Společnost Meta na dvoudenní konferenci Meta Connect 2025 představuje své novinky. První den byly představeny nové AI brýle: Ray-Ban Meta (Gen 2), sportovní Oakley Meta Vanguard a především Meta Ray-Ban Display s integrovaným displejem a EMG náramkem pro ovládání.
Po půl roce vývoje od vydání verze 48 bylo vydáno GNOME 49 s kódovým názvem Brescia (Mastodon). S přehrávačem videí Showtime místo Totemu a prohlížečem dokumentů Papers místo Evince. Podrobný přehled novinek i s náhledy v poznámkách k vydání a v novinkách pro vývojáře.
Open source softwarový stack ROCm (Wikipedie) pro vývoj AI a HPC na GPU od AMD byl vydán ve verzi 7.0.0. Přidána byla podpora AMD Instinct MI355X a MI350X.
Byla vydána nová verze 258 správce systému a služeb systemd (GitHub).
Byla vydána Java 25 / JDK 25. Nových vlastností (JEP - JDK Enhancement Proposal) je 18. Jedná se o LTS verzi.
Věra Pohlová před 26 lety: „Tyhle aféry každého jenom otravují. Já bych všechny ty internety a počítače zakázala“. Jde o odpověď na anketní otázku deníku Metro vydaného 17. září 1999 na téma zneužití údajů o sporožirových účtech klientů České spořitelny.
Byla publikována Výroční zpráva Blender Foundation za rok 2024 (pdf).
Byl vydán Mozilla Firefox 143.0. Přehled novinek v poznámkách k vydání a poznámkách k vydání pro vývojáře. Nově se Firefox při ukončování anonymního režimu zeptá, zda chcete smazat stažené soubory. Dialog pro povolení přístupu ke kameře zobrazuje náhled. Obzvláště užitečné při přepínání mezi více kamerami. Řešeny jsou rovněž bezpečnostní chyby. Nový Firefox 143 bude brzy k dispozici také na Flathubu a Snapcraftu.
Byla vydána betaverze Fedora Linuxu 43 (ChangeSet), tj. poslední zastávka před vydáním finální verze, která je naplánována na úterý 21. října.
Multiplatformní emulátor terminálu Ghostty byl vydán ve verzi 1.2 (𝕏, Mastodon). Přehled novinek, vylepšení a nových efektů v poznámkách k vydání.
V mnoha aplikacích je potřeba přidávat k dokumentům přílohy – ke knížce řekněme třeba obrázek obálky. Nebudeme dnes řešit, zda je výhodnější ukládat přílohy přímo do databáze nebo raději na souborový systém, a rovnou se podíváme, jak nám v tom může být CouchDB nápomocna:
$ curl -X GET http://localhost:5984/pokus/317d691f7c21937824bf9b55e1994486
{"_id":"317d691f7c21937824bf9b55e1994486","_rev":"2-fa897debf5c1a63193f121798e85b6e3",
"type":"book","author":"Dan Simmons","name":"Drood",
"genres":["fantasy","thriller","detektivka"]}
$ curl -X PUT --data-binary @drood.jpg -H "Content-Type: image/jpeg"
http://localhost:5984/pokus/317d691f7c21937824bf9b55e1994486/obalka?rev=2-fa897debf5c1a63193f121798e85b6e3
{"ok":true,"id":"317d691f7c21937824bf9b55e1994486","rev":"3-62565f7b979ad61382065c342571ba85"}
$ curl -X GET http://localhost:5984/pokus/317d691f7c21937824bf9b55e1994486/
{"_id":"317d691f7c21937824bf9b55e1994486","_rev":"3-62565f7b979ad61382065c342571ba85",
"type":"book","author":"Dan Simmons","name":"Drood", "genres":["fantasy","thriller","detektivka"],
"_attachments":{"obalka":{"stub":true,"content_type":"image/jpeg","length":8778,"revpos":3}}}
A – to je k přílohám všechno. Pozor na to, že při ukládání je potřeba zadat správný Content Type, protože právě s ním ho pak bude CouchDB posílat.
