Portál AbcLinuxu, 30. června 2026 02:29
Microsoft kupuje Xamarin. Společnost Xamarin založili v roce 2011 Miguel de Icaza a Nat Friedman. Xamarin pokračoval ve vývoji Mono, svobodné alternativy k platformě .NET od Microsoftu, po propuštění zaměstnanců Novellu, kteří na Mono pracovali (zprávička).
Tiskni
Sdílej:
![]()
![]()
![]()
![]()
![]()
![]()
 25.2.2016 08:30
Václav "Darm" Novák | skóre: 26
| blog: Darmovy_kecy
| Bechyně / Praha
25.2.2016 08:30
Václav "Darm" Novák | skóre: 26
| blog: Darmovy_kecy
| Bechyně / Praha
 25.2.2016 15:26
Salamek | skóre: 22
| blog: salamovo
26.2.2016 13:14
Salamek | skóre: 22
| blog: salamovo
27.2.2016 16:32
Václav "Darm" Novák | skóre: 26
| blog: Darmovy_kecy
| Bechyně / Praha
25.2.2016 15:26
Salamek | skóre: 22
| blog: salamovo
26.2.2016 13:14
Salamek | skóre: 22
| blog: salamovo
27.2.2016 16:32
Václav "Darm" Novák | skóre: 26
| blog: Darmovy_kecy
| Bechyně / Praha
There are rumors that Visual Studio code is either a fork or rebranding of Github's Atom Editor. This is not even remotely true. Inspecting the source of Visual Studio Code (which can be done by opening Chrome's built in dev tools while running the program by simply pressing F12) reveals that it uses Electron and Atom Shell Archive, but nothing else is from the Atom editor. The 'editor' (the thing that renders the code with syntax highlighting, line numbers, etc..) part of Visual Studio Code is Microsoft's Monaco editor. It is the same editor used for OneDrive, Windows Azure, TypeScript Playground, and Visual Studio Online. I have yet to find any real documentation on this editor from Microsoft but there are some articles about it around the web.
MS uz davno neni jakovy arcilotr jakym byval.Jo. S Win10 prešli na úplne iný level.
 25.2.2016 10:58
pavlix | skóre: 54
| blog: pavlix
25.2.2016 10:58
pavlix | skóre: 54
| blog: pavlix
Dneska se chovaji jako normalni pragmaticka firma, ktera se venuje vsemu co prinasi zisk.Jako normální pragmatická firma bez vize.

půlku věcí uvolní samo GC, a drouhou si řešíte hacky typu IDisposableGC uvolní i objekty implementující
IDisposable.
že GC nezná skutečnou velikost takového objektu, protože nemá páru, kolik naalokoval třeba přes malloc, nebo kolik file descriptorů vyplácal a nemůže ho tak odstranit prioritně1) Informaci, kolik paměti je alokováno mimo heap spravovaný GC, lze sdělit runtimu voláním GC.AddMemoryPressure. Tato informace se pak použije při plánování úklidu paměti. 2) Informace o velikosti jednotlivých objektů neumí GC z CoreCLR ani Mona k prioritnímu uvolňování využít.
Pořadí spuštění dtorů si určí GC, a dostanete se do situace, kdy zničíte factory objekt před tím závislým a pak dostanete pád.Tomu můžete předejít například pomocí GC.KeepAlive.
Máte pak program ve stylu C, který má navíc overheady při volání nativních C fcí kvůli marshalování ... a to můžete rovnou psát v C.Nevím, zda například C umí automaticky rezervovat paměť pro běh destruktorů.
1) Informaci, kolik paměti je alokováno mimo heap spravovaný GC, lze sdělit runtimu voláním GC.AddMemoryPressure. Tato informace se pak použije při plánování úklidu paměti.Jak tak čtu dokumentaci, tak to nevypadá, že je to informace pro jednotlivé objekty, ale nějaká globální iformace. GC tedy neví, jestli je můj objekt malý nebo velký.
Tomu můžete předejít například pomocí GC.KeepAlive.Tohle se zdá funguje úplně jinak. Navíc jsme pak opět zpět u manuálního se starání o prostředky.
Nevím, zda například C umí automaticky rezervovat paměť pro běh destruktorů.Nechápu tento komentář. C nemá destruktory, ale můžu za něj považovat třeba fci co objekt uvolní. Rezervovat paměť pro takovou fci není třeba. Je-li na zásobníku dostatek místa pro uložení návratové adresy pro call instrukci, fce se prostě spustí. Ale můj komentář byl o overheadech marshallování, to není většinou zadarmo, pokud často potřebuju volat takovou fci. Když se pak stejně navím musím manuálně starat o uvloňování dalších prostředků, tak pro mě NET nepřináší žádnou výhodu, jenom starosti. Jinak to samé platí i o Javě, vůbec to není namířené proti NETu.
