Portál AbcLinuxu, 25. července 2026 18:25
Už jste někdy jako programátor potřebovali přeložit svou aplikaci nebo jako překladatel vytvářet nové překlady a nevěděli „jak na to“? Tímto návodem se pokusím věc trochu objasnit a vysvětlit „vše“, co byste jako programátor nebo překladatel měli znát.
GNU Gettext je sada nástrojů poskytující framework pro vytváření vícejazyčných aplikací. Překlady jsou uloženy v tzv. katalozích, které mají formát .po a pro použití aplikací se překládají do binárního formátu .mo, který není závislý na systému, popř. architektuře procesoru. Šablony, ze kterých se vytváří soubory .po, mají příponu .pot.
Nejspíše se setkáte také se zkratkami l10n a i18n – první je „localization“ – to je samotný překlad a druhá je „internationalization“ – příprava vašeho programu k l10n. Čísla označují počet znaků ve slovu mezi prvním a posledním písmenem.
Gettext má tzv. „bindings“ pro velký počet jazyků:
Gettext samotný je napsaný v C. Návod se bude zabývat použitím s jazykem C.
Při použití s jazykem C můžete využít dvě metody pro podporu překladů: pomocí Autotools (doporučuji), nebo přímo na zdrojový kód C. Použití s autotools je mnohem univerzálnější a často i jednodušší díky podpůrným nástrojům jako autopoint.
V obou případech budeme překládat jednoduchý zdrojový kód:
#include <stdio.h>
#include <limits.h>
#include <string.h>
static void print_help(int argc, char **argv);
static void print_help(int argc, char **argv)
{
printf("--- Gettext testing app help information ---\n");
printf(" USAGE: %s [argument]\n", argv[0]);
printf(" Possible arguments:\n blah: print some message\n foo: print another message\n");
}
int main(int argc, char **argv)
{
if (argc != 1)
{
if (!strcmp(argv[1], "blah"))
printf("Some message to be translated.\nThis is a new line.\nAnother new line to make the message long.\n");
else if (!strcmp(argv[1], "foo"))
printf("Another message to be translated.\n\n\nSome newline after empty lines.\n\tMessage after a tab.\n");
else
printf("Translatable error – unsupported argument provided.\n");
}
else
{
printf("Translatable error – no arguments provided. Printing help.\n");
print_help(argc, argv);
}
return 0;
}
Při práci s gettextem je dobré dodržovat pár základních pravidel, která usnadňují další překlad.
Nedělte vypisovaní textu (třeba pomocí printf) – používejte místo toho znaky \n,\t atd. tzn. místo
printf("first line\n");
printf("second line\n");
napište
printf("first line\nsecond line\n");Používejte co nejvíce argumenty pro printf, snprintf. Věci, které nemají být přeloženy, si ukládejte zvlášť, tzn. místo
if (!strcmp(myvar, "blah"))
printf("value of myvar is: blah");
else if (!strcmp(myvar, "foo"))
printf("value of myvar is: foo");
else
printf("value of myvar is: unknown");
použijte raději
if (!strcmp(myvar, "blah") || !strcmp(myvar, "foo"))
printf("value of myvar is %s", myvar);
else
printf("value of myvar is: unknown");
Nezoznačujte interní řetězce programu k překladu.
Gettext inicializujte ve funkci main() vašeho programu a jeho definice zapisujte do hlavičkového souboru, pokud váš program nějaký má.
Před začátkem psaní Makefile, popř. použití autotools je nutné nejprve zdrojový kód připravit a označit řetězce k překladu.
Nejdříve přidáme nějaké inklůdy na začátek.
