Portál AbcLinuxu, 7. července 2026 14:17
V tomto díle volně navážeme na třináctý díl tohoto seriálu – v něm se psalo o programech ps a kill, které shodně pocházejí z balíčku procps. V procps je ovšem nástrojů pro práci s procesy mnohem více.
První takovou šikovnou „zkratkou“ je pgrep. Řekl bych, že snad každý někdy napsal něco jako:
ps -A | grep ZlobivýProces
Předchozí příkaz vypíše procesy, kde součástí názvu procesu je nějaký řetězec. Jenže každý správný unixák je líný psát, proto tu máme elegantnější pgrep. Základní použití je prosté – chceme se podívat třeba na PID procesu init:
$ pgrep init 1 4478 28469
Jedničku jsme čekali, ale co je ten zbytek? -l, neboli vypiš název procesu, hnedle přijde vhod. Ještě si ukážeme i -a, které vypíše celý příkazový řádek.
$ pgrep -l init 1 init 4478 kdeinit4 28469 kdeinit4 $ pgrep -a init 1 init [3] 4478 kdeinit4: kdeinit4 Running... 28469 kdeinit4: kdeinit4 Running...
Zde jsme svědky toho, jak mohou procesy ovlivňovat text zobrazovaný v různých nástrojích – prostě přepíší pole se svými argumenty jiným textem. Tak to zkusíme ještě jednou na něčem jiném, aby to bylo názornější:
$ pgrep -a bash 8164 /bin/bash 8301 bash 18886 bash /home/lubos/Steam/steam.sh 25089 /bin/bash 27833 /bin/bash 27963 bash -rcfile .bashrc
Teď už je to jasné. Z přehršle různých voleb pro filtrování si uvedeme ještě dvě. Pro filtrování podle uživatelů lze použít -u. Chceme-li omezit hledání podle přesného názvu (namísto střepu jako doposud), použijeme -x:
$ pgrep -u root -a bas 8301 bash $ pgrep -u root -a -x bas # Nic se nevypíše...
Ještě si ukážeme změnu oddělovače při výpisu procesů – volba -d:
$ pgrep -d ',' bash 8164,10114,18886,25089,27833,27963
Bratříčkem pgrep je pkill, který s ním dokonce sdílí manuálovou stránku. Účel pkill asi snadno odhadnete; jde o to, abyste nepsali něco jako:
$ kill $(pgrep bash)
Místo toho tedy pište jednoduché:
$ pkill bash
Tento příkaz by poslal signál SIGTERM všem procesům bash. pkill sdílí velkou část voleb s pgrep – následující dva příkazy proto mají stejný efekt:
$ pkill -x NázevProcesu $ killall NázevProcesu
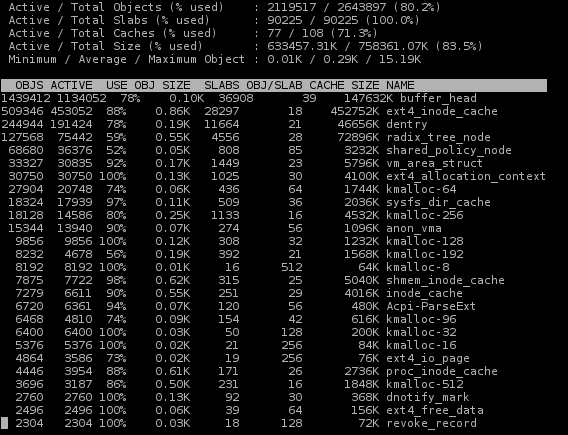
slabtop je nástroj, který nám pomůže nahlédnout do využití paměti jaderné SLAB cache. Nástroj má využití asi hlavně pro vývojáře, případně při dohledávání nějakých výjimečných chyb v jádře, pro mě osobně je to spíš jen věc pro zajímavost.
Pomocí různých písmen můžeme měnit řazení údajů (c výstup seřadí podle velikosti daných cache), mezerníkem vynutíme obnovení informací.
