějakým způsobem zajímavá (např. program v této verzi jde nejen zkompilovat, ale i spustit),
tak si ji pojmenujeme:
hg tag --rev 4 "tohle funguje"
A pak se na ni můžeme odkazovat tímto jménem místo čísla:
hg up "tohle funguje"
Všechny štítky si vypíšeme příkazem:
$ hg tags tip 8:89a449ab3cb0 tohle funguje 4:7f906c7d62cc třetí verze 3:07708ca1e12f
A kromě toho je i přehledně vidíme ve webovém rozhraní.
Dnešní úvod do Mercurialu byl pro některé možná příliš podrobný a zdlouhavý, ale článek by měl sloužit i těm, kteří zatím žádný verzovací systém nepoužívali a chtěli by s tím začít. Příště se budeme věnovat více týmové práci (stahování ze vzdálených úložišť i zpřístupnění vlastního úložiště pomocí různých protokolů ostatním) a práci s větvemi. Také si ukážeme některé GUI programy, protože příkazová řádka není všechno.
 Jinak se asi budu držet toho „postoupení změn“ (ale ideální by bylo jedno slovo).
Jinak se asi budu držet toho „postoupení změn“ (ale ideální by bylo jedno slovo).
 6.12.2011 12:59
Luboš Doležel (Doli) | skóre: 98
| blog: Doliho blog
| Kladensko
6.12.2011 13:03
Luboš Doležel (Doli) | skóre: 98
| blog: Doliho blog
| Kladensko
6.12.2011 12:59
Luboš Doležel (Doli) | skóre: 98
| blog: Doliho blog
| Kladensko
6.12.2011 13:03
Luboš Doležel (Doli) | skóre: 98
| blog: Doliho blog
| Kladensko
stačí se podívat na bzr a hg kolik věcí udělají automaticky oproti gituA jaké věci to jsou? (Neprudím, zajímá mě to) Uznávám, že třeba mazání vzdálené větve není zrovna logické:
git push origin :větev
 6.12.2011 19:31
pavlix | skóre: 54
| blog: pavlix
24.12.2011 23:19
pavlix | skóre: 54
| blog: pavlix
6.12.2011 19:31
pavlix | skóre: 54
| blog: pavlix
24.12.2011 23:19
pavlix | skóre: 54
| blog: pavlix
 25.12.2011 00:25
xkucf03 | skóre: 50
| blog: xkucf03
(to k tomu, jak ses mě ptal na to srovnání)
25.12.2011 00:34
pavlix | skóre: 54
| blog: pavlix
25.12.2011 00:25
xkucf03 | skóre: 50
| blog: xkucf03
(to k tomu, jak ses mě ptal na to srovnání)
25.12.2011 00:34
pavlix | skóre: 54
| blog: pavlix
Přesně. Mercurial = blondýna, Git = bruneta. A teď si vyberKdyž mě se líbí všechny :) (teda jako ne všechny kusy, ale všechny barvy vlasů). Tak od toho srovnání očekávám maličko víc, ale to je ti asi jasný :).
Pokud bych měl zahodit osvědčenou věc jako je git, která se IMO dá používat jak jednoduše, tak i složitě, tak k tomu musí být pádný důvod, ne plané řeči.Hele, pavlixi, kdybys tady celou dobu nenadával na osvědčený SVN a nesnažil se prosazovat "jediný správný" Git, tak bychom ti možná věřili, ale takhle je to jen sračka... ...nojo, holt děláš pro ten Git školení, tak to musí být jediná správná cesta(tm), zpátky ni krok, že?
24.12.2011 23:56
pavlix | skóre: 54
| blog: pavlix
Hele, pavlixi, kdybys tady celou dobu nenadával na osvědčený SVN a nesnažil se prosazovat "jediný správný" Git, tak bychom ti možná věřili, ale takhle je to jen sračka...Milý anonyme, zřejmě jsi natolik dobrý ve čtení mezi řádky, že čteš i věci, které tam nejsou.