#include <locale.h> #include <libintl.h>
Dále si musíme nadefinovat funkci k označení překladu:
#define _(string) gettext(string)
Ta je vcelku volitelná, nicméně psát pokaždé gettext() je zdlouhavé a _() se používá nejčastěji. Také ovlivňuje parametry --keywords v xgettext. Kromě funkce gettext() by vás mohly zajímat ještě dgettext a ngettext:
dgettext – chová se stejně jako gettext(), ale musíte poskytnout dva argumenty – druhý je tzv. domainname – většinou název vaší aplikace a název .mo souboru. Definuje se takto:
#define D_(domain, string) dgettext(domain, string)
ngettext – umožňuje specifikovat plurální formy určitého řetězce. Potřebuje tři argumenty a definuje se takto:
#define N_(string1, string2, n) ngettext(string1, string2, n)
A jeho použití:
printf(ngettext("%d file found.", "%d files found", num), num);num je typu int a pokud je jeho hodnota 1, vypíše se první řetězec, jinak se vypíše druhý.
Dále ještě existuje dngettext, který funguje podobně jako gettext vs dgettext.
#define DN_(domain, string1, string2, n) dngettext(domain, string1, string2, n)
Nyní se vraťme zpět k programu. Po definici _() můžete označit veškeré řetězce k překladu takhle:
printf(_(" USAGE: %s [argument]\n"), argv[0]);
Docílíte tím toho, že pokud gettext při spuštění programu najde katalog a přeložený řetězec, použije jej místo toho původního.
Po označení všech řetězců už stačí jen gettext inicializovat na začátku funkce main():
setlocale(LC_ALL, "");
bindtextdomain("gettexttest", "/usr/share/locale");
textdomain("gettexttest");
První řádek je určen ke zjištění lokalizace prostředí (zkuste si vypsat printf(setlocale(LC_ALL, ""));), dále se nastavuje domainname, o kterém jsem se zmiňoval už předtím. Druhý argument k bindtextdomain určuje, kde hledat složku LC_MESSAGES obsahující přeložené .mo soubory.
Tím máme základ hotov, váš připravený kód by měl vypadat takhle:
#include <stdio.h>
#include <limits.h>
#include <string.h>
#include <locale.h>
#include <libintl.h>
#define _(string) gettext(string)
static void print_help(int argc, char **argv);
static void print_help(int argc, char **argv)
{
printf(_("--- Gettext testing app help information ---\n"));
printf(_(" USAGE: %s [argument]\n"), argv[0]);
printf(_(" Possible arguments:\n blah: print some message\n foo: print another message\n"));
}
int main(int argc, char **argv)
{
setlocale(LC_ALL, "");
bindtextdomain("gettexttest", "/usr/share/locale");
textdomain("gettexttest");
if (argc != 1)
{
if (!strcmp(argv[1], "blah"))
printf(_("Some message to be translated.\nThis is a new line.\nAnother new line to make the message long.\n"));
else if (!strcmp(argv[1], "foo"))
printf(_("Another message to be translated.\n\n\nSome newline after empty lines.\n\tMessage after a tab.\n"));
else
printf(_("Translatable error – unsupported argument provided.\n"));
}
else
{
printf(_("Translatable error – no arguments provided. Printing help.\n"));
print_help(argc, argv);
}
return 0;
}
Kód si uložte do nějaké prázdné složky pod názvem gettexttest.c. Pak stačí nainstalovat balíčky gettext a gettext-base (na Debianu/Ubuntu, na jiných distribucích se může lišit), pokud je ještě nemáte, a standardním způsobem program přeložit:
gcc gettexttest.c -o gettexttest
Po spuštění ./gettexttest by se mělo vše správně vypsat – bez překladu. Pro zprovoznění překladu musíte vytahat řetězce ven z programu do .pot souboru. K tomu slouží program xgettext, pusťte tedy:
xgettext --keyword=_ gettexttest.c -o gettexttest.pot
Paremetr --keyword určuje, jaký prefix funkcí se použije: tzn. --keyword=_ bude hledat _(). Po spuštění příkazu by se měl vytvořit ve složce soubor gettexttest.pot. Otevřte si ho v textovém editoru a uvidíte:
# SOME DESCRIPTIVE TITLE. # Copyright (C) YEAR THE PACKAGE'S COPYRIGHT HOLDER # This file is distributed under the same license as the PACKAGE package. # FIRST AUTHOR <EMAIL@ADDRESS>, YEAR. # #, fuzzy msgid "" msgstr "" "Project-Id-Version: PACKAGE VERSION\n" "Report-Msgid-Bugs-To: \n" "POT-Creation-Date: 2009-11-17 20:54+0100\n" "PO-Revision-Date: YEAR-MO-DA HO:MI+ZONE\n" "Last-Translator: FULL NAME <EMAIL@ADDRESS>\n" "Language-Team: LANGUAGE <LL@li.org>\n" "MIME-Version: 1.0\n" "Content-Type: text/plain; charset=CHARSET\n" "Content-Transfer-Encoding: 8bit\n"
První řádky začínající na # jsou komentáře, tam si napište nějaký popis a vaši e-mailovou adresu. V Project-Id-Version si vyplňte třeba název vašeho programu. Další řádek je e-mailová adresa pro hlášení bugů, další řádky nechte. Poslední řádek, který by vás mohl zajímat, je Language-Team: – tam dopište cs <váš_e-mail>.