Jak tak čtu dokumentaci, tak to nevypadá, že je to informace pro jednotlivé objekty, ale nějaká globální iformace.Ano, jak píši v bodu 2), GC informaci o velikosti jednotlivých objektů neumí využít k jejich prioritnímu uvolňování dle velikosti – je zbytečné tuto informaci pro jednotlivé objekty uvádět.
Tohle se zdá funguje úplně jinak.Z dokumentace: The purpose of the KeepAlive method is to ensure the existence of a reference to an object that is at risk of being prematurely reclaimed by the garbage collector.
Nechápu tento komentář.Chtěl jsem poukázat na to, že .NET nabízí i něco v oblasti ruční správy paměti, co C nemá.
Rezervovat paměť pro takovou fci není třeba. Je-li na zásobníku dostatek místa pro uložení návratové adresy pro call instrukci, fce se prostě spustí.Takže je třeba minimálně rezervovat místo na zásobníku pro danou funkci a všechny funkce, jenž zavolá.
Ale můj komentář byl o overheadech marshallování, to není většinou zadarmo, pokud často potřebuju volat takovou fci.Výkon jde řešit pomocí tzv. FCallů (viz Choosing between FCall, QCall, P/Invoke, and writing in managed code), nicméně to není přenositelné a ani standardizované řešení.
Když se pak stejně navím musím manuálně starat o uvloňování dalších prostředků, tak pro mě NET nepřináší žádnou výhodu, jenom starosti. Jinak to samé platí i o Javě, vůbec to není namířené proti NETu.Pokud chcete spravovat paměť výhradně ručně, tak .NET není dobré řešení. Situace se ovšem může změnit, když chcete část paměti spravovat ručně a část automaticky. Oproti Javě má .NET ukazatele.
 25.2.2016 12:23
Bluebear | skóre: 30
| blog: Bluebearův samožerblog
| Praha
25.2.2016 12:23
Bluebear | skóre: 30
| blog: Bluebearův samožerblog
| Praha
 25.2.2016 09:49
xvasek | skóre: 21
| blog:
| Zlín
25.2.2016 09:49
xvasek | skóre: 21
| blog:
| Zlín
 25.2.2016 13:06
Ruža Becelin | skóre: 40
| blog: RuzaBecelinBlog
25.2.2016 13:06
Ruža Becelin | skóre: 40
| blog: RuzaBecelinBlog
na linuxu je to stale dost nepouzitelneProč myslíte?
objective c na iosu.dnes již hlavně Swiftu
vim ~/.emacs
 25.2.2016 20:46
xkucf03 | skóre: 50
| blog: xkucf03
25.2.2016 20:46
xkucf03 | skóre: 50
| blog: xkucf03
To jim to ale trvalo. Cekal jsem to mnohem driv.
A v cem by se mely delat open-source desktop aplikace pro Linux? QT/C++ GTK?Java swing/awt, qt, gtk.
Mozna ze Linux desktop nikdy neovladne a misto toho si pockame az desktop upne umre.Vyznam desktopu se posunuje, ale opravdu nikdy nevymre. Stroj, na kterem si pustis alespon prohlizec, budes potrebovat vzdy. Vzdycky tam bude muset byt nejaka vrstva, ktera bude pristupovat k hardware. V tomto bych pro Linux hledal naopak prilezitost.
Sam udrzuju opensource projekt ktery ma 300K radek v C++ a vidim ze to neni idealni.Hmmm. Chcete soutezit? Ja mel na starosti nasobne vetsi projekty, ale o open source se opravdu nejednalo.
Pokud nepravidelne prispivate do kodu, ktery z hlavy neznate tak potrebujete nastroje, ktere vam umozni se v nem rychle zorientovat a na to neni C/C++ uplne nejlepsi.Ono je velice lacine obvinit jazyk, ktery za to opravdu, ale opravdu nemuze.
 Kdyz se v kodu nevyznate, tak jsou mozne dve priciny: jste neschopny a mel byste delat jinou praci, nebo je navrh dane aplikace tak strasny, ze i kdyz jste schopny, tak se v nem nevyznate. Take je mozne, ze jste neschopny a dana aplikace ma hrozny navrh.
