Portál AbcLinuxu, 28. července 2026 19:22
Který prohlížeč webu nejraději používáte?
| Mozilla Firefox |
|
50% (1183) |
| Konqueror |
|
4% (91) |
| Opera |
|
23% (552) |
| Chrome(ium) |
|
16% (383) |
| Epiphany |
|
1% (33) |
| jiný |
|
5% (126) |
Celkem 2368 hlasů
Vytvořeno: 20.12.2009 23:35
Tiskni
Sdílej:
![]()
![]()
![]()
![]()
![]()
![]()
 20.12.2009 23:40
David Watzke | skóre: 74
| blog: Blog...
| Praha
20.12.2009 23:40
David Watzke | skóre: 74
| blog: Blog...
| Praha
 20.12.2009 23:47
vlk | skóre: 23
| blog: u_vlka
20.12.2009 23:47
vlk | skóre: 23
| blog: u_vlka


 22.12.2009 21:29
Nicky726 | skóre: 56
| blog: Nicky726
23.12.2009 12:22
Nicky726 | skóre: 56
| blog: Nicky726
24.12.2009 15:29
Nicky726 | skóre: 56
| blog: Nicky726
22.12.2009 21:29
Nicky726 | skóre: 56
| blog: Nicky726
23.12.2009 12:22
Nicky726 | skóre: 56
| blog: Nicky726
24.12.2009 15:29
Nicky726 | skóre: 56
| blog: Nicky726
 25.12.2009 10:38
Saljack | skóre: 28
| blog: Saljack
| Praha
25.12.2009 10:38
Saljack | skóre: 28
| blog: Saljack
| Praha
 ale tady musí napsat, že stahuje torrenty
ale tady musí napsat, že stahuje torrenty
 20.12.2009 23:48
Jendа | skóre: 78
| blog: Jenda
| JO70FB
.
20.12.2009 23:48
Jendа | skóre: 78
| blog: Jenda
| JO70FB
.
 20.12.2009 23:57
Cubic | skóre: 24
| blog: obcasne_vyplody
| Essex
20.12.2009 23:57
Cubic | skóre: 24
| blog: obcasne_vyplody
| Essex
 21.12.2009 01:15
Milan Lajtoš | skóre: 22
| blog: /blog/babraq
21.12.2009 01:15
Milan Lajtoš | skóre: 22
| blog: /blog/babraq
Čeckal bych, že tuhle vychytávku Chromium zaplatí větší spotřebou paměti, ale moje zkušenost je, že i tak zabere Chromium se spoustou otevřených tabů míň než Fireofx.Tomu vůbec nevěřím, většina lidí má úplně opačnou zkušenost: http://dotnetperls.com/chrome-memory http://www.flickr.com/photos/denisgobo/3322981762/ http://www.lockergnome.com/blade/2009/06/22/memory-usage-firefox-chrome-safari-opera-the-winner-is/ http://lifehacker.com/5286869/lifehacker-speed-tests-safari-4-chrome-2-and-more
 21.12.2009 06:58
|🇵🇸 | skóre: 94
| blog:
21.12.2009 06:58
|🇵🇸 | skóre: 94
| blog:
 21.12.2009 09:24
Amarok | skóre: 33
| blog: blogoblog
21.12.2009 09:29
|🇵🇸 | skóre: 94
| blog:
21.12.2009 20:15
Amarok | skóre: 33
| blog: blogoblog
21.12.2009 09:28
|🇵🇸 | skóre: 94
| blog:
21.12.2009 09:46
Amarok | skóre: 33
| blog: blogoblog
21.12.2009 09:47
Amarok | skóre: 33
| blog: blogoblog
21.12.2009 09:24
Amarok | skóre: 33
| blog: blogoblog
21.12.2009 09:29
|🇵🇸 | skóre: 94
| blog:
21.12.2009 20:15
Amarok | skóre: 33
| blog: blogoblog
21.12.2009 09:28
|🇵🇸 | skóre: 94
| blog:
21.12.2009 09:46
Amarok | skóre: 33
| blog: blogoblog
21.12.2009 09:47
Amarok | skóre: 33
| blog: blogoblog
Tohle ted pisu z Arory, ale z wysiwyg editoru, v normalnim to nejde odeslat. Jinak flashblock Arory mi u aktualni verze nejde, cele to spadne, kdyz kliknu na Load Flash, tak s tim jen cekam na dalsi verzi, kdyztak jim to pak napisu do buglistu. U vsech tehle novych prohlizecu to chce opravdu nevzdavat a po case zkusit znova, docela se na tom pracuje. Libi se mi, ze rendering maji vetsinou spolecne pres WebKit, cili pro webdesignery by ten stoupajici pocet prohlizecu nemel byt problem.
21.12.2009 09:49
Amarok | skóre: 33
| blog: blogoblog
Tak to je teda dobry, ten spam nebyl umysl. Ono to v Arore opravdu nejde ani ve wysiwyg ani v normalnim  Sice se to odesle (jak je videt), ale napise to "Chyba pri cteni dat".
Sice se to odesle (jak je videt), ale napise to "Chyba pri cteni dat".
Tohle ted pisu z Midori.
21.12.2009 09:59
|🇵🇸 | skóre: 94
| blog:
 22.12.2009 14:28
rADOn | skóre: 44
| blog: bloK
| Praha
22.12.2009 14:28
rADOn | skóre: 44
| blog: bloK
| Praha
 21.12.2009 15:28
Jan Drábek | skóre: 41
| blog: Tartar
| Brno
S Chromiem mám jen drobný problém - na notebooku dělá řádově 1000 wakeupů za sekundu!
21.12.2009 15:28
Jan Drábek | skóre: 41
| blog: Tartar
| Brno
S Chromiem mám jen drobný problém - na notebooku dělá řádově 1000 wakeupů za sekundu!
 21.12.2009 09:10
Pavel Půlpán | skóre: 22
| Trutnov
21.12.2009 11:03
Nicky726 | skóre: 56
| blog: Nicky726
21.12.2009 09:10
Pavel Půlpán | skóre: 22
| Trutnov
21.12.2009 11:03
Nicky726 | skóre: 56
| blog: Nicky726
 21.12.2009 11:04
otasomil | skóre: 39
| blog: puppylinux
21.12.2009 11:04
otasomil | skóre: 39
| blog: puppylinux
Hlasoval jsem Firefox ac i pomerne casto pouzivam Seamonkey.
 21.12.2009 11:05
stybla | skóre: 29
| Praha
21.12.2009 11:05
stybla | skóre: 29
| Praha
 21.12.2009 12:32
Drom | skóre: 24
| Kdyne
21.12.2009 12:32
Drom | skóre: 24
| Kdyne
 21.12.2009 15:23
Grunt | skóre: 23
| blog: Expresivní zabručení
| Lanžhot
21.12.2009 15:23
Grunt | skóre: 23
| blog: Expresivní zabručení
| Lanžhot
Skrýt lišty nástrojů? To považuji za geniální.
