Portál AbcLinuxu, 6. května 2025 23:16
Aktuální verze jádra. Citát týdne. Shrnutí API změn v 2.6.16. Virtualizační rozhraní VMI. Stromy I: Radix stromy. Přístup k linuxovému jádru prostřednictvím souborového systému /proc.
Poznámka redakce: Vzhledem k tomu, že Zack Brown ukončil svůj seriál Kernel Traffic a já nemám tolik času, abych mohl přípravu KT zcela převzít, bylo nutné najít náhradu (více k této situaci v zápisu Konec Jaderných novin? Snad ne...). Dohodl jsem se proto s redaktory LWN na překládání jejich zpravodajství o vývoji jádra a dění v LKML.
Tento díl Jaderných novin je tedy prvním, který je založen na LWN.net. Berte jej jako díl testovací, oťukávací a průzkumný. Zatím nemám jasnou představu o tom, jakým způsobem budu JN z materiálů dostupných na LWN připravovat. Pokud máte vlastní připomínky či návrhy, podělte se o ně v diskuzi.
Aktuální prepatch pro 2.6 je 2.6.16-rc6 - vydán 11. března. Linus poznamenává: "Ok, blížíme se, i když vydání 2.6.16 se rozhodně protahuje více, než by mělo." Jak by se dalo očekávat, patch obsahuje především opravy; viz dlouhý changelog.
Git repozitář hlavního stromu obsahuje několik desítek patchů začleněných od -rc6; mnohé z nich jsou opravy chyb nalezených díky kontrole pomocí Coverity. Také je tam patch, který vypíná sysfs rozhraní pro subsystém detekce a opravy chyb (EDAC); dané rozhraní "je potřeba lépe promyslet", takže bude schováno, dokud nebudou problémy vyřešeny.
Aktuální -mm strom je 2.6.16-rc6-mm1. Mezi nedávné změny v -mm patří nová sada patchů pro sdílení NFS superbloků (což způsobuje některým testerům problémy s NFS) a řádka oprav.
-- Mariusz Mazur vzdává linux-libc-headers.
2.6.16 by měla být v tuto chvíli již dostatečně stabilní na to, abychom sestavili seznam změn v API. Jako obvykle bude tento seznam také zařazen do LWN 2.6 API changes page.
Nikdo by se neodvážil tvrdit, že je na výběr málo linuxových virtualizačních technologií. Existuje množství přístupů, od odlehčených "kontejnerových" technik, které prostě vytvoří zdi mezi částmi systému, až po plně virtualizační přístupy, které implementují kompletní virtuální hardwarovou platformu schopnou provozovat více (neupravených) operačních systémů. Na pomezí těchto dvou jsou "paravirtualizační" přístupy vyžadující určitou míru porozumění ze strany hostovaného jádra. Pro mnohé je paravirtualizace nejlepším přístupem, protože slibuje kombinaci relativně vysokého výkonu se silnou izolací hostovaného systému. Nejčastěji vzpomínaným paravirtualizačním systémem je v současnosti Xen, ale existují další.
Každý paravirtualizační systém klade na hostovaný systém jisté požadavky. Než může být daný systém provozován pod konkrétním hypervisorem (software spravující hostované systémy), musí být upraven tak, aby spolupracoval s rozhraním hypervisora. Tento požadavek může znamenat více práce pro vytvoření virtuálního systému a zvyšuje i náročnost správy softwaru, především jsou-li hypervisor i hostované jádro aktivně vyvíjeny.
Ve snaze ulehčit virtualizačním hackerům život přišel Zachary Amsden (z VMware) s komplexním návrhem na společnou vrstvu rozhraní virtuálních strojů (VMI - Virtual Machine Interface) s některými zajímavými vlastnostmi. VMI vrstva definuje sadu volání pro provádění funkcí specifických pro daný stroj - tedy ten druh věcí, které obyčejně vyžadují zásah hypervisora. Tato volání jsou velmi nízkoúrovňová - operace jako ochrana stránek, povolování přerušení, zapisování registrů u konkrétních modelů, změny specifických kontrolních registrů, obsluha událostí časovače atd. V důsledku toho funguje v současné době VMI vrstva pouze se systémy s i386 architekturou, i když se pracuje na x86-64 portu.
