Josef Průša oznámil zveřejnění kompletních CAD souborů rámů tiskáren Prusa CORE One a CORE One L. Nejsou vydány pod obecnou veřejnou licenci GNU ani Creative Commons ale pod novou licencí OCL neboli Open Community License. Ta nepovoluje prodávat kompletní tiskárny či remixy založené na těchto zdrojích.
Nový CEO Mozilla Corporation Anthony Enzor-DeMeo tento týden prohlásil, že by se Firefox měl vyvinout v moderní AI prohlížeč. Po bouřlivých diskusích na redditu ujistil, že v nastavení Firefoxu bude existovat volba pro zakázání všech AI funkcí.
V pořadí šestou knihou autora Martina Malého, která vychází v Edici CZ.NIC, správce české národní domény, je titul Kity, bity, neurony. Kniha s podtitulem Moderní technologie pro hobby elektroniku přináší ucelený pohled na svět současných technologií a jejich praktické využití v domácích elektronických projektech. Tento knižní průvodce je ideální pro každého, kdo se chce podívat na současné trendy v oblasti hobby elektroniky, od
… více »Linux Foundation zveřejnila Výroční zprávu za rok 2025 (pdf). Příjmy Linux Foundation byly 311 miliónů dolarů. Výdaje 285 miliónů dolarů. Na podporu linuxového jádra (Linux Kernel Project) šlo 8,4 miliónu dolarů. Linux Foundation podporuje téměř 1 500 open source projektů.
Jean-Baptiste Mardelle se v příspěvku na blogu rozepsal o novinkám v nejnovější verzi 25.12.0 editoru videa Kdenlive (Wikipedie). Ke stažení také na Flathubu.
OpenZFS (Wikipedie), tj. implementace souborového systému ZFS pro Linux a FreeBSD, byl vydán ve verzi 2.4.0.
Kriminalisté z NCTEKK společně s českými i zahraničními kolegy objasnili mimořádně rozsáhlou trestnou činnost z oblasti kybernetické kriminality. V rámci operací OCTOPUS a CONNECT ukončili činnost čtyř call center na Ukrajině. V prvním případě se jednalo o podvodné investice, v případě druhém o podvodné telefonáty, při kterých se zločinci vydávali za policisty a pod legendou napadeného bankovního účtu okrádali své oběti o vysoké finanční částky.
Na lepší pokrytí mobilním signálem a dostupnější mobilní internet se mohou těšit cestující v Pendolinech, railjetech a InterPanterech Českých drah. Konsorcium firem ČD - Telematika a.s. a Kontron Transportation s.r.o. dokončilo instalaci 5G opakovačů mobilního signálu do jednotek Pendolino a InterPanter. Tento krok navazuje na zavedení této technologie v jednotkách Railjet z letošního jara.
Rozšíření webového prohlížeče Urban VPN Proxy a další rozšíření od stejného vydavatele (např. 1ClickVPN Proxy, Urban Browser Guard či Urban Ad Blocker) od července 2025 skrytě zachytávají a odesílají celé konverzace uživatelů s AI nástroji (včetně ChatGPT, Claude, Gemini, Copilot aj.), a to nezávisle na tom, zda je VPN aktivní. Sběr probíhá bez možnosti jej uživatelsky vypnout a zahrnuje plný obsah dotazů a odpovědí, metadata relací i
… více »QStudio, tj. nástroj pro práci s SQL podporující více než 30 databází (MySQL, PostgreSQL, DuckDB, QuestDB, kdb+, …), se stal s vydáním verze 5.0 open source. Zdrojové kódy jsou k dispozici na GitHubu pod licencí Apache 2.0.
V tomto seriálu se dozvíte to nejdůležitější, co budete potřebovat k tvorbě dobře strukturovaných databází i jejich správě v MySQL. Ve výkladu je počítáno i s úplnými začátečníky. MySQL jsem vybral, protože je v podstatě zadarmo (pro podrobnější informace si přečtěte licenční ujednání na domovské adrese MySQL), je velmi rychlý a jeho správa je poměrně jednoduchá. Navíc pokud budete v budoucnu nuceni naučit se pracovat s jiným relačním databázovým systémem, znalosti získané studiem a používáním MySQL snadno využijete.
