
Portál AbcLinuxu, 7. června 2026 07:35
Dnes nás čeká hned šest témat, která zahájíme pohledem na chystaný desktopový hi-end od Intelu a naopak uzavřeme dnes již postarší procesorovou architekturou konkurenční AMD. Děly se a dějí opravdu zajímavé věci…
Nejvyšší čip platformy LGA2011-3, tedy nástupce Haswellu-E pro stejný socket, ponese více jader. Zatímco Haswell-E jako první přišel s konečně 8 jádry, Broadwell-E má nabídnout 10. Tedy přesněji jeden konkrétní procesor, nejvyšší v nabídce zvaný Core i7-6950X. Čekejme od něj pracovní frekvenci 3,0 GHz (+ Turbo), 25MB cache a hodně vysokou cenu (téměř jistě obligátních 999 dolarů).
Pokud se tyto parametry potvrdí, lze z nich jistě usuzovat i na to, že po Intelu chtějí zákazníci přeci jen větší pokrok, než zase letité setrvání na počtu jader, které není ani poloviční ve srovnání s tím, co stejná platforma nabízí v podobě Xeonů pro enterprise trh. Možná také na Intel trochu tlačí představa toho, co AMD přinese pod názvem „Zen“. Ale jsou to zatím jen spekulace. Tak či onak bude nadále platit, že tato hi-endová desktopová platforma Intelu je ve skluzu oproti mainstreamové platformě minimálně o 1 generaci. Aktuálně je to o dvě, běžné desktopy totiž již nabízejí 14nm TOCK Skylake, zatímco tato HEDT platforma stále 22nm Haswell-E.
Nové generické cPU jádro od ARMu cílí na nejmenší zařízení a přístroje, do levných smartphonů či embedded segmentu. Cortex-A35 je 64bitový ARM architektury ARMv8a, který je o čtvrtinu menší a o třetinu energeticky efektivnější než předchůdce. Je velmi pravděpodobné, že jej nalezneme v počtu dvou či čtyř v levných smartphonech již během několika měsíců. Jeho výhodou je, že cílí na starou dobrou 28nm výrobu, přičemž i s ní spotřebovává jedno CPU jádro jen 90 mW.