21.12.2009 17:18
Grunt | skóre: 23
| blog: Expresivní zabručení
| Lanžhot
21.12.2009 17:25
Grunt | skóre: 23
| blog: Expresivní zabručení
| Lanžhot
21.12.2009 17:31
Grunt | skóre: 23
| blog: Expresivní zabručení
| Lanžhot
Skrýt lišty nástrojů, ale
Automatické skrývání lišty nástrojů. Stačí napsat adresu, zmizne to a když člověk chce napsat adresu, tak se to zase objeví. Něco takového co má FF ve full-screen módu akorát toto funguje i v módu okna. Škoda jen že nemizne i ten status-bar(jako u Chromia nebo ve full-screen módu) a taby se nenacpou do titulku jako v Chromiu.
21.12.2009 17:33
Grunt | skóre: 23
| blog: Expresivní zabručení
| Lanžhot
 21.12.2009 17:34
thingie | skóre: 8
21.12.2009 17:37
Grunt | skóre: 23
| blog: Expresivní zabručení
| Lanžhot
21.12.2009 17:49
|🇵🇸 | skóre: 94
| blog:
21.12.2009 17:55
Grunt | skóre: 23
| blog: Expresivní zabručení
| Lanžhot
21.12.2009 17:34
thingie | skóre: 8
21.12.2009 17:37
Grunt | skóre: 23
| blog: Expresivní zabručení
| Lanžhot
21.12.2009 17:49
|🇵🇸 | skóre: 94
| blog:
21.12.2009 17:55
Grunt | skóre: 23
| blog: Expresivní zabručení
| Lanžhot
 21.12.2009 23:07
MaFy | skóre: 24
| blog: kecy
| Praha
21.12.2009 17:35
Grunt | skóre: 23
| blog: Expresivní zabručení
| Lanžhot
21.12.2009 16:53
stybla | skóre: 29
| Praha
21.12.2009 11:45
MaFy | skóre: 24
| blog: kecy
| Praha
21.12.2009 23:07
MaFy | skóre: 24
| blog: kecy
| Praha
21.12.2009 17:35
Grunt | skóre: 23
| blog: Expresivní zabručení
| Lanžhot
21.12.2009 16:53
stybla | skóre: 29
| Praha
21.12.2009 11:45
MaFy | skóre: 24
| blog: kecy
| Praha
 21.12.2009 12:38
yac | skóre: 8
| blog: srckbin
| Ostrava
21.12.2009 12:38
yac | skóre: 8
| blog: srckbin
| Ostrava
 21.12.2009 12:53
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
21.12.2009 14:54
yac | skóre: 8
| blog: srckbin
| Ostrava
21.12.2009 12:53
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
21.12.2009 14:54
yac | skóre: 8
| blog: srckbin
| Ostrava
Firefox používám nerad
Dokázal prorazit monopol pohradjící standardy a hlavně díky němu si dnes můžeme užívat web v prohlížeči dle svého gusta na široké škále zařízení.není pravda, namísto psaní podle standardů se prostě jenom začalo přiohýbat i pro Firefox, který sám na standardy zvysoka sere
21.12.2009 17:44
Grunt | skóre: 23
| blog: Expresivní zabručení
| Lanžhot
21.12.2009 17:53
|🇵🇸 | skóre: 94
| blog:
Then the horsemen ride out,
everything grows cold
http://www.darklyrics.com/lyrics/gammaray/powerplant.html#5
Proč lžeš?nelžu, ale to dementi jako ty těžko pochopí ... přesto to zkusím:
1. "WONTFIX for HTML5-compliance reasons.což je jinými slovy to, že na standard XHTML 1.0 serou
Opera 10 renders the same as Firefox."a kde já mluvím o Opeře 10? v devítce to funguje, že to do desítky rozbili, o čemž jsem se dozvěděl až z reakce na bug, svědčí buď o absolutním diletantství vývojářů v Opera Software, anebo to jen potvrzuje mou tezi výše o tom, že teď se svět namísto zkriplenosti IE přizpůsobuje zkriplenosti FF
2. When can I use...a co já s tím? - ta stránka pojednává o "Compatibility tables for features in HTML5, CSS3, SVG and other upcoming web technologies" ... jestli neumíš číst ty kupko hnoje, tak ten testcase k bugu je v XHTML 1.0, a nemá nic společného ani s HTML5, ani s CSS3, ani se SVG, a už vůbec to není "upcoming web technology", neboť poslední revize XHTML 1.0 je z 1. srpna 2002, a první finální verze vyšla 26. ledna 2000, takže ta sračka jménem FireFox nezvládá nyní již skoro 10 let starý standard, a budou se přitom vymlouvat na něco, co s tím technicky pranic nesouvisí, a co je zatím ve fázi těžkých změn a ještě nedávno nikdo ani netušil, že tu něco takového bude ... ach ano, já zapomněl, já ti šláp na bebíčko, FF je přeci dokonalý
21.12.2009 19:24
thingie | skóre: 8
Ty té specifikaci ale taky dvakrát nedáváš. Přečti si třeba tohle, jmenovitě asi C.3.C. HTML Compatibility Guidelines This appendix is informative. This appendix summarizes design guidelines for authors who wish their XHTML documents to render on existing HTML user agents. hm, takže co z toho vyplývá pro čisté XHTML?
22.12.2009 00:25
thingie | skóre: 8
To je jak u blbejch.nemůžu za to, kdo se tady zapojil :-p
Ty to označuješ jako text/html,to není pravda, já o tom nikde netvrdím, že to je text/html (jestli si to tak Firefox vyhodnotí, to je jeho problém), tudíž máš blbě předpoklad, tudíž cokoliv z toho vyvozuješ stojí na vodě
21.12.2009 19:29
thingie | skóre: 8
Ty taky drž hubu, laskavě.
Sváťa Pulec (Švestka, Divadlo Járy Cimrmana)
22.12.2009 12:26
Grunt | skóre: 23
| blog: Expresivní zabručení
| Lanžhot
23.12.2009 19:42
yac | skóre: 8
| blog: srckbin
| Ostrava
23.12.2009 19:59
Grunt | skóre: 23
| blog: Expresivní zabručení
| Lanžhot
Já tu jasně píšu, že jsem si vědom, že Firefox nepodporuje všechno a že v různých oblastech vynikají různé produkty.hm, a kde to v tom předchozím příspěvku najdu?