Zatím jsme pořád jenom ukládali data, co takhle je začít zobrazovat? Myslím skutečnému uživateli, třeba jako HTML. A když už se s databází bavíme po HTTP, nemohla by nám to HTML taky servírovat ona? Představme si, inu…
function(doc, req) {
provides('html', function() {
// jako necislovany HTML seznam (<ul>) vyrenderuje pole list,
// renderFunction je nepovinna funkce s jednim parametrem
// volana na kazdem prvku pole list, jejiz navratova hodnota
// je pouzita jako obsah elementu <li>; neni-li renderFunction
// zadana, pouziji se jednotlive prvky pole list primo
function htmlList(list, renderFunction) {
if (!renderFunction) {
var renderFunction = function(item) { return item; }
}
var result = '';
if (list) {
result = '<ul>';
for (var item in list) {
result += '<li>' + renderFunction(list[item]) + '</li>';
}
result += '</ul>';
}
return result;
}
var obalka = '';
if (doc._attachments && doc._attachments.obalka) {
obalka = '<img src=/pokus/' + doc._id + '/obalka>';
}
return '<h1>' + doc.name + '</h1><h2>' + doc.author + '</h2>'
+ obalka + htmlList(doc.genres);
});
}
Zobrazovací funkce… řekněme poněkud ošklivá, ale pro ilustraci postačí. Zobrazovací funkce se, stejně jako pohledy, ukládají do design dokumentů. Pohledy lze relativně komfortně editovat ve Futonu, ale další funkce bohužel nikoliv. Musíme na to tedy složitěji. V dokumentu _design/books vytvoříme položku shows. Bude to mapa s jedinou položku, jejímž klíčem bude text book_detail. Hodnotou bude řetězec obsahující výše uvedenou funkci (vyhoďte komentáře a všechna odřádkování!). A pak už jenom:
http://localhost:5984/pokus/_design/books/_show/book_detail/317d691f7c21937824bf9b55e1994486
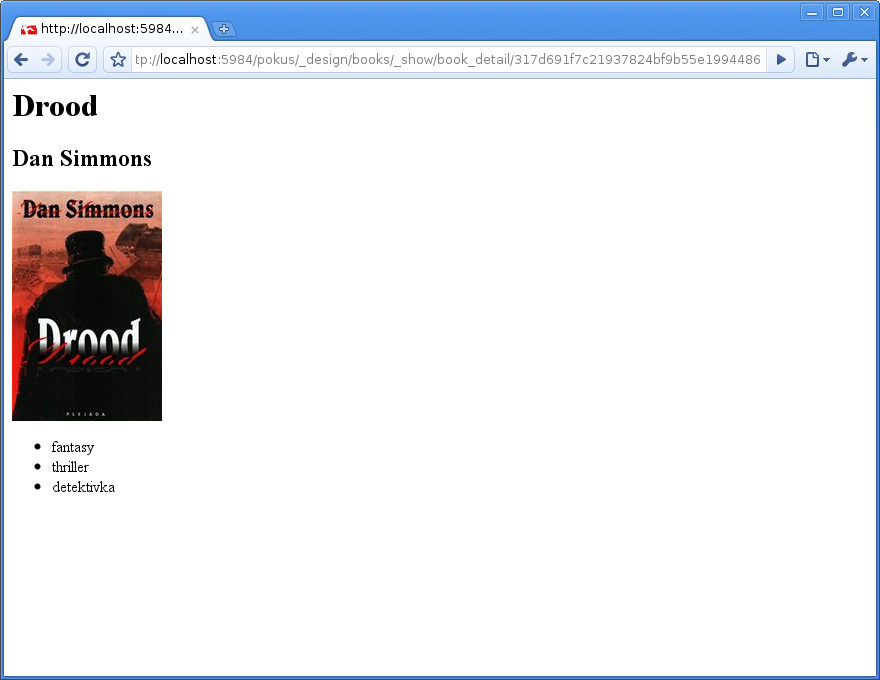
Stejně jako dokumenty lze zobrazovat i pohledy – obvykle výpisy dokumentů. Zkusíme do HTML vyrenderovat seznam knih podle žánrů, který jsme viděli minule. API je v tomhle případě poněkud odlišné:
function(head, req) {
start({'headers': {'Content-Type': 'text/html; charset=utf-8'}});
send('<h1>Knihy podle žánrů</h1>');
var row;
var lastGenre;
while (row = getRow()) {
var genre = row.key;
if (genre != lastGenre) {
// poprve neukoncovat <ul>
