 ) sub-20nm čipy čekejme nejdřív za 5 až 6 let, nejprve to budou jistě jednodušší jako flash paměti, procesory přijdou ještě později (nedejbože superčipy jako Larrabee).
) sub-20nm čipy čekejme nejdřív za 5 až 6 let, nejprve to budou jistě jednodušší jako flash paměti, procesory přijdou ještě později (nedejbože superčipy jako Larrabee).Portál AbcLinuxu, 16. července 2026 13:19
Dnešním hlavním tématem je popis poměrně zajímavého řešení, které pro jednotku výpočtů plovoucí řádové čárce zvolila společnost AMD pro architekturu Bulldozer. Předtím se ale ještě podíváme na tři firmy spojivší síly nad vývojem tranzistorů menších 20nm hranice, abychom si vše uzavřeli pohledem na jednu chystanou GeForce a to, jak nám i velikáni opouštějí trh zapisovacích/přepisovacích CD a DVD médií.
Ubrání každého dalšího nanometru z velikosti tranzistorů stojí nemálo peněz, někde v řádu stamiliónů až miliard dolarů, pokud do toho započteme vývoj i upgrade/stavbu továren. AMD se třeba s IBM spojila již dávno, takových spojení vzniká a vznikat bude více a jedním z takových je i nové konsorcium firem Intel, Toshiba a Samsung.
Tyto tři korporace spojily své síly nad vývojem výrobních technologií pod hodnotu 20 nanometrů, tedy tzv. 10nm-class výrobou. Vývoje se zúčastní desítka dalších menších firem a přispěje i japonské Ministerstvo mající na krku obchod a průmysl. Jako vždy v případě takového „megaprojektu“ nečekejme výstupy hned, první kusy křemíku s „vyleptanými“ (nebo spíše vypěstovanými? ) sub-20nm čipy čekejme nejdřív za 5 až 6 let, nejprve to budou jistě jednodušší jako flash paměti, procesory přijdou ještě později (nedejbože superčipy jako Larrabee).
Aktuálně je to Intel, kdo v rámci CPU udává prvenství svými 32nm procesory, ale AMD se taktéž chystá na 28nm výrobu. Intel v rámci své „tick-tock“ strategie již dávno představil 22nm plány, dokonce již v této kategorii vyrábí testovací kusy právě NAND flash čipů, ale například 16nm či ještě menší velikosti, to je další náročná výzva.
Sluší se také připomenout hlavního rivala na poli čipů různých typů, taiwanská TSMC se sice stále trápí s 40nm procesem (že však i zde je vidět posun k lepšímu, dokazuje GeForce GTX 580 s GPU GF110, ale o tom až za týden, karta byla uvedena teprve před pár dny), ale již vedle 20nm-class výroby stihla pohovořit o plánech na 10nm-class. Globalfoundries, která začne postupně přebírat výrobu GPU AMD, již zvládá první kusy 28nm čipů a pracují na 22 a 20nm výrobě. Pokud jsme tu loni měli 3miliardové GPU Nvidia GF100 (nyní pomíjím to, že plně aktivní žralo přes 0,5 kW v zátěži), myslím, že se během několika málo let budeme bavit o čipech s více než 10 miliardami tranzistorů. Bůh nás ochraňuj…
Společnost AMD je poslední týdny poměrně sdílná, kromě toho, že si dnes pohovoříme o sdílené FPU procesorů architektury „Bulldozer“, už dopředu vám můžu slíbit další povídání o křemíku z AMD na příští týden, ostatně firma měla svůj obvyklý Financial Day.