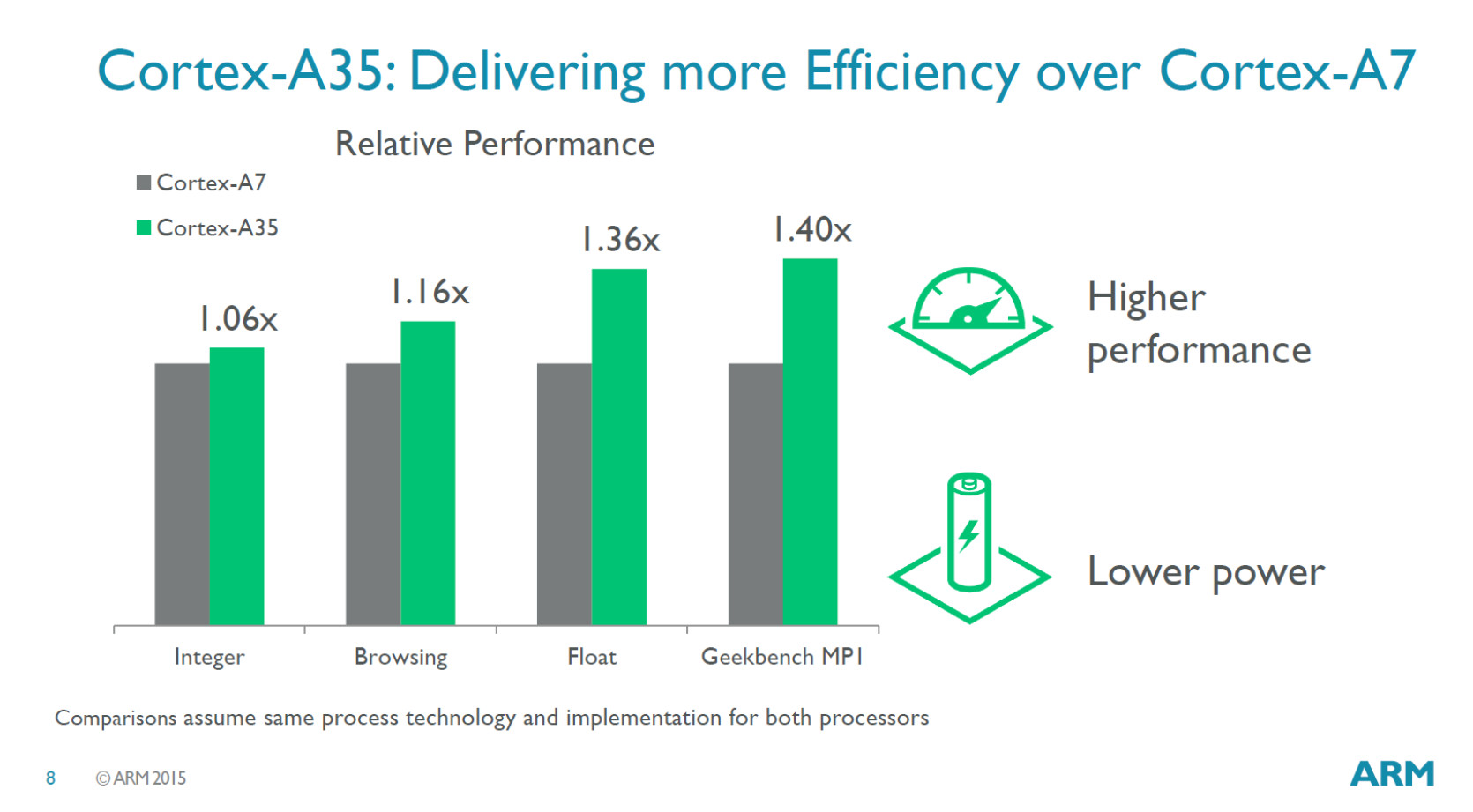
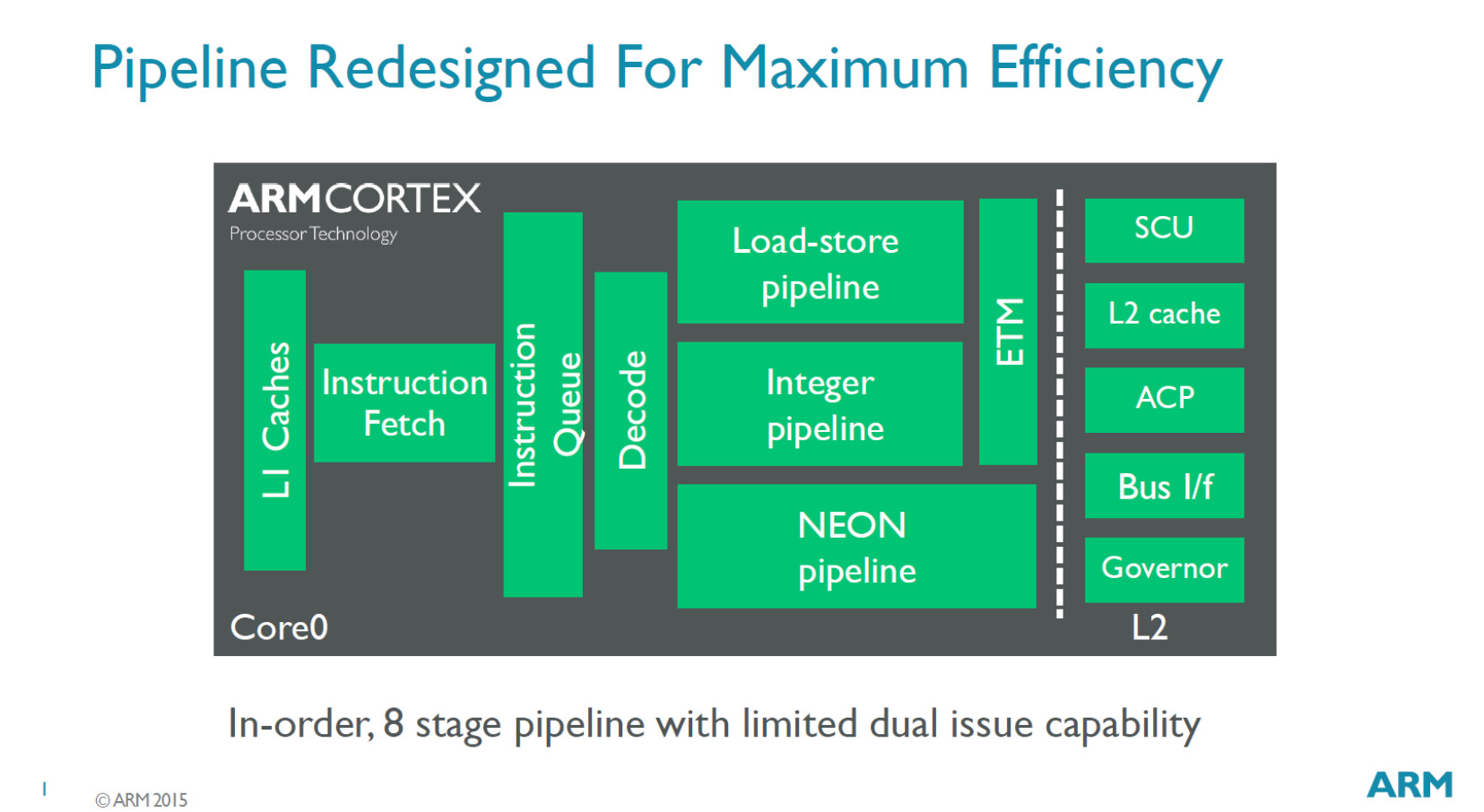

Nejmenší konfigurace tohoto CPU jádra vybavená 8kB L1 cache zabírá pouze 0,4 mm², takže výroba kupříkladu 16nm či 14nm FinFET technologií by neměla smysl (úspora zcela minimální až zanedbatelná, zato větší problémy s napojením čipu ven a také s vyšší cenou nejnovějších výrobních procesů). Uvedená minimální konfigurace má i při 28nm výrobě spotřebu pouze necelých 6 mW. Čipy Cortex-A35 vybavené tak nalezneme i v miniaturních síťových produktech, settopboxech či chytrých televizorech.
Současné hry si žádají více než mohou 2 GB grafické paměti ve výkonnostním segmentu, kam GeForce GTX 960 spadá, nabídnout. Takže zatímco toto množství paměti stačí kupříkladu pro řadu GeForce GTX 750 (Ti), 2GB GeForce GTX 960 končí. Výrobci zachovají pouze 4GB variantu. Rozhodnutí souvisí i s cenami radeonů, proti kterým 2GB verze neobstojí. Na trhu naopak posílí 4GB varianta, a to tak že aktuální 4GB modely s lepšími chladiči, kvalitnějšími napájecími obvody či lepším chlazením budou doplněny o levnější varianty, kde se nepředpokládá snaha zákazníka o nějaké masivní navyšování výkonu, spíše běžný provoz na stanovených taktech a kdo ví, možná i vyšší tolerance k mírně hlučnějšímu levnějšímu chladiči. Dochází ale i na modely s kratším PCB.
