V Praze probíhá Flock 2026, tj. konference pro přispěvatele a příznivce Fedory. Přednášky lze sledovat také na YouTube.
Node-RED (Wikipedie, GitHub), webová aplikace postavená na Node.js pro vizuální programování a propojování hardwarových zařízení, API a online služeb, byl vydán ve verzi 5.0. Přehled novinek v příspěvku na blogu.
Byla vydána nová verze 3.27.0 FreeRDP, tj. svobodné implementace protokolu RDP (Remote Desktop Protocol). Opraveno bylo 5 zranitelností.
Řídící výbor GCC schválil záměr do GCC začlenit backend WebAssembly.
Po 9 týdnech vývoje od vydání Linuxu 7.0 oznámil Linus Torvalds vydání Linuxu 7.1. Přehled novinek a vylepšení na LWN.net: první a druhá polovina začleňovacího okna a časem také na Linux Kernel Newbies.
Cheat Engine (Wikipedie) je s verzí 7.7 k dispozici už také pro Linux. Jedná se o proprietární skener/debugger paměti používaný především k cheatování v počítačových hrách.
Vláda USA nařídila společnosti Anthropic pozastavit přístup k modelům Fable 5 a Mythos 5 pro všechny cizince, včetně zaměstnanců Anthropicu.
Společnost Murena představila (YouTube) novou verzi 4.0 mobilního operačního systému /e/OS (Wikipedie) založeného na Androidu a LineageOS bez aplikací a služeb od Googlu.
V Arch User Repository (AUR) bylo kompromitováno přes 400 opomíjených balíčků (jejich seznam). Útočník do nich začlenil škodlivý npm balíček atomic-lockfile, který krade citlivá data uživatelů. Publikována byla předběžná analýza spouštěného malwaru deps.
Homebrew, správce balíčků nejen pro macOS, byl vydán ve verzi 6.0.0 (seznam změn). Hlavními novinkami jsou bezpečnostní mechanismus tap trust kvůli důvěryhodnosti závislostí, vylepšení sandboxingu na Linuxu, interní JSON API nebo zlepšení výkonu.
Byla vydána nová vývojová verze datového formátu a souvisejících nástrojů Relational pipes. Verze v0.9 obsahuje vstupní moduly pro fstab, CSV, XML a příkazový řádek; výstupní moduly pro CSV, XML, ODS (ODF), GUI (Qt), hodnoty oddělené nulovým bajtem a tabulkový výstup do konzole. Relační data lze upravovat relačními příkazy grep, cut a sed.
Tiskni
Sdílej:
![]()
![]()
![]()
![]()
![]()
![]()
relpipe-in-filesystem, což se mi po pár pokusech povedlo takto:
$ echo -e "path\n/etc/passwd\n/etc/shadow" | relpipe-in-csv | relpipe-out-nullbyte | relpipe-in-filesystem | relpipe-out-tabular filesystem: ╭───────────────┬───────────────┬────────────────┬────────────────┬────────────────╮ │ path (string) │ type (string) │ size (integer) │ owner (string) │ group (string) │ ├───────────────┼───────────────┼────────────────┼────────────────┼────────────────┤ │ /etc/passwd │ f │ 2870 │ root │ root │ │ /etc/shadow │ f │ 1684 │ root │ shadow │ ╰───────────────┴───────────────┴────────────────┴────────────────┴────────────────╯ Record count: 2Kdybych chtěl vylistovat třeba soubory v aktuálním adresáři, vyfiltrovat jen ty, které mají určitého vlastníka a seřadit je podle velikosti (kdybys měl implementovaný hypotetický
relpipe-sort), jak to udělám? Prvně bych potřeboval transformovat výstup ls na relační data. Přišlo mi, že to by mohl umět relpipe-in-cli, ale nepochopil jsem, jak ho použít. Co jsem se díval do kódu, tak to sice akceptuje příkaz generate-from-stdin, ale padalo mi to:
$ ls | relpipe-in-cli generate-from-stdin Caught CLI exception: Missing value on STDIN. Debug: Input stream: eof=true, lastRead=0Pak jsem narazil na ukázku, ze které jsem pochopil, že na to jdu špatně a správně by to bylo asi spíš třeba:
$ ls | tr \\n \\0 | relpipe-in-filesystem | relpipe-tr-grep filesystem type f | relpipe-out-tabular filesystem: ╭───────────────┬───────────────┬────────────────┬────────────────┬────────────────╮ │ path (string) │ type (string) │ size (integer) │ owner (string) │ group (string) │ ├───────────────┼───────────────┼────────────────┼────────────────┼────────────────┤ │ grub.cfg │ f │ 11862 │ root │ root │ │ grubenv │ f │ 1024 │ root │ root │ │ unicode.pf2 │ f │ 2397557 │ root │ root │ ╰───────────────┴───────────────┴────────────────┴────────────────┴────────────────╯ Record count: 3Nehodil by se nástroj na konverzi LF na nulový bajt, aby nebylo nutné to ručně nahrazovat pomocí
tr? Pak je trochu nepraktické muset relpipe-tr-grep volat se jménem relace. Pochopil jsem, že ve streamu těch „relací“ může být víc, ale tam jednak nevidím uplatnění (neříkám, že neexistuje, jen ho nevidím) a jednak nevím, jestli by nebylo lepší udělat z nich spíš „jmenné prostory“, jejichž uvedení bude explicitně vyžadováno jen v případě nejednoznačnosti; tj. v tomto případě bych mohl psát jak filesystem.type, tak jen type. Vím, že (všechny) ty argumenty jsou regulární výrazy, ale to by vadit nemuselo, ne?
Pak příliš nerozumím tomu, jaký je vlastně význam těch listů s položkami oddělenými nulovými bajty, resp. proč to relpipe-in-filesystem vyžaduje právě v tomto formátu.
A konečně, proč binární formát? Vím, že JSON nemáš zrovna v oblibě, ale je to jednoduchý a poměrně kompaktní formát, pro který existuje dobrá podpora snad ve všech jazycích (v shellu např. jq) a pokud na to přijde, tak jej lze snadno generovat i bez knihoven. To jde asi i ten tvůj formát, ale hůř se to debuguje a pro lidi bez nainstalovaných relational-pipes je to úplně k ničemu. Oproti tomu ten JSON má nějaký význam sám o sobě. U tabulek je i ta forma celkem jasná.
Mimochodem, pro jaké use-case to reálně zamýšlíš? Mně by se líbilo třeba grepovat logy podle data nebo úrovně, ale když opomenu, že bych si prvně musel ten parser napsat, tak bych ještě pokaždé musel uvádět, jaký parser použít. Možná bych do budoucna zvážil nějakou autodetekci (data se budou krmit všem parserům současně, pokud nastane EOF nebo se dosáhne maximální velikosti bufferu/přečtených bajtů a nebude existovat právě jeden parser, který dosud neohlásil chybu, tak autodetekce selhala), aby pak bylo možné psát třeba jen rcat <filename> a většinou to fungovalo. Chtělo by to ale nějakou přímou podporu v těch parserech, aby bylo možné jim sdělit dodatečné informace jako např. jméno souboru. V opačném případě by se nějaký generický parser klidně mohl chytnout toho /etc/fstab namísto specializovaného parseru.
To jen pár myšlenek, schválně to píšu trochu chaoticky tak, jak mi to přišlo na mysl.
moc nevím, jestli tomu tak říkat; viz tvoje diskuze s deda.jabko v jiném vlákně
Viz FAQ. Relační data jsou přirozená a primární forma dat, se kterými se tu pracuje. Že to použiješ i k něčemu jinému a třeba se i střelíš do nohy, je už tvoje věc. Je to jako když někdo prodává ředidla – jejich primárním účelem je ředit barvy, proto se to jmenuje ředidlo. Že to někdo bude čichat, to už je jeho věc, a obchodník s ředidly mu v tom nijak nezabrání. A ani to není důvod k tomu, aby se obchod „Barvy, laky a ředidla“ přejmenoval na „Potřeby pro feťáky“ :-)
Jak se generují ta „relační“ data
Viz Příklady – je tam jak vstup z CLI, tak ze STDIN. Tohle pak bude pořádně popsané ve specifikaci, ale syntaxe ještě není stabilizovaná, takže zatím je to zdokumentované jen formou pár příkladů.
Zkoušel jsem zavolat relpipe-in-filesystem, což se mi po pár pokusech povedlo takto
Ty první tři kroky v tvé rouře jsou zbytečné. Typické použití relpipe-in-filesystem bude společně s příkazem find, který ti ty nulou oddělené hodnoty vygeneruje.
Kdybych chtěl vylistovat třeba soubory v aktuálním adresáři, vyfiltrovat jen ty, které mají určitého vlastníka a seřadit je podle velikosti (kdybys měl implementovaný hypotetický relpipe-sort), jak to udělám?
Příkaz relpipe-tr-sort zatím není, ale pokročilejší filtrování tam už funguje. Zatím to tedy umí SELECT a WHERE, ale neumí ORDER BY. Zrovna dělám na podpoře Guile (Scheme), je to ještě hodně čerstvé, rozhraní i implementace se budou ještě dost měnit, ale zatím jako ukázka, co to bude umět – libovolně složité podmínky (AND, OR, funkce …) pro filtrování záznamů:
$ find /etc/ssh/ -print0 | relpipe-in-filesystem | relpipe-tr-guile '.*' '(and (equal? owner "root") (< 300 size) (> 1000 size) )' | relpipe-out-tabular filesystem: ╭───────────────────────────────┬───────────────┬────────────────┬────────────────┬────────────────╮ │ path (string) │ type (string) │ size (integer) │ owner (string) │ group (string) │ ├───────────────────────────────┼───────────────┼────────────────┼────────────────┼────────────────┤ │ /etc/ssh/ssh_host_ed25519_key │ f │ 399 │ root │ root │ │ /etc/ssh/ssh_import_id │ f │ 338 │ root │ root │ │ /etc/ssh/ssh_host_rsa_key.pub │ f │ 391 │ root │ root │ ╰───────────────────────────────┴───────────────┴────────────────┴────────────────┴────────────────╯ Record count: 3
Pak je trochu nepraktické muset relpipe-tr-grep volat se jménem relace.
Tohle se ještě může změnit. Zatím se tam dá psát '.*'. Ta současná syntaxe příkazů grep, sed, cut je jakási zjednodušená syntaxe, ve které se nepoužívají --pojmenované-parametry "s hodnotou", ale jen poziční parametry, kde musíš vědět, že na prvním místě je to, na druhém ono… ale zase je to kratší. Ještě nevím, jestli tahle zjednodušená syntaxe ve finální verzi vůbec bude. U té standardní syntaxe pak bude parametr např. --relation fstab a možné řešení je, že když ho vynecháš, aplikuje se transformace na všechny relace v proudu.
Pak příliš nerozumím tomu, jaký je vlastně význam těch listů s položkami oddělenými nulovými bajty, resp. proč to relpipe-in-filesystem vyžaduje právě v tomto formátu.
Např. název souboru může obsahovat znak konce řádku. Ano, je to okrajový případ, ale i s tím je potřeba počítat. A atributy můžou být delší texty, ve kterých se konce řádků můžou běžně vyskytovat a není na tom nic zvláštního. Nulový bajt je víceméně jediný znak, který se v textovém řetězci nemůže vyskytovat a je to i běžně používaný oddělovač. Např. v C se někdy používá pole řetězců (teď nemyslím pole ukazatelů na řetězce) tak, že je máš nasázené v paměti za sebou a oddělené nulovým bajtem (a znáš počet prvků).
Data v tomhle „formátu“ umí generovat find, používají se i v některých souborech (viz třeba cat /proc/self/cmdline | xargs -0 -n1 echo) a můžeš je vytvářet pomocí příkazu printf nebo i tím tr \\n \\0
A konečně, proč binární formát?
Těch důvodů je víc, viz Principy. Např. je důležitě, aby šlo relační proudy spojovat prostým zřetězením, např. cat soubor1 soubor2 nebo (příkaz1; přízak2) | příkaz3. Nebo by to mělo být úsporné z hlediska místa – např. když budeš mít relaci s velkým počtem malých atributů z nichž půlka většinou chybí, tak by to nemělo zabrat o moc víc místa než počet_záznamů × polovina_počtu_atributů × velikost_datového_typu. …
To jde asi i ten tvůj formát
Seznam řetězců oddělených nulovým bajtem vygeneruješ snadněji, než escapuješ data do JSONu.
pro lidi bez nainstalovaných relational-pipes je to úplně k ničemu
Typické použití je takové, že data se nebudou nikam ukládat (v souborech se budou vyskytovat zřídka) a jen se předají za běhu mezi procesy – relační roura má nějaký vstup/vstupy a nějaký výstup/výstupy a data v tomto formátu se vyskytují většinou jen v RAM a na počítači, kde potřebné nástroje dostupné jsou. Pro uložení relačních dat do souboru použiješ většinou nějaký textový formát. Pokud je to jen jedna relace, dá se použít CSV, které ale neumí uložit informaci o datových typech. Bezztrátová konverze na text a z textu je možná s XML. To si pak můžeš ukládat do verzovacího systému nebo upravovat v editoru. Časem bude možná i podpora bezztrátové konverze z a do JSONu (nebo spíš YAMLu).
Je to podobné jako s PNG – s ním taky prakticky vždy pracujeme v jeho binární formě – ale kdybys ho náhodou chtěl upravovat ručně nebo ho zkoumat, tak existují nástroje pro jeho konverzi na text a zase zpátky.
Mně by se líbilo třeba grepovat logy podle data nebo úrovně, ale když opomenu, že bych si prvně musel ten parser napsat, tak bych ještě pokaždé musel uvádět, jaký parser použít.
Zrovna u logů by bylo fajn je rovnou generovat v nějakém strukturovaném formátu. Škoda toho současného stavu, kdy v programu máš data ve strukturované formě, předáš je loggeru (pořád ještě strukturovaně) a ten je vyblije do textu, ve kterém se ztratí spousta informací, hranice mezi záznamy, parametry atd. Vychází to z toho, že původně měl být log jen jakýsi protokol pro člověka, který si lze zpětně přečíst a ad-hoc zjistit, co se dělo. Jenže dneska je situace jiná, logů je tolik, že to nikdo číst stejně nebude – automatizace je nevyhnutelná a žádoucí (logy můžeš automaticky číst pořád, i když nemáš žádný problém, a nějak je agregovat, korelovat a třeba odhalit problém dřív, než se někde viditelně projeví), jenže ty původní textové logy nejsou strojově zpracovatelné, protože se čekalo, že je bude číst člověk řádek po řádku. Pro svoje potřeby si asi napíšu logger pro Javu a Apache, který bude generovat rovnou relační data. Ono je totiž výrazně jednodušší generovat nějaký dobře definovaný/známý formát, než parsovat vágně definovaný formát.
Jinak parser pro ty textové logy se napsat dá, může např. načíst prvních pár řádků a rozhodnout, který z podporovaných formátů to je, a pak zpracovat ten zbytek. Občas se asi dostaneš do situace, že je zápis nejednoznačný a nějaký záznam se rozsype, ale to už je vada toho textového pseudo-formátu, ve kterém se některé informace ztrácí, s tím se nedá nic dělat.
Mimochodem, pro jaké use-case to reálně zamýšlíš?
Záměrně to není navržené pro žádný konkrétní scénář, je to koncipované jako obecný datový formát. Jedno ze zamýšlených použití je interakce s operačním systémem, činnosti se soubory, procesy, systémovými službami atd. Bude tam i podpora čtení metadat ze souborů (v multimediálních formátech, obrázcích, PDF – pravděpodobně přes GNU Libextractor). Další scénář je různé poloautomatizované zpracování dat – to, co spousta lidí dělá v tabulkových kalkulátorech – ty mi nevyhovují a myslím si, že tohle je lepší způsob práce s daty (alespoň pro mě). Např. si posbírám data z různých zdrojů, nějak je transformuji, a pak spočítám nějaké statistiky nebo nakreslím grafy v GNU R či Gnuplotu nebo to převedu na .dot a vykreslím diagram v GraphVizu. Dále to může sloužit jako most mezi různými systémy/formáty – např. souborový systém × relační databáze, libovolný formát × Bash (spustit příkaz pro každý záznam, viz while read_nullbyte v příkladech), např. můžeš načíst Atom (či RSS) a pak zpracovávat relačně (viz stránka s příklady), nebo takhle číst nebo generovat iCal, vCard, vzít historii z verzovacího systému, něco z ní vyfiltrovat a vypsat přehled na webu nebo v TeXu atd.