Databázový systém se skládá z programu pro práci s databázemi a celé řady podpůrných programů. Databázový systém obstarává přístup k datům. Mezi nejznámější databázové systémy patří např. Oracle9i, Microsoft SQL Server nebo PostgreSQL.
Jazyk SQL je dotazovací jazyk, který se používá k manipulaci s daty v databázích.
Databáze v sobě uchovává strukturovaná data. Se strukturovanými daty se pracuje mnohem lépe, než s daty uloženými např. v souborech. Databázový systém vám navíc poskytne řadu funkcí pro manipulaci s daty.
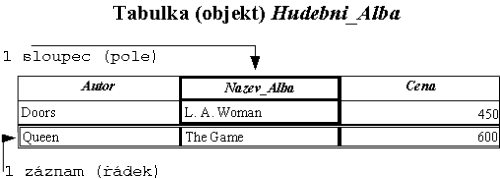
Databáze se skládá z tabulek (objektů). V tabulkách jsou uloženy
informace, které spolu nějakým způsobem souvisí. Například v tabulce
Hudebni_Alba budou informace o hudebních albech.
Ve sloupcích jsou popsány vlastnosti objektu. Objekt
Hudebni_Alba může mít sloupce
Autor, Nazev_Alba, Cena.
Záznamy jsou už konkrétní data uložená v databázi. Záznam v
tabulce Hudebni_Alba by mohl vypadat třeba takto:
Doors, L. A. Woman, 450 nebo
Queen, The Game, 600.
Primární klíč je sloupec, který jednoznačně identifikuje záznam. To znamená, že tento sloupec musí být u každého záznamu jiný.
Pokud by jste tedy v databázi chtěli mít alba o stejné ceně,
nemohl by primární klíč být sloupec Cena. Za
předpokladu, že by žádná skupina neměla album se stejným jménem
jako jakékoli album jakékoli jiné skupiny, mohl by primární klíč být
sloupec Jmeno_Alba. To ale vždy nemůžeme předpokládat,
proto si vytvoříme nový sloupec ID_Alba. Ten bude muset
mít vždy jinou hodnotu. Nejjednodušší je vkládat do tohoto sloupce
číslo, které bude u každého dalšího záznamu o jedna větší, než u
předchozího.(jak na to se dozvíte v některém z dalších dílů)
Primární klíč se používá k vytváření relací mezi tabulkami.
Relační databáze se skládá z více objektů (tabulek). Některé z
nich spolu mohou souviset - tvořit relaci. Máme-li například objekty
Hudebni_Alba(ID_Alba, Autor, Nazev_Alba, Cena),
Objednavky(ID_Objednavky, Datum_Objednavky, Mnozstvi, Produkt)
objekty Hudebni_Alba a Objednavky spolu
mohou souviset - sloupec Proudukt může být
Hudebni_Album.
Rozlišujeme několik typů relací.
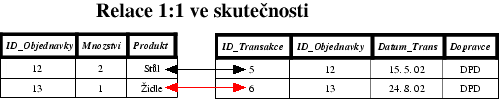
Mějme objekty Objednavky a
Transakce(ID_Transakce,
Datum_Transakce, Dopravce, Datum_odeslani). Tyto objekty spolu
mohou vytvořit relaci 1:1. Každá objednávka může souviset pouze s
jednou transakcí a každá transakce může souviset pouze s jednou
objednávkou.
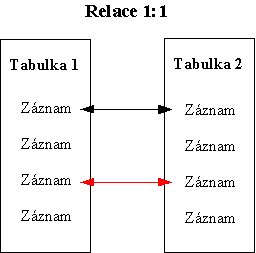
Relaci 1:1 mezi tabulkami vytvoříme tak, že do jednoho z objektů přidáme primární klíč souvisejícího objektu a ten označíme jako jedinečný(tj. v objektu do kterého vložím primární klíč souvisejícího objektu nebudou smět být záznamy se stejným primárním klíčem souvisejícího objektu).
