Poštovní klient Thunderbird byl vydán v nové verzi 145.0. Podporuje DNS přes HTTPS nebo Microsoft Exchange skrze Exchange Web Services. Ukončena byla podpora 32bitového Thunderbirdu pro Linux.
U příležitosti státního svátku 17. listopadu probíhá na Steamu i GOG.com již šestý ročník Czech & Slovak Games Week aneb týdenní oslava a také slevová akce českých a slovenských počítačových her.
Byla vydána nová verze 9.19 z Debianu vycházející linuxové distribuce DietPi pro (nejenom) jednodeskové počítače. Přehled novinek v poznámkách k vydání. Vypíchnout lze například nový balíček BirdNET-Go, tj. AI řešení pro nepřetržité monitorování a identifikaci ptáků.
Byla vydána nová verze 3.38 frameworku Flutter (Wikipedie) pro vývoj mobilních, webových i desktopových aplikací a nová verze 3.10 souvisejícího programovacího jazyka Dart (Wikipedie).
Organizace Apache Software Foundation (ASF) vydala verzi 28 integrovaného vývojového prostředí a vývojové platformy napsané v Javě NetBeans (Wikipedie). Přehled novinek na GitHubu. Instalovat lze také ze Snapcraftu a Flathubu.
Byl vydán Debian 13.2, tj. druhá opravná verze Debianu 13 s kódovým názvem Trixie. Řešeny jsou především bezpečnostní problémy, ale také několik vážných chyb. Instalační média Debianu 13 lze samozřejmě nadále k instalaci používat. Po instalaci stačí systém aktualizovat.
Google představil platformu Code Wiki pro rychlejší porozumění existujícímu kódu. Code Wiki pomocí AI Gemini udržuje průběžně aktualizovanou strukturovanou wiki pro softwarové repozitáře. Zatím jenom pro veřejné. V plánu je rozšíření Gemini CLI také pro soukromé a interní repozitáře.
V přihlašovací obrazovce LightDM KDE (lightdm-kde-greeter) byla nalezena a již opravena eskalace práv (CVE-2025-62876). Detaily v příspěvku na blogu SUSE Security.
Byla vydána nová verze 7.2 živé linuxové distribuce Tails (The Amnesic Incognito Live System), jež klade důraz na ochranu soukromí uživatelů a anonymitu. Tor Browser byl povýšen na verzi 15.0.1. Další novinky v příslušném seznamu.
Česká národní banka (ČNB) nakoupila digitální aktiva založená na blockchainu za milion dolarů (20,9 milionu korun). Na vytvořeném testovacím portfoliu, jehož součástí jsou bitcoin, stablecoiny navázané na dolar a tokenizované depozitum, chce získat praktickou zkušenost s držením digitálních aktiv. Portfolio nebude součástí devizových rezerv, uvedla dnes ČNB v tiskové zprávě.
Půjdeme na to čistě prakticky, teorii si můžeme nechat na později. CouchDB je dnes ve verzi 0.10.1, kterou najdete kupříkladu v Debianu unstable. V testingu je 0.10.0, což nám postačí, takže např. aptitude install couchdb a s chutí do toho; uživatelé jiných distribucí si snad poradí sami, případně se obrátí na wiki. Lehký přehled o vnitřnostech získáte třeba v technical overview – pro nás to teď nebude nutné, ale zájemcům vřele doporučuji. CouchDB se mimochodem používá například jako lokální úložiště dat pro Ubuntu One (viz též desktopcouch), což znamená, že vydáním Ubuntu 9.10 se zvýšil podíl instalací Erlangu na osobních počítačích minimálně o stovky procent :-)
CouchDB má jediné API: JSON přenášený přes HTTP. Skutečně, je to tak, můžete si pohrát třeba z příkazové řádky a HTTP klienta najdete snad pro jakýkoliv programovací jazyk. Server poslouchá na portu 5984, takže pro seznámení:
$ curl -X GET http://localhost:5984/
{"couchdb":"Welcome","version":"0.10.1"}
$ curl -X GET http://localhost:5984/_all_dbs
[]
Aha, ještě žádnou databázi nemáme vytvořenou! To snadno napravíme. API je RESTové, vytvořit novou kolekci objektů znamená volat PUT. A když jsme v tom, smazání je pochopitelně DELETE.