Potenciál vidím v tom, že když se dokážeš vejít do relačního modelu1, tak máš najednou I×T×O možností, kde I (vstupní filtry), T (transformace) a O (výstupní filtry) stačí implementovat vždy jen jednou a jsou opakovaně použitelné, univerzální – lze z těchto komponent poskládat libovolnou kombinaci.
[1] což dokážeš ve většině případů, viz úspěch a rozšíření relačních databází
Relační data jsou přirozená a primární forma dat, se kterými se tu pracuje.Mně přišlo, že se pracuje s tabulkami. Prvním argumentem
relpipe-tr-grep je údajně název relace, ale to je přece nesmysl. V praxi se AFAIK relace říká především vztahu dvou a více řádků z jiných tabulek (1:1, 1:N, …). Mohl bys trvat na tom, že budeš relací nazývat každý řádek, protože přece vyjadřuje vztah mezi nějakými veličinami (sloupci tabulky), ale ty tak nazýváš celou tu tabulku. Pokud mermomocí trváš na relacích, můžeš tomu říkat třeba vektor relací, a pak upřesnit, že tedy těmi relacemi myslíš to, čemu se jinak odborně říká také řádky.
U té standardní syntaxe pak bude parametr např. --relation fstab a možné řešení je, že když ho vynecháš, aplikuje se transformace na všechny relace v proudu.Oproti jmenným prostorům by odpadla starost o syntaxi a je snažší to vysvětlit, takže by to asi bylo lepší.
Např. název souboru může obsahovat znak konce řádku.To jsem si neuvědomil. Díky za upozornění.
Např. je důležitě, aby šlo relační proudy spojovat prostým zřetězením, např. cat soubor1 soubor2 nebo (příkaz1; přízak2) | příkaz3.S tím jsem se už setkal i u toho JSONu. Stačí, aby parser po zpracování dokumentu nekonzumoval další znaky.
Nebo by to mělo být úsporné z hlediska místa – např. když budeš mít relaci s velkým počtem malých atributů z nichž půlka většinou chybí, tak by to nemělo zabrat o moc víc místa než počet_záznamů × polovina_počtu_atributů × velikost_datového_typu. …Tak samozřejmě záleží, jaký objem dat očekáváš. JSON by byl větší ve skoro každém případě, ale ne nutně zrovna v tom, který zmiňuješ, protože klíč můžeš prostě vynechat.
Seznam řetězců oddělených nulovým bajtem vygeneruješ snadněji, než escapuješ data do JSONu.To přece ale nejsou ta relační data.
Škoda toho současného stavu, kdy v programu máš data ve strukturované formě, předáš je loggeru (pořád ještě strukturovaně) a ten je vyblije do textu, ve kterém se ztratí spousta informací, hranice mezi záznamy, parametry atd.Jo, to souhlasím.
Další scénář je různé poloautomatizované zpracování dat – to, co spousta lidí dělá v tabulkových kalkulátorech – ty mi nevyhovují a myslím si, že tohle je lepší způsob práce s daty (alespoň pro mě). Např. si posbírám data z různých zdrojů, nějak je transformuji, a pak spočítám nějaké statistiky nebo nakreslím grafy v GNU R či Gnuplotu nebo to převedu na .dot a vykreslím diagram v GraphVizu.To zní zajímavě, ale přijde mi, že v tom případě jsem to od začátku možná špatně uchopil a tedy ani nejsou relevantní ty připomínky ohledně použitého formátu. Pokud to zamýšlíš primárně na osobní zpracování dat, podpora třetích stran není natolik klíčová. Současně lze asi očekávat větší průtok a dává smysl použít kompaktnější formát. A v neposlední řadě mi to odpovídá na otázku, k čemu potřebuješ to filtrování pomocí
relpipe-tr-guile.
Já to bral jako de facto další pokus o objektový shell, ale ona je to spíš víc specializovaná podmnožina. Což není špatně, jen jsem to zprvu nepochopil. Uvidíme, jestli pro to najdu také časem najdu nějaké uplatnění.
 20.1.2019 19:28
okbob | skóre: 30
| blog: systemakuv_blog
| Benešov
20.1.2019 19:28
okbob | skóre: 30
| blog: systemakuv_blog
| Benešov
V praxi se AFAIK relace říká především vztahu dvou a více řádků z jiných tabulek (1:1, 1:N, …).To je docela rozšířený omyl - relačním databázím se jako relační rozhodně neoznačují kvůli možnosti nějakým způsobem spojovat tabulky - a kvůli pojmenování vazeb mezi tabulkami. Viz https://en.wikipedia.org/wiki/Relational_database#Relationships - A relation is defined as a set of tuples that have the same attributes.
Mně přišlo, že se pracuje s tabulkami. Prvním argumentem relpipe-tr-grep je údajně název relace, ale to je přece nesmysl. V praxi se AFAIK relace říká především vztahu dvou a více řádků z jiných tabulek (1:1, 1:N, …).
Relace právě odpovídá té tabulce. Ten vztah/vazba není relace (byť se to tak někdy chybně označuje).
S tím jsem se už setkal i u toho JSONu. Stačí, aby parser po zpracování dokumentu nekonzumoval další znaky.
Nad tím jsem chvíli uvažoval, ale problém mj. je v tom, že taková data nelze považovat za validní JSON (nebo třeba XML) a bylo by potřeba ten parser nějak ohýbat, aby po načtení dokumentu nepokračoval a nechal zbytek dat další instanci parseru, nebo aby začal číst další dokument a nějak to korektně ohlásil skrze svoje API.
JSON by byl větší ve skoro každém případě, ale ne nutně zrovna v tom, který zmiňuješ, protože klíč můžeš prostě vynechat.
Klíč/hodnotu lze vynechat, ale tam, kde hodnota přítomná je, musíš vždy opakovat název atributu. A když je to třeba boolean nebo nějaké malé číslo (což zabírá jeden bajt nebo v extrémním případě jeden bit), tak v JSONu pořád potřebuješ minimálně "x":1, nebo "x":true, a při delších názvech atributů mnohem více. V případě binárního formátu stačí jeden bit, který určí, zda je daný atribut null nebo ne, a potom přesně tolik bajtů, kolik má daný datový typ.
To přece ale nejsou ta relační data.
Jsou – i pomocí obyčejného seznamu lze zapsat relaci (tabulku). Jen potřebuješ znát počet atributů, jejich názvy a typy, což ale může být uvedeno na začátku toho seznamu:
$ printf 'moje_tabulka\0003\0první_atribut\0string\0druhý\0boolean\0třetí\0integer\0záznam 1\0true\0001\0záznam 2\0false\0002\0' | tr \\0 \\n moje_tabulka 3 první_atribut string druhý boolean třetí integer záznam 1 true 1 záznam 2 false 2 $ printf 'moje_tabulka\0003\0první_atribut\0string\0druhý\0boolean\0třetí\0integer\0záznam 1\0true\0001\0záznam 2\0false\0002\0' | relpipe-in-cli generate-from-stdin | relpipe-out-tabular moje_tabulka: ╭────────────────────────┬─────────────────┬─────────────────╮ │ první_atribut (string) │ druhý (boolean) │ třetí (integer) │ ├────────────────────────┼─────────────────┼─────────────────┤ │ záznam 1 │ true │ 1 │ │ záznam 2 │ false │ 2 │ ╰────────────────────────┴─────────────────┴─────────────────╯ Record count: 2 $ printf 'string\0druhý\0boolean\0třetí\0integer\0záznam 1\0true\0001\0záznam 2\0false\0002\0' | relpipe-in-cli generate-from-stdin moje_tabulka 3 první_atribut | relpipe-out-tabular moje_tabulka: ╭────────────────────────┬─────────────────┬─────────────────╮ │ první_atribut (string) │ druhý (boolean) │ třetí (integer) │ ├────────────────────────┼─────────────────┼─────────────────┤ │ záznam 1 │ true │ 1 │ │ záznam 2 │ false │ 2 │ ╰────────────────────────┴─────────────────┴─────────────────╯ Record count: 2
A jak CLI parametry, tak STDIN zde tvoří jeden seznam a je jedno, co kam napíšeš, kde bude ta hranice – čtou se nejdřív parametry a pak se plynule pokračuje standardním vstupem (tzn. druhý a třetí příklad výše jsou ekvivalentní).
Pokud to zamýšlíš primárně na osobní zpracování dat, podpora třetích stran není natolik klíčová. Současně lze asi očekávat větší průtok a dává smysl použít kompaktnější formát.
Já samozřejmě chápu všechny ty argumenty pro textové formáty, četl jsem Umění programování v Unixu atd. ale binární formáty prostě nevnímám jako nějaké apriorní zlo. Pokud je ten formát otevřený a dobře zdokumentovaný a jsou k němu nástroje pro konverzi na textový tvar a zpět, tak v binárních formátech nevidím problém – naopak to může mít řadu výhod.
Já to bral jako de facto další pokus o objektový shell, ale ona je to spíš víc specializovaná podmnožina.
Jak jsem psal, je to jedno z použití. Další je interakce s operačním systémem1, různými nástroji nebo propojování nějakých aplikací nebo konverze formátů. Spousta nástrojů poskytuje užitečná data – ale ještě lepší by bylo, kdyby je poskytovaly ve strojově čitelné formě. A velice často mají ta data relační povahu, jsou to tabulky nebo množiny tabulek.2 Stromové struktury (JSON, XML, YAML atd.) jsou sice univerzálnější, obecnější, ale psát pro ně obecné nástroje je složitější a i uživatelské rozhraní těchto nástrojů je z principu složitější a hůře se používá.
Že jsem se k tomu víc dostal teď v době těch blogů o objektovém shellu je náhoda. Tohle mi leží v hlavě už dlouho a něco málo jsem publikoval v roce 2014: alt2xml a sql-api + příloha. Ten objektový přístup tomu dává další dimenzi složitosti, protože nejenže tam máš strukturovaná data, ale máš k nim navázané i nějaké chování a musíš řešit řadu dalších problémů. Na jednu stranu je to hezké, ale na druhou nevím, kdy a jestli vůbec se dočkáme implementace – možná se Bystroushák nebo někdo podobný jednoho dne vytasí s fungujícím řešením, ale možná taky ne – a do té doby můžu spokojeně používat ty relační roury, které sice nespojují data a chování do objektů a jedná se jen o neživé struktury, ale aspoň je to něco, co jde v reálném čase implementovat a začít používat.
[1] BTW: něco podobného dělá osquery, které vznikalo taky někdy v létě 2014 a o kterém jsem tehdy nevěděl, ale to je řádově složitější a vyžaduje běžícího démona v systému. Můj přístup je ten, že by komplexita měla být volitelná, měl bys mít možnost si vybrat minimalistickou podmnožinu nástrojů a nic by tě nemělo nutit používat ten zbytek, který nepotřebuješ. A mělo by to běžet jen ve chvíli, kdy to používáš.
[2] Relačně můžeš namodelovat např. konfiguraci sítě, uživatele, procesy, systémové služby, výpis příkazu cloc, výpis historie verzovacích systémů, výpis příkazu df atd.
relpipe-in-json, nebo si napsat dodatečný lehký wrapper. Pravdou je, že i u toho JSONu by bylo těžké prosadit nějakou jednotnou podobu, ať by byla seberozumnější a sebejednodušší.
Ohledně té velikosti se nemá smysl bavit. Jak jsem psal: JSON bude oproti tvému formátu větší v naprosté většině případů.
ad nulovým bajtem oddělené hodnoty) To jsem se možná špatně vyjádřil. Neměl jsem na mysli relační data obecně, ale konkrétně v tom tvém formátu. Jinak řečeno: Pokud chci, aby výstup mého programu šel rovnou poslat do relpipe-out-tabular, určitě mi nestačí vyprodukovat jen seznam oddělený nulovými bajty. Předpokládám, že nechceš každý program nejprve pipovat do relpipe-in-cli.
(Kontext: Zmiňoval jsi, že generovat nulovým bajtem oddělené hodnoty je jednodušší než vyrábět JSON. Relevantní srovnání by bylo generování dat ve tvém formátu vs. generování JSONu.)
ad použití) Vím, že jsi těch příkladů použití uváděl víc, ale to zpracování dat mi přišlo jako nejvíc signifikantní a proto jsem se držel právě toho. Jde o to, že napsat si wrapper např. nad to passwd (jak ukazuješ v té prezentaci v příloze), procesy, možná balíčkovací systém a podobně je pořád ještě realizovatelné v jednom člověku – a celé se to točí zejména okolo zpracování nějakých dat z omezeného množství relativně stabilních zdrojů.
To není důležité. Omezím se na konstatování, že takhle (jak jsem to zatím pochopil) mi to dává smysl a vidím v tom nějaký prostor pro praktické použití. Držím palce, díky, že to zveřejňuješ jako FOSS, a budu to sledovat. 
Záměrně to není navržené pro žádný konkrétní scénář, je to koncipované jako obecný datový formát. Jedno ze zamýšlených použití je interakce s operačním systémem, činnosti se soubory, procesy, systémovými službami atd. Bude tam i podpora čtení metadat ze souborů (v multimediálních formátech, obrázcích, PDF – pravděpodobně přes GNU Libextractor). Další scénář je různé poloautomatizované zpracování dat – to, co spousta lidí dělá v tabulkových kalkulátorech – ty mi nevyhovují a myslím si, že tohle je lepší způsob práce s daty (alespoň pro mě). Např. si posbírám data z různých zdrojů, nějak je transformuji, a pak spočítám nějaké statistiky nebo nakreslím grafy v GNU R či Gnuplotu nebo to převedu na .dot a vykreslím diagram v GraphVizu. Dále to může sloužit jako most mezi různými systémy/formáty – např. souborový systém × relační databáze, libovolný formát × Bash (spustit příkaz pro každý záznam, viz while read_nullbyte v příkladech), např. můžeš načíst Atom (či RSS) a pak zpracovávat relačně (viz stránka s příklady), nebo takhle číst nebo generovat iCal, vCard, vzít historii z verzovacího systému, něco z ní vyfiltrovat a vypsat přehled na webu nebo v TeXu atd.
Já se stále nemůžu zbavit dojmu, že to je snaha znovuvynalézt Python.
Datový formát != programovací jazyk. Viz také kapitola „What Relational pipes are not?“ na úvodní stránce.
Časem by měly vniknout čtecí a zapisovací knihovny pro různé jazyky včetně Pythonu – takže to není konkurenční „produkt“, ale komplementární.
Ty nástroje, které vznikají, jsou jen vyčleněním určitých typických operací do spustitelných znovupoužitelných programů. Jsou totiž scénáře, kdy to dává smysl a je lepší spustit program, než něco programovat. Např. když si budu chtít zvýraznit syntaxi nějakého zdrojáku, aby se mi líp četl, tak ho taky jednoduše nasměruji rourou do programu pygmentize – místo toho, abych si zakládal nějaký .py soubor, programoval v něm volání dané funkce a věci kolem, následně ten skript spouštěl a nakonec ho mazal.
Datový formát != programovací jazyk. Viz také kapitola „What Relational pipes are not?“ na úvodní stránce.No jo, ale ten datový formát je hodně hodně obecný a ty nástroje k němu taky. Takže efektivně mi to přijde blízko. Kdybych měl řešit ty zmiňované úkoly, tak buď mi stačí shell, nebo napíšu krátký Python skript (nebo použiju Python REPL)...
Jsou totiž scénáře, kdy to dává smysl a je lepší spustit program, než něco programovat.Ta hranice je ale celkem tenká. Zejména když nestačí jen spustit jeden program, ale je potřeba je do té pajpy naskládat 4 + bash skript... Já z toho popisu a z těch příkladů úplně nedokážu nahlédnout, jestli pro ty zmiňované úkoly to použití relpipes bude přesdtavovat zjednodušení oproti obyč shellu nebo jednoduchému Python skriptu. Na první pohled mi přijde, že spíše ne, ale je to jen dojem. Zamýšlel ses nad otázkou, jestli jsou ty relpipes turing complete? Od boku bych střelil, že ano nebo alespoň že brzo budou...
Zamýšlel ses nad otázkou, jestli jsou ty relpipes turing complete? Od boku bych střelil, že ano nebo alespoň že brzo budou...
Vzhledem k tomu, že existují transformace, v rámci kterých se vykoná zadaný kód v Guile, Pythonu nebo (časem) v SQL, tak je to celkem jasné. Alespoň v rámci té jedné transformace.