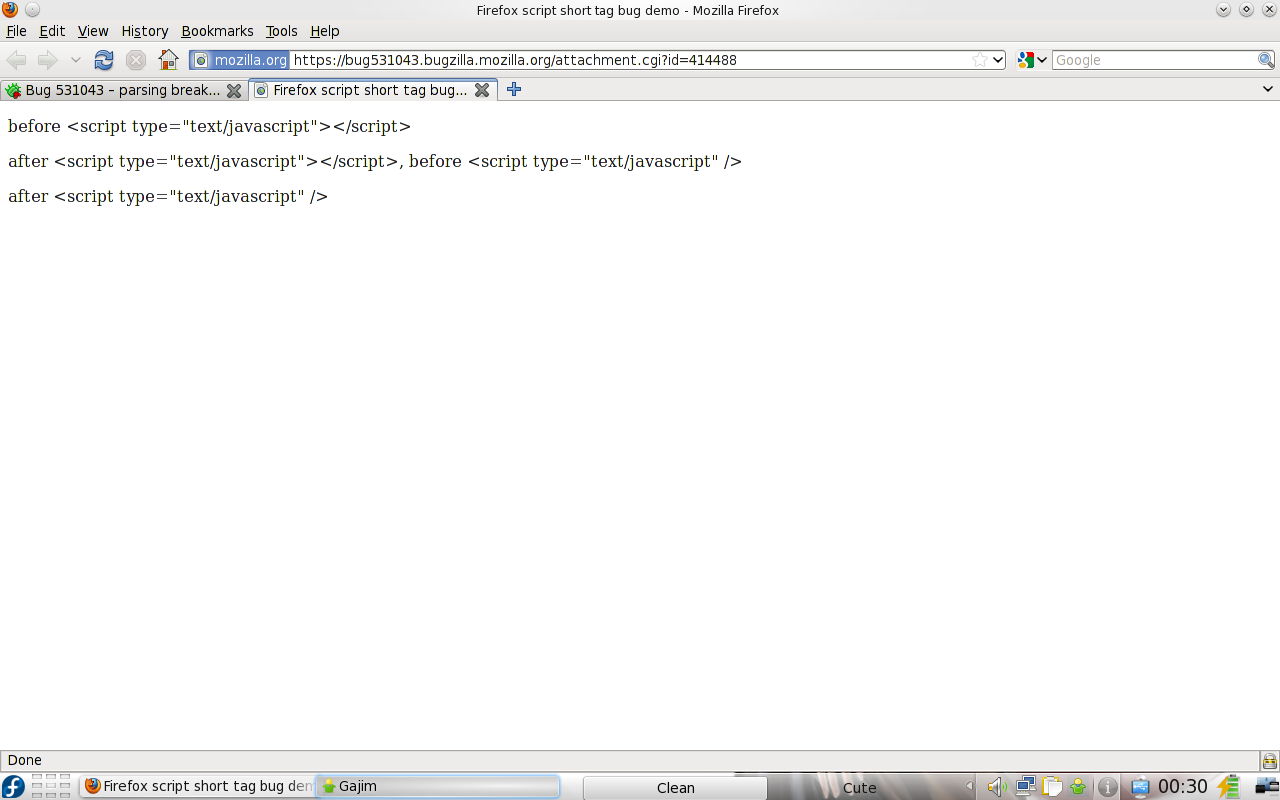
<script ...></script>)
Je zřejmě třeba říct to konečně na plnou hubu: "XHTML" poslané jako text/html není XHTML.1. "WONTFIX for HTML5-compliance reasons.což je jinými slovy to, že na standard XHTML 1.0 serou
Je zřejmě třeba říct to konečně na plnou hubu: "XHTML" poslané jako text/html není XHTML.
$ wget -S https://bug531043.bugzilla.mozilla.org/attachment.cgi?id=414488 --2009-12-22 00:23:21-- https://bug531043.bugzilla.mozilla.org/attachment.cgi?id=414488 Překládám bug531043.bugzilla.mozilla.org… 63.245.209.86 Navazuje se spojení s bug531043.bugzilla.mozilla.org|63.245.209.86|:443… spojeno. HTTP požadavek odeslán, program čeká na odpověď… HTTP/1.1 200 OK Date: Mon, 21 Dec 2009 23:23:21 GMT Server: Apache/2.2.3 (Red Hat) Content-disposition: inline; filename="scriptshorttagbug.html" Content-length: 655 X-Backend-Server: mrapp51 Keep-Alive: timeout=300, max=1000 Connection: Keep-Alive Content-Type: application/xhtml+xml; name="scriptshorttagbug.html" Délka: 655 [application/xhtml+xml] Ukládám do: „attachment.cgi?id=414488“ 100%[==================================================================>] 655 --.-K/s za 0s 2009-12-22 00:23:21 (109 MB/s) – „attachment.cgi?id=414488“ uloženo [655/655]
22.12.2009 00:28
thingie | skóre: 8
22.12.2009 14:28
thingie | skóre: 8
... jinak viz příloha :-p
23.12.2009 11:43
thingie | skóre: 8
Firefox soubor jmenující se něco.html interpretuje stejně jako přes HTTP s MIME typem text/html.hm, to je asi jako kdyby si nějaký grafický prohlížeč usmyslel, že když dostane soubor s příponou .tif, a nebude komprimovaný LZW, ale třeba RLE, tak ho prostě nezobrazí, zatímco RLE v .pcx nebo JPEG v .jpg umí, a přestože TIFF umožňuje nejen LZW ale i RLE i JPEG a další, stačí si z hlaviček přečíst, v čem soubor je ...
Ne že by se ten typ nedal poznat líp, ale označovat *tohle* jako „na standardy zvysoka sere“, to aby člověk skoro souhlasil s Tomešem, byť mu to bylo sebevíc odporný.přečetl sis zdůvodnění uzavření bugu? - zdá se, že jsem problém identifikoval nedokonale, děje se jen za určitých okolností, a ne že by to FF neuměl vůbec, nicméně toho člověka, co to zavřel, nějaká analýza, co je špatně, a co by se mělo opravit, nezajímá, prostě jinými slovy řekl, že na XHTML kašlou, a ještě to staví tak, že W3C validátor se chová chybně, což není pravda, parsuje to správně jako XML, protože dostane XML dokument, nikoliv HTML
přečetl sis zdůvodnění uzavření bugu?p.s. a samozřejmě tak nesoudím jen na základě tohoto jednoho bugu, nýbrž i dalších (například mé oblíbené rozdílné zpracování procentuálních rozměrů u sémanticky stejných elementů)
23.12.2009 19:49
thingie | skóre: 8
Udělej mi prosímtě tu radost a konečně mi ukaž aspoň jeden případ, kdy by Firefox tu ukázku nesprávně parsoval za předpokladu, že ji parsuje jako XML (application/xhtml+xml).neukážu, protože nevím kdy se to jak rozhodne parsovat - nejsem vývojář FF, nevidím do jeho vnitřností a v tom bugu nejde o nějaké předpoklady, ale o to, že není schopen parsovat validní kód - jestli je příčina jiná, než jsem si myslel, hm, ok, tak jsem se spletl, ale to nic nemění na tom, že problém existuje
Odpověď je možná maličko nepochopením (protože ten bug je napsaný vcelku bídně, nikde tam není zdůrazněno, že takové chování nastává právě s XML MIME typem (zřejmě proto, že ani nenastává)),eh? - je tam příloha, která je zcela zjevně XML, to mám ještě vložit její kopii do textu?