$ curl -X PUT http://localhost:5984/pokus
{"ok":true}
$ curl -X GET http://localhost:5984/_all_dbs
["pokus"]
$ curl -X DELETE http://localhost:5984/pokus
{"ok":true}
$ curl -X GET http://localhost:5984/_all_dbs
[]
Poznatek: „systémové“ identifikátory začínají podtržítkem.
Na ten DELETE na chvilku zapomeňme, řekněme, že tedy máme databázi pokus. Jen tak na hraní. Mějme dokument… nějaký pěkný, třeba tenhle:
{"type": "book", "author": "Dan Simmons", "name": "Drood"}
Co s ním?
$ curl -X POST -d '{"type": "book", "author": "Dan Simmons", "name": "Drood"}' http://localhost:5984/pokus
{"ok":true,"id":"317d691f7c21937824bf9b55e1994486","rev":"1-4ffc368db414b81bf524c6d4c421b93f"}
POST volaný na kolekci znamená vytvořit v ní nový objekt a automaticky mu přiřadit ID. Což se také stalo:
$ curl -X GET http://localhost:5984/pokus/317d691f7c21937824bf9b55e1994486
{"_id":"317d691f7c21937824bf9b55e1994486","_rev":"1-4ffc368db414b81bf524c6d4c421b93f",
"type":"book","author":"Dan Simmons","name":"Drood"}
(Pro snazší čtení odřádkovávám a odsazuji dvěma mezerami.)
Now come on, it can't be that simple, can it? Poznatek: CouchDB patří mezi dokumentové databáze, kterým není nutné předem říkat, jaká bude struktura ukládaných dat. Datové schéma je čistě věcí aplikace.
Řekněme, že bychom chtěli ukládat i žánrové zařazení. Nebo spíš žánrová zařazení, těch může být vždycky víc. Aktualizace existujícího objektu je PUT:
$ curl -X PUT -d '{"_id":"317d691f7c21937824bf9b55e1994486","_rev":"1-4ffc368db414b81bf524c6d4c421b93f",
"type":"book","author":"Dan Simmons","name":"Drood", "genres": ["fantasy", "thriller", "detektivka"]}'
http://localhost:5984/pokus/317d691f7c21937824bf9b55e1994486
{"ok":true,"id":"317d691f7c21937824bf9b55e1994486","rev":"2-fa897debf5c1a63193f121798e85b6e3"}
Nešálí vás zrak, jako jednu z položek jsem opravdu uložil seznam. Když se mi zlíbí, do toho seznamu si můžu klidně uložit třeba další dokumenty (mapy, hashe), není v tom problém. A pokud nevadí tohle – neměly by ty žánry být někde v číselníku a u knihy jenom odkazy do něj? Hm, člověk nikdy neví, tak prozatím řekněme, že žánry jsou pro nás něco jako tagy na webu a uvidíme, co s nimi dál.
Ostatně, když jsme u toho, co ten autor? Ten by přece určitě měl být uložený samostatně a u knihy by na něj měl být jen odkaz, ne? Přijde na to – v jednom mém oblíbeném webovém knihkupectví například vůbec nemají stránky autorů a umí podle jejich jmen jen vyhledávat.
A protože v tuhle chvíli z otázek až oči přecházejí, na chvilku zpomalíme a podíváme se na záhadné položky _id a _rev. _id je, inu, ID, jednoznačný klíč, podle kterého lze dokument najít. ID si můžu nechat generovat od CouchDB při vytváření nových dokumentů, jako tomu bylo výše (v takovém případě se vyrobí nové UUID), nebo si ho zadat sám:
$ curl -X PUT -d '{"type": "book", "author": "Orson Scott Card", "name": "Enderova hra",
"genres": ["sci-fi", "humanismus"]}' http://localhost:5984/pokus/enderova-hra
{"ok":true,"id":"enderova-hra","rev":"1-0b1b7e88639474892f4eb950bf139e27"}
$ curl -X GET http://localhost:5984/pokus/enderova-hra
{"_id":"enderova-hra","_rev":"1-0b1b7e88639474892f4eb950bf139e27","type":"book",
"author":"Orson Scott Card","name":"Enderova hra","genres":["sci-fi","humanismus"]}
Automatické generování UUIDů je víc než vhodné minimálně v případě, kdy je databáze „distribuovaná“ (CouchDB disponuje hezkou funkcí replikace s řešením konfliktů, ale tím se teď zabývat nebudeme). Naopak číselná ID v rostoucí posloupnosti mohou být pro databázi příjemnější kvůli způsobu, jakým jsou ukládána a vyhledávána data (už jsem říkal, že základní a vlastně jedinou diskovou strukturou CouchDB je B-strom?).