Když se ale díváš na tu rouru jako na celek, tak je to posloupnost kroků (transformací, na které se dá dívat i jako na funkce, pokud abstrahuješ od proudového zpracování), které mají fixní pořadí a nejsou mezi nimi žádné cykly ani větvení. Dalo by se to napsat jako:
var data = načtiSTDIN(); data = funkce1(data); data = funkce2(data); data = funkce3(data); zapišSTDOUT(data);
Maximálně může odněkud vyletět „výjimka“ a zpracování skončí předčasně. To je jediné „větvení“ na úrovni té roury.
Pokud do toho zapojíš Bash a třeba příkaz tee nebo process substitution, tak se tam toho dá vymyslet o něco víc, ale to už se bavíme o mocnosti Bashe (nebo jiného prostředí), nikoli o těch relačních rourách jako takových.
point-free style
Jedna z (hodně dlouhodobých) vizí je, že by se na tu rouru šlo dívat jako na jazyk a kód v tomto jazyce interpretovat nebo dokonce zkompilovat do nativního kódu (nebo třeba bajtkódu Javy atd.). Cílem by měla být hlavně optimalizace – mohla by tam totiž odpadnout ta opakovaná serializace a deserializace, data by neopouštěla jeden proces a jen by se volaly metody/funkce v rámci jednoho jazyka. Syntaxe by byla stejná (nebo alespoň principy) jako v tom Bashi, výsledek by byl stejný, ale zpracování by proběhlo jinak a efektivněji. Teoreticky by tam mohl být i nějaký exekuční plán a optimalizátor a mohlo by to přeskládat operace jinak, než uživatel zadal, ale se stejným výsledkem. Bylo by to víc deklarativní, trochu jako SQL, ale zároveň proudové. Tzn. odladil by sis rouru v Bashi nebo nějakém jiném REPLu, a když bys byl spokojený s výsledkem, tak by sis ji nechal zkompilovat do binárky nebo JARka a to bys pak používal.
Taky by k tomu mohlo existovat IDE a třeba i vizuální editor, kde bys transformace pospojoval, mohl bys tam přidat různé větvení (např. tyhle relace pošli sem, ostatní do druhé větve), pak by se ty dva proudy zpracovávaly paralelně a později by se zase spojily atd. Z toho diagramu bys líp viděl, jak je ten program navržen, kudy data proudí. Mohl bys do toho potrubí přidávat různá počítadla (obdoba pv v shellu), měřáky a odposlechy, pomocí kterých bys mohl za běhu sledovat, co se tam děje…
Ale to jsou hodně divoké vize a hodně daleká budoucnost, na kterou nejspíš ani nedojde. A když už, tak by to byl spíš projekt bokem, protože ty relační roury mají být jednoduché (a primárně datový formát), ostatně mezi předpoklady je to, že není snahou vymýšlet nový programovací nebo dotazovací jazyk nebo IDE a naopak je snaha použít co nejvíc stávajícího a začlenit se do současného ekosystému.
Akorát bych to chtělo dotáhnout a zpřístupnit nějaký bohatý ekosystém jako třeba Python nebo podobně.
A potřebuješ Python i pro ty řídící struktury a poskládání toho potrubí? Nebo ti stačí uvnitř jednotlivých transformací? Protože relpipe-tr-python už existuje. Je to tedy hodně špatně napsané :-), ale už teď to umí filtrovat i modifikovat záznamy a časem přibude (stejně jako u Guile) režim, kdy pracuješ nad celou relací nebo nad celým proudem, takže můžeš dělat i agregace, JOINy atd.
A potřebuješ Python i pro ty řídící struktury a poskládání toho potrubí? Nebo ti stačí uvnitř jednotlivých transformací?Oboje... Ta pointa toho Pythonu není ani tak, že by byl nějak děsně super na zpracování/transforamce dat (to popravdě moc není), ale prostě akorát to, že to je snadno použitelný general purpose jazyk s hromadou knihoven na všecko možný...
 21.1.2019 18:17
Bedňa | skóre: 34
| blog: Žumpa
| Horňany
21.1.2019 18:17
Bedňa | skóre: 34
| blog: Žumpa
| Horňany
 Je možné že sa mi to aj bude hodiť ak chcem obísť nejaký GUI tabuľkový procesor.
Ja som v KU tiež implementoval nejaké nástroje ktoré spracovávajú aj tabuľky a používam to aj v praxy. Môžeme tomu hovoriť aj relačné dáta (databázy).
Je možné že sa mi to aj bude hodiť ak chcem obísť nejaký GUI tabuľkový procesor.
Ja som v KU tiež implementoval nejaké nástroje ktoré spracovávajú aj tabuľky a používam to aj v praxy. Môžeme tomu hovoriť aj relačné dáta (databázy).
 21.1.2019 13:36
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
21.1.2019 13:36
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Já z toho popisu a z těch příkladů úplně nedokážu nahlédnout, jestli pro ty zmiňované úkoly to použití relpipes bude přesdtavovat zjednodušení oproti obyč shellu nebo jednoduchému Python skriptu. Na první pohled mi přijde, že spíše ne, ale je to jen dojem.Musím přiznat, že tohle byl taky můj pocit. Když si to vezmu z vysokoúrovňového pohledu, tak cílem co to tak chápu je vzít nějaká data a buď je z transformovat, a/nebo je filtrovat. Podpora všemožných formátů je tak nějak ekvivalentem stdlibu. Co to tedy přináší? Rád bych si myslel že strukturovaná data, ale ty z toho dostanu i v tom pythonu ve chvíli kdy je naparsuju. A narozdíl od těch relational pipes to bude škálovat podstatně líp co do vývoje. Když zjistím, že potřebuji nějakou další funkcionalitu, tak není problém dodělat. Například vyjít ze streamového paragimatu pipes. Tím projekt neshazuji, jen mám stejně jako ty problém si uvědomit ten use-case.
 22.1.2019 16:58
xkucf03 | skóre: 50
| blog: xkucf03
22.1.2019 16:58
xkucf03 | skóre: 50
| blog: xkucf03
Když trochu potrollím: můžeš to brát jako objektový shell :-)
$ cat objekty.csv 1,1,2,(+ $a $b),$c 2,10,1024,(expt $a $b),$c 3,3,9,(* $a $b),(+ $c 5) $ cat objekty.csv | relpipe-in-csv objekty a integer b integer c integer metodaA string metodaB string \ | relpipe-tr-guile '.*' '(= (eval-string $metodaA) (eval-string $metodaB) )' \ | relpipe-out-tabular objekty: ╭─────────────┬─────────────┬─────────────┬──────────────────┬──────────────────╮ │ a (integer) │ b (integer) │ c (integer) │ metodaA (string) │ metodaB (string) │ ├─────────────┼─────────────┼─────────────┼──────────────────┼──────────────────┤ │ 1 │ 1 │ 2 │ (+ $a $b) │ $c │ │ 2 │ 10 │ 1024 │ (expt $a $b) │ $c │ ╰─────────────┴─────────────┴─────────────┴──────────────────┴──────────────────╯ Record count: 2 $ cat objekty.csv | relpipe-in-csv objekty a integer b integer c integer metodaA string metodaB string \ | relpipe-out-tabular objekty: ╭─────────────┬─────────────┬─────────────┬──────────────────┬──────────────────╮ │ a (integer) │ b (integer) │ c (integer) │ metodaA (string) │ metodaB (string) │ ├─────────────┼─────────────┼─────────────┼──────────────────┼──────────────────┤ │ 1 │ 1 │ 2 │ (+ $a $b) │ $c │ │ 2 │ 10 │ 1024 │ (expt $a $b) │ $c │ │ 3 │ 3 │ 9 │ (* $a $b) │ (+ $c 5) │ ╰─────────────┴─────────────┴─────────────┴──────────────────┴──────────────────╯ Record count: 3
(teď to jenom filtruje, ale v příštích verzích to bude umět upravovat data a posílat spočtené hodnoty na výstup)
Nicméně na tom je vidět, jak je spojení dat a chování nebezpečné, když ty objekty pocházejí z nedůvěryhodných zdrojů. Spouštíš kód, který přišel odkudsi zvenku, a když už to tedy chceš dělat, tak by to mělo být alespoň v nějakém kontrolovaném prostředí.
A jinak považuji za přínos mj. to, že nejsi omezen na jeden programovací jazyk a můžeš kombinovat nástroje psané v různých jazycích.
Já se stále nemůžu zbavit dojmu, že to je snaha znovuvynalézt Python.Spis to vidim na zpracovani dat ala stara dobra sedesata/sedmdesata leta, coz odpovidalo moznostem tehdejsiho hardware. Zapsat data na derny stitek/pasek s nejakou zakladni strukturou, prekopirovat na magneticky pasek a pak v pocitaci sekvencne pasky zpracovat a vysledek zapsat sekvencne na jiny pasek, ktery se pak pouzil na vstup jineho programu, atd., atd. Jen mimochodem, odtud pak pochazi i (dnes uz) podivne pascalovske "file of record". Z dnesniho pohledu to muze mit urcite kouzlo a mozna i pouziti, ale: V dobe, kdy i bezne pocitace maji nizsi desitky GB RAM muze byt proudove zpracovani dat pomalejsi nez in-memory operace. Navic nektere operace ani sekvencne nejdou udelat. Ke spojeni/propojeni jednotlivych casti se pouziva shell, coz efektivne brani pouziti jakychkoliv poznatku z RM, k tomu, aby se optimalizovaly jednotlive operace. Takze v konecnem dusledku z relacniho modelu si to bere jen to, ze relace je tabulka, nebo tak neco.
V dobe, kdy i bezne pocitace maji nizsi desitky GB RAM muze byt proudove zpracovani dat pomalejsi nez in-memory operace. Navic nektere operace ani sekvencne nejdou udelat.
Je to navržené tak, aby proudové zpracování bylo možné. Což ale neznamená, že je vynucené – pokud nějaká operace pracuje nad celou relací nebo nad několika relacemi, tak si načte proud do paměti (případně odloží na disk), zpracuje a výsledek pošle na výstup celý najednou.
Díky tomu je možné zpracovávat nekonečné proudy nebo vidět první výsledky už v době, kdy se do roury na vstupu pořád ještě zapisuje.
Ke spojeni/propojeni jednotlivych casti se pouziva shell, coz efektivne brani pouziti jakychkoliv poznatku z RM, k tomu, aby se optimalizovaly jednotlive operace.
Viz #49. Nic nebrání tomu, aby se celá data držela v paměti a jednotlivé transformační kroky tato data opracovávala tam, kde jsou (pořád na tom samém místě v paměti), dokonce může optimalizátor některé kroky vypustit, změnit jejich pořadí atd. Nebo se můžou všechna data nasypat do relační databáze, pustit nad tím pár SQL příkazů (do kterých se transpiluje ta původní roura v té shellovské syntaxi) a nakonec se výsledek pár SELECTů pošle na STDOUT. Prostoru pro budoucí optimalizace je plno.
Ale snažím se ten projekt vést tak, aby z toho byl nějaký užitečný výsledek i v krátkodobém horizontu a nebylo potřeba čekat deset let.
aby proudové zpracování bylo možné. Což ale neznamená, že je vynucené
Díky tomu je možné zpracovávat nekonečné proudyMoznost zpracovavat nekonecne proudy a zaroven ulozit celou relaci do pameti mi prijde trochu jako ukol pro Chucka Norrise.
Nic nebrání tomu, aby se celá data držela v paměti a jednotlivé transformační kroky tato data opracovávala tam, kde jsou (pořád na tom samém místě v paměti), dokonce může optimalizátor některé kroky vypustit, změnit jejich pořadí atd. Nebo se můžou všechna data nasypat do relační databáze, pustit nad tím pár SQL příkazůAneb proc delat veci jednoduse, kdyz muzeme vymyslet hezke slozite reseni. Abych teda byl konstruktivni. Staci udelat maly krok stranou a roury mezi jednotlivymi moduly nevytvaret shellem, ale mit jednu aplikaci, ktera sestavi roury. Pokud bude "hlavni aplikace" znat vlastnosti jednotlivych operaci, muze na zaklade toho provadet vhodne optimalizace. Coz je podle me dost muziky za malo penez.
Moznost zpracovavat nekonecne proudy a zaroven ulozit celou relaci do pameti mi prijde trochu jako ukol pro Chucka Norrise.
aby proudové zpracování bylo možné. Což ale neznamená, že je vynucené → Díky tomu je možné zpracovávat nekonečné proudy
Ano, nemůžeš využít obě možnosti najednou, ale to je snad z podstaty věci zřejmé, ne?
Důležité je, aby ten datový formát a API čtecích a zapisovacích knihoven byly navržené tak, aby to proudové zpracování umožňovaly. Což souvisí i s tím, co tě tolik trápí: pokud by v tom datovém formátu a v API nízkoúrovňových knihoven bylo natvrdo zadrátované pravidlo, že se tam v žádný okamžik nesmí objevit duplicitní záznam, tak by proudové zpracování možné nebylo. Proto ten datový formát umožňuje popsat nadmnožinu1 relačního modelu a proto je odstraňování duplicit odloženo na okamžik, kdy je relevantní a neprovádí se neustále.
Říkej si tomu třeba inženýrská aproximace nebo kompromis, ale je to v podobný závěr, ke kterému dospěli implementátoři drtivé většiny relačních databází.
Aneb proc delat veci jednoduse, kdyz muzeme vymyslet hezke slozite reseni.
Klidně to někdo může používat stylem:
relpipe-in-x | relpipe-tr-sql … | relpipe-out-y
a z těch relačních rour využije jen ten vstupní a výstupní filtr pro formáty X a Y, zatímco všechny operace udělá v SQL. Ale i to je smysluplné využití, protože ty filtry jsou znovupoužitelné, stačilo je napsat jen jednou a poskytují jednotné rozhraní (zatímco běžné knihovny pro formáty X a Y mají prakticky vždy nekompatibilní rozhraní a nelze je zaměňovat jen tak kus za kus, přestože formáty X a Y mohou mít kompatibilní logickou strukturu).
A někdo jiný, kdo nechce být vystaven komplexitě SQL2, může použít jiné transformační nástroje s řádově nižší komplexitou3 a stále těžit z těch stejných vstupních a výstupních filtrů pro různé formáty.
Abych teda byl konstruktivni. Staci udelat maly krok stranou a roury mezi jednotlivymi moduly nevytvaret shellem, ale mit jednu aplikaci, ktera sestavi roury. Pokud bude "hlavni aplikace" znat vlastnosti jednotlivych operaci, muze na zaklade toho provadet vhodne optimalizace.
Viz #49. Třeba na to jednou dojde.
Coz je podle me dost muziky za malo penez.
To si právě nemyslím. Vytváření vlastního jazyka, jeho interpretru, nějakého démona, který to bude provádět… to všechno je poměrně dost práce a kromě zrychlení to nic nepřinese. V první řadě chci odladit funkčnost a až pak se případně věnovat optimalizacím.
Souhlasím, že to současné řešení je šíleně neefektivní4, ale přesto pro to vidím užitečné použití a ta pomalost bude navíc často pod rozlišovací schopností uživatele.
[1] podobně jako množina všech užití ředidla zahrnuje i čichání – a tato užití jsou nadmnožinou primárních/zamýšlených užití, podle kterých se ta věc jmenuje
[2] a teď nemyslím komplexitu toho jazyka, která je celkem malá a dobře se používá, ale komplexitu implementace a počtu řádků, které jsou za tím potřeba
[3] třeba desítky nebo stovky řádků (oproti statisícům nebo milionům u implementací SQL)
[4] data se neustále kopírují, serializují, deserializují, nejsou tam žádné optimalizace…
což souvisí i s tím, co tě tolik trápí: pokud by v tom datovém formátu a v API nízkoúrovňových knihoven bylo natvrdo zadrátované pravidlo, že se tam v žádný okamžik nesmí objevit duplicitní záznam, tak by proudové zpracování možné nebylo.Stale ti unika podstata problemu. Mne vubec netrapi, ze by se tam mohly objevit duplicitni zaznamy. Mne vadi, ze se zaklinas relacnim modelem, pricemz s RM to ma pramalo spolecneho. Duplicitni zaznamy jsou jen jedno z mnoha mist, ktere dela potencialni problemy. Vezmi si treba ty nekonecne proudy. Pokud bys mel v relacnim modelu nekonecne relace, nektere operace nemuzes korektne definovat/implementovat. Vezmi si treba operaci T1 INTERSECT T2, pokud je T1 nebo T2 nekonecny proud, podobne EXCEPT, pokud je druhy proud nekonecny. Takove problemy uz nelze pricist na vrub "inzenyrske aproximaci" ani "kompromisu". To jsou podstatne problemy, ktery prameni z chybneho navrhu (a nepochopeni RM).