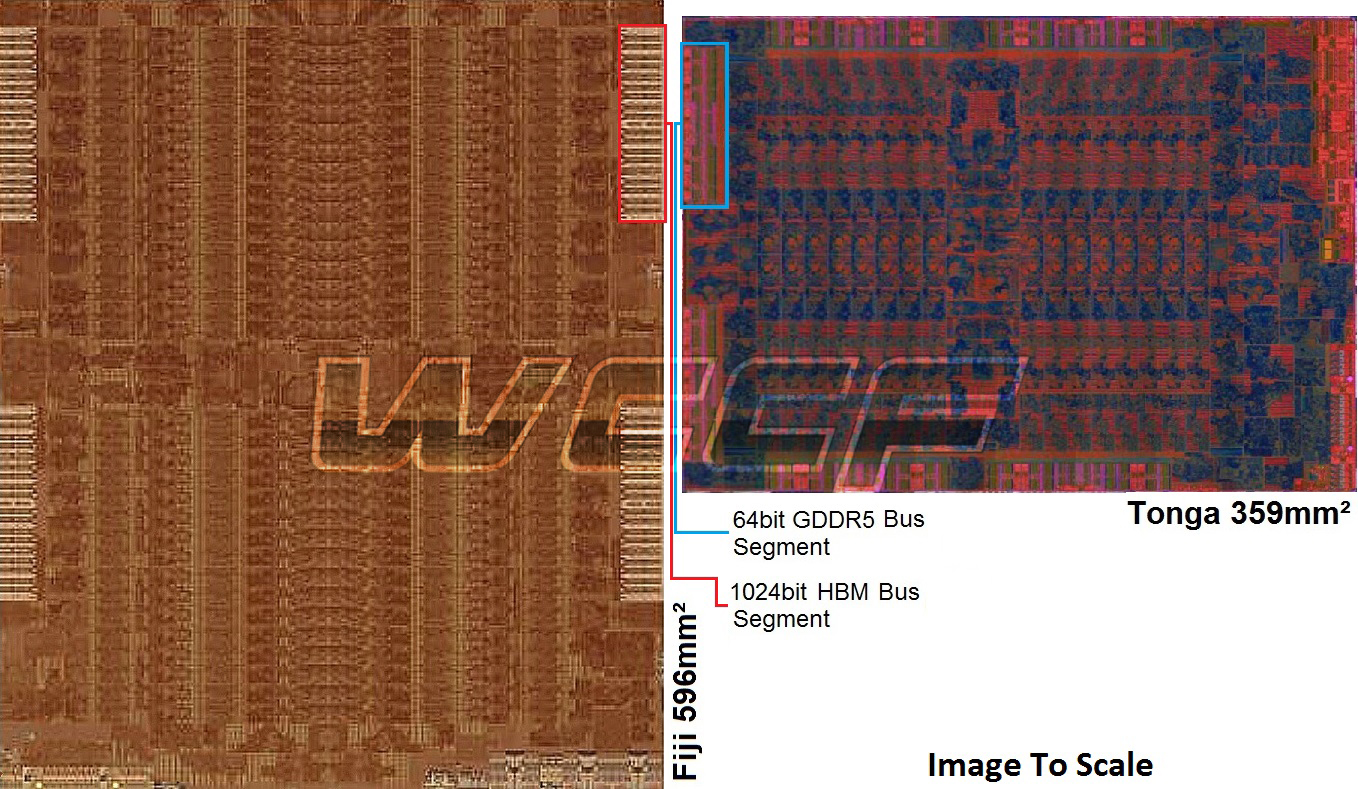

Velkou výhodou HBM pamětí je i skutečnost, že jejich řadič fyzicky zabere na čipu daleko méně prostoru než by zabral výkonu adekvátně široký řadič GDDR5. Na v současnosti jediném dostupném řešení, tedy GPU radeonů Fury, zabírá řadič pouze 6 % plochy čipu (nutno ale dodat, že čip je hodně velký, dosahuje 596 mm²). To je jistě výhodné pro tyto velké čipy, na druhou stranu to logicky limituje možnosti použití HBM řadiče u GPU nižší třídy, o to více v kombinaci s očekávanou 16nm FinFET výrobou - vnější propojení GPU s HBM čipy na pouzdře tak bude hodně malé a je otázka, jestli to bude dobře fungovat na daných frekvencích a napětích bez nadkritického rušení. To se ale dozvíme až příští rok, s 16nm FinFET / HBM2 generací GPU, ať již v podání AMD, Nvidie či kohokoli jiného, kdo se HBM 2. generace rozhodl v kombinaci s moderní FinFET výrobou nasadit.
Další variantou mezi spínači Cherry MX je MX RGB Nature White. Aby se to nepletlo s původními spínači White, ty nyní definitivně končí. Tento nový typ je parametrově posazen mezi spínače MX Red a MX Black. MX RGB Nature White vyžaduje sílu stisku 55 gramů, chod spínače je lineární bez hlasitého cvakání. Vnější část jeho konstrukce je z průsvitného plastu, takže dobře rozvádí podsvícení (i díky integrované pidi-čočce) a přímo se počítá s RGB LED podsvícením klávesnic jím vybavených.

Na kvalitě kontaktů se ale nic zásadního nemění, jsou opět zlacené a „mechanické“. Udávaná (garantovaná) životnost je opět 50 miliónů sepnutí. Doba sepnutí je přitom pod 1 milisekundu. Lze předpokládat, že nové spínače nasadí všichni hlavní i méně známí výrobci herních klávesnic.