Předpokládám, žes prostě stvořil tu ukázku, nazval ji .html, Firefox to pochopil jako text/html [1], ty sis řekl aha, vyplnil ten bug, přidal ukázku, ještě jí přihodil MIME typ sice správný, ale jiný než se použil předtím,viz výše - A JAK MÁM DOPRDELE VĚDĚT, CO SE FIREFOX ROZHODNE POUŽÍT?!
a teď tu žvaníš o tom jak Firefox sere na standardy.ano, sere, za určitých okolností nezpracuje naprosto validní kód a vývojáři s tím nehodlají nic dělat
[1] To je sice chování diskutabilní, možná i špatné, ale na úplně jiný bug, spíše žádost o vylepšení.v tom případě by bylo korektním řešením identifikovat příčinu problému, přiřadit správnou komponentu, změnit příslušně předmět, a problém fixnout
23.12.2009 20:29
thingie | skóre: 8
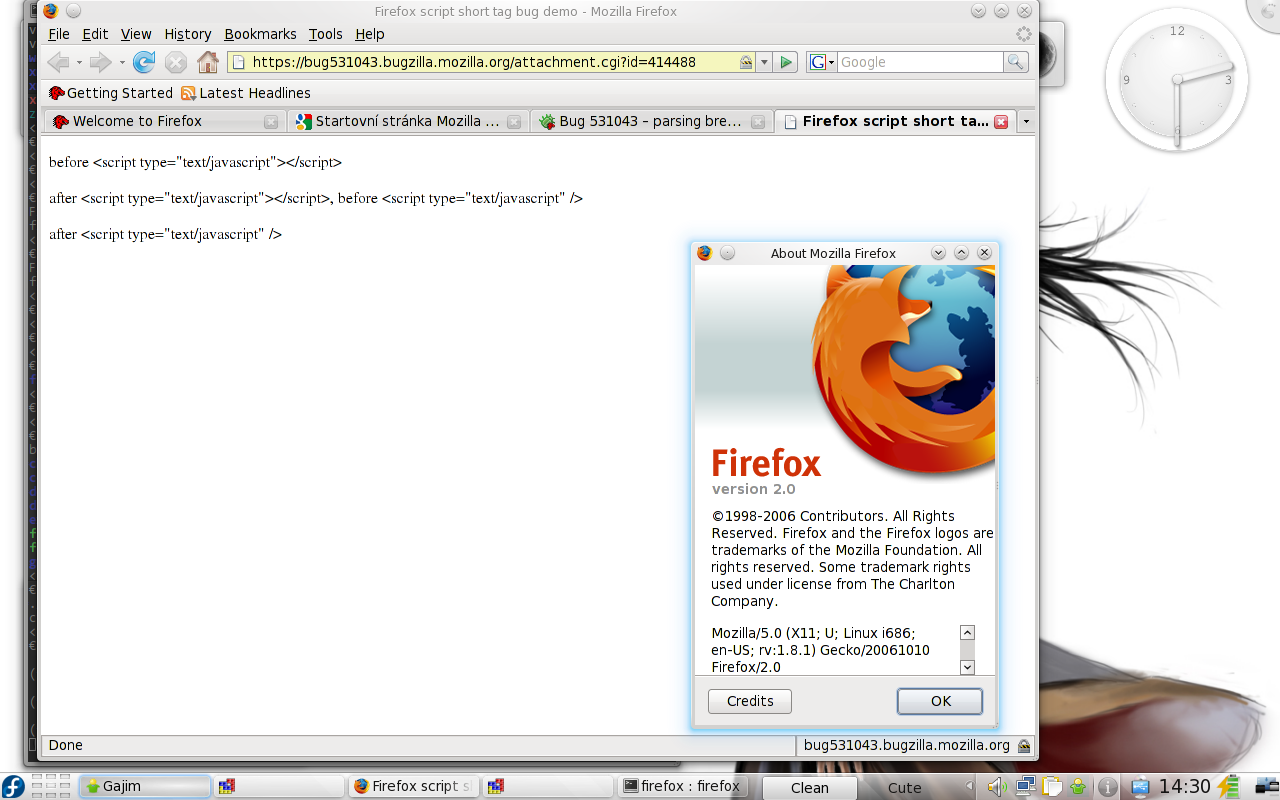
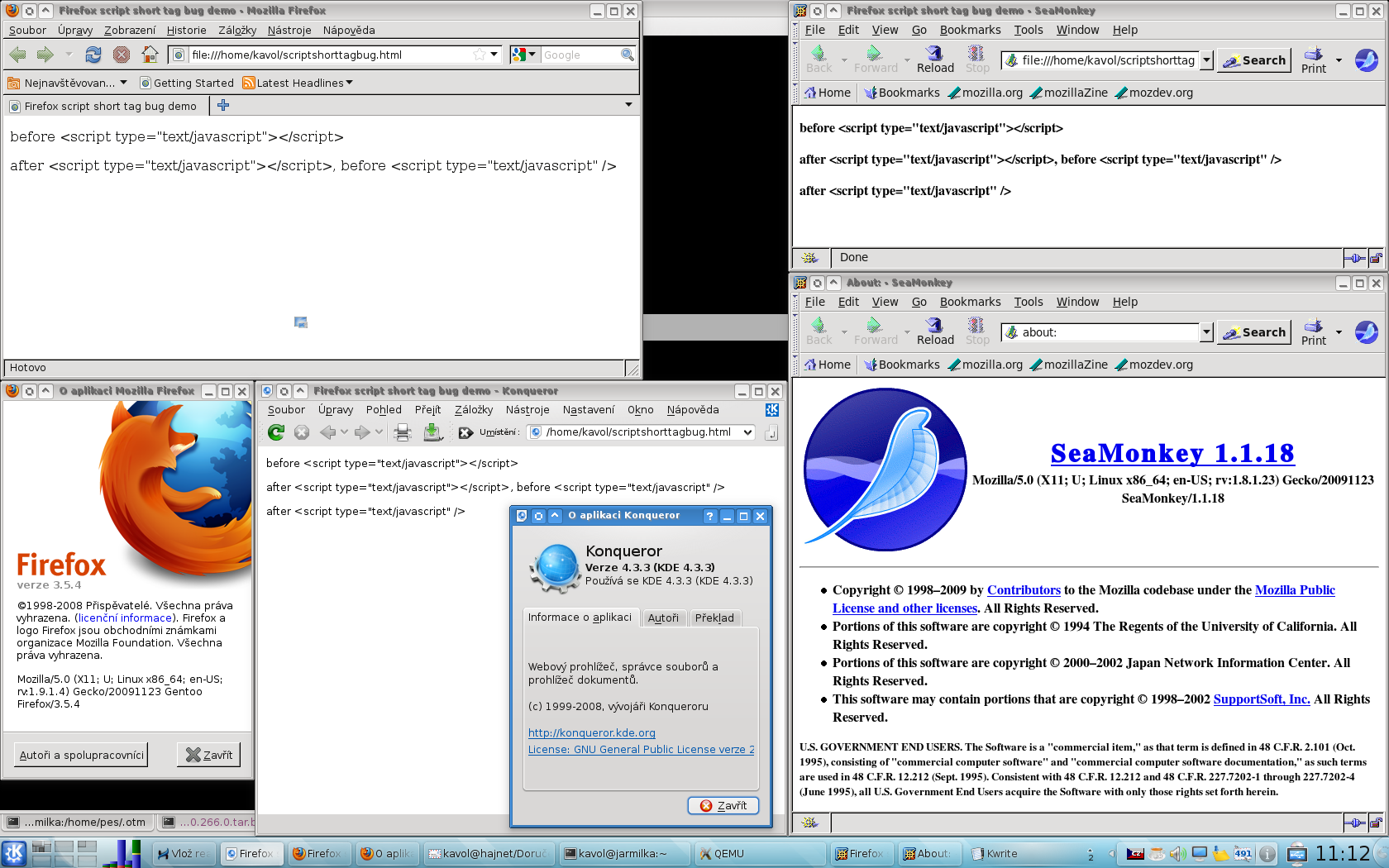
Zbytek se lze dočíst třeba tady https://developer.mozilla.org/en/How_Mozilla_determines_MIME_Types.ňák jim to nefunguje ... File URIs => ExternalHelperAppService "a hardcoded list of extensions is checked (containing currently 13 entries, nsExternalHelperAppService.cpp line 463" ... a realita? - srovnej FireFox a SeaMonkey na výše postnutém screenshotu
Zpracuje kód podle poměrně rozumných pravidel v souladu s doporučením uvedeným v XHTML specifikaci a s ohledem na dopřednou kompatibilitu s HTML5.můžeš laskavě elaborovat, jak toto míníš? - navrhovaná hlavička HTML5 se dosti zásadně liší od hlavičky XHTML 1.0, takže není problém poznat, že je dokument v XHTML 1.0, a jako takový by měl být zpracován, co s tím má kurva HTML5, které ještě ani není definované, společného?
Korektní řešení je, že si přečteš dokumentaci a specifikace kterými se oháníš :-Pó děkuji, já jsem si je přečetl několikrát, a nikde tam nevidím nic o tom, že by se XHTML 1.0 dokument neměl parsovat jako XHTML 1.0 dokument - jestli ty jo, tak cituj a dej odkaz (a podotýkám, že pokud by byl problém v tom, že standard praví jinak, pak je to NOTABUG a nikoliv WONTFIX)
24.12.2009 15:51
thingie | skóre: 8
XHTML 1.0 dokument by se neměl parsovat jako XML, je-li HTTP hlavičkou servírován s Content-type text/html.to už tu jednou bylo ... proč neustále vnucuješ předpoklad text/html?
Poznávání typu přes schéma file: u Firefoxu funguje tak jak má, Seamonkey to taky může mít jinak, možná nemá, to je teď fakt nad rámec toho, co by se mi chtělo zrovna řešit,hm, to je úžasný ... ten dokument je nadepsanej "How Mozilla determines MIME Types", nikoliv "How Firefox...", takže něco je zjevně špatně, ale ty si z toho vybereš k argumentaci jen co se ti hodí, a na zbytek nemáš chuť, hm
a taky tě to neopravněje tvrdit něco o sraní na standardy.je jistý rozdíl mezi "fungovat podle dokumentace" a "fungovat jak má" ... takže: je ten testcase korektní XHTML 1.0? - ano zobrazí Firefox ten testcase správně? - ne vědí o tom vývojáři (je nahlášen bug)? - ano hodlají ten bug spravit? - ne => Firefox sere na standardy