Když nabootuje virtualizované jádro, jednou z prvních věcí, které udělá, je vyhledání "VMI ROM" poskytnuté hypervisorem. Tato ROM obsahuje informace potřebné pro to, aby nízkoúrovňová VMI volání mohla spolupracovat s hypervisorem. S použitím informací nalezených v ROM si právě nabootované jádro samo upraví kód tak, aby využívalo funkce hypervisoru bez hledání v tabulkách nebo nepřímých volání funkcí. Výsledkem toho je, že operace hypervisoru jsou rychlé.
Tento přístup má několik zajímavých aspektů. Jedním je, že jádro vybavené VMI může být provozováno pod jakýmkoliv VMI hypervisorem bez úprav - dokonce bez překompilování. Prostě si vezme ROM poskytnutou kterýmkoliv dostupným hypervisorem a dál si jede po svém. Stejně zajímavá je skutečnost, že takové jádro může běžet na holém hardwaru bez jakéhokoliv hyoervisora a fungovat jako hostitelské jádro. Vývojáři VMI tvrdí, že dopad na výkon je v podstatě nulový. To vede k tomuto tvrzeni:
Vlastní kód je dodáván jako 24dílný patch. Zahrnuje dost nízkoúrovňového nastavování a fíglů s assemblerem. To může být jednou z příčin toho, že samotný kód nebyl zatím příliš komentován. Dosavadní diskuze se zdá myšlence nakloněná, i když odměřená. Kromě jiných věcí bude potřeba open source hypervisor, který toto rozhraní využívá - dříve než může být vážně uvažováno o začlenění. Prozatím si můžete další podrobnosti přečíst v dokumentaci.
Jádro obsahuje množství knihovních rutin pro implementaci užitečných datových struktur. Mezi ty patří i dva druhy stromů: radix stromy a red-black stromy. Tento článek se zaměří na API radix stromu, přičemž red-black stromy budou následovat v budoucnu.
Wikipedia má článek o radix stromech, ale linuxové radix stromy v něm nejsou dobře popsány. Linuxový radix strom je mechanismus, pomocí kterého může být (ukazatelová) hodnota propojena s (dlouhým) integerovým klíčem. Z hlediska ukládání je to rozumně efektivní a při vyhledávání docela rychlé. Kromě toho mají radix stromy v linuxovém jádře několik funkcí zaměřených na specifické potřeby jádra, včetně schopnosti přiřazovat značky [tags] konkrétním záznamům.
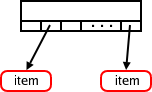
Ten roztomilý malý diagram ukazuje listový uzel linuxového radix stromu. Uzel obsahuje určitý počet slotů, z nichž každý může obsahovat ukazatel na něco, co je zajímavé pro tvůrce stromu. Prázdné sloty obsahují ukazatel NULL. Tyto stromy jsou poměrně rozsáhlé - v jádrech 2.6.16-rc je 64 slotů v každém uzlu radix stromu. Sloty jsou indexovány částí (dlouhého) integerového klíče. Je-li nejvyšší hodnota klíče méně než 64, může být celý strom reprezentován jediným uzlem. Obyčejně se však používá poněkud větší sada klíčů - jinak by stačilo obyčejné pole. Takže větší strom může vypadat nějak takto:
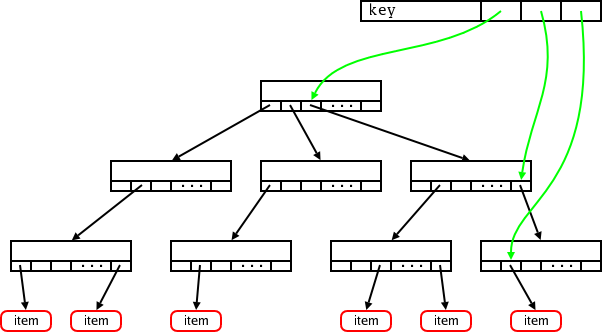
Tento strom má tři úrovně. Když chce jádro najít konkrétní klíč, bude šest nejvýznamnějších bitů použito k nalezení příslušného slotu v kořenovém uzlu. Dalších šest bitů indexuje slot ve středním uzlu a těch nejméně významných šest bitů bude označovat slot obsahující ukazatel na vlastní hodnotu. Uzly, které nemají žádné potomky, nejsou ve stromu přítomné, takže radix strom může poskytnout efektivní úložný prostor pro řídké stromy.