if (lastGenre != null) { send('</ul>'); }
send('<h2>' + genre + '</h2><ul>');
lastGenre = genre;
}
send('<li><a href=/pokus/_design/books/_show/book_detail/'
+ row.id + '>' + row.value + '</a></li>');
}
// ukoncit posledni <ul>, ale jen tehdy, pokud nejake opravdu bylo vypsano
if (lastGenre != null) { send('</ul>'); }
}
V dokumetu _design/books vytvoříme položku lists, opět jako mapu s jedinou položku, jejímž klíčem bude tentokrát text books_by_genre. Hodnotou pochopitelně řetězec obsahující výše uvedenou funkci. Výsledek najdeme na http://localhost:5984/pokus/_design/books/_list/books_by_genre/by_genre, kde předposlední parametr books_by_genre je název zobrazovací funkce a poslední parametr by_genre je název pohledu (ve stejném design dokumentu):
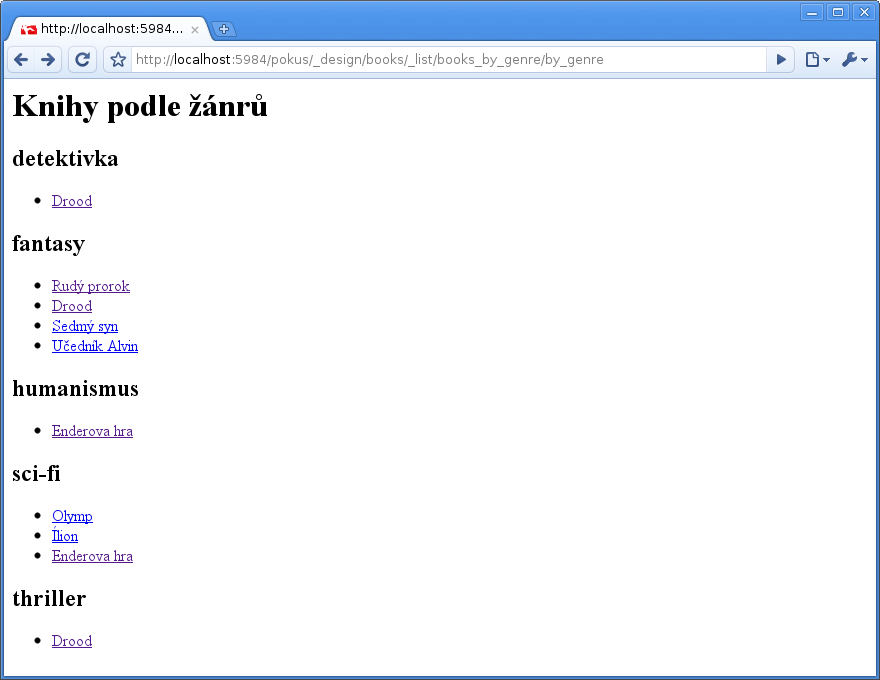
Zobrazovacích funkcí, pro dokumenty i pro pohledy, může být v mapách shows a lists uloženo víc, takže lze takto generovat třeba RSS feed nebo libovolné XML pro účely exportu. Pozor na to, že CouchDB je v případě syntaktických i sémantických chyb ve skriptu pekelně skoupá na slovo. Mnohem příjemnější prostředí pro vývoj aplikací v CouchDB poskytuje CouchApp (včetně šablonování atd.), ale protože to je jednak mimo záběr našeho povídání a jednak to nepovažuji za dobrou praktiku, nebudeme se tím dále zabývat – více se můžete dozvědět na wiki.
Poznatek: Generovat HTML v databázi je sice šílenství, ale proveditelné. Takto lze uložit do databáze celou aplikaci, což může mít jisté výhody.
Stejně, jako jsme do design dokumentu uložili zobrazovací funkce, lze uložit i funkci pro validaci – do každého dokumentu ovšem pouze jednu. Do dokumentu přidáme položku validate_doc_update s textovou hodnotou. Řekněme, že chceme vynutit, aby každá kniha byla zařazena aspoň do jednoho žánru:
function(newDoc, oldDoc, userCtx) {
if (newDoc.type == 'book') {
if (!newDoc.genres || newDoc.genres.length < 1) {
throw({forbidden: 'at least one genre required!'});
}
}
}
Při každém uložení dokumentu se spustí všechny validační funkce, které v databázi jsou, a všechny musí projít. Pokud vám to trochu připomíná triggery, tak se nepletete. Jak to vypadá?