...nojo, holt děláš pro ten Git školení, tak to musí být jediná správná cesta(tm),Obviňovat zrovna mě z „jediné správné“ cesty působí docela hloupě, ale jako anonym nic neriskuješ, že :). Původně jsem ti nechtěl ani odpovídat, ale nakonec mě napadlo, že by reakce mohla být zajímavá pro ostatní.
zpátky ni krok, že?Tedy i pro ostatní... Jako že bych se vrátil k Subversion, které jsem sám před časem několikrát prosadil jako první řešení i jako náhradu CVS? Řešení které jsem několikrát nasazoval a používal i pro vlastní projekty? Ano, to zní celkem rozumně... kdybych se od začátku nesetkával s neschopností plně centralizovaného řešení, které potřebuje server i na vytvoření commitu, i třeba na přestavbu adresářové struktury! Subversion v určitých situacích vykazuje omezení i oproti prostému zálohování adresářové struktury a sdílení patchů (dvě hlavní funkce verzovacího systému). Nehledě na to, že nepodporuje větve a tagy (omezeným workaroundem je checkout a kopírování adresářů), a že práce se vzdálenými repozitáři je v Subversion velice komplikovaná oproti třeba zmíněnému Gitu. Takže, opravdu nemám důvod se k Subversion vracet a už vůbec ne to komukoli doporučovat. Mně zajímají nástroje, které svým uživatelům nekladou zbytečné překážky, ale naopak jim pomůžou některé problémy překonávat. Proto mě velice zajímá, co nabízí Mercurial a jiné z mého pohledu plnohodnotné systémy správy verzí, třeba oproti Gitu, což je jediný decentralizovaný VCS, který mám opravdu v ruce. Nevím s čím jiným bych měl srovnávat než s tím, co dobře znám. Kecy o jediném správném řešení přenechám jiným, omezenějším, to není moje parketa :).
 6.12.2011 09:43
Marián Kyral | skóre: 29
| blog: Sem_Tam
| Frýdek-Místek
6.12.2011 09:43
Marián Kyral | skóre: 29
| blog: Sem_Tam
| Frýdek-Místek
git checkout <file> . Vždy musím googlit.
 6.12.2011 09:59
msk | skóre: 27
| blog: msk
6.12.2011 09:59
msk | skóre: 27
| blog: msk
Dodnes si třeba nepamatuji, jak je vrácení změn v konkrétním souboru - ekvivalent ke git checkout <file> . Vždy musím googlit.
Kupodivu hg revert <file>
6.12.2011 13:59
Marián Kyral | skóre: 29
| blog: Sem_Tam
| Frýdek-Místek
 6.12.2011 11:20
stativ | skóre: 54
| blog: SlaNé roury
6.12.2011 11:20
stativ | skóre: 54
| blog: SlaNé roury
Bohužel na hg přešel jeden projekt, který občas překládám.Rawtherapee? Tam jsem se o mercurial z části přičinil i já
 6.12.2011 13:29
Marián Kyral | skóre: 29
| blog: Sem_Tam
| Frýdek-Místek
6.12.2011 13:29
Marián Kyral | skóre: 29
| blog: Sem_Tam
| Frýdek-Místek
I ty jedenBohužel na hg přešel jeden projekt, který občas překládám.Rawtherapee? Tam jsem se o mercurial z části přičinil i já
Trochu mně mrzí, že se mi nepodařilo dokončit přechod RT na gettext. Začal jsem na tom těsně po otevření kódu, dostal jsem to skoro až do finiše, lokalizovaná verze padala po kliknutí na některé checkboxy a nebyl jsem schopen zjistit proč. Pak se spustila doslova smršť změn, přešlo se na HG. Chvíli jsem se snažil udržet se změnami tempo a vedl jsem vývoj v Gitu, chtěl jsem to dotáhnout do nějaké použitelné verze. Pak ale nebyl čas, vývoj mi utekl a v současné době bych musel začít zase od začátku a na to už nějak není čas 
Ale třeba někdy. Možná po přečtení tohohle seriálu. Ještě bych potřeboval trochu osvětlit, jak je to s větvemi. V Gitu jsou jednoduché a ve spojitosti s rebase je jednoduché udržet patch aktuální oproti aktuální větvi. Nevím jak je to v HG.