Proc hned delat vlastni jazyk, interpreter, demona? Jsou to roury, ne? Jako vstup dostanes seznam programu, ktere tvori jednotlive operace roury, tento seznam si rozdelis podle nejakeho oddelovace. Forknes si potomky, propojis je rourou a predas jim parametry, tak jak je dostals. Nic sloziteho. Neco takoveho jsme meli jako zapoctovy ukol ve druhaku. V kazdem pripade tim se dostanes na stavajici funkcionalitu, kterou mas ted, ale ktera ti zaroven otevira dalsi moznosti, treba ty optimalizace operaci. Nebo muzes data predavat v rozparsovane podobe, pokud zjistis, ze dva propojene programy v roure toto podporuji. To ale potrebuje mit API jednotlivych programu dobre navrzene uz od zacatku.Coz je podle me dost muziky za malo penez.To si právě nemyslím. Vytváření vlastního jazyka, jeho interpretru, nějakého démona, který to bude provádět…
Pokud bys mel v relacnim modelu nekonecne relace, nektere operace nemuzes korektne definovat/implementovat. Vezmi si treba operaci T1 INTERSECT T2, pokud je T1 nebo T2 nekonecny proud, podobne EXCEPT, pokud je druhy proud nekonecny. Takove problemy uz nelze pricist na vrub "inzenyrske aproximaci" ani "kompromisu". To jsou podstatne problemy, ktery prameni z chybneho navrhu (a nepochopeni RM).
Tohle je menší problém než ty duplicity. Operace jako EXCEPT nebo INTERSECT prostě doběhnou až se podaří načíst všechna data. Pokud necháš STDIN otevřený a zápis nedokončíš, tak prostě nedoběhnou nikdy. Na tom není nic překvapivého. Představ si to jako metodu, která nemá na vstupu hodnotu, ale iterátor, a výstup nevrací návratovou hodnotou, ale tím, že volá nějaké jiné metody. Některé metody tohoto typu jsou schopné vracet výsledky průběžně, některé po nějakých větších částech (např. čtou XML, přes iterátor jim chodí jednotlivé uzly stromu, ale výstup jsou schopné poslat až když načtou nějaký větší celek) a některé až všechno najednou. Není na tom nic záludného.
Proc hned delat vlastni jazyk, interpreter, demona? Jsou to roury, ne?
Nechci, s tím jsi přišel ty. Dobře, možná to nemusí být démon a program se spustí jen ad-hoc.
Jako vstup dostanes seznam programu, ktere tvori jednotlive operace roury, tento seznam si rozdelis podle nejakeho oddelovace.
Což je právě ten nový jazyk.
Forknes si potomky, propojis je rourou a predas jim parametry, tak jak je dostals.
Tohle nemá přínos oproti Bashi. Přínos by mělo, kdybych se na tu definici roury, např.
find /etc/ssh/ -print0 | relpipe-in-filesystem \
| relpipe-tr-guile '.*' '(and (equal? $owner "root") (> $size 300) (< $size 1000) )' \
| relpipe-tr-cut '.*' path \
| relpipe-out-tabular
podíval jako by to byl jazyk a interpretoval bych dotaz v tomto jazyce – podobně jako to dělají DBMS – a optimalizoval bych ho na něco jako:
find /etc/ssh/ -user root -size +300c -size -1000c -print0 \
| relpipe-in-cli generate-from-stdin filesystem 1 path string \
| relpipe-out-tabular
resp. bajtkód nebo nativní kód, který by udělal totéž. Tzn. optimalizátor by vypustil Guile, protože ten kód je tak jednoduchý, že ho lze interpretovat i bez Guile, vypustil by zjišťování nějakých metadat, protože by věděl, že v předposledním kroku se zahodí všechno kromě path atd.
Tohle je menší problém než ty duplicity. Operace jako EXCEPT nebo INTERSECT prostě doběhnou až se podaří načíst všechna dataVazne? Podivej se do nejake knizky o relacni databazich a relacni algebre. Urcite to prospeje. Vrele doporucuji treba C.J.Date: SQL and Relational Theory: How to Write Accurate SQL Code. Vezmi si, ze T je mnozina vsech relaci (konecnych mnozin n-tic). Pak jednotlive operace muzes chapat jako zobrazeni T x T -> T a s tim tak pracovat. Kdyz ale umoznis nekonecne "tabulky", pak takove vyjadreni neni mozne (neni implementovatelne) a cely vychozi model se ti rozpadne. V dusledku cehoz nebude dobre fungovat ani implementace.
Představ si to jako metodu, která nemá na vstupu hodnotu, ale iterátorPokud se pohybujes v intencich RM, musis se na relace divat jako na hodnoty. Pokud se na to budes divat jako na iteratory/proudy spousta veci prestane davat smysl, vcetne tak zakladnich operaci jako prunik nebo rozdil! Proto tady uz nekolikaty den brblu, ze to, s cim pracujes, nejsou relace a relacni model!
Tohle nemá přínos oproti Bashi.Cetls muj prispevek cely?
V kazdem pripade tim se dostanes na stavajici funkcionalitu, kterou mas ted, ale ktera ti zaroven otevira dalsi moznosti,Ty moznosti se ti otevrou v podstate okamzite, bez zasahu do existujicich modulu. Napr. pokud nekde uvidis za sebou projekci a restrikci nebo vice restrikci, misto vytvareni X procesu, je muzes sloucit do jednoho. S drobnou upravou se muzes zbavit problemu s neustalou serializaci a deserializaci, staci, kdyz rodicovsky proces bude umet prepnout rezim, v jakem si moduly predavaji data. Atp.
resp. bajtkód nebo nativní kód, který by udělal totéž.Neni duvod proc to na zacatku resit takto slozite.
Autoři reálných implementací mají naštěstí jiný názor, než ty, a dívají se na to spíš jako na ty proudy nebo iterátory. Viz databázové kurzory:
The database cursor characteristic of traversal makes cursors akin to the programming language concept of iterator.
A navrhují ta rozhraní tak, že obsahují konstrukce jako RETURN NEXT, místo aby tě nutili vždy vracet celý objekt najednou.
Tzn. pokud daná operace nevyžaduje, aby se všechna data natáhla najednou do paměti, tak je možné (a dokonce vhodné) data zpracovávat proudově.
Můžeš si to sám vyzkoušet:
DROP FUNCTION IF EXISTS streamed_relation(); DROP TYPE IF EXISTS streamed_record; CREATE TYPE streamed_record AS ( ordinal INTEGER, created TIMESTAMP WITH TIME ZONE, postprocessed TIMESTAMP WITH TIME ZONE ); CREATE OR REPLACE FUNCTION streamed_relation() RETURNS SETOF streamed_record AS $$ DECLARE n INTEGER := 10000; q NO SCROLL CURSOR FOR WITH RECURSIVE t(ordinal) AS ( SELECT 1 UNION ALL SELECT ordinal + 1 FROM t ) SELECT ordinal, clock_timestamp() AS created FROM t LIMIT n; r RECORD; sr streamed_record; BEGIN FOR r IN q LOOP IF r.ordinal IN (1,n) THEN sr.ordinal := r.ordinal; sr.created := r.created; sr.postprocessed := clock_timestamp(); RETURN NEXT sr; END IF; END LOOP; RETURN; END $$ LANGUAGE plpgsql; -- SELECT * FROM streamed_relation(); SELECT min(postprocessed) < max(created) FROM streamed_relation();
Vrátí ti to true, protože k opracování prvního záznamu došlo dříve, než k vytvoření posledního záznamu.
Stejně tak rozhraní mezi klientem a serverem se navrhují tak, aby umožňovala tahat výsledky postupně. Takže pokud šlape všechno, jak má, a není v tom zapojena nějaká operace, která by vyžadovala nějakou agregaci nebo třeba setřídění v paměti, tak můžeš třeba vypisovat první řádky na webu už ve chvíli, kdy se ty poslední teprve načítají z disku na databázovém serveru. Resp. není důvod, proč by to nemělo jít.
Další věc je reaktivní programování, které to posouvá ještě o kus dál.
Opravdu si nemyslím, že by tohle bylo nějaké zpronevěření se proti relačnímu modelu. A naopak považuji za žádoucí, aby se data zpracovala proudově, pokud to daná operace umožňuje. A pokud to neumožňuje a potřebuješ dělat třeba nějaký UNION, EXCEPT, ORDER BY, agregace atd. tak jednoduše ten iterátor projdeš celý, natáhneš si z něj všechna data a zpracuješ je najednou.
Další příklady toho, že relační model a proudové zpracování se navzájem nevylučují:
1) Dejme tomu, že chci udělat restrikci typu SELECT * FROM relace WHERE …; Tohle je relační operace i podle té nejčistší teorie, a přesto se nemusím na relaci dívat jako na objekt, nemusím ji natáhnout celou najednou do paměti. Můžu k ní přistupovat jako k iterátoru nebo proudu, průběžně číst, průběžně filtrovat a průběžně posílat záznamy na výstup. A když tam budu mít indexy, tak akorát líp vím, na která místa na disku jít, ale pořád budu zpracovávat data proudově.
2) Dejme tomu, že chci spočítat sumu nějakého atributu. V cyklu projedu postupně celou relaci a průběžně si přičítám hodnoty do lokální proměnné. Opět to nevyžaduje, abych si načetl celou relaci najednou do paměti.
3) Dejme tomu, že chci udělat sjednocení dvou relací. Normálně by to vyžadovalo UNION a odstranění duplicit, což nejde udělat proudově. Ale protože vím, že v tomto případě tam mám alespoň jeden atribut, jehož hodnoty budou napříč oběma relacemi unikátní, můžu to interně implementovat jako UNION ALL a data zpracovat proudově.
( \
find /etc/ssh/ -print0 | relpipe-in-filesystem; \
find /etc/default/ -print0 | relpipe-in-filesystem \
) | relpipe-tr-sed '.*' 'owner' 'root' 'hacker' | … | relpipe-out-tabular
(na místě … stačí odstranit hlavičku druhé relace a slít obě do jedné tzn. nějaký budoucí relpipe příkaz implementující operaci UNION ALL).
Autoři reálných implementací mají naštěstí jiný názor, než ty, a dívají se na to spíš jako na ty proudy nebo iterátory. Viz databázové kurzoryTo je ale něco úplně jiného, to je víceméně jen API pro čtení databáze, kde samozřejmě celkem dává smysl to iterátorové rozhraní.
Opravdu si nemyslím, že by tohle bylo nějaké zpronevěření se proti relačnímu modelu.Takhle: To, že těm relacím říkáš relace IMHO je oprávněné, protože prostě relace v té původní definici je víceméně jen homogenní pole tuplů (homogenní = ty tuply jsou všechny stejného typu). O relační model se ale IMHO nejedná, protože ty relace nejsou propojitelné a protože to streamové zpracování obecně vzato vylučuje relační algebru. Ano, některé ty algebraické operace se dají udělat i nad proudy, ale obecně to nejde. Osobně proti těm relacím celkem nic nemám, akorát mi to přijde jako určité omezení, které je dané spíše "historicky" než z nějakého návrhu. Odtud taky částečně pochází ta moje připomínka o Pythonu - v general purpose jazyku můžu zpracovat data v jakémkoli tvaru jak chci, kdežto tady je potřeba, abych se přízpůsobil tomu konceptu té série relací a jsou tim omezeny i ty operace nad těmi daty, ale přitom mi úplně není jasný důvod, proč je to potřeba.
protože ty relace nejsou propojitelné a protože to streamové zpracování obecně vzato vylučuje relační algebru
Ne tak úplně. Dejme tomu, že si na začátek proudu dám relaci uživatelů (kterých je třeba 20) a až za ní dám relaci souborů (kterých jsou stovky tisíc nebo miliony). A chci ke každému souboru vypsat i jméno a příjmení vlastníka – tzn. udělám si JOIN s relací uživatelů podle uživatelského jména nebo uid a dohledám si v ní další informace (třeba to jméno a příjmení). Tudíž mi stačí držet v paměti jen tu malou relaci, zatímco tu velkou zpracuji proudově. (BTW: vsadím se, že relační databáze to dělají stejně – načtou si malou tabulku, a pak iterují přes velkou – a ne naopak)
Celé to může být transparentní – v tom smyslu, že když si relace v proudu uspořádám špatně, tak nástroj natáhne všechna data do paměti nebo si je odloží na disk a bude to pomalejší nebo paměťově náročnější, ale výsledek bude stejný. A když si ty relace v proudu uspořádám inteligentně, tak můžu těžit z proudového zpracování a bude to rychlejší a spotřebuje to méně paměti.
Takže zatímco třeba find ještě traverzuje skrze souborový systém, mně už se na výstupu vypisují první zpracované záznamy. To proudové zpracování může přispět i k paralelizaci – dejme tomu, že chci počítat hashe těch souborů. A dejme tomu, že tam mám víc fyzických disků v RAIDu a to pole zvládne efektivně víc čtecích operací najednou. Pak může find vytěžovat jeden disk traverzováním, zatímco počítání hashů (již nalezených souborů) vytěžuje druhý disk. Kdežto kdyby se musela celá relace předem načíst jako jeden objekt, tak by se nejdřív dělal find a až by se všechno našlo, tak by se teprve začaly počítat hashe. (ano, můžu paralelizovat i find, a pak parelelizovat hash, ale to můžu v obou případech, takže to není relevantní argument) A navíc to proudové zpracování výrazně zkrátí TTFB (termín používaný spíš na webu, ale dá se to aplikovat i tady), což může mít výrazný vliv na uživatelský komfort.
Ano, některé ty algebraické operace se dají udělat i nad proudy, ale obecně to nejde.
Mně jde právě o to, nezavírat si cestu k případným optimalizacím a proudovému zpracování tam, kde to možné je. Třeba tím, že bych vynutil, že na relaci se musíš vždy dívat jen jako na objekt a musíš ji vždy načíst celou. Protože takové omezení je nesmyslné a zbytečné – přesně kvůli těm případům, kdy operaci proudově provést lze.
Osobně proti těm relacím celkem nic nemám, akorát mi to přijde jako určité omezení, které je dané spíše "historicky" než z nějakého návrhu. Odtud taky částečně pochází ta moje připomínka o Pythonu - v general purpose jazyku můžu zpracovat data v jakémkoli tvaru jak chci, kdežto tady je potřeba, abych se přízpůsobil tomu konceptu té série relací a jsou tim omezeny i ty operace nad těmi daty, ale přitom mi úplně není jasný důvod, proč je to potřeba.
Ten model je omezený až primitivní (oproti objektovému přístupu nebo stromům/grafům) a je to záměr. Když se podíváš na jazyky, které pracují s obecnými stromy (objektů), jako třeba XPath, XQuery nebo ten Python, tak jsou poměrně složité. Což není tím, že by to byly špatné jazyky, ale tím, že pracují s obecným stromem, z čehož ta složitost (jejich uživatelského/programátorského rozhraní) vyplývá. Resp. ono to není až tak složité, ale na jeden řádek v shellu si to většinou nenapíšeš (nebo si to srovnej s expresivností SQL např. u WHERE podmínek nebo projekce v SELECTu). Třeba takový XPath je hodně dobrý a jednoduchý, ale jeho použití jako filtru je nedotažené. Tam ho můžeš použít maximálně pro vytažení jedné atomické hodnoty. Ale pokud má vrátit hodnot víc, vysype ti seznam uzlů, což ale není validní XML, takže to musíš obalit nějakým kořenovým elementem, aby to dávalo smysl a šlo to v dalším kroku strojově zpracovat. XQuery tohle řeší velice elegantně, ale i tak si kvůli tomu musíš založit .xq skript – do jednoho řádku v shellu to těžko napíšeš. Naopak u těch nástrojů, které pracují s omezenými strukturami/modelem – jako třeba grep, sed, awk, SQL – je vidět ta elegance a efektivita, jak s minimem kódu a úsilí dokážeš udělat spoustu užitečné práce. S neomezenými obecnými stromovými/objektovými strukturami jde tohle hůř (byť se u nich nikdy nedostaneš do situace „moje data jsou tak složitá že je nejde napasovat na omezený datový model XY“).