27.2.2016 19:28
xkucf03 | skóre: 50
| blog: xkucf03
Kdyz se v kodu nevyznate, tak jsou mozne dve priciny: jste neschopny a mel byste delat jinou praci, nebo je navrh dane aplikace tak strasny, ze i kdyz jste schopny, tak se v nem nevyznate. Take je mozne, ze jste neschopny a dana aplikace ma hrozny navrh.
27.2.2016 19:28
xkucf03 | skóre: 50
| blog: xkucf03
Java swing/awt, qt, gtk.
AWT dneska už moc ne. Se zbytkem souhlas.
A jak Qt, tak GTK se dá používat i v Javě tzn. nativní GUI.
Na qt/gtk v jave se podivam. Dekuji za tip.
Pokud nepravidelne prispivate do kodu, ktery z hlavy neznate tak potrebujete nastroje, ktere vam umozni se v nem rychle zorientovat a na to neni C/C++ uplne nejlepsi.Ono je velice lacine obvinit jazyk, ktery za to opravdu, ale opravdu nemuze.
This is all very informal, but I heard someone say a good programmer can reasonably maintain about 20,000 lines of code. Whether that is 20,000 lines of assembler, C, or some high-level language doesn't matter. It's still 20,000 lines. If your language requires fewer lines to express the same ideas, you can spend more time on stuff that otherwise would go beyond those 20,000 lines.
A 20,000-line Python program would probably be a 100,000-line Java or C++ program. It might be a 200,000-line C program, because C offers you even less structure. Looking for a bug or making a systematic change is much more work in a 100,000-line program than in a 20,000-line program. For smaller scales, it works in the same way. A 500-line program feels much different than a 10,000-line program.
A 20,000-line Python program would probably be a 100,000-line Java or …
Docela úsměvné představy. Takových dojmů obvykle nabývají lidé, když se podívají na HelloWorld v Javě a porovnají to s nějakým skriptovacím jazykem.
U céčka bych možná souhlasil, i když ani tam to s použitím vhodných knihoven a vhodného návrhu nebude tolik kódu. U C++ to IMHO není pravda vůbec.
Whether that is 20,000 lines of assembler, C, or some high-level language doesn't matter.
Ne, to opravdu ne. Stejně jako jsou knihy, které se čtou snadno a jsou knihy, kde člověk musí přemýšlet nad každou větou, číst ji třikrát a stejně části z nich neporozumí… tak je i kód, který se čte lehce, který stačí proletět očima a člověk ví, co kód dělá a že v něm není žádná zákeřnost, a pak je kód, u kterého si ani po důkladném čtení nejsi úplně jistý a radši si ho spustíš nebo i projdeš v debuggeru.
Programy v Javě obsahují hodně lehkého vzdušného kódu. Stejně jako třeba SQL odsazené tak, že na spoustě řádků je jen jedno slovo (název sloupečku) nebo třeba jeden výraz (podmínka). I když by to samozřejmě šlo napsat na jeden řádek.
Looking for a bug or making a systematic change is much more work in a 100,000-line program than in a 20,000-line program.
Tohle už je úplně mimo – kdo má pochybnosti, ať si zkusí refaktorovat kód v Javě a kód v Pythonu.
Co se týče hledání chyb – hledal jsem chyby i v javovském kódu od Indů a i v pythoním kódu od kolegy od vedlejšího stolu – v Pythonu to bylo řádově složitější a to i když započtu fakt, že znám líp Javu než Python. Problém s hledáním chyby měl i autor toho kódu.
porovnají to s nějakým skriptovacím jazykem
Non sequitur.
Whether that is 20,000 lines of assembler, C, or some high-level language doesn't matter.Ne, to opravdu ne. Stejně jako jsou knihy, které se čtou snadno a jsou knihy, kde člověk musí přemýšlet nad každou větou, číst ji třikrát a stejně části z nich neporozumí…
To, o čem píšeš, je sémantika. Jenže člověk musí v prvé řadě interagovat s její reprezentací.
Můžeme použít jinou analogii, a sice že člověk kvůli fyzikálním limitům nedohlédne za obzor.
Pokud se vrátím k sémantice, je otázka, zda se tím myslí logické řádky kódu, nebo prostě řádky.
Nicméně, odpověď může poskytnout kognitivní věda, o jejíchž výsledcích v tomto směru aspoň z hlavy nevím; jinak je to jenom tvůj/můj/Odinův/Guidův názor.