Radix stromy mají v hlavním jádře několik uživatelů. PowerPC architektura používá strom k mapování mezi skutečnými a virtuálními IRQ čísly. NFS kód připojuje strom k relevantním inode strukturám, aby se udržel přehled o čekajících požadavcích. Nicméně nejrozšířenější využití radix stromů je k vidění v kódu správy paměti. Struktura address_space používaná k udržování přehledu o backing store (úložiště právě nepoužívaných stránek) obsahuje radix strom, který sleduje stránky v jádře [core] vázané na dané mapování. Kromě jiného umožňuje tento strom kódu pro správu paměti rychle nacházet stránky, které jsou buď nečisté nebo jsou právě zpětně zapisovány [writeback].
Jak je pro jaderné datové struktury typické, existují dva režimy pro deklaraci a inicializaci radix stromů:
#include <linux/radix-tree.h>
RADIX_TREE(name, gfp_mask); /* Declare and initialize */
struct radix_tree_root my_tree;
INIT_RADIX_TREE(my_tree, gfp_mask);
První způsob deklaruje a inicializuje radix strom daného jména (name); druhý provede inicializaci za běhu. V obou případech musí být zadána gfp_mask, která kódu říká, jak mají být prováděny alokace paměti. Pokud mají být operace radix stromu (především vkládání) prováděny v atomickém kontextu, maska by měla být zadána jako GFP_ATOMIC.
Funkce pro přidávání nebo odstraňování záznamů jsou přímočaré:
int radix_tree_insert(struct radix_tree_root *tree, unsigned long key,
void *item);
void *radix_tree_delete(struct radix_tree_root *tree, unsigned long key);
Volání radix_tree_insert() způsobí vložení daného item (propojeno s key) do daného tree. Tato operace může vyžadovat alokace paměti; jestliže alokace selže, selže i vložení a návratová hodnota bude -ENOMEM. Kód odmítne přepsat existující záznam; pokud key ve stromě již existuje, radix_tree_insert() vrátí -EEXIST. Při úspěchu je návratová hodnota nula. radix_tree_delete() odstraní položku propojenou key ze tree a pokud existoval, vrátí ukazatel na danou položku.
Mohou nastat situace, kdy selhání vložení nové položky do radix stromu může znamenat zásadní problém. Pro předcházení takovým situacím jsou poskytnuty dvě specializované funkce:
int radix_tree_preload(gfp_t gfp_mask);
void radix_tree_preload_end(void);
Tato funkce se pokusí alokovat dostatečné množství paměti (s použitím dané gfp_mask), aby se zaručilo, že následující vložení do radix stromu neselže. Alokované struktury jsou uloženy v proměnné pro každý procesor, což znamená, že volající funkce musí provést vložení předtím, než bude plánovat nebo než bude přesunuta na jiný procesor. Kvůli tomu se radix_tree_preload() při úspěchu vrátí s vypnutou preempcí; volající musí nakonec preempci opět zapnout voláním radix_tree_preload_end(). Při neúspěchu je vrácena hodnota -ENOMEM a preempce není vypnuta.