Na druhé straně spousta lidí používá textové proudy, kde mají data členěna do řádků a v rámci řádku do polí oddělených nějakým oddělovačem. Občas se jim to sice rozsype, protože se jim třeba přimíchá znak oddělovače nebo konce řádku dovnitř hodnoty nebo musí přijmout nějaká omezení, ale většinou jsou s tím celkem spokojení a přináší jim to užitek. Relational pipes jdou o kousek dál a říkají, že v tom proudu může být těch relací víc, definují jasné hranice mezi atributy a záznamy a přidávají datové typy a metadata jako názvy atributů a relací. A vedou tě k tomu, abys mohl udělat třeba JOIN mezi soubory/procesy a uživateli nebo abys mohl udělat restrikci nad soubory a jejich metadaty (XATTR, EXIF atd.).
P.S. Příklady s těmi soubory jsou trochu vykonstruované, ale nějak se začít musí a snažím se na tom ukázat ten princip. Jinak to má být obecný nástroj, kde zpracovávaná data nemusí mít nic společného se souborovým systémem.
Ne tak úplně. Dejme tomu, že si na začátek proudu dám relaci uživatelů (kterých je třeba 20) a až za ní dám relaci souborů (kterých jsou stovky tisíc nebo miliony).Já tomu rozumim, že ve specielních případech to není problém / jde to udělat. Ale není mi jasný, co z toho plyne, přijde mi, že celkem nic...
Mně jde právě o to, nezavírat si cestu k případným optimalizacím a proudovému zpracování tam, kde to možné je. Třeba tím, že bych vynutil, že na relaci se musíš vždy dívat jen jako na objekt a musíš ji vždy načíst celou.1. Nemyslim si, že by tady někdo navrhoval vynucovat načítání té relace vždy celé. 2. Jestliže použití relací představuje nějaké takovéhle potenciální omezení, pak tím spíš je na místě ta otázka, jaká je motivace pro ty relace. Pokud ti opravdu jde tolik o streamové zpracování, pak by možná nebylo špatné se podívat, jak tyhle věci dělají streamové protokoly. Napadá mě například interleaving. Pokud by ten formát něco takového podporoval, pak by nebylo potřeba používat berličky jako počítání, která tabulka je menší, ale přitom by to bylo efektivnější i pro případy, kde tabulky efektivní být nemohou. Představ si například, že máš 2 megózní tabulky s jedním sloupcem čísel a chceš provést operaci suma, tj. mít na výstupu tabulku kde v každém řádku bude součet těch dvou vstupních. V takovém případě ti přehazování pořadí tabulek obecně nijak nepomůže, zatímco interleaved formát by to vyřešil naprosto snadno. Ale je to samozřejmě jen jeden příklad z mnoha možných.
Ten model je omezený až primitivní (oproti objektovému přístupu nebo stromům/grafům) a je to záměr. Když se podíváš na jazyky, které pracují s obecnými stromy (objektů), jako třeba XPath, XQuery nebo ten Python, tak jsou poměrně složité.XPath nebo XQuery moc neznám. Python mi složitý nepřipadá, naopak mi přijde celkem jednoduchý. Zatím z toho popisu nevidím, že by ten relační přístup a tyhle nástroje představovaly zjednodušení oproti použití Pythonu. Možná že ano, ale jak říkám, nevidim to. Možná by pomohly nějaké srovnávací příklady. Přijde mi, že by možná nebylo špatné dát trochu více váhu teoretické přípravě a rešerším, třeba co se týče formátu a tranformací dat. Určitě bych doporučil se podívat na různé formáty. Pokud ti jde o to streamování, tak mi přijde skoro nezbytné se podívat, jak fungují streamovací formáty. To funkcionální programování už jsem zmiňoval, ještě k tomu dodám, že není nutně potřeba hned zabřednout do category theory nebo podobně (tomu já se popravdě taky raději vyhýbám), už jsi nakousl Guile/Scheme, tak proč tímto směrem nepokračovat. Pro tenhle use-case by možná mohl projednou Lisp i dávat smysl
Ještě poznámka: Přijde mi, že navrhnout takovýhle formát a operace nad ním tak, aby to bylo opravdu takhle hodně obecné, je poměrně hodně těžké. Přijde mi to skoro jako blížící se co do obtížnosti navrhování progamovacího jazyka. Takže se asi celkem dá očekávat, že to nepůjde úplně hladce, že to bude vyžadovat hodně teorie, případně že ten design může způsobovat kontroverze.
Nemyslim si, že by tady někdo navrhoval vynucovat načítání té relace vždy celé.
Viz „musis se na relace divat jako na hodnoty“ a jiné komentáře.
Napadá mě například interleaving.
Na to prokládání jsem myslel (v plánech na budoucí rozvoj to je, ale v první verzi to nebude). Částečně to jde dělat už teď – prostě mezi záznamy vrazíš jinou relaci, a pak se zase vrátíš k té původní – protože na začátku záznamu i relace je nějaký specifický bajt, kterého se parser chytne, takže pozná, jestli začíná další záznam nebo další relace.
Takže tam vlastně chybí jen signalizace typu „tahle relace ještě neskončila a přibudou do ní další záznamy, přestože teď následují data jiné relace“ nebo „žádné další záznamy v této relaci už následovat nebudou“ případně možnost se nějak odkázat na hlavičku předchozí relace, aby ji nebylo potřeba opakovat. Tyhle informace budou časem ve volitelných metadatech.
už jsi nakousl Guile/Scheme, tak proč tímto směrem nepokračovat
Např. pro zápis těch filtrovacích podmínek je to velice elegantní a má to svoje kouzlo. I ty transformace si v tom dovedu představit. A v současnosti mám radši relpipe-tr-guile než relpipe-tr-python :-). Ale pořád jsem nedospěl tak daleko, abych v tom psal nějaký větší program. V té hromadě kulatých závorek prostě tu strukturu nevidím. Asi je to o zvyku…
Ještě poznámka: Přijde mi, že navrhnout takovýhle formát a operace nad ním tak, aby to bylo opravdu takhle hodně obecné, je poměrně hodně těžké. Přijde mi to skoro jako blížící se co do obtížnosti navrhování progamovacího jazyka. Takže se asi celkem dá očekávat, že to nepůjde úplně hladce, že to bude vyžadovat hodně teorie, případně že ten design může způsobovat kontroverze.
Ano, je to náročné, byť je to vlastně hrozně primitivní nástroj a úlohy, které řeší. Ale s tím jsem tak nějak počítal.
Viz „musis se na relace divat jako na hodnoty“ a jiné komentáře.A cetls vubec muj komentar? Dokazes vstrebat, ze je rozdil mezi hodnotou (samotnou) a jeji reprezentaci?
Ano, je to náročné, byť je to vlastně hrozně primitivní nástroj a úlohy, které řeší. Ale s tím jsem tak nějak počítal.Dulezite je zachovat si skromnost za kazdou cenu.
Např. pro zápis těch filtrovacích podmínek je to velice elegantní a má to svoje kouzlo. I ty transformace si v tom dovedu představit. A v současnosti mám radšiNo tak já třeba osobně Lispy moc nemusim, mam radši jazyky z rodiny ML. Guile by pro mě taky byl nezvyk. Ale je to víceméně jen otázka osobní preference a ty koncepty fungují víceméně kdekoli. Ačkoli ML-style pattern matching je IMHO velmi elegantní věc která nemá úplně dobré ekvivalenty jinde.relpipe-tr-guilenežrelpipe-tr-python:-). Ale pořád jsem nedospěl tak daleko, abych v tom psal nějaký větší program. V té hromadě kulatých závorek prostě tu strukturu nevidím. Asi je to o zvyku…
To, že těm relacím říkáš relace IMHO je oprávněné, protože prostě relace v té původní definici je víceméně jen homogenní pole tuplů (homogenní = ty tuply jsou všechny stejného typu).Dabel je skryt v detailu a uvolnovani jednotlivych podminek prinasi problemy. Jednak relace je mnozina. At uz se bavime o relaci, ci relaci nad relacnim schematem. Ma to svoje opodstatneni. Kazdy tuple predstavuje nejaky fakt, tim, ze nalezi/nenalezi do nejake relace vlastne rikame, jestli je tento fakt pravdivy/nepravdivy. V tom pripade ale prilis nedava smysl, uvadet nejaky fakt vicekrat. Pokud uvolnis tuto podminku, a pripustis, ze nejaka ntice muze byt v relaci vicekrat, budes vedle toho mit problem definovat chovani jednotlivych operaci, uz se to tu resilo. Navic v te xkucf variante se na to neda divat ani jako na pole, protoze je to nekonecne. Takze jak dobre poznamenavas:
to streamové zpracování obecně vzato vylučuje relační algebru. Ano, některé ty algebraické operace se dají udělat i nad proudy, ale obecně to nejde.
Autoři reálných implementací mají naštěstí jiný názor, než ty, a dívají se na to spíš jako na ty proudy nebo iterátory. Viz databázové kurzory:To uz je zalezitost konkretni implementace a rozhrani pro pristup k datum. A vetsina implementaci opravdu data casto zpracovava proudove. Problem, ktery jsem vytahl v predchozim prispevku, je, ze pokud umoznis mit "nekonecne relace", nelze spravne definovat/implementovat celou radu naprosto zakladnich operaci, treba ten prunik! Problem tedy nespociva v tom jak pracujes s daty, ale s jakymi pracujes daty. (V tvem pripade proudove zpracovani dat pochazejici z libovolneho zdroje implikuje nekonecne velke tabulku, to v normalnim SQL i pri proudovem zpracovani neplati.)
A pokud to neumožňuje a potřebuješ dělat třeba nějaký UNION, EXCEPT, ORDER BY, agregace atd. tak jednoduše ten iterátor projdeš celý, natáhneš si z něj všechna data a zpracuješ je najednou.Obavam se, ze pokud mas nekonecne relace, abys dosel na konec iteratoru, budes potrebovat procesor Intel ChuckNorris Lake.
Opravdu si nemyslím, že by tohle bylo nějaké zpronevěření se proti relačnímu modelu.Mas pravdu proudove zpracovani neni zpronevereni se relacnimu modelu, ten dokonce (a to je jeho dulezita vlastnost) zadny typ zpracovani nevynucuje. Co je zpronevereni se podstate RM je uvoleneni podminek, ktere musi splnovat relace. V takovem pripade jednotlive operace prestanou davat rozumny smysl nebo povedou k neresitelnym problemum, viz jeste jednou treba ten prunik nebo rozdil.
1) Dejme tomu, že chci udělat restrikci typu SELECT * FROM relace WHERE …; Tohle je relační operace 3) Dejme tomu, že chci udělat sjednocení dvou relací.Dobre, vybral sis operace, kde to necini problem.
2) Dejme tomu, že chci spočítat sumu nějakého atributu.Dobre vybral sis data, kde to necini problem, protoze tise predpokladas, ze data budou konecna. Ale co ty ostatni operace a data, ktere povazujes za pripustne?
23.1.2019 14:13
xkucf03 | skóre: 50
| blog: xkucf03
To slovo nekonečné jsem použil možná trochu nešťastně a došlo k nedorozumění. Ve skutečnosti nic nekonečné není. Použil jsem to slovo1 v kontextu diskuse o spotřebě RAM a myslel jsem tím to, že velikost zpracovávaných dat o mnoho řádů převyšuje kapacitu RAM a disku, na kterém se data zpracovávají. Tzn. když řeknu, že zpracovávám „nekonečná“ data, znamená to, že těch dat může být „opravdu hodně“ a spotřeba paměti bude velmi malá (třeba jeden záznam, nebo jeden záznam + proměnná do které si počítám nějaké agregované výsledky atd.). Je to metafora a ty se toho chytneš a, s prominutím, prudíš.
Pokud budou data „nekonečná“ v tom smyslu, že k tobě budou proudit třeba týden, tak i na výsledek operací jako EXCEPT nebo SUM si počkáš týden. Ale to mi přijde jako zcela intuitivní chování a nikdo asi nečeká nic jiného, ne? Asi těžko můžu čekat, že mi to sumu spočte dnes, když poslední data přijdou až za týden, a těžko z takového chování nástroje můžu být zklamaný nebo překvapený.
Ty píšeš:
musis se na relace divat jako na hodnoty
A s tím právě nesouhlasím. Kdybych to tak dělal, tak bych se připravil o možnost efektivně provádět operace, které proudově provést lze. Proto se na relaci dívám spíš jako na ten iterátor. A buď ji zpracuji proudově (když to jde) a nebo si dojedu na konec toho iterátoru, data si shromáždím v nějakém objektu a ten pak zpracuji celý najednou.
Je to jako kdybys navrhoval nějaké API v Javě a po ostatních bys vyžadoval, aby ti posílali Collection<XY>. Pro malé objemy dat je to v pohodě a není potřeba řešit nic víc. Ale pro větší objemy nebo třeba nějaká „dražší“ data (jejichž výpočet byl náročnější) je lepší to API navrhnout tak, že ti budou předávat Iterator<XY>. A ten načte/spočte data až/pokud jsou potřeba. Což mj. znamená, že tvoje aplikace může zpracovat výrazně víc dat, než kolik máš RAM. (opět: za předpokladu, že to povaha operací umožňuje, ať mě nechytáš za slovo)
Pokud máš API postavené nad iterátorem (nebo něčím podobným), tak to v případě potřeby na objekt převedeš snadno. Ale pokud máš API postavené nad objektem, tak to na iterátor nepřevedeš.
[1] mimochodem psané kurzívou – možná to mělo být v uvozovkách, aby z toho bylo na první pohled zřejmé, že to není myšleno doslova
Pokud máš API postavené nad iterátorem (nebo něčím podobným), tak to v případě potřeby na objekt převedeš snadno. Ale pokud máš API postavené nad objektem, tak to na iterátor nepřevedeš.To mi prijde jako dost pochybny argument. Vzdyt jak sam pises, predpokladas, ze jsou to kolekce. Je to trochu jako kdyby jsi cele cislo ukladal jako double, protoze double na integer prevedes snadno. No jo, ale proc to delat, kdyz vis, ze ta hodnota ma byt cela? Obecne, smyslem typoveho modelovani ma byt zajistit, aby nevhodne hodnoty vubec nebyly reprezentovatelne.
jako kdyby jsi cele cislo ukladal jako doubleJsou ale pripady, kdy to smysl ma. SAS to treba dela, ze uklada vsechna cisla jako double. Protoze je to statisticky nastroj, dava to smysl. Pak se vyhneme typovemu modelovani a prevadeni typu (coz pro programovani veci zjednodusi), protoze zrovna v tomhle pouziti ta klasicka koncepce integeru a floatu ruznych velikosti neni moc uzitecna, spis by se hodilo neco jako kontrola jednotek.
23.1.2019 14:54
xkucf03 | skóre: 50
| blog: xkucf03
Obecne, smyslem typoveho modelovani ma byt zajistit, aby nevhodne hodnoty vubec nebyly reprezentovatelne.
Jenže tady ta hodnota je vhodná a reprezentovatelná, akorát ji třeba nemáme k dispozici teď hned a celou, třeba k nám přichází postupně nebo je tak velká, že se nevejde1 do paměti. Přesto ji lze zpracovat a ty operace dávají smysl.
[1] Ano, může se stát, že nám to zaplní RAM, pak to zaplní i disk a pak to spadne. Ale to je výjimečná situace a může k ní dojít i v případě, že se na relace díváme jako na objekty – stačí udělat kartézský součin všeho se vším a při „vhodném“ poměru velikosti databáze a velikosti RAM/disku ti ta paměť spolehlivě dojde taky. Implementace se s tím snaží různě vyrovnat, např. spadnout nějak šetrně, aniž by havarovalo úplně všechno, nebo předem odhadnout, že k problému dojde a odmítnout zpracování… Nicméně to jsou řešitelné problémy a není to důvod se vyhýbat iterátorům.
23.1.2019 16:26
xkucf03 | skóre: 50
| blog: xkucf03
Ne, tohle jsou dobré návrhy. Přemýšlel jsem o to, že tam budou nějaká metadata relace, kde tyhle věci půjde uvádět. Ale nechci to implementovat všechno v první verzi – mělo by to být rozšiřitelné, zpětně kompatibilní, aby to šlo vylepšovat průběžně…
23.1.2019 15:02
xkucf03 | skóre: 50
| blog: xkucf03
Ještě zkusím jeden příklad: SAX parser. Každé XML je konečné, jinak by to nebylo validní XML. Ale může být tak dlouhé, že se nevejde do paměti nebo by jí zabíralo zbytečně moc. Proto je to API navržené tak, že parser posílá události handleru a ten si je průběžně zpracovává. Jestli si na pozadí z toho staví DOM nebo posílá data rovnou někam dál, to je jeho věc. Ale to API je navržené tak, aby umožňovalo oba přístupy.