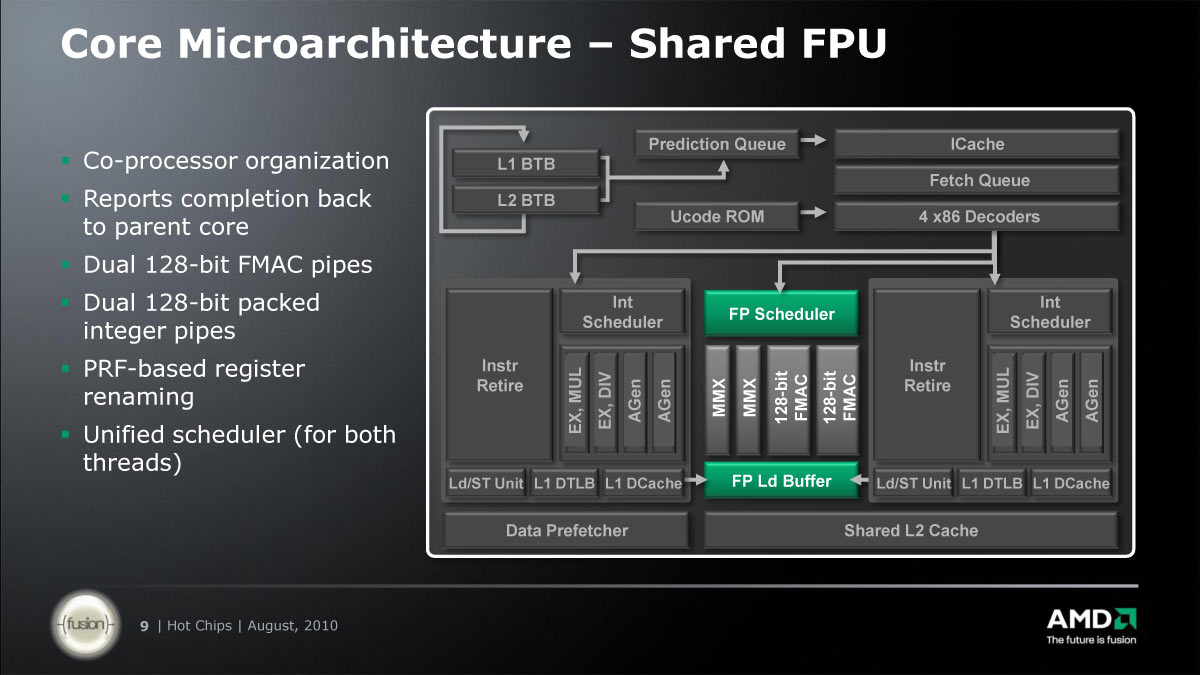
Ale k věci. V Bulldozeru se můžeme těšit na takové poměrně zajímavé řešení jednotky pro výpočty v plovoucí čárce. Protože tento střípek ze skládačky jménem „x86 procesor“ tvoří nemalou část, byť není vždy zcela plně využit, rozhodli se inženýři v AMD pro řešení, které jim „koupí k dobru“ mnoho tranzistorů, resp ušetří prostor na něčem, co není nezbytně nutné.
Sdílená FPU nese označení Flex FP (Flexible Floating Point Unit) a v Bulldozerech bude fungovat přesně tak, jak tušíte. Základní stavební kámen Bulldozeru, tedy dvoujádro, ponese vždy jen jednu Flex FP. Za běžného provozu nastávají typicky tři situace, pro jejichž řešení se Flex FP ukázala jako „optimálnější“ (kdo mě nahlásí na FAVce? ).
Za prvé je to situace, kdy FPU nepotřebuje ke své práci v danou chvíli ani jedno jádro – zde není co řešit, jestli jsou v dvoujádru dvě FPU, nebo jedna, je z hlediska výpočtů putna. Druhá situace se týká chvil, kdy bude FPU potřebovat jedno ze dvou jader, pak pochopitelně jejích služeb toto procesorové jádro využije, druhé to nijak neovlivní. Flex FP má každá vlastní scheduler (plánovač) nezávislý na tom, který má jednotka celočíselných operací (AMD toto zmiňuje v souvislosti s tím, že Intel používá společný scheduler pro INT i FPU).
Jediný moment, kdy by Flex FP mohla narazit na svoji limitaci, je potřeba obou jader využít FPU. Na tomto místě je třeba připomenout, že Bulldozer, stejně jako Intel Sandy Bridge, přinese instrukční sadu AVX (Advanced Vector Extensions) využívající 256bitové instrukce/registry (výhledově v příštích generacích i 512 a 1024 bitové). Pokud tedy nastane potřeba vykonat něco 256bitového, není problém, Bulldozerové jádro prostě použije obě 128bitové FMAC jednotky (fused multiply accumulate), ale když tuto potřebu 256bitové operace mají obě jádra, jedno bude muset počkat.
Podle zjištění AMD to je ale „worst case scenario“, které zas tak běžně nenastává. Bulldozer nejdříve míří do serverů, tedy datových center, a tam se většinou pracuje s celočíselnými operacemi, pouze minorita výpočtů vyžaduje použití FPU, natož aby šlo o 256bitové operace. Proto AMD zvolila pro Bulldozer toto řešení, neboť z hlediska výrazné majority výpočtů je úspornější než plné FPU na každé procesorové jádro a když by náhodou došlo k mezní situaci, je CPU samozřejmě schopno si se situací poradit, byť za cenu toho, že se na výpočet spotřebuje více taktů procesoru (pokud by tedy nebylo možné tento výpočet přehodit případně na nepoužité Flex FP z jiného dvoujádra v procesoru – samozřejmě v případě, že to půjde realizovat během stejného hodinového taktu, jinak by to ve většině případů postrádalo smysl, ale dejme AMD ještě čas na to, jak bude průběžně informace o Bulldozeru doplňovat).
V případě osazení plných FPU na každé jádro by se na běžných 32/64/128bitových operacích vždy polovina FPU nudila. S Flex FP samozřejmě mohou obě jádra zpracovávat souběžně až 128bitové operace, zde již žádný limit není.