proč neustále vnucuješ předpoklad text/html?
To není předpoklad, tak to ve vámi uváděných příkladech bylo.
ten dokument je nadepsanej "How Mozilla determines MIME Types", nikoliv "How Firefox...", takže něco je zjevně špatně
Proč by v tom měl být rozdíl? Tohle se netýká uživatelského rozhraní, takže nevidím důvod, proč by se v tomto ohledu měl lišit Firefox od Seamonkey.
zobrazí Firefox ten testcase správně? - ne
Kdybyste mu ho prezentoval jako XHTML a on ho tak zobrazil, měl byste pravdu. Ale tak tomu nebylo.
eh? - já jsem Firefoxu nikde netvrdil, že ten dokument je text/html, máte nějaký doklad o opaku?proč neustále vnucuješ předpoklad text/html?To není předpoklad, tak to ve vámi uváděných příkladech bylo.
no to já nevím, proč by tam měl být rozdíl, ale zjevně tam je ... a kolegovi, zdá se, vůbec nevadí, že se realita rozchází s dokumentací (byť jen v jednom případě ze dvou, kterých by se to mělo týkat)ten dokument je nadepsanej "How Mozilla determines MIME Types", nikoliv "How Firefox...", takže něco je zjevně špatněProč by v tom měl být rozdíl? Tohle se netýká uživatelského rozhraní, takže nevidím důvod, proč by se v tomto ohledu měl lišit Firefox od Seamonkey.
já ho jako XHTML prezentuju, je tam XML hlavička a DTD XHTML 1.0 ...zobrazí Firefox ten testcase správně? - neKdybyste mu ho prezentoval jako XHTML a on ho tak zobrazil, měl byste pravdu. Ale tak tomu nebylo.
Jak už jsem několikrát vysvětloval, psát informaci o datovém typu dovnitř souboru je principiální nesmysl.to je sice možné, ale lepší řešení není, jestliže metadata neexistují (nelze přenést) ... pročež je tento principiální nesmysl standardizován, zkuste to reklamovat u autorů toho textu, já jej pouze respektuju, což Firefox zjevně nedělá
Zbytek nemá smysl znovu a znovu opakovat, několik různých lidí už se vám tu pokusilo vysvětlit, že jste ten dokument prezentoval jako HTML, ale vzhledem k tomu, že odmítáte vnímat, je veškerá snaha marná.zatím mi bylo pouze vysvětleno, že Firefox se jej rozhodl vnímat jako HTML, ale ještě nikdo mi nedokázal, že bych tak ten soubor prezentoval já - to není odmítání vnímat, to je prostě argumentační nouze na vaší straně, tím, že budete donekonečna opakovat nesmysl, mě nepřesvědčíte, sorry, Goebbels nefunguje na všechny, zkuste přihodit nějaké zdůvodnění ... ukažte mi nějaký dokument W3C, který říká, že soubor začínající XML hlavičkou má být chápán jako prosté HTML, a já dám pokoj
pročež je tento principiální nesmysl standardizován
Jenže tohle funguje pouze za předpokladu, že už odněkud (z metadat) víme, že jde o XML dokument. A to se zde nestalo.