Jakoby toho nebylo málo, dlouholetou krizí, mnoha restrukturalizacemi a neschopností dostat se pořádně „do černých čísel“ zmítaná AMD má na krku zvláštní žalobu. Firma je žalována za to, že u procesorů architektury Bulldozer lhala o tom, že mají 8 CPU jader. AMD toto obvinění odmítá.
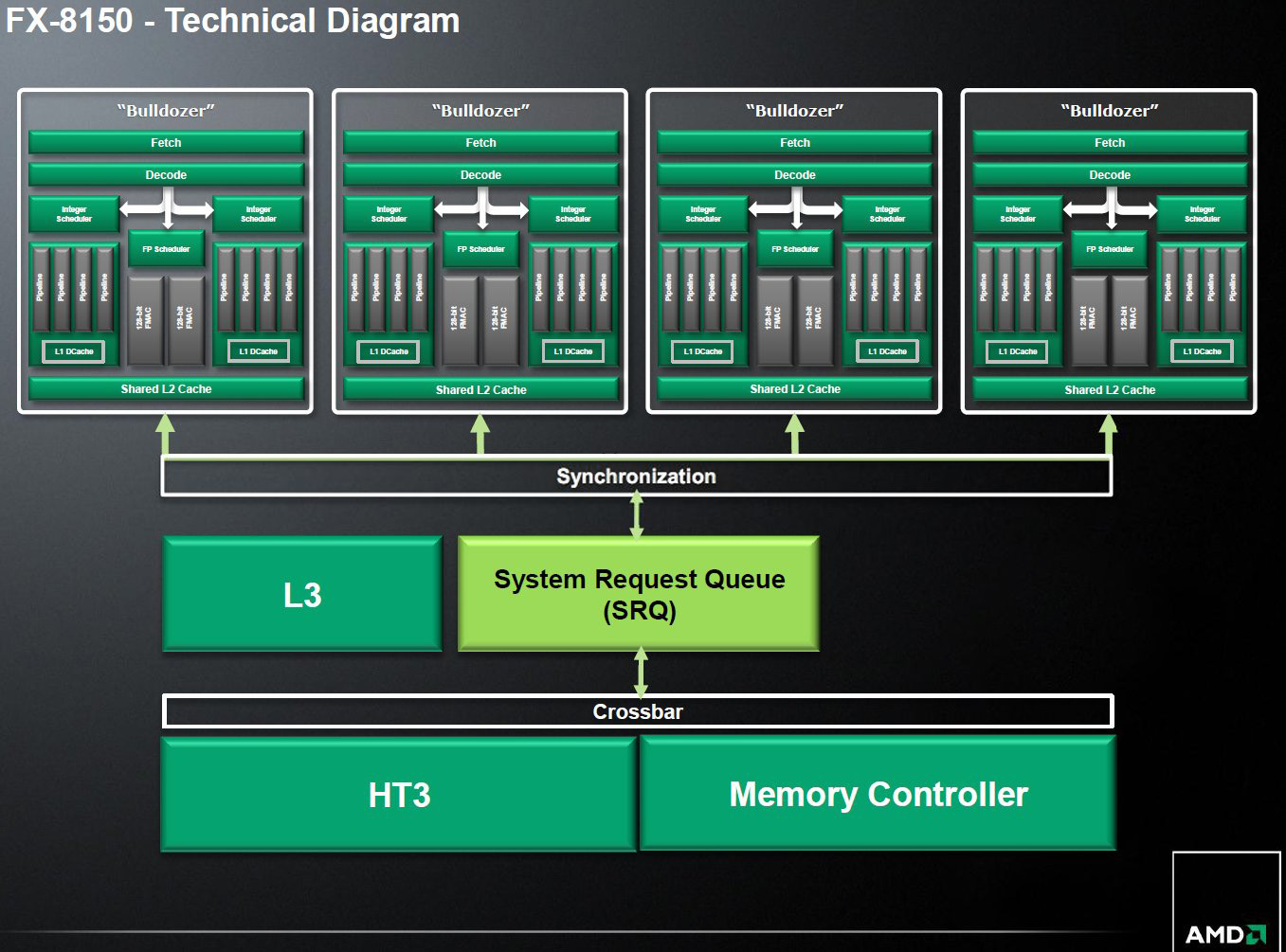
V základu jde o to, že 8jádrový Bulldozer je tvořen čtveřicí dvoujádrových modulů. Každý tento modul nese řadu částí, včetně dvou Integer Schedulerů, ale jen jednoho společného Floating Point Scheduleru. Odpůrci tak tvrdí, že nejde o plnohodnotnou dvojici CPU v modulu, zatímco AMD říká, že jo a že o těchto věcech plně informovala od samotného počátku. Jenže dle mnohých odpůrců to nebylo napsáno na obalu výrobku. Soud bude probíhat v Kalifornii, tedy USA, kde je potřeba do manuálu k mikrovlnce napsat, že neslouží k sušení psů. Výsledek tedy může být jakýkoli.
Pro AMD hovoří to, že historicky je CPU (dnes CPU jádro) chápáno jako jednotka pro integer výpočty. Těch opravdu osmijádrové Bulldozery (od původního FX-8150 až po současný FX-9590) nese osm. FPU jednotka byla historicky přídavným kusem, samostatným koprocesorem, než byla v generaci 486 fyzicky začleněna do vlastního CPU. Ostatně podobným způsobem by se daly kritizovat procesory i jiných výrobců, neboť sdílení prvků CPU je běžnou praxí, kupříkladu taková sdílená L2 či L3 cache. Paradoxem u Bulldozeru je snad jedině to, že tyto procesory byly horší než předchozí generace (Phenomy X6) v jednovláknových úlohách, naopak ve vícevláknových si vedly velice dobře, i srovnatelně či lépe než Intel CPU (pokud pomineme spotřebu či poměr výkon/spotřeba, kdy se pochopitelně ukazovala naprostá výrobní nadřazenosti Intelu).
