Byla vydána nová stabilní verze 3.24.0, tj. první z nové řady 3.24, minimalistické linuxové distribuce zaměřené na bezpečnost Alpine Linux (Wikipedie) postavené na standardní knihovně jazyka C musl libc a BusyBoxu. Přehled novinek v poznámkách k vydání.
Na čem pracují vývojáři v Rustu napsaného mikrokernelového unixového operačního systému Redox OS (Wikipedie)? Byl publikován přehled vývoje za květen. Vypíchnout lze nový scheduler EEVDF nebo port desktopového prostředí Xfce na Redox OS.
Upozornění pro uživatele Asahi Linuxu: Neaktualizujte macOS na verzi 27 Golden Gate! Apple změnil detekci spouštěcích oddílů. Po aktualizaci oddíl s Asahi Linuxem nevidí. Snad je to jenom chyba.
Na webu konference Den IPv6, která se konala 4. června v Národní technické knihovně v pražských Dejvicích, jsou nyní k dispozici všechny prezentace (v PDF) a jejich videozáznamy. Organizátory konference byly i letos sdružení CESNET, CZ.NIC a NIX.CZ.
Byla vydána nová verze 9.1.0 správce sbírky fotografií digiKam (Wikipedie). Přehled novinek i s náhledy v oficiálním oznámení (NEWS). Vypíchnout lze vylepšené vyhledávání nebo podporu Pixel Motion Photos. Nejnovější digiKam je ke stažení také jako balíček ve formátu AppImage. Stačí jej stáhnout, nastavit právo ke spuštění a spustit.
Přihlaste svou přednášku na další ročník konference LinuxDays, který proběhne 3. a 4. října na FIT ČVUT v pražských Dejvicích. Příjem témat poběží do konce prázdnin, pak proběhne veřejné hlasování a následně sestavení programu.
Byla vydána nová verze 2.4.68 svobodného multiplatformního webového serveru Apache (httpd). Řešeno je mimo jiné 13 zranitelností.
Apple na své vývojářské konferenci WWDC26 (Worldwide Developers Conference, keynote) představil řadu novinek. Vypíchnout lze novou generaci Apple Intelligence a zbrusu novou Siri, která dostala název Siri AI. Kvůli Aktu o digitálních trzích (DMA) však funkce Siri AI nebudou v systémech iOS 27 a iPadOS 27 k dispozici uživatelům v Evropské unii.
Byla vydána nová verze 1.18.0 distribučního frameworku Flatpak (Wikipedie), tj. technologie umožňující distribuovat aplikace v podobě jednoho instalačního souboru na různé linuxové distribuce a jejich různá vydání. Přehled novinek na GitHubu. Vypíchnout lze podporu rozhraní /dev/kfd pro výpočty na kartách AMD (AMDKFD).
aMule (Wikipedie), tj. multiplatformní klient pro peer-to-peer sdílení souborů pro sítě eD2k and Kademlia, byl po více než pěti letech od vydání poslední verze 2.3.3, vydán v nové major verzi 3.0.0 (GitHub). S novou webovou stránkou a dokumentací.
