V jádře Linux byla nalezena a v upstreamu již byla opravena kritická zranitelnost GhostLock aneb CVE-2026-43499. Lokálnímu uživateli umožňuje získat práva roota a také obejít kontejnerovou izolaci. Zranitelnost existovala v Linuxu 15 let, tj. od roku 2011, od Linuxu verze 2.6.39.
Evropská komise předběžně shledala, že návykový design aplikací Instagram a Facebook od americké společnosti Meta porušuje unijní nařízení o digitálních službách (DSA). Návykový design zahrnuje například takzvané nekonečné posouvání, automatické přehrávání videí, tzv. push notifikace, kdy aplikace uživatele vybízí k návratu do jejího prostředí, či vysoce personalizovaný algoritmus, který rychle pozná, co uživatele baví a snaží
… více »Byla vydána verze 1.97.0 programovacího jazyka Rust (Wikipedie). Podrobnosti v poznámkách k vydání. Vyzkoušet Rust lze například na stránce Rust by Example.
Švýcarská společnost Punkt. má nově v nabídce telefon Punkt. MC03. Telefon byl navržen ve Švýcarsku s důrazem na soukromí a digitální suverenitu a vyroben v Německu. V telefonu běží operační systém AphyOS (Apostrophy OS) založený na AOSP (Android Open Source Project) 15. Cena telefonu je 745 eur.
TypeScript (Wikipedie), tj. JavaScript rozšířený o statické typování a další atributy, byl vydán v nové verzi 7.0. Kompilátor byl kvůli výkonu přepsán z TypeScriptu do Go.
Europarlament podpořil pozměněnou verzi výjimky známé jako „chat control 1.0“ umožňující firmám skenovat soukromou komunikaci na internetu kvůli ochraně dětí před zneužitím. Pozměňovací návrhy přijaté europoslanci však počítají s tím, že z výjimky bude vyřazena šifrovaná komunikace. Výjimka přestala platit začátkem dubna poté, co se Evropský parlament a Rada EU nedokázaly shodnout na jejím prodloužení. Rada následně přijala
… více »Nejnovější X.Org X server 21.1.24 a Xwayland 24.1.13 řeší 2 bezpečnostní chyby.
Clement "Clem" Lefebvre publikoval souhrn dění v Linux Mintu za červen 2026. Vypíchnuta je vylepšená podpora Waylandu. Už není považována za experimentální. V příští verzi Linux Mintu, plánována je na Vánoce, bude běh Cinnamonu plně podporován na X11 i Waylandu. V květnu na vývoj Linux Mintu přispělo 611 dárců celkovou částkou 19 612 dolarů. Dalších 2 326 patronů přispělo na Patreonu celkovou částkou 5 334 dolarů.
V Linuxu v KVM byla nalezena a v upstreamu již byla opravena kritická zranitelnost Januscape aneb CVE-2026-53359. Root na hostovaném počítači (virtuální stroj) může obejít izolaci a získat plnou kontrolu nad hostitelským systémem (DoS útok nebo vzdálené spuštění kódu s právy roota). Na obou hlavních architekturách – Intel i AMD. Zranitelnost v Linuxu existovala téměř 16 let (od srpna 2010 do června 2026).
Tribunál Soudního dvora Evropské unie dnes zamítl několik žalob, v nichž se americká společnost Apple ohrazovala proti pravidlům fungování velkých technologických společností na unijním trhu. Applu se nelíbilo, že jeho obchod s aplikacemi a operační systém iOS mají podléhat přísnějším povinnostem jen proto, že Brusel firmu považuje za takzvaného gatekeepera, tedy strážce přístupu.
Ale pochybujem, ze prave toto bude printerd riesit...Jasně, že to řeší! Vyrobí z toho PDF, a z PDF vyrobí PS, který pošle na tiskárnu. Jooo a má to to supr dupr výhodu v integraci s tou nesmyslnou polkit srágorou.

 25.5.2012 09:56
xkucf03 | skóre: 50
| blog: xkucf03
25.5.2012 09:56
xkucf03 | skóre: 50
| blog: xkucf03
file/libmagic.
Nebo např. Wayland, ten taky vypadá, že by mohl být v budoucnu fajn...
O Waylandu jsem mluvil s developerem, který naportoval na Wayland celý EFL, a prý je to taky bordel..
expresivita detekčních výrazů v shared MIME info je tristní -- v podstatě se uchyluješ ke koncovkámTak ta expresivita možná není dokonalá, ale ke koncovkám se uchylovat nemusíš. S
file/libmagic je spíš ten problém, že spousta věcí (hlavně pokročilejší náčítání informací z formátu) je tam prostě hardcodována. Např. ELF, ale i jiné. A multiplatformnost je taky hodně špatná - v podstatě bys to musel přepsat.
Jinak já měl například u file problém s matroškou. Polovinu matrošek, co mám na disku, není file schopen určit, zatímco shared MIME-magic nemá problém (bez přípony samozřejmě).