Když je primární klíč nějakého objektu přidán do souvisejícího objektu,
v souvisejícím objektu mu říkáme cizí klíč. To, zda-li přidáme v našem
případě do objektuObjenavky primární klíč objektu
Transakce nebo naopak záleží na nás. My vložíme primární klíč
objektu Objednavky do objektu Transakce.
Objekt Transakce tedy bude vypadat takto
Transakce(ID_Transakce, ID_Objednavky Datum_Transakce, Dopravce,
Datum_Odeslani). Sloupec ID_Objednavky bude v objektu
Objednavky primární klíč, kdežto v objektu
Transakce to bude cizí klíč. Cizí klíč je vrelaci 1:1
jedinečný.
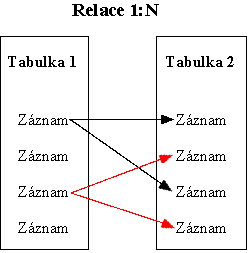
Mějme objekty Objednavky a Zakaznici(ID_Zakaznika,
Jmeno, Adresa, Mesto, PSC). Mezi objekty Objednavky a
Zakaznici je relace 1:N. Jeden zákazník může mít více
objednávek, ale každá objednávka přísluší pouze jednomu zákazníku.
Při relaci 1:1 byly oba objekty rovnocenné. V relaci 1:N je jeden objekt primární a druhý s ním související. Primární objekt obsahuje záznamy, jejichž jeden záznam odpovídá mnoha záznamům souvisejícího objektu. Relaci 1:N vytvoříme tak, že do souvisejícího objektu vložíme primární klíč primárního objektu. Primární klíč primárního objektu ale nebude v souvisejícím objektu jedinečný. Související objekt bude tedy obsahovat svůj primární klíč, který bude jedinečný, a cizí klíč, který bude moci obsahovat i duplicitní hodnoty.
V našem případě bude primární objekt objekt Zakaznici a
související objekt bude objekt Objednavky. Objekt
Objednavky bude tedy vypadat takto:
Objednavky(ID_Objednavky, ID_Zakaznika, Datum_Objednavky, Mnozstvi,
Produkt).
Sloupec ID_Zakaznika nebude v objektu Objednavky označen jako jedinečný. Kdyby byl cizí klíč jedinečný, vytvořili bychom relaci 1:1!
Relace M:N by mohla vzniknout mezi objekty Objednavky a
Hudebni_Alba. Jedno hudební album může být ve více
objednávkách a jedna objednávka může obsahovat více hudebních alb.
Relaci M:N si můžeme představit jako dvě relace 1:N. Potřebujeme,
aby oba dva objekty byly primární. Abychom toho dosáhli, musíme vytvořit
nový objekt Rozpis_Objednavek a vytvořit relaci 1:N mezi
objekty Objednavky a Rozpis_Objednavek a dále mezi
objekty Hudebni_Alba a Rozpis_Objednavek, kde
objekty Objednavky a Hudebni_Alba budou primární
objekty. Objekt Rozpis_Objednavek bude tedy obsahovat
sloupce Rozpis_Objednavek(ID_Rozpisu_Objednavek, ID_Objednavky,
ID_Alba), kde ID_Rozpisu_Objednavek bude primární klíč
a ID_Objednavky,ID_Alba budou cizí klíče, které budou moci
obsahovat duplicitní hodnoty.
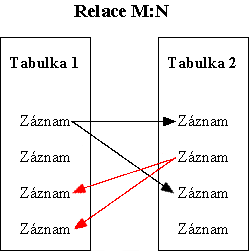
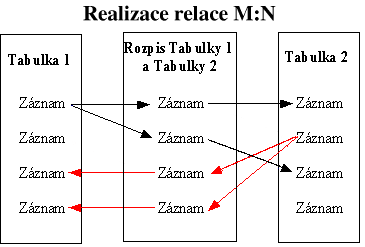
Normalizace databáze je v podstatě souhrn pravidel, které nám pomáhají vytvářet správné objekty, které obsahují správná pole. Normalizace také usnadňuje pochopení vzájemných vazeb (relací) mezi objekty.