A co to _rev? Jistě, je to od slova revision, což ovšem neznamená, že by se CouchDB dala použít jako verzovací systém. Číslo revize slouží k řešení současného přístupu k datům: Už výše jsme viděli, že když chci dokument změnit, musím ho poslat včetně položky _rev. CouchDB povolí zápis jen tehdy, pokud se číslo revize v ukládaném dokumentu shoduje s aktuálně platným číslem revize v databázi.
$ curl -X PUT -d '{"_id":"enderova-hra","_rev":"1-0b1b7e88639474892f4eb950bf139e27",
"type":"book","author":"Orson Scott Card","name":"Enderova hra","genres":["sci-fi","humanismus"],
"stars": "5/5"}' http://localhost:5984/pokus/enderova-hra
{"ok":true,"id":"enderova-hra","rev":"2-823eb2f692da425220f17b96b231082b"}
$ curl -X PUT -d '{"_id":"enderova-hra","_rev":"1-0b1b7e88639474892f4eb950bf139e27",
"type":"book","author":"Orson Scott Card","name":"Enderova hra","genres":["sci-fi","humanismus"],
"stars": "6/5"}' http://localhost:5984/pokus/enderova-hra
{"error":"conflict","reason":"Document update conflict."}
$ curl -X PUT -d '{"_id":"enderova-hra","_rev":"2-823eb2f692da425220f17b96b231082b",
"type":"book","author":"Orson Scott Card","name":"Enderova hra","genres":["sci-fi","humanismus"],
"stars": "6/5"}' http://localhost:5984/pokus/enderova-hra
{"ok":true,"id":"enderova-hra","rev":"3-1be8a2371b004f49b284061433ba9b48"}
Staré revize je stále možné získat, ovšem pouze tehdy, pokud jsou v databázi ještě dostupné.
$ curl -X GET http://localhost:5984/pokus/enderova-hra?rev=1-0b1b7e88639474892f4eb950bf139e27
{"_id":"enderova-hra","_rev":"1-0b1b7e88639474892f4eb950bf139e27","type":"book",
"author":"Orson Scott Card","name":"Enderova hra","genres":["sci-fi","humanismus"]}
$ curl -X POST http://localhost:5984/pokus/_compact
{"ok":true}
$ curl -X GET http://localhost:5984/pokus/enderova-hra?rev=1-0b1b7e88639474892f4eb950bf139e27
{"error":"not_found","reason":"missing"}
Poznatek: CouchDB používá multigenerační architekturu a řešení souběžných přístupů je tedy optimistické. Garbage collector (compact) je, pokud vím, nutné volat ručně (viz též wiki) a po dobu jeho běhu lze databázi normálně používat.
Bližší informace o revizích dokumentu získáte použitím parametrů revs=true nebo revs_info=true:
$ curl -X GET http://localhost:5984/pokus/enderova-hra?revs_info=true
{"_id":"enderova-hra","_rev":"3-1be8a2371b004f49b284061433ba9b48","type":"book",
"author":"Orson Scott Card","name":"Enderova hra","genres":["sci-fi","humanismus"],
"stars":"6/5","_revs_info":[
{"rev":"3-1be8a2371b004f49b284061433ba9b48","status":"available"},
{"rev":"2-823eb2f692da425220f17b96b231082b","status":"missing"},
{"rev":"1-0b1b7e88639474892f4eb950bf139e27","status":"missing"}
]}
Obdobně funguje mazání: Je to vlastně vytvoření nové revize.