Asi moc nepřekvapilo, že se cache využívá hlavně kolem systémů souborů, a tedy pro cachování dat, která jsou umístěna na médiu s vysokou latencí (pevném disku).
Několikrát jsem se musel ujišťovat, že se v tomto seriálu ještě nepsalo o příkazu free a opravdu ne. free vypíše množství paměti a swapu v systému a jejich využití.
$ free
total used free shared buffers cached
Mem: 16322180 15347748 974432 0 676240 10532900
-/+ buffers/cache: 4138608 12183572
Swap: 3863548 127336 3736212
Tady se dostáváme k častému pomýlení uživatelů, kteří na Linux přišli s Windows a jsou šokováni tím, kolik paměti Linux spotřebovává. Výše vidíme systém s 16 GB RAM a jen necelý gigabajt je volný. Důležité ale je, kolik z toho jádro chytře využívá pro buffery a cache – jde tedy o paměť, kterou Linux „nesežral“. Linux zkrátka využívá toho, že ne všechna paměť je momentálně potřeba, ke zrychlení systému pomocí různých cache.
Pro informaci o tom, kolik paměti zabírají aplikace v systému doopravdy, je lepší se podívat na prostřední řádek. Tam vidíme, že skutečně spotřebováno je jen něco přes 4 GB. Řádek s údaji o swapu – tedy oblasti na disku, kam se odkládá obsah RAM, pokud je vhodné/nutné nějakou část uvolnit – je samopopisný. Jen ještě jednou zdůrazním to, že se Linux může rozhodnout swapovat i v případě, že má systém volné RAM dostatek. Může totiž usoudit, že je vhodné dlouhodobě odložit využitou, ale aktivně nepoužívanou paměť, a raději mít více pro cache.
Nejzajímavějším parametrem pro free je asi -h, které nám ulehčí od počítání číslic a dělení v hlavě a zobrazí údaje v lidštějších jednotkách:
$ free -h
total used free shared buffers cached
Mem: 15G 14G 885M 0B 661M 10G
-/+ buffers/cache: 4.0G 11G
Swap: 3.7G 124M 3.6G
Tyto dva příkazy se hodí pravděpodobně jen programátorům. pmap vypíše strukturu virtuálního paměťového prostoru vybraného procesu. pwdx vypíše aktuální adresář procesu.
$ pmap $$ 25089: /bin/bash 0000000000400000 708K r-x-- /bin/bash 00000000006b1000 4K r---- /bin/bash 00000000006b2000 36K rw--- /bin/bash 00000000006bb000 20K rw--- [ anon ] 00000000008ba000 28K rw--- /bin/bash 000000000139d000 392K rw--- [ anon ] 0000003676600000 132K r-x-- /lib64/ld-2.17.so 0000003676821000 4K r---- /lib64/ld-2.17.so 0000003676822000 4K rw--- /lib64/ld-2.17.so 0000003676823000 4K rw--- [ anon ] 0000003676a00000 1676K r-x-- /lib64/libc-2.17.so 0000003676ba3000 2048K ----- /lib64/libc-2.17.so 0000003676da3000 16K r---- /lib64/libc-2.17.so 0000003676da7000 8K rw--- /lib64/libc-2.17.so 0000003676da9000 16K rw--- [ anon ] 0000003677200000 8K r-x-- /lib64/libdl-2.17.so 0000003677202000 2048K ----- /lib64/libdl-2.17.so 0000003677402000 4K r---- /lib64/libdl-2.17.so 0000003677403000 4K rw--- /lib64/libdl-2.17.so 0000003678a00000 248K r-x-- /lib64/libreadline.so.6.2 0000003678a3e000 2048K ----- /lib64/libreadline.so.6.2 0000003678c3e000 8K r---- /lib64/libreadline.so.6.2 0000003678c40000 24K rw--- /lib64/libreadline.so.6.2 0000003678c46000 8K rw--- [ anon ] 0000003678e00000 84K r-x-- /lib64/libnsl-2.17.so 0000003678e15000 2044K ----- /lib64/libnsl-2.17.so 0000003679014000 4K r---- /lib64/libnsl-2.17.so 