;jmeno;delka;povodi;prutok;usti do;staty 1.;Amazonka - Ucayali - Apurimac;7062;6915000;219000;Atlantsky ocean;Brazilie, Peru, Bolivie, Kolumbie, Ekvador, Venezuela, Guyana 2.;Nil;6695;2870000;5100;Stredozemni more;Etiopie, Eritrea, Sudan, Uganda, Tanzanie, Kena, Rwanda, Burundi, Egypt, Demokraticka republika Kongo 3.;Jang-c-tiang;6300;1800000;31900;Vychodocinske more;CLR 4.;Mississippi - Missouri;6275;2980000;16200;Mexicky zaliv;USA (98.5%), Kanada (1.5%) 5.;Jenisej - Angara - Selenga;5539;2580000;19600;Karske more;Rusko, MongolskoJde mi o to aby se taot databaze v terminalu vypasala a nabidla serazeni podle povodi, prutoku a delky (standartne je serazena podle abecedy). Vyskytli se mi vsak dva probleme. Tim prvnim je vubec design databaze, rozhodl jsem se, ze za nazev reky doplnim urcitej pocet mezer aby vsechny delky rek zacinali na stejnem miste. Zatim se mi povedlo pouze napsat for cyklus ktery zjisti kolik znaku ma nazev nejdelsi reky, nyni potrebuju nejaky cyklus ktery by zjistil pocet znaku urcite reky, odecetl tento pocet od poctu znaku nejdelsi reky a ten vysledny rozdil by byl pocet mezer, ktere by cyklus za ten nazev reky dosadil. Druhy problem je u samotneho menu a sortovani. Podarilo se mi nahazet kazdy sloupec do jedne promene typu array, co policko to jedo array pole. Nyni potrebuju nejaky menu (Pokud chcete seradit podle blabla dejte napiste jednicku, pokud podle blabla napiste dvojku...) - tudis asi read -p a IF. Nasledne vsak tu nejtezsi cast to podle toho seradit, kdyz dam sort podle povodi, potrebuju aby se pak prehazeli i ostani sloupce aby bylo u kazdeho povodi spravny nazev reky a dalsi informace. V tom by imho meli pomoc indexi polí. Nic méně nemůžu přijít jak na to. Doufám, že si s tím někdo poradí, předem děkuji za všechny rady. Zde už zmíněný skript, s postupem ke kterému, jsem se dopracoval sám:
#!/bin/bash
declare x
declare -a y
declare z
declare pozice
declare -a idecko
declare -a jmena
declare -a delka
declare -a povodi
declare -a prutok
IFS=$'\n';
pozice=1
for x in $( cat reky.csv | grep -v "jmeno" | cut -f1 -d';' ); do idecko[$pozice]=$x && pozice=$((pozice + 1)); done
pozice=1
for x in $( cat reky.csv | grep -v "jmeno" | cut -f2 -d';' ); do jmena[$pozice]=$x && pozice=$((pozice + 1)); done
pozice=1
for x in $( cat reky.csv | grep -v "jmeno" | cut -f3 -d';' ); do delka[$pozice]=$x && pozice=$((pozice + 1)); done
pozice=1
for x in $( cat reky.csv | grep -v "jmeno" | cut -f4 -d';' ); do povodi[$pozice]=$x && pozice=$((pozice + 1)); done
pozice=1
for x in $( cat reky.csv | grep -v "jmeno" | cut -f5 -d';' ); do prutok[$pozice]=$x && pozice=$((pozice + 1)); done
pozice=1
y=0
z=0
for x in $( cat reky.csv | grep -v "jmeno" | cut -f2 -d';' ); do
y[$pozice]=$x &&
if [ $z -lt ${#y[$pozice]} ]; then
z=${#y[$pozice]} && pozice=$((pozice + 1));
fi
done
pozice=1
for x in $( cat reky.csv | grep -v "jmeno" );
do echo -n -e " ${idecko[$pozice]} \t"
${jmena[$pozice]}
echo "${delka[$pozice]} ${povodi[$pozice]} ${prutok[$pozice]}" && pozice=$((pozice + 1));
done
mezery=""
for((i=${#promennaobsahujicijmenoreky}; $i<$delkanejdelsireky; i++)); do
mezery=" $mezery"
done
echo "'$mezery'"
K tomu:
read -p a IF
to by šlo
read -p "Zvolte a nebo b"
case $REPLY in
a)
delejneco
;;
b)
delejnecojineho
;;
*)
chybnavolba
;;
esac
ale s ohledem na možnost překlepu by to asi chtělo do while cyklu apod, no a nebo zkuste třeba select
PS3="Vaše volba: " select i in a b exit; do [[ "$i" == "exit" ]] && break echo "$i" doneŘazení podle něčeho jsem přesně nepochopil, nestačil by sort podle určitého sloupce?