IMO více než polovinu programu v Javě tvoří balast, který by šlo odstranit. Konkrétně například nepotřebná klíčová slova public a private (stačí zvolit vhodný default a výraznou část jich nebudete potřebovat), gettery a settery, složené závorky, středníky, typy uvnitř metod (lze většinou odvodit lokální typovou inferencí). Další kód odstraníte, když dovolíte, aby se některé řídíci konstrukce (např. if a switch) chovaly jako výrazy. Standardní knihovna v Javě není příliš dobře navržená – řada funkcí tam chybí, některé části jsou zdvojené (nio a io).A 20,000-line Python program would probably be a 100,000-line Java or …Docela úsměvné představy. Takových dojmů obvykle nabývají lidé, když se podívají na HelloWorld v Javě a porovnají to s nějakým skriptovacím jazykem.
Jenže tohle všechno jsou věci, které při čtení prakticky nevnímám, nebrzdí mě to a pokud ano, je to pod moji rozlišovací schopnost. Řádově víc času trávím přemýšlením nad obsahem – co program dělá a proč ho právě tak někdo napsal, jaký je za tím smysl. Ne jestli jsou někde složené závorky nebo ne, to je opravdu nepodstatné. A tam hraje daleko větší roli návrh programu, použití vhodných knihoven a jak schopný programátor ten kód psal, než detaily zápisu, o kterých píšeš.
Je to podobné jako honit se za co nejvyšším počtem úhozů za minutu – když ti řádově víc času zabere přemýšlení, než zápis myšlenek na klávesnici. Rozdíl mezi normální rychlostí psaní a přeborníkem v psaní na stroji pak na celkový výsledek nemá prakticky žádný vliv.
typy uvnitř metod (lze většinou odvodit lokální typovou inferencí)
Někdy se to může hodit, ale taky to může být kontraproduktivní.
Pokud tam je třeba:
Map<Integer,String> proměnná = new HashMap<>();
tak je tam sice vpravo a vlevo částečně duplicitní informace, ale je to přesně kód který jen přeletím očima a moc se nezdržuji s jeho čtením. Kdyby tam místo toho bylo:
var proměnná = new HashMap<Integer,String>();
Tak mi to čtení nijak zásadně neusnadní. A dokonce i délka řádku je skoro stejná.
A kdyby tam bylo:
var proměnná = získejData();
tak ani nevím, jaký typ tam bude – musím se podívat na hlavičku té metody nebo si zobrazit JavaDoc. Což zabere víc času, odvádí to pozornost a narušuje to plynulost čtení víc, než třeba částečně duplicitní informace v prvním příkladu.
Navíc tu levou část často vygeneruje přímo IDEAno, kód ale bude delší než v Pythonu nebo Scale nebo F# (a o tom se tu bavíme).
Osobně moc nerozumím snaze mít kód co nejkratší, když daleko důležitější je přehlednost/čitelnost/udržovatelnost.IMO přehlednost/čitelnost/udržovatelnost souvisí s délkou kódu.
IMO přehlednost/čitelnost/udržovatelnost souvisí s délkou kódu.To si až tak nemyslím. Pro mě je podstatné v každém okamžiku vidět podstatné údaje. A vůbec mi nevadí, že to o ně bude delší. Příklad z níže uvedeného lomboku:
13 public void example2() {
14 val map = new HashMap<Integer String>();
15 map.put(0, "zero");
16 map.put(5, "five");
17 for (val entry : map.entrySet()) {
18 System.out.printf("%d: %s\n", entry.getKey(), entry.getValue());
19 }
20 }
13 public void example2() {
14 final HashMap<Integer, String> map = new HashMap<Integer, String>();
15 map.put(0, "zero");
16 map.put(5, "five");
17 for (final Map.Entry<Integer, String> entry : map.entrySet()) {
18 System.out.printf("%d: %s\n", entry.getKey(), entry.getValue());
19 }
20 }
Stokrát raději budu číst
for(final Map.Entry<Integer, String> entry : map.entrySet())a vědět přesně, co v tom entry je, než sice krátké, ale pro mě naprosto nepřehledné
for (val entry : map.entrySet())I kdyby IDE správně nabízelo konkrétní typy entry.key, entry.value, stejně raději explicitně uvidím, co tam vlastně je. Navíc ta map vůbec nemusí být definovaná o pár řádků výše, ale může jít o volání funkce a návratová hodnota pak nebude nijak vidět.
Může tam být proměnná = HashMap()To může, ale v takovém případě jde ten kód úplně do kytek.
Příklad z níže uvedeného lomboku:Obojí je ukázka, jak obrovské množství balastu je v Javě.