Otázkou je jak se toto bude chovat do budoucna v jiných typech využití, vše záleží na tom, jak rychle se AVX zabydlí v aplikacích – a Intel tuto instrukční sadu velmi rád předvádí na multimédiích, třeba při kompresi videa, kde bude Sandy Bridge opět výrazným skokem oproti současné generaci Nehalem. Z hlediska Linuxu se pak, když si můžeme odmyslet komerční aplikace pro Windows, má smysl bavit asi zejména o x264, kterážto implementace H.264 zahrnuje novinky do kódu poměrně rychle. Pak si budeme schopni rozlousknout souboj Intel Sandy Bridge versus AMD Bulldozer, který bude zajímavý i z toho hlediska, že Intel v Sandy Bridge „nešetří“ a každému procesorovému jádru dopřává jeho vlastní 256bitovou FPU.

Částečně za současné snížení produkce CD a DVD médií japonské firmy Taiyo Yuden může nevýhodný kurz Jenu, ale hlavní problém je jinde: zájem o vypalování CD a DVD upadá a pozornost trhu se přesouvá k Blu-ray diskům. Zatímco CD-R/RW nepochybně začal zákazníky „krást“ hned první uvedený iPod, s příchodem vysokokapacitních flashek, disků a bůhví čeho dalšího začínají skomírat i DVD média. Taiyo Yuden tak výrazně snižuje svoji produkci, a když k tomuto kroku přistoupí i legenda mezi výrobci vysoce kvalitních médií, tak už je co říci.
Taiyo Yuden bylo ještě loni čtvrtým největším výrobcem optických disků s 9,4, resp. 8.8% podílem na trhu CD, resp. DVD. Firma nyní snižuje svoji produkci ze 110 na 65 miliónů disků a podle analytiků prý bude další kapacity outsourcovat směrem na Taiwan k firmám CMC Magnetics a Ritek.
Taiwanští výrobci jsou však poměrně progresivní a většinu svého úsilí soustředí v tuto chvíli na jednovrstvé 25GB BD disky a pomalu vzhlížejí ke dvouvrstvým 50GB, jejichž dodávky by měly příští rok překonat hranici 35 miliónů kusů. A přiznejme si, že i přes razantní pokles cen se na BD-R/RE vydělává na kusu víc než na CD/DVD, kde vše limituje ostrá konkurence levných výrobců (kvalitu a stálost záznamu pomíjíme).

GeForce GTX 580 si rozebereme podrobněji příští týden, ale abych vás dnes neochudil, podíváme se na leak, který prozrazuje údajně chystanou GeForce GTX 460 SE. Zatímco GPU GF104 v plné GeForce GTX 460 nese 336 CUDA procesorů, SE model jich má mít jen 288 – zjevně tedy půjde o vyprázdnění skladů od méně povedených čipů, kde je deaktivován jeden blok CUDA jader.
Kromě 256bitových GDDR5 pamětí o velikosti 1 GB s efektivním taktem 3,4 GHz se toho zatím moc neví, kdybych si měl tipnout, tak bych čekal i lehce snížený počet TMU i ROP, aby tak karta dala o něco vyšší výkon než GTS 450, ale současně neohrožovala pozice GTX 460. Nvidia bude v dohledné době na trh pouštět ještě GTX 570, ale to je hi-endový segment. Více se toho asi letos nestihne, cokoli dalšího čekejme nejdříve na lednové výstavě CES.

memmove() z glibc pouziva SSE instrukce, ktere patri do floating point rodiny. Je tedy otazka, jak moc je FPU skutence vyuzivana.
 16.11.2010 09:58
Acci | skóre: 3
| blog: Jen na chvíli…
16.11.2010 09:58
Acci | skóre: 3
| blog: Jen na chvíli…
 16.11.2010 14:39
tomboytom-deviant | skóre: 7
| blog: lojdovo
| .com
16.11.2010 14:39
tomboytom-deviant | skóre: 7
| blog: lojdovo
| .com
Namotovat do každé přednáškové místnosti IP kamery s mikrofony a vše streamovat na školní web.Na FIT VUT je to už roky. Zaměstnanec školy musí záznam nastříhat, opatřit titulky a dát překódovat do něčeho menšího k archivaci. Takže nějaká práce s tím je. Vyučování je od 7:00 do 21:00, pět dní v týdnu a je 7 přednáškových místností. Samozřejmě ne ve všech je přednáška, ale práce s tím je. Kromě toho je to opruz. Já se nedonutím roztřídit ani své vlastní fotografie a dokážu si představit, že kdybych to měl dělat na škole já, tak záznamy nebudou k dispozici nikdy.