Mimochodem, myslíš, že je šance přejít v RT na gettext? Současný systém překládání má jisté mouchy - o aktualizaci anglického řetězce se překladatel doví jen a pouze ze seznamu změn na google code. Taky se špatně dělá revize překladu - v souboru chybí anglický rětezec na kontrolu.
Bohužel momentálně všechno padá na nedostatku času, případně naprosté nechuti cokoli po večerech dělat. Stačí mi to v práci
6.12.2011 10:05
msk | skóre: 27
| blog: msk
Mercurial je podstatně jednodušší na používáni.Dokud jsem nečetl dokumentaci ohledně větví (jmenovitě LocalBranchExtension, NamedBranches, PruningDeadBranches BookmarksExtension a mercurial bookmarks), myslel jsem si to samé. Poté jsem bylo docela rád za hg-fast-export
.
6.12.2011 19:36
pavlix | skóre: 54
| blog: pavlix
Mercurial je podstatně jednodušší na používániSlyšel jsem o tom, i když je pravda, že si o moc jednodušší ovládání základních věcí gitu neumím představit. A pokročilé věci přece začátečníkovi nemůžou překážet, když je nechce používat.
je lépe integrovaný v programech které používám (částečně historický důvod)Jakých? Netvrdím, že ne, ale zatím o žádném nevím.
je multiplatformní (historický důvod)To je snad každý software této kategorie, který má mít aspoň trochu šanci.
Možná že dneska nebo za rok už to je jinak, ale já rozhodně nebudu každý rok migrovat jinam, jenom kvůli tomu, že je to zrovna in.Což ale nebude fungovat na spolupracovníky jako důvod proto, aby migrovali oni třeba z Gitu.
6.12.2011 10:10
msk | skóre: 27
| blog: msk
Ma dneska vyznam pouzivat nieco ine ako git ?To sa pytam dnes a denne pri praci s neuveritelnou megasrackou od IBM, ktorej meno sa mi len hnusi vyslovit...
V com je toto lepsie ako git ? Co som pocul tak to poizivaju jedine preto lebo toto ma krajsie gui pre widly ako git.Tak si pocul zle. GUI sice nepouzivam ( nie som uchyl ), ale existuje TortoiseGit a TortoiseHg, ktore pre 98% klikacich vyvojarov asi budu poskytovat identicku funkcionalitu. Inak dovody preco hg su diskutovane nizsie.
6.12.2011 16:00
msk | skóre: 27
| blog: msk
6.12.2011 16:07
xkucf03 | skóre: 50
| blog: xkucf03
6.12.2011 10:17
stativ | skóre: 54
| blog: SlaNé roury
V com je toto lepsie ako git?V čem je git lepší než mercurial?
6.12.2011 10:52
msk | skóre: 27
| blog: msk
6.12.2011 10:52
stativ | skóre: 54
| blog: SlaNé roury
Git ma ovela vyssi vykon.
To je hodně odvážné tvrzení. Z vlastní zkušenosti rozdíl postřehnout nelze. Když mi merge bude trvat 1 s u gitu a 1.5 s u mercurialu tak mě to vážně netrápí a za značný rozdíl to nepovažuji. Ostatně
Naopak vidím pár důvodů proč mercurial ano a git ne. Mercurial má jednodušší rozhraní, takže se na něj snáze přechází, hlavně z VCS typu SVN a CVS. U gitu hodně bobtná repozitář, zapnutí garbage collection ale vše znatelně zpomalí. Mercurial má lepší podporu pro velké binární soubory.
6.12.2011 18:03
stativ | skóre: 54
| blog: SlaNé roury
6.12.2011 19:41
pavlix | skóre: 54
| blog: pavlix
Mercurial má jednodušší rozhraní, takže se na něj snáze přechází, hlavně z VCS typu SVN a CVS.A existuje i nějaký důvod pro člověka, který považuje přechod ke Gitu za přirozený a přímočarý?