Totéž při generování XML – tam zase existuje StAX. Ano, mohli bychom celý strom předat jako jeden objekt. Ale taky ho můžeme předávat postupně jako události (volání metod) a mnohdy je to šikovnější (a zase: pokud by příjemce potřeboval celý strom jako jeden objekt, není problém, aby si ho z těch událostí poskládal).
23.1.2019 15:45
xkucf03 | skóre: 50
| blog: xkucf03
XML s tím nijak nesouvisí, vzhledem k tomu, že nad ním není definovaná žádná algebra (alespoň doufám).
Obávám se, že existuje :-) 1, 2, 3.
A hlavně takové FLWOR výrazy nabízejí podobné operace jako SQL – a XQuery je srovnatelně mocný (nebo i mocnější) jazyk.
Jinak když budu chtít být hnidopich, ani to XML obecně nezpracuješ s konstatní pamětí, vzhledem k tomu, že může být libovolně hluboko zanořené nebo obsahovat např. libovolně dlouhé stringy. Ačkoli samozřejmě u praktických existujících XML to obvykle jde.
Dlouhé texty nejsou problém – ty se prostě rozpadnou na několik volání characters() a ty si to poskládáš dohromady, nebo posíláš průběžně dál, takže můžeš zpracovat nekonečně „opravdu velmi dlouhé“ texty.
S tím zanořením je to pravda, potřebuješ si udržovat zásobník s aktuální pozicí ve stromě + informaci o jmenných prostorech (ale těch bývá jen pár). Ale i kdybys měl milion úrovní zanoření a na každý název elementu potřeboval deset bajtů, tak to máš deset mega, což není žádná tragédie. Navíc pokud to nebude milion unikátních názvů elementů (či jmenných prostorů), tak si ty unikátní hodíš do nějakého setříděného seznamu/stromu a v tom zásobníku budeš mít jen ukazatele. Striktně vzato ta paměťová náročnost není konstantní, ale není to problém.
V pořádku. Však mj. právě proto nemá moc význam se snažit na to napasovat ten relační model (relační operace jsou definované na hodnotách).musis se na relace divat jako na hodnotyA s tím právě nesouhlasím. Kdybych to tak dělal, tak bych se připravil o možnost efektivně provádět operace, které proudově provést lze.
23.1.2019 15:12
xkucf03 | skóre: 50
| blog: xkucf03
Viz #85. To, že budu mít na vstupu SAX parser přece neznamená, že jedna z operací nemůže být XSLT (které potřebuje celý strom načtený najednou v paměti). Může, protože si ten DOM z těch SAX událostí snadno poskládá. A výhoda je v tom, že tam budou efektivně fungovat i operace, které celý strom najednou nepotřebují. Přijde mi to jako správnější a flexibilnější návrh. Byť to může někomu připadat trochu složitější, protože musí vystavovat nějaký handler a přijímat přes něj jakési události, místo aby dostal jeden objekt.
23.1.2019 16:22
xkucf03 | skóre: 50
| blog: xkucf03
To je součást implementace jednotlivých1 nástrojů, a pak se to akorát napíše do dokumentace. Tzn. bude tam napsané třeba to, že a) data se zpracovávají průběžně a paměťová náročnost je minimální b) máš si připravit 2× tolik RAM, než kolik máš dat c) program si načte 10 M do RAM a pokud pořád přicházejí další data, tak je začne odkládat na disk, což se dá nastavit tak a tak… atd.
Nicméně snažím se toho kódu psát co nejméně a použít pokud možno už hotová řešení – nechce se mi ty operace implementovat. Takže v plánu je třeba relpipe-tr-sql, která nasype data do SQLite (v paměti, případně se dají volitelně odložit na disk), pustí na tom zadané SQL dotazy a výsledky pošle rourou dál. Tím budou rázem implementované všechny možné operace. Sice je to jen „pouhé“ SQL, takže deda.jabko zase bude remcat, ale takový už je život.
BTW: SQLite je pekelně rychlá:
$ time (echo "SELECT 1+1" | sqlite3) 2 real 0m0,008s user 0m0,003s sys 0m0,008s
$ time (echo 1+1 | bc) 2 real 0m0,006s user 0m0,006s sys 0m0,003s
$ time (echo "CREATE TABLE t (id integer, x text); insert into t values (1, 'aaa'), (2, 'bbb'); SELECT * FROM t;" | sqlite3) 1|aaa 2|bbb real 0m0,008s user 0m0,003s sys 0m0,008s
Takže i když to vypadá jako prasárna a plýtvání (nalít data do DB a vzápětí ji zahodit), tak uživatel to ani nepocítí.
Totéž jde dělat s XQuery, kde srovnatelné operace můžeš provádět už teď. Akorát to SQL se bude psát přeci jen pohodlněji (což je výhoda relačního přístupu oproti tomu obecnějšímu stromovému v XML).
Tohle jsou zrovna příklady transformací, které proudové nejsou a vyžadují načtení všech dat do paměti nebo na disk. Vedle toho ale jiné operace budou proudové (některé už existují).
[1] všechno to jsou samostatné programy – není tam žádný centrální bod, který by rozhodoval, co se zpracuje proudově a co ne
Takže v plánu je třeba relpipe-tr-sql, která nasype data do SQLite (v paměti, případně se dají volitelně odložit na disk), pustí na tom zadané SQL dotazy a výsledky pošle rourou dál.To bych viděl asi takhle:
#!/usr/bin/env python3
# Odnekud si vycucam data, stdin, server v Kanade, whatever:
data = [
('foo', 'bar', 3.14),
('quz', 'qux', 2.71828),
('xyz', 'abc', 1.618),
]
import sqlite3
conn = sqlite3.connect(':memory:')
c = conn.cursor()
c.execute('CREATE TABLE tmp (a text, b text, c real)')
c.executemany('INSERT INTO tmp VALUES (?, ?, ?)', data)
for row in c.execute('SELECT * FROM tmp ORDER BY c'):
print(row)
# Pripadne mozno serializovat do formatu XY, poslat zpet do Kanady, etc...
use rusqlite::types::ToSql;
use rusqlite::{Connection, NO_PARAMS};
type Data = (String, String, f64);
fn main() -> rusqlite::Result<()> {
let conn = Connection::open_in_memory() ?;
conn.execute("CREATE TABLE tmp (a text, b text, c real)", NO_PARAMS) ?;
let data = [
("foo", "bar", 3.14),
("quz", "qux", 2.71828),
("xyz", "abc", 1.618),
];
let mut insert = conn.prepare("INSERT INTO tmp VALUES (?, ?, ?)") ?;
for tuple in data.iter() {
insert.execute(&[&tuple.0 as &ToSql, &tuple.1, &tuple.2]) ?;
}
let mut select = conn.prepare("SELECT * FROM tmp ORDER BY c") ?;
let rows = select.query_map(NO_PARAMS, |row| -> Data { (row.get(0), row.get(1), row.get(2)) }) ?;
for data in rows {
println!("{:?}", data?);
}
Ok(())
}
BTW: tak mě napadá – to v Pythonu ani Rustu neexistuje nějaké standardní API pro práci s databázemi? Nebo se to nepoužívá? Něco jako JDBC/ODBC/PDO/DBI atd.? Myslel jsem, že tohle má snad každý jazyk.
23.1.2019 18:52
xkucf03 | skóre: 50
| blog: xkucf03
 Vždyť to mají i v PHP.
23.1.2019 18:07
xkucf03 | skóre: 50
| blog: xkucf03
Vždyť to mají i v PHP.
23.1.2019 18:07
xkucf03 | skóre: 50
| blog: xkucf03
Ano, takhle nějak to bude vypadat. Resp. toho kódu bude trochu víc, ale to je asi jasné – data je potřeba přijmout ze vstupu a nebudou se cpát do proměnné, ale budou se průběžně překládat na SQL a sypat do SQLite (včetně toho CREATE TABLE, které nemůže být zadrátované v kódu a musí se dynamicky vygenerovat na základě vstupu); z CLI je potřeba vzít jednotlivé dotazy (a názvy relací, pod kterými se mají objevit na výstupu), případně jejich parametry; postupně provést a posílat serializované výsledky na výstup.
relpipes-tr-sql když víceméně to samé udělám na pár řádkách Pythonu (a rozšiřitelněji).
 23.1.2019 16:00
Josef Kufner | skóre: 70
23.1.2019 16:00
Josef Kufner | skóre: 70
Jak to tak sleduju, ono tu o nějaký relační model vůbec nejde. Vlastně to je úplně mimo. Tady jde jen a pouze o předávání dat.Ja to rikam furt! ;-]
23.1.2019 16:41
xkucf03 | skóre: 50
| blog: xkucf03
A já vám zase od začátku říkám, že je to datový formát, jehož primárním/zamýšleným účelem je předávání relačních dat (a proto se tak jmenuje. :-)
Tzn. když řeknu, že zpracovávám „nekonečná“ data, znamená to, že těch dat může být „opravdu hodně“Ale kdo to mel vedet, ze nekonecno bylo predefinovano na opravdu hodne. Obzvlast, kdyz to tvoje reseni umoznuje pracovat s nekonecnymi daty (ve smyslu, ze jsou opravdu nekonecna!). Obzvlast, kdyz proudove zpracovani nekonecnych dat (ve smyslu, ze jsou opravdu nekonecna!) je naprosto bezne, napr. ve funkcionalnich jazycich.
Prosim te, podivej se do te knizky, co jsem postoval vys. Jde to vygooglit i jako PDF. Je to fakt vyborne cteni a otevira uplne jiny pohled na databaze. Pujcim si z tama definici:musis se na relace divat jako na hodnotyA s tím právě nesouhlasím.
Definition: A value is what the logicians call an “individual constant,” such as the integer 3. A value has no location in time or space. However, values can be represented in memory by means of some encoding, and those representations or encodings do have location in time and space. Indeed, distinct representations of the same value can appear at any number of distinct locations in time and space─meaning, loosely, that any number of different variables (see the next definition) can have the same value, at the same time or different times. Observe in particular that, by definition, a value can’t be updated; for if it could, then after such an update it wouldn’t be that value any longer.Ergo, je potreba rozlisovat, co je to hodnota a co jeji reprezentace. RM je postaveny na tom, ze relace jsou hodnoty a z toho plynou i jednotlive operace. Implementace pak pracuje s nejakou jeji reprezentaci, napr. pomoci tabulek nebo iteratoru, chces-li a z toho plyne i realizace jednotlivych operaci. Problem nastava v momente, kdyz hodnoty nahradis temi iteratory uz v RM. V takovem pripade si ti jednotlive vychodiska rozpadnou a prestanou ti funguovat i jenotlive operace.
24.1.2019 15:15
xkucf03 | skóre: 50
| blog: xkucf03
Ale kdo to mel vedet, ze nekonecno bylo predefinovano na opravdu hodne. … Obzvlast, kdyz proudove zpracovani nekonecnych dat (ve smyslu, ze jsou opravdu nekonecna!) je naprosto bezne, napr. ve funkcionalnich jazycich.
Vzhledem ke kontextu si jsi jistě vědom, že vím o existenci operací jako SUM nebo EXCEPT. A snad jsi nepředpokládal, že si myslím, že jde spočítat sumu z nekonečné (resp. v tu chvíli neznámé) posloupnosti čísel, ne? Tak ti snad muselo být jasné, že to nekonečné (psané kurzívou) není myšleno úplně doslovně. BTW: nemíváš s tímhle přístupem někdy problém v komunikaci s lidmi? On totiž přirozený jazyk není tak jednoznačný jako třeba zdrojový kód a běžně obsahuje řadu nepřesností a nejednoznačností (a zároveň dostatek redundance, která to zase koriguje).
Problem nastava v momente, kdyz hodnoty nahradis temi iteratory uz v RM. V takovem pripade si ti jednotlive vychodiska rozpadnou a prestanou ti funguovat i jenotlive operace.
Hledáš problém, kde není. Podívej se třeba na to XML a jeho API. XML jako struktura je strom. A nad ním jsou definované nějaké operace jako XPath nebo XSLT. K jejich vykonání potřebuješ1 celý ten strom2 (objekt). Ale jak k tobě ta data doputovala, jak vypadá to API, to je věc jiná – klidně se k tobě můžou dostat jako iterátor, jako proud nějakých událostí. Což je úplně v pořádku a nijak to nepopírá ty operace pracující nad stromem jako celkem. Stejně tak si pouštím XQuery jako filtr v shellové rouře – čte XML ze standardního vstupu a výsledek posílá na standardní výstup. A funguje to – přestože to uvnitř pracuje nad DOM objektem. Tak prosím netvrď, že něco nejde, když to zcela prokazatelně jde.
Nebo takový obrázek či video. To je pár mega nebo giga velký binární blob. Přesto to API, přes které k tobě tato data obvykle putují je proudové, nepředává ti objekt jako jeden celek. Některé operace nad tím obrázkem/videem můžeš provádět, až když ti přijde všechno, ale jiné operace můžeš provádět (byť třeba v omezené míře) i průběžně, už ve chvíli, kdy máš jen část dat. A je to lépe navržené API, přináší užitek a rozhodně není horší než API, které tě nutí přijmout všechna data jako jeden objekt najednou. A není to náhoda – ty formáty jsou přímo navržené s ohledem na to, aby (alespoň některé) operace šlo provádět proudově nebo nad částečnými daty a ten formát/API ti neházel klacky pod nohy.
[1] později vzniklo proudové XSLT, ale to teď nechme stranou
[2] protože bez něj třeba XPath dotaz odvolávající se na jiné části stromu nebo počítající celkový počet uzlů nedává smysl
A snad jsi nepředpokládal, že si myslím, že jde spočítat sumu z nekonečné (resp. v tu chvíli neznámé) posloupnosti čísel, ne? Tak ti snad muselo být jasné, že to nekonečné (psané kurzívou) není myšleno úplně doslovně.Ja uz fakt nevim. V jistych kruzich pracovat a delat ruzne kejkle s nekonecnymi proudy je naprosto bezne. A jen tak mimochodem, kdyby ses na to nasnazil napasovat operace relacni algebry, ale operace pro praci s proudy, davalo by to reseni velice dobry smysl i v pripade opravdu nekoncnych proudu.
Nebo takový obrázek či video. To je pár mega nebo giga velký binární blob.Precti si prosim jeste jednou predchozi prispevek, abys dokazal rozlisit mezi hodnotou a jeji reprezentaci. Jinak ja tuto debatu koncim. Puvodne jsem myslel, ze kdyz zacals s relacnimi daty, ze nektere miskoncepce, kterych se dopoustis jsou jen urcite nedorozumeni plynouci z toho, ze o relacnim modelu mas predstavu zprostredkovanou hlavne pres SQL. Coz je teda problem spousty lidi. Ale kdyz ctu tvoje komentare, zejmena ty z posledni doby, nabyvam dojmu, ze ta teorie, ktera stoji za praci s relacnimi daty, te absolutne nezajima a bastlis si to tak nejak po svem a mas radost z toho, ze tomu muzes rikat relacni data.
ale operace pro praci s proudy, davalo by to reseni velice dobry smysl i v pripade opravdu nekoncnych prouduNapriklad Reactive Extensions.
25.1.2019 10:41
Josef Kufner | skóre: 70
v Javě teď frčí FP konceptyUz delsi dobu. A to nemluvim o hipsta-jazycich jako Kotlin (nebo Scala, ta je ted uz trochu za zenitem).
By mě zajímalo, co bude dál, uvědomí si třeba, že hodnotové typy nejsou úplná kravina?Na tomto se uz delsi dobu pracuje, projekt Valhalla. Na YT jsou k tomu i zajimave prednasky, co to obnasi. Zatim to vypada, ze se to nejdriv dostane do JVM, protoze jazyky jako Kotlin nebo Scala musi hodnotove typy emulovat pres value-based classes, coz ma svoji rezii. Dalsi krok bude asi zasah do samotne javy. Jinak na pristupu, kterym se toho chopili v Jave, je mi sympaticke, ze hodnoty udelali nemenne, coz dava vetsi smysl, nez ten hybrid, ktery je v C++ nebo C#.