0000003679015000 4K rw--- /lib64/libnsl-2.17.so 0000003679016000 8K rw--- [ anon ] 0000003687c00000 316K r-x-- /lib64/libncurses.so.5.9 0000003687c4f000 2044K ----- /lib64/libncurses.so.5.9 0000003687e4e000 16K r---- /lib64/libncurses.so.5.9 0000003687e52000 4K rw--- /lib64/libncurses.so.5.9 0000003687e53000 4K rw--- [ anon ] 00007f00b8f43000 48K r-x-- /lib64/libnss_files-2.17.so 00007f00b8f4f000 2044K ----- /lib64/libnss_files-2.17.so 00007f00b914e000 4K r---- /lib64/libnss_files-2.17.so 00007f00b914f000 4K rw--- /lib64/libnss_files-2.17.so 00007f00b9150000 40K r-x-- /lib64/libnss_nis-2.17.so 00007f00b915a000 2044K ----- /lib64/libnss_nis-2.17.so 00007f00b9359000 4K r---- /lib64/libnss_nis-2.17.so 00007f00b935a000 4K rw--- /lib64/libnss_nis-2.17.so 00007f00b935b000 32K r-x-- /lib64/libnss_compat-2.17.so 00007f00b9363000 2044K ----- /lib64/libnss_compat-2.17.so 00007f00b9562000 4K r---- /lib64/libnss_compat-2.17.so 00007f00b9563000 4K rw--- /lib64/libnss_compat-2.17.so 00007f00b9564000 1684K r---- /usr/lib64/locale/locale-archive 00007f00b9709000 16K rw--- [ anon ] 00007f00b9742000 8K rw--- [ anon ] 00007f00b9744000 28K r--s- /usr/lib64/gconv/gconv-modules.cache 00007f00b974b000 4K rw--- [ anon ] 00007fff4d9c4000 132K rw--- [ stack ] 00007fff4d9f3000 4K r-x-- [ anon ] ffffffffff600000 4K r-x-- [ anon ] total 22180K
/tmp $ pwdx $$ 25089: /tmp
uptime je klasika – zobrazí, jak dlouho systém běží, a jaká je zátěž systému.
$ uptime 22:24:29 up 5 days, 13:24, 7 users, load average: 0.78, 1.01, 1.09
Tři čísla zátěže systému jsou průměrné údaje za posledních 1, 5 a 15 minut. Vysvětleme si, co se myslí pod touto zátěží a jak údaje interpretovat. Za zatěžující se považuje každý proces, který něco dělá (tedy zatěžuje procesor) nebo by rád něco dělal (ale zátěž v systému je taková, že se na něj nedostává) nebo čeká na I/O (obvykle na pevný disk).
Číslo zátěže si můžeme představit jako vyjádření zátěže nějaké silnice. Pokud má silnice jediný pruh (a v naší analogii má náš systém jen jedno jádro CPU), pak nejvyšší možná zátěž, kterou silnice (neboli náš systém) bude stíhat odbavit, je 1.00. Jakmile zátěž přesáhne 1.00, pak se začínají tvořit kolony – ve světě počítačů se procesy nedostávají ke slovu a systém začíná reagovat zpomaleně. Pokud máme jádra CPU dvě (což by odpovídalo silnici o dvou pruzích), pak je maximální zátěž, kdy systém v průměru ještě stíhá, rovna 2.00. Zátěž je tedy nutné vždy interpretovat v závislosti na procesorech v systému. Druhou věcí je pak analýza vysoké udávané zátěže – zpravidla může jít o nedostatečný výkon CPU, příliš pomalý přenos dat z/na disk nebo příliš nízký počet operací, které za sekundu dokáže disk zpracovat (IOPS). Výjimečně pak může mít vysoký load i jiné důvody – nejrůznější havárie ovladačů v systému mohou vést k nesmyslným údajům, kdy load je klidně v řádu stovek, aniž bychom třeba nějaký problém pozorovali.
tload nám opět ukazuje tři čísla se zátěží systému. Rozdíl je v tom, že tload na rozdíl od uptime nevypíše údaj jen jednorázově; údaj je na obrazovce pravidelně obnovován a ve spodní části je vykreslován graf.