Stokrát raději budu čístV tomto případě bych raději četl kód bez typu, protože typ je zřejmý. Naopak nevidím důvod, proč typ neuvést explicitně na místech, kde to kód zpřehlední.
Typ vůbec není zřejmý, nikde.Když je o pár řádků nad tím vidět, co do mapy přiřazujete, tak jsou typy jasné.
čím víc přesných typů je uvedeno, tím přehlednější a udržovatelnější to je.V Javě příliš přesné typy uvádět nejde, bohužel. Například je problematické odlišit id od obyčejného integeru. V Javě byste zřejmě musel vytvořit třídu a do ní integer zabalit, jenže to může mít neblahé důsledky na výkon programu (nemáte hodnotové třídy). V C#, F# i Scale to můžete udělat lépe. Například Scala má hodnotové třídy a refinement typy (
type IdUzivatele = Int @@ Uzivatel), kde
type Tagged[U] = { type Tag = U }
type @@[T, U] = T with Tagged[U]
Navíc jsem přesvědčený, že java tu bude ještě hodně dlouho a pořád se bude rozvíjet.To asi ano, jenže ten rozvoj je velmi pomalý a v řadě věcí byl C# napřed (například hodnotové typy, generika, lambda funkce).
Před 15 lety, kdy jsme designovali základy toho řešení, tyhle věci možná existovaly teoreticky, prakticky to nikdo neznal, natož aby mohl v praxi používat.Záleží, co přesně myslíte. Řada věcí jako například lepší typová inference, generika a vůbec silnější typový systém jsou v OCamlu více než 15 let. Bohužel OCaml málokdo používá, tudíž má málo knihoven – to byl velký problém dříve a stále je to problém i dnes.
Řada věcí jako například lepší typová inference, generika a vůbec silnější typový systém jsou v OCamlu více než 15 let.To je hezké teoreticky, ale prakticky k ničemu. Zvolit před 15 lety OCaml místo javy by opravdu nebyla výhra. I když jsme už v té době synchronizovali síťové disky mezi lokalitami unisonem, který je v OCamlu napsaný a dodnes funguje parádně
C# je daleko mladší než java, navíc není multiplatformní.Multiplatformní již je několik let.
Dlouhodobé projekty mají vůči novinkám stejně zpoždění, takže je často nemohou používat hned od jejich zavedení.Řadu těch věcí uměl OCaml v roce 1995 (tehdy pod názvem Caml Special Light) a další přidal v roce 1996 (pod názvem Objective Caml) – tj. v době JDK 1.0 nebo ještě dříve.
Zvolit před 15 lety OCaml místo javy by opravdu nebyla výhra.Třeba by vám stačila desetina kódu, co máte dnes v Javě.
Multiplatformní již je několik let.
Opravdu doporučujete klientům pro větší dlouhodobé projekty mono na linuxu? Tahle diskuse se posouvá úplně mimo realitu...
Sice by to bylo daleko dražší (personálně i časově - neexistující knihovny) a totálně neudržitelné z důvodu neexistence kvalitního vývojového prostředí, ale ušetřili bychom trochu diskového prostoru na gití commity. To je přesně to, o čem mluvím. Stručnost zdrojáku je z mé zkušenosti u dlouhodobých projektů téměř irelevantní, daleko důležitější jsou jejich rozvíjitelnost, aktualizovatelnost na nové technologie a samozřejmě taky dostupnost šikovných lidí, kteří jsou ochotni za zaplatitelné peníze na tom dělat. V těchhle diskusích mi přijde, že diskutují samí teoretici z akademické sféry, kteří jsou placení bezedným erárem...Zvolit před 15 lety OCaml místo javy by opravdu nebyla výhra.Třeba by vám stačila desetina kódu, co máte dnes v Javě.
Opravdu doporučujete klientům pro větší dlouhodobé projekty mono na linuxu?Ano, nebál bych se toho. Proč myslíte, že to není dobrý nápad?
a totálně neudržitelné z důvodu neexistence kvalitního vývojového prostředí, ale ušetřili bychom trochu diskového prostoru na gití commityDíky bohatému typovému systému je to lépe udržovatelné a refaktorovatelné než Java s těmi nejlepšími IDE.
Sice by to bylo daleko dražší (personálně i časově - neexistující knihovny)Třeba v Jane Street došli k opačnému závěru. Revize kódu v Javě byly mnohem dražší a méně učinné než pro OCaml.
Díky bohatému typovému systému je to lépe udržovatelné a refaktorovatelné než Java s těmi nejlepšími IDE.
Proč se v OCamlu tedy nepíše víc programů?