A to nemluvim o hipsta-jazycich jako Kotlin (nebo Scala, ta je ted uz trochu za zenitem).Jj, v Kotlinu jsem něco dělal a je mi sympatický, je fajn, že existuje slušný jazyk pro JVM (samozřejmě už dřív existovaly i jazyky jako Clojure nebo Scala, ale to první je lisp a Scalu moc neznám a při letmém pohledu působila na mě jako tak trochu všehochuť (ačkoli Akka je asi zajímavá věc)).
Jinak na pristupu, kterym se toho chopili v Jave, je mi sympaticke, ze hodnoty udelali nemenne, coz dava vetsi smysl, nez ten hybrid, ktery je v C++ nebo C#.Tak imutabilní hodnoty jsou samozřejmě fajn. Jestli by jazyk měl umožňovat i mutabilní hodnoty, to je na delší zamšlení a záleží na okolnostech. Nevim, jak C#, ale C++ je IMHO potřebuje už proto, jak je nízkoúrovňový. Další věc je, že v C++ je dojebaná move sémantika, která mutabilitu vyžaduje. Rust na tom je trochu lépe v tom, že imutabilita je default a move semantics nevyžadují mutabilitu, nicméně mutabilitu taky poskytuje (opět protože nízkoúrovňovost a podpora imperitivního programování).
Jinak to ale nechci shazovat, me prijde prave to zpracovani ze 70. let jak rikas, velice jednoduche a casto ucinne.Uz jsem to psal driv, v podstate ten projekt mi nevadi, ale vadi mi, ze teoreticky model, se kterym pracuje, absolutne neodpovida implementaci. Kdyby si priznal, ze to nejsou relace, ale proste ploche soubory, tak by veci naraz vypadaly jinak. Dalo by se cerpat z pristupu a algoritmu, ktere vznikly v tech sedesatych a sedmdesatych letech.
velice jednoduche a casto ucinne.To jo, ale in-memory zpracovani ma taky co do sebe, obzlast pro relativne mala data (statisice az miliony zaznamu).
Jestli je tohle jediná věc, která ti na tom vadí, tak to vlastně musím brát jako pochvalu :-)
Viz komentář výše – pokud chceš mermomocí čichat ředidlo, tak můžeš :-) já ti v tom nebráním, jen do dokumentace napíšu, že bys ho čichat neměl, případně co se pak stane.
A pokud tě tahle otázka tak trápí, tak si můžeš jít stěžovat třeba sem – ono totiž většina databází, ke kterým bys mohl mít stejné výhrady, se běžně označuje právě jako relační databáze.
Most relational databases use the SQL data definition and query language; these systems implement what can be regarded as an engineering approximation to the relational model.
Tvoje komentáře jsou značně nekonstruktivní1 a přijde mi, že jsi sem přišel jen prudit (i když tedy moc nevím proč – např. s JS1 se zásadně neshodnu v politických otázkách, tak tam ty osobní antipatie chápu…).
Je to jako kdybys argumentoval, že nějaký systém není unixový, protože si do něj můžeš nainstalovat Wine nebo v něm provozovat monolitické aplikace, které odporují původním unixovým myšlenkám.
Relational pipes jsou datový formát určený k serializaci relačních dat. Stejně jako ředidlo je určené k ředění barev, a proto se tak jmenuje. Že ty věci jde použít i k něčemu jinému a případně i nějakým nevhodným způsobem, není můj problém. Nevhodně můžeš použít jakýkoli nástroj (dynamicky či slabě typované jazyky, funkcionální jazyky, objektové jazyky, Python, Perl, C, Lisp, zápalky a benzín, nůž…), ale to nemění nic na tom, že věci se obvykle pojmenovávají podle primárního/zamýšleného použití.
[1] Pokud chceš být konstruktivní, tak můžeš zkusit navrhnout, jak řešit syntaxi dotazování v Guile nebo Pythonu tak, aby byla jednoduchá, dobře se psala, byla pokud možno idiomatická pro daný jazyk a zároveň nedocházelo ke kolizím mezi názvy atributů a klíčovými slovy a existujícími funkcemi/objekty daného jazyka. V tomhle má výhodu SQL, kde lze psát identifikátory do uvozovek, takže tohle je validní kód: create table "where" ("create" integer, "select" text); SELECT * FROM "where" WHERE "select" = "a" AND "create" = 1;. Někde jsem viděl příklad pro nějaký Lisp/Scheme, kde se používaly |svislítka|, ale v Guile mi to nefungovalo. Tam jsem někde viděl syntaxi s *hvězdičkami* ale mezery to stejně neřešilo a navíc psát kolem všech názvů hvězdičky by bylo trochu otravné.
Viz komentář výše – pokud chceš mermomocí čichat ředidlo, tak můžešJa bych to prirovnal spis k predchozimu rezimu. Ten o sobe tvrdil taky, ze je to demokracie, mel s ni i radu spolecnych vlastnosti, napr. existovaly volby, voleni zastupci, atd., ale protoze se od demokracie lisil v rade drobnych technickych detailu, demokracie to opravdu nebyla. A to je, co mi vadi.
Most relational databases use the SQL data definition and query language; these systems implement what can be regarded as an engineering approximation to the relational model.Kdyz uz jsi nakousl citaty z wikipedie
However, SQL databases deviate from the relational model in many details, and Codd fiercely argued against deviations that compromise the original principles.[4]
i když tedy moc nevím pročProtoze je to do oci bijici blbost, rikat necemu, ze jsou to relacni data, kdyz nejsou. V predchozim prispevku jsem polozil nekolik otazek. Jejich smyslem nebylo prudit, ale pochopit podstatu, proc lpis na nejakych relacich a relacnim modelu, kdyz to s tim ma spolecneho v podstate jen nazev.
Tvoje komentáře jsou značně nekonstruktivníK tomu dve poznamky. Kdyz se clovek do neceho pousti, je dobre kdyz ma nejake teoreticke vychodiska/framework, a pak muze sledovat, jestli to, co dela, z toho nevybocuje a stale dava smysl. Jinak hrozi, ze z toho vznikne splacanina. U relacniho modelu je problem v tom, ze jednotlive odchylky, ktere udelas tu a tam, aby sis neco usetril, se ti vrati jako komplikace nekde uplne jinde a bude z toho vznikat kockopes.
Je to jako kdybys argumentoval, že nějaký systém není unixový, protože si do něj můžeš nainstalovat Wine nebo v něm provozovat monolitické aplikace, které odporují původním unixovým myšlenkám.To neni uplne dobre prirovnani, co je unixovy system neni nikde presne definovano a nema to zadne jasne implikace. V pripade relacniho modelu to neplati, tam mas jasne definovane, co je to relace, operace s relacemi, vztahy mezi operacemi, atd. Pomuzu si prikladem z minula. V RM plati (T EXCEPT {} = T) v tvem pripade to neplati a takovych veci tam bude opravdu hodne. A neni to chyba uzivatele, ze se sam streli do nohy (to je alibismus), to je evidentne chyba nastroje, ze neco dela blbe.
20.1.2019 19:51
Bedňa | skóre: 34
| blog: Žumpa
| Horňany
Libi se mi to moc. Jeste by to chtelo podporu nejakeho dotazovaciho jazyka
Dík. Co se týče dotazování, zatím asi nejpoužitelnější/nejkompletnější je XQuery, kde se používá již existující software, takže už je odladěný – dají se tam dělat i různé JOINy, řazení, filtrování, úpravy dat… Nicméně je to spíš skript než jeden dva řádky kódu, které bys napsal ad-hoc do konsole. Ve vývoji je relpipe-tr-guile, relpipe-tr-python a bude i SQL. Tzn. několik jazyků, ve kterých půjde psát filtrovací podmínky nebo upravovat data.
neco jako Stream API v java
Časem by mělo vzniknout jakési jednoduché ORM, které namapuje záznamy na objekty (bez nějakých vazeb), takže pak bys mohl použít přímo to Stream API. Ale to je poměrně daleká budoucnost.
Ale SQL bude skvele.
20.1.2019 19:30
okbob | skóre: 30
| blog: systemakuv_blog
| Benešov
20.1.2019 20:58
xkucf03 | skóre: 50
| blog: xkucf03
To je luxusní rozhraní! :-) Ten formát jsem zatím narychlo trochu nahackoval pomocí:
relpipe-out-pspg() { relpipe-out-tabular | perl -pe 's/\e\[?.*?[\@-~]//g' | grep '^ ' | sed -e 's/(string)/ /g' -e 's/(integer)/ /g' -e 's/(boolean)/ /g' -e ''| pspg; }
find ~/src/ -print0 | relpipe-in-filesystem | relpipe-out-pspg
A vypadá to, že to funguje. Ten rámeček v tom prvním řádku tak má být? Vypadá to jinak, než na obrázcích.
Ještě by bylo super mít tam možnost označit vybrané záznamy a ty pak poslat na standardní výstup. Případně pak možnost editace.
20.1.2019 21:58
xkucf03 | skóre: 50
| blog: xkucf03
Koukám, že se mi tam kus ztratil – s tímhle by to mělo fungovat líp:
relpipe-out-pspg() { relpipe-out-tabular | perl -pe 's/\e\[?.*?[\@-~]//g' | grep '^ ' | sed -e 's/(string)/ /g' -e 's/(integer)/ /g' -e 's/(boolean)/ /g' -e 's/^ //g'| pspg; }
Na spodní rámeček se dostanu taky, ale do záhlaví tabulky ne.
relpipe-in-fstab: Schéma specifikovat lépe než prázdným stringem. U mě to totiž produkuje tohle:
fstab: ╭─────────────────┬──────────────────────────────────────┬──────────────────────┬───────────────┬───────────────────┬────────────────┬────────────────╮ │ scheme (string) │ device (string) │ mount_point (string) │ type (string) │ options (string) │ dump (integer) │ pass (integer) │ ├─────────────────┼──────────────────────────────────────┼──────────────────────┼───────────────┼───────────────────┼────────────────┼────────────────┤ │ │ /dev/mapper/desktop--vg-root │ / │ ext4 │ errors=remount-ro │ 0 │ 1 │ │ │ /dev/mapper/storage1-data │ /data │ ext4 │ errors=remount-ro │ 0 │ 1 │ │ UUID │ 18798bc1-96cf-4b89-8cd4-cbb7118511cf │ /boot │ ext2 │ defaults │ 0 │ 2 │ │ │ /dev/sr0 │ /media/cdrom0 │ udf,iso9660 │ user,noauto │ 0 │ 0 │ ╰─────────────────┴──────────────────────────────────────┴──────────────────────┴───────────────┴───────────────────┴────────────────┴────────────────╯ Record count: 4Obsahu jsem nevěnoval moc pozornosti a v první chvíli jsem si říkal, jak je to cool, že když se někde opakují hodnoty, tak je „zagreguješ“ a vypíšeš jen jednou vycentrovaně napříč všemi řádky, ke kterým se ta hodnota vztahuje. Pak jsem si všiml, že přes UUID ale mám přece specifikované jen jediné zařízení, no a pak už mi to docvaklo. :) Kdyby tam bylo třeba
filename místo prázdného stringu, tak to bude trochu přehlednější.
20.1.2019 23:00
xkucf03 | skóre: 50
| blog: xkucf03
Akorát to zvýrazňuje i hodnoty v prvním sloupci, což by asi nemělo.
To je ukotvený sloupec – když bude tabulka moc široká, můžeš se šipkami posouvat na další sloupce vpravo, a tenhle (třeba ID) tam zůstane. Počet ukotvených sloupců se dá nastavit v nabídce (i na nulu).
Kdyby tam bylo třeba filename místo prázdného stringu, tak to bude trochu přehlednější.
Bylo to myšleno jako NULL hodnota, akorát NULL hodnoty ještě nejsou implementované, tak je tam prázdný řetězec. Až budou, tak by mělo být možné si nastavit textovou reprezentaci pro NULL. Ale je fakt, že zrovna u fstabu by mohlo být i file/filename.
To je ukotvený sloupecOK.
21.1.2019 09:21
okbob | skóre: 30
| blog: systemakuv_blog
| Benešov
21.1.2019 09:20
okbob | skóre: 30
| blog: systemakuv_blog
| Benešov
21.1.2019 09:17
okbob | skóre: 30
| blog: systemakuv_blog
| Benešov
Pokud přidáš float a null, bude možná snadná konverze z/na seznam JSON objektů beze ztrát.
Ona ta struktura je takováto: proud / relace* / záznam* / atribut+. Kde relace obsahuje určitá metadata a časem jich bude víc, takže by se mapovala na objekt. Záznamy jde namapovat na pole objektů.
Podpora dalších primitivních typů je jen detail. Ty tam budou a není na tom nic složitého.
NULL není datový typ – atribut jakéhokoli typu může být NULL resp. záleží, jak bude daný atribut dané relace deklarován v metadatech.
A co takle obecná binární data?
Viz Roadmap. Binární data budou, stejně jako další typy.
Stránka popisující formát nepopisuje formát, jen říká, že se používá pár řidicích znaků. V jakém pořadí a jak to vlastně vypadá tam už není.
Ano, píše se to hned v prvním odstavci:
Currently only fragments of the specification are published and the incompatible changes might (and will) come before the v1.0.0 release. Please stay tuned for this stable version which will deliver specification such complete and precise that independent implementation of the format will be possible.
Až se ten formát stabilizuje a bude jasno v těch otázkách, které je potřeba vyřešit před v1.0.0, tak bude i specifikace – tak kompletní, aby kdokoli podle ní mohl napsat vstupní nebo výstupní knihovnu pro svůj jazyk.
Do té doby implementace trochu předbíhá specifikaci (alespoň tu, co je někde zveřejněná – zbytek mám v hlavě nebo nějakých svých poznámkách). Chápu, že bys chtěl přesnou specifikaci, ale na tu je potřeba si ještě chvíli počkat – přeci jen je to pořád vývojová verze a do v1.0.0 zbývá ještě poměrně dost práce (byť to z určitého úhlu pohledu může vypadat jako „skoro hotové“). Přijde mi to jako lepší způsob, než si něco vysnít na papíře – a pak zpětně zjistit, že to nejde implementovat (nebo jen velmi obtížně).
Po vydání v1.0.0 by změny měly přicházet v menších iteracích a zpětně kompatibilní (až do nekompatibilní v2.0.0 formátu, která ale snad nikdy nepřijde).
Btw, nebylo by lepší použít nějaký existující formát?
Na stránce Principles jsou předpoklady, ze kterých vycházím. Samozřejmě jsem se to snažil postavit na něčem existujícím, porovnával jsem různé varianty, vždy to na něčem narazilo – nemožnost řetězení, datová náročnost, složitost implementace daného formátu…
Hodně chybí srovnání s AWK. Je to nástroj, který dělá víceméně totéž (alespoň na první pohled) a je dobře známý.
Přiznám se, že AWK jsem nikdy pořádně nepoužíval – když mi nestačil grep/cut/sed, tak jsem vždy spíš sáhl po Perlu. Jak moc je dnes AWK relevantní? Např. podle Case Study: awk to vypadá, že moc ne. (a to je v knize z roku 2003)
Nicméně na aktuální popularitě až tolik nezáleží, pokud by to byl vhodný nástroj/přístup. Ale AWK je textově orientovaný, data posílá na výstup příkazem print a vstup čte pomocí regulárních výrazů. Jak bys na to napasoval strukturovaná data? Možná to jde, ale teď mne moc nenapadá jak. Asi by bylo potřeba si místo funkce print napsat funkce pro generování relačních dat (tzn. udělat zapisovací knihovnu pro AWK). A vstup řešit tak, že by se relační data převedla na nějaký text, který by se dobře parsoval regulárními výrazy. Takhle jsi to myslel?
"relpipe-" je moc dlouhý prefix. Chtělo by to max 3 znaky. Možná bych se inspiroval u CLI rozhraní Gitu a udělal to vše s jedním entrypointem.
Souhlasím, že je to dlouhé. Na druhou stranu mě docela deptá, když je někdo schopný zahnojit globální jmenný prostor shellových příkazů krátkými/nicneříkajícími/obecnými slovy, takže nechci dělat totéž. Chápu to u tradičních příkazů, které vznikaly v určité době a v určité poměrně malé komunitě a těch příkazů a vývojářů bylo celkem málo a byli schopní se ještě nějak dohodnout. V současnosti je v oboru o několik řádů víc lidí, vzniká mnohem víc softwaru… a u krátkých názvů jsou kolize nevyhnutelné. Ano, mohl bych udělat třeba příkaz rp, který by sloužil jako vstupní bod pro všechny ostatní příkazy, ale bylo by to tak správně? Zkrátit se to dá vždycky (vytvořit aliasy, symlinky, jeden vstupní bod…), ale opačným směrem už je to horší – takže jsem prozatím zvolil delší název.