Soubor uložte jako gettexttest.po a nepokoušejte se jej překládat.
Nyní si nainstalujte program POedit, pokud chcete program pro Gtk+, nebo KBabel či Lokalize, což jsou programy pro KDE.Tyto programy slouží k překladu .po souborů. Já používám POEdit. Po spuštění programu budete nejspíš vyzváni k vyplnění e-mailové adresy a dalších informací. Vyplňte je, budou se ukládat do .po souborů. Teď si v POEditu otevřete váš gettextest.po. Ovládání je intuitivní – nahoře je toolbar, pak seznam řetězců k překladu. Pro přeložení řetězce na něj stačí kliknout, zkopírovat obsah horního pole, vložit do spodního a přeložit. Uložením si POEdit sám generuje .mo soubor. Pokud chcete vytvořit .mo ručně, tak použijte program msgfmt:
msgfmt gettexttest.po -o gettexttest.mo
O dalších nástrojích se dále rozepíšu v překladatelské sekci. Měli byste ale systém překladů znát.
Až budete mít .mo soubor, zkopírujte jej jako root do /usr/share/locale/cs/LC_MESSAGES/ (/usr/share/locale jste zadávali v bindtextdomain, název gettexttest.mo v bindtextdomain a textdomain, cs je kód země)
Teď si zkuste pustit váš program a uvidíte, že je přeložen :)
V tomto případě záleží pouze na tom, jak si systém vymyslíte – důležité je to navrhnout tak, aby nebyl problém s více jazyky. Já udělal něco takového:
APP=gettexttest
SOURCE=gettexttest.c
PREFIX=/usr
LANGUAGES=cs
all: po build
build: $(SOURCE)
if test ! -f $(APP); then gcc $(SOURCE) -o $(APP); fi
install: build install-po
/usr/bin/install -m 755 $(APP) $(PREFIX)/bin/
pot: $(SOURCE)
xgettext --keyword=_ $(SOURCE) -o $(APP).pot
po:
for x in $(LANGUAGES) ; do \
if test -f $$x.po; then msgfmt $$x.po -o $$x.mo; fi ; \
done
install-po: po
for x in $(LANGUAGES) ; do \
if test -f $$x.mo; then /usr/bin/install -m 644 $$x.mo /usr/share/locale/cs/LC_MESSAGES/$(APP).mo; fi ; \
done
clean:
if test -f $(APP); then rm $(APP); fi
if test $(shell ls *.mo); then rm *.mo; fi
distclean: clean
if test $(shell ls *.pot); then rm *.pot; fi
Zde je situace podle mě jednodušší. V rootu vašeho programu (tzn. tam, kde se nachází soubor configure.ac) si vytvořte složku s názvem po. Přepněte se do ní, vytvořte tam soubor Makevars a vložte do něj:
DOMAIN = $(PACKAGE) subdir = po top_builddir = .. XGETTEXT_OPTIONS = --keyword=_ --keyword=N_ --from-code=UTF-8 --foreign-user COPYRIGHT_HOLDER = your developer team or you MSGID_BUGS_ADDRESS = your@email.com EXTRA_LOCALE_CATEGORIES =
Tím specifikujete parametry pro xgettext atd.