 20.11.2015 01:55
Jendа | skóre: 78
| blog: Jenda
| JO70FB
20.11.2015 01:55
Jendа | skóre: 78
| blog: Jenda
| JO70FB
 ). A každé skupině pak nastavit affinitu procesoru. A samozřejmě zjistit topologii nejdřív.
Ale jestli tam máš tisíc vláken, tak i kdyby jsi polovinu jader vyřadil (třeba úplně vypnul někde v /sys/bus/cpu/devices/cpu0/ po natažení cpuhotplug), tak se ti stejně budou na zbylých mezi sebou přetahovat o zdroje.
20.11.2015 16:39
Jendа | skóre: 78
| blog: Jenda
| JO70FB
). A každé skupině pak nastavit affinitu procesoru. A samozřejmě zjistit topologii nejdřív.
Ale jestli tam máš tisíc vláken, tak i kdyby jsi polovinu jader vyřadil (třeba úplně vypnul někde v /sys/bus/cpu/devices/cpu0/ po natažení cpuhotplug), tak se ti stejně budou na zbylých mezi sebou přetahovat o zdroje.
20.11.2015 16:39
Jendа | skóre: 78
| blog: Jenda
| JO70FB
Ale jestli tam máš tisíc vláken, tak i kdyby jsi polovinu jader vyřadil (třeba úplně vypnul někde v /sys/bus/cpu/devices/cpu0/ po natažení cpuhotplug), tak se ti stejně budou na zbylých mezi sebou přetahovat o zdroje.Mně jde o to, abych vedle tisícivláknového floatového gnuradia, kterému efektivně stačí čtyři jádra (protože ten signál mi tam prostě přitéká realtime, takže ho víc není), mohl provozovat ještě celočíselné aplikace (které bych rád naalokoval na ta zbylá jádra). Ty cgrupy zní jako dobrý nápad.
Pokud nemáš hodně staré jádro, tak se defaultně scheduluje tak, aby se přednostně obsazovala jádra v různých modulech. Takže pokud mi na FX-8150 poběží jen čtyři thready, nestane se, že by měly dohromady jen dva nebo tři FPU schedulery. Pokud jich ale poběží tisíc a jen čtyři budou používat FPU, pak to AFAIK scheduler sám nepozná, aby je podle toho přemigroval.
Zajímavé je, že je k tomu využit stejný mechanismus, který se používá kvůli intelímu hyperthreadingu, takže třeba lscpu reportuje údaje, které jsou vůču Bulldozerům hodně nefér:
unicorn:~ # lscpu Architecture: x86_64 CPU op-mode(s): 32-bit, 64-bit Byte Order: Little Endian CPU(s): 8 On-line CPU(s) list: 0-7 Thread(s) per core: 2 Core(s) per socket: 4 Socket(s): 1 NUMA node(s): 1 Vendor ID: AuthenticAMD CPU family: 21 Model: 1 Model name: AMD FX(tm)-8150 Eight-Core Processor ...
De facto je to pravý opak toho, kvůli čemu je ta žaloba.
Prťavoučké ARM jádro Cortex-A35To bude zajímavý porovnat real life výkon s tím Intel Quarkem. Podle všeho Intel tvrdí, že Quark má menší spotřebu, ale při takových velikostech bude záležet i na pár kB RAM. Chtělo by to tabulku závislosti taktu a spotřeby (předpokládám, že ten ARM půjde taktovat dost dolů). Bylo by hustý mít v kalkulačce něco co může skutečně spustit třeba Octave
(a na rozdíl od výkonného CPU to utáhnou i wonderky).
Pro AMD hovoří to, že historicky je CPU (dnes CPU jádro) chápáno jako jednotka pro integer výpočtyNechápu proč všechny zpravodajské servery řešej integer výpočty, některý procesory nemusí umět ani násobit, nebo jen omezeně. Důležité je kolik zvládne najednou skoků. Každopádně žalující by mohl být nemile překvapen až zjistí, že moderní procesory obsahují SIMD instrukce, kde se pracuje nad několika integery současně
.
BTW RISC architektury můžou v jedné superskalární pipeline počítat třeba se třema integer a dvěma float operacema najednou (integer trvá třeba 2 takty, float třeba 4).
P.S. Doufám, že nikdo nebude žalovat třeba cache plánovač, že děla bubliny (teda spíš halt) v pipeline .
Zalujici postavi zalobu uplne jednoduse - veme jedno(dvoj)jadrovy CPU a zmeri jeho vykon, 8 jader = rekneme 7-7,5x zvednuti vykonu. Pokud to pro AMD neplati (pro libovolnou ulohu) tak ma AMD problem a to hodne velkej.
A dost pravdepodobne se mu povede dolozit, ze prave pro vypocet ve float ... je to "8mijadro" jen cca 3-3,5x rychlejsi nez jedno jadro.
Tímhle způsobem pomocí vhodně zvolené úlohy "dokážete", že žádný procesor nemá tolik jader, kolik uvádí (kromě jednojádrových, pochopitelně). Takže spíš - jako obvykle - půjde o to, kdo bude mít přesvědčivější právníky a experty.
 20.11.2015 16:13
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
20.11.2015 16:13
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
 ), obvykle také vyšší levely cache, instrukční dekodéry, paměťové řadiče apod. Důležité tedy není najít test, který vytíží danou jednu sdílenou jednotku a vítězoslavně vyplivne výsledek: 1x, ale test, který dokáže, že ten cpu je schopný paralelizace. Protože to, že je něco sdílené víme, to se nemusí testovat.