Radix stromy lze prohledávat několika způsoby:
void *radix_tree_lookup(struct radix_tree_root *tree, unsigned long key);
void **radix_tree_lookup_slot(struct radix_tree_root *tree, unsigned long key);
unsigned int radix_tree_gang_lookup(struct radix_tree_root *root,
void **results,
unsigned long first_index,
unsigned int max_items);
Nejjednodušší způsob, radix_tree_lookup(), hledá key v tree a vrací přiřazenou položku (nebo NULL při neúspěchu). radix_tree_lookup_slot() místo toho vrátí ukazatel na slot, který drží ukazatel na danou položku. Volající pak může ukazatel změnit, aby byl key přiřazen k nové položce. Pokud však položka neexistuje, radix_tree_lookup_slot() pro ni nevytvoří slot, takže tato funkce nemůže používána místo radix_tree_insert().
A konečně, volání radix_tree_gang_lookup() vrátí až max_items položek v results se vzestupnými hodnotami klíčů začínajícími na first_index. Počet vrácených položek může být nižší než bylo požadováno, ale krátký výsledek (nenulový) nemusí nutně znamenat, že ve stromě nejsou žádné další hodnoty.
Mělo by se poznamenat, že žádná z funkcí radix stromů neprovádí interně zamykání. Je na volajícím, aby si pohlídal, že jednotlivá vlákna strom nepoškodí, nebo se nedostanou do jinak problémových situací. Nick Piggin dal do oběhu patch, který by pro uvolňování uzlů používal posloupnost číst-zkopírovat-aktualizovat (RCU - Read-Copy-Update); patch by umožnil provádění vyhledávacích operací bez uzamykání za předpokladu, že (1) výsledný ukazatel bude použit pouze v atomickém kontextu a (2) volající kód se vyvaruje vytváření vlastních problémových situací. Není však jasné, kdy by mohl být patch začleněn.
Kód radix stromů podporuje funkci nazývanou "tags", díky které mohou být určité bity nastaveny na položky ve stromu. Tagy se používají například k označení stránek paměti, které jsou nečisté nebo jsou právě zpětně zapisovány. API pro práci s tagy je:
void *radix_tree_tag_set(struct radix_tree_root *tree,
unsigned long key, int tag);
void *radix_tree_tag_clear(struct radix_tree_root *tree,
unsigned long key, int tag);
int radix_tree_tag_get(struct radix_tree_root *tree,
unsigned long key, int tag);
radix_tree_tag_set() nastaví daný tag na položku indexovanou pomocí key; je chyba pokoušet se nastavit tag na neexistující klíč. Návratová hodnota bude ukazatel na otagovanou položku. Ačkoliv tag vypadá jako běžný integer, kód zatím umožňuje maximálně dva tagy. Použití jakékoliv jiné hodnoty tagu než nula nebo jedna způsobí tiché narušení paměti na nějakém nechtěném místě; byli jste varováni.
Tagy lze odstranit pomocí radix_tree_tag_clear(); návratovou hodnotou je opět ukazatel na (ne)otagovanou položku. Funkce radix_tree_tag_get() zkontroluje, jestli má položka indexovaná pomocí key nastavený daný tag; návratová hodnota je nula, pokud key neexistuje, -1 pokud key existuje, ale tag není nastaven, a +1 v ostatních případech. Tato funkce je však v současné době ve zdrojovém kódu zakomentována, protože ji nepoužívá žádný kód uvnitř jádra.
Pro dotazování se na tagy existují další dvě funkce:
int radix_tree_tagged(struct radix_tree_root *tree, int tag);
unsigned int radix_tree_gang_lookup_tag(struct radix_tree_root *tree,
void **results,
unsigned long first_index,
unsigned int max_items,
int tag);
radix_tree_tagged() vrací nenulovou hodnotu, pokud nějaká položka ve stromě nese daný tag. Seznam položek s daným tagem získáte pomocí radix_tree_gang_lookup_tag().
