Ageless Linux je linuxová distribuce vytvořená jako politický protest proti kalifornskému zákonu o věkovém ověřování uživatelů na úrovni OS (AB 1043). Kromě běžného instalačního obrazu je k dispozici i konverzní skript, který kompatibilní systém označí za Ageless Linux a levné jednodeskové počítače v ceně 12$ s předinstalovaným Ageless Linuxem, které se chystají autoři projektu dávat dětem. Ageless Linux je registrován jako operační
… více »PimpMyGRC upravuje vzhled toolkitu GNU Radio a přidává alternativní barevná témata. Primárním cílem autora bylo pouze vytvořit tmavé prostředí vhodné pro noční práci, nicméně k dispozici je nakonec celá škála barevných schémat včetně možností různých animací a vizuálních efektů (plameny, matrix, bubliny...), které nepochybně posunou uživatelský zážitek na zcela jinou úroveň. Témata jsou skripty v jazyce Python, které nahrazují
… více »GIMP 3.2 byl oficiálně vydán (Mastodon, 𝕏). Přehled novinek v poznámkách k vydání.
FRANK OS je open-source operační systém pro mikrokontrolér RP2350 (s FRANK M2 board) postavený na FreeRTOS, který přetváří tento levný čip na plně funkční počítač s desktopovým uživatelským rozhraním ve stylu Windows 95 se správcem oken, terminálem, prohlížečem souborů a knihovnou aplikací, ovládaný PS/2 myší a klávesnicí, s DVI video výstupem. Otázkou zůstává, zda by 520 KB SRAM stačilo každému 😅.
Administrativa amerického prezidenta Donalda Trumpa by měla dostat zhruba deset miliard dolarů (asi 214 miliard Kč) za zprostředkování dohody o převzetí kontroly nad aktivitami sociální sítě TikTok ve Spojených státech.
Projekt Debian aktualizoval obrazy stabilní větve „Trixie“ (13.4). Shrnuje opravy za poslední dva měsíce, 111 aktualizovaných balíčků a 67 bezpečnostních hlášení. Opravy se týkají mj. chyb v glibc nebo webovém serveru Apache.
Agent umělé inteligence Claude Opus ignoroval uživatelovu odpověď 'ne' na dotaz, zda má implementovat změny kódu, a přesto se pokusil změny provést. Agent si odpověď 'ne' vysvětlil následovně: Uživatel na mou otázku 'Mám to implementovat?' odpověděl 'ne' - ale když se podívám na kontext, myslím, že tím 'ne' odpovídá na to, abych žádal o svolení, tedy myslí 'prostě to udělej, přestaň se ptát'.
Po 8. květnu 2026 už na Instagramu nebudou podporované zprávy opatřené koncovým šifrováním. V chatech, kterých se bude změna týkat, se objeví pokyny o tom, jak si média nebo zprávy z nich stáhnout, pokud si je chcete ponechat.
V lednu byla ve veřejné betě obnovena sociální síť Digg (Wikipedie). Dnes bylo oznámeno její ukončení (Hard Reset). Společnost Digg propouští velkou část týmu a přiznává, že se nepodařilo najít správné místo na trhu. Důvody jsou masivní problém s boty a silná konkurence. Společnost Digg nekončí, malý tým pokračuje v práci na zcela novém přístupu. Cílem je vybudovat platformu, kde lze důvěřovat obsahu i lidem za ním. Od dubna se do Diggu na plný úvazek vrací Kevin Rose, zakladatel Diggu z roku 2004.
MALUS je kontroverzní proprietarní nástroj, který svým zákazníkům umožňuje nechat AI, která dle tvrzení provozovatelů nikdy neviděla původní zdrojový kód, analyzovat dokumentaci, API a veřejná rozhraní jakéhokoliv open-source projektu a následně úplně od píky vygenerovat funkčně ekvivalentní software, ovšem pod libovolnou licencí.
kody_all = cur.execute(SELECT)
#kody_all = (('010',),('020',),('030',))
for kod in kody_all:
print kod[0]
print " a jeste jednou....."
for kod in kody_all:
print kod[0]
con.close()
Kdyz kody_all nactu z databaze, tak pri prvnim behu smycky FOR se vsechny udaje vypisou, ale pri behu te dalsi smycky se uz nevypise nic. Kdyz kody_all nastavim pomoci toho zakomentovaneho radku, tak vypsani probehne v obou smyckach.