A to je pro dnešek vše.
Super článek pro Linuxáky, pro Unixáky moc ne :|
85% z článku nelze použít v AIXu, 15% v Solarisu.
…a to jsou taky Unixy :)
 24.4.2013 05:55
Marián Kyral | skóre: 29
| blog: Sem_Tam
| Frýdek-Místek
24.4.2013 05:55
Marián Kyral | skóre: 29
| blog: Sem_Tam
| Frýdek-Místek
 24.4.2013 07:32
Conscript89
| Brno
24.4.2013 14:27
Marián Kyral | skóre: 29
| blog: Sem_Tam
| Frýdek-Místek
24.4.2013 07:32
Conscript89
| Brno
24.4.2013 14:27
Marián Kyral | skóre: 29
| blog: Sem_Tam
| Frýdek-Místek
rpm -i zip-2.3-3.aix4.3.ppc.rpm.
Teda, v pripaze, ze jeho admin pozna a pouziva AIX Toolbox for Linux Applications :)
BTW ps ax vs ps -ef ... matne si pamatam, ze jedna varianta pochadza a BSD vetvy unixu, a ta druha z System V... kazdopadne v linuxe funguju oboje :)
25.4.2013 13:02
Marián Kyral | skóre: 29
| blog: Sem_Tam
| Frýdek-Místek
Obavam sa, ze tvoj problem mal povod skor v adminovi toho AIXu, ako v AIXe samotnom...Asi jsi nikdy nepracoval pro velkou korporaci. Tam je i maličkost velký problém. A admini si nemůžou instalovat co a kam je napadne.

kazdopadne v linuxe funguju oboje :)No když to jde v Linuxu, proč to nejde v AIXu (bez potřeby dointalovávat extra balíky)?
Asi jsi nikdy nepracoval pro velkou korporaci. Tam je i maličkost velký problém. A admini si nemůžou instalovat co a kam je napadne.Nahodou pre velku korporaciu pracujem, konkretne ako AIX admin :) Samozrejme nie je vzdy jednoduche pretlacit nejake zmeny v baseline pre unix servre, no to neznamena, ze je to nemozne.. vsetko castokrat zavisi na adminovi, ci taketo zmeny (prenho castokrat velmi bolestivo) presadzovat bude, alebo nie. Trebarz ja verim, ze cim uzivatelsky pritulnejsi system uzivatelom pripravim, tym menej roboty s "nefungujucimi" aplikaciami a zmatenymi uzivatelmi ("ved na linuxe to ide inac!") na svojich systemoch budem mat.
No když to jde v Linuxu, proč to nejde v AIXu (bez potřeby dointalovávat extra balíky)?Prave pri tychto "velkych" unixoch, ktore sa castokrat pouzivaju vyhradne v korporatnej sfere, je kladeny ovela vacsi doraz na pripravu baseline systemu, ktory bude pouzivany v produkcii, na zvazenie, ktore baliky sa do systemu zahrnu a ktore nie... Nie je to len o tom, ze sa strci instalacne CD do mechaniky a nahodi sa "vanilla" AIX... prave naopak, (minimalne nase) systemy su castokrat silno customizovane, a ak sa rozhodlo, ze bezne linux nastroje, na ktore su casto vyvojari zvyknuti sa do baseline nezahrnu, nie je to chyba vendora systemu ktory tieto nastroje ponuka (aj ked nie v zaklade), ale prave chyba admina / architekta / kohokolvek, kto je za tieto rozhodnutia plateny. A konkretne AIX s jeho "Linux affinity" programom, ktory sa pri AIXe 5L rozbehol, je, dovolim si tvrdit, na kompatibilite s linuxom celkom dobre :)
25.4.2013 13:55
Marián Kyral | skóre: 29
| blog: Sem_Tam
| Frýdek-Místek
25.4.2013 20:30
Marián Kyral | skóre: 29
| blog: Sem_Tam
| Frýdek-Místek
Samozrejme nie je vzdy jednoduche pretlacit nejake zmeny v baseline pre unix servre, no to neznamena, ze je to nemozne.. vsetko castokrat zavisi na adminovi, ci taketo zmeny (prenho castokrat velmi bolestivo) presadzovat bude, alebo nie.A hlavně, když už admin rozhodne, že tam zip nebude, tak si ho tam uživatel nemá instalovat, protože tím zcela určitě bude porušovat interní předpisy.