sort -k N
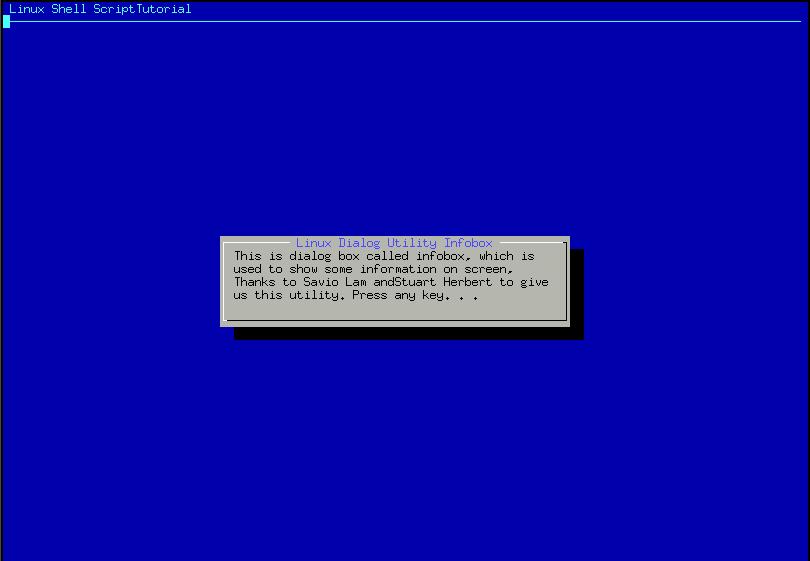
Nyni potrebuju nejaky menu (Pokud chcete seradit podle blabla dejte napiste jednicku, pokud podle blabla napiste dvojku...)Dialog, pripadne vsechny jeho derivaty, inspirace, kopie, napodobeniny apod. (lxdialog, cdialog, Xdialog, Newt/whiptail, Zenity, ...) by mohly byt tvojimi kamarady. screenshot a jeste jeden. Samozrejme to muzes pokazde udelat tim nejbrutalnejsim zpusobem, jak uz ti tady radili vyse, tedy vypisovat text primo na terminal. Navod je treba tady (dalsi stranka pak dava lehounky uvod do dialogu) Musim se take pripojit k te zadosti o mene otazek najednou a hlavne lepe formatovat. Je az z podivem, ze jsem se tim prokouskal. Takhle ti vazne moc lidi neporadi, kdyz to vypada, jako by sem jen tak ledabyle odhodil nejaky nepouceny klikaci uzivatel. A abych nezapomnel, tak doporucim cteni
Oh, my eyes!pozice=1 for x in $( cat reky.csv | grep -v "jmeno" | cut -f1 -d';' ); do idecko[$pozice]=$x && pozice=$((pozice + 1)); done pozice=1 for x in $( cat reky.csv | grep -v "jmeno" | cut -f1 -d';' ); do idecko[$pozice]=$x && pozice=$((pozice + 1)); done pozice=1 for x in $( cat reky.csv | grep -v "jmeno" | cut -f2 -d';' ); do jmena[$pozice]=$x && pozice=$((pozice + 1)); done pozice=1 for x in $( cat reky.csv | grep -v "jmeno" | cut -f3 -d';' ); do delka[$pozice]=$x && pozice=$((pozice + 1)); done pozice=1 for x in $( cat reky.csv | grep -v "jmeno" | cut -f4 -d';' ); do povodi[$pozice]=$x && pozice=$((pozice + 1)); done pozice=1 for x in $( cat reky.csv | grep -v "jmeno" | cut -f5 -d';' ); do prutok[$pozice]=$x && pozice=$((pozice + 1)); done pozice=1
 Cteni ze souboru a prirazovani promennym je popsano v jednom z predchozich dotazu.
Take to pouzivani '&&' je zbytecne. Staci oddelit stredniky nebo jeste lepe psat na novy radek.
Zvysovani pozicniho indexu jsem nejak nepochopil. Nemelo by tam byt: pozice=(($pozice + 1)) ?
Cteni ze souboru a prirazovani promennym je popsano v jednom z predchozich dotazu.
Take to pouzivani '&&' je zbytecne. Staci oddelit stredniky nebo jeste lepe psat na novy radek.
Zvysovani pozicniho indexu jsem nejak nepochopil. Nemelo by tam byt: pozice=(($pozice + 1)) ?