Typ vůbec není zřejmý, nikde. Obzvláště s kvalitou pojmenování proměnných průměrných programátorem. Viz např. ono použité "map" místo např. namesByID. Každý den refaktoruji/rozšiřuji/čistím kód poměrně rozsáhlého projektu a čím víc přesných typů je uvedeno, tím přehlednější a udržovatelnější to je. Počet znaků/omáčka kolem má pro mě podstatně nižší prioritu.K čemu je to dobré uvádět tam ty typy (když inference funguje)? Pro mě jsou typy životně důležité, ale nevím proč bych je tam měl nutně číst? Důležité je, aby to chcíplo, když tam typy nesedí. Toto nechápu. Vysvětlíte?
Když přijdu k nějakému kódu, tak bych rád na první pohled viděl o jaké datové typy jde, abych nemusel postupovat metodou pokus-omyl a čekal, až mi kompilátor zahlásí chybu, nebo abych musel odskakovat někam jinam (do hlavičky volané metody nebo otevírat JavaDoc).
Nechci dělat z nouze ctnost – někdy je to opravdu zřejmé a odvozování typů místo jejich explicitní deklarace smysl má, ale až tak bych ho nepřeceňoval – jednak deklarovat typy explicitně není až taková tragédie a jednak nedeklarovat je může mít naopak negativní vliv na čitelnost a těch ušetřených pár znaků se nevyplatí.
Proč byste to dělal? Prostě kouknete a vidíte, aha tady teče kurzor z téhle funkce sem, tady se s tím dělají tyto operace, tady se to transformuje na toto... K čemu typy? Typy budete zkoumat v okamžiku, kdy řešíte omezení hodnot, polymorfizums, etc, a tam je Java poněkud málo příkladná, takže toto bych raději nerozváděl.Když přijdu k nějakému kódu, tak bych rád na první pohled viděl o jaké datové typy jde, abych nemusel postupovat metodou pokus-omyl a čekal, až mi kompilátor zahlásí chybu, nebo abych musel odskakovat někam jinam (do hlavičky volané metody nebo otevírat JavaDoc).
může mít naopak negativní vliv na čitelnost a těch ušetřených pár znaků se nevyplatíMůže být. Stejně jako že zbytečná ukecanost. Mě přijde, že Java naučila Céčkové programátory, že funkce a proměnné se dají pojmenovávat inteligentně. To je její historická zásluha. A také, že se to krapet zvrhlo.
Mě přijde, že Java naučila Céčkové programátory, že funkce a proměnné se dají pojmenovávat inteligentně.Lze to nějak historicky doložit nebo je to dojmologie? Ptám se vážně.
A že všechny funkce musí začínat get/set/is i když dělají s tím zcela nesouvisející věci.
Konvence je, že název metody má obsahovat sloveso (zatímco název třídy podstatné jméno, název rozhraní přídavné…). Když metoda něco vrací, tak se logicky jmenuje getNěco() ne něco(). Je to IMHO dobrá konvence. A konkrétní předpony get/set/is jsou součástí specifikace JavaBean a tam ty metody dělají přesně to, co název říká. Někdy mají lidé tendenci je používat i jinde – např. getNěco(…) s parametrem – tam je lepší použít find/lookup/create/najdi/… nebo třeba metoda setNěco(…, …) se dvěma parametry, která něco nastavuje tomu prvnímu parametru místo instanci, na které je volána – tam stojí za zvážení zase slova fill, update atd. aby se to odlišilo od klasických getterů a setterů. Každopádně sloveso v názvu metody je dobrá věc.
Osobně moc nerozumím snaze mít kód co nejkratší, když daleko důležitější je přehlednost/čitelnost/udržovatelnost.Třeba proto, abych si nemusel kupovat obří display jen proto, aby se mi smysluplná část kódu zobrazila najednou.
Jenže tohle všechno jsou věci, které při čtení prakticky nevnímám, nebrzdí mě to a pokud ano, je to pod moji rozlišovací schopnost.Mě osobně to brzdí. Například mezi triviálními gettery a settery se může ztratit jeden důležitý netrivální setter. Například pro 10 veřejných tříd, kdy každá má 2 vlastnosti s getterem a setterm budu v Javě potřebovat 10 souborů, každý o cca 10 řádcích:
public class Foo {
private int x;
private int y;
public int getX() { return x; }
public void setX(int n) { x = n; }
public int getY() { return y; }
public void setY(int n) { y = n; }
}
Tj. celkem 100 řádků. Ve Scale jednu takovou třídu zapíšete
case class Foo(x: Int, y: Int)a všechny můžete dát do jednoho souboru. Celkem tedy 10 řádků.