ale ještě nikdo mi nedokázal, že bych tak ten soubor prezentoval já
Ukázal, to jen vy jste se to rozhodl ignorovat.
ukažte mi nějaký dokument W3C, který říká, že soubor začínající XML hlavičkou má být chápán jako prosté HTML
Dokument W3C vám říká, jakým způsobem říct správně prohlížeči, že mu posíláte XHTML dokument. Když to podle něj uděláte, je všechno v nejlepším pořádku. O tom, jak má prohlížeč rozeznávat XHTML a HTML u lokálního souboru, neříká W3C ani slovo. Firefox - a zdaleka ne jen on - to dělá určitým způsobem. Že to holt není zrovna ten, který byste si představoval (heuristická analýza obsahu), to ještě neznamená, že je to chyba, a už vůbec to neznamená, že Firefox, cituji, "sere na standardy". Pokud chcete tvrdit že ano, pak nám ukažte ten standard, který říká, že prohlížeč je povinen zjišťovat typ dokumentu na základě heuristické analýzy jeho obsahu. Já žádný takový standard neznám.
ale já to milerád zopakuju:pročež je tento principiální nesmysl standardizovánJenže tohle funguje pouze za předpokladu, že už odněkud (z metadat) víme, že jde o XML dokument. A to se zde nestalo.
hm, takže triviální utilitkakavol@jarmilka ~ $ file scriptshorttagbug.html scriptshorttagbug.html: XML document text
file je chytřejší než stokrát větší Firefox :-p
nevím, jestli to má z křišťálové koule, protože z metadat mimo soubor to určitě nemá, nicméně je zřejmé, že předpoklad "víme že jde o XML dokument" může být splněn, takže "zde nestalo" platí nejspíš pouze pokud zde = ve Firefoxu - což je problém Firefoxu, ne můj, já jsem ten zdroják napsal tak, že z něj lze poznat o co jde, jak nám tato malá šikovná utilitka dokazuje (čímž zároveň popírá následující tvrzení, které se mi snažíte vnutit neustálým opakováním)
a že byste se obtěžoval říci kde? - jenže to by prvně muselo být nač odkázat, na nějaký argument, a ne jen na neustále opakované nepravdivé tvrzení, že ...ale ještě nikdo mi nedokázal, že bych tak ten soubor prezentoval jáUkázal, to jen vy jste se to rozhodl ignorovat.
ano, to jsem podle W3C udělal, a podle W3C validátoru je všechno v nejlepším pořádku, u Konqueroru je vše v pořádku, dokonce i verze SeaMonkey, kterou jsem zkoušel pro vyrobení screenshotu odkazovaného výše, to nějak zvládne, akorát Firefox to jaksi podle toho W3C nedává ... a vůbec, neměl byste do bugtrackerů zmíněného software zahlásit, že to dělají úplně špatně, že to musí dělat stejně jako Firefox?ukažte mi nějaký dokument W3C, který říká, že soubor začínající XML hlavičkou má být chápán jako prosté HTMLDokument W3C vám říká, jakým způsobem říct správně prohlížeči, že mu posíláte XHTML dokument. Když to podle něj uděláte, je všechno v nejlepším pořádku.
O tom, jak má prohlížeč rozeznávat XHTML a HTML u lokálního souboru, neříká W3C ani slovo.blá blá blá, ani odkazy na standard nepomáhají - ale zkusím vaší taktiku, tak to prostě zopakuju znova: ŘÍKÁ! (a tady)
Firefox - a zdaleka ne jen on - to dělá určitým způsobem. Že to holt není zrovna ten, který byste si představoval (heuristická analýza obsahu), to ještě neznamená, že je to chyba,ať si to dělá jak chce, důležitý je výsledek - a ten je v tomto případě špatně, v rozporu se standardem dobře, přistupme tedy na chvilku na to, že by bylo korektní si o tom souboru myslet, že je to HTML - ale v tom případě hlavička nesplňuje požadavky žádné verze HTML, bum, chyba, HTML to není, končíme se zpracováním, jak je možné dále zpracovávat něco, co neznáme, nějak to dokurvit, a tvrdit, že je to správnější výsledek, než totéž nepovažovat za HTML?
a už vůbec to neznamená, že Firefox, cituji, "sere na standardy".ale ano, sere, zpracovává jako HTML něco, co HTML není, a co o sobě jasně hlásá, že to HTML není
Pokud chcete tvrdit že ano, pak nám ukažte ten standard, který říká, že prohlížeč je povinen zjišťovat typ dokumentu na základě heuristické analýzy jeho obsahu. Já žádný takový standard neznám.až po vás, až po vás - ještě jste mi neukázal ten standard, podle kterého má prohlížeč dokument s XML hlavičkou chápat jako HTML (nehledě na to, že váš požadavek je nesmyslný - standardy tu nejsou od toho, aby určovaly implementační detaily na této úrovni, prohlížeč to může klidně určovat pomocí té křišťálové koule, standard říká pouze jak by měla příslušná data vypadat)
hm, takže triviální utilitka file je chytřejší než stokrát větší Firefox :-p
"Triviální utilitka" je speciální nástroj pro heuristickou analýzu obsahu, po němž se nic jiného nechce. Naopak, vůbec by se mi nelíbilo, pokud by se něčím takovým zdržoval Firefox.
ano, to jsem podle W3C udělal
Ne, neudělal. Když to uděláte - tj. pošlete odpovídající Content-Type v hlavičce odpovědi, Firefox zobrazí dokument správně.
blá blá blá, ani odkazy na standard nepomáhají - ale zkusím vaší taktiku, tak to prostě zopakuju znova: ŘÍKÁ! (a tady)
Tak ještě jednou: tento dokument říká pouze to, jak v případě, že už odněkud víte, že se jedná o XML, poznat, zda jde o XHTML, a pokud ano, jaké verze. Tento velmi podstatný předpoklad ve vašem případě nebyl splněn.
zpracovává jako HTML něco, co HTML není
Pokud jste mu o tom řekl, že je to HTML (ať už v hlavičce HTTP odpovědi nebo příponou souboru), pak je to zcela v pořádku. Když příkazem mount zkusíte přimountovat XFS s parametrem -t ext3, také vám vynadá, že je vadný superblock, místo toho, aby si prostě řekl, že tomu nerozumíte, a přimountoval to jako XFS.
ještě jste mi neukázal ten standard, podle kterého má prohlížeč dokument s XML hlavičkou chápat jako HTML
Proč bych to měl dělat? Já přeci netvrdil, že takový existuje. Zato vy se pořád snažíte (ať už explicitně nebo implicitně) tvrdit, že podle nějakého standardu je prohlížeč povinen zjišťovat typ souboru tak, že se podívá do jeho obsahu a aplikuje nějakou heuristiku.
standardy tu nejsou od toho, aby určovaly implementační detaily na této úrovni, prohlížeč to může klidně určovat pomocí té křišťálové koule, standard říká pouze jak by měla příslušná data vypadat
Přesně tak. Standard říká, jak má vypadat XHTML, ale neříká nic o tom, podle čeho má prohlížeč u lokálního souboru (tedy při absenci hlavičky HTTP odpovědi) rozhodnout, zda daný soubor parsovat jako HTML nebo XHTML.