$ curl -X PUT -d '{"type": "book", "author": "Dan Simmons", "name": "Kantos Hyperionu"}'
http://localhost:5984/pokus/kantos-hyperionu
{"error":"forbidden","reason":"at least one genre required!"}
$ curl -X PUT -d '{"type": "book", "author": "Dan Simmons", "name": "Kantos Hyperionu",
"genres": ["sci-fi", "neprekonatelne"]}' http://localhost:5984/pokus/kantos-hyperionu
{"ok":true,"id":"kantos-hyperionu","rev":"1-db48ca2a29a6b50ad59cc1f7d3962326"}
Lze validovat i mazání, dokument před smazáním lze poznat takto: if (newDoc._deleted) { … }.
Stejně jako minule se ve druhé půlce budeme věnovat jinému tématu, zato však patřičně zajímavějšímu (složitějšímu). Asi bychom chtěli přidávat ke knihám komentáře. Co třeba takto?
{"type":"book","author":"Dan Simmons","name":"Drood", "comments": [
{"author": "Ladicek", "content": "Uff, ten dickensovský jazyk mi dává zabrat! Opět úplně jiná tvář neúnavného génia současné fantastiky."},
{"author": "http://neviditelnypes.lidovky.cz/recenze-dan-simmons-drood-0y6-/p_scifi.asp?c=A091203_215429_p_scifi_hpe", "content": "Celkově je Drood velmi dobrá kniha…"}
]}
To, prosím pěkně, není vůbec žádný problém. Tedy jeden problém by vlastně vyvstat mohl: Pokud budou komentáře přibývat velmi často, může docházet ke konfliktům (Minulý díl? Revize dokumentu? Současný přístup více uživatelů?). To lze řešit několika způsoby, jedním z nich je v případě konfliktu načíst aktuální verzi dokumentu a zkusit akci znovu. Na webu zabývajícím se kvalitní fantastikou ovšem problém příliš mnoha čtenářů (a ještě k tomu komentujících) není příliš pravděpodobný :-), takže bychom u tohoto řešení mohli klidně zůstat. Výhodou je zcela triviální vypsání komentářů na stránce knížky.
Poznatek: Dokumenty, které obsahují další (pod)dokumenty, nejsou nic špatného. V mnoha případech mohou být lepším řešením než snažit se emulovat joiny (viz níže).
Druhým způsobem je uložit každý komentář do samostatného dokumentu a komentáře s knihami pak nějakým způsobem propojit. Jak na to, si ukážeme na slíbeném propojení knih a autorů. Minule jsme vyslovili podezření, zda by nebylo lepší, kdyby byl autor uložen samostatně a v knize by na něj byl jenom odkaz. Záleží samozřejmě na tom, co má aplikace dělat, ale zdaleka nejsou výjimkou situace, kdy zadání zní „autory není potřeba řešit, jen u knih zobrazovat jejich jména a vyhledávat podle nich“, po půlroce lehce poupravené na „ty autory přece jenom budeme muset řešit“. Pokud se držíme rady nedělejte nic, co se po vás teď nechce, po zmíněném půlroce máme problém.
A nebo ne?
$ curl -X POST -d '{"type": "author", "name": "Dan Simmons", "birth_date": "1948-04-04"}'
http://localhost:5984/pokus
{"ok":true,"id":"04d61059857c9fb3a254e914e2f5736a","rev":"1-2155d1ec9d816f4d1b74c77fc72072d5"}
Dobře, tím se ještě nic nezměnilo.
$ curl -X PUT -d '{"_id":"317d691f7c21937824bf9b55e1994486","_rev":"3-62565f7b979ad61382065c342571ba85",
"type":"book","author":"Dan Simmons","name":"Drood","genres":["fantasy","thriller","detektivka"],
"author_ref": "04d61059857c9fb3a254e914e2f5736a"}'
http://localhost:5984/pokus/317d691f7c21937824bf9b55e1994486
{"ok":true,"id":"317d691f7c21937824bf9b55e1994486","rev":"4-2c34edf7d54947bc7095d634b2b85487"}
Á… ani tím se nic nezměnilo, aplikace může fungovat pořád dál postaru, a teprve když si usmyslím, může začít používat i nová data (a to klidně postupně, jak budou nová data přibývat).