Závěrem můžeme poukázat na další zajímavý aspekt API radix stromů: neexistuje žádná funkce pro zrušení stromu. Zjevně se očekává, že radix stromy budou existovat věčně. V praxi lze však vymazáním všech položek z radix stromu uvolnit veškerou paměť, která s ním byla spojena - kromě kořenového uzlu, jehož se lze potom zbavit normálně.
developerWorks nabízí tutoriál k vytváření /proc souborů z natahovatelných jaderných modulů. "Tady je [modul], který podporuje jak čtení, tak zápis. Tato jednoduchá aplikace funguje jako zásobník citátů. Po natažení modulu do něj může uživatel nahrát text citátů pomocí příkazu echo a pak je po jednom zase číst pomocí příkazu cat." Jen se nesnažte o začlenění do hlavního jádra.
 Dakujem, Roberte!
Dakujem, Roberte!
 29.3.2006 07:50
xvasek | skóre: 21
| blog:
| Zlín
29.3.2006 07:50
xvasek | skóre: 21
| blog:
| Zlín
 29.3.2006 08:20
David Ježek | skóre: 83
| blog: Mostly_IMDB
29.3.2006 08:20
David Ježek | skóre: 83
| blog: Mostly_IMDB
 ).
Osobně bych v Jaderných novinách oželel dlouhou pasáž o radix stromech a udělal z ní samostatný článek. Dala by se k tomu přidat nějaká omáčka, ale zveřejnil bych to i v téhle podobě, prostě jen ze současného článku vyjmout část a osamostatnit jí - aby jednotlivé články zůstaly tematicky jednotné.
Někoho třeba tyhle detaily nezajímají vůbec, někdo (jako já) si je přečte rád, ale jindy (Jaderné noviny čtu jako admin, radix stromy jako programátor - a můj mozek chce být někdy více adminem a na programování nemá náladu, jindy zase naopak ). Navíc budu-li vyhledávat v budoucnosti něco o stromech, a vyskočí na mne Jaderné noviny, asi článek rovnou přeskočím, protože co v Jaderných novinách může být o programování stromů...
).
Osobně bych v Jaderných novinách oželel dlouhou pasáž o radix stromech a udělal z ní samostatný článek. Dala by se k tomu přidat nějaká omáčka, ale zveřejnil bych to i v téhle podobě, prostě jen ze současného článku vyjmout část a osamostatnit jí - aby jednotlivé články zůstaly tematicky jednotné.
Někoho třeba tyhle detaily nezajímají vůbec, někdo (jako já) si je přečte rád, ale jindy (Jaderné noviny čtu jako admin, radix stromy jako programátor - a můj mozek chce být někdy více adminem a na programování nemá náladu, jindy zase naopak ). Navíc budu-li vyhledávat v budoucnosti něco o stromech, a vyskočí na mne Jaderné noviny, asi článek rovnou přeskočím, protože co v Jaderných novinách může být o programování stromů...
Osobně bych v Jaderných novinách oželel dlouhou pasáž o radix stromech a udělal z ní samostatný článek.Díky za podnět. Sám jsem o tom uvažoval, ale pak jsem se rozhodl ponechat první z těchto "nových" dílů stejný jako na LWN s tím, že se čtenáři sami ozvou s připomínkami. Základním problémem je skutečnost, že na rozdíl od Kernel Traffic se zpravodajství z LWN nesnaží přinést shrnutí co nejvíce diskuzních témat z konference o jádře. Místo toho nabízí méně článků, které jdou více do hloubky. Rád bych JN sestavoval tak, aby jejich větší část byla stručným shrnutím debat z LKML. Do každého čísla by pak mohl být zařazen jeden rozsáhlejší článek o vybrané problematice. Bohužel však zatím nemám vhodný zdroj, ze kterého by šlo čerpat to zmiňované stručné shrnutí diskuzí. V dalších dílech tedy budu vycházet z LWN, ale zároveň budu hledat způsob, který by JN přiblížil jejich původnímu stylu.
