Zákaz používání mobilních telefonů a dalších elektronických komunikačních zařízení ve školách, jehož uzákonění navrhli jako poslanci premiér Andrej Babiš (ANO) a ministr školství Robert Plaga (za ANO), dnes podle očekávání vláda podpořila. Novinářům to oznámil Babiš, podle Plagy byla podpora kabinetu jednomyslná. Účinnost předkladatelé navrhují od 1. září 2027. Podle opoziční ODS je plošný zákaz líbivé populistické opatření namířené proti digitální gramotnosti dětí.
Vládní CERT upozorňuje (𝕏) na zranitelnost ve WordPress Core: CVE-2026-63030 s přezdívkou wp2shell. Zranitelnost typu vzdálené spuštění kódu (RCE) bez nutnosti autentizace umožňuje útočníkovi spouštět libovolný kód prostřednictvím endpointu WordPress REST API Batch. Ke zneužití není vyžadován platný uživatelský účet ani interakce uživatele. Úspěšné zneužití může vést ke kompletnímu kompromitování webové stránky a souvisejících dat. Zranitelnost postihuje verze WordPress 6.9.0 až 6.9.4 a 7.0.0 až 7.0.1.
Evropská komise (EK) vyměřila čínskému internetovému prodejci AliExpress pokutu 550 milionů eur (13,3 miliardy korun) za porušení povinností vyplývajících z nařízení o digitálních službách (DSA). Platforma podle EK řádně neposuzovala a neomezovala rizika související s prodejem nelegálních, nebezpečných nebo padělaných výrobků na svém internetovém tržišti. Komise zároveň firmě nařídila přijmout nápravná opatření. Podle AliExpressu je pokuta nepřiměřená.
Ruffle, tj. open source emulátor Flash Playeru napsaný v Rustu, byl vydán ve verzi 0.4.0. Ke stažení je také na Flathubu. Přímo ve webovém prohlížeči lze vyzkoušet online dema nebo vlastní swf soubory.
HollowByte je zranitelnost typu Denial of Service (DoS) v kryptografické knihovně OpenSSL. Útočník může odesíláním škodlivého payloadu o velikosti pouhých 11 bajtů zaplnit paměť serveru. OpenSSL před ověřením dat vyhradí nepřiměřený blok paměti (až 131 KB). Server pak čeká na data, která nepřišla. Zranitelnost je opravena ve verzích OpenSSL 4.0.1, 3.6.3, 3.5.7, 3.4.6 a 3.0.21.
Ve španělské A Coruñě probíhá GUADEC 2026, tj. letošní konference vývojářů a uživatelů desktopového prostředí GNOME. Videozáznamy přednášek jsou k dispozici na YouTube.
Společnost Collabora ve spolupráci s Valve vyvíjí Holo Core, tj. port Arch Linuxu pro ARM64 procesory (AArch64), který bude pohánět VR headset Steam Frame. Pro testování Arch Linuxu pro AArch64 jsou k dispozici binární balíčky, zdrojové kódy i kontejner pro Docker nebo Podman.
Mikroprocesor Zilog Z80 byl oficiálně uveden na trh před 50 lety, tj. v červenci 1976. Výroba mikroprocesoru skončila v roce 2024.
Výzkumníci ze společnosti ESET objevili 11 zapomenutých UEFI shim zavaděčů, které byly podepsány společností Microsoft, a které umožňují útočníkům obejít ochranu UEFI Secure Boot na většině zařízení. Microsoft je zneplatnil (přidal jejich hash do databáze dbx) v rámci aktualizace Patch Tuesday dne 9. června 2026. Uživatelé Linuxu mohou databází aktualizovat pomocí LVFS. Ověřit zneplatnění zavaděčů lze pomocí skriptu uefi-dbx-audit. Jedná se o CVE-2026-8863 a CVE-2026-10797.
pico-usb-wifi je open source firmware pro Raspberry Pi Pico W, který jej promění v USB Wi-Fi adaptér. Po připojení k počítači se objeví jako zařízení USB CDC-NCM.