Existují 3 běžně používané stupně normalizace. Jsou uspořádány vzestupně podle úrovně uspořádání.
Pravidlo 1NF říká, že všechny objekty obsahující opakující se sloupce je třeba rozdělit do nových objektů.
V nerelační databázi bychom vytvořili objekt Zakaznici,
který by obsahoval veškerá data týkající se zákazníků. Objekt
Zakaznici by mohl vypadat třeba takto:
Zakaznici(ID_Zakaznika, Jmeno, Adresa, Mesto, PSC, Produkt_Cena,
Produkt_Nazev, Produkt_Cena, Produkt_Nazev2, Produkt_Cena2,
Objednavka_Datum, Objednavka_Mnozstvi, Dodavatel_Nazev).
Sloupce vztahující se k produktům budou zcela jistě obsahovat duplicitní
hodnoty. Proto podle pravidla 1NF musíme objekt Zakaznici
rozbít a sloupce s duplicitními položkami umístit do samostatného objektu.
Nový objekt nazveme Produkty. Mezi objekty
Zakaznici a Produkty vytvoříme relaci
1:N, kde zákazníci bude primární objekt.
Objekty normalizované na úroveň 1NF budou tedy vypadat takto:
Zakaznici(ID_Zakaznika, Jmeno, Adresa, Mesto, PSC, Objednavka_Datum,
Objednavka_Mnozstvi, Dodavatel_Nazev)
Produkty(ID_Produktu, ID_Zakaznika, Produkt_Nazev, Produkt_Cena)
Nyní, když je databáze normalizovaná na úroveň 1NF, je mnohem snažší jak vyhledávání informací v databázi, tak přidávání nových položek do databáze.
Pravidlo 2NF říká, že všechny objekty obsahující sloupce s duplicitními položkami, které mezi sebou vytvářejí částečné závislosti, je třeba rozdělit do objektů nových, v nichž bude každý záznam uložen pouze jednou.
Každý záznam v objektu Zakaznici obsahuje informace o
objednávce. Jestliže si zákazníci budou objednávat pouze jeden druh zboží,
bude vše vpořádku. Jestliže si ale objednají více druhů zboží, bude se
muset pro každý druh objednaného zboží vytvořit nový záznam v objektu
Zakaznici. Lepší by bylo vytvořit nový objekt
Objednavky a mezi objekty Produkty a
Objednavky vytvořit relaci M:N. K tomu ale potřebujeme
vytvořit nový objekt Rozpis_Objednavek.
Objekty budou tedy vypadat takto:
Zakaznici(ID_Zakaznika, Jmeno, Adresa, Mesto, PSC),.
Objednavky(ID_Zakaznika, ID_Objednavky, Objednavka_Datum,
Objednavka_Mnozstvi, Dodavatel_Nazev),
Rozpis_Objednavek(ID_Rozpisu, ID_Pruduktu, ID_Objednavky),
Produkty(ID_Produktu, Produkt_Nazev, Produkt_Cena)
A to už je něco jiného. Nyní jsme se můžeme doslova kochat výhodami relační databáze. Můžeme do databáze přidávat zákazníky, bez toho, aby to mělo negativní dopad na ostatní objekty.
Pravidlo třetí normalizované formy vyžaduje důsledné odstranění a oddělení veškerých dat, která nejsou v přímém vztahu s daným objektem.
Objekt Objednavky obsahuje sloupec
Dodavatel_Nazev. Tento sloupec ale přímo nesouvisí s daným
objektem Objednavky (nepopisuje žádnou jeho vlastnost). Podle
pravidel 3NF je nutné tento sloupec vyčlenit do nového objektu. Vytvoříme
proto nový objekt Dodavatele a mezi objekty
Objednavky a Dodavatele vytvoříme relaci 1:1.
Objekty naší databáze normalizované na úroveň 3NF budou vypadat takto:
Zakaznici(ID_Zakaznika, Jmeno, Adresa, Mesto, PSC),.