Rozdíl mezi normální rychlostí psaní a přeborníkem v psaní na stroji pak na celkový výsledek nemá prakticky žádný vliv.Problém je to spíš při čtení – v hromadě balastu je třeba objevit důležitý kód. Brzdí to při review a prodlužuje úpravy.
A kdyby tam bylo: var proměnná = new HashMap<Integer,String>();
Může tam být
proměnná = HashMap()
Někdy se to může hodit, ale taky to může být kontraproduktivní.Ano, když si myslím, že se to hodí, typ tam nechám. V Javě ho tam musíte nechat vždy.
Například mezi triviálními gettery a settery se může ztratit jeden důležitý netrivální setter.
Tohle je hlavně o kvalitách programátora, který to psal – slušnost je dát ten netriviální setter nahoru a/nebo ho okomentovat. Ne si hrát s ostatními na schovávanou.
Co mi v Javě chybí je zvláštní druh JARů, který by mohl obsahovat jen rozhraní a datové struktury, ale žádnou funkcionalitu, což by se kontrolovalo při načítání toho JARu. Pak bys mohl snadno použít knihovnu definující nějaké API a nemusel bys dělat audit jejího kódu – ten by udělalo běhové prostředí.
Nebo se na to dá jít z opačného konce – mít IDE, které rozparsuje zdroják, detekuje triviální gettery/settery a skryje je – uvidíš je v navigátoru a bude ti je napovídat, ale nebudeš ten kód muset číst – zbudou ti tam jen netriviální metody.
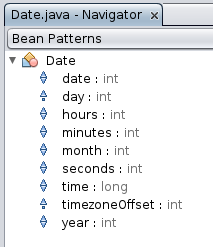
Netbeans umí rozpoznat JavaBean a ukáže ti, jestli je tam getter, setter nebo obojí (viz příloha). Šlo by tam přidat detekci těch triviálních, které jen nastaví/přečtou stejnojmennou proměnnou, a skrytí jejich kódu.
Může tam být proměnná = HashMap()
Což je dost na nic, protože neznám typ klíčů a hodnot, takže se mi těch ušetřených pár znaků (<Integer,String>) brzo vrátí (typová nebezpečnost, nutnost ručního přetypování).
Nebo snad nějaký jazyk dokáže odvozovat typy tak, že uhlídá tohle:
proměnná = HashMap();
proměnná.put(1, "ahoj");
proměnná.put(2, "nazdar");
proměnná.put("x", "3");
proměnná.put(4, new Date());
metoda5(proměnná.get(1));
int x6 = proměnná.get(1);
U 3 by měl kompilátor zahlásit chybu – nebo taky ne (co když chci jako klíč mít Object?).
U 4 taky – ale co když chci mít jako hodnotu Object (nebo nejbližší společný nadtyp)?
U 5 metoda očekává parametr typu int, ale z proměnná = HashMap() není poznat, co bude uvnitř.
Totéž u 6.
let proměnná = Dictionary()
proměnná.Add(1, "ahoj")
proměnná.Add(2, "nazdar")
proměnná.Add("x", "3")
proměnná.Add(4, DateTime.Now)
zahlásí kompilátor F# chybu pro 3 a 4.
U 4 taky – ale co když chci mít jako hodnotu Object (nebo nejbližší společný nadtyp)?Musíte si to ručně ošetřit – buď tam napsat typy (například
Dictionary<_, obj>() pro 4) nebo první hodnotu přetypovat ("ahoj" :> obj).
BTW: co se týče getterů a setterů – projekt Lombok, předpokládám, znáš. Není to úplně optimální, je to trošku hack, ale používat se to v zásadě dá.
Struktura pak vypadá zhruba takhle:
@Data
public class MojeStruktura {
private int id;
private String jméno;
private Data datum;
}
A gettery/settery jsou jen v bajtkódu a ne ve zdrojáku. Samozřejmě se to dá kombinovat s dalším kódem, takže to nemusí být jen hloupá struktura, může mít zároveň metody, a taky se dají anotovat jen některé proměnné pomocí @Getter, @Setter.
co se týče getterů a setterů – projekt Lombok, předpokládám, znášTo už ale není platná Java (je třeba preprocessing). Navíc se nezbavíte prefixů
get, set a is u vygenerovaných metod.