Dál, cpu není black box, výrobci cpu uvádějí, jaké je vnitřní uspořádání, aby bylo možné napsat OS a optimalizovat aplikace. To, že zrovna FPU je sdílené se ví. Stejně tak se ví, že jedno jádro umí (a to už od Athlonů) zpracovat víc integer výpočtů současně (na škole v 2002 jsme se bavili tím, jak AMD Athlon správně napsanou smyčkou počítající 4 integer výpočty projde na takt 4x rychleji, než tehdejší P4). Takže co? Je to snad každé jádro čtyřjádro? Ne není.
Pokud chcete skutečnou paralelizaci bez kompromisů (i když...) tak nutně potřebujete x kompletních cpu. I tam potom budete řešit takové srandy jako třeba velmi drahý přesun procesů mezi cpu a koherenci cache. Pro některé úlohy je lepší multicore (protože jádra jsou blízko, na stejné sběrnici, rychlejší už to nebude), pro některé úlohy s oddělenými procesy je lepší více cpu.
Potom je také otázkou cena takového řešení.
Je velmi úsměvné, jak se v některých případech a v některých redakcích dělá z Intel HT "skutečné" 2*Xjádro, zatímco skutečné AMD osmijádro se degraduje na 4 jádro, protože si dovolí sdílet FPU (a ještě to drze přiznává). No tak si to pro ty real výpočty nekupujte. Nebo možná si raději spočítejte, zda nebude stále levnější si ty AMDčka koupit dvě (kdykoliv si k tomu sednu, naposledy letos v létě, tak pořád vychází AMD cca 2x levnější než stejně výkonný Intel s tím, že za ušetřené peníze za CPU lze nakoupit i desku a paměť), získat tak "plný" FPU výkon a jako bonus, dvojnásobný integer (nejen).
20.11.2015 16:43
Jendа | skóre: 78
| blog: Jenda
| JO70FB
), obvykle také vyšší levely cache, instrukční dekodéry, paměťové řadiče apod. Důležité tedy není najít test, který vytíží danou jednu sdílenou jednotku a vítězoslavně vyplivne výsledek: 1x, ale test, který dokáže, že ten cpu je schopný paralelizace. Protože to, že je něco sdílené víme, to se nemusí testovat.
Dál, cpu není black box, výrobci cpu uvádějí, jaké je vnitřní uspořádání, aby bylo možné napsat OS a optimalizovat aplikace. To, že zrovna FPU je sdílené se ví. Stejně tak se ví, že jedno jádro umí (a to už od Athlonů) zpracovat víc integer výpočtů současně (na škole v 2002 jsme se bavili tím, jak AMD Athlon správně napsanou smyčkou počítající 4 integer výpočty projde na takt 4x rychleji, než tehdejší P4). Takže co? Je to snad každé jádro čtyřjádro? Ne není.
Pokud chcete skutečnou paralelizaci bez kompromisů (i když...) tak nutně potřebujete x kompletních cpu. I tam potom budete řešit takové srandy jako třeba velmi drahý přesun procesů mezi cpu a koherenci cache. Pro některé úlohy je lepší multicore (protože jádra jsou blízko, na stejné sběrnici, rychlejší už to nebude), pro některé úlohy s oddělenými procesy je lepší více cpu.
Potom je také otázkou cena takového řešení.
Je velmi úsměvné, jak se v některých případech a v některých redakcích dělá z Intel HT "skutečné" 2*Xjádro, zatímco skutečné AMD osmijádro se degraduje na 4 jádro, protože si dovolí sdílet FPU (a ještě to drze přiznává). No tak si to pro ty real výpočty nekupujte. Nebo možná si raději spočítejte, zda nebude stále levnější si ty AMDčka koupit dvě (kdykoliv si k tomu sednu, naposledy letos v létě, tak pořád vychází AMD cca 2x levnější než stejně výkonný Intel s tím, že za ušetřené peníze za CPU lze nakoupit i desku a paměť), získat tak "plný" FPU výkon a jako bonus, dvojnásobný integer (nejen).
20.11.2015 16:43
Jendа | skóre: 78
| blog: Jenda
| JO70FB
Pokud to pro AMD neplati (pro libovolnou ulohu) tak ma AMD problem a to hodne velkej.Aby pak tímhle způsobem neplatil i Intel. Ten může viset třeba na sdílené cache nebo na čekání na paměť.
ze od dob 486 az do prvniho vicejadra byl vzdy soucasti kazdeho CPU i matematickej modulNebyl
.
Já jsem nikde o externím švábu nepsal. Dokonce jsem ve své úvaze vyhodil i ALU.
 20.11.2015 19:24
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
20.11.2015 19:24
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
Zalujici postavi zalobu uplne jednoduse - veme jedno(dvoj)jadrovy CPU a zmeri jeho vykon, 8 jader = rekneme 7-7,5x zvednuti vykonu. Pokud to pro AMD neplati (pro libovolnou ulohu) tak ma AMD problem a to hodne velkej.To je pitomost, scaling neni dan jen poctem vypocetnich jader a sdileni casti subsystemu procesoru je celkem bezne. AMD se zde chova v mezich standardu a architekturu na teto urovni netajilo, at na urovni verejne prezentace ci manualech pro vyvojare.