Objednavky(ID_Zakaznika, ID_Objednavky, Objednavka_Datum, Objednavka_Mnozstvi),
Dodavatele(ID_Dodavatele, ID_Objednavky),
Rozpis_Objednavek(ID_Rozpisu, ID_Pruduktu, ID_Objednavky),
Produkty(ID_Produktu, Produkt_Nazev, Produkt_Cena)
Nyní naše databáze vyhovuje pravidlům 3NF. Tento typ normalizace poskytuje maximální pružnost (stejně jako 2NF) a navíc předchází vzniku logických chyb. Každý sloupec objektu přímo souvisí s daným objektem a je proto jednoznačně identifikován primárním klíčem daného objektu.
To záleží na konkrétní databázi. Normalizace je tu proto, aby udělala databázi přehlednější, lépe rozšiřitelnou a výkonnější. Je proto zbytečné normalizovat, když normalizace nepřinese zvýšení přehlednosti, rozšiřitelnosti nebo výkonu. Zbytečně velký počet objektů může naopak udělat databázi nepřehlednou.
Jako příklad zbytečné normalizace uvedu toto: Máme objekt
Zakaznici(ID_Zakaznika, Jmeno, Adresa1, Adresa2). Podle
pravidel 1NF bychom měli informace o adrese z objektu
Zakaznici odstranit, vytvořit nový objekt Adresy
a mezi těmito objekty vytvořit relaci M:N - 1 zákazník může mít více adres
a 1 adresa může příslušet více zákazníkům (spolubydlící). Musíme tedy
vytvořit nový objekt Rozpis_Adres.
Objekty by vypadaly takto:
Zakaznici(ID_Zakaznika, Jmeno).
Rozpis_Adres(ID_Rozpisu_Adres, ID_Zakaznika, ID_Adresy)
Adresy(ID_Adresy)
Teď databáze odpovídá standardům normalizace, ale kde je přehlednost?
Proces návrhu databáze se skládá z následujících kroků.
Definice aplikačního procesu je posloupnost kroků, které vedou ke splnění určitého cíle.
Například Aplikační proces internetového obchodu by mohl vypadat takto:
Zákazník si vybere produkty, které si u vás chce zakoupit -> bude
ověřeno, zda je uživatel přihlášen, jestliže ne, musí se přihlásit
popřípadě zaregistrovat -> bude odeslána zpráva,která bude obsahovat
zákazníkovu objednávku -> pracovníci expedice zabalí objednávku, ověří
adresu příjemce a poštou odešlou objednávku zákazníkovi
Aplikační objekty obsahují informace, které chcete v databázi uchovávat. Většinou obsahují klíčové informace, které jsou pro uskutečnění dané operace nezbytné. Aplikační objekt je například produkt nebo zákazník. Dále musímevytvořit sloupce objektů.
Aplikační pravidla jsou pravidla, kterými se koncová aplikace bude řídit.
Uvedu několik příkladů:
Rozlišujeme dva typy aplikačních pravidel. Předpokládaná aplikační pravidla a platná aplikační pravidla. Předpokládané aplikační pravidlo by mohlo být, že každý zákazník má jméno, nebo že má adresu. Platné pravidlo je pravidlo vynucené konkrétní implementací. Tak například, že objednávka může obsahovat víc produktů.
Modelování databáze je nakreslení si všech objektů a jejich sloupců. Dále by jste měli stanovit datové typy sloupců a stanovit, zda-li budou jednotlivé sloupce v databázi vyžadovaná.
Tyto dvě činnosti mezi sebou do značné míry souvisí. Na normalizaci by jste měli myslet už při modelování databáze, ale často se vám může stát, že při vytváření relací zjistíte, že vaše databáze není dostatečně normalizovaná.
Při vytváření relací musíte nejprve určit, jestli mezi objekty existuje nějaký vztah a pak určit jaký.
Příští díl bude podstatně méně teoretický. Napřed si v rychlosti připomeneme výhody MySQL a dále se naučíte MySQL používat.