 24.5.2012 12:07
Pavel Stárek | skóre: 43
| blog: Tady bloguju já :-)
| Kolín
24.5.2012 12:07
Pavel Stárek | skóre: 43
| blog: Tady bloguju já :-)
| Kolín
 24.5.2012 12:25
Tomáš Bžatek | skóre: 29
| Brno
24.5.2012 12:25
Tomáš Bžatek | skóre: 29
| Brno
dodnes by se používalo kódování 8859-2Mně by to teda nevadilo. Unicode stejně používám asi jen v OO a FF. V teminálu mám stále ISO8859-2 a zbytek locales v C a vyhovuje mi to lépe než vícebajtové sady s tisíci obskurními znaky. Zunikódování celého systému včetně jmen souborů je mi přínosem asi jako doménová jména ve swahilštině.
Dnešní linuxové distribuce jsou směsí nedodělaných aplikací a totálně rozvrtaného zmrveného systému.A tohle jakože není dogmatický blábol? Meh...
 24.5.2012 21:12
pavlix | skóre: 54
| blog: pavlix
25.5.2012 09:59
xkucf03 | skóre: 50
| blog: xkucf03
25.5.2012 12:27
xkucf03 | skóre: 50
| blog: xkucf03
24.5.2012 21:12
pavlix | skóre: 54
| blog: pavlix
25.5.2012 09:59
xkucf03 | skóre: 50
| blog: xkucf03
25.5.2012 12:27
xkucf03 | skóre: 50
| blog: xkucf03
Dle diskuse vidím, že se to blbě vysvětluje sotva zletilým windowsákům, kteří "přešli" na linux, protože je kůl.Zrovna nedávno si mi někdo stěžoval, že nemůže ve Windows otevřít přílohu od někoho ze zahraničí (jednou tam byla azbuka, podruhé nějaké francouzské znaky). Resp. šlo mu to uložit na disk, ale otevřít už ne. V mém GNU/Linuxu s tím nebyl žádný problém, tak jsem mu ty soubory přejmenoval a poslal zpátky

V mém GNU/Linuxu s tím nebyl žádný problém, tak jsem mu ty soubory přejmenoval a poslal zpátkyTak mi ukaž, jak v tom tvém linuxu rozbalíš .zip s názvy souborů v jiném kódování, než máš sám.
 Ale ono to stejně nejde, zkusil jsem to, a při
Ale ono to stejně nejde, zkusil jsem to, a při bind se tyhle možnosti nenastaví.
Existuje ale mnohem jednodušší způsob: convmv.
25.5.2012 15:23
xkucf03 | skóre: 50
| blog: xkucf03
Výsledkem jsou sice nějaké paznaky, ale pořád s tím jde (alespoň v mém OS) normálně pracovat – můžu takový soubor otevřít, přejmenovat nebo třeba smazat.Zrovna ale tohle je problem, ktery je na Linuxu spojen s nastupem UTF-8. Zatimco u beznych osmibitovych kodovani s tim problem nebyl, nebot vicemene jakakoliv sekvence znaku byla vicemene korektni (tedy az na ruzne veci jako escape sekvence ve jmene, ale ty obvykle nicemu krome zobrazeni nevadily), tak u UTF-8 existuji nevalidni sekvence a nekterym programum prace s takovymi soubory dela dost vazne potize.
25.5.2012 16:02
Pavel Stárek | skóre: 43
| blog: Tady bloguju já :-)
| Kolín
Mně přijdou háčky a čárky (a další znaky) v názvech souborů a jinde jako samozřejmost a jsem rád, že to můj OS zvládá. Nikomu to nenutím, kdo nechce, ať to nepoužívá, ale OS by to si s tím podle mého měl umět poradit.No, v ramci jednoho systemu to jeste jde, ale jakmile takove soubory budes chtit tahat pres sit ci jinak prenaset mezi ruznymi systemy, tak narazis na znacne mnozstvi vice ci mene neresitelnych potizi (vychazejicich zejm. z odlisne koncepce mezi Windowsovym "jmeno souboru je posloupnost unicode znaku" a Unixovym "jmeno souboru je posloupnost bytu bez interpretace". Coz v konecnem dusledku rika, ze jedine pragmaticke reseni je cokoliv jineho nez ASCII ve jmenech souboru nepouzivat.
26.5.2012 16:33
xkucf03 | skóre: 50
| blog: xkucf03
No, v ramci jednoho systemu to jeste jde, ale jakmile takove soubory budes chtit tahat pres sit ci jinak prenaset mezi ruznymi systemyPři těch přenosech po síti je to vyřešené celkem dobře, jsou na to standardy, RFCčka… je definované URL kódování, kódování příloh v e-mailech, příloh na webu (když se stahovaný soubor má uložit pod jiným názvem než je poslední část URL) atd. Většinou to tedy funguje a když ne, tak to beru tak, že by se to mělo opravit (podle patřičného standardu) a ne že by se uživatel měl přizpůsobovat rozbité technice. Tak zbývají jen ty archivy a diskové oddíly… Ale i v takovém ZIPu se kódování řeší:
Bit 11: Language encoding flag (EFS). If this bit is set,
the filename and comment fields for this file
must be encoded using UTF-8. (see APPENDIX D)
takže by to fungovat mělo.