$ curl -X DELETE http://localhost:5984/pokus/enderova-hra
{"error":"conflict","reason":"Document update conflict."}
$ curl -X DELETE http://localhost:5984/pokus/enderova-hra?rev=3-1be8a2371b004f49b284061433ba9b48
{"ok":true,"id":"enderova-hra","rev":"4-d71e7ad84ec3801b0504b739e925e8b7"}
$ curl -X GET http://localhost:5984/pokus/enderova-hra
{"error":"not_found","reason":"deleted"}
Nu, takže základní operace s dokumenty máme za sebou, co dál? Ovšem, dotazy. SQL? Ale kdeže, JavaScript! JavaScript a MapReduce. Přidejme si nejdřív pár dalších knih, ať je to zajímavější:
$ curl -X POST -d '{"type": "book", "author": "Dan Simmons", "name": "Ílion",
"genres": ["sci-fi"]}' http://localhost:5984/pokus
{"ok":true,"id":"4ac9d40eff110178bfbb73d0e2c808bc","rev":"1-987ed35e7539446335290fb6ef1ed909"}
$ curl -X POST -d '{"type": "book", "author": "Dan Simmons", "name": "Olymp",
"genres": ["sci-fi"]}' http://localhost:5984/pokus
{"ok":true,"id":"0ddd69f92f541e27b554f3ebed1d87a3","rev":"1-b4e1ebabd59a3bb677f1d00cb3a2c935"}
$ curl -X POST -d '{"type": "book", "author": "Orson Scott Card", "name": "Enderova hra",
"genres": ["sci-fi", "humanismus"]}' http://localhost:5984/pokus
{"ok":true,"id":"59403880473a6bda402a21d64ad8c4cf","rev":"1-0b1b7e88639474892f4eb950bf139e27"}
$ curl -X POST -d '{"type": "book", "author": "Orson Scott Card", "name": "Sedmý syn",
"genres": ["fantasy"]}' http://localhost:5984/pokus
{"ok":true,"id":"7e3891e4e1b5cf147137a0b0d609420e","rev":"1-ce3f425332eff2edd000b059a1aee8b9"}
$ curl -X POST -d '{"type": "book", "author": "Orson Scott Card", "name": "Rudý prorok",
"genres": ["fantasy"]}' http://localhost:5984/pokus
{"ok":true,"id":"309a09f8ea790c232472cb66049fa2dd","rev":"1-9a1af3cbc31c3b1a3dc5dacc131a9003"}
$ curl -X POST -d '{"type": "book", "author": "Orson Scott Card", "name": "Učedník Alvin",
"genres": ["fantasy"]}' http://localhost:5984/pokus
{"ok":true,"id":"82df2dd330d5c426d7509789fdda9bb8","rev":"1-42c1f75fc1046ed1c458b0b670bb61ef"}
Pozn.: Kódování znaků musí být utf-8, případně lze používat klasické unicode escape sekvence \uNNNN.
A co dál? Třeba jména knih podle žánrů:
// map
function(doc) {
if (doc.type == "book" && doc.genres) {
for (var genre in doc.genres) {
emit(doc.genres[genre], doc.name);
}
}
}
Hodně… neobvyklé, to přinejmenším. Pojďme se na to podívat podrobněji: CouchDB má pohledy. Ty pohledy jsou definovány jednou nebo dvěma funkcemi v programovacím jazyce (konkrétně v JavaScriptu, ale rozhraní je obecné a existuje podpora pro další jazyky, viz wiki). Názvy těch funkcí pocházejí z funkcionálního světa: map a reduce, a nesou si z něj ještě jednu vlastnost: Musí být idempotentní. To zjednodušeně znamená, že nesmí nic změnit (pro jeden dokument musí za každých okolností vrátit tu samou hodnotu, nepřichází v úvahu ani žádné globální proměnné), a to zase zjednodušeně vede ke krásným důsledkům: Pohledy lze počítat inkrementálně a paralelně. Funkce map je povinná a slouží k filtrování a transformování. Je zavolána pro každý dokument v databázi a sama každým voláním emit generuje jednu položku pohledu: Dvojici <klíč; hodnota> (v příkladu výše <žánr; název knihy>). Funkce reduce je nepovinná, takže ji na chviličku vynecháme. Výsledky se ukládají na disk (takže ten pohled je vlastně materializovaný), a to vždy seřazené podle klíče (takže je to vlastně i index).