Nástroje: Tisk bez diskuse
Tiskni
Sdílej:
![]()
![]()
![]()
![]()
![]()
![]()

ad 2. Lepe receno hodnota primarniho klice nemuze byt duplicitni. Tato hodnota totiz slouzi k tomu, aby jednoznacne identifikovala prave jeden radek v tabulce. Primarni klic muze byt tvoren i kombinaci vice sloupcu. Relacni model nezna jiny zpusob, jak jednoznacne identifikovat jeden radek tabulky. Proto to tak musi byt a databaze hlida, ze je tato vlastnost splnena.
.
Na zaver len dodam, ze "milujem" ludi, ktory si niekde nieco precitaju alebo vypocuju na prednaske a zacnu sirit FUD. Pri tom tito ludia ani netusia, co to je full table scan, prip. rollback segment, redo log alebo aky je rozdiel medzi B-tree indexom a bitmapovym indexom a co a kedy pouzit.
MySQL je velmi dobry a rychly SQL server a vrele ho doporucujem.
Neexistuje najlepsi ani "unbreakable" SQL server, kazdy je na nieco dobry, len je potrebne poznat ich prednosti a slabiny a podla toho postupovat pri vybere pre nejaky projekt.
Zdroje ze kterych jsem pri psani tohoto prvniho dilu cerpal: Naucte se MySQL za 21 dni, clanek (a jeho komentare) Modelovani databazi ze serveru root.cz, okrajove jeste i z PHP pokrocile programovani pro world wide web.
Jinak na tom, ze jsem pouzil stejnou definici normalizovanych forem, nevidim nic spatneho. Tech definic normalizovanych norem je sice vice, vsechny jsou ale obdoby originalni anglicke.
Cely dil je zalozen na vytvareni databaze internetoveho obchodu. Neni to zrovna originalini reseni (priklad tvorby internetoveho obchodu se dnes vyskytuje temer ve vsech knihah o PHP nebo MySQL), nicmene databaze internetoveho obchodu je prakticky a pro lidi snadno predstavitelny priklad).
Priklad k normalizaci databaze je vytvoren tak, ze se do jednoho objektu z databaze internetoveho obchodu "nacpou" vsechny sloupce z ostatnich objektu (pro prehlednost jsem vybral jen nektere z nich) a objekt se pak pomoci normalizacnich pravidel rozklada. Vim, ze stejne je to provedeno i v MySQL za 21 dni, toto je ale nejlepsi reseni. (samozrejme bych mohl vymyslet na normalizaci priklad nesouvisejici z databazi internetoveho obchodu. Vzhledem k tomu, ze vyuzivam priklad internetoveho obchodu v predchozi casti, nebylo by to tak vhodne).
Nadpisy odstavcu: Odstavec pojednavajici o prvni normalizovane forme se ve vetsine literatury jmenuje Prvni normalizovana forma atd.
PS: Procital jste si uz manual o MySQL? Jiste (by) jste si vsiml, ze v MySQL za 21 dni jsou nektere nadpisy odstavcu identicke a nektere texty temer stejne jako v manualu. Vetsinou totiz nema smysl vymyslet nove definice, popisy funkci apod.