Unixovym "jmeno souboru je posloupnost bytu bez interpretace"Tahle diskuse už tu jednou byla a tuším, že jsem psal něco v tom smyslu, že jména klidně můžou být posloupnost bajtů, ale ať je někde v metadatech daného oddílu napsané, jaké kódování se používá (aby si ho člověk nemusel pamatovat a psát ho jako parametr
mount příkazu nebo do fstab).
Při těch přenosech po síti je to vyřešené celkem dobře, jsou na to standardy, RFCčkaJe mnoho standardu, pro ktere rozsireni pro kodovani to snad nikdo nikdy nerozsiril, nebo se rozsireni neujalo. Napr. FTP nebo talk. Nebo standard existuje, ale konceptualni rozdily mezi OSy ho znemoznuji implementovat tak, aby tam nebyly problematicke okrajove pripady (to je treba pripad sitovych windows-like filesystemu a jejich podpore v Linuxu).
Tahle diskuse už tu jednou byla a tuším, že jsem psal něco v tom smyslu, že jména klidně můžou být posloupnost bajtů, ale ať je někde v metadatech daného oddílu napsané, jaké kódování se používáJenze prave v Linuxu kodovani nema vubec nic spolecneho s oddily, ale s procesy (a typicky s uzivateli). Neni neobvykle, kdyz na jednom oddilu je mnoho uzivatelu a kazdy pouziva jine kodovani (napr. u multiuzivatelskych sdilenych serveru, kam se lide obvykle prihlasuji pres SSH ze sveho domaciho stroje a pouzivaji tam tedy stejne kodovani jako doma). Protoze v Linuxu je kodovani veci procesu, tak nelze rozumne implementovat serverove konce sitovych file-protokolu, ktere predavaji explicitne kodovana jmena souboru. Na klientske strane (napr. MUA pri posilani souboru e-mailem), tam klient kodovani zna, ale napr. SFTP server nema sanci zjistit, jake kodovani jmena soboru ma dany soubor (pokud odmyslim, ze by parsoval prihlasovaci shellove skripty daneho uzivatele). A to ani nemluvim o pripadu, ze v Linuxu je korektni, aby byly v jednom adresari dva ruzne soubory, jejichz jmeno po prevodu do Unicode je stejne (napr. proto, ze kazdy je jineho uzivatele a oba pouzivai odlisne kodovani). Na tom se ti rozbije spousta encoding-aware sitovych protokolu. Nebo pripad, kdy na disku je soubor, jehoz jmeno vubec neni platnou UTF-8 sekvenci, i kdyz by jinak mel byt UTF-8 kodovany.
ale napr. SFTP server nema sanci zjistit, jake kodovani jmena soboru ma dany souborCoz je, BTW, mozna taky duvod, proc soucasne OpenSSH implementuje jen SFTP verzi 2 (alespon co jsem se naposledy dival), ktera je jeste agnosticka co se tyce obsahu jmena souboru, zatimco novejsi verze uz predpoklada jednoznacnou interpretaci predavaneho jmena.
25.5.2012 10:02
xkucf03 | skóre: 50
| blog: xkucf03
 23.5.2012 19:53
David Watzke | skóre: 74
| blog: Blog...
| Praha
23.5.2012 19:53
David Watzke | skóre: 74
| blog: Blog...
| Praha
 24.5.2012 09:05
Saljack | skóre: 28
| blog: Saljack
| Praha
24.5.2012 09:05
Saljack | skóre: 28
| blog: Saljack
| Praha
Ked clovek nepotrebuje mat zo svojho PC tlacovy server, tak by tam naozaj nemusel ziadny bezat.
printerd je jenom spooler, ne printserver.
 23.5.2012 21:55
Jakub Lucký | skóre: 40
| Praha
23.5.2012 21:55
Jakub Lucký | skóre: 40
| Praha
Původní idea přišla od lidí kolem GNOMETo dává smysl. Ti už několikrát předvedli, že jsou zralí pro svěrací kazajku!
24.5.2012 16:09
David Watzke | skóre: 74
| blog: Blog...
| Praha
Tiskni
Sdílej:
![]()
![]()
![]()
![]()
![]()
![]()
 AbcLinuxu.cz
AbcLinuxu.cz ITBiz.cz
ITBiz.cz HDmag.cz
HDmag.cz AbcPráce.cz
AbcPráce.cz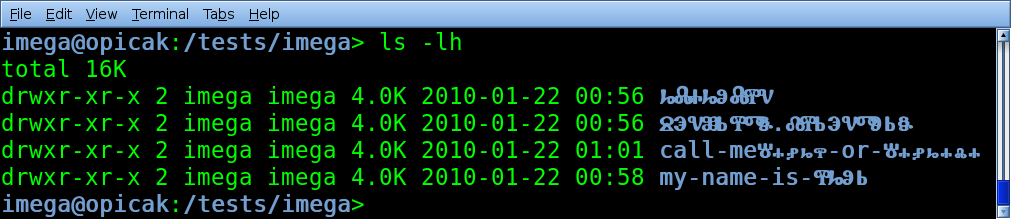{kind=link}