Label: 'archiv' uuid: d1722103-0c1e-4627-bbc7-9f1f0bf91739
Total devices 4 FS bytes used 4.56TiB
devid 1 size 3.64TiB used 3.30TiB path /dev/mapper/archiv
devid 2 size 3.64TiB used 3.30TiB path /dev/mapper/com
devid 3 size 1.36TiB used 1.03TiB path /dev/mapper/miraza
devid 4 size 1.82TiB used 1.49TiB path /dev/mapper/securestorage
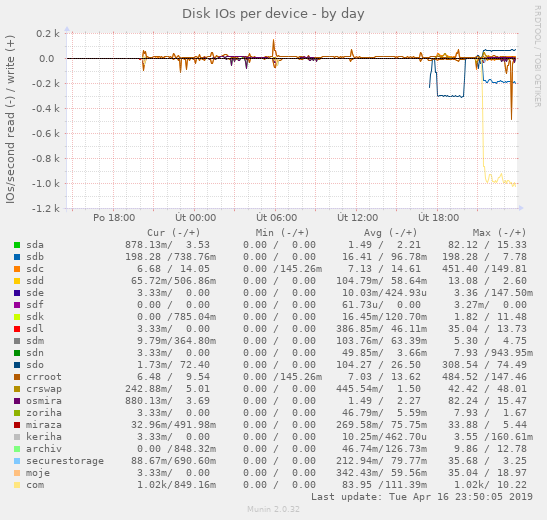
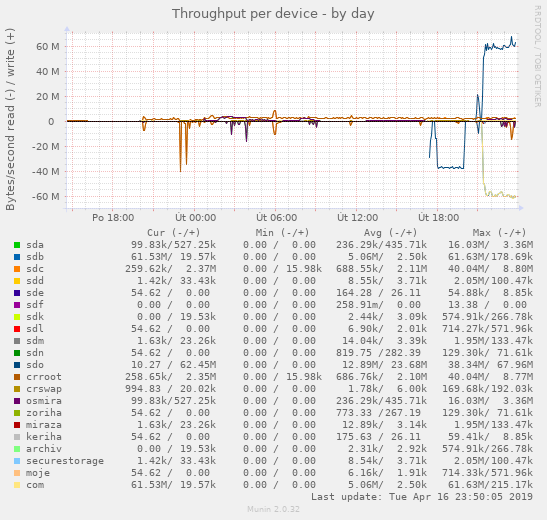
cíl: extení disk USB 3.0 připojený jako sdo má ntfs filesystem. Kopírování rsync -av zdroj cíl To co mne zaráží je mrňavé požadavky na IOPS pro zápis na ntfs a naopak obrovské IOPS, které se koncentrují do disku com. Soubor throughput ukazuje, že co se přečte, to se zapíše. mount btrfs je/dev/mapper/archiv /disky/archiv btrfs commit=100,defaults 0 0(v mount je
type btrfs (rw,relatime,space_cache,commit=100,subvolid=5,subvol=/)
) a ntfs je standardní automount(v mount je type fuseblk (rw,nosuid,nodev,relatime,user_id=0,group_id=0,default_permissions,allow_other,blksize=4096,uhelper=udisks2)) Případně jak pole mountnout aby výkon byl větší (každý /dev/mapper toho pole je LUKS2 volume)
 17.4.2019 10:17
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
17.4.2019 10:17
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
Naopak kdybys mel btrfs na obou stranachPokud je to záloha, tak je dobré mít pro zálohu jiný FS než na zálohovaném systému. Kdyby byl bug v kernel modulu daného FS, který by ten FS zničil, tak ti to zničí jak originální FS tak i zálohu. Takže jiný FS je zde na místě. (Otázkou je proč zrovna NTFS přes fuse...)
17.4.2019 10:13
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
To co mne zaráží je mrňavé požadavky na IOPS pro zápis na ntfs a naopak obrovské IOPSAno, tohle je docela běžné, protože pro zápis se používá mnoho technik pro odložený zápis, aby si to FS mohl srovnat v paměti a zapsat to co nejefektivněji. Při čtení těch souborů se příliš optimalizovat nedá, program ty soubory čte v neoptimalizovaném pořadí (protože ho ani nemá jak zjistit), FS musí vyhledat soubor v adresářovém stromu a FS musí vyhledat polohu bloků daného souboru v inodě. Tzn při náhodném čtení mnoha souborů je tam těch IOPS víc než při zápisu, kdy to FS může zapsat všechno naráz (po větších celcích). (Jaké přesně má optimalizace NTFS nevím, ale výše popsané platí třeba pro XFS nebo pro ext4 - delayed allocation).
které se koncentrují do disku comPodle obsazeného místa soudím, že v tom raid1 byly nejdřív disky archiv a com, které jsou plné a potom se tam přidaly ty dva další disky. Tedy ty fotky budou asi zřejmě uloženy pouze na devid 1 a devid 2 a btrfs je čte pouze z jednoho disku (proč taky ne). Celkově na té situaci nevidím nic zvláštního (teda až na poměrně creativně pojmenované disky v tom r1).