tady to snad pujde
zdar
jj sem to pujde
/*1 vytvořte funkce sachta_max(id_trpaslika,mesic, rok) vstupními argumenty jsou id_trpaslika, mesic a rok v číselném vyjádření(rok na 4 číslice), pro které dany trpaslik zadanem mesici vytezil nejvice kg rudy. pokud v danem mesici trpaslik v zadne sachte netezil, vrati funkce hodnotu null, pokud mel ve vice sachtach stejny max vysledek, vrati funkce zreteteny seznam techt sachat, napr 'u potoka, v chvoji
/*2 vytvorte pohled trp_max_smen, jehoz vystupem jsou sloupce s nazvy, trpaslik, sachta, pro kazdeho trpaslik z tabulky trpaslici bude v pohledu uvedeno, v ktere sachte natezil nejvice kg rudy v roce 2006 v unoru pokud to bylove vice sachtach budou tyto zretezeny ve 2.sloupce-viz popis predchozi funkce */
/*3 */
to je pekny teda :X
/*1 vytvořte funkce sachta_max(id_trpaslika,mesic, rok) vstupními argumenty jsou id_trpaslika, mesic a rok v číselném vyjádření(rok na 4 číslice), pro které chceme vratit nazev sachty, v ktere dany trpaslik v zadanem mesici vytezil nejvice kg rudy. pokud v danem mesici trpaslik v zadne sachte netezil, vrati funkce hodnotu null, pokud mel ve vice sachtach stejny max vysledek, vrati funkce zreteteny seznam techt sachat, napr 'u potoka, v chvoji*/
znova byla tam chyba
create or replace view trp_max_smen as
select jmeno,sachta from
(select trpaslici.jmeno,sachty.sachta,max(tezby.skutecnost)as pocet from trpaslik.trpaslici
join trpaslik.tezby on trpaslici.id=tezby.id_trpaslika
join trpaslik.sachty on tezby.id_sachty=sachty.id
where tezby.den BETWEEN TO_DATE('01.02.2006','dd.mm.yyyy') AND
TO_DATE('28.02.2006','dd.mm.yyyy')
group by trpaslici.jmeno,sachty.sachta)
nejni osetreny kdyz so utreba dve sachty kde ma stejne
RETURN VARCHAR2 AS v_vysledek VARCHAR2; BEGIN SELECT trpaslici.id, trpaslici.jmeno, id_sachty, sachty.sachta INTO v_vysledek, MAX(tezby.skutecnost) FROM trpaslik.trpaslici JOIN trpaslik.tezby ON trpaslici.id = tezby.id_trpaslika JOIN trpaslik.sachty ON tezby.id_sachty = sachty.id WHERE trpaslici.id = in_id_trpaslika AND (TO_CHAR(den, 'MM') = in_mesic) AND (TO_CHAR(den, 'YYYY') = in_rok) GROUP BY trpaslici.id, trpaslici.jmeno, id_sachty, sachty.sachta HAVING MAX(tezby.skutecnost) = (SELECT MAX(tezby.skutecnost) FROM trpaslik.trpaslici JOIN trpaslik.tezby ON trpaslici.id = tezby.id_trpaslika JOIN trpaslik.sachty ON tezby.id_sachty = sachty.id WHERE trpaslici.id = in_id_trpaslika AND (TO_CHAR(den, 'MM') = in_mesic) AND (TO_CHAR(den, 'YYYY') = in_rok) GROUP BY trpaslici.id, trpaslici.jmeno); RETURN v_vysledek; END;
CREATE OR REPLACE FUNCTION sachta_max(in_id_trpaslika NUMBER, in_mesic NUMBER, in_rok NUMBER)
RETURN VARCHAR2
AS
v_vysledek VARCHAR2;
BEGIN
SELECT trpaslici.id, trpaslici.jmeno, id_sachty, sachty.sachta INTO v_vysledek, MAX(tezby.skutecnost)
FROM trpaslik.trpaslici
JOIN trpaslik.tezby ON trpaslici.id = tezby.id_trpaslika
JOIN trpaslik.sachty ON tezby.id_sachty = sachty.id
WHERE trpaslici.id = in_id_trpaslika AND (TO_CHAR(den, 'MM') = in_mesic) AND (TO_CHAR(den, 'YYYY') = in_rok)
GROUP BY trpaslici.id, trpaslici.jmeno, id_sachty, sachty.sachta
HAVING MAX(tezby.skutecnost) =
(SELECT MAX(tezby.skutecnost)
FROM trpaslik.trpaslici
JOIN trpaslik.tezby ON trpaslici.id = tezby.id_trpaslika
JOIN trpaslik.sachty ON tezby.id_sachty = sachty.id
WHERE trpaslici.id = in_id_trpaslika AND (TO_CHAR(den, 'MM') = in_mesic) AND (TO_CHAR(den, 'YYYY') = in_rok)
GROUP BY trpaslici.id, trpaslici.jmeno);
RETURN v_vysledek;
END;
 AbcLinuxu.cz
AbcLinuxu.cz ITBiz.cz
ITBiz.cz HDmag.cz
HDmag.cz AbcPráce.cz
AbcPráce.cz 27.3.2003 21:10
27.3.2003 21:10