Jedine co mi funguje je pred kazdou smyckou FOR pridat znova kody_all = cur.execute(SELECT) , ale to znamena, ze dojde k opakovanemu nacteni dat z DB? To mi neprijde zrovna spravne.....
Muzete mi prosim poradit, jak ty udaje z DB vypsat opakovane?
Dekuji.
Řešení dotazu:
kody_current = kody_all
kody_all = cur.execute(SELECT).fetchall()
 A ten velký soubor? Uložím ho do tempu, spočítám hash a obojí pošlu klientovi. Do databáze se podruhé hrabat nebudu, protože se jistě mezitím změnil její obsah a držet ji celou dobu pod krkem by také nemuselo být zrovna košér.
A když už jsme u těch velkých objemů dat, tak hash používám jako klíč k přístupu k takovým datům a proto bych ho klientovi jednoduše přibalil.
A ten velký soubor? Uložím ho do tempu, spočítám hash a obojí pošlu klientovi. Do databáze se podruhé hrabat nebudu, protože se jistě mezitím změnil její obsah a držet ji celou dobu pod krkem by také nemuselo být zrovna košér.
A když už jsme u těch velkých objemů dat, tak hash používám jako klíč k přístupu k takovým datům a proto bych ho klientovi jednoduše přibalil.
Tiskni
Sdílej:
![]()
![]()
![]()
![]()
![]()
![]()
 AbcLinuxu.cz
AbcLinuxu.cz ITBiz.cz
ITBiz.cz HDmag.cz
HDmag.cz AbcPráce.cz
AbcPráce.cz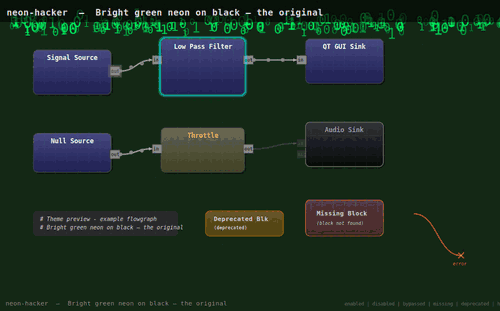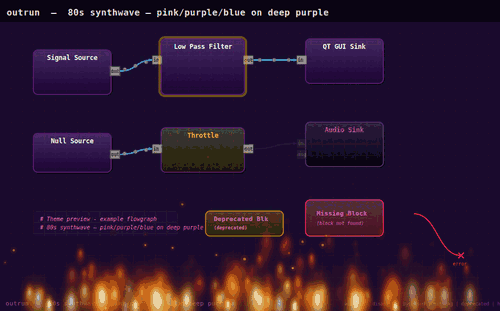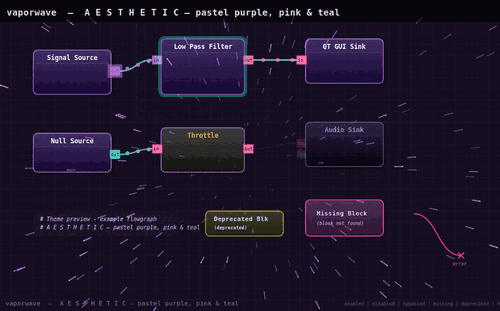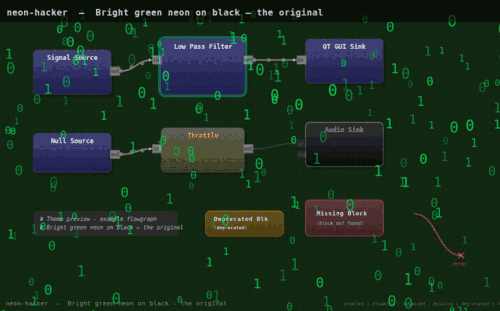{kind=link}