Dále potřebujete soubor POTFILES.in. V něm jsou napsány soubory, které se mají použít jako zdroj pro xgettext. V POTFILES.in jednoho z mých projektů například je:
src/bin/about.c src/bin/conf.c src/bin/plugin.c src/bin/stickies.c src/bin/config_gui.c
Tzn. zapíšete na každý řádek nový soubor tak, že výchozí adresář je root adresář vašeho projektu.
Posledním potřebným souborem je LINGUAS. V něm jsou zapsány všechny jazyky, které jsou přeloženy. Tzn. něco jako:
cs fr it
Nezapisujte do něj nepřeložené jazyky.
O zbytek se postará pomocný nástroj autopoint.
Dále je nutné upravit váš configure.ac popř. configure.in. Vložte do něj:
if test "x${prefix}" = "xNONE"; then
AC_DEFINE_UNQUOTED(PACKAGE_LOCALE_DIR, "${ac_default_prefix}/share/locale", [Locale-specific data directory])
else
AC_DEFINE_UNQUOTED(PACKAGE_LOCALE_DIR, "${prefix}/share/locale", [Locale-specific data directory])
fi
AM_GNU_GETTEXT([external])
AM_GNU_GETTEXT_VERSION([0.12.1])
Často se hodí definovat věcí více:
if test "x${prefix}" = "xNONE"; then
AC_DEFINE_UNQUOTED(PACKAGE_LOCALE_DIR, "${ac_default_prefix}/share/locale", [Locale-specific data directory])
else
AC_DEFINE_UNQUOTED(PACKAGE_LOCALE_DIR, "${prefix}/share/locale", [Locale-specific data directory])
fi
if test "x${prefix}" = "xNONE"; then
AC_DEFINE_UNQUOTED(PACKAGE_DATA_DIR, "${ac_default_prefix}/share/${PACKAGE}", [Shared Data Directory])
else
AC_DEFINE_UNQUOTED(PACKAGE_DATA_DIR, "${prefix}/share/${PACKAGE}", [Shared Data Directory])
fi
if test "x${datadir}" = 'x${prefix}/bin'; then
if test "x${prefix}" = "xNONE"; then
AC_DEFINE_UNQUOTED(PACKAGE_BIN_DIR, "${ac_default_prefix}/bin", [Installation directory for user executables])
else
AC_DEFINE_UNQUOTED(PACKAGE_BIN_DIR, "${prefix}/bin", [Installation directory for user executables])
fi
else
AC_DEFINE_UNQUOTED(PACKAGE_BIN_DIR, "${bindir}", [Installation directory for user executables])
fi
packagesrcdir=`cd $srcdir && pwd`
AC_DEFINE_UNQUOTED(PACKAGE_SOURCE_DIR, "${packagesrcdir}", [Source code directory])
AM_GNU_GETTEXT([external])
AM_GNU_GETTEXT_VERSION([0.12.1])
Podle toho, jestli váš projekt využívá BINDIR, nebo DATADIR. Tyto řádky vložte třeba před PKG_CHECK_MODULES.
Nakonec vložte jako jednu z položek AC_OUTPUT:
po/Makefile.in
Pak si otevřete hlavní Makefile.am a pokud tam máte třeba:
SUBDIRS = src data
tak upravte na:
SUBDIRS = src data po
Pokud proměnnou nemáte, vytvořte ji jako:
SUBDIRS = po
Tím by byly úpravy autotools hotové. Teď bude potřeba provést pár úprav do zdrojáku.