Mercurial má lepší podporu pro velké binární soubory.A to jako v čem? :)
7.12.2011 14:47
pavlix | skóre: 54
| blog: pavlix
na rozdíl od databáze není ale v našem případě volby mercurialu čeho litovatNemůžu posoudit, znám dobře pouze Git. Ale když slyším o výhodách a v čem je něco lepší, jsem zvědavý na konkrétní údaje.
7.12.2011 17:02
pavlix | skóre: 54
| blog: pavlix
7.12.2011 22:30
xkucf03 | skóre: 50
| blog: xkucf03
Tak obecněji: jeden si např. oblíbil Volvo a druhý BMW. Myslím, že tady je jakýkoli flame zbytečnýTak moment, já o čínských autech nic nepsal
 .
8.12.2011 10:33
xkucf03 | skóre: 50
| blog: xkucf03
8.12.2011 10:45
msk | skóre: 27
| blog: msk
7.12.2011 17:03
pavlix | skóre: 54
| blog: pavlix
.
8.12.2011 10:33
xkucf03 | skóre: 50
| blog: xkucf03
8.12.2011 10:45
msk | skóre: 27
| blog: msk
7.12.2011 17:03
pavlix | skóre: 54
| blog: pavlix
stejně tak před delším časem se mohl někdo zeptat: mysql nebo postgres? musíme bejt na widlích takže mysql
To je ale problém dotyčného, že si z nedostatku informací výběr zúží na jen na dvě databáze. :-)
7.12.2011 14:54
stativ | skóre: 54
| blog: SlaNé roury
A existuje i nějaký důvod pro člověka, který považuje přechod ke Gitu za přirozený a přímočarý?Třeba ty další dva. Každopádně nevěřím tomu, že by někomu, kdo přechází ze SVN nebo CVS, přišel přechod ke Gitu přirozenější a přímočařejší než k Mercurialu. I kdyby jen proto, že Mercurial používá v mnoha případech stejné názvy příkazů jako svn. A pokud ti přijde přechod ke Gitu přirozený, nevidím důvod, proč by ti měl přechod k Mercurialu přijít méně přirozený. V tom případě to bude plichta.
A to jako v čem? :)To jako v tom, že ukládá celé soubory a zvlášť trackuje jejich hashe. Navíc Mercurial umožňuje při klonování repozitáře s binárními soubory stahovat pouze zadanou verzi binárních souborů (vlastně se tedy chová jako centralizovaný server), což je pěkné hlavně když ony binární soubory mají třeba několik set MB. Samozřejmě historie je kompletní, navíc ti nic nebrání v tom mít všechny uložené lokálně. V době, kdy jsem pracoval s Gitem, Git řešil binární soubory stejně jako textové, takže overhead byl hodně velký. Rychlé hledání mi nepomohlo najít nic, co by naznačovalo tomu, že se to nějak výrazně změnilo.
7.12.2011 15:13
stativ | skóre: 54
| blog: SlaNé roury
7.12.2011 15:04
pavlix | skóre: 54
| blog: pavlix
Samozřejmě historie je kompletní, navíc ti nic nebrání v tom mít všechny uložené lokálně.Takže něco jako git clone --depth 1, akorát s tím, že hranice toho, co se stahuje a co ne, souvisí vedle poloze na grafu i se signaturou daného objektu? Vázat to na složení souboru mi přijde zbytečnost, ale pokud by šlo o velikost, byla by to první zajímavá informace, kterou bych se o Hg v této diskuzi dozvěděl. A taky první věc, která představuje alespoň jednu jasnou výhodu (i když bych ji osobně nevyužil). Ale zatím se tu dozvídám cosi o rozlišování binárních a textových souborů, což mi pro účely ukládání přijde úplně k ničemu. Ani unixové systémy nerozlišují binární a textové soubory.
V době, kdy jsem pracoval s Gitem, Git řešil binární soubory stejně jako textové, takže overhead byl hodně velký. Rychlé hledání mi nepomohlo najít nic, co by naznačovalo tomu, že se to nějak výrazně změnilo.Nevidím jediný důvod, proč by měl Git pracovat s binárními soubory jinak, a nevidím v tom ani žádný overhead. Pravda, statisticky bývají velké soubory mezi binárními, ale rozpoznávat velikost souborů podle toho, jestli jsou binární mi přijde jako drbání levou nohou za pravým uchem.