21.11.2015 01:45
Jendа | skóre: 78
| blog: Jenda
| JO70FB
Pokud to bude škálovat jen na 3-3,5násobek, tak bude chyba v programu, že prostě nesaturuje osm vláken, ne v Bulldozeru.Jo, určitě to bude tím, že jsem ve skutečnosti nespustil osm vláken, a ne tím, že ve všech počítám floaty a AVX a tyhle jednotky tam jsou prostě jenom čtyři, nebo že čekám na náhodné přístupy do paměti, nebo že jsem zahltil paměťovou sběrnici, nebo že už se mi ty dvě paralelně běžící FFT nevejdou do sdílené L2 cache, zatímco jedna instance se tam těsně vešla.
22.11.2015 13:08
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
V dnešní době, kdy se šifruje a jedou multimédia snad na každým kroku (i když osobně si teď nejsem jistej, jestli komprimace jedou floaty) je od AMD nerozvážnost tam ty jednotky nemít
Na šifrování je tam spešl HW podpora a šifrování v CPU je mnohem rychlejší, než jak rychle jsou schopné jakékoliv konvenční zdroje dat (síť, disky - možná až na PCI-E SSD) ta data dodávat. Na šifrování navíc FPU není potřeba, to jsou většinou logické operace nad bloky dat, tam se víc hodí SIMD.
Na multimedia existují AVX. Buldozer má dvě 128b jednotky na modul (tedy jednu FMAC na jádro) a umožňuje je spojit do jedné 256b. Tedy čtyřmodulový buldozer má buď 8x128b FMAC nebo 4x256b FMAC (přičemž není nutné spojovat všechny jednotky). (Převod do řeči AVX je komplikovaný, některé instrukce udělají v buldozeru jiné jednotky a FMAC je volná.) Každopádně, když něco komprimuju v handbrake (což je asi stejně jen nastavba nad ffmpeg), tak to jede skoro osmijaderně (asi tak 720%). Což nevím, zda je dáno tím, že něco nestíhá dodávat data do threadů, nebo je to dané architekturou toho programu. Je to celkem jedno, těch 300fps (při konverzi na něco jako 576p (něco jako full non interleaved pal) to umí 300fps). A zvládá to i realtime 1080p záznam během hraní her (stejně málokterá umí víc jak 2 výpočetní threadu).
Pokud někdo potřebuje FPU výpočty, tak je mu k disposici GPU. Tam to spočítá rychleji a levněji, než na kterémkoliv general purpose cpu. Tam třeba AMD směruje s APU (CPU + GPU v jednom socketu).
Intelu taky kdysi neprošlo když měl na prvních Pentiích chybu právě v FPU, a taky by principiálně šlo tehdy říct „tak tu jednotku prostě vypnem a u složitějších výpočtů si chvíli počkáte”.
Tj snad úplně jiné téma, ne? Mít tam vadnou jednotku a mít tam deklarovaný počet funkčních jednotek.
22.11.2015 13:17
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
), které se bez toho neobejdou a které ještě nikdo nepřepsal do OpenCL (pro výpočty na gpu). Ale troufnu si říct, že pro běžnou práci to až tak často potřeba není a navíc, když je zaměstnaná FPU, tak ALU může (pokud to dovolí out of order execution) vykonávat další instrukce. Takže kromě speciálních věcí je to stejně jedno.
aby vesnice správně fungovala tak tam toho divnýho matematika prostě potřebujou
Ne všechny architektury ho mají. A zdaleka ne pro všechny úlohy ho potřebujete. Např. v jádře se nepoužívá vůbec a spousta userspace aplikací se bez FPU taky pohodlně obejde.
V dnešní době, kdy se šifruje a jedou multimédia snad na každým kroku (i když osobně si teď nejsem jistej, jestli komprimace jedou floaty) je od AMD nerozvážnost tam ty jednotky nemít
Tak třeba pro AES-NI se FPU nepoužívá vůbec (prakticky vyzkoušeno, na FX-8150 to škáluje perfektně až do osmi threadů) a tipoval bych, že výrazná většina šifrovacích algoritmů na tom bude stejně.
Sečteno a podtrženo, snažit se po tomhle vozit je nesmysl. Pokud někdo potřebuje vysoký výkon v aplikacích masivně používajících FPU, tak si takový procesor nekoupí. A pro zbávajících 100-ε procent aplikací vůbec nepoznáte, že jsou tam jen čtyři FPU. Naopak, kdyby jich tam dali osm a místo toho museli slevit někde jinde (třeba cache), byl byste na tom v drtivé většině případů hůř.
Jde o class action lawsuit, takže jediný, kdo má šanci na tom něco netriviálního vydělat, jsou právníci.
 23.11.2015 23:38
Agent
| blog: Life_in_Pieces
| HC city
23.11.2015 23:38
Agent
| blog: Life_in_Pieces
| HC city
Rád bych se zeptal, u Zenu plánují až 40% nátůst výkonu, je to reálné a pokud jo, čím ho dosáhnou, když FPU jednotky nejsou až tak důležité? Zen prý staví na tom, že bude mít zas "plnohodnotné" FPU.
Jinak děkuji fšem za pěknou diskusi. Už asi začínám chápat, proč se AMD vydalo touto cestou. Každopádně podle různých (zejména herních) testů má FX nižší výkon hlavně v single tasku, čím to může být, kromě možná FPU, ještě způsobeno?
u Zenu plánují až 40% nátůst výkonu, je to reálné
Uvidíme příští rok.
čím ho dosáhnou, když FPU jednotky nejsou až tak důležité?
Podle materiálů, které byly zatím zveřejněny, se má především zlepšit "instructions per clock" poměr, tj. snížit průměrný počet taktů potřebných k vykonání instrukce. To je zatím jeden z hlavních faktorů, v němž AMD za Intelem zaostává (druhým je tempo přechodu na vyšší hustotu součástek).
Zen prý staví na tom, že bude mít zas "plnohodnotné" FPU.