Teď jak tedy tu funkci do databáze dostat. Z řádky už mě to nebaví, takže si v prohlížeči otevřu http://localhost:5984/_utils, kde se nachází Futon, webové GUI ke CouchDB. Futon je z velké části javascriptová aplikace, s CouchDB komunikuje AJAXem stejným způsobem, jako jsme si to předvedli výše. Vlezu do databáze pokus a vpravo nahoře zvolím View: Temporary view… Do pole Map Function vložím kód uvedený výše a tlačítkem Run si můžu hned zobrazit výsledky:
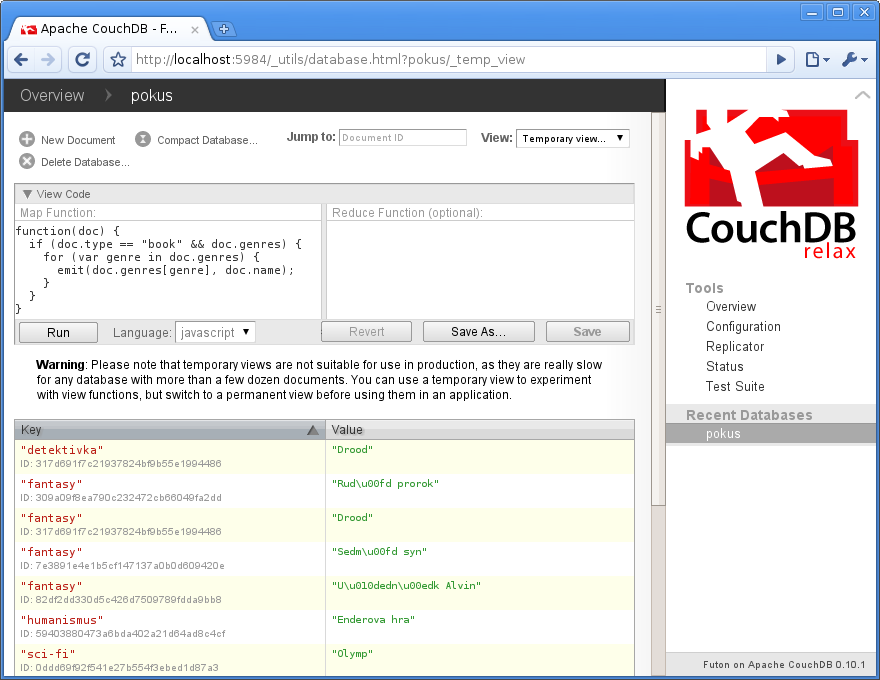
To je dočasný pohled, ten ještě není uložený na disku a pokaždé se počítá znovu. Tak tedy Save As…, Design Document: _design/books, View Name: by_genre a Save. Když pak opět vpravo nahoře zvolím View: All documents, vidím, že v databázi vznikl nový dokument s ID _design/books. Zkuste se podívat na jeho obsah, případně pod záložkou Source se skrývá čistý JSON.
$ curl -X GET http://localhost:5984/pokus/_design/books/_view/by_genre
{"total_rows":10,"offset":0,"rows":[
{"id":"317d691f7c21937824bf9b55e1994486","key":"detektivka","value":"Drood"},
{"id":"309a09f8ea790c232472cb66049fa2dd","key":"fantasy","value":"Rud\u00fd prorok"},
{"id":"317d691f7c21937824bf9b55e1994486","key":"fantasy","value":"Drood"},
{"id":"7e3891e4e1b5cf147137a0b0d609420e","key":"fantasy","value":"Sedm\u00fd syn"},
{"id":"82df2dd330d5c426d7509789fdda9bb8","key":"fantasy","value":"U\u010dedn\u00edk Alvin"},
{"id":"59403880473a6bda402a21d64ad8c4cf","key":"humanismus","value":"Enderova hra"},
{"id":"0ddd69f92f541e27b554f3ebed1d87a3","key":"sci-fi","value":"Olymp"},
{"id":"4ac9d40eff110178bfbb73d0e2c808bc","key":"sci-fi","value":"\u00cdlion"},
{"id":"59403880473a6bda402a21d64ad8c4cf","key":"sci-fi","value":"Enderova hra"},
{"id":"317d691f7c21937824bf9b55e1994486","key":"thriller","value":"Drood"}
]}
$ curl -X GET 'http://localhost:5984/pokus/_design/books/_view/by_genre?key="sci-fi"'
{"total_rows":10,"offset":6,"rows":[
{"id":"0ddd69f92f541e27b554f3ebed1d87a3","key":"sci-fi","value":"Olymp"},
{"id":"4ac9d40eff110178bfbb73d0e2c808bc","key":"sci-fi","value":"\u00cdlion"},
{"id":"59403880473a6bda402a21d64ad8c4cf","key":"sci-fi","value":"Enderova hra"}
]}
$ curl -X GET 'http://localhost:5984/pokus/_design/books/_view/by_genre?startkey="a"&endkey="n"'
{"total_rows":10,"offset":0,"rows":[
{"id":"317d691f7c21937824bf9b55e1994486","key":"detektivka","value":"Drood"},
{"id":"309a09f8ea790c232472cb66049fa2dd","key":"fantasy","value":"Rud\u00fd prorok"},
{"id":"317d691f7c21937824bf9b55e1994486","key":"fantasy","value":"Drood"},
{"id":"7e3891e4e1b5cf147137a0b0d609420e","key":"fantasy","value":"Sedm\u00fd syn"},
{"id":"82df2dd330d5c426d7509789fdda9bb8","key":"fantasy","value":"U\u010dedn\u00edk Alvin"},
{"id":"59403880473a6bda402a21d64ad8c4cf","key":"humanismus","value":"Enderova hra"}
]}
Vidíme, že výsledky pohledu jsou skutečně řazené podle klíče (key) a nádavkem pro každou položku obsahují ID dokumentu. Parametry key, startkey a endkey musí být platný JSON, proto ty uvozovky. Takže umíme hledat podle hodnoty i podle rozsahu; o dalších možnostech si můžete přečíst na wiki. Podobně jako materializované pohledy v relačních databázích mají pohledy v CouchDB výhodu výborného výkonu: Není potřeba nic počítat, stačí jen číst.