7.12.2011 15:23
stativ | skóre: 54
| blog: SlaNé roury
Takže něco jako git clone --depth 1, akorát s tím, že hranice toho, co se stahuje a co ne, souvisí vedle poloze na grafu i se signaturou daného objektu?Dalo by se to tak říct, akorát se nepoužívá nějaká signatura objektu, kterou si mercurial vycucá z prstu, ale to, co mu uživatel řekne. Když přidáváš soubor, můžeš explicitně říct, že ho má zpracovávat jako largefile. V nastaveních repozitáře je pak nastavení velikosti, při jejímž překročení jsou nově přidané soubory přednastavané jako largefile. Taky se dá nastavit maska jmen, které se mají automaticky považovat za large files (typicky něco jako *.jpg data/*).
7.12.2011 15:55
pavlix | skóre: 54
| blog: pavlix
 6.12.2011 23:26
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
6.12.2011 23:26
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
 6.12.2011 12:26
GandY | skóre: 3
| blog: Zo života
| Bratislava
6.12.2011 13:00
Luboš Doležel (Doli) | skóre: 98
| blog: Doliho blog
| Kladensko
6.12.2011 14:27
GandY | skóre: 3
| blog: Zo života
| Bratislava
6.12.2011 19:42
pavlix | skóre: 54
| blog: pavlix
6.12.2011 12:26
GandY | skóre: 3
| blog: Zo života
| Bratislava
6.12.2011 13:00
Luboš Doležel (Doli) | skóre: 98
| blog: Doliho blog
| Kladensko
6.12.2011 14:27
GandY | skóre: 3
| blog: Zo života
| Bratislava
6.12.2011 19:42
pavlix | skóre: 54
| blog: pavlix
Co som pocul tak to poizivaju jedine preto lebo toto ma krajsie gui pre widly ako git.A MacOSX, afaik...
Samotný soubor .hgignore je rovněž verzovaný – to je dobré jednak proto, že seznam se může v čase měnit (např. soubory, které jsme chtěli ignorovat v prvních verzích teď chceme verzovat a naopak), a jednak proto, že tento seznam se bude šířit společně s ostatními soubory – když uděláme push nebo pull, seznam ignorovaných souborů bude všude stejný.Soubor .hgignore – aspoň já si to myslím – naopak není dobré vkládat do repozitáře, protože různí lidé mohou chtít ignorovat různé soubory.
.gitignore. To, co si chtějí různí lidé ignorovat navíc a nehodí se do "globálního" nastavení, to se narve do .git/info/exclude. Neznám Mercurial, ale předpokládám, že nějaká obdoba tam bude.
8.12.2011 15:26
stativ | skóre: 54
| blog: SlaNé roury
různí lidé mohou chtít ignorovat různé souboryChtít mohou, ale to je asi tak všechno. Když si nastavím, že soubory
.bž chci já ignorovat a někdo jiný je ignorovat nebude, dotyčný je commitne do úložiště a já je s příštím updatem odsud dostanu. Výsledkem bude, že změny v úložišti se budou propagovat ke mně, ale opačně ne, takže jen budu neustále řešit konflikty.
9.12.2011 10:37
xkucf03 | skóre: 50
| blog: xkucf03
.bž soubor může být třeba .class soubor. Já budu společný .hgignore uznávat ale někdo jiný** ne, nebo tam ty .class soubory přidá ručně… Tak to bude přesně jak píše Filip – při příští aktualizaci si je stáhnu, při kompilaci je změním a při hg commit mi je to bude nabízet k postoupení do úložiště.
*) když se v týmu objeví anarchista, který ignoruje společný .hgignore.
**) protože si myslí, že je nejchytřejší a že verzovací systém mu nemá co kecat do jeho práce.
.[git|hg]ignore to v zásadě nesouvisí...