28.12.2009 22:02
Drom | skóre: 24
| Kdyne
29.12.2009 21:14
Drom | skóre: 24
| Kdyne
Misto, aby doslo k identifikaci souboru, vy chcete, aby vam nekdo rekl, co je to zac.Jenže nikdo jiný než autor neví lépe, co je soubor zač. Jak podle analýzy obsahu rozpoznáte třeba XML dokument od čistého textu? Zkusíte to rozparsovat, a když to jde, tak je to XML, když ne, je to čistý text? A co když to mělo jít, mělo to být XML, ale je v něm chyba? Nebo co když to je čistý text a náhodou jde rozparsovat jako XML? Jak u čistého textu poznáte kódování? Jak podle začátku souboru odlišíte ZIP, JAR, WAR, EAR, DOCX, ODT?
Jak server posilajici HTTP odpoved pozna, jaky je to typ souboru?
To se dočtete k dokumentaci k tomu HTTP démonovi. Případně si u dynamicky generovaného dokumentu tu položku do hlavičky určíte sám.
Nic lepsiho, nez hlavicka (v) souboru neni. Soubor v sobe, na zacatku, nese informaci o tom, v jakem formatu jsou v nem data. tohle netrumfne (v soucasny) dobe nic.
Naopak, není nic horšího. Každý typ souboru má tu "hlavičku" jinde (některé i na konci), v jiném formátu a jak už jsem upozornil, není problém vytvořit příklad souboru, který lze zcela korektně interpretovat jako několik různých datových formátů.
Aby ta hlavička uvnitř souboru měla šanci rozumně fungovat, musela by být jednotná a musely by ji respektovat všechny datové formáty. Jenže to už by pak vlastně byla metadata.
Misto, aby doslo k identifikaci souboru, vy chcete, aby vam nekdo rekl, co je to zac.
Přesně tak, identifikovat ho stejně spolehlivě nemohu, navíc je to i v té většině případů, kdy to jde, neefektivní a nepraktické. Takže bude lepší, když mi to řekne ten, kdo mi ta data poskytl - kdo by to měl vědět lépe?
30.12.2009 00:32
Drom | skóre: 24
| Kdyne
Ja, kdyz si prectu ten soubor.Tak mi určete typ tohoto souboru:
<?xml version="1.0" ?> <root />
Me porad neni jasny, kde se ta prvotni informace o typu/formatu souboru vezme.Určí ji uživatel, ten, který daný soubor vytvořil. Třeba já když píšu textový dokument ve formátu ODT, určím, že je to textový dokument ve formátu ODT. Nějaký program si o tom klidně může myslet, že je to bitmapový obrázek nebo zvukový soubor, může to klidně i jako obrázek zobrazit nebo jako zvuk přehrát, pořád to ale bude textový dokument ve formátu ODT. Proč vám tolik vadí ukládat do metadat vedle souboru zrovna typ? Proč vám stejně nevadí datum vytvoření nebo název souboru? To přece také může být schované uvnitř daného formátu, a každý program si to tam najde…
31.12.2009 00:11
Drom | skóre: 24
| Kdyne
31.12.2009 00:12
Drom | skóre: 24
| Kdyne
4.1.2010 20:29
Drom | skóre: 24
| Kdyne
4.1.2010 21:04
Drom | skóre: 24
| Kdyne
Rozhoduje o tom tak, že o tom rozhodne. Prostě si řekne „tenhle textový dokument teď uložím ve formátu OpenDocument Text“.no, výborně, to jsem chtěl slyšet
- takže já jsem se rozhodl, že ten testcase uložím jako XHTML 1.0, proč tady někdo neustále mele něco o tom, že je to prosté HTML?
8.1.2010 22:43
Drom | skóre: 24
| Kdyne
9.1.2010 14:15
Drom | skóre: 24
| Kdyne
9.1.2010 17:55
Drom | skóre: 24
| Kdyne
9.1.2010 18:01
Drom | skóre: 24
| Kdyne
9.1.2010 18:24
Drom | skóre: 24
| Kdyne
9.1.2010 18:21
Drom | skóre: 24
| Kdyne
Takze Vam vadi (resp. neverite v) urcovani typu souboru jeho analyzou, ale nevadi Vam, ze Vam kamarad posle nejakej takybastl o kterym jeho takyprogram tvrdi, ze ma nejakej format a pritom po otevreni na me vyskoci hromada nesmyslu, protoze muj spravce souboru se nestara, co to je za soubor, ale veri predane informaci a asociuje ho s predpokladanym programem. To mi pripomina Windows a jejich neschopnost rozlisovat soubory, resp. spolehani se na priponu.Kamarád mi pošle soubor, o kterém tvrdí, že je to ODT, a můj program na prohlížení ODT se jej pokusí otevřít. Buď se mu to podaří (soubor má správný formát), nebo se mu to nepodaří – pak je chyba buď v programu, nebo v souboru. Takže můžu zkusit ještě jiný program. Nevím, co vám na tom pořád připadá divného. Mně to připadá naprosto normální, mnohem lepší, než když se program pokouší uhodnout, co je to zač, uhodne to špatně a já ho pak musím pracně přesvědčovat o tom, o jaký formát se jedná (přičemž já to opět zjistím pohledem do křišťálové koule nebo dotazem na autora).
Veta je "format" a obsah vety je "informace". Pokud pisu slova nahodne, tak nedavaji smysl cloveku, ktery je cte a nevi, jak je radit. Ale ta informace tam porad je, staci na zacatku poznamenat, JAK se ma ta veta cist (hlavicka souboru).OK. Tak mi přeložte do češtiny tuhle větu (informace o tom, jak ji číst, je na začátku): skdh sdišč sruhs s kuhd wkjehiýwč sdkjhs ieuz sk dj.
Ale moje pracovni prostredi, resp. spravce souboru, dokaze poznat (ano, s jistou toleranci), ze to neni obrazek JPG, pokud jim opravdu neni. Jak se bude branit Vas server, az na nej bude uzivatel cpat nepovoleny typy souboru a tvrdit, ze to jsou obrazky? Bude ten blud sirit dal.Jaký blud? Autor ten obrázek prohlásil za obrázek ve formátu JPG, tak to tak server má šířit dál. Chování, kdy program je chytřejší než uživatel, přenechte programům Microsoftu.