Dál: Co si trochu zaredukovat? Nepovinná funkce reduce slouží k agregování. Řekněme, že chceme pro každý žánr vědět, kolik knih do něj patří. Zkusíme si takový lehký myšlenkový veletoč:
// map
function(doc) {
if (doc.type == "book" && doc.genres) {
for (var genre in doc.genres) {
emit(doc.genres[genre], 1);
}
}
}
// reduce
function(keys, values, rereduce) {
// log({"keys": keys, "values": values, "rereduce": rereduce});
return sum(values);
}
Tak tohle už začíná být víc než zvláštní – kdo nikdy neslyšel o MapReduce, bude asi pořádně zmatený. Zkusme trochu osvětlit princip: Pro každý dokument systém zavolá mapovací funkci, která může emitovat libovolně mnoho dvojic <klíč; hodnota>, to už jsme viděli. Všechny takto vyrobené dvojice se vezmou, vyrobí se z nich množina dvojic <klíč; seznam všech hodnot emitovaných pro tento klíč> a pro každou z těchto dvojic se následně zavolá redukční funkce. Ta musí být komutativní a asociativní a musí vždy vrátit právě jednu hodnotu (v našem případě je to číslo, ale může to být klidně i seznam apod.), proto se jí říká redukční.
V našem případě funkce map vygeneruje pro každou knihu v každém žánru jednu jedničku a funkce reduce ty jedničky po jednotlivých žánrech sčítá.
$ curl -X GET http://localhost:5984/pokus/_design/books/_view/genres_count?group=true
{"rows":[
{"key":"detektivka","value":1},
{"key":"fantasy","value":4},
{"key":"humanismus","value":1},
{"key":"sci-fi","value":3},
{"key":"thriller","value":1}
]}
S trochou snahy se tenhle princip dá pochopit, je tu ale jeden problém: Výklad výše je ve skutečnosti lež. Redukce v CouchDB neprochází prostřední fází (seskupování hodnot podle klíče). Parametr keys obsahuje pole různých emitovaných klíčů (a také ID dokumentů, ze kterých byly klíče emitovány), parametr values pole odpovídajících emitovaných hodnot. K tomu se ještě přidává skutečnost, že pohledy se v CouchDB vyhodnocují inkrementálně. Kvůli tomu přibývá ještě parametr rereduce: Je-li jeho hodnota true, znamená to, že redukční funkce nedostane na vstup hodnoty z mapovací funkce, ale musí zkombinovat svoje vlastní předchozí výstupy. Ty jsou v parametru values, v parametru keys je v takovém případě null.
Protože tohle už je poměrně vysoká magie a detailní vysvětlení předchozího odstavce by zabralo celý další článek, odkazuji na wiki a přidávám jeden užitečný tip: Jak vidno na zakomentovaném řádku v kódu výše, při vyhodnocování javascriptových funkcí v CouchDB lze logovat. (Zkuste si to, log je ve /var/log/couchdb/couch.log). Každopádně když nic jiného, můžete těchto pár odstavců brát jako ukázku způsobu, kterým se dneska hromadně zpracovávají obrovské objemy dat – na ad hoc dotazování to ovšem stojí za starou belu. Pro tyto účely je asi nejlepší použít couchdb-lucene (i když například vývojáři Mozilla Raindropu používají techniku zvanou Megaview).