8.12.2011 23:39
pavlix | skóre: 54
| blog: pavlix
 9.12.2011 01:33
Gilhad | skóre: 20
| blog: gilhadoviny
9.12.2011 10:29
xkucf03 | skóre: 50
| blog: xkucf03
9.12.2011 01:33
Gilhad | skóre: 20
| blog: gilhadoviny
9.12.2011 10:29
xkucf03 | skóre: 50
| blog: xkucf03
hg add .hgignore nebo ne. Akorát já bych doporučoval to udělat, protože si myslím, že každý projekt by měl mít nějaká společná pravidla, kterými se všichni řídí – ať už je to způsob odsazování, konvence pojmenování metod, nebo třeba rozhodnutí, které soubory se verzují a které ne.
9.12.2011 12:18
Gilhad | skóre: 20
| blog: gilhadoviny
9.12.2011 11:38
pavlix | skóre: 54
| blog: pavlix
git to ma udelane tak, ze .gitignore verzovat muzes, ale nemusis.O tom řeč není, je to stejné v Gitu i v Hg.
Takze si kazdy muze vybrat podle svych potreb.Ale každý projekt, ne každý jednotlivec, a to jak v Gitu, tak v Hg.
Nemam rad, kdyz nekdo vi lip nez ja, co vlastne potrebuju a proto mi to nasilim vnucuje ... vetsinou se totiz myliV některých projektech se i spolupracuje. Proto se do správy verzí dávají. Hele já netuším, co dáváš do .gitignore ty, ale já tam dávám například výsledky kompilace a neverzované konfigurační soubory. A zatím jsem ani jednou nenarazil na situaci, kdy by bylo užitečné něco u jednoho uživatele v .gitignore mít a u druhého ne. To, jestli je soubor určený pro zařazení do repozitáře stejně nejde rozhodnout u různých uživatelů různě, když větve daného repozitáře sdílejí mezi sebou. A pokud by je z nějakého důvodu nesdíleli, tak problém ani neexistuje.
9.12.2011 12:16
Gilhad | skóre: 20
| blog: gilhadoviny
9.12.2011 18:26
Gilhad | skóre: 20
| blog: gilhadoviny
11.12.2011 00:39
Gilhad | skóre: 20
| blog: gilhadoviny
1 název = 1 soubor je u těch systémů jasně deklarovaná a je vaše chyba, že ji ignorujete.
11.12.2011 13:21
Gilhad | skóre: 20
| blog: gilhadoviny
Když se někdo podívá na váš projekt, nedokáže vůbec určit, které soubory jsou společné a mají být verzované, které jsou jen vaše pomocné atd.Myslíš tím, že někdo nakoukne do jeho lokální pracovní kopie? A proč by to někdo dělal? Když se chce někdo "podívat na projekt", stáhne si přece to, co je v repo, ne? Tam jsou všechny soubory potřebné pro projekt.
A nemusí si pamatovat, že tenhle README.txt je jen jeho a ve skutečnosti tam patří soubor, který vytvořil kolegaAle vždyť to si nemusí pamatovat. Ten "správný" README.txt, který má na daném místě být, je uložen ve VCS. A VCS nezapomíná, od toho to přece je VCS. Přijde mi, že hledáš problémy tam, kde nejsou.
11.12.2011 16:24
Gilhad | skóre: 20
| blog: gilhadoviny
11.12.2011 16:38
pavlix | skóre: 54
| blog: pavlix
11.12.2011 16:56
xkucf03 | skóre: 50
| blog: xkucf03
Ze stejného důvodu mnozí nemůžou přejít na Git od Subversion. Mají zavedené nějaké špatně zvolené procesy, které nechtějí měnit.Jaké třeba? Docela by mě to zajímalo. Z těch věcných mě napadá snad leda zamykání* (které v SVN jde krásně, zatímco v distribuovaných systémech z principu nejde), ale jinak to jsou všechno jen technologické problémy a nekompatibility (např. máme podporu v IDE pro systém X ale ne pro Y, nebo: napsali jsme si pro to spoustu skriptů a nechce** se nám je předělávat), ale na ty člověk narazí při přechodu z jakéhokoli systému na jakýkoli. Jinak bych řekl, že přejít na Mercurial (Git to podobně) a používat ho stejným stylem jako SVN jde bez problémů – bude se používat jako centralizovaný systém (v podstatě stačí si spojit commit+push a update+pull) a ta distribuovanost nového systému zůstane akorát nevyužita. *) to navíc není z principu špatné – je to jen jiný (a někdy lepší) způsob práce **) mimochodem tohle je zcela legitimní důvod – když přechod bude znamenat víc práce než užitku, tak prostě přecházet nebudu, i kdyby ten nový systém byl sebekrásnější
11.12.2011 18:56
pavlix | skóre: 54
| blog: pavlix
11.12.2011 19:01
xkucf03 | skóre: 50
| blog: xkucf03
Třeba možnost řízení přístupu na úrovni jednotlivých adresářů a souborů uvnitř jedné větve.hmm a chtít tohle je „špatně zvolený proces“?