A kdo hada? Ja nemam v USB kristalovou kouli, ale muj OS obsahuje nastroje pro analyzu souboru. Prijde mi racionalnejsi pokusit se urcit, co je to za soubor, nez verit informaci u ktere neznam ani jeji puvod.Napíšu to po sté, a doufám, že naposledy: soubor sám o sobě nemá žádný typ. Typ určuje autor. Takže nejde o tom, zda této informaci budete věřit nebo nebudete, autor tu informaci vytváří. Navíc ten váš program neurčuje typ souboru, ale zase jenom se pokouší určit tu informaci, kterou tam uložil autor – když vytvořím Java Class soubor a přepíšu první 4 znaky na „%PDF“, bude si vaše utilita myslet, že jde o PDF soubor. Ale pokud jej předhodíte upravené Javě, která si nekontroluje hlavičku, normálně to spustí jako třídu. Takže vaše utilita stejně věří informaci, o které neznáte její původ, jenže tahle informace je navíc nejednoznačná a obtížně se zjišťuje.
22.12.2009 10:02
Amarok | skóre: 33
| blog: blogoblog
Vy jste vsichni nejak mimo. V tom prikladu, ktery pres wget stahujes, vubec ani Content-Type definice neni, tudiz je ten priklad nesmyslny.
A Ladicek je taky vedle, jelikoz veta ma znit spravne: XHTML poslané jako text/html není XML. XHTML to ale je.
Sending XHTML as text/html Considered Harmful, a tím bych to uzavřel.
22.12.2009 11:08
Amarok | skóre: 33
| blog: blogoblog
text/html (tady to nenapáchá žádnou škodu, protože MSIE to bude jako HTML parsovat tak jako tak) a ostatním správný typ.
22.12.2009 16:31
Drom | skóre: 24
| Kdyne
22.12.2009 22:11
Drom | skóre: 24
| Kdyne
Dokud to neopravi, tak to tak musim definovat, protoze nechci vyradit 40% uzivateluAle nemusíš... Otázkou je, jestli to stojí za to.
V tom prikladu, ktery pres wget stahujes, vubec ani Content-Type definice neni, tudiz je ten priklad nesmyslny.
eh? - ještě jednou cituju část výstupu wgetu:
Content-Type: application/xhtml+xml; name="scriptshorttagbug.html" Délka: 655 [application/xhtml+xml]
22.12.2009 11:03
Amarok | skóre: 33
| blog: blogoblog
22.12.2009 11:12
Amarok | skóre: 33
| blog: blogoblog
22.12.2009 11:25
Amarok | skóre: 33
| blog: blogoblog
22.12.2009 13:38
Amarok | skóre: 33
| blog: blogoblog
23.12.2009 10:30
Amarok | skóre: 33
| blog: blogoblog
Myslel jsem tim ve zdrojaku content-type neni. V hlavicce uz pak je.no a proč by tam měl být probůh? - jak správně píše Michal Kubeček, to je otázkou metadat, Content-Type je hlavička HTTP protokolu, nikoliv hlavička definovaná samotným (X)HTML, v rámci textu souboru je už jenom hlavička XML a následně DOCTYPE (plně v souladu se standardem)
file nemá problém poznat, že je to XML:
kavol@jarmilka ~ $ file scriptshorttagbug.html scriptshorttagbug.html: XML document textW3C validátor s tím nemá problém, Konqueror s tím nemá problém, jenom blbej Firefox to místo jako XML zpracovává jako ... no vlastně ani moc nezpracovává, po dojití k tomu problematickýmu tagu mu na tom umře parser a je vymalováno :-/
 23.12.2009 14:56
theo | skóre: 15
| Rožnov ... hádej který?
23.12.2009 14:56
theo | skóre: 15
| Rožnov ... hádej který?
No to sem zvedavy jak potom nejaky prohlizec pozna v jakem je to kodovani (pokud nema autodetekci kodovani), kdyz si takovou stranku ulozim na disk a budu si ji pak chtit prohlidnout :)
<?xml version="1.0" encoding="UTF-8"?>
24.12.2009 10:20
Amarok | skóre: 33
| blog: blogoblog
24.12.2009 12:36
thingie | skóre: 8
(Nemluvě o duchem chudších OS, které by před ní ještě byly schopné nacpat třeba BOM.)
24.12.2009 12:47
Amarok | skóre: 33
| blog: blogoblog
21.12.2009 17:54
thingie | skóre: 8
21.12.2009 17:26
Jendа | skóre: 78
| blog: Jenda
| JO70FB
21.12.2009 18:46
stybla | skóre: 29
| Praha
 21.12.2009 14:51
Tomáš Bžatek | skóre: 29
| Brno
22.12.2009 16:35
Drom | skóre: 24
| Kdyne
21.12.2009 14:51
Tomáš Bžatek | skóre: 29
| Brno
22.12.2009 16:35
Drom | skóre: 24
| Kdyne
 21.12.2009 17:26
WIFT
| "The 2nd Capital City of Beer"
.
21.12.2009 17:26
WIFT
| "The 2nd Capital City of Beer"
.
 21.12.2009 21:43
gtz | skóre: 27
| blog: gtz
| Brno
21.12.2009 21:43
gtz | skóre: 27
| blog: gtz
| Brno
 22.12.2009 09:51
tsLnox | skóre: 31
| blog: Blog jednoho ukecaného Gentoolemana
| Žďár nad Sázavou
22.12.2009 14:25
theo | skóre: 15
| Rožnov ... hádej který?
22.12.2009 09:51
tsLnox | skóre: 31
| blog: Blog jednoho ukecaného Gentoolemana
| Žďár nad Sázavou
22.12.2009 14:25
theo | skóre: 15
| Rožnov ... hádej který?
nc pro ziskani obsahu stranky, ktery si pak prohlizim ve zdrojovem kodu...
To jsou mi ale ankety... :/
 22.12.2009 14:51
mikirc | skóre: 19
| blog: MikiSoft
| Vsetín
23.12.2009 12:09
|🇵🇸 | skóre: 94
| blog:
23.12.2009 14:59
stybla | skóre: 29
| Praha
22.12.2009 14:51
mikirc | skóre: 19
| blog: MikiSoft
| Vsetín
23.12.2009 12:09
|🇵🇸 | skóre: 94
| blog:
23.12.2009 14:59
stybla | skóre: 29
| Praha
 24.12.2009 21:04
Limoto | skóre: 32
| blog: Limotův blog
24.12.2009 21:04
Limoto | skóre: 32
| blog: Limotův blog
 25.12.2009 10:51
hankey | skóre: 16
26.12.2009 17:17
Amarok | skóre: 33
| blog: blogoblog
25.12.2009 10:51
hankey | skóre: 16
26.12.2009 17:17
Amarok | skóre: 33
| blog: blogoblog
links -g je rychly a po tych rokoch to cloveku ani nepride ze by mal web vypadat inak. Pre ostatne normalne stranky (asi 2%) - Seamonkey.
26.12.2009 23:29
|🇵🇸 | skóre: 94
| blog:
ISSN 1214-1267, (c) 1999-2007 Stickfish s.r.o.
 22.12.2009 09:04
22.12.2009 09:04

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}