Nejdříve upravte:
#include <locale.h> #include <libintl.h> #define _(string) gettext(string)
na
#include <locale.h> #include "config.h"; #define _(string) gettext(string)
Dále je dobré kvůli definici PACKAGE_LOCALE_DIR nenastavovat napevno /usr/share/locale a gettexttest nenastavovat v kódu, ale z configure.ac, takže upravte:
setlocale(LC_ALL, "");
bindtextdomain("gettexttest", "/usr/share/locale");
textdomain("gettexttest");
na
setlocale(LC_ALL, ""); bindtextdomain(PACKAGE, PACKAGE_LOCALE_DIR); textdomain(PACKAGE);
PACKAGE definuje AC_INIT, takže pokud vypadá takto:
AC_INIT([gettexttest], [0.1], [quaker66@gmail.com])
tak se PACKAGE automaticky nahradí za gettexttest. Makefile ze složky po se postará o automatické přejmenování a instalaci .mo souborů podle proměnné PACKAGE.
Soubor si uložte a můžete přejít k poslední části, a tou je úprava autogen.sh (pokud používáte) nebo spuštění autopoint.
Skript autogen.sh nejspíš používáte, pokud je váš program někde v SVN. S podporou překladu vypadá takto (některé části mohou ve vašem projektu chybět):
#!/bin/sh
rm -rf autom4te.cache
rm -f aclocal.m4 ltmain.sh
touch README
touch ABOUT-NLS
echo "Running autopoint…" ; autopoint -f || :
echo "Running aclocal…" ; aclocal -I m4 $ACLOCAL_FLAGS || exit 1
echo "Running autoconf…" ; autoconf || exit 1
echo "Running autoheader…" ; autoheader || exit 1
echo "Running libtoolize…" ; (libtoolize --copy --automake || glibtoolize --automake) || exit 1
echo "Running automake…" ; automake --add-missing --copy --gnu ||
exit 1
if [ -z "$NOCONFIGURE" ]; then
./configure "$@"
fi
Pro ty, kdo jej nepoužívají: Je to skript, který spustí jednotlivé části autotools tak, aby se vygeneroval skript configure z configure.ac. Pro překlad je důležitý řádek
echo "Running autopoint…" ; autopoint -f || :
Autopoint je pomocný program z balíku gettext, který sám do složky po zkopíruje veškeré důležité soubory jako Makefile.in.in. Pokud autogen nepoužíváte, pusťte jej samostatně:
autopoint -f
Nyní je podpora překladu hotova. Můžete pustit:
./autogen.sh
Nebo, pokud jste autopoint pustili zvlášť, a váš program bude správně manipulovat se složkou po a instalovat překlady:
./configure
Pokračování: Návod pro překladatele
Pokud jste pouze překladatel, není nutné znát všechny metody úpravy zdrojového kódu. Spíše musíte znát několik nástrojů pro práci s překlady a jak to celé funguje. Překladatelská část bude počítat se standardní složkou po.
Jedna z možností, které u překladu programu mohou nastat, je, že do vašeho jazyka ještě program nebyl přeložen. V tomto případě je nutné vygenerovat šablonu pro překlad a tu pak přeložit. Vlezte si proto v terminálu do složky po (nachází se ve složce se zdrojovým kódem programu a soubory jako Makefile.am a configure.ac).
cd po
A vygenerujeme si novou šablonu (.pot soubor) – k tomu slouží program intltool-update:
intltool-update -p
Parametr -p řekne programu, aby vygeneroval pouze .pot šablonu. Měl by se tam vytvořit soubor nazevprogramu.pot. Ten si otevřete v textovém editoru a upravte podle části „Testujeme“ ve vývojářské části.