A hlavně, když už admin rozhodne, že tam zip nebude, tak si ho tam uživatel nemá instalovat, protože tím zcela určitě bude porušovat interní předpisy.To samozrejme zalezi prave na tych predpisoch, a hlavne na dohodnutych postupoch rieseni takychto poziadaviek, niekedy moze, niekedy nie :) A hlavne takto rozhodnutie uz je nezavisle od pouzitej platformy, zip menusi admin nainstalovat ani na linuxe :) Z mnou vyskusanych sa mi najviac paci system, kde je testbed kompletne odizolovany od live systemov, a nie su nan kladene take naroky (ci uz z pohladu bezpecnosti, auditovatelnosti, ITIL process compliance) ako na live systemoch... Proste si vyvojar zaziada o stroj, a ked mu v jeho poziadavke byrokrati vyhoveju, proste ho odo mna dostane tak, ako si ho specifikoval. Ked svoju robotu na nom dokonci, ja ho len restornem z system backupu a mam ho cisty, pripraveny pre dalsieho vyvojara. (A samozrejme, velmi sa hodi ak vyvojar v specifikacii produktu pre live nasadenie uvedie, ze ako zavislost je trebarz ten zip potrebne mat na live systeme nainstalovany :) )
 26.4.2013 20:34
xkucf03 | skóre: 50
| blog: xkucf03
26.4.2013 20:34
xkucf03 | skóre: 50
| blog: xkucf03
Z mnou vyskusanych sa mi najviac paci system, kde je testbed kompletne odizolovany od live systemov, a nie su nan kladene take naroky...Je potřeba rozlišovat testovací a vývojové servery -- na vývojových si programátoři můžou dělat prakticky cokoli, ale pro testovací by měl platit stejný režim jako pro produkční, mělo by to být pokud možno identické. Jinak je to testování z velké části na nic.
Je potřeba rozlišovat testovací a vývojové servery -- na vývojových si programátoři můžou dělat prakticky cokoli, ale pro testovací by měl platit stejný režim jako pro produkční, mělo by to být pokud možno identické. Jinak je to testování z velké části na nic.Na to predsa povacsinou existuju vyssie stage ako integration a preprod... test vzal pes, to je skoro ako developlment, akurat sa na nom neblaznia vyvojari, ale application admini :)
26.4.2013 21:53
xkucf03 | skóre: 50
| blog: xkucf03
ps -ef" funguje také.
 24.4.2013 17:13
Jakub Lucký | skóre: 40
| Praha
24.4.2013 22:13
xkucf03 | skóre: 50
| blog: xkucf03
24.4.2013 17:13
Jakub Lucký | skóre: 40
| Praha
24.4.2013 22:13
xkucf03 | skóre: 50
| blog: xkucf03


 24.4.2013 12:06
Max | skóre: 73
| blog: Max_Devaine
24.4.2013 12:06
Max | skóre: 73
| blog: Max_Devaine
 24.4.2013 12:22
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
24.4.2013 12:22
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
 24.4.2013 17:41
David Ježek | skóre: 83
| blog: Mostly_IMDB
24.4.2013 17:41
David Ježek | skóre: 83
| blog: Mostly_IMDB
pgrep -aa
free -hCentOS 5.9
ps axf | grep volac[o]je lepsia volba. grep takto cez ps nechyti sam seba...
ISSN 1214-1267, (c) 1999-2007 Stickfish s.r.o.