11.12.2011 21:46
pavlix | skóre: 54
| blog: pavlix
11.12.2011 22:47
xkucf03 | skóre: 50
| blog: xkucf03
Podle mě ano. Projekt lze rozdělit na podprojekty a utvářet přístup na základě podprojektů...To si právě nemyslím. Dejme tomu, že máš nějaký větší projekt a chceš omezit právo zápisu do jednotlivých částí. Testeři můžou psát testy (→ zapisovat do
/testy), ale jinak nikam. Programátoři můžou zapisovat do implementace a do testů. Analytici a dokumentarista můžou zapisovat do /analýza resp. /dokumentace. A číst můžou všichni všechno.
Samozřejmě se to jde řešit i ex-post – když zjistíš, že někdo zapisoval někam, kam neměl, tak mu dojdeš vynadat. Většinou v tom nebude zlý úmysl, ale prostě jen někdo přepsal omylem jiné soubory… A když jde takovým chybám zabránit dobrým nastavením práv, tak je to lepší (než ručně všechno kontrolovat).
A když to uděláš jako víc úložišť, tak se ti to velice snadno rozjede a za chvíli nebudeš vědět, které testy pasují ke které verzi implementace… Nemluvě o větvích a štítkách, které je potřeba udržovat napříč několika úložišti.
Vzhledem k Gitu a obecně DVCS je to opravdu špatně zvolený proces.Proces je podle mého primární – a VCS je jen nástroj, který ho má podporovat. Takže jestli to Git neumí, tak je to spíš špatná volba nástroje.
princip DVCS přináší i určitá omezení, to je potřeba si přiznat.Pokud jde o řízení přístupu pro čtení, tak souhlas, to je více méně nemožné (nebo minimálně hodně pracné a neefektivní). Ale řídit práva k zápisu v principu není problém (ostatně některé distribuované systémy to podporují).
11.12.2011 22:54
pavlix | skóre: 54
| blog: pavlix
omezit právo zápisuTo si ale špatně rozumíme. Omezit právo zápisu není v Gitu až takový problém, stačí kontrolovat commity před přijetím. Pokud to nechceš dělat na lidské úrovni, umí to tuším Gitolite. Takže zde nejsme ve při :).
Proces je podle mého primární – a VCS je jen nástroj, který ho má podporovat. Takže jestli to Git neumí, tak je to spíš špatná volba nástroje.Procesy se mezi VCS a DVCS můžou výrazně lišit. A mírně se můžou lišit i mezi jednotlivými DVCS. Můžeš být idealista, ale občas je vhodnější se přizpůsobit, než psát si vlastní DVCS, protože ti ostatní nevyhovují. Občas ne – tak přece vznikl Git.
Pokud jde o řízení přístupu pro čtení, tak souhlas, to je více méně nemožné (nebo minimálně hodně pracné a neefektivní).Já ale psal přístup, čímž jsem měl samozřejmě na mysli obecný přístup. Nenapadlo mě, že si to hned přeložíš jako zápis. Ale ono je prakticky nemožné řídit i ten zápis, pokud za zápis považuješ commit do vlastního repozitáře. Konceptuálně tak vlastně neřídíš zápis do adresářů, protože zápis do adresářů Git neumožňuje (je v něm vše neměnné, kromě seznamů referencí). Je možné pouze limitovat to, co odeslané commity můžou zahrnovat. Ale jde se na to samozřejmě dívat různě.