Jak teď ale na to, když chci na jeden požadavek do databáze získat autora a všechny jeho knihy? CouchDB přece nemá joiny! Pohleďte – trik. Tedy lépe řečeno, doporučená praxe.
// map
function(doc) {
if (doc.type == "author") {
emit([doc._id, 0], doc);
} else if (doc.type == "book" && doc.author_ref) {
emit([doc.author_ref, 1], doc);
}
}
(Emitovat v mapovací funkci celé dokumenty je sice intuitivní a názorné, ale může to být i poněkud nevhodné. Už víme, že s každou dvojicí <klíč; hodnota> dostaneme při čtení pohledu ještě ID příslušného dokumentu, a použitím parametru include_docs=true snadno získáme i samotný dokument. Emitovat pak stačí třeba hodnoty null; pohled tak neobsahuje zbytečně data, která lze najít jinde. Vizte též wiki.)
Klíče, které vystupují z mapovací funkce, mohou být i strukturované. CouchDB poměrně podrobně definuje, jak se JSONové struktury řadí, a protože z minula víme, že dokumenty jsou v pohledu řazeny vždy podle svého klíče, pak vhodným omezením (parametry startkey a endkey) snadno získáme množinu dokumentů, v níž ten první je vždy autor a ty ostatní jsou všechny jeho knihy (téhle technice se říká view collation). Mějme tedy u knih odkazy na autora (to už byste měli zvládnout sami). Když pak uložíme výše definovaný pohled do dokumentu _design/authors pod názvem author_and_books, lze se ptát třeba takto:
$ curl -X GET -g 'http://localhost:5984/pokus/_design/authors/_view/author_and_books?startkey=["04d61059857c9fb3a254e914e2f5736a"]&endkey=["04d61059857c9fb3a254e914e2f5736a",2]'
{"total_rows":9,"offset":0,"rows":[
{"id":"04d61059857c9fb3a254e914e2f5736a","key":["04d61059857c9fb3a254e914e2f5736a",0],
"value":{"_id":"04d61059857c9fb3a254e914e2f5736a","_rev":"1-2155d1ec9d816f4d1b74c77fc72072d5",
"type":"author","name":"Dan Simmons","birth_date":"1948-04-04"}},
{"id":"0ddd69f92f541e27b554f3ebed1d87a3","key":["04d61059857c9fb3a254e914e2f5736a",1],
"value":{"_id":"0ddd69f92f541e27b554f3ebed1d87a3","_rev":"2-dd5bacbaac5a983b6146f00a099f63b7",
"type":"book","author":"Dan Simmons","name":"Olymp","genres":["sci-fi"],
"author_ref":"04d61059857c9fb3a254e914e2f5736a"}},
{"id":"317d691f7c21937824bf9b55e1994486","key":["04d61059857c9fb3a254e914e2f5736a",1],
"value":{"_id":"317d691f7c21937824bf9b55e1994486","_rev":"4-2c34edf7d54947bc7095d634b2b85487",
"type":"book","author":"Dan Simmons","name":"Drood","genres":["fantasy","thriller","detektivka"],
"author_ref":"04d61059857c9fb3a254e914e2f5736a"}},
{"id":"4ac9d40eff110178bfbb73d0e2c808bc","key":["04d61059857c9fb3a254e914e2f5736a",1],
"value":{"_id":"4ac9d40eff110178bfbb73d0e2c808bc","_rev":"2-86a463c5f826149a16f609fe3bbaa351",
"type":"book","author":"Dan Simmons","name":"\u00cdlion","genres":["sci-fi"],
"author_ref":"04d61059857c9fb3a254e914e2f5736a"}}
]}
Laskavý čtenář si může za domácí cvičení seřadit knihy například podle jejich názvu, případně tento pohled rozšířit i na autory, kteří nejsou uloženi samostatně, ale jen v podobě jména u dokumentu knihy.
Poznatek: Strukturované klíče emitované funkcí map lze s výhodou použít k „joinování“.