Zpět k streamu/záznamům: postupem času je stav takový, že přednášející streamy a často i záznamy zakazují, protože jim na přednášky nikdo nechodí (ale jen málokdy se tím situace zlepší :-P) a tímto si chtějí zajistit účast. Záznamy pak zakazují především ti, kteří zároveň přednáší ty nejsložitější a nejnáročnější předměty na škole, zřejmě aby studentům usnadnili sutdium. 
 Tím by kantor získal pocit, že ho někdo poslouchá. Dokážu si představit i nějaký chat, kam by studenti mohli posílat své dotazy k probíranému tématu.
Obávám se však, že by se tím přišlo na zcela evidentní věc: osobní účast studentů ve škole je u většiny předmětů naprosto zbytečná. V dnešní době by v podstatě stačil nějaký videoserver s bandou videí a videotutoriálů k probíraným tématům + nějaká doprovodná skripta či opory. Student by pak přišel jen na zkoušku. Takové telestudium (ze slova teleworking ) Náklady minimální, spokojenost studentů velká. Jen tam trochu chybí ten sociální rozměr školy, což pro mě je dost velkou motivací k návštěvě onoho ústavu.
Tím by kantor získal pocit, že ho někdo poslouchá. Dokážu si představit i nějaký chat, kam by studenti mohli posílat své dotazy k probíranému tématu.
Obávám se však, že by se tím přišlo na zcela evidentní věc: osobní účast studentů ve škole je u většiny předmětů naprosto zbytečná. V dnešní době by v podstatě stačil nějaký videoserver s bandou videí a videotutoriálů k probíraným tématům + nějaká doprovodná skripta či opory. Student by pak přišel jen na zkoušku. Takové telestudium (ze slova teleworking ) Náklady minimální, spokojenost studentů velká. Jen tam trochu chybí ten sociální rozměr školy, což pro mě je dost velkou motivací k návštěvě onoho ústavu.
 16.11.2010 17:57
Jendа | skóre: 78
| blog: Jenda
| JO70FB
16.11.2010 17:57
Jendа | skóre: 78
| blog: Jenda
| JO70FB
Celý problém je v očích přednášejících je prý v tom, že jsou tací, kteří si video zrychlí na 120-140% (znám přednášejícícho, kde by nebyl problém i 180%) a projedou záznamy za celý semestr dva dny před zkouškou.Já u některých při 1,0 neudržím pozornost… Ale je pravda, že se jedná o přednášky, které jsou jaksi nad rámec SŠ a nehrozí mi z nich tedy zkoušení. Pro získání většiny informací je to v pohodě a detaily bych si stejně nepamatoval.
16.11.2010 14:38
tomboytom-deviant | skóre: 7
| blog: lojdovo
| .com
graficke programy dnes casto dou cestou cuda/opencl .....
a vzhledem k tomu ze gpu je masivene paralelni procak ... tak to jede rychleji nez intelovo avx ....
ono avx u Intelu je jen nouzovka proti pocitani na grafice .... vzhledem k tomu ze intel nema zadnou grafiku ktera by toho byla schopna , narozdil od amd.... a i nvidie
Power a dalsi risc cpu maji avx uz leta ..
graficke programy dnes casto dou cestou cuda/opencl .....Zaprvé, zatím jich moc není. (Ačkoli dobudoucna se dá očekávat, že jich bude víc)
To, že "GPU je masivní paralelní procák", je mýtus. GPU nemá tu flexibilitu, co CPU, nemá tu programabilitu. Každej if, každej jump, každej branch má na GPU velký dopad na výkon. GPGPU je (se současnou technologií) efektivní pro single instruction multiple data, kde multiple data opravdu znamená hodně multiple.a vzhledem k tomu ze gpu je masivene paralelni procak ... tak to jede rychleji nez intelovo avx ....
ono avx u Intelu je jen nouzovka proti pocitani na grafice .... vzhledem k tomu ze intel nema zadnou grafiku ktera by toho byla schopna , narozdil od amd.... a i nvidie
Power a dalsi risc cpu maji avx uz leta ..
Power a dalsi risc cpu maji avx uz leta ..Mají něco jako AVX už léta, problém je, že, pokud vím, každé CPU si to řeší trošku jinak a po svém.
 16.11.2010 17:45
otasomil | skóre: 39
| blog: puppylinux
16.11.2010 17:45
otasomil | skóre: 39
| blog: puppylinux
Prijit na trh dneska s nosicem majicim 25 resp 50 GB je takrka k smichu.
Aktuálně je to Intel, kdo v rámci CPU udává prvenství svými 32nm procesory, ale AMD se taktéž chystá na 28nm výrobu.To záleží za jak dlouho, aby je nepředběhl embedded ARM od Xilinxu (ten by se měl začít dodávat příští rok)
.
ISSN 1214-1267, (c) 1999-2007 Stickfish s.r.o.
{kind=link}