Nevím, tuhle informaci jsem zatím nezaznamenal a, upřímně řečeno, je mi úplně jedno, jestli je to pravda nebo mne. U aplikací, kde je pro mne výkon nejdůležitější, na FPU nezáleží.
nižší výkon hlavně v single tasku, čím to může být, kromě možná FPU, ještě způsobeno
Především již zmíněná vyšší taktová náročnost instrukcí. Tím při stejné frekvenci stejný kus kódu trvá déle. Možná tam bude i nějaký rozdíl v efektivitě přístupu do paměti, ale to nevím jistě.
Ale ono to celé záleží na tom, jak se porovnání postaví. Pro mne je třeba zajímavé kritérium "jsem ochoten za procesor dát přibližně 5000-6000 Kč, kdo mi nabídne nejvyšší výkon?" A v takovém případě odpověď zní AMD. Nasadím-li cenu dostatečně vysoko, odpovědí bude Intel. A stejně tak u kritéria "chci co nejvyšší výkon, ať to stojí, co to stojí" (tedy aspoň bavíme-li se o x86_64 architektuře) - jenže to je otázka, která zajímá především autory srovnávacích článků v časopisech a na webech, ty, kdo procesory opravdu kupují, většinou ne.
22.11.2015 14:20
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
V dnešní době, kdy se šifruje a jedou multimédia snad na každým kroku (i když osobně si teď nejsem jistej, jestli komprimace jedou floaty) je od AMD nerozvážnost tam ty jednotky nemít,Vetsina aplikaci jede na intech, vcetne sifrovani. V praxi FPU jednotka neni i u vetsiny aplikaci vytizena a tak jeji sdileni nevadi, a navic bottleneck je vetsinou u pristupu k pameti.
Jo, určitě to bude tím, že jsem ve skutečnosti nespustil osm vláken, a ne tím, že ve všech počítám floaty a AVX a tyhle jednotky tam jsou prostě jenom čtyři
Z té argumentace vidím, že jsem to asi měl vysvětlit víc po lopatě.
Vidím, že máte představu, že ta sdílená FPU má prostředky akorát tak na to, aby ji vytížilo jedno z těch integerových jader a když by si chtělo líznout i druhé, tak oba dostanou jen polovinu toho, co by mohlo jedno, takže rychlost spadne na 50 %. Ale to je vyslověně cyhbný předpoklad a tak to nefunguje, na což jsem ve svém komentu narážel. Ve skutečnosti je ta FPU pro jedno jádro silně předimenzovaná, ona je skutečně stavěná na dva thready.
Právěže kdybyste si to pořádně ověřil benchmarky, tak byste dostal to škálování, o kteérm jsem mluvil, dejme tomu ze 100 % na jednom vlákně na 180 % na dvou. Platí to i pro úlohy které tu FPU silně vyěžují, například x264, které stráví 60% času v SIMD kódu (jede v té sdílené FPU). Ta jednotka má docela velkou kapacitu, jsou tam čtyři nebo u Steamrolleru tři pipe (eveidentně máte představu, že FPU je nějaká "jedna" jednotka), které jedno vlákno nemá v praxi moc šanci vytížit samo. Prostě v AMD nebyli dle vašeho předpokladu až tak pitomí aby si mysleli, že tam stačí šoupnout jednu FPU jaká by stačila na jedno jádro, ale použili o něco silnější.
Fakt si to na těch CPU zkuste vyzkoušet, než budete říkat s prominutím blbosti jako to ocitované.
22.11.2015 20:52
Jendа | skóre: 78
| blog: Jenda
| JO70FB
22.11.2015 23:46
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
To mi trochu připomíná mou první zkušenost s FPU ještě v době, kdy to byl samostatný koprocesor (387). Když jsem si ho pořídil, chtěl jsem ho hned vyzkoušet, tak jsem narychlo v Turbo Pascalu napsal vizualizaci Juliovy množiny tím nejtupějším způsobem a v double precision. Přeložil jsem to bez využití koprocesoru a s ním; s využitím koprocesoru byl sice program rychlejší, ale jen asi třikrát, což mi přišlo málo. Tak jsem se podíval disassemblerem a nevěřil jsem svým očím. Překladač vyrobil kód, kde např. vynásobení tří čísel probíhalo asi takto:
Tak jsem vnitřní smyčku přepsal do assembleru s tím, že se celý výraz vždy počítal v FPU a zpátky se četl až výsledek. Finální verze byla oproti původnímu programu (bez FPU) rychlejší asi stokrát.
Dnešní překladače jsou samozřejmě mnohem chytřejší, ale i tak je potřeba mít na paměti, že ani složitý výpočet ve float/double nemusí zdaleka celý probíhat v FPU. Ono i u "normálních" instrukcí se běžně stává, že se nějaká komplexní instrukce nepoužije, protože v konkrétním případě (nebo dokonce obecně) je rychlejší ji rozepsat do jednodušších.
23.11.2015 21:19
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
kdy to byl samostatný koprocesor (387).Podobna zkusenost s 80287 a pocitanim fraktalu v assembleru
 .
.
Dnešní překladače jsou samozřejmě mnohem chytřejší, ale i tak je potřeba mít na paměti, že ani složitý výpočet ve float/double nemusí zdaleka celý probíhat v FPU.Stale se nam u numerickych algoritmu vyplaci pouziti SIMD (NEON/AVX/SSEx) a compiler intrinsics.
 21.11.2015 23:27
Blaazen | skóre: 24
| blog: BL
21.11.2015 23:27
Blaazen | skóre: 24
| blog: BL
ISSN 1214-1267, (c) 1999-2007 Stickfish s.r.o.