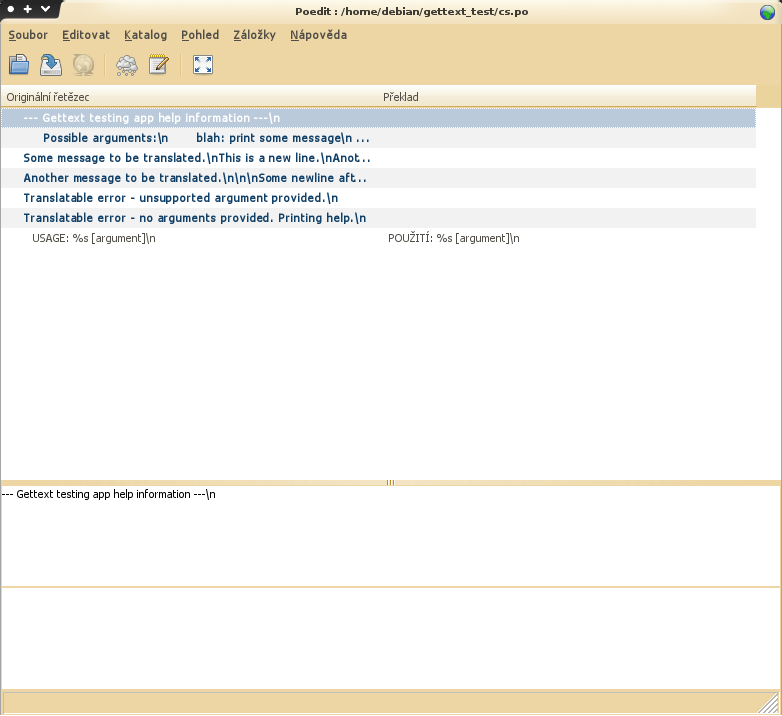
Po úpravách jej přejmenujte na cs.po (pokud překládáte do češtiny). Teď je soubor připraven k překladu. Pro další překlad budete potřebovat nějaký překladatelský nástroj. Jak už bylo zmíněno ve vývojářské části, dva nejlepší jsou POEdit a KBabel (jeden je pro Gtk+, druhý pro Qt/KDE). Já doporučuji nainstalovat POedit. Po instalaci si jej spusťte. Zeptá se vás na určité údaje, vyplňte je, budou se zaznamenávat do překladu. Potom si ním už můžete otevřít váš cs.po. Rozhraní je velice jednoduché a nemyslím, že by s ním měl mít někdo problémy. Další věci už popíše následující obrázek:
Lišta menu nahoře:
Dále můžete vidět toolbar (nástrojovou lištu) a pod ním seznam přeložených/nepřeložených/starých řetězců. Ty se barevně odlišují:
Pod seznamem jsou dvě pole. To horní je původní řetězec. Překlad tedy probíhá tak, že pomocí Alt+C zkopírujete horní do spodního a spodní přeložíte. Až bude vše přeloženo, uložte soubor. Pokud budete chtít svůj překlad později aktualizovat, vygenerujte si nový .pot pomocí intltool-update a z menu Katalog vyberte Aktualizovat z POT souboru.
Nyní, když máte přeloženo, zbývá upravit soubor LINGUAS ve složce po – vypadá nějak takhle:
fr it km pl
Prostě kódy zemí oddělené mezerami. Kódy MUSÍ být seřazeny podle abecedy. Upravte si soubor, aby vypadal takto:
cs fr it km pl
Jeho obsah závisí na počtu překladů. Pokud program ještě nebyl překládán, je prázdný. Tím by byla práce hotova.
Pokud program využívá jiný systém, jako třeba vlastní Makefile, pak vám intltool-update nebude fungovat a pro vytvoření POT souboru budete muset použít xgettext:
xgettext --keyword=_ --keyword=N_ --keyword=D_ --keyword=DN_ *.c -o program.pot
Při překladu postupujte stejně, ale systém skladování po souborů a jejich instalace se může lišit, podle Makefile.
Pokud je program psán v jazyce Python, místo xgettext použijte pygettext:
pygettext --keyword=_ --keyword=N_ --keyword=D_ --keyword=DN_ *.py -o program.pot
Programy, které se chovají stejně jako volby v POEditu, ale jsou do příkazové řádky. Často mají parametr -D(--directory), který určuje složku, kde se má hledat vstupní soubor(y).