17.4.2019 14:59
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
Fakticky jsem dosáhl rychlosti jen asi 50-60 MB/s což mi připadalo trochu málo.No pokud tam jsou soubory o velikosti 1MB a ten disk předpokládám 7200rpm, tak pro každý soubor je potřeba přečíst inode a potom začít číst bloky toho souboru. Tj 2 operace per soubor (a to jen pokud není fragmentovanej). 60*2 = 120 IOPS, což přesně odpovídá 7200rpm (7200rpm/60s = 120IOPS). Čtení těch rawů by mělo jít rychleji. Ono taky záleží, kde na tom disku ta data jsou, protože rychlost čtení rotačního disku na obvodu disku je nejrychlejší (to jsou úžasné hodnoty v testech) a potom to ke středu disku klesá docela znatelně. Tj disk zvládající 140MB/s může u středu klidně spadnout až pod 80MB/s.
18.4.2019 09:06
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
ostatně ani to inode by nemusel číst při každé operaciPsal jsem per soubor. Program si vyžádá data souboru, FS se musí podívat na to, které bloky má přečíst (tj v inode) a potom je začne číst. To jsou dvě operace. Navíc je to btrfs, takže by si měl na druhém disku číst ještě checksum a porovnávat jej s těmi čtenými daty. Tj další operace, ale na druhém disku.
time du -a * | wc -l 105632 du -a * 0,10s user 0,42s system 99% cpu 0,524 total wc -l 0,03s user 0,31s system 64% cpu 0,523 total
18.4.2019 10:16
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
Myslel jsem to tak, že by přečetl balík inode dopředu a ty měl v paměti a pak už je jen z paměti vybral.Pro x různých souborů? Ten FS neví, které další soubory bude ten program po něm chtít. Jasně, kdyby existovala možnost tomu fs říct: "připrav si všechny tyhle soubory, za chvíli je po tobě budu chtít", tak je to jiná. Ale FS tohle neumožňuje.
18.4.2019 09:26
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
18.4.2019 10:03
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
2k: 4194303 * 2k = 8 GiB 4k: 4194303 * 4k = 16 GiB 8k: 4194303 * 8k = 32 GiB 16k: 4194303 * 16k = 64 GiB 32k: 4194303 * 32k = 128 GiBKaždopádně je rozumné mít full backup v nějakých intervalech, protože je mnohem rychlejší obnovit full dump a dohrát pár dní transakčních logů, než dohrávat transakční logy třeba za měsíc. Obzvláště, pokud se jede na minimální rollback a každou minutu, někdy i častěji z db padají logy a za den je těch souborů třeba 15 000.
Export dat je zase v některých případech výhodný v tom, že se lze dostat k nějaké tabulce z noční zálohy do pár minut.Pokud tedy rebuild potřebných indexů nad tabulkou netrvá déle než úplná záloha/obnova.
 OT: Jak často rotujete s logfile? Činí se tak automaticky až při jejich zaplnění(což by naznačovala frekvence přepínání), nebo máte nastavenu vynucenou rotaci po uplynutí určité doby? Jde mi o zajištění explicitně definované časové ztráty dat v případě total disaster (k dispozici je pouze poslední záloha a následný archiv redologů na jiné lokalitě). Případně, máte více memberů logfile group rozmístěných na různých typech storage, aby se dal aspoň některý z memberů živé RedoLogGroup v případě selhání storage-HW snadněji externě "vytěžit" (ztráta se minimalizovala "uplně")?
18.4.2019 09:14
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
18.4.2019 12:47
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
OT: Jak často rotujete s logfile? Činí se tak automaticky až při jejich zaplnění(což by naznačovala frekvence přepínání), nebo máte nastavenu vynucenou rotaci po uplynutí určité doby? Jde mi o zajištění explicitně definované časové ztráty dat v případě total disaster (k dispozici je pouze poslední záloha a následný archiv redologů na jiné lokalitě). Případně, máte více memberů logfile group rozmístěných na různých typech storage, aby se dal aspoň některý z memberů živé RedoLogGroup v případě selhání storage-HW snadněji externě "vytěžit" (ztráta se minimalizovala "uplně")?
18.4.2019 09:14
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
18.4.2019 12:47
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
To fakt není FS na 2GB flashku.
18.4.2019 13:44
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
Tiskni
Sdílej:
![]()
![]()
![]()
![]()
![]()
![]()
 AbcLinuxu.cz
AbcLinuxu.cz ITBiz.cz
ITBiz.cz HDmag.cz
HDmag.cz AbcPráce.cz
AbcPráce.cz 18.4.2019 08:29
18.4.2019 08:29
{kind=link}
{kind=link}
{kind=link}
{kind=link}