Pokud bude konkrétní lepší návrh, tak se to před v1.0.0 dá změnit. Ale zatím mne to moc netrápí – stejně píši rel<TAB> doplní mi to zbytek, pak dám i/t/o<TAB> atd., takže klávesnici si neošoupu :-) Ono napsat git<MEZERA> nebo rel<TAB> vlastně vyjde nastejno.
Sice o Relational Pipes se pořád tvrdí, že to je datový formát, ale to hlavní jsou nástroje. Spíš to dává smysl prezentovat jako trochu širší celek (framework?) a zadefinovat konvence okolo těch příkazů a nástrojů.
Já se chci držet toho, že je to v první řadě datový formát. Protože ideál je ten, že autor jiného programu (který poskytuje nějaká zajímavá data nebo funkce) použije knihovnu z Relational Pipes (případně si napíše vlastní) a bude generovat výstup v tomto formátu – což vytvoří spoustu nových možností (najednou půjde ten program propojit se všemi existujícími relačními nástroji). I proto mají být ty knihovny tak minimalistické, aby sis je mohl třeba během hodiny dvou celé pročíst a mohl je bez obav začlenit do svého programu. I tak je mi jasné, že tohle je běh na dlouhou trať a že to potrvá, než ostatní autoři začnou nadšeně používat tenhle formát. Do té doby / paralelně s tím budou vznikat vstupní filtry relpipe-in-* pro různé formáty, které budou zrovna potřeba. Ten vstupní filtr může být klidně pár řádků v Bashi/Perlu/Pythonu/XQuery atd. nemusí jít o nějaké velké programování. Viz třeba příklad načtení Atomu – to je jen šest řádků, na kterých je nějaký (triviální) kód, a zbytek je jen šablona dat.
Na druhou stranu je mi jasné, že uživatele nějaký formát až tak nezajímá a vidí v první řadě ty nástroje. Ano, bez nich to nejde a formát nebo teoretický koncept bez patřičných nástrojů by byl k ničemu.
Spíš to dává smysl prezentovat jako trochu širší celek (framework?) a zadefinovat konvence okolo těch příkazů a nástrojů.
Framework (technický i myšlenkový) to je a jednotné konvence (např. syntaxe příkazů, logiku) tam držet chci. Nicméně nerad bych, aby to lidi vnímali jako nějaký produkt/program resp. monolitickou hromadu kódu, který si mají stáhnout a nainstalovat. Důležitá je ta modulárnost, kdy si stáhneš a nainstaluješ jen to, co potřebuješ. Proto je na prvním místě ten datový formát – jako společný jazyk, kterým ty moduly/programy mezi sebou komunikují. Resp. BFU si klidně nainstaluje úplně všechno včetně všech knihoven pro XML, YAML, JSON, EXIF, sqlite, ASN.1 a spoustu dalších formátů – a nijak ho to netrápí. Ale pokud někdo trpí např. xmlfóbií a špičaté závorky mu nahánějí hrůzu, tak já ho nechci nutit, aby si instaloval Xerces. Takový člověk použije jen ty moduly, které opravdu potřebuje, a komplexita, které bude vystaven bude čítat jen nějaké stovky nebo malé tisíce řádků kódu. Viz taky Optional complexity na stránce Principy.
Ten příklad s tty-aware relpipe-in-fstab a čtením mtab je fakt špatný nápad. Bude to dělat ve skriptech bordel.
To „tty-aware“ je trochu kontroverzní otázka a tohle rozhodnutí není definitivní. BTW: Tyhle věci bych rád diskutoval ve více lidech v e-mailové konferenci.
Asi myslíš to, že v konsoli si člověk zvykne, že relpipe-in-fstab bez parametrů čte /etc/fstab, a pak se ve skriptu bude divit, že to najednou chce číst standardní vstup. Nešlo by tohle řešit varováním, které by se vypisovalo v konsoli a upozorňovalo na to, že se tentokrát čte z výchozího umístění, ale že ve skriptech tomu tak není?
awk '$3 == "vfat" { print $2 }' < /etc/fstab # Vypiš druhý sloupeček, pokud třetí je "vfat".
Vlastně to je nástroj, který pracuje nad jednou tabulkou stringů (absenci rozumného parsování ponechme stranou). Také tam je k dispozici pár užitečných proměnných, např. číslo řádku, které nahradí tail a head:
awk '$3 == "vfat" && NR >= 2 { print $2 }' < /etc/fstab # ... ale až od druhého řádku.
Podobnost s Relpipes je tu velká.
22.1.2019 18:47
xkucf03 | skóre: 50
| blog: xkucf03
Bral jsem to tak, že normálně se pracuje s regulárním výrazem, a když chybí, tak to spadne do režimu čtení podle oddělovače, viz:
echo -e 'a b\nc d' | awk '/(.*) (.*)/ { print $1 }'
echo -e 'a b\nc d' | awk '{ print $1 }'
Ale na tom nesejde, dejme tomu, že se tedy atributy namapují na $1, $2, $3 atd.
Pak je potřeba nějak řešit výstup a místo print volat jinou funkci, která vrátí strukturovaná data, aby nehrozilo, že se ztratí hranice mezi atributy nebo bude jiný problém s interpretací.
Jak bys to řešil? Vlastní reimplementací jazyka awk? Nebo úpravou gawku a dopsáním nějakých funkcí do něj? Nebo převodem na text, posláním standardnímu příkazu awk a následně převodem jeho textového výstupu zpět na relační data?
Je fakt, že pokud by se podařilo nějak elegantně vyřešit ty oddělovače, mohlo by to být jako dotazovací/transformační jazyk docela fajn:
relpipe-in-fstab | relpipe-out-csv | tr -d '"' \
| awk --field-separator=, 'NR > 1 && $4 == "btrfs" { printf "%s\0%s\0", $2, $3; }' \
| relpipe-in-cli generate-from-stdin fstab 2 device string mount_point string \
| relpipe-out-tabular
A ideálně ještě nemuset psát $1, $2, ale mít ty proměnné pojmenované.
22.1.2019 19:19
xkucf03 | skóre: 50
| blog: xkucf03
Co mne tak v rychlosti napadá:
relpipe-tr-awk --relation 'regulární výraz pro název relace, která se bude transformovat' --expression 'kód v awku'
relpipe-tr-awk převedly na hexadecimální tvar nebo Base64 (nebo by se nějak jinak ošetřily), mezi ně by se vložila třeba čárka nebo mezera jako oddělovač + záznamy by byly oddělené znakem konce řádku.--expressionPak by šlo psát něco jako:
… | relpipe-tr-awk '.*' '$type = "btrfs" { printRecord; }' | … # prosté filtrování
… | relpipe-tr-awk '.*' '$type = "btrfs" { printAttribute "…"; printAttribute "…"; … }' | … # filtrování + transformace
… | relpipe-tr-awk '.*' '$type = "btrfs" { printAttributes "…", "…", "…"; }' | … # totéž, asi lepší syntaxe
kde u transformace by musel počet a typy atributů odpovídat vstupu, nebo bys výstupní počet, typy a názvy atributů zadal jako parametr příkazu relpipe-tr-awk. Funkce print_attribute by tiskla hodnotu + nulový bajt a relpipe-tr-awk by si to pak parsoval.
22.1.2019 23:20
xkucf03 | skóre: 50
| blog: xkucf03
Zapomeň na regulární výrazy a tr. Jakmile použiješ tr, tak to máš rozbité, neboť neescapuješ oddělovač.
Jaké tr myslíš? To v relpipe-tr-awk znamená, že jde o transformaci – je to jen jmenná konvence, žádné tr se tady nespouští.
Regulární výraz za --relation říká, na jaké relace se má tato transformace aplikovat (protože v proudu jich může být víc a ty chceš typicky transformovat jen jednu). Nemusel by to být regulární výraz, ale přijde mi to šikovnější než se muset odkazovat na přesný název.
Když do awk doplníš parser relpipes tabulek a přidáš funkci na výpis ve správném tvaru, tak máš hotovo.
Viz výše, těch relací v jednom proudu může být víc, takže prostě nemůžu celý proud nasměrovat do awku (… | awk … | …), je potřeba mu vybrat tu jednu relaci (případně relace, ale každá půjde do jiného procesu awku) a zbytek nechat projít skrz beze změny.
| tr -d '"'. To není korektní kód. Pokud máš štěstí, tak funguje, ale jakmile ti přijde řádně escapovaná uvozovka, tak ti to rozbije data.
23.1.2019 13:40
xkucf03 | skóre: 50
| blog: xkucf03
Jo tohle – to bylo jen tak rychle nahackované jako ukázka. Taky hned nad tím píšu: „pokud by se podařilo nějak elegantně vyřešit ty oddělovače“.
Bude prostě potřeba udělat nějaké escapování a pak to v tom AWKu odescapovat a naplnit jednoltivé atributy do proměnných. Ale neměl by to být až takový problém. Celkem se mi ten nápad z AWKem líbí, takže dík za tip.
8.5.2019 18:35
xkucf03 | skóre: 50
| blog: xkucf03
Dostal jsem se k implementaci té AWK transformace. Ještě to není úplně hotové – zatím jen malá ochutnávka na Trollí farmě: AWK transformace v Relational pipes :-)
Na tom není nic kontroverzního. Je to prostě ptákovina a ještě jsem neviděl program, který by to dělal. Běžné chování je, že program vypne barvičky, pokud nepíše na terminál. Případně se program přepne do neinteraktivního režimu, kdy se neptá na doplňující otázky, pokud na vstupu není uživatel. Vždy ale musí být k dispozici přepínač, který jedno nebo druhé chování vynutí. V případěTen příklad s tty-aware relpipe-in-fstab a čtením mtab je fakt špatný nápad. Bude to dělat ve skriptech bordel.To „tty-aware“ je trochu kontroverzní otázka a tohle rozhodnutí není definitivní. BTW: Tyhle věci bych rád diskutoval ve více lidech v e-mailové konferenci.
Asi myslíš to, že v konsoli si člověk zvykne, že
relpipe-in-fstabbez parametrů čte/etc/fstab, a pak se ve skriptu bude divit, že to najednou chce číst standardní vstup. Nešlo by tohle řešit varováním, které by se vypisovalo v konsoli a upozorňovalo na to, že se tentokrát čte z výchozího umístění, ale že ve skriptech tomu tak není?
relpipe-in-fstab bych očekával parametr, který by určoval vstupní soubor a výchozí hodnota by byla /etc/fstab s možností uvést "-" pro stdin. Tedy následující příkazy by udělaly totéž:
relpipe-in-fstab cat /etc/fstab | relpipe-in-fstab - relpipe-in-fstab /etc/fstabJe to zavedená konvence.
:-)
BTW: Nemáš nějaký nápad ohledně propojení s Guile/Scheme? Jde mi o kolize názvů atributů s již existujícími symboly. Zatím jsem to vyřešil tím, že jsem na začátek přidal dolar, takže jde psát:
$ find /etc/ssh/ -print0 | relpipe-in-filesystem | relpipe-tr-guile '.*' '(and (equal? $owner "root") (> $size 300) (< $size 1000) )' | relpipe-out-tabular filesystem: ╭───────────────────────────────┬───────────────┬────────────────┬────────────────┬────────────────╮ │ path (string) │ type (string) │ size (integer) │ owner (string) │ group (string) │ ├───────────────────────────────┼───────────────┼────────────────┼────────────────┼────────────────┤ │ /etc/ssh/ssh_host_ed25519_key │ f │ 399 │ root │ root │ │ /etc/ssh/ssh_import_id │ f │ 338 │ root │ root │ │ /etc/ssh/ssh_host_rsa_key.pub │ f │ 391 │ root │ root │ ╰───────────────────────────────┴───────────────┴────────────────┴────────────────┴────────────────╯ Record count: 3
Syntaxe těch CLI parametrů se ještě změní (bude to umět i UPDATE a další věci), ale teď mi jde spíš o syntaxi uvnitř těch apostrofů.
P.S. ohledně toho formátu – něco už jsem tu psal, formát není definitivní, ale z různých důvodů to směřuje k vlastnímu formátu, byť z toho samozřejmě mám trochu smíšené pocity (protože „zase další formát“), asi se o tom ještě rozepíšu… A možná zkusím napsat relpipe-in-cbor a relpipe-out-cbor pro bezztrátovou konverzi tam a zpět (jako to jde teď s XML).
 AbcLinuxu.cz
AbcLinuxu.cz ITBiz.cz
ITBiz.cz HDmag.cz
HDmag.cz AbcPráce.cz
AbcPráce.cz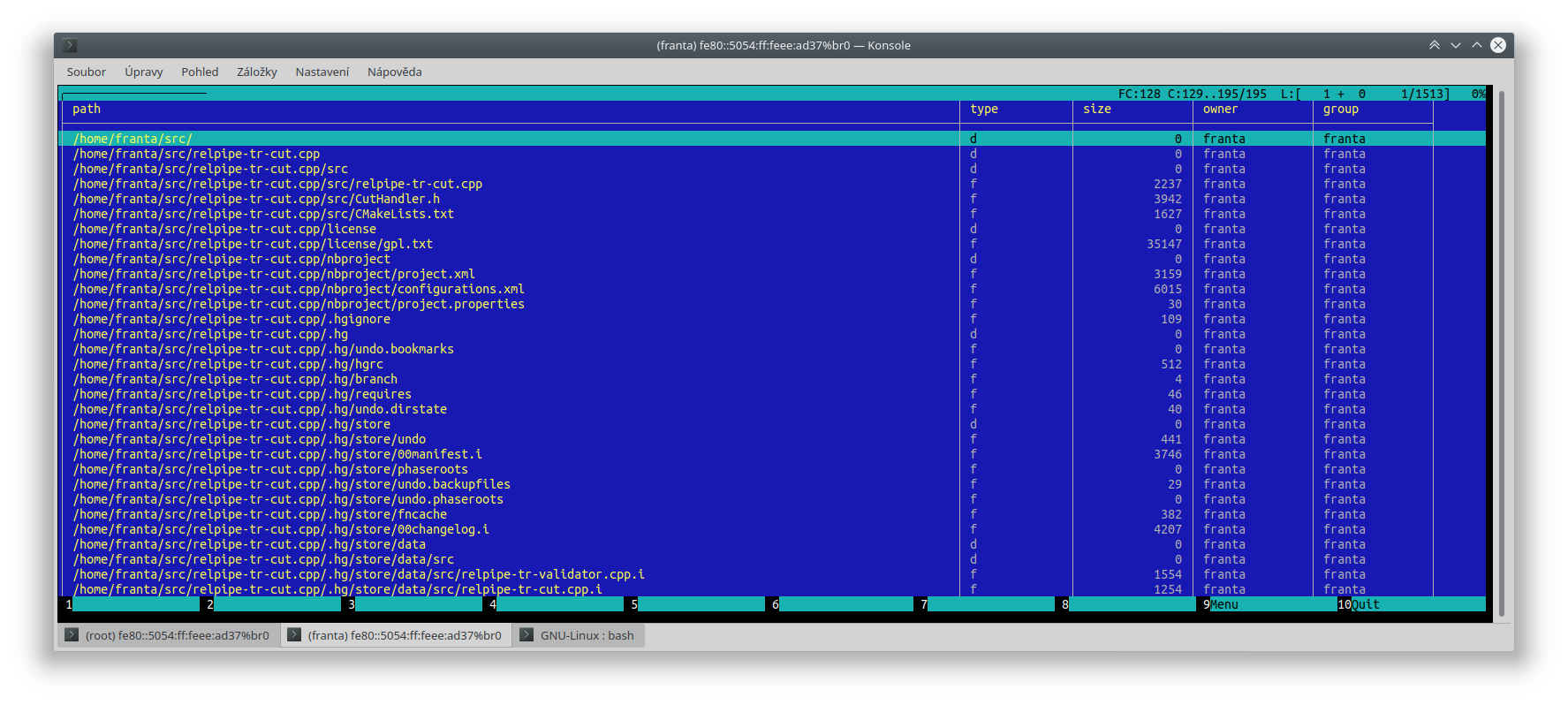{kind=link}