11.12.2011 17:09
Gilhad | skóre: 20
| blog: gilhadoviny
11.12.2011 18:58
pavlix | skóre: 54
| blog: pavlix
Takhle debata nevznikla o tom, zda je lepsi verzovat ci neverzovat .gitignore (obecne je lepsi verzovat), ale zda ma smysl tato moznost a zda ji vubec muze nekdo rozumne vyuzit (muze - ve znacne specifickych pripadech).Potom ale začátek této debaty vnímám přesně opačně než ty.
11.12.2011 14:47
xkucf03 | skóre: 50
| blog: xkucf03
Moje soubory jsou znacne docasne, kolegovy jsou trvaleA nebylo by jednodušší si pro dočasné soubory dohodnout nějakou jinou příponu (třeba
.poznámky místo .txt)?
Ale samozrejme kazda nutnost rucni zmeny neceho vnasi prostor pro chyby a snizuje uzivatelsky komfort.Jak bez společného
.*ignore souboru řešíš situaci, kdy se např. změní proces sestavování a začnou vznikat nové dočasné soubory, které není žádoucí verzovat?
Se společným ignorovacím souborem by jednoduše ten, kdo změnil proces, upravil i ignorovací seznam a všichni ostatní by si stáhli oboje najednou při příští aktualizaci. Tzn. nestane se mi, že bych si např. stáhl nový Makefile, ale zapomněl ručně upravit .*ignore soubor a přidat do něj další výjimky (Jak se o nich mám dozvědět? Pošle mi je někdo e-mailem? Nebo si je mám domyslet z toho, jaké nové dočasné soubory teď nově vznikají?).
11.12.2011 16:33
Gilhad | skóre: 20
| blog: gilhadoviny
A nebylo by jednodušší si pro dočasné soubory dohodnout nějakou jinou příponu (třebaA nebylo by jednodušší, když už to Git umí, používat společný (a verzovaný).poznámkymísto.txt)?
.gitignore a individuální (a z principu neverzovaný) .git/info/exclude (příp. ~/.gitconfig)? Já bych tyhle internety zakázala.
11.12.2011 21:48
pavlix | skóre: 54
| blog: pavlix
11.12.2011 22:36
xkucf03 | skóre: 50
| blog: xkucf03
Proto jsem navrhoval třeba tu jinou příponu. Dalším možným řešením je tyhle dočasné soubory vůbec nevytvářet – většinou si tam stejně vývojář syslí nějaké informace, o které se nechce podělit s ostatníma – ať je laskavě hodí do wiki, na síťový disk nebo do úložiště. Protože pak to v některých týmech vypadá tak, že po odchodu jednoho člověka (který si s sebou vezme i tyhle soubory, které měl jen on) se práce na nějakou dobu zastaví – než někdo jiný znovu vynalezne kolo a objeví to, co bylo původně v těch neverzovaných souborech…
11.12.2011 22:56
pavlix | skóre: 54
| blog: pavlix
většinou si tam stejně vývojář syslí nějaké informace, o které se nechce podělit s ostatníma – ať je laskavě hodí do wiki, na síťový disk nebo do úložištěNebo do samostatného na to určeného adresáře, jak jsem navrhoval já, pokud už trvá na tom, že to musí být uvnitř pracovního adresáře.
11.12.2011 12:07
pavlix | skóre: 54
| blog: pavlix
Až někdo ten soubor v úložišti vytvoří a vy si uděláte update, o ten svůj obsah přijdeteNení pravda. Záleží samozřejmě, jakou metodou a v jaké situaci se ten update provede, ale afaik v žádném případě git jen tak nepřepíše změněné lokální soubory (bez
--force). Zobrazí nějaké upozornění, kolega Gilhad si svůj obsah přesune někam pod nekonfliktní název, a všecko je ok.
11.12.2011 15:53
pavlix | skóre: 54
| blog: pavlix
24.12.2011 23:36
pavlix | skóre: 54
| blog: pavlix
ISSN 1214-1267, (c) 1999-2007 Stickfish s.r.o.