 28.2.2016 12:57
Hans1024 | skóre: 5
| blog: hansovo
28.2.2016 13:33
xkucf03 | skóre: 50
| blog: xkucf03
28.2.2016 12:57
Hans1024 | skóre: 5
| blog: hansovo
28.2.2016 13:33
xkucf03 | skóre: 50
| blog: xkucf03
-1
Samozřejmě nativní GUI je nativní GUI1, ale na prvním místě je pro mě funkcionalita – a tam mám mnohem lepší zkušenost s programy psanými v Javě – programy v jiných jazycích bývají často neskutečný bastl (nespolehlivost, pády) nebo kladou vysoké nároky na programátora (tzn. pomalejší vývoj a/nebo vyšší náklady) nebo obsahují bezpečnostní chyby, které by se v Javě (za jinak stejných okolností) nestaly.
Neříkám, že jinde nejde napsat dobrá desktopová aplikace, ale má to řadu rizik. Kdybych si jako firma objednával podnikový software (resp. jeho desktopovou část), tak bych mnohem radši šel do Javy (klidně i Swingu) než něčeho jiného.
[1] ale i to je v Javě dosažitelné
28.2.2016 15:52
Hans1024 | skóre: 5
| blog: hansovo
27.2.2016 19:52
xkucf03 | skóre: 50
| blog: xkucf03
A jdou na to moc dobře - bych řekl komponentově, což právě chybí Javě, tam se o to snaží léta a furt nic.
Modularita v Javě je přes patnáct let (viz OSGi) a od verze 9 bude přímo součástí platformy. Co se týče modularity standardní knihovny, tam myslím Java trefila právě vhodný stupeň granularity – jsou tu edice SE/EE/ME, ale víc už se to netříští, takže když nějaký program vyžaduje třeba Javu SE 6+ a ty stejnou nebo vyšší verzi Javy SE máš, tak víš, že ti to bude fungovat – celkem jednoduchá rovnice, kterou si každý dokáže spočítat, snadno se specifikují požadavky na instalované komponenty. Ne jako jinde, kde nestačí říct, jakou verzi platformy vyžaduješ, ale musíš říct, jaké všechny moduly/komponenty se mají nainstalovat – na což autoři programů zhusta kašlou, takže pak musíš postupovat metodou pokus-omyl a zkoumat, v jaké fázi běhu program spadl a kterou knihovnu vyžadoval, a doprošovat se administrátora, aby ti ji doinstaloval. Nebo si ji můžeš doinstalovat sám do ~/, ale to je nesystémové a má to řadu úskalí – možná bezpečnostní rizika při stahování, ne/ověřování podpisů, musíš se starat sám o aktualizace knihoven (nedělá to za tebe autor aplikace ani správce systému a/nebo balíčkovací systém).
Posunout to někam dál než jen SE/EE/ME může být přínos… ale než to udělat špatně, to to raději nedělat vůbec a odložit to – nenadělat víc škody než užitku.
Takže pokud do toho zapojí vývojáře Mona, které stejně táhl jedině Xamarin a zúročí jejich zkušenosti, tak jsem pro a ať Mono skončí, proč mít zas dvě implementace téhož.
Smyslem Mona bylo umožnit běh původních aplikací na svobodné platformě a zbavit se závislosti na proprietárním OS. Smysl současných snah Microsoftu a jeho „otevřenosti“ je přesně opačný – přetáhnout k sobě autory aplikací a pak donutit uživatele migrovat na MS Windows. S různými nekalými praktikami má MS dlouhodobé zkušenosti a je v tom hodně dobrý. Když se někdo celou dobu chová jako svině, tak není důvod mu věřit, že se najednou bude chovat slušně. Je mi líto lidí, kteří mají tak krátkou paměť.
Modularita v Javě je přes patnáct let (viz OSGi) a od verze 9 bude přímo součástí platformy.To je přesně o čem mluvím, 15 let se snaží a pořád nic.
Smyslem Mona bylo umožnit běh původních aplikací na svobodné platformě a zbavit se závislosti na proprietárním OS. Smysl současných snah Microsoftu a jeho „otevřenosti“ je přesně opačný.Tak Mono je a bude dál open source, je na komunitě, jak s ním naloží. MS svůj soft uvolňuje povětšinou pod MIT, kdokoli může forkovat, když se mu otevřenost MS nebude líbit. MS se mění a Vaše teorie s nezměnitelnou sviní je Vaše osobní antipatie a s budoucností .NET platformy nemá nic společného.
ISSN 1214-1267, (c) 1999-2007 Stickfish s.r.o.
 25.2.2016 17:50
25.2.2016 17:50
 25.2.2016 18:23
25.2.2016 18:23
{kind=link}
{kind=link}