. Taky se přimlouvám za oddělení radix stromů (a podobných témat) do samostatného článku.
 29.3.2006 18:27
David Watzke | skóre: 74
| blog: Blog...
| Praha
29.3.2006 18:27
David Watzke | skóre: 74
| blog: Blog...
| Praha
 30.3.2006 14:49
David Watzke | skóre: 74
| blog: Blog...
| Praha
30.3.2006 14:49
David Watzke | skóre: 74
| blog: Blog...
| Praha

Přidávám hlas k názoru, že JN by měly více zachycovat dění v komunitě jako sociálním celku - ale i takhle to je super, po JN se mi stýskalo! Chápu, že nebude lehké najít nějaký zdroj (jak už bylo zmíněno, je potřeba nalézt souhrn z LKML), takže držím palce a doufám v úspěch. Jen tak dál!
al-QuaknaaKratce jsem je kouknul na KernelTrap a vypadato, ze v tomto ohledu vypada lepe nez LWN.Ani mě nenapadlo uvažovat o kerneltrap.org - z dřívějška pamatuji jen velmi dlouhé rozestupy mezi jednotlivými příspěvky a kratinké komentáře. Často to bývalo jen upozornění na zajímavou diskuzi (která byla zařazena úplně kompletní). Ale je pravda, že poslední dobou to vypadá na změnu k lepšímu. Jeremy se činí a mohlo by být zajímavé zkusit něco z toho začlenit do JN. Byl jsem s ním už dříve v kontaktu, takže se pozeptám, jak by se na to tvářil. Díky za nápad.
Termín mutual exclusion se běžně překládá jako vzájemné vyloučení.Díky.
"stranky, ... do nichz se prave zpetne zapisuje [writeback]" --- writeback jsou stranky ktere se zapisuji na diskRozumím-li tomu správně, tak by to tedy nejlepší překlad zněl takto: "stránky, ... které jsou právě zpětně zapisovány". Ta snaha o používání českých termínů tu samozřejmě je. Vždy se pokouším o co nejlepší rovnováhu. Některé pojmy už jsou v angličtině natolik ustálené, že není nutné je překládat, jiné považuji za vhodné přeložit nebo alespoň překladem opsat. V případě, že hrozí nejasnosti, uvádím původní termín v hranatých závorkách. Díky za vysvětlení toho "writeback". Ačkoliv se snažím všechno vygooglit a správně pochopit, než se pustím do překladu, někdy to pochopím špatně...
atomic_long_t je 64-bitovy na 64-bitovych pocitacich a 32-bitovy na 32-bitovych pocitacich.V tomto případě nevidím chybu. V originále se píše: "A 64-bit atomic type, atomic_long_t, has been added."
(to "zpětně" bych tam taky nedával --- nemá smysl to překládat doslova --- ty stránky se nezapisují pozpátku).Nemyslel jsem "pozpátku", nýbrž "až potom". Jak by se tedy dal odlišit writeback od běžného zápisu?
Ad ten 64-bitový atomic_long_t --- v tom případě je chyba už v původním článku. Správně je to v include/asm-generic/atomic.hDíky.
Behold, AstorLights had spoken !
Velmi mě potěšila sklatba odkazů do LWN, keré sice znám, ale na najití těch aktuálních a podstatných událostí v nich nemám taky čas. Přehledný popis radix tree se mi líbil také.
Přeji hodně sil. Zdá se, že se budu muset naučit číst
informace o jádře česky
ISSN 1214-1267, (c) 1999-2007 Stickfish s.r.o.
 29.3.2006 21:24
29.3.2006 21:24