Použití:
msgfmt cs.po -o myapp.mo # vytvoří z cs.po myapp.mo
Použití:
msginit -i my.pot -o my.po # vytvoří z my.pot my.po
Použití:
msgmerge -U my.po my.pot # aktualizuje my.po z my.pot
Použití:
msgunfmt myapp.mo -o cs.po # udělá z myapp.mo soubor cs.po
Použití:
msgattrib --translated cs.po # vypíše přeložené řetězce
Použití:
msgcat one.po two.po -o three.po # sloučí one.po a two.po do souboru three.po
Použití:
msgcmp my.po program.pot # porovná my.po a program.pot
Použití:
msgcomm one.po two.po # porovná dva po soubory
Použití:
msgconf --to-code=utf-8 -o utf.po cp1250.po # převede cs1250.po do utf-8 kódování a výsledek zapíše do utf.po
Použití:
msgen my.pot -o en.po # vyplní pot šablonu
Použití:
msgexec -i my.po cat # vypíše přeložené řetězce + hlavičku .po souboru (řádky jako language-team atd.)
Použití:
msgfilter -i en.po sed -e 's/error/success/g' # nahradí v překladu všechna slova „error“ za „success“
Použití:
msggrep --msgstr -F -e "error" en.po # vypíše všechny přeložené řetězce, které obsahují slovo „error“; # pokud nahradíte --msgstr s --msgid, tak vypíše z předloh, # pokud nahradíte -F za -E, můžete zadat regulární výraz
Použití:
msguniq -o unified.po my.po # sloučí duplicitní řetězce v my.po a uloží jako unified.po
Návod se blíží ke konci.. pokud potřebujete další informace, zde je kompletní manuál k gettextu:
http:#www.gnu.org/software/gettext/manual/gettext.htmlV článku se bohužel nedalo popsat vše, ale alespoň určitý základ a nejdůležitější věci nutné pro správu překladů jsem popsal. Při psaní článku jsem čerpal z výše uvedeného odkazu a vlastních zkušeností (většinou pokus-omyl). Na další věci se také můžete ptát v diskusi. Kompletní projekt jak se standardním Makefile, tak s autotools je přiložen k článku.
 20.1.2010 07:08
Jan Drábek | skóre: 41
| blog: Tartar
| Brno
20.1.2010 07:08
Jan Drábek | skóre: 41
| blog: Tartar
| Brno

Soubor uložte jako gettexttest.po a nepokoušejte se jej překládat.Proc ne??? Ja to vzdycky otevren ve vimu a prekladal jsem. Co je na tom za problem?
Nejenom kódování, ale také jméno posledního překladatele, časovou značku poslední úpravy překladu.
Na druhou stranu musím říct, že já mám univerzální Makefile, který tohle (a spoustu jiných věcí jako odeslání překladu robotovi) za mě dělá a používám taky vim. Grafické nástroje mě neoslovili (asi protože mám zkušenost jen s příšerným linguistem).
pybabel extract -F babel.cfg -o app.pot app pybabel update -i app.pot -d . -D app -l sk
Gettext umí podle klíčových slov hlídat syntaxi mezi msgid a msgstr. Například printf(3) escapovací sekvence:
#: ../src/aosd/aosd_ui.c:242 #, c-format msgid "monitor %i" msgstr "monitoru %i"
Nevíte, jestli lze ve zdrojovém kódu vyznačit, že daný řetězec není formátovací printf řetězec?
V jednom programu je použito něco jako _("100% during") a xgettext takovému msgid přidává příznak c-format, což je samozřejmě špatně. Kontrolní mechanismy pak křičí, že v překladu nesedí formátovací sekvence kolem procentítka. A mně nebaví opakovaně odmazávat příznak c-format.
Čekal bych, že gettext něco takového bude umět, protože zrovna tak umí extrahovat kontextové komentáře zdrojového kódu ohledně překladu (často se používá na upozornění překladatelů programátorem, že určité slovo v hlášce je lexikál nebo vlastní jméno).
20.1.2010 19:39
Jan Drábek | skóre: 41
| blog: Tartar
| Brno
ISSN 1214-1267, (c) 1999-2007 Stickfish s.r.o.
 20.1.2010 17:14
20.1.2010 17:14
 20.1.2010 19:05
20.1.2010 19:05