Poznatek: Indexované MapReduce pohledy jsou silná zbraň, ale v ad hoc dotazování je CouchDB slabý.
A to by bylo dneska všechno. Příště se podíváme, jak tedy uložit toho autora, jak k dokumentu přidat přílohu, jak validovat ukládaná data nebo přímo z databáze servírovat HTML.
Nástroje: Tisk bez diskuse
Tiskni
Sdílej:
![]()
![]()
![]()
![]()
![]()
![]()

 27.1.2010 10:02
okbob | skóre: 30
| blog: systemakuv_blog
| Benešov
27.1.2010 11:24
okbob | skóre: 30
| blog: systemakuv_blog
| Benešov
27.1.2010 12:59
okbob | skóre: 30
| blog: systemakuv_blog
| Benešov
27.1.2010 13:44
okbob | skóre: 30
| blog: systemakuv_blog
| Benešov
27.1.2010 10:02
okbob | skóre: 30
| blog: systemakuv_blog
| Benešov
27.1.2010 11:24
okbob | skóre: 30
| blog: systemakuv_blog
| Benešov
27.1.2010 12:59
okbob | skóre: 30
| blog: systemakuv_blog
| Benešov
27.1.2010 13:44
okbob | skóre: 30
| blog: systemakuv_blog
| Benešov
stale=ok) a aktualizovat na pozadí. Viz též http://wiki.apache.org/couchdb/Regenerating_views_on_update.
 27.1.2010 09:26
Amarok | skóre: 33
| blog: blogoblog
27.1.2010 09:26
Amarok | skóre: 33
| blog: blogoblog
 27.1.2010 10:13
alblaho | skóre: 17
| blog: alblog
Mně se ty curl examply právě líbí, ukazuje to pravou podstatu technologie.
27.1.2010 10:13
alblaho | skóre: 17
| blog: alblog
Mně se ty curl examply právě líbí, ukazuje to pravou podstatu technologie.
curl? Je to úplně normální HTTP, můžete použít cokoliv, co se umí tvářit jako HTTP klient. Pro spoustu jazyků jsou dostupné přímo knihovny zaměřené na CouchDB, ale těmi jsem článek nechtěl zatěžovat. Pár odkazů bude v posledním díle, ale Google rád poradí
 No uvidime...
No uvidime...
 27.1.2010 15:26
Přemek Vyhnal | skóre: 24
| blog: Toto není blog!
| Dobřichovice
27.1.2010 15:26
Přemek Vyhnal | skóre: 24
| blog: Toto není blog!
| Dobřichovice
 28.1.2010 15:19
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
28.1.2010 15:19
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
 29.1.2010 10:52
okbob | skóre: 30
| blog: systemakuv_blog
| Benešov
29.1.2010 12:59
okbob | skóre: 30
| blog: systemakuv_blog
| Benešov
Může být, že mám tu terminologii špatně – funkcionální teorii nemám úplně zmáknutou.
29.1.2010 10:52
okbob | skóre: 30
| blog: systemakuv_blog
| Benešov
29.1.2010 12:59
okbob | skóre: 30
| blog: systemakuv_blog
| Benešov
Může být, že mám tu terminologii špatně – funkcionální teorii nemám úplně zmáknutou.
Osobně si nemyslím, že je to totéž. Ve Wikipedii říkají
invoking the procedure a single time or multiple times has the same result; i.e., after any number of method calls all variables have the same value as they did after the first call
a podle mne tím myslí f(f(x))=f(x) případně u procedur, co nic nevrací tím myslí, že se stav světa nezmění po 2., 3. a dalších voláních (například zruším objednávku).
Zato referenční transparentnost znamená, že výraz mohu nahradit jeho výsledkem, tedy u procedur to znamená, že je nemusím vůbec volat, protože nic nevrací -- idempotentní procedury mohou mít side-effect, ale referenčně transparentní ne (čistě funkcionální jazyky nemají procedury).
 AbcLinuxu.cz
AbcLinuxu.cz ITBiz.cz
ITBiz.cz HDmag.cz
HDmag.cz AbcPráce.cz
AbcPráce.cz