To je samozřejmě přístup relačních databází. Zde jsme ho použili, abychom nemuseli měnit strukturu dat – další možné použití, jak již je uvedeno výše, by bylo například u komentářů pro zajištění, že nebudou nastávat konflikty. Kdybychom ukládali autory už od začátku, mohli bychom na to jít jinak:
{"type": "author", "name": "Dan Simmons", "birth_date": "1948-04-04", "books": [
{"id": "…", "name": "Drood"},
{"id": "…", "name": "Ílion"},
{"id": "…", "name": "Olymp"}
]}
S touto strukturou získáme snadný výpis knih jednoho autora a pro výpis detailu knihy (proto tam jsou ta ID) si vytvoříme jednoduchý pohled. Taky možnost. A abychom čtenáře nepřipravili o všechna překvapení, jedno zajímavé téma k zamyšlení na dlouhé zimní večery (pořád ještě jsou): O-ou, co když má kniha víc autorů? Realita: Mnoho systémů to vůbec neřeší a je třeba v nich vytvářet „virtuální“ autory.
Pro dnešek už je to vše, v posledním díle si ukážeme, kterak vměstnat CMS na pár řádek javascriptového kódu v prohlížeči, který přes AJAX komunikuje přímo s databází. Krátkým zhodnocením bychom pak naši sérii věnovanou CouchDB ukončili.
Nástroje: Tisk bez diskuse
Tiskni
Sdílej:
![]()
![]()
![]()
![]()
![]()
![]()
 Vtip je v tom, že záznamy lezou z mapovací funkce seřazené, takže už je není potřeba "dávat k sobě". Stačí se vhodně zeptat.
Vtip je v tom, že záznamy lezou z mapovací funkce seřazené, takže už je není potřeba "dávat k sobě". Stačí se vhodně zeptat.
SELECT autor.jmeno FROM autor NATURAL JOIN kniha
GROUP BY autor.id
HAVING COUNT(kniha.jazyk) > 2
SELECT * FROM autor NATURAL JOIN kniha WHERE 1800 < autor.rok_narozeni < 1900
Konkrétně k tomu příkladu: chcete autory knih napsaných ve více jazycích, chápu to správně? Když budete mít jméno autora přímo u knihy ({"type": "book", "name": "Ílion (dvojjazyčné vydání)", "author": "Dan Simmons", "langs": ["čeština", "angličtina"]}), tak je to jednoduché:
// map
function(doc) {
if (doc.type == "book") {
emit(length(doc.langs), doc.author);
}
}
Pro knihy ve dvou a více jazycích se pak zeptáte nějak takhle: http://localhost:5984/pokus/_design/books/_view/author_by_langs_count?startkey=2. To samozřejmě dostanete každého autora tolikrát, kolik takových knih má. Dalo by se to doplnit nějakou redukcí, ale na tu si z hlavy netroufám
Pokud jméno autora u knihy nemáte, pak to lze s drobnou pomocí z aplikace na dva requesty taky snadno: z obdobného pohledu jako výše dostanete ID autorů a pak jedním POSTem na http://localhost:5984/pokus/_all_docs dostanete autory (vizte http://wiki.apache.org/couchdb/HTTP_Bulk_Document_API).
To slovo join jsem asi neměl používat ani v uvozovkách, skutečně to není joinování ani unionování a přemýšlet nad dokumentovou databází v pojmech ze světa SQL nemůže vést k ničemu dobrému. Pokud potřebujete takovéhle dotazy často (a z nějakého jiného důvodu opravdu chcete používat dokumentovou databázi), pak je obvyklé si potřebné hodnoty předpočítávat.
struct word { char* name; /*void* data;*/ }
words []={ {"abracadabra"},
{"hotenpotem"},
{"brekeke"},
{"tamten"}
};
char *substrings[]={
"bra", "bre", "ten", "tam"
};
for(char** fac=substrings; fac<substrings+sizeof(substrings)/sizeof(*substrings);fac++) {
int cnt=0;
for(word* w=words; w<words+sizeof(words)/sizeof(*words);w++)
if(strstr(w->name, *fac))
cnt++;
printf("%s %d", *fac, cnt);
}
Uznávám, že možnosti dotazování jsou v CouchDB chudé (což nemusí být nutně na závadu, a couchdb-lucene spoustu požadavků řeší) – lidem, kterým by chyběly dotazovací možnosti SQL, by se mohlo víc líbit MongoDB (o dotazování třeba tady).
 12.2.2010 16:52
okbob | skóre: 30
| blog: systemakuv_blog
| Benešov
12.2.2010 16:52
okbob | skóre: 30
| blog: systemakuv_blog
| Benešov
 AbcLinuxu.cz
AbcLinuxu.cz ITBiz.cz
ITBiz.cz HDmag.cz
HDmag.cz AbcPráce.cz
AbcPráce.cz