Zvysovani pozicniho indexu jsem nejak nepochopil. Nemelo by tam byt: pozice=(($pozice + 1)) ?Nebo pochopitelne hezci Bashova verze:
((pozice++)) (viz "man bash", sekce ARITHMETIC EVALUATION)
Aby to bylo uplne jasne, tak ta "oskliva" verze by pak vypadala:pozice=1 for x in $( cat reky.csv | grep -v "jmeno" | cut -f5 -d';' ); do prutok[$pozice]=$x && pozice=$((pozice + 1)); done
pozice=1
for reka in $(cat reky.csv | grep -v "jmeno" | cut -f5 -d';' )
do
prutok[$((pozice++))]=$reka
done;
prutok[$(cat reky.csv | grep -v "jmeno" | cut -f5 -d';' )] a pak by to bylo indexovane automaticky od nuly
Nemelo by tam byt: pozice=(($pozice + 1)) ?Odpovim si sam: nemelo
Autor to mel spravne: pozice = $((pozice + 1))
printf %10s string printf %-10s stringPokial vadi spustanie externeho procesu (je to napr. volane v cykle 100000x), tak cisto v Bashi (ukazane na cislach, pouzivam to v jednom skripte a nechce sa mi to prerabat):
#!/bin/bash
zeros=0000000000 # 10 nul
num=123
if [[ ${#num} -lt 10 ]]; then
len=$((10 - ${#num}))
num="${zeros:0:$len}$num"
fi
echo $num
 1.6.2010 02:42
m$ lipo $m | skóre: 19
| blog: čaj o páté
| Redmond
1.6.2010 02:42
m$ lipo $m | skóre: 19
| blog: čaj o páté
| Redmond
sh a jeste je potreba dodelat pekne formatovani):
#!/bin/sh
DB="db.csv"
OFF=10
echo "Available sort orders:"
I=1
head -1 $DB | sed "s/;/\n/g" | while read H; do
echo "$I.) $H"
I=`expr $I + 1`
done
MAX=`head -1 $DB | sed "s/[^;]//g" | wc -c`
SORT=""
while [ "X" = "X$SORT" ]; do
echo
printf "Select sort order (use value +$OFF for numeric sort): "
read SORT
if [ "X" = "X$SORT" ]; then
echo "Sort order can not be empty!"
else
if expr $SORT + 0 1>/dev/null 2>&1; then
NUM=""
if [ $SORT -gt $OFF ]; then
SORT=`expr $SORT - $OFF`
NUM="-n"
fi
if [ $SORT -gt $MAX ]; then
echo "Sort order is over maximal ($MAX) allowed value!"
SORT=""
fi
else
echo "Value \"$SORT\" is not numeric!"
SORT=""
fi
fi
done
echo
tail -n +2 $DB | sort -k $SORT -t ";" $NUM
Tiskni
Sdílej:
![]()
![]()
![]()
![]()
![]()
![]()
 AbcLinuxu.cz
AbcLinuxu.cz ITBiz.cz
ITBiz.cz HDmag.cz
HDmag.cz AbcPráce.cz
AbcPráce.cz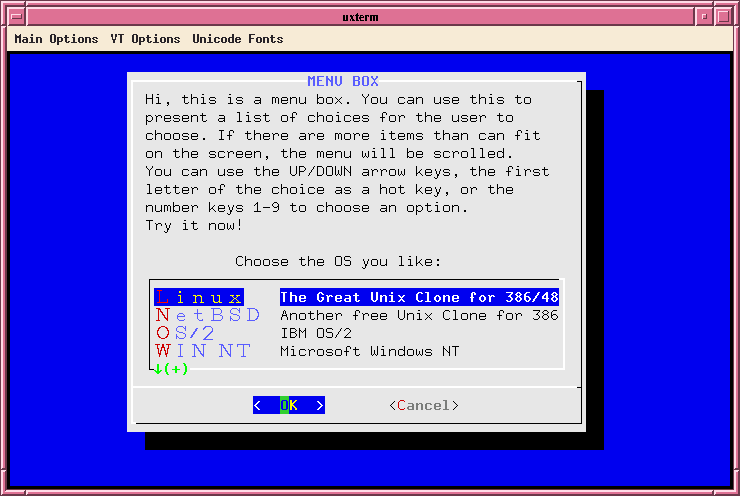{kind=link}
{kind=link}